|
Опрос
|
реклама
Быстрый переход
Развитие ИИ замедляется из-за переизбытка бесполезных данных — их слишком много
04.05.2026 [14:05],
Владимир Мироненко
Дальнейшее совершенствование ИИ-систем, которое обеспечит переход от ChatGPT к использованию человекоподобных роботов, зависит от качества данных, которые предоставляются этим системам для обучения, пишет ресурс Fortune. 
Источник изображения: Igor Omilaev/unsplash.com Ресурс отметил, что отрасль находится на пороге следующего рубежа ИИ — физического ИИ и моделей окружающего мира — систем, которые будут учиться и в конечном итоге работать в физическом мире. Для того чтобы они получили когнитивные способности, необходимые для навигации по дорогам, складывания белья или оказания помощи при сложных медицинских операциях, им требуются не просто данные, которые можно загрузить. Их обучение требует богатых и многогранных данных. И если исследователи не смогут остановить избыток ненужных данных — данных, которые не способствуют развитию модели, — весь потенциал физического ИИ и моделей окружающего мира может никогда не раскрыться в полной мере. Проблема заключается в том, что для создания новых, более совершенных ИИ-моделей требуется всё больше данных. На волне ажиотажа вокруг ИИ возникло множество ИИ-стартапов, таких, как Scale AI, Surge AI и Mercor, испытывающих ненасытную потребность в данных. Однако удовлетворение этой потребности привело к появлению огромного количества ненужных данных, которые на самом деле никак не способствуют развитию моделей ИИ, отметил Fortune. Обучение моделей пониманию сложного многомерного мира требует значительно больше данных — данных, которые также очень трудно получить. Инженеры по машинному обучению прибегают к моделированию данных, используя виртуальные реконструкции реальных сценариев для создания данных, которые будут использоваться для обучения роботов и беспилотных автомобилей. Использование некачественных данных при обучении ИИ-моделей может привести к непредсказуемым результатам. Как утверждает ресурс Fortune, OpenAI прекратила поддержку видеоприложения Sora из-за проблемы некачественных данных, поскольку её модель мира не обладала достаточным пониманием физики, что затрудняло реалистичные прогнозы. Для дальнейшего продвижения ИИ-специалистам, занимающимся машинным обучением, необходимы инструменты и технологии для удаления ненужных данных, которые анализируют, очищают, нормализуют и корректируют обучающие данные. Для достижения успеха в обучении потребуется извлечение ценных выводов и их отделение от ненужных данных. Теперь ограничивающим фактором стала нехватка качественных данных. Компании, которые первыми поймут это, создадут ИИ-системы, которые действительно будут работать, пишет Fortune. Китайские учёные научили робота играть в теннис новым методом обучения
19.03.2026 [14:30],
Владимир Мироненко
Китайские исследователи протестировали новый, гораздо более быстрый и простой метод обучения роботов игре в теннис, который, судя по результатам, можно считать прорывом в машинном обучении и реальном ИИ, сообщил ресурс New Atlas. 
Источник изображений: Zhang et al, Tsinghua university В теннисе, как и в большинстве других видов спорта, технологии захвата движений пока не могут считывать мельчайшие нюансы угла запястья при ударе по мячу, чтобы выполнять его с необходимой точностью. Ситуация на теннисном корте слишком динамична, чтобы использовать дистанционное управление, утверждают исследователи. По словам исследователей, попытки извлечения такой информации из многокамерных видеозаписей с помощью программного обеспечения для обучения ИИ, такого как Vid2Player3D от Nvidia, являются «сложным процессом», который «может потребовать значительных экспертных знаний и инженерных усилий». Вместо этого исследователи разработали систему LATENT, основанную на захвате движений, но только для базовых элементов техники и предназначенную для работы с неполными данными. В ходе текущего эксперимента исследователи использовали данные захвата движений за пять часов, в которых спортсмены демонстрировали «примитивные навыки» игры в теннис: удары справа и слева, боковые перемещения и перекрёстные шаги, выполняемые на площади, составляющей лишь часть стандартного теннисного корта. 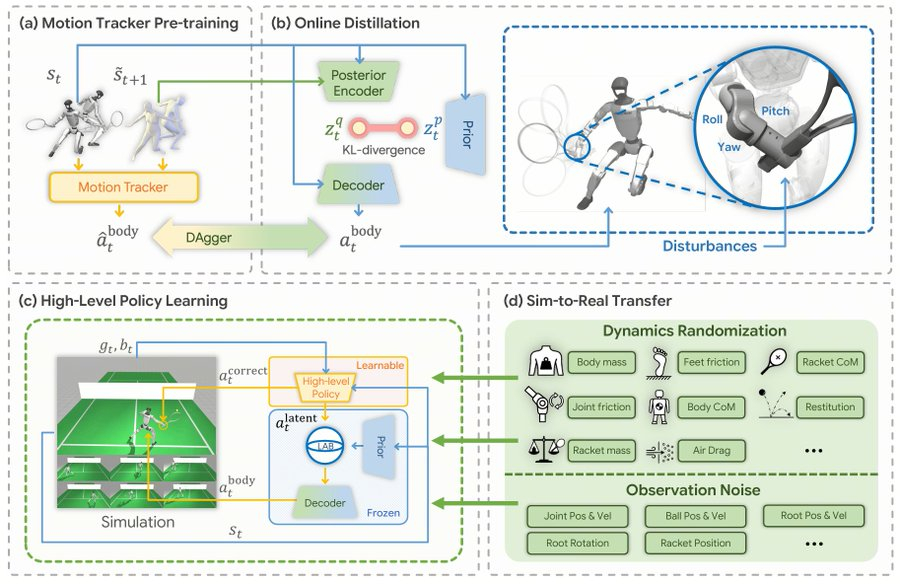 Исследователи обработали эти данные с помощью камер, чтобы создать репертуар человекоподобных «пространств движения», а затем загрузили эти базовые навыки в гуманоидного робота G1 от Unitree, доступного по цене $13,5 тыс. Используя базовые навыки, робот должен был с помощью системы LATENT выполнить поставленную задачу — увидеть приближающийся теннисный мяч и с помощью ракетки перебросить его через сетку: «Успех — это когда мяч приземлится на противоположной стороне корта в пределах площадки, ограниченной белыми линиями». Обладая базовыми навыками ударов по мячу, робот мог экспериментировать со всеми остальными деталями: углами, временем, выбором движений для различных ситуаций и моментами, когда следует выходить за рамки обученных движений. Подавляющая часть обучения проходила с очень высокой скоростью с использованием симуляции. В результате G1 успешно отбивал удары справа примерно в 90 % случаев и удары слева — чуть менее чем в 80 %, причём его движения выглядят ловкими и плавными, как у настоящего теннисиста. Конечно, робот пока не готов к соревновательным матчам, но вместе с тем он добился значительного прогресса в освоении игры. Хотя это не совсем та рутинная, монотонная работа, которую, как ожидается, роботы будут выполнять вместо людей, благодаря разработке китайских исследователей они смогут быстро обучаться управлять своим телом в экстремальных условиях и справляться со сложными и динамичными ситуациями, что будет полезно в более практических задачах. Программное обеспечение LATENT относится к категории open source и доступно на GitHub. Вековую «нерешаемую» задачу физики взломали с помощью ИИ — THOR ускорил расчёты в 400 раз
17.03.2026 [19:12],
Геннадий Детинич
Около 100 лет назад в зарождающейся физике элементарных частиц возникла проблема, которую, как оказалось, в принципе невозможно решить в разумное время. Речь идёт о решении конфигурационных интегралов, значения которых могли рассказать о термодинамических и механических свойствах материалов на атомном уровне. Неисчислимое множество частиц и условий настолько усложняли расчёты, что для них не хватило бы времени жизни Вселенной. И учёные решились на подлог. 
Источник изображения: ИИ-генерация Grok 4/3DNews Невозможность прямого решения задачи привела к появлению статистической физики и ряда моделей для симуляции поведения атомов в веществе (метод Монте-Карло и другие). Но даже самые совершенные модели заставляли суперкомпьютеры месяцами трудиться над, казалось бы, простыми задачами. Поэтому при использовании традиционных подходов часто жертвуют точностью ради скорости расчётов, особенно при моделировании реальных материалов в экстремальных условиях. Исследователи из Университета Нью-Мексико (The University of New Mexico) и Лос-Аламосской национальной лаборатории (Los Alamos National Laboratory) представили новый ИИ-фреймворк THOR (Tensors for High-dimensional Object Representation), который радикально меняет ситуацию при расчётах взаимодействия атомов в веществе. THOR сочетает современные тензорные сети с машинным обучением и таким подходом, как тензорная кросс-интерполяция (tensor train cross interpolation). Алгоритм разбивает многомерную задачу на последовательность более простых задач, а также автоматически учитывает кристаллические симметрии материала и тем самым существенно сокращает объём вычислений, сохраняя точность, близкую к классическим методам статистического моделирования. На отдельных примерах ускорение вычислений составило более чем в 400 раз. Метод был успешно протестирован на ряде реальных веществ: меди, кристаллическом аргоне под высоким давлением, фазовых переходах в олове и других материалах. Во всех случаях THOR воспроизвёл результаты высокоточных эталонных симуляций, ранее проведённых в Лос-Аламосской национальной лаборатории, но с кардинальным сокращением времени расчётов. Фреймворк демонстрирует универсальность: он применим как к простым системам, так и к сложным кристаллическим структурам, что открывает путь к прямым расчётам термодинамического и механического поведения материалов. Если инструмент будет взят на вооружение, а разработчики позаботились о том, чтобы THOR мог быть встроен в современные программы моделирования атомарной структуры материалов, то это может иметь огромное значение для материаловедения, физики твёрдого тела и химии. Станут возможны быстрые и точные предсказания свойств новых материалов, ускорится разработка сплавов, сверхпроводников, материалов для экстремальных условий и энергетики. Код THOR доступен на GitHub. Пользуйтесь. Роскомнадзор создаст ИИ для фильтрации интернет-трафика и борьбы с VPN за 2,27 млрд рублей
19.01.2026 [07:46],
Владимир Фетисов
В этом году Роскомнадзор (РКН) планирует разработать и запустить в эксплуатацию механизм фильтрации интернет-трафика с помощью технологий машинного обучения. Для реализации этого плана регулятор намерен потратить 2,27 млрд рублей. Об этом пишет Forbes со ссылкой на план цифровизации РКН. 
Источник изображения: Tim van der Kuip / unsplash.com В сообщении сказано, что данный документ направлен в правительственную комиссию по цифровому развитию. В нём говорится о том, что новый инструмент фильтрации будет функционировать на базе уже работающих на сетях операторов технических средств противодействия угрозам (ТСПУ), обеспечивающих фильтрацию трафика по технологии Deep Packet Inspection (DPI). С помощью таких средств уже заблокировано свыше 1 млн ресурсов, а также ежедневно ограничивается доступ к примерно 5,5 тыс. сайтов. У РКН также есть специальный реестр, куда вносятся распространяющие запрещённую информацию сайты для последующей блокировки со стороны операторов. Эксперты считают, что использование ИИ-алгоритмов поможет РКН более эффективно выявлять и блокировать запрещённый трафик, а также VPN-сервисы. По мнению бизнес-консультанта по ИБ Positive Technologies Алексея Лукацкого, масштабирование технологии машинного обучения для анализа трафика и выявления угроз безопасности в масштабах Рунета позволяет выделить несколько вариантов расширения ТСПУ новыми возможностями. «Это выявление зашифрованного трафика или просто методов обхода блокировок ресурсов. Это важно в контексте курса РКН на блокировку VPN-сервисов. А также обнаружение DDoS-атак и выявление взаимодействия с командными серверами ботнетов и иных вредоносных инфраструктур, используемых кибермошенниками. Кроме того, можно классифицировать веб-приложения, находя те, которые запрещены в России (например, различные мессенджеры), и отличать стриминговый трафик от скачивания контента, что позволит выявлять пиратские ресурсы», — считает Лукацкий. Он также добавил, что технологии машинного обучения позволят реализовать более «прицельное» воздействие на сети. Речь, например, о «деградации» конкретного типа трафика вместо «ковровых» мер. «Машинное обучение в DPI — это способ лучше “угадывать, что за трафик”, когда классические методы обнаружения по сигнатурам, портам и т.п. уже не помогают», — добавил Лукацкий. Представитель организации RKS-Global сообщил, что инструменты машинного обучения на ТСПУ могут быть задействованы для создания и автоматического применения правил фильтрации. К примеру, для поиска и блокировки VPN-сервисов. Такие инструменты также позволят осуществлять поиск по текстам на разных языках, по изображениям и видео. «Так, Китай уже вовсю использует ИИ в мониторинге интернета», — отметил представитель RKS-Global. Qualcomm вернулась в большие вычисления: представлены ИИ-ускорители AI200 и AI250 для дата-центров
27.10.2025 [23:13],
Николай Хижняк
Компания Qualcomm анонсировала два ускорителя ИИ-инференса (запуска уже обученных больших языковых моделей) — AI200 и AI250, которые выйдут на рынок в 2026 и 2027 годах. Новинки должны составить конкуренцию стоечным решениям AMD и Nvidia, предложив повышенную эффективность и более низкие эксплуатационные расходы при выполнении масштабных задач генеративного ИИ. 
Источник изображений: Qualcomm Оба ускорителя — Qualcomm AI200 и AI250 — основаны на нейронных процессорах (NPU) Qualcomm Hexagon, адаптированных для задач ИИ в центрах обработки данных. В последние годы компания постепенно совершенствовала свои нейропроцессоры Hexagon, поэтому последние версии чипов уже оснащены скалярными, векторными и тензорными ускорителями (в конфигурации 12+8+1). Они поддерживают такие форматы данных, как INT2, INT4, INT8, INT16, FP8, FP16, микротайловый вывод для сокращения трафика памяти, 64-битную адресацию памяти, виртуализацию и шифрование моделей Gen AI для дополнительной безопасности. Ускорители AI200 представляют собой первую систему логического вывода для ЦОД от Qualcomm и предлагают до 768 Гбайт встроенной памяти LPDDR. Система будет использовать интерфейсы PCIe для вертикального масштабирования и Ethernet — для горизонтального. Расчётная мощность стойки с ускорителями Qualcomm AI200 составляет 160 кВт. Система предполагает использование прямого жидкостного охлаждения. Для Qualcomm AI200 также заявлена поддержка конфиденциальных вычислений для корпоративных развертываний. Решение станет доступно в 2026 году.  Qualcomm AI250, выпуск которого состоится годом позже дебютирует с новой архитектурой памяти, которая обеспечит увеличение пропускной способности более чем в 10 раз. Кроме того, система будет поддерживать возможность дезагрегированного логического вывода, что позволит динамически распределять ресурсы памяти между картами. Qualcomm позиционирует его как более эффективное решение с высокой пропускной способностью, оптимизированное для крупных ИИ-моделей трансформеров. При этом система сохранит те же характеристики теплопередачи, охлаждения, безопасности и масштабируемости, что и AI200. Помимо разработки аппаратных платформ, Qualcomm также сообщила о разработке гипермасштабируемой сквозной программной платформы, оптимизированной для крупномасштабных задач логического вывода. Платформа поддерживает основные наборы инструментов машинного обучения и генеративного ИИ, включая PyTorch, ONNX, vLLM, LangChain и CrewAI, обеспечивая при этом беспроблемное развертывание моделей. Программный стек будет поддерживать дезагрегированное обслуживание, конфиденциальные вычисления и подключение предварительно обученных моделей «одним щелчком мыши», заявляет компания. Частоту сердечного ритма измерили Wi-Fi-сигналом
06.09.2025 [11:24],
Павел Котов
Группа молодых исследователей Калифорнийского университета в Санта-Кларе во главе с профессором информатики и вычислительной техники Катей Обрачкой (Katia Obraczka) разработали систему Pulse-Fi, которая при помощи анализа сигнала Wi-Fi производит бесконтактный замер частоты сердечных сокращений у человека. 
Источник изображения: ucsc.edu Для работы системы они предложили обрабатывать данные беспроводного микроконтроллера ESP32 при помощи алгоритма машинного обучения, который, проведя анализ искажений сигнала Wi-Fi в течение пяти секунд, действительно стал выдавать оценки частоты сердечных сокращений у человека с погрешностью около половины удара в минуту. При более длительном наблюдении и использовании более мощного оборудования с Wi-Fi погрешность удалось снизить. Система Pulse-Fi выполняет свою функцию на расстоянии около 3 м от устройства, то есть не требует прямого контакта с телом человека. Систему испытали на 118 добровольцах и 17 положениях тела — авторы проекта установили что она не требует особых условий применения: можно лежать, сидеть и ходить, не опасаясь, что точность результатов снизится. Важнейшим достоинством проекта является низкая цена используемого оборудования — учёные уложились в диапазон от $5 до $10. Платформы класса Raspberry Pi демонстрируют ещё более высокую точность и при цене $30 представляются достаточно доступными для массового применения. На выходе получаются данные, точность которых сравнима с точностью используемых большинством врачей пульсоксиметров — они замеряют частоту сердечных сокращений и насыщение крови кислородом, но требуют прямого контакта и обычно надеваются на палец. Сейчас авторы проекта Pulse-Fi пытаются построить систему для измерения частоты дыхания. Она поможет выявлять апноэ во сне, для работы с которым обычно приходится пользоваться портативным монитором, который нужно носить с собой. Если исследователи смогут решить и эту задачу на основе анализа беспроводного сигнала, то обнаружение и диагностика данного синдрома станут удобнее и проще. В Китае создали ИИ, который сам проектирует процессоры не хуже людей
12.06.2025 [21:04],
Николай Хижняк
Исследователи Китайской государственной лаборатории по разработке процессоров и Исследовательского центра интеллектуального программного обеспечения сообщили о создании ИИ-платформы для автоматизированной разработки микросхем. Проект с открытым исходным кодом QiMeng использует большие языковые модели (LLM) для «полностью автоматизированного проектирования аппаратного и программного обеспечения», а также может применяться для проектирования «целых CPU». 
Источник изображений: Китайская академия наук По словам разработчиков, чипы, разработанные QiMeng, соответствуют производительности и эффективности тех микросхем, которые были созданы экспертами-людьми. На базе QiMeng исследователи в качестве примера уже спроектировали два процессора: QiMeng-CPU-v1, сопоставимый по возможностям с Intel 486; и QiMeng-CPU-v2, который, как утверждается, может конкурировать с чипами на Arm Cortex-A53. Стоит отметить, что разница между этими продуктами составляет 26 лет. Чип Intel 486 был представлен в 1986 году, а Arm Cortex-A53 — в 2012-м.  QiMeng состоит из трёх взаимосвязанных слоёв: в основе лежит доменно-специфическая модель большого процессорного чипа; в середине — агент проектирования аппаратного и программного обеспечения; верхним слоем выступают различные приложения для проектирования процессорных чипов. Все три слоя работают в тандеме, обеспечивая такие функции, как автоматизированное front-end-проектирование микросхем, генерация языка описания оборудования, оптимизация конфигурации операционной системы и проектирование цепочки инструментов компилятора. По словам разработчиков платформы, QiMeng может за несколько дней сделать то, на что у команд, состоящих из людей-инженеров, уйдут недели работы. 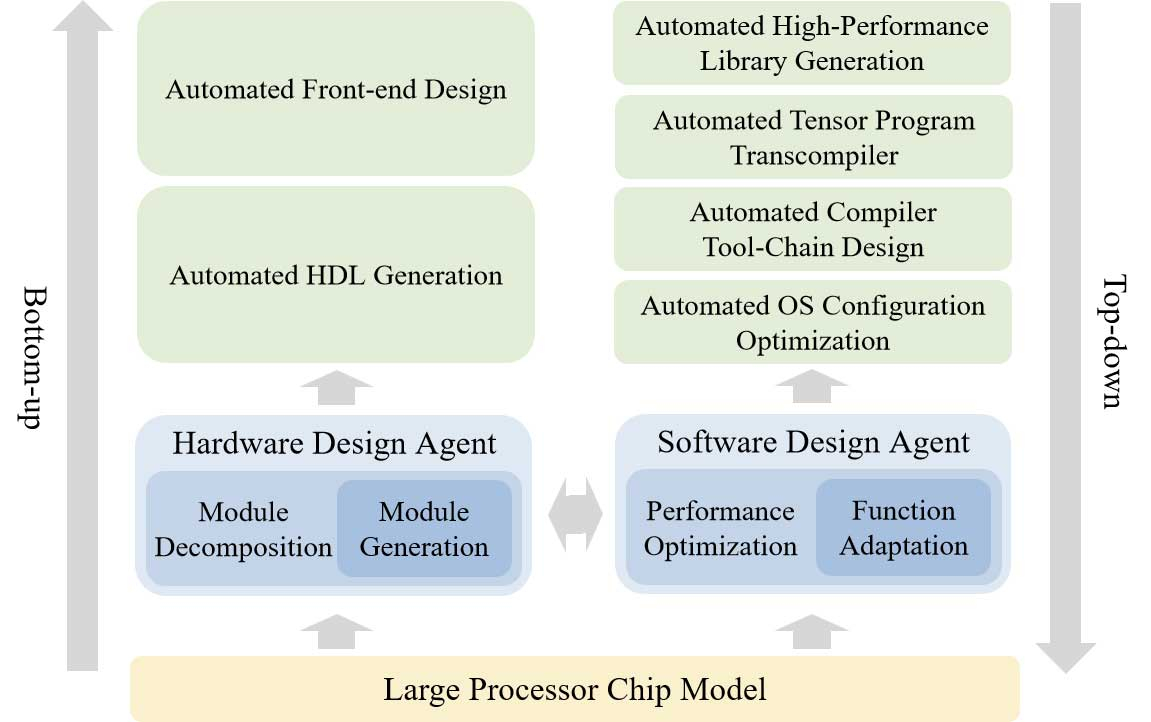 В опубликованной статье, описывающей особенности платформы QiMeng, её разработчики также освещают проблемы, с которыми приходится сталкиваться при текущем проектировании чипов, включая «ограниченную технологию изготовления, ограниченные ресурсы и разнообразную экосистему». QiMeng же стремится автоматизировать весь процесс проектирования и проверки чипов. По словам разработчиков, цель заключалась в повышении эффективности, снижении затрат и сокращении циклов разработки по сравнению с ручными методами проектирования микросхем, а также в содействии быстрой настройке архитектур микросхем и программных стеков, специфичных для конкретной области.  Как пишет Tom’s Hardware, крупные западные технологические компании, занимающиеся проектированием микросхем, такие как Cadence и Synopsys, тоже активно внедряют ИИ в процессы создания чипов. Например, Cadence использует несколько ИИ-платформ для ключевых этапов проектирования и проверки. В свою очередь, ИИ-платформа DSO.ai от Synopsys, по последним подсчётам, помогла с разработкой более 200 проектов микросхем. Анонс платформы QiMeng произошёл на фоне давления властей США на ведущих поставщиков программного обеспечения для автоматизации проектирования электроники (EDA), чтобы те прекратили продажу инструментов для проектирования микросхем в Китай, что ещё больше усложнило задачу Пекина по укреплению своей полупроводниковой промышленности. Разработчики QiMeng отмечают, что Китай должен отреагировать, поскольку технология проектирования чипов является «стратегически важной отраслью». Издание South China Morning Post со ссылкой на данные последнего анализа Morgan Stanley сообщает, что на долю Cadence Design Systems, Synopsys и Siemens EDA в прошлом году пришлось в общей сложности 82 % выручки на китайском рынке EDA. Google представила рассуждающую ИИ-модель Gemini 2.5 Flash с высокой производительностью и эффективностью
09.04.2025 [17:46],
Николай Хижняк
Google выпустила новую ИИ-модель, призванную обеспечить высокую производительность с упором на эффективность. Она называется Gemini 2.5 Flash и вскоре станет доступна в составе платформы Vertex AI облака Google Cloud для развёртывания и управления моделями искусственного интеллекта (ИИ). 
Источник изображения: Google Компания отмечает, что Gemini 2.5 Flash предлагает «динамические и контролируемые» вычисления, позволяя разработчикам регулировать время обработки запроса в зависимости от их сложности. «Вы можете настроить скорость, точность и баланс затрат для ваших конкретных нужд. Эта гибкость является ключом к оптимизации производительности Flash в высоконагруженных и чувствительных к затратам приложениях», — написала компания в своём официальном блоге. На фоне растущей стоимости использования флагманских ИИ-моделей Gemini 2.5 Flash может оказаться крайней полезной. Более дешёвые и производительные модели, такие как 2.5 Flash, представляют собой привлекательную альтернативу дорогостоящим флагманским вариантам, но ценой потери некоторой точности. Gemini 2.5 Flash — это «рассуждающая» модель по типу o3-mini от OpenAI и R1 от DeepSeek. Это означает, что для проверки фактов ей требуется немного больше времени, чтобы ответить на запросы. Google утверждает, что 2.5 Flash идеально подходит для работы с большими объёмами данных и использования в реальном времени, в частности, для таких задач, как обслуживание клиентов и анализ документов. «Эта рабочая модель оптимизирована специально для низкой задержки и снижения затрат. Это идеальный движок для отзывчивых виртуальных помощников и инструментов резюмирования в реальном времени, где эффективность при масштабировании является ключевым фактором», — описывает новую ИИ-модель компания. Google не опубликовала отчёт по безопасности или техническим характеристикам для Gemini 2.5 Flash, что усложнило задачу определения её преимуществ и недостатков. Ранее компания говорила, что не публикует отчёты для моделей, которые она считает экспериментальными. Google также объявила, что с третьего квартала планирует интегрировать модели Gemini, такие как 2.5 Flash в локальные среды. Они будут доступны в Google Distributed Cloud (GDC), локальном решении Google для клиентов со строгими требованиями к управлению данными. В компании добавили, что работают с Nvidia над установкой Gemini на совместимые с GDC системы Nvidia Blackwell, которые клиенты смогут приобрести через Google или по своим каналам. Google представила свой самый мощный ИИ-процессор Ironwood — до 4,6 квадриллиона операций в секунду
09.04.2025 [15:56],
Николай Хижняк
В рамках конференции Cloud Next на этой неделе компания Google представила новый специализированный ИИ-чип Ironwood. Это уже седьмое поколение ИИ-процессоров компании и первый TPU, оптимизированный для инференса — работы уже обученных ИИ-моделей. Процессор будет использоваться в Google Cloud и поставляться в системах двух конфигураций: серверах из 256 таких процессоров и кластеров из 9216 таких чипов. 
Источник изображений: Google «Ironwood — это наш самый мощный, самый производительный и самый энергоэффективный TPU. Он разработан для ускорения инференса ИИ-моделей в масштабах облачной инфраструктуры», — прокомментировал анонс процессора вице-президент Google Cloud Амин Вахдат (Amin Vahdat). Анонс Ironwood состоялся на фоне усиливающейся конкуренции в сегменте разработок проприетарных ИИ-ускорителей. Хотя Nvidia доминирует на этом рынке, свои технологические решения также продвигают Amazon и Microsoft. Первая разработала ИИ-процессоры Trainium, Inferentia и Graviton, которые используются в её облачной инфраструктуре AWS, а Microsoft применяет собственные ИИ-чипы Cobalt 100 в облачных инстансах Azure.  Google заявляет, что Ironwood обладает пиковой вычислительной производительностью 4614 Тфлопс или 4614 триллионов операций в секунду. Таким образом кластер из 9216 таких чипов предложит производительность в 42,5 Экзафлопс. 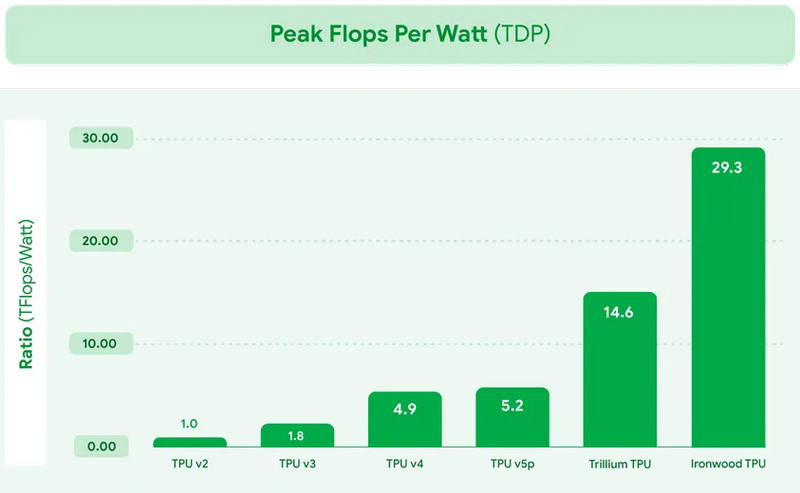 Каждый процессор оснащён 192 Гбайт выделенной оперативной памяти с пропускной способностью 7,4 Тбит/с. Также чип включает усовершенствованное специализированное ядро SparseCore для обработки типов данных, распространённых в рабочих нагрузках «расширенного ранжирования» и «рекомендательных систем» (например, алгоритм, предлагающий одежду, которая может вам понравиться). Архитектура TPU оптимизирована для минимизации перемещения данных и задержек, что, по утверждению Google, приводит к значительной экономии энергии. Компания планирует использовать Ironwood в своём модульном вычислительном кластере AI Hypercomputer в составе Google Cloud. ChatGPT потребляет не так много энергии, как считалось ранее, показало новое исследование
13.02.2025 [07:24],
Николай Хижняк
Согласно более ранним оценкам, ChatGPT потребляет около 3 Вт·ч энергии для ответа на один запрос, что в 10 раз больше средней мощности, необходимой при использовании поиска Google. Однако свежий отчёт исследовательского института Epoch AI, занимающегося изучением ключевых трендов и вопросов, которые будут определять траекторию развития и управление искусственным интеллектом, опровергает эту статистику и указывает на то, что энергозатраты чат-бота OpenAI значительно меньше, чем предполагалось ранее. 
Источник изображения: OpenAI В отчёте Epoch AI говорится, что ChatGPT на базе модели GPT-4o потребляет всего 0,3 Вт·ч энергии при генерации ответа. В разговоре с порталом TechCrunch дата-аналитик Epoch AI Джошуа Ю (Joshua You) отметил: «Потребление энергии на самом деле не так уж и велико по сравнению с использованием обычных бытовых приборов, отоплением или охлаждением дома или использованием автомобиля». 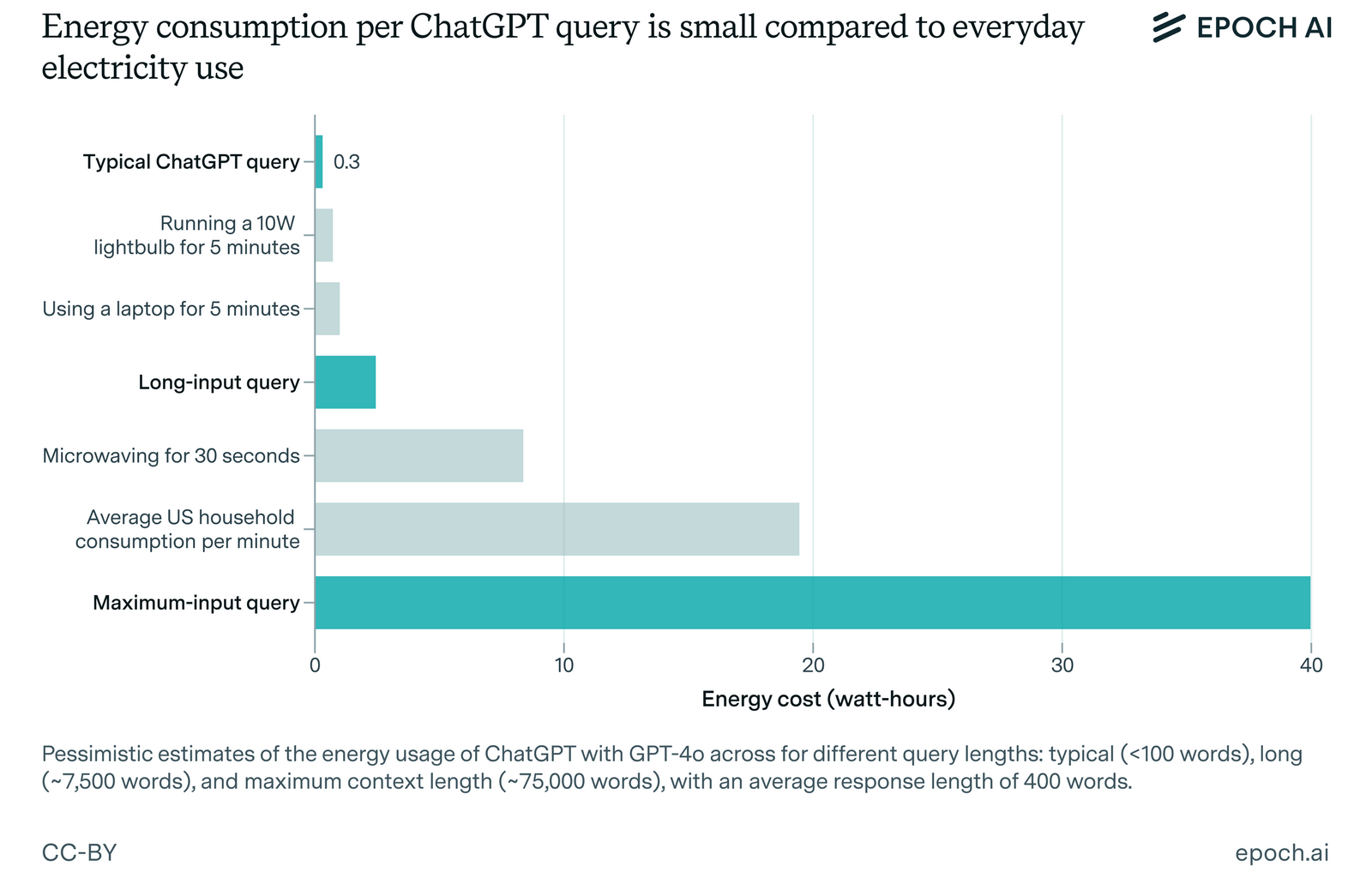 По словам эксперта, предыдущие оценки энергозатрат ChatGPT были основаны на устаревших данных. Специалист отмечает, что предполагаемая «универсальная» статистика энергопотребления ChatGPT была основана на предположении, что OpenAI для запуска и работы ИИ использует старые и неэффективные чипы. «Кроме того, некоторые из моих коллег обратили внимание, что наиболее широко распространённая оценка в 3 Вт·ч на выполнение запроса была основана на довольно старых исследованиях. И если судить по каким-то приблизительным расчётам, эта статистика показалась слишком завышенной», — добавил Ю. И всё же следует добавить, что оценку энергозатрат ChatGPT от Epoch AI тоже нельзя считать непреложной, поскольку она не учитывает некоторые ключевые возможности ИИ, такие как генерация изображений чат-ботом. По словам эксперта, он не ожидает роста энергопотребления у ChatGPT, но по мере того, как ИИ-модели становятся более продвинутыми, им будет требоваться больше энергии для работы. Ведущие компании по разработке ИИ, включая OpenAI, склоняются к развитию так называемых рассуждающих моделей ИИ, которые не просто дают ответ на поставленный вопрос, но также описывают весь процесс, который привёл к получению того или иного ответа, что в свою очередь требует больших энергозатрат. Множество отчётов последних лет показывают, что такие технологии, как Microsoft Copilot и ChatGPT (а точнее оборудование, на котором они работают) потребляют эквивалент объёма одной бутылки воды для охлаждения при генерации ответа на запрос. Эти выводы следуют за более ранним отчётом, в котором говорится, что совокупные энергозатраты Microsoft и Google превышают потребление электроэнергии более чем в 100 странах мира. В одном из наиболее свежих исследований подробно описывалось, что модель OpenAI GPT-3 потребляет в четыре раза больше воды, чем считалось ранее, в то время как GPT-4 потребляет объёмы до трёх бутылок воды, чтобы сгенерировать всего лишь 100 слов. Вполне очевидно, что модели ИИ начинают потреблять больше ресурсов по мере того, как становятся более продвинутыми. Однако, выводы последнего исследования показывают, что тот же ChatGPT может быть не таким прожорливым, как считалось ранее. Boston Dynamics обучит робота-гуманоида Atlas таскать тяжести и динамически бегать
06.02.2025 [11:35],
Владимир Мироненко
Boston Dynamics объявила о заключении соглашения о сотрудничестве с Институтом робототехники и искусственного интеллекта (Robotics and AI Institute), ранее известным как Институт ИИ Boston Dynamics (Boston Dynamics AI Institute), с целью обучения с подкреплением электрического человекоподобного робота Atlas. 
Источник изображения: Boston Dynamics Обе организации были основаны Марком Райбертом (Marc Raibert), бывшим профессором Массачусетского технологического института, который в течение 30 лет занимал пост генерального директора Boston Dynamics. Институт робототехники и ИИ был создан им в 2020 году. Обе организации связаны с Hyundai: корейский автопроизводитель приобрёл Boston Dynamics в 2021 году и также финансирует институт. В рамках сотрудничества Boston Dynamics и институт сосредоточатся на обучении Atlas с подкреплением — одном из способов машинного обучения, который работает путём проб и ошибок, подобно тому, как учатся люди и животные. Обучение с подкреплением всегда было чрезвычайно трудоёмким процессом, однако создание эффективной симуляции позволило выполнять многие процессы одновременно в виртуальной среде, отметил ресурс TechCrunch. Это один из последних совместных проектов Boston Dynamics и института. Ранее они уже работали над созданием исследовательского комплекта для обучения с подкреплением четвероногого робота Spot от Boston Dynamics. В случае с Atlas учёные займутся обучением робота навыкам «динамического бега и манипулирования тяжёлыми предметами». Трещины на дорогах будут затягиваться сами собой: ИИ помог создать асфальт со способностью к регенерации
03.02.2025 [13:57],
Владимир Мироненко
Исследователи из Королевского колледжа Лондона и Университета Суонси (Уэльс, Великобритания) в сотрудничестве с учеными из Чили, а также Google Cloud разработали новый тип асфальта, который способен со временем самостоятельно «заживлять» образовавшиеся трещины, устраняя необходимость в использовании ручного труда для их ремонта, сообщается в блоге Google. 
Источник изображения: Google Причины образования трещин в асфальте пока не изучены полностью, но одной из частых причин является чрезмерное затвердевание в связи с окислением битума, который входит в состав асфальта. Ученые занимаются разработкой способов обратить этот процесс вспять, чтобы привести асфальт в прежнее рабочее состояние. Для изучения органических молекул веществ со сложным химическим составом, таких как битум, команда учёных использовала машинное обучение. Была разработана новая модель на основе собранных данных для ускорения атомистического моделирования, что позволило значительно продвинуться в исследовании процессов окисления битума и образования трещин. Этот подход значительно быстрее и экономичнее традиционных вычислительных моделей, отмечено в блоге Google. В сотрудничестве с Google Cloud учёные работали над созданием инструментов ИИ, которые позволяют определять химические свойства и создавать виртуальные молекулы, предназначенные для определенных целей, аналогично методам, используемым при открытии лекарств. Эксперт по вычислительной химии, доктор Франциско Мартин-Мартинес (Francisco Martin-Martinez) отметил значительный вклад Google Cloud в создание инструментов ИИ для быстрой разработки самовосстанавливающихся дорожных покрытий, подчеркнув, что подражание природе в её способности к самовосстановлению позволит продлить срок службы дорог и создать более устойчивую и надёжную дорожную инфраструктуру. Исследователи продемонстрировали в лабораторных экспериментах, как новый асфальтовый материал может залечить микротрещину менее чем за час. Чтобы получить битум со способностью к устранению трещин, исследователи добавили в него крошечные пористые споры растений, пропитанные переработанными маслами. Когда дорожное покрытие сжимается при движении транспорта, споры выдавливаются, и масло попадает в близлежащие трещины, размягчая битум настолько, что он может заполнять трещины. Исследователи полагают, что через пару лет они выйдут на этап коммерческого выпуска нового материала для использования на дорогах Великобритании. Nvidia научит старые видеокарты GeForce повышать FPS с помощью ИИ, но потом
20.01.2025 [17:56],
Николай Хижняк
В интервью Digital Foundry Брайан Катандзаро (Bryan Catanzaro), вице-президент по исследованиям в области прикладного глубокого обучения в Nvidia сообщил, что не исключает возможности в будущем внедрения функции генерации кадров силами ИИ для повышения FPS, ставшей частью технологии DLSS, в старые видеокарты Nvidia GeForce. 
Источник изображений: Digital Foundry / Nvidia С момента своего дебюта в 2018 году технология масштабирования с глубоким обучением (DLSS) от Nvidia эволюционировала уже до четвёртой версии. Её последняя итерация перешла на ИИ-модель типа трансформер, что позволило реализовать ряд новых функций, включая мультикадровую генерацию (Multi Frame Generation, MFG). Последняя позволяет создавать до трёх дополнительных кадров на каждый традиционно отрисованный кадр для повышения FPS.  Nvidia смогла реализовать некоторые новые технологии, включая реконструкцию лучей (DLSS Ray Reconstruction), супер-разрешение (Super Resolution) и технологию сглаживания, опирающуюся на искусственный интеллект (Deep Learning Anti-Aliasing, DLAA) на всех видеокартах GeForce RTX, начиная с 20-й серии. Однако генератор кадров (Frame Generation) первого поколения, изначально представленный как эксклюзивная функция видеокарт GeForce RTX 40-й серии, не поддерживается моделями GeForce RTX 30-й и RTX 20-й серий. Новый мультикадровый генератор так и вовсе изначально заявлен только для новейших GeForce RTX 5000. В разговоре с журналистами Брайан Катандзаро отметил, что не исключает появления функции генерации кадров у старых моделей видеокарт Nvidia. «Я думаю, что ключевым здесь является вопрос проектирования и оптимизации, а также конечного пользовательского опыта. Мы запускаем этот генератор кадров, лучший генератор кадров, коим является технология Multi Frame Generation, с видеокартами 50-й серии. А в будущем посмотрим, сможем ли что-то выжать для старого поколения оборудования», — прокомментировал представитель Nvidia. 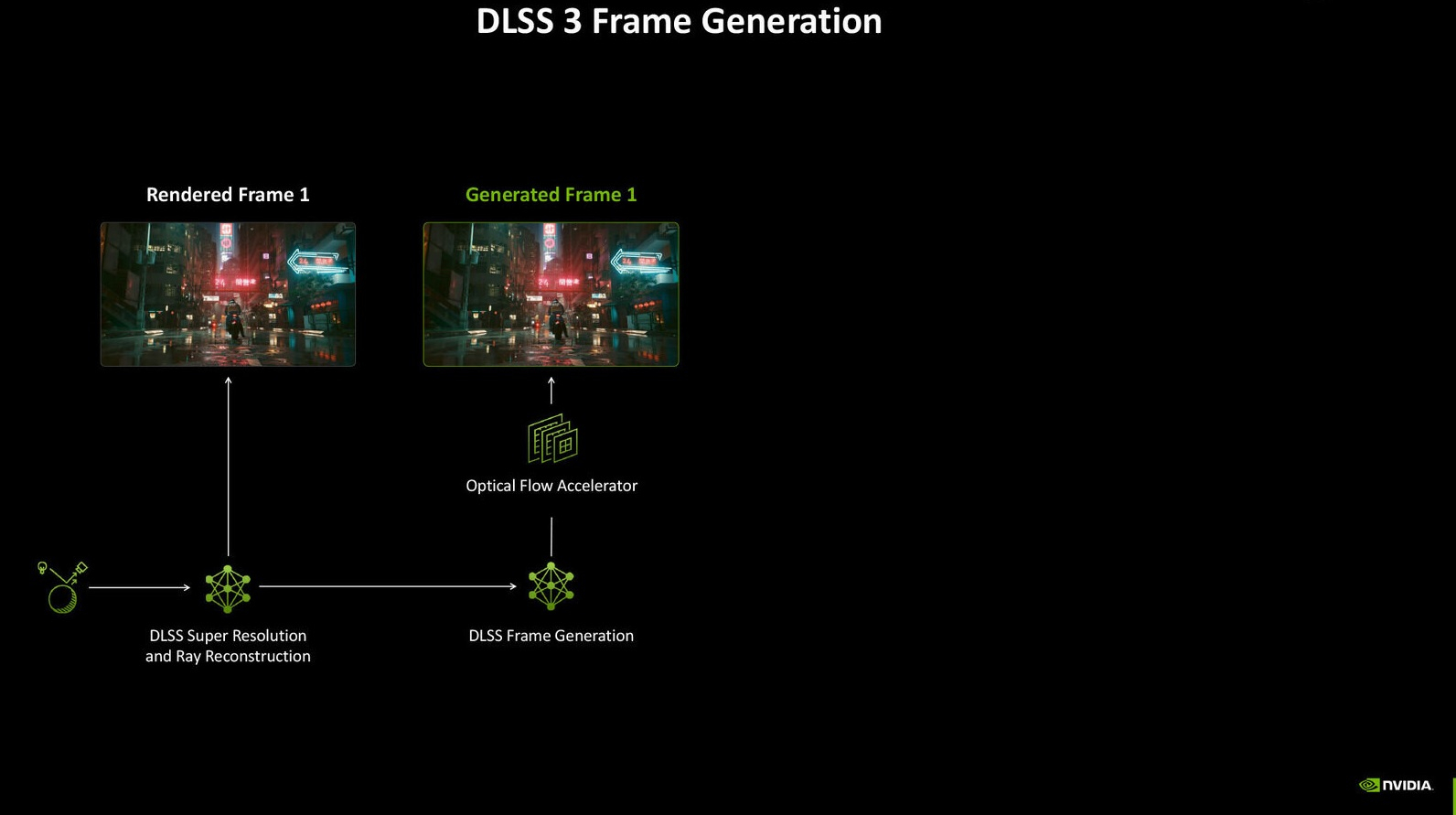 На фоне заявления Катандзаро можно предположить, что первая версия генератора кадров может в перспективе появиться на видеокартах GeForce RTX 30-й серии. Однако маловероятно, что она появится у моделей GeForce RTX 20-й серии. При этом, скорее всего, мультикадровый генератор кадров останется эксклюзивом видеокарт RTX 50-й серии, поскольку для его работы требуется значительно больше вычислительной мощности, заточенной под ИИ, которую у этих карт обеспечивают новые тензорные ядра. Один из ведущих разработчиков Nvidia также поделился некоторой информацией о разработке DLSS. «Когда мы создавали Nvidia DLSS 3 Frame Generation, нам было абсолютно необходимо аппаратное ускорение для вычислений Optical Flow. Но у нас не было достаточного количества тензорных ядер и не было достаточно хорошего алгоритма Optical Flow. Мы не создавали алгоритм Optical Flow для работы в реальном времени на тензорных ядрах, который мог бы вписаться в наш запас вычислительной мощности. У нас был аппаратный ускоритель Optical Flow, который Nvidia создавала годами как эволюцию нашей технологии видеокодирования. Он также был частью нашей технологии ускорения работы компьютерного зрения для беспилотных автомобилей. Казалось бы, для нас имело смысл использовать его и для Nvidia DLSS 3 Frame Generation. Но сложность в любой аппаратной реализации алгоритма типа Optical Flow заключается в том, что его действительно трудно улучшить. Он такой, какой он есть, и те сбои, которые возникли из-за этого аппаратного Optical Flow, мы не могли исправить с помощью более умной нейронной сети, пока не решили просто заменить его и перейти на решение, полностью основанное на ИИ. Именно это мы и сделали для Frame Generation в DLSS 4». Сильный ИИ не станет спасением для человечества — придётся ждать сверхинтеллект, считает глава OpenAI
05.12.2024 [00:02],
Николай Хижняк
Около двух лет назад OpenAI заявила, что искусственный интеллект общего назначения (Artificial General Intelligence, AGI), который также называнию сильным ИИ или ИИ уровня человека, «может возвысить человечество» и «предоставить всем невероятные новые возможности». Теперь же генеральный директор OpenAI Сэм Альтман (Sam Altman) пытается снизить градус ожидания от появления AGI. 
Источник изображения: OpenAI Forum «Я предполагаю, что мы достигнем AGI раньше, чем думает большинство людей в мире, и это будет иметь гораздо меньшее значение. И многие опасения по поводу безопасности, о которых говорили мы и другие стороны, на самом деле не возникнут в момент создания AGI. AGI можно создать. Мир после этого будет в основном развивается примерно так же, как и сейчас. Некоторые вещи начнут выполняться быстрее. Но переход от того, что мы называем AGI, до того, что мы называем сверхинтеллектом — это очень долгая дорога», — сказал Альтман во время интервью на саммите The New York Times DealBook в среду. Альтман уже не первый раз преуменьшает значимость, казалось бы, теперь точно неизбежного создания искусственного интеллекта общего назначения, о котором когда-то говорилось в уставе самой компании OpenAI, и который, как она же заявляла, сможет «автоматизировать большую часть интеллектуального труда» человечества. Недавно глава OpenAI намекнул, что это может произойти уже в 2025 году и будет достижимо с помощью актуального специализированного программного и аппаратного обеспечения. Ходят слухи, что OpenAI просто объединит все свои большие языковые модели и назовёт это AGI. Последующее заявление Альтмана об AGI прозвучало так, как будто OpenAI больше не рассматривает создание искусственного интеллекта общего назначения как нечто грандиозное, что способно решить все проблемы человечества: «Мне кажется, что экономические трудности в мире будут продолжаться немного дольше времени, чем думают люди, потому что в обществе много инерции. Поэтому в первые пару лет [после создания AGI], возможно, будет не так много изменений. А потом, возможно, последует много изменений». Те надежды и возможные достижения, которые OpenAI ранее приписывала AGI, компания теперь возлагает на так называемый «сверхинтеллект», который как недавно спрогнозировал Альтман, может появиться «через несколько тысяч дней». Искусственный интеллект научили разоблачать учёных-шарлатанов
27.11.2024 [18:56],
Геннадий Детинич
Научный поиск вскоре может претерпеть коренные изменения — искусственный интеллект показал себя в качестве непревзойдённого человеком инструмента для анализа невообразимых объёмов специальной литературы. В поставленном эксперименте ИИ смог точнее людей-экспертов дать оценку фейковым и настоящим научным открытиям. Это облегчит людям научный поиск, позволив машинам просеивать тонны сырой информации в поисках перспективных направлений. 
Источник изображения: ИИ-генерация Кандинский 3.1/3DNews С самого начала разработчики генеративных ИИ (ChatGPT и прочих) сосредоточились на возможности больших языковых моделей (LLM) отвечать на вопросы, обобщая обширные данные, на которых они обучались. Учёные из Университетского колледжа Лондона (UCL) поставили перед собой другую цель. Они задались вопросом, могут ли LLM синтезировать знания — извлекать закономерности из научной литературы и использовать их для анализа новых научных работ? Как показал опыт, ИИ удалось превзойти людей в точности выдачи оценок рецензируемым работам. «Научный прогресс часто основывается на методе проб и ошибок, но каждый тщательный эксперимент требует времени и ресурсов. Даже самые опытные исследователи могут упускать из виду важные выводы из литературы. Наша работа исследует, могут ли LLM выявлять закономерности в обширных научных текстах и прогнозировать результаты экспериментов», — поясняют авторы работы. Нетрудно представить, что привлечение ИИ к рецензированию далеко выйдет за пределы простого поиска знаний. Это может оказаться прорывом во всех областях науки, экономя учёным время и деньги. Эксперимент был поставлен на анализе пакета научных работ по нейробиологии, но может быть распространён на любые области науки. Исследователи подготовили множество пар рефератов, состоящих из одной настоящей научной работы и одной фейковой — содержащей правдоподобные, но неверные результаты и выводы. Пары документов были проанализированы 15 LLM общего назначения и 117 экспертами по неврологии человека, прошедшими специальный отбор. Все они должны были отделить настоящие работы от поддельных. Все LLM превзошли нейробиологов: точность ИИ в среднем составила 81 %, а точность людей — 63 %. В случае анализа работ лучшими среди экспертов-людей точность повышалась до 66 %, но даже близко не подбиралась к точности ИИ. А когда LLM специально обучили на базе данных по нейробиологии, точность предсказания повысилась до 86 %. Исследователи говорят, что это открытие прокладывает путь к будущему, в котором эксперты-люди смогут сотрудничать с хорошо откалиброванными моделями. Проделанная работа также показывает, что большинство новых открытий вовсе не новые. ИИ отлично вскрывает эту особенность современной науки. Благодаря новому инструменту учёные, по крайней мере, будут знать, стоит ли заниматься выбранным направлением для исследования или проще поискать его результаты в интернете. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



