В номенклатуре дискретных видеоадаптеров NVIDIA произошло нечто необычное: видеокарты GeForce минуют 800-ю серию и сразу переходят к линейке GeForce 900. Сделано это для того, чтобы синхронизировать наименования десктопных и мобильных SKU. В ноутбуках уже используются адаптеры 800-й серии, большинство из которых оснащены GPU архитектуры Kepler, а поскольку новые десктопные видеокарты основаны на архитектуре Maxwell, эту разницу следовало подчеркнуть, сразу запустив серию GeForce 900.
Сегодня NVIDIA представила две модели, в основе которых лежит графический процессор GM204. Если судить по этому коду, чип принадлежит к той же категории, что и GK104, первенец архитектуры Kepler, — это GPU второго эшелона. За более производительным ядром должно быть зарезервировано наименование GM201 или GM210. Ну а пока NVIDIA предлагает GM204 в качестве полноценной замены GK110 — топового ядра предыдущей архитектуры — в игровых видеоадаптерах. Пример GeForce GTX 680 показал, что относительно компактное ядро нового поколения может справиться с такой задачей, но в прошлый раз GK104 поспособствовал переход с техпроцесса 40 на 28 нм.
Однако оба основных производителя GPU вот уже три года как пользуются узлом 28 нм на TSMC и не имеют возможности перейти на 20 нм в ближайшей перспективе. Такая линия уже действует на TSMC, но пока что зарезервирована для производства мобильных SoC. Поэтому сейчас NVIDIA полагается исключительно на архитектурные изменения, которые должны увеличить производительность, используя резерв технологии 28 нм. Это и есть краеугольный камень Maxwell — радикальное увеличение производительности на ватт. Вплоть до 100%, если верить NVIDIA.
Поставки GeForce GTX 770, 780 и 780 Ti с сегодняшнего дня официально прекращаются. На смену им приходят GeForce GTX 970 и GTX 980. Новые адаптеры изначально дешевле, чем их предшественники: $329 (14 990 р. для России) за GTX 970 и $549 (23 990 р.) за GTX 980. Осталось убедиться в том, что они обладают как минимум не худшей производительностью. Начнем с GTX 980. Обзор GeForce GTX 970 вы увидите в ближайшее время.
⇡#Архитектура Maxwell: общие принципы
С архитектурой Maxwell мы уже познакомились на примере процессора GM107, который был представлен ранее в составе карт GeForce GTX 750 и 750 Ti. В целом, как и следовало ожидать, GM204 представляет собой увеличенный аналог GM107, а устройство строительных блоков GPU осталось по большей части неизменным. Повторим описание архитектуры Maxwell, данное в обзоре GTX 750 Ti и дополненное той информацией, которую мы получили позднее.
Maxwell является первым плодом стратегии NVIDIA, в соответствии с которой новые архитектуры GPU создаются в первую очередь с расчетом на мобильные и ультрамобильные устройства, а во главе угла стоит энергоэффективность.
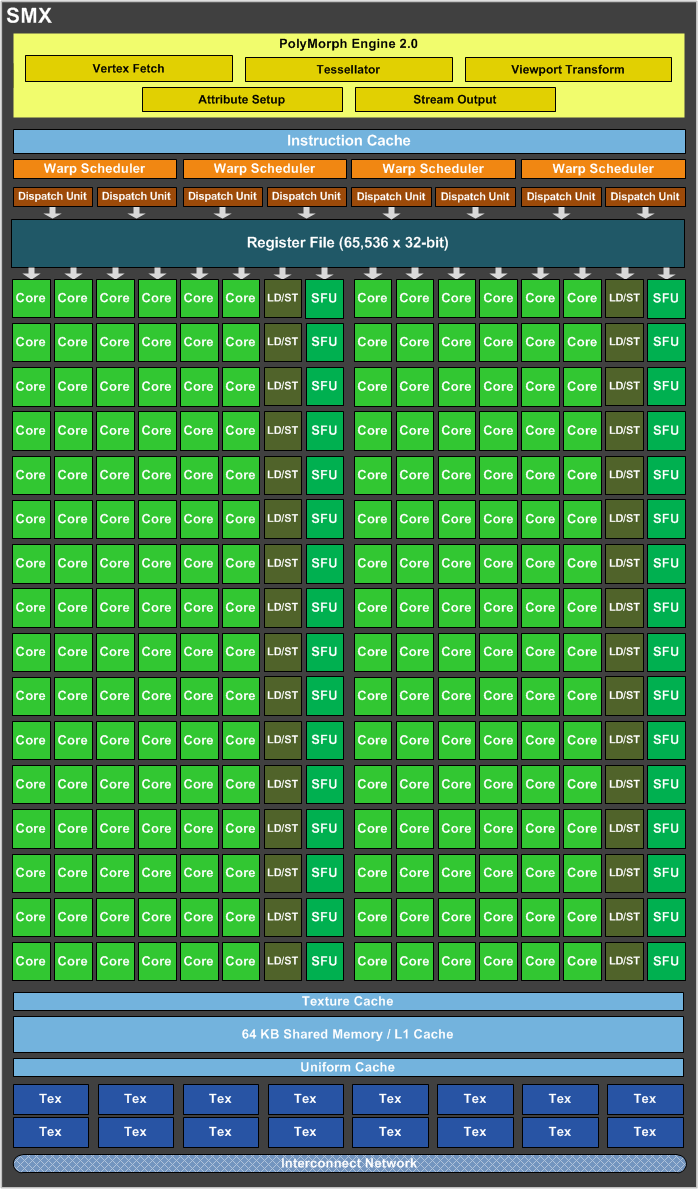
Если судить по представленным блок-схемам, основное новшество Maxwell заключается в эффективной реорганизации исполнительных компонентов GPU. На глобальном уровне GM204 следует принципам, заложенным еще в Kepler (подробнее о них можно прочитать в обзоре GeForce GTX 680). Вся вычислительная логика сосредоточена в структурах под названием Graphics Processing Cluster (GPC), которых в GM204 четыре. Вне GPC расположен весь back-end процессора в виде блоков ROP и нескольких 64-битных контроллеров памяти, а также Giga Thread Engine, выполняющий функции смены контекста, одновременного исполнения kernel’ов и распределения потоков нагрузки между GPC.
Первое количественное отличие от Kepler здесь состоит в кеше L2, увеличенном с 256 до 2048 Кбайт, что должно компенсировать узкую, 128-битную шину, а также сократить расход энергии на транзакции с весьма прожорливой памятью, каковой является GDDR5 SDRAM.
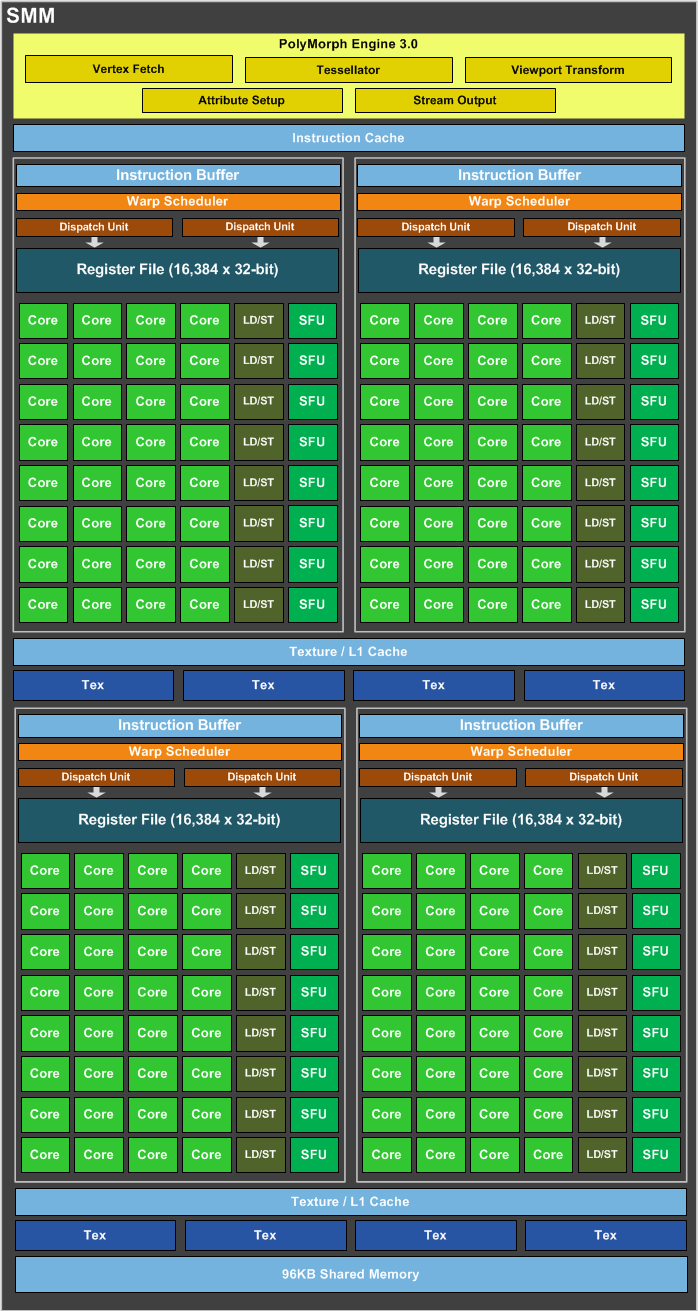
На уровне GPC значимых нововведений по сравнению с Kepler не заметно. Есть несколько Stream Multiprocessors (которые теперь называются аббревиатурой SMM, а не SMX), и есть единственный Raster Engine, выполняющий первоначальные стадии рендеринга: определение граней полигонов, проекцию и отсечение невидимых пикселов.
Главные изменения произошли внутри потоковых мультипроцессоров. Идея состоит в том, чтобы сместить соотношение управляющей и вычислительной логики в пользу первого компонента. Как и в Kepler, потоковый мультипроцессор содержит четыре планировщика, но число ядер CUDA уменьшилось с 192 до 128, а текстурных блоков — с 16 до 8.
Известно, что отдельно взятый планировщик за такт может обратиться к одному (а при наличии параллелизма в потоке — сразу к двум) из следующих массивов вычислительных блоков:
- 32 ядра CUDA;
- 8 блоков Load/Store;
- 8 SFU;
- 4 текстурных блока.
Ключевое нововведение Maxwell состоит в том, что исполнительные блоки теперь не являются одинаково доступными для адресации любому планировщику. Каждый планировщик теперь получил в свое распоряжение фиксированную часть ресурсов: 32 ядра CUDA, 8 блоков Load/Store и SFU (Special Function Units, выполняющие, к примеру, тригонометрические операции). Только текстурные блоки и ядра CUDA, совместимые с вычислениями FP64, по-прежнему являются общими ресурсами.
Какие преимущества по сравнению с Kepler дает такая организация? Во-первых, потоковый мультипроцессор Maxwell, избавившись от 64 ядер CUDA, меньше полагается на параллелизм инструкций: четыре планировщика даже в пессимистичном сценарии способны обслужить 128 ядер CUDA. Разделение исполнительных блоков на отдельные «домены» также позволило сократить логику, которая соединяет с ними планировщики (crossbars) и координирует действия самих планировщиков. Планировщики также оптимизированы с целью уменьшения латентности исполнения инструкций. В конечном счете эти изменения позволили сохранить 90% производительности отдельного потокового мультипроцессора при существенно меньшей площади SMM.
Maxwell базируется на оптимизациях энергопотребления, представленных в архитектуре Kepler. После архитектуры Fermi NVIDIA отказалась от динамических планировщиков внутри GPU, переложив всю работу по планированию внеочередного исполнения инструкций на компилятор в составе драйвера. Такой подход позволил существенно сократить мощность, к тому же он не оказывает большого негативного влияния на собственно шейдерные вычисления. Однако задачи общего назначения (GP-GPU), не связанные с графикой, не всегда предсказуемы для компилятора, поэтому, в то время как архитектура GCN от AMD наращивает производительность за счет дополнительного ILP (параллелизма на уровне инструкций), чипы Kepler/Maxwell достигают равной эффективности только за счет грубой силы в виде большого количества CUDA-ядер.
Что касается именно GM204, то, поскольку это чип второй категории, а более крупное ядро на базе Maxwell, возможно, ожидает нас в будущем, NVIDIA нашла приемлемым оставить в каждом SMM только четыре ядра CUDA с поддержкой F64. В результате производительность GM204 в вычислениях двойной точности относительно производительности при работе с FP32 даже меньше, чем у GK104, — 1/32 против 1/24.
⇡#GM204: вторая итерация Maxwell
Рассмотрим конфигурацию GM204 более внимательно. Цифра два в названи чипа указывает на вторую версию архитектуры Maxwel. И действительно, GM204 имеет несколько отличий от предтсавленных ранее GPU GM107 и GM108. Во-первых, на блок-схемах геометрический движок Polymorph Engine имеет версию 3.0, в то время как в GM107 — 2.0. Апгрейд обесечивает работу некоторых из новых аппаратных функций GM204.
Представленные в GM204 функции рендеринга делают его совместимым с наиболее полным feature level, официально существующим в стандарте DirectX — 11_1. Подробнее о них — в разделе ниже.
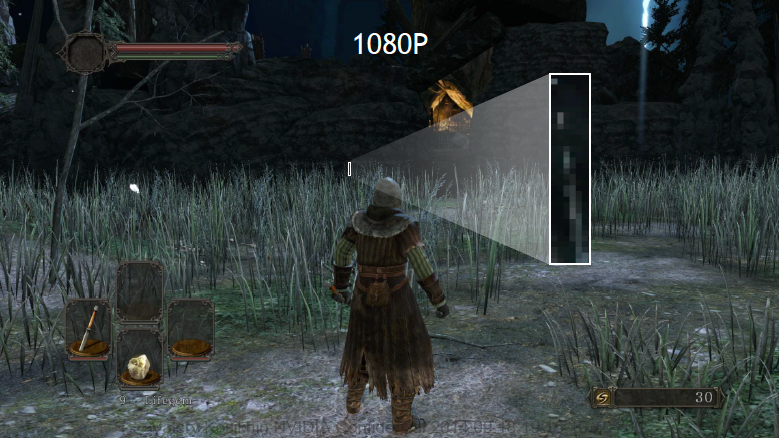
Другим дополнением архитектуры Maxwell второй волны стал усовершенствованный аппаратный кодек H.264 — NVENC. В Maxwell первой волны GPU уже был способен кодировать видео 1080p на скорости в 6-8 раз быстрее реального времени (4х для Kepler) и декодировать в 8-10 раз быстрее. Поддерживаются и 4K-разрешения. Кроме того, в Maxwell предусмотрен новый режим энергопотребления GC5, предназначенный для снижения мощности при легкой нагрузке — такой как декодирование видео силами NVENC. NVIDIA еще не внедрила в кремний декодер стандарта H.265 — он ускорятся лишь частично, с выполнением доли операций на CPU. Чем в этом плане отличается GM204, так это поддержкой полностью аппаратного кодирования видео стандарта H.265. Необходимая для этого производительность используется функцией NVIDIA ShadowPlay, которая позволяет на GM204 делать запись игрового процесса в разрешении Ultra HD с частотой 60 кадров/с. Увы, дела с поддержкой fixed-function-логики для кодирования видео в других, даже профессиональных приложениях, обстоят из рук вон плохо, хотя само железо давно присутствует в чипах NVIDIA и AMD.
По числу вычислительных блоков чип представляет собой промежуточный вариант между GK104 и GK110. В нем нет такого количества ядер CUDA, как в GK110. Но, принимая во внимание разную архитектуру, нельзя сравнивать чипы на базе Kepler и Maxwell напрямую по количеству исполнительных блоков. NVIDIA утверждает, что благодаря реогранизации логики GPU удалось увеличить эффективность ядра CUDA на 40%.
Наконец, GM204 имеет больше ROP, чем топовый Kepler, — 64 против 48. Это явно пойдет на пользу видеоадаптеру в 4К-разрешении, как показывает пример GPU AMD Hawaii, который также несет 64 ROP. Однако для того, чтобы реализовать потенциально столь большую скорость заполнения пикселов, требуется достаточная пропускная способность DRAM.
Между тем, конфигурация шины памяти адаптеров на GM204 такая же, как у GeForce GTX 770: разрядность 256 бит и эффективная частота 7 ГГц, в то время как GK110 и Hawaii используют, соответственно, 384- и 512-битные шины. Создателям GM204 пришлось принять меры для экономии пропускной способности интерфейса, которые, помимо увеличенного кеша L2, состоят в новом алгоритме цветовой компрессии. Это третья версия алгоритма, впервые представленного в чипе NV40, позволяющая сжимать данные с соотношением вплоть до 8:1 без потери информации.
⇡#GeForce GTX 970/980: технические характеристики
На основе GM204 NVIDIA выпустила два видеоадаптера — GeForce GTX 970 и GTX 980, которые различаются числом активных вычислительных блоков и тактовыми частотами. Флагманский адаптер имеет 1126 МГц базовой частоты по штатным спецификациям — это, прямо скажем, внушительное значение для техпроцесса 28 нм и 5,2 млрд транзисторов.
Новинки имеют беспрецедентно низкий TDP для своего класса: 145 и 165 Вт соответственно. Также весьма впечатляет, если учесть, что новинки заменяют в линейке GeForce модели с энергопотреблением от 230 до 250 Вт. Впрочем, забегая вперед, отметим, что в реальности запросы GM204 оказались повыше.
Поскольку GPU имеет 256-битную шину памяти, объем DRAM обеих моделей составляет 4 Гбайта. В этом плане GTX 970/980 превзошел модели GTX 780/780 Ti, имеющие 3 Гбайт RAM по референсным спецификациям, и не уступает топовым видеокартам AMD, которые также комплектуются 4 Гбайт видеопамяти на ядро.
Большие изменения GTX 980 принес в конфигурации видеовыходов. NVIDIA удалила один из портов DVI, зато теперь карта несет три разъема DisplayPort и HDMI стандарта 2.0 (что означает поддержку 4К-разрешений при частоте 60 Гц).
| Модель |
Графический процессор |
Видеопамять |
Шина ввода/
вывода |
TDP, Вт |
|
|
Кодовое название
|
Число транзисторов, млн
|
Техпроцесс, нм
|
Тактовая частота, МГц:
High State /Boost State
|
Число шейдерных потоковых процессоров
|
Число текстурных блоков
|
Число ROP
|
Разрядность шины, бит
|
Тип микросхем
|
Тактовая частота: реальная (эффективная), МГц
|
Объем, Мбайт
|
|
|
|
GeForce GTX 980
|
GM204
|
5200
|
28
|
1126/1216
|
2048
|
128
|
64
|
256
|
GDDR5 SDRAM
|
1750 (7000)
|
4096
|
PCI-Express 3.0 x16
|
165
|
|
GeForce GTX 970
|
GM204
|
5200
|
28
|
1050/1178
|
1664
|
104
|
64
|
256
|
GDDR5 SDRAM
|
1750 (7000)
|
4096
|
PCI-Express 3.0 x16
|
145
|
|
GeForce GTX 780 Ti
|
GK110
|
7100
|
28
|
875/928
|
2880
|
240
|
48
|
384
|
GDDR5 SDRAM
|
1750 (7000)
|
3072
|
PCI-Express 3.0 x16
|
250
|
|
GeForce GTX 780
|
GK110
|
7100
|
28
|
863/900
|
2304
|
192
|
48
|
384
|
GDDR5 SDRAM
|
1502 (6008)
|
3072
|
PCI-Express 3.0 x16
|
250
|
|
GeForce GTX 770
|
GK104
|
3540
|
28
|
1046/1085
|
1536
|
128
|
32
|
256
|
GDDR5 SDRAM
|
1502 (7010)
|
2048
|
PCI-Express 3.0 x16
|
230
|
Новые технологии рендеринга
Помимо оптимизаций, направленных на повышение производительности и энергоэффективности, Maxwell принес несколько дополнительных функций графичекого конвейера. Некоторые опираются на аппаратные средства GPU, другие – чисто программные. Кое-что из этого, как уже известно, войдет в набор новых функций API DirectX 12.
Dynamic Super Resolution (DSR)
Эта опция поначалу будет эксклюзивной для Maxwell, но затем в драйвере появится поддержка других GPU. DSR – простая в основе своей функция, которая состоит в том, что изображение рендерится в повышенном разрешении, а затем масштабируется к родному разрешению экрана при помощи гауссовского фильтра. Выглядит как старый добрый антиалиасинг методом суперсемплинга (SSAA). Фактически это он и есть, только — в отличие от «истинного» SSAA — DSR применяется к итоговому кадру на выходе с конвейера рендеринга. Следовательно, а) DSR можно форсировать в любой игре, б) всегда корректно применяются эффекты пост-обработки. С другой стороны, GUI в играх также отрисовывается в повышенном разрешении и масштабируется, из-за чего может выглядеть слишком мелко.
Драйвер позволяет выбрать множитель повышенного разрешения – от 1,2 до 4,0, а также резкость фильтрации.
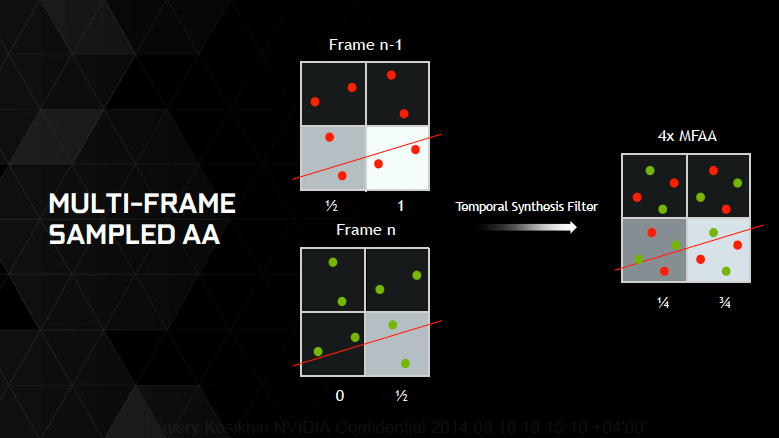
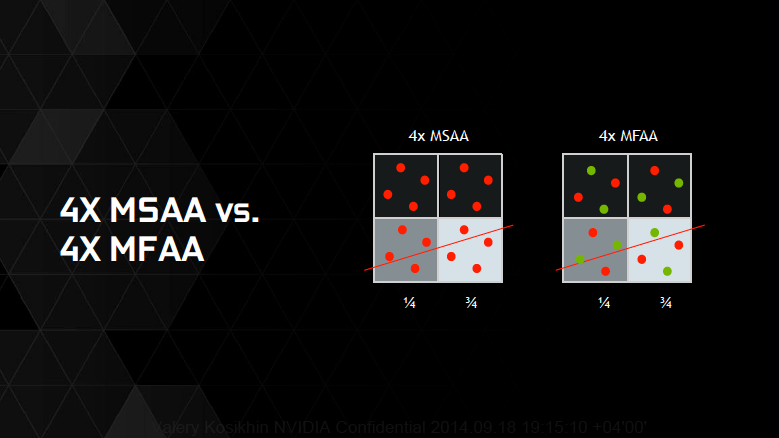
Multi-Frame Anti-Aliasing (MFAA)
Очередная фирменная технология полноэкранного сглаживания от NVIDIA представляет собой вариацию на тему мультисемплинга, которая увеличивает производительность по сравнению с традиционной реализацией MSAA. При использовании MSAA с мощностью, допустим, 4х происходит выборка четырех точек в проекции пиксела. Вместо этого MFAA 4x делает выборку по две точки в двух соседних кадрах, но со смещением паттерна, а затем комбинирует результат. Вычислительная нагрузка, таким образом, снижается (максимум на 30%) по сравнению с MSAA.
Для MFAA требуется GPU Maxwell, поскольку только он позволяет программировать позиции внутри пиксела, из которых происходит выборка. Технология пока находится в разработке и еще не включена в публичный драйвер NVIDIA.
Voxel Global Illumination (VXGI)
Самое интересное – это созданная NVIDIA реализация глобального освещения, обеспечивающая относительно нетребовательную к ресурсам и качественную аппроксимацию метода трассировки лучей (Ray Tracing) и других схожих алгоритмов, которые используются в производстве медиаконтента – компьютерной графики в кино и фотореалистичных изображений, но для исполнения в реальном времени требует колоссальных вычислительных мощностей. Скажем, отлично подходит кластер из 200 ускорителей Quadro на базе GK110 в установках NVIDIA VCA.
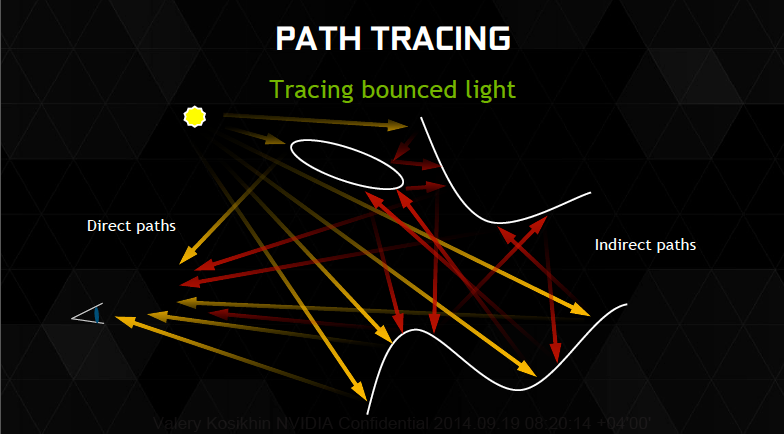
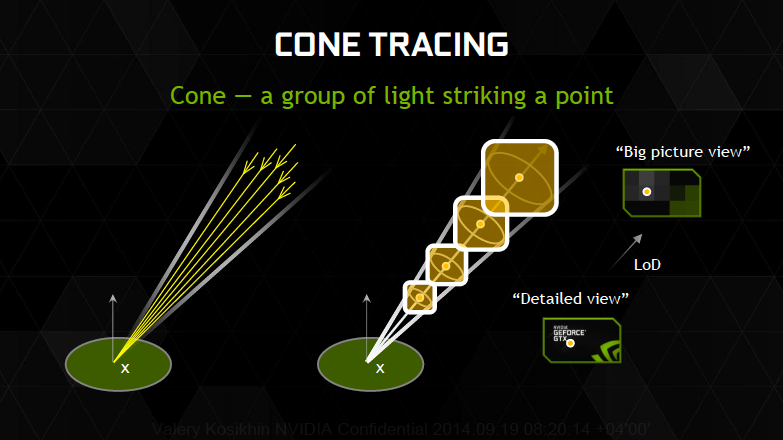
Типичная трассировка лучей строится на следующем алгоритме: из точки обзора прослеживается множество линий, исходящих во все стороны. Если линия (луч) наталкивается на геометрический примитив, уже из этой точки выпускается множество лучей (с учетом отражающих свойств материала) и так далее. Таким образом, источником колоссальной вычислительной нагрузки при трассировке лучей является сложность геометрии сцены, от которой зависит количество порождаемых лучей второго, третьего и последующих порядков.
В отличие от Ray Tracing (Path Tracing, Ray Casting), VXGI не является сам по себе методом рендеринга, но представляет собой дополнение к конвейеру растеризации, который ускоряется блоками фиксированной функциональности в GPU (T&L, текстурные модули, ROP) и применяется в компьютерных играх. Множественные отражения света от элементов геометрии сцены вычисляются при помощи аппроксимированной модели, благодаря чему соблюдается скорость обработки, необходимая для рендеринга в реальном времени.
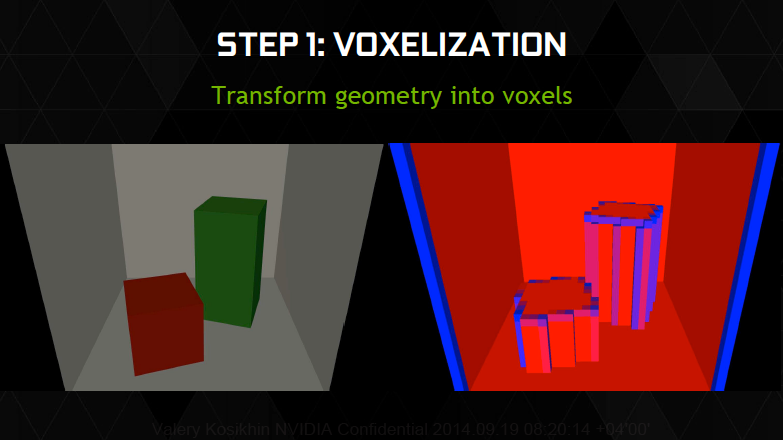
На первом этапе VXGI формируется модель сцены, состоящая из вокселов – кубических квантов пространства. Отрисовывая сцену с позиции каждой грани воксела, для воксела вычисляется доля объема, которая пересекается с объектами геометрии.
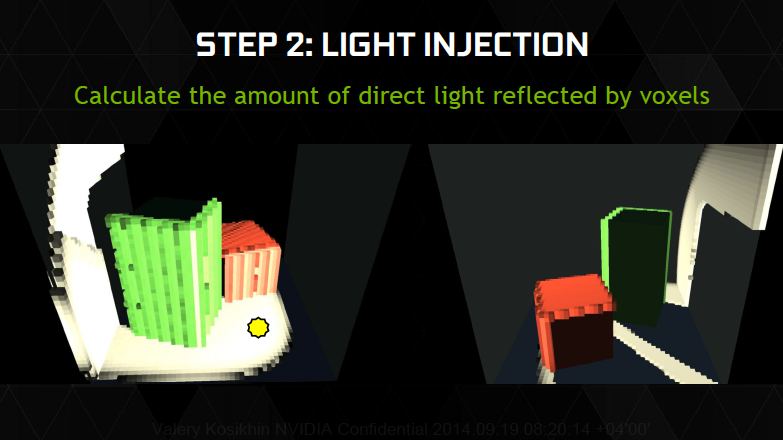
На втором этапе сцена отрисовывается множество раз с точки каждого воксела из тех, которые не оказались пустыми на предыдущем этапе. Записываются параметры света, падающего на воксел от прямых источников (включая направление и яркость) и свойства материала объектов, находящихся внутри.
Третий этап является частью конвейера растеризации. Когда пиксел проецируется на участок полигона, из этой «точки» испускаются конусы во всех направлениях. Вот первое ключевое отличие VXGI от Ray Tracing: вместо тысяч вторичных лучей используются немногочисленные конусы. Второе отличие: регистрируется пересечение конуса не с геометрией сцены как таковой, а с воксельной сеткой, которая аппроксимирует геометрию. Варьируя размер конусов, можно задавать оптические свойства материала. Широкие конусы дадут эффект поверхности, рассеивающей свет, узкие конусы – глянцевой.
В принципе, VXGI может использоваться и на других GPU, помимо Maxwell, однако именно в Maxwell есть аппаратные функции, которые ускоряют необходимые вычисления и приводят к приросту частоты смены кадров вплоть до 200% по сравнению с полностью софтверной реализацией VXGI.
- Viewport Multicast. Позволяет рендерить сцену с множественных точек обзора, предварительно только один раз загрузив геометрию без необходимости каждый раз проходить конвейер от начала до конца. Необходимо для ускорения первого этапа VXGI – вокселизации сцены.
- Volume Tiled Resources. GM204 получил поддержку Tiled Resources версии Tier 2. Эта технология аналогична том, что в железе AMD называется Partially Resident Textures. Смысл ее состоит в том, чтобы при использовании больших текстур не держать их целиком в памяти видеоадаптера в каждый момент времени. Вместо этого текстура разделяется на части (tiles), из которых загружаются в память только те, которые необходимы, и в необходимом разрешении. Volume Tiled Resources распространяет эту идею на трехмерные текстуры, в качестве которых могут выступать карты теней (shadowmaps) — традиционное средство в моделях статического освещения, как и воксельные сетки в DXGI.
- Conservative Raster. Также используется на этапе вокселизации и обеспечивает более точное определение пересечений воксела с полигонами сцены. Без поддержки этой функции в железе приходится прибегать к более затратным с позиции вычислительных ресурсов методам. Считается, что эта технология войдет в feature set ныне еще незавершенного API DirectX 12.

В сочетании с прямым освещением VXGI производит реалистичную сцену, свет в которой распространяется как от прямых источников, так и путем отражений от объектов, которые сами не светятся.
Внешний вид, конструкция
В отличие от большинства референсных образцов, GeForce GTX 980 прибыл к нам не в простом антистатическом пакете, а в стильной подарочной коробке. Любо-дорого взглянуть.
Сама видеокарта следует стилистике предшествующих топовых продуктов от NVIDIA, но есть нововведение: задняя поверхность PCB покрыта рифленой алюминиевой пластиной, как у GTX TITAN Z. Только в отличие от двухпроцессорного монстра, здесь пластина имеет лишь декоративную и защитную функции: на задней поверхности нет чипов DRAM. Пластина увеличивает толщину устройства на пару миллиметров. Поэтому для того, чтобы в режиме SLI видеокарта не перкрывала доступ воздуха к системе охлаждения соседки, установленной вплотную, в пластине сделали разрез напротив горловины турбинки. Закрепленный винтом фрагмент легко удаляется.


NVIDIA сконструировала практически идеальный радиальный кулер («турбинку», или blower), эффективность и высокие акустические качества которого были проверены не раз. Ну а в дополнение к практическим достоинствам увесистую видеокарту в цельнометаллическом кожухе просто приятно взять в руки. Однако система охлаждения GeForce GTX 980 кое в чем отличается от тех образцов, которые были представлены в референсных версиях GeForce GTX 770 и GTX TITAN.
Массивная крыльчатка продувает большую часть забираемого воздуха через радиатор GPU и выбрасывает за пределы корпуса ПК. В основание радиатора вмонтированы три тепловые трубки, а не испарительная камера, как прежде, — и это главное изменение. Кроме того, с времен GeForce GTX 780 Ti и TITAN Black — последних однопроцессорных адаптеров на базе GK110 — NVIDIA поменяла форму крепежной планки и расположение видеовыходов. Решетка имеет более крупные ячейки и распространилась на площадь, которую в предшествующих продуктах занимал второй разъем DVI. Часть воздуха исходит в противоположном от планки направлении, охлаждая небольшой блок ребер, смонтированных на раме, которая покрывает печатную плату.
Алюминиевая рама отводит тепло от микросхем памяти, которые в полном составе находятся на лицевой поверхности платы, и от мощных транзисторов системы питания.
⇡#Плата
Видеопамять объемом 4 Гбайт набрана микросхемами Samsung K4G41325FC-HC28, для которых 7 ГГц являются штатной эффективной частотой. Система питания довольно скромная для видеоадаптера такого класса: она включает четыре фазы для питания GPU, одну — для видеопамяти и еще одну — для PLL. Производителя и модель контроллера питания по маркировке определить не удалось.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex