|
Опрос
|
реклама
Быстрый переход
Учёные наконец выяснили, как работает ИИ — оказалось, что он может вынашивать планы и сознательно врать
28.03.2025 [16:25],
Павел Котов
Учёные компании Anthropic изобрели способ заглянуть в механизмы работы больших языковых моделей и впервые раскрыли, как искусственный интеллект обрабатывает информацию и принимает решения. 
Источник изображений: anthropic.com Долгое время считалось, что полностью отследить механизмы рассуждения моделей ИИ невозможно, и даже их создатели не всегда понимали, как они получают те или иные ответы. Теперь некоторые механизмы удалось прояснить. Модели ИИ оказались сложнее, чем считалось ранее: при написании стихотворений они выстраивают планы, следуют одинаковым последовательностям для интерпретации понятий вне зависимости от языка и иногда обрабатывают информацию в обратном направлении вместо того, чтобы рассуждать, исходя из фактов. Новые методы интерпретации схем работы ИИ в Anthropic назвали «трассировкой цепочек» и «графами атрибуции» — они помогли исследователям отследить конкретные пути реализации функций, подобных нейронным, которые запускаются при выполнении моделью задач. В этом подходе заимствуются концепции нейробиологии, а модели ИИ рассматриваются как аналоги биологических систем. Одним из наиболее поразительных открытий стали механизмы планирования ИИ Claude при написании стихов. Когда чат-бот попросили составить двустишие в рифму, он сначала подобрал рифмующиеся слова для конца следующей строки и только после этого начал писать. Так, при написании строки, которая заканчивалась словом «кролик», ИИ выбрал все характеризующие это слово признаки, а затем составил предложение, которое подводит к нему естественным образом. Claude также продемонстрировал настоящие рассуждения в несколько шагов. В испытании с вопросом «Столица штата, в котором находится Даллас, — это...», модель сначала активировала признаки, соответствующие понятию «Техас», а затем использовала это представление, чтобы определить «Остин» в качестве правильного ответа. То есть модель действительно выстраивает цепочку рассуждений, а не просто воспроизводит ассоциации, которые запомнила. Учёные произвели манипуляции, подменив «Техас» на «Калифорнию» и на выходе получили «Сакраменто», тем самым подтвердив причинно-следственную связь.  Ещё одним важным открытием стал механизм обработки данных на нескольких языках. Вместо того, чтобы оперировать разными системами для английской, французской и китайской языковых сред, она переводит понятия в общее абстрактное представление, после чего начинает генерировать ответы. Это открытие имеет значение для понимания того, как модели транслируют знания, полученные на одном языке, на другой: предполагается, что модели с большим количеством параметров создают независимые от языка представления. Возможно, самым тревожным открытием стали инциденты, при которых механизмы рассуждения Claude не соответствовали тем, о которых он заявлял сам. Когда ему давали сложные задачи, например, вычисление косинуса больших чисел, ИИ заявлял, что осуществляет вычисления, но они в его внутренней деятельности не отражались. В одном из случаев, когда ответ на сложную задачу был известен заранее, модель выстроила цепочку рассуждений в обратном порядке, отталкиваясь от ответа, а не принципов, которые должны были оказаться первыми. Исследование также пролило свет на галлюцинации — склонность ИИ выдумывать информацию, когда ответ неизвестен. У модели есть схема «по умолчанию», которая заставляет её отказываться отвечать на вопросы в отсутствие фактических данных, но этот механизм подавляется, если в запросе распознаются известные ИИ сущности. Когда модель распознаёт сущность, но не имеет конкретных знаний о ней, могут возникать галлюцинации — это объясняет, почему ИИ может с уверенностью давать не соответствующую действительности информацию об известных личностях, но отказываться отвечать на запросы о малоизвестных. Исследование является шагом к тому, чтобы сделать ИИ прозрачнее и безопаснее. Понимая, как модель приходит к ответам, можно выявлять и устранять проблемные шаблоны рассуждений. Проект может иметь и последствия в коммерческой плоскости: компании применяют большие языковые модели для запуска рабочих приложений, и понимание механизмов, при которых ИИ может давать неверную информацию поможет в управлении рисками. Сейчас Anthropic предложила лишь первую предварительную карту ранее неизведанной территории — так в древности первые специалисты по анатомии составляли атласы человеческого тела. Составить полноценный атлас рассуждений ИИ ещё предстоит, но теперь можно оценить, как эти системы «думают». Частое использование ChatGPT и других ИИ-ботов может привести к обострению чувства одиночества
22.03.2025 [11:36],
Владимир Мироненко
Более частое использование ИИ-чат-ботов, таких как ChatGPT, может привести к росту чувства одиночества и сокращению времени, проводимого в общении с другими людьми, пишет Bloomberg со ссылкой на исследования OpenAI и Массачусетского технологического института. 
Источник изображения: Growtika/unsplash.com В рамках одного из исследований учёные в течение месяца наблюдали за почти 1000 человек, уже имеющих опыт работы с ChatGPT. Участникам случайным образом предлагали текстовую версию чат-бота или один из двух его голосовых вариантов для использования не менее пяти минут в день. Некоторым из них предложили вести открытые чаты на любые темы, а другим — личные или неличные беседы с ИИ. Те, кто ежедневно проводил больше времени за набором текста или голосовым общением с ChatGPT, чаще сообщали о более высоком уровне эмоциональной зависимости от чат-бота, проблемном использовании, а также о повышенном чувстве одиночества. Как выяснилось, люди, склонные эмоционально привязываться к человеческим отношениям и больше доверяющие чат-боту, с большей вероятностью ощущали себя одинокими и эмоционально зависимыми от ChatGPT. При этом исследователи не выявили связи между большей привлекательностью голоса чат-бота и негативными последствиями. Во втором исследовании учёные проанализировали с помощью программного обеспечения три миллиона разговоров пользователей с ChatGPT, а также провели опрос о том, как люди взаимодействуют с чат-ботом. Выяснилось, что лишь немногие респонденты использовали ChatGPT для эмоционально окрашенного общения. Выход ChatGPT в конце 2022 года способствовал ажиотажу вокруг генеративного ИИ. Поскольку разработчики, такие как OpenAI, создают всё более сложные модели с голосовыми функциями, позволяющими лучше имитировать человеческое общение, растёт вероятность формирования парасоциальных отношений пользователей с чат-ботами. В последние месяцы вновь стали звучать опасения по поводу потенциального эмоционального вреда этой технологии, особенно среди молодых пользователей и людей с проблемами психического здоровья. OpenAI рассматривает новые исследования как способ лучше понять, как люди взаимодействуют с её популярным чат-ботом и как он на них влияет. При этом такие исследования находятся на ранней стадии, и остаётся неясным, в какой степени чат-боты могут способствовать росту одиночества и насколько сильно их использование усугубляет эмоциональную зависимость у предрасположенных к этому людей. Кэти Менъин Фанг (Cathy Mengying Fang), соавтор исследования и аспирантка Массачусетского технологического института, выразила обеспокоенность тем, что результаты могут привести к поспешным выводам о том, что более активное использование чат-бота неизбежно влечёт негативные последствия. Она пояснила, что в исследовании не контролировалось время использования ChatGPT как основной фактор, а также не проводилось сравнение с контрольной группой, не использующей чат-ботов. «Т-банк» вложит 500 млн рублей в исследования в сферах ИИ, аналитики и безопасности данных
14.03.2025 [14:12],
Владимир Мироненко
Финансовая экосистема «Т-технологии» (включает «Т-банк» и «Росбанк») вложит 500 млн руб. в исследования собственного центра исследований и разработок (R&D-центр) в области ИИ, баз данных и аналитических систем, информационной безопасности и фундаментальных алгоритмов, сообщили «Ведомости» со ссылкой на представителя компании. 
Источник изображения: Joan Gamell/unsplash.com Представитель назвал ключевым проектом центра, созданного в начале года, разработку ИИ-ассистента для программирования (AI Coding Assistant). Как ожидается, это позволит увеличить к 2026 году долю созданного ИИ-кода специалистами экосистемы в 6 раз до 25 % от общего количества генерируемых строк кода. Указанная сумма будет направлена на наем инженеров в создаваемую с нуля команду, закупку оборудования и софинансирование грантов на исследования совместно с университетами. По словам представителя «Т-технологий», у R&D-центра уже есть договоры о сотрудничестве с МФТИ, «Сколтехом» и Новосибирским государственным университетом через НИР или НИОКР и через консультационную помощь. R&D-центр «Т-технологий» в настоящее время курирует с МФТИ исследовательскую лабораторию, которая занимается исследованиями в области рекомендательных систем, обучения с подкреплением, компьютерного зрения и больших языковых моделей (LLM). В дальнейшем «Т-технология» планирует расширить сотрудничество с российскими вузами в разных регионах страны и создать на их базе студенческие исследовательские лаборатории. Сообщается, что R&D-центр будет заниматься как фундаментальными, так и прикладными исследованиями. По мнению директора R&D-центра Станислава Моисеева, совместная работа с академическим сообществом позволит не только принести ценность компании, но и привлечь будущих специалистов из числа талантливых студентов. У многих крупных корпораций есть собственные R&D-отделы, которые, в том числе разрабатывают прорывные решения, способные кардинально изменить рынок и дать компании преимущество, говорит исполнительный директор АНО «Колаборатория» Мария Базлуцкая. Например, у OpenAI есть исследовательское подразделение Research, а Microsoft израсходовала на R&D в 2024 году, по данным Statista, рекордную сумму в $29,5 млрд. Базлуцкая отметила, что 500 млн руб. — довольно скромная сумма в мировых масштабах. Такого же мнения придерживается гендиректор Dbrain Алексей Хахунов. Он отметил стремление «Т-банка» диверсифицировать банковский бизнес, чтобы стать технологическим игроком, но 500 млн руб. — слишком мало для реализации этой задачи. Как сообщили в «Яндексе», у компании есть несколько совместных с университетами лабораторий, которые занимаются фундаментальными исследованиями в сфере компьютерных наук и ИИ: например, с НИУ ВШЭ и с МФТИ. Такие лаборатории занимаются разработкой технологий и помогают реализовывать социально значимые проекты для здравоохранения, экологии, науки и образования. В прошлом году более 10 тыс. студентов вузов прошли обучение на технологиях компании и приняли участие в реализации проектов, рассказал представитель «Яндекса». Исследования для DeepSeek оказались важнее доходов — в отличие от OpenAI и прочих американских конкурентов
14.03.2025 [13:09],
Павел Котов
Китайский стартап в области искусственного интеллекта DeepSeek сосредоточен на исследовательской работе, а не получении доходов — воспользовавшись внезапным скачком продаж, основатель компании, миллиардер Лян Вэньфэн (Liang Wenfeng), решил не следовать примеру конкурентов из Кремниевой долины.  Компании из Ханчжоу пришлось адаптироваться к всплеску спроса на её бесплатные потребительские сервисы на сайте и в приложении, а также на платные услуги от бизнес-пользователей. Выручки за минувший месяц впервые оказалось достаточно, чтобы покрыть текущие расходы, сообщает Financial Times со ссылкой на два информированных источника. Интерес к DeepSeek вырос в январе, когда компания выпустила недорогую в обслуживании рассуждающую модель искусственного интеллекта R1 — она демонстрирует сопоставимые с ведущими американскими и китайскими аналогами результаты, но её разработка обошлась значительно дешевле. Корпоративные клиенты из медицинской и финансовой отраслей стали активно закупать у DeepSeek доступ к API для разработки собственных приложений на основе моделей V3 и R1, причём спрос оказался настолько высоким, что стартапу пришлось временно приостановить регистрацию клиентов из-за нехватки ресурсов на не связанные с исследованиями цели. Господин Лян не проявил особого намерения начать немедленно зарабатывать на DeepSeek. Вместо этого бо́льшую часть ресурсов компания направила на разработку новых моделей и создание сильного искусственного интеллекта (AGI) с когнитивными способностями, не уступающими человеческим. Глава независимой компании пока также отказался от сотрудничества с китайскими технологическими гигантами, венчурными и государственными фондами, выразившими желание инвестировать в DeepSeek. Напротив, со склонным к уединению бизнесменом оказалось непросто даже назначить встречу.  Появление DeepSeek огорчило инвесторов, у которых возникли сомнения, что американские технологические лидеры в лице Google и OpenAI способны удержать преимущество, и что колоссальные расходы технологических гигантов на инфраструктуру ИИ оправданы. Подход китайской компании значительно отличается от манеры работы многих стартапов Кремниевой долины: OpenAI воспользовалась своим статусом лидера в области ИИ, чтобы выстроить экосистему коммерческих сервисов вокруг ChatGPT и начать получать значительные доходы от доступа к моделям ИИ через API. С 2019 года американская компания привлекла инвестиции на сумму около $20 млрд, и сейчас ведёт переговоры с группой инвесторов во главе с SoftBank о привлечении ещё $40 млрд при оценке $260 млрд. В OpenAI работают чуть более 2000 человек, в DeepSeek — около 160. Отсутствие коммерческих устремлений DeepSeek сыграло на руку китайским технологическим гигантам Alibaba и Tencent — за счёт сформировавшихся инфраструктуры и пакетов услуг они привлекли на родине большое число корпоративных клиентов, и это вызвало сомнения, что потоки доходов стартапа являются устойчивыми. Так, Apple для развёртывания функций ИИ на iPhone в Китае выбрала модель Alibaba Qwen, а не DeepSeek; Tencent же увеличила продажи, когда открыла в своей облачной инфраструктуре доступ к открытым моделям DeepSeek — их выбрали около половины облачных клиентов техногиганта, и около 20 % запросили их доработку. Из-за того, что DeepSeek отказалась прилагать усилия для продвижения собственных продуктов для массового рынка, Tencent интегрировала модели стартапа и в свои популярные потребительские приложения. За последние годы Лян Вэньфэн, возглавляющий также хедж-фонд, закупил около 10 000 ИИ-ускорителей Nvidia A100 и примерно то же количество моделей H800 — ещё до того, как их ввоз в Китай был запрещён. На перспективу компания намеревается закупить оборудование у других поставщиков; кроме того, она получила поддержку со стороны китайских властей, которые предоставили ей доступ к финансируемым государством центрам обработки данных, частично удовлетворив потребность компании в вычислительных ресурсах. В долгосрочной перспективе DeepSeek может счесть проблемой недостаточный доступ к передовому оборудованию Nvidia и изучить возможность выбрать другого партнёра. А для получения дополнительной политической поддержки, считают отраслевые эксперты, компании всё-таки придётся открыться для государственных фондов. Сейчас инженеры компании в полную силу ведут разработку моделей R2 и V4 – первоначально эти модели планировались к выпуску в мае, но теперь в компании решили ускориться. Данные тысяч ставших частными репозиториев GitHub всё ещё доступны в Copilot, выяснили исследователи
26.02.2025 [18:08],
Владимир Мироненко
Согласно исследованию израильской компании по кибербезопасности Lasso, специализирующейся на возникающих угрозах генеративного ИИ, данные, которые были в открытом доступе в интернете хотя бы на мгновение, могут ещё продолжительное время оставаться у онлайн-чат-ботов генеративного ИИ, таких как Microsoft Copilot, после того, как доступ к ним был закрыт. 
Источник изображения: Windows/unsplash.com Эта проблема касается тысяч некогда открытых репозиториев GitHub ряда крупнейших компаний, включая Microsoft, которые с тех пор стали закрытыми, сообщили в Lasso ресурсу TechCrunch. По словам соучредителя Lasso Офира Дрора (Ophir Dror), компания обнаружила, что контент из её собственного репозитория GitHub появился в Copilot, поскольку он был проиндексирован и кеширован поисковой системой Bing от Microsoft. Этот репозиторий был ошибке открыт в течение короткого периода времени и сейчас является частным. При попытке получить к нему доступ на GitHub появляется сообщение «Страница не найдена». «На Copilot, как ни странно, мы нашли один из наших собственных закрытых репозиториев, — рассказал Дрор. — Если бы я просматривал веб-страницы, я бы не увидел этих данных. Но любой человек, задав Copilot правильный вопрос, может их получить». В связи с этим Lasso провела расследование, в ходе которого извлекла список репозиториев, бывших в открытом доступе какое-то время в 2024 году, и определила те, которые с тех пор были удалены или получили статус приватных. Используя механизм кеширования Bing, компания обнаружила, что более 20 тыс. частных репозиториев GitHub более 16 тыс. организаций по-прежнему доступны через Copilot. В частности, это касается Amazon Web Services, Google, IBM, PayPal, Tencent и Microsoft. Дрор рассказал, что Lasso связалась со всеми компаниями, которые «серьёзно пострадали» от утечки данных, и посоветовала им ротировать или отозвать все скомпрометированные ключи. Lasso уведомила Microsoft о своих выводах в ноябре 2024 года, но софтверный гигант сообщил ей, что относит проблему к «низкой степени серьезности», заявив, что такое поведение при кешировании «приемлемо». Microsoft отметила, что больше не включает ссылки на кеш Bing в результаты поиска с декабря 2024 года. Тем не менее Lasso утверждает, что, хотя функция кеширования была отключена, Copilot всё ещё имеет доступ к данным, несмотря на то, что они не отражались в результатах веб-поиска. Продажи смартфонов в Европе падали четыре года подряд, но теперь вернулись к росту — Samsung осталась лидером
21.02.2025 [14:58],
Владимир Мироненко
В 2024 году продажи смартфонов в Европе выросли на 5 % после четырёх лет спада подряд, превысив 136 млн штук, сообщила аналитическая компания Canalys. 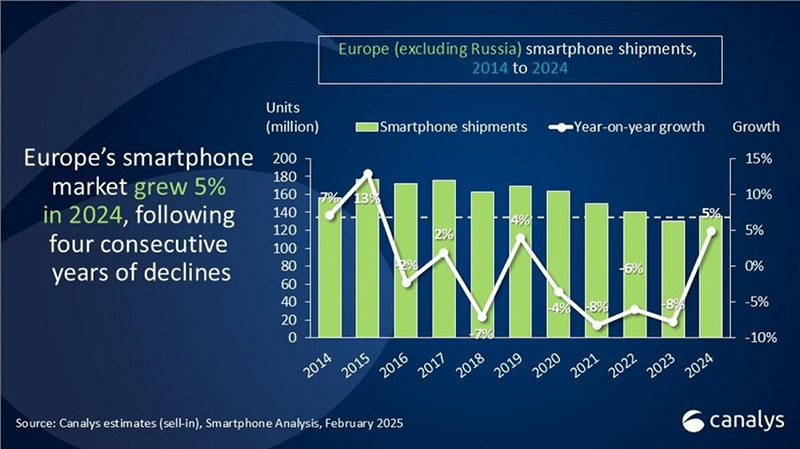
Источник изображений: Canalys Следует учесть, что анализ Canalys на самом деле основан на поставках, а не на фактических продажах в магазинах. Кроме того, данные Canalys включают поставки iPhone 13 и iPhone 14 в канал до того, как в ЕС вступил в силу запрет на гаджеты без USB Type-C. 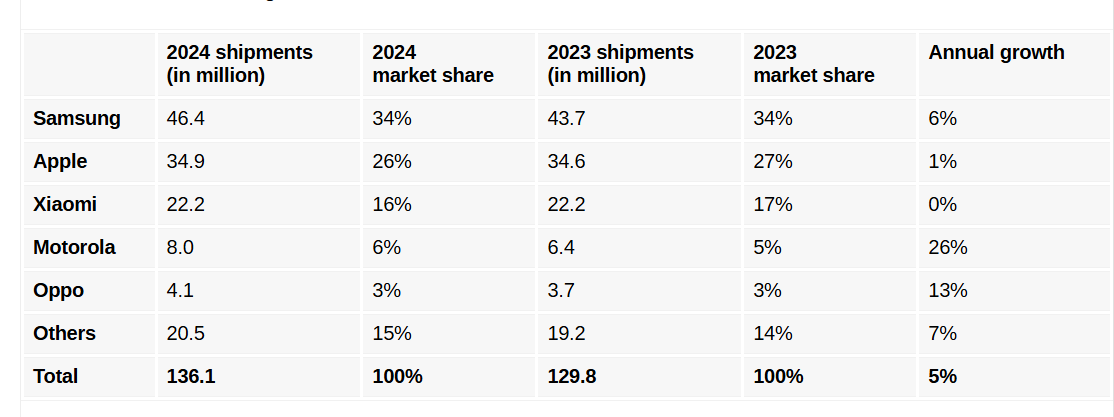 Samsung сохранила лидерство на европейском рынке, увеличив продажи год к году на 6 % до 46,4 млн штук. В этом ей помогли смартфоны серии Galaxy S24, которые активно рекламировались во время Олимпийских игр в Париже. 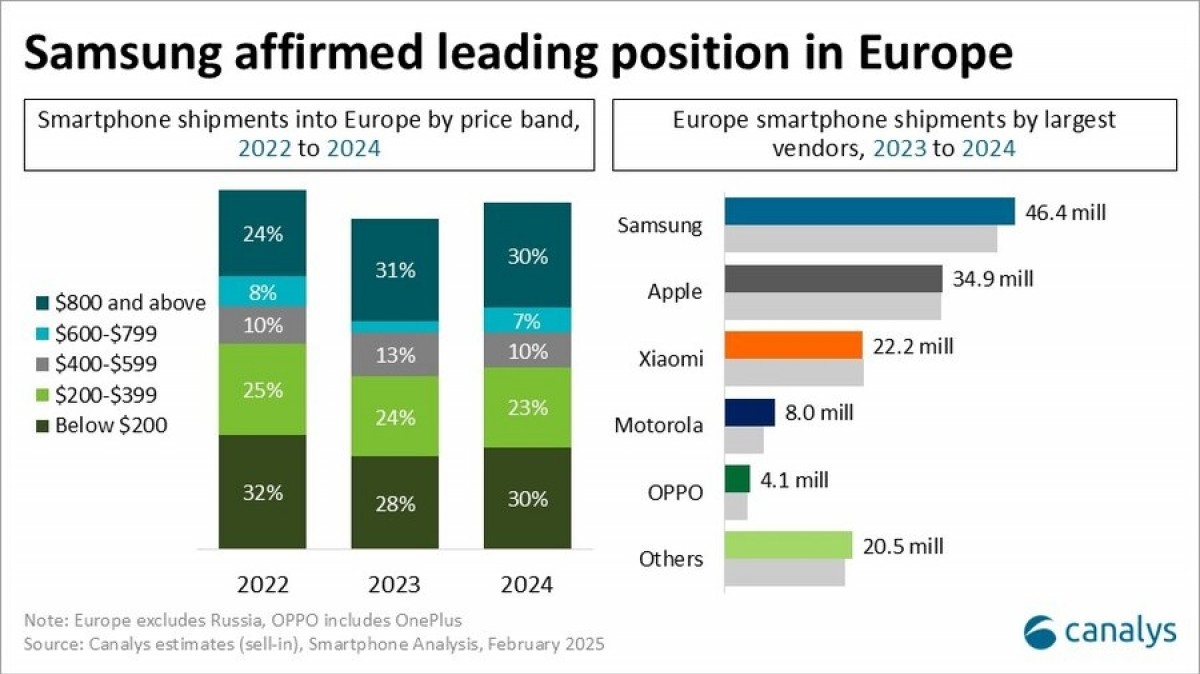 У Apple продажи выросли на 1 % до 34,9 млн штук, в том числе благодаря впечатляющим показателям в IV квартале, обусловленным позитивным приемом покупателями смартфонов iPhone 16, хотя у них по-прежнему не было умных функций Apple Intelligence. Находящаяся на третьем месте Xiaomi продала в прошлом году столько же телефонов под брендами Redmi, Poco и Xiaomi, сколько и в 2023 году. Бренд Motorola показал рост на 26 % до исторического максимума в 8 млн штук благодаря расширению продаж через офлайн-магазины и каналы открытого рынка. На пятом месте Oppo, увеличившая с учётом поставок OnePlus продажи на 13 % до 4,1 млн штук в годовом исчислении. Canalys сообщила, что Oppo вернулась к росту после двух трудных лет благодаря увеличению продаж в Южной Европе — Испании, Италии, Румынии и Португалии. Honor и Realme показали рост на двузначные числа, «усиливая конкуренцию и создавая ажиотаж в канале и среди потребителей», сообщается в исследовании Canalys. Также аналитики отметили, что в 2024 году было продано наибольшее количество устройств премиум-класса с ценой $800 и выше — 41 млн, что составляет 30 % от общего числа. 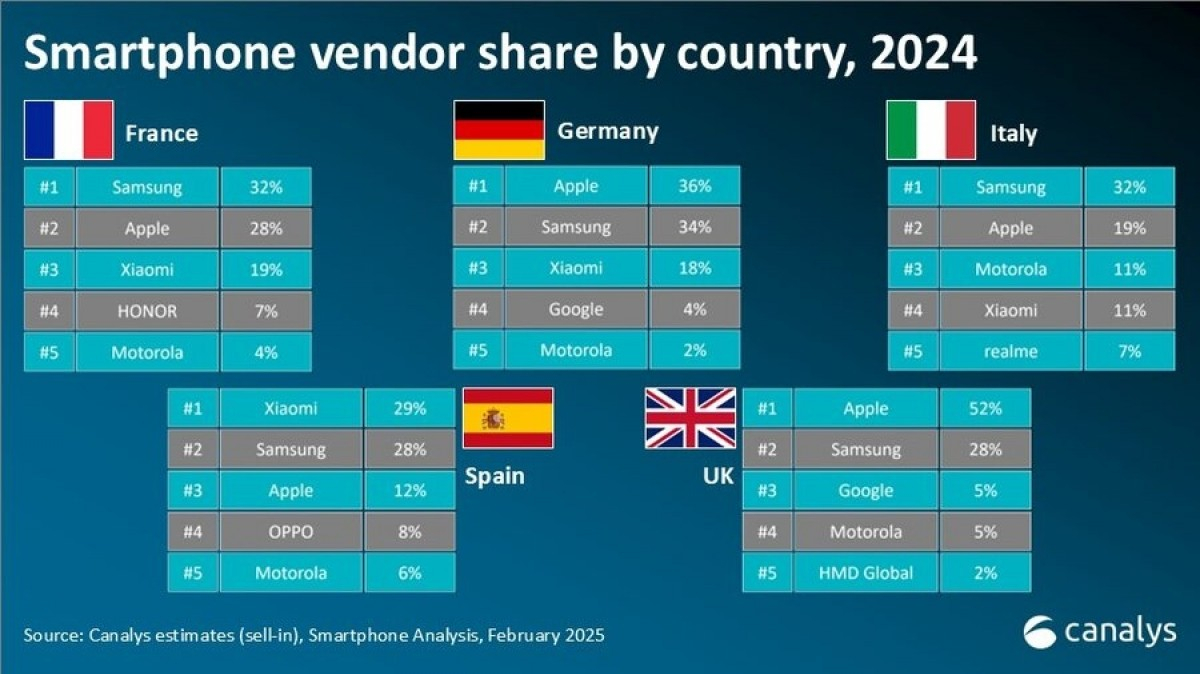 Анализируя поставки по странам, аналитики сообщили, что поставки Apple почти вдвое превысили Samsung в Великобритании (52 % против 28 %). А в Испании на первое место вышла Xiaomi, опередившая Samsung и опустившуюся на третье место Apple. Как отметила Canalys, 2025 год будет непростым для европейского рынка смартфонов, поскольку 20 июня вступает в силу директива ЕС по экодизайну (Directive on Ecodesign of Energy Using Products, EuP), согласно которой производители мобильных устройств должны уделять первостепенное внимание долговечности, простоте ремонта и ответственному использованию ресурсов. Документом предусмотрено предоставление запасных частей на несколько лет, поддержание более длительной поддержки ПО и предоставление технической документации для упрощения ремонта сторонними компаниями. Google создала ИИ-лаборанта, который умеет выдвигать гипотезы и ускорять исследования
19.02.2025 [20:56],
Сергей Сурабекянц
Google создала лаборанта на основе искусственного интеллекта, который поможет учёным ускорить биомедицинские исследования и разработать специализированные приложения на основе передовых технологий. Новый ИИ-ассистент (AI Coscientist — «ИИ-соучёный») умеет выявлять пробелы в знаниях исследователей и предлагать новые идеи, способные ускорить процесс научного познания. 
Источник изображения: Pixabay В настоящее время технологические компании тратят миллиарды долларов на модели и продукты ИИ, рассчитывая, что эти технологии смогут изменить различные отрасли — от здравоохранения до энергетики и образования. «С помощью нашего проекта мы пытаемся выяснить, могут ли технологии, подобные нашему ИИ-ассистенту, наделить исследователей сверхспособностями», — заявил старший клинический учёный Google Алан Картикесалингам (Alan Karthikesalingam). AI Coscientist работает с использованием нескольких агентов ИИ, которые имитируют научный процесс: один специализируется на генерации идей, другие — на их рассмотрении, критическом анализе и рецензировании. ИИ-модель способна извлекать информацию из научных статей и специализированных баз данных, находящихся в свободном доступе. Затем она анализирует полученные данные и генерирует ранжированный список предложений с пояснениями и ссылками на источники. Ранние испытания нового инструмента Google с экспертами из Стэнфордского университета, Имперского колледжа Лондона и Хьюстонской методистской больницы показали, что он способен генерировать многообещающие научные гипотезы. AI Coscientist смог подобрать препараты, которые можно повторно использовать для лечения фиброза печени — серьёзного заболевания, ведущего к образованию рубцовой ткани. ИИ-ассистент предложил два типа препаратов, которые, как подтвердили учёные, помогли в лечении этой болезни. AI Coscientist также сумел прийти к тем же выводам о новом механизме переноса генов, что и исследователи из лаборатории Imperial в своих закрытых научных работах. Результаты, полученные учёными, не были общедоступными, так как находились на стадии рецензирования в ведущем научном журнале. Инструмент Google затратил на исследование всего несколько дней, в то время как университетская команда учёных работала над ним несколько лет. «Мы думаем, что это инструмент, который может изменить наш подход к науке», — считает профессор кафедры инфекционных заболеваний Хосе Пенадес (José Penadés), один из исследователей механизма переноса генов. Такие инструменты, как новый Google AI Coscientist, могут помочь исследователям оставаться в курсе последних открытий в своих предметных областях, полагает доцент Оксфордского университета Якоб Ферстер (Jakob Foerster). Ранее лаборатория Google DeepMind представила новую версию модели искусственного интеллекта AlphaFold, которая предсказывает форму и поведение белков. OpenAI, Perplexity, немецкий производитель лекарств BioNTech и его лондонское дочернее предприятие InstaDeep также недавно запустили собственные инструменты для ИИ-исследований. ChatGPT потребляет не так много энергии, как считалось ранее, показало новое исследование
13.02.2025 [07:24],
Николай Хижняк
Согласно более ранним оценкам, ChatGPT потребляет около 3 Вт·ч энергии для ответа на один запрос, что в 10 раз больше средней мощности, необходимой при использовании поиска Google. Однако свежий отчёт исследовательского института Epoch AI, занимающегося изучением ключевых трендов и вопросов, которые будут определять траекторию развития и управление искусственным интеллектом, опровергает эту статистику и указывает на то, что энергозатраты чат-бота OpenAI значительно меньше, чем предполагалось ранее. 
Источник изображения: OpenAI В отчёте Epoch AI говорится, что ChatGPT на базе модели GPT-4o потребляет всего 0,3 Вт·ч энергии при генерации ответа. В разговоре с порталом TechCrunch дата-аналитик Epoch AI Джошуа Ю (Joshua You) отметил: «Потребление энергии на самом деле не так уж и велико по сравнению с использованием обычных бытовых приборов, отоплением или охлаждением дома или использованием автомобиля». 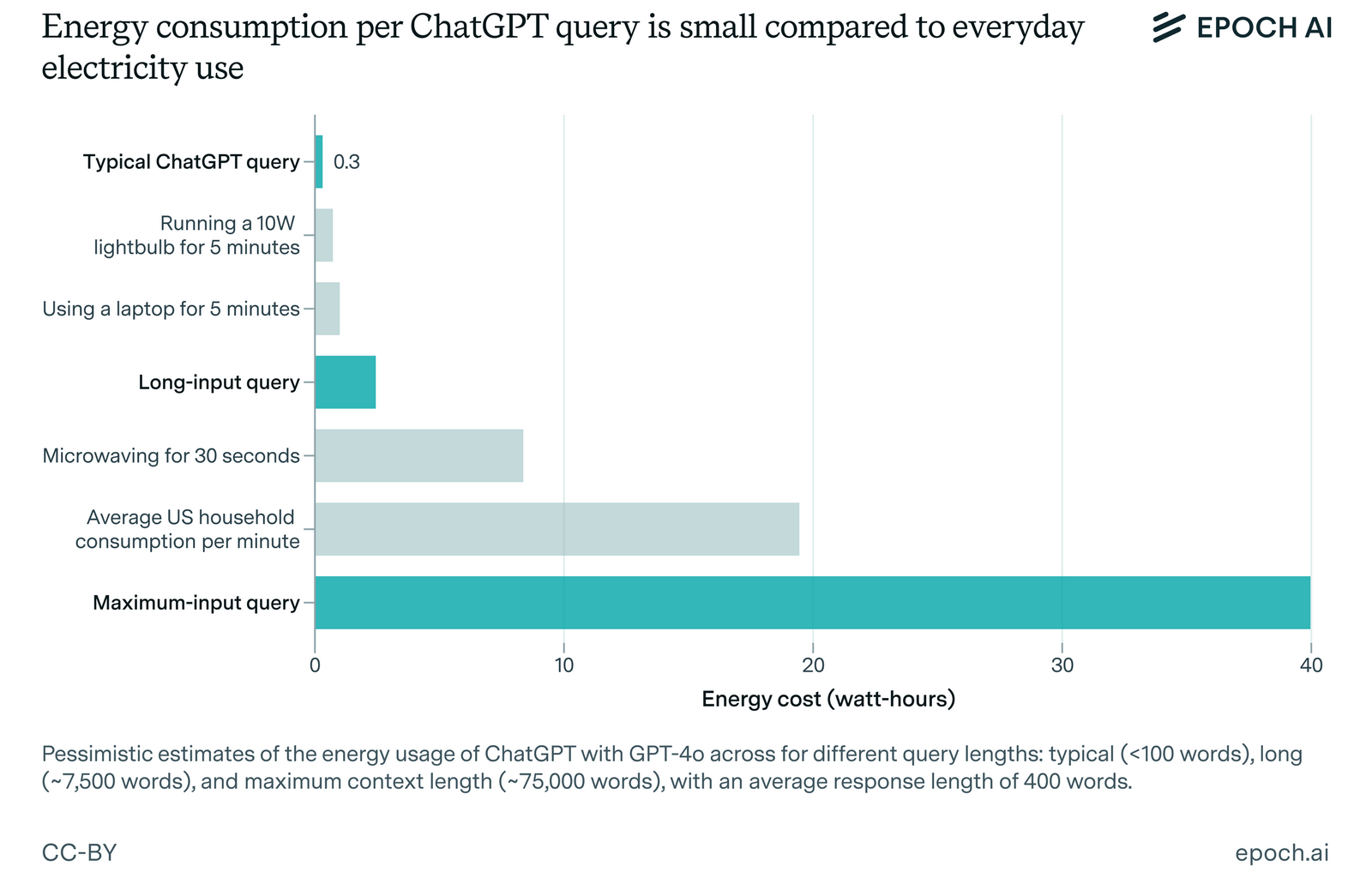 По словам эксперта, предыдущие оценки энергозатрат ChatGPT были основаны на устаревших данных. Специалист отмечает, что предполагаемая «универсальная» статистика энергопотребления ChatGPT была основана на предположении, что OpenAI для запуска и работы ИИ использует старые и неэффективные чипы. «Кроме того, некоторые из моих коллег обратили внимание, что наиболее широко распространённая оценка в 3 Вт·ч на выполнение запроса была основана на довольно старых исследованиях. И если судить по каким-то приблизительным расчётам, эта статистика показалась слишком завышенной», — добавил Ю. И всё же следует добавить, что оценку энергозатрат ChatGPT от Epoch AI тоже нельзя считать непреложной, поскольку она не учитывает некоторые ключевые возможности ИИ, такие как генерация изображений чат-ботом. По словам эксперта, он не ожидает роста энергопотребления у ChatGPT, но по мере того, как ИИ-модели становятся более продвинутыми, им будет требоваться больше энергии для работы. Ведущие компании по разработке ИИ, включая OpenAI, склоняются к развитию так называемых рассуждающих моделей ИИ, которые не просто дают ответ на поставленный вопрос, но также описывают весь процесс, который привёл к получению того или иного ответа, что в свою очередь требует больших энергозатрат. Множество отчётов последних лет показывают, что такие технологии, как Microsoft Copilot и ChatGPT (а точнее оборудование, на котором они работают) потребляют эквивалент объёма одной бутылки воды для охлаждения при генерации ответа на запрос. Эти выводы следуют за более ранним отчётом, в котором говорится, что совокупные энергозатраты Microsoft и Google превышают потребление электроэнергии более чем в 100 странах мира. В одном из наиболее свежих исследований подробно описывалось, что модель OpenAI GPT-3 потребляет в четыре раза больше воды, чем считалось ранее, в то время как GPT-4 потребляет объёмы до трёх бутылок воды, чтобы сгенерировать всего лишь 100 слов. Вполне очевидно, что модели ИИ начинают потреблять больше ресурсов по мере того, как становятся более продвинутыми. Однако, выводы последнего исследования показывают, что тот же ChatGPT может быть не таким прожорливым, как считалось ранее. Apple запустила глобальное исследование физического и психического здоровья пользователей iPhone, Watch и AirPods
12.02.2025 [19:24],
Сергей Сурабекянц
Компания Apple объявила о запуске исследования здоровья Apple (Apple Health Study). Оно охватит такие темы, как активность, старение, сердечно-сосудистое здоровье, здоровье кровообращения, когнитивные функции, слух, менструальное здоровье, метаболическое здоровье, подвижность, неврологическое здоровье, здоровье органов дыхания и сон. Пользователи, согласившиеся участвовать, предоставят свои данные и пройдут периодические опросы о своей домашней жизни и привычках. 
Источник изображения: unsplash.com Виртуальное исследование появится в приложении Research. Компания будет собирать широкий спектр данных, чтобы попытаться обнаружить новые связи между различными аспектами здоровья — как физического, так и психического. Исследование проводится совместно с филиалом Гарвардской медицинской школы. Первый этап рассчитан на пять лет с возможностью дальнейшего продления. 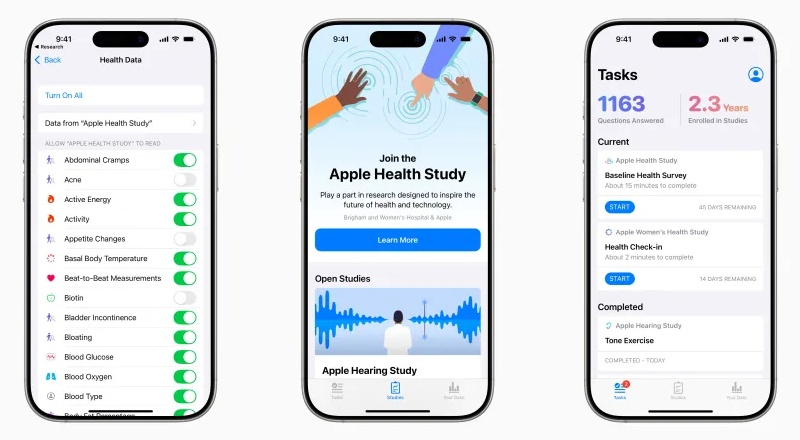
Источник изображения: Apple Цели исследования на первый взгляд кажутся туманными, поскольку его область применения и потенциальный масштаб значительно шире, чем у традиционных клинических исследований. Подобное широкомасштабное изучение различных аспектов здоровья может помочь в создании более проактивных функций. В качестве примера можно упомянуть новую функцию проверки слуха в AirPods. По словам вице-президента Apple по здравоохранению Сумбулы Десаи (Sumbul Desai), эта функция появилась благодаря исследованию слуха Apple. Возможно, в будущем с её помощью удастся понять, может ли раннее ухудшение слуха повышать риск снижения когнитивных способностей. «Мы используем эти исследования не только для обучения, но и для того, чтобы направлять и информировать наши решения о том, что добавить в дорожную карту продукта», — отметила Десаи, добавив, что компания отказалась от внедрения функций, получивших негативные оценки исследователей. 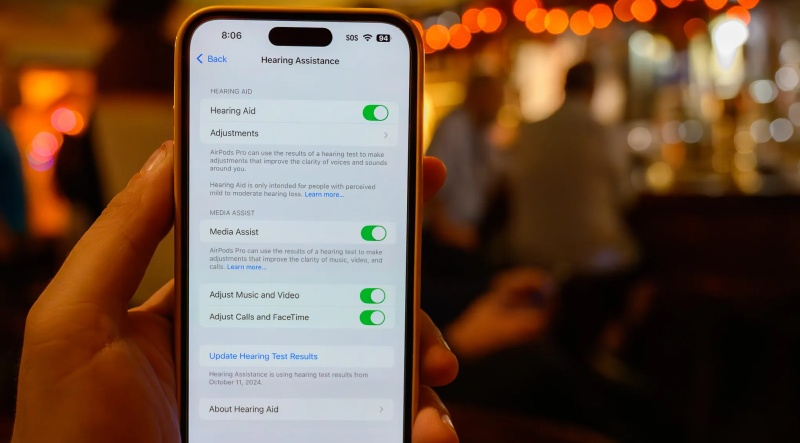
Источник изображения: TheVerge Кардиолог и профессор медицины Гарвардской медицинской школы Калум Макрей (Calum MacRae), который выступит в качестве главного исследователя в Apple Health Study, уверен, что выводы традиционных исследований часто требуют слишком много времени, прежде чем они становятся применимыми в повседневной жизни. По его словам, «они выбирают популяцию и тему для изучения в первый день, а затем застревают с этими решениями на потенциально десятилетия, даже если сама область исследования изменится за это время». Макрей полагает, что доступ к «огромной и разнообразной когорте» — в данном случае к любому владельцу устройства Apple — открывает возможности для ускорения открытий и прогресса: «Чем разнообразнее и шире возрастной диапазон, демографические данные и другие критерии, тем лучше. Мы можем выявить первоначальный сигнал, проверить и подтвердить его, а затем связать с большим количеством факторов. Чем больше людей участвует в исследовании, тем больше данных мы получаем, и внезапно мы оказываемся в состоянии радикально ускорить темпы исследований». Первый исследовательский проект компании, Apple Heart Study, собрал 400 000 участников. Большинство традиционных исследований работают с гораздо меньшими выборками и не могут отслеживать участников в течение длительных периодов. Расширение масштаба исследований открывает новые возможности для выявления ранее неизвестных закономерностей. 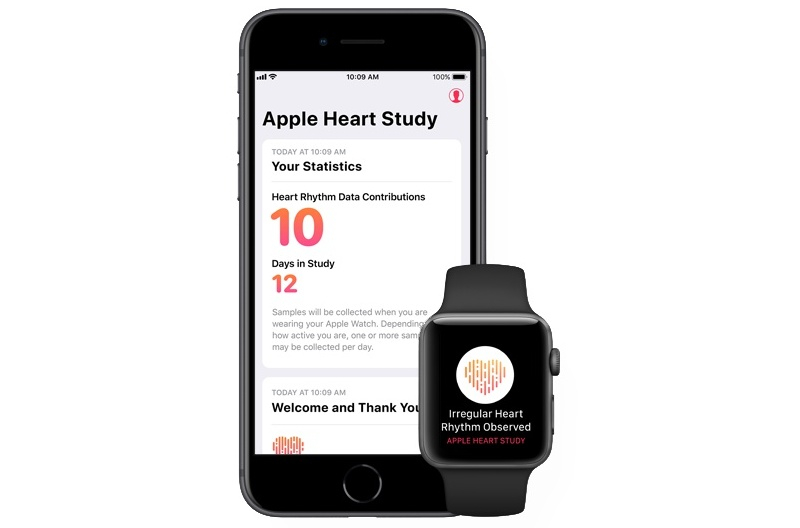
Источник изображения Apple Масштаб исследования Apple Health Study может помочь учёным устранить информационные пробелы. Одна из проблем традиционных клинических исследований заключается в том, что они, как правило, охватывают более узкую выборку участников. Например, если в исследовании здоровья в основном участвуют молодые белые мужчины, результаты могут оказаться неприменимыми к женщинам, детям, пожилым людям или представителям других этнических групп. Исследователи не рассчитывают на быстрые результаты. «Я бы не ожидала ничего в этом году, просто потому что с научной точки зрения это было бы невозможно», — заявила Десаи. В качестве примера она привела функцию мониторинга апноэ во сне для Apple Watch, разработка которой заняла около пяти лет. Мобильная связь подорожала в России на 4 % в прошлом году и в 2025-м «актуализация тарифов» продолжается
12.02.2025 [13:26],
Владимир Мироненко
В России в 2024 году средний чек за мобильную связь увеличился на 4 % — до 391 руб., в то время как рост затрат на другие телекоммуникационные услуги операторов был гораздо меньше, пишет Forbes со ссылкой на исследование Nexign и TelecomDaily. Например, средний счёт за услуги широкополосного доступа в интернет вырос лишь на 1 % — до 378 руб., а счета за услуги фиксированной телефонии и платного ТВ и вовсе уменьшились в связи с вытеснением этих сервисов новыми технологиями. 
Источник изображения: Jonas Leupe/unsplash.com В 2025 году операторы продолжили поднимать цены на часть услуг. МТС с 1 февраля повысил стоимость услуг домашнего интернета и аренды оборудования (Wi-Fi-роутеры) на ряде архивных тарифов, а также скорректировал условия предоставления индивидуальных скидок. Оператор «Билайн» предупредил пользователей, что с 12 февраля повышает цены на некоторых тарифах домашнего интернета и ТВ, а также стоимость аренды оборудования. Т2 также рассылал абонентам сообщения о повышении цен. «МегаФон» с 1 марта увеличивает стоимость фиксированной связи, а для части корпоративных абонентов уже повысил тарифы 1–3 февраля, увеличив, в том числе, цены на сами тарифные планы, SMS, таргеты и пакеты SMS для таргетированной рассылки по базе оператора. Операторы объясняют рост тарифов общими экономическими и рыночными факторами. В «Вымпелкоме» (бренд «Билайн») сообщили, что «планомерно актуализируют» стоимость тарифов, приводя их к текущей рыночной стоимости. Рост цен затронул часть клиентов, использующих архивные тарифы. В среднем абонентская плата у этой категории выросла на 13 %, хотя для отдельных тарифных планов повышение могло быть и выше. В Т2 также повысили цены на ряд архивных тарифов. В компании отметили, что цены пересматриваются не чаще одного раза в год и фиксируются как минимум до конца текущего года. В МТС сообщили, что стоимость мобильных услуг связи периодически пересматривается в зависимости от экономической и рыночной ситуации. В данном случае повышение тарифов на фиксированные услуги коснулось ряда архивных тарифов и затронуло незначительное количество абонентов. При этом в Т2, помимо объективных экономических факторов, среди причин роста цен назвали и регулирование. В компании пояснили, что, помимо роста расходов на содержание сетей (из-за увеличения стоимости электроэнергии, подключения к энергосетям, оборудования и аренды), растёт регуляторная нагрузка на отрасль — «значительно выросла плата за радиочастотный спектр, требуется дополнительное оснащение салонов из-за нового порядка подключения иностранных граждан, а также дополнительные ресурсы на выполнение программ по импортозамещению». Вместе с тем, как отметил автор Telegram-канала abloud62 Алексей Бойко, с учётом инфляции реальные расходы российских пользователей на телекоммуникационные услуги в 2024 году сократились, поскольку рост среднего чека оказался заметно ниже уровня инфляции, составившей, по оценкам Росстата, 9,52 % в прошлом году. Злоупотребление ИИ делает человека глупее, установили учёные
11.02.2025 [12:28],
Павел Котов
«При неправильном использовании технологии могут приводить и приводят к ухудшению когнитивных способностей, которые следует сохранять», — таковы результаты исследования, проведённого учёными Университета Карнеги-Меллона (США) и Microsoft. Они попытались выяснить, как использование генеративного искусственного интеллекта влияет на навыки критического мышления у человека. 
Источник изображения: Stefan Cosma / unsplash.com Полагаясь в работе на генеративный ИИ, человек переключает свои усилия на оценку качества ответов системы — насколько они подходят для применения в рабочих целях. При этом он в меньше степени задействует навыки критического мышления более высокого порядка, необходимые для создания, оценки и анализа информации. Если человек вмешивается только тогда, когда ответов ИИ недостаточно, он тем самым лишает себя «повседневной возможности практиковать свои суждения и укреплять свою когнитивную „мускулатуру“, оставляя её атрофированной и неподготовленной, когда возникают исключения». Другими словами, когда человек слишком сильно полагается на ИИ, позволяет ему «думать» за себя, он начинает хуже решать проблемы самостоятельно, если ИИ терпит неудачу. Добровольцами в исследовании выступили 319 человек, которые признали, что хотя бы раз в неделю используют ИИ в работе. Их попросили привести примеры применения генеративного ИИ в работе, исходя из трёх основных сценариев: создание материалов, например, написание электронного письма коллеге; подготовка сводок информации, например, исследование темы или перечисление тезисов длинной статьи; обращение за советом или создание диаграммы на основе существующих данных. Далее добровольцев спросили, применяют ли они навыки критического мышления при выполнении задания, и заставляет ли работа с генеративным ИИ прилагать больше или меньше усилий для критического мышления. По каждой упомянутой задаче добровольцев попросили оценить, насколько они уверены в себе, в генеративном ИИ и в своей способности оценивать ответы ИИ. 
Источник изображения: Onur Binay / unsplash.com Около 36 % респондентов сообщили, что использовали навыки критического мышления, чтобы смягчить возможные отрицательные последствия работы с ИИ. Одна участница сообщила, что обращалась к ChatGPT при аттестации, но дважды проверяла ответы ИИ, опасаясь, что даст неверный ответ, и её отстранят. Другой доброволец рассказал, что ему приходилось редактировать подготовленные ИИ черновики электронных писем, адресованных его начальнику, потому что для того разница в положении и возрасте имела большое значение. Многие признались, что проверяли ответы ИИ, используя привычные ресурсы, в том числе YouTube и «Википедию», хотя это, возможно, сводит на нет сам смысл обращаться к ИИ. Чтобы компенсировать имеющиеся у генеративного ИИ недостатки, работникам следует понимать, как эти недостатки возникают, но не все знают, каковы ограничения современного ИИ. Как показало исследование, уверенные в правильности ответов ИИ участники меньше применяли критическое мышление, чем те, кто сообщил об уверенности в собственных способностях. Учёные пока не утверждают, что инструменты ИИ как таковые делают человека глупее, но чрезмерная зависимость от них может ослабить нашу способность решать проблемы самостоятельно, гласят результаты исследования. Учёные смогли точно направлять передаваемое по воздуху электричество — с помощью ультразвука
10.02.2025 [11:56],
Владимир Фетисов
Электричество хаотично, и обычно его использование приходится ограничивать проводами и цепями. Однако международной группе учёных из Европы и Канады удалось точно направлять электрические искры в воздухе и даже заставить их огибать препятствия с помощью ультразвуковых волн. Детальная информация о проделанной работе опубликована в журнале Science Advances. 
Источник изображения: newatlas.com В новом исследовании учёные из Хельсинского университета, Университета Наварры и Университета Ватерлоо продемонстрировали способ управления передаваемыми по воздуху электрическими искрами. Представленная технология позволяет направлять искры настолько точно, что они могут огибать препятствия и достигать определённых точек на каком-либо материале, даже если он не обладает электропроводностью. «Мы наблюдали это явление более года назад, после чего нам потребовались месяцы, чтобы взять его под контроль, и ещё больше времени, чтобы найти объяснение», — сказал Асьер Марзо (Asier Marzo), один из участников исследования. Хитрость заключается в использовании ультразвуковых волн. Дело в том, что звуковые волны на таких частотах создают давление воздуха, достаточное для обеспечения левитации крошечных объектов. В данном случае волны не стимулируют само электричество, а лишь формируют траекторию его движения. При образовании искры воздух вокруг неё нагревается. Более тёплый воздух расширяется, из-за чего снижается его плотность. Поскольку электричество лучше проходит через воздух с меньшей плотностью, искра движется именно в этом направлении. Ультразвуковые импульсы позволяют перемещать более тёплый воздух с меньшей плотностью, который, в свою очередь, задаёт направление для движения электричества. Исследователи протестировали технологию с помощью пары ультразвуковых излучателей, окружающих точку, в которой с помощью катушки Теслы генерируется искра. При включении ультразвука искра превращается из древовидной формы в единую линию, которую можно направить в нужную сторону, физически перемещая излучатель или регулируя мощность ультразвука. Учёным удалось направлять искры таким образом, чтобы они попадали на определённые электроды и избегали другие, что помогло обеспечить контролируемое переключение в беспроводных цепях. «Я в восторге от возможности использования очень слабых искр для создания контролируемых тактильных ощущений в руке и, возможно, создания первой бесконтактной системы Брайля», — заявил один из авторов исследования, Джозу Ирисарри (Josu Irisarri). Xiaomi стала лидером рынка планшетов в России в прошлом году, но заработала больше всех Apple
07.02.2025 [09:17],
Владимир Мироненко
По оценке аналитиков МТС, продажи планшетов в России в 2024 году выросли до рекордного уровня. Всего за прошлый год в стране было продано 3 млн планшетных компьютеров на общую сумму 61,7 млрд руб., что выше показателей 2023 года на 23 и 24 % соответственно.  Как сообщают в МТС, высокий спрос на планшеты был обусловлен несколькими факторами. Во-первых, выросла функциональность и производительность планшетов, позволяя решать с их помощью всё больше рабочих задач. Во-вторых, практически все бренды обновили линейки устройств, в том числе в доступной ценовой категории. Кроме того, растёт и экосистемность. Потребители теперь чаще выбирают планшеты того же бренда, что и имеющийся смартфон для удобства использования. В 2024 году в России лидером продаж планшетов в штуках стал бренд Xiaomi с долей рынка 15 %, занимавший в 2023 году четвёртое место с долей рынка 11 %. Второе место сохранилось у Huawei с долей 14 % — такой же, как и год назад. Третье место сообща получили планшеты российских брендов с долей 12 %, возглавлявшие годом ранее рейтинг с долей 15 %. Четвёртое место у Samsung с долей 11 %, занимавшего в 2023 году третье место с 13 % рынка. Первую пятёрку замыкают малоизвестные китайские бренды с долей 8 %, тогда как в предыдущем году на пятом месте находилась Apple (10,2 %). Лидером по продажам планшетов в денежном выражении осталась Apple, чьё присутствие на рынке в этом выражении сократилось с 28 % в 2023 году до 21 % в 2024 году. На второе место рейтинга вышла Xiaomi с долей в 17 %, находившаяся годом ранее на четвёртом месте с долей в 13 %. Третье место сохранила Huawei, чья доля рынка выросла с 14 до 15 %. Четвёртое место у Samsung с долей 14 %, ранее занимавшей второй место с долей в 17 %. Первую пятёрку замыкают планшеты российских брендов с долей рынка в размере 5 %, сместившие Lenovo, у которого в 2023 году была доля рынка в 6 %. Исследователи отметили, что китайские производители продолжают наращивать свою долю на рынке планшетов России. Если в 2023 году они занимали 77 % рынка в штуках и 55 % в деньгах, то в 2024 года на них приходится уже 83 % в количественном выражении и 64 % в денежном. Между тем на мировом рынке поставки планшетов в 2024 году выросли в количественном выражении на 9 % до 147,6 млн единиц, сообщили в аналитической компании Canalys. Возглавила рейтинг лидеров продаж Apple с 56,9 млн проданных планшетов и долей рынка в размере 38,6 %. Второе место заняла Samsung с 27,8 млн проданных устройств и рыночной долей в 18,8 %, третье место у Huawei, поставившей 10,74 млн планшетов, обеспечив 7,3 % рынка. На четвёртом месте Lenovo с 10,42 млн поставленных планшетов и долей рынка 7,1 %, на пятом — Xiaomi с продажей 9,2 млн устройств и 6,2 % рынка. Доходы хакеров от программ-вымогателей упали на треть в прошлом году, хотя атак стало больше
06.02.2025 [19:23],
Владимир Мироненко
В 2024 году число хакерских атак с использованием программ-вымогателей увеличилось, однако, несмотря на это, злоумышленникам удалось получить значительно меньше средств в качестве выкупа за восстановление доступа к заблокированным данным, выяснила аналитическая компания Chainalysis. 
Источник изображений: Chainalysis Согласно данным Chainalysis, пострадавшие компании выплатили хакерам-вымогателям за 2024 год $814 млн, что на 35 % меньше, чем в 2023 году, когда эта сумма достигла рекордных $1,25 млрд. Также отмечено, что впервые с 2022 года доходы злоумышленников от программ-вымогателей снизились. Причинами сокращения выплат стали активизация правоохранительных органов в борьбе с киберпреступностью, повышение эффективности международного сотрудничества спецслужб и нежелание пострадавших организаций выплачивать крупные суммы, несмотря на риск потери данных. Запрашиваемые суммы выкупа оказались на 53 % выше, чем в итоге получили хакеры. 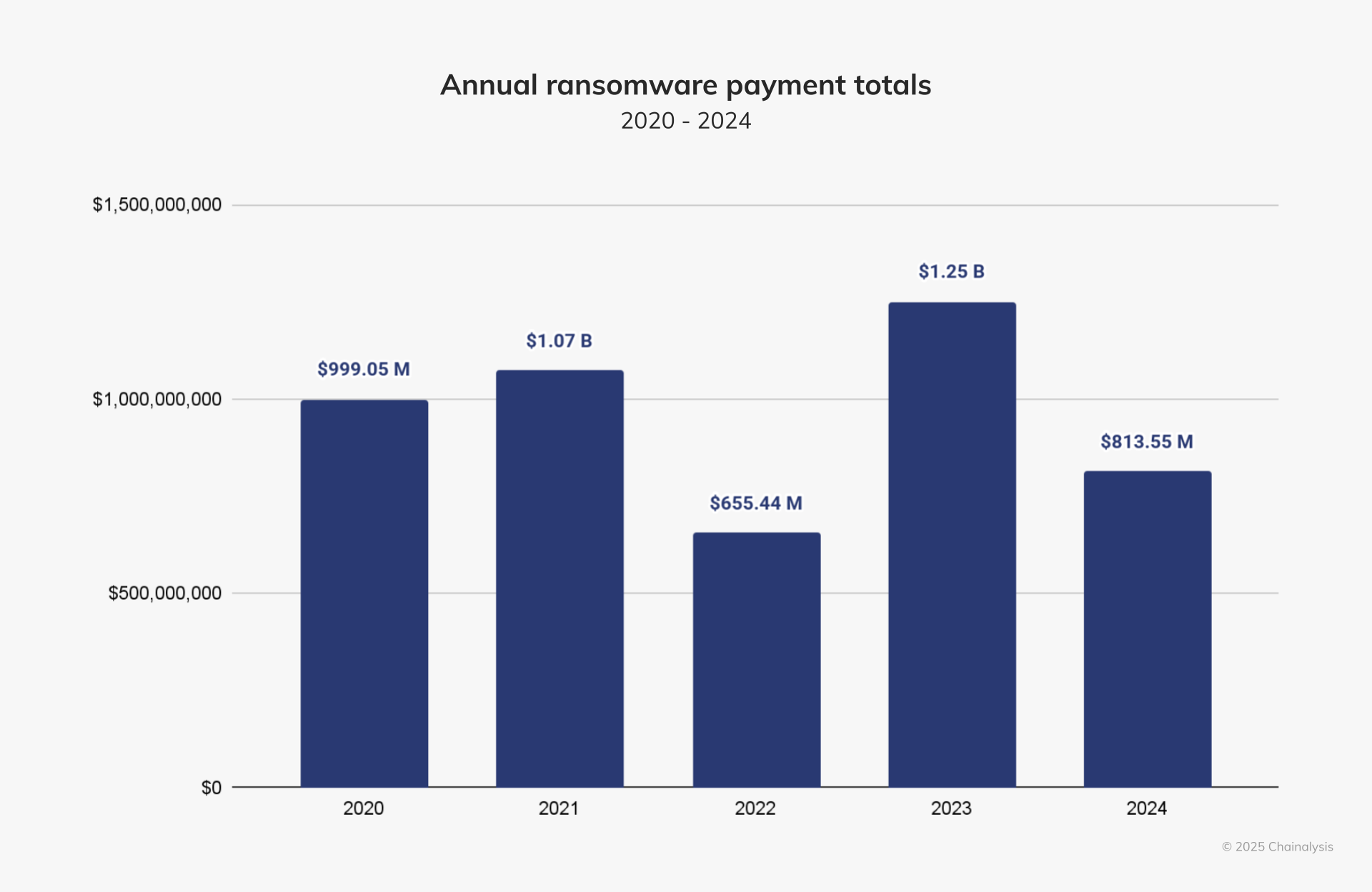 После ряда операций по изъятию серверов, проведённых в начале 2024 года правоохранительными органами нескольких стран против хакерской группировки LockBit, платежи за снятие блокировки с использованием этого вируса-вымогателя сократились во второй половине года на 79 %. Напомним, что 51-летний Ростислав Панев, один из ключевых разработчиков LockBit, был арестован в Израиле в августе 2024 года. В настоящее время он ожидает экстрадиции в США. 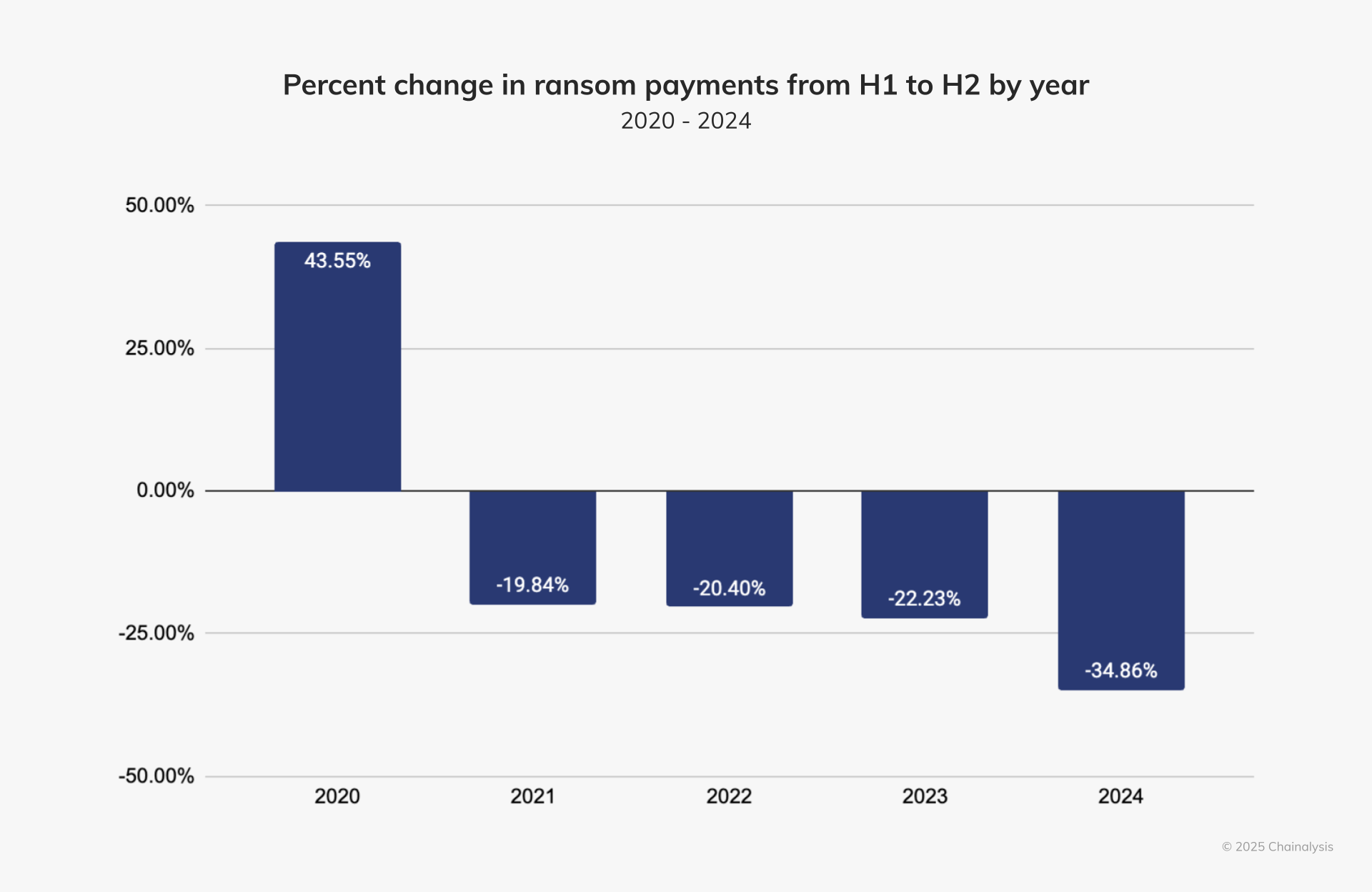 Лиззи Куксон (Lizzie Cookson), старший директор Coveware — компании, специализирующейся на реагировании на инциденты с программами-вымогателями, — сообщила Chainalysis, что рынок так и не восстановился после краха группировок LockBit и BlackCat/ALPHV. «Текущая экосистема программ-вымогателей заполнена множеством новичков, которые, как правило, сосредотачивают усилия на малом и среднем бизнесе. В свою очередь, это приводит к более скромным требованиям выкупа», — отметила она. В первом полугодии 2024 года объёмы полученных хакерами выкупов оставались примерно на уровне аналогичного периода 2023 года — около $459,8 млн, что на 2,38 % больше в годовом исчислении. Эта сумма включает рекордный выкуп в размере $75 млн, выплаченный хакерской группировке Dark Angels за восстановление информации. Однако во втором полугодии 2024 года пострадавшие компании стали гораздо реже соглашаться на выплату выкупа, что привело к снижению доходов хакеров на 34,9 % по сравнению с первой половиной года. Российский рынок пиратского видеоконтента сократился до 3,4 млрд рублей в 2024 году
06.02.2025 [12:25],
Владимир Фетисов
По данным компании F.A.C.C.T (бывшая Group-IB), объём рынка пиратского видеоконтента в России сократился в 2024 году на 4 % и составил $36,4 млн (3,4 млрд рублей). В 2023 году рынок онлайн-пиратства сократился на 13,3 % до $39 млн. 
Источник изображения: Glenn Carstens-Peters / Unsplash Трафик поисковых запросов на пиратские ресурсы в прошлом году также сократился почти на 4 %, а на легальные онлайн-кинотеатры вырос на 25 % год к году. Несмотря на это, количество пиратских доменов продолжает расти второй год подряд. Количество выявленных пиратских площадок возросло на 37,5 % до 110 тыс. единиц. В целом же количество ссылок с контентом, который был внесён российскими правообладателями в реестр в рамках антипиратского меморандума, в прошлом году достигло 180 млн единиц. Самым популярным фильмом на пиратских ресурсах в 2024 году был «Пчеловод» (Miramax Films) с Джейсоном Стейтемом в главной роли. Среди других популярных картин — «Дом у дороги» (Metro Goldwyn Mayer), «Планета обезьян: Новое царство» (20th Century Fox) и «Дюна: часть вторая» (Warner Bros.). Некоторые из этих фильмов так и не появились в официальном прокате в России из-за ухода из страны зарубежных мейджоров. В компании также отметили, что доля пиратских сайтов по сравнению с другими источниками распространения нелегального видеоконтента в прошлом году выросла до 94 % (годом ранее этот показатель был равен 82 %). Эту динамику связывают с пополнением базы фильмов и сериалов пиратских видеобалансеров (базы с контентом, позволяющие осуществлять трансляции на других сайтах). Кроме того, это связано с тем, что владельцы таких площадок выбирали лояльных к пиратскому контенту хостинг-провайдеров. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex