|
Опрос
|
реклама
Быстрый переход
Meta✴ обжаловала вердикт на $4,2 млн по делу о зависимости от соцсетей и вреде для психики
07.05.2026 [13:57],
Анжелла Марина
Meta✴✴ обратилась в суд с просьбой отменить вердикт присяжных, признавших социальную сеть компании виновной в нанесении вреда психическому здоровью одного из пользователей. По сообщению Reuters, Meta✴✴ настаивает на полном оправдании или проведении нового судебного разбирательства по делу о зависимости от социальных сетей. 
Источник изображения: Darya Ezerskaya/Unsplash В документе, опубликованном в среду, Meta✴✴ утверждает, что защищена от подобных претензий статьёй 230 Закона о пристойности в коммуникациях (Communications Decency Act) федерального закона от 1996 года, который освобождает платформы от ответственности за пользовательский контент. Юристы компании заявили, что доказательства в суде были основаны на возникшей депрессии истца — некой Кейли (Kaley G.M.), именно с просматриваемыми материалами, а не с такими элементами дизайна, как бесконечная лента или автовоспроизведение видео. Напомним, в марте коллегия присяжных признала действия Meta✴✴ и Google (в отношении YouTube) недобросовестными в отношении разработки платформ, в результате чего компании обязаны выплатить компенсацию в размере $4,2 млн и $1,8 млн соответственно. Google также намерена обжаловать решение, тогда как другие фигуранты дела, Snap и TikTok, урегулировали споры до начала судебных слушаний. Meta✴✴, YouTube и другие компании, работающие в сфере социальных сетей, сталкиваются с тысячами аналогичных исков, в которых семьи и учебные заведения обвиняют соцсети в провоцировании кризиса ментального здоровья среди молодёжи. Хотя нижестоящие суды ранее отклоняли попытки компаний сослаться на статью 230 федерального Закона, итоговая интерпретация статьи станет ключевым фактором при рассмотрении апелляций и может иметь широкие последствия для всей интернет-индустрии, подчёркивает Reuters. Meta✴ готовит персонального ИИ-помощника для миллиардов пользователей — проект на $145 млрд пугает инвесторов
06.05.2026 [19:24],
Анжелла Марина
Meta✴✴ приступила к разработке высокоперсонализированного ИИ-ассистента, способного самостоятельно выполнять повседневные задачи для миллиардов пользователей своих платформ. Как пишет Financial Times, инициатива реализуется на фоне растущего давления со стороны инвесторов, обеспокоенных стремительным ростом расходов компании на искусственный интеллект. 
Источник изображения: AI В настоящее время продукт проходит внутреннее тестирование среди сотрудников, а его концепция во многом ориентируется на возможности платформы OpenClaw, позволяющей создавать ботов для автоматизации рутинных процессов. Ключевым элементом проекта станет продвинутый ИИ-ассистент, работающий на базе новой модели Muse Spark. ИИ-ассистенту можно будет передавать полномочия на выполнение задач, связанных с чувствительными данными, например информацией о здоровье и финансах. Однако внутри компании звучат опасения относительно готовности пользователей доверять такие данные алгоритмам. По словам одного из информированных лиц, между пользователями и технологическими платформами сегодня существует «дефицит доверия, широкий, как Гранд-Каньон», что может стать серьёзным препятствием для массового внедрения системы. Кроме того, стратегия генерального директора Марка Цукерберга (Mark Zuckerberg) по интеграции ИИ в центр потребительских продуктов требует колоссальных вливаний, несмотря на планы сократить 10 % рабочей силы в ближайшее время. На прошлой неделе Meta✴✴ объявила об увеличении капитальных затрат на $10 млрд, доведя их общий объём в этом году до $145 млрд. При этом реакция Уолл-стрит оказалась негативной: опасения по поводу растущих расходов привели к резкому падению курса акций, в результате чего рыночная капитализация компании уменьшилась почти на $170 млрд всего за неделю. Помимо персональных ассистентов, компания работает над созданием фотореалистичных 3D-персонажей для общения в реальном времени, начав с цифровой копии самого Цукерберга. Глава компании, который лично участвует в обучении и тестировании своего анимированного ИИ-клона, отметил, что существующие решения, такие как OpenClaw, слишком сложны для обычного пользователя, и Meta✴✴ намерена предложить более простой продукт, который «просто работает» без необходимости сложной настройки инфраструктуры. В долгосрочной перспективе Meta✴✴ планирует расширить присутствие ИИ в физическом мире, инвестируя в разработку человекоподобных роботов, и даже недавно приобрела стартап Assured Robot Intelligence, специализирующийся на искусственном интеллекте для робототехники. Соучредитель приобретённой компании Сяолун Ван (Xiaolong Wang) подтвердил, что их команда присоединится к Meta✴✴, чтобы помочь воплотить концепцию «персонального суперинтеллекта» в физические устройства. Одновременно попытки Meta✴✴ укрепить позиции на рынке агентного ИИ столкнулись с геополитическими трудностями: в частности, пекинские власти потребовали расторгнуть сделку по покупке китайской компании Manus за $2 млрд. Тем не менее Meta✴✴ продолжает искать способы монетизации новых технологий, рассматривая возможности ИИ в сфере шопинга и электронной коммерции. Партнёр венчурного фонда Wing Venture Capital и бывший продукт-менеджер Meta✴✴ Танай Джайпурия (Tanay Jaipuria) отметил, что, хотя проект OpenClaw и «захватывает воображение», он вряд ли станет массовым продуктом. По его словам, у Meta✴✴ есть серьёзные шансы на успех благодаря огромной пользовательской базе, но только при условии, что внутренние разработки компании, такие как модель Muse Spark, окажутся достаточно конкурентоспособными. Meta✴ снова навязала пользователям алгоритмы: ирландский регулятор открыл два расследования по жалобам на манипулятивный дизайн
06.05.2026 [06:00],
Дмитрий Федоров
Ирландский медиарегулятор Coimisiún na Meán открыл сразу два расследования в отношении Meta✴✴. Компанию подозревают в применении «тёмных паттернов» — манипулятивных приёмов в интерфейсе приложений, мешающих пользователям Facebook✴✴ и Instagram✴✴ отказаться от алгоритмической ленты в пользу хронологической. Регулятор проверит, соблюдает ли Meta✴✴ европейский Закон о цифровых услугах (DSA). 
Источник изображения: Dahlia E. Akhaine / unsplash.com Закон вступил в силу в Европейском союзе (ЕС) в 2023 году. Он обязывает крупные платформы, в том числе Meta✴✴, давать пользователям альтернативу таргетированным лентам, в основе которых лежит профилирование. Meta✴✴ в ответ добавила хронологические варианты ленты для Stories и Reels в ЕС. Однако в Coimisiún na Meán подозревают, что компания не обеспечивает «лёгкий доступ» к этим вариантам ленты и намеренно уводит пользователей от такого выбора, — это и есть классический «тёмный паттерн». Регулятор признал обоснованной обеспокоенность многих пользователей по поводу рекомендательных систем: их алгоритмы способны раз за разом подсовывать вредный контент в ленту пользователя, прежде всего детям и молодёжи. «Наша позиция ясна: недопустимо, чтобы платформы мешали людям пользоваться законными правами или пытались манипуляциями увести их от самостоятельного осознанного выбора — позволять ли рекомендательным лентам определять, что они видят в сети», — говорится в заявлении регулятора. Если нарушение DSA будет подтверждено, Meta✴✴ грозит крупный штраф: закон допускает санкции в размере до 6 % годового оборота компании на мировом рынке. В Meta✴✴ с обвинениями не согласились. «Мы отвергаем любые предположения о том, что мы нарушили DSA», — заявил представитель компании. По его словам, Meta✴✴ уже внесла существенные изменения в процессы и системы для выполнения регуляторных требований и намерена представить Coimisiún na Meán подробности этой работы. «Это не распознавание лиц»: в Facebook✴ и Instagram✴ встроили ИИ, который выявляет детей по росту и строению скелета
05.05.2026 [16:25],
Дмитрий Федоров
Meta✴✴ запустила ИИ-систему, которая по фотографиям и видео анализирует рост и строение скелета пользователей Facebook✴✴ и Instagram✴✴, чтобы находить и удалять аккаунты детей младше 13 лет. Компания подчёркивает, что технология не распознаёт лица и не определяет конкретного человека на снимке. Алгоритм пока работает в нескольких странах, включая США, и Meta✴✴ планирует расширить его географию. 
Источник изображения: Markus Spiske / unsplash.com ИИ сканирует публикации на обеих платформах и анализирует визуальные признаки возраста пользователей — прежде всего рост и строение скелета. Помимо изображений алгоритм проверяет сообщения, комментарии, биографические сведения, подписи и собирает по ним признаки того, что автор может быть несовершеннолетним. По принципу действия инструмент похож на систему сканирования лиц. Если система решит, что аккаунт принадлежит ребёнку, то заблокирует его. Чтобы учётную запись не удалили, владельцу нужно подтвердить возраст. 
Заявление прозвучало через несколько дней после того, как присяжные в штате Нью-Мексико (США) признали Meta✴✴ виновной в нарушении законодательства. Компания вводила пользователей в заблуждение относительно безопасности своих платформ и не защищала детей от вредоносного контента. Meta✴✴ обязали выплатить $375 млн. Помимо штрафа компании, возможно, придётся внести изменения в работу платформ, из-за которых она уже пригрозила уйти из штата. Параллельно Meta✴✴ распространяет на Facebook✴✴ подростковые аккаунты Teen Accounts. Система автоматически определяет пользователей от 13 до 18 лет и переводит их в этот режим, в котором ограничен контент, заблокированы сообщения от незнакомцев и запрещены прямые трансляции для тех, кому ещё нет 16. В Instagram✴✴ технология работает с 2024 года. Теперь Meta✴✴ запустит её на Facebook✴✴ сначала в США, а в июне подключит Великобританию и Европу. В заявлении Meta✴✴ также высказалась за то, чтобы возраст пользователя проверяли на уровне магазинов приложений и операционных систем. Такой подход поддерживают всё больше политиков в Конгрессе США и в нескольких штатах, в том числе в Калифорнии и Колорадо. Из WhatsApp исчезнут аватары для метавселенной
05.05.2026 [16:00],
Павел Котов
Когда Марк Цукерберг (Mark Zuckerberg) и команда Meta✴✴ верили в технологии виртуальной реальности (метавселенной), соответствующие функции появлялись в приложениях компании. Теперь наблюдается обратный процесс, который затронул и мессенджер WhatsApp. 
Источник изображения: wabetainfo.com Из профилей WhatsApp начнут пропадать аватары — трёхмерные персонажи, созданные на основе внешности пользователей; на начальном этапе исчезнет возможность редактировать эти модели. Соответствующее предупреждение появилось в профиле пользователя WhatsApp, обратил внимание ресурс WABetaInfo, а в перспективе аватары вообще пропадут из приложения. Цифровые версии пользователей WhatsApp появились в конце 2022 года, и уведомление в мессенджере указывает, что эта функция более не является приоритетной. Пока в профиле WhatsApp в качестве основной отображается фотография пользователя, и если тот создал аватар, то можно открыть и его. Аватары появились, когда Meta✴✴ планировала сформировать экосистему виртуальной реальности и стремилась добиться единообразия во всех приложениях. Вместе с аватарами из пользовательских коллекций исчезнут и созданные на основе аватаров стикеры — конкретные сроки, когда это случится, не указываются, но многие пользователи уже увидели соответствующее предупреждение в приложении. Создавать аватары, редактировать их или отправлять их другим больше не получится. Прочих функций профиля WhatsApp нововведения не затронут. Meta✴ тестирует для Instagram✴ метку для контента, созданного с помощью ИИ
04.05.2026 [18:13],
Владимир Мироненко
Meta✴✴ тестирует возможность использования метки AI creator, которая позволит авторам публикаций в социальной сети Instagram✴✴ самостоятельно идентифицировать себя как «создателя контента с использованием искусственного интеллекта». 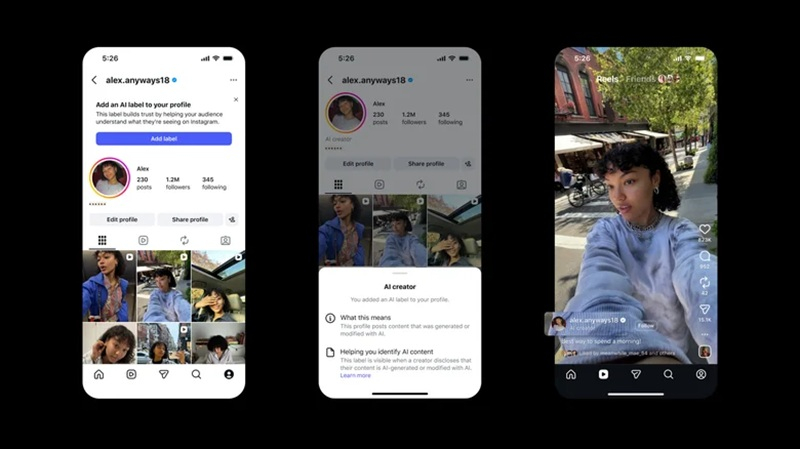
Источник изображения: Meta✴✴ Метка будет отображаться как в профилях авторов, так и рядом с их публикациями на видном месте в приложении. «Этот профиль публикует контент, который был создан или изменён с помощью ИИ», — говорится в сообщении. Как сообщила Meta✴✴, новая метка — это попытка поднять планку прозрачности в отношении ИИ в Instagram✴✴. И формулировки к ней более чёткие, чем значки Meta✴✴ AI info («Информация об ИИ»), которые указывают на то, что данная публикация могла быть создана или отредактирована с помощью инструмента ИИ. Вместе с тем, метки AI creator являются необязательными. То есть, многие пользователи соцсети по-прежнему могут столкнуться с контентом, созданным с помощью ИИ, хотя его автор предпочёл об этом умолчать. Как недавно отметила наблюдательная комиссия Meta✴✴, эти раскрытия информации применяются несколько хаотично, поскольку у Meta✴✴ пока нет возможностей для надёжного выявления в её приложениях контента, созданного с помощью искусственного разума. Вместе с тем Meta✴✴ призывает всех, кто публикует контент, созданный с помощью ИИ, использовать эту функцию. «Эта метка укрепляет доверие, помогая вашей аудитории понять, что они видят в Instagram✴✴», — говорится в сообщении компании. Meta✴ купила стартап Assured Robot Intelligence, разрабатывающий ИИ для роботов
02.05.2026 [06:24],
Алексей Разин
Сферу робототехники многие участники рынка сейчас называют «физическим воплощением искусственного интеллекта», она привлекает всё новых игроков. По всей видимости, Meta✴✴ Platforms входит в их число, поскольку на этой неделе она поглотила стартап Assured Robot Intelligence, который разрабатывает ИИ-модели для роботов. 
Источник изображения: Unsplash, Cash Macanaya Сделка была завершена вчера, как отмечает Bloomberg со ссылкой на представителей Meta✴✴. Они охарактеризовали стартап следующим образом: «Он находится на переднем крае ИИ для роботов, позволяющем роботам понимать, предсказывать и адаптироваться к поведению человека в сложных и динамически меняющихся условиях». Судя по описанию, разработки Assured Robot Intelligence направлены на создание ИИ для роботов, способных функционировать в бытовых условиях, поскольку они значительно сложнее промышленных, как неоднократно отмечали профильные специалисты. Финансовая сторона сделки не раскрывается. Команда разработчиков стартапа присоединится к подразделению Meta✴✴ Superintelligence Labs, включая сооснователей Assured Robot Intelligence Леррела Пинто (Lerrel Pinto) и Сяолун Вана (Xiaolong Wang). В структуре Meta✴✴ с прошлого года функционирует Robotics Studio, которая как раз занимается программным обеспечением для человекоподобных роботов. Meta✴✴ в этой сфере старается не отставать от конкурентов, поскольку интерес к человекообразным роботам проявляют Tesla, Alphabet (Google) и Amazon. Именно последняя в позапрошлом месяце поглотила стартап Fauna Robotics, который был основан при участии Леррела Пинто. Впрочем, он успел уйти из него в прошлом году. Сяолун Ван до основания Assured Robot Intelligence занимался исследованиями в компании Nvidia. Сотрудники Assured Robot Intelligence были сосредоточены в Нью-Йорке и Сан-Диего, им предстоит влиться в команду Meta✴✴. Представители последней подчеркнули, что надеются получить от стартапа технологии управления и самообучения для человекоподобных роботов. Meta✴✴ занимается разработкой и аппаратных компонентов для таких роботов, включая разного рода сенсоры. Не исключено, что их Meta✴✴ будет поставлять и другим производителям роботов, как и программное обеспечение. Компания хочет стать важным игроком на рынке человекоподобных роботов, как это удалось сделать Google и Qualcomm в сегменте смартфонов. Марк Цукерберг объяснил очередные сокращения ростом затрат на ИИ, и не исключил дальнейших увольнений
01.05.2026 [11:38],
Павел Котов
Гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) объяснил предстоящую волну увольнений в компании ростом капитальных затрат на направление искусственного интеллекта и заявил, что не исключает дальнейших сокращений рабочих мест. 
Источник изображения: Mark Zuckerberg «В компании у нас, по сути, два основных источника затрат: вычислительная инфраструктура и люди. Если вкладываем больше в одну область для обслуживания нашего сообщества, значит, у нас [остаётся] меньше капитала, который можно выделить на другую. Поэтому нам нужно несколько сократить размер компании», — цитирует Reuters слова господина Цукерберга на встрече с подчинёнными. С реорганизацией отделов Meta✴✴ вокруг новой структуры AI native и проектом по разработке ИИ-агентов сокращения штата не связаны, добавил он. В ряде случаев работники Meta✴✴ выступили с открытой критикой этих решений. «Увольнения не связаны ни с принуждением всех сотрудников пользоваться инструментами ИИ, ни с повышением эффективности работы», — отметил глава компании, но добавил, что «посмотрим, как всё это будет развиваться» и пообещал, что «в ближайшее время компания сможет поделиться дополнительной информацией». Встреча Марка Цукерберга с сотрудниками Meta✴✴ прошла накануне, и она была первой с тех пор, как стало известно об очередной волне сокращений. К 20 мая она планирует расстаться с 10 % сотрудников, а во второй половине года грядёт ещё одна волна увольнений. Какие-то планы на будущее гендиректор Meta✴✴ комментировать отказался. Meta✴ по-тихому разорвала контракт с подрядчиком на фоне скандала с видео с Ray-Ban Meta✴
01.05.2026 [10:54],
Павел Котов
В феврале работники кенийской компании Sama, которая выступала подрядчиком Meta✴✴ в задаче описания материалов, снятых умными очками, сообщили, что в рамках рабочих задач были вынуждены просматривать и аннотировать видео чрезмерно конфиденциального характера. В ответ на это гигант соцсетей спустя два месяца расторг контракт с африканским партнёром, узнало BBC. 
Источник изображения: ray-ban.com Два шведских издания сообщили, что работники Sama жаловались на вынужденный просмотр откровенных видеозаписей, снятых на Ray-Ban Meta✴✴. Люди на этих видео, предположительно, не знали, что идёт запись, и под камеру переодевались, посещали уборную и вступали в интимные контакты. Сотрудники Sama считают, что Meta✴✴ расторгла контракт из-за того, что этот факт получил огласку; мера затронула 1108 работников кенийской компании. «Мы не комментируем конкретные процессы или решения клиентов, но можем подтвердить, что сотрудничество с Meta✴✴ прекращается. Sama всегда соответствовала рабочим стандартам, стандартам безопасности и качества, предъявляемым ко всем нашим проектам с клиентами; мы гарантируем этический характер нашей работы. Наша задача — поддержать сотрудников в этот переходный период, продолжая при этом оказывать услуги нашим клиентам», — заявили в Sama. В Meta✴✴ подтвердили, что «решили прекратить сотрудничество с Sama, потому что они не соответствуют нашим стандартам». «В минувшем месяце мы приостановили работу с Sams на время расследования этих заявлений. Мы относимся к ним серьёзно. Фотографии и видео носят для пользователей личный характер. Люди проверяют материалы для искусственного интеллекта, предназначенные для улучшения производительности продукта, и мы получаем явное согласие пользователей», — подчеркнули в американской компании. При включённой видеозаписи на очках Ray-Ban Meta✴✴ загорается светодиодный индикатор, но, по словам работников Sama, некоторые их пользователи, видимо, порой не знали, что шла запись. В Meta✴✴ подтвердили, что иногда передают контент, направленный владельцами очков чат-боту с генеративным ИИ Meta✴✴ AI, подрядчикам для анализа данных с целью «улучшения пользовательского опыта». Однако такие «данные сначала обрабатываются для защиты конфиденциальности пользователей». Инцидент привлёк пристальное внимание к деятельности Meta✴✴. В США в отношении Meta✴✴ и Luxottica of America (входит во владеющую брендом Ray-Ban компанию EssilorLuxottica) коллективный судебный иск — ответчиков обвиняют в нарушении прав потребителей, требуя возмещения ущерба, штрафных санкций и изменения политики Meta✴✴. Управление комиссара по вопросам информации (ICO) Великобритании заявило но намерении направить Meta✴✴ письмо, в котором напомнить, что подобные устройства «должны предоставлять пользователям контроль и обеспечивать надлежащую прозрачность». Проверку инициировало и кенийское Управление уполномоченного по защите данных. Акции Meta✴ упали на 9 %, а Alphabet выросли на 7 % — обе наращивают капитальные расходы на ИИ
30.04.2026 [22:30],
Владимир Фетисов
Стоимость ценных бумаг Alphabet выросла более чем на 7 %, тогда как акции Meta✴✴ подешевели на 9 %. Это произошло после публикации финансовых результатов компаний по итогам первого квартала нынешнего года, в которых также были озвучены планы по увеличению расходов на инфраструктуру для искусственного интеллекта. 
Источник изображений: unsplash.com Разнонаправленное движение курсов акций указывает на то, что Уолл-стрит не гарантированно поддерживает каждого технологического гиганта за его траты на ИИ. «Рынок оказался менее единодушен в оценке планов по расходам: инвесторы по-прежнему пытаются соотнести масштаб возможностей, которые открывает ИИ, с объёмом денежных средств, необходимых для их реализации. Но главный вывод заключается в том, что этот цикл далёк от того, чтобы пойти на спад», — считает аналитик Hargreaves Lansdown Мэтт Бритцман (Matt Britzman). Alphabet превзошла оценки аналитиков по выручке за первый квартал благодаря быстрому росту облачного бизнеса Google Cloud. За отчётный период выручка в этом направлении подскочила на 63 % по сравнению с первым кварталом прошлого года. Генеральный директор Google Сундар Пичаи (Sundar Pichai) заявил, что рост облачного бизнеса был обусловлен высоким спросом на корпоративные ИИ-решения. На этом фоне компания повысила прогноз по капитальным расходам на весь год до $180-190 млрд, тогда как ранее планировала потратить $175-185 млрд. Meta✴✴ превзошла ожидания Уолл-стрит по прибыли и выручке в первом квартале, хотя показатель ежедневно активных пользователей снизился по сравнению с предыдущим кварталом из-за «перебоев с интернетом в Иране». Компания объявила об увеличении прогноза по капитальным расходам на год до $125-145 млрд, тогда как ранее планировалось потратить $115-135 млрд. Meta✴✴ заявила, что этот шаг «отражает ожидание более высоких цен на компоненты в этом году, и в меньшей степени, дополнительных затрат на центры обработки данных для поддержки вычислительных мощностей в будущие годы». По данным источника, на этой неделе Meta✴✴ предложила инвесторам сделку с облигациями на сумму $20-25 млрд, поскольку стоимость создания ИИ-инфраструктуры продолжает расти. По данным осведомлённых источников, в долговой сделке Meta✴✴ примут участие Goldman Sachs и Morgan Stanley. За последние семь месяцев эта сделка с облигациями станет для компании уже второй. Официальные представители Meta✴✴ отказались от комментариев по данному вопросу. Во время общения с инвесторами во время оглашения финансовых результатов Сундар Пичаи заявил, что Alphabet фиксирует «огромный» спрос на свои ИИ-инструменты и чипы компании. Он добавил, что ИИ «стимулирует каждое направление бизнеса». Руководство Meta✴✴ попыталось оправдать огромные расходы компании на ИИ, заявив, что они необходимы для «удовлетворения инфраструктурных потребностей» и обеспечения роста в будущем, а также для укрепления бизнеса в сфере онлайн-рекламы. В отличие от Alphabet, Microsoft и Amazon, которые обладают крупными бизнес-направлениями в сфере облачной инфраструктуры, что позволяет им превращать свои инвестиции в ИИ в доход, у Meta✴✴ таких возможностей нет. Из-за этого гиганту социальных сетей труднее доказать инвесторам свою способность обеспечить прибыльность бизнеса. Обеспокоенность по поводу расходов Meta✴✴ в сфере ИИ побудила аналитиков JPMorgan понизить рейтинг акций компании с «выше рынка» до «нейтрального». Аналитики считают, что компании предстоит «непростой путь» к получению отдачи от запланированных капитальных затрат. «В целом мы рассчитываем на более чёткое понимание того, как будет обеспечиваться окупаемость инвестиций в ИИ за пределами основного рекламного бизнеса. Мы полагаем, что создание, доработка, масштабирование и монетизация новых продуктов и пользовательского опыта потребуют времени», — говорится в сообщении аналитиков JPMorgan. Гонка ИИ обойдётся четвёрке бигтехов в $725 млрд только в этом году — недавно речь шла о $650 млрд
30.04.2026 [15:14],
Николай Хижняк
Четыре крупнейшие технологические компании США — Alphabet, Meta✴✴ Platforms, Microsoft и Amazon — теперь планируют совокупно выделить в этом году на капитальные затраты до $725 млрд. А ещё в феврале планировалось, что инвестиции составят $650 млрд. В основном эти траты будут связаны с закупками нового оборудования для центров обработки данных с искусственным интеллектом, пишет издание Bloomberg. 
Источник изображения: Nebius Alphabet и Meta✴✴ Platforms повысили свои прогнозы капитальных затрат на весь год, а Microsoft впервые озвучила свои расходы до конца декабря. Они практически сравняются с показателями Alphabet и составят $190 млрд. Amazon.com оказалась единственной из «большой четвёрки» владельцев центров обработки данных, кто не стал менять прогноз и оставил его на уровне $200 млрд, хотя компания сообщила о резком росте расходов в первом квартале, что привело к снижению свободного денежного потока. «Мы увеличиваем прогноз капитальных затрат на инфраструктуру на этот год. В основном это связано с ростом цен на комплектующие, особенно на память. Но всё, что мы видим в нашей работе и в отрасли в целом, вселяет в нас уверенность в целесообразности этих инвестиций», — заявил генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) в ходе телефонной конференции с аналитиками в среду. Компания повысила верхнюю границу запланированного диапазона расходов до $145 млрд. Увеличение расходов четырёх крупнейших технологических компаний США было обусловлено их высокими финансовыми результатами, которые по ряду показателей превзошли ожидания аналитиков или как минимум оказались на уровне прогнозов. Bloomberg отмечает, что Amazon и Alphabet показали более впечатляющие результаты, чем Meta✴✴, чьи расходы также считались более рискованными по сравнению с конкурентами, предоставляющими услуги облачных вычислений, позволяющие сдавать в аренду избыточные мощности. Meta✴ разрабатывает ИИ-агентов, которые помогут людям и бизнесу «достигать различных целей»
30.04.2026 [14:02],
Павел Котов
Подразделение Meta✴✴ Superintelligence Labs (MSL) ведёт разработку пакета агентов искусственного интеллекта, которые помогут людям «достигать различных целей в своей жизни», сообщил глава компании Марк Цукерберг (Mark Zuckerberg). 
Источник изображения: Daniele D'Andreti / unsplash.com Цель проекта, рассказал господин Цукерберг, сделать ИИ-агентов более доступными и простыми в использовании по сравнению с существующими приложениями, в том числе популярным OpenClaw. ИИ-агенты для бизнеса и личного использования будут основаны на представленной недавно компанией модели Muse Spark. «Наша цель — не просто предоставить Meta✴✴ AI в качестве помощника, а создать агентов, которые могут понимать ваши цели и работать днём и ночью, чтобы помочь вам достичь их. Мы разрабатываем персонального агента, ориентированного на помощь людям в достижении различных целей в их жизни. Мы также разрабатываем бизнес-агента для помощи предпринимателям и компаниям по всему миру, использующим наши и другие инструменты для развития деятельности, привлечения новых клиентов и улучшения обслуживания существующих», — рассказал Марк Цукерберг. Сроков выпуска ИИ-агентов от Meta✴✴ он не уточнил, но отметил, что цель проекта — сделать эту категорию приложений более доступной по сравнению с существующими. OpenClaw, по его словам, позволяет взглянуть на то, что «должно быть возможно», но он «довольно непрост» в настройке. «Существует множество агентов, которые используются людьми в различных целях, и не так много из них я бы дал маме. Как создать более отточенный, настроенный и простой вариант того же, чтобы вся инфраструктура была уже готова для людей?» — задался он риторическим вопросом. Meta✴ потеряла очередные $4 млрд на виртуальной реальности — общий убыток достиг $83,5 млрд
30.04.2026 [12:20],
Павел Котов
Накануне Meta✴✴ опубликовала квартальный финансовый отчёт, в котором сообщила, что минувшие три месяца подразделение Reality Labs, ответственное за технологии виртуальной реальности, завершило с убытком $4 млрд. Это средний показатель за последние более чем пять лет, но ИИ потребует ещё больше. 
Источник изображения: Meta✴✴ Колоссальная сумма убытка в $4 млрд по направлению метавселенной превратилась для компании Meta✴✴ в повседневную реальность. За последние 21 квартальный отчёт о доходах, начиная с 2021 года, гигант соцсетей потерял на подразделении Reality Labs в общей сложности $83,5 млрд, то есть $4 млрд за квартал — это средний показатель. На этом компания явно не остановится: направление метавселенной продолжает оставаться резко убыточным, но приоритетным оно больше не является — ключевым стал сегмент искусственного интеллекта, расходы на который будут ещё более астрономическими. И Meta✴✴ вполне может позволить себе такие траты. По итогам I квартала 2026 года чистая прибыль компании составила $26,8 млрд, что на 61 % больше, чем за аналогичный период прошлого года; выручка увеличилась на 33 % год к году и достигла $56,3 млрд. Основные доходы Meta✴✴ обеспечивают принадлежащие компании социальные сети, но она стремится оставаться конкурентоспособной по отношению к лидерам в области ИИ, в том числе OpenAI и Anthropic. По итогам 2026 года компания намеревается потратить от $125 млрд до $145 млрд — это больше прогнозов аналитиков и самой компании. «Мы увеличили собственный прогноз капитальных затрат на инфраструктуру в этом году. Это преимущественно связано с более высокими расходами на компоненты, особенно на память. <..> Мы очень стремимся повысить эффективность наших инвестиций», — заявил гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) в беседе с инвесторами. Компания потратила огромные деньги на метавселенную, которая не отозвалась спросом со стороны потребителей — передовой ИИ обещает быть более востребованным, но и расходов он предполагает более значительных. В прошлом году Meta✴✴ переманила более полусотни ведущих специалистов в области ИИ и в начале апреля представила передовую ИИ-модель Muse Spark. Дальнейшие планы компании в отношении ИИ оказались неутешительными для инвесторов: прогноз расходов на 2027 год оказался ещё не готов, но низкими затраты точно не будут. «Мы не даём конкретного прогноза капитальных затрат на 2027 год, и, честно говоря, сами находимся в очень динамичном процессе планирования, прорабатывая наши потребности в мощностях на ближайшие годы. Опыт показывает, что мы всё ещё недооцениваем собственные потребности в вычислительных ресурсах», — призналась финансовый директор Meta✴✴ Сьюзан Ли (Susan Li). После публикации квартального отчёта акции Meta✴✴ подешевели на 5 %. Meta✴ отчиталась о росте прибыли, но сокращение аудитории обвалило акции на 7 %
30.04.2026 [12:18],
Владимир Мироненко
Акции Meta✴✴ упали на 7 % на внебиржевых торгах после публикации финансовых результатов первого квартала 2026 года, несмотря на то, что выручка и прибыль превысили прогнозы Уолл-стрит. Рынок негативно отреагировал на более низкие, чем ожидалось капитальные затраты, а также сокращение ежедневной посещаемости сервисов, которое компания объяснила перебоями в работе интернета в Иране и ограничениями доступа к WhatsApp в России. 
Источник изображения: ROBIN WORRALL/unsplash.com Чистая прибыль компании составила $26,77 млрд, или $10,44 на акцию, что на 61 % больше, чем $16,64 млрд, или $6,43 на акцию, за тот же период годом ранее. Выручка выросла на 33 % по сравнению с прошлым годом и составила $56,31 млрд. Согласно прогнозу аналитиков, опрошенных FactSet Research, ожидалось, что Meta✴✴ заработает $6,67 на акцию при выручке в $55,6 млрд. Количество ежедневно активных пользователей (DAP) в первом квартале составило 3,56 млрд, что на 4 % больше, чем за аналогичный период прошлого года, но более чем на 5 % меньше, чем в четвертом квартале. Аналитики Уолл-стрит прогнозировали, что DAP в отчётном квартале составит 3,62 млрд человек. Капитальные затраты Meta✴✴ составили за квартал $19,84 млрд, что ниже среднего прогноза StreetAccount в $27,57 млрд. Однако Meta✴✴ заявила, что капитальные затраты за год составят от $125 до $145 млрд, что больше ранее планировавшихся затрат в диапазоне от $115 до $135 млрд. «Это отражает наши ожидания более высоких цен на компоненты в этом году и, в меньшей степени, дополнительных затрат на ЦОД для поддержки мощностей в будущем», — заявила Meta✴✴. Во втором квартале компания прогнозирует выручку в диапазоне от $58 до $61 млрд, в то время как аналитики ожидают выручку в размере $59,5 млрд. Финансовый директор Meta✴✴ Сьюзан Ли (Susan Li) в ходе телефонной конференции, посвящённой итогам первого квартала, сообщила аналитикам, многочисленные судебные иски с обвинениями компании во вреде её сервисов для психического здоровья молодежи в конечном итоге могут привести к существенным убыткам. Meta✴✴ потерпела два поражения в судебных процессах в марте, оба связаны с обвинениями в том, что компания вводила потребителей в заблуждение относительно безопасности своих сервисов для подрастающего поколения. Численность персонала Meta✴✴ выросла на 1 % в годовом исчислении, составив 77 986 человек по состоянию на 31 марта. По мере увеличения капитальных затрат Meta✴✴ стремится сократить свой штат. На прошлой неделе компания объявила об увольнении около 10 % сотрудников, или 8 тыс. человек, а также о прекращении набора персонала на 6 тыс. открытых вакансий. Еврокомиссия обвинила Meta✴ в неспособности оградить детей от Instagram✴ и Facebook✴ — компании грозит огромный штраф
29.04.2026 [13:29],
Владимир Фетисов
Еврокомиссия, являющаяся исполнительным органом Евросоюза, обвинила компанию Meta✴✴ Platforms в неспособности оградить детей от своих сервисов. На этом фоне регулятор инициировал расследование, которое может закончиться для гиганта соцсетей крупными штрафами. 
Источник изображения: Julie Ricard / Unsplash На этой неделе Еврокомиссия опубликовала предварительные результаты проведённого расследования в отношении Meta✴✴. В них сказано, что американская компания, владеющая соцсетями Facebook✴✴ и Instagram✴✴, не соблюдает собственную политику, в соответствии с которой регистрироваться на упомянутых площадках могут люди, возраст которых не менее 13 лет. «В приложениях нет эффективных средств контроля для проверки правильности самостоятельно указанной даты рождения», — говорится в заявлении Еврокомиссии. Там также сказано, что используемый Meta✴✴ инструмент выявления пользователей младше 13 лет с целью последующего удаления их аккаунтов «сложен в использовании и неэффективен». Meta✴✴ и другие технологические компании по всему миру находятся под давлением со стороны регуляторов разных стран, которые принуждают платформы делать больше для предотвращения доступа детей к своим сервисам. В то время как некоторые страны стремятся к полному запрету соцсетей, Евросоюз в основном сосредоточен на обеспечении соблюдения действующего в регионе свода правил регулирования контента в рамках Закона о цифровых услугах (DSA). Предварительное заключение Еврокомиссии по данному вопросу активизирует расследование в отношении Meta✴✴, которое было начато ещё в мае 2024 года. Теперь Meta✴✴ должна защитить себя от выдвинутых обвинений и, возможно, предложить меры, которые позволят устранить замечания регулятора. Напомним, DSA обязывает цифровые платформы бороться с незаконным или вредоносным контентом под угрозой штрафов, размер которых может достигать 6 % глобального оборота компании за год. В рамках DSA также предусматривается установка возрастных ограничений на доступ к сервисам, на которых публикуется контент для взрослых. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


