|
Опрос
|
реклама
Быстрый переход
PlayStation 3 служила в армии: ВВС США построили из приставок суперкомпьютер в 2010 году
28.07.2026 [14:00],
Владимир Фетисов
Исследовательская лаборатория ВВС США (AFRL) в 2010 году построила суперкомпьютер на базе 1760 игровых консолей Sony PlayStation 3. Система получила название Condor Cluster, она размещалась в Риме, штат Нью-Йорк, и использовалась для повышения эффективности радаров, обработки спутниковых снимков и проведения исследований в области ИИ. На тот момент Condor Cluster занимал 33-е место в рейтинге самых производительных суперкомпьютеров в мире. 
Источник изображения: techspot.com Директор по высокопроизводительным вычислениям в AFLR Марк Барнелл (Mark Barnell) рассказал, что общая стоимость кластера оценивалась всего в $2 млн, что составляло всего 5-10 % стоимости сопоставимых по мощности суперкомпьютеров того времени. В то время стоимость одной консоли PlayStation 3 составляла около $400. Если бы AFLR использовала стандартные компьютерные компоненты, то пришлось бы тратить $10 тыс. за единицу оборудования. Консоль PlayStation 3 была выбрана из-за её эффективности при обработке высококачественной графики, а также относительно невысокой стоимости. Condor Cluster включал в себя 168 отдельных графических процессоров и 84 координирующих сервера в параллельном массиве. Мощность кластера составляла 500 TFLOPS. PlayStation 3 подходила для задач AFLR ещё и потому, что консоль могла работать на Linux. Позднее такая возможность исчезла, что воспрепятствовало созданию подобных кластеров другими исследователями. Успех Condor Cluster подчеркнул потенциал игровых технологий для выполнения научных и военных задач. Проект наглядно показал, как потребительская электроника, обычно используемая для развлечений, может быть перепрофилирована для выполнения серьёзной вычислительной работы. С тех пор прошло ещё десятилетие, прежде чем графические процессоры стали основой для обучения больших языковых моделей и выполнения других задач. Этот разрыв выглядит сегодня ещё более поразительно: несколько современных высокопроизводительных графических процессоров могут обеспечить производительность, сопоставимую с возможностями Condor Cluster, что напоминает о том, несколько быстро масштабировались вычисления с 2010 года. До появления Condor Cluster реализовывались менее масштабные проекты, в рамках которых в кластеры объединились консоли PlayStation 3, но не в таком количестве, как в случае проекта AFLR. Отметим, что Condor Cluster просуществовал недолго после введения в эксплуатацию. Уже в 2015 году систему перестали использовать, поскольку Sony лишила консоль возможности запуска Linux, а пришедшая ей на смену PlayStation 4 не позволяла объединять устройства в кластеры аналогичным образом. Это лишило исследователей возможности для создания нового кластера или расширения существующего. Илон Маск предложил превратить зарядные станции Tesla в площадки для ИИ-суперкомпьютеров Megapod
23.07.2026 [12:26],
Алексей Разин
Слова главы SpaceX и Tesla Илона Маска (Elon Musk) о пересечении бизнеса этих компаний на недавней квартальной отчётной конференции нашли подтверждение в ещё одной идее миллиардера. Он предложил использовать силовую инфраструктуру мощных зарядных станций Tesla для энергоснабжения блочных суперкомпьютеров, формирующих распределённую вычислительную сеть. 
Источник изображения: Tesla Иронично, что эти блочные суперкомпьютеры Маск нарёк Megapod — точно так же, как AMD называет свои серверные системы, насчитывающие по 64 центральных процессора EPYC и 256 ускорителей вычислений Instinct MI500. Учитывая, что AMD данное наименование упоминала ещё осенью прошлого года, Tesla наверняка придётся присвоить своим решениям иное имя ради исключения путаницы и претензий со стороны AMD. Так или иначе, на недавней квартальной конференции Илон Маск упомянул блочный суперкомпьютер Megapod, который должен сочетать чипы Tesla AI4 собственной разработки и центральные процессоры с x86-совместимой архитектурой. Кто будет поставлять последние, не уточняется, но главной особенностью такого суперкомпьютера будет инфраструктурная самодостаточность. Его буквально можно будет перевезти в контейнере в нужное место, подключить к источнику питания и каналам связи, после чего он сможет влиться в распределённую фирменную сеть вычислений. Ради оптимизации расходов на создание инфраструктуры Маск предложил ставить такие суперкомпьютеры возле мощных зарядных станций Supercharger, поскольку те обеспечены линиями энергоснабжения подходящего номинала. Идея здравая, нужно только убедиться, что пропускная способность каналов связи не станет узким местом в такой распределённой вычислительной системе. Возможно, в этой сфере Маск готов опираться на возможности ещё одной своей компании — Starlink, которая обеспечивает скоростной спутниковой связью даже самые отдалённые уголки планеты. Китай снова на вершине TOP500: суперкомпьютер LineShine без чипов Nvidia, Intel и AMD стал самым мощным в мире
23.06.2026 [14:10],
Владимир Мироненко
23 июня на конференции ISC 2026 в Гамбурге (Германия) был объявлен 67-й выпуск списка TOP500 самых мощных суперкомпьютеров мира. На первом месте дебютировала система LineShine из Китая, ранее не входившая в список, сместив американский El Capitan с позиции самого мощного суперкомпьютера в мире по результатам теста High Performance Linpack (HPL). 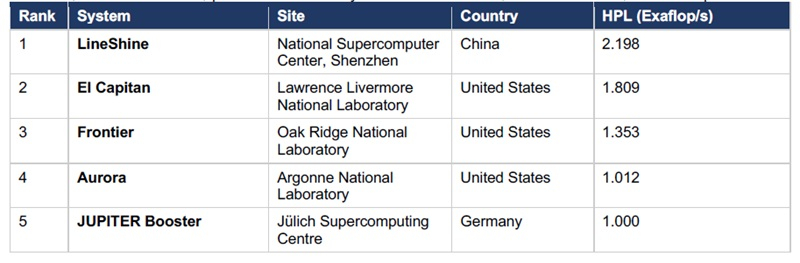
Источник изображения: hpcwire.com LineShine стал первым суперкомпьютером, официально превысившим 2 Эфлопс в бенчмарке Linpack от TOP500, вторым китайским суперкомпьютером, занявшим первое место в TOP500, и пятой в мире системой с вычислительной мощностью уровня экзаскейл. Система LineShine достигла производительности 2,198 Эфлопс в HPL — около 80 % от своего теоретического пика в 2,736 Эфлопс, став первой системой в TOP500, превысившей 2 Эфлопс устойчивой производительности в вычислениях с двойной точностью, используя только центральные процессоры. Установленная в Национальном суперкомпьютерном центре в Шэньчжэне (NSCS) и созданная Шэньчжэньским центром облачных вычислений, система основана на кастомном китайском процессоре LX2 и платформе LingKun: 13,79 млн ядер в 304-ядерных процессорах LX2 с частотой 1,55 ГГц, соединённых фирменным интерконнектом LingQi и работающих под управлением ОС Kylin. Сообщается, что LineShine потребляет приблизительно 42,2 МВт энергии, что обеспечивает энергоэффективность на уровне 52,07 Гфлопс/Вт. В последний раз китайская система возглавляла рейтинг TOP500 в 2017 году — речь идёт о Sunway TaihuLight, показавшей производительность 93 Пфлопс в бенчмарке HPL. Система LineShine также заняла первое место в рейтинге HPCG с результатом 22,00 Пфлопс. В бенчмарке HPL-MxP со смешанной точностью LineShine достигла 7,92 Эфлопс, заняв четвёртое место, что представляет собой сравнительно скромное ускорение в 3,6 раза по сравнению с результатом HPL и указывает на использование только ЦП, без выделенных ускорителей. LineShine, заняв первое место в TOP500, оттеснила остальные суперкомпьютеры на одну позицию ниже. Суперкомпьютер El Capitan из Ливерморской национальной лаборатории имени Эрнеста Лоуренса (LLNL) занял второе место с производительностью 1,809 Эфлопс, Frontier из Национальной лаборатории Ок-Ридж (ORNL) — третье с 1,353 Эфлопс, Aurora из Аргоннской национальной лаборатории Министерства энергетики США (ANL) — четвёртое с 1,012 Эфлопс, а JUPITER Booster из Юлихского суперкомпьютерного центра оказался на пятом месте с показателем 1,000 Эфлопс. Ещё один новичок в топ-10 — HPC7 компании Eni S.p.A. из Италии с производительностью 571,5 Пфлопс, построенный на той же архитектуре HPE Cray EX255a с AMD Instinct MI300A, что и El Capitan. Среди стран США по-прежнему имеют наибольшее количество суперкомпьютерных систем, однако их число уменьшилось на десять по сравнению с предыдущим рейтингом от ноября 2025 года. Благодаря новой системе Китай располагает второй по величине суммарной вычислительной мощностью, но, имея всего 30 систем, занимает четвёртое место по их количеству. Германия и Япония опередили Китай, а Франция вновь заняла пятое место. Asus представила настольный компьютер с Nvidia GB300 и 748 Гбайт памяти по цене однушки в Москве
15.06.2026 [22:58],
Николай Хижняк
Компания Asus выпустила ExpertCenter Pro ET900N G3 — настольную систему искусственного интеллекта на базе платформы Nvidia DGX Station GB300. В составе ПК используется суперчип Nvidia GB300 Grace Blackwell Ultra. Система предназначена для локального обучения ИИ, инференса и выполнения задач агентного ИИ. 
Источник изображений: Asus В отличие от большинства ИИ-систем на базе оборудования для центров обработки данных, ExpertCenter Pro ET900N G3 выглядит как большой домашний компьютер. Сама Asus называет его настольным суперкомпьютером для ИИ, что означает, что он предназначен для развёртывания в офисе или лаборатории, а не для установки в серверную стойку.  Система оснащена 748 Гбайт когерентной памяти, распределённой между 72-ядерным процессором Arm Neoverse V2 Grace (496 Гбайт памяти LPDDR5X) и графическим процессором Blackwell Ultra (252 Гбайт памяти HBM3e). Пропускная способность памяти процессора составляет 396 Гбайт/с, а графического процессора — 7,1 Тбайт/с.  Asus заявляет о производительности системы до 20 Пфлопс в задачах ИИ. В ExpertCenter Pro ET900N G3 используется сетевая карта Nvidia ConnectX-8 SuperNIC и заявлена поддержка интерфейса Nvidia NVLink-C2C, который соединяет процессор и GPU.  В качестве операционной системы ExpertCenter Pro ET900N G3 использует Ubuntu с инструментами разработчика Nvidia AI. Однако Asus подтверждает, что в будущем планируется поддержка Windows для разработки ИИ и агентных сред на базе Windows. ExpertCenter Pro ET900N G3 также поддерживает до четырёх твердотельных накопителей M.2 2280 NVMe. Для системы заявлены два слота PCIe 5.0 x4 с поддержкой RAID 1 и два слота PCIe 6.0 x4 для хранения обучающих данных. В составе также имеются три слота расширения PCIe: один PCIe 5.0 x16 и два PCIe 5.0 x8. 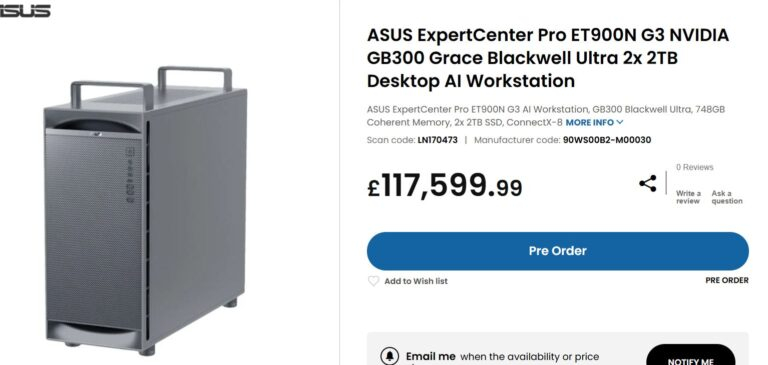
Источник изображения: Scan UK По данным британского ретейлера Scan UK, ExpertCenter Pro ET900N G3 стоит 117 599,99 фунта стерлингов, что эквивалентно примерно 11,5 млн рублей по нынешнему курсу. Nvidia представила настольный суперкомпьютер DGX Station на Windows — суперчип GB300 и 748 Гбайт памяти
01.06.2026 [23:21],
Николай Хижняк
На выставке Computex 2026 компания Nvidia анонсировала DGX Station для Windows — настольный суперкомпьютер на базе процессора Nvidia GB300 Grace Blackwell Ultra Desktop Superchip, разработанный для мощных ИИ-агентов и ресурсоёмких корпоративных задач в области ИИ. Платформа переносит инфраструктуру ИИ класса Grace Blackwell от Nvidia в экосистему Windows, обеспечивая поддержку ИИ-моделей с триллионами параметров. 
Источник изображений: Nvidia В основе системы, которая выглядит как рабочая станция, лежит SoC Nvidia GB300 Grace Blackwell Ultra Desktop Superchip. Чип сочетает мощный 72-ядерный CPU Nvidia Grace с унифицированной памятью объёмом до 748 Гбайт и может подключаться к дискретному графическому процессору Nvidia Blackwell, например Nvidia RTX PRO 6000 Blackwell Workstation Edition, через интерфейс NVLink-C2C, обеспечивающий лучшую в своём классе связь и производительность. Заявленная производительность DGX Station в операциях FP4 составляет до 20 Пфлопс. Впечатляет и сетевая пропускная способность рабочей станции: до 800 Гбайт/с через сетевой адаптер ConnectX-8 SuperNIC, который обеспечивает быструю передачу данных по сети и возможность подключения нескольких систем DGX Station. Nvidia отмечает, что DGX Station была разработана в сотрудничестве с Microsoft для масштабируемого запуска ИИ-агентов для инженерных, проектных и других задач в рамках новой защищённой управляемой платформы с открытым исходным кодом Nvidia OpenShell.  «На протяжении десятилетий Microsoft и Nvidia сотрудничают для развития самых мощных вычислительных платформ в мире. Сегодня мы выводим это сотрудничество на новый уровень, масштабируя всю мощь Windows от тонких и лёгких ПК до рабочих станций центров обработки данных с помощью DGX Station на базе GB300. Это открывает новый класс производительности ИИ на Windows, платформе, которой предприятия доверяют в вопросах безопасности, управляемости и совместимости», — сказал Паван Давулури (Pavan Davuluri), исполнительный вице-президент Windows & Devices в Microsoft. «По мере того, как предприятия масштабируют агентов ИИ по всей своей организации, им необходима инфраструктура ИИ, которая может напрямую подключаться к приложениям и рабочим процессам, обеспечивающим работу их бизнеса. DGX Station предоставляет возможности ИИ суперкомпьютерного класса непосредственно в среде Windows, где миллионы людей уже ежедневно занимаются проектированием, разработкой, исследованиями и созданием», — сказал Крис Марриотт (Chris Marriott), вице-президент по корпоративным платформам Nvidia. Выпуск DGX Station для Windows запланирован на четвёртый квартал 2026 года. Системы будут поставляться компаниями Asus, Dell Technologies, Gigabyte, HP, MSI и Supermicro. В Китае построят мощнейший в мире суперкомпьютер на одних лишь CPU — LineShine обеспечит 2 Эфлопс
29.04.2026 [13:50],
Павел Котов
Национальный суперкомпьютерный центр Китая в Шэньчжэне анонсировал проект суперкомпьютера LineShine, который сможет обеспечить производительность в 2 Эфлопс, что сделает его одной из самых производительных машин в мире. Его отличительной особенностью является применение только центральных процессоров и использование только китайских компонентов. 
Источник изображения: Joshua Sortino / unsplash.com Суперкомпьютер будет построен в два этапа — на первом будут установлены 100 серверов Huawei Kunpeng, располагающих в общей сложности 12 800 ядрами. На втором этапе будут установлены ещё 47 000 процессоров, распределенных по 92 вычислительным стойкам; узлы будут соединяться миллионом портов; архитектура также предусматривает 36 стоек коммутаторов, 67 стоек систем хранения данных, 428 узлов накопителей с пропускной способностью 10 Тбайт/с. После ввода в эксплуатацию общий объем хранилища составит 650 Пбайт. В общей сложности суперкомпьютер будет включать 20 480 вычислительных узлов по два процессора LX2 на каждый. Каждый чип LX2 включает в себя два вычислительных кристалла на архитектуре ARMv9, всего 304 ядра и восемь встроенных стеков HBM ёмкостью 32 Гбайт с пропускной способностью 4 Тбайт/с. Вычислительный кристалл содержит 152 ядра и 128 Гбайт внешней памяти DDR в четырёх доменах NUMA; обмен данными между DDR и HBM обеспечит специальный механизм SDMA. Расширения SME и SVE позволяют LX2 обрабатывать данные форматов FP64/FP32/FP16/INT8; производительность FP64 и FP32 составляет 60,3 и 120,6 Тфлопс на чип соответственно. Узлы соединяются высокоскоростной сетью LingQi в двухплоскостную инфраструктуру с многоканальной схемой и топологией «толстого дерева» с пропускной способностью 1,6 Тбит/с. С общей производительностью 2 Эфлопс это будет один из мощнейших суперкомпьютеров мира, и уж точно самый быстрый из работающих только на центральных процессорах. LineShine будет использоваться для инженерных, научных расчётов и в приложениях искусственного интеллекта для таких областей как молекулярная динамика, моделирование жидкостей, биологические науки, а также обучение и развёртывание ИИ-моделей. В ближайшие годы человек станет «ходячим суперкомпьютером» с ИИ
21.04.2026 [16:33],
Павел Котов
Персональная электроника подходит к тому моменту, когда суммарная вычислительная мощность систем искусственного интеллекта в повседневных устройствах окажется наравне с системами, которые когда-то имели масштабы центров обработки данных. Таков прогноз консалтинговой компании Futuresource. 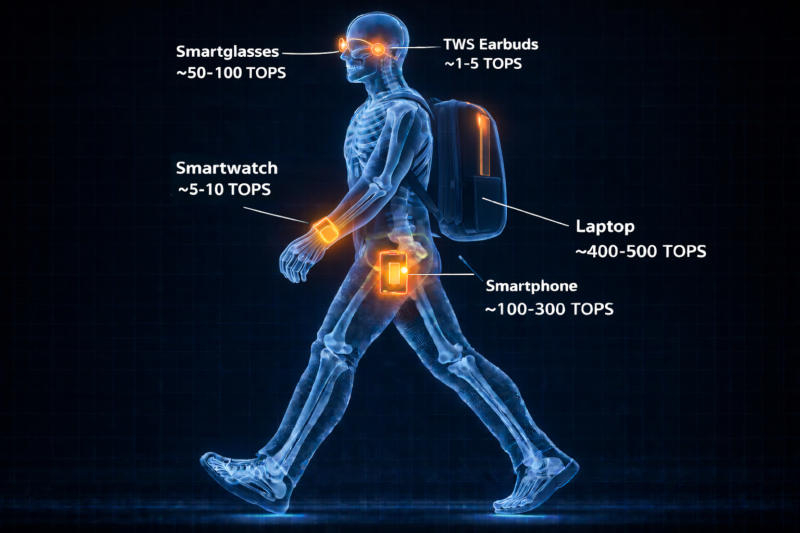
Источник изображения: techradar.com В исследовании говорится о распространении нейропроцессоров в смартфонах, аудиоустройствах и носимой электронике — рост производительности в этих категориях способен поменять наши ожидания от вычислительной мощности персональных устройств. Главная роль в этом отводится смартфонам — флагманские чипы Qualcomm, MediaTek, Samsung и Apple уже предлагают производительность до 100 TOPS для систем ИИ. К концу десятилетия, гласит прогноз, производительность нейропроцессоров на одних только смартфонах может вырасти в три раза. От смартфонов не отстают и смарт-часы, в которых также начинают появляться небольшие ускорители ИИ. К 2025 году мировые поставки умных часов достигли около 94 млн единиц, что свидетельствует об их высокой популярности. Ещё популярнее беспроводные наушники — ежегодно отгружаются по 360 млн пар, а поскольку собственный процессор присутствует в каждом наушнике речь идёт о более чем 700 млн единиц. Присутствие такого числа устройств с поддержкой ИИ указывает, что человек превращается в своего рода «ходячий суперкомпьютер». Допускается, что уже к 2030 году суммарная ИИ-производительность персональной электроники, которую человек носит с собой, превысит 1000 TOPS (1 POPS), хотя привычным явлением это ещё не станет. Средний показатель будет варьироваться в диапазоне от 450 до 550 TOPS. Одни только показатели производительности не всегда отражают результат, но переход на локальную обработку данных с облачной снижает зависимость от сторонних сервисов, сокращает время отклика и позволяет хранить конфиденциальные данные на самом устройстве. Хакеры взломали китайский суперкомпьютер и украли 10 Пбайт секретных данных, включая схемы ракет и военные исследования
09.04.2026 [11:48],
Павел Котов
Некий хакер взломал принадлежащий китайским властям суперкомпьютер и, сохраняя доступ к нему в течение полугода, незаметно для его администраторов похитил из системы 10 петабайтов секретных данных, в том числе документы министерства обороны и схемы ракет. 
Источник изображения: Arif Riyanto / unsplash.com Данные были похищены из Национального суперкомпьютерного центра в Тяньцзине, который предлагает услуги более чем 6000 клиентам по всему Китаю, в том числе научным и оборонным ведомствам. Хакер выложил под псевдонимом FlamingChina в Telegram образцы похищенных документов — по его словам, они включают материалы исследований в области аэрокосмической техники, военного направления, биоинформатики, моделирования термоядерного синтеза и многого другого. Информация принадлежит ведущим организациям страны, в том числе Китайской корпорации авиационной промышленности, Китайской корпорации коммерческого самолётостроения и Национальному университету оборонных технологий. За несколько тысяч долларов предлагается ограниченный предварительный обзор набора данных, стоимость полного доступа к ним исчисляется сотнями тысяч долларов — оплата принимается в криптовалюте. В образцах данных приводятся документы на китайском языке с пометкой «секретно», технические файлы, анимированные симуляции, а также изображения военной техники, включая ракеты и бомбы. Материалы в целом соответствуют тому, что предполагается обнаружить в суперкомпьютерном центре — большинству его клиентов нет смысла строить и поддерживать собственную инфраструктуру суперкомпьютера, считают эксперты. Центр в Тяньцзине открылся в 2009 году и был первым в своём роде в Китае, сейчас подобные работают также в Гуанчжоу, Шэньчжэне и Чэнду. Учитывая объём похищенных данных, изучить эти материалы под силу разве что государственным разведслужбам недружественных Китаю государств, потому что только у них могут быть достаточные ресурсы для этого. Хакер сообщил, что получил доступ к суперкомпьютеру в Тяньцзине через скомпрометированный VPN-домен. Осуществив взлом, он развернул ботнет — сеть систем, которые смогли проникнуть в сеть, извлечь, загрузить и сохранить данные. Скачивание 10 Пбайт данных заняло около шести месяцев. Распределив задачу по большому числу систем одновременно, злоумышленник снизил угрозу обнаружения: у администраторов было меньше шансов зафиксировать небольшие объёмы данных, передаваемых из системы одновременно, тогда как большой поток информации, передаваемый в одно место, привлёк бы внимание. Инцидент указывает на уязвимость технологической инфраструктуры Китая, и власти страны признают это проблему, отмечают эксперты. Сейчас Китай стремится повышать надёжность средств киберзащиты. Россияне стали чаще покупать дорогие комплектующие, чтобы запускать ИИ на собственных ПК
08.04.2026 [14:06],
Дмитрий Федоров
Россияне увеличили покупки дорогих комплектующих для «суперкомпьютеров», на которых можно запускать локальный ИИ. В марте спрос на видеокарту Nvidia RTX PRO 6000 Blackwell Workstation Edition с 96 Гбайт памяти за 892 000 руб. вырос на 91 % к предыдущим двум месяцам, а заказы на процессоры AMD Ryzen Threadripper PRO 7995WX и 7985WX за месяц прибавили 66 %, следует из данных CDEK.Shopping. 
Источник изображения: Barbara Zandoval / unsplash.com CDEK.Shopping объяснил рост спроса развитием ИИ и интересом граждан к его локальному запуску на домашних компьютерах. Повышенный спрос пришёлся не только на отдельные комплектующие для сборки таких конфигураций, но и на готовые решения. Заказы на дорогие системные блоки Enine выросли на 48 %. Среди наиболее востребованных оказались модели стоимостью от почти 3,3 млн до более 4 млн руб. 
NVIDIA RTX PRO 6000 Blackwell Workstation Edition. Источник изображения: nvidia.com Рост спроса на дорогие конфигурации происходит на фоне общего снижения российского рынка персональных компьютеров (ПК). В марте «Ведомости» со ссылкой на аналитиков компании «Интеллектуальная аналитика» сообщали, что по итогам 2025 года розничные продажи ПК в России сократились на 25—30 % как в количественном, так и в денежном выражении. Объём продаж снизился до 981 000 устройств, а объём рынка — до 48 млрд руб. По данным «Платформы ОФД», в 2025 году медианный чек на ПК в сетевой и несетевой рознице, как онлайн, так и офлайн, составил 45 205 руб. Показатель оказался на 4 % ниже уровня 2024 года. Количество покупок, по оценке компании, сократилось на 14 % год к году. Авторы «невзламываемого» шифрования на основе квантовой физики получили премию Тьюринга
18.03.2026 [20:43],
Анжелла Марина
Ассоциация вычислительной техники (Association for Computing Machinery) объявила о присуждении премии Тьюринга Чарльзу Беннету (Charles Bennett) и Жилю Брассару (Gilles Brassard) за их работу в области квантовой криптографии. Эта награда включает денежный приз в размере $1 млн, который учёные разделят между собой. Технология, которую они создали в середине 1980-х годов, изначально казалась интересной, но непрактичной. Однако спустя 40 лет она превратилась в необходимый инструмент для защиты самой конфиденциальной информации в мире. 
Источник изображения: xAI Основой их открытия стали законы квантовой механики, описывающие поведение элементарных частиц, таких как электроны и фотоны. В то время как такие компании, как Google и Microsoft, активно разрабатывают квантовые компьютеры, способные взламывать существующие с 1970-х годов методы шифрования, разработки Беннета и Брассара предлагают решение этой нарастающей проблемы, основанное на новых криптографических технологиях. 
Источник изображения: Association for Computing Machinery Совместная работа исследователей привела к публикации статьи в 1983 году, где они описали квантовые жетоны для метро, которые нельзя было подделать даже при краже оборудования. Год спустя они представили концепцию квантовой криптографии, а через пять лет подтвердили её работоспособность физическим экспериментом. Их система, получившая название BB84, использовала фотоны для генерации ключей шифрования и основывалась на законе физики, согласно которому любая попытка наблюдения за фотоном меняет его состояние, оставляя след вмешательства, подобный нарушению пломбы на упаковке лекарств. 
Источник изображения: Association for Computing Machinery Признанный эксперт Принеха Наранг (Prineha Narang) из Калифорнийского университета в Лос-Анджелесе подчеркнула, что учёные предложили совершенно новый подход к шифрованию, сделав его невзламываемым благодаря фундаментальным законам физики. Важность этого открытия стала очевидна в 1994 году, когда Питер Шор (Peter Shor) из Bell Labs доказал уязвимость традиционных схем перед квантовыми вычислениями. В том же десятилетии Беннет и Брассар продемонстрировали возможность безопасной передачи данных на большие расстояния посредством квантовой телепортации, использующей эффект запутанности частиц. Это явление, которое Альберт Эйнштейн образно называл «жутким действием на расстоянии», теперь может кардинально изменить передачу информации между квантовыми компьютерами, исключая возможность перехвата. Сегодня правительства и крупные компании активно стремятся внедрить эти технологии для создания сетей будущего. История сотрудничества учёных началась в 1979 году. Они встретились, отдыхая у северного побережья Пуэрто-Рико во время участия в научной конференции в Сан-Хуане. Беннет, ныне работающий в лаборатории IBM в Йорктауне, предложил Брассару, профессору Университета Монреаля, идею создания банкноты, которую невозможно подделать, используя принципы квантовой механики. Брассар позже отметил, что это событие шокировало его, так как подобные встречи случаются крайне редко. По состоянию на 2026 год американскому физику-теоретику Чарльзу Беннету 82 года, Жилю Брассару (канадскому физику-теоретику) — 72 года. Huawei продемонстрирует суперкомпьютерные системы в Барселоне на MWC 2026
01.03.2026 [06:20],
Алексей Разин
Границы жанров в наши дни размываются, поэтому решение китайской Huawei Technologies рассказать о суперкомпьютерных новинках на выставке MWC в Барселоне, которая традиционно концентрировалась на мобильных устройствах, воспринимается совершенно обыденно. Компания использует это мероприятие для продвижения своих серверных систем на международном рынке. 
Источник изображения: Huawei Technologies С 2019 года растущее влияние Huawei Technologies беспокоит американские власти до такой степени, что они последовательно наложили на компанию и всю китайскую полупроводниковую отрасль беспрецедентно жёсткие санкции. Лишившись доступа к зарубежным компонентам, Huawei была вынуждена самостоятельно их разрабатывать, и сейчас предлагает как мобильные чипы собственного дизайна, так и серверные решения. Среди последних крупнейшим считается стоечное решение Atlas 950 SuperPoD, в составе которого работают 8192 ускорителя Ascend 950 DT. Продемонстрировать такую систему Huawei собирается на выставке MWC 2026 в Барселоне, которая начинает работу завтра. Суперкомпьютерная система SuperPoD создана Huawei для машинного обучения и рассуждения, она обладает высокой степенью самодостаточности. Полномасштабный вариант Atlas 950 SuperPoD объединит 128 вычислительных и 32 телекоммуникационные стойки при помощи оптоволокна. Huawei разработала собственный скоростной интерфейс UnifiedBus, который является аналогом NVLink компании Nvidia. Суперкомпьютер Huawei занимает площадь около 1000 квадратных метров, что примерно соответствует четырём теннисным кортам. В удельном выражении решения Huawei пока не могут соперничать с суперкомпьютерами на основе чипов Nvidia, но масштабируя системы в более крупные кластеры, китайская компания надеется составить конкуренцию западным суперкомпьютерам. Как считает руководство Huawei, Atlas 950 SuperPoD будет превосходить Nvidia NVL144 в 6,7 раз по чистой производительности, предлагая в 56,8 раза больше NPU, чем предусмотрено GPU в составе системы Nvidia. Глава последней компании Дженсен Хуанг (Jensen Huang) считает Huawei серьёзным соперником, из-за которого она теряет позиции на внутреннем рынке Китая. По данным Bernstein Research, на рынке КНР Huawei уступает только Nvidia, хотя сама она оценивает свою текущую долю в Китае в ноль процентов. На MWC 2026 компания Huawei также продемонстрирует серверные системы общего назначения: TaiShan 950 SuperPoD, TaiShan 500 и TaiShan 200. В этом году Huawei собирается представить ускорители вычислений Ascend 950 PR и Ascend 950 DT. Новейшее поколение чипов, которые будут лежать в их основе, будет выпускаться китайской SMIC по технологии N+3, которая считается усовершенствованным вариантом 7-нм техпроцесса в общепринятом понимании. Продажи суперкомпьютерных систем SuperPoD должны стартовать в четвёртом квартале текущего года. Дефицит памяти добрался до Nvidia: настольный суперкомпьютер DGX Spark подорожал до $4699
27.02.2026 [15:17],
Николай Хижняк
Nvidia сообщила о повышении рекомендованной розничной цены своего мини-суперкомпьютера DGX Spark (Founders Edition). Компания связывает корректировку с глобальными ограничениями поставок памяти. Конфигурация системы при этом осталась неизменной. 
Источник изображения: Nvidia Рекомендованная розничная цена DGX Spark (Founders Edition) выросла с $3999 до $4699. Новая цена действует с этой недели. Nvidia также отмечает, что обновлённая рекомендованная цена распространяется на все регионы, а для существующих заказов сохраняется цена, указанная при оформлении заказа. «В связи с глобальными ограничениями поставок памяти мы скорректировали рекомендованную розничную цену DGX Spark (Founders Edition). Рекомендованная розничная цена DGX Spark (Founders Edition) была скорректирована с 3999 до 4699 долларов США в связи с ограничениями поставок памяти. DGX Spark продолжает предлагать лучшие в отрасли показатели производительности ИИ в сверхкомпактном формфакторе для настольных компьютеров», — говорится в заявлении на форуме Nvidia для разработчиков. 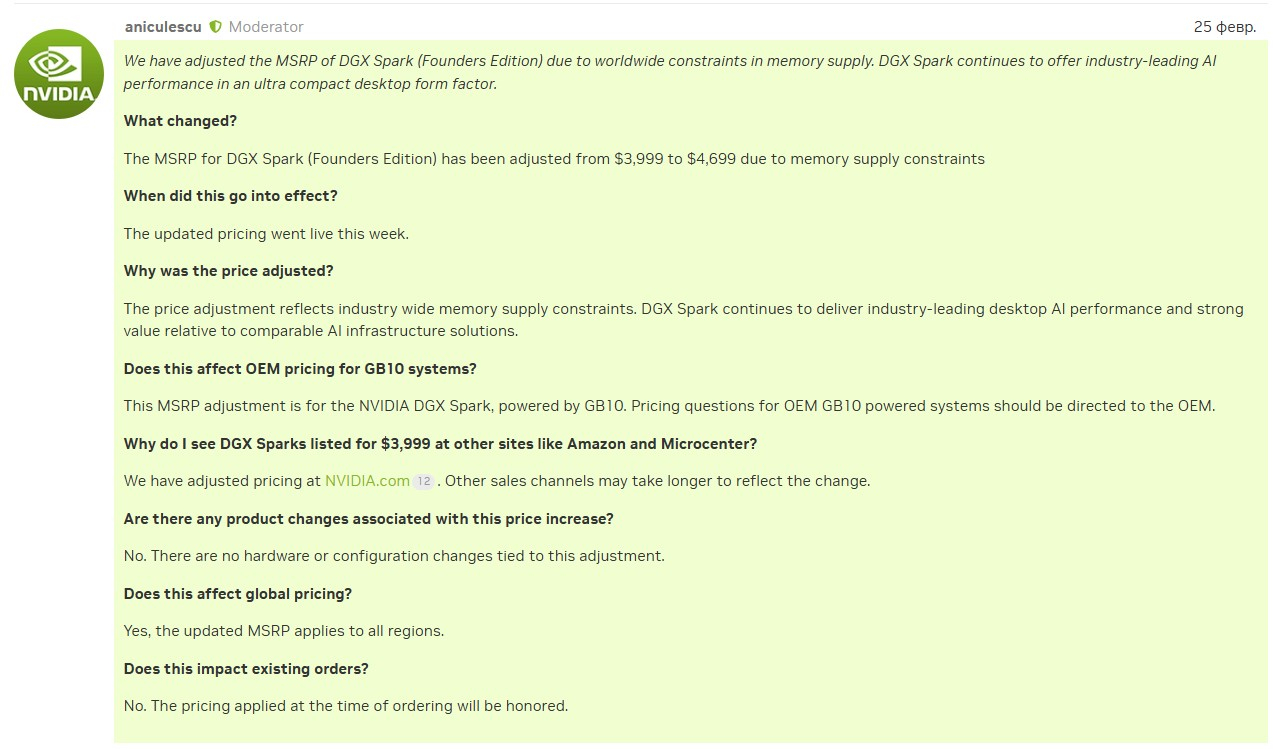 Компания поясняет, что изменение касается только DGX Spark, продаваемых через Nvidia.com, и что другим каналам поставок может потребоваться больше времени для отражения новой рекомендованной цены. Вопросы ценообразования OEM-систем, построенных на базе GB10, предлагается направлять непосредственно соответствующим производителям. В составе DGX Spark используется процессор Nvidia GB10. Компания ранее подтвердила, что ведёт разработку ПК-процессоров семейства N1. Согласно утечкам, конфигурация этих чипов может соответствовать GB10. Также появлялись сообщения о готовящихся ноутбуках с процессорами N1 и N1X в 2026 году. Связь между изменением цены DGX Spark и будущими ценами на ноутбуки с процессорами N1 или N1X пока не подтверждена, однако ключевым фактором может быть объём памяти. DGX Spark позиционируется как устройство с большим унифицированным пулом памяти (128 Гбайт), тогда как большинство потребительских ноутбуков обычно поставляются с конфигурациями на 16–32 Гбайт ОЗУ. «Сбербанк» потратит 500 миллиардов рублей на третий суперкомпьютер
10.02.2026 [11:46],
Павел Котов
В «Сбербанке» принято решение построить новый суперкомпьютер и вложить в него не менее 500 млрд руб., сообщают «Ведомости» со ссылкой на информированный источник. Суперкомпьютер сможет использоваться как для высокопроизводительных вычислений, так и для обучения моделей искусственного интеллекта. 
Источник изображения: İsmail Enes Ayhan / unsplash.com Новый суперкомпьютер «Сбербанка» будет включать вычислительные узлы с центральными и графическими процессорами, пояснили опрошенные «Ведомостями» эксперты, — он подойдёт для обучения моделей ИИ, а также моделирования сложных атмосферных и океанических процессов, исследования в области химии, физики и проектирования сложных механизмов. Ещё в 2019 году дочерняя компания «Сбера» SberCloud (сейчас независимая Cloud.ru) запустила систему «Кристофари», а в 2021 году был представлен «Кристофари нео» — в 2025 году первый занял 125 место в списке 500 мощнейших суперкомпьютеров мира, а второй — 201-е. В Балакове Саратовской области «Сбербанк» сейчас строит ещё один суперкомпьютер на базе «супер-ЦОДа» — в 2027 году это будет крупнейший такой агрегат в России: 3000 стоек, в которым смогут работать 120 000–130 000 серверов, что сравнимо со всем российским рынком серверов. Для нашей страны бюджет в 500 млрд руб. представляется внушительным, рассуждают эксперты, хотя американская OpenAI намеревается инвестировать в глобальную сеть ЦОД Stargate $500 млрд. Тем временем в Москве уже почти закончились свободные мощности для ЦОД — объекты заполнены на 95 %; свободная мощность не превышает 1400 стойко-мест. Новый суперкомпьютер нужен «Сбербанку» как основа для обучения и запуска моделей ИИ, говорят эксперты — старые мощности были ориентированы на нагрузки для центральных процессоров, и на современные архитектуры они не рассчитаны. Модернизировать эти объекты не получится, потому что требуется не только новое оборудование, но и полная переработка логики сетей, хранения данных, охлаждения и программной части. Спустя полгода после заморозки, Илон Маск решил возобновить работу над созданием суперкомпьютера Dojo 3
20.01.2026 [07:01],
Алексей Разин
В августе прошлого года стало известно, что Tesla простилась с группой специалистов, которые работали над созданием суперкомпьютера Dojo. Глава компании Илон Маск (Elon Musk) тогда заявил, что фирменные чипы AI5 и AI6 будут использоваться преимущественно для работы с уже обученными ИИ-моделями. На этой неделе он признался, что работа над Dojo 3 возобновлена. 
Источник изображения: X, Elon Musk Судя по краткой формулировке, которая появилась на личной странице миллиардера в социальной сети X, дизайн чипов AI5 настолько хорош, что для Tesla имеет смысл возобновить работу над созданием фирменного суперкомпьютера Dojo 3. Напомним, процессоры собственной разработки Tesla исторически намеревалась применять в бортовых системах активной помощи водителю электромобилей, позже решила использовать их для управления человекоподобными роботами Optimus, а в фирменный суперкомпьютер решила внедрить ради унификации. Внутренняя структура суперкомпьютера Dojo 3 пока не определена, но она может подразумевать хотя бы частичное использование чипов AI5 и их преемников AI6, выпуском которых по заказу Tesla на территории Техаса должна заняться компания Samsung Electronics. Считается, что чипы AI5 и AI6 не очень хорошо годятся для обучения нейросетей, но они показывают впечатляющие результаты в инференсе. Исходя из такой расстановки приоритетов, Tesla и может заниматься компоновкой своего очередного суперкомпьютера. Сообщив о возобновлении работы над созданием Dojo 3, Илон Маск попутно пригласил заинтересованных специалистов подавать резюме с примерами проблем, над решением которых им приходилось работать. По словам главы Tesla, «эти чипы будут самыми массовыми в мире». Судя по контексту, здесь имеются в виду процессоры AI5 собственной разработки. Маск позже добавил, что разработка AI5 была жизненно важна для Tesla, и компания бросила на это все ресурсы, а сам миллиардер на протяжении нескольких месяцев по субботам курировал эти работы. По его словам, AI5 будет весьма способным чипом, в одиночном исполнении сопоставимым с Nvidia Hopper, а в сдвоенном достигающим уровня быстродействия Blackwell. При этом решение Tesla будет существенно дешевле и значительно экономичнее с точки зрения энергопотребления. Настольный суперкомпьютер Nvidia DGX Spark запустил Cyberpunk 2077 и не только — но только после «танцев с бубном»
06.11.2025 [20:59],
Николай Хижняк
Nvidia DGX Spark — компактный ПК, созданный для разработчиков систем искусственного интеллекта и специалистов смежных направлений. Первые системы на суперчипе GB10 начали поставляться не так давно, с некоторым опозданием, и первые тесты этих мини-ПК были посвящены ИИ, полностью игнорируя игры. Однако на DGX Spark и других системах на GB10 можно запускать игры — правда, это потребует специфических умений и терпения. 
Источник изображения: VideoCardz Системы DGX Spark и первые решения на этой платформе от партнёров Nvidia начали появляться в руках пользователей, которым также интересны игры. Суперчип GB10 Blackwell сочетает 20-ядерный процессор Arm, графический процессор с 6144 ядрами CUDA (базовая частота — 1665 МГц, Boost-частота — 2525 МГц) и 128 Гбайт памяти LPDDR5X с пропускной способностью около 600 Гбайт/с, поэтому теоретически он должен быть близок к графическим процессорам класса GeForce RTX 5070. Проблема заключается в архитектуре: на сегодняшний день официальной сборки Windows для Arm с поддержкой указанной платформы нет. Вместо этого покупатели получают DGX OS — дистрибутив на базе Ubuntu, который позволяет устанавливать собственные инструменты, но не предлагает готовый игровой стек. 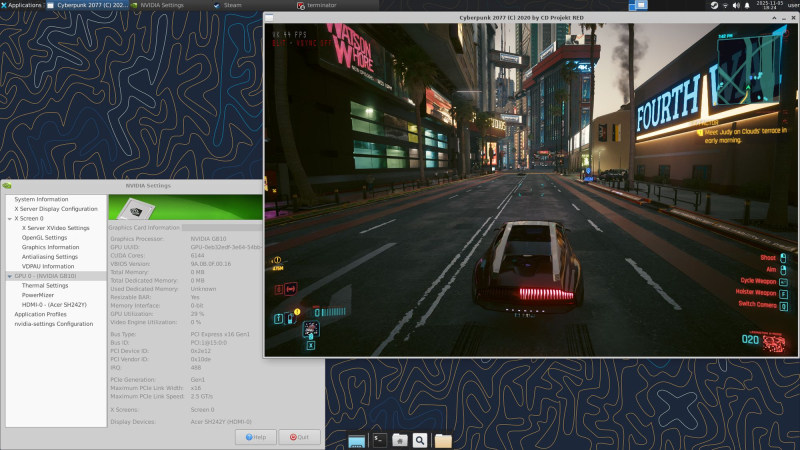
Источник изображения: Reddit В недавнем посте на Reddit показана работа игры Cyberpunk 2077 на DGX Spark через Box64 — слой трансляции x86–Arm. Пользователь скомпилировал Box64 v0.3.8 с поддержкой BOX32, установил Steam с помощью предоставленного скрипта, перезапустил systemd-binfmt, а затем запустил Steam и игру под управлением Box64. В итоге Cyberpunk 2077 показал на такой системе до 50 кадров в секунду в разрешении 1080p на средних настройках. При отсутствии поддержки DLSS и наличии неоднозначной стабильности автор называет всю эту схему использования «крутым, но бесполезным способом потратить около $4000». Именно столько стоит DGX Spark. 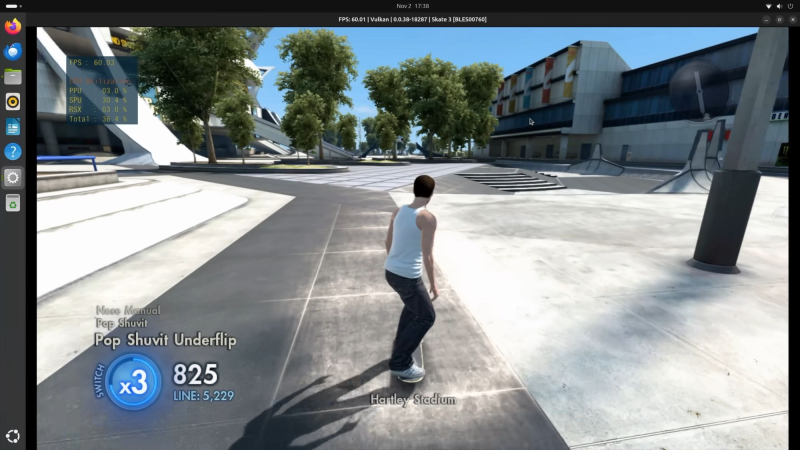
Источник изображений здесь и ниже: YouTube / ETA Prime MSI EdgeXpert AI — один из первых мини-ПК на базе DGX Spark. Он использует ту же конфигурацию GB10 и 128 Гбайт памяти, но поставляется в более традиционном корпусе по цене около $2999. В ранних тестах системы YouTube-блогер ETA Prime использовал эмулятор RPCS3 для запуска на ней игры Skate 3 для PlayStation 3 и Xemu для оригинальной Xbox. В этих рабочих нагрузках система поддерживала около 60 кадров в секунду при разрешении 1080p. 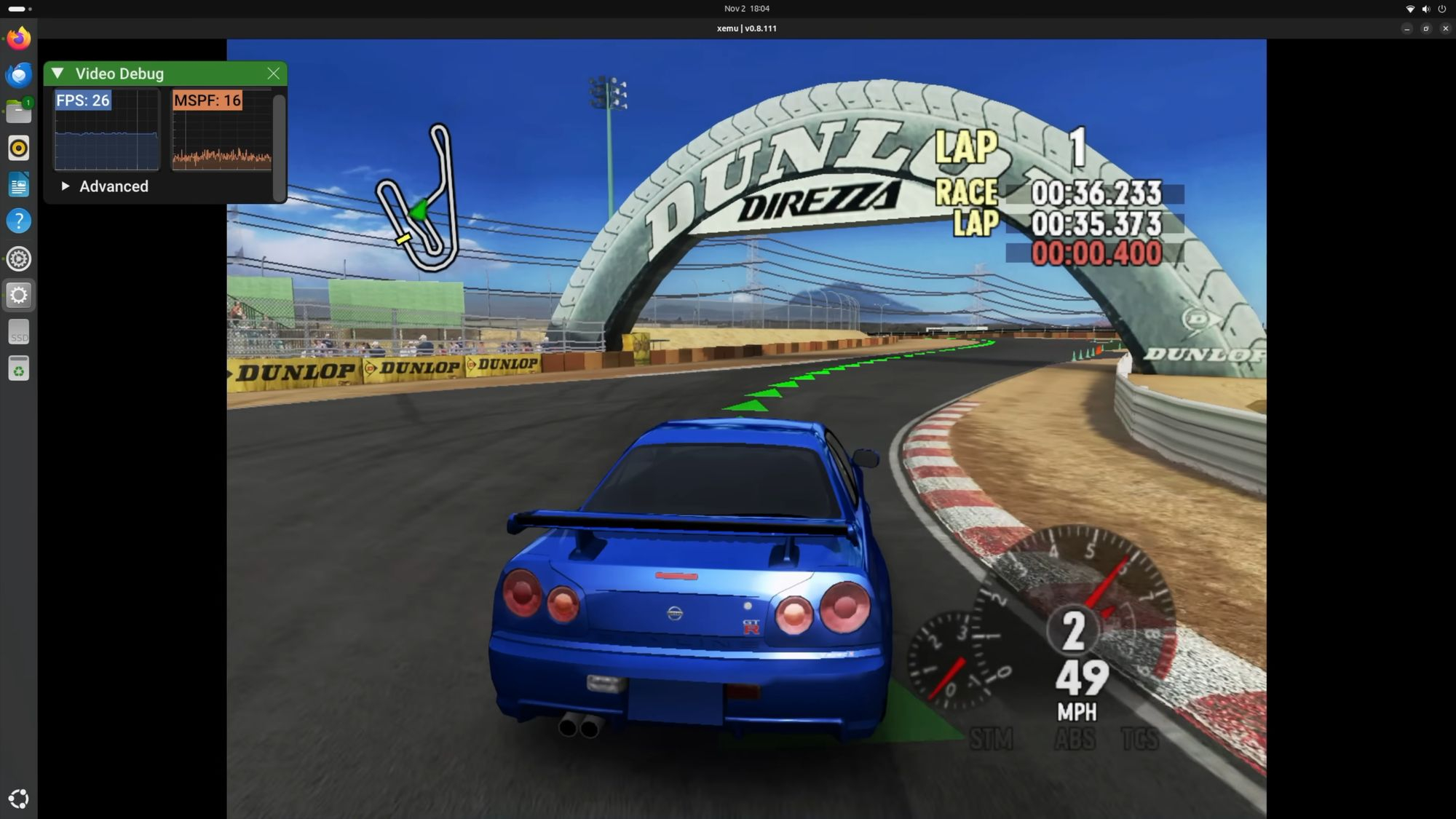 Первые тесты показывают, что DGX Spark и его клоны способны запускать игры, но только с использованием слоя трансляции, тонкой настройки Linux и изрядной доли терпения. Nvidia позиционирует платформу как устройство для искусственного интеллекта, а не как игровую систему. Для неё вряд ли когда-либо появятся официальные игровые драйверы, как и оптимизированные под платформу версии Windows. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


