|
Опрос
|
реклама
Быстрый переход
Nvidia поможет зажечь искусственное Солнце на Земле — прожорливость ИИ ни при чём
29.10.2025 [20:53],
Геннадий Детинич
Nvidia в союзе с General Atomics, Калифорнийским университетом в Сан-Диего, Аргоннской национальной лабораторией и Национальным энергетическим исследовательским научным центром (NERSC) разработала высокоточный цифровой двойник термоядерного реактора для исследований в сфере управляемой термоядерной энергетики с использованием искусственного интеллекта. Виртуальный двойник приблизит момент создания настоящего реактора, сократив затраты и время. 
Источник изображения: Nvidia Несмотря на десятилетия усилий учёных множества стран, практичный термоядерный реактор — или искусственное Солнце на Земле — остаётся далёкой мечтой. В земных условиях невозможно создать то давление, которое испытывают атомы водорода внутри звезды, чтобы слиться и синтезировать атом гелия. Поэтому приходится увеличивать нагрев плазмы — ионизированных ядер водорода — чтобы повысить шансы на слияние, преодолев кулоновское отталкивание между ядрами. Температура плазмы в термоядерных реакторах должна приближаться к 150 млн ℃ и даже превышать её — то есть быть в 10 раз выше, чем в ядре Солнца. В таких условиях плазма крайне нестабильна, и её удержание становится первоочерёдной задачей, которую и будет решать ИИ на цифровом двойнике реактора. Цифровой двойник будет создан на платформе Nvidia Omniverse с использованием CUDA-X. Платформа позволит моделировать поведение плазмы в реальном времени, сокращая длительность симуляций с недель до секунд. Для этого также на суперкомпьютерах Polaris (в ALCF) и Perlmutter (в NERSC) были натренированы три суррогатных ИИ — упрощённые модели, имитирующие поведение плазмы в заданных условиях. Они обеспечат предсказание поведения плазмы для более точного управления реактором в режиме реального времени. Во-первых, это позволит избежать ошибок, способных повредить реактор. Во-вторых, такие предсказания помогут исключить ошибочные и тупиковые решения, сокращая длительность исследовательских циклов. Созданный в партнёрстве Nvidia и научных коллективов цифровой двойник термоядерного реактора DIII-D получает данные с сенсоров реального реактора, которые затем используются для симуляций с привлечением набора моделей и суррогатных ИИ: EFIT — для оценки равновесия плазмы, CAKE — для определения её границ, ION ORB — для расчёта плотности теплового потока от ионов. Все данные объединяются в единую интерактивную среду на базе Nvidia RTX PRO и DGX Spark. Платформа Omniverse обеспечивает динамическое взаимодействие, а CUDA-X — ускорение вычислений. Система синхронизируется с физическим реактором, позволяя 700 учёным из 100 организаций проводить смелые эксперименты в виртуальной среде — без риска последствий. На выходе проекта получается нечто вроде «термоядерного ускорителя», сочетающего физику, вычисления и алгоритмы для исследований в реальном времени, предсказаний и оптимизации дизайна реакторов. Nvidia построит в США семь эксафлопсных суперкомпьютеров — два на Vera Rubin для Лос-Аламосской лаборатории
28.10.2025 [23:30],
Николай Хижняк
На конференции GTC 2025 компания Nvidia объявила о том, что построит в США семь эксафлопсных суперкомпьютеров в США. Две системы будут построены совместно с Oracle и будут использовать более 100 000 чипов Blackwell с производительностью до 2200 Эфлопс. Ещё две системы будут созданы совместно с HPE на перспективной платформе Vera Rubin для Лос-Аламосской национальной лаборатории. 
Источник изображения: Nvidia Эти системы будут использоваться для обеспечения национальной безопасности и проведения научных исследований с применением ИИ-моделирования и высокопроизводительных вычислений. Что интересно, заявление Nvidia последовало за вчерашним объявлением AMD о победе в тендерах на поставку пары суперкомпьютеров для Министерства энергетики США. Лос-Аламосская национальная лаборатория заключила контракт с HPE на создание суперкомпьютеров Mission и Vision на базе платформы Vera Rubin от Nvidia, которая включает центральные процессоры Vera и графические процессоры Rubin нового поколения. Масштабирование машин будет осуществляться с помощью технологии NVLink Gen6, а горизонтальное — посредством сетевого интерфейса Nvidia QuantumX 800 Infiniband. Суперкомпьютер Mission, разработанный для Национального управления по ядерной безопасности, планируется ввести в эксплуатацию в 2027 году. Компьютер Vision будет опираться на достижения предыдущего суперкомпьютера Venado и использоваться для открытых научных исследований, включая исследования в области искусственного интеллекта. «Mission — пятая передовая технологическая система в рамках программы Лос-Аламоса по развитию искусственного интеллекта для научной безопасности. Ожидается, что она будет введена в эксплуатацию в 2027 году и предназначена для запуска секретных приложений. Система Vision основана на достижениях суперкомпьютера Venado из LANL и предназначена для несекретных исследований в области искусственного интеллекта и открытой науки. Системы Mission и Vision представляют собой значительные инвестиции в национальную безопасность США и развитие открытых научных возможностей», — заявил Дион Харрис (Dion Harris), руководитель отдела маркетинга продуктов центров обработки данных Nvidia. Nvidia не раскрыла ожидаемую производительность Mission и Vision. Однако Vision примет эстафету у Venado — 19-го по скорости суперкомпьютера в мире с производительностью Rmax FP64 98,51 Пфлопс. Поэтому вполне логично ожидать, что Vision обеспечит как минимум вдвое большую вычислительную мощность для научных задач. «Мы предоставим более подробную информацию о конкретных конфигурациях [суперкомпьютеров] позже. Самое замечательное в этой [платформе], учитывая, как эти системы будут использоваться как в открытой науке, так и в исследованиях в области национальной безопасности, заключается в том, что, по нашему мнению, она позволит использовать как возможности ИИ, так и традиционные возможности моделирования для научных исследований», — добавил Харрис. Хуанг показал Vera Rubin Superchip — CPU, два огромных GPU и 100 Пфлопс на одной плате для ИИ нового поколения
28.10.2025 [22:26],
Андрей Созинов
На конференции GTC 2025 глава компании Nvidia Дженсен Хуанг (Jensen Huang) продемонстрировал графический процессор следующего поколения — Rubin. Точнее, он показал со сцены прототип ускорителя Vera Rubin Superchip, который объединяет на одной плате совершенно новый центральный процессор Vera и пару огромных графических чипов Rubin. Такое сочетание обещает новый уровень производительности для ИИ-суперкомпьютеров будущего. 
Источник изображений: Nvidia Каждый GPU Rubin состоит из двух больших кристаллов с ядрами CUDA и восьми стеков высокоскоростной памяти HBM4 объёмом 288 Гбайт. Характеристики GPU не уточняются, равно как и пропускная способность памяти. Однако отмечается, что одна система Vera Rubin Superchip обеспечивает производительность в ИИ-операциях (FP4) на уровне 100 Пфлопс (100 квадриллионов операций в секунду).  Что касается центрального процессора Vera, то известно, что он предложит 88 ядер на неназванной версии архитектуры Arm с 176 потоками, а для его связи с графическими процессорами будет задействован интерфейс NVLink-C2C с пропускной способностью 1,8 Тбайт/с. Также на плате расположится оперативная память LPDDR (версия не уточняется, но вполне возможно, что это будет уже LPDDR6), в результате чего общий объём оперативной памяти на один «суперчип» достигнет 2 Тбайт.  На базе новых ускорителей Nvidia предложит самые разные системы, например новые Compute Tray, включая CPX-версию для задач с большим контекстом ИИ-моделей. Также компания рассказала о готовых серверных стойках Vera Rubin NVL144 с производительностью 3,6 Эфлопс (3,6 квинтильона операций в секунду) для запуска уже обученных ИИ-моделей (FP4 inference), а также 1,2 Эфлопс для обучения моделей (FP8 training).  Это примерно в 3,3 раза быстрее актуальных систем GB300 NVL72. Система предложит 13 Тбайт/c общей пропускной способности для памяти HBM4 и в совокупности 75 Тбайт быстрой системной памяти, а общая пропускная способность интерфейсов NVLink и CX9 достигнет 260 Тбайт/с и 28,8 Тбайт/с соответственно.   Nvidia также раскрыла детали о системе NVL576 на базе чипов Rubin Ultra, которые ожидаются во второй половине 2027 года. Эти чипы будут включать четыре крупных GPU-чиплета на одной подложке и 1 Тбайт памяти HBM4e. В итоге система NVL576 обеспечит производительность до 15 Эфлопс FP4 и 5 Эфлопс FP8, предлагая до 365 Тбайт быстрой системной памяти и сетевую пропускную способность до 1,5 Пбайт/с через NVLink.  Nvidia сообщила, что первые тестовые экземпляры Rubin уже поступили в лаборатории компании для испытаний, а старт массового производства запланирован на 2026 год. На смену этой архитектуре придёт совершенно новая архитектура Feynman, запуск которой намечен на 2027–2028 годы. Однако никаких чипов на этой платформе Nvidia пока не показала — вряд ли на данный момент они вообще существуют в физическом воплощении. AMD построит пару суперкомпьютеров за $1 млрд для Министерства энергетики США
28.10.2025 [15:11],
Алексей Разин
Поскольку Министерство энергетики США традиционно является крупным заказчиком на строительство суперкомпьютеров, а компания AMD в этой сфере давно и успешно укрепляет позиции, новая сделка, о которой сообщило агентство Reuters, не стала неожиданностью. Стороны намерены потратить $1 млрд на строительство двух суперкомпьютеров. 
Источник изображения: AMD Министр энергетики США Крис Райт (Chris Wright) пояснил, что указанные суперкомпьютеры будут использоваться ведомством для различных научных исследований и расчётов, начиная от симуляции процессов в ядерной энергетике и поиском методом лечения онкологических заболеваний, и заканчивая специфическими исследованиями в области национальной безопасности. Чиновник выразил надежду, что с помощью новых суперкомпьютеров США продвинутся в сфере ядерной энергетики и управляемого термоядерного синтеза, разработке оборонных технологий нового поколения и создании передовых лекарств. Суперкомпьютеры, по его мнению, при помощи технологий искусственного интеллекта позволят американским учёным продвинуться в сфере технологий управляемого ядерного синтеза до получения каких-то практических результатов в течение ближайших двух или трёх лет. Министр энергетики также пояснил, что суперкомпьютеры помогут американским властям управлять национальным ядерным арсеналом. Впрочем, и вполне гуманное медицинское направление тоже получит импульс к развитию, поскольку поиск новых лекарств за счёт симуляции биохимических процессов на молекулярном уровне ускорится. «Я надеюсь, что в ближайшие пять или восемь лет мы сможем превратить многие онкологические заболевания, которые сегодня становятся смертными приговорами для пациентов, в управляемые состояния», — подчеркнул американский министр. Первый суперкомпьютер по имени Lux будет построен в ближайшие шесть месяцев, он будет использовать ускорители вычислений AMD Instinct MI355X, а также центральные процессоры и сетевые решения этой марки. Помогать AMD в создании такого суперкомпьютера будут компании HPE, Oracle Cloud и знаменитая Национальная лаборатория Ок-Ридж. По словам главы AMD Лизы Су (Lisa Su), этот суперкомпьютер был разработан в рекордные сроки для системы своих масштабов. Lux позволит поднять быстродействие имеющихся у профильной лаборатории суперкомпьютеров в три раза. Второй суперкомпьютер по имени Discovery будет использовать ускорители Instinct MI430, он будет построен в 2028 году и приступит к работе в 2029 году. Ускорители Instinct MI430, по словам Лизы Су, сочетают элементы решений обычных решений для ИИ со специальными функциями, используемыми конкретно в суперкомпьютерах. Вычислительными ресурсами обоих суперкомпьютеров смогут пользоваться как Министерство энергетики США, так и построившие их компании, они же предоставят оборудование и финансы для их строительства. Ведомство собирается подобную схему использовать для создания вычислительных центров по всей стране, привлекая частный бизнес к таким инициативам. Китайцы построили суперкомпьютер размером с холодильник, работающий по аналогии с человеческим мозгом
27.10.2025 [15:58],
Алексей Разин
Первые компьютеры в первой половине прошлого века занимали огромные площади, с появлением современных суперкомпьютеров ситуация не особо улучшилась, но китайским разработчикам удалось создать компактный и экономичный суперкомпьютер, который по размерам сопоставим с небольшим бытовым холодильником. 
Источник изображения: BI Explorer, SCMP Как сообщает South China Morning Post, вычислительная система BIE-1 (BI Explorer) была представлена на отраслевом форуме в Макао представителями Гуандунского института интеллектуальных наук и технологий. Способная соперничать с более крупными суперкомпьютерами, она позволяет работать с обучением языковых моделей и инференсом, потребляя при этом в десять раз меньше электроэнергии. Разработанная китайскими учёными нейронная сеть использует алгоритмы, свойственные человеческому мозгу. По словам разработчиков, такой компактный суперкомпьютер можно применять не только в небольших офисах и дома, но и в мобильном окружении. Появление такой системы значительно упрощает доступ к передовым вычислительным ресурсам. В создании BIE-1 принимали участие компании Zhuhai Hengqin Neogenint Technology и Suiren (Zhuhai) Medical Technology, основанные выходцами из указанного китайского вуза. Компактный суперкомпьютер может питаться от обычной бытовой розетки, хотя его полные характеристики не раскрываются разработчиками. Известно, что внутри него находятся 1152 процессорных ядра в сочетании с 4,8 Тбайт памяти типа DDR5 и накопители совокупным объёмом 204 Тбайт. Алгоритмы, подсмотренные разработчиками нейронной сети у человеческого мозга, позволяют добиваться высокой интуитивности и получать внятно толкуемые логические выводы, для обучения системы можно использовать небольшие объёмы данных. Система способна одновременно работать с разнородной информацией, включая текст, изображения и речь, обучение языковых моделей с её помощью происходит быстро и эффективно, по словам разработчиков. BIE-1 способна обрабатывать до 100 000 токенов в секунду в операциях обучения и до 500 000 токенов в секунду в инференсе соответственно, это позволяет её соперничать с более крупными и прожорливыми системами, оснащаемыми множеством ускорителей на базе GPU. При этом даже самая высокая вычислительная нагрузка не позволяет находящимся внутри BIE-1 процессору не нагреваться выше 70 градусов Цельсия, а система охлаждения не издаёт излишнего шума. По словам создателей, компактный суперкомпьютер можно использовать в образовании школьников, медицине и технической поддержке сотрудников в офисах. Китайцы научились моделировать масштабные квантовые процессы на классических компьютерах
22.10.2025 [20:13],
Геннадий Детинич
Квантовая революция подкралась откуда не ждали — китайские инженеры сделали, казалось бы, невозможное: на классическом суперкомпьютере они запустили квантовую симуляцию сложных химических процессов, чего ранее ожидали лишь с появлением квантовых компьютеров. В этом им помогла нейросеть, обученная работать с квантовыми уравнениями. 
Источник изображения: ИИ-генерация Grok 4/3DNews Значительного прорыва в квантовой химии добились китайские специалисты из компании Sunway, которые показали успешное моделирование сложного поведения молекул на классическом суперкомпьютере Oceanlite с привлечением к решению задачи искусственного интеллекта. Традиционно такие симуляции требуют огромной вычислительной мощности, часто недоступной даже для мощнейших в мире вычислительных платформ из-за экспоненциального роста числа квантовых состояний. Однако привлечение нейронных сетей позволило преодолеть эти ограничения, обработав поведение почти «настоящих» молекул с десятками электронов и более чем 100 спиновыми орбиталями — функциями спиновых координат, иначе говоря, комплексной информацией о спине электрона и его положении в пространстве в электронном облаке в составе молекулы. Тем самым исследователи показали, что для квантовой физики и химии вовсе необязательно ждать пришествия квантовых компьютеров. При определённом умении работать с квантовым миром можно делать это уже сегодня. В квантовой механике состояние системы описывается волновой функцией Ψ, которая определяет все возможные конфигурации частиц — от позиций и спинов электронов до энергетических уровней и вероятностей. С ростом числа частиц пространство состояний экспоненциально расширяется, делая точное моделирование на классических компьютерах практически невозможным и вынуждая учёных прибегать к упрощениям. Упрощения заставляют балансировать между точностью симуляции процессов и требуемыми для расчётов ресурсами. На современных суперкомпьютерах высочайшей точности можно достичь лишь при моделировании совсем простых молекул, что не даёт развернуться для научных прорывов. Тогда китайские инженеры начали рассматривать вариант стыка ИИ и квантовых симуляций, что привело к разработке нейронных сетей квантовых состояний — NNQS. Эта технология позволила сочетать масштабируемость машинного обучения с квантовой точностью. Тем самым появилась возможность на обычной системе моделировать многоэлектронные молекулы с сильными корреляциями, в которых взаимодействуют десятки и даже сотни спиновых орбиталей. Нейронную сеть обучили предсказывать волновую функцию для моделирования молекулы со 120 спиновыми орбиталями, что стало самой масштабной симуляцией на классическом компьютере — пусть даже с приставкой «супер». Сеть оценивала вероятные положения электронов, вычисляя локальные энергии и корректируя параметры до соответствия реальной квантовой структуре. Этот метод позволил симулировать динамику электронов в сложных молекулах, открывая путь к анализу процессов, ранее недоступных для вычислений. Расчёты были проделаны на суперкомпьютере Oceanlite, построенном на 384-ядерных процессорах Sunway SW26010-Pro. Нюанс в том, что эта система создавалась для высокопроизводительной обработки данных, а не для ИИ. Для «подселения» ИИ на непривычную для него вычислительную архитектуру пришлось адаптировать программное обеспечение, чтобы обеспечить наивысший параллелизм и оптимальную загрузку всех миллионов ядер платформы. Оптимизация была проведена настолько блестяще, что обеспечила 92 % сильного и 98 % слабого масштабирования задач при подгонке «железа» под программную нагрузку. В целом китайская классическая платформа справилась с химической симуляцией молекул со 120 спиновыми орбиталями — немыслимый ранее масштаб для квантовой симуляции на классических платформах. Без лишней скромности учёные заявили о прорыве для ИИ в квантовом моделировании. И у этого будут последствия. Надеемся, хорошие. Настольные суперкомпьютеры Nvidia DGX Spark на суперчипе GB10 снова не вышли в назначенные сроки
08.10.2025 [15:01],
Николай Хижняк
Nvidia, судя по всему, снова задерживает выпуск своего суперчипа для ИИ — GB10. Как пишет VideoCardz, компания могла перенести выпуск предназначенного для компактных рабочих станций DGX Spark процессора, на четвёртый квартал этого года. Эти системы ориентированы на ИИ-разработчиков, исследователей и других специалистов, занимающихся созданием прототипов, настройкой и доработкой больших ИИ-моделей. 
Источник изображения: VideoCardz По мнению VideoCardz, GB10 на архитектуре Blackwell, вероятно, является ближайшим конкурентом AMD Strix Halo — однопроцессорной системы, разработанной в первую очередь для задач ИИ и сочетающей в себе два кристалла CPU, а также мощный графический процессор. Каждый чип Nvidia GB10 оснащён 128 Гбайт унифицированной памяти LPPDR5X, явно предназначенной для задач обучения ИИ. Изначально Nvidia планировала выпустить рабочие станции DGX Spark в мае, затем выпуск был смещён на июль. Лето прошло, но в продаже новинки до сих пор так и не появились, на что указывает полное отсутствие каких-либо обзоров или демонстраций систем. На пороге четвёртого квартала на странице продукта на официальном сайте Nvidia по-прежнему отображается всё то же сообщение «Уведомите меня» о поступлении DGX Spark в продажу. 
Источник изображения: Nvidia Партнёры Nvidia в лице Asus и HP в свою очередь подтверждают, что их системы DGX Spark должны выйти в четвёртом квартале, хотя никто не называет конкретных дат. VideoCardz отмечает, что за пределами Nvidia никто точно не знает, когда DGX Spark поступит в продажу. Например, британский магазин электроники Scan UK, изначально указывавший, что компактные рабочие станции поступят в продажу 15 сентября, а затем 30 сентября, теперь даже не называет дату. 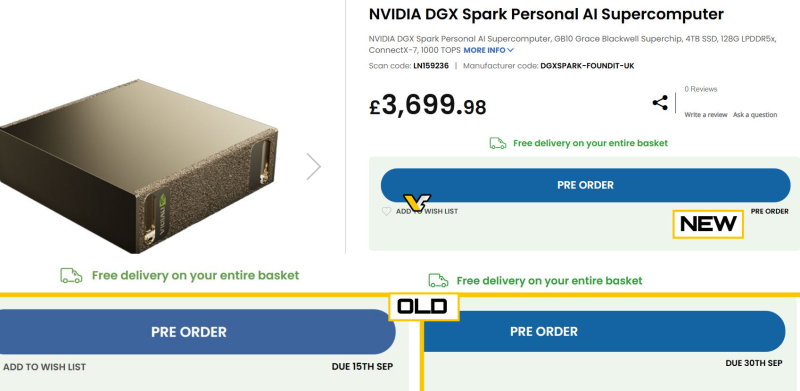
Источник изображения: VideoCardz / Scan UK Ранее ходили слухи, что Nvidia также собиралась представить SoC серии N1 для потребительских ноутбуков и настольных компьютеров, но ни на CES, ни на Computex компания не анонсировала такой продукт. Более того, Nvidia никогда официально не подтверждала такие планы. Недавно генеральный директор Nvidia сообщил, что суперчип GB10 носит внутреннее кодовое название «N1», что подтверждает ранние слухи о том, что эти два чипа не просто похожи по характеристикам, а фактически являются одним и тем же. Возможно, имя «N1» изначально предназначалось для внутреннего использования, и Nvidia вообще не планировала выпускать продукт с именно таким названием на потребительский рынок. Fujitsu внедрит технологии Nvidia в суперкомпьютеры на собственных процессорах
03.10.2025 [11:34],
Алексей Разин
Некоторое время назад Nvidia представила инициативу NVLink Fusion, которая позволит сторонним разработчикам полупроводниковых компонентов добиваться более эффективной интеграции чипов Nvidia в свои системы. Очередным партнёром по внедрению NVLink в этом смысле для Nvidia станет японская компания Fujitsu. 
Источник изображений: Fujitsu Строго говоря, содержательный пресс-релиз на страницах сайта Fujitsu перечисляет многие сферы сотрудничества с Nvidia, включая и область квантовых вычислений, но решение о соединении процессоров Monaka компании Fujitsu и GPU компании Nvidia при помощи NVLink Fusion стоит особняком. Первые плоды сотрудничества двух компаний появятся к 2030 году. Для совместных заявлений на эту тему основатель Nvidia Дженсен Хуанг (Jensen Huang) даже отправился в японскую столицу, где разделил сцену с главой Fujitsu Такахито Токитой (Takahito Tokita). Финансовые условия сотрудничества Nvidia и Fujitsu остались за рамками заявлений. По словам главы первой из компаний, Fujitsu буквально создаст аппаратное решение, позволяющие «объединить» свои центральные процессоры с технологиями Nvidia. К 2030 году Fujitsu при поддержке партнёров, в число которых вошла и Nvidia, намеревается построить суперкомпьютер Fugaku NEXT, производительность которого превысит предшественника в пять или десять раз. 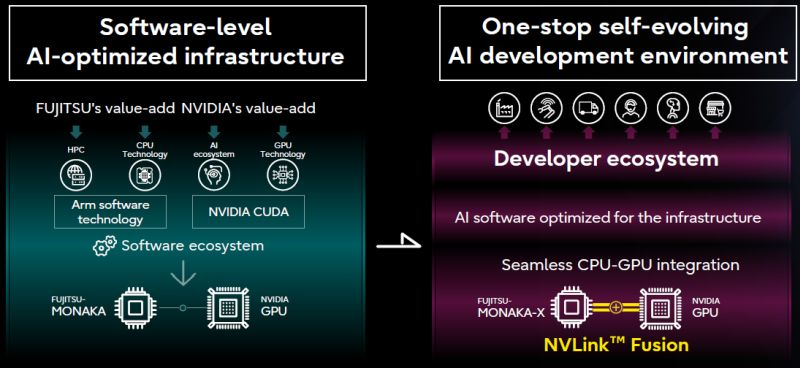 Как признался Хуанг, создание Fugaku NEXT будет только первым шагом на пути реализации множества совместных инициатив Fujitsu и Nvidia. Интеграция с технологиями Nvidia позволит Fujitsu увеличить рыночный охват для своих решений. Японская компания также продвигает идею «ИИ-суверенитета» нации и готова прилагать к её реализации максимум усилий со своей стороны. Кроме того, у Fujitsu за счёт интеграции с частью экосистемы Nvidia откроются перспективы на европейском рынке ИИ. По словам главы компании, её японскую штаб-квартиру регулярно посещают делегации из Европы, интерес к решениям Fujitsu на этом рынке очень высок. Fujitsu и Nvidia при участии разнообразных партнёров также собираются разрабатывать большие языковые модели для робототехники, промышленной автоматизации, торговли, автономного транспорта и здравоохранения. В Европе появился первый экзафлопсный суперкомпьютер Jupiter — в мировом рейтинге он занял четвёртое место
06.09.2025 [14:03],
Анжелла Марина
В Германии, в Юлихском исследовательском центре (Jülich Supercomputing Center) близ Кёльна, состоялось официальное открытие первого в Европе суперкомпьютера Jupiter, преодолевшего порог экзафлопсной производительности (10¹⁸ операций в секунду). 
Источник изображения: Forschungszentrum Jülich/YouTube На церемонии присутствовали канцлер Германии Фридрих Мерц (Friedrich Merz), федеральный министр по вопросам исследований, технологий и космоса Дороте Бэр (Dorothee Bär), министр-президент земли Северный Рейн-Вестфалия Хендрик Вюст (Hendrik Wüst) и министр культуры и науки Инна Брандес (Ina Brandes), информирует The Register. Открытие касалось пока только модуля Booster — кластера графических процессоров, предназначенного для масштабных симуляций и обучения ИИ, включающего около 6000 вычислительных узлов, каждый из которых оснащён четырьмя суперчипами Nvidia GH200 Grace Hopper и объединён сетевым оборудованием Quantum-2 InfiniBand от Nvidia. Этот модуль позволил Jupiter занять первое место в Европе и четвёртое в мире по производительности, а его тестовый модуль Jedi годом ранее возглавил рейтинг Green500 как самый энергоэффективный суперкомпьютер планеты.  Как заявила еврокомиссар по вопросам стартапов, исследований и инноваций Экатерина Захариева (Ekaterina Zaharieva), этот суперкомпьютер «открывает новую главу для науки, искусственного интеллекта и инноваций, укрепляя цифровой суверенитет Европы и обеспечивая её исследователей мощными вычислительными ресурсами». Несмотря на достижение, система ещё не завершена полностью. Модуль общего назначения (Cluster Module), предназначенный для рабочих процессов, не требующих использования ускорителей, ожидается не раньше конца 2026 года. Он будет основан на европейском процессоре Rhea1 от компании SiPearl, финальный дизайн которого был готов только в июле этого года. Этот чип содержит 80 ядер Arm Neoverse V1, в кластере планируется использовать 1300 узлов, каждый с двумя такими процессорами.  Пока Европа отстаёт в экзафлопсной гонке от США, которые достигли этого рубежа три года назад с системой Frontier, а также от Китая, который, как полагают, уже имеет подобные системы, но не раскрывает детали. Проект Jupiter реализуется консорциумом ParTec-Eviden, а его общая стоимость, включая шесть лет эксплуатации, оценивается в 500 миллионов евро. Финансирование поровну разделено между инициативой EuroHPC JU и немецкими министерствами. Вся система размещается в модульном дата-центре площадью 2300 квадратных метров, что позволяет при необходимости легко её расширять и модифицировать. Tesla закрыла проект по созданию ИИ-суперкомпьютера Dojo на гигантских чипах
08.08.2025 [05:14],
Алексей Разин
Агентство Bloomberg накануне сообщило, что компанию Tesla покинет руководитель группы специалистов, которые создавали суперкомпьютер Dojo, вместе с этим около 20 его теперь уже бывших коллег сформировали новую компанию DensityAI, в штате которой надеются найти применение своим профильным навыкам. 
Источник изображения: Nvidia Прежде всего, стало известно об уходе из Tesla Питера Бэннона (Peter Bannon), который руководил строительством фирменного суперкомпьютера Dojo. Около двадцати бывших специалистов Tesla по суперкомпьютерам основали компанию DensityAI, а оставшаяся часть коллектива была перераспределена по другим проектам внутри Tesla, как сообщают источники. Бэннон в 2016 году перешёл на работу в Tesla из компании Apple. До недавних пор он занимал в Tesla пост вице-президента по разработке аппаратного обеспечения. До сих пор считалось, что создание собственного суперкомпьютера Dojo для Tesla является одним из приоритетов в гонке по развитию технологий искусственного интеллекта. Мощности Dojo планировалось использовать для обучения технологий автопилота электромобилей Tesla и человекоподобных роботов Optimus. В ответ на сообщение Bloomberg о роспуске команды Dojo генеральный директор Tesla Илон Маск (Elon Musk) сказал: «Для Tesla не имеет смысла разделять свои ресурсы и масштабировать два совершенно разных дизайна чипов искусственного интеллекта. Tesla AI5, AI6 и последующие чипы будут отлично подходить для запуска обученных нейросетей и, по крайней мере, довольно хороши для обучения. Все усилия сосредоточены на этом». Маск имеет в виду чип AI6 следующего поколения Tesla, который будет производиться Samsung в рамках сделки на $16,5 млрд. Эти чипы будут обеспечивать принятие решений в режиме реального времени на борту автомобилей и роботов Tesla. Закрытие Dojo фактически положит конец амбициозным планам Tesla по созданию собственной внутренней архитектуры обучения ИИ и консолидирует усилия компании на платформах AI5 и AI6. Хотя Маск говорит, что фирменные чипы «довольно хороши» для обучения, теперь компания будет в значительной степени полагаться на ускорители вычислений Nvidia и других поставщиков. Начало производства AI5 запланировано на 2026 год, а AI6 — на 2027 год. Это уже не первый случай ухода из Tesla видных специалистов в отдельных областях. Ранее компанию покинул Милан Ковач (Milan Kovac), который руководил разработкой человекоподобных роботов Optimus. Компания также лишилась главы по разработке программного обеспечения Дэвида Лау (David Lau). В июне стало известно об уходе из Tesla одного из давних соратников Tesla Омеада Афшара (Omead Afshar). Илон Маск на недавней квартальной отчётной конференции дал понять, что при разработке будущих поколений чипов типа AI6 компания будет придерживаться принципа унификации, чтобы использовать их как в собственных центрах обработки данных, так и в человекоподобных роботах, не говоря уже о бортовых системах электромобилей. AMD похвасталась, что её чипы стали основой для трети мощнейших суперкомпьютеров мира
06.08.2025 [14:16],
Алексей Разин
На квартальной конференции представители AMD старались всячески подчеркнуть, что трудности с увеличением выручки в серверном сегменте носят временный характер, и в целом дела у компании на этом направлении идут очень хорошо. По меньшей мере, компоненты AMD уже используются более чем в трети мощнейших суперкомпьютеров мира, а доля компании на рынке серверных процессоров растёт уже 33 квартала подряд. 
Источник изображения: AMD По сути, число 33 с этой точки зрения стало для компании магическим. Выручка от реализации центральных процессоров семейства EPYC в прошлом квартале обновила рекорды как в сегменте облачных вычислений, так и на корпоративном направлении. Эти процессоры пользуются высоким спросом, как подчеркнула на отчётном мероприятии глава AMD Лиза Су (Lisa Su). Это тем более заметно в контексте развития инфраструктуры искусственного интеллекта и появления новых сфер применения данных технологий и самих процессоров. По словам Лизы Су, развитие инфраструктуры ИИ повышает спрос на вычислительные ресурсы общего назначения, которые могут предоставить многоядерные центральные процессоры. Во втором квартале значительно вырос объём поставок процессоров EPYC новейшего поколения Turin, а спрос на их предшественников и не думает снижаться, оставаясь стабильным. Доля AMD на рынке центральных процессоров серверного применения непрерывно растёт уже 33 квартала подряд — то бишь, уже более восьми лет. В сегменте суперкомпьютеров AMD есть чем похвастаться. Во-первых, на её компонентах построены две мощнейшие системы в списке Top 500, а именно — El Capitan и Frontier. Во-вторых, более трети мощнейших суперкомпьютеров мира используют компоненты AMD. В-третьих, на решениях этой марки построены 12 из 20 лучших суперкомпьютерных систем Green 500 с точки зрения энергоэффективности. Экс-глава Intel вложился в стартап, создающий сверхпроводниковые чипы для суперкомпьютеров
23.06.2025 [14:04],
Алексей Разин
Спектр интересов Патрика Гелсингера (Patrick Gelsinger) после его отставки с поста генерального директора Intel в начале декабря прошлого года то и дело становится предметом обсуждения в прессе, и очередной поддерживаемый им стартап интригует своей миссией. Компания Snowcap Compute собирается создавать чипы для суперкомпьютеров, которые обладают свойством сверхпроводимости. 
Источник изображения: Snowcap Compute В свою очередь, состояние сверхпроводимости позволит заметно снизить энергопотребление таких чипов, хотя достигаться оно будет традиционно при сверхнизких температурах, что также требует серьёзных энергозатрат на их поддержание. Так или иначе, как поясняет Reuters, представители Snowcap Compute убеждены, что игра будет стоить свеч, поскольку эффективность итоговых вычислительных систем будет покрывать дополнительные затраты на мощное охлаждение. Соотношение производительности и энергопотребления для разрабатываемых стартапом чипов будет в 25 раз выше, чем у лучших представителей текущего поколения ускорителей. Генеральный директор Snowcap Compute Майкл Лафферти (Michael Lafferty) поясняет: «Энергоэффективность — это хорошо, но продажами движет производительность. То есть, мы одновременно поднимаем производительность и опускаем уровень энергопотребления». Предполагается, что для выпуска чипов с подобными свойствами понадобится доступ к нитриду ниобия-титана — сплаву, составляющие которого нужно получать из Бразилии и Канады. Первые образцы готовых чипов компания рассчитывает получить к концу следующего года, но наладить выпуск полноценных вычислительных систем на их основе удастся лишь значительно позже. Нюанс заключается в том, что поддержку стартапу на данном этапе оказал бывший глава Intel Патрик Гелсингер, вложивший через связанный с ним венчурный фонд Playground Digital часть из $23 млн, собранных инвесторами. Кроме того, Гелсингеру за это полагается и место в совете директоров Snowcap Compute, поэтому в жизни стартапа бывший руководитель Intel будет принимать самое непосредственное участие. Сам Гелсингер подчеркнул: «Многие дата-центры сегодня ограничены в своём масштабировании только количеством доступной энергии». Жизнь после «Яндекса» есть: Nebius Group Аркадия Воложа создала второй суперкомпьютер, и он попал в топ-15 мира
11.06.2025 [21:15],
Анжелла Марина
У нидерландской компании Nebius Group (бывшая Yandex NV), возглавляемой сооснователем «Яндекса» Аркадием Воложом, появился ещё один суперкомпьютер. Речь идёт об ISEG 2, который занял 13-е место в рейтинге TOP500 самых мощных суперкомпьютеров в мире. 
Источник изображения: AI FP64-производительность ISEG 2 составляет 202,4 Пфлопс (в пике 338,49 Пфлопс) и насчитывает 718 848 вычислительных ядер. Система оснащена процессорами Intel Xeon Platinum 8468 (48 ядер, 96 потоков), ускорителями Nvidia H200 и интерконнектом InfiniBand NDR400. ISEG 2 размещён в Исландии. Как отметила компания в своём аккаунте X, система стала самым мощным коммерчески доступным суперкомпьютером в Европе и второй по производительности коммерческой системой в мире, что подтверждается данными TOP500. Напомним, первый суперкомпьютер ISEG, названный в честь сооснователя «Яндекса» Ильи Сегаловича (Ilya Segalovich), дебютировал в рейтинге TOP500 в ноябре 2023 года, заняв 16-е место. Его пиковая вычислительная мощность составила 86,79 Пфлопс, а фактическая — 46,54 Пфлопс. На данный момент компьютер находится на 39-й позиции рейтинга. ISEG размещён в бывшем дата-центре «Яндекса» в Финляндии. Nvidia построит на Тайване штаб-квартиру и мощный суперкомпьютер с 10 000 ускорителями Blackwell
19.05.2025 [11:40],
Алексей Разин
Свой приуроченный к выступлению на Computex 2025 визит на Тайвань основатель и бессменный руководитель Nvidia Дженсен Хуанг (Jensen Huang) использовал для заявления о намерениях потратить внушительные средства на строительство здесь локальной штаб-квартиры компании и мощного суперкомпьютера. 
Источник изображения: Nvidia Тайвань он назвал «крупнейшим регионом по производству электроники», отметив его важное значение в формировании мировой компьютерной экосистемы. Подразделение тайваньской Foxconn (Big Innovation Company) поможет Nvidia построить для нужд местной вычислительной инфраструктуры современный суперкомпьютер, использующий 10 000 новейших ускорителей вычислений семейства Blackwell. На его строительство уйдёт несколько сотен тысяч долларов, по предварительным оценкам. Примечательно, что пользоваться этим суперкомпьютером, помимо прочих, будет тайваньская компания TSMC, которая остаётся основным контрактным производителем чипов Nvidia. С помощью современного суперкомпьютера TSMC будет совершенствовать имеющиеся и разрабатывать новые технологические процессы в сфере литографии. Хуанг также подчеркнул, что Nvidia становится тесно в пределах имеющегося офиса компании на Тайване, она построит новое здание местной штаб-квартиры Constellation в одном из районов Тайбэя. Не исключено, что на этой площадке будет осуществляться более тесное взаимодействие с тайваньскими партнёрами Nvidia, особенно в контексте инициативы по продвижению интерфейса NVLink Fusion, позволяющего интегрировать собственные вычислительные решения компании со сторонними. В Китае Nvidia также готовится открыть локальный исследовательский центр, но связанные с разработкой графических процессоров ценные данные она передавать его сотрудникам не будет. Autonomous представила дизайнерский домашний ИИ-суперкомпьютер за $40 000 — его функциональность вызывает вопросы
16.05.2025 [01:28],
Анжелла Марина
Компания Autonomous из США представила первую в своём роде рабочую станцию Brainy с очень высокой производительностью, предназначенную для ускорения разработки искусственного интеллекта (ИИ). Устройство создано для исследователей, разработчиков и стартапов, которые стремятся выйти за рамки возможностей облачных решений и работать с самыми сложными ИИ-моделями локально, а значит быстро и безопасно. 
Источник изображений: Autonomous Система Brainy создана для самых сложных задач в области ИИ и оснащена видеокартами Nvidia RTX 4090. Её производительность превышает один петафлопс в максимальной конфигурации, которые могут включать от двух до восьми GPU. Это позволяет обучать модели с 70 миллиардами параметров, добиваться результатов уровня суперкомпьютеров прямо с рабочего стола и оптимизировать обучение ИИ-моделей. Как отмечает TechPowerUp, станция особенно эффективна для тонкой настройки больших языковых моделей (LLM), задач компьютерного зрения и других областей глубокого обучения. Autonomous разработала Brainy, чтобы решить проблемы дорогих облачных GPU-решений. Хотя облачные сервисы, как известно, обладают высокой гибкостью, их оплата по мере использования может стать чрезмерно затратной для долгосрочных проектов. Autonomous предлагает альтернативу в виде локальной мощности, повышенной безопасности данных и значительной экономии. По оценкам компании, владельцы Brainy могут сэкономить тысячи долларов уже в первый год по сравнению с арендой облачных мощностей. Ещё одним преимуществом Brainy является стабильность работы. Система исключает такие типичные для облака проблемы, как очереди, внезапные отключения и задержки из-за интернета. Кроме того, пользователи могут начать с конфигурации из двух видеокарт и при необходимости расширить её до восьми. Готовые проекты можно легко перенести в облако или дата-центр без дополнительных настроек. 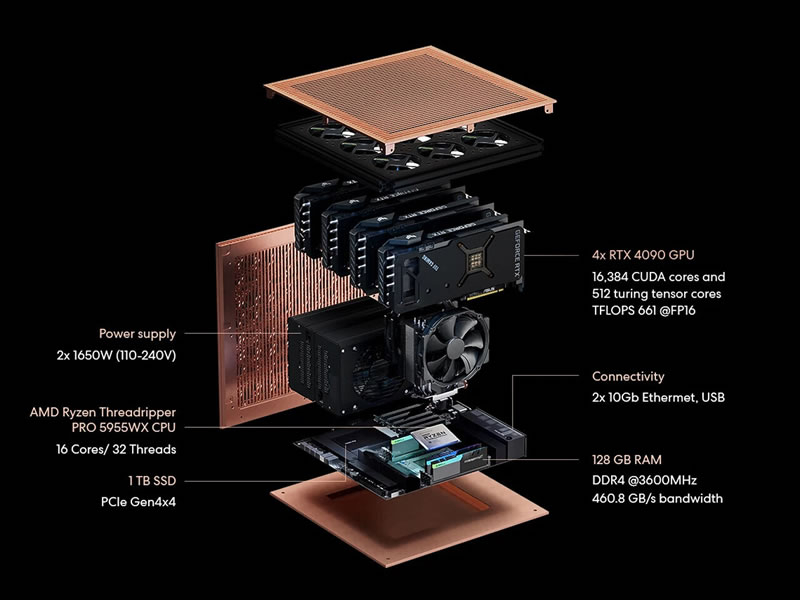 Производитель отмечает, что Brainy поддерживает популярные фреймворки, включая PyTorch и TensorFlow, а также технологии Nvidia — CUDA, cuDNN и TensorRT. Все эти возможности ускоряют разработку ИИ-моделей и научных вычислений. Ко всему прочему, Autonomous входит в программу Nvidia Inception, что даёт ей доступ к ресурсам и обучению для оптимизации Brainy, а также позволяет предложить клиентам конкурентные цены. По словам компании, с помощью станции стартапы и организации смогут быстрее разрабатывать ИИ-решения в таких сферах, как медицина, образование, логистика и финансы. Помимо видеокарт Nvidia системы Autonomous Brainy предлагают процессоры AMD Ryzen Threadripper — в базовой модели это 24-ядерный Ryzen Threadripper 3960X, тогда как в более продвинутых конфигурациях предлагаются более свежие 16-ядерные Ryzen Threadripper 5955WX. А самая мощная версия и вовсе оснащена 16-ядерным чипом AMD Epyc 9124. Объём оперативной памяти составляет соответственно 96, 128 и 192 Гбайт. Заметим, что в одной из конфигураций видеокарты не смогут работать в полную силу. В частности, у Ryzen Threadripper 5955WX имеется лишь 80 линий PCIe, а на шесть видеокарт нужно 96 линий. А ещё ведь надо выделить четыре линии для SSD. Так что даже у флагманской модели со 128 линиями PCIe 4.0 будет их дефицит. Также вызывает беспокойство охлаждение: не будет ли видеокартам тесно в корпусе. Что касается стоимости, то системы Autonomous Brainy предлагаются по цене от $9000 до $40 000.  |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


