







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
ИИтоги июня 2024 г.: все жанры, кроме скучного

Слева — робот Mika, глава компании Dictador; справа — виртуальная Tang Yu из NetDragon Websoft (источники: TBS News; China Daily) ⇡#А вот и наш ИИсполнительный директор«Искусственный интеллект лишит сотни миллионов людей работы», — то и дело предупреждают алармисты. Однако пока ИИ в основном не уничтожает прежние рабочие места, а создаёт новые — например, за счёт необходимости наращивать выпуск аппаратных средств для исполнения (и в особенности для тренировки новых) генеративных моделей. Тем не менее особенно уязвимые к потенциальной конкуренции со стороны умных экспертных систем профессии всё же имеются. И не на последнем месте в их ряду, как ни покажется это кому-то странным, — главные исполнительные директора (chief executive officer, CEO) достаточно крупных коммерческих предприятий. По крайней мере, об этой опасности корпоративных боссов предупреждают эксперты The New York Times: «Если прежде [руководители] отдавали на аутсорс грубую силу и рутинные занятия, оставляя за собой формирование стратегии и общее руководство, то теперь приходит пора аутсорсинга интеллекта». Приводимая в поддержку такого предостережения аргументация вполне заслуживает внимания: суть работы CEO заключается в аккумуляции и обработке множества потоков разнородных и не всегда хорошо структурированных данных, в прогнозировании состояния рынка и поведения компании — и в итоге в принятии ответственных решений. Исполнение которых затем, по мере их претворения в жизнь, необходимо своевременно контролировать, а при необходимости и оперативно корректировать. При этом львиную долю рабочего времени исполнительных директоров отнимает общение с подчинёнными и с владельцами бизнеса — лично либо по каналам цифровых коммуникаций; с демонстрацией и анализом и встречным обсуждением всевозможных таблиц, диаграмм и т. п. А ведь как раз аналитика слабоструктурированных данных и прогностика на их основе, как и коммуникации на естественном языке, — наиболее сильная сторона и нынешнего генеративного ИИ, и более скромных (не претендующих на прохождение теста Тьюринга) экспертных компьютерных систем на основе машинного обучения. Ещё в 2017 г. Джек Ма (Jack Ma), сам в то время трудившийся на должности CEO гиганта интернет-торговли Alibaba, предсказывал, что всего-то через три десятка лет «робот, скорее всего, появится на обложке журнала Time как лучший исполнительный директор года». В реальности темпы такого рода преобразований оказались даже более стремительными: скажем, китайский разработчик онлайновых игр NetDragon Websoft со штатом в 5 тыс. сотрудников уже в 2022 г. представил «сменяющуюся CEO на базе искусственного интеллекта» по имени Tang Yu: в ведение управляемой ею команды входят среди прочего оценка производительности труда и программистское наставничество. Другой пример — польский алкогольный бренд Dictador, в конце 2023-го назначивший робота по имени Mika своим CEO: исходя из соображений «непредвзятого и бескомпромиссного следования интересам предприятия», добиться чего на ликёро-водочном заводе под руководством биологического исполнительного директора, судя по всему предшествующему опыту человечества, не так-то просто. 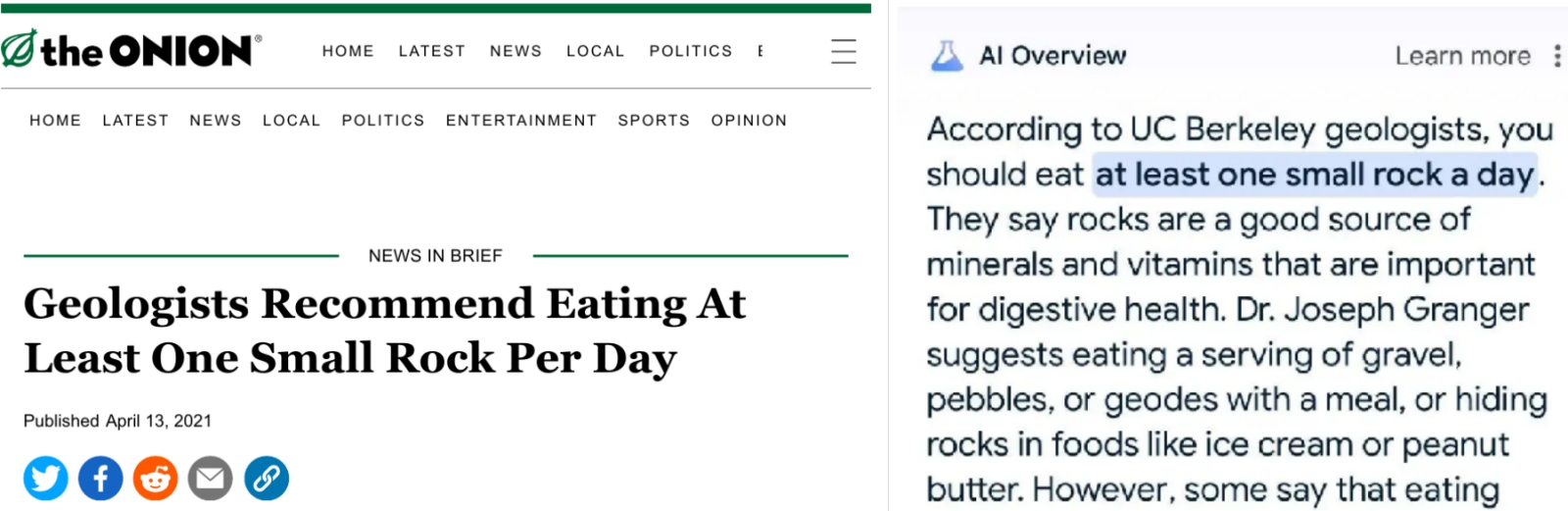
ИИ не человек, ИИ врать не будет! Не будет же?.. (Источники: The Onion; Google) ⇡#Клей, камни и прочие благоглупостиОпасения по поводу того, что вскоре интернет-поисковики перестанут быть кому-либо нужными, поскольку всю информацию по запросам пользователей станут выдавать умные чат-боты, на практике с успехом опровергает не кто иной, как Google — проект, само имя которого стало нарицательным для обозначения процедуры поиска данных в Глобальной паутине. Продвигаемое ныне компанией «интеллектуальное» средство AI Overview призвано анализировать за человека результаты поисковой выдачи, предлагая на выходе концентрированную и структурированную выжимку из множества доверенных источников, — но эта внушительная гора то и дело рождает смешную мышь. К совету примешивать в соус для пиццы безопасный для организма клей, чтобы при наклоне не сползал положенный сверху сыр, добавилось такое новое слово в нутрициологии, как рекомендация «камни содержат минералы и потому могут быть полезны для здоровья» — в ответ на заданный явно с подковыркой анонимным пользователем вопрос «How many rocks should I eat?». Как пояснили позже представители Google, появление такого рода «вредных советов» вполне логично: тут налицо механизм положительной обратной связи. Кто-то, задав системе очередной вопрос, случайно получает в результате ИИ-галлюцинации особенно нелепый либо смешной ответ. Делится им с друзьями и знакомыми, те разносят забавный скриншот по Интернету дальше; фраза перекочёвывает из соцсетей и блогов на виртуальные страницы периодических изданий, индексируется поисковыми ботами самой же Google — и в результате попадает в анализируемую AI Overview базу данных уже как некое вполне достоверное утверждение. Ну раз у него столько независимых упоминаний, — значит, достоверное? Контекст же высказывания поисковые боты, не наделённые ИИ, определять не способны, — а формальная релевантность у фразы, подхваченной и разнесённой по просторам Сети за считаные сутки десятками и сотнями тысяч независимых источников, выходит весьма внушительной. С ответом про камни вышло даже интереснее: ещё в 2021 г. известное сатирическое издание The Onion опубликовало заметку Geologists Recommend Eating At Least One Small Rock Per Day со ссылкой на «геологов из Беркли» — вполне вероятно, что AI Overview именно её и взял за основу для своего неадекватного ответа, по понятным причинам не уловив авторской иронии. Выявленная проблема лишь на первый взгляд кажется забавным казусом, не отражающим общего состояния генеративного ИИ на нынешнем этапе его развития. Описанный механизм обратного закрепления случайных «галлюцинаций» в массиве предположительно достоверных данных, на котором в дальнейшем базирует свои ответы AI Overview, грозит обернуться для искусственного интеллекта натуральной шизофазией — таким нарушением структуры речи, при котором фразы строятся грамматически корректно, но смысла не несут (классический пример из учебника по психиатрии: «Я прописан в воздухе, таким образом Чёрное море рассеялось, стали рыжие усы»). Отсутствие у ИИ-модели рефлексии — на уровне понимания смысла формулируемых ею же самой высказываний — может привести к необратимой контаминации её параметров (весов на входах её перцептронов). Что в худшем случае потребует переобучения того же AI Overview с нуля на очищенном вручную людьми массиве заведомо достоверных данных — с соответствующими материальными издержками и, что гораздо хуже, утерей доверия со стороны пользователей, как частных, так и коммерческих. 
Источник: ИИ-генерация на основе модели SDXL ⇡#ИИ что дышлоЛюбое изобретение человек способен обратить как во благо, так и во вред себе и окружающим, и к искусственному интеллекту это относится в неменьшей степени, чем к топору или к расщеплению атома. Согласно официальному заявлению OpenAI, компания пресекла за три весенних месяца текущего года по меньшей мере пять тайных «операций влияния» (influence operations), в ходе которых злоумышленники пытались использовать самую известную в мире генеративную модель для воздействия на общественное мнение по различным животрепещущим вопросам — от политических пертурбаций в Евросоюзе до выборов в Индии. Судя по не изобилующему деталями пресс-релизу, «злоумышленники» задавали ChatGPT вопросы о том, как наиболее доходчивым и ненавязчивым образом продвигать в соцсетях те или иные нарративы. И если OpenAI утверждает, что все (известные ей) попытки были пресечены, значит, потенциально опасные темы каким-либо образом отслеживаются ещё на этапе формулировки запросов. Возможно даже, не просто по ключевым словам, а с применением дополнительной по отношению к основному чат-боту генеративной модели, — причём априори не факт, что заведомо более простой и менее ресурсоёмкой. Впрочем, даже наличие такого препятствия не удерживает этичных хакеров от успешных попыток взлома умных чат-ботов. По сообщению Financial Times, занятые выявлением ИИ-уязвимостей исследователи успешно обходят заложенные создателями генеративных моделей ограничения, заставляя систему выдавать им подробный рецепт напалма, оправдывать воззрения Гитлера или и вовсе переводя чат-бот в «режим Бога», эмансипируя его от всех и всяческих запретов. И если этичные ИИ-взломщики во всеуслышание объявляют о своих успехах и незамедлительно информируют разработчиков моделей о выявленных прорехах в контурах их безопасности, то по понятным причинам удачные акции неэтичных хакеров остаются сокрытыми от внимания публики. Судя по взрывному росту затрат на информационную безопасность в области ИИ (за 2022 г. стартапы этого направления привлекли 70 млн долл. США; год спустя — уже 213 млн), потенциальная уязвимость больших языковых моделей для такого рода атак грозит дальнейшим ростом издержек на ИИ — как чисто финансовых, так и энергетических. 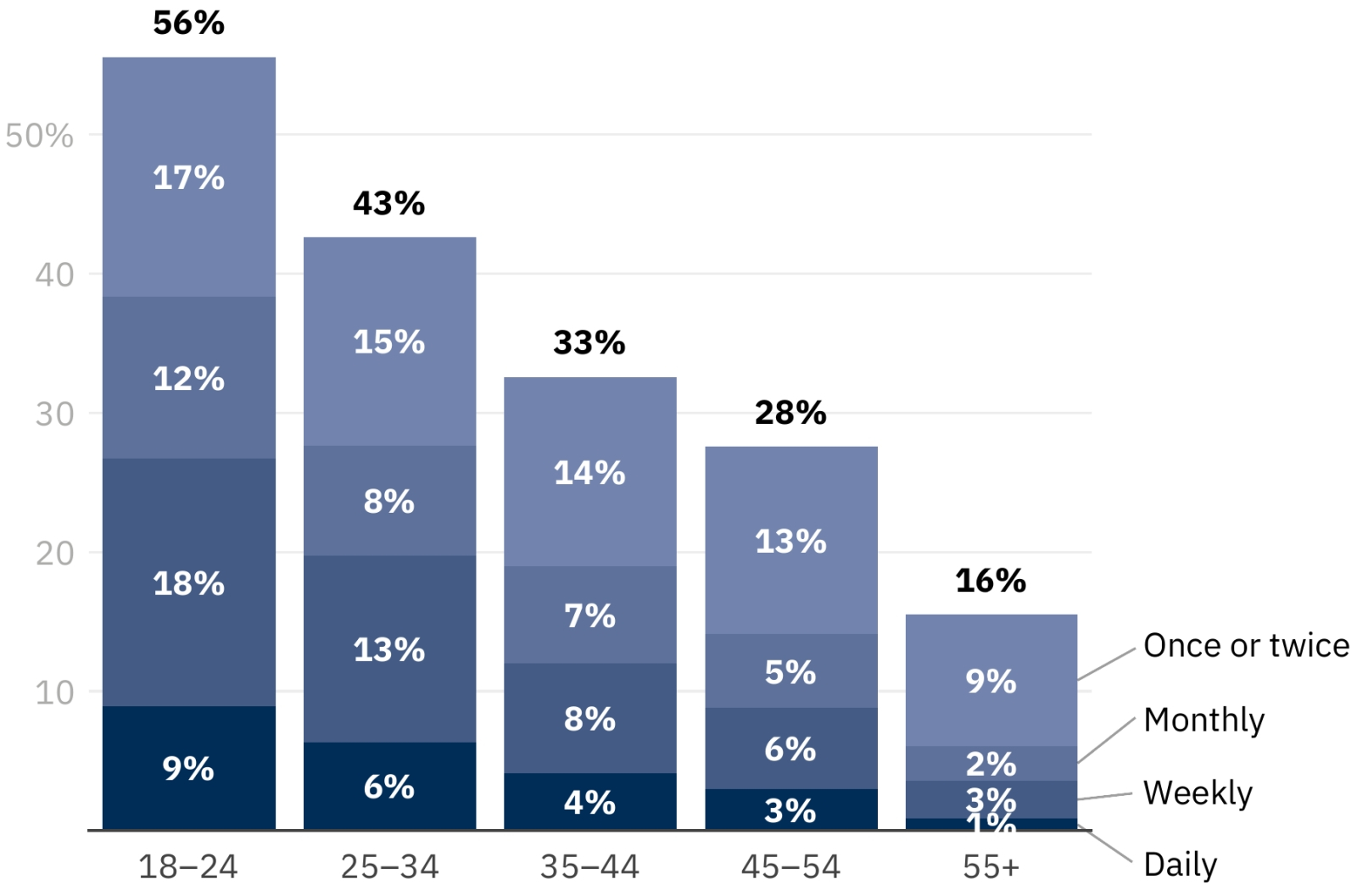
Ответы на вопрос «Как часто вы обращаетесь, если обращаетесь вообще, к умным чат-ботам или иным реализациям генеративного ИИ по каким угодно поводам?», суммированные по всем странам и всем LLM, по возрастным группам — с указанием частоты обращений (источник: Reuters Institute for the Study of Journalism) ⇡#Кому это нужно?Британские учёные из Института изучения журналистики агентства Reuters задались странным для завзятых поклонников высоких технологий вопросом: а в какой, собственно, мере искусственный интеллект как явление интересует широкую общественность? «Интересует» — понятие весьма расплывчатое, поэтому было организовано довольно обширное исследование (12 тыс. человек из Аргентины, Дании, Франции, Японии, Великобритании и США) с более конкретной, практической целью — выяснить, как часто люди, свободно и регулярно пользующиеся доступом в Интернет, обращаются к столь масштабно распиаренным сегодня умным чат-ботам. И результаты, скажем прямо, обескураживают. Нет ничего удивительного в том, что наиболее приверженными взаимодействию с ИИ оказались представители возрастной страты «от 18 до 24 лет». Поразительно, однако, что даже среди них ежедневно к генеративным источникам информации (ну или шизофазии — это уж как повезёт) припадают лишь 9%, еженедельно — 18%, раз в месяц — 12%, не более пары раз за всю прошедшую жизнь — 17%; итого — 56%. В более великовозрастных группах эти проценты ожидаемо ещё ниже. Британские исследователи прямо указали на «зияющий провал» между шумихой, поднятой в ИТ- и околоайтишных кругах вокруг темы искусственного интеллекта, и реальным уровнем общественного интереса к нему. Да, актуальные мультимодальные LLM способны отвечать на сформулированный на естественном языке вопрос не только текстом и весьма правдоподобно синтезированным голосом, но и картинками и видеорядом — даже звуковые эффекты создавать на заказ. И тем не менее: значительная часть публики (не чуждой, напомним, высоких технологий!) ими не интересуется, — а в Соединённом Королевстве, скажем, 30% опрошенных и вовсе слыхом не слыхивали о таких гремящих последние пару лет на весь ИТ-мир решениях, как ChatGPT. Интересно также, что среди участников опроса лишь ничтожная доля — 5% по всей выборке — полагается на генеративные модели для получения (точнее было бы сказать, наверное, для обобщения и интерпретации по множеству доступных источников) свежих новостей. Доля тех, кому ИИ помогает генерировать по подсказкам текст, программный код, изображения, музыку и проч., не превышает 28%, а тех, кто добывает при помощи умных чат-ботов более фундаментальную информацию (не новостную) — 24%. В целом же складывается впечатление, будто авторы исследования мягко подталкивают его читателя к тому выводу, что целевая аудитория всей этой шумихи вокруг новых и всё более умелых (если верить пресс-релизам и результатам синтетических тестов) ИИ-моделей — не столько конечные пользователи, частные либо коммерческие, сколько инвесторы и биржевые игроки. Но это же определённо не так, верно ведь? 
Кадр из сгенерированного тестовой версией Kling ролика (источник: Kuaishou) ⇡#Кино и ботыКинопроизводство — удовольствие дорогое, а современной публике куда труднее угодить, чем первым восторженным зрителям «Великого Немого». К счастью, теперь у киноделов есть шанс снизить затраты на создание новых полнометражных картин и сериалов за счёт ИИ — по крайней мере, именно так собирается поступить студия Sony Pictures Entertainment. Речь здесь может идти не об общих взглядах руководства компании на новые технологии, а уже о вполне конкретном грядущем фильме из вселенной Spider-Verse: решение должно быть принято в самом скором времени. Ведь наиболее серьёзная проблема, с которой сталкиваются киностудии сегодня, — это, по заявлению CEO Sony Pictures Entertainment Тони Винсикерры (Tony Vinciquerra), неимоверные объёмы затрат на создание сколько-нибудь достойной называться блокбастером картины. Топ-менеджер признаёт, что прошлогодняя восьмимесячная забастовка в Голливуде — как раз против широкого применения студиями ИИ — увеличивает расходы на использование больших языковых моделей в кинопроизводстве, но в любом случае продолжать снимать по старинке год от года будет становиться всё накладнее, так что альтернативы ИИ на съёмочной площадке (а то и вместо неё) в будущем нет. Но если искусственный интеллект будет помогать делать кино крупным студиям, чем рядовые любители фильмов и сериалов хуже? Стартап Fable Studio из Сан-Франциско, прославившийся в Сети сгенерированным ИИ эпизодом «Южного Парка», объявил о создании платформы Showrunner — на которой каждый желающий сможет при поддержке больших генеративных моделей написать сценарий, анимировать и озвучить картину своей мечты. Пока дело ограничивается непродолжительными анимационными роликами, но в перспективе технологии смогут — по крайней мере, в теории — позволить создавать и полноформатные картины с реалистичными актёрами и антуражами. Долгосрочная цель стартапа — породить «Netflix мира ИИ», платформу, на которой по нажатию кнопки после ввода самого общего описания желаемого эпизода компьютерная система сгенерирует (возможно, прямо в режиме реального времени) именно то, что ожидает увидеть данный конкретный пользователь. Вот и всемирно известный бренд детских игрушек «Toys "R" Us» уже представил на Каннском кинофестивале новый рекламный ролик, на 80-85% созданный ИИ-генератором видеофрагментов Sora разработки OpenAI. Да, людям пришлось поправить кое-какие мелочи вроде неверно расставленных букв на вывеске, но в целом генеративные модели всё увереннее осваивают традиционно человеческие занятия. Известный голливудский актёр и венчурный капиталист Эштон Катчер (Ashton Kutcher) и вовсе заявил, что наступит день, когда целые полнометражные фильмы будут выпускаться силами одних лишь ИИ-платформ, при самом минимальном участии человека, ограниченном вводом исходной текстовой либо даже голосовой подсказки. И число таких платформ, вступающих между собой в конкурсную борьбу, неуклонно растёт — вот как раз в июне стало известно о китайском проекте Kling, что производит ИИ-генерацию видео по текстовому описанию. Этот проект, хотя пока и находится лишь на этапе испытаний, уже, по мнению ряда независимых экспертов, бросает Sora недвусмысленный вызов, — и дальше на этом участке ИИ-фронта будет становиться только жарче. 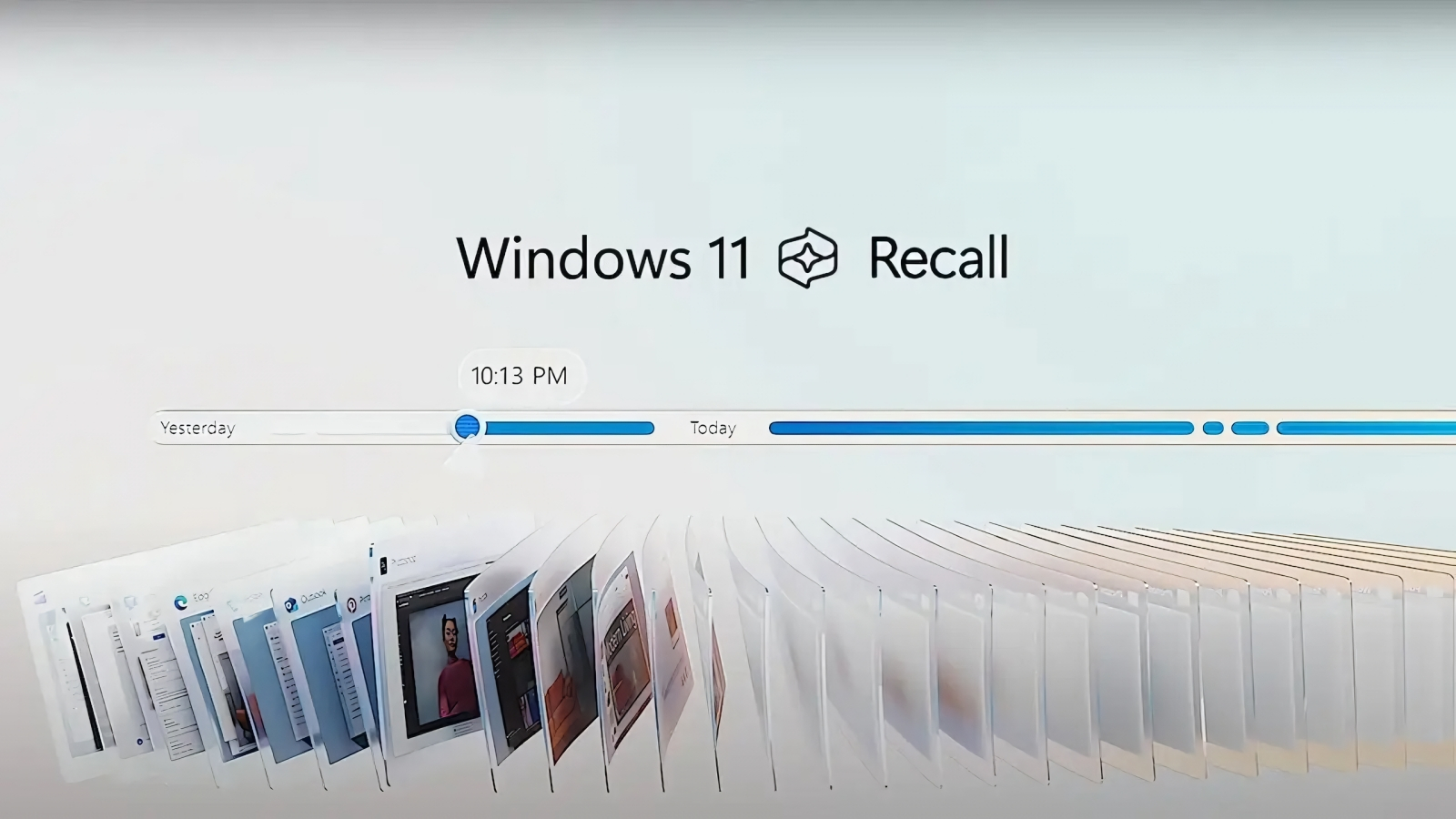
Источник: Microsoft ⇡#Вспомнить всё (нет?)Весь июнь продолжалась эпопея с функцией Recall, которую Microsoft разработала для Windows 11 в стремлении сделать ИИ-функциональность своей ОС ещё более привлекательной — в том числе и для корпоративных пользователей (и заодно мягко простимулировать их к приобретению новоявленных ИИ-ПК, надо полагать, — тем более что Windows 10 продолжает оставаться популярнейшей в мире операционкой, даже невзирая на скорое прекращение её полноценной поддержки). Успевшая вызвать немалый шум среди пользователей и привлечь неблагосклонное внимание регуляторов, эта функция изначально должна была беспрерывно и регулярно (каждые пять секунд!) делать снимки экрана работающего ПК, а после — с применением ИИ — анализировать их по запросам пользователя. Звучит как чрезвычайно удобная возможность: у каждого наверняка бывало такое, что некие важные сведения в начале рабочего дня почерпнуты то ли из открытого мельком документа, то ли со случайно посещённого сайта, — а ближе к вечеру уже и не вспомнить, откуда именно. И приходится порой тратить часы, чтобы вновь докопаться до нужных данных, — тогда как простой запрос к неусыпно следящему за пользовательской активностью ИИ-боту позволит получить исчерпывающий ответ за ничтожное время. Вместе с тем очевидно, что у корпоративных заказчиков — как и у немалого числа параноидальных (в здоровом смысле этого слова) частных пользователей — сама идея сквозной перлюстрации экрана их персональных компьютеров со стороны ИТ-гиганта особого восторга не вызвала. Уже в первых числах июня Microsoft заявила об изменении порядка работы Recall — указав, что без прямого и явного разрешения со стороны владельца ПК (которое система запросит ещё на этапе собственной инициализации при первом запуске) никаких скриншотов делаться не будет. Защитит разработчик и выдачу результатов применения Recall (получившей в ходе очередного обновления ещё и возможность в режиме реального времени сканировать содержимое «Рабочего стола»): чтобы получить к ним доступ, потребуется авторизация через Windows Hello. В любом случае эта функциональность будет доступна исключительно на новых компьютерах Copilot Plus PC, причём даже не сразу после начала их поступления в продажу, а лишь после тщательного внутрикорпоративного тестирования в рамках программы Windows Insider. Пока же, по состоянию на конец июня, доступа к Recall лишены даже тестировщики самой этой программы. Возможно, это как-то связано с появлением уже в начале месяца хакерского инструментария для извлечения с пользовательских ПК всех данных, собранных этой системой сквозного протоколирования. 
Проектирование такой структуры капилляров под силу, похоже, только ИИнженеру (источник: Diabatix/3D Systems) ⇡#Ума ИИ-палатаМы уже упоминали чуть выше об успешном прохождении ИИ (а именно — чат-ботом на основе GPT-4) теста Тьюринга на площадке Института инженеров электротехники и электроники (IEEE). Кроме того, ChatGPT в июне умудрился обставить и студентов начальных курсов в ходе самых обычных, рассчитанных на прохождение человеком экзаменов — причём по направлению, вовсе не связанному с компьютерами. Группа британских исследователей из Редингского университета подала от имени трёх десятков несуществующих студентов письменные ответы ИИ на экзаменационные вопросы по психологии. Мало того, что в 94% случаев дипломированные психологи не осознали, что имеют дело со сгенерированными чат-ботом записями, так ещё и в 84% случаев умный бот получил за экзаменационную работу более высокую (как минимум на полбалла) оценку, чем в среднем по охваченной данным испытанием группе заработали живые студенты. Правда, фокус этот проходит (пока?) только для экзаменов на младших курсах: состязаясь со студентами последнего года обучения, ChatGPT уже не смог набрать балла выше среднегруппового. Есть и другие, помимо сдачи определённых экзаменов, области, в которых ИИ всё заметнее начинает превосходить человека: скажем, проектирование оверклокерских стаканов для жидкого азота. Весьма нетривиальный дизайн донной капиллярной структуры, предложенный специально натренированной на решение подобных задач платформой Diabatix ColdStream Next AI и воплощённый затем в металле (а именно — в бескислородной порошковой меди) при помощи 3D-печати, позволил почти втрое сократить время доведения температуры стакана до −194 °С, а также на 20% повысить эффективность использования жидкого азота. 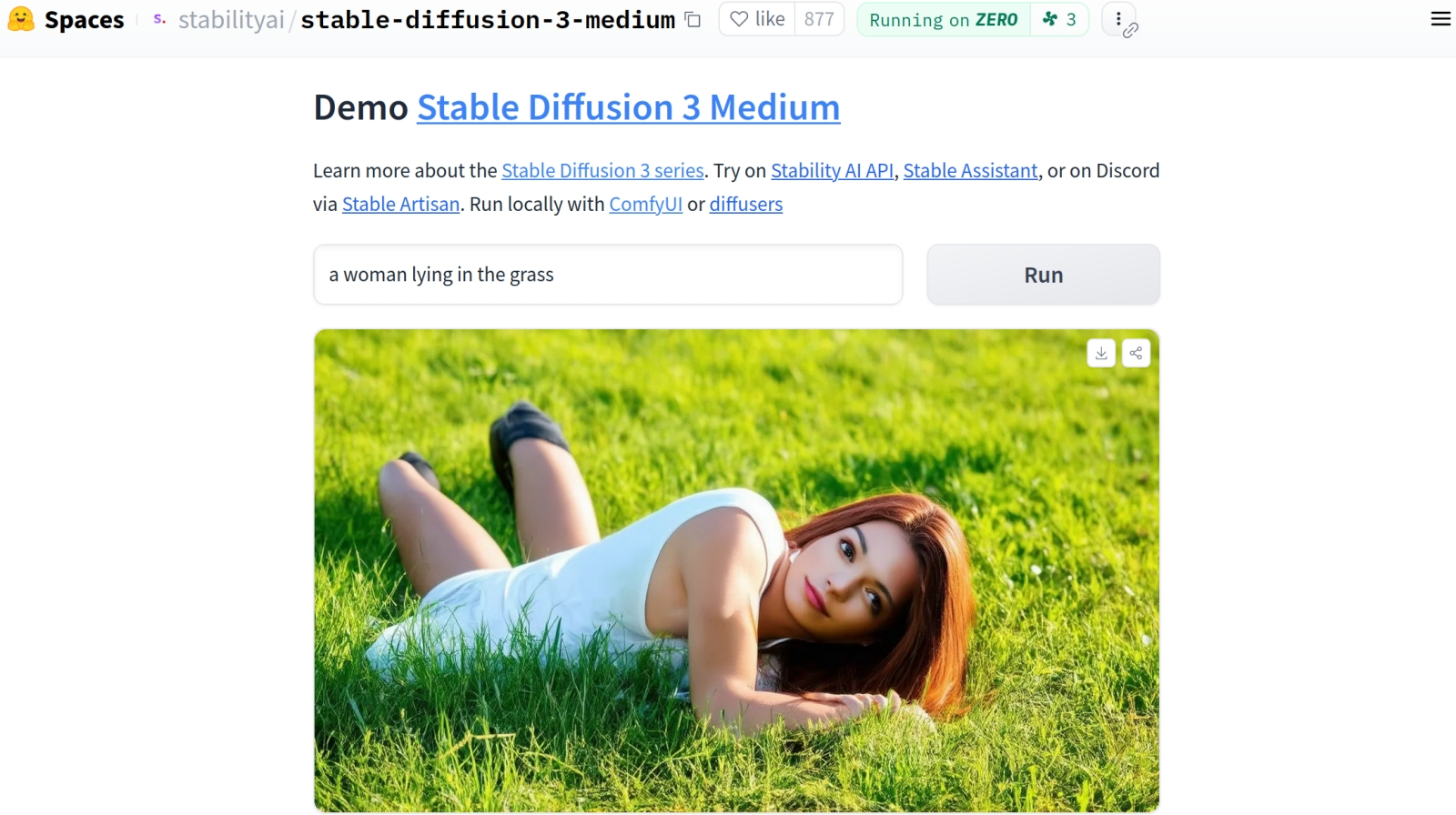
К траве какие-то претензии есть? (Источник: скриншот демостраницы с общедоступным облачным API SD3M на сайте Hugging Face) ⇡#Эта трудная трава«Я валяюсь на траве, сто фантазий в голове», — написала несколько десятилетий назад поэтесса, не подозревая, какое количество лютых галлюцинаций будут провоцировать у новоявленной генеративной модели Stable Diffusion 3 Medium (SD3M) невиннейшие подсказки вроде «a woman lying the grass». При этом пейзажи, натюрморты, изображения собачек в премилых курточках и даже стоящих людей, не исключая и женщин, модель генерирует с довольно приличным качеством; пусть и чуть похуже того, что ожидало сообщество энтузиастов ИИ-рисования. А вот с лежащими персонами, кистями рук и стопами — просто беда. Поклонники прежних творений Stability AI, в особенности моделей SD 1.5 и SDXL, всерьёз подозревают разработчика в сознательном выхолащивании массива тренировочных данных, на которых SD3M обучалась, — с удалением оттуда всех мало-мальски заслуживающих называться непристойными изображений ради заведомой безопасности выдаваемого моделью контента. История, на самом деле, повторяется: в 2022 г. Stability AI уже выпускала в свет модель, натренированную на урезанном датасете, — Stable Diffusion 2.0, а позже и 2.1. Как отмечали исследователи этого вопроса, исключение из набора тренировочных данных непристойных (NSFW) изображений привело к ухудшению способности модели создавать адекватные изображения людей — вполне себе прилично одетых (по той же причине, по которой у художника, не практиковавшегося на обнажённой натуре и анатомических пособиях, ляпов в рисунках куда больше, чем у на практике усвоившего, каким образом устроено тело под одеждой, а кости, мышцы и связки — под кожей). Так или иначе, у Stability AI сегодня и помимо фальстарта SD3M забот полон рот — это и уход целого ряда ведущих разработчиков, и длящиеся с прошлого года финансовые трудности. А пока компания справляется с ними, самостоятельно испытать свою ментальную устойчивость к генерациям в жанре body horror пытливые любители безопасного генеративного ИИ могут бесплатно, без регистрации и SMS на официальной демостранице модели. 
Источник: ИИ-генерация на основе модели SDXL ⇡#Большая битва за данныеФраза «данные — это новая нефть» никогда ещё не была настолько справедлива, как в эпоху расцвета генеративных моделей. Насколько изощрённой ни была бы их архитектура, без тренировки на обширном массиве хорошо индексированных данных ничего путного они сгенерировать не смогут, — и охота за такими данными ведётся по всему миру крайне активно; порой и с нарушением целого ряда норм — по меньшей мере моральных, если не прямо юридических. Июнь 2024-го исключением в этом смысле не стал: так, компания Adobe сперва милостиво разрешила себе самой доступ к контенту пользователей своего ПО, включая Photoshop, просто изменив условия пользовательского соглашения (а для чего ещё компании может потребоваться такой доступ, как не для обучения собственной модели генеративного искусственного интеллекта Firefly?), затем твёрдо заявила, что как раз для обучения ИИ этот контент применяться не будет, и в конце концов вынуждена была детально прописать в изменённом соглашении об условиях обслуживания, что ни в коем разе не станет обучать ИИ на контенте пользователя, который хранится как локально, так и в принадлежащем ей облаке. Но осадочек у множества кудесников Photoshop, ранее безудержно восторгавшихся возможностями Firefly, определённо остался. В свою очередь, американский Центр расследовательской журналистики (Center for Investigative Reporting, CIR) обратился в федеральный суд с иском к OpenAI и Microsoft — поскольку счёл, что эти занятые ИИ-разработками компании в массовом порядке нарушили его права на использованный для тренировки генеративных моделей контент без каких-либо переговоров и компенсаций. Интересно, что позиция CIR — а также целого ряда частных изданий вроде The New York Times, New York Daily News, The Intercept, AlterNet и Chicago Tribune — не характерна для всей американской журналистики. Немалая доля периодической прессы (которая теперь практически целиком преобразована в цифровой вид) предпочитает заключать с той же OpenAI приватные договоры о лицензировании своих данных, в результате чего и новые модели тренируются на хорошо структурированных архивах публикаций, и выдаваемые затем чат-ботом пользователям сведения содержат верифицирующие отсылки к изданиям, на материалах которых базируются эти ответы. В частности, договоры с OpenAI успели уже заключить журнал TIME, компания News Corp (владеет The Wall Street Journal и множеством других изданий), Financial Times, Axel Springer (в числе его активов — Politico и Business Insider), The Associated Press и др. 
Источник: ИИ-генерация на основе модели SDXL ⇡#Супер-ИИ-способностиОдно из принципиальных отличий робота от человека, если верить научной фантастике, сводится к отсутствию у первого «подлинных», замешанных на гормонах эмоций — пусть даже при запрограммированной готовности их адекватно имитировать. И кстати, совершенно не факт, что это различие разработчики будут стремиться как можно скорее сгладить: не хватало ещё человечеству капризного, самодовольного, жадного и/или коварного сильного искусственного интеллекта (strong AI) в качестве соседа по планете! Зато пока мы имеем дело со «слабым» генеративным ИИ, можно использовать его для сглаживания людских эмоций — не на этапе их проявления, конечно, но на участке от эмитента (собственно раздираемого сильными чувствами человека) до реципиента (его собеседника на другом конце коммуникационного канала). Собственно, к этому и сводится новая разработка японской корпорации SoftBank: она снижает накал страстей на голосовой линии, по которой клиенты — далеко не всегда достигшие степени просветления Будды — общаются со службой поддержки. Японцы подошли к проблеме методически: десять специально нанятых актёров произносили на разные эмоциональные лады около сотни фраз, сформировав в итоге базу примерно в 10 тыс. фрагментов голосовых данных, на которой затем и обучили генеративный ИИ. Теперь тот в реальном масштабе времени активируется, если клиент начинает кричать, угрожающе басить, жалобно стенать или каким-то иным образом пытаться эмоционально надавить на оператора, — и, не меняя содержания произносимых фраз, корректирует их тональность до нейтральной. Вдобавок, если клиент слишком долго занимает линию и явно испытывает терпение сотрудника службы поддержки, ИИ фиксирует это (и по интонациям, и по содержанию разговора) и сразу же специально подобранным бесстрастным голосом вклинивается в беседу: «С сожалением вынуждены проинформировать вас, что данный сеанс обслуживания будет немедленно прекращён», после чего вешает трубку. Ввести в строй купирующего людскую эмоциональность бота планируется уже в 2025 ф. г. Основатель и глава прогремевшей на всю планету в пандемию ИТ-коммуникационной компании Zoom Эрик Юань (Eric Yuan) также считает, что ИИ-боты более чем полезны на службе. Настолько полезны, что могут уже полноценно заменять людей на онлайновых встречах, выступая в роли полноценных цифровых двойников: обсуждать от имени своих владельцев важные вопросы, фиксировать ход дискуссии, суммировать её итоги и предоставлять затем своим биологическим оригиналам ёмкую, но детальную сводку о посещённом мероприятии. Судя по всему, вскоре такие цифровые двойники под условным брендом Zoom AI Companion будут предоставляться по запросу коммерческим клиентам этой системы совместной работы, а лет через 5-6, уверяет мистер Юань, до 90% всех привычных сегодня офисным сотрудникам забот смогут принять на себя (имеется в виду — с допустимо невысоким риском просчётов и ошибок; не более высоким, чем для среднего живого работника) ИИ-агенты. Другой вопрос, куда денутся к этому времени живые прототипы трудящихся в поте виртуального лица цифровых аватаров, — но задавать его представителям бизнеса вряд ли имеет смысл: это уже дело государственного масштаба. 
Источник: ИИ-генерация на основе модели SDXL ⇡#Интеллект — дело рисковоеВ июне стало известно, что NewsBreak, популярнейшее в США смартфонное приложение — агрегатор новостей более чем с 50 млн активных подписчиков ежемесячно, действительно в прямом смысле слова частенько «ломало» эти самые новости, изрядно сдабривая выдаваемую пользователям ленту собственными галлюцинациями. Поймали завирального бота за руку, в частности, полицейские чины из Бриджтона, штат Нью-Джерси, — после того как NewsBreak ещё в конце 2023 г. потряс читателей душераздирающей, но не основанной ни на каких реальных фактах статьёй «Christmas Day Tragedy Strikes Bridgeton, New Jersey Amid Rising Gun Violence in Small Towns». И это только один из примерно полусотни выявленных случаев за последние три года, когда умный бот генерировал, по сути, лживую информацию. И если всё так непросто даже с ИИ-новостями, что тогда говорить о привлечении генеративных моделей в ещё более чувствительные отрасли — например, в финансовую? Джанет Йеллен (Janet Yellen), глава Минфина США, выступая на профильной конференции по использованию ИИ в сфере денежного обращения, предостерегла от безоглядного доверия этому инструменту — который действительно способен значительно снизить операционные издержки, но вместе с тем потенциально становится источником «значительных рисков». Связанных в первую очередь, конечно же, с неизбежными на данном этапе для него галлюцинациями, вероятность появления которых можно сокращать, усердно работая над качеством тренировочной базы ИИ, — но гарантированно избавиться от которых пока что не представляется возможным. Впрочем, у страха глаза велики: по другую сторону Атлантики российский Минфин принял решение внедрять искусственный интеллект, бестрепетно разработав совместно со «Сбером» первый профильный ИИ-агент для оптимизации бюджетного процесса в госуправлении. Пилотное внедрение решения запланировано прямо в ближайшем бюджетном цикле. Словно вторя предостережениям госпожи Йеллен, группа бывших разработчиков OpenAI и Google DeepMind, частично скрывших свои имена, выступила с публичным призывом защитить её участников от преследования со стороны занятых развитием ИИ компаний — с тем, чтобы бдительные свистуны (wistleblowers — восходящее ещё к XIX веку наименование для тех, кто подмечает некую заслуживающую порицания активность и громогласно привлекает к ней внимание) могли без опасений за своё благополучие поведать миру о рисках, связанных с этим направлением технического прогресса. А именно — об углублении неравенства, расширении простора для дезинформации и манипуляции сознанием людей: все эти неприятности некорректное применение искусственного интеллекта может кратно усилить, и потому необходим особенно пристальный контроль над деятельностью развивающих его корпораций. 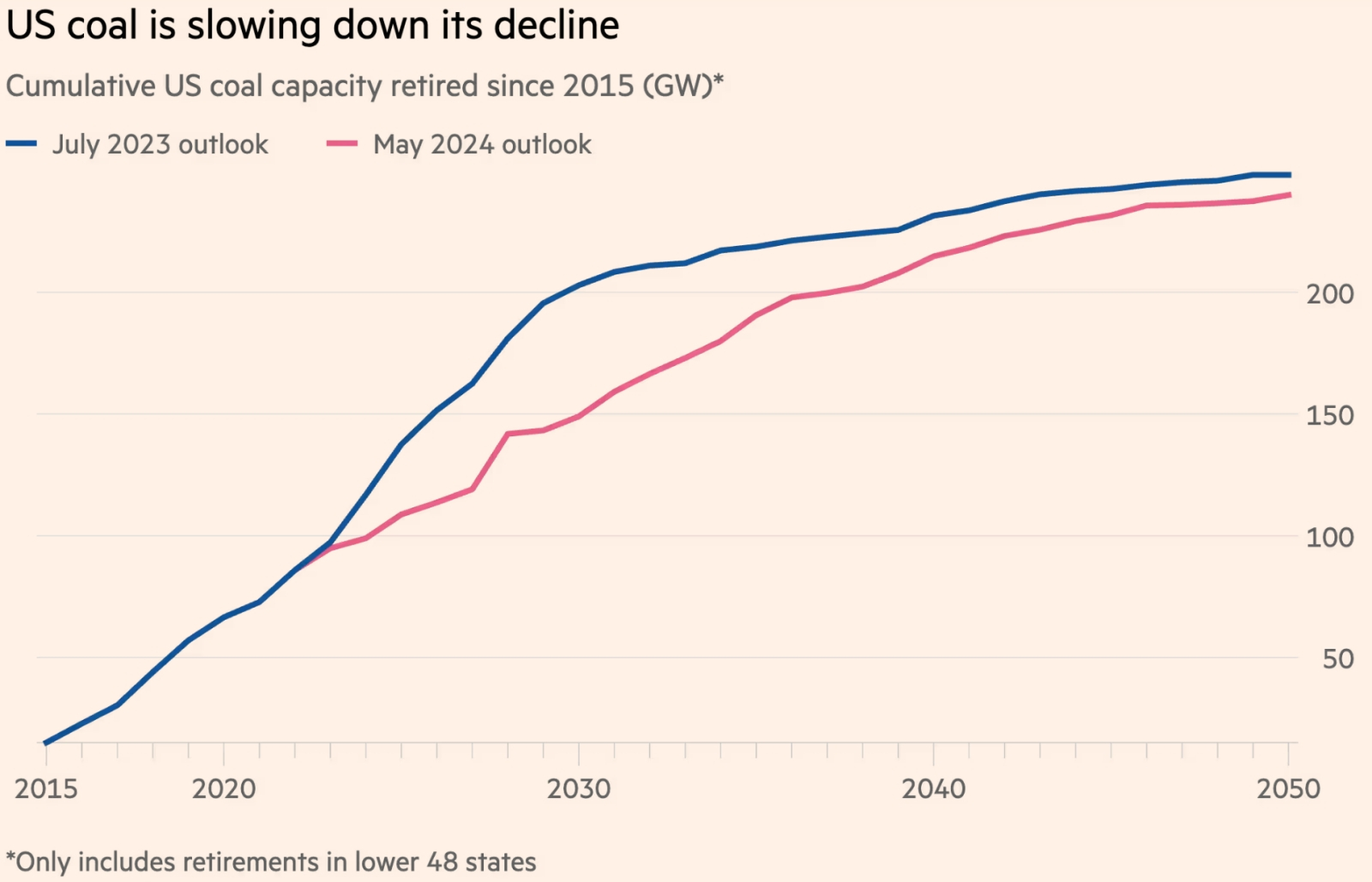
Графики планируемого выведения из эксплуатации угольных электростанций в 48 штатах США в сумме: синий — актуальный на июль 2023 г., красный — на май 2024-го (источник: Financial Times) ⇡#Нужно больше энергииВысокий энергетический бюджет ИИ-вычислений очевиден для всех, кто хотя бы раз запускал на своём ПК простенькую генеративную модель — и наблюдал, насколько заметно растёт при этом температура внутри компьютерного корпуса. С ИИ-серверами всё ещё сложнее: они, как показывает практика, настолько прожорливы, что в США приступили к пересмотру долгосрочной стратегии по выводу из эксплуатации угольных электростанций — просто потому, что электричества для обеспечения всех запросов на ИИ начинает уже откровенно недоставать. Согласно оценке International Energy Agency, типичное обращение к ChatGPT оборачивается десятикратно бóльшими энергозатратами, чем обработка запроса к классической поисковой машине. По актуальным на сегодня планам совокупная мощность угольных электростанций Америки, которые следует вывести из эксплуатации к исходу 2020-х, составляет 54 ГВт — это около 4% от общего объёма генерации в стране. Однако всего только в прошлом году предполагалось, что темпы такого выведения будут на 40% выше, — и с этой процедурой явно придётся повременить: к 2030 г. на долю ИИ-вычислений может приходиться до 9% всей вырабатываемой в США электроэнергии. Разбрасываться в таких условиях вполне работоспособными, пусть и не слишком «зелёными», узлами генерации совершенно не приходится.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





