|
Опрос
|
реклама
Быстрый переход
Каждый пятый ПК теперь оснащён ИИ-ускорителем, но люди покупают их не из-за этого
15.11.2024 [00:30],
Николай Хижняк
Поставки настольных и мобильных компьютеров с ускорителями для приложений искусственного интеллекта достигли 13,2 млн единиц в третьем квартале 2024 года, что составляет 20 % от всех поставок ПК за указанный период, по подсчётам агентства Canalys. Во втором квартале объём поставок таких компьютеров составлял 8,8 млн единиц. 
Источник изображения: Microsoft Сразу стоит отметить, что к «ИИ-совместимым» персональным компьютерам аналитики Canalys относят все настольные и мобильные компьютеры, оснащённые специализированным ИИ-ускорителем NPU или «его аналогом». Таким образом к данной категории относятся не только системы на Copilot+PC на новейших чипах AMD, Intel и Qualcomm, но и Windows-компьютеры на чипах Intel и AMD прошлого поколения, а также все Apple Mac на процессорах M-серии. 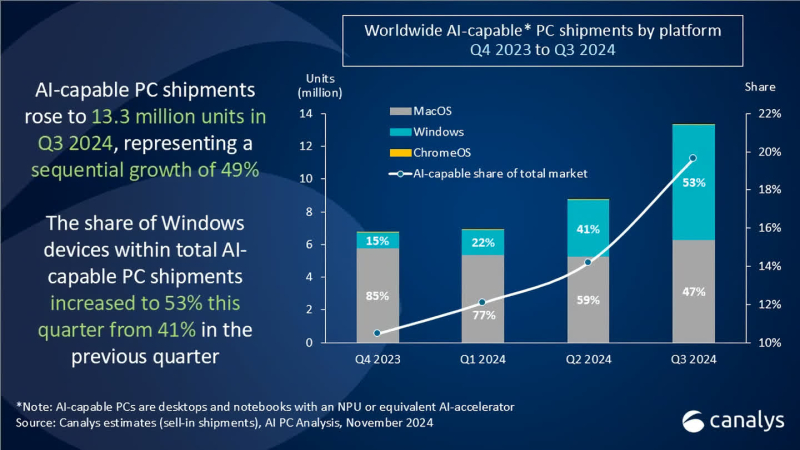
Источник изображения: Canalys Согласно свежему анализу Canalys, на системы с Windows пришлось более половины (53 %) поставок ПК с ИИ в третьем квартале, тогда как доля Apple снизилась до 47 %. Во втором квартале лидером являлась как раз компания Apple с 59 % поставок систем с поддержкой ИИ, тогда как на долю систем с Windows приходилось 41 % поставок. Несмотря на прогресс в развитии ПК с поддержкой ИИ производителям по-прежнему приходится убеждать покупателей в том, что покупка такой системы, а стоят они зачастую дороже, того стоит. Некоторые наблюдатели утверждают, что рост поставок таких компьютеров не обязательно связан с тем, что люди ищут именно ПК с ИИ. Просто многие современные системы изначально оснащены ИИ-ускорителем. 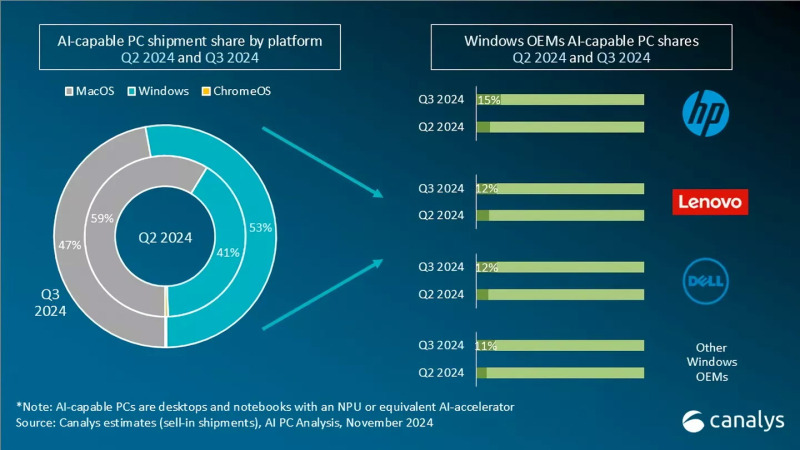
Источник изображения: Canalys Главный аналитик Canalys Ишан Датт (Ishan Dutt) рассказал, что проведённый в ноябре опрос компаний, занимающихся продажами компьютеров, показал, что 31 % не планирует продавать системы Copilot+PC в следующем году, а 34 % респондентов ожидают, что такие устройства составят менее десятой части от общего объёма продаж в 2025 году. Для получения заветного обозначения Copilot+PC компания Microsoft требует от производителей ПК, чтобы система оснащалась ИИ-движком (NPU), производительность которого составляет не менее 40 TOPS (триллионов операций в секунду). В любом случае поставки и продажи ИИ-совместимых ПК в ближайшие месяцы должны вырасти, поскольку до даты окончания поддержки Windows 10, не имеющей функции ИИ, осталось меньше года. По данным StatCounter, Windows 10 по-прежнему занимает более 60 % рынка настольных ПК на базе Windows во всём мире. С прекращением поддержки многие потребители перейдут на новые ПК с Windows 11 в 2025 году. The Beatles номинированы на «Грэмми» с песней, восстановленной с помощью искусственного интеллекта
10.11.2024 [05:26],
Анжелла Марина
Легендарные The Beatles вновь номинированы на музыкальную премию «Грэмми» спустя более 50 лет после распада группы. Их последняя песня «Now and Then», отреставрированная в прошлом году с помощью искусственного интеллекта, претендует на звание «Запись года» наряду с песенными хитами Билли Айлиш (Billie Eilish) и Тейлор Свифт (Taylor Swift). 
Источник изображения: Now And Then / YouTube Песня «Now and Then» была выпущена в ноябре 2023 года, но её история началась ещё в конце 1970-х годов. Тогда Джон Леннон (John Lennon) записал демоверсию этой композиции не в студийных условиях. Позднее запись, вместе с другими треками «Free As A Bird» и «Real Love», была передана оставшимся участникам группы в 1990-х годах для включения в проект The Beatles Anthology. Однако «Now and Then» так и не была завершена из-за технических ограничений того времени, которые не позволяли качественно отделить вокал Джона Леннона от инструментального сопровождения. Изменить ситуацию удалось только в 2021 году, когда режиссёр Питер Джексон (Peter Jackson) и его команда, снимавшие документальный фильм о «Битлз», использовали технологию машинного обучения. Это позволило ныне живущим Полу Маккартни (Paul McCartney) и Ринго Старру (Ringo Starr) завершить работу над песней, отделив голос от фортепиано и создав полноценный трек с сопровождением музыкальных инструментов. «Теперь, благодаря ИИ, мы смогли вернуть эту песню к жизни», — отметил Маккартни. Несмотря на то, что «Now and Then» была закончена с использованием искусственного интеллекта, она соответствует правилам «Грэмми» в отношении ИИ. Правила гласят, что «только люди имеют право быть номинированными или выиграть премию Grammy, но работы, содержащие элементы ИИ, имеют право участвовать в соответствующих категориях». Церемония «Грэмми» состоится 2 февраля 2025 года, а песне The Beatles придётся конкурировать с современными хитами известных артистов. «Больше, чем у кого-либо»: Цукерберг похвастался системой с более чем 100 тыс. Nvidia H100 — на ней обучается Llama 4
31.10.2024 [22:31],
Николай Хижняк
Среди американских IT-гигантов зародилась новая забава — соревнование, у кого больше кластеры и твёрже уверенность в превосходстве своих мощностей для обучения больших языковых моделей ИИ. Лишь недавно глава компании Tesla Илон Маск (Elon Musk) хвастался завершением сборки суперкомпьютера xAI Colossus со 100 тыс. ускорителей Nvidia H100 для обучения ИИ, как об использовании более 100 тыс. таких же ИИ-ускорителей сообщил глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg). 
Источник изображения: CNET/YouTube Глава Meta✴✴ отметил, что упомянутая система используется для обучения большой языковой модели нового поколения Llama 4. Эта LLM обучается «на кластере, в котором используется больше 100 000 графических ИИ-процессоров H100, и это больше, чем что-либо, что я видел в отчётах о том, что делают другие», — заявил Цукерберг. Он не поделился деталями о том, что именно уже умеет делать Llama 4. Однако, как пишет издание Wired со ссылкой на заявление главы Meta✴✴, их ИИ-модель обрела «новые модальности», «стала сильнее в рассуждениях» и «значительно быстрее». Этим комментарием Цукерберг явно хотел уколоть Маска, который ранее заявлял, что в составе его суперкластера xAI Colossus для обучения ИИ-модели Grok используются 100 тыс. ускорителей Nvidia H100. Позже Маск заявил, что количество ускорителей в xAI Colossus в перспективе будет увеличено втрое. Meta✴✴ также ранее заявила, что планирует получить до конца текущего года ИИ-ускорители, эквивалентные более чем полумиллиону H100. Таким образом, у компании Цукерберга уже имеется значительное количество оборудования для обучения своих ИИ-моделей, и будет ещё больше. Meta✴✴ использует уникальный подход к распространению своих моделей Llama — она предоставляет их полностью бесплатно, позволяя другим исследователям, компаниям и организациям создавать на их базе новые продукты. Это отличает её от тех же GPT-4o от OpenAI и Gemini от Google, доступных только через API. Однако Meta✴✴ всё же накладывает некоторые ограничения на лицензию Llama, например, на коммерческое использование. Кроме того, компания не сообщает, как именно обучаются её модели. В остальном модели Llama имеют природу «открытого исходного кода». С учётом заявленного количества используемых ускорителей для обучения ИИ-моделей возникает вопрос — сколько электричества всё это требует? Один специализированный ускоритель может съедать до 3,7 МВт·ч энергии в год. Это означает, что 100 тыс. таких ускорителей будут потреблять как минимум 370 ГВт·ч электроэнергии — как отмечается, достаточно для того, чтобы обеспечить энергией свыше 34 млн среднестатистических американских домохозяйств. Каким образом компании добывают всю эту энергию? По признанию самого Цукерберга, со временем сфера ИИ столкнётся с ограничением доступных энергетических мощностей. Компания Илона Маска, например, использует несколько огромных мобильных генераторов для питания суперкластера из 100 тыс. ускорителей, расположенных в здании площадью более 7000 м2 в Мемфисе, штат Теннесси. Та же Google может не достичь своих целевых показателей по выбросам углерода, поскольку с 2019 года увеличила выбросы парниковых газов своими дата-центрами на 48 %. На этом фоне бывший генеральный директор Google даже предложил США отказаться от поставленных климатических целей, позволив компаниям, занимающимся ИИ, работать на полную мощность, а затем использовать разработанные технологии ИИ для решения климатического кризиса. Meta✴✴ увильнула от ответа на вопрос о том, как компании удалось запитать такой гигантский вычислительный кластер. Необходимость в обеспечении растущего объёма используемой энергии для ИИ вынудила те же технологические гиганты Amazon, Oracle, Microsoft и Google обратиться к атомной энергетике. Одни инвестируют в разработку малых ядерных реакторов, другие подписали контракты на перезапуск старых атомных электростанций для обеспечения растущих энергетических потребностей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



