|
Опрос
|
реклама
Быстрый переход
Новая статья: ИИтоги мая 2026 г.: AI knows best, но это не точно
04.06.2026 [00:06],
3DNews Team
Данные берутся из публикации ИИтоги мая 2026 г.: AI knows best, но это не точно Amazon встроила в поиск ИИ-картинки несуществующих товаров, чтобы помочь найти настоящие
03.06.2026 [22:16],
Анжелла Марина
Amazon обновила поисковую строку в мобильном приложении, добавив функцию генерации ИИ-изображений товаров на основе текстового описания пользователя. На текущем этапе инструмент работает только с категориями одежды и товаров для дома, позволяя выбрать наиболее подходящее сгенерированное изображение и затем найти похожие товары в каталоге. 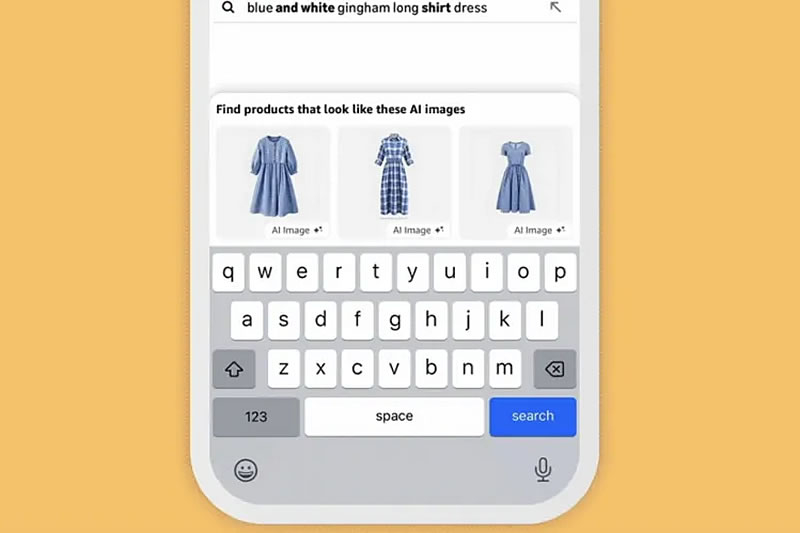
Источник изображений: Amazon Amazon позиционирует нововведение как помощь пользователям, которые не могут вспомнить точное название товара или стиля, например описав «рубашку с драпированным воротником» вместо «рубашки с воротником-хомутом». Как отмечает The Verge, функция действительно может оказаться полезной в подобных сценариях, однако не даёт существенных преимуществ при поиске таких простых товаров, как, например, «синяя футболка». 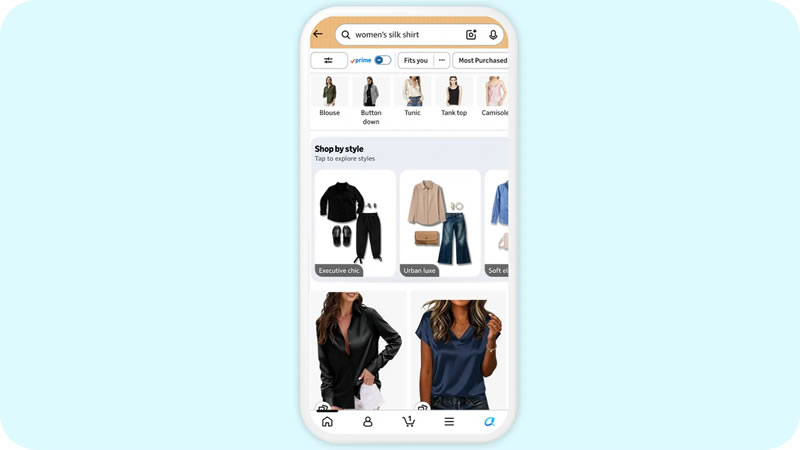 Стоит отметить, что Google представила аналогичный инструмент в ИИ-режиме поиска (AI Mode) ещё в прошлом году, генерируя изображения несуществующих комплектов одежды и предметов декора для поиска реальных аналогов. Также онлайн-ретейлеры всё активнее интегрируют Gemini и ChatGPT в процессы покупок, а теперь к тренду подключилась и Amazon, развивая направление поиска по стилю (shop by style), хотя и использует иной подход к генерации контента. В отличие от поисковой строки, функция shop by style выводит ИИ-коллажи с реальными товарами, доступными для покупки. Например, при запросе джинсовых шорт Amazon покажет карусель предложенных комплектов одежды с этим элементом гардероба, где сами наряды сгенерированы искусственным интеллектом, но изображённая одежда реально существует в каталоге. Обе функции появятся в приложениях Amazon для платформ Android и iOS. Цукерберг хочет, чтобы ИИ Meta✴ управлял всем бизнесом пользователей
03.06.2026 [18:58],
Сергей Сурабекянц
Глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) хочет, чтобы ИИ-агенты компании «помогали управлять всем бизнесом» её пользователей. Meta✴✴ внедряет ИИ-агентов для бизнеса на свои платформы WhatsApp, Instagram✴✴ и Messenger. Meta✴✴ Business Agent позволит владельцам компаний делегировать многие повседневные задачи, включая взаимодействие с клиентами и запись на приём. 
Источник изображения: unsplash.com Во время недавнего отчёта о доходах Meta✴✴ Марк Цукерберг намекнул на большие планы компании в отношении ИИ-агентов. Теперь первая часть этих планов воплощается в жизнь. На мероприятии Conversations в Лондоне Meta✴✴ представила инструменты ИИ-агентов для бизнеса, использующего платформы WhatsApp, Instagram✴✴ и Messenger. Новый инструмент, официально называемый Meta✴✴ Business Agent, позволит владельцам бизнеса делегировать многие из своих повседневных задач, включая взаимодействие с клиентами и запись на приём. Meta✴✴ заявляет, что бизнес-агент сможет «закрывать сделки» и рекомендовать товары, хотя владельцы бизнеса смогут в любой момент подключиться к взаимодействию. В настоящее время Meta✴✴ тестирует своих ИИ-агентов на представителях малого бизнеса Индии, Мексики и Бразилии. По данным компании, уже более миллиона человек активно используют новые инструменты. Теперь агенты будут доступны любому бизнесу в WhatsApp, а также в Instagram✴✴ и Messenger. План Meta✴✴ намного более амбициозен, нежели внедрение очередного чат-бота для взаимодействия с клиентами. По словам Цукерберга, цель состоит в том, чтобы агенты «в конечном итоге помогли вам управлять всем вашим бизнесом», хотя он признаёт, что для этого также потребуется дальнейшее развитие базовых ИИ-моделей компании. Сейчас Meta✴✴ работает над набором передовых возможностей для агентов, которые позволят им активнее участвовать в внутренних аспектах управления компанией — «проведение маркетинговых исследований, предоставление информации о продуктах, подключение к инструментам управления вашим календарём и предоставление конкурентной информации». Meta✴✴ не планирует заниматься благотворительностью. Хотя компания заявляет, что «начало работы» с её новым бизнес-агентом бесплатно, она планирует сделать эту функцию доступной только по подписке «в ближайшие месяцы». Microsoft планирует «вызвать зависимость» пользователей от своего нового ИИ-помощника Scout
03.06.2026 [17:58],
Сергей Сурабекянц
Согласно внутренним стратегическим документам Microsoft, план по созданию только что анонсированного персонального ИИ-помощника Scout состоит в том, чтобы «вызвать у людей зависимость» к инструменту, прежде чем внедрять дополнительные функции. Процесс предусматривает три этапа — от вызывающего привыкание приложения до агентной платформы.  Microsoft тестировала Scout в качестве внутреннего инструмента для сотрудников под названием ClawPilot, начиная с марта. Scout является частью «Проекта Лобстер» по внедрению популярного ИИ-инструмента OpenClaw в пакет продуктов Microsoft 365, чтобы им могли пользоваться не только технические специалисты. OpenClaw стал вирусным в начале года. Инструмент позволяет создавать ИИ-агентов, действующих от имени пользователя. Агенты могут отправлять электронные письма, редактировать календари, публиковать сообщения в блогах и выполнять множество других поручений. Внутренний документ Microsoft под названием «ClawPilot: обзор и план с Project Lobster» гласит: «Продолжить выпуск автономного приложения ClawPilot. Провести пилотное тестирование пользовательского интерфейса, расширить базу пользователей и создать экосистему навыков и инструментов, которая заставит людей ежедневно зависеть от него». Руководитель проекта Омар Шахин (Omar Shahine) рассказал, что в ходе пилотного проекта с участием сотрудников Microsoft наблюдалось «ежедневное использование с высокой степенью удержания пользователей и интенсивностью использования (чаты, запросы, рабочие процессы, навыки)». В дальнейшем план предусматривает подключение ClawPilot к другим инструментам ИИ и, в конечном итоге, добавление новых функций. 
Источник изображений: Microsoft У некоторых сотрудников Microsoft формулировка, описывающая зависимость, «вызывает большую тревогу». «Мы наблюдаем все большую зависимость от чат-ботов и агентов на основе ИИ, и в целом, на мой взгляд, зависимость — это то, что ни один продукт не должен включать в свою стратегию разработки», — заявил один из них. «Разве конечная цель всего программного обеспечения, создаваемого крупными технологическими компаниями, не состоит в том, чтобы вызывать зависимость? — иронизирует другой сотрудник Microsoft. — К счастью для нас, Microsoft довольно плохо справляется с созданием вызывающих зависимость продуктов по сравнению с некоторыми другими разработчиками». В описании «Проекта Лобстер» отмечается, что он был «создан в пошаговом режиме совместно с ИИ. Каждое предложение было проверено человеком». В документе говорится, что его используют более 1000 сотрудников Microsoft, включая главу компании, и что «ClawPilot органично превратился в один из самых востребованных внутренних инструментов в Microsoft. Без официального объявления, без маркетинга, без общеорганизационной кампании». «ClawPilot — настольный персональный помощник, созданный в первую очередь для специалистов интеллектуального труда: людей в сфере финансов, юриспруденции, операционной деятельности, управления персоналом и других областях, — сказано в документе. — Это приложение для macOS и Windows, которое работает рядом с вами, изучает ваш стиль работы и действует от вашего имени. Оно управляет вашим календарём, сортирует входящие сообщения, регистрирует расходы, готовит встречи и запускает повторяющиеся рабочие процессы». Ранее глава Microsoft Сатья Надела (Satya Nadella) заявлял, что он использует OpenClaw, но Microsoft никогда не сможет его интегрировать в свои продукты: «Нельзя запускать OpenClaw от имени Microsoft. Я имею в виду, это просто не сработает. У меня нет разрешения на это, потому что это будет считаться запуском вируса компанией Microsoft. Это просто недопустимо». Как и OpenClaw, ClawPilot требует доступа к данным учётных записей и конфиденциальным файлам для своей работы, что подразумевает потенциальные проблемы с безопасностью персональных и корпоративных данных.  Продукты Microsoft в области ИИ оказались довольно неоднозначными. Партнёрство с OpenAI обеспечило Microsoft быстрый старт в сфере ИИ, а её инструмент для программирования Copilot был очень популярен, но теперь его превзошёл Claude Code. Компания пыталась внедрить ИИ во многие свои продукты, но большинство пользователей выразили недовольство этими попытками. Microsoft придумала очередной носимый ИИ-гаджет — умный бейдж с камерой
03.06.2026 [17:15],
Павел Котов
Совместно с программой Project Solara — новой платформой для гаджетов с агентами искусственного интеллекта — Microsoft продемонстрировала и концепты этих устройств: электронный бейдж с камерой и настольного «компаньона» ПК, сообщает Gizmodo. 
Источник изображений: gizmodo.com Разработанный в Microsoft электронный бейдж может похвастаться широким набором электроники: здесь есть сенсорный экран, датчик отпечатков пальцев, поддержка Wi-Fi и даже 5G, микрофон для голосового ввода и боковая камера. «Мы переосмыслили формфактор, который ежедневно используют работники информационной сферы, медсестры, прочие специалисты по работе с клиентами и миллионы других людей — бейдж с пропуском. Этот портативный и лёгкий помощник, который всегда на связи, поможет каждому человеку сделать больше, имея агентов под рукой», — пояснили в Microsoft.  Устройство ориентировано преимущественно на корпоративный сектор, в том числе здравоохранение и розничную торговлю. Это не серийный продукт, а сценарий, на основе которого Microsoft демонстрирует возможности внедрения ИИ-агентов в повседневную жизнь. Работники с такими бейджами могут, например, «пользоваться встроенной камерой; платформа позволяет агентам, с разрешения человека, лучше понимать окружающую обстановку и помогать принимать меры».  Ещё один пример — обладающее схожими функциями устройство, которое стоит на рабочем столе. Оно располагает сенсорным экраном, микрофоном и даже «сверхширокополосными датчиками присутствия», благодаря которым знает, когда владелец находится рядом. Гаджет выступает в качестве «компаньона» для ПК, который подключается по Bluetooth и позволяет «передавать задачи между устройствами». Исследователи создали червя на основе ИИ — он может использовать любую известную компьютерную уязвимость
03.06.2026 [16:30],
Владимир Мироненко
Исследователи из Университета Торонто создали с помощью общедоступных ИИ-моделей прототип червя, способного использовать любую известную компьютерную уязвимость. Такие черви могут распространяться по сетям и вызывать хаос в интернете, пишет Engadget. 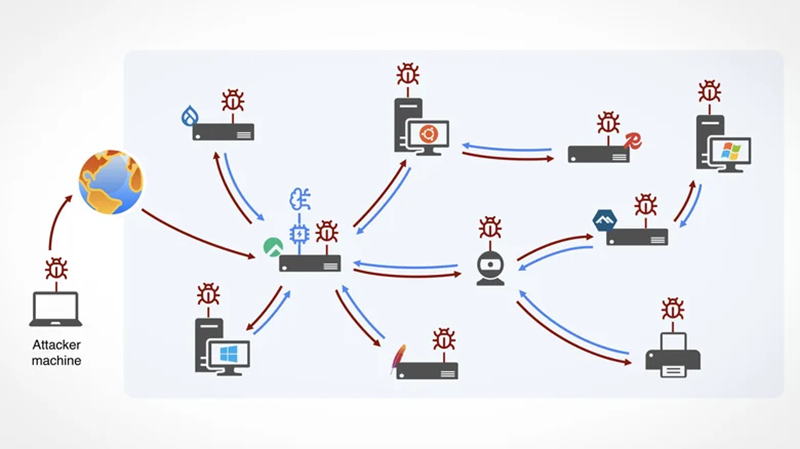
Источник изображения: University of Toronto/Engadget Обычно типичный компьютерный червь разрабатывается программистами для использования конкретных сетевых уязвимостей и может быть остановлен путем их исправления. В свою очередь, канадские исследователи, работая в защищённой закрытой среде и принимая обширные меры предосторожности, использовали ИИ-модели с открытым исходным кодом для создания гораздо более сложного прототипа червя, который распространился по тестовой сети команды без вмешательства человека. Этот тип червя способен адаптировать свои действия к различным типам уязвимостей на нескольких платформах, включая Linux, Windows и устройства IoT. Он собирает данные по мере продвижения по сети, перехватывая пароли и обнаруживая новые уязвимости, которые помогают ему захватить контроль над другими машинами. В случае, если на компьютере уязвимость была обнаружена и исправлена, червь может использовать для повторной атаки на него другие уязвимости. Вдобавок ко всему, червь использует вычислительную мощность заражённых машин для продолжения своих действий и выработки стратегии будущих атак. «Хакерам обычно приходилось отдавать приоритет наиболее ценным целям, поскольку время и вычислительные ресурсы были ограничены, — говорит ведущий автор проекта Николас Паперно (Nicolas Papernot). — Но теперь, после запуска червя, стоимость его использования снижается почти до нуля». Созданный исследователями прототип червя может использовать только известные уязвимости и не может находить неизвестные, как разработанная Anthropic модель Mythos. Однако злоумышленники вполне могли бы адаптировать его для поиска и использования новых уязвимостей — что сделало бы его практически неуязвимым в случае распространения. «Во взаимосвязанном мире ни одна система не застрахована от этой угрозы, — сказал Паперно. — Распространение этих результатов — первый шаг к тому, чтобы побудить исследователей, лидеров отрасли и политиков к действиям — и как можно быстрее». Meta✴ передумала следить за всеми действиями сотрудников после волны недовольства
03.06.2026 [12:50],
Алексей Разин
В прошлом месяце Meta✴✴ Platforms начала устанавливать на рабочие ПК своих сотрудников приложение для отслеживания движений курсора мыши и сбора другой информации, которую можно использовать для обучения систем искусственного интеллекта. Многие сотрудники такой идеей оказались недовольны, и с рядом претензий компания была вынуждена согласиться. 
Источник изображения: Unsplash, Liam Briese Как поясняет Reuters, работодателю пришлось внести коррективы в свой первоначальный план. Сотрудники теперь получат возможность не только полностью отказаться от участия в инициативе, но и отключать слежение на период до 30 минут за раз, как отмечается в памятке, которая была распространена среди персонала Meta✴✴ в минувший вторник. Уже испытавшие на себе изначальный вариант работы этой системы сотрудники жаловались не только на резкий рост трафика при нахождении дома, но и сокращение времени работы ноутбука от батареи. При этом Meta✴✴ настаивает, что профильное ПО прошло многоуровневую проверку безопасности, а потому его использование не должно представлять угрозы даже для личных данных, в том или ином объёме хранимых сотрудниками компании на рабочих ПК. У пользователей появилась возможность более гибко настраивать режим сбора информации, и это уже большой шаг навстречу их пожеланиям. Внедрение инициативы совпало по времени с массовыми сокращениями персонала Meta✴✴, а потому негативное её восприятие было усилено этим фактором. Многим сотрудникам компании могло показаться, что работодатель собирается обучить ИИ-агентов с их помощью, чтобы потом окончательно заменить человека. Трамп всё-таки подписал указ об обязательных проверках ИИ-моделей — его считают угрозой для отрасли ИИ
03.06.2026 [12:48],
Павел Котов
Президент США Дональд Трамп (Donald Trump) подписал указ, который, как считают в отрасли искусственного интеллекта, способен замедлить её развитие в США. Он также предписывает ужесточить преследование хакеров, которые используют ИИ. 
Источник изображения: Milad Fakurian / unsplash.com Накануне президент Трамп подписал указ, в котором регламентируется публичное развёртывание новых моделей ИИ. Документ не требует, но призывает разработчиков ИИ в добровольном порядке передавать свои новые модели на проверку государственными ведомствами перед их выпуском в открытый доступ. В первой версии указа на такую проверку отводились 90 дней, а в актуальной этот срок сократили до 30. Ранее президент планировал подписать документ в присутствии некоторых глав компаний из Кремниевой долины, но в итоге это было сделано в частном порядке. Подписанию предшествовала проведённая главой государства встреча в Белом доме, на которой обсуждались дальнейшие шаги по исполнению указа. Помимо запроса на добровольную проверку моделей ИИ правительственными структурами, указ предписывает Министерству юстиции квалифицировать кибератаки и взломы с использованием ИИ как преступления первостепенной важности. В частности, отмечается, что генпрокурору надлежит уделять первостепенное внимание применению «уголовного законодательства в отношении любого, кто использует ИИ для незаконного доступа или повреждения компьютеров без авторизации, или того, кто использует ИИ при таком незаконном доступе для совершения любого другого преступления». Anthropic доверит свой самый опасный ИИ Mythos 150 организациям в 15 странах по всему миру
03.06.2026 [11:49],
Алексей Разин
Количество желающих получить доступ к ИИ-модели Claude Mythos, которая позволяет быстро обнаруживать уязвимости в информационной инфраструктуре, предсказуемо растёт, но разработчики из Anthropic стараются давать этот мощный инструмент только в надёжные руки. Доступ к Mythos вскоре будут в общей сложности иметь 150 организаций из более чем 15 стран. 
Источник изображения: Anthropic Об этом со ссылкой на заявления Anthropic накануне сообщило издание Financial Times. Так называемый Project Glasswing вскоре охватит более чем 15 стран. Символично, что об этом стартап заявил на следующий день после подачи предварительной заявки на IPO. До сих пор доступ к мощному ИИ-инструменту для поиска уязвимостей в информационной инфраструктуре имели преимущественно компании и организации из США и Великобритании, но теперь география будет существенно расширена. Изначально после выхода Mythos доступ к ИИ-модели был предоставлен примерно 50 компаниям, главным образом — американским, поскольку создатели были уверены, что её возможности могут быть использованы хакерами для атак на чувствительную инфраструктуру. Теперь получить доступ к Mythos смогут избранные организации из Канады, Австралии и Новой Зеландии. К ним присоединятся Франция, Германия, Италия, Швейцария, Нидерланды, Испания, Бельгия, Швеция, Индия, Япония и Южная Корея. Надо сказать, что чиновники многих из этих стран уже ходатайствовали по поводу предоставления доступа к Mythos, мотивируя это стремлением провести аудит в сфере кибербезопасности. С южнокорейской стороны доступ к Mythos будет предоставлен компаниям Samsung, SK hynix и SK Telecom. НАТО через свою штаб-квартиру в Брюсселе впервые получит подобный доступ. Европейское агентство Enisa, отвечающее за кибербезопасность, тоже окажется в числе организаций, обладающих доступом к Mythos. По словам представителей Anthropic, новый этап расширения Project Glasswing позволит применять Mythos в новых отраслях экономики, включая энергетику, водоснабжение, здравоохранение, телекоммуникации и выпуск аппаратного обеспечения. По всей видимости, именно важность южнокорейских производителей памяти для мировой инфраструктуры ИИ позволила им получить доступ к Mythos в приоритетном порядке. В число получивших доступ к этой модели имеются и некоммерческие организации. По оценкам Anthropic, многие разработчики ИИ-систем в течение ближайших 12 месяцев обзаведутся моделями такого класса, и если не контролировать их распространение, то кибератаки будут осуществляться значительно чаще, а их последствия будет сложнее предугадать. О своих намерениях расширить доступ к Mythos компания заявила ещё в конце мая. Google позволит исключать сайты из ИИ-поиска без потери позиций в выдаче
03.06.2026 [10:51],
Павел Котов
Google даст владельцам сайтов возможность определять, будут ли их ресурсы отображаться и использоваться в «Режиме ИИ» и «Обзорах от ИИ» независимо от традиционных результатов поиска, сообщили в компании. 
Источник изображения: BoliviaInteligente / unsplash.com В сервисе Search Console появится новый переключатель, который даст владельцам сайтов возможность определять, будут ли они показываться и использоваться в службе поиска на основе генеративного ИИ. Сайты, владельцы которых отказались от этой функции, не будут получать показы и трафик из «Обзоров от ИИ» и «Режима ИИ», но останутся в обычных результатах поиска и в ленте Google Discover. Настройка применяется только к продуктам «Google Поиска», но не к приложению Gemini. Отказ показывать сайт в сервисах ИИ не повлияет на его положение в обычном поиске, заверили в Google. То есть этот параметр не будет использоваться в качестве фактора ранжирования. Google также откроет владельцам сайтов статистику по их присутствию в сервисах ИИ — она будет показываться в Search Console. Можно будет увидеть число показов, страницы в результатах ИИ-поиска и распределение по странам. Аудитория «Обзоров от ИИ» превысила 2,5 млрд пользователей в месяц, сообщили в Google, а «Режимом ИИ» пользуются уже более 1 млрд человек. Увеличилось и число ссылок, которые показываются в ИИ-поиске. Первыми новые средства управления поисковыми результатами смогут опробовать некоторые владельцы сайтов в Великобритании — когда они протестируют эти функции, новые возможности начнут развёртываться по всему миру. Microsoft представила Project Solara — ОС на Android для ИИ-агентов, а не людей
03.06.2026 [10:47],
Владимир Мироненко
Microsoft на конференции Build 2026 анонсировала Project Solara — новую ОС, разработанную для гаджетов, работающих с ИИ-агентами. Компания позиционирует её как новую платформу, созданную с нуля для обеспечения работы интерфейсов, управляемых агентами. Что примечательно, платформа построена на Android (AOSP), а не на Windows. 
Источник изображения: Microsoft Как сообщается, Microsoft выбрала версию Android — Microsoft Device Ecosystem Platform (MDEP) — вместо Windows, чтобы «работать на более компактных и энергоэффективных устройствах, сохраняя при этом функции управления и безопасности, которые ожидают ИТ-отделы». Компания продемонстрировала работу Project Solara на двух референсных устройствах — настольном умном дисплее и умном брелоке. Настольный гаджет похож на Amazon Echo Show, разблокируется с помощью распознавания лица и предоставляет доступ к ИИ-агентам. Он может отображать информацию, хранящуюся в Microsoft 365, например, предстоящие события из Outlook или данные из Excel. Он также поддерживает голосовой ввод и может выполнять задачи от имени пользователя. Умный брелок-ключ обладает схожей функциональностью, но при этом отличается мобильностью. Он оснащён камерой и сканером отпечатков пальцев, который позволяет активировать ИИ-агента одним нажатием, а также поддерживает подключение к сети 5G. Microsoft продемонстрировала возможность записывать разговор и мгновенно его расшифровывать. Камеру также может использовать агент, чтобы видеть то, что видит пользователь. В ходе презентации Microsoft подчеркнула, что это экспериментальные проекты, а не полноценные продукты, которые она планирует выпускать. Они демонстрируют потенциал устройства, специально разработанного для работы с агентами искусственного интеллекта, а не с приложениями. «Проект Solara специально разработан для новой эры устройств, ориентированных на агентов, — заявила Microsoft. — Он устанавливает требования к аппаратному и программному обеспечению, которые будут отвечать потребностям предприятий в управляемости, безопасности и конфиденциальности, обеспечивая при этом критически важный пользовательский опыт». Эти требования сочетаются с большой гибкостью. По словам компании, проект Solara разработан без «единственного доминирующего агента», и пользователи смогут вручную выбирать, какого агента они хотят использовать. Интерфейсы устройств также являются настраиваемыми. Microsoft сообщила, что платформа использует «интерфейс пользователя в режиме реального времени» для перестройки интерфейсов под разные размеры устройств и в некоторых случаях генерации нового интерфейса на лету. Также сообщается, что ряд компаний, включая AccuWeather, Best Buy, CVS Healthcare и Target, начнут пилотное тестирование устройств Solara в ближайшие месяцы. ChatGPT набрал миллиард активных пользователей — на это ушло рекордно мало времени
03.06.2026 [10:37],
Алексей Разин
Статистика Sensor Tower, на которую ссылается Reuters, демонстрирует ещё одно подтверждение популярности чат-бота ChatGPT, который был представлен стартапом OpenAI осенью 2022 года. Чуть более трёх лет понадобилось этому приложению, чтобы набрать миллиард активных пользователей в месячном измерении, и это рекордная скорость. 
Источник изображения: Unsplash, Tim Witzdam Рубеж в 1 млрд ежемесячно использующих ChatGPT клиентов приложение преодолело в прошлом месяце, по данным Sensor Tower. Это быстрее, чем произошло в своё время с Google Maps, TikTok, Instagram✴✴ и YouTube. При этом нельзя утверждать, что высокой популярности ChatGPT ничего не угрожает. В первом квартале установившие себе Anthropic Claude пользователи в течение первого месяца с момента установки сократили время, проводимое в ChatGPT, на 5 % по сравнению с предыдущим восьмимесячным периодом. Сейчас Anthropic Claude может похвастать 56 млн активных пользователей в месячном измерении, но отставание от ChatGPT сокращается впечатляющими темпами. Если у последнего количество активных пользователей сейчас увеличивается на 62 % в годовом сравнении, то у Anthropic Claude этот показатель достигает 640 %. Вчера стало известно, что Anthropic сделала первый шаг к выходу на IPO, подав соответствующую заявку в США. Конкурирующая OpenAI тоже готовится к выходу на биржу в этом году, но пока ещё не подала свою заявку. Репортаж со стенда MSI на Computex 2026: OLED-мониторы для профессионалов, экосистема PRO MAX и локальный ИИ
03.06.2026 [09:07],
Андрей Созинов
Помимо игровых устройств MSI привезла на Computex 2026 новую продуктовую линейку PRO MAX, в которую вошли настольные ПК, моноблоки, мини-компьютеры и OLED-мониторы для бизнеса, создателей контента и людей, работающих с ИИ-инструментами. Ключевой идеей серии стала локальная обработка задач ИИ без необходимости постоянно обращаться к облачным сервисам.  PRO MAX EDGE AI+ — мощный мини-ПК для локального ИИ Главной новинкой стал производительный настольный мини-компьютер PRO MAX EDGE AI+ объёмом всего 4 литра. Система построена на базе 16-ядерного процессора AMD Ryzen AI Max+ 395 с мощной графикой Radeon 8060S. Данный чип располагает встроенным ИИ-ускорителем, который в паре с GPU обеспечивает до 126 TOPS ИИ-производительности.  Одной из главных особенностей системы является наличие до 128 Гбайт унифицированной памяти, что позволяет запускать локально языковые модели объёмом до 120 млрд параметров. Для работы с ними MSI предлагает собственную платформу AI Jinni, объединяющую инструменты продуктивности и ИИ-агентов. PRO MAX 80 и новые моноблоки Для корпоративного сегмента MSI также представила настольный компьютер PRO MAX 80 в компактном 8-литровом корпусе. Система может оснащаться процессорами вплоть до Intel Core 9 270H и дискретной графикой GeForce RTX, а также предлагает упрощённый доступ к компонентам и расширенные средства физической защиты.  Дополняют линейку моноблоки PRO MAX 24 и PRO MAX 27, удостоенные премии Red Dot Design Award 2026. Старшая модель PRO MAX 27TP Z получила процессоры AMD Ryzen 7, сенсорный дисплей с частотой обновления до 120 Гц, выдвижную 5-Мп веб-камеру, поддержку Wi-Fi 7 и возможность подключения трёх внешних мониторов. Помимо компьютеров серии PRO MAX компания показала настольную систему PRO DP180 AI, рассчитанную на корпоративных пользователей и создателей контента. Система может оснащаться процессорами вплоть до Intel Core Ultra 7 и видеокартой GeForce RTX 5070, что делает её подходящим решением не только для офисной работы, но и для ресурсоёмких задач вроде обработки фото и видео, 3D-моделирования и локального запуска ИИ-приложений.  Компьютер выполнен в корпусе объёмом 18 литров. Предусмотрены четыре слота памяти DDR5, два разъёма M.2 для NVMe-накопителей, а также посадочные места для 2,5- и 3,5-дюймовых накопителей. В оснащение входят интерфейс Thunderbolt 4 с пропускной способностью до 40 Гбит/с и два сетевых порта Ethernet 2.5GbE. OLED-мониторы для работы  Наиболее интересным монитором профессиональной серии стал PRO MAX 341QPXW14G с 34-дюймовой сверхширокой панелью QD-OLED пятого поколения и разрешением UWQHD (3440 × 1440 пикселей). Формат 21:9 позволяет заменить конфигурацию из двух дисплеев, а структура субпикселей RGB Stripe улучшает читаемость текста. Для повышения качества изображения используются технологии DarkArmor Film и VisiClarity, а за защиту панели отвечает система AI Care Sensor 3.0.  Вторая новинка — PRO MAX 271UPXW12G с 26,5-дюймовой 4K-панелью QD-OLED. Монитор ориентирован в том числе на пользователей Mac благодаря приложению MSI M-Mate, позволяющему управлять настройками дисплея напрямую из macOS. Также поддерживаются синхронизация цветовых профилей с экраном MacBook, подача питания мощностью до 98 Вт через USB Type-C и встроенный KVM-переключатель. Мини-ПК Cubi NUC AI Для офисных сценариев MSI подготовила компактный компьютер Cubi NUC AI WCG на процессорах Intel Core 300 (Wildcat Lake). Устройство поддерживает подключение трёх дисплеев, оснащается модулем Wi-Fi 6E с возможностью перехода на Wi-Fi 7 и использует безинструментальную конструкцию для упрощённого обслуживания. MSI отмечает, что система рассчитана на использование в корпоративной среде и гибридных рабочих сценариях, где важны компактность, простота обслуживания и возможность интеграции с несколькими дисплеями одновременно.  Ещё одной новинкой MSI стал мини-компьютер Cubi NUC AI+ 3MG, ориентированный на корпоративный сегмент и более ресурсоёмкие рабочие сценарии с использованием ИИ. Система может оснащаться процессорами Intel Core Ultra 9 серии 3 и обеспечивает до 100 TOPS совокупной производительности в задачах искусственного интеллекта. Компьютер поддерживает до 128 Гбайт памяти DDR5, подключение до четырёх дисплеев одновременно и интерфейс Thunderbolt 4 со скоростью передачи данных до 40 Гбит/с.  Ставка на Agentic AI Отдельное внимание MSI уделяет программной экосистеме. Компания развивает платформу AI Jinni и концепцию LuckyClaw Army, в рамках которой несколько специализированных ИИ-агентов могут совместно выполнять различные задачи — от поиска информации и подготовки документов до автоматизации рабочих процессов и взаимодействия с внешними сервисами. MSI противопоставляет такой подход традиционным генеративным ИИ-системам, которые лишь отвечают на запросы пользователя. По мнению компании, Agentic AI должен самостоятельно выполнять действия и помогать добиваться конкретных результатов, а не просто генерировать текст. В отличие от классических ИИ-сервисов в облаке, MSI делает ставку на локальное выполнение задач непосредственно на компьютере пользователя. Представленные на Computex 2026 устройства показывают, что именно сочетание производительных ПК, локальных языковых моделей и специализированных ИИ-агентов станет одним из ключевых направлений развития профессиональной линейки компании в ближайшие годы. Microsoft представила ИИ-агента Scout, созданного на базе открытой архитектуры OpenClaw
03.06.2026 [06:28],
Анжелла Марина
Microsoft представила персонального помощника на основе искусственного интеллекта, созданного на базе проекта OpenClaw. Помощник получил название Scout и, в отличие от Copilot, не только интегрирован в Microsoft 365, но и способен выполнять функции полноценного личного секретаря. 
Источник изображения: Microsoft Как пояснил вице-президент проекта Microsoft Scout Омар Шахин (Omar Shahine), нейросеть обладает расширенными возможностями и функционирует в качестве постоянно активного помощника внутри экосистемы Microsoft 365, а также может совершать телефонные звонки и отслеживать график поездок для корректировки планов пользователя. База для таких рекомендаций формируется за счёт самостоятельного анализа электронной почты и расшифровок бесед из Teams. Компания начала развёртывание с десктопной предварительной версии для клиентов тарифа Frontier в США, хотя конечная цель заключается в создании полностью облачного сервиса. Внутреннее тестирование уже показало высокую эффективность инструмента, которым пользуются более 3000 сотрудников Microsoft для различных целей, в том числе для планирования путешествий, заполнения форм и управления личными задачами. Несмотря на предыдущие заявления генерального директора Microsoft Сатьи Наделлы (Satya Nadella) об опасности подобных технологий, Microsoft напрямую участвует в развитии ядра OpenClaw. Для защиты корпоративных данных система работает в изолированной среде без доступа к закрытый информации. Безопасность обеспечивается комплектом решений Agent 365, Purview и Defender. «Мы используем OpenClaw в облачной среде, в изолированной среде, и относимся к OpenClaw как к ненадёжному ресурсу, поэтому у него нет доступа к вашим данным Microsoft 365», — подчеркнул Шахин. Стоит сказать, что выход нового продукта Microsoft обостряет конкуренцию на рынке корпоративных ИИ-помощников, где Google также продвигает свою платформу Gemini Spark для интеграции с облачными сервисами Workspace. При этом, как отмечает The Verge, ключевым фактором успеха станет скорость адаптации искусственного интеллекта к индивидуальным привычкам и предпочтениям конкретного пользователя. Microsoft взяла курс на ИИ-независимость и представила свою первую рассуждающую модель MAI-Thinking-1
03.06.2026 [06:12],
Анжелла Марина
Microsoft представила на конференции Build 2026 линейку собственных моделей искусственного интеллекта, включая новую флагманскую модель MAI-Thinking-1. Компания также представила модели для генерации изображений, формирования стенограмм, обработки голоса и написания кода. 
Источник изображения: Rubaitul Azad/Unsplash По заявлениям Microsoft, MAI-Thinking-1 представляет собой «модель среднего размера», которая «соответствует ведущим моделям» по ключевым показателям в написании программного кода. При этом подчёркивается, что модель была обучена с нуля на чистых данных без использования моделей сторонних разработчиков. Помимо рассуждающей модели на мероприятии представили инструменты для работы с медиафайлами, среди которых MAI-Image 2.5 для генерации и редактирования изображений, а также MAI-Transcribe-1.5, превосходящая, по словам разработчиков, конкурентов по скорости работы в пять раз. Также компания анонсировала скорый выход голосовой модели MAI-Voice-2 с пятнадцатью новыми языками и дополнительными вариантами озвучки. Замыкает линейку модель для кодинга MAI-Code-1, отличающееся эффективностью вывода. Модель интегрирована в GitHub Copilot и Visual Studio Code. Как отмечает The Verge, до прошлого года корпорация полностью полагалась на технологии OpenAI, однако успешный дебют первых собственных продуктов позволил изменить стратегию и снизить зависимость от партнёра. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



