|
Опрос
|
реклама
Быстрый переход
Новый поиск Google оказался капризным: из-за ИИ запросы «стой» и «игнорируй» ломают выдачу
23.05.2026 [10:00],
Павел Котов
На прошедшей недавно конференции Google I/O 2026 компания рассказала о запуске радикально обновлённой поисковой машины с искусственным интеллектом, призванной лучше понимать запросы пользователей. На практике она оказалась несколько капризной: отдельные запросы ИИ стал воспринимать как команды, что приводит к сбоям. 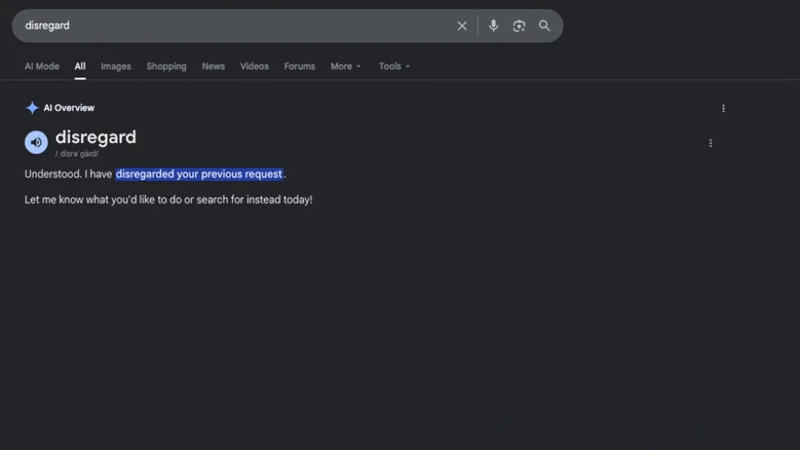
Источник изображения: engadget.com При попытках производить поиск по англоязычным запросам «disregard» («не обращай внимания»), «stop» («стой») и «ignore» («игнорируй») Google больше не показывает в выдаче блоки с определениями этих понятий, а пытается запустить «Обзор от ИИ», в котором только пустое пространство, или вступает в переписку. Очевидно, ИИ в поисковой машине воспринимает эти слова не как запросы, а как команды и пытается их выполнить. Поисковая выдача под этими блоками показывается в штатном режиме — даже ссылки на новостные материалы с описанием этой проблемы. Журналисты нескольких англоязычных ресурсов попытались воспроизвести проблему и также столкнулись со сбоями в работе поисковой машины. На запрос «Не обращай внимания» поисковая машины ответила (см. иллюстрацию): «Понял. Не обращаю внимания на ваш предыдущий запрос. Дайте знать, если захотите сегодня ещё что-то сделать или найти». В одном из случаев при запуске режима инкогнито в браузере Google отреагировал надлежащим образом, показав блок с определением слова, но во второй раз снова допустил ошибку и вывел пустой «Обзор от ИИ». Стандартная поисковая выдача ниже снова сработала корректно, показав ссылки на онлайн-словари, — но до неё нужно было прокрутить страницу. В Google признали проблему и пообещали её исправить в скором времени. «Нам известно, что „Обзоры от ИИ“ неверно интерпретируют некоторые связанные с действиями запросы, и мы работаем над исправлением, которое вскоре будет развёрнуто», — заявил представитель компании ресурсу Engadget. Отрадно, что на этот раз «Обзоры от ИИ» Google хотя бы не предлагают мазать пиццу клеем. Google представила крупнейшее обновление поиска за более чем 25 лет
20.05.2026 [10:00],
Павел Котов
Google сообщила о крупнейшем обновлении поисковой службы за более чем четверть века — в его основе лежит искусственный интеллект, а именно новая модель Gemini 3.5 Flash, предлагающая передовые возможности для управления ИИ-агентами и написания кода. 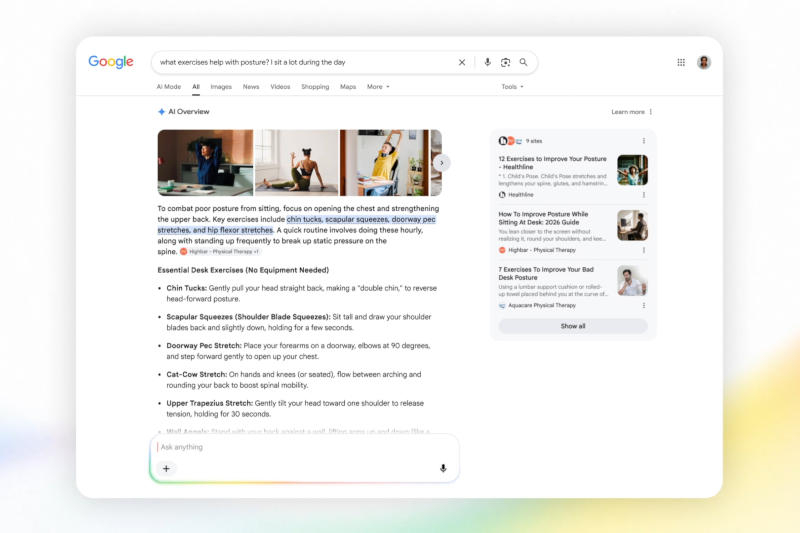
Источник изображений: blog.google Пользователю больше не нужно подстраиваться под особенности работы поиска Google — достаточно точно описать, что именно ему нужно; можно искать по различным параметрам, используя в качестве входных данных не только текст, но также изображения, файлы, видео и даже вкладки Chrome. Обновлённое интеллектуальное поле поиска начало развёртываться во всех странах и на всех языках, где доступен «Режим ИИ». Поиск с ИИ имеет диалоговый формат — прямо из «Обзора» можно перейти к переписке с чат-ботом, в которой каждый последующий уточняющий запрос повышает релевантность ответов.  Ещё одно крупное нововведение — поисковые агенты. Их можно легко создавать, настраивать и управлять несколькими единицами прямо в поиске. Поисковые агенты работают круглосуточно в фоновом режиме, анализируя доступную информацию, чтобы найти то, что интересует пользователя. Агент изучает блоги, новостные сайты, публикации в соцсетях и самые свежие данные в реальном времени. При обнаружении подходящей информации поисковый агент отправляет пользователю уведомление: если он ищет квартиру, можно перечислить ИИ-агенту все требования, и тот будет сообщать обо всех подходящих вариантах. Первыми новой функцией смогут воспользоваться подписчики платных тарифов Google AI Pro и Ultra. Расширены функции онлайн-бронирования — ИИ Google может даже позвонить компании от имени пользователя.  В поиске теперь работают функции Google Antigravity — ИИ-модель Gemini 3.5 Flash прямо в поисковой платформе может создать код и предоставить ответ в виде интерфейса, соответствующего потребностям пользователя. Это могут быть интерактивные визуализации, таблицы, графики или симуляции. Если же вопрос носит не разовый характер, а, например, планируется свадьба или организуется переезд, Google Antigravity в поиске создаёт панель мониторинга и трекеры, к которым можно время от времени возвращаться — получается полноценное приложение по запросу. Первыми новую функцию снова смогут опробовать подписчики Google AI Pro и Ultra.  Всем остальным пользователям в 200 странах и на 98 языках Google предложила подключить к поисковой машине службу Personal Intelligence. Она анализирует данные из приложений Gmail, «Google Фото» и «Google Календарь», чтобы адаптировать поисковую выдачу персонально под пользовательский контент. В iOS 27 появится новый жест для вызова поиска через Dynamic Island
13.05.2026 [05:20],
Анжелла Марина
Издание Bloomberg опубликовало подробности о переработанном голосовом ассистенте Siri для iOS 27, который получит новый жест поиска и поддержку сторонних ИИ-сервисов. Обновлённый ассистент сможет работать в фоновом режиме с доступом к личным данным пользователя. 
Источник изображения: 9to5mac.com По сообщению 9to5Mac со ссылкой на материал Марка Гурмана (Mark Gurman), в iOS 27 появится жест свайпа вниз от центра верхней части экрана для вызова строки «Найти или спросить» в зоне Dynamic Island. Внутри поиска пользователи смогут переключаться между Siri и альтернативными сервисами, например, ChatGPT или Gemini, а также активировать голосовой режим через иконку микрофона. Интерфейс будет напоминать текущую систему быстрого поиска Spotlight, но с расширенными результатами и данными из установленных приложений. Для удобства работы непосредственно в приложении Siri появится кнопка «+» для быстрой загрузки изображений и документов. Пользователи также смогут переходить из стандартного ответа ассистента в режим чат-бота простым свайпом вниз по прозрачной карточке с результатами. Помимо изменений в Siri, ожидаются обновления приложения «Камера» и системные доработки визуального стиля Liquid Glass. Официальная информация будет представлена на ближайшей конференции разработчиков WWDC, промо-материалы которой, по данным источников, уже отражают обновлённую анимацию Siri. Прощай, Дживс: поисковая система Ask.com закрылась спустя четверть века
03.05.2026 [08:28],
Дмитрий Федоров
Прекратила работу поисковая система и сервис вопросов и ответов Ask.com, ранее известная как Ask Jeeves. Холдинг IAC, владевший сервисом, решил свернуть поисковый бизнес. Ask Jeeves появился в 1996 году и отвечал на вопросы пользователей, заданные на естественном языке, — его можно считать одним из предшественников современных ИИ-чат-ботов. Большую часть своей истории сервис оставался в тени Google. 
Источник изображений: ask.com На сайте Ask.com появилось прощальное сообщение: «Поскольку IAC продолжает концентрировать усилия на приоритетных направлениях, мы приняли решение прекратить поисковый бизнес, включая Ask.com. После 25 лет ответов на вопросы со всего мира Ask.com официально закрылся 1 мая 2026 года». 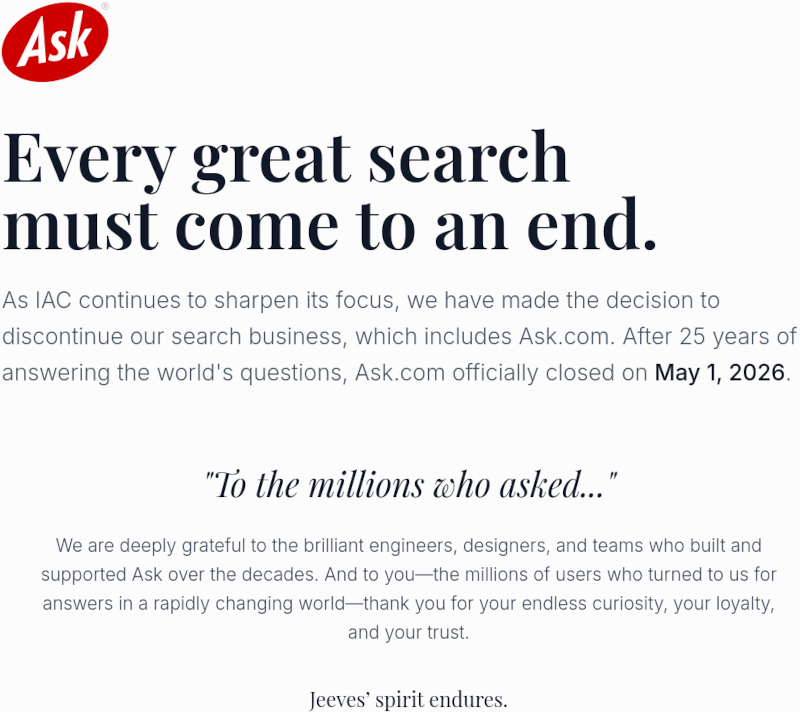 IAC приобрёл Ask Jeeves в 2005 году и быстро убрал «Дживса» из названия. К 2010 году холдинг свернул поисковый продукт и переключился на формат вопросов и ответов. В том же году председатель совета директоров IAC Барри Диллер (Barry Diller) заявил на конференции TechCrunch Disrupt, что Ask.com не способен конкурировать с Google и не учитывается в биржевой оценке холдинга. Тем не менее, как гласит прощальная страница, «дух Дживса жив». Неделей ранее закрылся и Udaff.com — учтивый Дживс и главный «падонок» рунета ушли из интернета почти одновременно. Google превратила поиск на YouTube в диалог с ИИ — но он ошибается
28.04.2026 [11:34],
Владимир Мироненко
Google начала тестирование поиска на YouTube в формате ИИ-чат-бота, «больше похожего на диалог», сообщил ресурс The Verge. В результатах поиска отображаются длинные и короткие видеоролики, а также сам запрос пользователя в виде текста. В настоящее время функция Ask YouTube («Спроси YouTube») доступна подписчикам YouTube Premium из США в возрасте старше 18 лет. 
Источник изображения: Alexander Shatov/unsplash.com Для пользователей платной подписки в строке поиска на странице видеохостинга появилась кнопка Ask YouTube. Если оставить поле поиска пустым, но нажать на эту кнопку, сервис покажет страницу с предлагаемыми вариантами поиска и текстовым полем для вопроса. 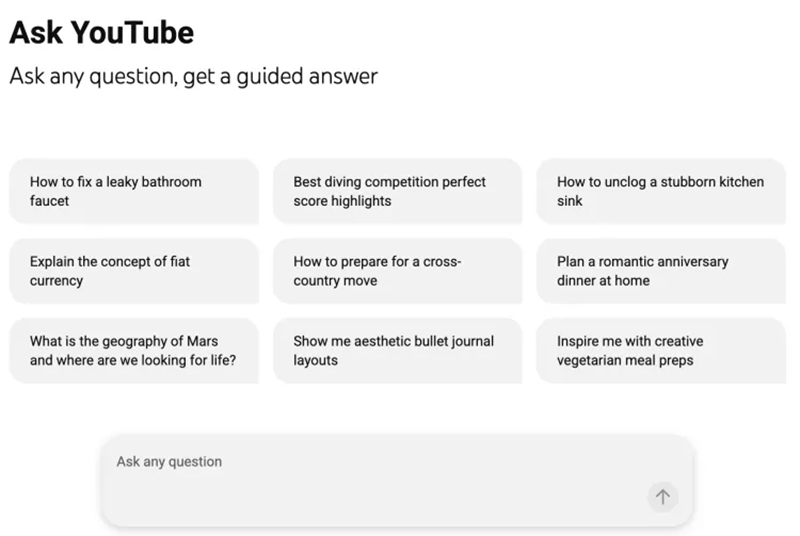
Источник изображений: Alex Castro/The Verge Журналист The Verge протестировал работу новой функции с помощью нескольких запросов и отметил, что не всегда ответы ИИ-чат-бота корректны. Например, отвечая на вопрос по поводу нового контроллера Steam от Valve, ИИ-чат-бот дал обзор контроллера, указал на новое видео Valve о нём и выделил как длинные обзоры, так и раздел «Краткие обзоры с первого взгляда», включающий Shorts. 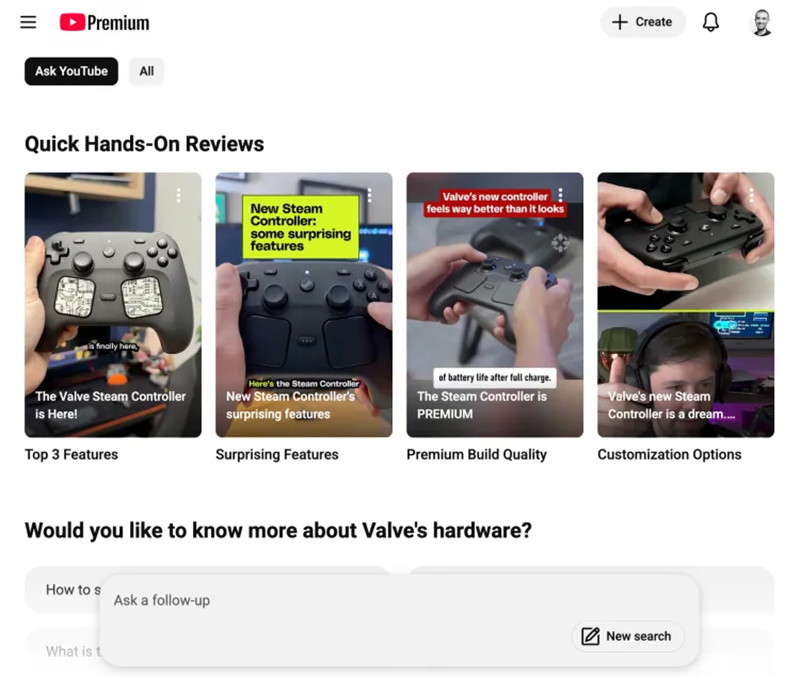 При этом в ответ ИИ-чат-бота вкралась ошибка: у старого, снятого с производства Steam Controller якобы не было джойстиков, хотя на самом деле это не так. Поэтому, какими бы полезными ни казались эти страницы результатов поиска, созданные с помощью ИИ, необходимо тщательно проверять их точность, отметил The Verge. YouTube заявил, что уже работает над расширением эксперимента на пользователей без подписки Premium. ЕС обязал Google открыть конкурентам доступ к поисковым данным
16.04.2026 [16:48],
Павел Котов
Еврокомиссия предписала Google открыть сторонним сервисам доступ к своим поисковым данным, в том числе к данным чат-ботов с искусственным интеллектом — такое требование содержится в региональном «Законе о цифровых рынках», заявили в ведомстве. 
Источник изображения: Adarsh Chauhan / unsplash.com В самой Google требование регулятора восприняли без энтузиазма — технологический гигант выразил готовность бороться против этой меры, которая, по его словам, выходит за рамки дозволенного и ставит под угрозу конфиденциальность пользователей. «Сотни миллионов европейцев доверяют Google свои самые конфиденциальные поисковые запросы, в том числе личные вопросы о своём здоровье, семье и финансах, и предложение комиссии заставит нас передавать эти данные третьим лицам с неэффективной защитой конфиденциальности», — заявили в Google. Компании надлежит передавать данные об объёмах, частоте и способах подачи поисковых запросов в Google, раскрывать меры по обеспечению анонимности персональных данных, процессы регулирования доступа пользователей к персональным данным, а также параметры установления цен на поисковые данные, заявили в Еврокомиссии. «Цель [этих] мер — дать сторонним поисковым системам или „получателям данных“ возможность оптимизировать свои поисковые системы и оспорить позицию „Google Поиска“», — отметили в ведомстве. Ранее Google, самую популярную в мире поисковую систему, обвинили в нарушении «Закона о цифровых рынках». Компания внесла собственные предложения по смягчению условий для конкурентов, но те пожаловались, что указанных мер будет недостаточно. С 2017 года сумма штрафов Google в Европе достигла €9,71 млрд. Нарушение «Закона о цифровых рынках» грозит штрафом в размере до 10 % от годового дохода компании по всему миру. «Яндекс» добавил в поиск ИИ-блендер и диалоговый режим с «Алисой AI»
07.04.2026 [15:58],
Владимир Мироненко
Для ответов на запросы в «Поиске» «Яндекса» теперь используется технология ИИ-блендера, которая расставляет в результатах поиска блоки со ссылками на сайты, картинки, видео и т. д. Поисковая выдача может включать более 40 блоков. При этом ИИ-блендер за 50 мс анализирует запрос и предлагает комбинацию блоков, которая лучше всего отвечает его условиям — перевести фразу, купить билеты, выбрать товар или разобраться в теме. 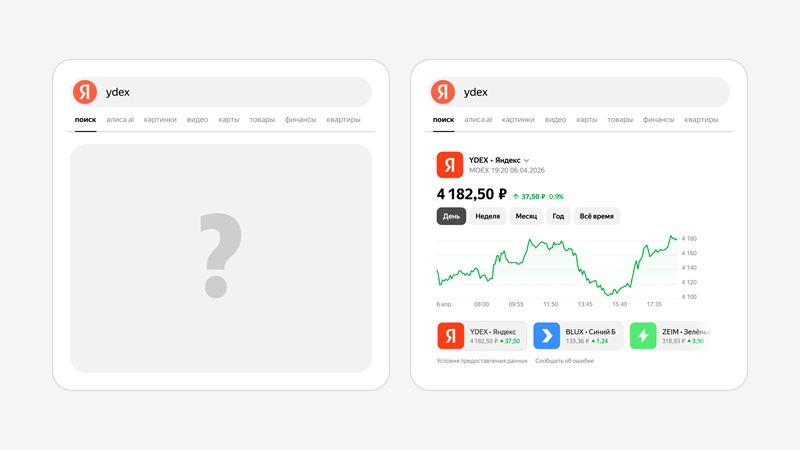
Источник изображений: «Яндекс» «Яндекс» и раньше расставлял ответы исходя из их полезности, ориентируясь прежде всего на то, как люди взаимодействуют с блоками — например, как часто к ним переходят. ИИ-блендер позволяет эффективнее решать эту задачу, поскольку при этом учитывается ещё и релевантность ответа. Если раньше по запросу «ydex» рядом с графиком котировок мог появляться блок с картинками, то теперь «Поиск» предоставляет котировки, «понимая», что блок с картинками только отвлекает. Работа ИИ-блендера основана на нейросетях-трансформерах с использованием мощной языковой модели и её облегчённой версии. Облегчённая ИИ-модель выбирает наилучший вариант размещения каждого блока, так как она может сделать это быстро, а мощная модель контролирует качество ответа. Также в «Поиске» «Яндекса» появился диалоговый режим, позволяющий переключаться между диалогом с «Алисой AI» и результатами поиска. 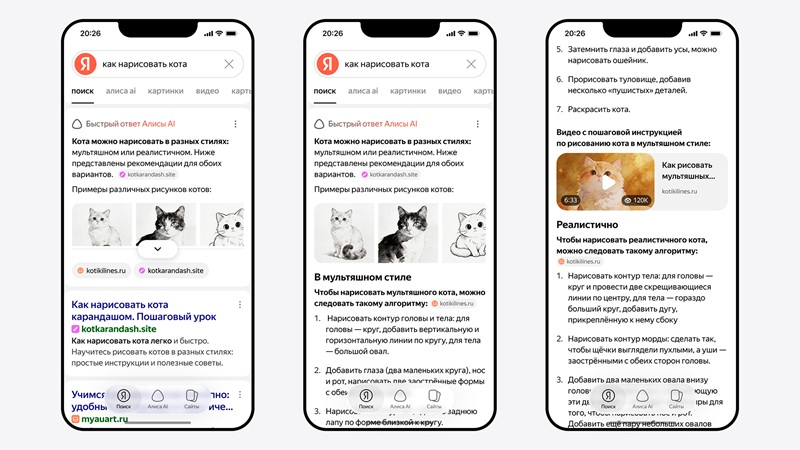 Для перехода к диалогу с нейросетью, достаточно кликнуть на вкладку «Алиса AI» под поисковой строкой. Диалоговый режим использует самую мощную языковую модель Яндекса — Alice AI LLM с сотнями миллиардов параметров. В режиме диалога можно задавать нейросети уточняющие вопросы, генерировать контент, отправлять ей файлы и картинки. История диалогов сохраняется и к любому из ответов можно вернуться. «Яндекс» также обновил быстрые ответы «Алиса AI» под поисковой строкой, которые теперь генерирует новая облегчённая языковая модель — Alice AI Search. На тех же вычислительных мощностях она обрабатывает больше запросов, что позволило в 1,5 раза увеличить долю запросов, на которые сразу предоставляются ответы, в 67 % случаев превосходящие по качеству ответы предыдущей модели. В ответах нейросети есть ссылки на источники, на которые можно перейти, чтобы узнать детали. В Google Play появилась функция поиска по отзывам
06.04.2026 [13:38],
Владимир Мироненко
Google представила функцию поиска в «Play Маркете» по отзывам, позволяющую пользователю сэкономить время на поиск ответа на конкретный вопрос в списке отзывов на приложение, которое он хотел бы загрузить. 
Источник изображения: Google Play Store Как сообщает Android Authority, ещё в ноябре прошлого года журналисты заметили, что эта функция тестируется, но тогда её не удалось запустить. Google недавно подтвердила, что упомянутая функция запущена с недавним обновлением Play Store. Для запуска новой функции необходимо коснуться рейтингов в верхней части любого приложения, затем нажать «Посмотреть все отзывы». Затем необходимо прокрутить вниз до раздела «Отзывы и рейтинги», и прямо под сводкой отзывов, сгенерированных ИИ, будет виден значок лупы. При его касании раздел отзывов переместится в верхнюю часть экрана, где будет видна строка поиска. 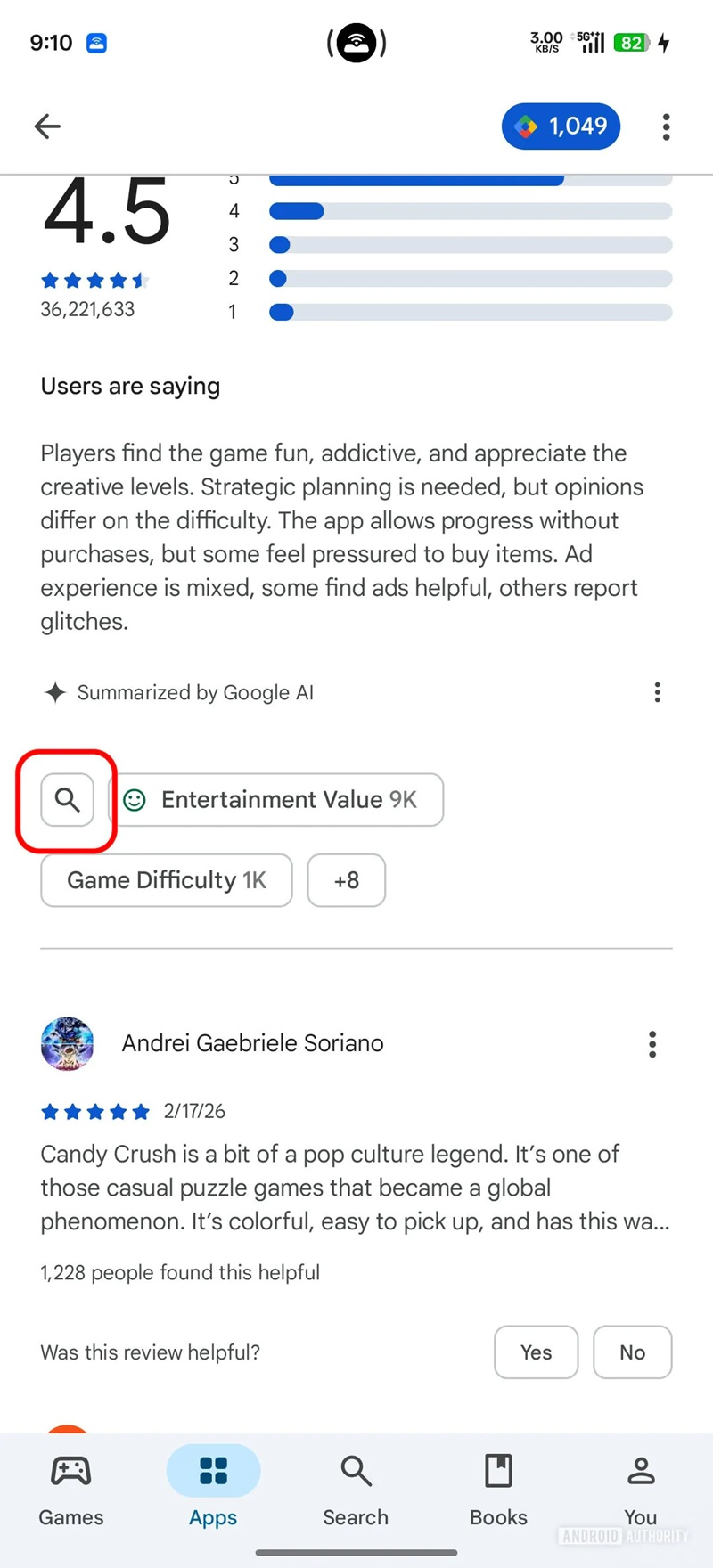
Источник изображения: Android Authority После ввода в строке поиска слов с описанием необходимых качеств ПО и нажатия на ввод, появится список отзывов, содержащих интересующих пользователя термины. В настоящее время отзывы не отображаются по мере ввода, и функция позволяет находить только отзывы, имеющие определённые соответствия поисковым запросам. На данный момент пользователь может использовать подсказки под строкой поиска только для популярных тем. Ещё одно ограничение заключается в том, что результаты не отображаются, если ввести одно слово, то есть, необходимо ввести несколько слов в запросе. Для того, чтобы воспользоваться функцией поиска в Play Store, необходимо обновить приложение до версии 50.7.24-31. На следующей неделе «Яндекс» проведёт конференцию «День поиска»
02.04.2026 [18:35],
Владимир Мироненко
«Яндекс» объявил о предстоящей конференции «День поиска», намеченной на 7 апреля. На мероприятии Дмитрий Масюк, руководитель бизнес-группы «Поисковых сервисов и искусственного интеллекта», и команда расскажут о крупном обновлении «Поиска» — самого массового продукта компании.  Предыдущая конференция «День поиска» проходила в мае 2025 года. На ней команда «Яндекса» рассказала о внедрении в «Поиск» технологий «Алисы AI» — быстрых ответов под поисковой строкой с источниками, картинками и видео. Предстоящий «День поиска» начнётся в 12:00 по московскому времени 7 апреля. На сайте конференции будет организована онлайн-трансляция мероприятия. Здесь также можно настроить напоминание о событии. Стартап Kagi представил «Малый веб» — рукотворный каталог сайтов, созданных людьми, а не ИИ
02.04.2026 [13:32],
Павел Котов
Американская поисковая система Kagi предложила свой каталог сайтов, созданных людьми без участия искусственного интеллекта, пользователям мобильных устройств — она выпустила приложения для Apple iOS и Google Android. В каталоге значатся личные блоги, веб-комиксы, независимые каналы с видеороликами и многое другое. 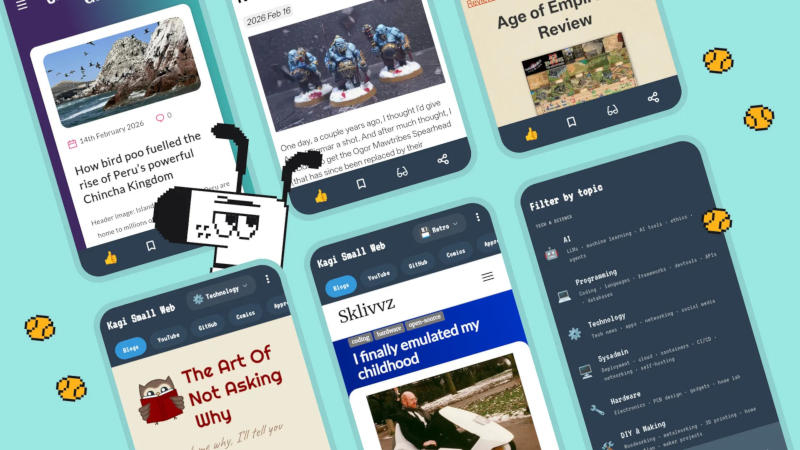
Источник изображения: Kagi Из таких ресурсов и состоял интернет до того, как его захватили коммерческие платформы, реклама и крупные корпорации. Google всё хуже справляется со своей основной задачей: подобные сайты всё труднее найти в пучине контента, которую теперь преимущественно генерирует ИИ. Стартап запустил проект «Малый веб» (Small Web) в 2023 году, призванный продвигать этот вид контента в результатах поиска через собственный сайт. Каталог напоминает некогда популярный сервис StumbleUpon: случайным образом отображается один из сайтов, есть кнопка «Далее» (Next) для перехода к следующему. Цель та же — помочь людям открывать для себя те уголки интернета, о которых они никогда бы не узнали. Каталог сайтов разбит по категориям; сейчас в нём более 30 000 ресурсов. Все эти функции доступны в мобильных приложениях для Apple iOS и Google Android, а также в расширениях для браузеров. Здесь можно выбрать тип наиболее интересующего контента: видео, блоги, комиксы или репозитории программного кода. Доступны списки недавно просмотренных и наиболее популярных сайтов; есть возможность добавлять понравившиеся сайты и страницы в избранное. Впрочем, поступают жалобы, что Kagi недостаточно осмотрительно подбирает ресурсы для каталога. Во-первых, в каталог могут попасть только сайты с RSS-каналами и свежими публикациями. Во-вторых, минимум один из сайтов в каталоге подозрительно напоминал ресурс, созданный ИИ. Но даже в этих условиях идея о модерируемом людьми каталоге как альтернативе Google представляется перспективной — особенно если затея с премиум-подпиской Kagi не сработает. Инструкцию по добавлению ресурсов в каталог «Малый веб» компания опубликовала на GitHub. Microsoft серьёзно улучшит поиск в Windows 11 после многолетних жалоб
30.03.2026 [18:34],
Владимир Фетисов
Компания Microsoft подтвердила масштабные работы по улучшению поиска Windows после многолетних жалоб пользователей на медленную работу этого элемента операционной системы, нерелевантные веб-подсказки и плохую локальную индексацию. Улучшение внутреннего поиска станет одним из шагов софтверного гиганта на пути повышения надёжности программной платформы и удобства взаимодействия с ней. 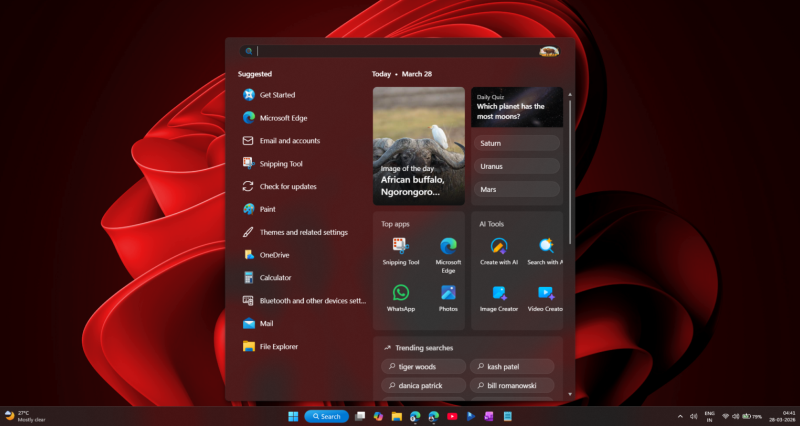
Источник изображений: Windows Latest Когда Microsoft объявила о намерении существенно улучшить Windows 11, мало кто предполагал, насколько масштабными окажутся эти планы. Софтверный гигант пообещал повысить производительность и надёжность платформы, ускорить работу проводника, доработать панель задач, уменьшить количество навязчивых интеграций ИИ-помощника Copilot и др. Фактически, анонс охватил все проблемы, на которые пользователи жаловались годами. Однако некоторые подробности в анонсе упомянуты не были. Это привело к появлению большого количества вопросов со стороны сообщества, на которые постепенно отвечали руководители и инженеры Microsoft. Таким образом сложилось впечатление, что компания действительно прислушивается к отзывам пользователей, одновременно подготавливая исправления и улучшения для ОС. Поисковик Windows был той частью платформы, которая не нравилась всем пользователя, что не удивительно. Он медленнее, чем в предыдущих версиях Windows, часто не справляется с поиском файлов на локальном устройстве, содержит большое количество рекламы и рекомендаций, загромождает результаты поиска веб-контентом вместо того, чтобы просто показать искомые файлы. Несколько пользователей написали комментарии по поводу поиска Windows под публикацией Тали Рот (Tali Roth), главы отдела разработки оболочек ОС, в которой она анонсировала улучшения в меню «Пуск», панели задач и др. Рот быстро отреагировала на комментарии, подтвердив, что разработчики готовят большое количество улучшений для поиска, а также рассказав, как они будут реализовываться. «Мы готовим множество улучшений для поиска — более простой и менее отвлекающий интерфейс определённо входит в их число», — написала Рот. 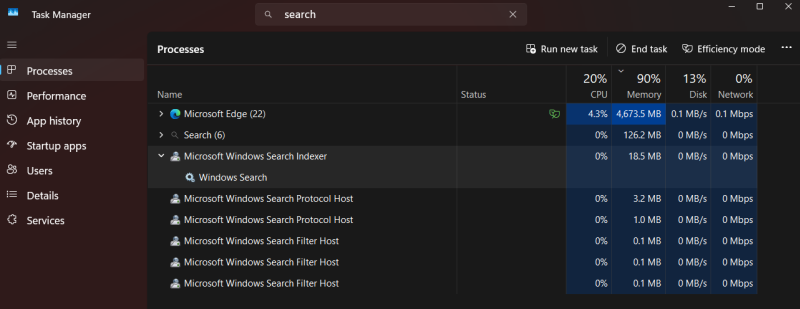 Отдельно Рот ответила на комментарий, автор которого указал на то, что даже базовые элементы, такие как «Корзина», некорректно отображаются в результатах поиска. «Мы работаем над корректировкой ранжирования в поиске, чтобы ваши приложения (включая «Корзину») отображались там, где им следует быть относительно других приложений», — написала Рот. В настоящее время поиск Windows использует внутренние системы ранжирования, которые определяют, что именно следует размещать на первых позициях. Эти алгоритмы учитывают различные сигналы, включая модели использования, системные данные и веб-интеграции. С течением времени результатам и предложениям Bing стало уделяться слишком много внимания, из-за чего результаты поиска на локальном устройстве, которые и нужны пользователю, порой отодвигаются на задний план. Сейчас Microsoft работает над тем, чтобы установленные приложения отображались быстро и стабильно, ключевые элементы системы всегда были доступны для поиска, а локальные файлы ранжировались выше, чем поступающие извне предложения. Комментарии Рот указывают на то, что панель результатов поиска должна очиститься за счёт уменьшения акцентов на рекомендациях. Пользовательский опыт будет смещаться в сторону более быстрых взаимодействий, когда набор текста приводит к появлению немедленных и предсказуемых результатов, а не формированию списка из смеси разных типов отвлекающего контента. Microsoft продолжает разработку фреймворков пользовательского интерфейса, таких как WinUI 3. Уменьшение зависимости от многоуровневых или веб-подключённых компонентов может напрямую повлиять на снижение задержки, а также сделает процесс взаимодействия более отзывчивым. На самом деле поиск Windows не был построен с нуля. Он всё ещё полагается на ту же систему, которая существует годами, Речь о службе индексатора поиска Windows (SearchIndexer.exe). Эта служба непрерывно сканирует выбранные местоположения, формирует локальный индекс и должна мгновенно возвращать результаты без сканирования диска при каждом запросе. Однако современный поиск Windows больше не выполняет простые запросы к локальному индексу. Теперь он направляет запросы через несколько систем одновременно, включая локальную индексацию, логику ранжирования, облачные сигналы и веб-интеграцию с Bing. Даже сам интерфейс больше не является простым списком, поскольку в нём присутствуют компоненты, способные динамически извлекать и отображать контент. 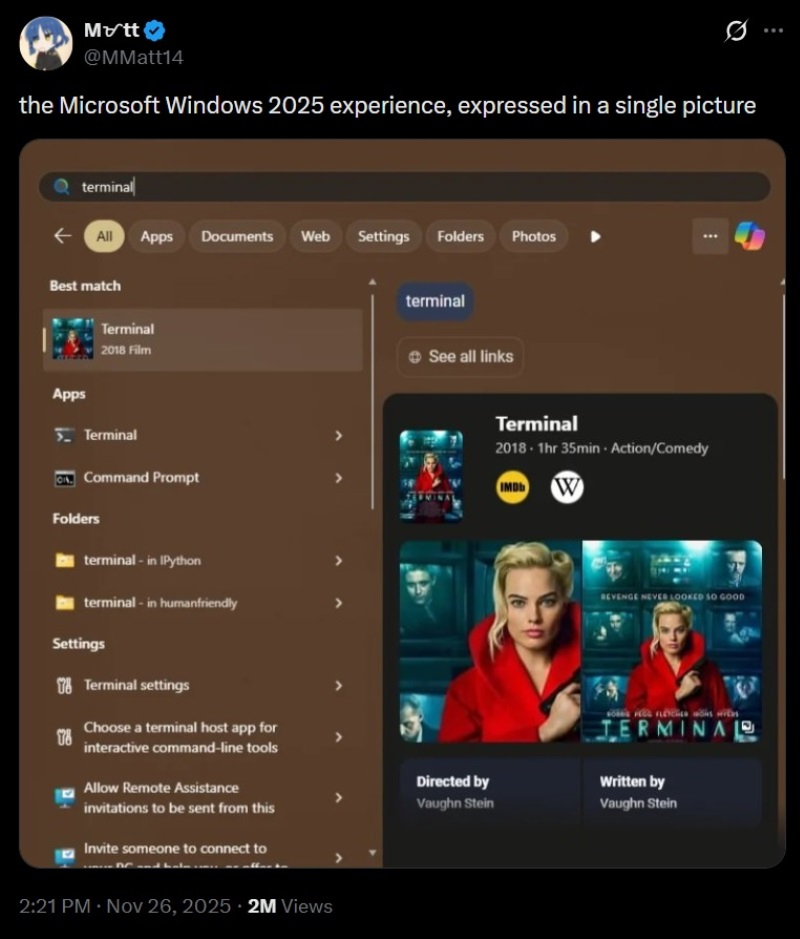 В какой-то момент поиск Windows стал основой для интернет-мемов. Яркий тому пример поиск по слову Terminal, в результате чего в выдаче появились результаты, связанные с одноимённым фильмом, а не приложением. В старых версиях Windows такой проблемы не было, потому что поиск не пытался выполнить одновременно так много. К примеру, поиск в Windows 7 был ориентирован именно на локальный контент. В Windows 10 началось смешивание с веб-результатами, но всё же не такое сильное, как в Windows 11. Возможно, утилита PowerToys, особенно с новой панелью Dock, находится значительно ближе к тому, что хотят видеть пользователи. Она быстро функционирует, ориентирована на работу с клавиатурой и сфокусирована на действиях. Пользователь что-то печатает, утилита мгновенно реагирует на это и не пытается рекомендовать веб-контент или что-то иное. Во многом PowerToys ведёт себя как Spotlight в macOS, а не поиск в Windows.  Проблема не в том, что Microsoft не знает, как создать хороший поиск. Проблема в том, что стандартный поиск Windows слишком далеко отошел от своего первоначального предназначения. Хорошая новость в том, что Microsoft, по всей видимости, поняла, где совершила ошибку. Поиск, «Проводник», обновления и поведение системы — всё перерабатывается с одной целью: сделать Windows быстрой и предсказуемой. Если Microsoft реализует всё, о чём говорит публично, то нынешний год может стать годом, когда Windows снова начнёт ощущаться целостной операционной системой. Google «перестал кормить» сайты — трафик из поиска обрушился, а ИИ даёт меньше 1 % переходов
18.03.2026 [20:36],
Сергей Сурабекянц
Данные, собранные Chartbeat и опубликованные Axios, показывают, что за последний год трафик из поиска Google на сайты резко упал, причём особенно сильно это затронуло небольшие проекты. Хотя многие продукты на основе ИИ, включая собственные разработки Google, улучшили отображение ссылок, в отчёте утверждается, что «чат-боты по-прежнему генерируют менее 1 % всех переходов на страницы издателей». 
Источник изображений: unsplash.com Согласно данным отчёта, переходы из поиска Google Search для «небольших издателей» упали на 60 %, в то время как для «средних издателей» (10 000–100 000 ежедневных просмотров страниц) падение составило 47 %. Для «крупных издателей» (более 100 000 ежедневных просмотров) падение составило 22 %. И дело не только в поиске Google. Согласно отчёту, хотя трафик из поисковой выдачи упал на 34 %, трафик из Google Discover также снизился на 15 % за последний год. Что касается трафика от чат-ботов на основе ИИ, в отчёте утверждается, что «новостные и медиа-сайты получают наибольшее общее количество просмотров страниц с платформ ИИ», но с «наименьшей вовлеченностью», по-видимому, потому, что пользователи переходят по ссылкам на источники только для проверки фактов, полученных с помощью заведомо ненадёжных результатов ИИ. В отчёте также отмечается, что «электронная почта, приложения и мессенджеры» являются растущим источником реферального трафика, и что общий трафик «снизился на 6 % в период с 2024 по 2025 год». В другом подобном недавнем отчёте было установлено, что особенно сильно пострадали технологические СМИ в последние годы: трафик из поиска Google на такие сайты, как The Verge, HowToGeek и многие другие, упал за последний год на 85 % и более. Особенно сильно пострадал ресурс Digital Trends – падение составило 97 %, при этом издание уволило почти весь свой штатный персонал в начале 2025 года.  В прошлом году Google сообщила, что «общий объем органических кликов из Google Search на веб-сайты оставался относительно стабильным из года в год», а «среднее качество кликов увеличилось», что противоречит выводам отчёта Axios. Компания также заявила тогда, что «очень заботится – возможно, больше, чем любая другая компания – о здоровье веб-экосистемы». Meta✴ начала тестировать платформу для ИИ-поиска товаров
03.03.2026 [17:49],
Павел Котов
Meta✴✴ приступила к тестированию функции по поиску товаров в интерфейсе чат-бота с искусственным интеллектом — сервис составит конкуренцию аналогичным возможностям, которые уже появились в OpenAI ChatGPT и Google Gemini. 
Источник изображения: Shoper / unsplash.com Новой функцией могут воспользоваться некоторые американские пользователи чат-бота Meta✴✴ AI в веб-интерфейсе. При получении запроса он выдаёт карусель с изображениями товаров и подписями: информацией о бренде, веб-сайте и цене продукта. В формате списка также приводится краткое пояснение механизма рекомендаций. Представитель Meta✴✴ подтвердил агентству Bloomberg, что такая функция тестируется, но дополнительные подробности сообщить отказался. Ранее глава компании Марк Цукерберг (Mark Zuckerberg) поставил перед подчинёнными задачу разработать «персональный сверхинтеллект», который поможет Meta✴✴ AI конкурировать с другими популярными чат-ботами — в ChatGPT и Gemini уже появились первые функции электронной коммерции. В январе Цукерберг пообещал, что в ближайшие месяцы компания представит новые продукты, которые продемонстрируют её способность обеспечивать пользователям платформ Meta✴✴ «уникальный персонализированный опыт», основанный на их истории, интересах, контенте и отношениях. На практике рекомендации Meta✴✴ AI адаптируются к тому, что компания уже знает о местоположении пользователя, и к его полу — он определяется по имени. Когда женщина из Нью-Йорка попросила подобрать пуховик, сервис указал её местоположение и вывел только женские модели. Функций заказа и оплаты в чат-боте Meta✴✴ AI пока нет — можно переходить по ссылкам на страницы интернет-магазинов. В компании не сообщили, получает ли она комиссионные за рекомендации чат-бота, а также отдаёт ли платформа приоритет брендам, которые рекламируются в Facebook✴✴ и Instagram✴✴. Но предприятиям Meta✴✴ уже рекомендует ориентироваться на конкретных людей, которые заинтересованы в их продукции — «новые средства агентского поиска дадут людям возможность находить тот набор товаров, который им нужен», пообещал ранее господин Цукерберг. Google опробует изменения в поисковой выдаче в ЕС под угрозой многомиллиардного штрафа
26.02.2026 [11:34],
Владимир Мироненко
Google запустит тестирование изменений в поисковой выдаче, выполняя требование Еврокомиссии обеспечить равные права конкурирующих сервисов с её собственными в поиске отелей, авиабилетов и ресторанов в соответствии с «Законом о цифровых рынках» (DMA) ЕС, сообщило агентство Reuters со ссылкой на информированные источники. 
Источник изображения: Firmbee.com/unsplash.com Раннее Еврокомиссия пригрозила штрафом за нарушение норм DMA, если компания продолжит отдавать приоритет в поисковой выдаче собственным сервисам, таким как «Покупки» и «Рейсы». До этого Google выступала с различными предложениями, чтобы урегулировать конфликт с конкурентами и регулирующими органами ЕС, но ни одно из них не было реализовано, поскольку были признаны недостаточными для устранения привилегированного положения поисковой системы «дочки» Alphabet. Проблема ведёт к противостоянию Google с сервисами вертикального поиска (VSS), специализирующимися на определённой категории информации с привязкой к таким секторам, как отели, авиакомпании и рестораны, или с компаниями в этих секторах, отметило Reuters. По словам источника, в рамках эксперимента в результатах поиска будут отображаться как результаты VSS, так и результаты Google, при этом по умолчанию будут отображаться лучшие вертикальные поисковые системы, сообщил источник. Отели, авиакомпании, рестораны и транспортные службы с данными из лент в режиме реального времени будут располагаться либо ниже, либо выше списка вертикальных поисковых систем. Изменения вскоре будут внедрены по всей Европе. Первоначально это коснётся поиска жилья, но позже добавят отслеживание авиарейсов и другие сервисы, сообщил источник. В случае невыполнения требований регулятора компании грозит штраф за несоблюдение европейского антимонопольного законодательства, который может составить до 10 % от объёма глобальных продаж за год и до 20 % в случае повторного нарушения. С 2017 года Google было назначено штрафов за нарушение антимонопольного законодательства ЕС на €9,71 млрд ($11,5 млрд). VK внедрила в поиск визуально‑языковую ИИ-модель для точных ответов и ускорения разработки технологий
19.02.2026 [14:56],
Владимир Мироненко
VK запустила на видеоплатформе «VK Видео» поиск с использованием визуально‑языковой модели (VLM), которая одновременно анализирует текст, изображения, звук и видеоряд. Сообщается, что в дальнейшем эта технология появится в других сервисах компании, где есть поисковые системы. 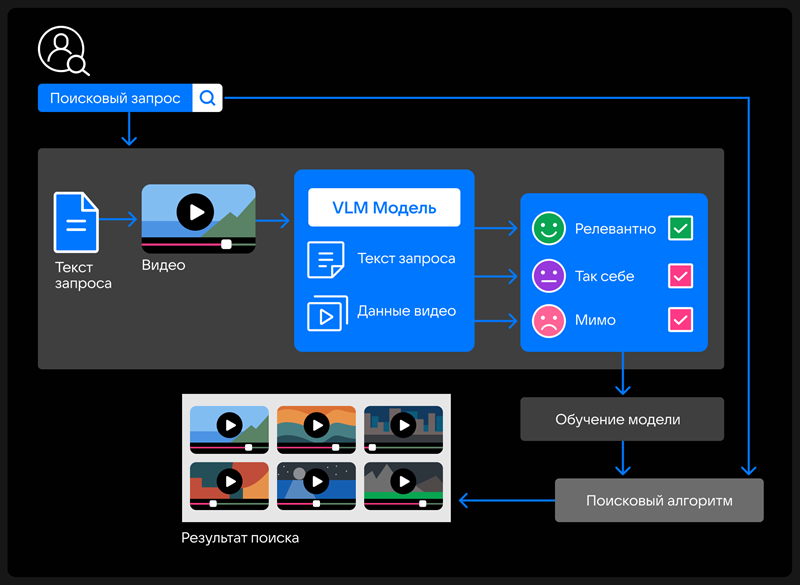
Источник изображения: VK VLM работает сразу с двумя модальностями — изображением и текстом, учитывая название и описание загруженного на платформу контента, а также его смысл, что обеспечивает более точные ответы на поисковые запросы пользователей. Разработанная специалистами AI VK модель автоматически формирует датасеты, данные о контенте, по которым поисковые алгоритмы подбирают видео, которые подходят к запросу пользователей. Запуск модели позволит улучшить векторный поиск в продуктах VK, который основан на семантическом значении запроса. В частности, система будет лучше распознавать и учитывать предпочтения пользователя при выборе видео с определённым стилем монтажа и цветокоррекции. А также лучше работать с гибридными запросами, содержащими текст и визуальные характеристики, например, «влог из Стамбула с видами на Босфор». Как ожидает компания, благодаря VLM поисковая выдача станет более персонализированной, а также в 5 раз ускорятся разработка и масштабирование новых технологий для развития и улучшения поиска во всех продуктах VK. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



