







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Обзор процессоров Ryzen 9 5950X и Ryzen 9 5900X на архитектуре Zen 3, в которой AMD починила игровую производительность
С тех пор, как в ассортименте компании AMD появились процессоры Ryzen, её доля на процессорном рынке растёт, не останавливаясь. Если, например, говорить о CPU для настольных систем, то в этом сегменте AMD уже располагает 20-процентной долей, в то время как на момент выхода Ryzen первого поколения её доля составляла лишь 11 %. Столь заметный рост продаж – явный показатель того, что процессоры компании нравятся потребителям, и они всё чаще предпочитают при покупке настольных компьютеров предложения AMD, а не Intel Core. Почему так происходит, понять несложно. AMD раз за разом предлагает такие процессоры и платформы, которые пусть не всегда и не везде быстрее и лучше, но зато интереснее по соотношению цены и производительности. Именно такая стратегия – делать недорогие, но достойные процессоры, которые к тому же чаще отличаются и более развитой многопоточностью – привела AMD на то место, где она находится сегодня. Но теперь компания намеревается сменить стратегию своей игры. Получив достаточный импульс пользовательских симпатий и разработав новую прогрессивную микроархитектуру Zen 3, AMD собралась двигаться другим путем – путём, которым обычно ходят не догоняющие, а лидеры рынка, которые способны предлагать продукты, превосходящие конкурирующие предложения по потребительским свойствам.  В результате, сегодня мы становимся свидетелями переломного момента, в который AMD заявляет о серьёзно возросших амбициях и превращении процессоров Ryzen из доступных в дорогие. Компания явно считает, что для такой кардинальной смены парадигмы она выбрала очень подходящее время. Дело в том, что прямо сейчас на рынок выходит новое поколение процессоров Ryzen, которое обещает солидный пакет улучшений: 19-процентное увеличение удельной производительности в пересчёте на такт и как результат – полную и безоговорочную победу над конкурентом не только по однопоточному и многопоточному быстродействию в ресурсоёмких приложениях, но и в играх, а заодно и по энергоэффективности. Более того, для пущей убедительности эти процессоры имеют возросшие сразу на две тысячи модельные номера: таким образом AMD как будто хочет показать, что совершённый с переходом на микроархитектуру Zen 3 шаг по сути двойной и непохож на всё то, что мы видели до этого. Такой набор убийственных аргументов кажется AMD достаточным для того, чтобы попросить покупателей платить за новые процессоры на $50-100 больше, чем они привыкли. И мы даже склонны согласиться с такой постановкой вопроса, но при условии, что все утверждения относительно двойного шага и роста производительности на двузначное количество процентов соответствуют действительности. Именно проверкой этих тезисов мы и займёмся в данном материале, посвященном микроархитектуре Zen 3 и паре старших представителей нового модельного ряда Ryzen 5000, которые поступят в продажу с сегодняшнего дня и будут доступны за $800 и $550. ⇡#Главное в Zen 3 – удвоенные CCX С разработкой и внедрением микроархитектур семейства Zen компания AMD взяла очень высокий темп внедрения обновлений. Первые Zen вышли совсем недавно – в 2017 году, а сегодня мы уже имеем дело с процессорами на микроархитектуре Zen 3, которые отстоят от родоначальников этого класса CPU на три полноценных поколения. И что самое интересное, как Zen, так и Zen 3, нам приходится сопоставлять с микроархитектурой Skylake, поскольку за всё это время компания Intel так и не сподобилась как-то заметно видоизменить свои процессоры. Всё это дало AMD хороший шанс не просто угнаться за конкурентом, но и превзойти его, ведь того, кто топчется на месте обогнать проще простого – было бы желание. Zen 3 – это как раз и есть та самая точка, в которой разговоры о том, будто продукция AMD лучше там-то, но слабее вот там-то, придётся прекратить. Действуя методом последовательных приближений, разработчики Zen планомерно исправляли все узкие места своей первоначальной микроархитектуры и наконец-то пришли к тому, что на четвёртой итерации Zen 3 стали если не идеальны, то по крайней мере лучше Skylake в подавляющем большинстве реальных задач. Собственно, для достижения этой цели оставалось недалеко ещё полтора года назад, когда на рынок пришла микроархитектура Zen 2. Тогда носители Zen 2 фактически уже превосходили Skylake во всех типах вычислительных нагрузок, уступая им лишь в одном случае – в играх. Эта проблема не была серьёзной с архитектурной точки зрения, но в глазах значительной доли пользователей капитально портила имидж Ryzen. И поэтому совершенно неудивительно, что все силы в разработке Zen 3 были направлены на то, чтобы устранить именно этот недостаток.  Впрочем, нужно понимать, что разработчики процессорных архитектур не оперируют понятиями уровня «недостаточная производительность в Shadow of the Tomb Raider», для них эта общая проблема должна быть формализована на более понятном им низкоуровневом языке – с объяснением того, что именно не давало Zen 2 достойно проявлять себя в играх, в то время как по удельной производительности они явно превосходили существующие процессоры Intel. И здесь AMD наверняка помогла помощь сообщества, которое неустанно указывало на наиболее критичные недостатки микроархитектуры. Суть проблемы с играми заключается в том, что все приложения такого типа, даже хорошо оптимизированные под многоядерность, работают совсем не так, как традиционные многопоточные вычислительные алгоритмы, где исходная задача разбивается на несколько равноправных и параллельно решаемых подзадач. Игровая нагрузка характерна тем, что в ней всё равно остаётся один ярко выраженный центральный поток, который в конечном итоге управляет всем происходящим, в то время как все остальные создаваемые потоки носят вспомогательный характер и фактически работают на него. Это приводит к тому, что для игр оказывается важной как способность процессора быстро перебрасывать данные между разными ядрами, так и возможность эффективной обработки одного и того же массива данных разными ядрами одновременно. Причём речь в данном случае идёт о довольно значительных объёмах информации, что накладывает дополнительные требования на эффективность работы с памятью. Всё перечисленное – это как раз то, с чем у Zen 2 дело обстояло не лучшим образом. Но корень проблем по большей части один – использование для построения процессора замкнутых в себе CCX-комплексов (Core Complex), которые содержат по четыре ядра и 16 Мбайт L3-кеша и объединяются в единое целое сравнительно медленной шиной Infinity Fabric. Из-за такого строения любой Zen 2 с числом ядер более четырёх неспособен эффективно работать с общим массивом данных: каждое ядро имеет доступ лишь к той части L3-кеша, которая находится в его собственном CCX-комплексе, а обращение к данным, хранящимся в кеш-памяти за его пределами, приводит к возникновению заметных паразитных задержек. Как раз поэтому и страдает производительность в современных играх: хотя процессоры Zen и Zen 2 наглядно пропагандируют многоядерность спецификациями, реализация этой многоядерности не предполагает гладкого взаимодействия между ядрами: какие-то ядра получаются «близкими» по отношению друг к другу, а какие-то – «далёкими», что для игровой нагрузки противопоказано. Главное улучшение, сделанное в Zen 3, устраняет это неравноправие. Не полностью, но в той степени, чтобы ситуация в целом стала выглядеть заметно иначе. CCX-комплексы в Zen 3 стали конструироваться не из четырёх, а из восьми процессорных ядер с удвоением относящегося к ним размера разделяемой кеш-памяти до 32 Мбайт. И это – очень важная перемена, поскольку теперь самые ходовые Ryzen с шестью и восемью ядрами станут наконец-то единым целым – чипами с полностью равнозначными по отношению друг к другу ядрами и действительно общей разделяемой кеш-памятью третьего уровня, обращения к разным частям которой будут вызывать предсказуемые, равные и невысокие задержки.  То, что каждое из восьми ядер процессора, собранного из одного CCD-чиплета, сможет без проблем работать со всеми 32 Мбайт кеш-памяти, неминуемо выльется в ускорение межъядерного взаимодействия, снижение задержек при обращениях к закешированным данным и как следствие – в снижение общей латентности при многопоточной работе с большими массивами данных. Иными словами, с точки зрения топологии процессора CCX-комплекс в Zen 3 становится эквивалентом CCD-чиплета: один чиплет всегда содержит один комплекс, что делает ненужными все разговоры о том, в каком отношении между собой находятся ядра внутри чиплета. Следовательно, шести- и восьмиядерные Zen 3 наконец-то получают возможность стать хорошим выбором для игр, поскольку они уходят от необходимости использования шины Infinity Fabric при межъядерном взаимодействии и при обращениях к L3-кешу. Вся работа внутри нового восьмиядерного CCX-комплекса происходит без привлечения универсальной, но сравнительно медленной Infinity Fabric, а вместо этого всегда будет использоваться быстрая специализированная внутренняя кольцевая шина, подобная той, которая уже много лет существует в процессорах Intel. Вся же бывшая традиционной для процессоров AMD канитель с пересылками данных через Infinity Fabric и сегментированием кеш-памяти с выходом Zen 3 остаётся исключительно прерогативой процессоров с 12, 16 и большим числом ядер (когда они появятся на рынке). А в контексте потребительских Ryzen 5000 это значит, что покупатели четырех-, шести- и восьмиядерников нового поколения теперь будут получать структурно монолитный процессор, а не своебразный аналог двухпроцессорной системы в миниатюре. Что же касается шины Infinity Fabric, то в третьем поколении микроархитектуры Zen она сохранила своё изначальное предназначение в качестве среды для связи ядер лишь только в старших 12- и 16-ядерных процессорах, где, как и ранее, используется по два CCD-чиплета. Но там без этой шины обойтись действительно не получится, по крайней мере пока AMD будет продолжать следовать выбранным ею принципам многочиплетного дизайна. В теории это может привести к тому, что многоядерные процессоры окажутся медленнее более простых моделей в каких-то специфических многопоточных приложениях, но в реальности такие ситуации возникают крайне редко. Сделав ставку на сборку процессоров из нескольких полупроводниковых кристаллов – чиплетов, компания AMD оправдывала свой выбор в том числе и тем, что такие CPU проще обновлять, ведь их составные части можно совершенствовать по частям. Серия Ryzen 5000, построенная на архитектуре Zen 3, сделана в полном соответствии с этой концепцией. Из двух видов чиплетов, которые применяются для конструирования процессоров, – собственно процессорных CCD и интерфейсных I/O-чиплетов – в Ryzen 5000 новы только те кристаллы, которые содержат непосредственно вычислительные ядра. Чиплет I/O в Ryzen 5000 остался точно тем же, что был в Ryzen 3000, и это означает идентичность новых и старых процессоров с точки зрения внешних интерфейсов. Не обновлять эту часть CPU – вполне закономерное решение в текущих условиях. Производимые на мощностях GlobalFoundries по 12-нм техпроцессу I/O чиплеты вполне соответствуют возлагаемым на них требованиям и по сей день. Со стороны процессора они отвечают за функционирование шины Infinity Fabric, а с наружной стороны – обеспечивают поддержку 24 линий PCI Express 4.0 для видеокарты, NVMe-накопителя и связи с набором системной логики, а также предлагают поддержку четырёх портов USB 3.2. Кроме того, в I/O-чиплете находится и контроллер DDR4 SDRAM, который ещё в Ryzen 3000 получил вполне приемлемые для современных систем свойства, включая (наконец-то) предсказуемую и стабильную работу и официальную поддержку двухканальной DDR4-3200 с неофициальной возможностью разгона памяти до состояния DDR4-3733 в синхронном режиме. Справедливости ради стоит заметить, что некоторые пользователи выражали своё неудовольствие тем, как в Ryzen 3000 обстояло дело с поддержкой оверклокерской DDR4 SDRAM из-за того, что применение более скоростных, нежели DDR4-3733, модулей приводило к падению производительности из-за необходимости включения асинхронного режима работы Infinity Fabric. Но модернизировать I/O-чиплет ради улучшения совместимости со скоростными модулями памяти было бы бессмысленно. Корень проблемы находится не в отсутствии каких-то внутренних оптимизаций контроллера, а в достижении предела частоты шины Infinity Fabric, проложенной от CCD-чиплета до I/O-чиплета по текстолиту процессорной платы. Иными словами, предельная скорость памяти в синхронном режиме определяется самой чиплетной конструкцией процессора. И тем не менее, даже при условии использования того же контроллера памяти и того же I/O чиплета AMD обещает, что в Ryzen 5000 память в целом сможет разгоняться немного лучше, чем в процессорах прошлого поколения. За счёт существенной разгрузки шины Infinity Fabric от межъядерных пересылок данных пределом стабильного разгона памяти в Zen 3 в синхронном режиме может оказаться режим DDR4-3800 или DDR4-3933, а если повезёт с экземпляром процессора и материнской платой, то реальностью может стать и режим DDR4-4000. По крайней мере, такие оценки даёт сама AMD. Неизменность I/O-чиплета «притащила» за собой в Ryzen 5000 и ещё одну особенность конструкции прошлых процессоров: а именно, урезанную вдвое по ширине шину данных в направлении от CCD к I/O-чиплетам. Поэтому процессоры, построенные с участием одного CCD-чиплета, в тестах пропускной способности памяти будут продолжать показывать вдвое более низкую скорость записи по сравнению со скоростью чтения – точно так же, как это было у процессоров Ryzen 3000. Но на реальной производительности это вряд ли способно как-то отрицательно сказаться. Обеспечиваемое существующей схемой чтение из памяти со скоростью 32 байта за такт при скорости записи 16 байт за такт вполне соответствует потребностям существующих алгоритмов, которые в общем случае запрашивают данные из памяти чаще, чем туда их отправляют.  С учётом сказанного, мы совсем не удивимся, если вдруг выяснится, что AMD для Ryzen 5000 не стала даже переделывать процессорную плату – по большому счёту для этого нет никаких объективных предпосылок. А вот CCD-чиплеты в составе Ryzen 5000 действительно новые – это видно как минимум по их габаритам. Они стали побольше, что невольно наводит на мысли о том, что помимо оптимизации внутренней структуры в Zen 3 произошло нечто ещё. Подтверждают это и объективные показатели: если восьмиядерные CCD-чиплеты с микроархитектурой Zen 2 состояли из 3,8 млрд. транзисторов и занимали площадь 74 мм2, то при переходе на микроархитектуру Zen 3 их размер вырос до 80,7 мм2, а транзисторный бюджет увеличился до 4,15 млрд. Налицо примерно 10-процентное усложнение кристалла.  При этом прямое сравнение Zen 2 и Zen 3 по занимаемой чиплетом площади вполне корректно. Ходившие ранее слухи, будто при переходе на новую микроархитектуру AMD начнёт применять и улучшенный технологический процесс, не подтвердились. CCD-чиплеты Zen 3 продолжают печататься на предприятиях TSMC с применением ровно того же базового 7-нм техпроцесса, что использовался до того, без каких-то принципиальных усовершенствований и без литографии в сверхжёстком ультрафиолете. Единственное, что имеет место, так это достижение данным техпроцессом некоторой зрелости. Именно это и позволило открыть в Ryzen 5000 дополнительный частотный потенциал, плюс помогла более тонкая настройка адаптивной технологии Precision Boost 2. Что же касается действительно новых техпроцессов, то их внедрения в процессорах AMD придётся подождать до 2022 года, когда компания представит последователей сегодняшних Zen 3, построенных на микроархитектуре Zen 4. Вот там будет применяться и технология с нормами 5 нм, и EUV-литография. Ещё во время первой ознакомительной презентации новых Ryzen 5000 представители AMD заявили о том, что показатель IPC, то есть удельная производительность одного ядра в пересчёте на такт, выросла на 19 % по сравнению с предшественниками. Очевидно, что столь серьёзное ускорение обеспечить одним лишь реформированием CCX было бы невозможно, ведь от скорости работы с кешем и от латентности при межъядерном обмене данными зависят лишь избранные алгоритмы. А значит, в Zen 3 есть что-то ещё, и те самые добавочные 10 % транзисторов в процессорном ядре появились совсем не просто так. И действительно, когда AMD заводила речь про выдающийся 19-процентный рост IPC, она демонстрировала недвусмысленный слайд, говорящий о том, что вклад изменения структуры кеша составляет лишь порядка 3 %, а за остальные 16 % несут ответственность разнообразные микроархитектурные улучшения, затрагивающими все этапы исполнительного конвейера, включая его входную часть, исполнительный домен и подсистему работы с данными. 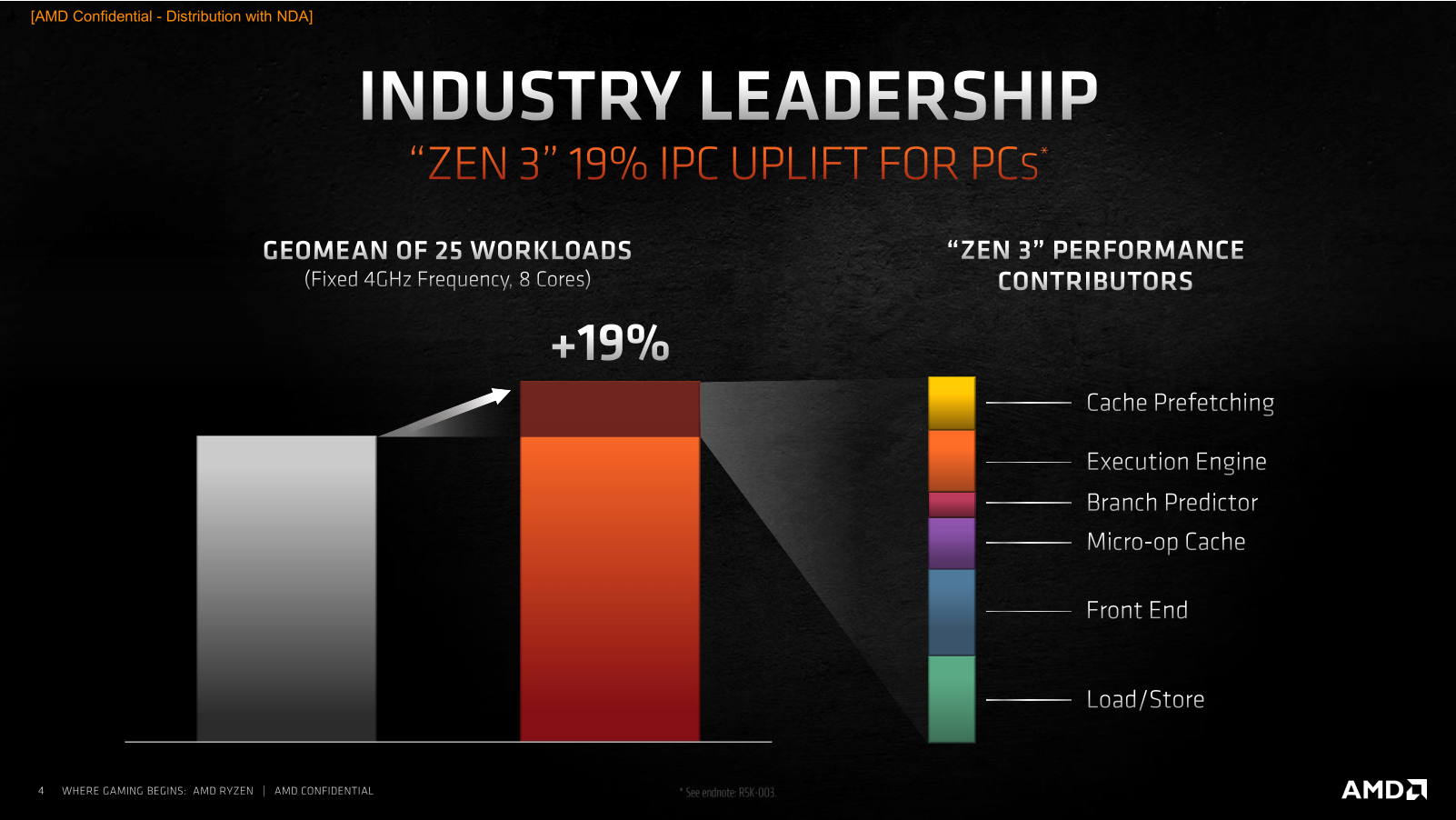 Однако сразу же следует пояснить, что ни о каких кардинальных переменах речь всё-таки не идёт. Zen 3 остаётся типичным Zen, и в нём угадываются все черты изначальной микроархитектуры. Фактически инженеры AMD продолжают работать над устранением узких мест первоначального дизайна, а то, что у них это получается настолько эффективно, может объясняться эффектом низкой базы и служить показателем изначальной несбалансированности первых поколений Zen. 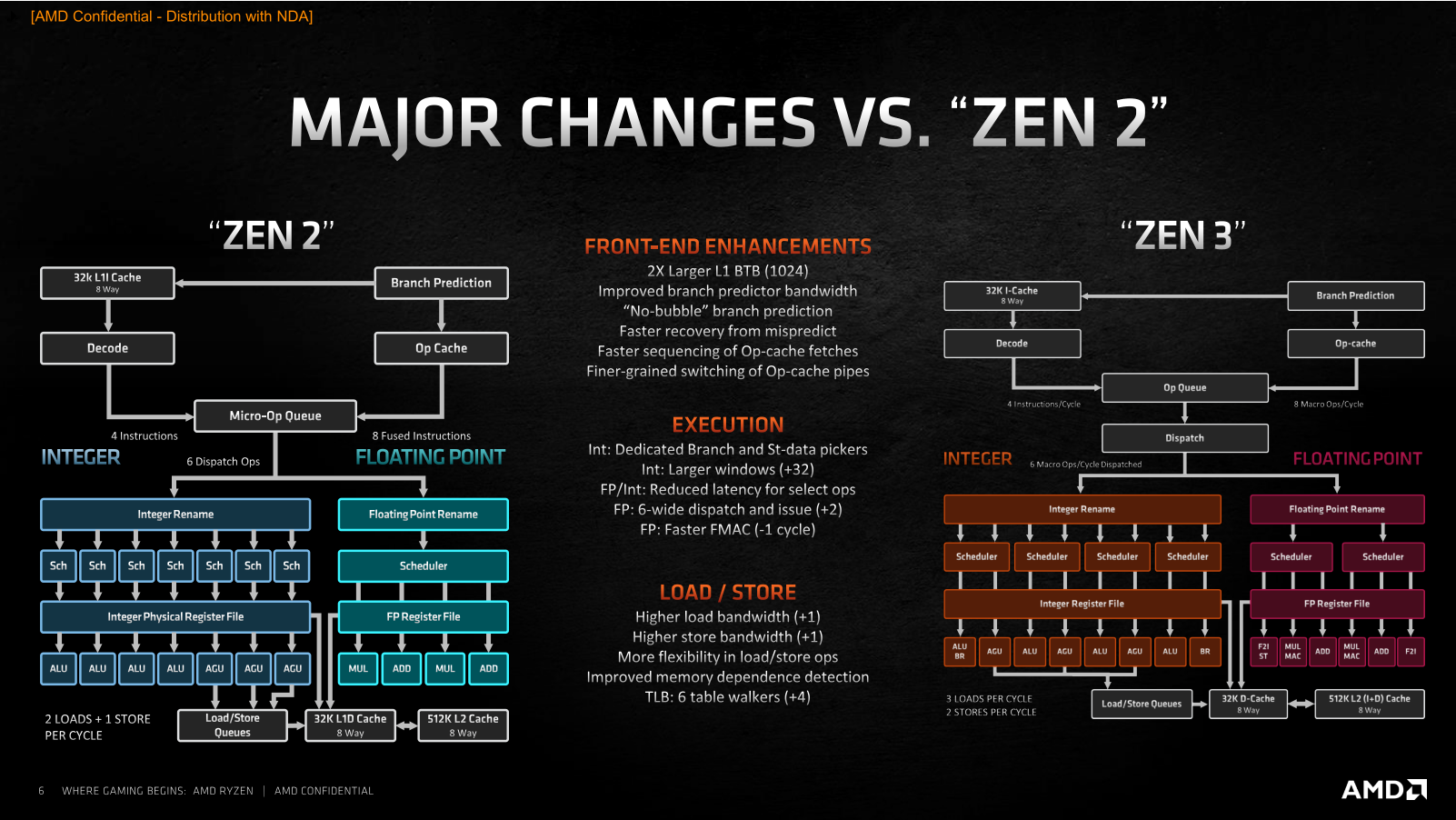 Если вернуться к приведённой AMD «разблюдовке» 19-процентного прироста IPC, то окажется, что усовершенствования во фронтальной части конвейера, включая блок предсказания ветвлений и кеш микроопераций, обуславливают почти его половину. При этом нельзя сказать, что в Zen 3 имеют место какие-то кардинальные перемены: диспетчер ядра отправляет на исполнение всё те же шесть микроопераций за такт, которые поставляются либо декодером с привычной производительностью четыре x86-инструкции за такт, либо кешем микроопераций, способным отдавать в очередь на исполнение по восемь ранее декодированных микроопераций. Не изменился и сам кеш микроопераций: как и в Zen 2, его объём рассчитан на четыре тысячи записей. 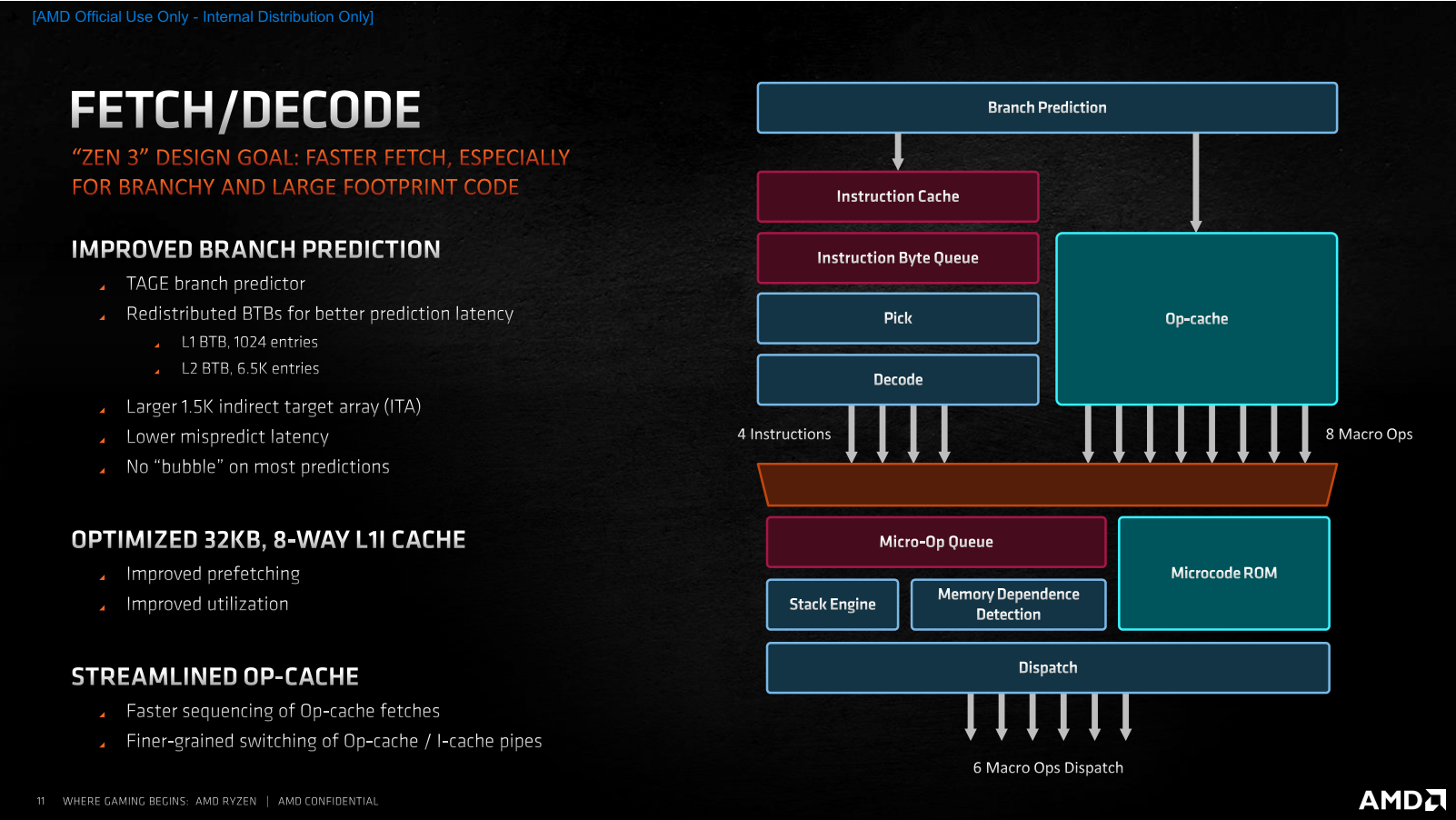 Перемены же стоит искать в первую очередь в том, как работает предсказание ветвлений. Буфер целей ветвления первого уровня расширился вдвое, до 1024 записей, а многоступенчатый статистический алгоритм предсказания TAGE (Tagged geometric) стал играть первоочередную роль. Вместе с увеличением размера массива целей непрямых переходов это позволило уменьшить задержки, возникающие при неправильном предсказании и фактически избавиться от «пузырей» при загрузке исполнительного конвейера. Вместе с этим AMD удалось ускорить работу кеша микроопераций. Он получил способность выдавать результаты декодирования последовательных команд с лучшим темпом, а переключение диспетчера между ним и декодером происходит теперь с лучшей эффективностью. В дополнение AMD говорит и об улучшении алгоритмов кеша первого уровня для инструкций. Его 32-Кбайт размер не изменился, но предварительная выборка должна была стать более эффективной. О том, что перечисленные меры при своей кажущейся незначительности дали весомый результат, говорят не только численные оценки эффективности, но и тот факт, что разработчикам архитектуры пришлось заняться существенным расширением исполнительного домена, как в целочисленной, так и в вещественночисленной его части. Целочисленный блок Zen 3 стал способен параллельно исполнять до десяти микроопераций вместо семи в Zen 2, а блок операций с плавающей запятой получил возможность обрабатывать параллельно по шесть инструкций вместо четырёх. При этом особенно любопытно, что в целочисленном блоке Zen 3 появились не новые арифметико-логические ALU или генераторы адресов AGU (их количество осталось неизменным по сравнению с Zen 2), а выделенные исполнительные устройства для обработки ветвлений (одно добавленное устройство) и для записи данных (два добавленных устройства). Похоже, идея о необходимости выполнять такие операции отдельно от основного потока команд была подсмотрена разработчиками AMD в микроархитектуре Skylake, где данный подход вполне успешно применяется много лет. 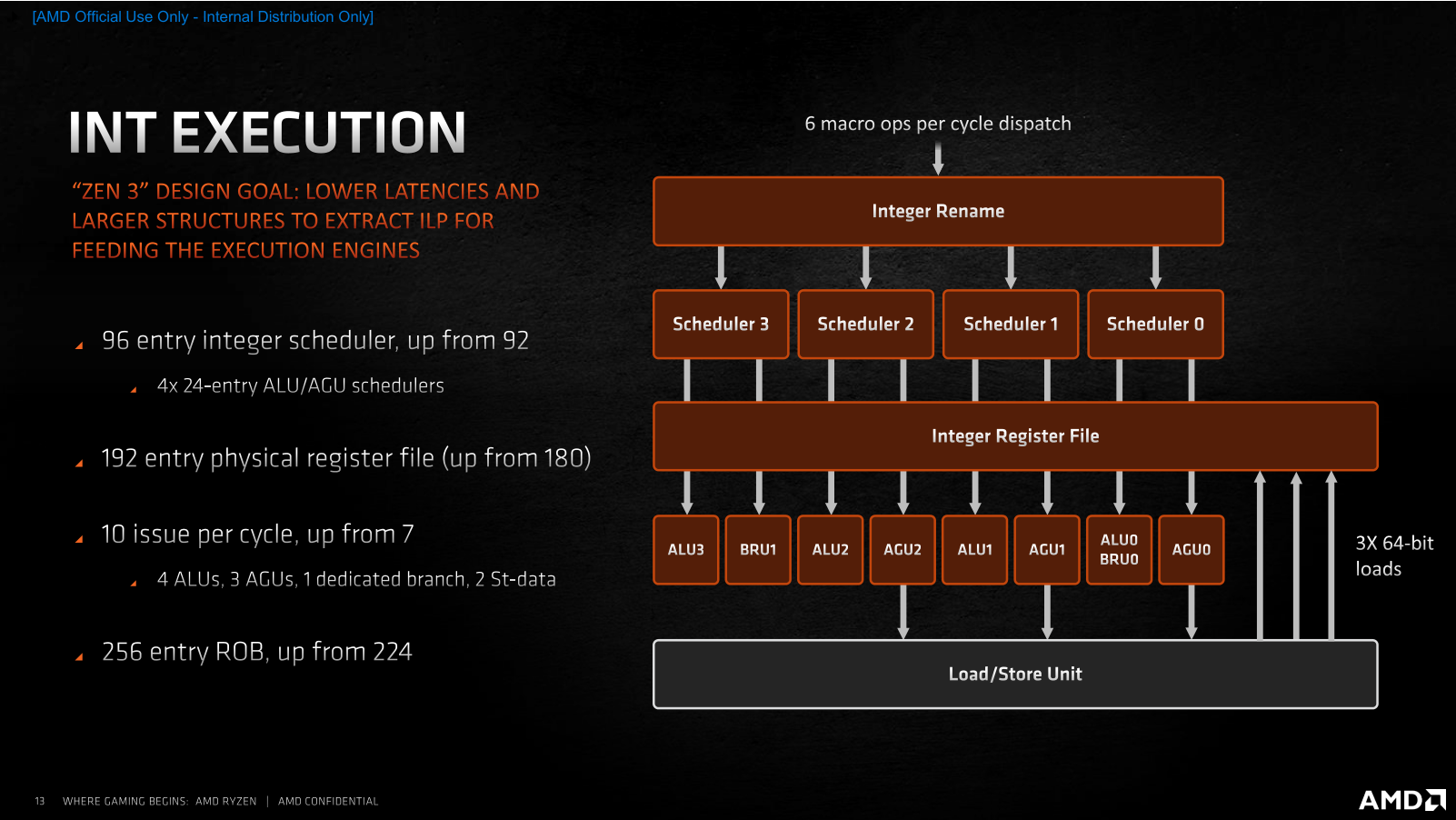 Но это – далеко не единственное улучшение в механизме исполнения целочисленных инструкций. Полезным нововведением стало объединение планировщиков по парам устройств – ALU и AGU – вместе с увеличением их суммарной вместимости это послужило цели лучшей балансировки нагрузки. А кроме того, в Zen 3 с 180 до 192 записей вырос размер регистрового файла, и с 224 до 256 записей – буфера переупорядочивания инструкций. Подобные изменения нашли место и в процессорном блоке, отвечающем за вещественные операции. Тут добавилось два новых исполнительных устройства, выделенных для сохранения данных и для целочисленной конвертации чисел с плавающей запятой. Дополнительно увеличилась и вместимость соответствующих планировщиков. А в качестве приятного бонуса AMD говорит и об ускорении темпа исполнения некоторых команд, в частности, совмещённых умножений-сложений. 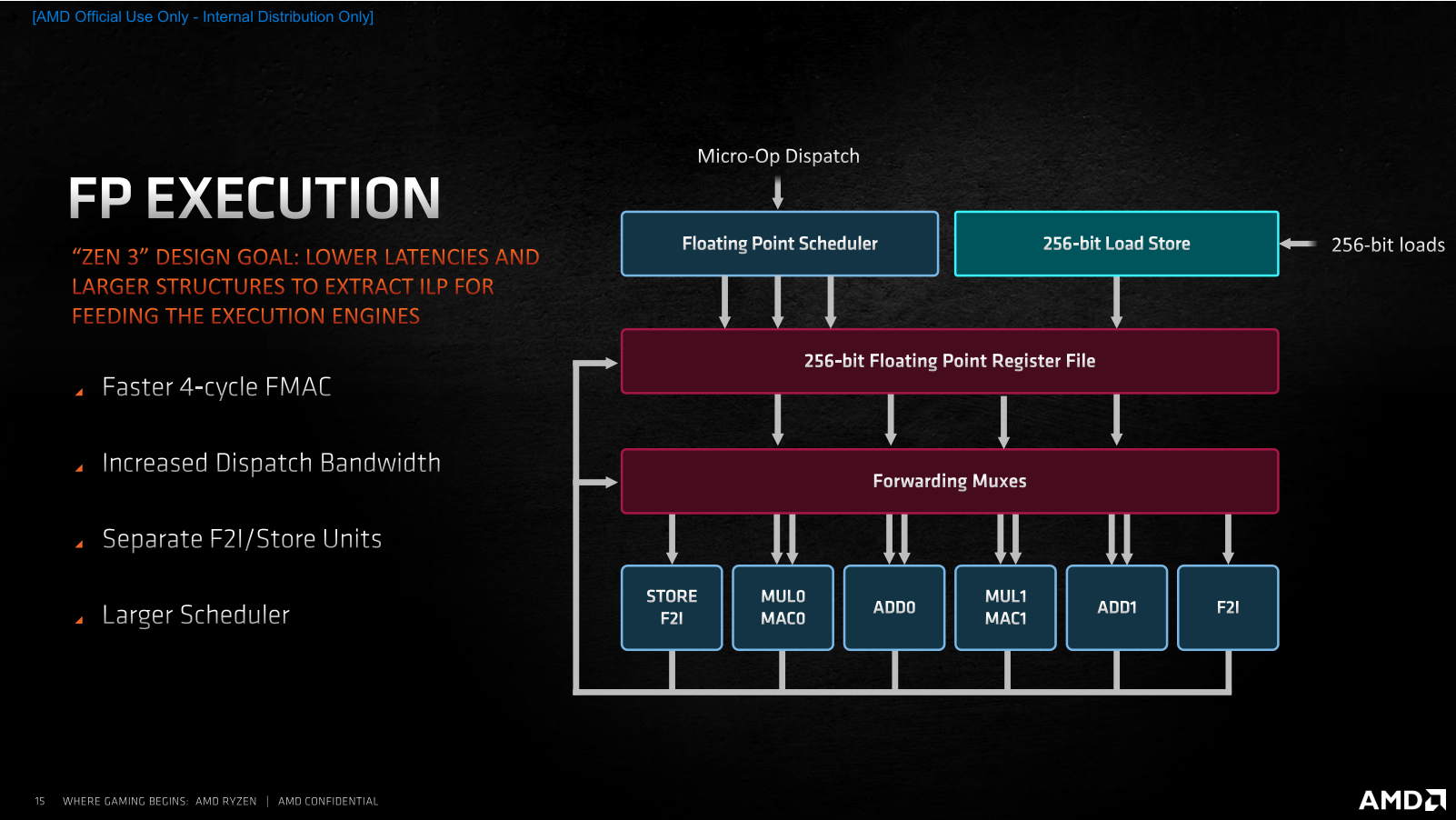 Расширение параллелизма при исполнении инструкций влечёт за собой увеличение потребностей в обращении к данным. Это – ещё один важный аспект, на который обратили внимание разработчики Zen 3, и поэтому пропускная способность загрузки и сохранения данных в и из кеша данных первого уровня была увеличена. Zen 2 могли выполнять две операции загрузки и одну выгрузку, в Zen 3 же может выполняться до трёх загрузок и до двух сохранений за такт, правда, при условии, что общее число одновременно проводимых операций не превышает трёх. Иными словами, кеш L1D остался трёхпортовым (а заодно и 32-килобайтным с 8-кратной ассоциативностью), однако его интерфейс стал более гибким и за счёт этого более быстродействующим. Правда, нужно иметь в виду, что при обслуживании 256-битных пересылок его пропускная способность снижается до двух чтений и одной записи за такт. 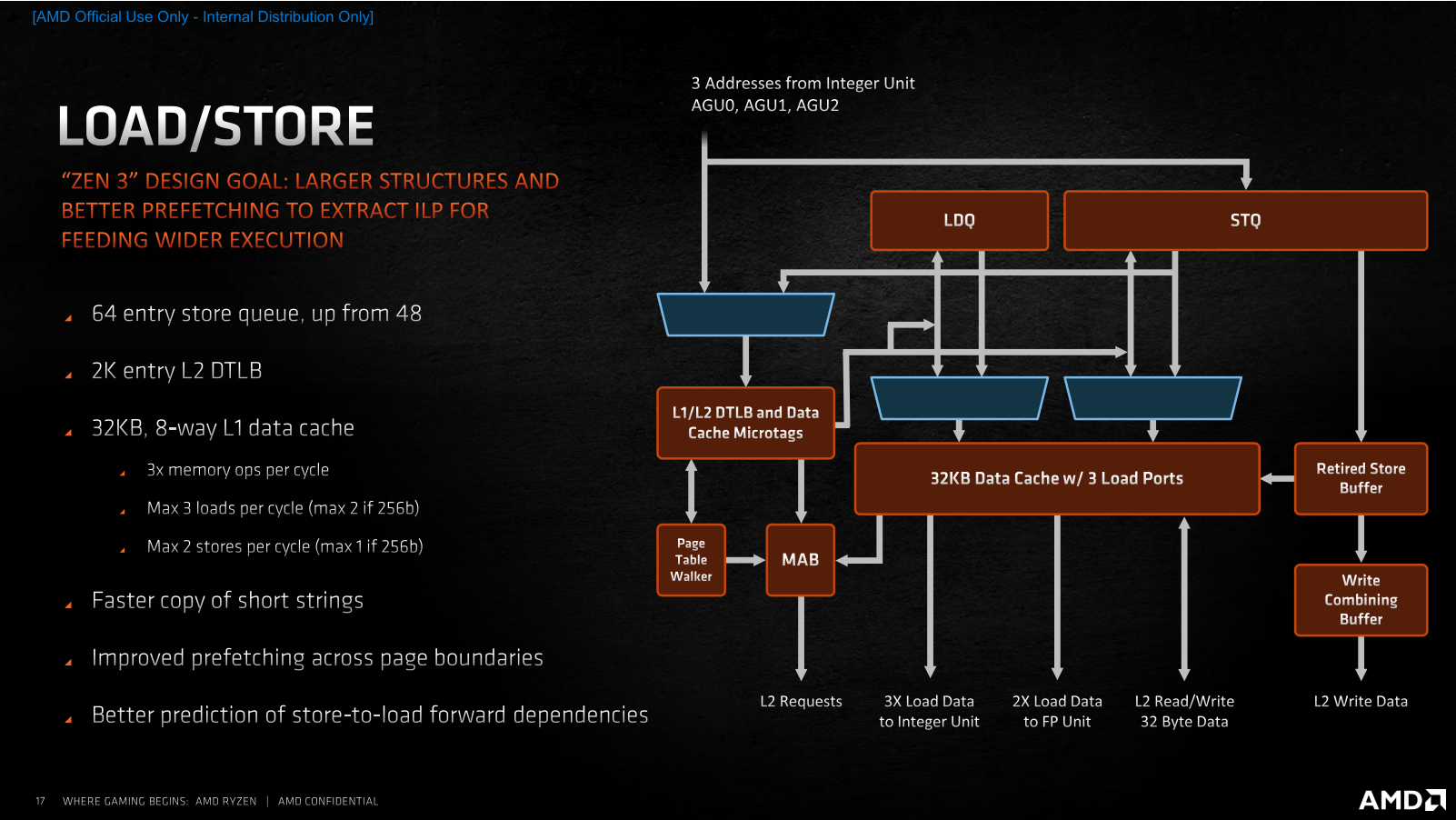 Чтобы увеличить эффективность расширенного интерфейса данных, инженеры AMD провели и некоторые вспомогательные оптимизации. Среди них – увеличение с 48 до 64 записей глубины очереди выгрузки, а также ускоренная выборка при обращениях к разным страницам памяти. В конечном итоге изменения в микроархитектуре ядра сводятся к трём принципиальным вещам: к улучшению предсказания переходов, 45-процентному расширению параллелизма в исполнительном домене и к росту пропускной способности при работе с данными в тыльной части конвейера. В сумме всё это – довольно весомые преобразования, которые сама AMD характеризует как наиболее значительные перемены за весь период эволюционного развития процессоров Zen с 2017 года. 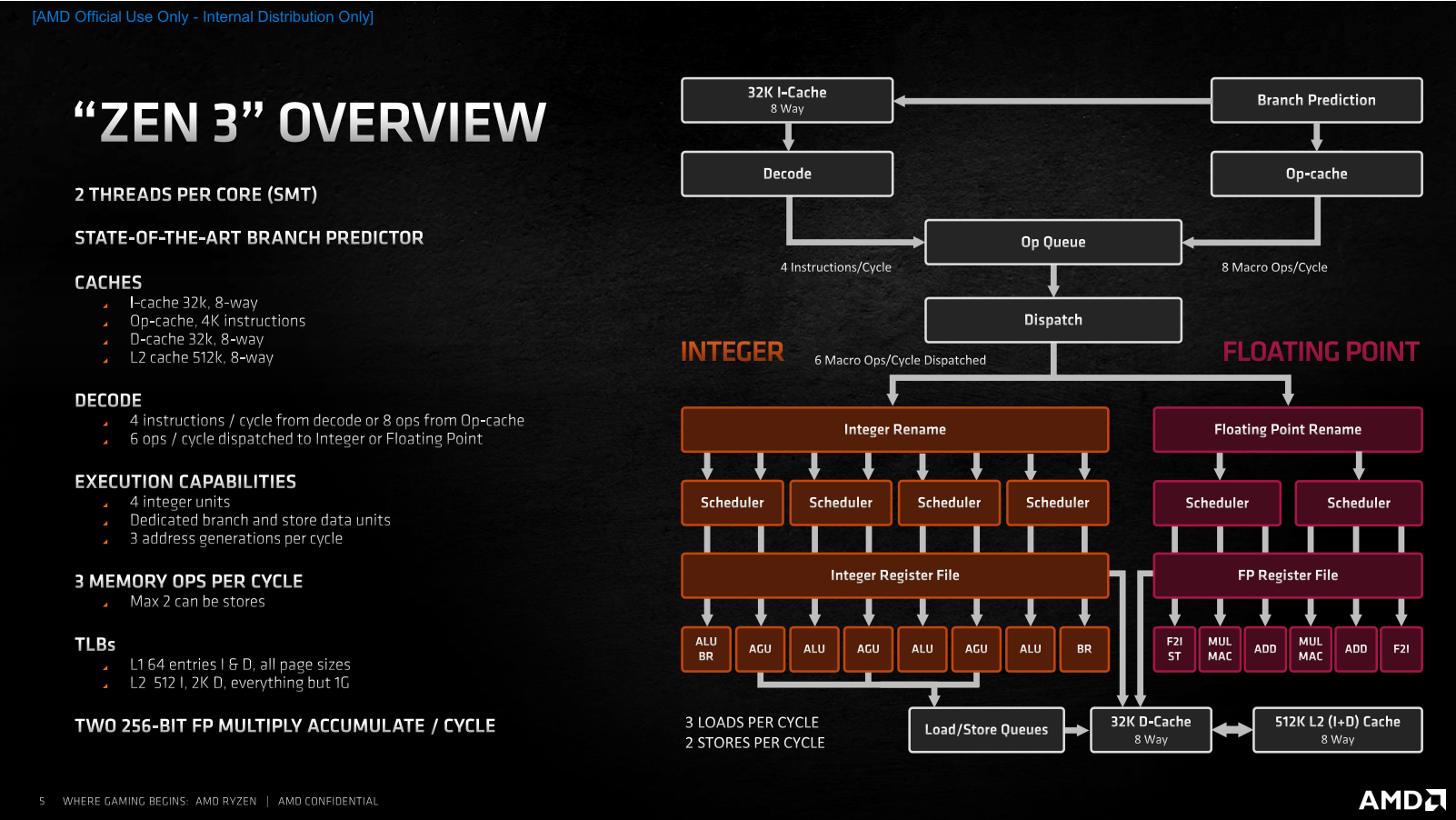 Это как раз и подтверждается тем, что достигнутый в Zen 3 19-процентный прирост IPC по сравнению с прошлым поколением превышает тот прирост IPC, который произошёл при смене микроархитектур с Zen+ до Zen 2 – тогда он оценивался в 15 %. И более того, если смотреть на полную последовательность разных Zen, то IPC новой микроархитектуры Zen 3 превышает показатель изначального Zen на 41 %, и почти половина этого прогресса приходится на сегодняшний рывок.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











