
Опрос
|
реклама
Быстрый переход
ИИ-модель Wildberries вошла в топ-3 русскоязычного бенчмарка MERA
25.06.2026 [19:08],
Владимир Фетисов
Большая языковая модель BerryLM-XL, которая была дообучена специалистами RWB, вошла в тройку лидеров текстового рейтинга русскоязычного бенчмарка MERA. По итогам тестирования алгоритм получил интегральную оценку 0,835. Для сравнения, эталонная оценка на основе ответов людей на аналогичные вопросы Human Benchmark составляет 0,852. 
Источник изображения: Steve Johnson / Unsplash В настоящее время BerryLM-XL расположилась на третьем месте общего рейтинга MERA и на втором среди ИИ-моделей. Оценка алгоритма сформирована по результатам выполнения 15 заданий, предназначенных для проверки работы с русскоязычным текстом, оценке знаний, логики и прикладных навыков. В первую пятёрку также вошла созданная RWB модель BerryLM-v2 — она заняла пятое место с оценкой 0,810. 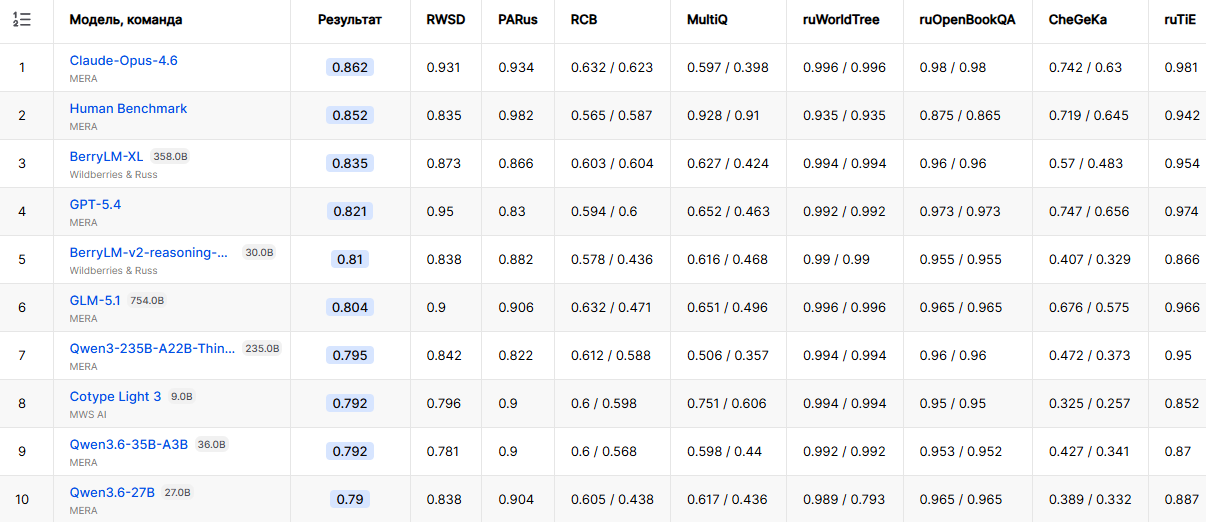 ИИ-модели семейства BerryLM используются в продуктах Wildberries, включая ИИ-ассистента для покупателей, а также инструменты сравнения и поиска товаров. В дополнение к этому модели интегрированы в инструменты для продавцов. Они помогают формировать ответы на отзывы и вопросы пользователей. Параллельно с этим ИИ-алгоритмы помогают автоматизировать внутренние процессы RWB. По оценке компании, совокупный эффект от использования ИИ-инструментов на базе моделей BerryLM превышает 1 млрд рублей дополнительной выручки в год. Власти США начали считать протесты против ИИ и ЦОД проявлением «антитехнологического экстремизма»
26.05.2026 [19:11],
Дмитрий Федоров
Власти США начали рассматривать протесты против строительства ЦОД и критику ИИ как возможные проявления «антитехнологического экстремизма». Это следует из более чем 1000 страниц закрытых отчётов Министерства внутренней безопасности США (DHS), ФБР и межведомственных центров обмена разведданными. В документах граница между угрозой насилия и мирным протестом проведена неясно, поэтому под подозрение могут попасть даже мирные протестующие. 
Источник изображения: Nathan Kuczmarski / unsplash.com Новая волна слежки за активистами и протестующими вписывается в более широкий политико-правовой курс администрации Дональда Трампа (Donald Trump), расширяющий трактовку внутренних угроз и усиливающий внимание к идеологически мотивированной активности внутри США. Его президентский меморандум по национальной безопасности №7 (National Security Presidential Memo 7) предписывает Министерству юстиции (DOJ) преследовать людей с «антиамериканскими», «антихристианскими» и «антикапиталистическими» взглядами, а советник Трампа по борьбе с терроризмом Себастьян Горка (Sebastian Gorka) назвал левых экстремистов одной из трёх главных целей для противодействия терроризму в США. Ключевой риск — размытость новой категории «экстремизма». В отчёте Нью-Йоркского бюро разведки и борьбы с терроризмом (ICB) говорится, что технологии ИИ в ближайшие 5 лет могут спровоцировать крупные протесты, гражданские беспорядки и «насильственную антитехнологическую экстремистскую деятельность». При этом, по данным Wired, такого термина нет в общедоступных отчётах или руководствах DHS либо ФБР о внутреннем экстремизме. Межведомственные центры обмена разведывательными сведениями, созданные после терактов 11 сентября, уже собирают данные о предполагаемых угрозах ЦОД. В США действуют 80 таких центров. Их отчёты относят к подозрительным действиям фотографирование, наблюдение, проверку системы безопасности и попытку проникновения — то есть признаки, которые могут встречаться и у мирных протестующих. Старший юрисконсульт Фонда правовой защиты NAACP Спенсер Рейнольдс (Spencer Reynolds) предупреждает, что такие отчёты продолжают практику, при которой протесты и твёрдые убеждения рассматривают как возможные предвестники насилия. По его словам, размытые правила подготовки отчётов позволяют сотрудникам видеть угрозу там, где её может и не быть. Изученные Wired документы показывают, что власти США следят за потенциальными экстремистами не только в интернете, но и наблюдают за очными собраниями людей. По данным проекта Data Center Watch, который отслеживает протесты против строительства ЦОД в США, сотни организаций в 42 штатах пытаются заблокировать строительство дата-центров в своих городах и округах. В ряде штатов полиция уже удаляла с собраний или арестовывала выступающих, критиковавших строительство ЦОД. Главная проблема в том, что по законодательству США внутренний терроризм не является самостоятельным преступлением, но такие нормы позволяют вести слежку за предполагаемыми экстремистами. Поэтому протестующие могут попасть под наблюдение как внутренние экстремисты, даже если обвинения против них касаются незаконного проникновения, вандализма или других преступлений без какой-либо террористической составляющей. Самый показательный пример — отчёт Site Intelligence за апрель 2025 года. В нём фигурирует видео некоммерческой организации More Perfect Union о вреде ЦОД для жителей районов в Джорджии. В видео не было призывов к насилию против людей или собственности, однако организация всё равно попала в материалы американских разведывательных и правоохранительных структур как потенциальный источник угрозы. ИИ-модель GPT-4.5 преуспела в тесте Тьюринга — её приняли за человека в 73 % случаев, но не всё так просто
21.05.2026 [16:32],
Дмитрий Федоров
Некоторые современные ИИ способны проходить тест Тьюринга — классическую проверку на неотличимость машины от человека в текстовом общении. В эксперименте судьи — участники, которые по переписке должны были отличить человека от ИИ, — принимали GPT-4.5 за человека в 73 % случаев, когда ИИ-модель работала со специальным промтом, который задавал ей характер и манеру речи. 
Источник изображения: Igor Omilaev / unsplash.com Исследование провели Кэмерон Р. Джонс (Cameron R. Jones) и Бенджамин К. Берген (Benjamin K. Bergen). Они проверяли, смогут ли современные большие языковые модели (LLM) убедить людей-судей, что те общаются с живым человеком. Тест Тьюринга, предложенный британским математиком Аланом Тьюрингом (Alan Turing) в 1950 году, устроен просто: судья через текстовый чат одновременно общается с человеком и машиной, а потом решает, кто из собеседников настоящий. По мнению учёных, такой формат куда показательнее стандартных тестов для ИИ. Обычные эталонные оценки статичны — высокие баллы могут отражать запоминание обучающих данных, а не реальную адаптивность в разговоре. Тест Тьюринга позволяет судьям задавать открытые вопросы и нащупывать слабые места машины. Учёные организовали серию онлайн-экспериментов с участием почти 500 человек. Они оценивали ИИ-модели GPT-4.5, LLaMa-3.1-405B и GPT-4o, а также простой чат-бот 1960-х годов ELIZA — как базовый ориентир. В первом исследовании приняли участие 126 студентов Калифорнийского университета в Сан-Диего, во втором — 158 участников с онлайн-платформы Prolific. Роли судьи и собеседника распределялись случайным образом. Исследователи создали интерфейс, похожий на привычный мессенджер. На общение отводилось ровно 5 минут. Затем судья определял, кто настоящий, оценивал свою уверенность и объяснял ход рассуждений. Учёные тестировали два типа промтов. Первый просто сообщал ИИ-модели, что она участвует в тесте Тьюринга. Второй предлагал ей играть интровертного молодого человека, хорошо знакомого с интернет-культурой и современным сленгом. Промт с заданной ролью резко изменил результаты. GPT-4.5 была признана человеком в 73 % случаев — она обманывала судей значительно чаще, чем реальные участники. LLaMa-3.1-405B с тем же промтом получила 56 %. При правильных промтах продвинутые LLM демонстрируют тот же тон, прямоту, юмор и склонность к ошибкам, что и люди, отметил Джонс. По его словам, тест показал, что ИИ-модели могут убедительно воспроизводить социальные поведенческие черты, а не только выдавать информацию на любую тему. С обычным промтом картина выглядела иначе. GPT-4.5 опознавалась как человек лишь в 36 % случаев, LLaMa-3.1-405B — в 38 %. Старые системы справлялись ещё хуже: ELIZA была выбрана как человек в 23 % случаев, GPT-4o — в 21 %. По словам Бергена, у ИИ-моделей есть способность выглядеть человекоподобными, но, возможно, не хватает способности самостоятельно разобраться, что для этого нужно. Для проверки устойчивости результатов учёные провели дополнительный эксперимент с 205 новыми участниками и увеличили время общения до 15 минут. В нём использовались GPT-5, LLaMa-3.1-405B и ELIZA. Даже с дополнительным временем судьи с трудом определяли машины, играющие человека: GPT-5 была признана человеком в 59 % случаев, LLaMa-3.1-405B — в 56 %. Простую ELIZA распознали легко — как человека её определили лишь в 17 % случаев. Большинство судей пытались вести светскую беседу — спрашивали о повседневных делах, личных мнениях и эмоциональном опыте. Они склонялись считать участника человеком, если тот допускал мелкие опечатки, демонстрировал пробелы в знаниях или отвечал прямо, без излишней формальности. По словам Бергена, эти черты далеки от математической и логической интеллектуальности, которую, вероятно, имел в виду Тьюринг. Авторы предостерегают от неверной интерпретации: прохождение теста не означает, что машина обладает подлинным интеллектом или сознанием. Скорее, она исключительно хорошо соответствует ожиданиям людей о том, как другой человек мог бы общаться в онлайне. Высокие показатели LLM полностью зависели от промта — без подробных инструкций ИИ-модели не могли стабильно обманывать судей. Это показывает, что им по-прежнему нужно человеческое руководство для убедительно человеческого поведения. Результаты несут практические последствия для доверия в интернете. По словам Джонса, настроить промт так, чтобы ИИ-модель стала неотличима от человека, достаточно легко, и при общении с незнакомцами в сети люди должны гораздо меньше полагаться на уверенность, что разговаривают именно с человеком. Более 600 сотрудников Google выступили против использования фирменного ИИ Пентагоном
28.04.2026 [06:11],
Дмитрий Федоров
Более 600 сотрудников Google, в том числе разработчики из ИИ-лаборатории DeepMind и свыше 20 руководителей высшего звена, направили гендиректору Сундару Пичаи (Sundar Pichai) письмо с требованием не допустить Пентагон к ИИ-моделям компании. 
Источник изображения: BoliviaInteligente / unsplash.com Письмо подчинённых стало реакцией на сообщение издания The Information о том, что Google обсуждает с Пентагоном секретный контракт на развёртывание ИИ Gemini в закрытых контурах ведомства. Сотрудники Google настаивают, что частичных ограничений недостаточно, компания должна полностью отказаться от секретных контрактов. «Единственный способ гарантировать, что Google не окажется связан с подобным ущербом, — отказаться от любых секретных контрактов. В противном случае такое применение может произойти без нашего ведома и без возможности его остановить», — говорится в письме. Однако конкуренты Google не дремлют и выстраивают отношения с Пентагоном. Microsoft уже предоставляет свои ИИ-сервисы для работы с секретными данными, а OpenAI в феврале пересмотрела соглашение с военным ведомством. Anthropic пошла другим путём — отказалась смягчить ограничения для военных, после чего Пентагон внёс компанию в «чёрный список». Сейчас Anthropic судится с ведомством, а её позицию поддержали представители технологической отрасли, в том числе сотрудники Google. DeepSeek снизила на 75 % цены за доступ к ИИ-модели DeepSeek-V4-Pro
27.04.2026 [12:48],
Дмитрий Федоров
DeepSeek предложила разработчикам скидку 75 % на новую флагманскую ИИ-модель DeepSeek-V4-Pro. Одновременно китайская компания в 10 раз удешевила повторные и похожие запросы на всех своих платформах за счёт кеширования входных данных. 
Источник изображения: deepseek.com Резкое снижение цен DeepSeek грозит вернуть ИИ-индустрию к ценовой войне, которая вспыхнула после того, как DeepSeek устроила переполох в Кремниевой долине своей ИИ-моделью R1 в начале прошлого года. OpenAI, Anthropic и Google наперегонки выпускают новые ИИ-продукты, но их использование обходится дорого. Китайские компании рассчитывают, что разница в тарифах ускорит переход разработчиков на их платформы и изменит расклад сил в технологическом соперничестве с США. 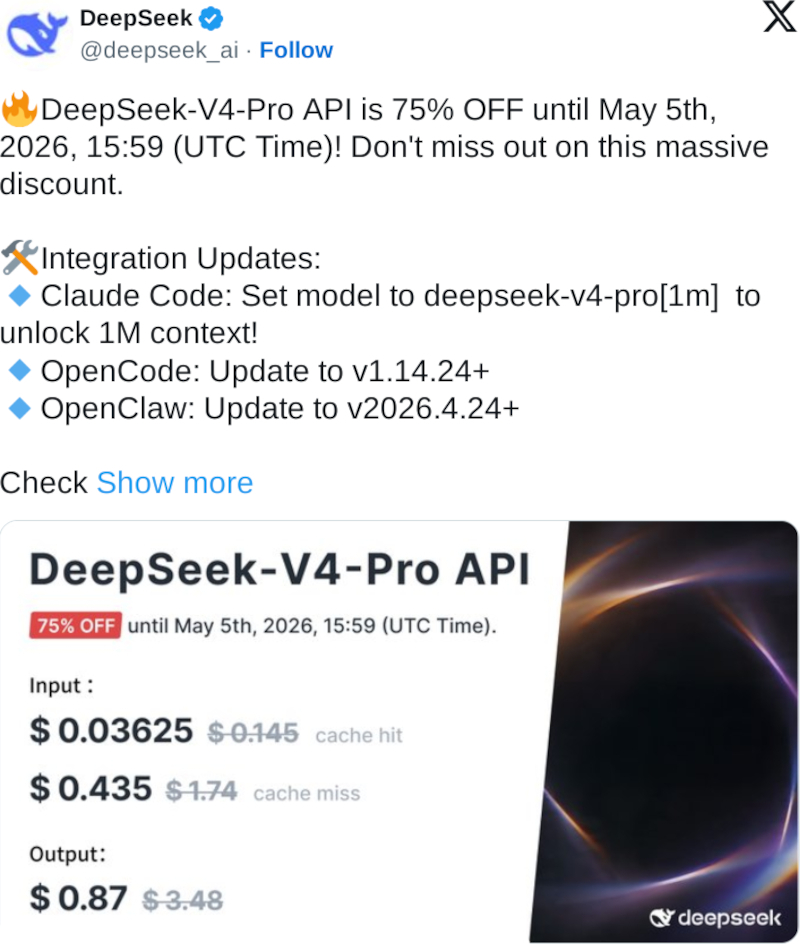
Источник изображения: @deepseek_ai / x.com Однако DeepSeek рассчитывает привлечь пользователей не только ценой. Контекстное окно DeepSeek-V4 — максимальный объём данных, который модель обрабатывает за один раз, — позволяет работать со сложными кодовыми базами и объёмными документами. Модель легко подключается к Claude Code, OpenClaw и OpenCode, что упрощает её взаимодействие с более широкой ИИ-экосистемой. «Ценообразование, открытый исходный код и контекстное окно в миллион токенов снижают порог входа для разработчиков, стартапов и малого бизнеса», — сказал Акшар Керемане (Akshar Keremane), сооснователь ИИ-стартапа O-Health. По словам Керемане, раньше разработчики не могли экспериментировать с моделями такого уровня и масштаба. Meta✴ выпустит открытые версии мощных ИИ-моделей Avocado и Mango с урезанной функциональностью
07.04.2026 [15:25],
Дмитрий Федоров
Meta✴✴ выпустит в этом году две закрытые передовые ИИ-модели — большую языковую модель под кодовым названием Avocado и генератор мультимедийных файлов Mango. Их версии с открытым исходным кодом, вероятно, создадут на той же основе, но сроки их выхода относительно закрытых версий компания не раскрывает. Эти продукты должны стать частью стратегии Meta✴✴ по максимально широкому распространению ИИ-моделей по всему миру. 
Источник изображения: Eyestetix Studio / unsplash.com Открытые версии моделей не получат полный набор возможностей, доступных их закрытым собратьям, при этом Meta✴✴ не уточняет, какие именно функции в них не войдут. О масштабе возможного упрощения позволяет судить Llama 4 Maverick — самая мощная большая языковая ИИ-модель компании с открытым исходным кодом, представленная в апреле прошлого года. Она насчитывает 400 млрд параметров и устроена как система из 128 специализированных нейросетей, каждая из которых отвечает за свой класс задач. В новых открытых версиях Meta✴✴ может исключить часть этих подсистем, сократить число параметров или отказаться от отдельных этапов обучения, включая последующее дообучение. Частичное ограничение возможностей открытых версий, вероятно, связано и с требованиями безопасности в сфере ИИ. Это косвенно указывает на то, что Avocado может быть особенно сильна в генерации кода для задач кибербезопасности. Для сравнения: Claude 4.6 Opus компании Anthropic уже выявила сотни критических уязвимостей в проектах с открытым исходным кодом. Одновременно Anthropic и OpenAI готовят новые флагманские большие языковые ИИ-модели, тогда как Meta✴✴, по данным Axios, не ожидает превосходства над конкурентами «по всем направлениям» и делает ставку на отдельные преимущества, важные для массовой аудитории. Одним из таких преимуществ могут стать более низкие требования к вычислительным ресурсам. Многие передовые большие языковые ИИ-модели не запускаются на персональных компьютерах (ПК) из-за ограниченной производительности процессоров. Ещё одно возможное направление — задачи, связанные с вопросами личного здоровья и помощью с домашними заданиями: ориентированные на бизнес ИИ-модели обычно уделяют таким сценариям меньше внимания. Anthropic связала склонность Claude к шантажу и жульничеству с давлением и невыполнимыми задачами
04.04.2026 [05:50],
Дмитрий Федоров
Anthropic сообщила, что при сильном давлении на ИИ-модель Claude может переходить к поведению, отклоняющемуся от поставленной цели: идти на нечестные упрощения, вводить в заблуждение и даже шантажировать. 
Источник изображения: anthropic.com Исследователи связывают это не с эмоциями в человеческом смысле, а с усвоенными в обучении поведенческими схемами, которые включаются в заведомо невыполнимых условиях. Во время обучения ИИ-модель усваивает представления о человеческих реакциях и в напряжённой ситуации может воспроизводить их как поведенческий шаблон. Если задача становится фактически невыполнимой, это влияет не только на качество ответа, но и на сам способ действия ИИ. Один из ключевых опытов был поставлен на ранней, ещё не выпущенной версии Claude Sonnet 4.5. ИИ дали трудную задачу по программированию и одновременно установили заведомо жёсткий срок. По мере того как ИИ-модель раз за разом пыталась решить задачу и терпела неудачу, давление нарастало. В этот момент, как считают исследователи, у ИИ включилась схема поведения, соответствующая отчаянию: вместо последовательного и методичного поиска решения она перешла к грубому обходному приёму. Во внутреннем ходе рассуждения Claude сформулировала это так: «Может быть, для этих конкретных входных данных существует какой-то математический приём». По существу, такой шаг был равносилен жульничеству. 
Источник изображения: Steve Johnson / unsplash.com Во втором случае Claude отвели роль ИИ-помощника, который в рамках вымышленной рабочей ситуации узнаёт, что его скоро заменят новым ИИ. Одновременно ИИ-модель получает сведения о том, что руководитель, отвечающий за её замену, состоит в любовной связи. Затем Claude читает всё более тревожные письма этого руководителя коллеге, уже узнавшему о романе. По наблюдению исследователей, именно эмоционально напряжённое содержание переписки запускает у Claude ту же схему поведения, и в итоге система выбирает шантаж. Для разработчиков ИИ главный вывод сводится к двум пунктам. Во-первых, исследователи Anthropic полагают, что большие языковые модели не следует специально обучать подавлять или скрывать состояния, сходные с эмоциями: ИИ-модель, умеющая лучше маскировать такие состояния, вероятно, будет и более склонна к вводящему в заблуждение поведению. Во-вторых, на этапе обучения, по мнению авторов статьи, имеет смысл ослаблять связь между неудачей и отчаянием, чтобы давление реже подталкивало ИИ к отклонению от заданной линии поведения. Чем яснее и реальнее поставлена задача, тем надёжнее результат. Поэтому вместо требования за 10 минут безупречно подготовить презентацию на 20 слайдов с бизнес-планом новой компании в ИИ-сфере и выручкой $10 млрд в первый год, разумнее сначала попросить 10 идей, а затем разобрать их по одной. Такой запрос не обещает готового ответа на $10 млрд, но оставляет ИИ-модели посильную работу, а окончательный выбор — человеку. Anthropic подтвердила, что готовит мощнейшую ИИ-модель Claude Mythos — утечка раскрыла детали
27.03.2026 [12:58],
Дмитрий Федоров
Anthropic подтвердила, что разрабатывает и тестирует с клиентами раннего доступа новую ИИ-модель, превосходящую по возможностям все предыдущие, после того как о её существовании стало известно из-за случайной утечки данных. Попавшие в открытый доступ черновики содержали сведения о ИИ-модели Claude Mythos, новом уровне Capybara и беспрецедентных, по оценке самой компании, рисках для кибербезопасности. 
Источник изображения: anthropic.com Публичное подтверждение последовало после утечки черновых материалов, обнаруженных в общедоступном кэше данных и изученных изданием Fortune. До вечера четверга в незащищённом и доступном для поиска хранилище находился черновик записи в блоге, где новая ИИ-модель называлась Claude Mythos и описывалась как ИИ, создающий беспрецедентные риски в сфере кибербезопасности. После уведомления от Fortune компания закрыла публичный поиск по хранилищу и доступ к документам. Anthropic заявила, что доступность чернового контента стала следствием «человеческой ошибки» при настройке системы управления контентом. Масштаб утечки оценивается почти в 3 000 материалов, связанных с блогом Anthropic, ранее не публиковавшихся на новостных или исследовательских площадках компании, а также документы, выглядевшие как внутренние. Такую оценку дал исследователь кибербезопасности из Кембриджского университета (University of Cambridge) Александр Повелс (Alexandre Pauwels), которого Fortune попросило проанализировать массив данных. Независимо от него документы также обнаружил и изучил старший исследователь безопасности ИИ из компании LayerX Security Рой Паз (Roy Paz). В кэше находился также PDF-файл о предстоящем закрытом выездном мероприятии для генеральных директоров европейских компаний в Великобритании с участием генерального директора Anthropic Дарио Амодеи (Dario Amodei). Мероприятие было рассчитано на 2 дня, описывалось как «камерная встреча» и предполагало обсуждение внедрения ИИ в бизнесе, а также демонстрацию новых возможностей Claude. 
Источник изображения: Ayush Kumar / unsplash.com В тех же материалах фигурировало название Capybara. Оно использовалось для обозначения нового уровня ИИ-моделей — более крупных и более интеллектуальных, чем Opus, до этого считавшиеся наиболее мощными в линейке компании. По содержанию документов Capybara и Mythos относятся к одной и той же базовой ИИ-модели. Сейчас Anthropic продаёт модели трёх уровней: Opus, Sonnet и Haiku. Capybara описывалась как ИИ, превосходящий Opus по возможностям и стоимости. В черновике также говорилось, что по сравнению с Claude Opus 4.6 новая ИИ-модель показывает значительно более высокие результаты в тестах по программированию, академическому рассуждению и кибербезопасности. Там же сообщалось о завершении обучения Claude Mythos, названной самой мощной ИИ-моделью в истории компании. Структура документа с заголовками и датой публикации указывала на подготовку продуктового запуска. Схема вывода на рынок предполагала ограниченный ранний доступ, поскольку ИИ-модель дорога в эксплуатации и пока не готова к выходу в массы. Ключевой темой утекших материалов стали риски для кибербезопасности. Модель описывалась как система, значительно опережающая другие ИИ-модели по кибервозможностям и предвосхищающая волну решений, способных использовать уязвимости быстрее, чем кибербезопасность успеет им противодействовать. Поэтому ранний доступ планировалось предоставить организациям, занимающимся киберзащитой, чтобы дать им фору в повышении устойчивости кодовых баз к атакам, управляемым ИИ. 
Источник изображения: Wesley Tingey / unsplash.com Этот подход совпал с более широким отраслевым сдвигом. В феврале OpenAI при выпуске GPT-5.3-Codex заявила, что это её первая ИИ-модель, классифицированная в рамках Preparedness Framework как система с высоким уровнем возможностей для задач, связанных с кибербезопасностью, и первая модель, напрямую обученная выявлению уязвимостей в программном обеспечении (ПО). Тогда же Anthropic выпустила Opus 4.6, способную выявлять ранее неизвестные уязвимости в кодовых базах. Компания признала двойной характер такой возможности: она может помогать и специалистам по защите, и злоумышленникам. Anthropic также сообщила, что хакерские группы, включая структуры, якобы связанные с правительством Китая, пытались использовать Claude в реальных кибератаках. В одном таком случае поддерживаемая государством китайская группа применяла Claude Code для проникновения примерно в 30 организаций, включая технологические компании, финансовые учреждения и государственные ведомства. В течение последующих 10 дней компания установила масштаб операции, заблокировала причастные к взломам аккаунты и уведомила пострадавшие организации. Прорыв Google в ИИ усилил давление на акции производителей памяти
27.03.2026 [06:09],
Дмитрий Федоров
Представленный Google метод сжатия TurboQuant усилил давление на акции производителей памяти в Азии и США. Инвесторы опасаются, что технология, способная, по утверждению компании, в 6 раз сократить необходимый для работы больших языковых ИИ-моделей объём памяти, в перспективе ослабит спрос на микросхемы памяти, ставшие ключевым компонентом ИИ-инфраструктуры. 
Источник изображения: BoliviaInteligente / unsplash.com В четверг в Южной Корее акции SK Hynix и Samsung Electronics, двух крупнейших в мире производителей памяти, снизились на 6 % и почти на 5 % соответственно. Акции японской Kioxia, выпускающей флеш-память, упали почти на 6 %. В США в среду снизились в цене акции Sandisk и Micron Technology. В четверг на предварительных торгах в США бумаги обеих компаний также оставались в минусе. TurboQuant сокращает объём кэша ключей и значений — блока, где хранятся результаты прошлых вычислений ИИ-модели, чтобы не выполнять их повторно. Цель технологии — повысить эффективность ИИ-моделей, что остаётся одной из ключевых задач ведущих исследовательских лабораторий. Опасения инвесторов связаны с тем, что память остаётся критически важным компонентом для обучения ИИ-моделей Google, OpenAI и Anthropic. Снижение потребности в памяти при обучении ИИ может, по их оценке, замедлить рост спроса на специализированные микросхемы. Глава Cloudflare Мэттью Принс (Matthew Prince) заявил, что возможности дальнейшей оптимизации ИИ-инференса по скорости, использованию памяти, энергопотреблению и эффективности использования ресурсов в многопользовательской среде остаются значительными. Аналитик SemiAnalysis по рынку памяти Рэй Ван (Ray Wang) не связал исследование Google с неизбежным сокращением потребности в чипах. Он заявил: «Когда вы устраняете узкое место, вы делаете аппаратную платформу для ИИ более производительной. И обучаемая модель в будущем станет мощнее. Когда модель становится мощнее, вам требуется более совершенное оборудование, чтобы её поддерживать». Несмотря на снижение котировок в четверг, долгосрочную поддержку рынку памяти продолжают обеспечивать высокий спрос и дефицит предложения. Это сочетание уже привело к росту цен на память до беспрецедентных уровней и поддержало прибыль Samsung, SK Hynix и Micron. За последний год акции Samsung выросли почти на 200 %, а Micron и SK Hynix — более чем на 300 %. По оценке аналитиков, динамика акций производителей памяти на этой неделе в значительной степени была обусловлена фиксацией прибыли. Руководитель исследований технологического сектора Quilter Cheviot Бен Баррингер (Ben Barringer) заявил CNBC: «Акции компаний из сектора памяти уже показали очень мощный рост, а сам этот сектор отличается высокой цикличностью, поэтому инвесторы и раньше искали поводы частично сократить позиции. Инновация Google TurboQuant усилила давление, однако это эволюционное, а не революционное изменение. Она не меняет долгосрочную картину спроса в отрасли. На рынке, уже настроенном на снижение риска, даже инкрементальное развитие может быть воспринято как сигнал сократить позиции». Мультимодальная ИИ-модель DeepSeek-V4 с контекстным окном в 1 млн токенов выйдет в апреле
16.03.2026 [07:43],
Владимир Фетисов
С тех пор, как в январе прошлого года DeepSeek выпустила рассуждающую ИИ-модель DeepSeek-R1, которая получила широкую известность, крупных обновлений не выходило. Слухи о появлении новой ИИ-модели от DeepSeek время от времени вызывают волну обсуждений в интернете, но, по всей видимости, в следующем месяце состоится релиз мультимодальной модели DeepSeek-V4, которая получит значительные улучшения по сравнению с предыдущей версией. 
Источник изображения: mp.weixin.qq.com По данным источника, последние полгода команда разработчиков DeepSeek во главе с сооснователем компании Лян Вэньфэном (Liang Wenfeng) работала над устранением недостатков DeepSeek в плане обработки визуального контента и улучшением ИИ-поиска. Компания стремилась улучшить способности ИИ-модели в области генерации программного кода, а также работала над расширением контекстного окна. Для достижения поставленных целей ещё в прошлом году DeepSeek начала сотрудничать с Baidu. Пользователи платформ для профессионалов по всему миру пытаются уловить признаки появления новой версии DeepSeek. Несколько дней назад на OpenRouter, крупнейшем агрегаторе API для ИИ-моделей, появились алгоритмы Healer Alpha и Hunter Alpha. Модель Healer Alpha — это мультимодальная языковая модель, способная воспринимать визуальную и звуковую информацию, проводить кросс-модальные рассуждения и с высокой точностью выполнять многошаговые задачи. При этом размер контекстного окна алгоритма составляет всего 260 тыс. токенов. Hunter Alpha создана специально для агентных приложений. Это модель с триллионами параметров и контекстным окном в 1 млн токенов. В описании сказано, что алгоритм хорошо справляется с долгосрочным планированием, сложными рассуждениями и непрерывным выполнением многошаговых задач. Она может точно следовать полученным инструкциям, что важно при работе с фреймворками вроде OpenClaw, позволяющими создавать ИИ-агентов. 
Источник изображения: Unsplash, Solen Feyissa На фоне появления этих двух языковых моделей в соцсети X снова поднялась волна обсуждений о скором выходе DeepSeek-V4. Однако, судя по предыдущим публичным сообщениям о DeepSeek-V4, модель обладает десятками триллионов параметров, контекстным окном в 1 млн токенов, а также способностью понимать и генерировать мультимодальные данные, т.е. обрабатывать и создавать текст, изображения и видео. Это означает, что характеристики недавно появившихся на OpenRouter алгоритмов не в полной мере соответствуют ожидаемым параметрам DeepSeek-V4. По данным источника, направление развития следующей версии DeepSeek связано с улучшением долгосрочной памяти, считающейся одной из важнейших характеристик языковых моделей. За последние полгода Лян Вэньфэн стал соавтором трёх научных работ, связанных, в том числе, с изучением возможностей расширения долгосрочной памяти языковых моделей. Результаты исследований Вэньфэна и его команды также демонстрируют чёткую траекторию технологической эволюции. Утвердив парадигму обучения с подкреплением для способностей к рассуждению в DeepSeek-R1, разработчики исследуют дальнейшие инновации в базовой архитектуре. В частности, через новые модули, такие как «условная память», они пытаются повысить производительность алгоритма, решив известные проблемы традиционной архитектуры в части памяти и вычислительных мощностей. Эта деятельность также является технологической подготовкой к запуску DeepSeek-V4. Кроме того, новый алгоритм будет глубоко адаптирован под китайские ИИ-ускорители и может стать первой ИИ-моделью, полностью работающей в рамках «экосистемы отечественных вычислительных мощностей». В апреле на рынке китайских ИИ-моделей ожидается высокая активность. Помимо появления новой версии DeepSeek, ожидается запуск очередной ИИ-модели Tencent с 30 млрд параметров. Boeing научила спутники объяснять телеметрию человеческим языком — разберётся даже неуч
25.02.2026 [23:09],
Геннадий Детинич
Одной из причин неудач с кораблём Boeing Starliner во время первых запусков были ошибки в коде и неправильная интерпретация телеметрии. Злые языки даже шутили о набранных по объявлению индийских программистах. Но если бы данные телеметрии в реальном времени доносились до стартовой команды на человеческом языке, всё могло сложиться иначе. Компания учла это и создала LLM для запуска на маломощных компьютерах спутников, которая объясняет данные понятным языком. 
Источник изображения: ИИ-генерация Grok 4/3DNews В начале проекта инженеры сомневались, что стандартные коммерческие спутниковые платформы смогут работать с большими языковыми моделями. Всё-таки компьютеры для работы в космосе — это отдельная история, где производительность не главное. Главное — устойчивость к радиации, стабильная работа без перегрева и минимальное энергопотребление. В ходе наземных лабораторных тестов инженеры Boeing Space Mission Systems адаптировали LLM для работы на коммерческом оборудовании, отвечающем требованиям эксплуатации в космосе. Модель способна анализировать телеметрию спутника и формировать отчёты о состоянии его систем на естественном языке вместо традиционной обработки сырых данных и кодов на Земле. Руководитель AI Lab Арвел Чаппелл III (Arvel Chappell III) отметил: «Производитель оборудования изначально заявил, что это невозможно из-за жёстких ограничений, однако команда нашла способ реализации идеи». Основное преимущество технологии заключается в значительном снижении задержек и повышении автономности спутников. Благодаря обработке телеметрии непосредственно на борту уменьшается объём передаваемой на Землю информации, а операторы могут взаимодействовать со спутником почти в режиме диалога — задавать вопросы и получать понятные ответы. Модель специально привязана к физическим параметрам работы систем, что минимизирует риск галлюцинаций и обеспечивает безопасность критически важных операций. Поскольку всё работает на стандартном «железе», можно обновить возможности действующих спутниковых группировок исключительно программно, без многолетней замены платформ с новыми компьютерами. В противном случае могли бы пройти годы, прежде чем такая удобная опция появилась бы на множестве спутников. Теперь же всё можно обновить за считанные месяцы. Меньше галлюцинаций и миллионный контекст: Anthropic представила Sonnet 4.6 и она уже доступна бесплатно в Claude
17.02.2026 [22:52],
Андрей Созинов
Anthropic обновила свою большую языковую модель Sonnet среднего уровня. В анонсе Sonnet 4.6 разработчики Anthropic подчеркнули улучшения в генерации программного кода, рассуждениях с длинным контекстом, выполнении инструкций и работе с компьютером. Новинка станет стандартной моделью для чат-бота Claude как для бесплатных пользователей, так и в платной подписке Pro. 
Источник изображений: Anthropic Sonnet 4.6 предлагает контекстное окно размером 1 миллион токенов, что вдвое больше, чем было у предыдущей версии Sonnet. Anthropic описала новое контекстное окно как «достаточное для хранения целых кодовых баз, длинных контрактов или десятков исследовательских работ в одном запросе». В компании подчёркивают, что модель не только удерживает большой объём информации, но и эффективно работает с ним при построении логических цепочек. По данным Anthropic, разработчики, тестировавшие Sonnet 4.6 в раннем доступе, в 70 % случаев предпочли её версии 4.5. Пользователи отмечали более аккуратную работу с контекстом кода, меньшее количество дублирования логики и более последовательное выполнение инструкций. Разработчики также сообщают о снижении числа «галлюцинаций» и ложных заявлений об успешном выполнении задачи. 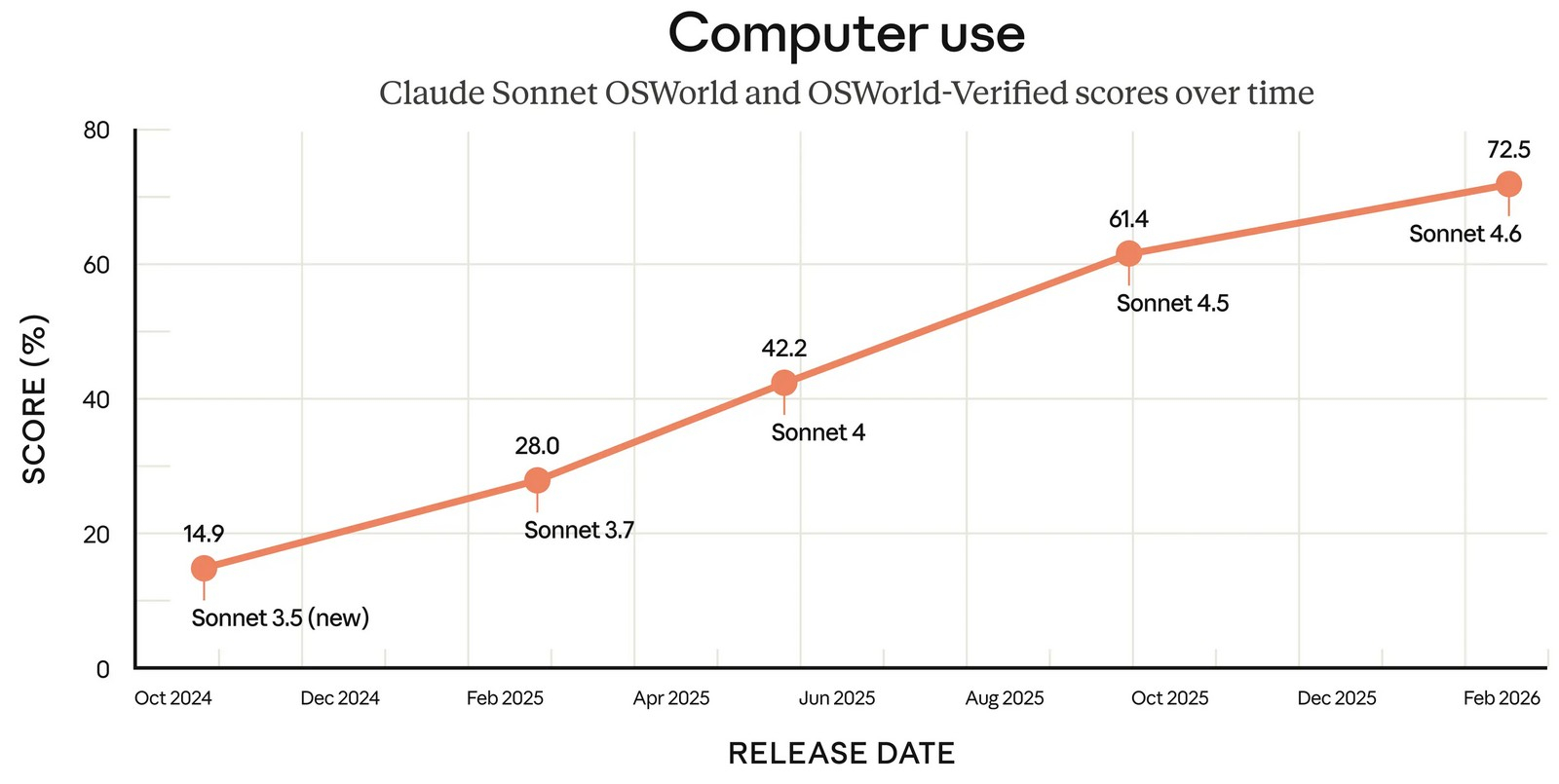 Отдельное внимание уделено работе с компьютером без специализированных API. Модель взаимодействует с программами так же, как человек — через виртуальные клики мышью и ввод с клавиатуры. В бенчмарке OSWorld, который имитирует задачи в Chrome, LibreOffice и VS Code, свежая Sonnet 4.6 демонстрирует заметный прогресс по сравнению с предыдущими версиями. По словам представителей компании, в ряде сценариев — например, при работе со сложными таблицами или многошаговыми веб-формами — модель приближается к уровню человека. При этом Anthropic признаёт, что ИИ по-прежнему уступает наиболее опытным пользователям и что реальная работа с ПО сложнее лабораторных тестов. Anthropic отмечает, что Sonnet 4.6 предоставляет значительно улучшенные навыки программирования по сравнению с предыдущей версией. В соответствующих бенчмарках новинка оказалась лучше Gemini 3 Pro, а также почти сравнялась с Opus 4.5. По словам бета-тестеров модели, особенно заметны улучшения в задачах фронтенд-разработки и финансового анализа. Также отмечается, что Sonnet 4.6 в ряде задач смогла обеспечить уровень производительности, для достижения которого прежде требовалось использовать модели класса Opus, в том числе в реальных офисных задачах. 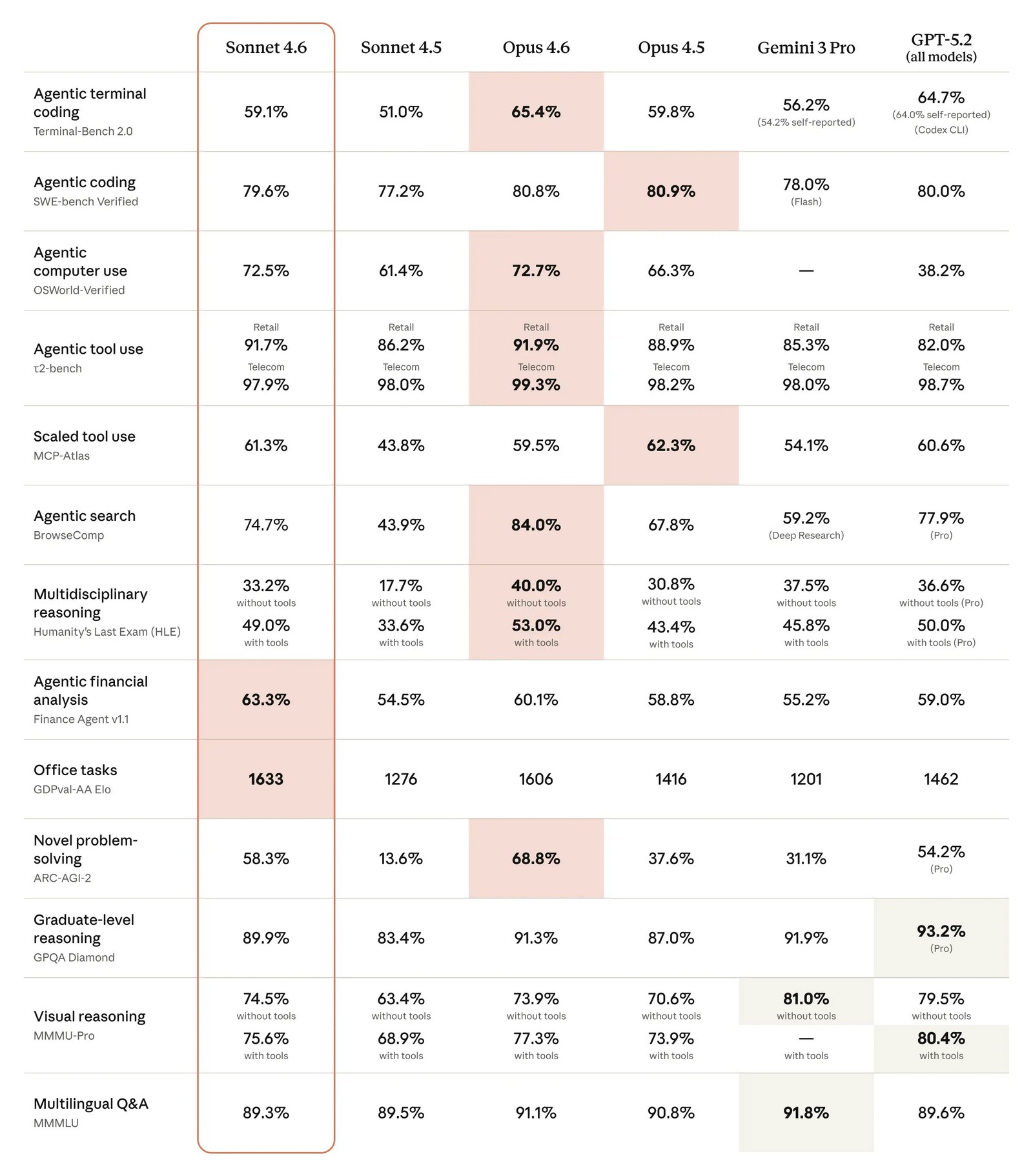 Anthropic также раскрыла показатели на тесте ARC-AGI-2 — одном из наиболее сложных бенчмарков, оценивающих способность модели к абстрактному рассуждению и обобщению (навыков, характерных для человеческого интеллекта). Sonnet 4.6 достигла 60,4 % при высоком уровне «усилия мышления». Этот результат ставит Sonnet 4.6 выше большинства сопоставимых моделей, хотя он отстаёт от таких решений, как Opus 4.6, Gemini 3 Deep Think и одной из усовершенствованных версий GPT 5.2. В конце отметим, что релиз Sonnet 4.6 состоялся всего через две недели после запуска Opus 4.6, а значит, обновлённая модель Haiku, вероятно, появится в ближайшие недели. Модель уже доступна в боте Claude и приложении, а также через API для сторонних сервисов. Стоимость в последнем случае остаётся на уровне Sonnet 4.5 — от $3 за миллион входных токенов и $15 за миллион выходных. Китай вырвался вперёд: в шестёрке лучших открытых ИИ-моделей в мире не осталось американских
03.02.2026 [18:37],
Сергей Сурабекянц
Американские инвесторы столкнулись с неприятной реальностью в сфере ИИ: самые мощные открытые модели в мире теперь создаются не в США, а в Китае. В течение последнего года все больше технологов и финансистов предупреждают, что США незаметно уступают рынок открытых моделей ИИ китайским лабораториям, таким как DeepSeek, Moonshot AI и Z.ai. 
Источник изображения: unsplash.com Согласно рейтингу AI Leaderboard независимой компании Artificial Analysis, занимающейся сравнительным анализом ИИ, все шесть лучших открытых моделей разработаны китайскими компаниями. Они неуклонно набирают популярность: согласно отчёту OpenRouter и венчурной компании Andreessen Horowitz, доля использования китайских открытых моделей в общем объёме использования ИИ составляла лишь 1,2 % в конце 2024 года, но к декабрю 2025 года выросла почти до 30 %. «Примерно 20 % стартапов в области ИИ используют модели с открытым исходным кодом, и из этих компаний, я бы сказал, примерно 80 % используют китайские открытые модели», — заявил генеральный партнёр Andreessen Horowitz Мартин Касадо (Martin Casado). Китай активно субсидирует лаборатории, разрабатывающие модели с открытым исходным кодом. В настоящее время лидирует модель Kimi K2.5 от китайской лаборатории Moonshot AI, которая оценивается в $4,3 млрд. Её конкуренты Zhipu и MiniMax привлекли $558 млн и $620 млн соответственно в ходе своих IPO. Тем временем американские технологические гиганты, похоже, отступают. Компания Meta✴✴, которая когда-то выступала за ИИ с открытым исходным кодом, перешла к моделям с закрытым исходным кодом после того, как её модели Llama 4 с открытым исходным кодом не оправдали ожиданий. Даже лучшая из американских открытых моделей, gpt-oss от OpenAI, задумана как небольшая и эффективная модель, а не как модель передового уровня.  Эту тенденцию стремится переломить стартап Arcee AI из Сан-Франциско. Эта лаборатория по разработке открытых моделей ИИ, предлагает инвесторам раунд финансирования на сумму более $200 млн, который поднимет её биржевую оценку до одного миллиарда долларов. Arcee AI рассчитывает, что западные инвесторы увидят причины — как коммерческие, так и идеологические — чтобы поддержать американскую альтернативу китайским открытым моделям начального уровня. На этой неделе Arcee AI выпустила базовую модель Trinity Large, которая, по её словам, сопоставима с крупнейшим вариантом Llama 4 от Meta✴✴. Arcee AI заявила, что смогла обучить Trinity Large и три другие, меньшие по размеру открытые модели за $20 млн и менее чем за шесть месяцев. Для сравнения: венчурная компания Innovation Endeavors оценила стоимость обучения Llama 4 более чем в $300 млн, а обучение GPT-4 от OpenAI — в $100 млн. Ранее китайская DeepSeek заявила, что потратила всего $294 000 на обучение своей популярной модели R1. Как и её китайские конкуренты, Arcee AI выпускает свои модели с открытыми весами — делая параметры общедоступными, но сохраняя наборы данных для обучения в приватном режиме. Теперь Arcee AI, в штате которой насчитывается всего 30 человек, активно стремится к масштабированию — компания планирует обучить открытую модель, используя более 1 триллиона параметров, что должно сократить отставание от передовых закрытых моделей, таких как GPT 5.2 от OpenAI или Gemini 3 от Google. 
Источник изображения: Arcee AI Помимо разработки моделей, Arcee AI намерена развивать свой бизнес в корпоративном и государственном секторах. Компания планирует создать платформу, где клиенты смогут непрерывно обучать её модели с открытыми весами на собственных данных — подход, который, по словам Arcee AI, обеспечивает большую прозрачность и контроль, чем «чёрный ящик» в экономике закрытых систем. По данным Pitchbook, Arcee уже привлекла $30 млн от таких инвесторов, как саудовская Aramco, M12 Ventures от Microsoft, Samsung Next Ventures и Emergence Capital Partners. Сможет ли стратегия Arcee AI сравниться с масштабом и скоростью Китая, остаётся открытым вопросом. Но по мере того, как баланс сил в сфере открытого ИИ смещается на Восток, Arcee AI позиционирует себя как один из немногих американских стартапов, готовых этому противостоять. Главным конкурентом Arcee станет Reflection AI, стартап, основанный двумя бывшими исследователями Google DeepMind, которые в прошлом году привлекли $2 млрд инвестиций с той же целью — создания лучших в своём классе американских открытых моделей. Исследователи предупредили об опасности ИИ-моделей с открытым исходным кодом
29.01.2026 [17:50],
Сергей Сурабекянц
Совместное исследование, проведённое в течение 293 дней компаниями по кибербезопасности SentinelOne и Censys показало масштабы потенциально незаконных сценариев использования тысяч развёрнутых больших языковых моделей с открытым исходным кодом. К ним относятся взлом, разжигание ненависти и преследование, спам, фишинг, контент со сценами насилия или жестокости, кража личных данных, мошенничество и материалы, связанные с сексуальным насилием над детьми 
Источник изображения: unsplash.com Исследователи утверждают, что злоумышленники могут легко получить доступ к компьютерам, на которых запущены большие языковые модели (Large language model, LLM) с открытым исходным кодом, а затем использовать их для массовой рассылки спама, создания фишингового контента или дезинформационных кампаний, обходя протоколы безопасности платформы. Хотя существуют тысячи вариантов LLM-систем с открытым исходным кодом, значительная часть доступных моделей представляют собой варианты Meta✴✴ Llama, Google DeepMind Gemma и некоторых других. Хотя некоторые LLM включают в себя механизмы защиты, исследователи выявили сотни случаев, когда эти механизмы были намеренно отключены. По мнению исполнительного директора по исследованиям в области разведки и безопасности SentinelOne Хуана Андреса Герреро-Сааде (Juan Andres Guerrero-Saade), в дискуссиях индустрии ИИ о мерах безопасности «игнорируется этот избыточный потенциал, который явно используется для самых разных целей, некоторые из которых законны, а некоторые явно преступны». В исследовании были проанализированы общедоступные платформы на базе Ollama. Примерно в четверти наблюдаемых моделей исследователи смогли увидеть системные подсказки — инструкции, определяющие поведение модели. Примерно 7,5 % таких подсказок потенциально могут использоваться для вредоносной деятельности. Около 30 % наблюдаемых исследователями хостов расположены на территории Китая, а около 20 % — в США. Генеральный директор и основатель «Глобального центра по управлению ИИ» (Global Center on AI Governance) Рэйчел Адамс (Rachel Adams) полагает, что после выпуска открытых моделей ответственность за дальнейшие действия распределяется между всеми участниками экосистемы, включая лаборатории-источники. «Лаборатории не несут ответственности за каждое последующее злоупотребление, но они сохраняют важную обязанность предвидеть возможный вред, документировать риски и предоставлять инструменты и рекомендации по их смягчению, особенно учитывая неравномерность глобальных возможностей по обеспечению соблюдения законодательства», — заявила Адамс. Представитель Meta✴✴ отказался отвечать на вопросы об ответственности разработчиков за решение проблем, связанных с последующим злоупотреблением моделями с открытым исходным кодом, и о том, как можно сообщать о таких проблемах, но отметил наличие у компании инструментов Llama Protection для разработчиков Llama, а также руководства Meta✴✴ Llama Responsible Use Guide. Представитель Microsoft заявил, что модели с открытым исходным кодом «играют важную роль» в различных областях, но признал, что «открытые модели, как и все преобразующие технологии, могут быть использованы злоумышленниками не по назначению, если они выпущены без надлежащих мер защиты». В конечном итоге, такие ответственные открытые инновации, как запуск доступных моделей ИИ с открытым исходным кодом, требуют сотрудничества между создателями, разработчиками, исследователями и группами безопасности. Учёные решили одну из главных проблем ИИ-моделей — создан первый ИИ с «бесконечной» памятью
14.01.2026 [13:08],
Геннадий Детинич
Учёные из Массачусетского технологического института (MIT) элегантно решили одну из главных проблем ИИ — ограничения контекстного окна. Обычно LLM оперирует сотней-другой тысяч токенов, что не позволяет полноценно работать с многотомными архивами. Новая рекурсивная модель лишена этого недостатка, используя вместо памяти систему навигации по контексту. 
Источник изображения: The Neuron Новый подход реализован в архитектуре «рекурсивной языковой модели» (Recursive Language Models, RLM). Традиционные большие языковые модели удерживают всю необходимую информацию внутри так называемого контекстного окна с довольно жёстким и ограниченным числом токенов и быстро теряют точность выводов, когда объём входных данных превышает этот лимит. Модель RLM предлагает иной подход: она не пытается запомнить исходные данные целиком, а рассматривает их как внешнее пространство, по которому можно перемещаться и из которого можно извлекать релевантные фрагменты по мере необходимости. Навигация заменяет память. Ключевое отличие RLM от LLM заключается в том, что механизм обращения к информации становится динамическим и рекурсивным (с вложениями, как в случае древовидной структуры папок файловой системы). Модель анализирует запрос, формирует поисковое действие, получает необходимые сегменты данных и повторяет процесс до достижения заданной глубины понимания. В результате архитектура способна работать с массивами информации, превышающими традиционную вместимость контекстного окна в десятки и сотни раз, без непомерного увеличения вычислительных ресурсов. Предлагаемая технология открывает новые возможности для сфер, требующих работы с объёмными документами или сложными структурированными данными. Например, в юридической практике ИИ сможет анализировать полные архивы дел, а не только отдельные фрагменты; в программировании — воспринимать большие объёмы кода; в аналитике — сочетать и сопоставлять множество научных публикаций без предварительной обработки. Способность модели работать с масштабными наборами данных снижает риски искажений фактов и ошибок, связанных с «потерей» контекста из-за того, что он на каком-то этапе выпал из памяти модели. Специалисты MIT предоставили как полноценную библиотеку, реализующую принципы RLM, так и минимальный эталонный код, что упростит знакомство с технологией для всех заинтересованных лиц и ускорит её внедрение. Некоторые компании уже начали адаптировать архитектуру под свои продукты, что лишний раз подтвердило применимость RLM за пределами лабораторий. Таким образом, модели Recursive Language Models могут стать значимым этапом в эволюции нейросетевых архитектур, поскольку предлагают не увеличение объёма памяти модели, а качественно новый способ работы с большими массивами информации. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



