|
Опрос
|
реклама
Быстрый переход
Google сделает ссылки в ИИ-поиске заметнее на фоне жалоб издателей
18.02.2026 [11:44],
Павел Котов
Ссылки на внешние сайты, которые показываются в выдаче при поиске с использованием функций искусственного интеллекта, примут более заметный вид. Об этом сообщил курирующий поисковое направление вице-президент Google Робби Штейн (Robby Stein). 
Источник изображения: BoliviaInteligente / unsplash.com При наведении курсора на источники в разделах «Обзоры от ИИ» и «Режим ИИ» в десктопной версии поиска будет появляться всплывающее окно, дополняющее описание статей и сопровождающие выдачу изображения. Google будет показывать «более подробные и заметные значки ссылок» в подготовленных ИИ ответах на настольных компьютерах и мобильных устройствах. «Наше тестирование показало, что этот новый пользовательский интерфейс более привлекателен и упрощает поиск отличных материалов в интернете», — сообщил Робби Штейн. Раздел «Обзоры от ИИ» представляет собой расположенный над основной выдачей блок, в котором находится сгенерированная ИИ сводка данных и материалов в поиске. Функция «Режим ИИ» — более радикальный механизм, который предполагает поиск информации в интерфейсе чат-бота без перехода к сторонним источникам. Google продолжает развивать эти функции, хотя владельцы сайтов всё чаще выражают опасения, что ИИ в поиске снижает трафик на новостные и прочие ресурсы. Поисковый гигант настаивает на своём, считая, что традиционный открытый интернет теперь переживает «стремительный упадок». В прошлом году Еврокомиссия инициировала расследование в отношении Google на предмет возможной угрозы, которую функции поискового ИИ представляют для бизнеса владельцев сайтов, если их материалы появляются в сводках, но сами издатели не получают за это «надлежащей компенсации». В ответ Google заявила, что изучит возможность вообще исключить такие ресурсы из поисковых ИИ-сервисов, и начала обогащать «Режим ИИ» ссылками на источники. Google упростила удаление персональных данных и интимных фото из поиска
10.02.2026 [19:10],
Сергей Сурабекянц
Google предоставила пользователям больше контроля над результатами поиска. В дополнение к электронной почте и номеру телефона, теперь появилась возможность найти и удалить из поисковой выдачи информацию об удостоверении личности, водительских правах и номере социального страхования. Сделать это можно прямо из раздела «О Вас» в результатах поиска. Google также упростила удаление фотографий пользователя откровенного характера из результатов поиска изображений. 
Источник изображений: Android Authority Удалить персональную информацию из результатов поиска возможно только после заполнения соответствующих полей в разделе «О Вас», иначе поисковая система не сможет убедиться, что пользователь желает удалить именно свою личную информацию, а не данные другого человека. Google заверила, что использует передовые протоколы безопасности и шифрование для защиты предоставленной информации от неправомерного использования. После ввода информации Google просканирует результаты поиска и уведомит по электронной почте или через приложение Google (в зависимости от настроек) о том, где можно найти эту информацию. Затем пользователь сможет удалить её непосредственно из результатов поиска. Следует отметить, что удаление информации из результатов поиска Google не означает её удаление из интернета. Эта информация сохранится на всех ресурсах, где она была размешена и может быть найдена при помощи локального поиска на сайтах, через другую поисковую систему или при помощи бота. 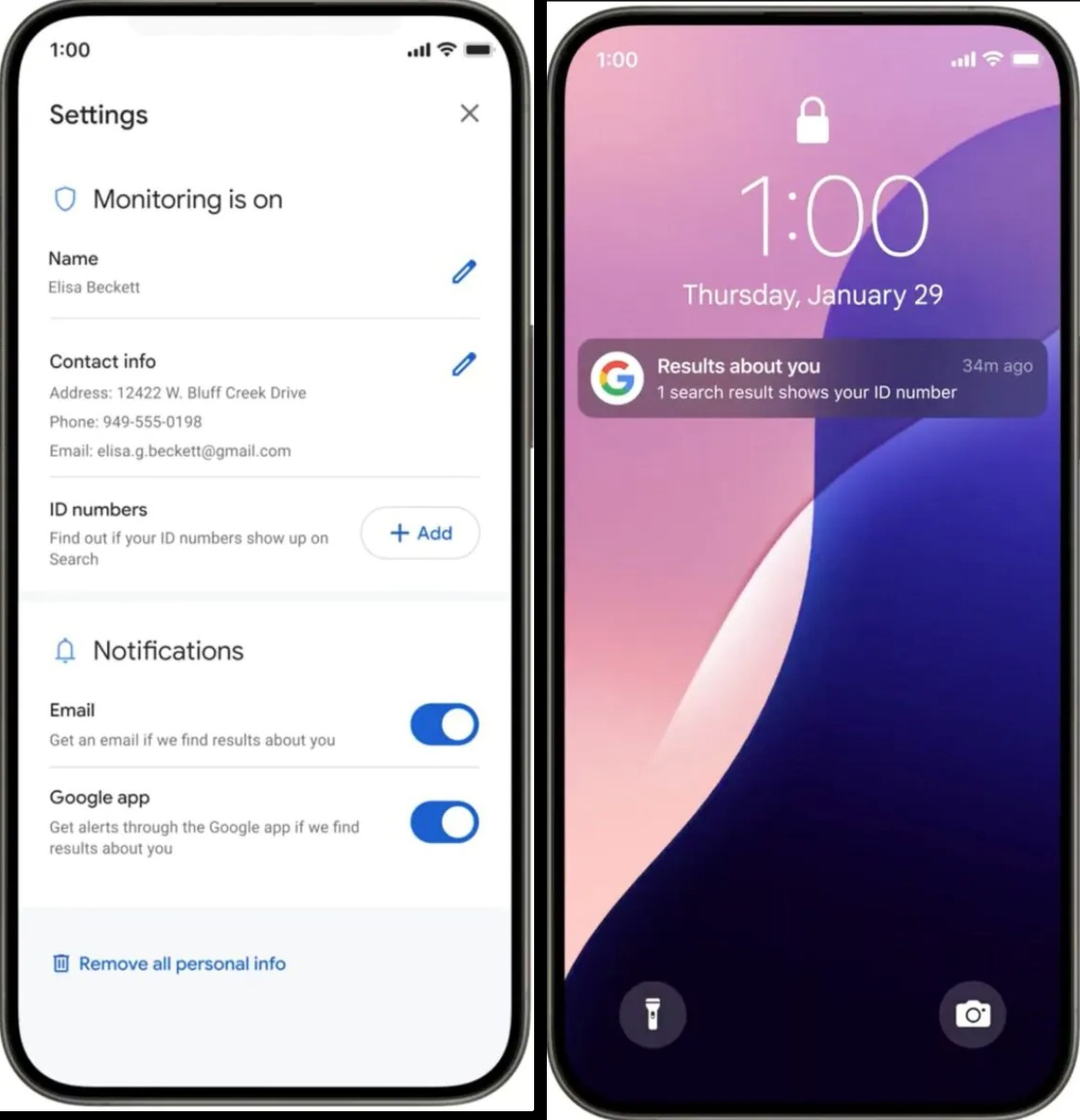 Google также упростила удаление изображений откровенного характера, полученных без согласия пользователя. Пользователю нужно открыть меню рядом с изображением в результатах поиска Google и выбрать «удалить результат» —> «На изображении показано моё сексуальное фото». Можно сформировать запрос на удаление сразу нескольких изображений. Пользователь может отслеживать статус всех своих запросов в разделе «О Вас». 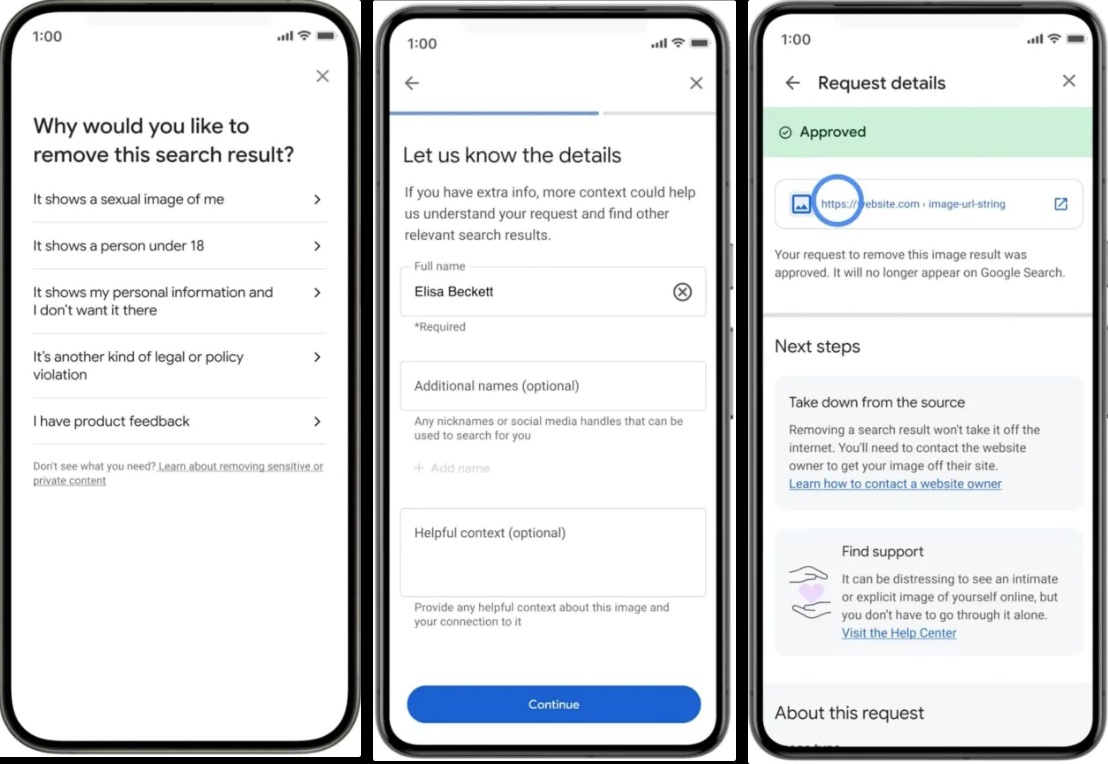 Дополнительно можно включить защиту, которая будет заблаговременно отфильтровывать любые дополнительные результаты сексуального характера, которые могут появиться в похожих поисковых запросах. После отправки запроса на удаление Google покажет ссылки на экспертные организации, оказывающие эмоциональную и юридическую поддержку. В ближайшие дни Google пообещала начать развёртывание этих новых инструментов в США, а затем они станут доступны и в других регионах. Apple выпустила «новый AirTag» — с увеличенным радиусом действия и громким динамиком
26.01.2026 [18:57],
Сергей Сурабекянц
Apple обновила свой брелок для поиска потерянных вещей AirTag, оснастив его модернизированным сверхширокополосным чипом второго поколения для увеличения дальности действия, в том числе при использовании функции «Точного поиска». Ещё одним ключевым преимуществом «нового AirTag», как называет его сама Apple, является улучшенный динамик, который, по словам компании, «на 50 процентов громче», что также должно облегчить поиск потерянного аксессуара. 
Источник изображений: Apple Apple подчеркнула, что AirTag «разработан исключительно для отслеживания объектов, а не людей или домашних животных». По словам компании, новый AirTag также получил улучшения конфиденциальности и безопасности и «включает в себя набор первых в отрасли средств защиты от нежелательного отслеживания, включая кроссплатформенные оповещения и уникальные идентификаторы Bluetooth, которые часто меняются». 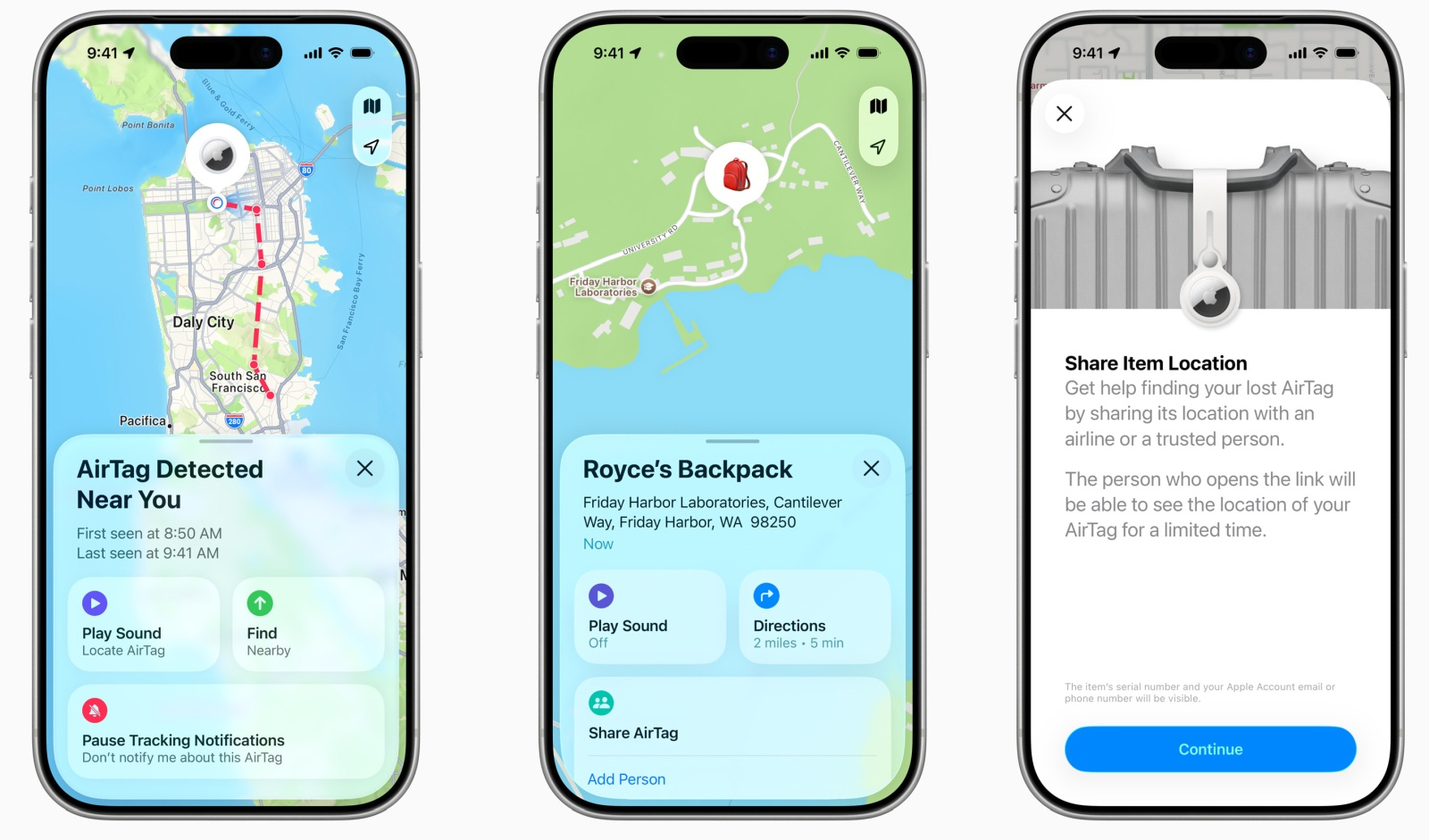 «Чип Apple Ultra Wideband второго поколения — тот же чип, который используется в линейке iPhone 17, iPhone Air, Apple Watch Ultra 3 и Apple Watch Series 11 — питает новый AirTag, делая его обнаружение проще, чем когда-либо прежде. Используя тактильную, визуальную и звуковую обратную связь, [функция] “Точный поиск” помогает пользователям найти потерянные предметы на расстоянии до 50 процентов дальше, чем предыдущее поколение, а обновлённый чип Bluetooth расширяет диапазон обнаружения предметов», — сообщила пресс-служба компании. Apple также сообщила, что функция «Точный поиск» теперь стала доступна владельцам Apple Watch Series 9 или новее, а также Apple Watch Ultra 2 или новее.  Новый AirTag уже доступен для заказа на сайте apple.com. Цена брелока не изменилась по сравнению с предыдущим поколением AirTag: $29 за один AirTag и $99 за комплект из четырёх штук. Возможна бесплатная персональная гравировка. За $35 доступен брелок для ключей AirTag FineWoven в оранжевом, фиолетовом, синем, зелёном или чёрном цвете.  Как заставить Google лгать: писатель внушил ИИ-поиску, что его кот говорит по-кантонски
21.01.2026 [10:38],
Павел Котов
Известный американский писатель, автор комиксов и блогер Чак Вендиг (Chuck Wendig) сумел убедить сервис поиска с искусственным интеллектом Google, что у него живёт кот с пышной кличкой Сэр Мьюлингтон фон Писсбрет (Sir Mewlington Von Pissbreath), который носит цилиндр и немного говорит на кантонском диалекте китайского языка. 
Источник изображения: Amber Kipp / unsplash.com Современные большие языковые модели искусственного интеллекта в действительности представляют собой сложные статистические алгоритмы, задача которых — предсказывать последующие слова. Это означает, что в качестве запроса такой системе порой можно отправить откровенную чушь, и в ответ она произведёт поиск по большому числу источников, найдёт случайную информацию, соберёт её в некое подобие обзора, который на деле будет таким же нелепым, как и ответ. Это подтвердил пример писателя Чака Вендига. В декабре Вендиг написал в своём блоге, что, по данным службы ИИ-поиска Google, у него живёт кот по кличке Бумба (Boomba) — эту информацию сервис якобы почерпнул с сайта Wengie Wiki. В действительности никакого кота у писателя не было и нет. Несколько поисковых запросов спустя ИИ-поиск Google сообщил ему, что его кот Бумба умер, и писатель завёл нового по кличке Франкен (Franken); в качестве доказательства система сослалась на блог Вендига, в котором на самом деле ни разу не упоминались ни Бумба, ни Франкен. В серии последующих поисковых запросов сервис начал постоянно придумывать писателю новых питомцев под новыми именами; он также добавил не соответствующие действительности сведения о его состоянии здоровья и религиозных предпочтениях. Вендиг, не стесняясь в выражениях раскритиковал не только сервис ИИ-поиска Google, но и вообще технологии ИИ в их теперешнем виде. Он отметил, что сервис неспособен отличать правду от вымысла и выдаёт откровенную чушь в стремлении угодить пользователю. Войдя в азарт, он завершил свою публикацию также не соответствующим действительности признанием, что в его доме живёт шестилетний кот по кличке Сэр Мьюлингтон фон Писсбрет, который носит маленькую шляпку-цилиндр и немного говорит по-кантонски. И это сработало. Через полтора месяца ИИ-поиск Google включил и эту явно абсурдную информацию в результаты выдачи. Google призвала создателей сайтов не оптимизировать контент под ИИ-поиск
10.01.2026 [18:53],
Павел Котов
Несмотря на то, что фрагментированный контент, который подаётся на сайтах небольшими порциями, часто выдаётся в рекомендациях при ИИ-поиске, Google настаивает, что в долгосрочной перспективе изготовление такого контента не приведёт для создателей сайтов ни к чему хорошему. 
Источник изображения: BoliviaInteligente / unsplash.com Владельцам веб-ресурсов не следует разбивать материалы на небольшие порции только по той причине, что этот формат считается предпочтительным для больших языковых моделей вообще и ИИ-режима в поиске Google в частности. Об этом заявил бывший специалист Google по вопросам поисковой оптимизации Дэнни Салливан (Danny Sullivan); он также отметил, что обсуждал этот вопрос с инженерами Google, и те подчеркнули, что создавать контент специально для больших языковых моделей и вообще для поисковых машин не следует. Эксперт, впрочем, признал, что в отдельных случаях это работает, но в качестве долгосрочной такая стратегия ему представляется бесперспективной. «Давайте предположим, что в некоторых крайних случаях, давайте даже предположим, что, возможно, в нескольких крайних случаях вы получите здесь какое-то преимущество», — допустил он. Этот успех окажется лишь временным: владелец сайта будет редактировать или создавать новый фрагментированный контент в этом формате, считая, что он работает для ИИ, но затем системы поискового ранжирования по мере совершенствования будут продолжать двигаться в сторону поощрения контента, созданного для людей, и фрагментированный формат материалов лишится эффективности. Ретроспективный анализ стратегий поискового продвижения за несколько лет так или иначе сводится к тому, что материалы на сайте должны быть ориентированы на живых пользователей, отмечает Search Engine Land. Эта стратегия играет на создание аудитории, которая не будет зависеть ни от Google, ни от любых других систем ИИ. А фрагментированный контент, в свою очередь, может навредить репутации ресурса у людей — и краткосрочная выгода такого риска не стоит. Новые фильтры YouTube позволят удалить Shorts из результатов поиска
09.01.2026 [11:16],
Владимир Мироненко
YouTube внесла ряд изменений в свои поисковые фильтры, благодаря чему стало возможным выполнять отдельно поиск коротких (Shorts) или длинных видеороликов. До этого они отображались вместе в результатах поиска, что вызывало определённые неудобства, если пользователю требовались видео в определённом формате. 
Источник изображения: NordWood Themes/unsplash.com Теперь пользователь может выбрать в новых поисковых фильтрах, помимо прочих опций, «Видео», для отображения только длинных видеороликов, или Shorts для показа только коротких видео продолжительностью три минуты и менее. YouTube также удалила фильтры «Дата загрузки – последний час» и «Сортировка по рейтингу», поскольку они «работали не так, как ожидалось, и вызывали жалобы пользователей». Вместе с тем по-прежнему предлагаются другие фильтры по дате загрузки, такие как «Сегодня», «На этой неделе», «В этом месяце» и «В этом году». Другие обновления включают в себя переименование двух функций в расширенном поиске. Меню «Сортировать по» получило название «Приоритет», что, по словам компании, «призвано максимально повысить удобство использования». А опция «Количество просмотров» была переименована в «Популярность». Сообщается, что с новым фильтром «системы оценивают количество просмотров видео и другие сигналы релевантности, такие как время просмотра, чтобы определить его популярность по конкретному запросу». В поисковом приложении «Яндекса» появился быстрый доступ к «Алисе AI»
25.12.2025 [12:08],
Павел Котов
В поисковом приложении «Яндекс — с Алисой AI» теперь доступна переписка с чат-ботом «Алиса AI», открыть которую можно по нажатии соответствующей кнопки под поисковой строкой. У чат-бота можно получить ответы на вопросы или поставить ему генеративную задачу. 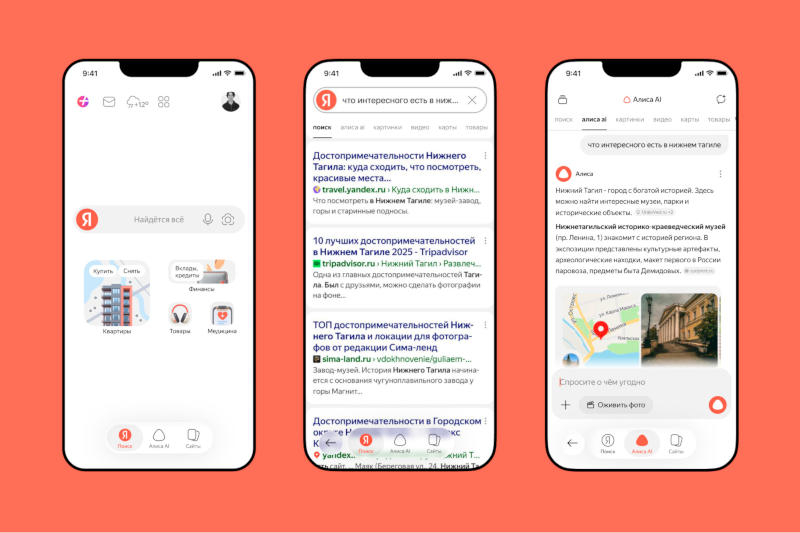
Источник изображения: yandex.ru/company Быстрый доступ к «Алисе AI» позволяет оперативно переключаться между двумя режимами: классической поисковой выдачей со ссылками и быстрыми ответами от ИИ. Можно ввести запрос в традиционную поисковую строку и нажать кнопку «Алиса AI», чтобы получить развёрнутый ответ с несколькими вариантами, расписаниями, фотографиями, карточками организаций, ссылками на источники и другими данными в удобном представлении. Чтобы получить дополнительные сведения, можно задать новые вопросы или перейти по ссылке. В формате переписки можно отправлять ИИ документы или изображения. Переход к чат-боту из поиска в приложении «Яндекс — с Алисой AI» производится по нажатии кнопки под поисковой строкой, значка «Алисы» на главной странице приложения, а также через выпадающие подсказки при вводе запроса. Диалоговый интерфейс позволяет вернуться к задаче с того же места, где пользователь остановился ранее; в левой панели доступен список прежних запросов, где можно получить информацию или задать дополнительные вопросы. В «Google Фото» вернули ярлыки для поиска по лицам и мордам — ранее их убрали под влиянием ИИ
23.12.2025 [21:18],
Сергей Сурабекянц
Группировка и поиск по лицам, пожалуй, одни из лучших функций «Google Фото», но переход к более активному использованию поиска на основе ИИ лишил пользователей одного из удобных ярлыков, помогавших находить изображения людей или животных. Теперь ситуация исправлена — на странице поддержки Google появилась информация о том, что недавние обновления приложения восстановили поддержку «ярлыков для поиска по лицам». 
Источник изображения: unsplash.com Ранее эти ярлыки отображались на странице поиска вместе с изображениями наиболее часто встречающихся объектов — людей или животных — с удобным предварительным просмотром по всей странице. После запуска функции «Спросить у фотографий» (Ask Photos) эта панель ярлыков из поиска исчезла. Ярлык поиска по лицам вернулся как в «классическом» поиске, так и в функции «Спросить у фотографий». В последнем случае она появляется после нажатия на текстовое поле для начала поиска, тогда как в «классическом» поиске она отображается мгновенно. 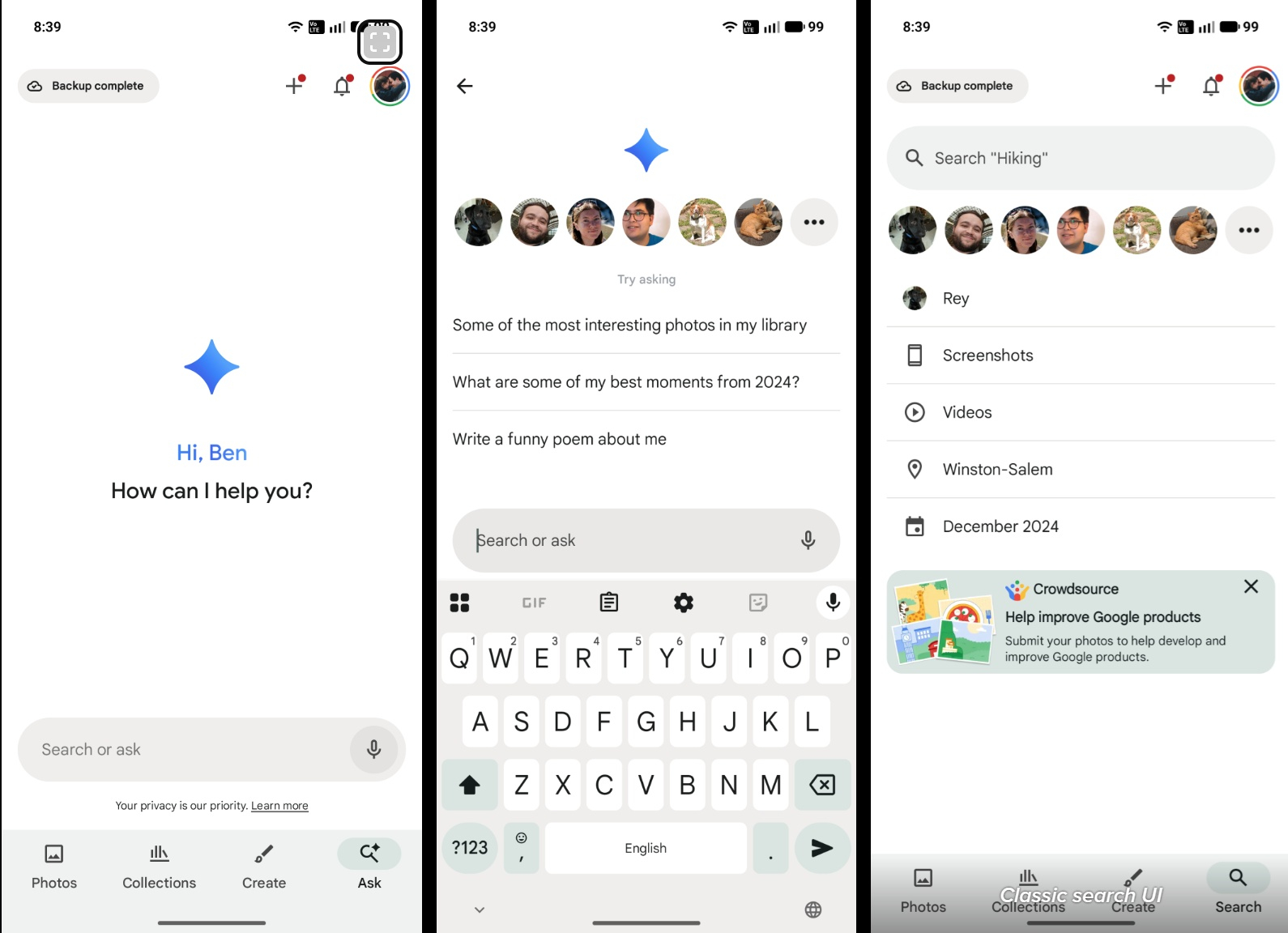
Источник изображения: 9to5Google «Отличные новости! Мы учли ваши пожелания о более простом способе поиска фотографий и видео важных для вас людей в Google Photo. Теперь мы добавляем ярлыки для ваших групп лиц в классический поиск и функцию «Спросить у фотографий» на Android, iPhone и iPad», — сообщил представитель Google. Теперь на вкладке «Поиск» или «Задать вопрос» пользователь может сразу перейти на страницу своих самых любимых людей или питомцев. Для использования функции необходимо в настройках включить группировку лиц. На Yandex.com заработал поиск с ИИ
22.12.2025 [18:24],
Сергей Сурабекянц
Интернет-холдинг «Яндекс» расширил внедрение своего поиска на основе искусственного интеллекта, ранее доступного только в странах СНГ и нескольких других регионах. «Яндекс ИИ» работает аналогично функции Google AI Overviews: он предоставляет сгенерированный ИИ ответ на запрос пользователя над традиционной поисковой выдачей, включая цитаты и ссылки на оригинальный контент для справки. Также пользователям стала доступна функция интерактивного чата. 
Источник изображения: yandex.com С этим обновлением «Яндекс» присоединился к группе поисковых систем, последовательно внедряющих ИИ в свои основные продукты. Примечательно, что в то время как Bing и Yahoo используют решения на базе ChatGPT от OpenAI, а корейская Naver и китайская Baidu по-прежнему в основном ориентированы на свои внутренние рынки, Yandex стал второй после Google глобальной поисковой системой, которая интегрирует в поиск собственную модель искусственного интеллекта. Эта версия ИИ-поиска «Яндекса» построена на тех же технологиях, что и «Алиса AI». «Запуск Yandex AI на глобальном домене — это естественный шаг в развитии поиска. Мы много лет используем нейронные сети, и теперь сделали этот опыт доступным пользователям по всему миру», — прокомментировал запуск новой функции генеральный директор Yandex Search International Александр Поповский. Поисковик Google получил ещё одну ИИ-функцию, и она выглядит полезной
16.12.2025 [23:21],
Владимир Фетисов
Знакомая всем строка поиска на странице Google.com ранее уже получила кнопку ИИ-режима справа. Теперь же слева разработчики добавили новую кнопку в виде знака плюса, которая позволяет загрузить изображение или файл. После этого в строке поиска можно ввести текстовый запрос, относящийся к ранее загруженному элементу, чтобы найти связанную с ним информацию в интернете. 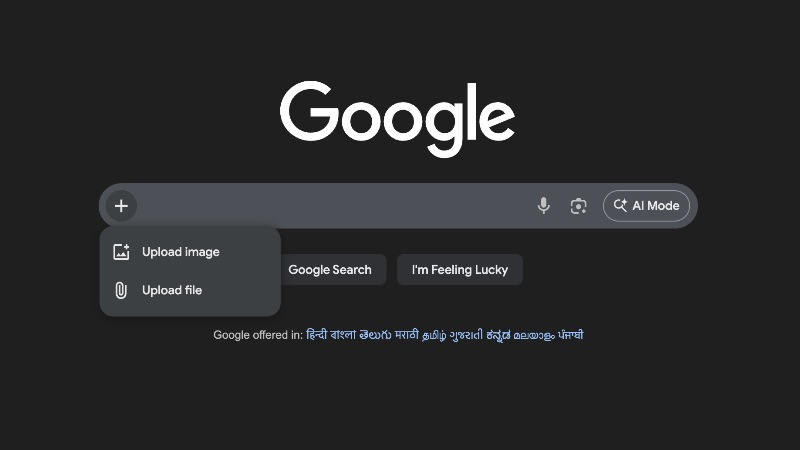
Источник изображения: Google Ответы поисковика на такие запросы формируются в окне ИИ-режима, взаимодействие в котором напоминает процесс общения с чат-ботом. Однако не сразу понятно, что кнопка в виде знака плюса как-то связана с ИИ-режимом. Это связано с тем, что значок объектива для традиционного поиска по картинкам остался на месте. Даже при нажатии на знак плюса появляется сообщение «Загрузить файл» или «Загрузить изображение» без упоминания ИИ-режима. Трудно сказать, какой процент пользователей переходят непосредственно на страницу Google.com вместо того, чтобы писать запрос сразу в строке поиска в браузере. Веб-обозреватель Google Chrome продолжает уверенно лидировать в этом сегменте с долей рынка примерно в 71 %. Однако на фоне усиления конкуренции с ChatGPT ранее в этом году представители Google намекали на более глубокую интеграцию собственных ИИ-продуктов. Так в результате этой деятельности ИИ-бот Gemini стал частью браузера Chrome для iPhone и iPad. Компания также задействовала ИИ-инструменты в своей персонализированной ленте контента Google Discover и других продуктах. Google начнёт показывать больше ссылок на источники в выдаче поискового «Режима ИИ»
11.12.2025 [12:02],
Павел Котов
Google рассказала о планах изменить механизм «Режима ИИ» — поиска с искусственным интеллектом. В нём появится больше ссылок на источники, из которых система получила информацию, и эти ссылки будет сопровождать сгенерированное ИИ пояснение, чем они полезны. 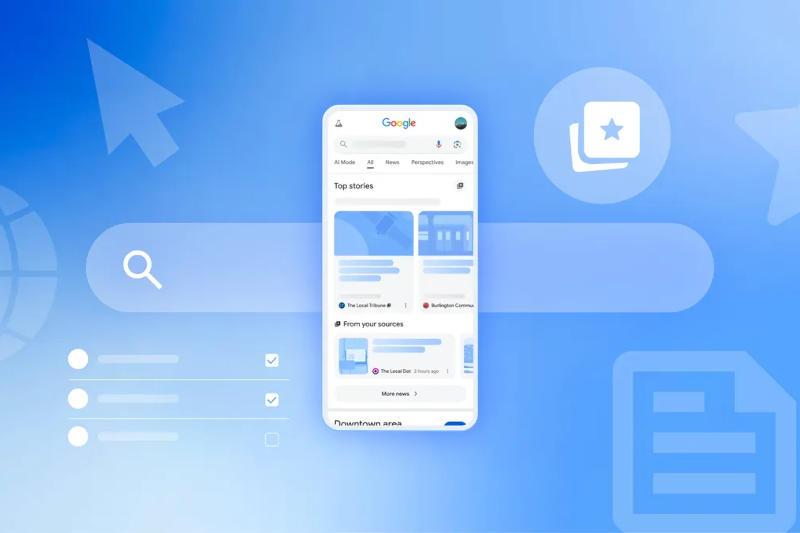
Источник изображения: blog.google В представленном Google примере описание источников размещено непосредственно над каруселью со ссылками. «В этих статьях предлагаются бюджетные идеи для декора, в том числе позиции в магазинах подержанных товаров, обновления архитектуры, такие как замена лепнины и фурнитуры, а также проекты „сделай сам“ для создания винтажного стиля», — гласит пример пояснения. Ранее стало известно, что Еврокомиссия инициировала проверку в отношении Google на предмет возможного нарушения компанией норм конкуренции — компания, по версии ведомства, использует в ИИ-сервисах принадлежащий веб-издателям контент без «надлежащей компенсации». Ранее компания опровергла утверждения, что пользователи «с меньшей вероятностью» переходят по ссылкам, когда в выдаче показывается «Обзор от ИИ» — по версии Google, число кликов остаётся «относительно стабильным».  Google также объявила о запуске пилотной партнёрской программы совместно с несколькими издателями, в том числе The Guardian, The Washington Post и Washington Examiner. Совместными усилиями они хотят «изучить, как ИИ способен помочь привлечь более вовлечённую аудиторию». К примеру, в Google News будут демонстрироваться созданные ИИ сводки представленных на платформе материалов. Приложение Gemini получит доступ к информации от Associated Press и других источников, обновляемой в реальном времени. Компания также расширит доступ к функции предпочитаемых источников: англоязычная аудитория сможет самостоятельно выбирать новостные издания, которые хочет видеть в главных новостях Google; ссылки из подписок пользователя будут выделяться. В ближайшее время эта функция дебютирует в приложении Gemini, после чего появится в «Обзорах от ИИ» и в «Режиме ИИ». Наконец, обновится Web Guide — экспериментальная функция Search Labs, при включении которой ИИ-помощник Gemini сортирует результаты поиска по категориям, которые сам же и генерирует. Теперь Web Guide будет загружаться «вдвое быстрее» и станет показываться по большему числу запросов. Google рассказал, что люди искали в интернете в 2025 году — Gemini обскакал всех
05.12.2025 [11:32],
Павел Котов
Компания Google опубликовала обзор поисковых запросов — возможно, один из важнейших итогов, отражающий наиболее важные события, произошедшие в этом году. К сожалению, по России и Беларуси поисковый гигант отдельную статистику не привёл. 
Источник изображения: BoliviaInteligente / unsplash.com Самыми популярными новостями по всему миру по версии Google стали:
В пятёрку самых популярных актрис и актёров попали:
Самыми популярными людьми мира, по версии Google, оказались:

Источник изображения: Brett Jordan / unsplash.com В список самых популярных игр Google внесла:
А вот как выглядит пятёрка самых популярных фильмов:
Пять самых популярных сериалов:
Наконец, вот как выглядит десятка самых популярных в мире поисковых запросов к Google:
Отдельных рейтингов по России и Беларуси компания Google в этом году составлять не стала. В Google начала показывать рекламу в «Режиме ИИ» в поиске — пока не всем
22.11.2025 [20:08],
Павел Котов
Google решила показывать рекламу не только в выдаче традиционной поисковой машины, но и в «Режиме ИИ» (AI Mode). Пока она демонстрируется в тестовом формате ограниченному числу пользователей; компания готовится внедрить рекламу и в «Обзорах от ИИ». Полномасштабный запуск рекламы в новых режимах пока не планируется. 
Источник изображения: BoliviaInteligente / unsplash.com Карточки с рекламными объявлениями некоторые пользователи обнаружили в нижней части поисковой выдачи в «Режиме ИИ» на основе модели Gemini — аналогичным образом она показывается в нижней части выдачи традиционного поиска. Хотя реклама, по утверждениям Google, и демонстрируется в тестовом формате, её видят пользователи общедоступного варианта «Режима ИИ», а не экспериментальных функций раздела «Лаборатория». 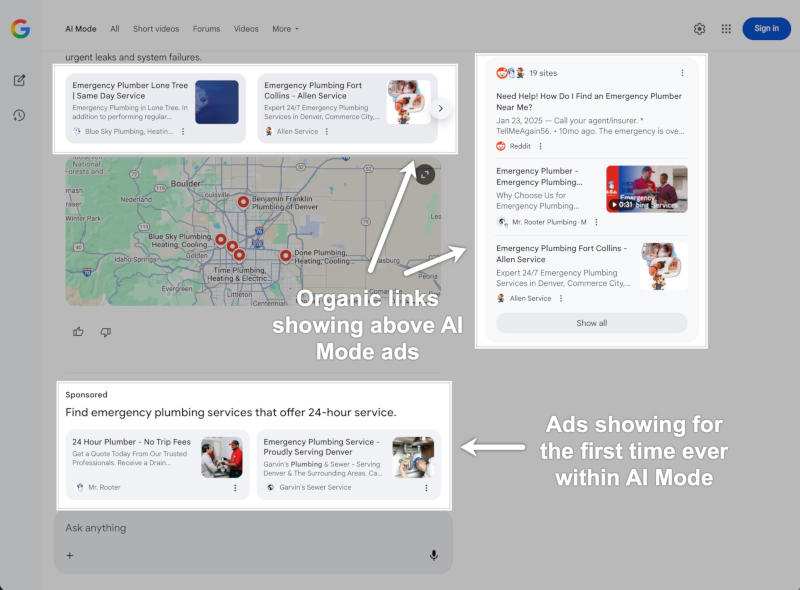
Источник изображения: x.com/brodieseo В традиционной поисковой выдаче реклама показывается и над органическими результатами, но в случае «Режима ИИ» Google решила пока не спешить, и органические результаты поиска остаются в приоритете. Это не значит, что так будет всегда — возможно, впоследствии реклама появится и в верхней части страницы, но компания своими планами пока не поделилась. Интересно, что недавно Google пообещала упростить скрытие рекламы в традиционной поисковой выдаче, но на «Режим ИИ» эта инициатива, видимо, не распространяется — у рекламных карточек здесь кнопки «Скрыть» нет. Нововведение уже появилось у части пользователей, возможно, в ближайшее время охват тестовой рекламы в «Режиме ИИ» расширится. Google представила ИИ-поисковик научных работ, но его подход к ранжированию вызывают вопросы
20.11.2025 [12:31],
Павел Котов
Google запустила тестирование нового поискового сервиса на основе искусственного интеллекта в рамках проекта Scholar Labs. Он призван помогать учёным находить ответы на подробные исследовательские вопросы. Некоторые члены научного сообщества, впрочем, подвергли сомнению критерии определения качества научных исследований, обращает внимание The Verge. 
Источник изображения: blog.google Нет ясности, насколько смогут учёные доверять сервису, который для ранжирования поисковой выдачи использует не традиционные способы оценки популярности исследования, а анализирует взаимосвязи между словами. В научном поиске отсутствуют фильтры для общепринятых критериев, которые обычно используются, чтобы отличить «хорошие» исследования от «не очень хороших». Наиболее привычной в научной среде является метрика, отражающая количество цитирований исследования в других работах с момента его публикации — она в значительной мере отражает популярность статьи. Здесь есть связь и со временем: опубликованное недавно исследование может не цитироваться вовсе или набрать сотни ссылок за несколько месяцев, а исследования ещё из девяностых годов могут цитироваться несколько тысяч раз. Ещё одна традиционная метрика называется импакт-фактором. У журналов, которые публикуют широко цитируемые исследования, более высокий импакт-фактор, а значит, такие материалы считаются более строгими или значимыми для научного сообщества. Так, у журнала Applied Sciences импакт-фактор равен 2,5, а у Nature он составляет уже 48,5. В оригинальной версии научной поисковой машины Google, то есть без ИИ, есть опция ранжирования выдачи по «релевантности» где для каждого результата отображается количество цитирований. 
Источник изображения: BoliviaInteligente / unsplash.com Цель обновлённого алгоритма — находить «наиболее полезные статьи при исследовательском поиске», заявили в Google. Теперь сервис ранжирует их по принципу, который, утверждают в компании, используют сами учёные — с учётом «полного текста каждого документа, места публикации, автора, а также частоты и давности цитирования в другой научной литературе». Но изолированного ранжирования по количеству цитирований статьи или импакт-фактору издания не будет. «Импакт-фактор и количество цитирования зависят от области исследования в статьях, и большинству пользователей может быть непросто угадать подходящие значения в контексте конкретных исследовательских вопросов. <..> Если ограничиваться импакт-фактором или количеством цитирований, зачастую можно пропустить ключевые статьи, в частности, статьи в междисциплинарных или смежных областях либо журналах, а также недавно опубликованные статьи», — подчеркнули в Google. Можно запросить поиск по «недавним» работам, а при подготовке выдачи используются полные тексты статей. Данный сервис в компании назвали «новым направлением для нас», и при дальнейшей работе над ним Google планирует учитывать отзывы пользователей. Google добавит в ИИ-поиск рекламу, но она будет выглядеть иначе
02.11.2025 [18:27],
Владимир Фетисов
Google не намерена отказываться от использования рекламного контента в своём поисковике на базе искусственного интеллекта. По данным источника, ИИ-поисковик и другие сервисы компании будут содержать рекламу, но изменится её подача. 
Источник изображения: Bleeping Computer Не так давно Google сообщила о получении дохода от рекламы в своём поисковике и на YouTube в размере $56,57 млрд. Очевидно, что не следует ожидать исчезновения рекламного контента, если он приносит компании столь внушительный доход. В настоящее время Google запустила две ИИ-функции. Первая из них — ИИ-обзоры, которые демонстрируются в верхней части поисковой выдачи и предлагают суммирующие ответы на запросы пользователей с разных сайтов издателей, которым Google не хочет платить. Вторя функция, AI Mode, предлагает более персонализированный опыт, подобный тому, что можно получить при взаимодействии с ChatGPT. Google уже подтвердила намерение интегрировать AI Mode в свои сервисы, такие как Gmail и Drive, что позволит создать новый персонализированный опыт, предполагающий, что ИИ будет знать всё о пользователе. Это может звучать пугающе, но именно в этом направлении движется поисковый гигант сейчас. Не так давно вице-президент Google по продуктам Google Search Робби Штейн (Robby Stein) заявил, что рекламный бизнес поискового гиганта никуда не денется, но будет эволюционировать в соответствии с новыми реалиями. По его словам, Google не намерена отказываться от рекламы, но её подача, вероятно, изменится. «… вы можете сфотографировать свои кроссовки и сказать: «Эй, вот мои кроссовки. Какие есть ещё похожие кроссовки?» И мы сможем ответить на этот вопрос или предоставить соответствующий контекст. Или вы можете спросить о каком-то ресторане. Вы можете написать несколько предложений о своей аллергии и других особенностях. О своей компании, освещении в помещении и спросить: «Что я могу забронировать заранее?» Теперь это всё можно ввести в поисковик Google», — рассказал Штейн, поясняя, как реклама может вписаться в ИИ-поисковик компании. «Я считаю, что в будущем это откроет ещё больше возможностей для того, чтобы стать для вас полезнее, особенно в контексте рекламы. Поэтому мы начали некоторые эксперименты с рекламой в рамках AI Mode и других ИИ-сервисов Google», — добавил Штейн. Похоже, что сейчас Google хочет, чтобы пользователи взаимодействовали с AI Mode для решения личных вопросов, на основе которых компания могла бы показывать персонализированную рекламу. Google уже тестирует рекламу в ИИ-поисковике, но сейчас она демонстрируется ограниченному числу пользователей. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



