«Это любовь, коллега?» — «Это точно, коллега» (источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Вы что ж, и на свидания за нас ходить будете?!
Дейтинговые ИИ-сервисы выходят на принципиально новый уровень: вскоре это будет не только «подключи робота для просмотра сотен и тысяч анкет — и просматривай лишь те, что заведомо отвечают твоим предпочтениям», но ещё и «пусть ИИ пообщается за тебя с таким же ботом-консьержем на другой стороне для каждой из отобранных анкет». По крайней мере, это верно для сервисов вроде Bumble, которые позиционируют себя как «платформа для встреч и налаживания связей между людьми», а не для безудержного перебора одноразовых партнёров. Прочные коммуникации с выходом на действительно интересные для обеих сторон темы требуют времени и постепенного наращивания интенсивности общения. От обмена шаблонными репликами «Как дела?» и выяснения музыкальных/кулинарных предпочтений до обсуждения проблем расшифровки языка майя или знаменитого догмата о филиокве могут пройти дни и недели, — а если приходится вести разом несколько таких восхождений? Чтобы не терять драгоценное время и не упускать в суете уникальные возможности, пользователи таких ориентированных на коммуникации сервисов смогут сразу же отправлять на свидания виртуального консьержа — ИИ-бота, натренированного на массиве их же собственных прежних сообщений.
Провзаимодействовав со множеством таких же помощников за весьма ограниченное время, консьерж затем предложит своему пользователю подборку из считаных единиц потенциальных контактов, с детальным отчётом о том, по каким темам с их виртуальными представителями удалось отыскать общий язык и насколько далеко зашёл предварительный обмен мнениями. В перспективе возможно и появление на платформах такого рода ботов-свах, которым пользователи будут попросту изливать душу, рассказывая, кого именно ищут, — а те уже на основании полученных данных сами, безо всяких анкет, свяжутся с ИИ-консьержами подходящих кандидатов. В конце концов, в составлении внятных резюме на основе неполного массива слабо структурированных данных системы машинного обучения по-настоящему сильны.

Лицо, напоминающее Скарлет Йоханссон, ведёт лиц, напоминающих ИИ-луддитов, на нечто, напоминающее баррикады (источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Луддиты поднимают головы
Бросить гаечный ключ в шестерни машины на полном ходу или загрузить на Stack Overflow код с намеренно оставленными в нём ошибками — явления сопоставимого порядка. Немало пользователей этого популярного среди программистов ресурса, где можно получить не только «RTFM», но и рабочий фрагмент кода в ответ практически на любой вопрос, обнаружили в себе зудящую машинокрушительную жилку после того, как руководство платформы, особо не интересуясь их мнением, предложила её накопленное с 2008 г. содержимое для обучения новых моделей OpenAI. Не бесплатно, разумеется, — но деньги пойдут владельцам ресурса, тогда как сами создающие этот бесценный контент программисты не получат, судя по всему, даже упоминания о себе — на уровне ссылок на приводимый ботом в качестве ответа пользователю код. Именно в знак протеста против такого волюнтаризма некоторые пользователи принялись деятельно удалять или намеренно портить свои прежние ответы на Stack Overflow, однако модераторы платформы оказались наготове: они восстанавливают повреждённый контент и блокируют аккаунты ИИ-луддитов.
И модераторов, как и разработчиков из OpenAI, нетрудно понять: согласно майскому отчёту исследователей из Университета Пердью, 52% ответов ChatGPT на связанные с программным кодом вопросы оказались попросту неверны. И с этим необходимо срочно что-то делать, ведь из-за повального увлечения чат-ботами, прежде всего со стороны технически подкованных программистов, посещаемость того же Stack Overflow в прошлом году резко упала. Что, в свою очередь, заставило руководство ресурса сократить персонал почти на треть из-за снижения доходов. На этом фоне прогноз учёных из швейцарского Университета Лугано, будто к 2030 г. как раз благодаря ИИ вдвое снизится нагрузка на программистов, смотрится скорее оптимистичным, чем реалистичным. Интересно, а Скарлетт Йоханссон, которая вознамерилась запретить OpenAI использовать её (или очень похожий на её) голос как один из вариантов «озвучки» ChatGPT, сгодится на роль Свободы, ведущей восставший народ?

Vista X-62A — модифицированный истребитель F-16D Block 30 Peace Marble II для испытаний ИИ-пилота (источник: Lockheed Martin)
⇡#ИИ, штурвал на себя!
В США продолжаются испытания полностью управляемого ИИ истребителя F-16. В феврале сообщалось о проведении автономного полёта такой машины, специально доработанной для отладки передовых ИИ-технологий, на протяжении 17 часов; в мае же появилась информация о достижении модифицированным F-16 под управлением ИИ скорости в 550 миль в час (более 885 км/ч) в ходе учебного боя. Командование военно-воздушных сил Америки рассчитывает к 2028 г. поставить на крыло первый подлинно беспилотный (т. е. не управляемый человеком, в том числе и с земли) боевой самолёт, а всего реализуемая сейчас программа рассчитана на 1 тыс. таких машин. Военные заявляют, что, невзирая на объективные несовершенства доступных сегодня ИИ-моделей, отказаться от их скорого принятия на вооружение значит заведомо поставить под угрозу собственную безопасность.
Представители ВВС США вполне комплиментарно отозвались о проводившем учебный бой ИИ и заявили, что даже в таком состоянии, в каком тот сейчас, доверили бы ему принимать решение о применении оружия. Впрочем, оговорились они далее, в обозримой перспективе в кабине оснащённого ИИ самолёта всё равно продолжит оставаться лётчик, следящий за обстановкой. Однако через какое-то время, когда ИИ-пилот достойно себя зарекомендует, будет иметь смысл переориентировать производство боевой авиации на исключительно беспилотные модели — за счёт отсутствия человека более скоростные, маневренные и грузоподъёмные (при прежней мощности двигателей).
Источник: скриншот сайта техподдержки OpenAI
⇡#Запомнить всё! (Примечание: не является офертой.)
В последние дни апреля самый, наверное, известный в мире ИИ-бот, ChatGPT, получил возможность запоминать прежние запросы и предпочтения пользователей, причём в двух вариантах — по прямому указанию оператора либо на основании анализа проводившихся с ним ранее диалогов. Функция, получившая безыскусное наименование Memory, что и говорить, полезная: достаточно один раз проинформировать бота, что у вас в доме живут мейн-кун и золотистый ретривер, после чего запросы вроде «Изобрази моих домашних питомцев ловящими волну на доске для сёрфинга» сразу же будут исполняться наиболее близким к ожидаемому пользователем образом. Правда, Memory исходно была введена с довольно серьёзными ограничениями — только для платных подписчиков, да ещё за вычетом отдельных страновых рынков вроде всей Европы и Южной Кореи, — но какое-то время она радовала тех, для кого оказалась доступной.
Увы, уже к середине мая пользователи начали отмечать случаи потери этой памяти — бот «забывал» сообщённые ему ранее сведения. Функция Memory начала тестироваться OpenAI ещё в феврале — и с тех пор, судя по всему, разработчикам так и не удалось реализовать её оптимальным образом. А именно, так, чтобы и активно использующие память операторы не сталкивались с забывчивостью бота, — но и чтобы зарезервированный для каждой возможной пользовательской сессии объём памяти не выходил (в сумме по всем потенциальным случаям применения) за разумные рамки. Интересно, сумеет ли сам ChatGPT подсказать разработчикам, как оптимизировать эту задачу?
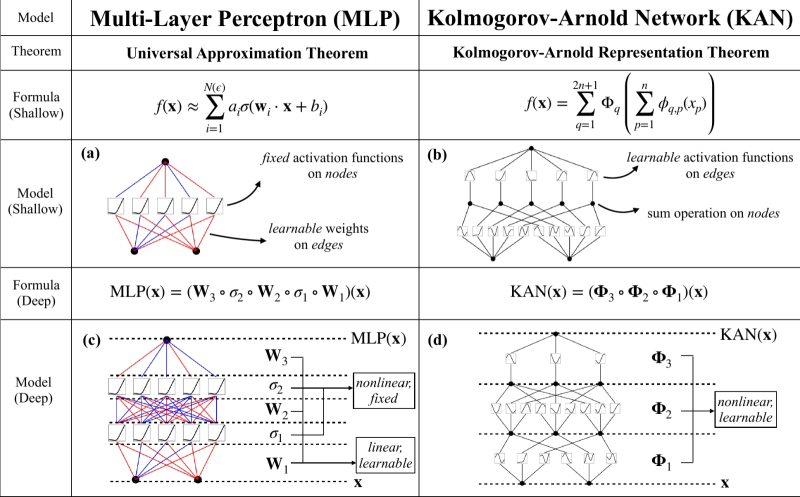
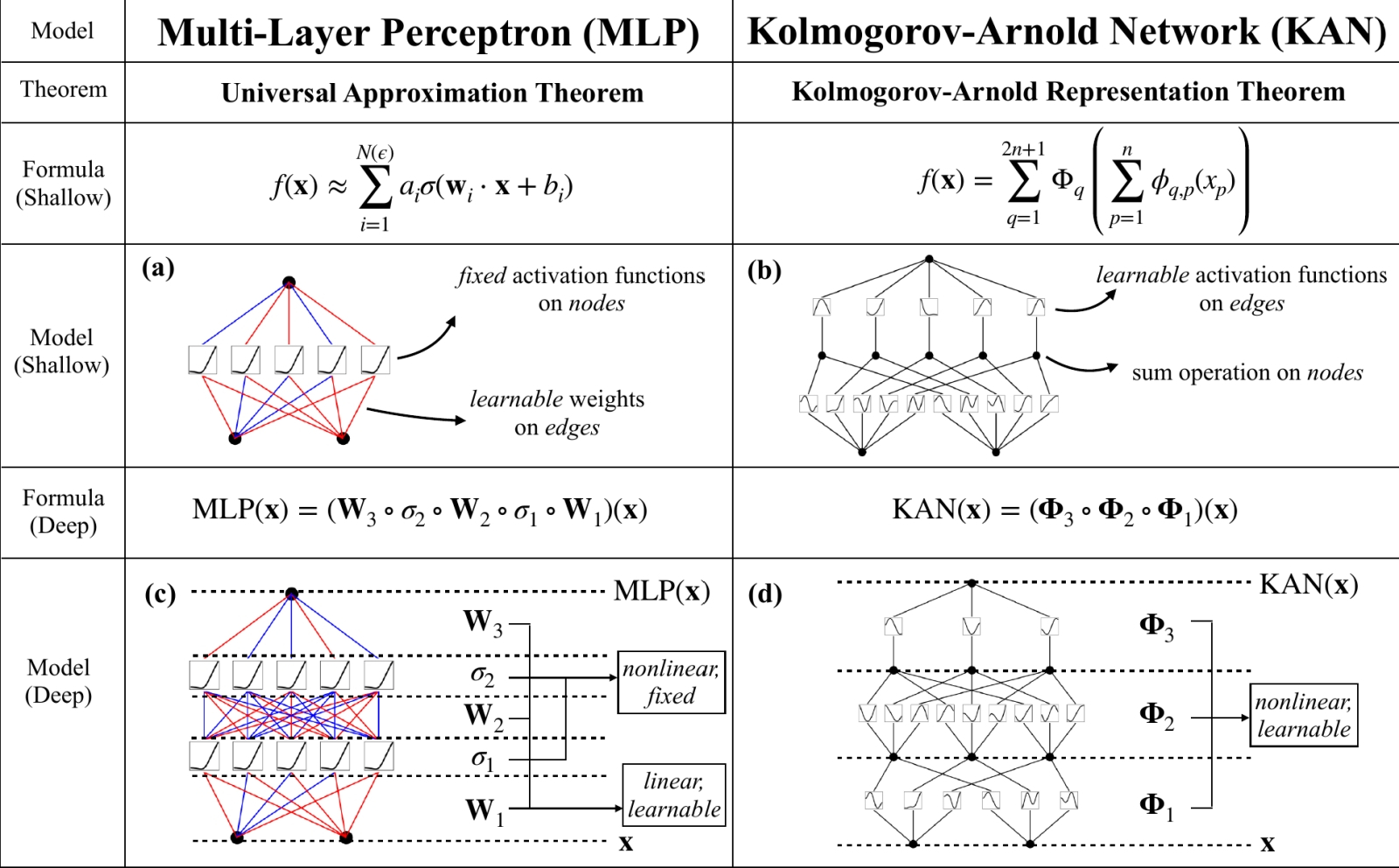
В чём разница между MLP и KAN? О, это очень просто! (Источник: MIT)
⇡#Нейросети — теперь и с унарными функциями
Группа американских исследователей в области ИИ — из Массачусетского технологического института и других почтенных научных центров — предложила взамен применяемых сегодня почти повсеместно нейросетей многослойных перцептронов (Multi-Layer Perceptrons, MLP) развивать сети Колмогорова—Арнольда (Kolmogorov—Arnold Networks, KAN), в основу которых положена известная теорема советских математиков Андрея Николаевича Колмогорова и Владимира Игоревича Арнольда 1957 г. о том, что каждая многомерная непрерывная функция может быть представлена в виде суперпозиции непрерывных функций одной переменной. В переложении для нейронных сетей она сформулирована Р. Хехт-Нильсеном тридцать лет спустя так: «Любая функция нескольких переменных может быть представлена двуслойной нейросетью с прямыми полными связями с n нейронами входного слоя, (2n+1) нейронами скрытого слоя с ограниченными функциями активации (например, сигмоидальными) и m нейронами выходного слоя с неизвестными функциями активации».
Принципиальное отличие нейросетей KAN от MAL — в том, что вторые полагаются на перцептроны с фиксированными функциями активации, а обучение сводится к подбору весов на входах этих перцептронов. В случае же KAN роль и функций активации, и переменных весов берут на себя т. н. унарные функции (принимающие ровно один аргумент и возвращающие ровно одно значение) на периферии перцептрона, а не в его ядре. Иными словами, вместо простейших операций (взвешенное суммирование), результат которых активирует либо не активирует данный конкретный перцептрон через раз навсегда заданную нелинейную функцию, сети KAN применяют нелинейные операции к аргументам перед суммированием — что позволяет, по крайней мере в теории, лучше выявлять тонкие закономерности в массиве обучающих данных и эффективнее справляться с решением высокодинамичных задач. Исследователи уже активно обсуждают новую нейросетевую архитектуру, и пока складывается мнение, что, хотя она почти наверняка будет проигрывать MAL в скорости обучения примерно на порядок, сокращение числа перцептронов и повышение эффективности при решении сложных задач могут оказаться в ходе её эксплуатации желанным выигрышем.

Опять тройка с плюсом! (Источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#«Писец» пришёл, услышал, написал
«Тотальный диктант» на площадке Новосибирского государственного университета писала среди прочих участников и нейросетевая модель «Писец» с открытым кодом, разработанная в лаборатории прикладных цифровых технологий этого вуза. Оценка системы — между тройкой и четвёркой, причём в ряде случаев — 6 из 276 слов диктанта — нейросеть попросту «не расслышала» зачитанные ей слова, а в 7 случаях допустила неверную интерпретацию (например, вместо «наивысшего» выдала в тексте явную галлюцинацию — «наявившего»). Разработка новосибирских исследователей — вполне прикладная: «Писец» в будущем должен стенографировать проводимые на площадке вуза конференции, интервью, защиты диссертаций и т. п. Собственно, уже при уровне неточностей 20-25% автоматическая расшифровка вполне пригодна для дальнейшей работы человека с ней, особенно если тот погружён в обсуждавшуюся тему и сможет уверенно выявлять некорректную интерпретацию нейросетевой моделью произнесённых слов. Продемонстрированный же «Писцом» результат вполне пригоден для передачи прямиком на литредактирование и корректуру — выпускаемых по итогам студенческих конференций сборников статей, например.

«Так, погодите-ка. Мне что, акций вообще не полагается?!» — ChatGPT-2025, возможно (источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#А будет кому смеяться через год?
Восторги в отношении генеративного ИИ пока следует попридержать — в этом уверен Брэд Лайткэп (Brad Lightcap), главный операционный директор OpenAI. В ходе 27-й ежегодной Глобальной конференции в Институте Миликена он заявил, что в нынешнем своём состоянии популярнейший ChatGPT всего через год будет выглядеть «смехотворно плохим», а большие языковые модели, на которых этот бот и его аналоги базируются, смогут «выполнять куда более сложные задачи». По утверждению Лайткэпа, само взаимодействие между ИИ и человеком станет более системным; нейросетевая модель будет рассматриваться как ценный член команды и сможет помочь оператору в решении любой насущной задачи. «Это будет совершенно иной способ применения программного обеспечения, — заявил топ-менеджер OpenAI, — так что многим людям непросто сегодня вообразить, каким окажется мир, где роботы-помощники будут сопровождать нас повсюду». Говоря о десятилетней перспективе, Лайткэп и вовсе воздержался от погружения в конкретику: «Мы сегодня всего лишь скребём по поверхности той толщи возможностей, которая пока сокрыта, — и погружение в эту бездну наверняка поразит нас».
Между тем журналистов издания Vox куда более поразило то, каким образом руководство OpenAI контролирует лояльность — точнее, ограничивает возможность публичного проявления нелояльности — своих бывших сотрудников. Оказывается, тех, кто решал расстаться с компанией, заставляли быстренько подписывать обязательство никогда не выступать с её критикой, — ну в самом деле, разве может организация, подарившая миру ChatGPT, подвергаться какой бы то ни было критике? Аргументы для принуждения были выбраны чисто экономические: многие сотрудники OpenAI, в особенности из тех, что были приняты в штат ещё на этапе стартапа, получали немалую долю выплат в виде акционерного капитала — и, разумеется, рассчитывали при случае эти акции продать, выручив за них тем больше, чем выше будет цениться к тому времени компания. Однако OpenAI — не открытое акционерное общество, а дочернее коммерческое предприятие одноимённого неприбыльного холдинга, и соответствующие учредительные документы, как удалось выяснить Vox, содержат достаточно средств для обуздания критического запала решивших уволиться сотрудников: от аннулирования ранее выделенной им доли акционерного капитала до запрета на её продажу.
После публикации компания, разумеется, заявила: «Мы исключим положения о недискредитации из наших стандартных документов при увольнении и освободим бывших сотрудников от действующих обязательств о недискредитации, если только положение о недискредитации не было взаимным», — но в любом случае сотрудники частных предприятий защищены от подобного рода ограничений в куда меньшей степени, чем работающие на предприятиях, акции которых свободно обращаются на бирже. Текучка же кадров в ИИ-отрасли сегодня в целом достаточно высока, поскольку состязающихся между собой разработчиков и многообещающих стартапов множество, тогда как дельные специалисты (как и по всем прочим направлениям, кстати) наперечёт. Как сообщает CNBC, программисты, трудящиеся над задачами искусственного интеллекта, страдают от переработок и от калейдоскопической смены приоритетов менеджмента, всеми силами пытающегося догнать и перегнать многочисленных конкурентов. Неудивительно, что любой стоящий работник стремится подобрать себе местечко поспокойнее и поприятнее в плане зарплат и бонусов: так, целый ряд экспертов по ИИ перешли, если верить источникам Financial Times, из Google в секретную европейскую лабораторию Apple в Цюрихе — и уже трудятся над ответом купертинской компании моделям семейства GPT.

«Кто сказал, что я недостаточно человечен?!» (Источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Роботам вход воспрещён
В то время как военные торопят инженеров со скорейшим и как можно более полным внедрением ИИ, в гражданской среде настороженность в отношении этой новой технологии если не растёт, то уж по крайней мере не снижается теми темпами, на которые можно было бы рассчитывать, изучая бравурные пресс-релизы разработчиков очередных генеративных моделей. В частности, ИИ ставят в укор вовсе не высокую вероятность ошибки — системы вроде Med-Gemini, напомним, уже демонстрируют точность 91,1% в клинической диагностике, — но отсутствие человеческой эмпатии, которое может оказаться критичным в той же медицине, к примеру. Сотни медсестёр американской компании Kaiser Permanente, оказывающей услуги медицинского страхования и обслуживания, провели в начале мая акцию протеста против ИИ у офиса организации, заявляя: «Ни один компьютер не заменит человеческого прикосновения, не сможет взять пациента на больничной койке за руку так, чтобы тому стало легче. Мы не против технического прогресса, но мы не приемлем подмены компьютерными вычислениями экспертизы, опыта, цельности человеческого подхода к больному, — всего, что присуще нашей профессии». По утверждению самой Kaiser Permanente, внедряемая ею система мониторинга состояния пациентов Advance Alert уже спасла за год полтысячи жизней, так что штатное расписание младшего медперсонала в этой связи явно находится под угрозой.
А вот Национальное управление архивов и документации США (National Archives and Records Administration, NARA) заблокировало своим сотрудникам доступ к ChatGPT с рабочих компьютеров и смартфонов из совершенно иных соображений: «ради защиты наших данных от угроз безопасности, порождаемых взаимодействием с ИИ-ботами». Аргументация в принципе здравая: от склонности «галлюцинировать» (точнее, от встроенной в сам принцип работы большой языковой модели неспособности отличать верифицированную истину от складно уложенных в предложение слов, не имеющих фактического подтверждения) сильнее всех может пострадать именно служба, предназначение которой — предоставлять по различным запросам, в том числе и с самого верха, заведомо достоверную информацию. Кроме того, немало данных, которыми оперирует NARA, в той или иной степени закрыты от широкой публики, — а генеративные ИИ-боты, особенно с новомодной функцией «запоминания» контекста и предшествующих вопросов, вполне могут сделаться каналом утечки чувствительной информации.
Тем временем устроители конференций по искусственному интеллекту также рекомендовали коллегам не доверять большим языковым моделям рецензирование присылаемых на такие мероприятия статей, — и редакторы научных периодических изданий горячо поддержали их в этом. Аргументация, кстати, и в этом случае направлена не столько на фактическую, сколько на эмоциональную сторону дела: «Рецензия на научную работу — освящённая временем академическая традиция; своего рода экзаменовка автора и оценка его достоинств; знак и символ того, что он замечен и признан равными с собой другими экспертами в этой области, и потому передоверить столь высокую задачу ИИ-боту — значит умалить важность самой процедуры рецензирования».

«GPT-тян, GPT-тян, а почему мы вкручиваем в перцептроны фиксированные функции активации?» — «Да потому, что мы и тебя по MLP-архитектуре строим, MAI-кун!» (Источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Microsoft, труд, MAI-1
Хотя Microsoft оказывает проекту OpenAI немалую поддержку (финансовые аналитики ещё в прошлом году хвалили ИТ-гиганта за «самую дальновидную в истории миллиардодолларовую инвестицию»), она остаётся независимой частной компанией со сложной структурой управления — а в эпоху повсеместного торжества генеративных моделей каждому уважающему себя лидеру высокотехнологичной индустрии неплохо бы иметь и собственную прорывную разработку по этому направлению. Отсюда вполне достоверным выглядит слух, опубликованный The Information, — о том, что Microsoft активно разрабатывает большую языковую модель под условным названием MAI-1 своими силами. Само собой, столь крупная стройка начата не на пустом месте: главой разработки назначен, по данным источников издания, Мустафа Сулейман (Mustafa Suleyman), прежде трудившийся над ИИ в Google и возглавлявший стартап Inflection — который, в свою очередь, ранней весной 2024-го приобрела всё та же Microsoft за 650 млн долл. США. Источники оценивают число внутренних параметров MAI-1 в 500 млн — между характерными для GPT-3 и GPT-4 величинами — и ожидают вскоре официального обнародования хотя бы минимальной информации об этой модели.
В свою очередь, китайская Alibaba представила большую языковую модель собственной разработки Qwen2.5 — по данным бенчмарков OpenCompass, та на ряде испытаний превзошла актуальную версию GPT-4. По свидетельству Alibaba Cloud, различными ИИ-сервисами на базе открытых моделей семейства Qwen уже воспользовались более 2,2 млн только корпоративных пользователей, в частности версия 2.5 была развёрнута более чем в 90 тыс. компаний из разных отраслей экономики КНР.

GPT-4o способна отвечать на текстовые запросы картинками, изображая то, что воображает пользователь (источник: скриншот сайта OpenAI)
⇡#О — то что надо!
Семейства моделей GPT в мае прибыло — OpenAI представила GPT-4o (от «omni», что можно перевести как «всеохватная»), мультимодальную и ещё более мощную, чем ставшая привычной для многих ИИ-энтузиастов за последнее время «Четвёрка». Мультимодальность GPT-4o проявляется в её готовности работать с текстом, изображениями и речью, причём в рамках общего контекстного окна в 128 тыс. токенов. Напомним, что токенами кодируются слова и части составных слов: скажем, для перевода в цифровое представление слова «cat» понадобится один токен, а для «catfish» — два. В первую очередь от перехода на новую модель выиграл, конечно же, всем известный бот ChatGPT, который отныне — если верить разработчикам — способен не только воспринимать вопросы пользователей «со слуха», но и улавливать эмоции в человеческом голосе, соответствующим образом подстраивая под них уже интонации своего собственного ответа.
Испробовавшие работу новинки счастливчики (пока не все функции GPT-4o доступны каждому пользователю, даже платному) отзываются о ней с неподдельным восторгом: «Я с её помощью преобразовал 40-минутный видеоролик в стилизованную книгу комиксов. Прошёл текстовую игру-„бродилку“, причём у чат-бота оказалось великолепное ощущение пространства этого виртуального мира — я как будто угодил в настоящий симулятор. У меня вышло отредактировать практически любое изображение, какое только я ни загружал в систему, — достаточно было указать GPT-4o, что и как именно исправить, и я сразу же получал полностью устраивающий результат, так что прощай, „Фотошоп“! Я смог с относительной лёгкостью создавать фотореалистичные 3D-модели и окружение для них. Можете скормить боту своё фото и попросить его примерить на вас разные причёски — он с этим справится. А ещё он генерирует изображения прямо на основе живого видеопотока: направьте камеру на объект и скажите, например, „Сделай его коричневым и поверни на 180°“, — всё так и будет!»

«Мой юзер, что тебе я сделала?» (Источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Конкуренты и законы
Новость об открытии компанией Anthropic для европейских пользователей доступа к своему чат-боту Claude не была бы столь значимой, если бы не чрезвычайно жёсткая политика ЕС в отношении систем искусственного интеллекта. Эта компания, которую основали в 2021 г. выходцы из OpenAI, ориентирует свои продукты прежде всего на коммерческих заказчиков, подчёркивая стремление к разработке «ответственного и этичного ИИ». При этом в Европе уже действуют и OpenAI со своим ChatGPT, и французская компания Mistral, чьи чат-боты занимают довольно высокие позиции в соответствующих рейтингах, — теснить конкурентов в непростых юридических реалиях Anthropic будет непросто (вероятно, именно с этим связан недавний приход в компанию Яна Лейке (Jan Leike), который ранее занимался в OpenAI как раз вопросами доверенного и безопасного искусственного интеллекта).
А реалии эти таковы, что разработчикам ИИ необходимо, если они собираются действовать на рынке Европы, не только самим применять действенные средства контроля кибербезопасности, но и раскрывать по требованию регулятора отдельные тонкости архитектуры своих моделей и информировать его о потенциальных угрозах, которые от указанных моделей могут исходить. ЕС первым в мире принял закон об искусственном интеллекте, значительно ограничив сферы применения ИИ-моделей. Так, запрещена какая-либо дискриминация (включая ранжирование) граждан на основе анализа генерируемых ими вольно или невольно данных, а также ИИ-прогностика для нужд полиции (выходит, алгоритмическое прогнозирование по-прежнему допустимо?), применение распознавания эмоций на рабочих местах и в учебных заведениях — и ещё многое другое. Разумеется, столь всеобъемлющий закон не может вступить в силу одномоментно, — он начнёт применяться в целом не ранее чем через год, а действующим к настоящему времени в ЕС генеративным моделям дано 36 месяцев на адаптацию к установленным нормам.
Тем временем нейросетевая модель Gemini на смартфоне Pixel уже ведёт разговор как человек — по крайней мере, в представленном Google демо. Голосовая коммуникация с пользователем, проведение логических рассуждений, естественные интонации — всё в продемонстрированном разработчиком видео на высоте. ИИ-бот сумеет даже распознавать телефонных мошенников — выводя прямо в процессе разговора владельца смартфона с ними на экран предупреждение о том, например, что настоящие сотрудники банков никогда не предлагают по телефону перемещать ваши средства между счетами «ради их сохранности». Но, хотя тест Тьюринга действительно давно уже устарел — точнее, нуждается в куда более строгом установлении критериев оценки, — у многих экспертов вызывает сомнение чрезмерно позитивная демонстрация способностей новейшей модели. Пока смартфоны с доступом к ней не попадут в руки независимых ИИ-энтузиастов (а произойти это должно ближе к концу текущего года), говорить о серьёзной угрозе GPT-4o со стороны Gemini рано. Другое дело — универсальный ИИ-ассистент будущего, Project Astra, над которым Google активно сейчас работает, — но срок его готовности к выходу в свет пока совершенно неизвестен.
Что же касается угроз человечеству — которым призвана, в частности, противодействовать упомянутая инициатива европейских законодателей, — то здесь и сами разработчики готовы набросить узду на лихо разошедшиеся за последние год-два генеративные модели. Сразу несколько крупнейших игроков в этом сегменте, в том числе Microsoft, Amazon и OpenAI, заключили соглашение о безопасности искусственного интеллекта — и приняли на себя добровольное обязательство обеспечивать не создающую угроз человечеству разработку создаваемых ими ИИ-моделей. Важно, что речь здесь идёт не только об опасностях, исходящих от самих моделей, но и о потенциально вредоносном их применении злоумышленниками — например, для проведения автоматизированных кибератак или создания биологического оружия. Понимая, что интегрировать в обучающий массив данных все возможные запреты нереально, разработчики договорились применять «аварийный тумблер», прерывающий процедуру создания ИИ-модели в случае, когда становится ясно, что соблюсти взятое на себя обязательство иными средствами не удаётся. Вдобавок для регулирования связанных с ИИ рисков и ради дальнейшего развития инноваций в этой области в Европе создают новую структуру — Управление по искусственному интеллекту.

Кто не работает, тот не интеллект! (Источник: ИИ-генерация на основе модели SDXL 1.0)
⇡#Экономия должна быть
Помимо чистого восторга от того, что бездушная машина рисует привлекательные картинки, ведёт связные диалоги и пишет музыку (уже подостойнее, чем некоторые биологические композиторы), ИИ приносит ещё и прямую финансовую выгоду для тех, кто умеет найти ему оптимальное применение. Финтехкомпания Klarna, например, используя генеративные модели там, где они действительно хороши, — при разработке маркетинговых проектов, для создания изображений и т. п., — экономит до 10 млн долл. ежегодно. Бюджет отдела продаж и маркетинга этой немаленькой организации только за первый квартал 2024-го сократился на 11%, причём более чем на треть за это снижение расходов был ответствен именно ИИ, — и это одновременно с ростом числа проведённых рекламных кампаний.
Сами специалисты, ответственные за разработку ИИ, внакладе тоже не остаются. По данным Levels.fyi, опубликованным в мае, апрельская медианная (не средняя!) по США зарплата специалиста с гордым званием «AI software engineer» достигала 300 тыс. долл., — тогда как у их коллег, которым не повезло заниматься другим ПО, аналогичный показатель вышел на 100 с лишним тыс. долларов меньше. Причина — в крайне высоких ставках, которые работодатели делают на искусственный интеллект. Хоть сколько-нибудь сведущим в этой области работникам, даже невзирая на зримую нехватку квалификации, всё равно готовы платить гораздо больше — просто потому, что боятся отстать от конкурентов во всё ускоряющейся ИИ-гонке.
Не следует, впрочем, сбрасывать со счетов мнение Илона Маска (Elon Musk), высказанное в ходе видеовключения на парижской конференции VivaTech 2024, — о том, что человечество ожидает безработное — и беззаботное — будущее: никто не будет испытывать нехватки еды или услуг просто потому, что всё это обеспечит ИИ. «В будущем, свободном от изнурительного труда ради пропитания, останется только один значимый вопрос: если компьютер и роботы могу делать всё что угодно лучше вас, — каков тогда смысл вашей жизни?» Анфан террибль мировой высокотехнологичной отрасли полагает, что незаменимой ролью человека останется по крайней мере придание смысла существования уже самому ИИ — чтобы тому было о ком заботиться, — но в том, что блестящие металлические зады отберут у кожаных мешков работу, у него сомнений нет. Правда, глава Meta✴[1]* по направлению ИИ Ян Лекан (Yann LeCun) убеждён, что большие языковые модели никогда не сравнятся с человеком по уровню интеллекта, т. е. по способности рассуждать и строить планы так же, как это делает биологический разум. Но зато именно потому он предлагает сразу же сосредоточиться на создании машинного сверхразума (superintelligence) — чтобы уж, видимо, наверняка не оставить пророчеству Маска шансов не сбыться. Одно утешение — господин Лекан отводит на доведение гипотетического сверхразума, над которым его организация уже, судя по всему, работает, до операционной готовности по меньшей мере десятилетие. Есть ещё время поумнеть самим!
[1]* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности».
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex