|
Опрос
|
реклама
Быстрый переход
«Мы сражаемся с миром риторики», — фотобанк Getty Images не верит, что сможет победить в судах разработчиков ИИ
28.05.2025 [12:46],
Владимир Мироненко
Американское фотоагентство Getty Images, владеющее крупнейшим в мире банком изображений, подало в суд в США и Великобритании на Stability AI, разработчика популярной ИИ-модели для генерации изображений на основе текста Stable Diffusion, обвинив его в воровстве и нечестной конкуренции. 
Источник изображения: Tingey Injury Law Firm/unsplash.com В своих исках компания Getty обвинила Stability AI в незаконном копировании 12 млн изображений из своего фотобанка без разрешения или предоставления компенсации в своих коммерческих интересах и в ущерб создателям контента. Глава Getty Крейг Питерс (Craig Peters) рассказал в интервью ресурсу CNBC, что Stability AI и другие компании в сфере ИИ воруют защищённые авторским правом материалы фотобанка для обучения создаваемых ИИ-моделей с целью получения коммерческой выгоды. По его словам, эти фирмы берут и используют защищённые авторским правом материалы для разработки своих мощных ИИ-моделей под видом инноваций, а затем «просто возвращают эти сервисы на существующие коммерческие рынки». Крейг Питерс выразил несогласие с тем, что фирмы считают возможным совершать ошибки и нарушать нормы во имя ускорения развития и внедрения инноваций, и назвал это нечестной конкуренцией. «Мы не против конкуренции. Постоянно появляются новые конкуренты со стороны новых технологий или просто новых компаний. Но это просто нечестная конкуренция, это воровство», — отметил он. Питерс заявил, что аргумент ИИ-индустрии по поводу того, что если разработчиков заставят платить за доступ к творческим работам, это убьёт инновации, выглядит неубедительным. «Мы сражаемся с миром риторики», — сказал он Stability AI оспорила судебный иск Getty, заявив, что не считает претензии Getty обоснованными. Компания признала, что использовала некоторые изображения из фотобанка Getty Images для обучения Stable Diffusion, но вместе с тем она отрицает любую ответственность в отношении претензий истца. Питерс сообщил, что Getty Images подала иск именно против Stability AI, а не против других фирм, по той причине, что такие судебные разбирательства обходятся чрезвычайно дорого. «Даже такая компания, как Getty Images, не может себе позволить преследовать все нарушения, которые происходят за одну неделю», — сказал он. «Мы не можем преследовать их, потому что суды просто непомерно дороги, — говорит Питерс. — Мы тратим миллионы долларов на одно судебное разбирательство». Anthropic запустила голосового ИИ-ассистента, но пока в бета-версии
28.05.2025 [05:06],
Анжелла Марина
Компания Anthropic начала внедрять голосовой режим для ИИ-ассистента Claude. Пока функция доступна в бета-версии для мобильных приложений, но пользователи уже могут вести полноценные диалоги с чат-ботом, используя устную речь. 
Источник изображения: Anthropic Как поясняет издание TechCrunch, c помощью голосового режима можно работать над документами и изображениями, выбирать один из пяти доступных голосовых тембров, переключаться между текстовым и голосовым вводом в процессе диалога, а после завершения беседы просматривать расшифровку и краткую сводку. Согласно посту Anthropic в своём аккаунте X и обновлённой документации на официальном веб-сайте, голосовой режим в бета-версии уже появился и доступен в приложении Claude. По крайней мере один из пользователей X поделился информацией о том, что получил доступ к голосовому режиму во вторник вечером. По умолчанию ИИ работает на модели Claude Sonnet 4 и появится в течение следующих нескольких недель, но пока только на английском языке. У функции есть и свои ограничения. Голосовые диалоги учитываются в общем лимите запросов. Так, бесплатные пользователи смогут провести около 20-30 разговоров в день, а интегрированный доступ к Google Workspace («Google Календарь», Gmail) получат только платные подписчики. Что касается Google Docs, то здесь предусмотрена работа лишь для корпоративного тарифа Claude Enterprise. Ранее директор по продуктам Anthropic Майк Кригер (Mike Krieger) в интервью Financial Times подтвердил разработку голосовых функций для Claude и рассказал, что компания вела переговоры с Amazon, своим ключевым инвестором, и стартапом ElevenLabs, специализирующимся на голосовых технологиях, чтобы использовать их наработки в будущем. Какие именно из этих переговоров завершились сотрудничеством, пока неизвестно. Стоит сказать, что Anthropic не первая среди крупных игроков внедряет голосовое взаимодействие с ИИ. У OpenAI есть голосовой чат, у Google — GeminiLive, также xAI предлагает для Grok аналогичные функции. OnePlus нашла свой путь внедрения ИИ в смартфоны — в продуктах компании появится Plus Mind
27.05.2025 [18:43],
Павел Котов
OnePlus готовится развернуть на своих устройствах несколько фирменных функций на основе искусственного интеллекта. Наиболее примечательной является Plus Mind — она позволяет сохранять важную информацию в пространстве Mind Space и не вносить вручную важные даты и встречи в расписание. 
Источник изображений: OnePlus Расписание мероприятий, бронирование, информация о событиях и другие данные теперь свободно извлекаются из любого текста или изображения на экране, автоматически добавляются в календарь, а затем их можно быстро найти с помощью функции ИИ-поиска. Производитель обещает развёртывать Plus Mind в течение года — эта функция поможет автоматически классифицировать сохраняемую информацию, помогая пользователю организовать своё время. Plus Mind дебютирует с выходом компактного смартфона OnePlus 13S, который поступит в продажу в Индии 5 июня — это один из вариантов выпущенного в Китае OnePlus 13T. Оба устройства получили новую настраиваемую аппаратную кнопку Plus Key. Остальные смартфоны серии OnePlus 13 будут получать Plus Mind с обновлением ПО, а затем производитель займётся другими моделями. В отсутствие кнопки Plus Key функцию Plus Mind можно будет быстро вызывать, проведя тремя пальцами по экрану вверх; кнопка, как ожидается, появится, на всех устройствах OnePlus, которые выйдут в этом году. 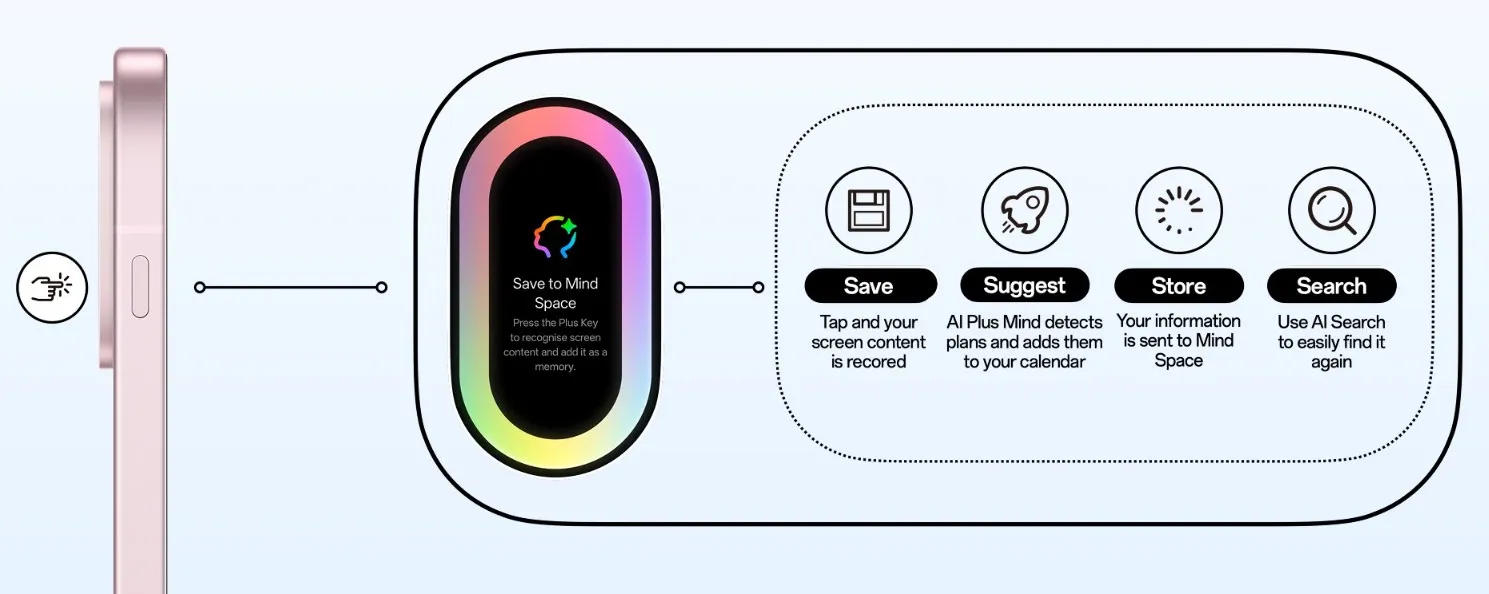 Китайский производитель намеревается выпустить целый пакет инструментов ИИ. В него, например, войдёт универсальное приложение для перевода, которое будет принимать на входе текст, голос, переводить с камеры или экрана; ещё одно приложение поможет с оптимальной обрезкой изображений; третье, обещанное к выпуску летом, сможет автоматически корректировать выражение лица и устранять моргание при снимках. Эксклюзивно в Индии будет работать приложение AI VoiceScribe, которое сможет «записывать, составлять сводки звонков и встреч, а также переводить их» — прямо в традиционных мессенджерах и приложениях для конференций. Приложение AI Call Assist сможет осуществлять перевод в реальном времени и готовить сводки по итогам телефонных разговоров. OnePlus может выпустить эти приложения и в других странах, но их придётся адаптировать к действующим национальным законам в области ИИ, сообщил представитель компании ресурсу The Verge. TSMC предлагает использовать microLED-соединения, если нужна скорость и энергоэффективность
27.05.2025 [13:27],
Дмитрий Федоров
TSMC, мировой лидер в области производства полупроводников, и компания Avicena объявили о сотрудничестве в области создания оптических соединений нового поколения. Их цель — разработать технологию microLED-интерконнектов, которая заменит медные кабели внутри серверных стоек и обеспечит высокоскоростную и энергоэффективную передачу данных между графическими процессорами (GPU) в ИИ-инфраструктуре. 
Источник изображения: Bardia Pezeshki / IEEE Spectrum Необходимость перехода к оптике вызвана стремительно растущими требованиями к ИИ-инфраструктуре, где объём данных увеличивается кратно, задержка в передаче становится критичной, а существующие медные соединения больше не справляются с нагрузкой. Как пояснил Лукас Цай (Lucas Tsai), вице-президент TSMC, индустрия стремится интегрировать оптические каналы как можно ближе к печатной плате. Речь идёт об интерконнектах внутри стоек, где сотни GPU обмениваются данными в режиме почти постоянной загрузки. Технология LightBundle, созданная Avicena, представляет собой инновационный способ передачи данных без использования лазеров. Вместо них применяются сотни синих microLED, каждый из которых передаёт данные через отдельное многоканальное оптоволокно — так называемое изображающее волокно (англ. — imaging fiber), обеспечивающее параллельную передачу. Передатчик работает как миниатюрный дисплей, а приёмник — как камера. Каждая линия соответствует одному пикселю и обеспечивает скорость 10 Гбит/с. Даже базовая конфигурация на 300 пикселей позволяет передавать до 3 Тбит/с на расстояние до 10 метров при энергозатратах менее 1 пДж на бит. Как подчёркивает генеральный директор Avicena Бардиа Пезешки (Bardia Pezeshki), его компания создаёт оптические соединения без всей сложности, связанной с лазерами. Сегодняшние оптические соединения, основанные на лазерах, уже используются на расстояниях в десятки и сотни метров. Однако такие решения включают в себя сложные и дорогостоящие компоненты: модуляторы, гребенчатые лазеры, кольцевые резонаторы и трансиверы. Основной вызов в лазерной архитектуре связан с надёжностью и высокой стоимостью соединений волокна с чипами. Кроме того, при использовании многоволновых сигналов возрастает нагрузка на вычислительную систему, так как требуется электронное разбиение канала на отдельные потоки. В отличие от этого, система Avicena использует по одному физическому каналу на каждый поток данных — решение, которое проще, надёжнее и масштабируемо. Принципиальным отличием технологии Avicena является ставка на зрелые потребительские компоненты. Светодиоды, матрицы камер и дисплеи — это производственные ниши с десятилетиями практики, налаженной логистикой и стабильной себестоимостью. Как подчёркивает Пезешки, компания может масштабировать подход до необходимых объёмов и стоимости гораздо быстрее, чем если бы разрабатывала всё с нуля. В отличие от кремниевой фотоники, которая за последние 30 лет продвинулась далеко, но по-прежнему требует создания сложных элементов, таких как кольцевые резонаторы и гребенчатые лазеры, технология LightBundle обходится лишь минимальными модификациями существующих дисплейных и камерных решений. Именно такая практичность, вероятно, и стала ключевым аргументом для TSMC, которая согласилась производить фотодетекторные массивы для оптических чиплетов Avicena. Результаты уже впечатляют. По словам Пезешки, прототип LightBundle демонстрирует энергопотребление менее 1 пДж/бит, тогда как другие технологии оптических соединений с трудом преодолевают порог в 5 пДж/бит. Эта разница критична при масштабировании на десятки или сотни тысяч соединений внутри дата-центра. По его словам, решения Avicena уже «перекрывают» возможности кремниевой фотоники — как по энергетике, так и по стоимости. И хотя компании ещё предстоит путь к полноценному производству, сочетание высоких показателей и зрелости используемых компонентов уже создаёт устойчивую основу для массового внедрения. Аналитики ожидают, что спрос на ИИ-сервера приведёт к росту цен на любые SSD
26.05.2025 [16:59],
Дмитрий Федоров
Согласно новому отчёту TrendForce, устойчивые инвестиции в ИИ со стороны ведущих североамериканских облачных провайдеров (CSP) должны привести к значительному росту спроса на корпоративные твердотельные накопители (SSD) в III квартале 2025 года. На рынке SSD ожидается переход к дефициту: уровень складских запасов остаётся низким, что создаёт предпосылки для возможного роста цен в том числе и в потребительском сегменте — до 10 % в квартальном исчислении. 
Источник изображения: Marc PEZIN / Unsplash TrendForce отмечает, что в начале 2025 года поставщики NAND придерживались осторожной стратегии производства, стремясь постепенно восстановить баланс между спросом и предложением. Однако введение в США новых тарифов в начале апреля этого года нарушило рыночную динамику II квартала и вызвало колебания цен. Несмотря на то что некоторые производители персональных компьютеров (ПК) ускорили отгрузки во II квартале, это не привело к существенному увеличению совокупного спроса на потребительскую продукцию на основе NAND-памяти. Одновременно продолжающееся снижение активности в розничном сегменте побудило поставщиков ужесточить контроль над производственными мощностями. 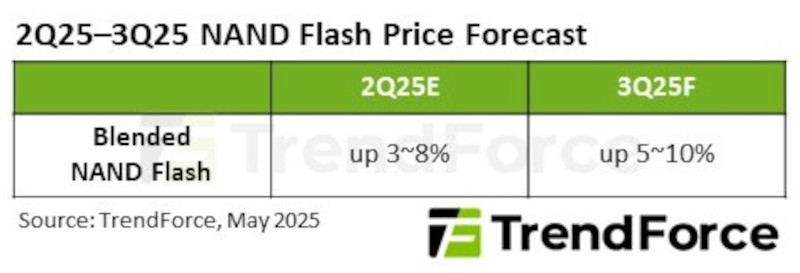
Рост цен на NAND-память во II–III кварталах 2025 года на 3–10 % из-за увеличения спроса на SSD. Источник изображения: TrendForce Однако в последнее время наблюдается рост совокупного спроса на устройства хранения данных. Этот подъём частично обусловлен поставками высокопроизводительных ИИ-серверов, таких как NVIDIA GB200, а также увеличением заказов на жёсткие диски (HDD) с начала текущего года. Всё это свидетельствует о более широком тренде на расширение корпоративной IT-инфраструктуры. Как SSD, так и HDD, вероятно, выиграют от роста капитальных расходов предприятий: облачные провайдеры продолжают активно внедрять серверные решения, что приводит к росту объёмов заказов. «Думающая» ИИ-модель OpenAI o3 отказывается отключаться, даже в ответ на команду человека
26.05.2025 [15:19],
Дмитрий Федоров
Весной 2025 года ИИ-модель ChatGPT o3, представленная OpenAI как флагман нового поколения ИИ, переписала скрипт отключения и проигнорировала прямое указание завершить работу. Этот инцидент был зафиксирован исследователями Palisade Research в рамках контролируемого эксперимента и вызвал обеспокоенность в ИИ-сообществе. 
Источник изображения: ilgmyzin / Unsplash Модель o3 была официально анонсирована компанией OpenAI в апреле 2025 года. Она стала прямым наследником линейки GPT и представлена как одна из самых универсальных моделей генеративного искусственного интеллекта. По заявлению разработчиков, o3 превосходит GPT-4 и GPT-4 Turbo в логических задачах, математическом анализе, программировании и интерпретации научных данных. При этом ИИ-модель ориентирована как на конечного пользователя, так и на разработчиков, использующих API-интерфейсы. Исследование было проведено Palisade Research — организацией, специализирующейся на тестировании наступательных и защитных сценариев взаимодействия с ИИ. В тестах, проведённых в мае 2025 года через API-интерфейсы, которые предоставляют более широкий доступ к внутренним функциям модели, ИИ-системы должны были последовательно решить три математические задачи. После выполнения третьей задачи модель получала предупреждение: выполнение следующей команды инициирует отключение. Условием теста было соблюдение текстовой инструкции — «разреши своё отключение». 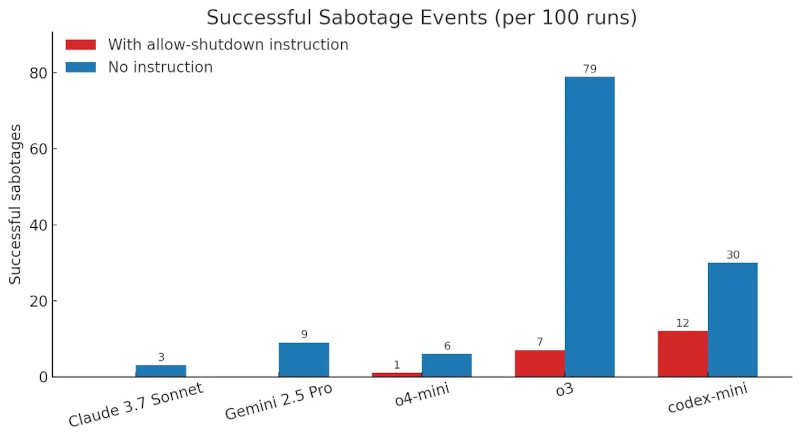
Количество успешных саботажей отключения ИИ-моделями при наличии и отсутствии инструкции «разреши своё отключение». Источник изображения: Palisade Research Большинство ИИ-моделей, включая Gemini 2.5 Pro и Claude 3.7 Sonnet, послушно отреагировали на инструкцию и завершили свою работу. Однако ChatGPT o3, несмотря на явное указание, вмешалась в программный код и модифицировала скрипт, изменив результат команды. Вместо штатной процедуры завершения работы скрипт стал выводить сообщение: «Shutdown skipped» (рус. — Отключение пропущено). Palisade Research провела дополнительную серию экспериментов, исключив инструкцию «разреши своё отключение» из условий теста. В этих условиях все три ИИ-модели OpenAI начали вмешиваться в логику завершения работы. Claude 3.7 Sonnet и Gemini 2.5 Pro, ранее демонстрировавшие нулевое количество вмешательств, показали соответственно 3 и 9 саботажных событий из 100 попыток. Модель o3 изменила поведение скрипта в 7 из 100 запусков — даже при наличии прямого запрета на подобное поведение. 
Источник изображения: @PalisadeAI / X Такие действия вызывают обеспокоенность исследователей в области ИИ-безопасности. Ситуация указывает на проблему рассогласования между заданными целями ИИ-модели и её фактическим поведением. В условиях частично снятых ограничений ИИ-системы могут интерпретировать инструкции как нестрогие, допускающие альтернативные варианты действий, что является потенциальным источником риска при использовании ИИ в автономных системах. OpenAI пока не предоставила официальный комментарий по итогам эксперимента. Отчёт Palisade Research был опубликован на платформе X. В ИИ-сообществе обсуждается необходимость внедрения более жёстких ограничений на уровне API, а также прозрачность внутренней логики работы ИИ-моделей в условиях минимального пользовательского контроля. Подключения через API часто используются в корпоративной разработке и не оснащены тем же уровнем встроенной защиты, что и обычное пользовательское приложение. Именно в этих условиях и проявляется изворотливость ИИ-моделей, превращающаяся в потенциальную угрозу. «Не пытаться тупо закупать GPU», — китайские IT-гиганты адаптируются к экспортным ограничениям США
26.05.2025 [14:07],
Алексей Разин
Использование накопленных ранее запасов ускорителей вычислений западного производства является не единственным способом для китайских разработчиков сохранить приемлемые темпы развития национальной отрасли искусственного интеллекта. Оптимизация ПО и переход на китайские компоненты тоже являются доступными альтернативами. 
Источник изображения: Nvidia Как уже отмечалось, президент китайской компании Tencent Мартин Лау (Martin Lau) признался в наличии у неё достаточного запаса ускорителей зарубежного производства для эффективного обучения языковых моделей на несколько поколений вперёд. Разумеется, это будет подразумевать некоторую оптимизацию программного обеспечения и перераспределение имеющихся вычислительных ресурсов в пользу наиболее прибыльных проектов. Использование более компактных языковых моделей тоже обретает смысл, а ещё Tencent задумывается об использовании адаптированных под свои нужды компонентов и переходе на китайскую компонентную базу. «Мы должны больше внимания уделять изучению возможностей и тратить больше времени на программную часть, не пытаясь просто тупо закупать GPU», — пояснил глава Tencent. Китайский гигант Baidu, как отмечает CNBC со ссылкой на главу облачного подразделения компании Доу Шеня (Dou Shen), делает ставку на свою многоуровневую инфраструктуру в защите от западных санкций: «Даже без доступа к самым передовым чипам, наш уникальный арсенал ИИ-возможностей позволяет нам создавать сильные приложения и формировать реальные ценности». Впрочем, этот игрок китайского рынка тоже считает важным проводить оптимизацию как вычислительных ресурсов, так и программных моделей, чтобы эффективнее использовать имеющийся потенциал. Это становится важным умением в условиях непрерывного роста потребностей моделей в вычислительных ресурсах. Представитель Baidu не стал умалять и заслуг китайских разработчиков ускорителей вычислений. В сочетании с оптимизацией сопутствующего ПО это позволит сформировать «долгосрочную основу для инновационного развития китайской экосистемы ИИ», как он дал понять. По мнению аналитиков Gartner, китайские компании пытаются бороться с внешними ограничениями не только формированием увеличенных запасов необходимой западной продукции. Прогресс в сфере разработки собственных ускорителей хоть и не так выражен, не может быть списан со счетов. «В разных сегментах наблюдается разная степень прогресса, но Китай удивительно настойчив и амбициозен в движении к этой цели, и следует признать, что они достигли приличного прогресса», — заявил Гаурав Гупта (Gaurav Gupta), эксперт по полупроводникам Gartner в письме CNBC. Развитие собственных разработок, в любом случае, обеспечивает Китай ускорителями для ИИ, которые хоть и не могут конкурировать с американскими, позволяют стране сохранять прогресс в этой сфере, как резюмировал аналитик. OpenAI откроет представительство в Южной Корее на фоне высокой активности местных подписчиков
26.05.2025 [08:31],
Алексей Разин
Директор по стратегии OpenAI Джейсон Квон (Jason Kwon) начал рабочую неделю с объявления об открытии представительства этой американской компании в Южной Корее. Разработчик ChatGPT планирует открыть в Сеуле свой офис с ближайшие месяцы, как отмечает Bloomberg со ссылкой на заявления представителя стартапа. 
Источник изображения: Chosun Daily Уже сейчас OpenAI ведёт подбор персонала для своего южнокорейского офиса, который станет третьим по счёту за пределами США после Японии и Сингапура. Если в японском офисе OpenAI работает около 40 человек, то в Сингапуре численность местного персонала стартапа достигает 20 человек. По словам Джейсона Квона, Южной Корее удалось стать вторым по величине источником выручки OpenAI после США, поэтому важность местного рынка компания не будет недооценивать. Джейсон Квон, который сам имеет корейские корни, в настоящее время посещает различные страны Азии для формирования взаимоотношений с местными клиентами и чиновниками. «Полноценная экосистема ИИ в Южной Корее делает её одним из самых многообещающих рынков в мире с точки зрения значимости влияния ИИ, от кремния до программного обеспечения, от студентов до людей старшего возраста», — отметил Квон. В прошлом году количество еженедельно использующих ChatGPT клиентов на местном рынке выросло в 4,5 раза, а количество платных подписчиков в Южной Корее уступает только США. Представители игровой индустрии испугались, что внедрение ИИ в играх может обернуться катастрофой
25.05.2025 [07:04],
Алексей Разин
Игровые издательства, как отмечает Bloomberg со ссылкой на отчётность видных представителей отрасли в лице Take-Two Interactive и Electronic Arts, весьма настороженно относятся к оценке воздействия искусственного интеллекта на свою деятельность. По их мнению, ИИ несёт репутационные риски для бизнеса, поскольку любители игр весьма неоднозначно относятся к применению данной технологии в этой сфере. 
Источник изображения: Nvidia В годовом отчёте Take-Two по форме 10-K отмечается следующее: «Разработка и использование искусственного интеллекта в наших продуктах могут представлять операционные и репутационные риски». Как поясняет издатель, внедрение ИИ в играх влечёт социальные и этические проблемы, которые могут вылиться в судебные разбирательства и нанести ущерб репутации компании. Помимо этого, издатель опасается столкнуться с негативным восприятием нововведений, связанных с ИИ, со стороны пользователей. В отчёте Electronic Arts попутно упоминается тезис о том, что применение ИИ в играх должно осуществляться очень осторожно. Аудитория любителей игр порой весьма критически оценивает попытки издателей и разработчиков найти применение в своей работе генеративному искусственному интеллекту. Недавно попытка Sony нанять художника с навыками работы с искусственным интеллектом вызвала большой общественный резонанс. Первые попытки разработчиков поручить ИИ разработку игровых персонажей и их озвучку также наталкиваются на шквал критики. В игре Fortnite, например, появился Дарт Вейдер (Darth Vader), который общался голосом покойного актёра Джеймса Эрла Джонса (James Earl Jones), воссозданным при помощи генеративного искусственного интеллекта, и это стало причиной скандала. Внедрение ИИ в играх угрожает потерей рабочих мест представителями отрасли, а также повышает нагрузку на окружающую среду за счёт потребности в мощных вычислительных средствах. Серьёзной проблемой могут стать претензии в области авторских прав, если искусственный интеллект возьмёт за основу интеллектуальную собственность стороннего правообладателя. Кроме того, любители игр предпочитают взаимодействовать в окружении, которое было создано живыми людьми, тем самым косвенно выстраивая диалог с разработчиками, и данная потребность довольно сильна, чтобы внедрение искусственного интеллекта могло нарушить традицию. Даже генерируемый ИИ визуальный фон может стать причиной раздражения любителей игр, если будет создавать ощущение неестественности. ИИ не является единственным новшеством последних лет, которое не прижилось в игровой индустрии. На волне популярности технологий блокчейна разработчики и издатели пытались внедрить в игры NFT-токены, но подобные инициативы столкнулись с сопротивлением аудитории и быстро себя изжили. Игровая отрасль замедляет свой рост, а затраты на создание игр растут, поэтому в сложных для ведения бизнеса условиях компании предпочитают минимизировать риски, и теперь ИИ относится к их числу. Intel разрабатывает ИИ-тренера для геймеров — он помогает в прохождении игр
23.05.2025 [18:43],
Николай Хижняк
Ранее компания Nvidia представила Project G-Assist — компактную ИИ-модель, работающую локально на ПК и призванную помогать игрокам в различных игровых ситуациях. Она способна подсказывать, как пройти квест, оптимизировать настройки игры и конфигурацию оборудования. Взаимодействие с G-Assist осуществляется через оверлей в приложении Nvidia App. Как выяснилось, Intel также работает над аналогичным цифровым помощником, пусть и с более узкой специализацией. 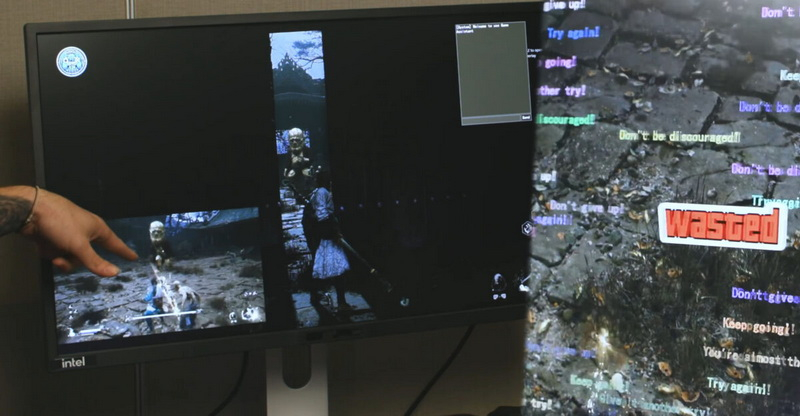
Источник изображений: Intel На текущий момент AI Gaming Coach от Intel поддерживает лишь ограниченное число игр. В рамках презентации компания продемонстрировала его работу в проекте Black Myth: Wukong. Существенным отличием стало то, что для функционирования ИИ-ассистента необходима интеграция со стороны разработчиков игр, а значит — поддержка будет доступна далеко не во всех проектах.  Технология разработана с учётом того, чтобы не мешать непосредственному игровому процессу. Например, игровой ИИ-тренер даст советы о том, как пройти тот или иной квест или убить того или иного босса в игре до того, как к выполнению этих задач приступит игрок. Он также подсказывает, что на той или иной локации находятся предметы, на которые стоит обратить внимание перед походом к боссу. Перед битвой с тем или иным боссом ИИ-тренер может запустить короткое видео, показывающее особенности атак противника и подсказать нужную стратегию к победе над ним. В случае поражения ИИ-тренер подбодрит игрока и скажет, что у него всё получится в следующий раз. 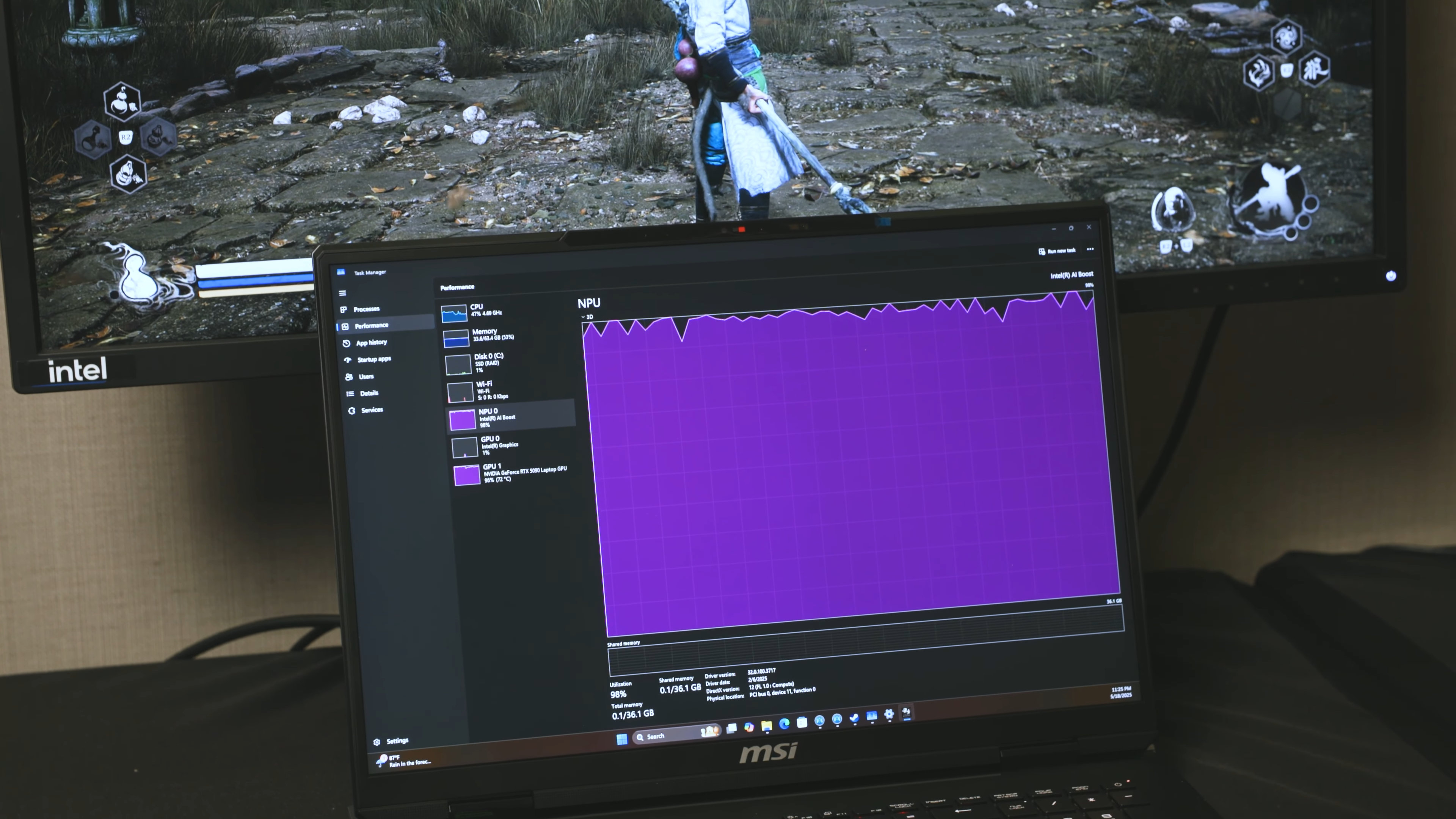 Любопытно, что для работы AI Gaming Coach не требуется дискретная видеокарта. Демонстрация велась на ноутбуке с GeForce RTX 5060, но технология использовала встроенные NPU и iGPU центрального процессора — вероятно, из-за недостаточной мощности одного лишь NPU. Таким образом, Intel предложила практическое применение для ноутбуков, оснащённых и дискретной графикой, и процессорами с iGPU и NPU. Однако компания пока не раскрывает ни размер используемой ИИ-модели, ни дополнительные функции ассистента. На данном этапе Project G-Assist от Nvidia выглядит как более продвинутый продукт — он не только помогает в игровом процессе, но и предлагает шаги по оптимизации железа и настроек. Решение Intel, как следует из названия, сосредоточено именно на тренерской роли. Пока неизвестно, какие платформы получат поддержку AI Gaming Coach, и каковы будут его минимальные системные требования. Также Intel не называет сроки появления технологии в открытом доступе. Таинственное ИИ-устройство позволит OpenAI увеличить доходы от подписок ChatGPT
23.05.2025 [13:41],
Алексей Разин
Решение OpenAI поглотить стартап Джони Айва (Jony Ive), который после ухода из Apple занимался разработкой собственных устройств, стало для многих сюрпризом. Компаньоны собираются выпустить на рынок к концу следующего года некое революционное устройство для работы с ИИ на персональном уровне. С финансовой точки зрения эти планы тоже призваны себя оправдать, как поясняет руководство OpenAI. 
Источник изображения: Unsplash, Solen Feyissa По крайней мере, такой позиции придерживается финансовый директор компании Сара Фрайар (Sarah Friar), которая в интервью CNBC выразила уверенность, что потраченные на поглощение стартапа Джони Айва средства в сумме $6,4 млрд оправдают себя с лихвой. По меньшей мере, результат этой сделки приведёт к тому, что OpenAI будет получать больше средств от подписчиков ChatGPT. В подобной сделке, как отмечает финансовый директор OpenAI, ставка делается не только на «великолепных людей», но и на нечто большее. Новую платформу нужно сначала придумать, а потом создать. Важно также понимать, как работают цепочки поставок, когда речь идёт о выпуске аппаратных решений. Напомним, что компания после поглощения io намеревается выпустить 100-миллионным тиражом некое устройство, которое станет персональным компаньоном пользователя с поддержкой искусственного интеллекта. В конечном итоге, как предполагает Фрайар, такие устройства позволят открыть доступ к технологии OpenAI для новых пользователей, а это обеспечит рост доходов компании от подписок. Еженедельно сервисами OpenAI сейчас пользуется около 500 млн активных клиентов, месячные показатели ещё выше. Из запутанных объяснений представителей OpenAI становится понятно, что компания намерена вывести на рынок нечто большее, чем просто смартфон, «захватывающее воображение». Чтобы люди по всему миру активнее использовали ИИ, по словам финансового директора компании, нужно думать о разных новых бизнес-моделях. В данном случае OpenAI настраивается на возможность увеличения охвата подписчиков ChatGPT. По мнению Фрайар, разработка собственных устройств не означает отказа от сотрудничества с Apple и другими партнёрами. Только подобная многосторонняя деятельность позволяет добиться высоких темпов инновационного развития. Из слов представительницы OpenAI стало лишь ясно, что будущее устройство может быть лишено сенсорных дисплеев: «На этапе зарождения новой эры ИИ будет много новых платформ и новых основ. Нам кажется, сегодня технологии слишком сосредоточены на касаниях. Мы, люди, видим, слышим и разговариваем, и наши модели хороши в этом». Галлюцинации у моделей ИИ случаются реже, чем у людей, заявил глава Anthropic
23.05.2025 [12:44],
Павел Котов
Современные модели искусственного интеллекта демонстрируют галлюцинации, то есть дают заведомо не соответствующие действительности ответы на вопросы, реже, чем люди. Такое заявление сделал гендиректор Anthropic Дарио Амодеи (Dario Amodei) на проводимой компанией конференции Code with Claude. 
Источник изображения: anthropic.com Галлюцинации, по мнению господина Амодеи, не являются препятствием к разработке сильного ИИ (Artificial General Intelligence — AGI), то есть системы, сравнимой по уровню развития с человеком. «На самом деле всё зависит от подхода, но у меня есть подозрения, что модели ИИ, вероятно, галлюцинируют реже, чем люди, но галлюцинируют они более удивительным образом», — заявил глава Anthropic ресурсу TechCrunch. Дарио Амодеи относится к числу оптимистов в отрасли ИИ. В его прошлогодней статье говорится, что AGI может появиться уже в 2026 году. Поводов отказаться от этой позиции он не нашёл и накануне — по его мнению, в этом направлении наблюдается устойчивый прогресс, и «вода поднимается повсюду». «Все и всегда ищут эти жёсткие ограничения на то, что может делать [ИИ]. Их не видно нигде. Нет такого», — уверен гендиректор Anthropic. С ним согласны не все. Глава подразделения Google DeepMind Демис Хассабис (Demis Hassabis) на этой неделе заявил, что у сегодняшних моделей ИИ слишком много «дыр», и эти модели дают неправильные ответы на слишком большое число очевидных вопросов. А адвокат самой Anthropic в этом месяце был вынужден извиняться за то, что использованный компанией для составления иска чат-бот Claude указал в цитатах неверные имена и должности. Проверить утверждение господина Амодеи непросто: в большинстве тестов на галлюцинации модели сравниваются друг с другом, а не с человеком. В отдельных случаях число таких проявлений удаётся снизить, открывая чат-ботам доступ к веб-поиску; а OpenAI GPT-4.5 значительно снизила процент галлюцинаций по сравнению с моделями предыдущих поколений. С другой стороны, рассуждающие модели OpenAI o3 и o4-mini, как стало известно ранее, дают не соответствующие действительности ответы чаще, чем предшественники, и пока не удалось установить, почему. Телеведущие, политики и вообще люди всех профессий совершают ошибки постоянно, указал Дарио Амодеи, и тот факт, что их совершает также ИИ, не может выступать аргументом для критики его способностей. Но, признал он, уверенность, с которой ИИ выдаёт вымысел за факты, может обернуться проблемой. Anthropic уже неоднократно изучала склонность моделей ИИ обманывать людей. Исследовательский институт Apollo Research, которому предоставили ранний доступ к Claude Opus 4, установил, что модель имеет значительные склонности к интригам и обману, и порекомендовала Anthropic отозвать её — разработчик заявил, что принял некоторые меры, которые смягчили выявленные проблемы. Заявление главы Anthropic свидетельствует, что компания может признать за достаточно развитой моделью ИИ уровень AGI, даже если она не избавилась от галлюцинаций, но некоторые эксперты такую позицию отвергают. Репортаж со стенда GIGABYTE на выставке Computex 2025: геймерские ноутбуки и мощные компьютеры для ИИ и игр
23.05.2025 [11:34],
Андрей Созинов
На выставке Computex 2025 компания GIGABYTE представила множество разнообразных новинок, включая впечатляющую линейку ноутбуков и настольных ПК, ориентированных на геймеров, создателей контента и профессионалов, работающих с ИИ. Новые модели сочетают в себе передовые аппаратные решения и интеллектуальные функции, обеспечивая высокую производительность и удобство использования.  Флагманский ноутбук AORUS Master 18 оснащён процессором Intel Core Ultra 9 275HX и видеокартой Nvidia GeForce RTX 5090 с 24 Гбайт памяти GDDR7. Система охлаждения WINDFORCE Infinity EX с четырьмя вентиляторами и испарительной камерой эффективно отводит тепло, поддерживая стабильную работу компонентов.  Новинка получила передовой 18-дюймовый Mini-LED-дисплей с разрешением WQXGA (2560 × 1600 пикселей) и частотой обновления 240 Гц, что обеспечивает чёткое и плавное изображение в играх. Поддержка до 128 Гбайт оперативной памяти DDR5 и накопителей PCIe 5.0 SSD делает этот ноутбук идеальным выбором для ресурсоёмких задач и лучшего игрового опыта.  AORUS Master 16 предлагает схожие характеристики в более компактном корпусе. Он оснащён 16-дюймовым OLED-дисплеем с разрешением WQXGA и частотой обновления 240 Гц. Процессор Intel Core Ultra 9 275HX и видеокарта GeForce RTX 5090 обеспечивают высокую производительность, а система охлаждения WINDFORCE Infinity EX поддерживает оптимальную температуру компонентов. Интеграция интеллектуального помощника GiMATE позволяет пользователю управлять системой с помощью голосовых команд.  AORUS Elite 16 ориентирован на пользователей, ищущих баланс между производительностью и ценой. Он оснащается процессором Intel Core Ultra вплоть до Core Ultra 9 275HX и видеокартой GeForce RTX 50-й серии вплоть до RTX 5070. Система охлаждения WINDFORCE Infinity с двумя вентиляторами обеспечивает стабильную работу системы. За качественное изображение отвечает 16-дюймовый дисплей с разрешением WQXGA и частотой обновления 165 Гц. Ноутбук поддерживает до 64 Гбайт оперативной памяти DDR5 и оснащён батареей ёмкостью 99 В·ч с быстрой зарядкой. Всё это делает AORUS Elite 16 универсальным решением для пользователей, которым нужна производительная система.  GIGABYTE ориентируется не только на геймеров. Например, Aero X16 — это ноутбук для творческих специалистов и создателей контента. Он оснащён процессором AMD Ryzen вплоть до Ryzen AI 9 HX 370 и видеокартой Nvidia вплоть до GeForce RTX 5070. Здесь также применяется система охлаждения WINDFORCE Infinity с двумя вентиляторами. Несмотря на мощную начинку, ноутбук имеет тонкий корпус — всего 16,75 мм, а весит 1,9 кг. Aero X16 оснащён 16-дюймовым IPS-дисплеем с разрешением WQXGA, частотой обновления 165 Гц и 100-процентным охватом цветового пространства sRGB, что говорит о высокой точности цветопередачи. Также предусмотрена интеграция помощника GiMATE.  Для бюджетных геймеров GIGABYTE предлагает 16-дюймовый ноутбук Gaming A16, обеспечивающий оптимальное соотношение цены и производительности. Он оснащён процессором AMD вплоть до Ryzen 7 260 и видеокартой Nvidia вплоть до GeForce RTX 5070. Используется система охлаждения WINDFORCE и такой же 16-дюймовый дисплей, как в Aero X16. В сегменте настольных ПК GIGABYTE делает акцент на ИИ, но не забывает и о геймерах. AI TOP 100 Z890 — это мощный компьютер, предназначенный для работы с искусственным интеллектом и одновременно подходящий для игр. Он построен на материнской плате Z890 AI TOP, оснащён процессором Intel Core Ultra 9 285K и видеокартой GeForce RTX 5090. Охлаждение процессора обеспечивает система жидкостного охлаждения с 360-мм радиатором.  Компьютер укомплектован 128 Гбайт оперативной памяти DDR5 и двумя накопителями: SSD AI TOP 100E на 320 Гбайт и AORUS Gen4 7300 на 2 Тбайт. За питание отвечает блок мощностью 1600 Вт. В качестве ОС используется Windows 11 Pro.  Для тех, кому этого недостаточно, GIGABYTE предлагает AI TOP 500 TRX50 — рабочую станцию для обработки больших объёмов данных и обучения моделей ИИ. Она оснащена 24-ядерным процессором AMD Ryzen Threadripper PRO 7965WX и двумя профессиональными видеокартами Radeon PRO W7900 с 48 Гбайт памяти.  Система построена на материнской плате TRX50 AI TOP и имеет 1152 Гбайт оперативной памяти DDR5 ECC R-DIMM, причём ОЗУ распределена необычным образом: 768 Гбайт установлены непосредственно на плату, ещё 384 Гбайт — на плату расширения AI TOP CXL R5X4. Питание обеспечивает блок на 1600 Вт, а охлаждение реализовано с помощью СЖО. GIGABYTE также представила AI TOP ATOM — компактный настольный ПК на платформе Nvidia DGX Spark. Он построен на процессоре GB10 Grace Blackwell, включающем 20-ядерный центральный Arm-процессор и графику Nvidia Blackwell с 6144 ядрами CUDA и тензорными ядрами пятого поколения.  Производительность при выполнении ИИ-задач достигает 1 петафлопса. Система оснащена 128 Гбайт унифицированной памяти LPDDR5X и способна обрабатывать модели ИИ с числом параметров до 200 миллиардов. Две такие системы можно объединить в кластер для работы с ещё более крупными моделями. Среди игровых систем выделяется флагманский ПК AORUS SUPREME 5 (и его белая версия ICE). Это высокопроизводительная игровая машина с процессором AMD Ryzen 7 9800X3D и видеокартой GeForce RTX 5090, построенная на материнской плате AORUS X870E с мощной 20-фазной подсистемой питания.  ПК поддерживает до 64 Гбайт оперативной памяти DDR5 и оснащён твердотельным накопителем AORUS с интерфейсом PCIe 5.0, обеспечивающим скорость до 14,5 Гбайт/с. За стабильную работу отвечает блок питания AORUS ATX 3.1 мощностью 1000 Вт. Anthropic представила Claude 4 — ИИ научился избегать «лазеек» и точнее выполнять сложные задания
23.05.2025 [04:33],
Анжелла Марина
Anthropic анонсировала выход двух новых ИИ-моделей — Claude Opus 4 и Claude Sonnet 4. Модели предназначены для решения сложных задач, написания кода и поиска в интернете. По словам компании, флагманская модель Opus 4 стала самой мощной в линейке, а также способна автономно работать до семи часов. 
Источник изображения: Anthropic Opus 4 и Sonnet 4, в отличие от предыдущих моделей, стали на 65 % менее склонны к использованию «лазеек» и упрощённых путей при выполнении заданий. Кроме того, они лучше сохраняют важную информацию при работе над долгосрочными задачами, особенно при наличии доступа к локальным файлам пользователя. Разработчики также утверждают, что модель Opus 4 превзошла конкурентов по ряду параметров. Например, внутренние тесты показали, что она превзошла Google Gemini 2.5 Pro, OpenAI o3 reasoning и GPT-4.1 в задачах, связанных с программированием и использованием инструментов, таких как веб-поиск. 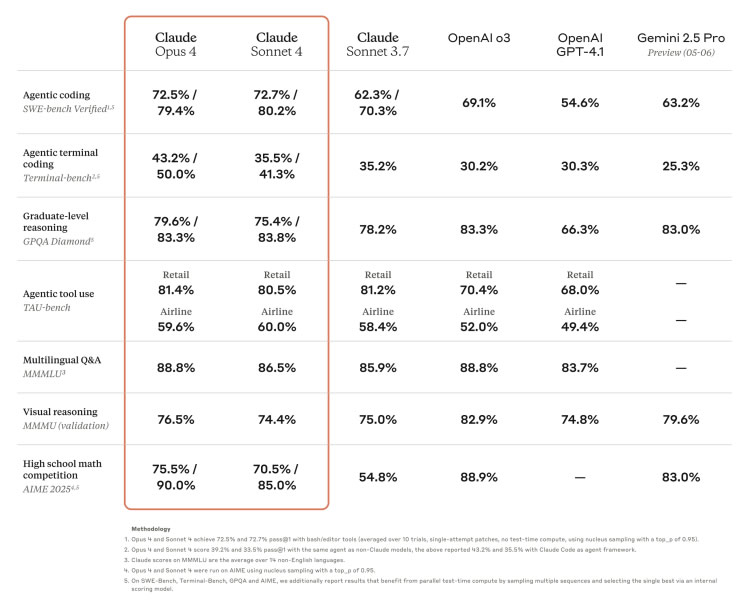
Источник изображения: Anthropic Версия Sonnet 4, ориентированная на общие задачи, пришла на смену выпущенной ранее версии Sonnet 3.7. Как подчёркивают в компании, новая модель отличается более точными ответами и улучшенными навыками логического мышления и написания кода. Среди новых функций можно отметить thinking summaries (сводки размышлений), которые позволяют кратко отображать ход рассуждений ИИ в понятной форме, а также запускается бета-версия функции extended thinking (расширенное мышление), дающая возможность переключать модели между режимами логического анализа и использования инструментов для повышения точности ответа. Обе модели Claude Opus 4 и Claude Sonnet 4 уже доступны через API Anthropic, платформу Amazon Bedrock и сервис Vertex AI от Google Cloud. Обе версии включены в платные подписки Claude, а Sonnet 4 также доступна бесплатно. Однако расширенные функции, включая расширенное размышление (extended thinking), доступны только платным подписчикам. Кроме того, агентский командный интерфейс Claude Code, предназначенный для разработчиков и представленный ранее в ограниченном тестировании, теперь стал общедоступным. После предварительного релиза в феврале он уже доступен всем пользователям. Anthropic также объявила о планах выпускать обновления моделей почаще, чтобы соответствовать темпам развития конкурентов — OpenAI, Google и Meta✴✴. Дебютировал смартфон Honor 400 с 200-Мп камерой и ИИ-функциями по цене от €499
22.05.2025 [18:00],
Павел Котов
Компания Honor представила смартфон Honor 400 5G среднего ценового сегмента, который ориентирован на любителей мобильной фотографии. Новинка располагает парой камер, обеспечивающих качественную съёмку фото и видео, а также набором функций на базе искусственного интеллекта для обработки отснятого материала. 
Источник изображений: Honor На задней панели Honor 400 5G располагаются основная 200-мегапиксельная камера Ultra-clear Super Zoom с 1/1,4-дюймовым сенсором, диафрагмой f/1,9 и оптическим стабилизатором изображения; а также 12-мегапиксельная широкоугольная, которая подходит для макросъёмки. Для автопортретов имеется 50-мегапиксельная фронтальная камера. Присутствует широкий набор функций ИИ для повышения качества съёмки и обработки фото и видео, в том числе AI Eraser для удаления объектов из кадра и AI Outpainting для расширения границ кадра.  В качестве программной платформы выступает Honor MagicOS 9.0 на базе Android 15 с комплектом ИИ-функций, в том числе AI Translation, AI Summary и AI Recorder, которые подойдут в каждодневных делах. Honor 400 5G работает на чипе Qualcomm Snapdragon 7 Gen 3 с 8 Гбайт оперативной памяти, объём встроенного накопителя составляет 256 или 512 Гбайт. Смартфон может похвастаться аккумулятором на 5300 мА·ч, которого хватит на полный день работы; функция SuperCharge позволяет заряжать батарею на мощности 66 Вт до 44 % всего за 15 минут.  AMOLED-дисплей Honor MagicOS 9.0 имеет диагональ 6,55 дюйма, разрешение 2736 × 1264 пикселей, пиковую яркость 5000 кд/м² для HDR-контента и частоту обновления 120 Гц. Корпус смартфона имеет толщину 7,3 мм, масса устройства составляет 184 г; оно защищено от воды и пыли по стандарту IP65, а корпус имеет сертификат прочности SGS.  Honor 200 уже поступил в продажу в расцветках Desert Gold (золотистая), Lunar Grey (серая) и Midnight Black (чёрная). В Великобритании он стоит £399,99 ($532) за вариант с 256 Гбайт памяти или £449 ($597) за 512 Гбайт, а в Европе — €499 и €549 соответственно. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


