|
Опрос
|
реклама
Быстрый переход
ИИ стал экзистенциальной угрозой для интернет-СМИ: посетителей на сайтах вытесняют роботы
20.06.2025 [11:37],
Сергей Сурабекянц
Глава Cloudflare Мэтью Принс (Matthew Prince) в интервью изданию Axios заявил, что издатели сталкиваются с экзистенциальной угрозой со стороны ИИ и должны получать справедливую компенсацию за свой контент. «Люди стали больше доверять ИИ за последние шесть месяцев, что означает, что они не читают оригинальный контент, — сказал он. — Будущее интернета будет всё больше и больше похоже на ИИ, значит люди [и дальше] будут читать резюме вашего контента». 
Источник изображения: Walls.io / unsplash.com Число переходов со страниц поисковых систем на сайты с оригинальным контентом сокращается с каждым днём, поэтому многим издателям придётся пересмотреть свои бизнес-модели или вообще уйти с рынка. Принс привёл впечатляющие статистические данные. По его словам, десять лет назад соотношение проиндексированных поисковиком Google страниц к числу посетителей, перенаправленных со страницы поисковой выдачи на сайт издателя, составляло 2:1. С тех пор это соотношение постепенно увеличивалось, но после начала ИИ-бума стало расти угрожающими темпами. Шесть месяцев назад:
В настоящий момент:
Поисковые системы и чат-боты ИИ предоставляют ссылки на оригинальные источники, но издатели могут получать доход от рекламы только в том случае, если читатели переходят по ссылкам. «Люди не переходят по ссылкам», — констатировал Принс. Он уверен, что эта проблема касается любого создателя оригинального контента. Принс сообщил, что Cloudflare разработала инструмент, который должен «остановить копирование контента». AI Labyrinth использует контент, сгенерированный ИИ, для замедления, запутывания и траты ресурсов ИИ-сканеров и других ботов, которые не соблюдают директивы веб-серверов. Своим клиентам Cloudflare предлагает автоматическое развёртывание такого набора сгенерированных ИИ страниц при обнаружении «ненадлежащей активности» ботов. Суд «заблокировал» кнопку «Удалить» в ChatGPT
06.06.2025 [19:45],
Сергей Сурабекянц
OpenAI сообщила, что вынуждена хранить историю общения пользователей с ChatGPT «бессрочно» из-за постановления суда, вынесенного в рамках иска от издания The New York Times о защите авторских прав. Компания планирует обжаловать это решение, которое считает «чрезмерным вмешательством, отменяющим общепринятые нормы конфиденциальности и ослабляющим безопасность». 
Источник изображения: unsplash.com Издание The New York Times подало в суд на OpenAI и Microsoft за нарушение авторских прав в 2023 году, обвинив компании в «копировании и использовании миллионов» материалов для обучения моделей ИИ. Издание утверждает, что только сохранение данных пользователей до завершения судебного процесса сможет обеспечить предоставление необходимых доказательств в поддержку иска. В ноябре 2024 года стало известно, что инженеры OpenAI якобы случайно удалили данные, которые потенциально могли стать доказательством вины разработчика ИИ-алгоритмов в нарушении авторских прав. Компания признала ошибку и попыталась восстановить данные, но сделать это в полном объёме не удалось. Те же данные, что удалось восстановить, не позволяли определить, что публикации изданий были задействованы при обучении нейросетей. Поэтому в мае 2025 года суд обязал OpenAI сохранять «все выходные данные журнала, которые в противном случае были бы удалены», даже если пользователь запрашивает удаление чата или если законы о конфиденциальности требуют от OpenAI удаления данных. В соответствии с политикой OpenAI, если пользователь стирает чат, через 30 дней он удаляется без возможности восстановления. Теперь компании придётся хранить чаты до тех пор, пока суд не решит иначе. OpenAI сообщила, что постановление суда затронет пользователей бесплатной версии ChatGPT, а также владельцев подписок Pro, Plus и Team. Оно не повлияет на клиентов ChatGPT Enterprise или ChatGPT Edu, а также на компании, заключившие соглашение о нулевом хранении данных. OpenAI заверила, что данные не попадут в общий доступ, а работать с ними сможет «только небольшая проверенная юридическая и безопасная команда OpenAI» исключительно в юридических целях. «Мы считаем, что это был неуместный запрос, который создаёт плохой прецедент. Мы будем бороться с любым требованием, которое ставит под угрозу конфиденциальность наших пользователей; это основной принцип», — отреагировал генеральный директор OpenAI Сэм Альтман (Sam Altman). Ранее OpenAI обвинила The New York Times в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у создателей контента. The New York Times не одинока в своих претензиях в OpenAI. В мае 2024 года восемь интернет-изданий подали иск к OpenAI и Microsoft за незаконное использование статей для обучения ИИ. Истцы упрекают OpenAI в незаконном копировании миллионов статей, размещённых в изданиях New York Daily News, Chicago Tribune, Orlando Sentinel, Sun Sentinel, The Mercury News, The Denver Post, The Orange County Register и Pioneer Press для обучения своих языковых моделей. Знаменитая антипиратская кампания из 2000-х использовала спираченный шрифт
27.04.2025 [18:44],
Анжелла Марина
Нашумевшая антипиратская кампания 2000-х годов MPAA, запущенная Американской ассоциацией кинокомпаний и проходившая под лозунгом «Вы же не станете угонять машину? Так что и фильм пиратить не стоит», как оказалось сама нарушила авторские права. По данным Ars Technica, в материалах MPAA, предположительно, использовался нелицензионный шрифт, а именно копия оригинального шрифта FF Confidential. 
Шрифт FF Confidential. Источник изображения: fontsinuse.com В роликах, которые крутили перед показом фильмов в кинотеатрах и на DVD с 2004 по 2008 год, зрителей пугали последствиями пиратства. Один из роликов показывал, как девушка скачивает фильм, после чего на экране появлялась надпись, стилизованная под граффити: «You wouldn’t steal a car» (Вы бы не угнали машину). Однако шрифт надписи был идентифицирован как шрифт FF Confidential, созданный известным дизайнером Юстом ван Россумом (Just van Rossum) в 1992 году, о чём сообщил сайт Fonts in Use. Репортёр Мелисса Льюис (Melissa Lewis) из Центра расследовательской журналистики, обратила внимание, что энтузиасты ранее обнаружили очень похожий шрифт с названием XBand Rough. Льюис связалась с Россумом, и тот подтвердил, что XBand Rough является клоном его дизайна. 
Шрифт XBand Rough. Источник изображения: arstechnica.com Позднее некий пользователь под ником Rib проверил PDF-файл с архивного сайта кампании и с помощью программы FontForge выяснил, что в документе действительно использовался XBand Rough. При этом ван Россум в интервью популярному изданию TorrentFreak, освещающему тенденции в области протокола BitTorrent, заявил, что знал о существовании клона, но не подозревал, что MPAA применила его в своей кампании. «Это забавно», — прокомментировал он, но отказался давать дополнительные разъяснения. Пока неясно, насколько широко XBand Rough применялся в материалах MPAA. Возможно, его использовали только в отдельных документах, а не в основном ролике. Однако проверить это сложно — исходные файлы кампании недоступны. Юридические тонкости дела также осложняются различиями в законах об авторском праве. В США дизайн шрифтов (typeface) как таковой не защищён, но файлы шрифтов (font files) могут охраняться, поскольку считаются программным кодом. В Великобритании, где также транслировались антипиратские трейлеры, вопрос защиты авторских прав более сложен, хотя закон об авторских правах обычно защищает шрифты в течение 25 лет после первой публикации. В Германии, где находился головной офис оригинального издателя FontFont, шрифты находятся под защитой в течение первых 10 лет, а затем ещё 15 лет, если правообладатель платит взнос. «Большинство шрифтов очень похожи друг на друга, поэтому доказать их уникальность сложно», — пояснил адвокат из США по интеллектуальной собственности Джеймс Аквилина (James Aquilina). FF Confidential изначально выпустила студия FontFont, которую в 2014 году купила компания Monotype. Сейчас шрифт продаётся с пометкой о регистрации в USPTO (Ведомство по патентам и товарным знакам США). Аквилина отметил, что использование пиратских шрифтов в коммерческих проектах в целом не редкость. «Это происходит из-за популярности определённых шрифтов и желания добиться нужного стиля», — сказал он. Однако судебные иски по этому поводу встречаются нечасто, и правообладатели чаще преследуют распространителей, а не конечных пользователей. Одновременно происхождение XBand Rough, клона FF Confidential, остаётся загадкой. Название шрифта отсылает к игровой платформе XBAND (1994–1997), поэтому предполагается, что шрифт появился около 1996 года. Один из пользователей Bluesky даже выдвинул версию, что XBAND мог легально лицензировать FF Confidential, а затем переименовать его. А дальше XBand Rough просто случайно «утёк» в Сеть. MPA (бывшая MPAA) отказалась комментировать ситуацию, но, как отметили эксперты, законы об интеллектуальной собственности куда сложнее, чем сравнение «воровства фильмов с кражей автомобилей». OpenAI и Google поспорили с правительством Великобритании, что обучение ИИ в интернете «должно быть бесплатным»
06.04.2025 [11:05],
Владимир Мироненко
OpenAI и Google раскритиковали подготовленный правительством Великобритании «предпочтительный вариант» поправок в закон об авторских правах, которые касаются регулирования обучения ИИ-моделей с использованием общедоступного интернет-контента. 
Источник изображения: Steve Johnson/unsplash.com В ходе общественного обсуждения предложений правительства, закончившегося в феврале, было подано около 11 тыс. предложений со стороны компаний и пользователей. OpenAI и Google изложили свою позицию после того, как Комитет по науке, инновациям и технологиям парламента Великобритании направил им запрос по этому поводу, поскольку представители обеих компаний отказались дать свою оценку законопроекту перед парламентариями. Согласно предлагаемым правительством поправкам в закон, компании в сфере ИИ смогут обучать свои модели на общедоступном контенте в коммерческих целях без разрешения правообладателей, если только правообладатели не пожелают «сохранить свои права» и не откажут им в этом. Также поправки предполагают более жёсткие требования к прозрачности в деятельности компаний в сфере ИИ. В своих комментариях OpenAI заявила, что опыт других юрисдикций, включая ЕС, показывает, что закрепление за правообладателями права на отказ предоставления контента влечёт за собой «значительные проблемы внедрения», в то время как введение обязательства по соблюдения прозрачности может привести к исключению рынка из числа приоритетных среди разработчиков. «У Великобритании есть редкая возможность закрепиться в качестве европейской столицы ИИ, сделав выбор, который избежит политической неопределённости, будет способствовать инновациям и будет стимулировать экономический рост», — отметила компания. В свою очередь, Google заявила, что правообладатели уже сейчас могут эффективно осуществлять контроль, чтобы не допустить, чтобы веб-сканеры копировали контент в интернете, но предположила, что те, кто отказывает в предоставлении контента для обучения ИИ, не обязательно будут иметь право на вознаграждение, если он всё же будет замечен в данных для обучения модели. «Мы считаем, что обучение в открытом интернете должно быть бесплатным», — заявила компания, добавив, что «чрезмерные требования к прозрачности... могут помешать развитию ИИ и повлиять на конкурентоспособность Великобритании в этой сфере». Представитель правительства Великобритании сообщил ресурсу Politico, что окончательное решение по этому вопросу пока не принято. Google протестировала отключение новостей в ЕС без потери рекламной выручки
23.03.2025 [05:59],
Дмитрий Федоров
Google провела эксперимент в восьми странах Европейского союза (ЕС), временно исключив из поисковой выдачи ссылки на контент европейских новостных издателей для 1 % пользователей. Согласно заявлению компании, это не оказало измеримого влияния на её рекламную выручку. Google, вероятно, использует эти данные в жёстких переговорах с медиа, стремясь ослабить их позиции в контексте требований законодательства ЕС. 
Источник изображения: Brett Jordan / Unsplash В ноябре Google начала тестирование, охватившее восемь стран Европейского союза: Бельгию, Хорватию, Данию, Грецию, Италию, Нидерланды, Польшу и Испанию. Изначально в тест включалась и Франция, но Google отказалась от её участия после того, как суд предупредил, что это может нарушить ранее заключённое соглашение, что повлекло бы штрафы. Как сообщил директор по экономике Google Пол Лю (Paul Liu), удаление новостного контента не оказало никакого воздействия на рекламную выручку компании. Единственное зарегистрированное изменение — снижение использования поисковой системы на 0,8 %. Лю уточнил, что это снижение обусловлено потерей запросов, которые изначально не приносили значительной выручки — либо минимальной, либо нулевой. В официальном заявлении в блоге компании, опубликованном по итогам эксперимента, подчёркивается: «Во время наших переговоров по соблюдению Европейской директивы об авторском праве (EUCD) мы сталкивались с рядом неточных сообщений, которые значительно переоценивают значимость новостного контента для Google. Результаты получены: новостной контент из Европы в Поиске не оказывает измеримого влияния на рекламную выручку Google». Компания подчёркивает, что целью теста было опровержение ошибочных представлений о коммерческой важности новостных материалов для её поисковой модели. Контекстом эксперимента стала Европейская директива об авторском праве (EUCD), в соответствии с которой цифровые платформы обязаны выплачивать издателям вознаграждение за использование фрагментов их статей в поисковой выдаче. На основании полученных данных Google намерена продемонстрировать, что ценность такого контента для компании была изначально преувеличена, а значит, и требования о выплатах не подкреплены объективными экономическими показателями. Франция и Германия, несмотря на значимость их медиарынков, в тестировании участия не приняли. Google уже сталкивалась с антимонопольными санкциями во Франции, а в Германии растёт давление на практики лицензирования новостей. Эти страны, судя по всему, были исключены из эксперимента в целях минимизации юридических рисков и во избежание дальнейших конфликтов с регуляторами. Эксперименты, подобные проведённому в ЕС, Google проводила и в других юрисдикциях — в частности, в Канаде, Калифорнии и Австралии. В последнем случае компания пригрозила отключить поиск на территории всей страны, когда правительство предложило закон, обязывающий технологические платформы заключать лицензионные соглашения с медиа. Премьер-министр Австралии Скотт Моррисон (Scott Morrison) отреагировал жёстко: «Австралия сама устанавливает правила для своей территории». Закон был принят, Google осталась, и позже компания заключила соглашения с местными СМИ. Разработчик поисковика и браузера Brave поборется с издателям News Corp за свободу индексации авторского контента
14.03.2025 [15:20],
Дмитрий Федоров
Brave Software, разработчик поисковика Brave Search и браузера Brave, подала иск в федеральный суд Сан-Франциско против медиахолдинга News Corp. Разработчик требует признать законной индексацию веб-контента, используемого в её поисковике. В ответ News Corp обвиняет компанию в незаконном копировании и распространении защищённых авторским правом материалов The Wall Street Journal и New York Post. Этот конфликт отражает углубляющееся противостояние между медиакомпаниями и технологическими корпорациями в борьбе за контроль над цифровым контентом. 
Источник изображения: Wesley Tingey / Unsplash 27 февраля 2025 года News Corp направила Brave официальную претензию, в которой обвинила компанию в незаконном сканировании её веб-ресурсов, индексации контента и его последующем использовании. Согласно заявлению медиахолдинга, Brave извлекает коммерческую выгоду из несанкционированного копирования контента, применяя его в своей поисковой системе. News Corp утверждает, что индексированные материалы не просто отображаются в поисковой выдаче, но и могут быть монетизированы или переданы третьим сторонам. В письме содержится требование немедленно прекратить подобные практики и возместить причинённый ущерб. В ответ Brave подала судебный иск, настаивая на том, что индексация веб-страниц является фундаментальным механизмом работы поисковых систем — от Google и Bing до Brave Search. Компания заявила, что её деятельность соответствует принципу «добросовестного использования», поскольку она не копирует контент в исходном виде, а лишь создаёт ссылки на оригинальные материалы. Brave также подчеркнула, что News Corp пытается воспользоваться своим влиянием, чтобы создать искусственные барьеры, затрудняющие доступ новых игроков к рынку поисковых технологий. По оценкам Brave, её поисковая система Brave Search занимает менее 1 % мирового рынка, в то время как Google контролирует почти 90 %, а оставшуюся часть делят Microsoft Bing и другие сервисы. Компания подчёркивает, что её поисковый движок не использует API Google или Bing, а формирует собственный индекс на основе анализа веб-страниц. Однако News Corp утверждает, что Brave незаконно коммерциализирует чужой контент, применяя материалы без лицензии, что наносит урон медиаотрасли. Brave также предупредила, что претензии News Corp могут существенно замедлить развитие генеративного ИИ. Современные ИИ-модели, включая ChatGPT компании OpenAI и Gemini компании Google, активно используют поисковые индексы для генерации ответов. Если News Corp добьётся запрета на индексацию её ресурсов, это создаст опасный прецедент, который в перспективе может ограничить работу не только поисковых систем, но и технологий ИИ в целом. 
Источник изображения: Brave Software К иску против Brave News Corp подключила свои британские и австралийские подразделения, а также дочернюю компанию Dow Jones, что подчёркивает международный масштаб конфликта. Этот процесс является частью стратегии медиаиндустрии по защите авторских прав и противодействию использованию журналистского контента технологическими корпорациями. Стоит отметить, что в октябре News Corp уже подала аналогичный иск против Perplexity AI, обвинив стартап в массовом копировании её статей и использовании их в ответах на запросы пользователей без должного указания источника. Генеральный директор News Corp Роберт Томсон (Robert Thomson) жёстко раскритиковал Brave, заявив, что её бизнес-модель основана на паразитировании на чужом контенте. «Несанкционированное сканирование и последующая перепродажа наших материалов поисковым системам и компаниям, занимающимся ИИ, — это не „добросовестное использование“, а наглое злоупотребление», — подчеркнул Томсон. Он также отметил, что Brave использует чужой контент для получения прибыли, не создавая при этом никакой оригинальной ценности. Этот судебный процесс — лишь один из множества конфликтов между медиаотраслью и технологическими корпорациями. В последние годы крупнейшие издатели добиваются законодательного регулирования использования их контента в цифровой среде. В 2023 году The New York Times подала в суд на OpenAI, обвинив компанию в обучении ChatGPT на её статьях без разрешения. Brave требует от суда признания законности индексации веб-контента, утверждая, что её поисковая деятельность не нарушает авторских прав, а способствует свободному доступу к информации. Однако если суд встанет на сторону News Corp, это может создать прецедент, согласно которому поисковые системы и компании в сфере ИИ будут обязаны получать лицензии на использование новостного контента. Такой сценарий может привести к формированию закрытых цифровых экосистем, в которых медиахолдинги будут монетизировать доступ к своим материалам, значительно ограничивая их распространение. Олды тут? Sony обновила прошивку PlayStation 3, несмотря на то, что устройству почти 20 лет
06.03.2025 [19:02],
Сергей Сурабекянц
Компания Sony только что выпустила обновление системного программного обеспечения для своей игровой консоли PS3, которой в этом году исполняется 19 лет. Компания сообщила, что это обновление с номером версии 4.92 улучшает производительность системы, а также обновляет ключ шифрования проигрывателя Blu-ray, чтобы обеспечить воспроизведение дисков с фильмами. 
Источник изображения: Eurogamer Обновления такого рода происходят ежегодно, поскольку срок актуальности ключа шифрования Advanced Access Content System (AACS), используемого для защиты авторских прав, регулярно истекает. Эта технология защиты авторских прав требует наличия соответствующего ключа как на диске, так и на консоли для воспроизведения новых фильмов. На более «свежих» консолях PS4 и PS5 применяется та же технология, но эти устройства умеют получать новый ключ автоматически, в то время как на PS3 это можно сделать лишь при обновлении прошивки. Компания прекратила производство PS3 ещё в 2017 году, примерно через десять лет после её первого запуска. По состоянию на март 2017 года было продано более 87,4 млн консолей PS3. PS5 продалась в количестве 75 млн единиц, показатели продаж PS4 примерно такие же. Судя по всему, Sony продолжит выпускать обновления ключа шифрования AACS для PS3, пока полностью не прекратит поддержку консоли. «Разве этого мы хотим?» — 1000 артистов выпустили безмолвный альбом-протест против воровства музыки в угоду ИИ
25.02.2025 [18:21],
Сергей Сурабекянц
Великобритания собирается изменить закон об авторском праве, чтобы привлечь в страну больше ИИ-компаний. Обновлённый закон позволит обучать модели ИИ на контенте из интернета без разрешения владельцев авторских прав и оплаты, если создатели заранее не «откажутся» от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is This What We Want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. 
Источник изображения: Pixabay Альбом «Is This What We Want?», который иначе как «криком души» не назвать, содержит треки Кейт Буш (Kate Bush), Имоджен Хип (Imogen Heap), а также современных классических композиторов Макса Рихтера (Max Richter) и Томаса Хьюитта Джонса (Thomas Hewitt Jones). Их соавторами выступили Энни Леннокс (Annie Lennox), Дэймон Албарн (Damon Albarn), Билли Оушен (Billy Ocean), The Clash, Pet Shop Boys, Mystery Jets, Юсуф (Yusuf), Кэт Стивенс (Cat Stevens), Риз Ахмед (Riz Ahmed), Тори Амос (Tori Amos), Ханс Циммер (Hans Zimmer) и другие композиторы и исполнители. Но это не совместное выступление артистов, подобное всемирно известной композиции «We are the world». Новый альбом вообще не содержит музыки, как таковой. Вместо этого артисты собрали записи пустых студий и концертных залов — символическое представление того, к чему приведут запланированные изменения в законе об авторском праве. Названия 12 треков, вошедших в альбом, образуют предложение «Британское правительство не должно легализовать воровство музыки в целях получения выгоды компаниями, занимающимися искусственным интеллектом» («The British government must not legalize music theft to benefit AI companies»). 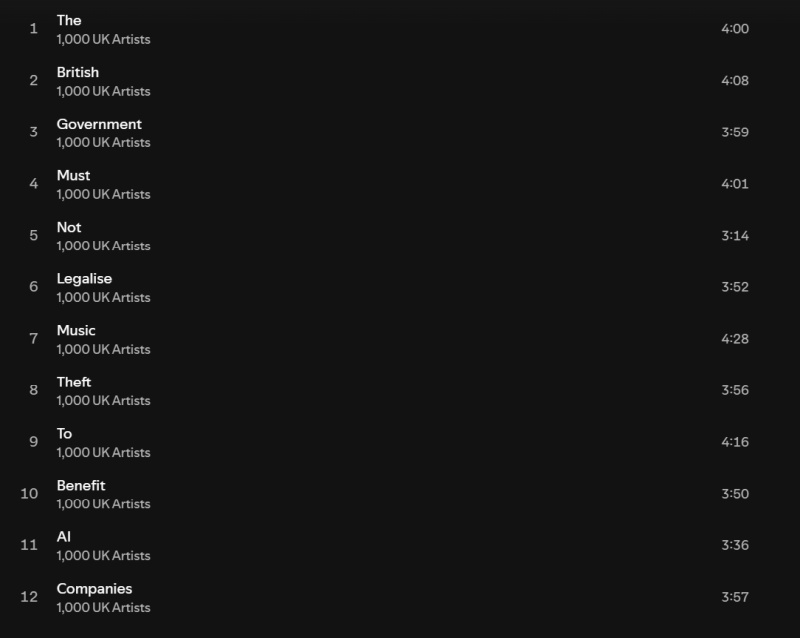
Источник изображений: Spotify «Вы можете услышать, как носятся мои кошки, — так Хьюитт Джонс описал свой вклад в альбом. — У меня в студии две кошки, которые целыми днями мешают мне работать». Организатор проекта Эд Ньютон-Рекс (Ed Newton-Rex) возглавляет масштабную кампанию против обучения ИИ без лицензии. Опубликованную им петицию подписали более 47 000 писателей, художников, актёров и других представителей творческих кругов, причём почти 10 000 из них примкнули к протестам в последние пять недель, после объявления правительства Великобритании о масштабном изменении стратегии в области ИИ и авторского права. Выпуск альбома состоится как раз перед запланированными изменениями в законе об авторском праве в Великобритании, согласно которым артисты, не желающие, чтобы их работы использовались для обучения ИИ, должны будут заблаговременно «отказаться» от такой перспективы. Это фактически создаёт проигрышную ситуацию для музыкантов, поскольку нет никакого метода заблаговременного отказа или чёткого способа отслеживать, какой именно материал был использован для обучения ИИ. «Мы знаем, что схемы отказа просто не принимаются», — утверждает Ньютон-Рекс. «Нам десятилетиями говорили, что мы должны делиться своей работой в Сети, потому что это хорошо для распространения. Но теперь компании, занимающиеся ИИ, и, что невероятно, правительства разворачиваются и говорят: “Ну, вы выкладываете это в сеть бесплатно…” — говорит Ньютон-Рекс. — Так что теперь артисты просто прекращают создавать и делиться своей работой». По словам артистов, единственным решением в этой ситуации является выпуск своих произведений на других рынках, где они будут лучше защищены, например, в Швейцарии.  Альбом «Is This What We Want?» — лишь одна из форм протеста против сложившейся ситуации с авторским правом при обучении ИИ. Организаторы сообщили, что альбом будет широко размещён на музыкальных платформах уже сегодня, и любые пожертвования или доходы от его реализации будут направлены в благотворительную организацию Help Musicians. Суд поддержал Thomson Reuters в деле об ИИ и авторских правах
13.02.2025 [07:09],
Анжелла Марина
Американский суд вынес решение в пользу Thomson Reuters в громком деле об использовании искусственного интеллекта (ИИ) и авторских правах. Судья отклонил аргумент о «добросовестном использовании» и признал, что копирование контента без разрешения является нарушением закона. Ответчиком по делу выступил ИИ-стартап Ross Intelligence, который пытался создать конкурирующий продукт на основе данных Thomson Reuters. 
Источник изображения: Conny Schneider / Unsplash Как пишет PCMag, иск был подан ещё в 2020 году. Thomson Reuters обвинила Ross Intelligence в незаконном использовании материалов платной юридической платформы Westlaw. В частности, стартап копировал закрытые краткие аннотации положений того или иного закона в конкретных судебных делах, которые составляли редакторы Westlaw. Судья Стефанос Бибас (Stephanos Bibas) постановил, что такие аннотации защищены авторским правом, и их использование без разрешения нарушает закон. ИИ-стартап пытался защититься, утверждая, что его действия были «невинным нарушением», однако суд не принял этот аргумент. Судья также рассмотрел стандартные критерии добросовестного использования (коммерческая или некоммерческая природа использования), характер защищённого материала и влияние на рынок. В итоге два фактора были в пользу Ross Intelligence, а два — в пользу Thomson Reuters. Решающим оказался фактор нанесения ущерба для рынка. Суд постановил, что Ross Intelligence использовал контент для создания конкурирующего продукта, нарушая авторское право. При этом судья подчеркнул, что речь идёт не о генеративном ИИ, а о прямом копировании текстов без разрешения. Данное судебное решение может стать важным прецедентом, особенно на фоне множества исков против разработчиков искусственного интеллекта. Например, The New York Times судится с OpenAI и Microsoft, обвиняя их в незаконном использовании журналистских материалов. Иск против компании Perplexity подал американский медиахолдинг News Corp, и ещё несколько крупных канадских СМИ судятся также с OpenAI. Интересно, что некоторые компании предпочли заключить коммерческое соглашение вместо судебных разбирательств. Например, медиаходинг Vox Media и журнал The Atlantic подписали сделку с OpenAI, а новостной сайт Axios — с Meta✴✴. Эти соглашения позволят компаниям контролировать использование их материалов в ИИ-моделях. YouTube запустит ИИ-дубляж уже в феврале, а в будущем ИИ будет определять возраст зрителей и защищать блогеров
11.02.2025 [20:21],
Сергей Сурабекянц
Сегодня генеральный директор YouTube Нил Мохан (Neal Mohan) назвал ИИ одной из четырёх «крупных ставок» компании на 2025 год. Он подчеркнул инвестиции компании в инструменты ИИ для создателей, в том числе для генерации идей, создания миниатюр и синхронного перевода. ИИ-дубляж станет доступен для создателей уже в этом месяце. Также ИИ будет определять возраст пользователей, чтобы предлагать соответствующий контент. А ещё ИИ будет защищать блогеров от ИИ. 
Источник изображения: Pixabay Мохан сообщил, что уже в этом месяце функция автоматического дубляжа станет доступной всем создателям в партнёрской программе YouTube. Этот инструмент поможет кардинально увеличить охват аудитории благодаря синхронному переводу на несколько языков с минимальными усилиями. YouTube планирует использовать ИИ в том числе и для контроля за использованием ИИ (как говорят следователи — «главное в процессе следствия не выйти на себя»). В первую очередь будет существенно расширена программа взаимодействия с агентством Creative Artists Agency (CAA). Она должна защитить людей творческих профессий, включая художников, актёров, музыкантов и спортсменов, от копирования их внешности или голоса. CAA расширит возможности существующей системы идентификации авторских прав Content ID, обнаруживая образы или голоса, созданные с помощью инструментов ИИ. Мохан рассказал, что уже в этом году YouTube начнёт использовать технологию машинного обучения для оценки возраста пользователей, чтобы показывать соответствующие возрасту рекомендации. Он не раскрыл способы, которыми новая технология будет определять возраст. Также он обошёл стороной вопрос о возможных ошибках ИИ, которые обязательно возникнут. За последний год YouTube развернул целый ряд ИИ-функций для создания изображений, фонов видео или генерации звукового сопровождения к коротким роликам. Однако добавление ИИ в сам процесс создания видео не обошлось без споров, поскольку противники этого процесса уверены, что некачественный контент, созданный ИИ, заполонит YouTube, вытеснив авторские произведения. Помимо дальнейшего безоглядного внедрения ИИ, YouTube в 2025 году ставит перед собой другие, довольно амбициозные задачи:
«Масштабы поразительны»: Meta✴ незаконно раздавала на торрентах терабайты файлов, заявили правообладатели
07.02.2025 [17:59],
Сергей Сурабекянц
Писатели и владельцы авторских прав подали иск против Meta✴✴. Они утверждают, что недавно раскрытые внутренние электронные письма работников компании предоставляют весомые доказательства масштабного нарушения Meta✴✴ авторских прав. По словам истцов, компания обучала свои модели ИИ на пиратских книгах и участвовала в гигантской незаконной торрент-раздаче, включающей в себя десятки миллионов произведений. 
Источник изображения: unsplash.com В исковом заявлении владельцы авторских прав утверждают, что Meta✴✴ участвовала в торрент-раздаче «не менее 81,7 терабайт данных из нескольких теневых библиотек через сайт Anna’s Archive, включая не менее 35,7 терабайт данных из Z-Library и LibGen, […] масштабы незаконной схемы торрентов Meta✴✴ поразительны». В исковом заявлении подчёркивается, что «гораздо меньшие акты пиратства данных — всего 0,008 процента от количества защищённых авторским правом работ, которые Meta✴✴ пиратски скопировала» приводили к уголовному преследованию. Meta✴✴ долгое время сопротивлялась попыткам раскрытия информации о нарушении компанией авторских прав и участии в незаконных торрент-раздачах. В ходатайстве об отклонении иска компания утверждала, что обучение ИИ на данных библиотеки LibGen является «добросовестным использованием». Юристы компании заявили суду, что «истцы не ссылаются ни на один случай, в котором какая-либо часть какой-либо книги была фактически загружена третьей стороной с Meta✴✴ через торрент, не говоря уже о том, что книги истцов каким-либо образом распространялись Meta✴✴». Тем не менее в распоряжение владельцев авторских прав попали внутренние электронные письма инженера-исследователя Meta✴✴ Николая Башлыкова, в которых он выражает озабоченность по поводу использования корпоративных компьютеров и IP-адресов Meta✴✴ «для загрузки пиратского контента через торренты». В сентябре 2023 года после консультаций с юристами Башлыков снова попытался привлечь внимание к проблеме, подчеркнув в письме, что «использование торрентов повлечёт за собой “раздачу” файлов, т. е. распространение контента за пределами компании, что может быть юридически недопустимо». Предупреждения Башлыкова, по-видимому, не были услышаны, поскольку Meta✴✴ продолжала загрузку и раздачу терабайтов данных из нескольких теневых библиотек вплоть до апреля 2024 года, приняв некоторые шаги для маскировки своей деятельности. Предположительно, Meta✴✴ пыталась скрыть раздачу, не используя серверы Facebook✴✴ при загрузке набора данных, чтобы избежать отслеживания источника раздачи. Компания также якобы изменила настройки торрент-клиента, чтобы минимизировать объём раздаваемой информации. Поскольку ограниченное раскрытие информации в настоящее время продолжается, компания уже не оспаривает сам факт нарушения авторских прав. Для Meta✴✴ ситуация теперь осложняется обвинениями в участии в массовом распространении пиратского контента. Тем не менее, представитель Meta✴✴ заявил в суде, что компания планирует «установить факты и развенчать это беспочвенное обвинение в порядке упрощённого судопроизводства». Российские медиа объявили войну пиратам: число заблокированных ссылок в поисковиках удвоилось за год
31.01.2025 [13:05],
Владимир Мироненко
В 2024 году резко выросло количество обращений российских медиахолдингов-правообладателей по поводу блокировки в выдаче поисковиков ссылок на пиратский контент, пишет «Коммерсантъ». 
Источник изображения: Glenn Carstens-Peters/unsplash.com Как сообщила «Коммерсанту» компания «Яндекс», число ссылок на сайты и страницы с пиратским контентом, которые российские правообладатели внесли в реестр в рамках антипиратского меморандума, в 2024 году составило 180 млн, более чем вдвое превысив показатель 2023 года в размере 89 млн ссылок. В 2022 году в реестр было внесено 76,5 млн ссылок, а с начала действия меморандума в 2018 году до марта 2021 года «Яндекс» добавила в реестр 15 млн ссылок на пиратский контент. Антипиратский меморандум был подписан поисковиками «Яндекс», Mail.ru, Rambler и правообладателями в РФ, включая производителей видеоконтента, 1 ноября 2018 года. Согласно документу, интернет-платформы обязаны удалять из выдачи ссылки на пиратские ресурсы во внесудебном порядке. В сентябре 2023 года Роскомнадзор сообщил о присоединении к меморандуму книжной и музыкальной отраслей. Впрочем, как утверждают издательства, включение в реестр пока не принесло ожидаемых результатов, поскольку он разрабатывался исключительно для нужд кинокомпаний. В «Газпром-медиа холдинге» (ГПМХ, включает телеканалы НТВ, ТНТ, ТВ-3, «Пятница!» и др.) рассказали, что в прошлом году инициировали блокировку около 17,4 тыс. сайтов. В частности, из выдачи «Яндекса» по его запросу было удалено более 6,2 млн ссылок, из выдачи Google — около 5 млн ссылок, что превышает показатель 2023 года на 17 %. Наибольшей популярностью у пиратов пользовались такие проекты, как «Жвачка», «Плевако», «Фарма», «Жуки», «Прелесть», «Красный 5», «Мир! Дружба! Жвачка!», «Бременские музыканты», «Сто лет тому вперед». В свою очередь, в «Национальной медиа группе» направили примерно на 60 % больше запросов, чем в 2023 году, на блокировку пиратского контента, включая такие проекты, как «Трудные подростки», «Слово пацана. Кровь на асфальте», «Библиотекарь», «Плакса». Также в 2024 году выросло число исков, в связи с нарушением авторских прав. Например, ГПМХ инициировал 904 судебных процесса, по 775 из них вынесены решения в пользу холдинга с возмещением ущерба в более чем 15,9 млн руб., что на 30 % больше, чем в 2023 году. Большие суммы взысканий заставляют нарушителей идти с ГПМХ на контакт в поисках путей урегулирования конфликта, говорит директор департамента обеспечения защиты интеллектуальной собственности «ГПМ Цифровые инновации» Павел Русаков. «Например, в 2024 году мы провели успешные переговоры с администраторами нескольких пиратских сайтов, по итогам которых с площадок был удалён контент компаний ГПМХ», — сообщил он. В Медиакоммуникационном союзе (объединяет телеком- и медиакомпании) связывают увеличение числа пиратских ссылок в реестре с ростом эффективности работы правообладателей по защите контента. При этом число охраняемых единиц контента не сильно выросло, утверждают источники на медиарынке. По данным «Индекса Кинопоиска Pro», российские онлайн-кинотеатры даже сократили в 2024 году число выпускаемых проектов на 25 %, с 201 до 151. Как полагает источник «Коммерсанта», такой рост показателей можно объяснить только двумя факторами: или крупные российские правообладатели резко увеличили число ссылок на одну охраняемую единицу контента, или же иностранные правообладатели (Sony, Universal, Warner, Disney) отказались от правовой охраны своего контента. — ИИ оставили без авторских прав на творчество, но есть и исключения
31.01.2025 [11:24],
Владимир Фетисов
Медиаконтент, созданный с помощью генеративных нейросетей и основанный только на текстовых подсказках автора, не защищён действующим в США законом об авторском праве. Об этом сказано в опубликованном на этой неделе документе Бюро авторского права США по вопросам политики ведомства в сфере ИИ и возможности защиты авторским правом контента, создаваемого с помощью нейросетей. 
Источник изображения: Copilot В ведомстве отметили, что при определении произведения, подлежащего защите авторским правом, основным моментом является творческая роль человека. Существует разница между искусственным интеллектом, используемым в качестве вспомогательного инструмента в творческом процессе, и искусственным интеллектом, заменяющим человеческое творчество. Это означает, что созданное с помощью ИИ произведение может быть защищено авторским правом, если алгоритм использовался для модификации работы человека. Для художников такими работами могут стать рисунки, которые обрабатывались ИИ-алгоритмами для добавления разных эффектов, например, эффекта 3D. Полностью сгенерированные ИИ изображения по-прежнему не будут защищены авторским правом, но это не касается работ, в которых после обработки остаётся узнаваема изначальная работа человека. Это также касается случаев, когда автор добавляет на принадлежащее ему изображение какие-то новые элементы с помощью ИИ. Аналогичным образом видео с добавленными с помощью ИИ эффектами по-прежнему будут защищены законом об авторском праве. Бюро авторского права США не исключает, что по мере развития технологий действующее законодательство потребует внесения изменений. Позднее в этом году ведомство планирует выпустить окончательную версию отчёта по результатам проведённых исследований в сфере генерации контента и произведений искусства с помощью ИИ. Telegram удалил официальный канал RuTracker
20.01.2025 [16:20],
Владимир Мироненко
Telegram заблокировал доступ к официальному каналу популярного в русскоязычном сегменте интернета торрент-трекера RuTracker за нарушение авторских прав, сообщил ресурс CNews. 
Источник изображения: Alex Kotliarskyi/unsplash.com Telegram-канал «RuTracker.org – официальный канал» (@rutracker_news) был создан в 2017 году, имел небольшую базу подписчиков в пределах 29 тыс. человек и не отличался особой активностью. Например, в 2024 году в нём не было ни одного сообщения, а за весь период деятельности Telegram-канала его администрация разместила всего два десятка сообщений. Сам торрент-трекер RuTracker («Рутрекер») начал работу в 2004 году под названием Torrents.ru. После того как мае 2015 года издательство «Эксмо» обратилось в Мосгорсуд с требованием полной блокировки сервиса на территории России в связи с нарушением авторских прав, суд удовлетворил его ходатайство, и сервис был заблокирован в январе 2016 года. Как пишет CNews, по состоянию на 20 января 2025 года, домен rutracker.org был включен в реестр Роскомнадзора на основании решений Мосгорсуда, вынесенных в ноябре и декабре 2015 года соответственно. В начале 2025 года Telegram также заблокировал по требованию правообладателей англоязычные каналы крупной теневой библиотеки Z-Library и метапоисковика Anna’s Archive. На момент блокировки аудитория Telegram-канала Z-Library Official превышала 629 тыс. человек. США включили «ВКонтакте» и «Авито» в список пиратов и продавцов контрафакта
13.01.2025 [12:02],
Владимир Мироненко
Соцсеть «ВКонтакте» и маркетплейс «Авито» внесли в ежегодный обзор рынков контрафакции и пиратства торгового представительства США (USTR) за 2024 год, поскольку они с 2022 года якобы отказываются удалять пиратский контент или нарушающие законы товары по запросу правообладателей из США. В «Авито» опровергли утверждение, что на платформе продаются товары, нарушающие авторские права, пишет «Коммерсант». 
Источник изображения: Anete Lūsiņa/unsplash.com USTR включало в свой список «ВКонтакте» и «Авито» и в 2023 году. Как утверждает американское ведомство, обе площадки не реагируют на обращения правообладателей из США, сообщающих о нарушении своих интеллектуальных прав. В частности, по словам USTR, «Авито» игнорирует множество запросов от правообладателей и не борется с продажей контрафакта. В списке USTR по итогам 2024 года также оказались такие IT-сервисы российского происхождения, как торрент-трекер Rutracker, файлообменик Rapidgator, библиотеки научной литературы LibGen и Sci-Hub. Также который год USTR включает в список российские рынки «Дубровка», «Садовод» и торговый центр «Горбушкин двор». Данный список, включающий страны и компании, публикуется с 2006 года и носит в первую очередь рекомендательный характер для тех, кто борется с продажей контрафакта. Для компаний, попавших в него, это несёт скорее репутационные риски, поскольку санкции не предусмотрены. В числе стран, где тоже наблюдаются проблемы с пиратством и контрафактом, ведомство назвало Китай, Индию, Турцию и т.д. В «Авито» отметили, что на платформе «предусмотрен налаженный процесс работы с любыми правообладателями вне зависимости от страны происхождения». В случае получения подтверждения нарушений прав контент блокируют. При этом удалённое объявление больше не появится на маркетплейсе. В «ВКонтакте» не стали комментировать действия американской организации. Как утверждает собеседник «Коммерсанта» на рынке цифровых платформ, включение сервисов в список «опасных» ресурсов, распространяющих пиратский контент и контрафакт, может быть вызвано, в том числе, недостаточным пониманием российского рынка западными исследователями. Вместе с тем исполнительный директор юридической компании «Медиа-НН» Георгий Давидьян отметил, что у администрации ресурсов «нет права не реагировать» на обращения правообладателей, которые сопровождаются документальным обоснованием. Собеседник «Коммерсанта» предупредил, что игнорирование требований зарубежных правообладателей может привести к удалению приложений таких сервисов из App Store или Google Play, хотя включение в список USTR на это не влияет. Эксперты также допускают, что отказ ресурсов реагировать на обоснованные обращения американских правообладателей может привести к тому, что те могут взыскать с них денежные компенсации. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



