Конец этого года оказался чрезвычайно плодотворным для IT-индустрии и тех, кто следит за ее развитием. Дебют чипов Ryzen 5000-й серии, видеокарт NVIDIA на базе кремния Ampere и, совсем недавно, мобильных SoC от Apple, которые намерены поколебать установившуюся иерархию в мире потребительских CPU — все это произошло буквально за один-два месяца. Не будем забывать и про консоли нового поколения, которые также имеют прямое отношение к инициативам AMD. На наших глазах проходит, пожалуй, самый горячий сезон новинок за последние несколько лет, как по количеству событий, так и по их значимости. Неспроста все передовое железо мгновенно оказалось в той или иной степени дефицитным товаром.
До сегодняшнего дня в картине отсутствовал только один важный элемент — давно обещанные видеокарты Radeon на большом чипе Navi, которые, на наш взгляд, заслуживают центрального места в ряду осенних релизов. Дело в том, что AMD со времен противостояния Radeon R9 Fury X и GeForce GTX 980 Ti фактически устранилась от борьбы за корону наивысшей производительности среди игровых GPU. Попытки вернуться на ринг, которые с тех пор предпринимал чипмейкер, сопровождались щедрыми обещаниями, но каждый раз надежды сторонников красной марки оказывались разбиты. Однако благодаря архитектуре RDNA у AMD появились все предпосылки для того, чтобы устранить технологическое отставание от кремния NVIDIA, а в каких-то аспектах даже занять лидирующую позицию.
Видеокарты Radeon 5000-й серии, пускай они несут на себе черты продуктов переходного периода, уже доказали свою конкурентоспособность в средней и средне-высокой ценовой категории, а теперь амбиции AMD вновь распространились на высший ценовой сегмент. Причем речь идет не только о соревновании в рамках традиционных метрик производительности, но и о возвращении функционального паритета между кремнием NVIDIA и AMD, ведь «большой Navi» тоже выполняет аппаратно-ускоренную трассировку лучей.

AMD анонсировала три видеокарты на базе чипа Navi 21. Сегодня мы рассмотрим две младшие модели — Radeon RX 6800 и Radeon RX 6800 XT, которые должны поступить в продажу в то время, когда вы читаете эту статью, по рекомендованным ценам $579 и $649 соответственно. Их прямые конкуренты со стороны продуктов NVIDIA очевидны — это GeForce RTX 3070 и RTX 3080, оцененные в $499 и $699. Флагманская модель семейства, Radeon RX 6900 XT, задерживается до 8 декабря и сулит быстродействие в одной категории с GeForce RTX 3090 за подобающую сумму $999.
Дебют Radeon RX 6800 и Radeon RX 6800 XT опирается на устройства референсного дизайна, которые изменились до неузнаваемости по сравнению с предшествующими и, прямо скажем, не слишком удачными эталонными решениями AMD, а появление партнерских версий ожидается позднее. Референсные видеокарты будут представлять чип Navi 21 в бенчмарках, но сперва нам предстоит обстоятельный разговор про его архитектуру, далекую от простых количественных изменений ядра RDNA предыдущего поколения.
⇡#Геометрический процессор с поддержкой Mesh Shaders
Логика RDNA 2, хоть и несет в себе немало нового, не претерпела столь же масштабных преобразований в принципах работы графического процессора, которые дистанцировали RDNA 1 от архитектуры Graphics CoreNext, служившей AMD почти восемь лет, со времен Radeon HD 7970 и вплоть до выхода Radeon 5000-й серии. Мы подробно анализировали различия между RDNA и GCN в обзоре Radeon RX 5700 XT и не будем заострять на них внимание сегодня, ведь GCN с тех пор не только ушла из потребительских продуктов AMD (лишь интегрированная графика процессоров Ryzen по-прежнему содержит блоки GCN), но и в серверных решениях для задач GP-GPU вот-вот отправится на пенсию и уступит место следующей архитектуре CDNA. Вместо этого рассмотрим структуру чипа в направлении от front-end’а к back-end’у конвейера рендеринга, освежим знания о принципах работы RDNA, оставшихся неизменными, и выделим те нововведения, что отличают логику Navi 21 от логики Navi 10 — кристалла, который лежит в основе Radeon RX 5600, RX 5700 и RX 5700 XT.
В начале цепочки лежат командные процессоры для шейдеров и вычислений общего назначения, геометрический процессор и аппаратный планировщик, который с недавних пор научилась использовать ОС Windows. Здесь же находится блок DMA, служащий для прямого доступа к памяти GPU по шине PCI Express в рамках совместной работы нескольких ускорителей, а также определенных новаторских функций Navi 21: Smart Access Memory на платформе Ryzen 5000 и поддержки DirectStorage — им мы уделим внимание позже. Однако главное изменение front-end’а GPU на качественном уровне все-таки связано с тем, как Navi 21 обращается с обработкой геометрии.
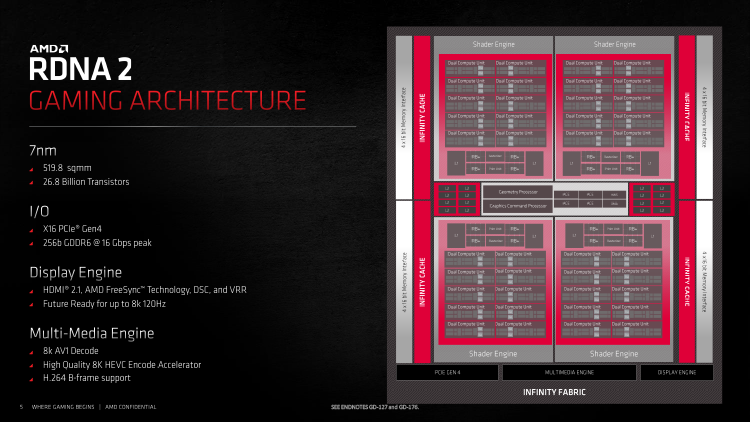
AMD использует распределенную топологию блоков, участвующих в подготовке примитивов для шейдинга, когда геометрический процессор выполняет общие этапы работы, а преобладающая часть операций до и после тесселяции ложится на блоки Primitive Unit, находящиеся внутри масштабируемых разделов GPU. В то время как геометрический процессор в старой архитектуре GCN тесно связан с моделью программирования Direct3D, RDNA научилась отсекать невидимые треугольники на ранних стадиях рендеринга и может принять до восьми примитивов за такт, чтобы отдать на растеризацию четыре. Условием для этого являются т. н. примитивные шейдеры — высокоэффективные программы, занимающие место доменных и геометрических шейдеров Direct3D в последовательности операций графического API.
Примитивные шейдеры задействуются в устройствах RDNA на уровне компилятора, и большая часть соответствующих вычислений проходит через них. Кроме того, в чипах Navi реализованы быстрые шейдеры поверхности (Surface Shaders), которые по решению компилятора заменяют часть шейдерной цепочки, вовлеченной в тесселяцию (Vertex Shaders и Hull Shaders) перед тем, как данные передаются самому тесселятору — блоку фиксированной функциональности. Описанные функции, которые в терминологии чипмейкера носят имя NGG (Next Generation Geometry), заменяют проблемные порции геометрического конвейера, свойственного Direct3D, на лету перекодируя старый тип шейдеров в новый, и таким образом выполняют прежнюю работу более эффективно без необходимости в эксплицитной поддержке со стороны разработчиков графических приложений.
Тем не менее нельзя скрыть тот факт, что пропорция между мощностью геометрического front-end’a и масштабируемых ресурсов GPU, которые занимаются текстурированием и работой шейдерных kernel’ов, обычная для чипа Navi 10, изменилась не в лучшую сторону. Графический процессор Navi 21 с увеличенным вдвое массивом шейдерных ALU по-прежнему вынужден довольствоваться четырьмя примитивами, прошедшими фильтрацию невидимых поверхностей. К счастью, в дополнение к оптимизациям, представленным в RDNA первого поколения, Navi 21 может воспользоваться совершенно новой моделью программирования геометрии — Mesh Shaders. Шейдеры такого рода были впервые реализованы в графических процессорах Turing от NVIDIA, но затем превратились в индустриальный стандарт и вошли в состав требований к железу, которые выдвигает DirectX 12 Ultimate (feature level 12_2).
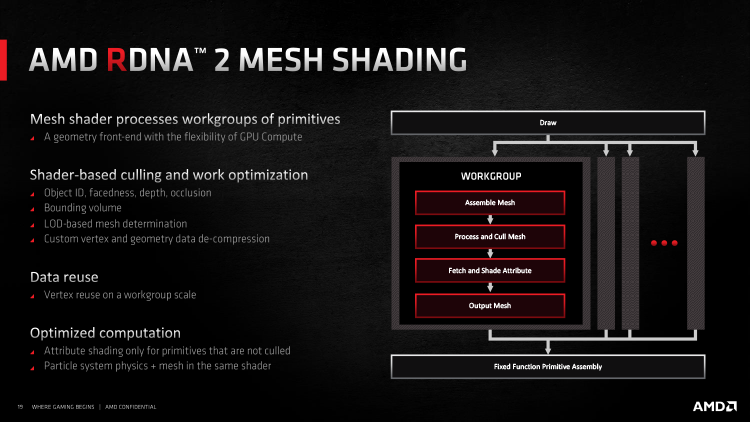
В предыдущих версиях Direct3D полигонная сетка (mesh) какого-либо объекта сцены обсчитывается целиком: все числа буфера индексов, который определяет положение вершин, рассматриваются в последовательном порядке. Таким образом, нагрузка на ранние этапы конвейера рендеринга возрастает линейно вместе с геометрической сложностью сцены. Модель Mesh Shaders параллелизирует данную задачу путем разделения полигонной сетки на фрагменты (meshlets), каждым из которых занимается отдельная группа потоков инструкций. Рука об руку с Mesh Shaders идут Amplifications Shaders, определяющие, как много групп инструкций будет запущено, и отдают последним необходимые данные. Как намекает название этого этапа рендеринга, Amplifications Shaders позволяют размножать геометрию на лету путем быстрого дублирования полигонных сеток — раньше это уже демонстрировала NVIDIA в качестве коронной функции Mesh Shaders. Кроме того, Mesh Shaders под управлением Amplifications Shaders выполняют раннее отсечение невидимых поверхностей и автоматический выбор необходимого уровня детализации (LOD) прямо на GPU.
В перспективе новая модель должна полностью заменить этап тесселяции поверхностей, который сегодня выполняется блоками фиксированной функциональности, или по крайней мере дополнить его в тех случаях, когда уместно более гибкое решение. Единственное, что сейчас сдерживает миграцию игровой графики на Mesh Shaders, — это необходимость эксплицитной поддержки технологии в каждой новой игре.
⇡#Удвоенный массив шейдерных ALU и полная поддержка DirectX 12 Ultimate
Несмотря на массу качественных, а кое в чем откровенно революционных изменений, которые принесла архитектура RDNA 2, главное, что привлекает внимание в характеристиках чипа Navi 21, — это удвоенный массив шейдерных ALU и блоков наложения текстур по сравнению с Navi 10, который лежит в основе флагманской модели предыдущего поколения, Radeon RX 5700 XT.
Инженеры AMD сделали именно то, на что указывали слухи про «большой Navi» с самого начала: произошел возврат к конфигурации с четырьмя Shader Engines, являющейся визитной карточкой топовых «красных» GPU еще со времен чипа Hawaii (серия Radeon R9 290). Shader Engine является крупнейшим масштабируемым компонентом архитектуры GCN или RDNA, вмещающим ряд Compute Unit’ов — по сути аналогов отдельного ядра в центральных процессорах. Число CU варьирует в зависимости от того или иного GPU и в данном случае составляет 20 штук. Полностью функциональный кристалл Navi 21 содержит в общей сложности 80 активных CU, что соответствует 5120 шейдерным ALU.
Таким образом, «большой Navi» и вправду стал самым крупным дискретным GPU от AMD с точки зрения сырой вычислительной мощности в количестве операций FP32 на такт. AMD не впервой производить графические процессоры подобного калибра. Так, чипы Fiji и Vega 10/20 уже достигали отметки в 4096 шейдерных ALU, что, кстати говоря, производит сильное впечатление в ретроспективе. Однако RDNA — архитектура, несравненно лучше оптимизированная для 3D-рендеринга, не говоря уже об инновациях второго поколения и высоких тактовых частотах, которые обещаны новому кремнию.
| Производитель | AMD |
|---|
| Название |
Navi 14 |
Navi 10 |
Navi 21 |
| Где используется |
Radeon RX 5300 – Radeon RX 5500 XT |
Radeon RX 5600 XT;
Radeon RX 5700;
Radeon RX 5700 XT |
Radeon RX 6800;
Radeon RX 6800 XT;
Radeon RX 6900 XT |
| Микроархитектура |
RDNA |
RDNA |
RDNA 2 |
| Техпроцесс, нм |
7 нм FinFET |
7 нм FinFET |
7 нм FinFET |
| Число транзисторов, млн |
6 400 |
10 300 |
26 800 |
| Площадь чипа, мм2 |
158 |
251 |
519,8 |
| Число CU/WGP/SA/SE |
| Compute Units (CU) |
24 |
40 |
80 |
| Workgroup Processors (WGP) |
12 |
20 |
40 |
| Shader Arrays (SA) |
2 (?) |
4 |
Нет |
| Shader Engines (SE) |
1 |
2 |
4 |
| Конфигурация Compute Unit'а |
| Векторные SIMD |
2 |
2 |
2 |
| Векторные ALU |
2 × 32 |
2 × 32 |
2 × 32 |
| Скалярные ALU |
2 |
2 |
2 |
| ALU специального назначения (SFU) |
2 × 8 |
2 × 8 |
2 × 8 |
| Блоки трассировки лучей (Ray Accelerators) |
Нет |
Нет |
1 |
| Блоки наложения текстур (TMU) |
4 |
4 |
4 |
| Векторные (vGPR)/скалярные регистры |
1024/2560 |
1024/2560 |
1024/2560 |
| Объем кеша L0, Кбайт |
16 |
16 |
16 |
| Конфигурация Workgrpoup Processor (WGP) |
| Local Data Store (LDS) |
128 (общее для 2 CU) |
128 (общее для 2 CU) |
128 (общее для 2 CU) |
| Кеш инструкций, Кбайт |
32 |
32 |
32 |
| Скалярный кеш, Кбайт |
16 |
16 |
16 |
| Объем кеша L1, Кбайт |
128 (общий для 12 CU ?) |
128 (общий для 10 CU) |
256 (общий для 20 CU) |
| Программируемые вычислительные блоки GPU |
| Векторные ALU |
1 536 |
2 560 |
5 120 |
| Скалярные ALU |
48 |
80 |
160 |
| ALU специального назначения (SFU) |
192 |
320 |
640 |
| Блоки GPU фиксированной функциональности |
| Блоки наложения текстур (TMU) |
96 |
160 |
320 |
| Блоки операций растеризации (ROP) |
32 |
64 |
128 |
| Конфигурация памяти |
| Объем кеша L2, Кбайт |
2 048 |
4 096 |
4 096 |
| Объем Infinity Cache, Мбайт |
Нет |
Нет |
128 |
| Разрядность шины RAM, бит |
128 |
256 |
256 |
| Тип микросхем RAM |
GDDR6 |
GDDR6 |
GDDR6 |
|
| Интерфейс PCI Express |
4.0 x8 |
4.0 x16 |
4.0 x16 |
В состав Shader Engine также входит секция кеша L1 и блок примитивов, ответственный за сборку треугольников из вершин и тесселяцию, и растеризатор, который осуществляет переход от операций над геометрическими данными к пиксельным. Наконец, здесь же лежат комбинированные Render Backends, выполняющие функцию отдельно стоящих ROP. И вот сейчас те немногочисленные читатели, которые могут по памяти нарисовать блок-схему предыдущих чипов AMD, должны кое-что заметить в строении Navi 21. Внутри Shader Engine исчезло разделение пополам на Shader Arrays, каждый из которых содержит 10 Compute Unit’ов, ассоциированные с ними блоки примитивов, RB и растеризаторы, то есть пропорция между количеством этих элементов и шейдерных ALU резко изменилась.
Складывается впечатление, что растеризаторы стали потенциально узким местом в конвейере Navi 21. Поскольку AMD не говорит о каких-либо изменениях в их пропускной способности, резонно предположить, что каждый растеризатор по-прежнему выдает 16 пикселов за такт. Таким образом устанавливается неоптимальное соотношение 1:2 между скоростью растеризации и пиксельным филлрейтом. Впрочем, так это в действительности или нет, мы не можем утверждать с уверенностью, пока AMD не опубликует whitepaper новой архитектуры.
Что касается RB, то Navi 21 поддерживает необходимый мощному шейдерному ядру пиксельный филлрейт за счет того, что каждый блок теперь способен семплировать, тестировать и смешивать восемь32-битных пикселов за такт вместо четырех, что дает графическому процессору эквивалент 128 отдельных ROP.

Кроме того, благодаря изменениям в RB ускоритель приобрел еще одну функцию, необходимую для соответствия стандарту DirectX 12 Ultimate, — Variable Rate Shading. Она открывает возможность гибко и произвольно регулировать вычислительные ресурсы, выделенные на рендеринг отдельных фрагментов изображения, которым требуется повышенная точность или для которых, наоборот, допустимо падение качества. Принцип работы VRS похож на полноэкранное сглаживание методом MSAA с суперсемплингом, когда на каждый пиксел экрана приходится несколько выборок цвета, каждый из которых вызывает пиксельный шейдер, только наоборот — количество выборок снижается произвольным образом. Имплементация VRS в Navi 21 поддерживает оба уровня функции, предусмотренные в рамках Direct3D feature level 12_2, то есть может быть задана точность шейдинга для отдельного вызова на отрисовку полигонной сетки (draw call), отдельного примитива или просто участка изображения. Допустимы различные сетки разреженных выборок, включая 1 × 2, 1 × 2 и 2 × 2.

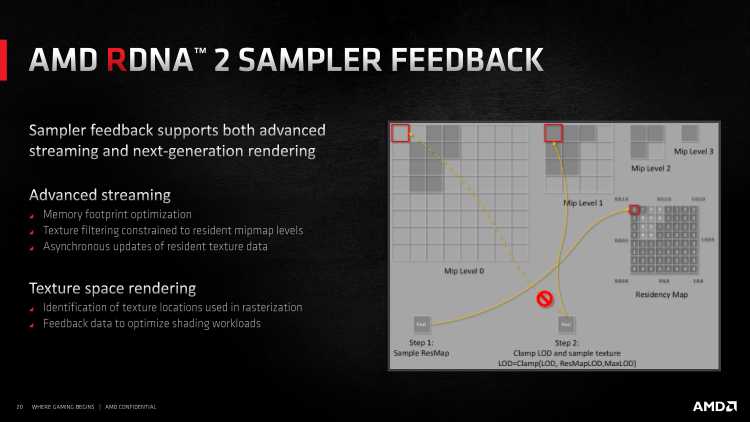
Кроме того, RDNA 2 поддерживает шейдинг в текстурном пространстве. Стандартный прямой рендеринг подразумевает, что GPU растеризирует геометрию в экранные пикселы, исполняет пиксельный шейдер для каждого пиксела и отправляет результат в кадровый буфер. В рамках Texture Space Shading результат пиксельных шейдеров сохраняется в виде текселов текстурного пространства, что позволяет использовать их многократно и тем сам экономить такты на дальнейших шейдерных вычислениях. А кроме того, повысить качество рендеринга в отдельных ситуациях, поскольку TSS разрушает привязку к координатам экранного пространства, и шейдеры могут выполняться за пределами графического конвейера как такового.
Условие эффективной эксплуатации TSS заключается в том, чтобы заранее определить, какие объекты целесообразно затенять в текстурном пространстве. Чтобы решить эту проблему, а также снизить общие требования рендерера к объему локальной памяти видеокарты, в рамках DirectX Ultimate существует механизм Samper Feedback. Каждый раз, когда GPU запрашивает определенный тайл (в случае, когда используются тайловые ресурсы) или MIP-уровень текстуры, в специальном буфере делается пометка, что данный ресурс был запрошен, причем с определенным уровнем детализации, и он подгружается в VRAM. В противном случае память содержит только низкодетализированные копии ресурсов.
⇡#RDNA 2 против Turing и Ampere
Теперь погрузимся глубже в устройство чипов RDNA 2, на уровень логики, занимающейся шейдерными вычислениями. Отдельный Compute Unit содержит 64 т. н. векторных ALU, разделенных на два блока SIMD (Single Instruction Multiple Data). Каждый SIMD за один такт выполняет одну инструкцию из группы 32 потоков операций (wavefront в терминологии AMD). Благодаря отдельным планировщикам, обслуживающим собственные SIMD’ы, и одновременной отдаче двух инструкций каждый такт, RDNA характеризуется пониженной латентностью исполнения индивидуальных инструкций по сравнению со старой архитектурой GCN. При этом RDNA допускает работу со старым, 64-поточным форматом wavefront’а — в таком случае SIMD исполняет одну инструкцию в течение двух тактов, и это несет свои преимущества: таким образом у CU появляется временное окно, чтобы дождаться получения данных, необходимых следующей инструкции, — например, из оперативной памяти GPU. Ширину wavefront'a для исполнения программ определяет компилятор. Вычислительные шейдеры обычно компилируются в формате Wave32, пиксельные — Wave64.

RDNA выполняет операции FP16 на своих SIMD’ах в удвоенном темпе, и то же относится к целочисленным операциям INT16. Кроме того, архитектура поддерживает несколько разновидностей смешанной точности, когда инструкция FMA требует перемножения двух матриц сниженной точности (FP16 для вещественных чисел и вплоть до INT4 для целых) и последующего сложения с матрицей FP32 или INT32. Такие вычисления происходят в ускоренном темпе кратно потере разрядности в исходных операндах (см. иллюстрацию). Согласно whitepaper RDNA графический процессор дополнительно оснащается специализированными ALU для расчетов двойной точности (FP64), которых может быть от 2 до 16 на каждый векторный SIMD, и темп исполнения инструкций меняется соответствующим образом — от 1/2 до 1/16 по отношению к FP32. Для Navi 21 справедливо последнее, ведь это в первую очередь игровой графический процессор, а высокую скорость обработки FP64 следует искать в представленных на днях устройствах архитектуры CDNA.

На самом деле здесь AMD приводит данные о пропускной способности одного WGP (Workgroup Processor), то есть пары CU, а не одного из них
В дополнение к векторным SIMD каждый Compute Unit имеет двойной скалярный конвейер, который используется операциями условного ветвления, перехода и подобной целочисленной арифметики. В таких случаях все значения операций одной инструкции waverfront’а одинаковы и происходит т. н. скаляризация в одну операцию, чтобы не тратить энергию, загружая SIMD ’ы одинаковыми вычислениями. Скалярные блоки RDNA могут получать свою инструкцию параллельно векторной инструкции соответствующего SIMD’а — недавно нам наконец-то удалось добиться от инженеров AMD подтверждения того, что параллелизм такого рода в RDNA действительно существует.
Наконец, еще один тип исполнительных блоков (SFU), который присутствует в Compute Unit’е, выполняет т. н. операции специального назначения: тригонометрические функции, которые нередко используются в задачах 3D-рендеринга. SFU представляет собой отдельный SIMD, который привязан к каждому из основных векторных SIMD’ов. Он служит резервным путем для инструкции wavefront’а и исполняет ее в темпе 1/4 по сравнению с обычными векторными инструкциями. Чтобы CU мог загрузить SFU, векторный SIMD пропускает один такт, а затем готов принимать и исполнять инструкции в стандартном режиме.
Таблица ниже резюмирует теоретическую пропускную способность CU в рамках архитектуры RDNA и RDNA 2 по сравнению с современной логикой Turing и Ampere от NVIDIA, а также решениями на чипах GCN, которые являются подходящими кандидатами для замены свежими ускорителями Radeon 6000-й серии. Мы взяли за единицу времени промежуток в 8 тактов GPU, чтобы минимизировать количество дробных чисел, и не стремились охватить все возможные комбинации типов инструкций: в данном случае нас интересуют только операции над вещественными и целыми числами стандартной точности (FP32 и INT32), а также расчет тригонометрических функций (SF) и арифметика с плавающей запятой сниженной точности (FP16).
RDNA 2 не удостоилась отдельной колонки в таблице, т. к. AMD не сообщает о каких-либо глубоких изменениях в работе Compute Unit’a. Говорят лишь о том, что CU прибавил 30 % быстродействия в пересчете на ватт потребляемой мощности за счет повышенных тактовых частот. Но это уже относится к энергоэффективности чипа Navi 21, которую мы обсудим (а затем измерим самостоятельно) позже.
| Compute Unit (GCN 5 поколения) | Compute Unit (RDNA 1/RDNA 2) | Streaming Multiprocessor (Turing) | Streaming Multiprocessor (Ampere) |
|---|
| Исполнительные блоки |
4 × векторных SIMD16;
4 × векторных SIMD4 SFU;
1 × скалярное ALU;
4 × TMU (блока фильтрации текстур)
|
2 × векторных SIMD32;
2 × векторных SIMD8 (SFU); 2 – 16 × ALU (FP64);
2 × скалярных ALU;
1 × Ray Accelerator (только в RDNA 2);
4 × TMU (блока фильтрации текстур)
|
4 × секции 16 ALU (FP32);
4 × секции 16 ALU (INT32);
2 × ALU (FP64); 4 × секции 4 SFU;
4 × скалярных ALU; 4 × секции 2 тензорных ядер (или 4 × секции 32 FP16 ALU);
1 × RT-ядро;
4 × TMU (блока фильтрации текстур)
|
8 × секции 16 ALU (FP32);
4 × секции 16 ALU (INT32);
2 × ALU (FP64);
4 × секции 4 SFU;
4 × скалярных ALU;
4 × тензорных ядер (эквивалент 128 × FP16 ALU);
1 × RT-ядро;
4 × TMU (блока фильтрации текстур)
|
| Пропускная способность, инструкций за 8 тактов |
8 × FP32 (64 рабочие единицы) + 8 × скалярных
ИЛИ
8 × FP16 (2 × 64 рабочие единицы) + 8 × скалярных
ИЛИ
4 × 1/2 SF FP32 (64 рабочих единицы) + 8 × скалярных
|
16 × FP32 (32 рабочие единицы) + 16 × скалярных
ИЛИ
16 × FP16 (2 × 32 рабочие единицы) + 16 × скалярных
ИЛИ
12 × FP32 (32 рабочие единицы) + 4 × SF FP32 (32 рабочие единицы) + 16 × скалярных
|
16 × FP32 (32 рабочие единицы) + 16 × INT32 (32 рабочие единицы)
ИЛИ
32 × FP16 (32 рабочие единицы)
ИЛИ
4 × (3 + 1/2) FP32 (32 рабочие единицы) + 4 × (3 + 1/2) INT32 (32 рабочие единицы) + 4 × SF FP32 (32 рабочие единицы)
|
32 × FP32 (32 рабочие единицы)
ИЛИ
16 × FP32 (32 рабочие единицы) + 16 × INT32 (32 рабочие единицы)
ИЛИ
32 × FP16 (32 рабочие единицы)
ИЛИ
8 × (3 + 1/2) FP32 (32 рабочие единицы) + 4 × SF FP32 (32 рабочие единицы)
ИЛИ
4 × (3 + 1/2) FP32 (32 рабочие единицы) + 4 × (3 + 1/2) INT32 (32 рабочие единицы) + 4 × SF FP32 (32 рабочие единицы)
|
| 8 × FP32 (64 рабочие единицы) + 16 × скалярных ИЛИ 8 × FP16 (2 × 64 рабочие единицы) + 16 × скалярных ИЛИ 6 × FP32 (64 рабочие единицы) + 2 × SF FP32 (64 рабочие единицы) + 16 × скалярных |
| Пропускная способность, операций за 8 тактов |
512 × FP32/INT32 + 8 скалярных
ИЛИ
1024 × FP16/INT16 + 8 скалярных
ИЛИ
128 × SF FP32 + 8 скалярных
|
512 × FP32/INT32 + 16 скалярных
ИЛИ
1024 × FP16/INT16 + 16 скалярных
ИЛИ
384 × FP32/INT32 + 128 × SF FP32 + 16 × скалярных
|
512 × FP32 + 512 × INT32
ИЛИ
1024 × FP16
ИЛИ
448 × FP32 + 448 × INT32 + 128 × SF FP32
|
1024 × FP32
ИЛИ
512 × FP32 + 512 × INT32
ИЛИ
1024 × FP16
ИЛИ
892 × FP32 + 128 × SF FP32
ИЛИ
448 × FP32 + 448 × INT32 + 128 × SF FP32
|
Как видите, архитектура RDNA эквивалентна Turing по теоретическому быстродействию в операциях FP32/INT32, FP16/INT16 или SFU, когда нагрузка состоит исключительно из одного типа инструкций. Однако бросается в глаза то, что RDNA/RDNA 2 не имеет возможности параллельно выполнять расчеты FP32 и INT32, которую приобрел Turing, или просто-напросто удвоить пропускную способность FP32, как сделано в Ampere. Впрочем, у RDNA есть ряд своих уникальных преимуществ. Так, скаляризация инструкций не увеличивает производительность чипов NVIDIA и служит только для экономии потребляемой мощности, в то время как в RDNA скалярные и векторные инструкции отдаются на исполнение одновременно. Далее, клиентами планировщика в «зеленых» GPU также являются тензорные ядра, блок ветвлений и группа блоков load/store. Чтобы задействовать какой-либо из них, в этот такт планировщик не может отправить инструкцию для исполнения на шейдерных CUDA-ядрах.
Не удивительно, что в контексте реальных приложений, а не теоретических оценок быстродействия весьма нелегко целиком раскрыть потенциал чипов Ampere. О результатах, приближающихся к паспортным значениям, речь может идтитолько при исключительно вещественночисленной нагрузке. Действительно, ни один игровой бенчмарк не повторил такой колоссальной разницы в производительности между продуктами Ampere и ускорителями предыдущего поколения, как, например, тесты в рейтрейсере Blender. Складывается впечатление, что графические архитектуры, которые развивают NVIDIA и AMD, поменялись местами: когда-то на стороне «красных» был перевес по числу шейдерных ALU, который ярче всего проявлялся в задачах GP-GPU. Теперь то же самое можно сказать про Ampere, явно тяготеющий к нагрузке расчетного типа, несмотря на преимущественно игровую ориентацию чипов GA102 и GA104.
А вот что AMD пока нечем крыть — так это вышеупомянутые тензорные ядра, предназначенные для чрезвычайно быстрого исполнения операций FMA над данными сниженной разрядности, которые используются главным образом в эксплуатации (а с некоторых пор и тренировке) нейронных сетей. Чипы на основе RDNA вынуждены делать эту работу сравнительно медленно силами векторных SIMD’ов. И пусть RDNA развивает двойной темп исполнения инструкций половинной точности, один CU за такт совершает не более 128 операций FP16, в то время как один потоковый мультипроцессор NVIDIA — целых 512 при условии, что это операции в тензорном формате. Вдобавок ко всему, пока задействованы тензорные ядра, шейдерные ALU тожене обязаны простаивать.
⇡#Аппаратная трассировка лучей
Про аппаратно ускоренный рейтрейсинг — одну из коронных функций архитектуры RDNA второго поколения, как бы странно это ни прозвучало, мы можем сообщить не так уж много. Точно так же, как соперничающие архитектуры Turing и Ampere от NVIDIA, RDNA 2 опирается на распространенный алгоритм Bounding Volume Hierarchy для оптимизации поиска пересечений между лучом и полигонами сцены. Алгоритм BVH заранее сортирует примитивы по вложенным друг в друга боксам. Таким образом, чтобы быстро найти точку пересечения луча с поверхностью примитива, программе нужно рекурсивным образом пройти сквозь древовидную структуру BVH и только затем вычислить барицентрические координаты пересечения луча с плоскостью вместо того, чтобы выполнять крайне неэффективный перебор всех треугольников сцены.
Тем не менее рейтрейсинг даже с помощью BVH по-прежнему остается чрезвычайно ресурсоемкой задачей, когда он выполняется на универсальных шейдерных ALU, поэтому в архитектуре Turing от NVIDIA и появились (а затем были усилены в чипах Ampere) блоки фиксированной функциональности, предназначенные именно для прохождения структуры BVH и расчетов пересечения луча с примитивами внутри наименьшего бокса. Аналогичные по назначению блоки под названием Ray Accelerators (RA) стали дополнением к архитектуре RDNA в чипе Navi 21. Одна часть RA занимается BVH, другая поиском координат на полигоне, а темп выполнения расчетов составляет 4 и 1 пересечение луча за такт соответственно. Увы, для сравнения с RDNA 2 у нас нет подобной информации об RT-блоках в чипах NVIDIA, но известно по крайней мере то, что Ampere (в отличие от Turing и RDNA 2) позволяет двум частям RT-блока в одно и то же время отслеживать разные лучи. Кроме того, Ampere содержит специфические оптимизации для ускорения трассированного размытия в движении, которые в RDNA 2 также отсутствуют.

Согласно данным внутреннего тестирования AMD ускоритель на базе Navi 21 развивает производительность в 10 раз больше за счет аппаратного рейтрейсинга по сравнению с исключительно софтверным рендерингом на том же оборудовании. Однако эти числа еще ничего не говорят о быстродействии реальных приложений. Чипмейкер избегает прямого сравнения новых видеокарт с предложениями NVIDIA в игровых бенчмарках с трассировкой лучей, и это неспроста. А абсолютные числа кадровой частоты не сопровождаются достаточно подробными комментариями о методике тестирования, чтобы мы могли сопоставить их с уже хорошо известными показателями Turing и Ampere. Впрочем, мы скоро выясним, как обстоят дела в действительности. Ведь главное, что аппаратно ускоренный рейтрейсинг, который прежде был невозможен на «красном» железе, теперь стал реальностью, а отставание от первопроходца вполне простительно для ранних решений AMD.
Более серьезной проблемой для Radeon c аппаратным рейтрейсингом является отсутствие настолько же эффективных инструментов масштабирования кадра, как DLSS версии 2.0 у видеокарт NVIDIA. Даже новейшие модели GeForce RTX 30-й серии при высоком разрешении далеко не всегда поддерживают комфортный фреймрейт без апскейлинга, и, судя по всему, разработчики игр уже привыкают закладывать в требования графического движка прибавку быстродействия, которую обеспечивает DLSS. Это ставит железо AMD, явно более слабое в трассировке лучей, в невыгодное положение. В настоящее время компания работает над очередным расширением библиотек FidelityFX под названием Super Resolution, которое является более качественным средством реконструкции деталей, чем существующий алгоритм FidelityFX CAS, но, как ни крути, рынок игр остается фрагментированным, и далеко не все игровые студии будут тратить силы на интеграцию двух соперничающих технологий.
Как и RT-ядра в чипах Turing и Ampere, RDNA 2 позволяет задействовать функции аппаратно ускоренного рейтрейсинга под управлением стандартных графических интерфейсов программирования DXR и аналогичных расширений Vulkan. В задачах профессиональной визуализации блоки Ray Accelerators активируют плагин RadeonProRender версии 3.0 (он еще находится в статусе бета-версии) для нескольких программ 3D-моделирования, а в будущем поддержка распространится на рендерер Cycles в пакете Blender. Здесь опять-таки NVIDIA успела пройти большую дистанцию со времен дебюта чипов Turing, и ускорение рейтрейсинга на видеокартах GeForce и Quadro теперь используется практически везде, где только можно. AMD придется наверстывать упущенное, но, с другой стороны, NVIDIA уже сыграла роль ледокола, и в результате программная инфраструктура игр и рабочих приложений теперь гораздо лучше приспособлена к аппаратным решениям такого рода.
Кстати, не будем удивлены, если одной из первых компаний, которые предоставят чипам архитектуры RDNA 2 софтверную платформу для рейтрейсинга, станет Apple. «Домашние» чипы этой фирмы выглядят многообещающе, но Apple наверняка еще нескоро обойдется без чужих графических процессоров в своих высокопроизводительных десктопах и рабочих станциях.
⇡#Иерархия памяти Navi 21 и Infinity Cache
Теперь пора, наконец, обсудить безоговорочно главное нововведение архитектуры RDNA 2 — стек локальной памяти, который включает громадный кеш третьего уровня. Все остальные хранилища, ближайшие к шейдерным ALU, не претерпели почти никаких изменений по сравнению с тем, что уже было сделано в чипах Navi первого поколения. Compute Unit’ы RDNA связаны в пары (Workgroup Processors), имеющие общий LDS (Local DataShare) объемом 128 Кбайт (если бы он вырос, AMD наверняка сообщила бы), который представляет собой наиболее быстрый тип памяти после регистров векторных SIMD’ов, а также 32-килобайтный кеш инструкций и скалярный кеш объемом в 16 Кбайт. Кеш нулевого уровня является эксклюзивным для каждого CU. Остался прежним и объем секции L1 в пределах каждого Shader Engine — четыре из них дают в сумме 1 Мбайт кеша первого уровня.
Имеет место даже определенный регресс характеристик: стала вдвое меньше пропускная способность в направлении от L0 к L1, а кеш L2, общий для блоков Shader Engine и командных процессоров, несмотря на удвоенный вычислительный потенциал Navi 21, сохранил объем 4 Мбайт. Однако все это с лихвой искупают меры, которые AMD приняла в отношении последних уровней памяти, доступных графическому процессору.

GPU такого калибра, как Navi 21, нуждаются в скоростном доступе к большим объемам данных. Чтобы обеспечить эту потребность, AMD могла пойти проторенной дорогой памяти HBM2, которая принесла Radeon VII все еще действующий среди потребительских видеокарт рекорд пропускной способности памяти в 1 Тбайт/с, или использовать 512-битную шину, которая в сочетании с обычными микросхемами GDDR6 гарантирует не меньшую ПСП. Но оба указанных решения проблематичны каждое по своим причинам, общей среди которых является цена. Наконец, существуют также далеко не дешевые в стоимости конечного продукта чипы GDDR6X, но пусть данный стандарт формально не является эксклюзивным для продуктов NVIDIA, Micron работала над ним в сотрудничестве с последней, и третий в этой истории наверняка был бы лишним.
Благо AMD нашла свой и, кажется, наиболее перспективный подход к проблеме. Компания оставила попытки ускорить внешнюю динамическую память и применяет в новых ускорителях банальные чипы GDDR6 с пропускной способностью 16 Гбит/с на 256-битной шине, что в совокупности дает 512 Гбайт/с. Таким образом, устройства 6000-й серии недалеко ушли от Radeon RX 5700 XT с его 448 Гбайт/с. Однако в дополнение к дискретной DRAM на самом кристалле GPU теперь расположен массивный кеш третьего уровня объемом 128 Мбайт под названием Infinity Cache.
Infinity Cache существенно отличается от кешей L1 и L2, которые являются неотъемлемой частью любого современного GPU, тем, что внутренние хранилища CU и Shader Engines больше заточены под высокую пропускную способность, нежели объем и, соответственно, хитрейт. Так, в RDNA канал между L1 и Compute Unit’ами в пределах Shader Engine передает в общей сложности 4096 байт за такт, а между всеми секциями L1 и L2 — 2048 байт. В пересчете на весь GPU эти величины составляют десятки терабайт в секунду, но в силу скромного объема кешей процент попаданий в них сравнительно мал. А главное, масштабировать такую структуру было бы чрезвычайно затратно с точки зрения площади кристалла. Вместо этого Navi 21 получил кеш последнего уровня в качестве прокладки между L2 и внешней динамической памятью, который создан по образцу L3 в центральных процессорах архитектуры Zen и отличается чрезвычайно высокой плотностью компоновки (вчетверо меньшая площадь относительно емкости, чем у L2-чипов Navi).

Сплошные горизонтальные блоки сверху и снизу — это Infinity Cache
В действительности решения такого рода, как Infinity Cache, — далеко не новость. Крупным массивом статической (или высокоскоростной динамической) памяти для нужд GPU — прямо на чипе или в виде отдельной микросхемы — не раз оснащали SoC игровых консолей, а также до недавнего времени он использовался в интеловских мобильных CPU. Но среди дискретных графических процессоров для ПК Navi 21 все-таки стал первопроходцем.
Жаль только, что AMD не сообщила, какую именно долю площади кристалла занимает Infinity Cache, и у нас нет реальных фотографий без диффузионного барьера, чтобы замерить ее хотя бы приблизительно (стачивать абразивом чип тестовой видеокарты, извините, рука не поднимается). Но вот сам кристалл получился ожидаемо крупным для такого количества вычислительных блоков. Navi 21 содержит в общей сложности 26,8 млрд транзисторов и, таким образом, не слишком отстает от флагмана среди потребительских чипов NVIDIA — GA102 (28,3 млрд). Вместе с тем Navi 21 не только в 2,6 раза превосходит Navi 10 по количеству транзисторов, но и отличается более высокой плотностью компонентов, что стоит отнести как раз на счет компактных библиотек SRAM, из которых сложен Infinity Cache, ведь оба процессора производятся на одном и том же 7-нанометровом конвейере TSMC.
Кеш L3 соединяется с кешем второго уровня шиной Infinity Fabric, которая состоит из 16 каналов шириной 64 байт и разгоняется до тактовой частоты 1,94 ГГц. Пропускная способность интерфейса существенно меньше по сравнению с более глубокими слоями стека памяти, но все равно достигает внушительной величины в 1,99 Тбайт/с, а это почти в четыре раза больше по сравнению с чипами GDDR6 на 256-битной шине (512 Гбайт/с в случае новых ускорителей AMD). Infinity Cache также расположен в собственном домене тактовой частоты, которая снижается — вплоть до 1,4 ГГц — в то время, когда частый доступ к L3 не происходит. Кроме того, благодаря высокой пропускной способности Infinity Fabric, клиентами которой являются контроллеры GDDR6, ускорился даже некешированный доступ к оперативной памяти.
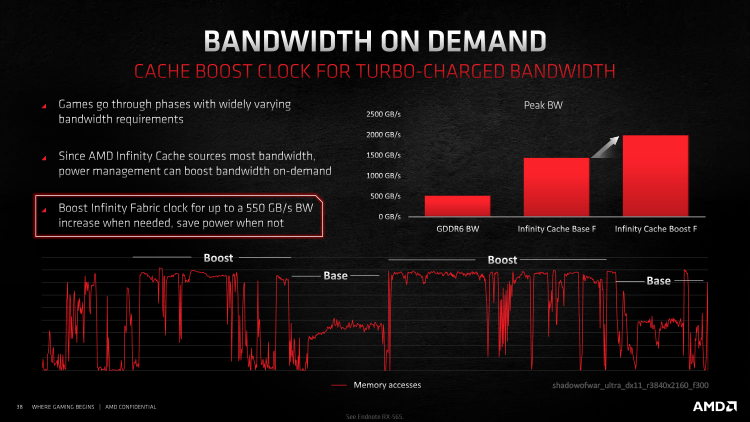
Численные оценки быстродействия Infinity Cache говорят о том, что его латентность на 48 % ниже, чем у памяти GDDR6 на скорости 14 Гбит/с, которая применяется в Radeon RX 5700 XT, а средняя латентность L3 и VRAM в ускорителях 6000-й серии снизилась на 34 % по сравнению с предыдущим поколением. Объема Infinity Cache хватает, чтобы вместить значительную часть данных, необходимых блокам трассировки лучей для прохождения структур BVH. Также, по данным чимпейкера, общая частота попаданий в L3 достигает 58 %, если речь идет об играх в режиме 4К, то есть вплоть до 58 % запросов GPU обслуживаются с чрезвычайно высокой скоростью, которая уступает лишь ПСП новейших серверных GPU с памятью HBM2.
Конечно, 58 % — это наиболее оптимистичная оценка, а гарантом высокого хитрейта в данном случае являются алгоритмы драйвера. AMD не требует от программного обеспечения прямых указаний, какие данные следует поместить в L3, хотя такая возможность имеется, так что все существующие приложения автоматически пользуются преимуществами новой архитектуры памяти.
Мы ожидаем, что эффективность Navi 21 в разных играх и профессиональном ПО не будет одинаково высокой и наверняка возрастет в будущем по мере того, как будет происходить оптимизация драйверов и приложений. Как бы то ни было, Infinity Cache уже позволил AMD смело удвоить количество шейдерных ALU и резко увеличить тактовые частоты графического процессора, не беспокоясь о ПСП, и одновременно повысить энергоэффективность памяти по сравнению с альтернативными решениями, подразумевающими разводку чипов GDDR6 на 384- или 512-битной шине.

Наконец, AMD объявила о поддержке API DirectStorage в среде Windows, который обеспечивает прямую загрузку игровых ресурсов с твердотельных накопителей в локальную память графического процессора. К сожалению, чипмейкер далеко не так подробно рассказывает об особенностях имплементации DirectStorage в собственных продуктах, как его конкурент об аналогичной технологии RTX IO. В частности, не упоминается аппаратная декомпрессия данных силами шейдерных ALU, которая является важной частью решения NVIDIA. Кроме того, DirectStorage производит впечатление прежде всего программного продукта, который не опирается на принципиально новые аппаратные инструменты. Так, RTX IO будет работать не только на свежих видеокартах GeForce 30-й серии, но с таким же успехом и на GeForce RTX 20. AMD, в свою очередь, не уточнила, распространяется ли совместимость с DirectStorage на чипы RDNA первого поколения, хотя мы не видим никаких технических причин, которые могли бы этому воспрепятствовать.

Нельзя обойти вниманием следующую функцию RDNA 2 под названием Smart Access Memory, принцип работы которой пока тоже не до конца ясен. Судя по тому, как SAM характеризуют ее создатели, она открывает центральному процессору прямой доступ к полному объему локальной памяти видеокарты. В типичных игровых компьютерах небольшая часть VRAM всегда является частью адресного пространства системной памяти, но SAM, как мы предполагаем, просто дает возможность целиком отображать VRAM в RAM, что позволит избежать ненужного копирования данных. Для того чтобы извлечь из этого максимальные дивиденды, приветствуется оптимизация программного обеспечения, но уже сейчас технология сулит, по усредненным оценкам AMD, дополнительные 6 % FPS в популярных играх при максимуме вплоть до 11 %. SAM доступна ускорителям Radeon 5000-й и 6000-й серий, но есть подвох: с ней могут работать только процессоры Ryzen 5000 и материнские платы на чипсете B550 или X570 (потребуется обновить BIOS и активировать SAM в его настройках).

Недавно стало известно, что NVIDIA трудится над собственным аналогом Smart Access Memory, который будет работать совместно с чипами Intel и, если AMD не будет возражать, Ryzen. Если так и получится, не исключено, что AMD снимет ограничения с SAM на стороне видеокарт, и полный доступ к VRAM, будем надеяться, рано или поздно будет открыт для любых комбинаций CPU и GPU.
⇡#Декодирование AV1 и выход HDMI 2.1
Судя по официальным оценкам производительности, мультимедийный блок Navi 21 не претерпел никаких изменений по сравнению с аналогичным компонентом чипов Navi первого поколения в части декодирования и кодирования видео стандартов H.264, HEVC и VP9, хотя надо сказать, что AMD преуменьшает его потенциал: в собственных бенчмарках мы получили от Radeon RX 5700 XT более высокие результаты. Однако Navi 21 приобрел возможность кодировать HEVC с разрешением 8К, которой у «красных» GPU не было раньше, и поддержку B-frames (одного из типов промежуточных кадров) в рамках H.264. Что более важно, Navi 21 научился декодировать передовой и чрезвычайно ресурсоемкий стандарт AV1 с кадровой частотой 30 FPS при разрешении 8К (пусть это и не 60 FPS или больше, как в кремнии Ampere от NVIDIA).

Наконец, передовой видеоинтерфейс HDMI 2.1 уже достиг коммерческого внедрения в телевизорах и мониторах, а теперь его осваивают и видеокарты. Контроллер дисплея Navi 21 использует полную пропускную способность HDMI 2.1 для вывода изображения с разрешением 8К и кадровой частотой 60 Гц или, что более актуально, 4К с частотой 120 Гц без необходимости в компрессии данных.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex