|
Опрос
|
реклама
Быстрый переход
В России наладят выпуск ИИ-серверов на отечественных ускорителях, но обучать ИИ они не смогут
17.10.2024 [15:09],
Павел Котов
Российский производитель электроники Fplus заявил, что в 2025 году наладит выпуск серверов с отечественными ИИ-ускорителями, созданными в НТЦ «Модуль». В первый год будет выпущено около сотни таких систем, а в 2026–2027 гг. счёт пойдёт на тысячи. На серверах Fplus с ускорителями «Модуля» можно будет запускать алгоритмы искусственного интеллекта, системы обработки сигналов и изображений, но для обучения ИИ они не подойдут, пишут «Ведомости». 
Источник изображения: kp yamu Jayanath / pixabay.com Серверы Fplus получат «большие» и «малые» ускорители, в зависимости от конфигурации: NM Quad и NM Card соответственно. Первый построен на DSP-процессоре К1879ВМ8Я, который включает 64 тензорных ядра NeuroMatrixCore4 (FP32/64, 1000 МГц) и 20 ядер ARM Cortex-A5 (800 МГц), а также имеет 20 Гбайт памяти DDR3L. В свою очередь, NM Card предлагает чип К1879ВМ8Я с 16 тензорными ядрами NMC4 (FP32/64, 1000 МГц) и пять ядер ARM Cortex-A5 (800 МГц), а также 5 Гбайт памяти DDR3L. В России производится поверхностный монтаж этих ускорителей — штатная загрузка предприятия позволяет выпускать 35 000 ускорителей в год. Сервер Fplus «Восход» с ускорителями вычислений НТЦ «Модуль» уже включён в реестр отечественного оборудования Минпромторга. «Мы видим большую потребность в таких комплексных продуктах для распознавания изображений, объектов и инцидентов, цифровой обработки сигналов и изображений для критической информационной инфраструктуры, где не должно использоваться оборудование западного производства, а также для работы с большими объёмами секретных или персональных данных, где важна не скорость, а защищённая среда», — рассказал о проекте управляющий партнёр Fplus Алексей Мельников. Фактическим мировым монополистом в сегменте чипов для ИИ является американская Nvidia, которая строго соблюдает санкционный режим, поэтому в Россию её продукция официально не поставляется, и это значительно сдерживает развитие отечественного производства серверов. Но российский рынок активно адаптируется к переменам — прорабатываются альтернативные решения, находятся новые пути поставок. Пока в реестре Минпромторга значится лишь один ИИ-сервер с поддержкой до пяти ускорителей, а его производителем значится «Гравитон»; сейчас компания разрабатывает несколько решений на базе центральных процессоров Intel и AMD нового поколения — в будущем году она готова поставить до 10 000 ИИ-серверов. 
Источник изображения: Pete Linforth / pixabay.com На рынке реестровой техники для госзаказчиков запросы на серверы с ИИ выросли двукратно: с января по сентябрь 2023 года было 16 таких закупок на 930 млн руб., а за аналогичный период этого года их было уже 30 на 1,7 млрд руб. В количественном выражении доля российских производителей на рынке серверов составляет не более 25 %, подсчитали в «Гравитоне». Модульный ИИ-сервер с возможностью установить до шести средних или двух мощных ускорителей есть и у Kraftway; компания также разрабатывает выделенный сервер на три высокопроизводительные карты — он сможет устанавливаться в ЦОД и использоваться для обучения больших языковых моделей. Система Fplus на ускорителях «Модуля» сможет применяться в критических системах, где законодательство требует устанавливать отечественные компоненты, но заменить решения на чипах Nvidia она не сможет, потому что не поддерживает обучения ИИ, отмечают опрошенные «Ведомостями» эксперты. Но решения «Модуля» могут оказаться конкурентоспособными в нишевых задачах, таких как обработка изображений и сигналов. К 2027 году ИИ-серверов в мире станет больше, чем обычных, говорят аналитики — к этому моменту рынок ИИ-серверов разрастётся до $95 млрд. В этом году рынок российских высокопроизводительных серверов (способных содержать ИИ-ускорители) оценивается в 30 млрд руб.; к 2027 году он составит 45,2 млрд руб. Через десять лет отечественный рынок ИИ-ускорителей вырастет трёхкратно. Пока же 80 % мирового рынка ИИ-ускорителей для ЦОД принадлежат Nvidia. Но её монополии уже бросили вызов Microsoft, OpenAI, Amazon и Google, которые разрабатывают собственные системы. Да и AMD не дремлет. AMD представила ИИ-ускоритель Instinct MI325X для конкуренции с Nvidia Blackwell и рассказала о ещё более мощном Instinct MI355X
11.10.2024 [08:44],
Анжелла Марина
Компания AMD официально представила флагманский ускоритель вычислений Instinct MI325X, который станет конкурентом для Nvidia Blackwell и уже поступил в производство. Вместе с тем производитель раскрыл подробности об ускорителе следующего поколения — Instinct MI355X на архитектуре CDNA4. 
Источник изображений: AMD В последние годы AMD отмечает значительный рост спроса на свои ИИ-ускорители. При этом серия MI300 пользуется особой популярностью. Однако, как пишет издание Tom's Hardware, MI355X вызывает определённые вопросы по части брендирования, поскольку архитектура CDNA использовалась в MI100, CDNA2 — в MI200, а CDNA3 — в серии MI300. Логично было бы увидеть CDNA4 в ускорителях MI400, но они получат архитектуру следующего поколения.  Как бы от ни было, CDNA4 — это новая архитектура, которая представляет собой значительное обновление прежней CDNA3. AMD описала её как «переосмысление с нуля», хотя, по мнению экспертов, это может быть и некоторым преувеличением. Ускоритель MI355X будет производиться по новому 3-нм техпроцессу N3 от TSMC, потребовав серьёзных изменений по сравнению с N5, но основные элементы дизайна могут остаться схожими с CDNA3. Объём памяти HBM3e достигнет 288 Гбайт. Ускоритель будет оснащён 10 вычислительными элементами на один GPU, а производительность достигнет 2,3 петафлопса вычислительной мощности для операций FP16 и 4,6 петафлопса для FP8, что на 77 % больше по сравнению с ускорителем предыдущего поколения.  Одним из ключевых нововведений MI355X станет поддержка чисел с плавающей запятой FP4 и FP6, которые удвоят вычислительную мощность по сравнению с FP8, позволив достигнуть 9,2 петафлопса производительности в FP4. Для сравнения, Nvidia Blackwell B200 предлагает до 9 Пфлопс производительности в FP4, а более мощная версия GB200 — 10 Пфлопс. Таким образом, AMD Instinct MI355X может стать серьёзным конкурентом для будущих продуктов Nvidia, в том числе благодаря 288 Гбайт памяти HBM3E — это на 50 % больше, чем у Nvidia Blackwell. При этом оба устройства будут иметь пропускную способность памяти до 8 Тбайт/с на GPU.  Как отмечают эксперты, вычислительная мощность и объём памяти — это не единственные ключевые параметры для ИИ-ускорителей. Важным фактором становится масштабируемость систем при использовании большого числа GPU. Пока AMD не раскрыла подробности о возможных изменениях в системе интерконнекта между GPU, что может оказаться важным аспектом в сравнении с Blackwell от Nvidia.  Вместе с анонсом Instinct MI355X компания AMD подтвердила, что ускоритель Instinct MI325X официально запущен в производство и поступит в продажу в этом квартале. Основным отличием MI325X от предыдущей модели MI300X стало увеличение объёма памяти со 192 до 256 Гбайт. Что интересно, изначально планировалось оснастить ускоритель 288 Гбайт памяти, но видимо AMD решили ограничиться приростом в 33 % вместо 50 %. Память HBM3E в новинке обеспечивает пропускную способность более 6 Тбайт/с, что на 13 % больше, чем 5,3 Тбайт/с у MI300X. 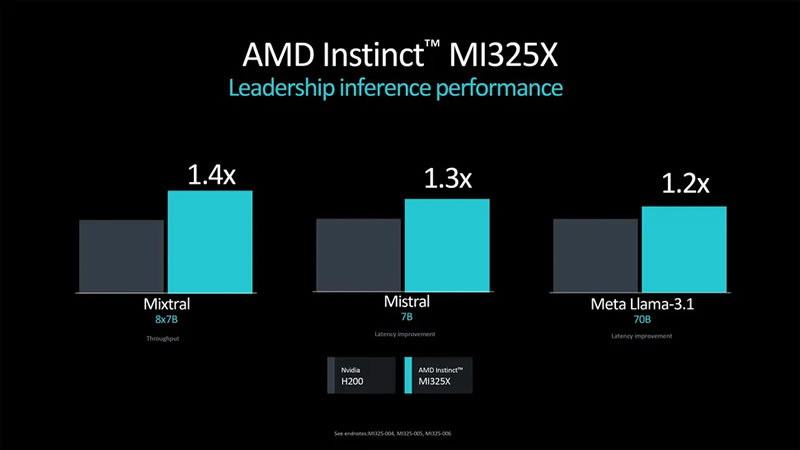 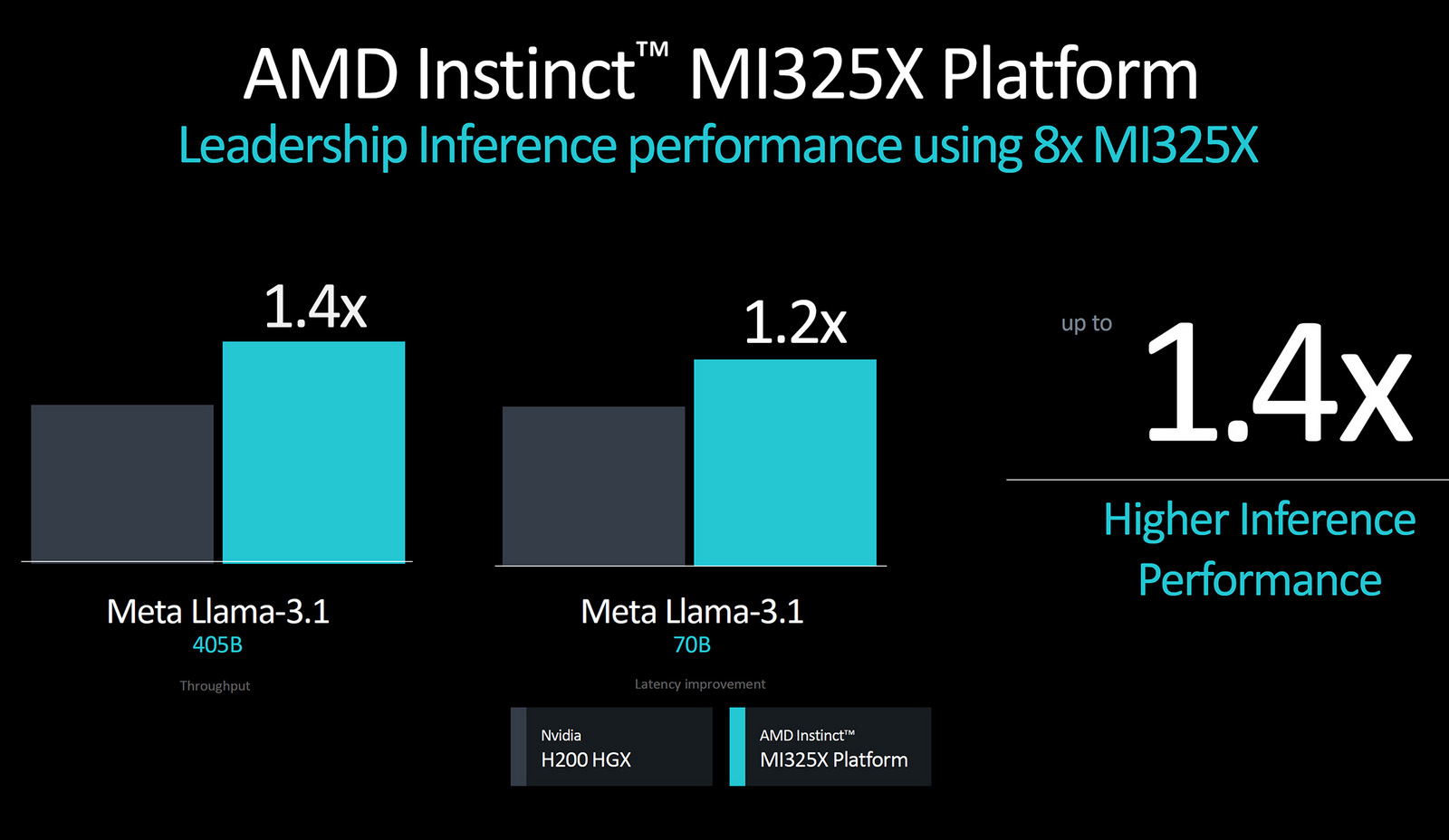 AMD провела сравнительный анализ производительности Instinct MI325X и Nvidia H200. Ускоритель AMD оказался на 20-40 % быстрее конкурента в запуске уже обученных больших языковых моделей, а в обучении нейросетей показал паритет производительности.  AMD не раскрыла стоимость своих ИИ-ускорителей, но представители компании заявили, что одной из целей является предоставление преимущества по совокупной стоимости владения (TCO). Это может быть достигнуто либо за счёт лучшей производительности при той же цене, либо за счёт более низкой цены при одинаковой производительности. Как отметил представитель AMD: «Мы являемся деловыми людьми и будем принимать ответственные решения относительно ценообразования». Instinct MI355X планируется к поставкам во второй половине 2025 года. Дженсен Хуанг: будущее за рассуждающим ИИ, но для этого необходимо в разы удешевить вычисления
09.10.2024 [21:55],
Дмитрий Федоров
Дженсен Хуанг (Jensen Huang), бессменный руководитель Nvidia, заявил, что будущее ИИ — за системами, способными к рассуждению. Однако для реализации этой концепции необходимо значительно снизить стоимость вычислений. Хуанг подчеркнул, что его компания стремится ежегодно увеличивать производительность чипов в 2–3 раза, сохраняя текущий уровень их стоимости и энергопотребления. 
Источник изображения: Nvidia В рамках подкаста, организованного Рене Хаасом (Rene Haas), генеральным директором Arm Holdings, Хуанг поделился своим видением развития ИИ. По его словам, следующее поколение интеллектуальных систем сможет отвечать на запросы пользователей, проходя через сотни или даже тысячи шагов анализа собственных выводов. Эта способность к глубокому рассуждению станет ключевым отличием от современных ИИ, таких как ChatGPT, которым, как признался Хуанг, он пользуется ежедневно. Nvidia стремится создать фундамент для такого прорыва и ставит перед собой амбициозную цель: ежегодно повышать производительность своих чипов в 2–3 раза при сохранении прежнего уровня стоимости и энергопотребления. Такой подход призван революционизировать способность ИИ-систем распознавать сложные паттерны и делать осознанные выводы. «Мы способны обеспечить беспрецедентное снижение затрат на интеллектуальные системы. Все мы осознаём ценность этого достижения. При существенном сокращении расходов мы сможем реализовать на этапе инференса такие сложные процессы, как рассуждение», — подчеркнул Хуанг. Nvidia занимает доминирующую позицию на рынке ускорителей для ИИ, контролируя более 90 % этого сегмента рынка. Однако компания не ограничивается только производством чипов. Её стратегия включает в себя разработку компьютеров, программного обеспечения (ПО), ИИ-моделей, сетевых решений и других сервисов. Такая диверсификация направлена на стимулирование более широкого внедрения ИИ в бизнес-процессы различных компаний. Несмотря на лидирующие позиции, Nvidia сталкивается с растущей конкуренцией. Крупные операторы дата-центров, такие как Amazon Web Services (AWS) и Microsoft, разрабатывают собственные альтернативные решения, чтобы ослабить зависимость от продуктов Nvidia. Кроме того, компания AMD, давний соперник Nvidia на рынке игровых чипов, активно выходит на рынок ИИ-ускорителей, что может усилить конкурентное давление на лидера индустрии. AMD выпустила серверную видеокарту Radeon Pro V710, которую нельзя купить — только арендовать в Microsoft Azure
08.10.2024 [14:39],
Николай Хижняк
Компания AMD представила профессиональный графический ускоритель Radeon Pro V710, созданный эксклюзивно для размещения в центрах обработки данных Microsoft Azure. Приобрести новинку не получится — его мощности можно будет только арендовать для вычислений, работы с ИИ и других задач. 
Источник изображений: AMD Radeon Pro V710 разработан для работы по моделям «рабочее место как услуга» и «рабочая станция как услуга», облачного гейминга, а также задач ИИ и машинного обучения. Возможность использования указанных ускорителей будет доступна эксклюзивно через облачные сервера Microsoft Azure, где клиентам на правах аренды будет предлагаться от 1/6 до 1x мощности указанного ускорителя и до 24 Гбайт видеопамяти, хотя сама видеокарта получила в общей сложности 28 Гбайт памяти. 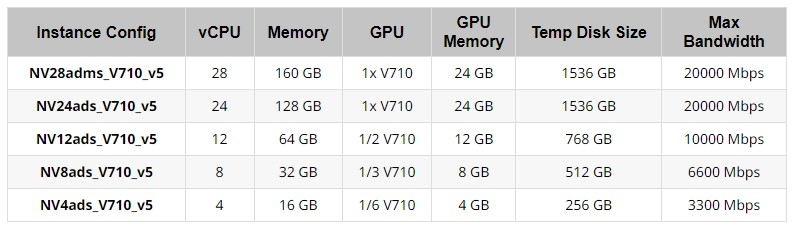 В основе Radeon Pro V710 используется графический процессор Navi 32 с 54 исполнительными блоками графической архитектуры RDNA 3. Аналогичная конфигурация GPU используется в игровой видеокарте Radeon RX 7700 XT. Однако специализированный ускоритель Radeon Pro V710 получил 28 Гбайт памяти GDDR6 вместо 12 Гбайт, которые присутствуют у модели RX 7700 XT. Максимальная пропускная способность памяти у Radeon Pro V710 заявлена на уровне 448 Гбайт/с. Radeon Pro V710 поддерживает технологию R-IOV, которая позволяет изолировать память между виртуальными машинами, что даёт возможность нескольким клиентам одновременно использовать одну и ту же видеокарту.  Карта также поддерживает аппаратное ускорение трассировки лучей, кодирования и декодирования AV1, HEVC (H.265) и AVC (H.264). Кроме того, она имеет поддержку программного обеспечения AMD ROCm. Последнее вместе с аппаратным ИИ-ускорителями для эффективного умножения матриц обеспечивают повышение вычислительной производительности для машинного обучения. 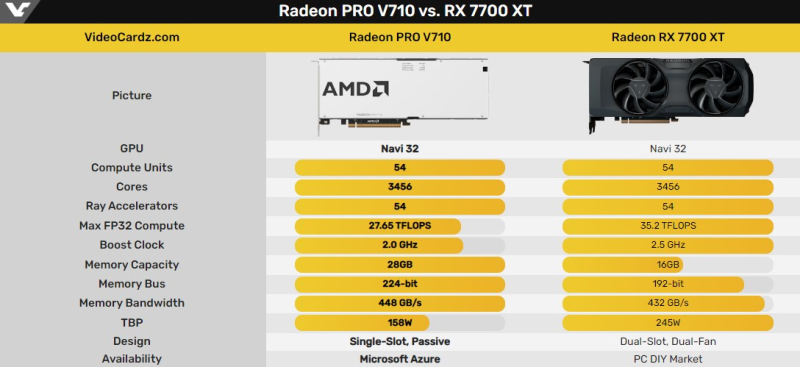
Источник изображения: VideoCardz Толщина видеокарты составляет один слот расширения, она оснащена пассивной системой охлаждения — за обдув будут отвечать корпусные вентиляторы самого сервера. По сравнению с игровой Radeon RX 7700 XT у Radeon Pro V710 вдвое больше памяти, более высокая пропускная способность памяти, но её GPU обладает частотой на 500 МГц ниже, чем у игрового решения. Кроме того, заявленный TDP специализированного ускорителя составляет 158 Вт, что на 35 % ниже, чем у игрового варианта. Intel выпустила серверные 128-ядерные процессоры Xeon 6 Granite Rapids и ИИ-ускорителя Gaudi 3
25.09.2024 [00:01],
Николай Хижняк
Компания Intel сообщила о выпуске новых серверных процессоров серии Xeon 6 (Granite Rapids), которые располагают исключительно P-ядрами. Также компания объявила о выпуске специализированного ИИ-ускорителя Gaudi 3. 
Источник изображений: Intel Granite Rapids производятся по техпроцессу Intel 3 (5 нм). В серию вошли пять моделей с количеством ядер от 72 до 128, базовой частотой от 2,0 до 2,7 ГГц и максимальной частотой 3,9 ГГц (на одном ядре), а также от 3,2 до 3,7 ГГц на всех ядрах. Процессоры получили от 432 до 504 Мбайт кеш-памяти L3 и обладают заявленным показателем TDP от 400 до 500 Вт. 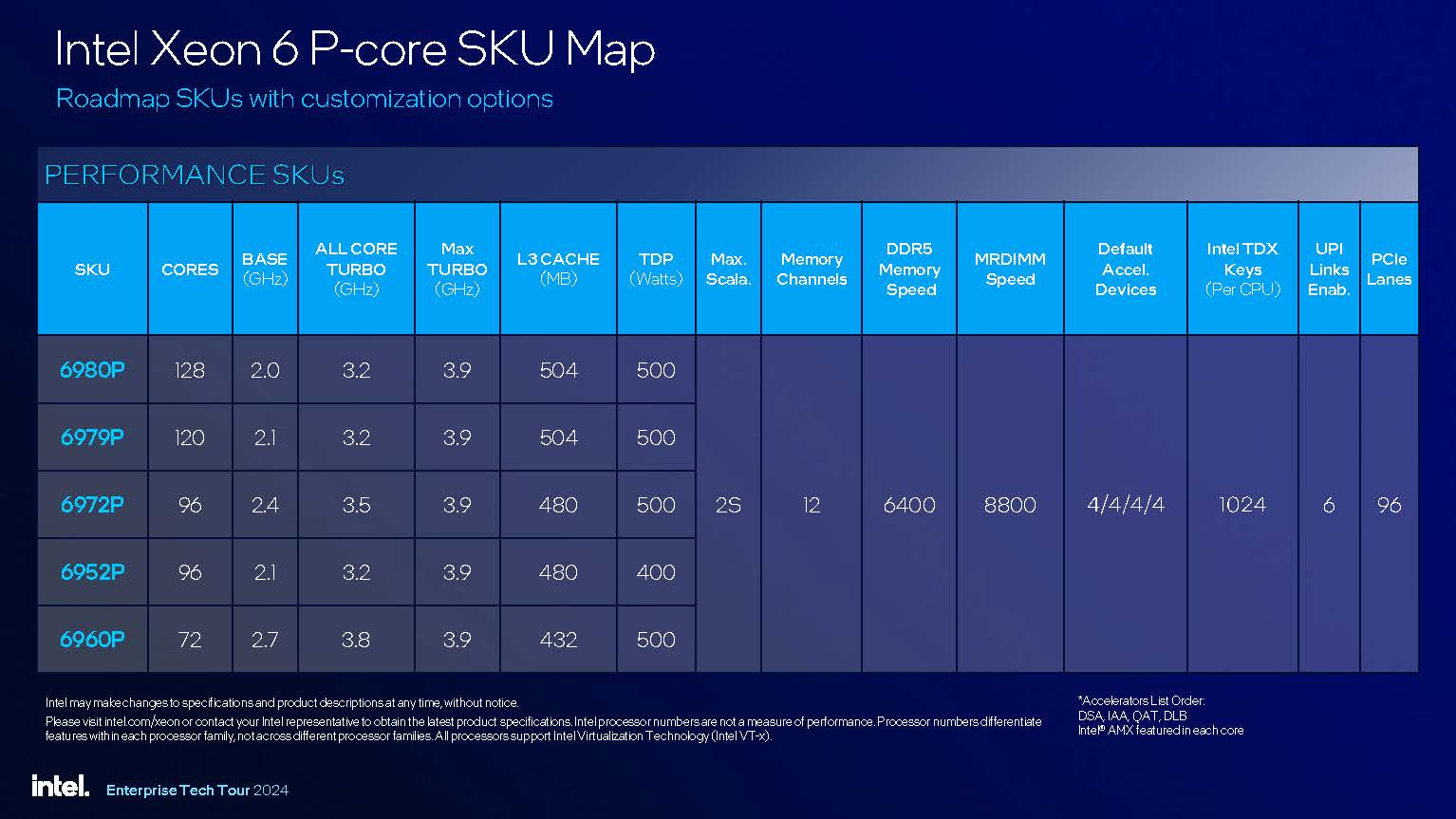 Чипы поддерживают как однопроцессорные, так и двухпроцессорные сборки, имеют поддержку 12-канальной ОЗУ DDR5-6400 и MRDIMM-8800, а также оснащены поддержкой 96 линий PCIe.  Intel заявляет, что Xeon 6 отличаются от предшественников увеличенным числом ядер, удвоенной пропускной способностью памяти и возможностями ускорения ИИ, встроенными в каждое ядро. Эти чипы разработаны для удовлетворения требований производительности ИИ — от Edge-систем до центров обработки данных и облачных сред.  Intel заявляет, что новые Xeon 6 более чем вдвое быстрее процессоров Epyc Genoa (максимально — 96 ядер Zen 4) в широком спектре вычислительных нагрузок и более чем впятеро быстрее в нейросетевых задачах.  В свою очередь специализированные ИИ-ускорители Gaudi 3 специально оптимизированы для работы с генеративными моделями. В их составе используются 64 тензорных процессора (TPC) и восемь движков матричного умножения (MME) для ускорения вычислений глубоких нейронных сетей. Также ускорители Gaudi 3 получили 128 Гбайт набортной памяти HBM2 и поддерживают до 24 портов Ethernet 200 Гбит для масштабируемых сетей. Для Gaudi 3 заявляется бесшовная совместимость с фреймворком PyTorch и усовершенствованными трансформными и диффузионными моделями Hugging Face. Intel заявляет, что новые ИИ-ускорители Gaudi 3 обеспечивают до 20 процентов большую пропускную способность и двукратное улучшение соотношения цены и производительности по сравнению с H100 для вывода модели LLaMa 2 70B. Для российского синхротрона СКИФ собран первый детектор
18.09.2024 [13:53],
Геннадий Детинич
Осталось около полугода до начала работы синхротрона СКИФ в наукограде Кольцово Новосибирской области и запуска первой очереди исследовательских станций на его основе. И одной из первых заработавших на комплексе станций станет лаборатория для изучения быстрых переходных процессов в материалах. На днях российские учёные сообщили об изготовлении первых детекторов как для этой лаборатории, так и для синхротрона. 
Источник изображения: https://strana-rosatom.ru Всего на СКИФе будет 30 экспериментальных станций. Полное их создание растянется на несколько лет, но сам синхротрон и первые станции будут завершены к концу 2024 года. Эксплуатация синхротрона и первой очереди лабораторий начнётся в первой половине 2025 года. Представленный на днях детектор позволит снимать быстрые процессы в материалах со скоростью до 10 млн кадров в секунду. Образцы будут облучаться синхротронным излучением (разогнанными до релятивистских скоростей электронами). Детектор GINTOS для лаборатории (координатный детектор на полупроводниках) изготовили сотрудники Томского государственного университета (ТГУ) и Института ядерной физики им. Будкера (ИЯФ). «Детектор GINTOS позволит исследовать реакцию материалов на импульсные тепловые и механические нагрузки. Это необходимо для понимания процессов, которые будут происходить, например, в термоядерном реакторе ИТЭР при попадании раскалённой плазмы на вольфрамовую стенку. Также детектор позволит изучать распространение ударных волн и других динамических процессов в микросекундном диапазоне», — рассказал главный научный сотрудник ИЯФ Лев Шехтман. Как нетрудно понять, датчики GINTOS должны быть очень быстродействующими. Для них радиофизики ТГУ разработали сенсоры на основе арсенида галлия, компенсированного хромом. Этот материал обладает повышенной радиационной стойкостью и чувствительностью к рентгеновскому излучению. «Полупроводниковые сенсоры преобразуют фотонный сигнал в электрический, а электроника регистрирует этот сигнал и передаёт изображение в компьютер, — объясняет заведующий лабораторией детекторов синхротронного излучения ТГУ Олег Толбанов. — Количество кадров очень велико, поэтому результат съёмки — это не отдельные изображения, а фильм». Синхротрон СКИФ станет первым в мире источником синхротронного излучения поколения 4+. Он откроет широкие возможности для исследований в области материаловедения, биологии, фармацевтики, физики, квантовой химии и многих других сфер. Глючный софт Huawei мешает Китаю заменить Nvidia в области искусственного интеллекта
03.09.2024 [12:39],
Павел Котов
Попытки Китая выйти на уровень США по вычислительной мощности в области искусственного интеллекта сдерживаются многими факторами, среди которых и проблемы с ПО. Например, пользователи ускорителей вычислений Huawei жалуются на проблемы с производительностью из-за сбоев и ошибок в работе программного обеспечения, а также на сложности перехода с продуктов Nvidia, сообщает Financial Times.  Huawei стала лидером в гонке за создание китайской альтернативы ускорителям Nvidia после того, как Вашингтон в октябре прошлого года ввёл очередной пакет санкций, затронувший высокопроизводительное оборудование. Ускорители Ascend всё чаще используются китайскими разработчиками для запуска моделей генеративного ИИ. Но на практике выясняется, что оборудование Huawei всё ещё сильно отстаёт от ускорителей Nvidia на этапе обучения моделей. Китайские ускорители работают нестабильно, у них более медленные межчиповые соединения и некачественное ПО Huawei Cann. Программная платформа Cuda — сильный продукт Nvidia. Она проста в использовании и способна значительно ускорять обработку данных. Huawei пытается ослабить хватку Nvidia в области чипов ИИ, внедряя альтернативное ПО собственной разработки. Но на Cann жалуются даже сотрудники Huawei. Из-за него ускорители Ascend «сложны и нестабильны в работе», а тестирование оказывается сложной задачей. Качество документации оставляет желать лучшего, и при возникновении ошибок определить их источник получается не всегда. Ускорители Huawei Ascend используются в Baidu, но они часто выходят из строя, что усложняет разработку ИИ. Чтобы преодолеть эту проблему Huawei направляет к крупнейшим клиентам своих инженеров, которые помогают в переносе кода обучения ИИ с Cuda на Cann — сотрудники компании работают в Baidu, iFlytek и Tencent. Более 50 % из 207 тыс. сотрудников Huawei заняты по направлению исследований и разработки, включая инженеров, которые помогают развернуть технологические решения компании у клиентов. И в этом Huawei выгодно отличается от Nvidia. Китайская компания даже запустила онлайн-портал для разработчиков, где они могут оставлять предложения по улучшению ПО. После введения очередного пакета американских санкций Huawei подняла цены на ускорители Ascend 910B, которые используются для обучения ИИ, на 20–30 %. При этом объёмы их поставок ограничены, вероятно, из-за производственных трудностей — китайские компании не могут закупать оборудование для выпуска чипов у нидерландской ASML. На ИИ-ускорители Huawei держится высокий спрос. За первое полугодие компания нарастила выручку на 34 %, но не привела разбивки по направлениям деятельности. На ускорителях Ascend уже были обучены и интегрированы более 50 базовых моделей ИИ, подсчитали в Huawei — iFlytek сообщила, что обучила свою нейросеть исключительно на оборудовании Huawei, и его производитель направил в компанию группу инженеров, которые помогли в развёртывании решений. Молодые компании серьёзно настроены потягаться с Nvidia на рынке систем для запуска ИИ-моделей
28.08.2024 [16:52],
Павел Котов
В попытке ослабить мёртвую хватку Nvidia на рынке чипов для систем искусственного интеллекта сейчас мобилизуется множество конкурентов компании — они привлекают сотни миллионов долларов инвестиций, стремясь воспользоваться волной бума ИИ. Среди наиболее перспективных конкурентов значатся такие компании, как Cerebras, d-Matrix и Groq. 
Источник изображения: Mariia Shalabaieva / unsplash.com Мелкие компании решили воспользоваться тем, что спрос на оборудование для инференса ИИ будет расти экспоненциальными темпами. Эти системы необходимы для запуска уже обученных систем вроде OpenAI ChatGPT и Google Gemini — популярность подобных приложений продолжает расти. Сейчас самыми популярными в этом сегменте являются графические процессоры Nvidia, принадлежащие к семейству Hopper. Компании Cerebras, d-Matrix и Groq заняты разработкой более дешёвых, но и более узконаправленных чипов, которые предназначаются для запуска моделей ИИ. Cerebras накануне представила платформу Cerebras Inference, которая работает на чипе CS-3, который занимает целую 300-мм кремниевую пластину. Этот чип, утверждает производитель, в 20 раз быстрее в задачах вывода ИИ, чем ускорители Nvidia Hopper, но стоит дешевле — это подтверждают тесты Artificial Analysis. Чип Cerebras CS-3 отличает другая архитектура, предусматривающая интеграцию компонентов памяти непосредственно в кремниевую пластину процессора. Ограничения, которые налагает пропускная способность памяти, значительно снижают производительность ИИ-ускорителей, утверждают в Cerebras — объединение логики и памяти на одном большом чипе даёт результаты «на порядки быстрее». В конце этого года ещё одна компания, d-Matrix, намеревается выпустить собственную аппаратную платформу Corsair, предназначенную для работы с Triton — открытой программной средой, которая выступает альтернативой Nvidia Cuda. В прошлом году компания привлекла $110 млн вложений, и в этом также проводит раунд финансирования, на котором намеревается привлечь от инвесторов ещё $200 млн или более. Бывший основатель команды, выступающей разработчиком тензорных процессоров Google, теперь возглавляет ещё одну компанию — Groq, которая в этом месяце привлекла $640 млн при оценке $2,8 млрд. Стартапам в области полупроводников, даже несмотря на шумиху в сегменте ИИ-оборудования, непросто выйти на рынок, предупреждают аналитики. Японский финансовый конгломерат SoftBank в июле поглотил чипмейкера Graphcore, заплатив $600 млн — при том, что с момента своего основания в 2016 году компания привлекла у около $700 млн. Но инвесторы не отчаиваются найти и поддержать «новую Nvidia», и этот процесс способствует развитию многих стартапов. IBM анонсировала 5-нм процессор Telum II и ускоритель Spyre для задач ИИ
27.08.2024 [05:45],
Анжелла Марина
Компания IBM анонсировала новое поколение вычислительных систем для искусственного интеллекта — процессор Telum II и ускоритель IBM Spyre. Оба продукта предназначены для ускорения ИИ и улучшения производительности корпоративных приложений. Telum II предлагает значительные улучшения благодаря увеличенной кеш-памяти и высокопроизводительным ядрам. Ускоритель Spyre дополняет его, обеспечивая ещё более высокие показатели для приложений на основе ИИ. 
Источник изображения: IBM Как сообщается в блоге компании, новый процессор IBM Telum II, разработанный с использованием 5-нанометровой технологии Samsung, будет оснащён восемью высокопроизводительными ядрами, работающими на частоте 5,5 ГГц. Объём кеш-памяти на кристалле получил увеличение на 40 %, при этом виртуальный L3-кеш вырос до 360 Мбайт, а L4-кеш до 2,88 Гбайт. Ещё одним нововведением является интегрированный блок обработки данных (DPU) для ускорения операций ввода-вывода и следующее поколение встроенного ускорителя ИИ. Telum II предлагает значительные улучшения производительности по сравнению с предыдущими поколениями. Встроенный ИИ-ускоритель обеспечивает в четыре раза большую вычислительную мощность, достигая 24 триллионов операций в секунду (TOPS). Архитектура ускорителя оптимизирована для работы с большими языковыми моделями и поддерживает широкий спектр ИИ-моделей для комплексного анализа структурированных и текстовых данных. Кроме того, новый процессор поддерживает тип данных INT8 для повышения эффективности вычислений. При этом на системном уровне Telum II позволяет каждому ядру процессора получать доступ к любому из восьми ИИ-ускорителей в рамках одного модуля, обеспечивая более эффективное распределение нагрузки и достигая общей производительности в 192 TOPS. IBM также представила ускоритель Spyre, разработанный совместно с IBM Research и IBM Infrastructure development. Spyre оснащён 32 ядрами ускорителя ИИ, архитектура которых схожа с архитектурой ускорителя, интегрированного в чип Telum II. Возможность подключения нескольких ускорителей Spyre к подсистеме ввода-вывода IBM Z через PCIe позволяет существенно увеличить доступные ресурсы для ускорения задач искусственного интеллекта. Telum II и Spyre разработаны для поддержки широкого спектра сценариев использования ИИ, включая метод ensemble AI. Этот метод использует преимущества одновременного использования нескольких ИИ-моделей для повышения общей производительности и точности прогнозирования. Примером может служить обнаружение мошенничества со страховыми выплатами, где традиционные нейронные сети успешно сочетаются с большими языковыми моделями для повышения эффективности анализа. Оба продукта были представлены 26 августа на конференции Hot Chips 2024 в Пало-Альто (Калифорния, США). Их выпуск планируется в 2025 году. Imagination отказалась от нейропроцессоров в пользу совершенствования GPU под нужды ИИ
25.08.2024 [22:00],
Анжелла Марина
Британский разработчик чипов Imagination Technologies на фоне получения $100 млн инвестиций меняет свою стратегию в сфере искусственного интеллекта, отказываясь от использования отдельных нейропроцессоров (NPU) и внедряя ИИ-функции в графические процессоры (GPU). 
Источник изображения: imaginationtech.com По данным Tom's Hardware со ссылкой на источник, это стратегическое решение было принято в течение последних 18 месяцев из-за сложностей с собственным разработанным ранее программным стеком, который не успевал за быстро меняющимися потребностями клиентов в области искусственного интеллекта. Создание ИИ-функциональности, способной раскрыть все возможности нейропроцессора от Imagination Technologiesоказалось было затруднено. Компания переключила внимание на GPU, которые по своей природе многопоточны и хорошо подходят для задач, требующих эффективной параллельной обработки данных. Imagination Technologies считает, что GPU можно усовершенствовать дополнительными вычислительными возможностями для ИИ, что сделает их подходящими для периферийных приложений, особенно в устройствах с уже существующими GPU, таких как смартфоны. Напомним, что Imagination Technologies, работающая на рынке около 40 лет, приобрела известность благодаря графическим процессорам PowerVR Kyro для ПК и IP-ядрам GPU PowerVR, используемым Apple, Intel и другими компаниями. Теперь же в рамках новой стратегии компания сотрудничает с UXL Foundation над разработкой SYCL — открытой платформой, конкурирующей с программно-аппаратной архитектурой параллельных вычислений CUDA от Nvidia. Такой подход отвечает потребностям клиентов, которые уже используют GPU для обработки графики и задач искусственного интеллекта. 
Источник изображения: imaginationtech.com Получение инвестиций в размере $100 млн от Fortress Investment Group, вероятно, связано с новой стратегией Imagination Technologies. Компания уверена, что GPU на данный момент являются лучшим решением для удовлетворения потребностей клиентов в области ИИ, прекратив разработку отдельных нейронных ускорителей. Тем не менее, Imagination не исключает возможности возвращения к разработке специализированных нейропроцессоров в будущем, если развитие программного обеспечения для ИИ изменит ситуацию. Продажи ИИ-серверов в 2024 году вырастут до $187 млрд — они займут 65 % всего рынка
17.07.2024 [16:22],
Павел Котов
Высокий спрос на передовые серверы для систем искусственного интеллекта со стороны крупных поставщиков облачных услуг и их клиентов сохранится до конца 2024 года, уверены аналитики TrendForce. Расширение производства TSMC, SK hynix, Samsung и Micron значительно сократило дефицит во II квартале 2024 года — срок выполнения заказа на флагманские ИИ-ускорители Nvidia H100 сократился с прежних 40–50 до менее чем 16 недель. 
Источник изображения: nvidia.com Объём поставок ИИ-серверов по итогам II квартала увеличился почти на 20 % по сравнению с предшествующим кварталом, гласит предварительная оценка TrendForce — годовой прогноз поставок был пересмотрен до значения 1,67 млн единиц, что соответствует росту на 41,5 % год к году. Крупные облачные провайдеры в этом году направляют свои бюджеты на закупку ИИ-серверов в ущерб темпам роста поставок обычных серверов — он составит всего 1,9 %. Ожидается, что доля ИИ-серверов в общем объёме поставок достигнет 12,5 %, что примерно на 3,4 п.п. выше, чем в 2023 году. С точки зрения рыночной стоимости ИИ-серверы вносят больший вклад в рост выручки, чем обычные серверы. По итогам 2024 года рыночная стоимость ИИ-серверов превысит $187 млрд при темпе роста 69 %, что составит 65 % от общей стоимости серверов, гласит прогноз TrendForce. Собственные ASIC-решения активно расширяют как североамериканские операторы AWS и Meta✴✴, так и китайские гиганты в лице Alibaba, Baidu и Huawei. Как ожидается, по итогам 2024 года доля ASIC-серверов составит до 26 % от общего серверного рынка, тогда как на ИИ-серверы с массовыми GPU придутся около 71 %. 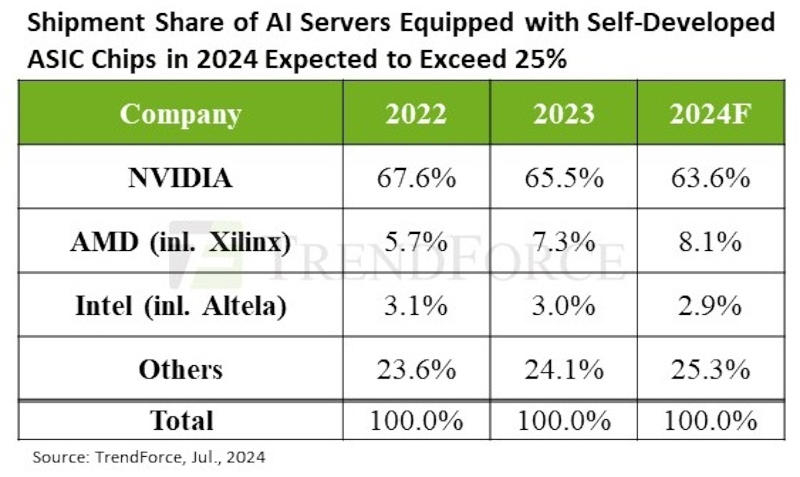
Источник изображения: trendforce.com Nvidia удержит крупнейшую долю около 90 % на рынке поставщиков ИИ-чипов для ИИ-серверов; доля рынка AMD будет всего около 8 %. Но если включить все чипы ИИ, используемые в ИИ-серверах (GPU, ASIC, FPGA), доля рынка Nvidia по итогам года составит около 64 %. Спрос на передовые ИИ-серверы, считают аналитики TrendForce, останется высоким на протяжении всего 2025 года, особенно с учётом того, что на смену Nvidia Hopper придёт новое поколение ИИ-ускорителей Blackwell (GB200, B100/B200). Из-за этого вырастет спрос на упаковку чипов TSMC CoWoS и память HBM: на ускорителе Nvidia B100 размер чипа вдвое больше. Производственная мощность TSMC CoWoS к концу 2025 года достигнет 550–600 тыс. единиц при темпах роста около 80 %. Массовый Nvidia H100 в 2024 году будет оснащаться 80 Гбайт HMB3; к 2025 году чипы Nvidia Blackwell Ultra и AMD MI350 получат до 288 Гбайт HBM3e, утроив расход компонентов памяти. Ожидается, что общее предложение HBM к 2025 году удвоится из-за высокого спроса на рынке ИИ-серверов. Nvidia в прошлом году захватила 98 % рынка графических процессоров для ЦОД — поставки достигли 3,76 млн единиц
11.06.2024 [19:58],
Сергей Сурабекянц
Недавний бум искусственного интеллекта озолотил Nvidia. В 2023 году компания поставила 3,76 миллиона графических процессоров для ЦОД, что на миллион больше, чем годом ранее, показав рост продаж на 42 %. Выручка Nvidia за 2023 год достигла $60,9 млрд, на 126 % превысив аналогичный показатель 2022 года. 
Источник изображений: Nvidia По результатам 2023 года Nvidia захватила 98 % рынка графических процессоров для центров обработки данных и 88 % рынка графических процессоров для настольных ПК. Такие результаты компания продемонстрировала несмотря на нехватку в 2023 году производственных мощностей TSMC, выпускающей чипы для Nvidia, и невзирая на запрет США на экспорт передовых чипов Nvidia в Китай. Однако Nvidia не может почивать на лаврах: AMD готовит выпуск гораздо более энергоэффективных чипов, чем полупроводниковый хит сезона Nvidia H100, потребляющий до 700 Вт, а Intel продвигает процессор Gaudi 3 AI, который будет стоить $15 000 — вдвое дешевле, чем H100. В гонку аппаратного обеспечения для ЦОД присоединяются и другие компании. Microsoft представила ускоритель искусственного интеллекта Maia 100, который она планирует использовать в своём анонсированном ЦОД стоимостью $100 млрд. Amazon производит специальные чипы для AWS, а Google планирует использовать собственные серверные процессоры для ЦОД уже в следующем году.  Однако, по утверждению Nvidia, все эти чипы пока менее производительны, чем её графические процессоры применительно к ускорению работы искусственного интеллекта. Nvidia также подчёркивает гибкость архитектуры своих графических процессоров. Таким образом, несмотря на появляющиеся альтернативы, ИИ-ускорители компании в ближайшем будущем сохранят свои лидирующие позиции. Nvidia будет ежегодно выпускать новые архитектуры для ИИ-ускорителей
02.06.2024 [21:10],
Владимир Фетисов
В преддверии ежегодной выставки Computex компания Nvidia провела презентацию, в рамках которой было сделано несколько важных заявлений. Поимо прочего, глава Nvidia Дженсен Хуанг (Jensen Huang) заявил о намерении ежегодно выпускать новые версии ИИ-ускорителей, а также анонсировал появление графических процессоров на архитектуре Blackwell Ultra в 2025 году и чипов следующего поколения на базе архитектуры Rubin в 2026 году. 
Источник изображения: Annabelle Chih/Bloomberg Nvidia рассматривает развитие генеративных нейросетей как новую промышленную революцию и рассчитывает сыграть важную роль в распространении этих технологий на персональные компьютеры, отметил глава компании в ходе выступления. Nvidia уже стала главным бенефициаром взрывного роста популярности ИИ-технологий, что позволило ей стать самым дорогим производителем полупроводниковой продукции в мире. Сейчас Nvidia стремится расширить свою клиентскую базу за пределы горстки корпораций, занимающихся облачными вычислениями, которые и обеспечили большую часть продаж ИИ-ускорителей компании. В рамках этой деятельности Хуанг ожидает, что функции на базе нейросетей начнут активно использовать самые разные компании и госучреждения, начиная от судостроителей и заканчивая производителей лекарственных средств. Он выразил уверенность в том, что компании, которые не будут обладать возможностями ИИ, останутся далеко позади конкурентов. Что касается будущих ИИ-ускорителей, то во время презентации Дженсен Хуанг мало что рассказал о их характеристиках. Он лишь упомянул, что в чипах на архитектуре Rubin будет использоваться память HBM4 с высокой пропускной способностью. Ожидается, что южнокорейская компания SK Hynix начнёт серийное производство чипов памяти HBM4 к 2026 году. Сроки поставок ИИ-ускорителей Nvidia H100 сократились до 2–3 месяцев
10.04.2024 [20:59],
Николай Хижняк
Cроки поставок ИИ-ускорителей Nvidia H100 сократились с 3–4 до 2–3 месяцев (8–12 недель), сообщает DigiTimes со ссылкой на заявление директора тайваньского офиса компании Dell Теренса Ляо (Terence Liao). ODM-поставщики серверного оборудования отмечают, что дефицит специализированных ускорителей начал снижаться по сравнению с 2023 годом, когда приобрести Nvidia H100 было практически невозможно. 
Источник изображения: Nvidia По словам Ляо, несмотря на сокращение сроков выполнения заказов на поставки ИИ-ускорителей, спрос на это оборудование на рынке по-прежнему чрезвычайно высок. И несмотря на высокую стоимость, объёмы закупок ИИ-серверов значительно выше закупок серверного оборудования общего назначения. Окно поставок в 2–3 месяца — это самый короткий срок поставки ускорителей Nvidia H100 за всё время. Всего шесть месяцев назад он составлял 11 месяцев. Иными словами, клиентам Nvidia приходилось почти год ждать выполнение своего заказа. С начала 2024 года сроки поставок значительно сократились. Сначала они упали до 3–4 месяцев, а теперь до 2–3 месяцев. При таком темпе дефицит ИИ-ускорителей может быть устранён к концу текущего года или даже раньше. Частично такая динамика может быть связана с самими покупателями ИИ-ускорителей. Как сообщается, некоторые компании, имеющие лишние и нигде не использующиеся H100, перепродают их для компенсации огромных затрат на их приобретение. Также нынешняя ситуация может являться следствием того, что провайдер облачных вычислительных мощностей AWS упростил аренду ИИ-ускорителей Nvidia H100 через облако, что в свою очередь тоже частично помогает снизить на них спрос. Единственными клиентами Nvidia, которым по-прежнему приходится сталкиваться с проблемами в поставках ИИ-оборудования, являются крупные ИИ-компании вроде OpenAI, которые используют десятки тысяч подобных ускорителей для быстрого и эффективного обучения своих больших языковых ИИ-моделей. Акции Nvidia упали на 10 % по сравнению с недавним историческим максимумом
10.04.2024 [19:50],
Сергей Сурабекянц
Nvidia вступила на «территорию коррекции»: её акции упали на 10 % по сравнению с последним историческим максимумом в $950 за акцию. Во вторник торги закрылись на отметке $853,54, падение за сессию составило 2 %. Аналитики связывают снижение стоимости акций Nvidia c представленным накануне компанией Intel ИИ-ускорителем Gaudi 3, «сокращением» моделей ИИ и перенаправлением инвестиций крупных клиентов на разработку собственного оборудования для ИИ. 
Источник изображения: Nvidia Nvidia за последние годы стала ключевым бенефициаром бума искусственного интеллекта благодаря ажиотажному спросу на её чипы, предназначенные для ресурсоёмких приложений ИИ. Ускорители компании являются ключевым компонентом множества центров обработки данных. Nvidia сообщила о росте в четвёртом квартале разводненной прибыли на акцию (non-GAAP) на 486 % благодаря беспрецедентной популярности генеративных моделей искусственного интеллекта. Однако последние две недели акции компании находятся под давлением. Падение курса ценных бумаг составило 10 % по сравнению с последним историческим максимумом, которого они достигли 25 марта. Сегодня акции Nvidia торговались с понижением на 0,7 % по состоянию на 9:45 утра по времени восточного побережья США (16:45 мск). Финансовые эксперты советуют инвесторам фиксировать прибыль, которая может составить более чем 200 % за последние 12 месяцев. 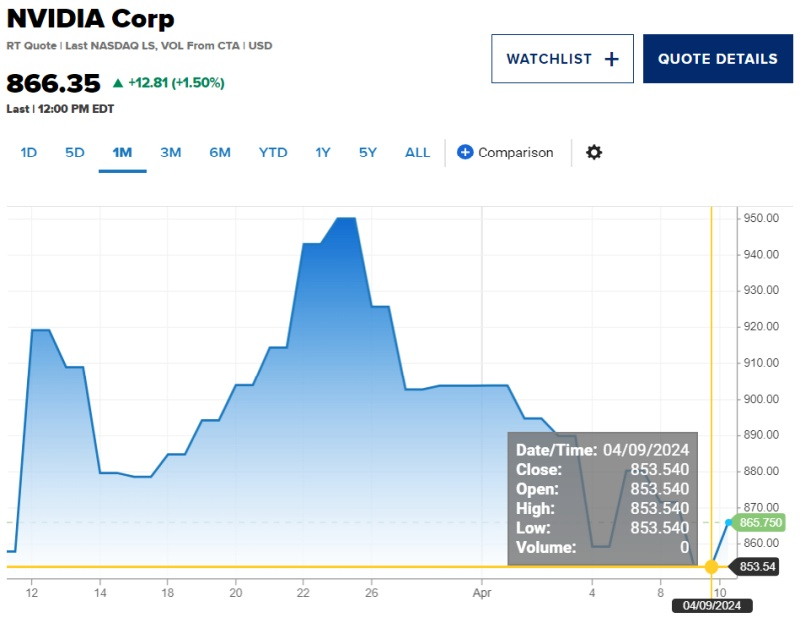
Источник изображения: cnbc.com Одной из возможных причин понижения курса акций Nvidia аналитики называют «сокращение» моделей искусственного интеллекта, включая альтернативы, такие как большая модель Mistral и система LLaMA от Meta✴✴. «Сочетание сокращения моделей, более устойчивого роста спроса, зрелых инвестиций в гиперскейлеры и растущего использования крупнейшими клиентами собственных чипов не сулит ничего хорошего для Nvidia в ближайшие годы», — полагают эксперты аналитической компании D.A. Davidson. Конкуренция в сфере ускорителей вычислений нарастает. Во вторник компания Intel представила свой новый чип для ускорения искусственного интеллекта под названием Gaudi 3. По утверждению компании, новый чип более чем в два раза энергоэффективнее, чем H100 — самый популярный из ныне выпускаемых ускорителей Nvidia, и может запускать модели искусственного интеллекта в 1,5 раза быстрее, чем H100. Хотя консенсус-оценки говорят о том, что спрос на графические процессоры Nvidia для технологий искусственного интеллекта в этом году будет высоким, в 2025 году ожидается замедление роста, а в 2026 году аналитики предрекают значительный спад для Nvidia, так как крупные покупатели чипов искусственного интеллекта, такие как Amazon и Microsoft, вероятно, направят большую часть своих инвестиций в собственное оборудование. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



