|
Опрос
|
реклама
Быстрый переход
OpenAI выпустила GPT-5.4 mini и nano — компактные версии флагманской LLM, оптимизированные под задачи с высокой нагрузкой
18.03.2026 [10:35],
Павел Котов
OpenAI представила мощные малые модели искусственного интеллекта GPT-5.4 mini и nano — они располагают некоторыми передовыми возможностями полноразмерной GPT-5.4 и предлагают более высокую производительность. Малые модели предназначены для быстрого решения базовых задач, в том числе для управления субагентами ИИ. 
Источник изображения: Mariia Shalabaieva / unsplash.com Старшая в дуэте GPT-5.4 mini является крупным шагом вперёд по сравнению с оригинальной GPT-5 mini — она пишет более качественный программный код, превосходит предшественницу в логических рассуждениях, управлении сторонними средствами и при этом работает более чем вдвое быстрее. В таких тестах, как SWE-Bench Pro и OSWorld-Verified, она выступает почти на уровне полноразмерной GPT-5.4. На практике GPT-5 mini пригодится в сценариях, где критически важна скорость работы: это могут быть ИИ-помощники для написания кода, субагенты для выполнения вспомогательных функций, средства управления интерфейсом с распознаванием снимков экрана и прочие приложения с мультимодальными функциями, где необходим анализ изображений. Все эти сценарии не предполагают использования самой мощной модели. 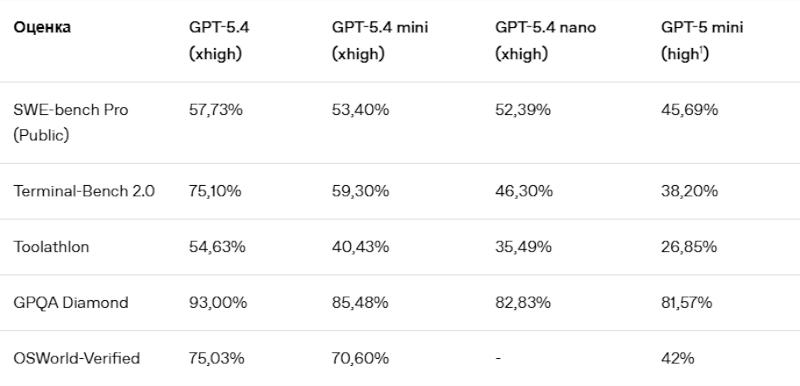
Здесь и далее источник изображения: openai.com GPT-5.4 nano выступает в качестве самой компактной и быстрой модели из семейства GPT-5.4; она также значительно превосходит свою предшественницу GPT-5 nano. На практике она будет полезна в задачах извлечения, классификации и ранжирования данных, а также в работе субагентов для решения базовых задач. 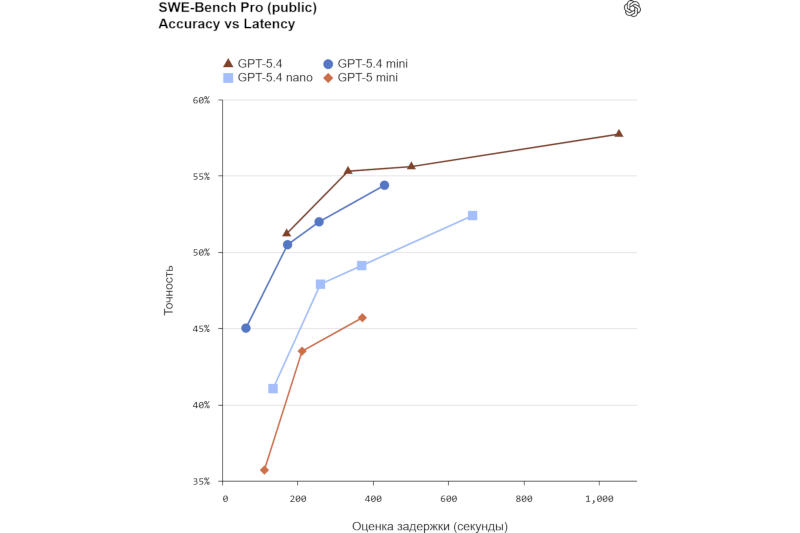 В сервисе по написанию кода OpenAI Codex старшая модель GPT-5.4, как более мощная, может планировать, координировать и оценивать работу параллельно действующих ИИ-субагентов под управлением GPT-5.4 mini. Им можно поручать поиск по базе кода, анализ больших файлов и работу с документацией. Эта стратегия востребована при подключении ИИ к рабочим процессам — разработчики используют не одну большую модель, а развёртывают системы, в которых крупные принимают решения, а малые быстро выполняют их в больших объёмах. GPT-5.4 mini идеально подходит на роль последних, заверяют в OpenAI. Она также способна эффективно управлять интерфейсом ПК. GPT-5.4 mini может работать и как модель для чат-бота — при достижении лимитов GPT-5.4 Thinking в ChatGPT пользователи будут автоматически переключаться на неё. 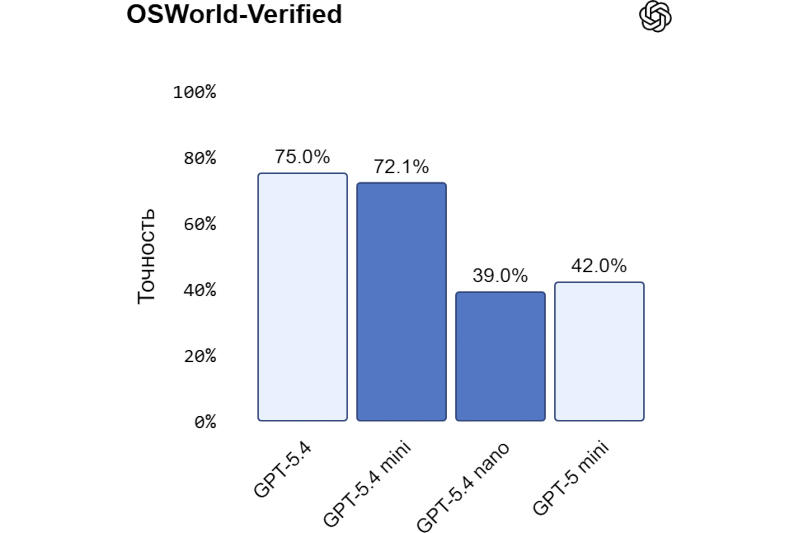 На платформе Codex модель GPT-5.4 mini доступна для работы в приложении, интерфейсе командной строки, расширении для IDE и веб-интерфейсе. К ней также открыт доступ по API — поддерживается работа с текстом и изображениями, управление интерфейсом и сторонними инструментами, вызов функций, поиск по сети и файлам. Максимальный размер контекстного окна составляет 400 тыс. токенов; стоимость доступа — $0,75 за 1 млн входных и $4,5 за 1 млн выходных токенов; модель потребляет 30 % квоты полноразмерной GPT-5.4. Доступ к GPT-5.4 nano открыт только через API по цене $0,20 за 1 млн входных и $1,25 — за 1 млн выходных токенов. Nvidia возобновила выпуск ускорителей H200, поскольку власти Китая дали добро на их импорт
18.03.2026 [07:35],
Алексей Разин
Как известно, власти США ещё с конца прошлого года пытаются создать условия для поставок ускорителей Nvidia H200 в Китай, но в силу ряда причин непосредственно поставки пока не осуществлялись. Основатель компании Дженсен Хуанг (Jensen Huang) вчера заявил, что Nvidia возобновила выпуск H200 с целью их поставки в Китай, поскольку необходимые экспортные лицензии были получены. 
Источник изображения: Nvidia Считается, что выпуск H200 был приостановлен в прошлом году, поскольку за пределами Китая эти ускорители с не самой передовой архитектурой Hopper не так востребованы, а поставлять их в Китай компания на тот момент не могла. К настоящему времени Nvidia не только получила необходимые экспортные лицензии в США, но и набрала некоторое количество заказов в Китае, и всё это позволило ей несколько недель назад возобновить производство ускорителей H200. По словам Хуанга, «цепочки поставок разогреваются». Агентство Reuters со ссылкой на собственные источники также сообщило, что китайские власти разрешили импорт ускорителей Nvidia H200, и это во многом создаёт все необходимые условия для их поставок в страну в сочетании с наличием экспортных лицензий США и заказов со стороны китайских клиентов. По словам главы Nvidia, приобрести H200 желают многие китайские компании. Последним также удалось получить необходимые лицензии от американской стороны, что не менее важно. Наличие одобрения на поставки H200 в Китай глава Nvidia отдельно подтвердил в интервью CNBC, подчеркнув, что соответствующие согласования пройдены как с американской, так и с китайской стороны. Накладываются ли на китайских клиентов Nvidia какие-то дополнительные условия со стороны местных властей, не уточняется. Ранее считалось, что ради возможности закупать американские ускорители H200 им придётся взять обязательства по приобретению ускорителей китайского происхождения в определённых пропорциях. Nvidia готовит для китайского рынка особую версию ИИ-чипов Groq
18.03.2026 [07:01],
Алексей Разин
В прошлом году Nvidia в рамках сделки на сумму $17 млрд получила доступ к разработкам стартапа Groq, и уже в этом месяце представила специализированные чипы LPU для ускорения работы ИИ в задачах инференса. Как отмечают источники, для Китая компания уже готовит адаптированную версию чипов Groq, с учётом существующих в США экспортных ограничений. 
Источник изображения: Nvidia Об этом накануне сообщило агентство Reuters со ссылкой на собственные источники. Одновременно глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что компания возобновила выпуск чипов H200 собственной разработки, которые собирается продавать на китайском рынке. Nvidia удалось получить необходимые для отгрузки H200 китайским клиентам экспортные лицензии США, а китайские органы власти разрешили их импорт в Поднебесную. Среди китайских конкурентов Nvidia немало тех, кто предлагает собственные специализированные чипы для инференса, поэтому возможность поставки адаптированных решений семейства Groq важна для американской компании с точки зрения сохранения своих позиций на китайском рынке. Как поясняет Reuters, адаптация чипов Groq для Китая будет заключаться не в снижении быстродействия, а в сохранении возможности работы с другими системами. Поставки чипов Groq начнутся в мае этого года, для Китая их не будут выпускать отдельно от основных партий. DuckDuckGo добавила в Duck.ai модели GPT-5 mini и GPT-5.2 с режимом рассуждений
18.03.2026 [06:12],
Дмитрий Федоров
DuckDuckGo добавила в своего ориентированного на конфиденциальность ИИ-бота Duck.ai более мощные рассуждающие ИИ-модели: GPT-5 mini — для бесплатных пользователей, а GPT-5.2 — для подписчиков. Для GPT-5.2 также появился переключаемый режим рассуждений. При этом компания подчёркивает, что чаты в Duck.ai анонимизируются по умолчанию и не используются для обучения ИИ-моделей. 
Источник изображений: Duck.ai Duck.ai — это платформа чат-ботов DuckDuckGo, которая предоставляет доступ к приватным разговорам с ИИ-моделями Anthropic, Meta✴✴, Mistral и OpenAI. Таким образом, сервис объединяет несколько ИИ-моделей в одном интерфейсе. За последние месяцы в сервисе появились голосовые чаты, генерация изображений, редактирование изображений и другие возможности. На этом фоне добавление новых ИИ-моделей выглядит логичным шагом. Duck.ai добавила более мощные рассуждающие ИИ-модели, включая GPT-5 mini для бесплатных пользователей и GPT-5.2 для подписчиков. Компания сообщила, что в GPT-5.2 пользователи могут включать и отключать режим рассуждения. Это связано с тем, что не каждое взаимодействие требует от ИИ-модели дополнительных «мыслительных» шагов перед ответом.  DuckDuckGo уточнила, что Duck.ai по умолчанию анонимизирует чаты. Кроме того, ни один разговор не используется для обучения ИИ-моделей. Этот принцип компания описывает как базовую характеристику сервиса. По словам DuckDuckGo, все метаданные, содержащие персональную информацию, например IP-адрес пользователя, полностью удаляются до отправки запроса поставщику модели. Следовательно, запросы к Anthropic, OpenAI и together.ai выглядят так, будто они исходят от DuckDuckGo, а не от отдельных пользователей. Компания также подчеркивает, что если пользователь отправляет в чате персональную информацию, ни DuckDuckGo, ни поставщики ИИ-моделей не могут определить, был ли этот запрос отправлен именно этим пользователем или кем-то другим. Иначе говоря, сервис отделяет содержание запроса от идентифицирующих метаданных.  DuckDuckGo напоминает, что ИИ-инструменты остаются опциональными и не связаны с её традиционной поисковой платформой. Следовательно, компания отделяет ИИ-функции Duck.ai от классического поискового сервиса. Google открыла доступ к «Персональному интеллекту» бесплатным пользователям Chrome, Gemini и AI Mode
17.03.2026 [22:41],
Анжелла Марина
Google объявила о запуске функции «Персональный интеллект» (Personal Intelligence) для бесплатных пользователей. Ранее возможность была доступна только подписчикам платных тарифов Google AI. Теперь технологию интегрируют в приложение Gemini, браузер Chrome через веб-версию Gemini, а также в новый режим ИИ (AI Mode). 
Источник изображений: Google Суть обновления заключается в том, что искусственный интеллект учится использовать личные данные пользователя для генерации ответов, не требуя детальных уточнений в запросе. Система анализирует информацию из экосистемы Google: Workspace (включая Gmail, «Календарь» и «Диск»), «Google Фото», YouTube, «Google Карты» и «Поиск». Далее, как уточняет 9to5Google, ИИ обрабатывает текст, фото и видео, чтобы понять предпочтения владельца аккаунта и адаптировать ответы под пользователя. 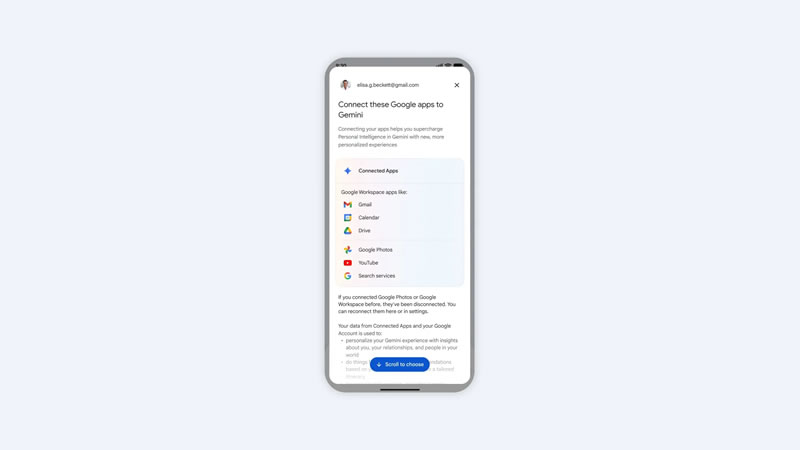 В качестве примеров работы системы приводятся несколько сценариев. Пользователи могут получить помощь в решении технических проблем, даже не помня точное название купленного продукта: достаточно описать неисправность, и система предложит шаги по отладке, такие как перезагрузка или сброс настроек, определив точную модель устройства по квитанциям о покупке. В дальних поездках функция поможет сориентироваться, например, во время пересадки: автоматически укажет выходы на посадку, предложит варианты питания с учётом вкусов пользователя, рассчитает остаток времени до вылета. Также доступно создание индивидуальных маршрутов вместо стандартных списков «топ-10» — с рекомендациями местных достопримечательностей на основе прошлых интересов. 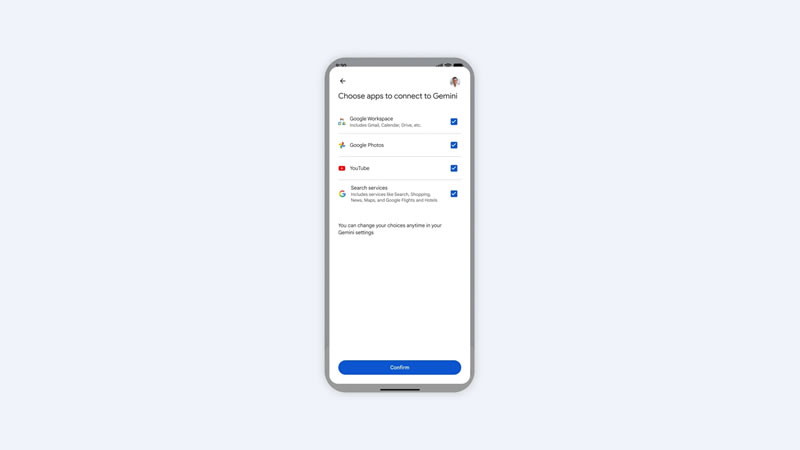 Распространение функции для бесплатных пользователей приложения Gemini и Gemini в Chrome начнётся на территории США. Для работы потребуется личный аккаунт Google и обязательное ручное включение функции. При этом пользователи смогут отключать доступ к определённым приложениям, а в меню аккаунта появится соответствующий раздел — «Персональный интеллект». Чат-бот Anthropic Claude научился генерировать шрифты на основе рукописного текста
17.03.2026 [18:46],
Павел Котов
Службы на основе искусственного интеллекта постепенно переходят к решению задач творческого характера, которые ранее требовали специального ПО — теперь чат-боты умеют преобразовывать рукописные символы в цифровой шрифт. Правда, пока система работает не идеально. 
Источник изображения: anthropic.com Чтобы получить свой собственный шрифт, пользователю необходимо изобразить от руки алфавит, цифры и знаки препинания, отсканировать страницу и загрузить получившийся файл чат-боту с ИИ — тот преобразует рукописное начертание в шрифт формата TrueType. Результат будет зависеть от почерка человека — те, у кого он разборчивый, получат более качественный результат, чем остальные. 
Источник изображения: x.com/ashebytes Функция неочевидна — её обнаружила инженер-программист и специалист по ИИ Аше Магальяеш (Ashe Magalhaes). Его подход основан на одной из функций Anthropic Claude, который для решения сложных задач может вызывать внешние инструменты на языке Python. Для генерации шрифта на основе латинского алфавита необходимо изобразить на бумаге все буквы в заглавном и строчном начертаниях, цифры и знаки препинания. Изображение сканируется и загружается в чат-бот. Он анализирует контуры каждой буквы и преобразует их в векторные фигуры, которые задают основу для файла шрифта. 
Источник изображения: x.com/ashebytes Процесс требует аккуратного подхода. В ходе тестирования служба ИИ сначала предоставила шаблон, чтобы пользователь разместил символы на странице. Буквы должны быть чёткими, расстояние между символами — равномерным, а сканировать необходимо в оптимальных условиях без теней или эффектов неравномерного освещения. Первые попытки были неудачными: в первом выходном файле формы были искажены и напоминали скорее чернильные пятна, а не буквы. Система проанализировала собственную работу и пришла к выводу, что внешние контуры некоторых символов она распознать не смогла и запустила процесс конвертации повторно. Второй заход оказался значительно удачнее, но такие буквы как «O», «A» и «R» изображались сплошными поверхностями, без отверстий. Пришлось производить доработку. Возникали и дальнейшие проблемы: в какой-то момент в единый глиф слились буквы «x» и «y» — это тоже пришлось корректировать. В окончательном варианте удалось добиться вполне приемлемого результата. В Google Gemini появится ветвление беседы — как в ChatGPT
17.03.2026 [16:20],
Павел Котов
Google готовится развернуть новую функцию чат-бота с искусственным интеллектом Gemini — переписку с ним можно будет разбивать на несколько веток и продолжать её по нескольким направлениям с одного и того же места. Эта функция уже есть в ChatGPT. 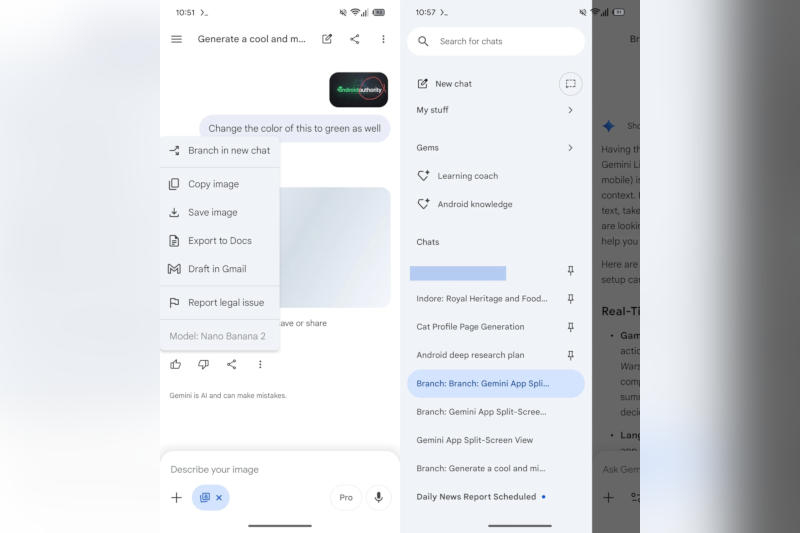
Источник изображения: androidauthority.com Признаки новой функции журналисты ресурса Android Authority обнаружили во время тестирования приложения Google версии 17.10.54.sa.arm64 — «ветвление» беседы пока не запущено официально и требует некоторых доводок, но представляется вполне работоспособным. Название и предназначение функции говорят сами за себя: вместо того, чтобы продолжать один долгий чат, пользователь может в любой момент создать его копию и исследовать с ИИ тему в другом направлении, оставив исходную ветку в прежнем состоянии. На практике это поможет экспериментировать с запросами или сравнивать ответы, не начиная переписку заново. Функция может показаться знакомой пользователям OpenAI ChatGPT, где есть схожая опция «Ветка в новом чате». Google ранее экспериментировала с этой идеей на платформе AI Studio, но теперь она появилась в приложении для обычных пользователей. Используется она просто: под ответом Gemini необходимо нажать кнопку с изображением трёх точек, выбрать «Ответвить в новый чат» («Branch in new chat») и система откроет его, используя фрагмент выше в качестве начального контента — новый чат получит пометку «Ветка:», чтобы его можно было отличить от первоначального. Ветвление пригодится в сложных переписках: сейчас попытки развить несколько направлений в одном потоке очень быстро заставляют ИИ путаться — в новых ветках можно эффективнее контролировать последующий диалог. Официальной информации о широкомасштабном развёртывании новой функции пока нет, но, учитывая, что Google уже экспериментировала с ней в AI Studio, она может появиться в пользовательском Gemini в обозримом будущем. Мошенники с ИИ зарабатывают до 4,5 раза больше обычных, сообщили в Интерполе
17.03.2026 [14:52],
Алексей Разин
Как и многие изобретения человечества, так называемый искусственный интеллект поставлен на службу не только добропорядочным гражданам, но и мошенникам. Последние с помощью ИИ получают прибыль в 4,5 раза выше, чем при использовании классических приёмов обмана своих жертв, подсчитали представители Интерпола. 
Источник изображения: Unsplash, Joshua Koblin ИИ не только повышает эффективность мошеннических действий, он привлекает к новым схемам всё большее количество злоумышленников. Чаще всего, по словам экспертов Интерпола, мошенники используют ИИ для устранения небольших просчётов, которые в противном случае выдали бы их истинную сущность. Например, при обращении к носителям других языков мошенники используют ИИ для устранения ошибок и погрешностей в тексте сообщений, которые могли бы насторожить потенциальных жертв. Подражание голосу кого-то из ближайшего окружения жертвы теперь тоже доверено ИИ-инструментам. Мошенникам достаточно голосового сообщения продолжительностью 10 секунд, чтобы правдоподобно сымитировать голос человека и попытаться с помощью такой подмены обмануть кого-то из его окружения. На чёрном рынке уже предлагаются целые комплексные услуги по имитации внешности и голоса людей из окружения потенциальной жертвы, поэтому мошенникам не требуется лично владеть соответствующими методами подлога для реализации своих преступных навыков. Такие услуги становятся всё более доступными, позволяя мошенникам чаще применять новые технологии в своих схемах обмана граждан. Соответственно, снижая затраты на реализацию преступного замысла, мошенник получает более высокую прибыль в случае успеха. Кроме того, количество обрабатываемых жертв также возрастает благодаря повышению производительности такого рода преступной деятельности. Сбор данных о потенциальных жертвах также поставлен на поток с помощью ИИ. Собрав всю доступную информацию о человеке из открытых источников, мошенники более ловко расставляют свои сети, чем это происходило ранее. Использование криптовалют для анонимных финансовых транзакций также позволяет преступникам избегать законного возмездия. В будущем, как считают представители Интерпола, преступники смогут ещё сильнее автоматизировать свои атаки на жертв. Сумму выкупа за похищенные данные такие преступные ИИ-агенты смогут назначать самостоятельно, а информационные ресурсы жертв будут постоянно мониториться на предмет наличия уязвимостей в системах защиты. Эксперты также выражают озабоченность растущим количеством схем вымогательства, связанных с генерацией компрометирующих жертву видео и фото деликатного характера. На реализацию таких схем работают целые организованные группы по всему миру, их количество только растёт. Организаторы буквально похищают людей в разных странах, чтобы заставлять их заниматься подобным преступным ремеслом под угрозой физической расправы. Органам правопорядка становится всё сложнее бороться с подобными группировками. Считается, что по всему миру в подобную деятельность могут быть вовлечены сотни тысяч людей. По итогам прошлого года финансовые потери от мошенничества достигли $442 млрд, по данным Интерпола, и в ближайшие несколько лет сумма будет только расти, во многом благодаря распространению ИИ. Одним только материальным ущербом жертвы мошенников не отделываются, часто страдает их репутация, социальные связи, а иногда даже речь идёт об утрате самой жизни. SRAM какой-то: Nvidia представила чип Groq 3 LPU для ускорения инференса ИИ-моделей на уровне токенов
17.03.2026 [14:45],
Дмитрий Федоров
На прошедшей в этом году конференции GTC генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) сообщил, что в этом году платформа Vera Rubin получит расширение. Nvidia использует для этого интеллектуальную собственность, приобретённую у Groq. В состав Rubin вошёл новый чип Nvidia Groq 3 LPU. Компания определяет его как ускоритель инференса. Его задача — выдавать токены в большом объёме и с низкой задержкой. 
Источник изображений: Nvidia Платформа Rubin уже включает шесть компонентов, из которых Nvidia собирает стоечные системы и затем масштабирует их до ИИ-фабрик. Это GPU Rubin, CPU Vera, коммутаторы внутрисистемного масштабирования NVLink 6, интеллектуальный сетевой адаптер ConnectX-9, процессор обработки данных BlueField-4 и коммутатор межсистемного масштабирования Spectrum-X с совместно интегрированной оптикой. Groq 3 LPU стал новым элементом этой платформы и ещё одним строительным блоком Rubin при масштабном развёртывании.  Groq 3 LPU отличается от большинства ИИ-ускорителей схемой памяти. Обычно такие системы используют HBM в качестве рабочего уровня памяти. Каждый Groq 3 LPU содержит 500 Мбайт SRAM. Для сравнения, каждый GPU Rubin оснащён 288 Гбайт HBM4. По ёмкости разница велика. По пропускной способности соотношение иное: SRAM обеспечивает до 150 Тбайт/с, а HBM4 — около 22 Тбайт/с. Для ИИ-задач, чувствительных к пропускной способности, рост этого показателя даёт преимущество при инференсе. Именно поэтому Nvidia вводит Groq 3 в состав Rubin.  Стойка Groq 3 LPX включает 256 чипов Groq 3 LPU. Такая система располагает 128 Гбайт SRAM. Её суммарная пропускная способность достигает 40 Пбайт/с. Для объединения чипов внутри стойки предусмотрен выделенный интерфейс внутрисистемного масштабирования. Его пропускная способность составляет 640 Тбайт/с на стойку.  Вице-президент Nvidia по гипермасштабируемым решениям Иэн Бак (Ian Buck) назвал Groq LPX сопроцессором для Rubin. По его словам, он повысит производительность декодирования «на каждом слое ИИ-модели на каждом токене». Nvidia связывает это решение со следующим рубежом ИИ — мультиагентными системами. Речь идёт о сценариях, где нужно обеспечивать интерактивную работу при инференсе моделей с триллионами параметров и окнами контекста в миллионы токенов.  Когда ИИ-агенты всё чаще обмениваются данными друг с другом, а не с человеком в окне чат-бота, меняется и порог приемлемого отклика. Скорость, достаточная для человека, оказывается слишком низкой для ИИ-агента. Бак описывает переход от мира, где разумным считался уровень 100 токенов в секунду, к уровню 1 500 токенов в секунду и выше для межагентного обмена.  Добавление Groq 3 LPU должно усилить позиции Rubin в сегменте низколатентного инференса. В тексте в качестве конкурента названа Cerebras. Компания использует процессоры Wafer-Scale Engine (WSE), выполненные на целой кремниевой пластине, где большие объёмы SRAM объединены с вычислениями для низколатентного инференса на продвинутых моделях. OpenAI также привлекала мощности Cerebras для обслуживания части передовых моделей из-за выгодных характеристик задержки этой платформы.  Иэн Бак также допустил, что появление Groq 3 LPU может сократить роль ускорителя инференса Rubin CPX. Он сказал, что сейчас Nvidia сосредоточена на интеграции стойки Groq 3 LPX с Rubin. Дополнительных подробностей он не привёл. При этом оба чипа рассчитаны на сходное усиление инференса, но Groq LPU не требует большого объёма памяти GDDR7, который нужен каждому модулю Rubin CPX. OpenAI откажется от второстепенных разработок, чтобы не проигрывать конкурентам ИИ-гонку
17.03.2026 [13:03],
Алексей Разин
После выхода осенью 2022 года ChatGPT стартап OpenAI проявлял завидную активность и всеядность с точки зрения поиска новых способов использования ИИ, но в условиях жёсткой конкуренции подобная тактика уже не может себя оправдывать с точки зрения бизнеса. Руководство компании готовится выделить приоритетные направления развития, чтобы отказаться от второстепенных. 
Источник изображения: OpenAI Как отмечает The Wall Street Journal, о грядущих изменениях в бизнес-стратегии OpenAI на общем собрании сотрудников сообщила директор по приложениям Фиджи Симо (Fidji Simo). По её словам, вышестоящие руководители в лице генерального директора Сэма Альтмана (Sam Altman) и ведущего исследователя Марка Чэня (Mark Chen) сейчас заняты поиском тех направлений деятельности, которые следует исключить из числа приоритетных. О принятых руководством решениях персонал OpenAI будет уведомлён в ближайшие недели. «Мы не можем упустить этот момент, поскольку нас отвлекают второстепенные задачи», — заявила сотрудникам OpenAI Фиджи Симо на прошлой неделе, как отмечает источник. «Нам реально нужно зафиксировать продуктивность в целом и в особенности — на бизнес-направлении», — добавила она. В прошлом году OpenAI анонсировала целый спектр инициатив, который охватывал самые разные сегменты рынка, от интернет-торговли и генерации видео до интернет-браузера и выпуска аппаратных устройств. Сэм Альтман пояснял такое многообразие проектов попыткой «ставить на несколько стартапов» внутри самой OpenAI. По имеющимся данным, в дальнейшем OpenAI хотела бы сосредоточиться на инструментах для генерирования программного кода и работе с корпоративными клиентами. В последней сфере преуспевает конкурирующая Anthropic, которой удаётся быстрее монетизировать собственные разработки, и OpenAI просто не желает отставать от соперника. Та же Anthropic пока не предложила клиентам средства для генерации видео и изображений, в отличие от OpenAI. Обе компании настроены выйти на IPO до конца текущего года, причём в случае с OpenAI выход на биржу может состояться в четвёртом квартале. Успех Anthropic в коммерческом сегменте рынка, по словам Симо, должен стать сигналом к пробуждению для OpenAI, и теперь компания ставит перед собой задачу выхода в лидеры как в сегменте инструментария для разработчиков ПО, так и для разного рода бизнес-клиентов. Бывшие и действующие сотрудники OpenAI признались The Wall Street Journal, что прежняя разнонаправленная стратегия компании мешала им сконцентрироваться на приоритетных задачах и понимать общую стратегию компании. Команда создателей генератора видео Sora, например, работала в подразделении стартапа, занимающегося исследованиями, хотя конечный продукт оказался одним из наиболее влиятельных и сложных среди разработок OpenAI. В прошлом сентябре Sora вышла в качестве самостоятельно приложения, но после первоначального наплыва пользователей последовал спад интереса, и теперь OpenAI намеревается встроить этот генератор видео в приложение ChatGPT. Нанятая в августе прошлого года Фиджи Симо предложила руководству более плотно интегрировать команды, занятые разработками и выпуском продуктов, а также унифицировать долгосрочную стратегию OpenAI вокруг повышения производительности труда своих пользователей. Инструмент Claude Code для автоматизации разработки ПО, выпущенный Anthropic, быстро набрал популярность среди профессионалов в этой сфере. Отыграть часть позиций на этом рынке OpenAI позволил выпуск инструмента Codex в прошлом месяце, а также дебют модели GPT 5.4, которая более ориентирована на профессиональное использование. Сейчас инструментом Codex еженедельно пользуются более двух миллионов пользователей, что в четыре раза выше показателя по состоянию на начало года. OpenAI решила активнее привлекать к разработке своих моделей консультантов со стороны и представителей клиентов. При этом Фиджи Симо не считает целесообразным регулярно объявлять «красный код опасности», но предлагает сотрудникам OpenAI работать, словно бы соответствующее объявление было сделано. Nvidia ускорит и обезопасит запуск ИИ-агентов — представлены Agent Toolkit и NemoClaw
17.03.2026 [12:51],
Павел Котов
Среди прочих крупных анонсов на мероприятии GTC 2026 глава компании Nvidia Дженсен Хуанг (Jensen Huang) анонсировал множество новых моделей искусственного интеллекта, а также инструменты Agent Toolkit и NemoClaw, предназначенные для быстрого запуска ИИ-агентов на оборудовании Nvidia. 
Источник изображений: nvidia.com Nvidia Agent Toolkit — платформа с открытым исходным кодом, предназначенная для разработчиков и располагающая средствами стандартизации и масштабирования при запуске автономных ИИ-агентов в масштабах предприятия. NemoClaw представляет собой программный стек на основе популярного OpenClaw с дополнительными средствами обеспечения конфиденциальности и контроля. Оба инструмента предназначены для ускоренного развёртывания ИИ-агентов и предлагают оптимизацию для оборудования Nvidia — от компактных DGX Spark до мощных серверов Vera Rubin. Компания отметила, что множество её партнёров уже взяли на себя обязательства вести разработку с использованием средств Agent Toolkit — среди них упомянуты Adobe, Salesforce, SAP, ServiceNow, Siemens, CrowdStrike, Atlassian и Palantir. Agent Toolkit позволяет быстро интегрировать функции ИИ-агентов в бизнес-приложения с общими ресурсами и едиными стандартами — это снижает нагрузку на инженеров и обеспечивает тесную связь с имеющимся вычислительным стеком Nvidia, что помогает оптимизировать производительность.  NemoClaw представляет собой готовый программный пакет, включающий установку OpenClaw, открытых моделей Nvidia Nemotron и среды выполнения OpenShell одной командой. Стандартный вариант OpenClaw получил дополнительные функции конфиденциальности, безопасности и оперативного контроля для ИИ-агентов. В качестве аппаратной платформы могут выступать ПК с видеокартами Nvidia RTX, компьютеры DGX Spark и DGX Station, а также серверы с ускорителями Nvidia. Компания упомянула, что с обновлением ПО появилась поддержка кластеризации до четырёх систем DGX Spark в единой конфигурации (против двух на момент запуска).  Отдельно было сказано о новом партнёрском проекте Nvidia с Adobe — последнюю заинтересовали средства Agent Toolkit, компания также решила интегрировать в свои приложения инструменты CUDA-X и Omniverse, а ИИ-модели нового поколения будут обучаться на ИИ-оборудовании Nvidia. «Зелёные» напомнили о семействе открытых моделей Alpamayo класса Vision-Language-Action (VLA) для систем автопилота. Наконец, было объявлено о создании организации Nemotron Coalition, в которую, помимо самой Nvidia, вошли Black Forest Labs, Cursor, LangChain, Mistral AI, Perplexity, Reflection AI, Sarvam и Thinking Machines Lab. Они решили вести разработку открытых ИИ-моделей совместно, используя единые ресурсы Nvidia DGX Cloud, что позволит им не дублировать усилия на базовых этапах. Специализация будет проводиться с учётом потребностей отраслей, регионов и сценариев использования — результаты работы коалиции лягут в основу перспективного семейства моделей Nemotron 4. Глава SK hynix рассказал, когда дефицит памяти может закончиться
17.03.2026 [12:28],
Алексей Разин
Одним из явных последствий бума систем искусственного интеллекта на данном этапе развития стал усиливающийся дефицит памяти большинства типов, который больно бьёт практически по всем сегментам рынка электроники. По мнению председателя совета директоров SK hynix Чхэ Тхэ Вона (Chey Tae-won), дефицит памяти продлится до 2030 года. 
Источник изображения: SK hynix Этот представитель отрасли вполне имеет право делать подобные прогнозы, поскольку SK hynix остаётся вторым после Samsung Electronics производителем памяти всех типов, а в сегменте HBM она лидирует благодаря своим плотным и давним связям с Nvidia. Как поясняет Nikkei Asian Review, главу южнокорейского гиганта пригласили в Калифорнию на конференцию GTC 2026, которую Nvidia использовала для анонса своей ИИ-платформы Vera Rubin. По мнению Чхэ Тхэ Вона, отрасли потребуется ещё от четырёх до пяти лет, чтобы наладить выпуск памяти в количествах, достаточных для удовлетворения спроса. В отличие от тайваньской TSMC, компания SK hynix пока не намерена активно расширять производство памяти за пределами родной страны. Как пояснил глава SK hynix, при реализации зарубежных проектов основной проблемой является доступ к водным и энергетическим ресурсам, и дело тут вовсе не в наличии государственных субсидий на строительство новых фабрик. Возможности производителей по наращиванию объёмов выпуска памяти ограничены, по словам представителя SK hynix, поэтому участникам рынка прежде всего следует постараться стабилизировать цены. Основатель Nvidia Дженсен Хуанг (Jensen Huang) вчера заявил, что спрос на ИИ-чипы вырос в 10 000 раз, поскольку профильные технологии применяются во многих отраслях экономики и весьма востребованы. Для SK hynix военные действия на Ближнем Востоке стали серьёзной проблемой с точки зрения сохранения доступа к энергетическим ресурсам и цен на них. Компании пришлось искать альтернативные источники энергоносителей для сохранения своей способности работать в обычном режиме. Это не мешает SK hynix задумываться о выходе на американский фондовый рынок через депозитарные расписки. Доступ к крупным рынкам капитала важен для любой компании, находящейся в стадии активного роста, а бум ИИ пока создаёт соответствующие условия для производителей памяти. Nvidia показала полный стек Vera Rubin — от GPU до сетей для ИИ-фабрик нового поколения
17.03.2026 [10:01],
Алексей Разин
Являясь одним из лидеров в сфере вычислительной инфраструктуры для систем искусственного интеллекта, Nvidia комплексно подходит к развитию собственных платформ, а потому вместе с ускорителями поколения Vera Rubin предложила ряд сопутствующих аппаратных решений. 
Источник изображений: Nvidia Как отмечается в корпоративном пресс-релизе, платформа Vera Rubin открывает новые рубежи в развитии агентского искусственного интеллекта. В массовом производстве сейчас находятся семь новых чипов Nvidia, позволяющих эффективно масштабировать так называемые ИИ-фабрики. В число семи аппаратных новинок Nvidia вошли графические процессоры Rubin, центральные процессоры Vera, коммутаторы NVLink 6, сетевые решения ConnectX-9 SuperNIC, специализированные процессоры BlueField-4 и Ethernet-коммутаторы Spectrum-6, а также созданные с помощью разработок одноимённого поглощённого стартапа процессоры Groq для ускорения инференса при работе с ИИ-агентами. В совокупности они работают, как ИИ-суперкомпьютер, как отмечается в материалах Nvidia для прессы на официальном сайте компании, позволяя ускорять создание профильных технологий на всех этапах жизненного цикла ИИ-систем. Основатель и глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что с выходом платформы Vera Rubin наступил переломный момент в развитии агентского ИИ, поскольку данная платформа будет способствовать самому масштабному развёртыванию инфраструктуры в истории. Руководители OpenAI и Anthropic прокомментировали анонс Vera Rubin в предсказуемо хвалебных выражениях, подчёркивая значение этого события для всей ИИ-отрасли. Разработчики ИИ-моделей теперь смогут совершенствовать их и делать это быстрее, чем на аппаратных решениях прошлого поколения. Структура ЦОД теперь строится на готовых модулях, как считают в Nvidia, которые содержат всё необходимое для эффективного масштабирования вычислительных мощностей с учётом постоянного роста сложности решаемых задач. Клиенты могут сочетать готовые модули ЦОД с учётом специфики своей деятельности. Например, в одной стойке Vera Rubin NVL72 находятся 72 графических процессора Rubin и 36 центральных процессоров Vera, соединённых скоростной шиной NVLink 6 и сетевыми контроллерами ConnectX-9 SuperNIC, а также специализированные процессоры BlueField-4, которые разгружают центральные процессоры от задач работы с сетевым трафиком. По сравнению с решениями поколения Blackwell новые системы Vera Rubin справляются с обучением сложных моделей силами в четыре раза меньшего количества GPU. Пропускная способность в пересчёте на ватт потребляемой энергии в задачах инференса у Vera Rubin до десяти раз выше, а затраты на один токен в десять раз ниже. В кластерах стойки NVL72 масштабируются при помощи Quantum-X800 InfiniBand и Spectrum-X Ethernet. Центральные процессоры Vera, по словам представителей Nvidia, хорошо себя проявляют в задачах обучения с подкреплением и агентских ИИ-нагрузках. Компания может объединять в одной стойке до 256 таких процессоров, оснащённых системой жидкостного охлаждения. С прочими компонентами кластера они могут сообщаться при помощи сетевых решений Spectrum-X. По сравнению с некими традиционными CPU, на которые ссылается Nvidia, её процессоры Vera могут справляться с ИИ-задачами на 50 % быстрее.  Специализированные чипы Groq 3 LPX обеспечивают эффективную работу с агентскими ИИ-нагрузками при минимальных задержках. В сочетании с другими чипами, входящими в состав платформы Vera Rubin, они обеспечивают увеличение пропускной способности в задачах инференса до 35 раз на один мегаватт потребляемой мощности, а потенциал выручки при использовании моделей с триллионом параметров увеличивается в десять раз. В состав одной стойки входит 256 чипов LPU, 128 Гбайт интегрированной на них памяти SRAM, а пропускная способность достигает 640 Тбайт/с. В сочетании с прочими компонентами платформы Vera Rubin, чипы LPU достигают максимальной эффективности как по быстродействию, так и по энергопотреблению, а также использованию ресурсов памяти. Стойки LPX будут доступны клиентам Nvidia со второй половины текущего года. Стойка BlueField-4 STX специализируется на унификации адресного пространства GPU между элементами кластера. Обработка хранимой в кеше информации в операциях инференса ускоряется до пяти раз, при этом обеспечивается высокая энергоэффективность по сравнению с системами на классической архитектуре. Достигается общий для кластера контекст, обеспечивающий быстрое взаимодействие с ИИ-агентами и более эффективно масштабируемыми ИИ-сервисами. Отдельная стойка Spectrum-6 SPX отвечает за скоростной обмен данными по интерфейсу Ethernet. Она может содержать не только коммутаторы Spectrum-X Ethernet, но и коммутаторы Nvidia Quantum-X800 InfiniBand в зависимости от потребностей конкретной конфигурации. В исполнении с кремниевой фотоникой и интеграцией на уровне упаковки чипов эффективность передачи информации возрастает в пять раз, а надёжность по сравнению с традиционными подключаемыми решениями увеличивается в десять раз. «Не могу поверить, что это не первоапрельская шутка»: нейронный рендеринг в DLSS 5 оказался больше похож на ИИ-фильтр
17.03.2026 [08:42],
Михаил Романов
Анонсированное компанией Nvidia на конференции GTC 2026 интеллектуальное масштабирование DLSS 5 вызвало стойкое отторжение среди геймеров, ценящих художественный замысел своих любимых игр. 
Источник изображений: Nvidia По словам Nvidia, DLSS 5 использует модель нейронного рендеринга в реальном времени, которая насыщает игровые кадры фотореалистичным освещением и детализацией материалов. Несмотря на громкие обещания, дебютная демонстрация DLSS 5 на YouTube-канале Nvidia (см. видео ниже) собрала в четыре раза больше дизлайков, чем лайков — 48 тыс. негативных оценок на 11 тыс. положительных. Пользователи массово раскритиковали то, как DLSS 5 преображает изображение и, в частности, персонажей. Например, Грейс Эшкрофт из Resident Evil Requiem после инъекции DLSS 5 получила более пухлые губы и более выразительные скулы. Предполагается, что новый апскейлер Nvidia должен сделать героев более реалистичными, но выглядит, словно их обработал ИИ-фильтр. «Не могу поверить, что это не первоапрельская шутка», — удивляется azul1458. Сравнения от Nvidia
В комментариях к ролику Nvidia уверяет, что DLSS 5 предоставляет разработчикам полный художественный контроль над эффектами масштабирования, что позволяет им «сохранять уникальную эстетику своей игры». Релиз DLSS 5 ожидается осенью. Первыми играми с поддержкой технологии станут Resident Evil Requiem, Starfield, The Elder Scrolls IV: Oblivion Remastered, Assassin’s Creed Shadows, Hogwarts Legacy, Delta Force и Naraka: Bladepoint. ИИ победил офисы: в США строят больше дата-центров, чем офисных зданий
17.03.2026 [07:31],
Алексей Разин
Рынок коммерческой недвижимости США, как отмечает Bloomberg, в условиях бума ИИ переживает важные структурные изменения. Впервые расходы на строительство центров обработки данных ($3,57 млрд) по итогам декабря прошлого года превысили затраты на строительство офисных помещений ($3,49 млрд). 
Источник изображения: Oracle Бум искусственного интеллекта заставляет участников рынка вкладываться в вычислительную инфраструктуру, большинство американских облачных гигантов сейчас активно вкладывается в строительство крупных ЦОД на территории США. На примере строительной компании Turner Construction поясняется, что сооружение ЦОД становится для девелоперов всё более важным направлением бизнеса. В прошлом году конкретный застройщик реализовал профильных проектов на сумму $9,4 млрд, что более чем в пять раз больше показателя 2020 года. В прошлом месяце компания Meta✴✴ Platforms выбрала Turner Construction в качестве подрядчика по строительству ЦОД стоимостью $10 млрд в штате Индиана. Более трети текущего портфеля проектов этого застройщика сейчас связано с возведением ЦОД. На их реализацию уйдёт несколько лет, и для компании это хороший бизнес. Крупные инвестиционные компании также интересуются подобными проектами в надежде неплохо заработать на буме ИИ. В то же время, строительство офисных помещений в США ведётся достаточно вяло ещё со времён пандемии, когда удалённая работа сделала потребность в новых площадях весьма ограниченной. В декабре прошлого года затраты на строительство ЦОД в США достигли $3,57 млрд, превысив затраты на строительство офисных помещений, которые составили $3,49 млрд. Эксперты считают, что в случае успешного внедрения ИИ корпорациям потребуется меньше новых сотрудников, и этот фактор также повлияет на снижение спроса в строительной сфере, если говорить о новых офисных площадях. Развитие инфраструктуры ЦОД на территории США подразумевает заключение контрактов сроком на 10 или даже 15 лет с участниками проектов, среди которых встречаются не только техногиганты, которые будут непосредственно эксплуатировать вводимые в строй вычислительные мощности. Потребности подобных объектов в адекватном энергоснабжении подталкивают тарифы на электроэнергию к росту, и это вызывает протесты жителей соседних с ЦОД районов. Строители, которые ранее не имели опыта возведения подобных объектов, изначально воспринимали специфику работы легкомысленно, но в процессе реализации проектов поняли, что всё не ограничивается возведением бетонного корпуса для ЦОД, а требует намного более сложных процессов и технологий. Объекты такого типа подразумевают создание серьёзнейшей инженерной инфраструктуры, от систем охлаждения до энергоснабжения с обязательным резервированием источников. На огромных площадях может располагаться более 10 зданий, которые соединяются между собой сложными техническими коммуникациями. По некоторым оценкам, если в 2020 году возведение условного ЦОД на 1 МВт обходилось в $8 млрд, то в прошлом году стоимость выросла до $11 млрд. При этом энергетическая инфраструктура формирует до 38 % профильных затрат. Потребность в кадровых ресурсах при строительстве ЦОД тоже заметно выше. Если офисное здание общей площадью 46 500 квадратных метров может требовать работы около 300 специалистов различных профилей, то сопоставимый по площади ЦОД потребует уже 800 рабочих, причём механики и электрики будут формировать от 70 до 80 % этого штата. Проекты по возведению ЦОД сильнее растянуты во времени, поэтому в общей сложности нанимаемые для строительства специалисты успевают заработать больше за период реализации проекта. Высокий спрос на специалистов по монтажу серверного оборудования открывает хорошие перспективы для их кадрового роста. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex













