|
Опрос
|
реклама
Быстрый переход
ByteDance представила Seedream 5.0 Pro — флагманскую ИИ-модель для генерации и редактирования изображений
11.07.2026 [07:31],
Владимир Фетисов
ByteDance выпустила Seedream5.0 Pro —мультимодальную языковую модель для генерации изображений, предназначенную для выполнения функций производственного дизайна. Алгоритм ориентирован на создателей контента, дизайнеров, маркетологов и других людей, которым требуются насыщенные визуальные макеты, локализованный текст, функции точного редактирования и возможность многократного использования шаблонов, созданных на основе текстовых запросов. 
Источник изображения: testingcatalog.com В Seedream 5.0 Pro разработчики реализовали несколько ключевых улучшений, включая возможность визуализации сложной инфографики, функции точного редактирования, генерацию реалистичных изображений и текстур портретов, а также поддержку ввода и генерации текста на разных языках. По данным ByteDance, алгоритм способен превращать данные, концепции и длинные тексты в профессиональные макеты, генерировать инфографику, изображения, UI-макеты, визуальные материалы для обучения и структурированные активы для коммерческого использования. По сравнению с предыдущими версиями ИИ-модели, новинка отличается более высоким уровнем согласованности между вводимым пользователем запросом и результатом генерации, улучшенной структурной целостностью и визуальной эстетикой. Seedream 5.0 Pro поддерживает функцию выделения отдельных областей изображения с помощью точки или лассо для редактирования без повторной генерации всего кадра. Перекрытые объектом редактирования участки генерируются автоматически. При необходимости изображение можно разделить на отдельно редактируемые слои, такие как основной объект, фон, текст и декоративные элементы. ИИ-модель обеспечивает генерацию изображений фотореалистичного качества за счёт проработки освещения в кадре, текстуры кожи на портретах, добавления физически достоверных отражений и других эффектов. Алгоритм может обрабатывать запросы и создавать изображения с текстом на более чем 10 языках, включая русский, английский, китайский, немецкий, арабский и др. На данном этапе модель Seedream 5.0 Pro доступна для тестирования через API BytePlus. Meta✴ представила Muse Image — свою первую серьёзную модель для генерации изображений, которая будет доступна Meta✴ AI и соцсетях
08.07.2026 [09:41],
Павел Котов
Meta✴✴ выпустила первую генерирующую изображения модель искусственного интеллекта, разработанную сформированным в прошлом году подразделением Superintelligence Labs. Muse Image интегрирована в графические редакторы приложений Meta✴✴ AI, Instagram✴✴ и WhatsApp; скоро она появится в Facebook✴✴ и Facebook✴✴ Messenger. 
Источник изображения: Meta✴✴ Модель стала новым членом семейства Muse, пришедшего на смену Llama. Muse Image располагает агентными функциями — она подключается к большой языковой модели Muse Spark, «чтобы проанализировать ваш запрос, выполнить поиск в интернете и спланировать работу до генерации», пояснил глава Superintelligence Labs Александр Ван (Alexandr Wang). Он также пообещал, что скоро компания выпустит модель Muse Video — она «конкурентоспособна по соответствию запросам, визуальной точности и временно́й согласованности». В запросах к Muse Image можно упоминать аккаунты других пользователей Instagram✴✴, чтобы включать фото с их страниц в свои работы. Такого рода редактирование и генерация смогут работать только с общедоступными материалами; при этом пользователи смогут контролировать, как другие используют их контент при работе с ИИ. По запросам доступно редактирование изображений, а также создание дизайна приглашений и открыток. Ещё одна функция — создание нового дизайна для объектов недвижимости на платформе Facebook✴✴ Marketplace. Muse Image будет использоваться для 30 новых ИИ-эффектов при публикации в разделе Instagram✴✴ Stories для пользователей в США — впоследствии функция будет доступна и в других странах, а также в других разделах приложений Meta✴✴. Учёные создали генератор идеальной случайности — надёжной, как швейцарские часы
30.05.2026 [11:47],
Геннадий Детинич
Учёные из Швейцарской высшей технической школы Цюриха (ETH Zurich) сообщили о первом экспериментальном получении так называемой идеальной случайности — последовательности нулей и единиц, которую можно смело сертифицировать как лишённую скрытых параметров, что архиважно для криптографии, блокчейна и розыгрыша лотерей. Метод превосходит обычные квантовые технологии получения случайных величин, хотя опирается на основополагающие принципы квантовой механики. 
Источник изображения: ИИ-генерация ChatGPT/3DNews Настоящая неопределённость может быть получена только в квантовых приложениях, но даже она не является идеальной, а значит, уязвима для вдумчивого дешифрования. В любом физическом воплощении квантового генератора всегда присутствуют вещи, приводящие к предсказуемому дрейфу значений. Поэтому швейцарские учёные копнули глубже — смогли использовать для очищения квантовых данных базовые принципы квантовой механики, а именно — проверку неравенств Белла. Сегодня без измерений Белла в квантовых экспериментах — никуда. Только они надёжно подтверждают, к какой физике можно отнести результаты эксперимента — к классической или к квантовой. Исследователи собрали систему для измерений Белла в виде двух сверхпроводящих кубитов, связанных 30-м линией связи, также охлаждённой. Система позволяет запутывать два кубита, а дальность в 30 метров означает, что квантовый эффект запутанности сработает без прямой передачи данных, ведь даже скорости света не хватит, чтобы в момент измерения передать информацию от одного кубита к другому. После получения последовательности случайных нулей и единиц на предложенной платформе, специальный алгоритм «очищает» или, как говорят сами разработчики, служит своеобразным «усилителем» неопределённости. Проверка данных с помощью измерений Белла позволяет утверждать, что это фактически сертифицированная платформа для генерации истинно случайных значений. Это как атомные часы в измерениях — придёт время, уверены учёные, и подобные идеальные квантовые генераторы станут работать эталоном для получения случайных чисел. Настанет век настоящих случайностей — надёжных, как швейцарские часы! Уход Sora открыл дорогу конкурентам: ИИ-генераторы видео Kling AI и AI Video ворвались в топы Apple App Store
13.05.2026 [18:53],
Дмитрий Федоров
Два приложения для создания видео с помощью ИИ — Kling AI и AI Video — поднялись на пятое и шестое места в рейтинге самых скачиваемых бесплатных приложений Apple App Store. Оба лидируют в своих категориях: Kling AI заняло первую строчку в «Графике и дизайне», AI Video — в «Фото и видео». Их рост начался спустя два месяца после закрытия видеосервиса Sora компании OpenAI. Оба приложения выигрывают от нового всплеска внимания пользователей iPhone к ИИ-генерации видео. 
Источник изображений: apps.apple.com OpenAI свернула Sora главным образом из-за стоимости обслуживания: бесплатный сервис потреблял слишком много ресурсов. Компания сосредоточилась на ChatGPT и Codex — инструментах для повышения продуктивности, причём Codex лучше раскрывается на платных тарифах. 
AI Video - AI Video Generator После ухода Sora конкурирующие ИИ-приложения стали активнее продвигать генерацию видео. Gemini и Grok уже позволяют превращать текстовые запросы и изображения в ролики, однако для этих универсальных чат-ботов видео остаётся лишь одной из возможностей. 
Kling AI: AI Image&Video Maker Kling AI и AI Video целиком посвящены созданию роликов. Kling AI появилось в App Store три месяца назад. AI Video выпущено компанией HUBX, у которой в магазине размещено 15 ИИ-приложений. Новое приложение нацелено на создание вирусных видеороликов. Выше обоих в рейтинге стоят только продукты OpenAI, Anthropic, Google и Meta✴✴. Sora тоже возглавляла чарт при запуске, но через несколько месяцев перестала показывать заметные результаты. Генераторы изображений стали главным драйвером роста ИИ-чат-ботов
05.05.2026 [11:50],
Павел Котов
Выпуск моделей с генераторами изображений стимулирует увеличение популярности мобильных приложений с искусственным интеллектом — рост по сравнению с простыми обновлениями ускоряется в 6,5 раза, показала статистика аналитической компании Appfigures. 
Источник изображения: Milad Fakurian / unsplash.com Для OpenAI ChatGPT и Google Gemini появление генераторов изображений увеличивало аудиторию на десятки миллионов пользователей. В течение 28 дней после выхода генератора изображений Nano Banana с чат-ботом Gemini 2.5 Flash приложение набрало 22 млн новых пользователей, что соответствует росту числа загрузок более чем вчетверо за указанный период. 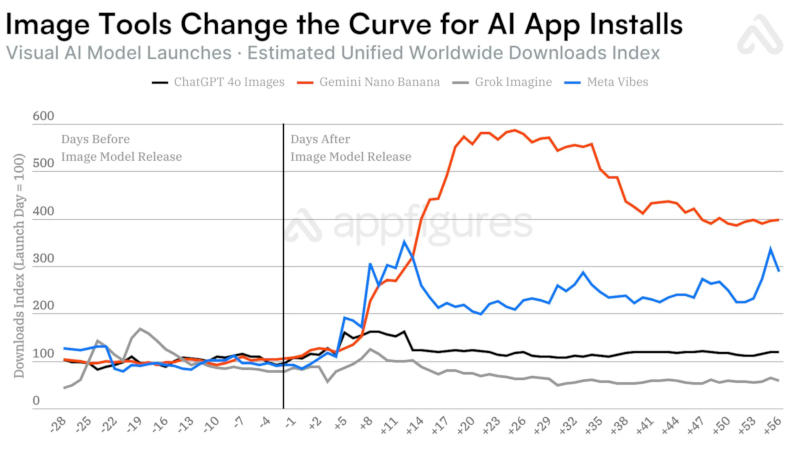 В случае генератора изображений в составе OpenAI GPT-4o рост аудитории составил 12 млн человек — в 4,5 раза быстрее по сравнению с базовым вариантом GPT-4o, а также GPT-4.5 и GPT-5. Аналогичная тенденция сработала и с появлением ленты Vibes в приложении Meta✴✴ AI, хотя оно предлагало генерацию не изображений, а видео — нововведение дало 2,6 млн дополнительных загрузок. 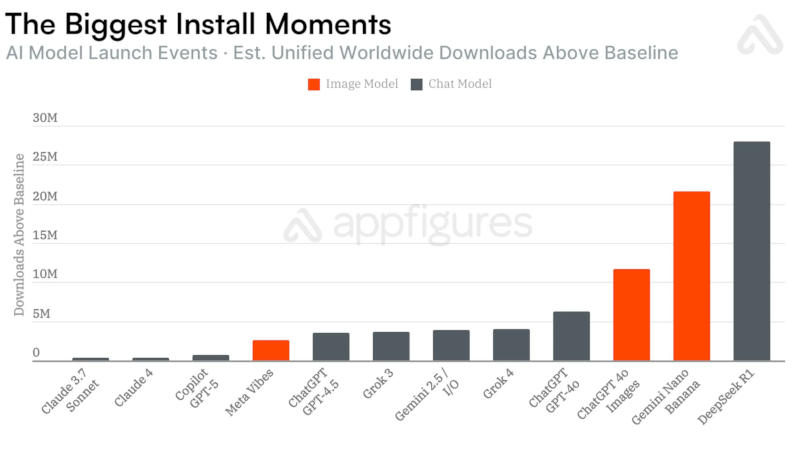 К сожалению для разработчиков, росту числа загрузок не всегда сопутствует рост выручки: в случае с Nano Banana компания Google заработала лишь на $181 тыс. больше; приложение Meta✴✴ AI с появлением Vibes существенного роста дохода не показало; и только в случае OpenAI модель GPT-4o с генератором изображения помогла компании нарастить выручку на $70 млн за 28 дней. 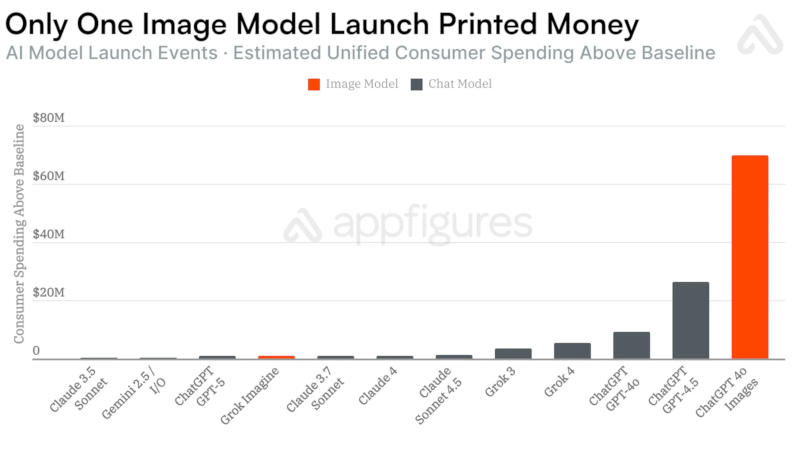 Единственным исключением из правил оказался взрывной рост в 28 млн загрузок с выходом модели DeepSeek R1, отметили в Appfigures. Всё потому, объясняют аналитики, что компания DeepSeek сама по себе стала мировой сенсацией из-за уникальных методов обучения ИИ с минимальными затратами по сравнению с конкурентами — генератора изображений в приложении не было. Microsoft представила облегчённый ИИ-генератор изображений MAI-Image-2-Efficient
15.04.2026 [14:50],
Павел Котов
Microsoft анонсировала обновлённую версию модели искусственного интеллекта, которая генерирует изображения по текстовым запросам, — она получила название MAI-Image-2-Efficient. Она и её предшественница MAI-Image-2 генерируют качественные фотореалистичные картинки, при этом новая работает на 22 % быстрее и вчетверо эффективнее. 
Источник изображения: BoliviaInteligente / unsplash.com В марте Microsoft запустила на платформах Copilot, Bing Image Creator и MAI Playground генератор изображений MAI-Image-2, который занял в рейтинге Arena.ai третье место среди себе подобных. Недавно компания расширила доступ к ней, добавив её на платформу Foundry наряду с MAI-Voice-1 и MAI-Transcribe-1. Обновлённая MAI-Image-2-Efficient создана для случаев, когда необходимо нечто быстрое, масштабируемое и не влекущие неоправданных расходов ресурсов. Если не требуется высокая точность изображений, MAI-Image-2-Efficient оказывается оптимальным вариантом — она пригодится для генерации иллюстраций в соцсетях, создания макетов-заглушек и миниатюр продуктов; то есть в тех случаях, когда скорость и объём контента важнее пиксельной точности. Microsoft MAI-Image-2, напротив, проявляет себя во всей красе, когда востребован, например, качественный портрет героя, кинематографическая сцена и внимание к деталям, а аспект скорости отходит на второй план. Обновлённая MAI-Image-2-Efficient по ряду параметров превосходит не только предшественницу от самой Microsoft, но также работает на 40 % быстрее таких систем как Google Gemini 3.1 Flash, Gemini 3.1 Flash Image и Gemini 3 Pro Image. Разработчики уже могут подключать MAI-Image-2-Efficient на платформах Microsoft Foundry и MAI Playground. Стоимость её работы составляет $5 за 1 млн входящих и $19,50 за 1 млн выходящих токенов — для сравнения, стоимость использования MAI-Image-2 составляет $5 и $33 соответственно. Скоро MAI-Image-2-Efficient появится в Copilot, Bing и на других платформах. Alibaba выпустила HappyHorse — открытый ИИ-генератор видео, который обошёл всех конкурентов
10.04.2026 [10:46],
Павел Котов
На платформе Artificial Analysis опубликовали предназначенную для генерации видео модель искусственного интеллекта HappyHorse-1.0, которая со значительным отрывом обошла лидера в лице Seedance 2.0 от ByteDance. 
Источник изображения: happyhorse-ai.com В категории генерации видео без звука по текстовому запросу HappyHorse-1.0 набрала рейтинг Elo 1357, опередив Seedance 2.0 на 84 балла; в задачах на анимацию статической картинки она показала Elo 1402, также выйдя на первое место. В генерации видео со звуком она оказалась второй, уступив Seedance 2.0 с 1215 баллами против 1220; а в анимации картинок снова оказалась первой с результатом 1160 против 1158 у прежнего лидера. Оторваться на 84 балла в этом рейтинге — это сильный результат, указывающий, что в слепом тестировании HappyHorse-1.0 оказывается лучше примерно в 62 % случаев. Разработчиком HappyHorse-1.0 оказалась Future Life Lab при Taotian Group — это подразделение Alibaba отвечает за технологии электронной коммерции. Главой лаборатории является Чжан Ди (Zhang Di), прежде занимавший пост вице-президента Kuaishou и технического руководителя проекта Kling AI, ранее выпускавшего мощные генераторы видео. В конце 2025 года он начал работу в Taotian, и модель HappyHorse-1.0 стала первым проектом новой структуры. Примечательно, что у Alibaba уже был собственный ИИ-генератор видео Wan, который тоже оказался слабее нового проекта. HappyHorse-1.0 представляет собой ИИ-модель на архитектуре 40-слойного трансформера с 15 млрд параметров, в котором данные генерируются диффузионным методом и обрабатываются единым потоком, включающим текст, изображения, видео и звук. Ресурсов ускорителя Nvidia H100 хватает для генерации 5-секундного клипа в разрешении 256p за 2 секунды; на генерацию 5-секундного ролика в 1080p уходят 38 секунд. Разработчики обещают в скором будущем выложить в открытом виде базовую модель HappyHorse-1.0, её уменьшенную дистиллированную версию, модуль повышения разрешения и код для запуска модели. Nvidia вывела из беты динамический генератор кадров и режим MFG 6X в DLSS 4.5
09.04.2026 [19:03],
Николай Хижняк
Компания Nvidia завершила тестирование новых функций динамического мультикадрового генератора и режима MFG 6X в составе DLSS 4.5, включив их в стабильную версию приложения Nvidia App для управления графикой GeForce. Ранее данные функции были доступны только в составе бета-версий. 
Источник изображений: Nvidia Новые функции доступны в разделе «Графика» > «Настройка программы» > «Настройки драйвера» > DLSS Override > «Режим генерации кадров». Компания сообщает, что в настоящий момент динамический режим генерации кадров несовместим с функциями ограничения частоты кадров и вертикальной синхронизации (V-Sync). В настройки Nvidia App также добавлены режимы генерации кадров 5X и 6X. По данным компании, в совместимых играх масштабирование может достигать шестикратного увеличения, а видеокарты серии GeForce RTX 50 могут повысить производительность в 4K-играх с трассировкой лучей на 35 % при переходе с четырёхкратного на шестикратный мультикадровый рендеринг.  Обновление также включает новую модель Frame Generation для видеокарт GeForce RTX 40-й и 50-й серий. По данным Nvidia, новая модель использует дополнительные данные движка в поддерживаемых играх для повышения чёткости мини-карт, статических элементов интерфейса и других компонентов пользовательского интерфейса при включённой функции Frame Generation. Nvidia также продолжает внедрять обновления DLSS на уровне приложений, не дожидаясь выхода патчей для самих игр. В новый список игр, получивших поддержку функции DLSS Override, вошли: Arknights: Endfield, Black One Blood Brothers, Carmageddon: Rogue Shift, Code Vein II, Corsairs Legacy, Crimson Desert, Death Stranding 2: On the Beach, Demonologist, For Honor, Grounded 2, Half Sword, High On Life 2, John Carpenter’s Toxic Commando, Let It Die: Inferno, Lort, Marathon, Monster Hunter Stories 3, Nightmare Frontier, Nioh 3, Norse: Oath of Blood, Of Ash and Steel, Quarantine Zone: The Last Check, Reanimal, Resident Evil Requiem, Star Trek: Voyager — Across the Unknown, StarRupture, Styx: Blades of Greed, The Gold River Project, The Legend of Heroes: Trails Beyond the Horizon, Vampires: Bloodlord Rising и Yakuza Kiwami 3 & Dark Ties.  Новая версия приложения Nvidia App также добавляет оптимальные игровые настройки для Arknights: Endfield, Ashes of Creation, Highguard, StarRupture и The Last Caretaker. Кроме того, в приложении исправлен ряд проблем и ошибок. С их списком можно ознакомиться выше. Скачать приложение Nvidia App можно с официального сайта Nvidia. Google представила ИИ-модель Veo 3.1 Lite для генерации видео до 8 секунд — он дешевле Veo 3.1 и Veo 3.1 Fast
31.03.2026 [22:44],
Николай Хижняк
Компания Google анонсировала генератор видео Veo 3.1 Lite. В иерархии продуктов он находится ниже версии Veo 3.1 Fast. При этом версия Veo 3.1 остаётся флагманским решением компании. Veo 3.1 Lite является «наиболее экономичной моделью для работы с видео» от Google. 
Источник изображений: Google Предназначенный для «приложений с большим объёмом видеоконтента» генератор Veo 3.1 Lite поддерживает преобразование текста в видео и изображений в видео, а также разрешения 720p или 1080p с горизонтальным (16:9) и вертикальным (9:16) соотношением сторон. Он предлагает ту же скорость генерации, что и Veo 3.1 Fast.  Пользователи могут настраивать продолжительность генерации в 4, 6 или 8 секунд — стоимость будет корректироваться соответствующим образом. Что касается цены, она составляет «менее 50 % от стоимости Veo 3.1 Fast», цена которого снизится 7 апреля.  Генератор видео Veo 3.1 Lite доступен через платный тарифный план в API Gemini и Google AI Studio. Решения для генерации видео Google Veo интегрированы в различные продукты компании, включая YouTube Shorts, Google Photos, Google Vids и приложение Gemini. Также генератор предлагается в составе видеоредактора Flow. Ещё больше ненастоящих кадров: Nvidia выпустила DLSS 4.5 с динамическим мультикадровым генератором и режимом MFG 6X
31.03.2026 [19:11],
Николай Хижняк
Компания Nvidia выпустила функцию динамического мультикадрового генератора (DLSS 4.5 Dynamic Multi Frame Generation), а также режим мультикадрового генератора 6X (Multi Frame Generation 6X, MFG 6X). Обе технологии доступны через бета-версию приложения Nvidia App и поддерживаются только видеокартами GeForce RTX 50-й серии. 
Источник изображений: Nvidia Nvidia заявляет, что для работы DLSS 4.5 Dynamic Multi Frame Generation и MFG 6X требуется драйвер GeForce Game Ready Driver 595.79 WHQL или более новая версия. 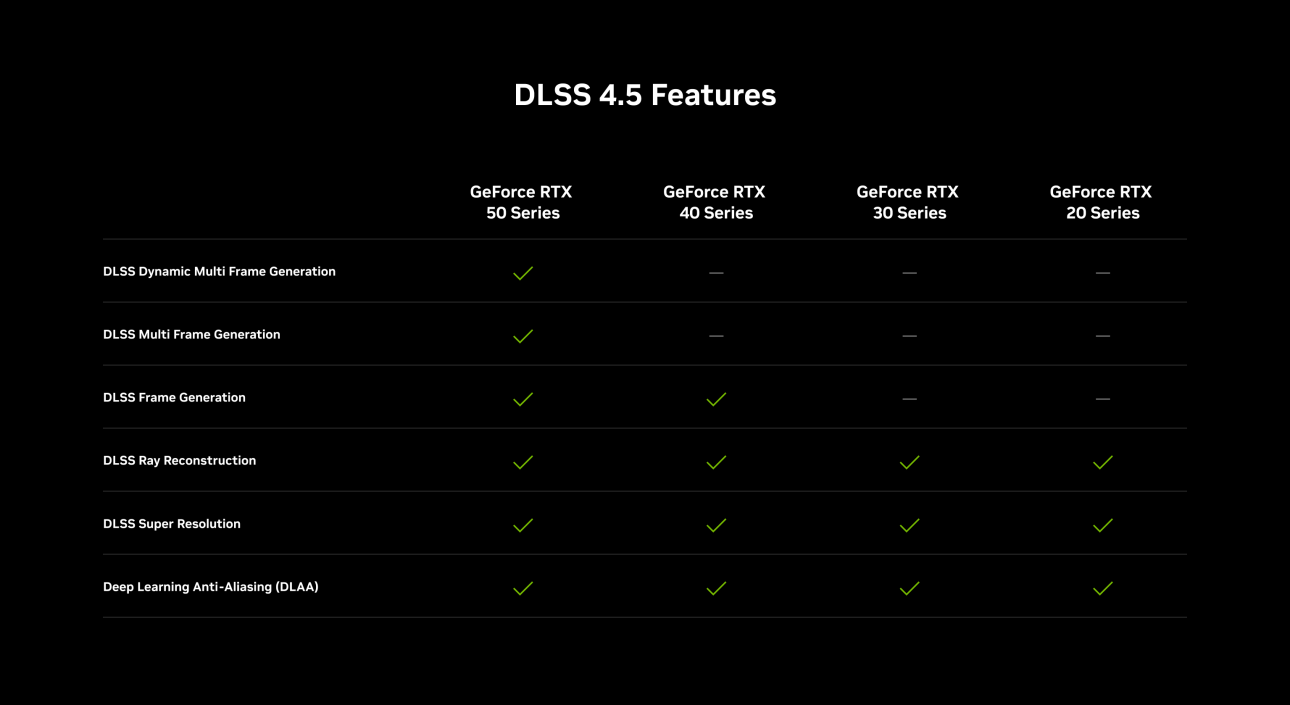 Новый динамический режим (DLSS 4.5 Dynamic Multi Frame Generation) заменяет фиксированный множитель кадров адаптивной системой, которая изменяется в реальном времени в зависимости от загрузки графического процессора и частоты обновления дисплея. Nvidia заявляет, что эта функция предназначена для генерации только того количества кадров, которое необходимо для достижения выбранного предела или частоты обновления монитора, вместо того, чтобы оставаться привязанным к одному предустановленному множителю на протяжении всего игрового процесса. 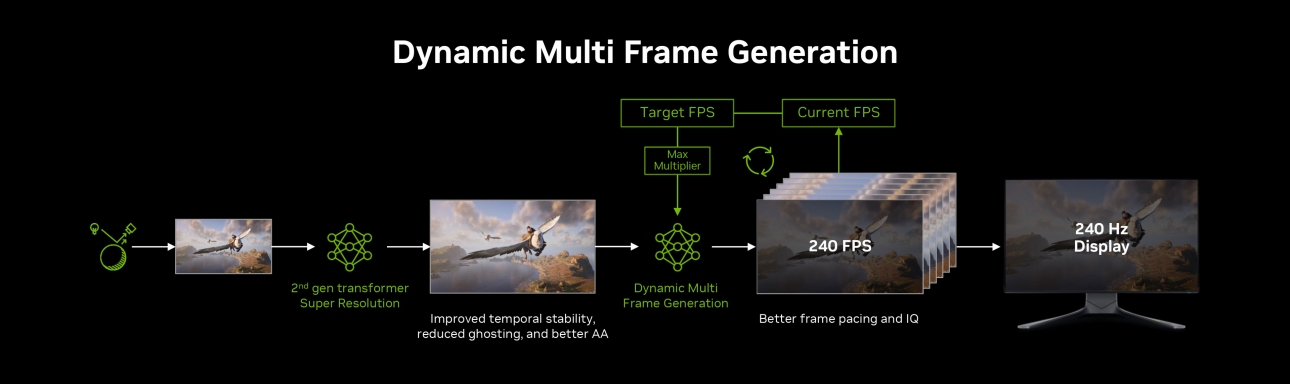 В режиме MFG 6X графический процессор может генерировать пять дополнительных кадров для каждого настоящего отрендеренного кадра. Nvidia заявляет, что переход с режима генерации 4X на 6X может повысить производительность в играх с трассировкой лучей в разрешении 4K до 35 % на видеокартах серии GeForce RTX 50. Для контроля уровня задержки используется технология Reflex. 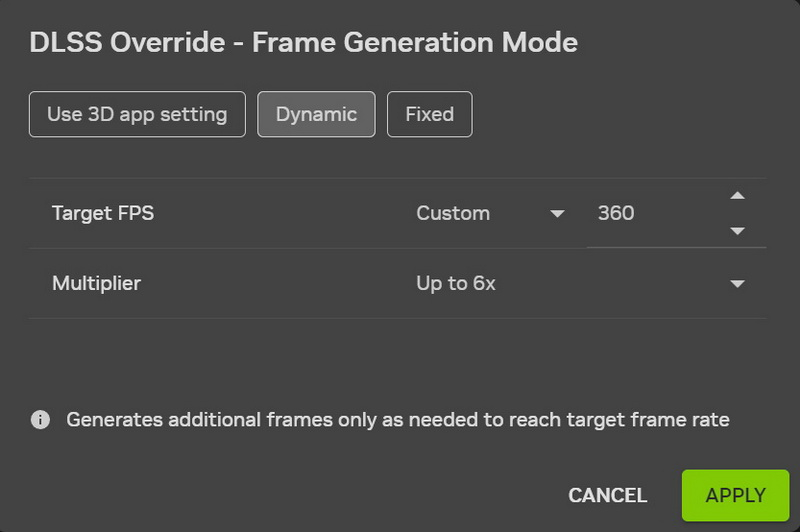 Новые функции доступны только через приложение Nvidia App (через настройки DLSS Override). Пользователям необходимо включить в настройках приложения поддержку бета-версий и экспериментальные функции, а затем на вкладке «Графика» выбрать параметр DLSS для режима генерации кадров. Nvidia заявляет, что динамический и фиксированный режимы теперь работают параллельно, при этом фиксированный режим работает как старые параметры ручного множителя. 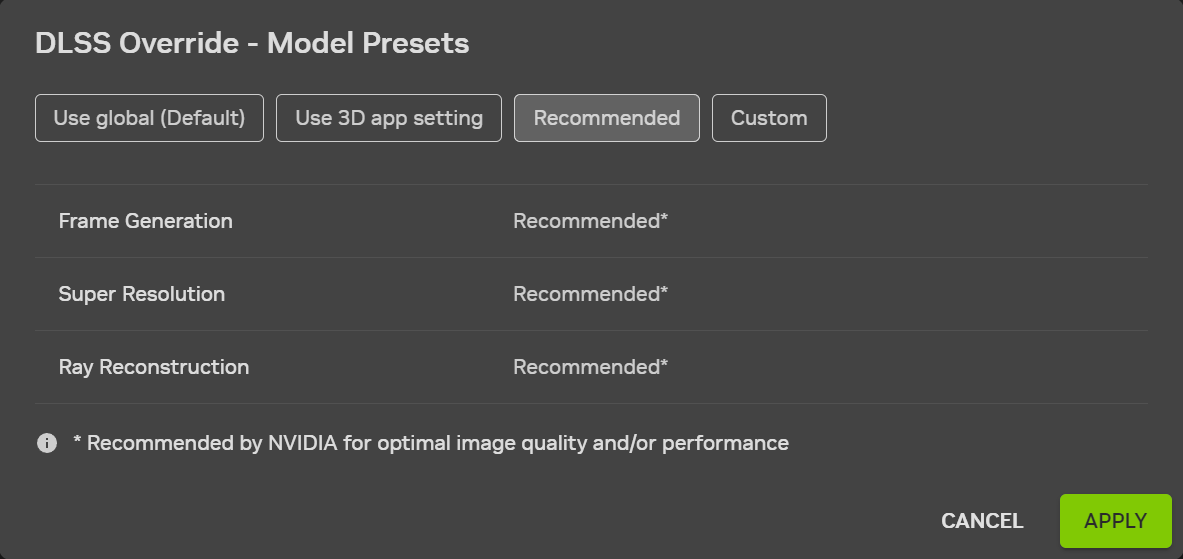 Бета-версия приложения Nvidia App также содержит поддержку обновления DLSS 4.5 Super Resolution для Arc Raiders и Marvel Rivals. Nvidia также сообщила, что поддержку DLSS 4.5 и технологии трассировки в перспективе получат ещё 20 новых и уже выпущенных игр: 007 First Light, Aniimo, Barkour, Control Resonant, Cthulhu: The Cosmic Abyss, Directive 8020, Edge of Memories, Edge of Memories, Endurance Motorsport Series, Gray Zone Warfare, Industria 2, Samson, Sea of Remnants, StarRupture, Star Wars: Galactic Racer, The Mound: Omen of Cthulhu, Tides of Annihilation, War Thunder, Where Winds Meet. Стала известна причина закрытия ИИ-генератора видео OpenAI Sora и она весьма прозаична
30.03.2026 [11:15],
Алексей Разин
На прошлой неделе OpenAI внезапно отказалась от поддержания ИИ-генератора видео Sora в строю, тем самым подведя студию Disney, которая успела ранее заключить договор, затрагивающий условия использования этого сервиса. Издание The Wall Street Journal со ссылкой на собственные источники сообщило, что основной причиной принятия столь серьёзного решения стала банальная нехватка ресурсов. 
Источник изображения: OpenAI Характерно, что речь идёт не только о финансовых ресурсах, хотя энергоёмкий сервис действительно требовал от OpenAI довольно высоких затрат на генерацию видео. Из этих соображений на раннем этапе популярности Sora компания даже ограничила продолжительность создаваемых одним пользователем видео десятью секундами, чтобы инфраструктура могла справляться с вычислительной нагрузкой. Монетизировать Sora в сжатые сроки не представлялось возможным, а расходов на своё развитие и эксплуатацию генератор видео по текстовому запросу требовал серьёзных. По некоторым данным, эксплуатация Sora обходилась OpenAI примерно в $1 млн в день. Популярность Sora хоть и взлетела до 1 млн пользователей на начальном этапе, в последнее время откатилась до уровня в 500 000 пользователей. При этом каждый из них отнимал у OpenAI востребованные в других проектах вычислительные ресурсы в приличном объёме. Источник подчёркивает, что внутренняя система мониторинга позволяет OpenAI отслеживать, чем заняты используемые в инфраструктуре стартапа ускорители вычислений. Команда разработчиков Sora, которая исторически обладала в стартапе определённой самостоятельностью, получила весьма солидную часть вычислительных ресурсов, что в условиях их нехватки на других направлениях вызвало вопросы у руководства OpenAI. Прилично заработать на Sora компания вряд ли могла бы, а вот тратить приходилось много. Кроме того, из-за дефицита ресурсов страдали другие направления развития, которые были признаны приоритетными. От идеи предлагать платный доступ к Sora через ChatGPT стартап в конечном итоге отказался. Внезапность решения OpenAI о закрытии проекта Sora подтверждают и представители Disney, с которой у стартапа был заключён договор на $1 млрд. Он предусматривал, что Disney вложит соответствующую сумму в капитал OpenAI и позволит пользователям Sora использовать лицензированных персонажей из множества принадлежащих студии франшиз в своём творчестве по созданию роликов с помощью ИИ. Руководство Disney об отказе OpenAI от поддержки Sora в работоспособном состоянии узнало примерно на час быстрее общественности, что нельзя считать заблаговременным предупреждением. В принципе, после смены руководства Disney сейчас ведёт переговоры более чем с 10 возможными партнёрами, которые смогут предоставить студии различные ИИ-услуги. На официальном уровне Disney выражает признательность OpenAI за полученный опыт сотрудничества и с уважением относится к принятому решению отказаться от развития Sora. Microsoft представила MAI-Image-2 — ИИ-генератор изображений, который оказался неожиданно хорош в фотореализме и инфографике
21.03.2026 [12:07],
Владимир Фетисов
В октябре прошлого года Microsoft представила ИИ-модель для генерации изображений MAI-Image-1, которая заняла девятое место рейтинга на платформе Arena.ai. Теперь же софтверный гигант объявил о запуске алгоритма второго поколения MAI-Image-2, способного создавать изображения с более естественным освещением, точной передачей тонов кожи и реалистичными деталями. Эта версия ИИ-модели поднялась на третью строчку рейтинга Arena.ai. 
Источник изображения: microsoft.ai Microsoft существенно улучшила возможности модели в плане корректного отображения текста на генерируемых изображениях. За счёт этого алгоритм лучше подходит для создания инфографики, слайдов, диаграмм и др. Microsoft заявила, что MAI-Image-2 лучше справляется с генерацией кинематографичных и гипердетализированных изображений, включая сюрреалистические концепции, замысловатые композиции и фантастические миры. «Вышел наш новый генератор изображений MAI-Image-2! Он уже доступен на MAI Playground для создания всего: от фотореализма до детализированной инфографики. Наша команда приложила невероятные усилия для этого релиза», — написал в соцсети X глава ИИ-подразделения Microsoft Мустафа Сулейман (Mustafa Suleyman). В рейтинге на платформе Arena.ai MAI-Image-2 занимает третье место. Лидерами остаются алгоритмы Google gemini-3.1-flash-image-preview и OpenAI gpt-image-1.5-high-fidelity. Пользователи Copilot и Bing Image Creator смогут задействовать модель MAI-Image-2 в ближайшее время. В настоящее время алгоритм доступен через платформу MAI Playground, а разработчик могут получить доступ к модели через соответствующий API на Microsoft Foundry. ИИ-генератор изображений Adobe Firefly теперь можно обучать на своих работах
19.03.2026 [18:18],
Владимир Фетисов
Adobe объявила о запуске настраиваемых ИИ-генераторов изображений, которые могут имитировать определённые художественные стили и дизайны персонажей. Модели Firefly Custom Models стали доступны в рамках публичного бета-тестирования, благодаря чему творческие люди и компании могут обучить ИИ-модели на собственных работах. За счёт этого генерируемые изображения будут соответствовать единой эстетике персонажей, иллюстраций и фотографий. 
Источник изображения: Adobe Ожидается, что такой подход позволит оптимизировать рабочие процессы создателей контента, которым требуется выполнять большие объёмы работ, за счёт сохранения визуальной согласованности в разных проектах, вместо того, чтобы каждый раз начинать всё с нуля. По данным Adobe, пользовательские ИИ-модели позволят сохранять разные детали, такие как толщина штрихов, цветовые гаммы, освещение и черты персонажей при генерации новых изображений. По умолчанию пользовательские модели являются частными, поэтому используемые для их обучения материалы не будут применяться для обучения общих языковых моделей Adobe Firefly. «Чтобы развивать бренд, вам нужен постоянный поток материалов, которые будут последовательно выражать вашу сущность. Эти материалы должны быть вашими и только вашими. После обучения ваша пользовательская модель становится частью вашего рабочего процесса. Вы можете генерировать новые идеи, соответствующие вашей эстетике, повторно использовать модель в разных проектах, брифингах и кампаниях, а также создавать контент в масштабе, не теряя того, что отличает вашу работу», — говорится в пресс-релизе Adobe. ByteDance отложила глобальный запуск ИИ-генератора видео Seedance 2.0 из-за проблем с авторскими правами
15.03.2026 [07:44],
Алексей Разин
Соблазн использования уже знакомых образов и сюжетов при генерации видео с помощью искусственного интеллекта весьма высок, поскольку это упрощает задачу создателю и одновременно позволяет гарантировать интерес аудитории к конечному результату. ByteDance решила отложить глобальный запуск генератора видео Seedance 2.0 из-за проблем с авторскими правами. 
Источник изображения: ByteDance Как отмечает Reuters со ссылкой на The Information, соответствующие трудности возникли у китайской компании в сфере взаимоотношений с крупными голливудскими студиями и стриминговыми платформами. Ещё в прошлом месяце ByteDance была вынуждена заявить, что предпримет меры для предотвращения неправомерного использования интеллектуальной собственности в работе ИИ-генератора видео Seedance 2.0 после того, как некоторые американские студии типа Disney пригрозили ей судебным преследованием. По версии Disney, компания ByteDance использовала персонажей, чьи образы принадлежат студии, для обучения Seedance 2.0 без соответствующего разрешения. Поводом для претензий стало распространение в китайских социальных сетях вирусного видео, на котором сгенерированные ИИ двойники Тома Круза (Tom Cruise) и Брэда Питта (Brad Pitt) участвуют в поединке. Как считает Disney, при обучении Seedance 2.0 китайская ByteDance использовала полученные незаконным способом образы персонажей из популярных кинофраншиз, включая Star Wars и Marvel, обращаясь с ними, как с общедоступными материалами. Представившая ИИ-генератор Seedance 2.0 на китайском рынке в феврале ByteDance отмечала, что он предназначен для профессионального использования при производстве фильмов и рекламных роликов. Способность данного продукта одновременно обрабатывать текст, изображения, видео и аудио, по словам представителей компании, позволяет снизить затраты на изготовление контента. Первоначально ByteDance намеревалась открыть доступ к Seedance 2.0 клиентам за пределами Китая в середине марта, но из-за потенциальных проблем с авторскими правами решила задержать график. Как отмечается, сейчас технические специалисты работают над внедрением защитных механизмов от использования охраняемых авторским правом персонажей, а юристы дополнительно прорабатывают правовые основы использования ИИ-модели. Владелец TikTok выпустил ИИ-модель Seedance 2.0 для генерации видео — она стала вирусной
12.02.2026 [17:43],
Павел Котов
Новая модель искусственного интеллекта ByteDance для генерации видео уже стала вирусной в Китае, где её успех сравнили с достижениями DeepSeek за способность создавать сюжеты кинематографического качества всего по нескольким запросам. 
Источник изображения: Claudio Schwarz / unsplash.com Наиболее популярными сегодня являются ИИ-модели, ориентированные в первую очередь на работу с текстом, такие как OpenAI ChatGPT и DeepSeek R1. Модели, предназначенные для генерации изображений и видео пока больше рассматриваются как перспективные. Сегодня ByteDance (владеет TikTok) официально представила модель Seedance 2.0 — она разработана для профессионального кинопроизводства, рекламы и электронной коммерции. Поддерживается одновременная обработка текста, изображений, звука и видео, что помогает снизить себестоимость создания контента. Новый проект ByteDance вышел в тот момент, когда инвесторы в Китае и по всему миру ищут разработчика масштабов DeepSeek, чьи модели R1 и V3 в начале минувшего года вызвали шок во всей отрасли. В китайских СМИ Seedance 2.0 сравнили как раз с фурором DeepSeek, и даже глава xAI Илон Маск (Elon Musk) отметил быстрый прогресс китайских разработчиков. Успеху проекта порадовались и пользователи китайской соцсети Weibo — они опубликовали множество созданных Seedance 2.0 видеороликов, в которых продемонстрировали сложность и высокое качество изображения вне зависимости от того, насколько неожиданным был запрос. В одном из роликов звёзды Канье Уэст (Kanye West) и Ким Кардашьян (Kim Kardashian) оказались персонажами драмы в дворцовом сеттинге времён Китайской империи — говорили и пели они тоже по-китайски. На Weibo завирусились связанные с Seedance 2.0 хэштеги — во всеобщем ликовании поучаствовала даже государственная газета Beijing Daily. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



