|
Опрос
|
реклама
Быстрый переход
Meta✴ начала отменять итоги сделки с Manus, стремясь избежать штрафов в Китае
28.04.2026 [07:52],
Алексей Разин
Вчера стало известно, что китайские власти заблокировали сделку Meta✴✴ по покупке ИИ-стартапа Manus, которая состоялась в прошлом году и повлекла выплату $2 млрд инвесторам последнего. По данным The Wall Street Journal, китайские регуляторы дали сторонам сделки несколько недель на её отмену, поэтому Meta✴✴ уже начала возвращать активы инвесторам Manus и предпринимать другие шаги по отмене сделки. 
Источник изображения: Manus Сингапурские инвесторы Manus уже получили от Meta✴✴ возвраты, которые отменяют сделку, бывшие инвесторы стартапа в других регионах Азии также сотрудничают с несостоявшимся покупателем в сфере отмены итогов сделки. По требованиям китайских властей, связанные с КНР активы Manus должны вернуться в исходное состояние за несколько недель, иначе штрафные санкции будут наложены как на Meta✴✴, так и на саму Manus. Последняя также должна будет вернуть Meta✴✴ любые данные или технологии, которые успела получить от неё после сделки. Напомним, стартап Manus был зарегистрирован гражданами Китая в Сингапуре, туда же переехала основная часть сотрудников, но китайские власти считают этот стартап своим с точки зрения регулирования экспорта критически важных для национальной безопасности технологий. Если итоги сделки не будут отменены в полной мере, её участникам также грозят штрафные санкции со стороны Китая. Министерство торговли КНР расследовало сделку между Meta✴✴ и Manus с января текущего года, на этой неделе она была признана нарушающей законодательство в сфере защиты критически важных технологий для национальной безопасности. Meta✴ договорилась о покупке 1 ГВт солнечной энергии из космоса — технология пока существует лишь на бумаге
27.04.2026 [17:05],
Дмитрий Федоров
Meta✴✴ договорилась со стартапом Overview Energy о поставках 1 ГВт солнечной энергии, собираемой в космосе. Эта мощность примерно равна выработке одного ядерного реактора. По замыслу проекта, спутники будут собирать солнечную энергию на околоземной орбите и передавать её на Землю. Старт коммерческих поставок электропитания для ИИ ЦОД Meta✴✴ намечен на 2030 год. Технология пока остаётся гипотетической. 
Источник изображения: Growtika / unsplash.com Финансовые условия сделки Meta✴✴ не раскрывает. Известно, что соглашение обеспечит ей первоочередной доступ к будущим мощностям стартапа. От проекта компания рассчитывает получить чистую «бесперебойную энергию», заявил её вице-президент по энергетике и устойчивому развитию Нат Сальстром (Nat Sahlstrom). Главный аргумент Overview Energy прост: в космосе солнце не заходит. Если стартапу удастся наладить непрерывный сбор энергии и её передачу на наземные приёмники, технология сможет снять ряд ограничений наземных солнечных панелей, выработка которых зависит от погоды, времени суток и сезона. Илон Маск (Elon Musk), Джефф Безос (Jeff Bezos) и другие техномагнаты рассматривают иной вариант: размещать на орбите сами вычислительные мощности. Сделка Meta✴✴ вписывается в её масштабные расходы на развитие ИИ. Компания направляет сотни миллиардов долларов на энергоснабжение, инфраструктуру и вычислительные мощности под эти проекты. До сих пор её основная инфраструктура строилась на природном газе. Meta✴✴ считает его более стабильным и надёжным источником, чем ряд более чистых альтернатив. Под крупнейший кластер ЦОД в сельской местности штата Луизиана компания возводит десять новых газовых электростанций. Китай заблокировал покупку ИИ-стартапа Manus компанией Meta✴ за $2 млрд
27.04.2026 [13:50],
Алексей Разин
В прошлом году Meta✴✴ Platforms достигла договорённости о покупке за $2 млрд активов стартапа Manus, который был основан китайскими предпринимателями и зарегистрирован в Сингапуре. Основатели Manus стали невыездными в Китае, а местные власти принялись изучать условия сделки. Очевидно, какие-то нарушения законодательства КНР были найдены, поскольку на этой неделе власти страны приняли решение заблокировать эту сделку. 
Источник изображения: Manus Как отмечается в скупых комментариях Национальной комиссии по развитию и реформам, на которые ссылается Bloomberg, сделка между Meta✴✴ и Manus была оформлена с нарушениями действующего законодательства КНР, а потому будет заблокирована. Время для оглашения такого решения было выбрано не самым удачным с дипломатической точки зрения образом, поскольку встреча президента США Дональда Трампа (Donald Trump) и китайского лидера Си Цзиньпина (Xi Jinping), намеченная на этот месяц, ещё не состоялась. Наверняка претензии китайских властей к сделке по покупке Manus вызовут негативную реакцию со стороны США. При помощи технологий Manus компания Meta✴✴ рассчитывала догнать и перегнать конкурентов в бурно развивающейся сфере агентского ИИ, который позволяет поручать ИИ-моделям работу с данными в соответствии с потребностями пользователей. Проблема заключается в том, что с момента оформления сделки прошло достаточно времени, и сотрудники Manus уже присоединились к штату Meta✴✴, а соответствующее перемещение капитала тоже состоялось. Бывший персонал Manus перебрался в офис сингапурского представительства Meta✴✴, а прочие инвесторы стартапа получили причитающиеся им по сделке средства. По всей видимости, решение китайских властей о блокировке сделки между Meta✴✴ и Manus укладывается в логику ограничения доступа американских инвесторов к стратегически важным отраслям китайской экономики. В рамках трёхлетней сделки Meta✴ будет использовать сотни тысяч чипов Amazon Graviton
26.04.2026 [06:34],
Алексей Разин
Эволюция вычислительной инфраструктуры искусственного интеллекта происходит стремительно, о чём отчасти говорит и недавний квартальный отчёт Intel, показавший резкий рост спроса на центральные процессоры серверного назначения. Американские техногиганты начинают активнее использовать чипы собственной разработки, а также предлагать их сторонним участникам рынка. 
Источник изображения: LinkedIn По крайней мере, эту тенденцию иллюстрирует заключённая недавно между Meta✴✴ Platforms и Amazon (AWS) сделка, по результатам которой первая получит на три года или более доступ к сотням тысячам чипов Graviton, которые Amazon изначально разрабатывала для собственных нужд. Эта сделка, по большому счёту, идёт в одном русле с договорённостями, которые Meta✴✴ недавно достигла с CoreWeave и Mebius, направив на расширение собственной вычислительной инфраструктуры $48 млрд в общей сложности. Финансовые условия сделки Meta✴✴ с Amazon раскрыты не были. По словам представителей первой, процессоры Graviton обеспечат её тем сочетанием производительности и эффективности при работе с агентскими задачами в ИИ, которое ей требуется. Как отметили представители AWS, процессоры Graviton используются многими разработчиками для предварительного обучения своих ИИ-моделей, и теперь Meta✴✴ окажется в их числе. В этом отношении она составит компанию и более известным клиентам AWS, включая Adobe, Apple, Snowflake и Anthropic. Среди доступных конфигураций облачного сервиса EC2 именно процессоры Graviton обеспечивают лучшее быстродействие за свои деньги, потребляя при этом на 60 % меньше электроэнергии по сравнению с альтернативами, как отмечают представители AWS. Компания Meta✴✴ и ранее использовала Graviton, но в скромных масштабах, а теперь она войдёт в число пяти крупнейших клиентов AWS и начнёт использовать сотни тысяч таких чипов. Арендой чипов Nvidia у AWS компания Meta✴✴ занималась с 2017 года. WhatsApp для Android получит поддержку «пузырей» — малоизвестного формата системных уведомлений
25.04.2026 [16:11],
Павел Котов
В Google Android есть встроенная функция «пузыри» (Bubbles) или «заголовки чатов» (Chat heads) — малоизвестный формат системных уведомлений, который появился в последних версиях системы. Поддержка этого формата обнаружена в бета-версии приложения WhatsApp, обратил внимание ресурс WABetaInfo. 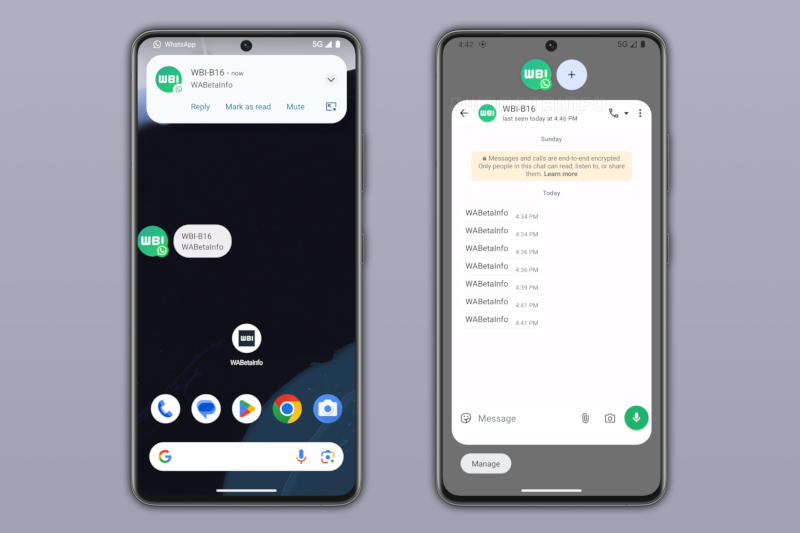
Источник изображения: wabetainfo.com Приложение Facebook✴✴ Messenger начало продвигать этот формат на Android много лет назад: при поступлении входящего сообщения на экране появляется плавающая фотография контакта, при раскрытии которой поверх всех запущенных приложений появляется окно чата. Такой формат подходит не всем, но Google решила развить эту идею и интегрировала его в Android, чтобы его могли использовать разработчики любых приложений. Поддержка «пузырей» теперь появилась и в бета-версиях WhatsApp для Android, обратил внимание ресурс WABetaInfo. Для широкого круга пользователей функция ещё не реализована, но в предварительном варианте приложения уже можно ознакомиться с её работой. Чаты WhatsApp появляются во всплывающем окне, а их формат позволяет переключаться между перепиской и другими приложениями. Facebook✴✴ Messenger поддерживает системный вариант «пузырей» только на устройствах Google Pixel, а на остальных используется собственная реализация этого формата, даже если другие приложения обращаются к штатным возможностям системы. К счастью, в случае WhatsApp такой путаницы не будет. Когда эта функция появится в общедоступной версии мессенджера, пока неизвестно. Instagram✴ начал тестировать Instants — приложение для обмена одноразовыми фотографиями
24.04.2026 [16:28],
Павел Котов
Instagram✴✴ ведёт тестирование нового приложения под названием Instants, сообщили представители соцсети ресурсу TechCrunch. Новый сервис, доступный в Испании и Италии, позволяет публиковать фотографии для подписчиков — они остаются доступными в течение 24 часов, и посмотреть эти снимки можно только один раз. 
Источник изображения: Miguelangel Perez / unsplash.com Снимок в Instants делается в одно касание, и отредактировать его уже не получится. Нельзя и загрузить фотографию из галереи — только снять на камеру устройства и сразу опубликовать. К таким снимкам можно добавить текст, но изменить его после публикации тоже невозможно. В отличие от Instagram✴✴, где публикуется тщательно отобранный и подготовленный контент, Instants предназначается для быстрых снимков в реальной жизни. Идея платформы частично позаимствована у таких сервисов как Snapchat, Locket и BeReal, которые тоже делают упор на аутентичность и быстрое устаревание контента. Воспользоваться сервисом можно или в основном приложении Instagram✴✴, или в отдельном Instants — оно тоже есть, причём и для Google Android, и для Apple iOS. Когда-то и Instagram✴✴ создавался как платформа для обмена фото с друзьями — это уже после её заполонили реклама и блогеры. Обновлённый сервис для публикации реальных фото выглядит своего рода попыткой вернуться к истокам, а также ответить конкурирующим платформам, которые предлагают альтернативные форматы. Будет ли новое приложение успешным, покажет время. Тот же сервис BeReal уже не так популярен, как раньше. Кроме того, люди активно пользуются Instagram✴✴ Stories — клоном Snapchat, и едва ли они увидят потребность в отдельном программном продукте для этих целей. В мае будет уволен каждый десятый сотрудник Meta✴
24.04.2026 [08:46],
Алексей Разин
Так называемый искусственный интеллект американскими корпорациями продвигается, в том числе, и под предлогом оптимизации расходов и повышения производительности труда, поэтому готовящиеся компанией Meta✴✴ Platforms сокращения персонала в мае как раз объясняются данными доводами. Каждый десятый или примерно 8000 человек в следующем месяце покинут штат компании. 
Источник изображения: Unsplash, Obie Fernandez Об этом сообщает издание The Wall Street Journal со ссылкой на внутреннюю рассылку Meta✴✴. Эти сокращения, по словам руководства компании, необходимы для повышения эффективности её работы, а также для высвобождения средств, которые будут инвестироваться в развитие бизнеса. Сотрудники, которых коснётся сокращение, будут уведомлены 20 мая. Кроме того, Meta✴✴ откажется от прежних планов нанять 6000 новых сотрудников. В этом году Meta✴✴ Platforms рассчитывает направить на расширение вычислительной инфраструктуры ИИ до $135 млрд. В этом месяце она представила свою новую ИИ-модель Muse Spark, но не собирается ею ограничиваться. Компания решила использовать буквальное слежение за действиями своих сотрудников для обучения ИИ. Вполне предсказуемо, что это не всем понравилось, как позволяют судить внутренние обсуждения на корпоративных ресурсах компании. В январе Meta✴✴ также сократила около 1500 сотрудников подразделения Reality Labs. Впервые компании пришлось пойти на увольнения в 2022 году, поскольку за время пандемии она увеличила штат почти в два раза до 87 000 человек. После её пришлось расстаться примерно с 11 000 сотрудников. К концу 2023 года штат компании уменьшился до 67 000 человек, но позже она вернулась к приёму на работу новых сотрудников. К сокращениям Meta✴✴ вернулась только в начале 2025 года. По состоянию на декабрь прошлого года, в Meta✴✴ работало 78 865 человек. Meta✴ расширила родительский контроль на общение с ИИ — родители увидят темы бесед подростков за неделю
24.04.2026 [05:08],
Дмитрий Федоров
Meta✴✴ откроет родителям доступ к темам, которые их дети-подростки обсуждают с ИИ-чат-ботом компании. Новая вкладка Insights в инструментах родительского контроля Facebook✴✴, Messenger и Instagram✴✴ покажет родителям темы разговоров их детей за последние семь дней. На старте функция заработает в пяти странах. 
Источник изображения: Solen Feyissa / unsplash.com Meta✴✴ уже уведомляет родителей, когда подростки затрагивают в Instagram✴✴ темы суицида или членовредительства. Теперь компания расширяет контроль на общение с Meta✴✴ AI. Родители, подключившие наблюдение за детьми в Facebook✴✴, Messenger или Instagram✴✴, увидят в новой вкладке Insights опцию Their AI interactions — перечень тем, которые подросток обсуждал с ИИ-чат-ботом за последние семь дней. Темы разбиты на крупные категории — учёба, развлечения, образ жизни, путешествия, тексты, здоровье и благополучие, — а внутри каждой выделены подтемы, сообщает Meta✴✴. В категорию «образ жизни» входят мода, еда и праздники, в «здоровье и благополучие» — физическое и психическое здоровье ребёнка. Родители могут нажать на основную тему, чтобы увидеть подробности. 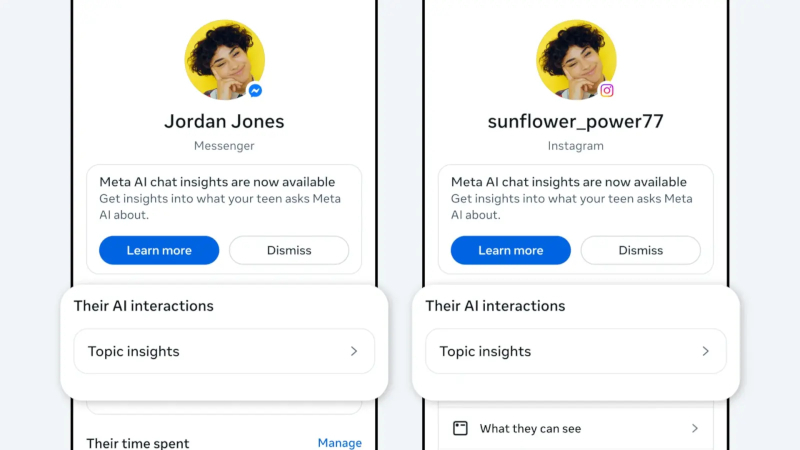
Источник изображения: Meta✴✴ На старте функция доступна родителям, контролирующим аккаунты детей в США, Великобритании, Австралии, Канаде и Бразилии. Широкое распространение функции запланировано на ближайшие недели. По умолчанию Meta✴✴ присваивает статус подросткового аккаунта всем пользователям младше 16 лет. Нововведение появляется на фоне серии судебных разбирательств против Meta✴✴. Компанию обвиняют в создании продуктов, вызывающих зависимость. Гендиректор Марк Цукерберг (Mark Zuckerberg) недавно давал показания по одному из таких дел. В прошлом месяце суд обязал компанию выплатить $375 млн за то, что она не пресекла распространение материалов с сексуальной эксплуатацией детей. 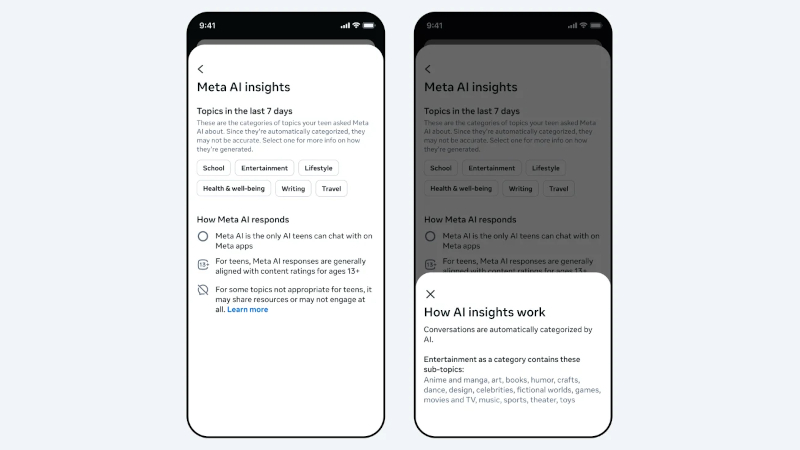
Источник изображения: Meta✴✴ Чтобы сделать ИИ-продукты безопаснее для несовершеннолетних, Meta✴✴ создала экспертный совет по цифровому благополучию при использовании ИИ (AI Wellbeing Expert Council). Сотрудники Meta✴✴ будут регулярно встречаться с членами совета, информировать их о новых функциях и собирать обратную связь. Meta✴ начнёт записывать все нажатия клавиш на компьютерах сотрудников — и обучать на этом ИИ
22.04.2026 [10:04],
Павел Котов
В Meta✴✴ нашли новый источник обучающих данных для моделей искусственного интеллекта — собственных сотрудников. Компания решила записывать все движения мыши и нажатия клавиш на клавиатурах рабочих компьютеров сотрудников и обучать на этих данных модели ИИ. 
Источник изображения: Onur Binay / unsplash.com Оригинальная инициатива наглядно демонстрирует, на какие ухищрения готовы идти технологические компании в поисках новых источников обучающих данных — теперь это жизненно важный ресурс для моделей ИИ, чтобы те более эффективно отвечали на запросы пользователей и выполняли их задачи. В самой Meta✴✴ инициативу отрицать не стали. «Если мы создаём агентов, которые помогут людям выполнять повседневные задачи на компьютерах, нашим моделям нужны реальные примеры того, как люди на самом деле ими пользуются — такие вещи как движения мыши, нажатия кнопок и работа с выпадающими навигационными меню. Для этого мы запустим внутреннюю систему, которая будет собирать подобные данные ввода в определённых приложениях, чтобы помочь нам в обучении моделей. Для защиты конфиденциальной информации приняты меры, ни для каких других целей данные не используются», — пояснил представитель компании ресурсу TechCrunch. Впрочем, вопросы конфиденциальности в деле обучения ИИ до сих пор вызывают вопросы: для обучения ИИ уже стали использовать корпоративную переписку в архивах Slack и на платформе постановки задач Jira. Meta✴ ответит в суде за попустительство мошеннической рекламе в Facebook✴ и Instagram✴
22.04.2026 [09:29],
Владимир Мироненко
Некоммерческая организация «Федерация потребителей Америки» (CFA) подала коллективный иск против Meta✴✴, в котором обвинила компанию в ведении пользователей в заблуждение и неспособности защитить их от мошеннической рекламы в Facebook✴✴ и Instagram✴✴. 
Источник изображения: Wesley Tingey/unsplash.com В иске CFA утверждается, что Meta✴✴ нарушила законы о защите прав потребителей в Вашингтоне (округ Колумбия), вводя в заблуждение пользователей Facebook✴✴ и Instagram✴✴ относительно мошенничества в своих приложениях, и что компания «гналась за прибылью, а не за защитой своих пользователей». В подтверждение обвинений организация привела многочисленные примеры предполагаемой мошеннической рекламы, обнаруженной в рекламной библиотеке Meta✴✴, которая представляет собой известные мошеннические схемы, включая объявления, рекламирующие «бесплатный государственный iPhone», а также объявления, предлагающие чеки на $1400 тем, кто родился в определённые годы. По данным CFA, во многих объявлениях размещаются видеоролики, созданные с использованием искусственного интеллекта. «Meta✴✴ утверждает, что делает всё возможное для борьбы с мошеннической рекламой на своих платформах. Но в действительности компания сознательно предпринимает шаги и принимает политику, которая увеличивает её прибыль за счёт безопасности и благополучия пользователей», — говорится в иске CFA. Организация отметила, что вместо того, чтобы запрещать рекламодателей, которых компания сама определила как представляющих высокий риск для своих пользователей, Meta✴✴ просто взимает с них более высокую плату. «Парадоксальный результат заключается в том, что чем рискованнее рекламодатель, тем больше денег зарабатывает Meta✴✴», — подчеркнула CFA. Комментируя предъявленные CFA обвинения, представитель Meta✴✴ заявил, что они «искажают реальность нашей работы, и мы будем бороться с ними»: «Мы активно боремся с мошенничеством на всех наших платформах, чтобы защитить людей и бизнес — только в прошлом году мы удалили более 159 млн мошеннических объявлений, 92 % из которых были сняты до того, как кто-либо сообщил о них, и заблокировали 10,9 млн аккаунтов в Facebook✴✴ и Instagram✴✴, связанных с преступными мошенническими центрами. Мы боремся с мошенничеством, потому что оно вредит бизнесу — люди не хотят его, рекламодатели не хотят его, и мы тоже». Рекламная практика Meta✴✴ находится в центре внимания общественности с прошлого года, когда агентство Reuters сообщило о внутренних документах компании, указывающих на то, что она зарабатывает миллиарды долларов на рекламе, продвигающей мошеннические схемы и запрещённые товары. В одном из документов Meta✴✴ за 2024 год оценивалось, что компания получила 10,1 % своей выручки в том году — около $16 млрд — от рекламы, которая на самом деле являлась мошенничеством или содержала другой запрещённый контент. CFA добивается возмещения убытков и возврата незаконно полученной прибыли от Meta✴✴, а также проведения бизнес-реформ, включая дополнительные меры для борьбы с неоднократными нарушителями и тщательную проверку рекламы, обещающей, например, бесплатные государственные программы, которых не существует, прежде чем она будет показана потребителям. Meta✴ уволит почти 10 % штата ради перестройки вокруг ИИ и роста эффективности
18.04.2026 [11:52],
Дмитрий Федоров
Meta✴✴ сократит около 8000 сотрудников — почти 10 % всего штата компании — 20 мая 2026 года. За первой волной увольнений последуют новые сокращения во II полугодии, сроки и масштаб которых пока не определены. Марк Цукерберг (Mark Zuckerberg) перестраивает компанию вокруг ИИ, жертвуя тысячами рабочих мест ради роста эффективности бизнеса. 
Источник изображения: Copilot Три источника, осведомлённых о планах компании, сообщили изданию Reuters о дате первой волны увольнений. Параметры сокращений во II полугодии руководство скорректирует с учётом развития возможностей ИИ. Месяцем ранее Reuters сообщало, что компания рассматривает сокращение 20 % и более персонала по всему миру. По состоянию на 31 декабря 2025 года в штате Meta✴✴ числилось около 79000 человек. Нынешние увольнения — это крупнейшие в истории компании со времён реорганизации конца 2022 — начала 2023 года, получившей внутреннее название «год эффективности», когда было ликвидировано около 21000 рабочих мест. Тогда акции Meta✴✴ стремительно падали, а компания исправляла последствия прогнозов роста, сформированных в условиях пандемии COVID-19. Сегодня финансовое положение Meta✴✴ принципиально иное. В 2025 году компания получила выручку свыше $200 млрд и прибыль $60 млрд. Акции с начала 2026 года прибавили 3,68 %, хотя пока не достигают рекордной отметки лета 2025 года. Цукерберг вкладывает сотни миллиардов долларов в ИИ, добиваясь сокращения числа управленческих уровней и роста эффективности за счёт ИИ-инструментов в работе сотрудников. Аналогичная тенденция охватывает весь американский технологический сектор. Amazon.com за последние несколько месяцев сократила 30000 служащих — почти 10 % сотрудников умственного труда. В феврале 2026 года компания в сфере финансовых технологий Block уволила почти половину штата. В обоих случаях руководство напрямую связало сокращения с повышением эффективности за счёт ИИ. По данным Layoffs.fyi, с начала 2026 года в технологическом секторе работы лишились 73212 человек — против 153000 за весь 2024 год. Параллельно Meta✴✴ реорганизовала подразделение Reality Labs и перевела инженеров из разных частей компании в новую структуру Applied AI с задачей ускорить разработку автономных программных систем на основе ИИ, способных писать код и самостоятельно выполнять сложные задачи. Часть сотрудников переведут в подразделение Meta✴✴ Small Business, созданное в марте 2026 года. Meta✴ подняла цены на VR-гарнитуры Quest 3S и Quest 3 — и снова из-за дефицита памяти
16.04.2026 [17:31],
Павел Котов
Дефицит памяти продолжает влиять на рынок электроники. На этот раз он добрался до VR-гарнитур Meta✴✴. Стоимость базовой гарнитуры виртуальной реальности Meta✴✴ Quest 3S увеличится на $50: до $350 за модель со 128 Гбайт памяти и до $450 за версию с 256 Гбайт, объявила компания. Модель Meta✴✴ Quest 3 прибавила в цене $100 и теперь стоит $600. 
Источник изображения: Meta✴✴ Как и другие технологические компании, Meta✴✴ столкнулась с дефицитом и последовавшим за ним ростом цен на чипы памяти, спровоцированными бумом технологий искусственного интеллекта. Apple и Microsoft были вынуждены повысить цены на ноутбуки, а Samsung — на некоторые смартфоны. Другие производители гарнитур также повысили цены или столкнулись с задержками в выпуске продукции. Гигант соцсетей, который в 2021 году сменил название с Facebook✴✴ на Meta✴✴, чтобы продвигать метавселенную — технологии дополненной и виртуальной реальности — добавил, что цены на восстановленные экземпляры гарнитур тоже вырастут; стоимость умных очков пока останется прежней. «Мы внесли эти изменения, потому что стоимость выпуска высокопроизводительного оборудования для виртуальной реальности значительно увеличилась. Чтобы и далее обеспечивать качество оборудования, ПО и поддержки, которое ожидается от платформы Quest, нам необходимо скорректировать цены», — пояснили в компании. Новые ценники на гарнитуры семейства Meta✴✴ Quest вступят в силу 19 апреля — помимо США, они поднимутся в Евросоюзе, Великобритании и Японии. Умные очки Meta✴✴ сейчас популярнее, чем гарнитуры закрытого типа, но компания не собирается отказываться от устройств виртуальной реальности, продолжая считать их «будущим вычислительной техники». Впрочем, некоторые действия Meta✴✴ дают основания предположить, что приоритет технологий виртуальной реальности в компании снижается. Под сокращение попали несколько сотен сотрудников профильного подразделения Reality Labs, чуть было не закрылась платформа Horizon Worlds, приостановлена работа над несколькими играми для систем виртуальной реальности. Apple, к слову, пока не объявляла о повышении стоимости своей гарнитуры Vision Pro — при ценнике $3499 это будет непросто. Еврокомиссия сочла плату WhatsApp за доступ конкурирующих ИИ равносильной запрету
15.04.2026 [18:11],
Дмитрий Федоров
Европейская комиссия заявила, что мартовское изменение условий доступа к WhatsApp для конкурирующих ИИ-сервисов не сняло антимонопольных претензий к Meta✴✴. По предварительной оценке регулятора, плата за доступ даёт тот же эффект, что и прямой запрет, поэтому компания получила второе уведомление о претензиях, а комиссия рассматривает временные обеспечительные меры. 
Источник изображения: Dima Solomin / unsplash.com Исполнительный вице-председатель Европейской комиссии Тереса Рибера (Teresa Ribera) заявила, что замена прямого правового запрета платой, дающей сходный эффект, не меняет предварительной позиции регулятора: комиссия по-прежнему исходит из того, что поведение Meta✴✴, по всей видимости, представляет собой злоупотребление доминирующим положением. Расследование продолжается с октября прошлого года, когда Meta✴✴ изменила условия доступа для других поставщиков ИИ-сервисов. Тогда конкуренты выразили опасение, что могут лишиться доступа к WhatsApp. Второе уведомление о претензиях последовало за мартовским заявлением Meta✴✴ о том, что компания заменила запрет новым порядком взимания платы. Тогда Meta✴✴ утверждала, что эти изменения в Европе должны дать комиссии время, необходимое для завершения расследования. Компания также настаивает, что сектор ИИ остаётся высококонкурентным, а конкурирующие ИИ-сервисы по-прежнему доступны пользователям через магазины приложений, поисковые системы, почтовые службы и операционные системы. Представитель Meta✴✴ Джошуа Брекман (Joshua Breckman) заявил в ответ на новое уведомление о претензиях, что Еврокомиссия своим решением позволит некоторым из крупнейших компаний бесплатно пользоваться платным сервисом WhatsApp Business. По его словам, обеспечительные меры пойдут на пользу OpenAI и во вред потребителям. Марк Цукерберг «перенёс свой рабочий стол» в лабораторию ИИ
15.04.2026 [16:11],
Павел Котов
Гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) «практически перенёс свой рабочий стол и сидит в лаборатории искусственного интеллекта <..> и весь день пишет код», — рассказала накануне изданию Semafor World Economy президент компании Дина Пауэлл Маккормик (Dina Powell McCormick). Пост президента и вице-председателя совета директоров она заняла в январе 2026 года. 
Источник изображения: Mark Zuckerberg «Думаю, он настолько убеждён в необходимости понимать это на таком уровне, чтобы по-настоящему задуматься, как сделать нашу модель максимально эффективной», — рассказала госпожа Маккормик. Её карьера развивалась от банка Goldman Sachs до заместителя советника по стратегии национальной безопасности при президенте Дональде Трампе (Donald Trump), но ей пришлось адаптироваться к головокружительному темпу работы в Meta✴✴. «В Кремниевой долине или как минимум в Meta✴✴ я увидела, всё происходит намного, намного быстрее, чем когда я работала в правительстве или даже на Уолл-стрит», — отметила она. На вопрос о недавних решениях суда по поводу юридической ответственности Meta✴✴ за вред, который компания причинила психическому здоровью подростков, она ответила: «К этим вердиктам мы относимся с уважением, но не согласны с ними и намерены подавать апелляцию. <..> Я видела, насколько серьёзно руководство компании относится к этому вопросу, чтобы не допускать вредного контента и, что наиболее важно, чтобы родители имели возможность влиять на ситуацию». Meta✴ и Broadcom продлили партнёрство до 2029 года для создания нескольких поколений кастомных ИИ-чипов
15.04.2026 [13:56],
Владимир Мироненко
Meta✴✴ и Broadcom объявили о расширении партнёрства с целью создания нескольких поколений кастомных чипов для ИИ-нагрузок, продлив соглашение до 2029 года с обязательством по обеспечению на первом этапе более 1 ГВт вычислительной мощности. 
Источник изображения: Meta✴✴ Соглашение охватывает программу Meta✴✴ Training and Inference Accelerator (MTIA), в рамках которой Broadcom предоставляет Meta✴✴ технологии проектирования, упаковки и сетевого оборудования для микросхем. MTIA является ключевым элементом более широкой стратегии Meta✴✴ в области микросхем, которая использует различные ускорители для разных рабочих нагрузок — портфель MTIA подбирает специализированное оборудование для оптимизации как производительности, так и общей стоимости владения в масштабе. Первый ИИ-ускоритель, созданный в рамках программы, — MTIA 300 — уже используется системами ранжирования и рекомендаций Meta✴✴ в Facebook✴✴, Instagram✴✴ и других приложениях. До 2027 года планируется выпуск еще трёх поколений кастомных чипов, предназначенных в первую очередь для инференса. Broadcom подчеркнула, что они станут первыми в отрасли специализированными ИИ-чипами, изготовленными по 2-нм техпроцессу. Технология Ethernet от Broadcom также будет использоваться для масштабного подключения расширяющихся ИИ-кластеров Meta✴✴. «Meta✴✴ сотрудничает с Broadcom в области проектирования чипов, упаковки и сетевых технологий для создания масштабной вычислительной базы, необходимой для предоставления персонального суперинтеллекта миллиардам людей», — сообщил основатель и генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg). В рамках сделки генеральный директор Broadcom Хок Тан (Hock Tan) покинет совет директоров Meta✴✴ и перейдёт на консультативную должность, где будет давать рекомендации по плану развития специализированных микросхем Meta✴✴ и помогать формировать стратегию инвестиций в инфраструктуру. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


