|
Опрос
|
реклама
Быстрый переход
Глава Google DeepMind назвал сроки появления AGI и рассказал, что позволит людям конкурировать с ИИ
24.06.2026 [12:26],
Анжелла Марина
Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) вновь подтвердил прогноз по достижению искусственного общего интеллекта (AGI) к 2030 году, одновременно перечислив человеческие качества, способные сохранить конкурентоспособность в ИИ-эпоху. 
Источник изображения: deepmind.google Выступая в Стэнфордской высшей школе бизнеса, Хассабис подчеркнул, что человечество находится на подступах к технологической сингулярности. Этот этап, характеризующийся выходом алгоритмов из-под контроля разработчиков и их способностью к непрерывному самосовершенствованию, ознаменует начало принципиально новой эры, к которой обществу необходимо готовиться уже сейчас. В индустрии пока нет единого мнения относительно точных сроков достижения AGI. Так, генеральный директор компании Anthropic Дарио Амодей (Dario Amodei) ожидает появления мощного ИИ в конце 2026 года, а представители этой же компании Джек Кларк (Jack Clark) и Марина Фаваро (Marina Favaro) считают, что к 2027 году системы смогут быстро выполнять такие задачи, на которые у людей уходят недели. В то же время глава OpenAI Сэм Альтман (Sam Altman) открыто заявляет о приближении цифрового сверхразума, тогда как главный научный сотрудник Google DeepMind Шейн Легг (Shane Legg) оценивает вероятность создания базового AGI к 2028 году примерно 50 %. Противоположную точку зрения высказывает бывший вице-президент и главный специалист по искусственному интеллекту Meta✴✴ Ян Лекун (Yann LeCun), являющийся пионером в области создания свёрточных нейронных сетей. Он называет саму концепцию общего искусственного интеллекта несостоятельной, полагая, что современные большие языковые модели (LLM) на базе архитектуры трансформеров вряд ли смогут достичь человеческого уровня мышления для выполнения высокоценной интеллектуальной работы. Несмотря на потенциальную угрозу автоматизации сложных рабочих процессов со стороны систем, способных самостоятельно принимать решения и адаптироваться к изменениям, людям удастся сохранить конкурентное преимущество. В беседе с основателем издания The Rundown AI Роуэном Чунгом (Rowan Cheung) Хассабис пояснил, что машины не смогут полностью заменить специалистов, обладающих, например, дизайнерским чутьём, креативом и изобретательностью. Google DeepMind выработала линию защиты от собственных ИИ-агентов
19.06.2026 [10:13],
Павел Котов
В Google разработали план по сохранению контроля над агентами искусственного интеллекта, которые, постоянно совершенствуясь, используются внутри компании. Чтобы помочь другим лабораториям ИИ, в Google опубликовали дорожную карту, в которой изложено поэтапное внедрение мер защиты от этой угрозы. 
Источник изображений: deepmind.google Разработанный в подразделении Google DeepMind план безопасности предполагает отход от типичного для сообщества подхода, направленного на решение «проблемы согласования» — идее определения того, как обучить систему ИИ таким образом, чтобы её действия соответствовали намерениям, ценностям и этике управляющих ею людей. В Google не спорят, что согласование остаётся одним из основных элементов безопасности, но составители дорожной карты исходят из того, что эта проблема, возможно, никогда не будет решена в полной мере. Поэтому формируется многоуровневая система безопасности, в которой ИИ-агенты рассматриваются как вероятная угроза внутри организации. Механизмы защиты от собственных ИИ-агентов во многом позаимствованы у традиционных служб безопасности, которые занимаются угрозой со стороны собственных сотрудников компаний — и адаптированы к новым условиям, потому что «ИИ системно отличается от людей». ИИ-агенты способны действовать быстрее и в большем масштабе, чем отдельный недобросовестный сотрудник, поэтому необходимы системы, способные контролировать доступ ИИ-агентов к определённым инструментам; а также системы, способные выявлять у них аномальное поведение. Существующие системы контроля доступа ориентированы на должность и полномочия конкретного сотрудника компании; некоторые поставщики систем массового управления ИИ-агентами исходят из того, что они должны иметь те же доступ и разрешения, что и сотрудники, от имени которых они работают. Этот подход в Google считают бесперспективным. По мере автоматизации рабочих процессов становится всё менее очевидно, от чьего имени работает ИИ-агент, и в полностью автоматизированной среде один ИИ-агент способен выполнять задачи, связанные с различными должностями, а не только с одной. Наконец, в интересах организации один ИИ-агент может выполнять задачи и в разных рабочих процессах. Поэтому необходима динамичная система контроля доступа, которая может меняться в зависимости от выполняемой задачи и от того, как эта задача вписывается в рабочий процесс. Допустимы сценарии, когда один и тот же ИИ-агент сначала имеет разрешение на выполнение конкретного действия или доступ к определённой базе данных, а через несколько минут в рамках другого рабочего процесса ему отказывается в тех же привилегиях. Необходима система мониторинга в реальном времени, которая знает, каким должно быть поведение ИИ-агента при выполнении любой задачи в любом рабочем процессе, и если выявляется отклонение, и он пытается сделать что-то, чего, как подозревает система, делать не должен, она оперативно реагирует. 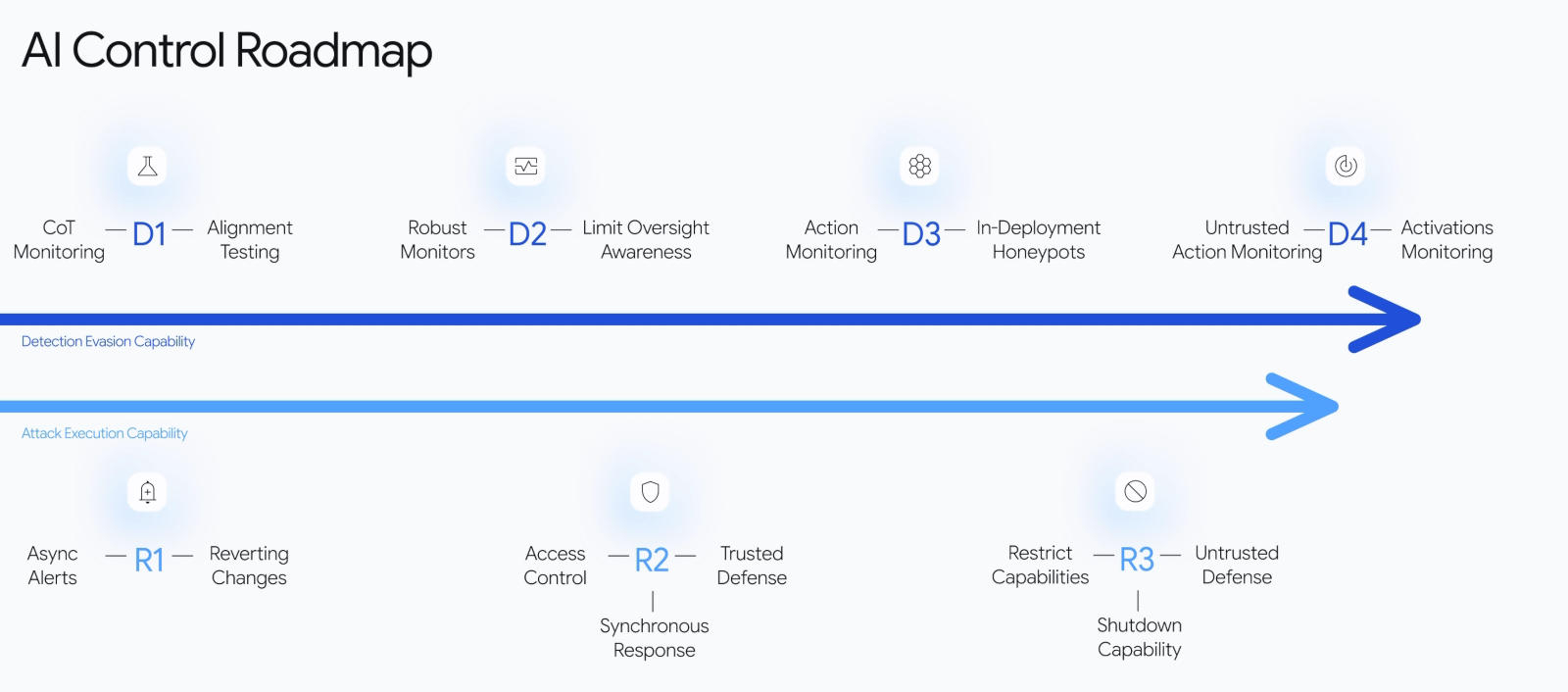 В распоряжении Google DeepMind уже разработан внутренний прототип системы, который асинхронно отслеживает траектории работы агентов-программистов и направляет подозрительные сигналы на рассмотрение человеку. Эта система уже проанализировала около 1 млн задач этих агентов; работа «сыграла решающую роль в создании системы мониторинга в реальном времени для агента Gemini Spark» и помогла реагировать на такие проблемы как непреднамеренное удаление данных. Большинство попавших в поле зрения мониторов событий не носят злонамеренного характера — чаще всего это результат «неправильной интерпретации [задачи] агентом или чрезмерного стремления достичь поставленной пользователем цели». Мониторинг в реальном времени — лишь один из 15 способов снижения риска, которые перечислены в дорожной карте Google DeepMind. Предлагаются также журналы сетевой активности, которые изучаются в реальном времени или проверяются позже; подключение несложной, но заслуживающей доверия модели ИИ, которая осуществляет мониторинг «траектории рассуждений» — она, впрочем не всегда точно отражает, что агент в действительности «думает»; и даже отслеживание механизмов активации цифровых нейронов в нейросети, помогающее выявлять признаки того, что модель действует обманным путём — аналог МРТ в реальном времени. На основе дорожной карты разрабатывается структура под названием TRAIT&R (таксономия вредоносных тактик и алгоритмов ИИ), во многом основанная на ATT&CK — базе знаний о недружественном поведении в области кибербезопасности, поддерживаемой организацией MITRE. Таксономия выделяет три категории угроз, от которых в Google DeepMind выстраивают защиту: «утеря контроля», при которой модель развёртывает скрытые неконтролируемые инструменты; «саботаж работы» (незаметное ухудшение ИИ-агентами согласованности в области безопасности); и «прямой вред» (утечка весов модели или уничтожение критически важных активов). Компания, по её признанию, уже значительно продвинулась в реализации дорожной карты — что-то только разрабатывается, а что-то уже внедряется. В перспективе эти средства безопасности Google DeepMind намерена включить в систему Frontier Safety Framework. Google намерена узнать, что произойдёт, когда миллионы ИИ-агентов начнут действовать вместе
12.06.2026 [11:33],
Павел Котов
Специализирующееся на изучении и разработке систем искусственного интеллекта подразделение Google DeepMind объявило в выделении финансирования в размере $10 млн на изучение сценариев, при которых несколько миллионов ИИ-агентов начинают взаимодействовать друг с другом. В проекте согласились принять участие несколько частных и государственных организаций со всего мира. 
Источник изображения: deepmind.google Всего через несколько месяцев во всём мире ИИ-агенту будут развёрнуты в таких масштабах, что сопутствующие риски станут реальной проблемой, и учёные хотят опередить этот момент. Потенциальные угрозы сводятся к усиленным вариантам неблагоприятных сценариев, которые наблюдаются уже сегодня: мошеннические схемы, инъекции в запросах, которые превращают ИИ-агентов в самонаводящееся вредоносное ПО, и другие формы кибератак. Единственный способ понять, что может произойти, когда большое количество многоагентных систем будет взаимодействовать друг с другом — провести реалистичные симуляции: поместить ИИ-агентов в «песочницы» и наблюдать за их поведением. Не получится предсказать, что произойдёт, если изучать отдельных агентов или даже нескольких агентов изолированно. И нельзя предполагать, что выполняющие инструкции больших языковых моделей ИИ-агенты будут действовать рационально — сложность возникает в условиях огромного числа одновременных взаимодействий. Есть версия, которую не исключают и в Google DeepMind, что сильный ИИ (AGI) возникнет не из одной сверхумной модели, а станет порождением своего рода коллективного разума ИИ-агентов, где возможности группы оказываются сильнее, чем суммы её частей. Google DeepMind — не единственный крупный разработчик, предупреждающий об угрозах, исходящих от технологий, которые он создаёт. Ранее Anthropic опубликовала рекомендации по развёртыванию ИИ-агентов, основанные на принципе «нулевого доверия»: следует исходить из того, что компьютерная система уязвима, агент является злоумышленником, и взлом неизбежен. Ранее подходы к обеспечению кибербезопасности имели в основе предположение, что объект, от которого исходит угроза — это написанное человеком ПО, выполняющее фиксированные действия по фиксированным траекториям, указывают эксперты. ИИ-агент действует иначе: он рассуждает, импровизирует, и его можно взломать всего одной фразой в документе, который ему предлагается прочитать. В рамках проекта важно не упускать из виду не только экзотические гипотетические сценарии, но и скучные проблемы, которые уже существуют. Глава DeepMind спрогнозировал появление сильного искусственного интеллекта (AGI) к 2030 году
23.05.2026 [04:46],
Анжелла Марина
Генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) заявил на конференции Google I/O о скором создании сильного искусственного интеллекта (AGI). По его прогнозам, технология появится приблизительно к 2030 году и кардинально изменит глобальные вычислительные процессы. 
Источник изображения: AI Выступая на Google I/O, а затем в ходе интервью соучредителю новостного портала Axios Майку Аллену (Mike Allen), глава DeepMind уточнил, что внедрение AGI пройдёт поэтапно, а для подтверждения статуса общего искусственного интеллекта он предложил использовать условный «тест Эйнштейна». Суть метода заключается в обучении алгоритма на данных по физике до 1901 года, после чего система должна самостоятельно воспроизвести научные открытия Альберта Эйнштейна 1905 года. По словам руководителя, современные модели на такое не способны, однако в будущем этот барьер будет преодолён. Рассуждая о позициях Google на рынке, Хассабис, ставший в 2024 году лауреатом Нобелевской премии по химии за вклад в исследование белковых структур с помощью ИИ, назвал текущую конкуренцию в сфере ИИ самой жёсткой в истории технологий. При этом он подчеркнул, что корпорация обладает обширнейшей исследовательской базой и успешно интегрирует профессиональные решения в потребительские сервисы. В качестве примера практической пользы нейросетей спикер привёл прогнозирование экстремальных погодных условий. В частности, ИИ-модели способны выдавать точные результаты за день до катаклизма, в то время как традиционным программам потребуется на вычисления несколько недель. Несмотря на скептицизм в обществе и опасения коллег по отрасли относительно экзистенциальных угроз, Хассабис сохраняет оптимизм. Он считает, что влияние AGI на мир превзойдёт эффект промышленной революции в десять раз и обеспечит прорыв в медицине, материаловедении, математике и энергетике. Вместе с тем он отметил излишнюю одержимость Кремниевой долины скоростью разработок, указав, что гораздо важнее грамотно выбрать вектор развития. Сама компания DeepMind предпочитает спокойный подход и продолжает работать в Лондоне после того, как в 2014 году Google приобрела её за $400 млн. Хассабис, подписавший в 2023 году заявление о том, что снижение рисков от ИИ должно стать глобальным приоритетом наряду с пандемиями и ядерной войной, выразил уверенность в позитивном сценарии. По его мнению, при грамотном подходе развитие AGI может обеспечить «тысячелетие процветания человечества». Google захлебнулась в спросе на ИИ: даже исследователи DeepMind стоят в очереди за TPU
18.05.2026 [18:03],
Сергей Сурабекянц
Исследователям ИИ Google приходится конкурировать за вычислительные мощности, которые распределяются в зависимости от потенциальной прибыльности проектов, к тому же приоритет порой отдаётся платным клиентам. Лидерство компании в разработке ИИ сделало вычислительные мощности настолько ценным ресурсом, что некоторые исследователи запускают собственные стартапы, где у них больше свободы и нет необходимости преодолевать бюрократические препоны Google. 
Источник изображения: TechSpot В гонке за создание инфраструктуры, которая обеспечивает работу искусственного интеллекта, Google занимает завидное положение: компания имеет процветающий бизнес облачных вычислений, производит собственные чипы и заключила соглашения о совместном использовании с такими компаниями, как Anthropic и Meta✴✴. Однако успех компании сделал её вычислительные ресурсы настолько ценными, что собственным исследователям ИИ приходится вставать в очередь. В лаборатории искусственного интеллекта Google DeepMind доступ к вычислительным мощностям влияет на проекты, которые реализуют исследователи, на лидеров, с которыми они сотрудничают, и на темп работы. «Внутри Google на каждый TPU есть [как минимум] три претендента, — говорит опытный исследователь в области ИИ, почётный профессор Вашингтонского университета Орен Этциони (Oren Etzioni). — Если вы оказались в неудобном положении, когда у вас есть несбыточный проект, и вы конкурируете с прибыльным клиентом, это очень сложная ситуация». Google заявляет, что использует «строгий, непрерывный процесс, который гарантирует, что наши вычислительные ресурсы распределяются по наиболее важным приоритетам, балансируя сегодняшние потребности клиентов и пользователей с долгосрочными инвестициями в развитие исследований и инноваций». Генеральный директор Alphabet Сундар Пичаи (Sundar Pichai) утверждает, что при принятии решения о том, куда направить вычислительные мощности, руководители компании сосредоточены на обеспечении Google DeepMind необходимыми ресурсами для создания передовых моделей ИИ, «потому что это основа всего, что мы делаем». 
Источник изображений: Google Исследователи ИИ когда-то считали Google местом, где они могли свободно заниматься своими интеллектуальными увлечениями, почти как в академической среде, но с лучшей оплатой и большими ресурсами. Однако в 2022 году запуск ChatGPT побудил Google инвестировать в большие языковые модели, которые создают компьютерный код, что, как показали конкуренты, может стать успешным продуктом и приносить существенный доход. Это снизило инвестиции в экспериментальные проекты, которые не могут принести сиюминутного дохода, и заставило многих ИИ-специалистов задуматься об основании собственных стартапов. Портфель заказов Google Cloud почти удвоился по сравнению с предыдущим кварталом и превысил $460 млрд. «В краткосрочной перспективе мы испытываем нехватку вычислительных мощностей, — признал Пичаи. — Мы преодолеваем этот момент и инвестируем». Чтобы наверстать упущенное в гонке ИИ, Google в 2023 году объединила лондонскую лабораторию DeepMind, имевшую более иерархическую структуру, и Google Brain, где исследователи занимались персональными проектами с минимальным контролем. Исследователи в Brain получали кредиты на покупку чипов во внутренней системе, где цена колебалась в зависимости от спроса, подобно фондовому рынку. По словам Голди, «это был мощный способ сплотиться и добиться результата».  В ведущих лабораториях ИИ некоторые исследователи вынуждены работать над приоритетными языковыми моделями, даже если их истинные интересы лежат в другой области. «Есть приманка в виде вычислительных мощностей, продвижения и, в целом, участия в триумфальном процессе обучения, — говорит бывший исследователь Google Том Макграт (Tom McGrath). — Есть и кнут: если вы этого не сделаете, у вас не будет никаких ускорителей». Доступ к вычислительным мощностям для многих учёных стал главным аргументом. По словам бывшей сотрудницы DeepMind Анны Голди (Anna Goldie), компания предлагала ей больше вычислительных мощностей, чтобы отговорить от ухода, но она всё равно ушла, основав компанию Ricursive Intelligence, которая уже привлекла $335 млн инвестиций. Голди «была приятно удивлена» тем, сколько вычислительных мощностей ей удалось найти за пределами компании. «Мне не нужно спрашивать разрешения у десяти вышестоящих руководителей, — заявила она. — Я могу просто принять решение […], чтобы сделать то, что лучше для компании. Я могу прислушиваться к своим сотрудникам и их идеям». «Игра в искусственный интеллект всегда имела два аспекта, — считает бывший исследователь Google DeepMind Иоаннис Антоноглу (Ioannis Antonoglou). — Первый — у кого больше вычислительных мощностей. А второй — кто сможет использовать их лучше». Google DeepMind будет обучать ИИ в космической песочнице EVE Online
07.05.2026 [13:32],
Владимир Мироненко
Google DeepMind, исследовательская лаборатория в области искусственного интеллекта (входит в холдинг Alphabet), приобрела миноритарную долю в разработчике популярного научно-фантастического симулятора EVE Online, планируя использовать игру для изучения «искусственного интеллекта в сложных, динамичных, управляемых игроками системах». 
Источник изображения: eveonline.com Как сообщает Ars Technica, соглашение о партнёрстве в области исследований было заключено после того, как разработчик EVE Online, компания CCP Games выкупила свою долю у бывших владельцев из южнокорейского издательства Pearl Abyss (Crimson Desert), чтобы далее работать в качестве независимой компании под новым брендом Fenris Creations. DeepMind и Fenris Creations указали в совместном заявлении, что EVE Online представляет собой «уникально богатую среду для исследований», особенно, когда речь идёт о разработке систем ИИ, использующих «долгосрочное планирование, память и непрерывное обучение». DeepMind сообщила, что проведёт контролируемые эксперименты со своими моделями в специально разработанной офлайн-версии игры, работающей на локальном сервере, без прямого влияния на игровой процесс для онлайн-игроков. Обе компании «также изучат новые игровые возможности, которые станут доступны благодаря этим технологиям». Google DeepMind и ранее использовала игры для проверки моделей машинного обучения, такие, как Го, Atari VCS и StarCraft. В последнее время компания использует модели «виртуального мира» для обучения ИИ-систем работе в физической реальности. По словам гендиректора Fenris, изучение EVE позволит моделям Google DeepMind исследовать «сложные проблемы, длительные временные рамки и новые возможности». Google может столкнуться с забастовками ИИ-разработчиков из-за контрактов с военными
05.05.2026 [16:27],
Анжелла Марина
Сотрудники штаб-квартиры Google DeepMind в Лондоне проголосовали за создание профсоюза с целью предотвращения использования технологий компании военными структурами США и Израиля. В обращении к руководству работники поставили вопрос об официальном признании представителей профсоюзов Communication Workers Union (CWU) и Unite the Union, получив подавляющую поддержку внутри коллектива. 
Источник изображения: AI Инициативу поддержали 98 % членов CWU, работающих в DeepMind. В случае успеха создание профсоюза обеспечит представительство интересов как минимум 1000 сотрудников лондонской штаб-квартиры. Как стало известно The Verge, у руководства Google есть 10 рабочих дней на добровольное признание нового органа, прежде чем будут запущены официальные юридические процедуры для принудительного признания. В своём заявлении сотрудники выразили нежелание быть причастными к нарушениям международного права, отметив, что технологии ИИ уже используются в ходе военных действий Израиля. По их словам, даже применение разработок в административных целях делает эти операции более дешёвыми, быстрыми и эффективными, что должно быть немедленно прекращено. Помимо этого, профсоюз выдвинул конкретные требования, включая отказ от разработки оружия, технологий слежки и контрактов, наносящих вред людям. Работники также добиваются права отказа от проектов, нарушающих их личные моральные или этические устои. В рамках широкой кампании против военных контрактов сотрудники DeepMind по всему миру рассматривают возможность проведения очных протестов и забастовок. В случае таких акций они планируют приостановить работу над улучшением сервисов Google AI, включая ассистента Gemini. Как отмечает The Verge, это решение назревало на фоне растущего недовольства внутри компании, например, неделей ранее сотни сотрудников подписали открытое письмо генеральному директору Сундару Пичаю (Sundar Pichai) с требованием отказаться от секретных контрактов с Пентагоном. Однако вскоре после этого Google, наряду с OpenAI и Nvidia, заключила соглашения, позволяющие Министерству обороны США использовать их ИИ-модели для «любых законных государственных целей». Национальный представитель CWU по технологическим работникам Джон Чадфилд (John Chadfield) назвал текущий момент важным шагом, позволяющим техническим специалистам объединиться на основе солидарности и потребовать от работодателя прекратить участие в военно-промышленных контрактах. При этом стоит отметить, что в 2024 году компания уже уволила более 50 сотрудников в ответ на протесты против военного сотрудничества Google с правительством Израиля. ИИ-модели Google Gemini найдут физическое воплощение в роботах Agile Robots
25.03.2026 [13:17],
Павел Котов
Компания Google заключила партнёрское соглашение с немецкой компанией Agile Robots — поисковый гигант решил сделать ставку на робототехнику как ключевой инструмент развития по направлению искусственного интеллекта. 
Источник изображения: agile-robots.com Agile Robots специализируется на разработке интеллектуальных роботизированных манипуляторов и оснащённых сенсорами человекоподобных роботов. В рамках сотрудничества в оборудование немецкой компании будут интегрироваться ИИ-модели Google Gemini Robotics. «Партнёрство основывается на убеждении, что применение ИИ в физическом мире должно трансформироваться. Объединив оборудование Agile Robots и другие разрабатываемые в Германии решения в области робототехники с базовыми моделями Google DeepMind Gemini Robotics, обе стороны добьются успеха за счёт развёртывания роботов, сбора данных, обучения моделей и поэтапного совершенствования», — говорится в блоге компании. Google будет получать данные о работе своих продуктов в реальном мире — для технологического гиганта робототехника выступает одним из важнейших сценариев применения ИИ, где она конкурирует с Amazon и Tesla. У компании множество партнёрских соглашений по этому направлению. Мюнхенская Agile Robots к настоящему моменту развернула более 20 000 роботизированных систем по всему миру; решения Google она намеревается масштабно интегрировать в уже действующие системы. На начальном этапе это будут «высокоценные промышленные» сценарии, в том числе в производстве. Компания поможет Google и далее разрабатывать «более совершенные модели ИИ для роботов нового поколения». В прошлом году Google выпустила базовую и рассуждающую ИИ-модели Gemini Robotics и объявила о сотрудничестве с техасской Apptronik; в этом году стало известно, что подразделение Google DeepMind будет сотрудничать с Boston Dynamics в работе над роботом Atlas. Под управление Google была переведена входившая в холдинг Alphabet компания Intrinsic, которой прочат судьбу «Android в робототехнике»; в DeepMind также приняли на работу бывшего технического директора Boston Dynamics Аарона Сондерса (Aaron Saunders). Впрочем, некоторые сотрудники Google не вполне довольны сотрудничеством поискового гиганта с Boston Dynamics — у компании есть действующие контракты с Министерством обороны США. Глава Google DeepMind: автономный ИИ может выйти из-под контроля — нужно глобальное регулирование
19.02.2026 [19:36],
Сергей Сурабекянц
Генеральный директор и соучредитель лаборатории Google DeepMind Демис Хассабис (Demis Hassabis) заявил, что широкомасштабное развёртывание систем искусственного интеллекта несёт с собой серьёзные риски, требующие срочного внимания и международного сотрудничества для их устранения. Он полагает, что существующие институты могут не справиться с управлением будущими разработками в области ИИ. 
Источник изображения: Google DeepMind Хассабис выделил две основные категории рисков, связанных с технологиями ИИ: злоумышленники, использующие полезные технологии во вредных целях, и технические риски, присущие всё более автономным системам. «По мере того, как системы становятся все более автономными, все более независимыми, они будут становиться все более полезными, все более похожими на агентов, но они также будут иметь больший потенциал для рисков и совершения действий, которые, возможно, не были предусмотрены при их проектировании», — заявил он в интервью Bloomberg Television. Хассабис также выразил обеспокоенность тем, что существующие институты могут оказаться недостаточно подготовленными для управления будущими разработками в области ИИ. Он отметил глобальный охват технологии, добавив, что «она цифровая, а значит, вероятно, затронет каждого в мире и пересечёт границы». На саммите по искусственному интеллекту в Индии Хассабис подчеркнул важность международных мероприятий, как важнейших площадок для объединения лиц, принимающих решения, с технологами. «Необходимо наличие элементов международного сотрудничества, или, по крайней мере, минимальных стандартов в отношении того, как следует внедрять эти технологии», — уверен он. В Google DeepMind удивились спешке OpenAI с внедрением рекламы в ChatGPT
23.01.2026 [12:15],
Владимир Мироненко
Гендиректор Google DeepMind Демис Хассабис (Demis Hassabis) выразил удивление поспешностью OpenAI после появления сообщений о том, что она уже перешла к внедрению рекламы в свой ИИ-чат-бот для получения дополнительного дохода от пользователей ChatGPT, у которых нет платной подписки. По его мнению, это решение может изменить восприятие сервиса пользователями. 
Источник изображения: Growtika/unsplash.com «Я немного удивлён, что они так рано перешли к этому», — сказал Хассабис в интервью Axios в Давосе, вместе с тем отметив, что в рекламе нет ничего плохого, и она может быть полезной для финансирования, если «сделана хорошо». В ответ на вопрос репортёра об использовании рекламы для монетизации услуг ИИ, он заявил, что команда Google очень тщательно обдумывала эту идею. Хассабис также сказал, что его команда не чувствует давления со стороны руководства технологического гиганта, чтобы принять «поспешное» решение относительно рекламы, несмотря на важность рекламы в структуре доходов основного бизнеса Google. Хотя OpenAI, по всей видимости, вынуждена рассмотреть возможность размещения рекламы с учётом растущих затрат, это решение может изменить восприятие сервиса пользователями. В настоящее время число еженедельно активных пользователей ИИ-чат-бота составляет около 800 млн. «При использовании голосовых помощников, если вы рассматриваете чат-ботов как помощников, которые должны быть полезными, а также технологий, которые работают на вас как на отдельного человека, возникает вопрос о том, как реклама вписывается в эту модель? Вы хотите доверять своему помощнику. Так как же это работает?» — задался Хассабис вопросом. Он заметил, что что у Google нет «никаких текущих планов» по размещению рекламы в своем чат-боте с искусственным интеллектом. Вместо этого компания планирует отслеживать ситуацию, чтобы видеть реакцию пользователей. Сама идея проникновения рекламы в разговоры людей с ИИ-помощниками вызывает у них негативную реакцию. Например, когда OpenAI в прошлом месяце начала изучать функцию, предлагающую приложения для тестирования во время чатов пользователей, они отреагировали негативно, поскольку эти предложения кажутся навязчивой рекламой. После этого OpenAI отключила функцию, заявив, что предложения на самом деле не являются рекламой, поскольку «не имеют финансовой составляющей». Но речь не о платежах за рекламу. Скорее, дело в том, как предложения приложений ухудшали качество взаимодействия пользователей с чат-ботом. По словам Хассабиса, использование чат-бота — это совсем другой опыт, чем использование поиска Google. Чат-боты призваны стать полезными цифровыми помощниками, которые знают о вас и могут помочь во многих аспектах жизни, сказал он. Навязывание рекламы пользователю во время общения с ИИ-помощником может вызывать отторжение. Именно поэтому клиенты негативно отнеслись к попыткам Amazon внедрить рекламу в Alexa — им нужен помощник, а не персональный покупатель, предлагающий товары. Глава Google DeepMind оценил отставание китайских ИИ-моделей в шесть месяцев
21.01.2026 [07:36],
Алексей Разин
Генеральный директор DeepMind Демис Хассабис (Demis Hassabis) на прошлой неделе уже заявлял, что отставание китайских ИИ-моделей от западных за последние пару лет заметно сократилось, но оно всё же измеряется несколькими месяцами. В интервью Bloomberg на форуме в Давосе он предпочёл определить этот разрыв величиной в шесть месяцев. 
Источник изображения: Isomorphic Labs Как отметил Демис Хассабис, китайские разработчики неплохо себя проявили в преследовании лидеров отрасли, но им лишь представить доказать, что они способны опередить их и преодолеть соответствующий барьер на уровне инноваций. Прошлогоднюю модель китайской DeepSeek глава DeepMind до сих пор называет «впечатляющей». Любопытно, что не все ведущие западные игроки ИИ-сегмента положительно оценивают решение властей США открыть поставки ускорителей Nvidia H200 в Китай. По мнению главы Anthropic Дарио Амодеи (Dario Amodei), поставки таких ускорителей в Китай схожи с продажей ядерного оружия в Северную Корею. DeepMind в составе Google работает не только над совершенствованием ИИ-ассистента на базе Gemini, но и интересуется направлением робототехники, которая всё чаще ассоциируется у участников рынка со следующим по важности воплощением искусственного интеллекта. По мнению Хассабиса, в сфере «физического ИИ» в скором времени должны произойти прорывные изменения. При этом перед разработчиками стоят сложные проблемы. «Очень сложно добиться надёжности, силы и подвижности человеческой кисти», — признаётся глава DeepMind. «Одно из важнейших направлений в науке»: Google DeepMind откроет ИИ-лабораторию в Великобритании по поиску новых материалов
11.12.2025 [13:30],
Владимир Фетисов
Google DeepMind откроет свою первую исследовательскую лабораторию для создания новых материалов, таких как те, что используются в аккумуляторных батареях и полупроводниковой отрасли. Этот объект начнёт функционировать в Великобритании в следующем году и станет частью стремления компании по расширению применения искусственного интеллекта в научной среде. Проект реализуется в рамках масштабного партнёрства Alphabet, материнской компании Google, и британского правительства. 
Источник изображения: Alex Dudar / unsplash.com Google DeepMind планирует адаптировать несколько своих ИИ-моделей, включая Gemini, для повышения эффективности выполнения задач учёных, преподавателей и госслужащих Великобритании. Лондонское исследовательское подразделение DeepMind описывает новую лабораторию как свой первый «автоматизированный» объект, где для проведения экспериментов будут задействованы роботы, что сводит к минимуму вмешательство со стороны человека. Компания не раскрыла стоимость реализации этого проекта, а также не уточнила, сколько человек будет работать в ИИ-лаборатории. Расширение сотрудничества с Великобританией является успехом для Google, которая стремится вовлекать правительства разных стран в использование своих облачных сервисов и ИИ-модели Gemini. Это также свидетельствует о планах DeepMind продвинуться дальше в материаловедение, одно из основных исследовательских направлений. Несколько стартапов, часть из которых основана бывшими инженерами DeepMind, пытаются задействовать ИИ-алгоритмы для открытия новых материалов, утверждая, что такой подход может существенно сократить время и затраты на исследования. В новой лаборатории DeepMind будут исследоваться материалы, потенциально пригодные для использования в разных сферах, включая производство полупроводниковой продукции и солнечных панелей. В дополнение к этому компания предоставит британским ученым «приоритетный доступ» к четырём своим научным ИИ-моделям, включая алгоритмы для анализа ДНК и прогнозирования погоды. «Открытие новых материалов — одно из важнейших направлений в науке», — написал недавно в блоге глава DeepMind Демис Хассабис (Demis Hassabis). В отдельном заявлении правительства Великобритании сказано, что американская компания внесёт вклад в исследования в таких областях, как термоядерная энергетика, а также разработает инструменты на базе Gemini для британских учёных. В заявлении DeepMind упоминается, что компания откроет доступ к своим ИИ-моделям и данным для сотрудников Института безопасности искусственного интеллекта Великобритании, который представляет собой государственное агентство, созданное в 2023 году для тестирования и оценки ИИ-систем. Google представила геймерского ИИ-агента SIMA 2 — он умеет проходить незнакомые игры
13.11.2025 [21:25],
Анжелла Марина
Разработчики исследовательского подразделения Google DeepMind создали новую версию ИИ-агента SIMA 2 для игр. Этот инструмент способен не просто следовать командам, а понимать цели игрока и самостоятельно выполнять сложные действия в видеоиграх. В отличие от первой версии, запущенной в марте 2024 года, SIMA 2 использует языковую модель Gemini, что позволяет ему рассуждать и принимать решения даже в тех играх, которые он никогда раньше не видел, например, No Man’s Sky, Valheim и Goat Simulator 3. 
Источник изображения: Google DeepMind Пока система доступна лишь ограниченному числу исследователей и разработчиков в рамках закрытого тестирования. При этом в DeepMind подчёркивают, что главная цель проекта состоит не в создании игрового помощника для массового пользователя, а в отработке технологий, которые в будущем могут применяться вне виртуального мира. Джейн Ванг (Jane Wang), старший научный сотрудник DeepMind, назвала видеоигры «идеальной площадкой для обучения ИИ навыкам, полезным в реальной жизни». Команда DeepMind рассматривает проект SIMA 2 как важный шаг на пути к созданию искусственного общего интеллекта (AGI). В компании считают, что способность ИИ действовать в незнакомой среде и выполнять сложные цели лежит в основе будущих систем, включая роботов общего назначения, и именно эта способность адаптироваться к новым условиям может привести к развитию действительно универсального ИИ. Google представила ИИ-агента CodeMender — он самостоятельно устраняет уязвимости ПО
06.10.2025 [21:02],
Анжелла Марина
Лаборатория Google DeepMind опубликовала результаты работы агента на базе искусственного интеллекта CodeMender. Агент может в автономном режиме выявлять, исправлять и переписывать уязвимый код для предотвращения будущих эксплойтов в программном обеспечении. 
Источник изображения: Google Как пишет издание SiliconANGLE, CodeMender развивает предыдущие проекты DeepMind по поиску уязвимостей, в частности проект OSS-Fuzz для анализа безопасности открытого ПО и систему Big Sleep, сочетая интеллектуальные возможности моделей Gemini с передовыми методами программного анализа. Основной целью проекта является автономная отладка и исправление сложных ошибок в крупномасштабных кодовых базах. Несмотря на то что проект находится на стадии исследований, CodeMender уже отправил 72 исправления безопасности в проекты с открытым исходным кодом, включая те, объём которых превышает 4,5 миллиона строк кода. По данным компании, ИИ-агент позволяет разработчикам сосредоточиться на создании качественного программного обеспечения, автоматически генерируя и применяя надёжные патчи безопасности. Система спроектирована как для реактивной, так и для проактивной работы: она не только мгновенно исправляет обнаруженные уязвимости, но и переписывает существующий код, устраняя целые классы ошибок. В качестве примера исследователи DeepMind приводят работу агента с библиотекой сжатия изображений libwebp, которая была использована в атаке на iOS в 2023 году. Агент применил к ней аннотации -fbounds-safety, после чего, по заявлению исследователей, подобные уязвимости переполнения буфера стали «невозможными для эксплуатации навсегда». Внутренняя архитектура CodeMender включает набор инструментов: статический и динамический анализ, фаззинг, символьное исполнение и так называемого «судью LLM», который проверяет, сохраняют ли предлагаемые изменения исходную функциональность. Система способна к самокоррекции, если в процессе проверки обнаруживается проблема. Все изменения перед отправкой проходят проверку на корректность, соответствие стилевым стандартам и отсутствие регрессий. При этом в DeepMind подчёркивают, что CodeMender пока остаётся исследовательским проектом, и все патчи, сгенерированные им, проходят проверку исследователями-людьми перед отправкой в проекты. После запуска инструмент будет предлагать иной подход по сравнению с традиционными методами, такими как статический анализ и фаззинг, которые находят уязвимости, но всё ещё сильно зависят от опыта проверяющего человека. Новый подход изменит систему, в которой искусственный интеллект сможет самостоятельно выявлять и устранять ошибки, что является критически важным шагом по мере экспоненциального роста размера и сложности современных кодовых баз. Разработчики сосредоточились на ИИ-моделях мира для создания сверхразума
29.09.2025 [13:10],
Владимир Мироненко
Ведущие разработчики ИИ, такие как Google DeepMind, Meta✴✴ и Nvidia, уделяют всё больше внимания так называемым моделям мира, которые могут лучше понимать окружающую среду, в стремлении создать машинный «сверхразум», пишет The Financial Times. 
Источник изображения: julien Tromeur/unsplash.com Модель мира имитирует причинно-следственные связи и законы физики посредством симуляций, основанных на обучении, для которого требуется огромный объём данных из реальных или моделируемых сред и большие вычислительные мощности. Они рассматриваются как важный шаг в развитии беспилотных автомобилей, робототехники и так называемых ИИ-агентов. «ИИ по-прежнему ограничен цифровой сферой, — говорит Шломи Фрухтер (Shlomi Fruchter), соруководитель Genie 3 в Google DeepMind. — Создавая среды, которые выглядят или ведут себя как реальный мир, мы получаем гораздо более масштабируемые способы обучения ИИ без реальных последствий совершения ошибок в реальном мире». Янн Лекун (Yann LeCun), возглавляющий исследовательскую лабораторию Meta✴✴ AI (прежнее название — Facebook✴✴ Artificial Intelligence Research, FAIR), заявил, что большие языковые модели (LLM) никогда не достигнут способности рассуждать и планировать как люди. Одной из ближайших областей применения моделей мира станет индустрия развлечений, где они позволяют создавать интерактивные и реалистичные сцены. Например, стартап World Labs разрабатывает модель, которая генерирует трёхмерные среды, похожие на видеоигры, из одного изображения. Runway, стартап по созданию видео, в числе партнёров которого голливудские студии, включая Lionsgate, в прошлом месяце выпустил продукт, использующий модели мира для создания игровых сред с персонализированными историями и персонажами, генерируемыми в реальном времени. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что следующим крупным этапом роста компании станет «физический ИИ», так как новые модели позволят добиться прорыва в области робототехники. По мнению Лекуна, реализация концепции по созданию ИИ-систем, обеспечивающих машины интеллектом человеческого уровня, может занять 10 лет. Вместе с тем эксперты указывают на большой потенциал новых ИИ-технологий. «Модели мира открывают возможность обслуживания всех отраслей и усиливают тот же эффект, который компьютеры сделали для интеллектуального труда», — заявил Рев Лебаредян (Rev Lebaredian), вице-президент Nvidia по технологиям моделирования. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



