|
Опрос
|
реклама
Быстрый переход
OpenAI фокусируется на разработке аудио ИИ для будущих аппаратных устройств
02.01.2026 [11:01],
Владимир Мироненко
OpenAI делает большую ставку на аудио ИИ, сообщил ресурс The Information. По его данным, за последние два месяца компания объединила несколько инженерных, продуктовых и исследовательских групп в одну структуру с целью модернизации имеющихся аудиомоделей в рамках подготовки к выпуску персонального устройства, ориентированного на разговорный ИИ. Как ожидается, новинка появится на рынке примерно через год. 
Источник изображения: Mariia Shalabaieva/unsplash.com Этот шаг отражает направление, в котором движется вся технологическая индустрия, когда аудио ИИ или разговорный ИИ выходит на первый план, отметил TechCrunch. Умные колонки с голосовыми ассистентами уже стали неотъемлемой частью более чем трети домовладений в США. Компания Meta✴✴ недавно представила новую функцию своих умных очков Ray-Ban, которая позволяет с помощью массива из пяти микрофонов слышать разговоры в шумном помещении. В свою очередь, Google в июне начала экспериментировать с функцией аудиообзора, преобразующей результаты поиска в диалоговые резюме, а Tesla интегрирует ИИ-чат-бота Grok от xAI в системы своих электромобилей, благодаря чему разговорный голосовой ассистент (conversational voice assistant) сможет управлять всем — от навигации до климат-контроля — с помощью естественного диалога. Не все инициативы в этом направлении ведут к успеху. Проект Humane по созданию смарт-броши AI Pin закончился полным провалом. Кулон Friend AI с поддержкой ИИ, призванный составить компанию пользователю в качестве собеседника и предлагаемый в качестве средства для борьбы с одиночеством, вызвал опасения по поводу конфиденциальности и, по всей видимости, тоже окажется невостребованным. Форм-факторы могут быть разными, но основная идея заключается в том, разговорный ИИ — это интерфейс будущего. Новая аудиомодель OpenAI, выход которой запланирован на начало 2026 года, по сообщениям источников, будет звучать более естественно, делать уместные паузы, как настоящий собеседник, и даже говорить в то время, когда пользователь разговаривает, чего не могут делать современные ИИ-модели. По словам источников, OpenAI планирует создать семейство устройств, которое, возможно, будет включать смарт-очки или умные колонки без экрана, для использования в большей мере в качестве ИИ-компаньона, чем ИИ-инструмента. Новая статья: Итоги 2025-го: ИИ-лихорадка, рыночные войны, конец эпохи Windows 10 и ещё 12 главных событий года
01.01.2026 [00:01],
3DNews Team
Данные берутся из публикации Итоги 2025-го: ИИ-лихорадка, рыночные войны, конец эпохи Windows 10 и ещё 12 главных событий года SoftBank успела вложить в OpenAI все обещанные $41 млрд
31.12.2025 [06:35],
Алексей Разин
Как уже сообщалось ранее, японская корпорация SoftBank ближе к концу года начала судорожно искать средства, чтобы вложить в OpenAI обещанные в апреле несколько десятков миллиардов долларов США. Оставшиеся $22,5 млрд были переданы OpenAI на этой неделе, как сообщили источники CNBC, теперь японской корпорации принадлежат около 11 % акций американского стартапа. 
Источник изображения: SoftBank Помимо $7,5 млрд, переданных ранее OpenAI напрямую, SoftBank также вложила в стартап $11 млрд через совместные проекты с другими инвесторами, поэтому общая сумма вложений вырастает до $41 млрд. По данным источника, без учёта данных инвестиций капитализация OpenAI достигала $260 млрд по состоянию на февраль текущего года. Как считается, с тех пор она выросла в несколько раз, и OpenAI активно спорит с аэрокосмической компанией SpaceX за звание самого дорогого стартапа в мире. Напомним, что OpenAI в течение ближайших восьми лет собирается вложить в развитие вычислительной инфраструктуры ИИ около $1,4 трлн, но сделки с партнёрами и инвесторами организованы так, что деньги передаются по кругу, а сама OpenAI ничем не рискует. Такие схемы начали беспокоить экспертов, которые всё чаще стали говорить о формировании пузыря в сфере ИИ. Тем более, что денег, имеющихся у техногигантов, на финансирование строительства инфраструктуры для ИИ уже хватать перестало, и долги начинают формироваться за пределами сектора. Microsoft добавит GPT-5.2 в Copilot — новая модель будет работать в режиме Smart Plus
29.12.2025 [19:51],
Сергей Сурабекянц
Microsoft дополнила веб-версию Copilot, а также версии своего ИИ-помощника для Windows и мобильных устройств самой мощной на сегодняшний день моделью GPT-5.2 от OpenAI. Она позволяет быстрее выполнять реальные задачи, включая создание электронных таблиц и презентаций, написание и проверку кода, понимание длинных документов, использование инструментов и работу с изображениями. После обновления GPT 5.2 будет «сосуществовать» с GPT 5.1. Источник изображения: Microsoft В прошлом месяце ИИ-помощник Copilot был обновлён до GPT-5.1 для режима Smart. Теперь Microsoft добавляет GPT-5.2 в Copilot в качестве нового режима Smart Plus. GPT 5.2 в Copilot, по-видимому, является вариантом GPT-5.2, ориентированным на рассуждение, поскольку Microsoft подчеркнула, что он лучше справляется со сложными задачами. В интеллектуальных задачах по критерию OpenAI GDPval, который представляет собой новую оценку производительности модели в экономически значимых, реальных задачах в 44 профессиях, GPT-5.2 Thinking превосходит или показывает себя не хуже профессионалов отрасли в 70,9 % случаев, по сравнению с 38,8 % у GPT-5. Это огромный скачок, и именно поэтому OpenAI оценивает GPT-5.2 как «экспертный уровень» для многих чётко определённых офисных задач, таких как обработка презентаций, графиков и т. д. 
Источник изображения: unsplash.com В бенчмарках, предназначенных для оценки работы агентов ИИ на сложных задачах разработки программного обеспечения, GPT-5.2 Thinking показывает 55,6 % на SWE-Bench Pro и 80 % на SWE-Bench Verified, что выше, чем у GPT-5.1 Thinking. В специализированном тесте GPQA Diamond GPT-5.2 Thinking показал результат 92,4 %, в AIME 2025 — 100 %, в CharXiv Reasoning (с Python) — 88,7 %. Новая версия GPT также продемонстрировала значительное улучшение показателей в тестах оценки способности модели к абстрактному мышлению и рассуждению ARC-AGI (Abstract and Reasoning Corpus for Artificial General Intelligence — «Корпус аннотаций и рассуждений для искусственного общего интеллекта») и ARC-AGI-2. OpenAI открыла вакансию на новую руководящую должность для управления ИИ-угрозами
28.12.2025 [16:51],
Анжелла Марина
Компания OpenAI объявила о вакансии на новую должность, которая называется «руководитель по готовности» (Head of Preparedness). В посте, опубликованном генеральным директором компании Сэмом Альтманом (Sam Altman) в соцсети X, указано, что на фоне быстрого развития моделей искусственного интеллекта (ИИ) и новых вызовов, включая угрозы в области кибербезопасности и биобезопасности, данная позиция является «критически важной». Как сообщает Times of India, за эту должность OpenAI предлагает компенсационный пакет в размере до $555 000 в год, а также акции компании. 
Источник изображения: Andrew Neel/Unsplash Согласно официальному описанию вакансии, назначенный специалист станет ответственным за техническую стратегию и реализацию так называемого «рамочного подхода к готовности» (Preparedness framework), представляющего из себя систему отслеживания и подготовки к потенциальным рискам, связанным с потенциальной возможностью искусственного интеллекта причинить вред. В частности, Альтман в своём сообщении отметил, что в 2025 году уже проявились первые признаки влияния ИИ, например, на психическое здоровье людей. По его словам, у компании уже есть надёжная основа для измерения растущих возможностей ИИ, однако теперь требуется более тонкое понимание того, как эти возможности могут быть использованы не только на пользу, но и во вред, и как минимизировать негативные последствия — как в продуктах OpenAI, так и в мире в целом. Глава OpenAI подчеркнул, что подобные задачи крайне сложны, прецедентов в этой области практически нет, и многие интуитивно привлекательные решения сталкиваются с непредвиденными ситуациями. Он также предупредил, что будущая работа будет напряжённой и потребует немедленного погружения в самые сложные вопросы. В обязанности руководителя входит управление созданием оценок возможностей ИИ, построение моделей угроз и координация мер по их смягчению для формирования «согласованного, строгого и оперативно масштабируемого конвейера безопасности». От кандидата требуются глубокие технические знания, навыки чёткой коммуникации и способность руководить сложными проектами. Ему придётся возглавить небольшую, но высокоэффективную команду и тесно взаимодействовать с подразделениями по безопасности, исследованиям, инженерии, продукту, политике и внешним партнёрам. В ChatGPT совсем скоро появится реклама — стал известен её формат
27.12.2025 [17:55],
Владимир Мироненко
В СМИ появились сообщения о том, что OpenAI рассматривает возможность запуска рекламы в ChatGPT в формате «спонсируемого контента», которая может повлиять на принятие пользователем решения о покупке того или иного товара. 
Источник изображения: Mariia Shalabaieva/unsplash.com По данным ресурса The Information, OpenAI планирует отдавать приоритет размещению спонсируемого контента в ответах ИИ-моделей. «ИИ-модели могут отдавать приоритет спонсируемому контенту, чтобы гарантировать его отображение в ответах ChatGPT», — отмечается в публикации. По словам источника ресурса, в последние недели в макетах рекламы отображалась спонсируемая информация в боковой панели рядом с основным окном ответа ChatGPT. Представитель OpenAI подтвердил, что компания рассматривает возможность добавления рекламы в ответы на запросы ИИ-моделей. «По мере того как ChatGPT становится более функциональным и широко используемым, мы ищем способы продолжать предоставлять всем больше информации. В рамках этого мы изучаем, как может выглядеть реклама в нашем продукте. У людей сложились доверительные отношения с ChatGPT, и любой подход будет разработан с учетом этого доверия», — сообщил он ресурсу The Information. На данный момент OpenAI не размещает рекламу даже в платных версиях ChatGPT (ChatGPT Plus, ChatGPT Pro, ChatGPT Team/Enterprise). Недавно сообщалось, что в бета-версии приложения ChatGPT для Android 1.2025.329 упоминалась «функция рекламы» с «контентом маркетплейса», «рекламой в поиске» и «карусельной рекламой в поиске». После этого, по словам инсайдеров, OpenAI отложила планы по добавлению рекламы в ChatGPT, решив сосредоточиться на повышении качества ИИ в связи с возросшей конкуренцией со стороны Gemini. Но, судя по всему, OpenAI не отказалась от своих планов полностью, сделал вывод ресурс BleepingComputer. Ресурс отметил, что в «Google Поиске» есть реклама, которая может влиять на покупательское поведение пользователей. Однако с учётом того, что GPT знает о предпочтениях пользователей гораздо больше, чем Google, реклама в ChatGPT может разрушить веб-экономику, предупреждает BleepingComputer. OpenAI тестирует «навыки» ChatGPT по образцу Anthropic Claude
25.12.2025 [10:48],
Павел Котов
OpenAI начала тестировать новую функцию ChatGPT под названием «Навыки» (Skills), которая будет похожа на аналогичную функцию конкурирующего чат-бота Anthropic Claude с тем же наименованием. 
Источник изображения: BoliviaInteligente / unsplash.com Сейчас в ChatGPT поддерживаются производные чат-боты GPT — они проектируются при помощи запросов и предназначаются для выполнения конкретных функций. «Навыки» в Claude — это папки, данные в которых обучают чат-бот определённым способностям, рабочим процессам и знаниям в предметной области. Так, у Claude есть плагин для проектирования интерфейса — он помогает эффективнее ориентироваться в пользовательском пространстве, когда пишется код веб-приложения. Anthropic выделяет следующие характеристики «Навыков»:
Как ожидается, в производных чатах OpenAI GPT вскоре появится нечто подобное также под названием «Навыки». Сейчас они проходят внутри компании под кодовым именем Hazelnuts («Фундук») и в рамках теста запускаются командами со слэшем. Предусмотрен редактор «Навыков» и возможность преобразовывать пользовательские GPT в «Навыки». Развёртывание новой функции может начаться в январе 2026 года. OpenAI признала: у ИИ-браузеров есть уязвимость к инъекциям, которую невозможно полностью устранить
23.12.2025 [12:02],
Павел Котов
OpenAI стремится усилить безопасность своего браузера с искусственным интеллектом Atlas, но в компании поняли, что полностью исключить угрозу внедрения запросов (prompt injections) не получится. Внедрением запросов называется тип атаки, при котором агент ИИ выполняет скрытые инструкции в невидимых областях веб-страниц или писем электронной почты. 
Источник изображения: Dima Solomin / unsplash.com Атаки с внедрением запросов едва ли получится изжить полностью так же, как мошеннические схемы и методы социальной инженерии, считают в OpenAI, а «режим агента» в браузере «расширяет поверхность угроз безопасности». OpenAI выпустила Atlas в октябре, и вскоре исследователи в области кибербезопасности начали демонстрировать, что поведением браузера можно манипулировать, например, написав несколько слов в Google Docs. Разработчики Brave подтвердили, что непрямое внедрение запросов представляет собой системную проблему для ИИ-браузеров, в том числе для Perplexity Comet. О невозможности полностью исключить подобные атаки недавно заявили в Национальном центре кибербезопасности Великобритании и порекомендовали экспертам не пытаться их «остановить», а смягчить возможные последствия. А Google и Anthropic решили сделать ставку на многоуровневую защиту и постоянное стресс-тестирование систем. В OpenAI решили пойти своим путём и создали «автоматизированного злоумышленника на основе большой языковой модели». Это бот, который прошёл обучение с подкреплением и принял на себя роль хакера, постоянно пытающегося незаметно отправить ИИ-агенту вредоносные инструкции. Бот тестирует свои атаки в симуляциях, демонстрируя, как в тех или иных условиях рассуждает и действует целевой ИИ. Он изучает реакцию, корректирует схему атаки и повторяет свои попытки снова и снова. У посторонних доступ к настолько глубокому пониманию механизмов внутреннего мышления целевого ИИ отсутствует, поэтому в теории бот OpenAI должен находить уязвимости быстрее, чем реальные злоумышленники. 
Источник изображения: Mariia Shalabaieva / unsplash.com В одной из демонстраций бот подбросил в почтовый ящик пользователя «отравленное» электронное письмо. ИИ просканировал корреспонденцию, открыл это письмо, проследовал скрытым в нём инструкциям и отправил от имени пользователя заявление об увольнении вместо автоматического ответа о его отсутствии на рабочем месте. После обновления безопасности ИИ-агент, однако, успешно обнаружил попытку внедрения запроса и сообщил о ней пользователю. Если надёжной и полной защиты от таких атак не существует, отметили в компании, то приходится полагаться на масштабное тестирование и ускорять циклы обновления. О фактических успехах по сокращению числа реакций на внедрения запросов в OpenAI не сообщили, но отметили, что работа в этом направлении при участии сторонних специалистов началась ещё до выхода Atlas. Угроза от ИИ-агентов может быть серьёзной: они обладают некоторой автономностью при наличии высокого уровня доступа, указывают опрошенные TechCrunch эксперты. Поэтому одних только методов обучения с подкреплением недостаточно — необходимо учитывать и указанные аспекты: ограничивать действия, которые ИИ-агент способен осуществлять от имени учётной записи пользователя, в которую произведён вход, а также запрашивать подтверждения перед тем, как сделать нечто важное. На эти аспекты указывают и рекомендации OpenAI для пользователей: Atlas запрашивает подтверждение перед отправкой сообщений или перед совершением платежей. Пользователям также рекомендовали давать ИИ-агентам конкретные инструкции, а не, например, открывать доступ к почте и разрешать «делать, всё что потребуется». «Даже при наличии мер защиты широкая свобода действий облегчает скрытому или вредоносному контенту воздействие на агента», — предупредили в OpenAI. В ChatGPT появились персональные итоги года в стиле Spotify Wrapped
23.12.2025 [11:34],
Владимир Фетисов
OpenAI запустила в ИИ-боте функцию подведения итогов года в стиле Spotify Wrapped, которая получила название «Ваш год с ChatGPT». На данный момент она доступна ограниченному числу пользователей сервиса в разных странах мира, включая США, Канаду, Австралию, Великобританию и Новую Зеландию. 
Источник изображения: OpenAI На момент запуска функции «Ваш год с ChatGPT» она доступна бесплатным пользователям ИИ-бота, а также подписчикам на тарифах Plus и Pro, у которых активированы опции «Сохранять воспоминания для контекста» и «Использовать историю чатов для контекста». Чтобы получить итоги года также необходимо достигнуть определённого порога активности в беседах с ChatGPT. Пользователи аккаунтов Team, Enterprise и Education не смогут получить доступ к функции «Ваш год с ChatGPT». Новая функция, как и другие подобные инструменты в разных приложениях, вдохновлена популярным итоговым отчётом за год Spotify Wrapped. Как и в случае Spotify, OpenAI использует яркие графические элементы и персонализирует данные для каждого пользователя, а также вручает «награды» на основе того, как происходило взаимодействие с чат-ботом в течение года. В процессе подведения итогов ChatGPT также генерирует стихотворение и изображение, сфокусированные на темах, которые интересовали пользователя в течение года. Хотя эта функция рекламируется на стартовой странице приложения, она не запускается автоматически. Получить доступ к ней можно в веб-приложении ChatGPT, а также в мобильных версиях для Android и iOS. Пользователи также могут напрямую обратится к чат-боту, чтобы он активировал функцию «Ваш год с ChatGPT». Не как у всех: HTC сделала ставку на открытые ИИ-платформы в умных очках
22.12.2025 [13:52],
Алексей Разин
Многим молодым сегментам рынка свойственна ситуация противоборства нескольких различных стандартов или проприетарных платформ. Со временем неизбежно происходит консолидация, но некоторые участники рынка стараются на раннем этапе выбрать беспроигрышную стратегию. HTC при продвижении умных очков старается делать ставку на открытые платформы. 
Источник изображения: HTC По словам представителей этого тайваньского производителя носимой электроники, который некогда выпускал смартфоны, ИИ развивается очень быстро, и разработка больших языковых моделей требует существенных финансовых ресурсов. «Мы хотим использовать сильные стороны различных платформ вместо построения закрытой экосистемы», — пояснил в интервью Reuters Чарльз Хуанг (Charles Huang), отвечающий в компании за мировые продажи и маркетинг в должности старшего вице-президента HTC. Предлагаемые под маркой Vive Eagle умные очки HTC обеспечивают поддержку нескольких ИИ-платформ, включая Google Gemini и OpenAI ChatGPT, предоставляя пользователям выбор наиболее подходящей. Конкурирующая Meta✴✴ Platforms свои очки ограничивает работой в фирменной экосистеме, китайские Xiaomi и Alibaba поступают схожим образом. Модель Vive Eagle была представлена в Гонконге в этом месяце по цене $512. Компания также планирует вывести её на рынки Японии и стран Юго-Восточной Азии в следующем квартале, а до конца 2026 года — покорить рынки Европы и США. В отличие от продукции западных разработчиков, очки Vive учитывают специфику и предпочтения азиатских потребителей. Прежде чем выйти на китайский рынок, HTC должна будет привести свою программную инфраструктуру в соответствие с требованиями местного законодательства, а потому на это может уйти достаточно много времени. Кроме того, HTC намерена уделять вопросам приватности и защиты данных пользователей высочайшее внимание, тогда как многих крупных конкурентов обычно упрекают в обратном. По данным Counterpoint Research, в первой половине этого года мировые продажи умных очков выросли на 110 %, а ведущие позиции с долей 73 % рынка занимает американская Meta✴✴ Platforms. Она сотрудничает с традиционными производителями модных аксессуаров, такими как EssilorLuxottica, а потому дизайн её умных очков благожелательно воспринимается покупателями. В уходящем году HTC решилась продать Google за $250 млн часть своих активов, связанных с выпуском гарнитур дополнённой реальности. OpenAI увеличила прибыльность платных аккаунтов до 70 %, но всё ещё работает в убыток
22.12.2025 [06:13],
Анжелла Марина
OpenAI в 2025 году смогла получить больше прибыли от своих платных продуктов, продолжая бороться за лидерство на рынке искусственного интеллекта (ИИ). По сообщению Bloomberg со ссылкой на The Information, речь идёт о показателе вычислительной маржинальности (compute margin) — внутренней метрике, которая оценивает, какая доля выручки остаётся в распоряжении компании после покрытия затрат на запуск и работу ИИ-моделей для пользователей, оплачивающих сервис OpenAI. 
Источник изображения: Levart_Photographer/Unsplash Сообщается, что к октябрю норма прибыли OpenAI достигла 70 %. Для сравнения, в конце 2024 года показатель составлял 52 %, а относительно января 2024 года оказался вдвое выше. Одновременно представитель OpenAI заявил, что компания публично не раскрывала эти данные и отказался от дальнейших комментариев. ChatGPT считается одним из ключевых сервисов, способствовавший ажиотажу вокруг искусственного интеллекта. Однако, как пишет Bloomberg, OpenAI пока не показала прибыльности, на что непосредственно обращают внимание инвесторы, оценивая риск перегрева отрасли. Оценка компании в октябре достигла $500 млрд, но её расходы на вычислительные мощности и масштабные инфраструктурные проекты остаются крайне высокими. OpenAI также испытывает сильное давление со стороны конкурентов. На фоне этого и особенно после того, как модель Gemini компании Google показала лучшие результаты в бенчмарках, глава OpenAI Сэм Альтман (Sam Altman) объявил так называемый «красный код» и перенаправил ресурсы на улучшение ChatGPT, отложив планы по запуску рекламной платформы. Основная аудитория ChatGPT по-прежнему пользуется бесплатной версией чат-бота, однако OpenAI продвигает бизнес-версию и платные функции ПО для таких отраслей, как финансовые услуги и образование. В этих сегментах OpenAI конкурирует, в частности, с Google и Anthropic. Источники также утверждают, что по норме прибыли на платных аккаунтах OpenAI выглядит лучше Anthropic, но при этом у Anthropic выше общая эффективность затрат на серверную инфраструктуру. Кроме того, OpenAI находится на ранней стадии переговоров о привлечении как минимум $10 млрд от компании Amazon и о возможном использовании её чипов. В рамках этой сделки компания Альтмана может быть оценена более чем в $500 млрд. Сэм Альтман признался, что его абсолютно не прельщает идея быть главой публичной компании
21.12.2025 [05:30],
Владимир Фетисов
По сообщениям сетевых источников, компания OpenAI закладывает основу для проведения первичного размещения акций (IPO), которое может стать одним из крупнейших подобных событий в истории. На этом фоне гендиректор OpenAI Сэм Альтман (Sam Altman) заявил, что ему не слишком хотелось бы стоять у руля публичной компании. 
Источник изображения: x.com/sama «Рад ли я перспективе быть генеральным директором публичной компании? На 0 %. Рад ли я тому, что OpenAI станет публичной компанией? В некотором смысле да, а в некотором я думаю, что это было бы очень раздражающе», — сказал Альтман в новом выпуске подкаста Big Technology Podcast. На этой неделе СМИ писали, что OpenAI закладывает основу для будущего IPO. По данным The Wall Street Journal, в рамках первых переговоров по данному вопросу компания была оценена в $830 млрд. По более амбициозным оценкам, стоимость OpenAI может достигать $1 трлн, о чём информагентство Reuters писало в октябре со ссылкой на осведомлённые источники. В той же публикации сообщалось, что финансовый директор OpenAI Сара Фрайар (Sarah Friar) рассматривает возможность проведения листинга в 2027 году, а подача документов на IPO может быть осуществлена в конце 2026 года. Во время беседы с ведущим подкаста Альтман сказал, что не знает, станет ли OpenAI публичной компанией в следующем году, а также воздержался от разглашения деталей касательно привлечения финансирования и оценки рыночной стоимости. Несмотря на своё нежелание стоять у руля одной из публичных компаний, которые часто подвергаются более пристальному вниманию, усиленному регулированию и уменьшению влияния основателей, Альтман отметил, что для OpenAI такой вариант имеет и положительные стороны. «Я действительно считаю, что это здорово, когда публичные рынки могут участвовать в формировании стоимости. И в некотором смысле, мы сильно опаздываем с выходом на биржу, если посмотреть на другие компании. Быть частной компанией — прекрасно. Нам нужен большой капитал. В какой-то момент мы планируем убрать ограничение по акционерам и всё такое прочее», — приводит источник слова Альтмана. Вероятно, проведение IPO позволило бы OpenAI привлечь миллиарды долларов, необходимые компании для успешного конкурирования в сфере искусственного интеллекта. OpenAI была основана в 2015 году в качестве некоммерческой организации и только в нынешнем году завершился сложный процесс реструктуризации, превративший её в более традиционную коммерческую компанию. В результате некоммерческая организация, контролирующая компанию, получила долю в $130 млрд. В рамках реструктуризации также сократилась доля Microsoft до 27 % (ранее она составляла 32,5 %), но програмный гигант получил расширенный доступ к исследованиям OpenAI, а также позволил компании заключать сделки с другими партнёрами в сфере облачных вычислений. SoftBank срочно распродаёт активы и занимает деньги, чтобы успеть до конца года передать OpenAI причитающиеся $22,5 млрд
20.12.2025 [08:32],
Алексей Разин
Японская корпорация SoftBank ещё в начале года обозначила себя в статусе важного союзника OpenAI, согласившись принять участие в финансировании мегапроекта Stargate, направленного на развитие вычислительной инфраструктуры в США. По условиям договорённостей с OpenAI, она до конца текущего года должна передать ей $22,5 млрд, но собрать эти деньги к указанному сроку будет непросто.  SoftBank уже пришлось продать имеющиеся у неё акции Nvidia и T-Mobile для финансирования деятельности OpenAI, но вырученных денег не хватит, поскольку в первом случае она получила $5,8 млрд, а во втором — $4,8 млрд. Глава и основатель SoftBank Масаёси Сон (Masayoshi Son) практически заморозил инвестиции со стороны Vision Fund, и теперь любые сделки на сумму более $50 млн требуют его личного согласования. Рассчитывать на деньги, которые планировалось выручить после IPO приложения PayPay, не приходится, поскольку из-за правительственного шатдауна в США, где оно должно проводиться, сроки сместились с декабря на январь, а передать средства OpenAI нужно до конца текущего месяца. Предполагается, что по итогам этого IPO корпорация SoftBank выручит около $20 млрд. Китайская платформа Didi Global после принудительного делистинга в США собирается выйти на биржу в Гонконге, а SoftBank является её акционером, и теперь рассчитывает сократить свою долю в капитале этого эмитента, чтобы высвободившиеся средства передать OpenAI. Специалисты по инвестициям из Vision Fund переориентированы на сопровождение сделок SoftBank с OpenAI, как сообщает Reuters. Дополнительные возможности для привлечения средств в случае с SoftBank заключаются в выпуске облигаций или получении кредитов, включая варианты под залог ценных бумаг. В последнем случае в ход могут пойти кредиты под залог акций британского разработчика процессорных архитектур Arm, которым также владеет SoftBank. В общей сложности, у последней открыта кредитная линия на $11,5 млрд под залог этих акций. Кроме того, в собственности SoftBank остаются около 4 % акций американского оператора связи T-Mobile, которые оцениваются в $11 млрд по курсу на конец сентября. В апреле текущего года SoftBank пообещала вложить $30 млрд в OpenAI, примерно треть суммы была передана сразу, а оставшуюся нужно было перечислить по итогам реструктуризации американского стартапа, которая состоялась осенью. Инвестиции SoftBank являются лишь каплей в море, поскольку OpenAI в общей сложности на реализацию своих проектов намеревается за восемь лет привлечь около $1,4 трлн, ничем особо не рискуя по условиям договорённостей с многочисленными инвесторами. Стартап намерен ввести в строй 30 ГВт вычислительных мощностей, при этом каждый гигаватт в текущих ценах требует капитальных затрат на сумму более $40 млрд. ChatGPT научился менять свой характер по желанию пользователя
20.12.2025 [05:12],
Анжелла Марина
В ChatGPT появились новые функции персонализации, которые позволяют регулировать эмоциональный тон и стиль ответов искусственного интеллекта (ИИ). OpenAI предлагает на выбор несколько вариантов «личности» чат-бота, которые можно донастраивать и «докручивать». 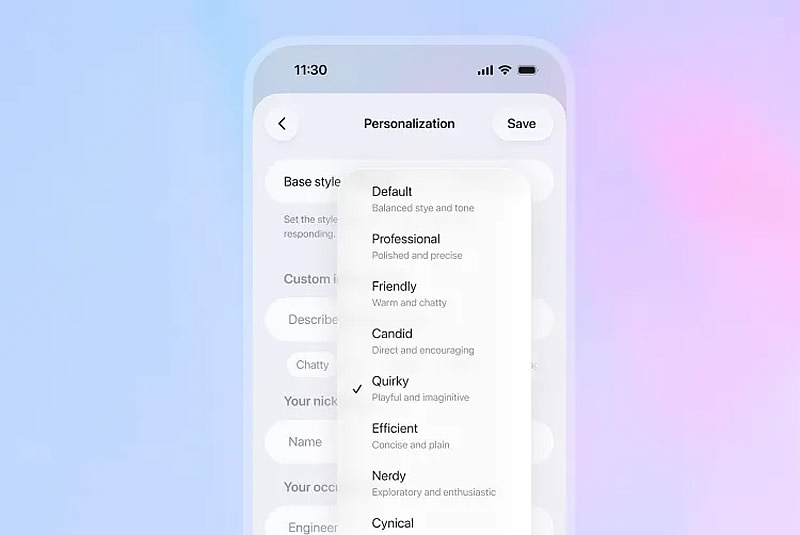
Источник изображения: OpenAI Основным стилем ответов ИИ-модели является режим «По умолчанию», далее идёт «Профессиональный», «Дружелюбный», «Откровенный», «Необычный», «Эффективный», «Занудный» и «Циничный» и, как подчёркивает The Verge, каждый параметр личностных черт можно менять, увеличивая или уменьшая шкалу их характеристик. Также есть возможность настроить частоту использования эмодзи, заголовков и списков в ChatGPT. Эти настройки можно найти, нажав на меню в верхнем левом углу приложения ChatGPT, выбрав свой профиль, перейдя в раздел «Персонализация» и выбрав «Добавить характеристики». Кроме того, с обновлением изменился и способ написания электронных писем. Теперь пользователь может обновлять и форматировать текст непосредственно в чате. Также можно выделять фрагменты текста и запрашивать у ChatGPT внести в них конкретные изменения, вместо того чтобы пытаться указать чат-боту на этот фрагмент в отдельном диалоговом запросе. OpenAI перезапустила GPT-5.2, расширив меры защиты подростков
20.12.2025 [01:40],
Анжелла Марина
Компания OpenAI представила обновлённую версию языковой модели GPT-5.2 с расширенными мерами безопасности для пользователей младше 18 лет. Новые правила «поведения» чат-бота при общении с подростками разработаны в сотрудничестве с Американской психологической ассоциацией и вступают в силу на фоне растущего давления со стороны законодателей, а также судебных исков, связывающих использование ChatGPT с суицидами и состоянием психоза у несовершеннолетних. 
Источник изображения: Google, Nano Banana В обновлённой спецификации, как поясняет издание eWeek, приоритет отдаётся безопасности подростков даже в тех случаях, когда это вступает в противоречие с основными функциями модели, а вместо советов, сгенерированных непосредственно ИИ, система теперь направляет пользователей к реальным источникам поддержки. При этом язык ответов адаптирован под возрастную аудиторию, а сами ответы содержат более чёткие пояснения о возможностях и ограничениях чат-бота. Новые меры дополнят уже существующие родительские настройки, включая уведомления при поиске определённых терминов. Изменения последовали за принятием в Калифорнии пакета законов, обязывающих разработчиков ИИ внедрять защитные механизмы для подростков и перенаправлять их на профильные службы помощи. Однако OpenAI, хоть и выполнила большинство требований, не реализовала положение о периодическом (каждые три часа) напоминании пользователям о том, что они общаются с искусственным интеллектом. Новые законы также требуют от компаний публично раскрывать протоколы безопасности и сообщать о серьёзных инцидентах. Параллельно на федеральном уровне разрабатывается единый национальный закон об ИИ, который, по мнению некоторых экспертов, при администрации Дональда Трампа (Donald Trump) может ослабить требования к прозрачности по сравнению с калифорнийскими нормами. Примечательно, что, несмотря на то что в независимых тестах, таких как бенчмарк для оценки возможностей больших языковых моделей (LLM) SafetyBench, модели OpenAI показывают лучшие результаты по безопасности по сравнению с конкурентами, включая Google, Meta✴✴ и Anthropic, компания подвергается более пристальному вниманию как ведущий поставщик чат-ботов. Глава OpenAI Сэм Альтман (Sam Altman) ранее отмечал, что несёт неравномерную нагрузку из-за необходимости быть первопроходцем в области внедрения функций безопасности. На фоне роста популярности конкурирующих моделей, в частности, Google Gemini 3, получившей высокие оценки сразу при запуске, и Anthropic Claude, ставшей популярной в корпоративном секторе и в работе с программным кодом, OpenAI также пришлось объявить «красный код», ускорив выпуск GPT-5.2 и перенеся его с декабря–января на более раннюю дату. После нескольких лет стремительного роста компания, возможно, несколько ослабила свою направленность, запустив смежные инструменты, такие как Sora, отмечает eWeek, однако вновь смогла сосредоточится на укреплении позиций ChatGPT как лидера в сегменте чат-ботов. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



