|
Опрос
|
реклама
Быстрый переход
Ежемесячная аудитория WhatsApp превысила 3 миллиарда пользователей
01.05.2025 [16:52],
Павел Котов
Хотя бы раз в месяц WhatsApp открывают более 3 млрд человек, рассказал гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) в ходе брифинга после публикации квартального финансового отчёта. 
Источник изображения: Dima Solomin / unsplash.com Мессенджер WhatsApp, появившийся в 2009 году и поглощённый компанией Facebook✴✴ (теперь Meta✴✴) в 2014 году за $19 млрд, остаётся бесплатным и не показывает пользователям рекламу. Рубеж в 2 млрд ежемесячно активных пользователей служба мгновенных сообщений преодолела ещё в 2020 году; теперь это одно из немногих приложений, помимо Facebook✴✴, которому покорилась отметка и в 3 млрд. Колоссальная база пользователей делает WhatsApp ключевым проектом для Meta✴✴, особенно сейчас, когда компания поставила всё на свою стратегию в области искусственного интеллекта. «Мы видим, что люди подключаются к Meta✴✴ AI через разные точки входа. WhatsApp продолжает демонстрировать самое активное использование Meta✴✴ AI», — рассказала финансовый директор Meta✴✴ Сьюзан Ли (Susan Li). Большинство пользователей WhatsApp обращается к Meta✴✴ AI в личных чатах, добавила она. Хотя WhatsApp и обеспечивает лёгкий доступ к функциям ИИ, компании пришлось изменить подход, чтобы стимулировать внедрение своих продуктов с ИИ на таких рынках как США, где большинство пользователей использует мессенджеры по прямому назначению — для общения, рассказал Цукерберг. Поэтому пришлось выпустить отдельное приложение Meta✴✴ AI. Активно развивается платформа WhatsApp Business — она составила значительную часть дохода в $510 млн от сегмента семейства приложений. Сейчас инструменты ИИ тестируются и для WhatsApp Business: компания разрабатывает новый интерфейс управления агентами ИИ и панель инструментов, который даст стороннему бизнесу возможность обучать ИИ-модели Meta✴✴ на своей информации. Тестируется также запуск чат-ботов с ИИ в чатах с клиентами таких компаний. Цукерберг похвастался, что месячная аудитория Threads превысила 350 млн — до X ещё далеко
01.05.2025 [14:38],
Владимир Мироненко
Аудитория платформы микроблогов Threads компании Meta✴✴ продолжает стремительно расти. Как сообщил в среду генеральный директор Марк Цукерберг (Mark Zuckerberg) в ходе отчёта о финансовых результатах компании за первый квартал 2025 года, у Threads более 350 млн активных пользователей в месяц — на 30 млн больше, чем в предыдущем квартале. 
Источник изображения: Wesley Tingey/unsplash.com Новые данные свидетельствуют об ускорении темпов роста Threads: в прошлом квартале платформа увеличила месячную аудиторию на 20 млн человек. Также стоит отметить, что всего за месяц Threads привлекла почти столько же новых пользователей, сколько в целом составляет текущая аудитория её конкурента — Bluesky. Согласно последним данным, у децентрализованного социального приложения Bluesky насчитывается около 35 млн пользователей. Между тем генеральный директор X Линда Яккарино (Linda Yaccarino) сообщила в среду, что у соцсети сейчас порядка 600 млн активных пользователей в месяц, что представляет собой незначительный рост по сравнению с январём 2025 года, когда X насчитывала около 586 млн пользователей. Хотя аудитория Threads пока значительно меньше, чем у других социальных приложений Meta✴✴ — Facebook✴✴, Instagram✴✴, Messenger и WhatsApp, её рост способствует укреплению позиции платформы в экосистеме сервисов для микроблогов. Meta✴✴ сообщила, что в общей сложности более 3,4 млрд человек ежедневно используют как минимум одно из её приложений. Цукерберг сообщил инвесторам, что рост Threads указывает на то, что платформа станет следующим крупным социальным приложением компании. В приложении Meta✴ AI появится платная подписка — Meta✴ хочет заработать $1,4 триллиона на ИИ к 2035 году
01.05.2025 [14:14],
Павел Котов
Приложение Meta✴✴ AI вскоре может получить платный тарифный план — аналогичные варианты есть у OpenAI, Google и Microsoft. Компания готова предложить «премиальный сервис для тех, кому нужны дополнительные вычислительные ресурсы или функции», заявил гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) в ходе брифинга по итогам квартального отчёта. А к 2035 году компания рассчитывает заработать на искусственном интеллекте до $1,4 трлн. 
Источник изображения: Jonas Leupe / unsplash.com В стремлении составить конкуренцию OpenAI компания на этой неделе запустила мобильное приложение Meta✴✴ AI, в котором можно переписываться с чат-ботом и генерировать изображения. Чат-бот, размер аудитории которого, по словам Meta✴✴, составляет уже почти 1 млрд пользователей, ранее был доступен только в приложениях Facebook✴✴, Facebook✴✴ Messenger и WhatsApp. В приложениях OpenAI ChatGPT, Google Gemini и Microsoft Copilot доступна платная подписка, предоставляющая доступ к более мощным вычислительным ресурсам и дополнительным функциям. Марк Цукерберг предупредил, что в Meta✴✴ AI появятся «рекомендации продуктов или реклама», — однако сроки как их появления, так и запуска платной подписки пока неизвестны. В прошлом году компания составила прогноз, согласно которому в 2025 году её продукты в области генеративного ИИ принесут выручку в размере $2–3 млрд, а к 2035 году этот показатель достигнет $460 млрд — $1,4 трлн. Эти сведения были преданы огласке в рамках судебного процесса, в ходе которого книгоиздатели обвинили Meta✴✴ в незаконном обучении ИИ на материалах, защищённых авторским правом. В 2024 году бюджет Meta✴✴ на направление генеративного ИИ составил $900 млн; в текущем году он может превысить $1 млрд. Эти показатели не включают расходы на инфраструктуру: в 2025 году они составят от $60 млрд до $80 млрд — в первую очередь на строительство центров обработки данных. В 2023 году в компании обсуждались расходы в размере $200 млн на покупку обучающих данных для ИИ-моделей Llama, причём около $100 млн должны были пойти только на закупку текстов книг. Ненастная метавселенная: Meta✴ отчиталась об $4,2 млрд убытков в Reality Labs за первый квартал
01.05.2025 [13:15],
Дмитрий Федоров
Meta✴✴ продолжает ежеквартально вливать миллиарды долларов в метавселенную. Финансовый разрыв между затратами и доходами поражает воображение. В отчёте за первый квартал 2025 года компания сообщила, что подразделение Reality Labs зафиксировало операционный убыток в размере $4,2 млрд при выручке всего $412 млн. Аналитики прогнозировали убыток в $4,6 млрд при выручке $492,7 млн. 
Источник изображения: Meta✴✴ Подразделение Reality Labs отвечает за разработку фирменных гарнитур виртуальной реальности Meta✴✴ Quest и умных очков Ray-Ban Meta✴✴. Именно это бизнес-направление является ключевым для реализации планов генерального директора Марка Цукерберга (Mark Zuckerberg) по созданию новой платформы с цифровыми мирами, доступными через устройства виртуальной (VR) и дополненной реальности (AR). С конца 2020 года совокупные убытки Reality Labs превысили впечатляющую отметку в $60 млрд, включая $3,85 млрд в I квартале прошлого года. Напомним, что в конце 2021 года Цукерберг переименовал свою компанию с Facebook✴✴ на Meta✴✴, подчеркнув стратегический вектор развития. 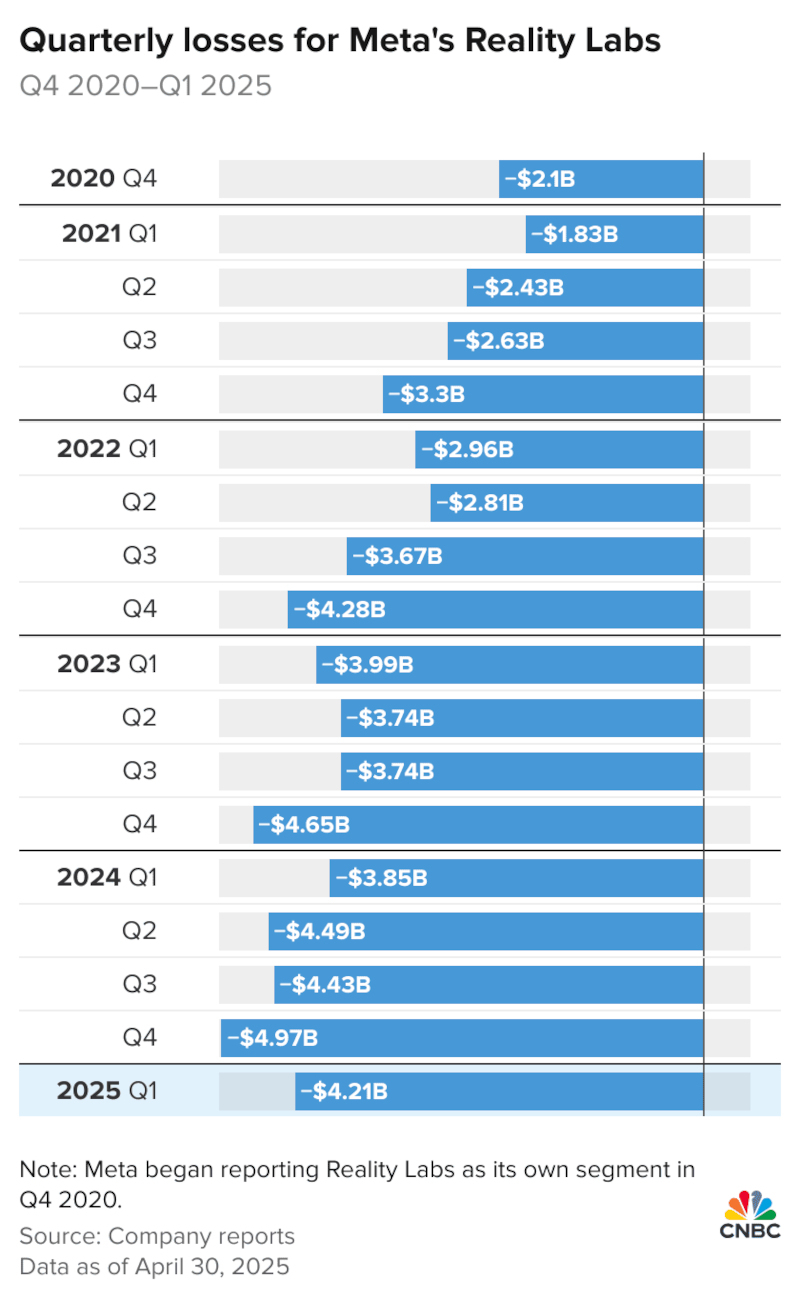
Источник изображения: CNBC Уолл-стрит неоднократно выражала сомнения относительно масштабных инвестиций Meta✴✴ в метавселенную. Сам Цукерберг признавал, что для превращения этого направления в реальный бизнес могут потребоваться долгие годы. Теперь компания столкнулась с новыми вызовами — всеобъемлющими тарифами, введёнными 47-м президентом США Дональдом Трампом (Donald Trump), и неизбежным ростом издержек, что потенциально приведёт к удорожанию устройств. На прошлой неделе Meta✴✴ объявила о сокращении ряда сотрудников Reality Labs. Эти работники входили в подразделение Oculus Studios, создающее игры и контент для VR и AR на базе гарнитур Meta✴✴ Quest. «В некоторых командах Oculus Studios происходят изменения в структуре и ролях, которые влияют на численность команды. Эти изменения призваны помочь студии более эффективно работать над будущим опытом смешанной реальности для нашей растущей аудитории, продолжая при этом предоставлять отличный контент для людей сегодня», — прокомментировал представитель Meta✴✴. Meta✴ отчиталась о росте рекламных доходов, аудитории, выручки и прибыли — акции подскочили на 4 %
01.05.2025 [11:04],
Дмитрий Федоров
Meta✴✴ отчиталась о выручке в $42 млрд в первом квартале 2025 года и прогнозирует сохранение стабильного роста в ближайшие месяцы, развеяв опасения, что тарифы Дональда Трампа (Donald Trump) негативно повлияют на её международный бизнес цифровой рекламы. Рост выручки технологического гиганта составил 16 %, превысив прогнозы аналитиков, а чистая прибыль за период с января по март достигла $16,6 млрд. Всё это привело к росту акций Meta✴✴ более чем на 4 %. 
Источник изображения: Muhammad Asyfaul / Unsplash Ранее акции Meta✴✴ оказались среди наиболее пострадавших с момента первого анонса тарифных планов 47-го президента США. Цифровая реклама составляет основную часть бизнеса корпорации, причём в последние годы компания стала более зависимой от китайских рекламодателей, стремящихся охватить американских потребителей. Уверенные финансовые результаты I квартала продемонстрировали устойчивость бизнес-модели Meta✴✴ даже в условиях торговой напряжённости между США и Китаем. Трамп уже пересмотрел некоторые взаимные тарифы в отношении других стран и выразил готовность вести переговоры с Китаем для снижения пошлин, которые достигли 145 %. Несмотря на это, аналитики отмечают первые признаки сокращения рекламных расходов. Акции Snap обвалились во вторник после того, как материнская компания Snapchat заявила о трудностях в текущем квартале и отказалась предоставить прогноз выручки, сославшись на волатильность рынка. Meta✴✴ необходимы рекламные доходы для финансирования плана капитальных затрат в размере до $65 млрд, направленного на развитие ИИ. Компания стремится занять лидирующую позицию в области ИИ со своим чат-ботом Meta✴✴ AI и ИИ-моделями с открытым исходным кодом Llama. Инвестиции в ИИ-инфраструктуру являются стратегическим приоритетом для долгосрочного роста корпорации. Во вторник Meta✴✴ провела свою дебютную конференцию по ИИ для разработчиков. Компания представила отдельное приложение для своего ИИ-ассистента, который должен привлечь 1 млрд пользователей до конца года, и анонсировала новые инструменты для разработчиков. Значимым событием конференции стало интервью, которое генеральный директор Марк Цукерберг (Mark Zuckerberg) взял у главы Microsoft Сатьи Наделлы (Satya Nadella) на сцене мероприятия. Параллельно Meta✴✴ ведёт антимонопольную судебную тяжбу, недавно начавшуюся в Вашингтоне. Юристы Федеральной торговой комиссии США (FTC) утверждают, что компания обладает незаконной монополией в сфере социальных сетей и требуют принудительно отделить от компании Instagram✴✴ и WhatsApp. Цукерберг в первые дни судебного процесса доказывал, что Meta✴✴ не имеет такой монополии и помогла Instagram✴✴ и WhatsApp стать более успешными приложениями, чем они могли бы быть её помощи. Meta✴✴ отметила в свежем отчёте, что ежедневная аудитория её сервисов достигла 3,43 млрд пользователей — рост на 6 % по сравнению с первым кварталом 2024 года. До начала судебного процесса, Цукерберг пытался обратиться к Трампу с просьбой заключения мирового соглашения. Сделка так и не была заключена. Этот судебный процесс может иметь серьёзные последствия для структуры бизнеса Meta✴✴, если суд поддержит требования FTC об отмене её ключевых приобретений. Meta✴ разрешила своим умным очкам постоянно «смотреть» и «слушать» — отказаться от этого непросто
30.04.2025 [18:20],
Павел Котов
Meta✴✴ внесла несколько изменений в политику конфиденциальности умных очков Ray-Ban Meta✴✴, два из которых являются наиболее значимыми. Об этом говорится в письме, направленном компанией владельцам устройств. Умные очки будут чаще визуально исследовать окружающий пользователя мир и записывать его речь — собранные таким образом данные будут использоваться для обучения искусственного интеллекта. 
Источник изображения: ray-ban.com «[Функция] Meta✴✴ AI с подключённой камерой всегда активна в очках, если не отключить режим "Hey Meta✴✴"», — говорится в письме, где подразумевается функция быстрого запуска голосовых команд. Если не отключить эту удобную опцию, сервисы Meta✴✴ будут регулярно анализировать всё, что снимает встроенная в очки камера; если же её отключить, устройство будет выполнять функции обычной камеры без ИИ, а управлять им придётся исключительно с помощью физических элементов. Кроме того, владельцы Ray-Ban Meta✴✴ больше не смогут отказаться от хранения записей своего голоса в облаке. «Возможность отключить хранение голосовых записей больше недоступна, но вы можете удалить записи в любое время в настройках. <...> В противном случае голосовые расшифровки и аудиозаписи хранятся до одного года для улучшения продуктов Meta✴✴», — проинформировала компания. Если будет установлено, что голосовая команда была отдана случайно, соответствующая запись удаляется через 90 дней. Мотивация этих изменений очевидна: Meta✴✴ стремится обеспечить свои проекты большим объёмом данных для обучения ИИ. Некоторые пользователи сообщали об изменениях в политике конфиденциальности ещё в марте, но в Meta✴✴ заверили, что, по крайней мере в США, они вступили в силу с 29 апреля. Уже 30 % программного кода Microsoft написано искусственным интеллектом, а не людьми
30.04.2025 [11:55],
Владимир Фетисов
От 20 % до 30 % программного кода в репозиториях компании Microsoft «написано программным обеспечением», т.е. искусственным интеллектом. Об этом заявил гендиректор Microsoft Сатья Наделла (Satya Nadella) во время беседы с главой Meta✴✴ Platforms Марком Цукербергом (Mark Zuckerberg) на прошедшей на этой неделе конференции LlamaCon. 
Источник изображения: TechCrunch Наделла назвал указанные цифры в ответ на вопрос Цукерберга о том, какой объём программного кода компании в настоящее время создаётся с помощью искусственного интеллекта. Глава Microsoft добавил, что генеративные нейросети показывают разные результаты при написании кода в зависимости от языка программирования. Наибольших успехов такие алгоритмы добились при работе с Python, а менее эффективны — с C++. В ответ на аналогичный вопрос Наделлы, адресованный Цукербергу, глава Meta✴✴ отметил, что не располагает данными о том, какой объём программного кода в его компании создаётся ИИ. Технический директор Microsoft Кевин Скотт (Kevin Scott) ранее прогнозировал, что до 95 % программного кода будет генерироваться ИИ-алгоритмами уже к 2030 году. Не так давно генеральный директор Google Сундар Пичаи (Sundar Pichai) заявил, что ИИ генерирует более 30 % программного кода компании. Отметим, что озвученные цифры, вероятнее всего, являются весьма приблизительными, поскольку неясно, каким образом компании измеряют, что создаёт ИИ, а что — программисты. Meta✴ похвасталась, что число загрузок ИИ-моделей Llama перевалило за 1,2 млрд
29.04.2025 [22:21],
Николай Хижняк
В середине марта Meta✴✴ заявила, что количество загрузок открытых моделей искусственного интеллекта Llama достигло 1 млрд. На начало декабря прошлого года этот показатель составлял 650 млн, что соответствует росту более чем на 50 % за квартал. Во вторник на своей первой конференции разработчиков LlamaCon Meta✴✴ сообщила, что количество загрузок моделей Llama достигло 1,2 млрд. 
Источник изображения: Me «У нас есть тысячи разработчиков, которые создают десятки тысяч производных моделей, загружаемых сотни тысяч раз в месяц», — заявил директор по продуктам Meta✴✴ Крис Кокс (Chris Cox) во время основного доклада. Между тем количество пользователей Meta✴✴ AI — цифрового ИИ-помощника, работающего на моделях Llama, — составляет около миллиарда, добавил Кокс. 
Источник изображения: Alibaba Экосистема ИИ-моделей Llama от Meta✴✴ растёт стремительными темпами, но технологический гигант сталкивается с конкуренцией со стороны ряда серьёзных игроков в сфере ИИ. Так, буквально в понедельник китайская компания Alibaba представила Qwen3 — семейство флагманских ИИ-моделей, которое по ряду показателей является весьма конкурентоспособным. Meta✴ запустила самостоятельное ИИ-приложение для конкуренции с ChatGPT и другими ИИ-ботами
29.04.2025 [20:21],
Сергей Сурабекянц
После интеграции искусственного интеллекта Meta✴✴ в WhatsApp, Instagram✴✴, Facebook✴✴ и Messenger, сегодня компания представила на мероприятии LlamaCon отдельное приложение, похожее на софт других ИИ-чат-ботов. Meta✴✴ использовала своё главное конкурентное преимущество — профили большинства своих пользователей, созданные на основе данных, которые они на протяжении многих лет выкладывали в Facebook✴✴ или Instagram✴✴. 
Источник изображения: freepik.com Представитель Meta✴✴ заявил, что новый ИИ-помощник компании отличается от подобных приложений тем, что может «[использовать] информацию, которой вы уже решили поделиться в продуктах Meta✴✴». Пока что подобная персонализация будет доступна жителям США и Канады, а в дальнейшем может распространить своё действие на весь мир. Компания полагает, что в использовании ИИ-помощником персонализированной информации больше плюсов, чем минусов — пользователь может предоставить информацию о себе, которую ИИ запомнит и учтёт в дальнейшем. Например на основании данных о предпочтениях, фобиях или врождённых заболеваниях услужливый ИИ-ассистент спланирует свадьбу, отпуск, визит к врачу, посещение ресторана или похороны. Приложение ИИ Meta✴✴ также содержит ленту Discover, где пользователь при помощи ИИ может поделиться всеми интимными подробностями своего общения с ИИ — на макетном изображении от Meta✴✴ пользователь просит ИИ описать его тремя эмодзи, которые он затем отправит свои друзьям. Успокаивает то, что взаимодействие пользователя с ИИ публикуется в ленте только с его разрешения. 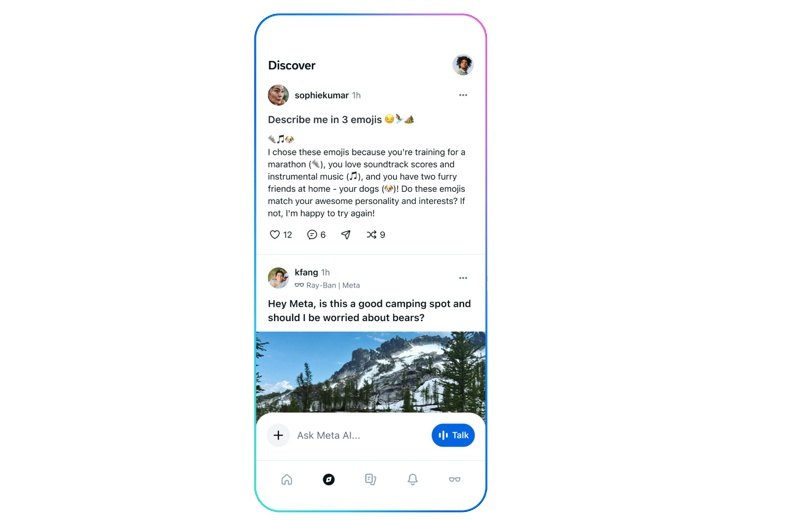
Источник изображения: techcrunch.com Использование ленты Discover может ещё сильнее спровоцировать массовые психозы вокруг генеративного ИИ, когда люди пытаются сделать себя похожими на кукол Барби или персонажей Ghibli. Социальная сеть Threads получила новое доменное имя и обновила веб-версию приложения
26.04.2025 [23:04],
Анжелла Марина
Социальная сеть Threads официально сменила домен с Threads.net на Threads.com. Одновременно с этим платформа получила ряд улучшений для веб-версии, включая удобный доступ к сохранённым постам, лайкам и новым инструментам для создателей контента. 
Источник изображения: Wesley Tingey / Unsplash Изначально Threads работал на threads.net, поскольку домен threads.com принадлежал стартапу, связанному с корпоративным мессенджером Slack. Однако в сентябре 2024 года Meta✴✴ приобрела этот адрес и начала перенаправлять пользователей с threads.com на threads.net. Но, как сообщает TechCrunch, с сегодняшнего дня при вводе в адресную строку имени threads.com будет открываться именно этот домен, а с threads.net наоборот будет происходить перенаправление. Это изменение, по мнению компании, сделает платформу более узнаваемой, что особенно важно в целях конкуренции с социальной сетью X, у которой короткий и запоминающийся домен. Тем более, что по данным Meta✴✴, Threads уже насчитывает более 320 млн активных пользователей в месяц, то есть больше, чем в Х (251 млн на конец 2024 года). Глава Instagram✴✴ Адам Моссери (Adam Mosseri) также анонсировал несколько обновлений для веб-версии приложения Threads. Теперь пользователи увидят свои кастомные ленты в том же порядке, что и в мобильном приложении. Кроме того, сохранённые и понравившиеся посты можно открывать через главное меню без необходимости создания отдельной колонки. Ещё одно нововведение позволяет копировать посты в виде изображений вместо того, чтобы создавать скриншоты. Это должно упростить перепубликацию постов в других соцсетях, например, в Instagram✴✴. Также в веб-версии появилась кнопка добавления новой колонки и быстрый доступ к созданию постов через значок «+» в углу экрана. Отдельная функция поможет пользователям найти на Threads авторов, на которых они были подписаны в X. Для этого нужно загрузить свой архив данных из X в Threads. Ранее это можно было сделать только путём поиска. По словам компании, пока функция находится в стадии тестирования. Meta✴ ограничит спамерам охват аудитории и монетизацию в Facebook✴
25.04.2025 [05:36],
Анжелла Марина
Компания Meta✴✴ объявила о новых мерах против спама и «накруток» в Facebook✴✴. Отныне аккаунты, злоупотребляющие длинными постами, бессмысленными хештегами и попыткой обмана алгоритма, будут ограничены в охвате аудитории, а их авторы лишены монетизации. 
Источник изображения: Shutter Speed / Unsplash Под ограничения также попадут аккаунты, которые создают посты с подписями, совершенно не связанными с изображением. Если аккаунты с таким типом постов будут платформой обнаружены, то их контент станет доступен только подписчикам. В качестве примера Meta✴✴ привела фотографию собаки с подписью «Топ-10 фактов о #САМОЛЕТАХ». Подобный контент, как пишет The Verge, расценивается алгоритмами как манипуляция и будет автоматически скрыт от широкой аудитории. 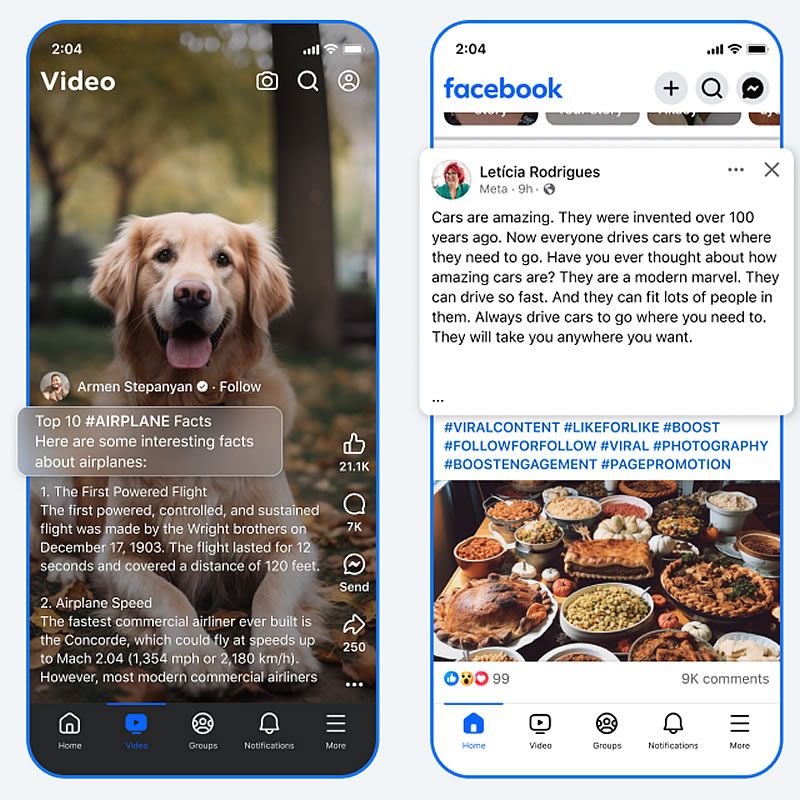
Источник изображения: Meta✴✴ «Спам мешает пользователям быть услышанными, независимо от их точки зрения. Поэтому мы будем отслеживать поведение, которое искусственно увеличивает охват и монетизацию», — заявили в Meta✴✴. Уточняется, что эти изменения появились спустя всего несколько недель после запуска ленты только для друзей (Friends-only feed), где алгоритмические рекомендации отсутствуют. Компания также начнёт ограничивать охват пользователей, которые создают «сотни аккаунтов для распространения одного и того же контента». Эти аккаунты больше не смогут зарабатывать на своих публикациях, так как, по данным Meta✴✴, большинство из них накручивают подписчиков и просмотры, чтобы получить нечестное преимущество в монетизации. Кроме того, будет снижена видимость комментариев с признаками скоординированной накрутки. Для этого соцсеть тестирует функцию, с помощью которой пользователи смогут отмечать бесполезные сообщения, а владельцы страниц получат инструмент для автоматического скрытия комментариев от фейковых профилей. Напомним, ранее Facebook✴✴ уже вводила аналогичные ограничения для групп и страниц, рассылающих массовый спам. Теперь это касается и отдельных пользователей, применяющих различные техники накрутки. Meta✴ подтвердила массовые сокращения в Reality Labs, затронувшие VR-разработчиков
25.04.2025 [05:19],
Анжелла Марина
Реструктуризация Meta✴✴ серьёзно «прошлась» и по исследовательскому подразделению Reality Labs — уволены сотрудники, работавшие над гарнитурой виртуальной реальности Quest, разработчики VR-игр и фитнес-приложений. Среди пострадавших проектов значится фитнес-игра Supernatural, которую Meta✴✴ приобрела более чем за $400 млн и защитила в суде от антимонопольного иска. 
Источник изображения: wikipedia.org Компания объяснила это стремлением к оптимизации рабочих процессов, одновременно пообещав не снижать инвестиции в технологию смешанной реальности (MR), пишет издание The Verge. «Некоторые команды Oculus Studios переживают изменения в структуре и ролях, — заявил представитель Meta✴✴ Трейси Клейтон (Tracy Clayton). — Однако это позволит нам эффективнее создавать проекты смешанной реальности (MR) для растущей аудитории, не прекращая поддержку текущих продуктов». Параллельно с оптимизацией кадров Meta✴✴ сталкивается с проблемами в продажах VR-шлемов. Если умные очки — Ray-Ban Smart Glasses — продаются лучше ожиданий, то линейка Quest продолжает терять позиции. В частности, гарнитура Quest 3S, выпущенная прошлой осенью, уже в некоторых комплектациях продаётся со скидкой около 10 %. Отметим, что это не первые сокращения в Meta✴✴. Ранее в компании уже прошла волна увольнений сотрудников в рамках общей стратегии сокращения расходов. Однако новые увольнения в Reality Labs указывают на возможный пересмотр приоритетов в развитии VR-направления. Похоже, что Meta✴✴ решила сделать ставку на технологию MR, но успех этой стратегии в конечном итоге будет зависеть от реакции рынка и пользователей, считают эксперты. Google Gemini проиграл ИИ-гонку — пользователи предпочитают ChatGPT и Meta✴ AI
24.04.2025 [00:52],
Николай Хижняк
Количество ежемесячных пользователей ИИ Gemini составляет около 350 млн человек, что значительно меньше, чем у ChatGPT от OpenAI и даже у Meta✴✴ AI. Такая цифра была озвучена в ходе недавно обнародованных данных судебного заседания, в котором Google принимает участие в качестве ответчика. 
Источник изображения: androidauthority.com По данным The Information, в ходе продолжающегося рассмотрения антимонопольного иска к Google компания на одном из последних судебных заседаний показала слайд, подробно описывающий количество активных пользователей ИИ-помощника Gemini. Согласно этим данным, по состоянию на март 2025 года число активных ежемесячных пользователей Gemini составило 350 млн человек по всему миру. Ежедневно ИИ от Google пользуются около 35 млн человек. Несмотря на отставание от конкурентов, Google увеличила долю пользователей Gemini с октября 2024 года. Тогда ежедневно ИИ-помощником пользовались 9 млн человек, а ежемесячная аудитория составляла 90 млн человек. Google представила эти цифры в контексте заявления Министерства юстиции США о том, что компании следует запретить расширять своё доминирование в поиске с использованием ИИ. Однако очевидно, что на данный момент Google является аутсайдером в этой области. По сравнению с её показателями OpenAI и Meta✴✴ значительно опережают её. TechCrunch сообщает, что по состоянию на сентябрь 2024 года число пользователей Meta✴✴ AI приближалось к 500 млн в месяц, в то время как OpenAI недавно заявила, что еженедельно ChatGPT пользуются более 400 млн человек по всему миру. Хотя методы расчёта этих данных варьируются от компании к компании, это, безусловно, указывает на значительное отставание Google от OpenAI по числу активных пользователей ИИ-ассистента. Однако остаётся неясным, учитываются ли в данных Google интеграции Gemini в такие продукты, как Workspace и Gmail, у которых, очевидно, гораздо более широкая пользовательская база. Meta✴ запустила онлайн-переводы и другие функции на базе ИИ для умных очков Ray-Ban
23.04.2025 [21:05],
Владимир Фетисов
Meta✴✴ Platforms анонсировала новые варианты цветового исполнения линз для смарт-очков, выпускаемых совместно с брендом Ray Ban. Параллельно с этим компания объявила о расширении доступности ряда функций. Среди них — функция перевода речи в реальном времени, возможность отправлять сообщения и осуществлять звонки через Instagram✴✴, а также общаться с фирменным ИИ-помощником, в том числе, обсуждая то, на что смотрит пользователь в это время.  Впервые функция перевода в режиме онлайн была анонсирована на конференции Meta✴✴ Connect 2024, которая состоялась в октябре прошлого года. В декабре компания сделала эту функцию доступной для участников программы предварительной оценки. Теперь же было объявлено о завершении этапа бета-тестирования, в связи с чем функция онлайн-перевода в ближайшее время станет доступна на всех рынках присутствия смарт-очков Ray Ban. На данном этапе поддерживается перевод с английского, французского, итальянского и испанского языков. Для того, чтобы использовать переводчик без подключения к Wi-Fi или мобильному интернету необходимо предварительно загрузить соответствующий языковой пакет. Вместе с этим Meta✴✴ рассказала о некоторых других функциях, которые только готовятся к выпуску или вскоре станут доступны более широкому числу пользователей. Так функция Live AI, позволяющая ИИ-помощнику Meta✴✴ AI постоянно видеть то, что видеть пользователь, «скоро станет общедоступной в США и Канаде». Возможность отправлять и получать сообщения, фотографии, аудиозвонки и видеозвонки из Instagram✴✴ также скоро станет доступна пользователям. Конечно, просматривать сообщения на очках не получится, ведь у них нет дисплея, но зато можно быстро поделиться тем, на что пользователь смотрит прямо сейчас.  Доступ к музыкальным приложениям, таким как Spotify, Amazon Music или Apple Music, в скором времени появится у пользователей смарт-очков за пределами США и Канады. Однако попросить ИИ-помощника воспроизвести что-либо или рассказать больше об исполнителе смогут только те пользователи устройства, которые в качестве языка по умолчанию установят английский. Сам же Meta✴✴ AI, который ранее уже стал доступен в Великобритании, в ближайшие дни появится во всех странах Евросоюза, где продаются смарт-очки компании. В будущем Meta✴✴ планирует начать продавать смарт-очки в Мексике, Индии и ОАЭ. В WhatsApp теперь можно запретить экспорт переписки и автозагрузку фото из чата, а также ограничить Meta✴ AI
23.04.2025 [19:07],
Дмитрий Федоров
WhatsApp объявила о запуске новой функции, которая позволит пользователям добавить дополнительный уровень конфиденциальности в чатах. Новая настройка под названием «Расширенная конфиденциальность чатов» (Advanced Chat Privacy) блокирует возможность экспорта переписки, а также автоматической загрузки медиафайлов на устройство — как для вас, так и для ваших собеседников. Прежде в WhatsApp можно было установить запрет на пересылку сообщений. 
Источник изображения: Mariia Shalabaieva / Unsplash Хотя переписка в WhatsApp уже защищена сквозным шифрованием, новая функция усиливает защиту конфиденциальности переписки. Она не только ограничивает возможность взаимодействия с Meta✴✴ AI, но и помогает участникам чувствовать себя увереннее: всё, что говорится и отправляется в чате, остаётся в его пределах. Следует отметить, что пользователи по-прежнему могут делать скриншоты отдельных сообщений. Однако WhatsApp заявляет, что в будущем планирует расширить функциональность «Расширенной конфиденциальности чатов», внедрив дополнительные меры защиты — возможно, в одной из следующих версий будет введён запрет на создание скриншотов. 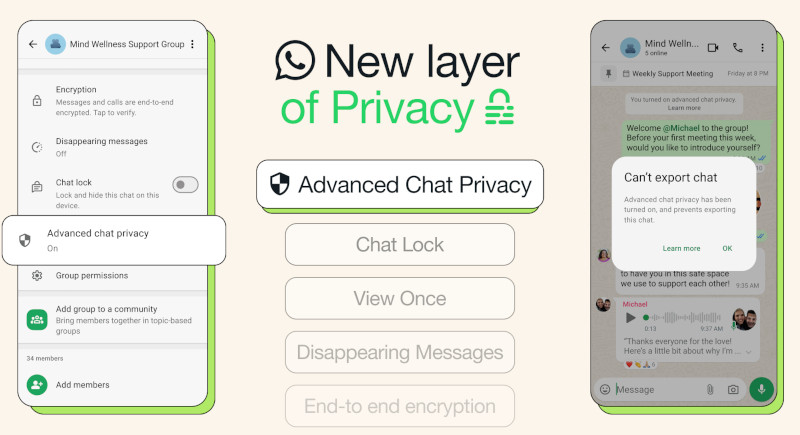
Источник изображения: Google Компания подчёркивает, что эта функция может быть особенно полезна в ситуациях, когда участники чата не знакомы лично, но обсуждают чувствительные темы. Например, речь может идти о проблемах со здоровьем в группе поддержки или о важных общественных вопросах. Включить новую настройку можно, нажав на название чата и выбрав пункт «Расширенная конфиденциальность чатов» в меню. Функция будет внедряться постепенно в течение ближайших месяцев и станет доступна как в индивидуальных, так и в групповых чатах. Она дополняет уже существующие инструменты конфиденциальности, такие как исчезающие сообщения и блокировка чата. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



