







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexАмериканский стартап Cerebras Systems представил гигантский процессор WSE-3 для машинного обучения и других ресурсоёмких задач, для которого заявляется двукратный прирост производительности на ватт потребляемой энергии по сравнению с предшественником.






Cerebras WSE-3. Источник изображений: Cerebras
Площадь нового процессора составляет 46 225 мм2. Он выпускается с использованием 5-нм техпроцесса компании TSMC, содержит 4 трлн транзисторов, 900 000 ядер и объединён с 44 Гбайт набортной памяти SRAM. Его производительность в операциях FP16 заявлена на уровне 125 Пфлопс.
Один WSE-3 составляет основу для новой вычислительной платформы Cerebras CS-3, которая, по утверждению компании, обеспечивает вдвое более высокую производительность, чем предыдущая платформа CS-2 при том же энергопотреблении в 23 кВт. По сравнению с ускорителем Nvidia H100 платформа Cerebras CS-3 на базе WSE-3 физически в 57 раз больше и примерно в 62 раза производительнее в операциях FP16. Но учитывая размеры и энергопотребление Cerebras CS-3, справедливее будет сравнить её с платформой Nvidia DGX с 16 ускорителями H100. Правда, даже в этом случае CS-3 примерно в 4 раза быстрее конкурента, если речь идёт именно об операциях FP16.

Cerebras CS-3
Одним из ключевых преимуществ систем Cerebras является их пропускная способность. Благодаря наличию 44 Гбайт набортной памяти SRAM в каждом WSE-3, пропускная способность новейшей системы Cerebras CS-3 составляет 21 Пбайт/с. Для сравнения, Nvidia H100 с памятью HBM3 обладает пропускной способностью в 3,9 Тбайт/с. Однако это не означает, что системы Cerebras быстрее во всех сценариях использования, чем конкурирующие решения. Их производительность зависит от коэффициента «разрежённости» операций. Та же Nvidia добилась от своих решений удвоения количества операций с плавающей запятой, используя «разреженность». В свою очередь Cerebras утверждает, что добилась улучшения примерно до 8 раз. Это значит, что новая система Cerebras CS-3 будет немного медленнее при более плотных операциях FP16, чем пара серверов Nvidia DGX H100 при одинаковом энергопотреблении и площади установки, и обеспечит производительность около 15 Пфлопс против 15,8 Пфлопс у Nvidia (16 ускорителей H100 выдают 986 Тфлопс производительности).

Одна из установок Condor Galaxy AI
Cerebras уже работает над внедрением CS-3 в состав своего суперкластера Condor Galaxy AI, предназначенного для решения ресурсоёмких задач с применением ИИ. Этот проект был инициирован в прошлом году при поддержке компании G42. В его рамках планируется создать девять суперкомпьютеров в разных частях мира. Две первые системы, CG-1 и CG-2, были собраны в прошлом году. В каждой из них сдержится по 64 платформы Cerebras CS-2 с совокупной ИИ-производительностью 4 экзафлопса.
В эту среду Cerebras сообщила, что построит систему CG-3 в Далласе, штат Техас. В ней будут использоваться несколько CS-3 с общей ИИ-производительностью 8 экзафлопсов. Если предположить, что на остальных шести площадках также будут использоваться по 64 системы CS-3, то общая производительность суперкластера Condor Galaxy AI составит 64 экзафлопса. В Cerebras отмечают, что платформа CS-3 может масштабироваться до 2048 ускорителей с общей производительностью до 256 экзафлопсов. По оценкам экспертов, такой суперкомпьютер сможет обучить модель Llama 70B компании Meta✴ всего за сутки.
Помимо анонса новых ИИ-ускорителей Cerebras также сообщила о сотрудничестве с компанией Qualcomm в вопросе создания оптимизированных моделей для ИИ-ускорителей Qualcomm с Arm-архитектурой. На потенциальное сотрудничество обе компании намекали с ноября прошлого года. Тогда же Qualcomm представила свой собственный ИИ-ускорители Cloud AI100 Ultra формата PCIe. Он содержит 64 ИИ-ядра, 128 Гбайт памяти LPDDR4X с пропускной способностью 548 Гбайт/с, обеспечивает производительность в операциях INT8 на уровне 870 TOPS и обладает TDP 150 Вт.

Источник изображения: Qualcomm
В Cerebras отмечают, что вместе с Qualcomm они будут работать над оптимизацией моделей для Cloud AI100 Ultra, в которых будут использоваться преимущества таких методов, как разреженность, спекулятивное декодирование, MX6 и поиск сетевой архитектуры.
«Как мы уже показали, разрежённость при правильной реализации способна значительно повысить производительность ускорителей. Спекулятивное декодирование предназначено для повышения эффективности модели при развёртывании за счёт использования небольшой и облегченной модели для генерации первоначального ответа, а затем использования более крупной модели для проверки точности этого ответа», — отметил гендиректор Cerebras Эндрю Фельдман (Andrew Feldman).
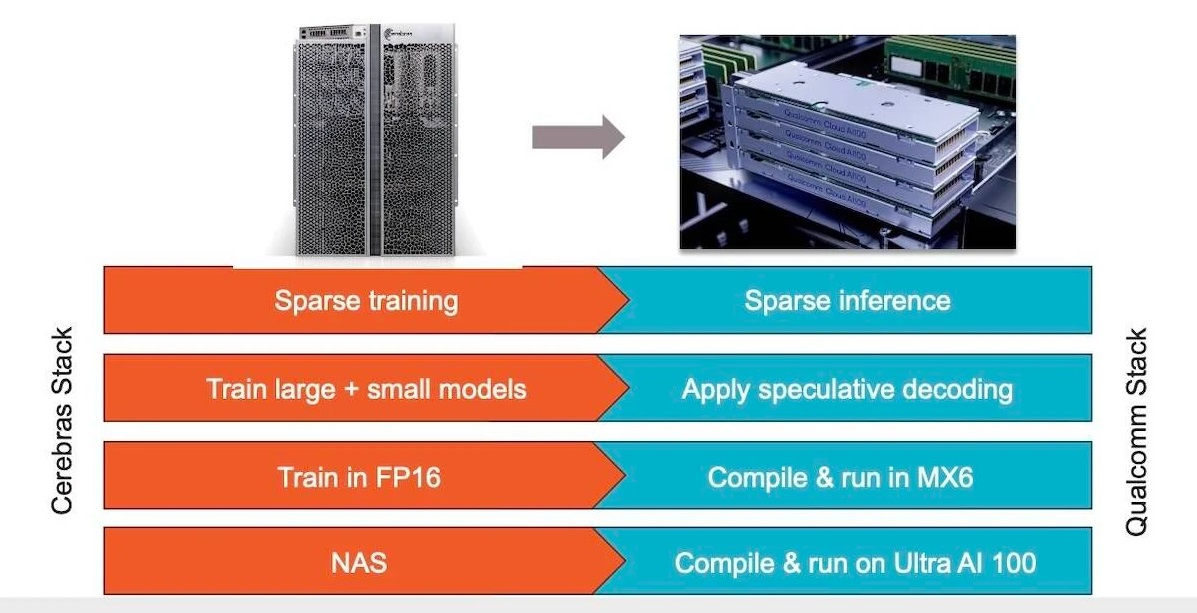
Обе компании также рассматривают возможность использования метода MX6, представляющего собой форму сжатия размера модели путём снижения её точности. В свою очередь, поиск сетевой архитектуры представляет собой процесс автоматизации проектирования нейронных сетей для конкретных задач с целью повышения их производительности. По словам Cerebras, сочетание этих методов способствует десятикратному повышению производительности на доллар.
Источник:





