







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
AMD Trinity для десктопа. Часть 2. Платформа и процессор
В прошлом обзоре Trinity мы подробно знакомились с архитектурой графического ядра Devastator и пришли к выводу, что произошедшая смена его архитектуры на VLIW4 – положительный шаг. Теперь настало время поговорить про вычислительные ядра. По сравнению с Llano изменения в них тоже крупномасштабные. Вместо x86-ядер Husky с микроархитектурой Stars теперь используются модули с микроархитектурой Piledriver – очередная итерация в развитии Bulldozer. Как известно, при внедрении Bulldozer процессорная команда AMD сменила приоритеты. Эта микроархитектура по сравнению со Stars уменьшила количество исполняемых за такт инструкций, но зато позволила развивать более высокие тактовые частоты. Однако достигнутым эффектом остались довольны далеко не все, поэтому спустя три квартала с момента появления на рынке первых версий Bulldozer, AMD подготовила обновление микроархитектуры – своеобразную работу над ошибками – Piledriver. 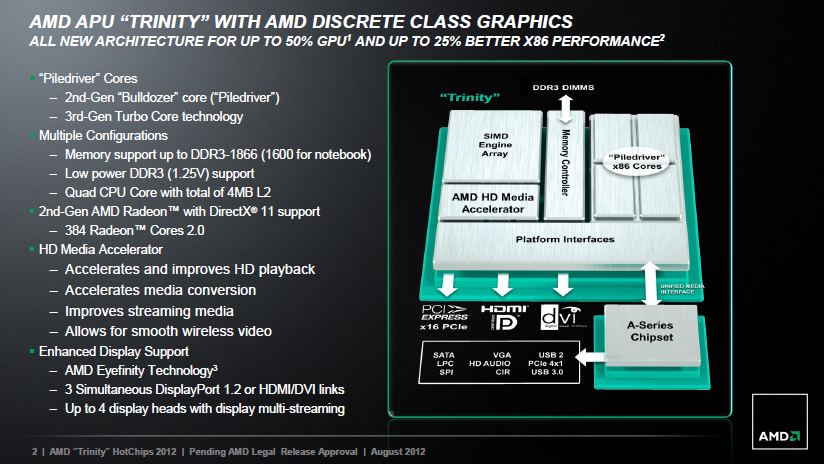 В процессорах Trinity как раз и используются ядра с дизайном Piledriver, и это – первое появление данной микроархитектуры на публике. AMD считает, что сделанных усовершенствований вполне достаточно для того, чтобы Trinity работали заметно быстрее процессоров Llano. Означает ли это, что новая версия вычислительных ядер позволит продукции AMD полноценно конкурировать с интеловскими предложениями? Актуальность этого вопроса связана в первую очередь с тем, что буквально через три-четыре недели будут представлены свежие процессоры серии FX, использующие аналогичные ядра Piledriver. И если про Trinity ещё можно говорить, что их производительность в традиционных задачах «вполне достаточна», скрывая реальный уровень x86-быстродействия за высокой скоростью графического ядра, то с процессорами FX этот фокус не пройдёт. Поэтому начать знакомство с Piledriver мы решили с выяснения превосходства этой версии микроархитектуры над «классическим» Bulldozer. Впрочем, не стоит возлагать на Piledriver какие-то особенные ожидания. Структурно эта микроархитектура полностью повторяет Bulldozer, то есть основывается на использовании условно-двухъядерных модулей, в которых имеется по два набора целочисленных исполнительных устройств, но часть ресурсов представлена лишь в единственном на два ядра экземпляре. К числу таких разделяемых компонентов относится кеш-память, блок выборки инструкций, их декодер и блок операций с плавающей точкой. В результате, модуль может обрабатывать два потока одновременно, но его пиковая производительность ограничена пропускной способностью объединённого декодера, способного декодировать не более четырёх инструкций за такт на два ядра. Для сравнения: в интеловских процессорах семейства Core декодер имеет сравнимый темп работы, но там он для каждого ядра индивидуален. Это значит, что число обрабатываемых за такт инструкций в Piledriver серьёзно увеличиться не могло. Качественные изменения произойдут только в следующем поколении микроархитектуры, Steamroller: предполагается, что в будущем AMD снабдит собственным декодером инструкций каждое из двух ядер в модуле. Пока же все улучшения Piledriver основываются на оптимизациях в алгоритме работы отдельных внутренних блоков, но не затрагивают дизайн в целом. 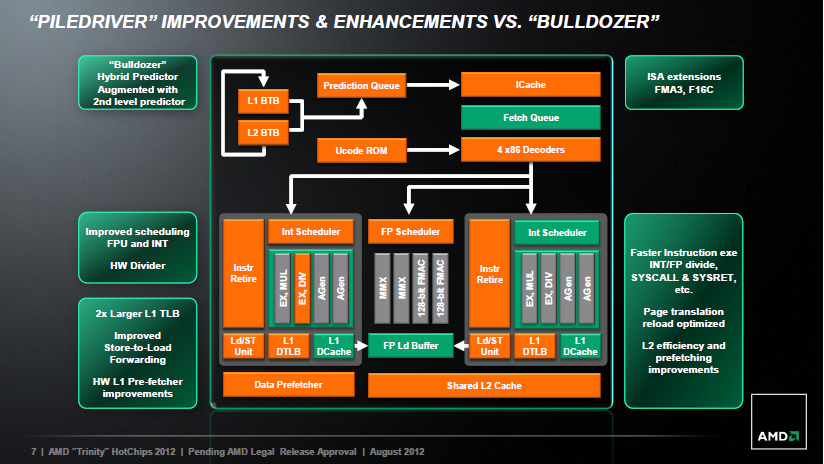 AMD к основным усовершенствованиям, выполненным в Piledriver, относит:
Темп декодирования инструкций все перечисленные нововведения нарастить не в состоянии, но, тем не менее, определённое ускорение они обеспечить могут. Для того чтобы представить себе, насколько микроархитектура Piledriver эффективнее своей предшественницы, мы провели небольшое сравнение на практических бенчмарках. В нём один на один сошлись четырёхъядерный процессор A10-5800K с микроархитектурой Piledriver и четырёхъядерный процессор FX-4170 с микроархитектурой Bulldozer. Для наглядности сравнения оба процессора были настроены на работу при фиксированной частоте 4,0 ГГц, а технология Turbo Core была выключена. Заметим, что в отличие от A10-5800K, имеющего двухуровневую кеш-память, FX-4170 снабжён 8-мегабайтным L3-кешем, который никак нельзя деактивировать. Поэтому просто будем иметь в виду, что носитель микроархитектуры Bulldozer выступал с небольшим гандикапом. В обеих сравниваемых системах была установлена память DDR3-1867 с таймингами 9-11-9-27-1T и видеокарта NVIDIA GeForce GTX 680. В первую очередь взглянем на скорость работы подсистемы памяти, измеренную тестом Cache & Memory Benchmark из пакета Aida64.  Bulldozer  Trinity У процессора A10-5800K, как видим, дела со скоростью работы с данными обстоят не самым лучшим образом. Bulldozer обеспечивает более высокие практические пропускные способности и более низкие латентности. Но дело тут, конечно, не в каких-то недостатках микроархитектуры Piledriver. Просто мы сравниваем процессоры, работающие в разных платформах. Особенность же Trinity в том, что их дизайн оптимизирован в первую очередь под совместное использование памяти графическим и вычислительными ядрами. Более сложные алгоритмы работы контроллера DDR3 SDRAM, учитывающие необходимость дополнительного арбитража запросов, вносят определённые задержки, и как раз из-за этого Trinity и уступает Bulldozer. К сожалению, даже в том случае, когда в Socket FM2-системе установлена дискретная графическая карта, а встроенное в APU графическое ядро не используется, скорость работы x86-ядер Trinity с системной памятью остаётся на том же недостаточно высоком уровне. Давайте посмотрим теперь, как обстоит дело с вычислительной производительностью.
Как можно судить по результатам, микроархитектура Piledriver с практической точки зрения превосходит Bulldozer незначительно. Максимальный наблюдаемый прирост скорости достигает лишь 7 процентов, а в среднем превосходство нового дизайна выражается примерно в полуторапроцентном преимуществе в бенчмарках. Впрочем, из внимания не следует упускать отсутствие в протестированном нами варианте Piledriver кеш-памяти третьего уровня, а также его более медленный контроллер памяти. Именно из-за этого в некоторых тестах, интенсивно работающих с большими объёмами данных, наблюдается не увеличение, а падение производительности. Однако мы не склонны полагать, что с появлением процессоров с новой микроархитектурой в Socket AM3+ исполнении ситуация серьёзно изменится. Заметному увеличению числа обрабатываемых за такт инструкций взяться попросту неоткуда, так что 5-10 процентов прироста в удельной производительности – это, пожалуй, тот максимум, на который могут рассчитывать поклонники продукции AMD и при предстоящем появлении на рынке процессоров с кодовым именем Vishera.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











