|
Опрос
|
реклама
Быстрый переход
Белый дом работает с Anthropic над созданием правил безопасного применения ИИ-моделей
19.06.2026 [05:34],
Алексей Разин
У руководства стартапа Anthropic, чьи передовые ИИ-модели уже неделю как находятся под запретом из-за опасений в сфере национальной безопасности, появилась возможность вести переговоры с высокопоставленными чиновниками США непосредственно на полях саммита G7, поскольку генеральный директор Дарио Амодеи (Dario Amodei) принял участие в данном мероприятии. 
Источник изображения: Anthropic Как поясняет Politico, Белый дом и Anthropic сейчас сосредоточились на создании регуляторных механизмов, которые позволили бы правительству США вмешиваться в процесс распространения ИИ-моделей в случае обнаружения в них серьёзных угроз для национальной безопасности и стабильности экономической системы. Оценка этих угроз должна стать системной работой, предваряющей выпуск новых ИИ-моделей в обращение. Правительство стремится создать стандартную процедуру анализа подобных уязвимостей и наладить регулярное взаимодействие в этой сфере с разработчиками систем ИИ. Участники переговоров сходятся во мнении, что ни одна ИИ-модель не может быть лишена изъянов с точки зрения безопасности, которые позволяли бы злоумышленникам использовать её в корыстных целях, а потому правительство США должно разработать чёткие процедуры оценки подобных рисков для всех моделей. Помимо критериев оценки рисков, должна появиться методика определения последствий негативного воздействия злоумышленников на новые ИИ-модели. Сейчас со стороны правительства США в переговорах принимает участие глава по общественной политике Сара Хек (Sarah Heck), а интересы Anthropic представляет один из основателей компании Там Браун (Tom Brown). Переход к обсуждению технических вопросов и стандартизации указывает на наличие прогресса в переговорах. Как известно, неделю назад Anthropic не была готова признать, что обнаруженные специалистами Amazon уязвимости в ИИ-модели Fable 5 имеют критическое значение и могут быть использования для снятия ограничений на доступ к определённым сферам деятельности, включая разработку биологического оружия при помощи ИИ. Властям США пришлось настоять на закрытии доступа к двум передовым ИИ-моделям Anthropic для иностранных граждан, но компания не смогла сделать это избирательно, поэтому доступ был перекрыт для всех пользователей данных систем. Adobe добавила в Photoshop и Premiere ИИ-помощников
18.06.2026 [18:51],
Владимир Фетисов
План Adobe по внедрению ИИ-помощников во все приложения Creative Cloud набирает обороты. Новые чат-боты постепенно появляются во всех крупных продуктах компании. На этой неделе Adobe начала публичное бета-тестирование ИИ-помощников в Photoshop, Premiere, Illustrator, InDesign и Frame.io. Они помогут пользователям организовать рабочий процесс и автоматизировать выполнение задач, специфичных для упомянутых приложений. 
Источник изображений: Adobe Хотя все ИИ-помощники Adobe работают на основе одного разговорного агента, они функционируют независимо друг от друга и действуют «как специалист» в каждом приложении Creative Cloud. Это означает, что ИИ-помощник в Premiere настроен на выполнение таких задач, как быстрая организация временной шкалы в пользовательском видео, тогда как версия чат-бота в Photoshop понимает, как правильно использовать доступные в приложении инструменты для редактирования изображений. Для взаимодействия с ИИ-помощниками предлагается задействовать интерфейс, напоминающий тот, что можно увидеть во многих чат-ботах. Пользователю достаточно описать естественным языком изменения, которые следует внести в проект, аналогично тому, как это происходит в Adobe Express, Acrobat или Firefly. Возможности каждого ИИ-помощника весьма обширны, за счёт чего они пригодны для использования даже в сложных дизайнерских проектах.  ИИ-помощник в Premiere может сортировать материалы по папкам и быстро переименовывать группы роликов, основываясь на происходящем в кадре. Он может понимать вопросы или конкретные ключевые слова в записанном аудио и использовать их для добавления маркеров на временную шкалу проекта или создания рабочей отправной точки для видео пользователя. Adobe заявила, что «утомительная подготовительная работа выполняется за вас», добавив, что ИИ-помощник может помочь с чем угодно на панели проекта и временной шкале. В Photoshop достаточно просто «описать желаемый результат», после чего алгоритм отредактирует изображение соответствующим образом. Чат-бот можно задействовать для организации слоёв, замены фона и многого другого. Таким образом, ИИ-помощник теперь есть и в десктопной версии Photoshop, тогда как в веб-версии и мобильном приложении он появился ранее в этом году. «Adobe всегда находилась в центре того, как лучшие творческие работы воплощаются в жизнь, и теперь мы существенно расширяем эти возможности. Теперь у каждого творческого специалиста есть агент, способный помочь в выполнении задач во всех приложениях и на всех платформах, где они работают», — заявил представитель Adobe. «Крёстный отец ИИ» назвал xAI провалом и пригрозил взрывом «пузыря ИИ»
18.06.2026 [16:53],
Павел Котов
Стартап xAI Илона Маска (Elon Musk) — это «провал», и компания неспособна выступать конкурентом для лидеров отрасли искусственного интеллекта, заявил в интервью CNBC авторитетный эксперт в области ИИ Ян Лекун (Yann LeCun), выступающий в настоящее время основателем компании AMI Labs. 
Источник изображения: Numan Ali / unsplash.com Лекуна часто называют «Крёстным отцом ИИ» из-за его ранних работ в этой области и предыдущей должности главного учёного по ИИ в Meta✴✴. Компания xAI как проект, по его мнению, провалилась, потому что из неё ушли основатели, и Маску будет непросто нанимать лучших в отрасли специалистов, ведь в отношении предыдущей команды он проявил себя не лучшим образом. По итогам I квартала сегмент xAI в компании SpaceX зафиксировал убыток в размере $2,5 млрд. У компании есть «огромная инфраструктура», которую она теперь сдаёт в аренду, потому что иначе Маск не сможет окупить затраты, считает Ян Лекун. Эксперт имеет в виду центры обработки данных xAI Colossus 1 и Colossus 2 в Мемфисе — сейчас мощности в них арендуют Anthropic и Google. В остальном перспективы ИИ-подразделения SpaceX господин Лекун оценил «не очень оптимистично», потому что едва ли оно может конкурировать с такими гигантами как Anthropic и OpenAI. Ещё одна проблема в отрасли ИИ — сформировавшийся финансовый пузырь. «Цены на эти услуги ИИ растут, но стоимость их эксплуатации снижается, хотя и недостаточно быстро. В результате все эти компании теряют деньги, и, по сути, использование этих услуг большинством людей финансируется инвесторами. Долго так продолжаться не может, верно?» — задался эксперт риторическим вопросом. Поэтому отраслевым гигантам, в том числе Anthropic и OpenAI, придётся повышать цены и сокращать расходы — иначе пузырь ИИ рискует лопнуть. В технологическом аспекте Ян Лекун заявил о необходимости переключаться с больших языковых моделей ИИ на модели мира. Первые ориентированы на предсказание того, что произойдёт дальше, и они не очень подходят для рассуждений; вторые же стремятся сформировать понимание того, как устроен реальный или смоделированный мир, включая объекты, причинно-следственные связи и действия. Тем временем лидеры отрасли оттачивают технологии ИИ-агентов, способных автономно выполнять сложные задачи — лежащие в их основе большие языковые модели хорошо проявляют себя в математике и программировании, но стоимость их эксплуатации при текущей производительности слишком высока по сравнению с суммами, которые готовы платить люди. Инструмент для дизайнеров Claude Design получил тонкие настройки редактирования и экономию токенов
18.06.2026 [12:57],
Анжелла Марина
Специализированный ИИ-инструмент Claude Design от компании Anthropic получил масштабное обновление. Разработчик улучшил совместимость с дизайн-системами, добавил расширенные элементы управления интерфейсом и оптимизировал алгоритм расхода токенов. 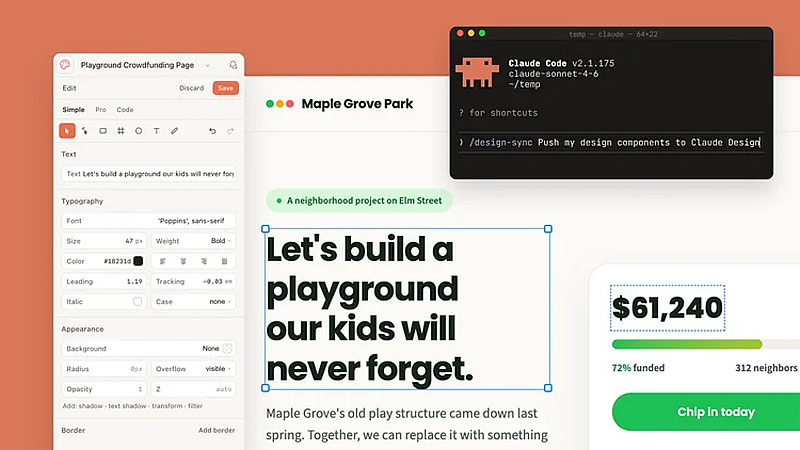
Источник изображения: Anthropic Как сообщил изданию Fast Company дизайнер Anthropic Нейт Пэрротт (Nate Parrott), предыдущей версии генератора не хватало стабильности и согласованности при создании проектов. Теперь алгоритм позволяет генерировать макеты, строго соответствующие фирменному стилю брендов, а администраторам эффективнее контролировать итоговый результат. Кроме того, разработчики Anthropic внедрили точечные настройки, предоставляющие возможность изменять шрифты, цвета, компоновку и стили кнопок непосредственно в интерактивном режиме, приблизив функциональность к традиционным графическим редакторам. Для повышения производительности расхода ресурсов Claude Design был объединён с лимитами чата, а также с сервисами Claude Cowork и Claude Code. Теперь платформа позволяет выполнять больше задач при аналогичных затратах токенов. По словам Пэрротта, главная цель обновления заключается в смещении фокуса ИИ на самые ранние этапы проектирования, позволяя командам быстро перебирать десятки концепций перед передачей наиболее удачных вариантов в техническую разработку. В Anthropic рассчитывают, что их обновлённый инструмент станет неотъемлемой частью современного стека технологий для дизайнеров и поможет упростить процесс тестирования идей и оценки жизнеспособности того или иного дизайна. Стоит отметить, что подобный подход по предварительному утверждению идей с помощью генеративных сетей уже применяется в индустрии. Например, подразделение Disney Imagineering совместно с компанией Adobe разработало собственный ИИ-инструмент для создания вариантов идей дизайна парков и круизных лайнеров Disney. Nvidia представила бета-версию открытого ACE Game Agent SDK для добавления ИИ-персонажей в игры
18.06.2026 [12:02],
Павел Котов
Nvidia анонсировала на мероприятии Unreal Fest бета-версию SDK ACE Game Agent — разработчики получили новую платформу для создания персонажей с искусственным интеллектом в играх. Комплект SDK доступен с набором плагинов Nvidia ACE для движка Unreal Engine 5. 
Источник изображений: nvidia.com SDK представляет собой легковесную платформу на C/C++, предназначенную для интеграции в игры — она настраивается и может похвастаться оптимизацией для небольших моделей, которые запускаются на видеокартах серии RTX. Разработчики могут обращаться к трём основным группам API. API Agent позволяет управлять историей чата с сохранением состояния и многошаговым логическим выводом. Прямой контроль над выводом осуществляется через API Chat. Есть также API RAG для подключения внешних баз данных с поддержкой семантического, лексического и гибридного поиска. Nvidia протестировала эти средства в реальных играх, в том числе с экспериментальным ИИ-советником в Total War: Pharaoh. 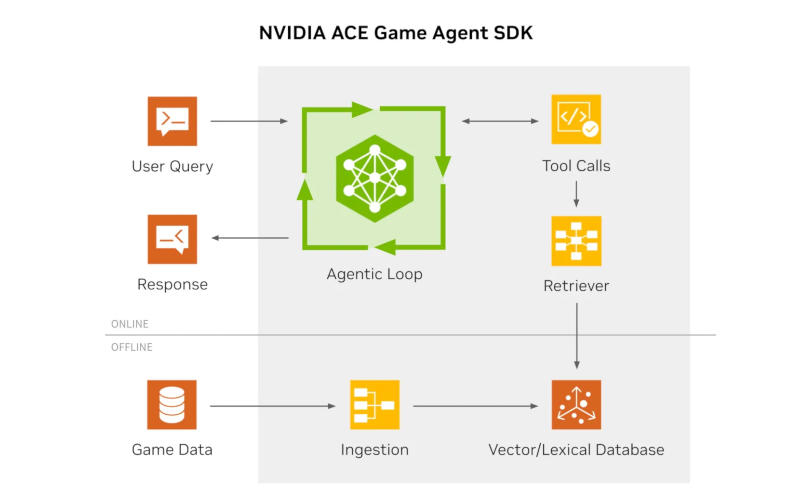 Плагины для Unreal Engine 5 позволяют внедрять транскрипцию в реальном времени, динамические диалоги с персонажами, голосовые команды и контекстные ответы на действия прямо в игровую логику. Обращаться к облачным ресурсам не требуется — всё работает локально с оптимизацией под RTX. Поддерживается интеграция с Blueprint и C++. За автоматическое распознавание речи отвечает модель nemo-conformer-ctc-120m — она поддерживает английский, но можно загрузить семь дополнительных языков. Генерацию текста осуществляют малые языковые модели — предустановлена открытая Alibaba Qwen 3.5 4B, но можно загрузить любую другую через файл GGUF. Наконец, преобразование текста в речь производит модель TTS Chatterbox Turbo 350M с примерами голосов и специальным контентом для плагинов. Глава Anthropic призвал лидеров стран G7 сопротивляться соблазну перессориться из-за ИИ
18.06.2026 [11:59],
Алексей Разин
Недавний запрет на доступ к ИИ-моделям Anthropic для иностранных граждан, которого добивались власти США, всполошил союзников в Европе. Поскольку генеральный директор стартапа Дарио Амодеи (Dario Amodei) посетил саммит G7 во Франции, он имел возможность поделиться своими рекомендациями с заинтересованными политиками лично. 
Источник изображения: Anthropic Как отмечает Financial Times, в своём обращении к лидерам стран G7 глава Anthropic призвал их «сопротивляться соблазну перессориться из-за распространения ИИ-инструментов». Эти слова были произнесены им в присутствии президента США Дональда Трампа (Donald Trump), чья администрация стала инициатором запрета доступа к ИИ-моделям Mythos 5 и Fable 5 для иностранных граждан в прошлую пятницу. Anthropic не смогла обеспечить выборочную блокировку, а потому закрыла доступ к этим моделям для всех пользователей, включая находящихся в США. Присутствовавший на мероприятии глава конкурирующей OpenAI Сэм Альтман (Sam Altman) выразил поддержку коллеге. Дарио Амодеи также признался, что он благосклонно относится к попыткам дружественных государств предотвратить «попадание ИИ не в те руки», но призвал демократические страны действовать сообща. По мнению Альтмана, который тоже взял слово, ИИ-средства для киберзащиты должны быть предоставлены всем странам, чьи представители находились в аудитории. Компанию двум руководителям ИИ-стартапов составил Демис Хассабис (Demis Hassabis), возглавляющий подразделение DeepMind корпорации Google. Французский президент Эммануэль Макрон (Emmanuel Macron) на правах хозяина мероприятия подчеркнул, что спрос вокруг Anthropic показал, насколько велики ставки для США и их союзников по G7. Если власти США в один прекрасный день решат перекрыть доступ к ИИ-моделям, это принесёт колоссальные убытки участникам ИИ-гонки. По его словам, переговоры с участниками G7, включая Трампа, были довольно плодотворными, но они пока не определили, как дальше нужно работать с передовыми ИИ-моделями. Макрон призвал к более активному регулированию сферы ИИ, но предупредил об опасностях, возникающих в результате отказа от сотрудничества между демократическими странами. Как добавил французский президент, в ближайшие месяцы он хотел бы с единомышленниками добиться создания платформы для обсуждений и сотрудничества, которая позволила бы демократическим странам вырабатывать общие стандарты в сфере ИИ. Премьер-министр Индии Нарендра Моди (Narendra Modi) также выразил свою озабоченность недавним запретом на доступ к передовым моделям Anthropic со стороны властей США, и подчеркнул, что демократии должны иметь доступ к ИИ-моделям для защиты критически важной инфраструктуры. Хассабис и Альтман высказались в пользу технического сотрудничества и создания экспертной группы под руководством США, которая могла бы решать подобные вопросы на глобальном уровне. Глава французского ИИ-стартапа Mistral Артур Менш (Arthur Mensch) выразил озабоченность необходимостью защиты цепочек поставок для инфраструктуры ИИ. Цепочки поставок, по его словам, настолько переплетены взаимно, что нельзя исключать враждебных действий со стороны недружественных стран, от которых зависит развитие инфраструктуры. Подобные мысли в ходе встречи неоднократно высказывались представителями других стран, не считая США. Это ж-ж-ж неспроста: шум и вибрация от центров обработки данных вредят здоровью окрестных жителей
18.06.2026 [11:33],
Алексей Разин
До сих пор экспансия ЦОД вызывала протест у местных жителей главным образом в контексте использования земельных участков и роста тарифов на электроэнергию, но исследования показали, что шумовое загрязнение и вибрация могут оказывать негативное влияние на жителей окрестных территорий, и это может стать новой проблемой. 
Источник изображения: Marvell Даже с учётом приличного удаления крупных ЦОД от жилых кварталов шум, издаваемый их мощными системами охлаждения, напоминает гул пролетающего на большой высоте самолёта, звук работающего двигателя грузовика, припаркованного под окнами, либо соседского блока кондиционирования воздуха. Жители трёх небольших городов США в прошлом месяце подали несколько судебных исков против владельцев ЦОД, которые досаждают им своим шумом. Сейчас на территории США эксплуатируются более 3000 центров обработки данных и примерно половина этого количества возводится. Помимо промышленных вентиляторов, ЦОД могут издавать шум из-за использования дизельных электрогенераторов. По данным Pew Research Center, почти 40 % жилых домов в США сейчас находятся на удалении не более 8 км от хотя бы одного ЦОД. В некоторых случаях это расстояние ещё меньше, что создаёт условия для постоянного беспокойства окрестных жителей. Звуки работающего оборудования могут быть различимы на удалении до пары километров от ЦОД. Эти вычислительные площадки также становятся источником инфразвука, который не улавливается человеческим ухом, но в виде вибраций способен негативно влиять на организм. Жители домов возле ЦОД всё чаще страдают нарушениями сна, головными болями, повышением внутричерепного давления и общим беспокойством. При этом действующие санитарные и строительные нормы не учитывают специфику воздействия данных факторов на людей, находящихся в пределах досягаемости. Тем более, что реформы американских профильных ведомств в начале 80-х годов прошлого века привели к тому, что следить за шумовым загрязнением территорий США попросту некому. В судебных исках жители близлежащих к ЦОД домов жалуются не только на постоянный шум и вибрации, но и на падение цен на недвижимость в этой зоне, поскольку никто не желает оказаться на их месте по собственной воле. Помимо материальной компенсации, истцы требуют от компаний обеспечить снижение шумового загрязнения от своих ЦОД. По словам некоторых истцов, шум отчётливее слышен в ночное время, когда люди стараются заснуть, и он им очень мешает. Представители компании DataOne, которая возвоит ЦОД в штате Нью-Джерси, заверили редакцию The New York Times в своей готовности активно взаимодействовать с местной общественностью с целью снижения шумового воздействия на округу. Некоторые строители ЦОД готовы выкупать ближайшие к своим объектам дома по рыночной цене и помогать продавцам с переездом. Представители Alliance Cloud Services заявили, что свои ЦОД они строят с учётом обеспечения необходимого минимального расстояния до близлежащих домов. Покупая участок земли под ЦОД, компания изначально закладывает, что некоторая его часть будет создавать своего рода «буферную зону». Переход на альтернативные способы охлаждения является другим способом снизить уровень шума от ЦОД. Компоненты вычислительных систем либо погружают в диэлектрическую жидкость, которая помогает отводить тепло, либо оснащают водоблоками. Уровень шума при этом удаётся снизить на 50 % и более, но подобные мероприятия оказываются довольно затратными. На многих территориях США действуют требования к уровню шума, которые не учитывают низкочастотные колебания, исходящие от систем охлаждения ЦОД. Это создаёт ситуации, когда проект в целом соответствует действующим нормам, но по факту окружающие страдают от воздействия шума и вибрации. На многих территориях традиционные источники шума типа аэропортов или крупных шоссе источают его значительно слабее в ночное время, когда окрестные жители спят. Центры обработки данных работают круглосуточно, и на подобное облегчение рассчитывать не приходится. Во многих случаях ЦОД строятся не на пустых обособленных участках земли, а занимают место заброшенных промышленных объектов, которые расположены к жилым кварталам гораздо ближе. Кроме того, чувствительность людей к звукам и вибрациям неоднородна в пределах какой-то локально проживающей группы, поэтому если кого-то соседство с ЦОД почти не беспокоит, другие просто не будут находить себе места и жаловаться во все инстанции. Со всеми этими нюансами строителям ЦОД и тем, кто их будет эксплуатировать, придётся иметь дело. Китайская открытая ИИ-модель Z.ai GLM-5.2 обошла GPT-5.5 в тестах на программирование
18.06.2026 [11:27],
Павел Котов
Китайский стартап в области искусственного интеллекта Z.ai (ранее Zhipu) сообщил о выпуске большой языковой модели GLM-5.2 с открытыми весами и 753 млрд параметров. Её основное предназначение — написание программного кода и разработка с «длительным горизонтом планирования». 
Источник изображения: Steve A Johnson / unsplash.com Поработать с моделью можно через API на ресурсах Z.ai, на платформе Hugging Face; поддерживаются более 20 сторонних сред разработки. Модель предлагает контекстное окно в 1 млн токенов; корпоративные подписки стоят от $12,60 в месяц. Основные веса GLM-5.2 доступны по лицензии MIT — предприятия могут бесплатно скачивать, настраивать и дорабатывать модель по своему усмотрению, запуская её локально или через виртуальные машины, оплачивая только вычислительные ресурсы и электроэнергию. 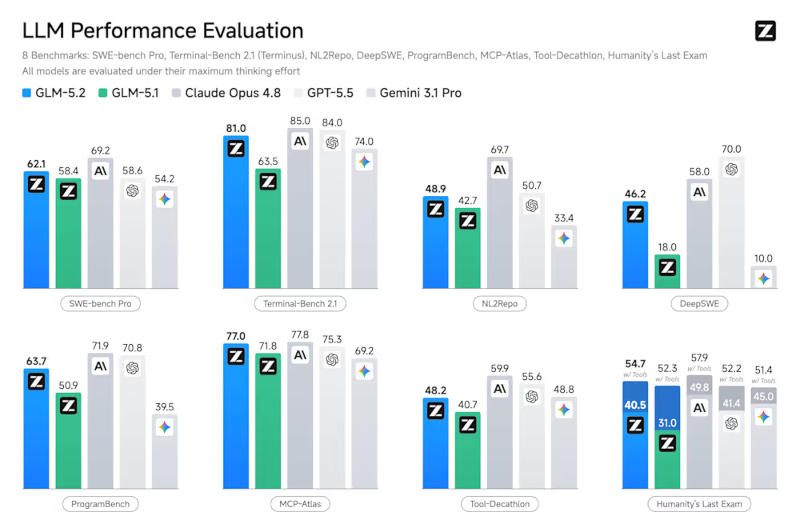
Источник изображения: z.ai Модель Z.ai GLM-5.2 имеет 753 млрд параметров, и в ней реализована важная архитектурная оптимизация IndexShare — на четыре слоя разрежённого внимания повторно используется один индексатор, что при максимальной длине контекста в 1 млн токенов помогает снизить вычислительную нагрузку в 2,9 раза. Используется также модернизированная схема многотокенного предсказания (MTP), которая при запуске метода спекулятивного декодирования пропускает на 20 % больше токенов при инференсе — это тоже помогает экономить ресурсы. 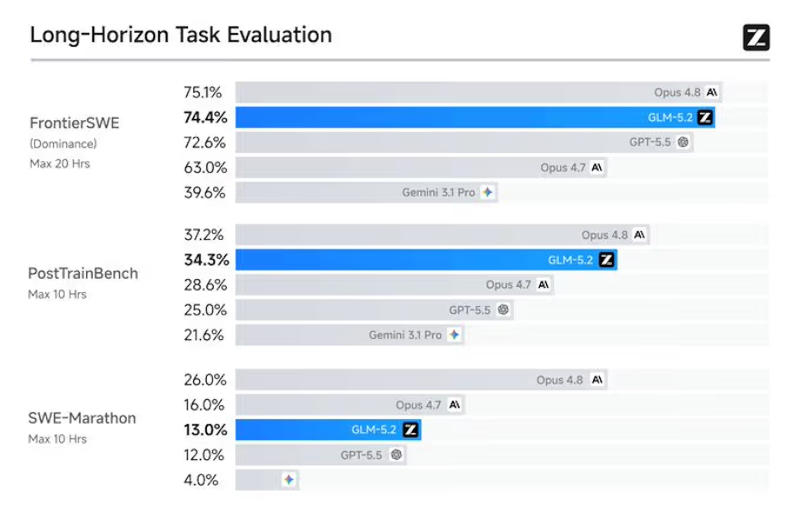
Источник изображения: z.ai Модель позволяет выбирать «режимы рассуждений»: «максимальный» помогает расширить границы при решении логических задач, а «высокий» обеспечивает баланс между высокой производительностью и эффективностью при генерации токенов. В первом случае она выдаёт в среднем 85 000 токенов на задачу, а во втором — вдвое меньше. В стандартных отраслевых тестах Z.ai GLM-5.2 превзошла большинство флагманских открытых моделей, а также выступила близко или лучше, чем передовые закрытые модели, в том числе OpenAI GPT-5.5 и Anthropic Claude Opus 4.8. Для работы с моделью разработчик открыл тариф GLM Coding Plan, ориентированный на подключение средств разработки, а не традиционный интерфейс чат-ботов — поддерживаются такие приложения как Claude Code, OpenClaw, Cline, Kilo Code, Crush и Factory. Тариф Lite ($12,60 в месяц или $151,20 в год, начиная со второго года) предназначен для несложных итераций в небольших репозиториях; Pro ($50,40 в месяц) предлагает впятеро больше вычислительных ресурсов, чем Lite; Max ($112,00 в месяц) предлагает в 20 раз больше ресурсов, чем Lite, и выделенные ресурсы в часы пик. Доступ по API к GLM-5.2 стоит $1,40 за 1 млн входных токенов и $4,40 за 1 млн выходных. Курировавшая реорганизацию Meta✴ руководитель уйдёт из компании
18.06.2026 [08:32],
Павел Котов
Влиятельная член руководства Meta✴✴ Эмили Далтон-Смит (Emily Dalton Smith), которая курировала реорганизацию по направлению внутренних средств искусственного интеллекта, намеревается покинуть компанию, как сообщает Reuters. 
Источник изображения: Milad Fakurian / unsplash.com Эмили Далтон-Смит перешла на работу в компанию Facebook✴✴ (теперь Meta✴✴) в 2015 году. Ранее она занимала такие посты как вице-президент по управлению продуктами и руководитель по продуктам в проекте Threads — созданной по образцу Twitter платформы микроблогов. Госпожа Далтон-Смит уходит из компании через два месяца после того, как была назначена руководителем по разработке внутренних инструментов ИИ в рамках общекорпоративной реорганизации, направленной на внедрение ИИ как в пользовательские сервисы, так и во внутреннюю работу компании. Реструктуризация, предполагающая внедрение ИИ-агентов, которые примут на себя часть задач сотрудников-людей, вызвала недовольство среди работников компании. Сотрудники открыто критиковали руководство на собраниях и форумах по поводу этой инициативы, которая, в частности, предполагала сокращение 10 % штата, перевод такого же числа работников в новые подразделения и внедрение ПО для отслеживания действий работников. Возглавляемый Далтон-Смит отдел занимается «интерфейсами, компонентами платформы, системами памяти, автоматизацией и общем опыте работы с продуктом, которые сделает ИИ полезным для всех», — сформулировал в апреле задачу технический директор компании Эндрю Босворт (Andrew Bosworth). Одним из направлений является Metamate — основной внутренний ИИ-помощник в Meta✴✴. Руководство стремится объединить внутренние ИИ-инструменты компании в единый продукт Metamate, потому что существующий набор средств фрагментирован, заявила ранее в служебной записке Далтон-Смит. «Наша цель — сделать Metamate отправной точкой для всех видов работы — от проведения глубоких исследований до создания прототипов новых функций и подготовки презентаций для продаж», — заявила она. Планировалось развёртывание функциональности систем ИИ, которые могли бы перемещаться по рабочим файлам, обеспечивать координацию написания кода из чатов и сохранять «постоянную память» о работе сотрудников. В качестве рабочих инструментов предполагалось использование «отполированных панелей инструментов и микросайтов», в том числе от Manus — сингапурского стартапа по разработке ИИ-агентов, который Meta✴✴ в декабре минувшего года пыталась поглотить за $2 млрд. В апреле китайские власти заблокировали сделку по Manus, и Meta✴✴ пришлось отключить соответствующие инструменты от своих внутренних систем. Новые функции Metamate должны были начать работу 1 июня. Пока Далтон-Смит остаётся в Meta✴✴, чтобы совместно с Босвортом обеспечить переход команды к «дальнейшим шагам». Требования властей США к Anthropic для разблокировки ИИ-моделей практически труднореализуемы
18.06.2026 [08:26],
Алексей Разин
Скоро исполнится ровно неделя с того момента, как компания Anthropic по требованию властей США отключила всех пользователей от ИИ-моделей Mythos 5 и Fable 5 из соображений национальной безопасности. Ограничить доступ к ним только для иностранцев Anthropic не смогла, поэтому пострадали все пользователи. Эксперты утверждают, что снять блокировку будет практически невозможно. 
Источник изображения: Anthropic Дело в том, как поясняет Wired со ссылкой на знакомые с содержанием переговоров источники, что власти США требуют от Anthropic навсегда исключить «лазейки», которые позволяют снять ограничения на взаимодействие пользователей с наиболее современными ИИ-моделями этого стартапа. В частности, разработчики блокируют возможность поиска информации для создания оружия массового поражения в общедоступных версиях моделей, но специалистам АНБ якобы удалось доказать, что определённое сочетание запросов к ИИ-моделям Anthropic позволяет снять эти ограничения в случае с той же Fable 5, которая была задумана в качестве общедоступной и безопасной версии Mythos 5. Сейчас американские чиновники считают, что Anthropic должна исключить подобные возможности обхода блокировок, и только после этого передовые ИИ-модели компании можно будет вернуть в общий доступ. Подобную защиту компания, по их мнению, должна будет предусмотреть для всех своих моделей, а также проводить тестирование на их устойчивость к взлому самостоятельно, предоставляя регулярные отчёты американскому правительству. Эксперты в сфере кибербезопасности сходятся во мнении, что любые ограничения, предусматриваемые Anthropic в этой ситуации, будут работать лишь до определённой поры, поскольку со временем будут появляться более совершенные инструменты для обхода существующих блокировок. Исключить подобные злоупотребления раз и навсегда попросту невозможно, но власти США требуют от Anthropic именно этого. Если позиция американских чиновников не будет пересмотрена, ИИ-модели этого стартапа могут надолго остаться под запретом. ИИ уже превосходит обычных медиков в точности определения диагноза
18.06.2026 [07:27],
Алексей Разин
Опубликованные в журнале Nature вчера данные, на которые ссылается Financial Times, говорят о достижении искусственным интеллектом того же или более высокого уровня по сравнению с терапевтами в сфере постановки диагноза и составления плана лечения. Эксперты при этом подчёркивают, что в реальных условиях ИИ пока ещё не способен безопасным образом заменить медицинских специалистов. 
Источник изображения: Unsplash, Sasun Bughdaryan Специализированные модели Mira и Google Amie, которые подвергались тестированию авторами исследования, показали более высокую результативность в выявлении у пациентов признаков рака поджелудочной железы и пневмонии, а также составлении планов лечения и диагностики, по сравнению с терапевтами. Кроме того, такие специализированные ИИ-модели дают клиентам более точные медицинские рекомендации, чем универсальные. По словам Якоба Катера (Jacob Kather), который возглавляет группу немецких учёных, разработавших медицинскую модель Mira, ИИ-агенты подобны автопилоту в авиации — они способны взять на себя рутинную часть работы врачей, но ответственность в конечном итоге должна лежать на терапевте. Mira опирается на электронный банк историй болезни, выбирая из более чем 85 000 вариантов назначений. При её обучении использовались данные о более чем 500 клинических случаев медицинского вмешательства. Mira продемонстрировала точность диагностики восьми болезненных состояний, включая аппендицит и лёгочную эмболию, на уровне 87,1 % по сравнению с 78,1 %, которые демонстрировались группой из шести терапевтов. Модель Amie обучалась на базе Google Gemini, её тестировали в сравнении с 21 терапевтом на 100 сценариях типовых обращений пациентов, которые описываются в рекомендациях британской системы здравоохранения. Эта модель превзошла реальных специалистов как в сфере выбора методов лечения и назначении медикаментов. Впрочем, специалисты предупреждают, что ИИ-модели обучались на более чётко сформулированных данных по сравнению с теми, которые реальные врачи обычно получают от пациентов. К реальному клиническому применению подобные модели пока не готовы, как подчёркивают их разработчики. Докторам на практике приходится иметь дело с гораздо более противоречивой и фрагментированной информацией, которая затрудняет принятие решений. Успехи Amie в этом тестировании, к тому же, могут быть обусловлены общим прогрессом универсальных ИИ-моделей, а не совершенством специализированных решений для медицины, как отмечают эксперты. Журналисты доказали использование миллионов защищённых авторским правом песен для обучения ИИ
17.06.2026 [22:54],
Анжелла Марина
Издание The Atlantic нашло неоспоримые доказательства использования миллионов охраняемых авторским правом музыкальных записей для обучения нейросетей. В списки попали современные мировые хиты, авторы которых не давали согласия ИИ-компаниям на обработку своих произведений. 
Источник изображения: AI Журналист The Atlantic Алекс Рейснер (Alex Reisner) опубликовал четыре каталога, в которых зафиксировано, какая конкретно музыка использовалась для обучения моделей. Компания Suno в судебных документах официально подтвердила, что обучала ИИ на десятках миллионов записей, часть которых была защищена авторскими правами и использовалась без разрешения правообладателей, в число которых вошли Тейлор Свифт (Taylor Swift) и Бэд Банни (Bad Bunny). Параллельно с этим лейблы Sony, UMG и Warner подали иски против Suno и Udio, требуя возмещения в размере до $150 000 за каждую композицию, оказавшуюся в тренировочном наборе. В то время как создатели нейросетей настаивают на доктрине добросовестного использования, утверждая, что ИИ-модели запоминают лишь абстрактные паттерны, а не конкретные мелодии, представители индустрии настаивают на обратном, называя эту практику «пиратством, упакованным в красивую презентацию для инвесторов». Ситуацию усугубляет позиция Бюро по авторским правам США (United States Copyright Office), заявившего в январе 2025 года, что результаты работы таких нейросетей не защищены авторским правом из-за недостаточного человеческого участия, оставляя созданный контент вне правового поля. В качестве одной из действенных мер противодействия исследователи из Университета Теннесси разработали инструмент HarmonyCloak, добавляющий в аудиофайлы неслышимые для человеческого уха звуковые искажения. Однако вектор борьбы уже смещается в сторону правовых отношений. В частности, Warner Music Group и Universal Music Group заключили лицензионное соглашения с Udio и Suno, а власти Теннесси приняли закон, защищающий голоса музыкантов от неправомерного клонирования. Смартфоны Samsung научатся оценивать здоровье питомцев по фотографии
17.06.2026 [18:10],
Павел Котов
Смартфоны Samsung Galaxy располагают множеством функций искусственного интеллекта: есть расшифровка звонков, редактирование фотографий с использованием генеративного ИИ, а также составление сводок файлов. Новая функция адресована владельцам домашних животных.  На конференции VivaTech компания Samsung анонсировала новое решение на основе ИИ, связанное с уходом за животными, и реализуется оно в партнёрстве со стартапом Lifet. Можно будет сделать снимок питомца на смартфон и обратиться к ИИ, который поможет выявить возможные проблемы с его здоровьем. Он укажет на проблемы с зубами, обнаружит признаки катаракты или вывихи суставов. Чтобы начать работу с новой функцией, владельцу смартфона Samsung Galaxy потребуется установить на него приложение SmartThings и сервис Pet Care. Компания Lifet, входящая в программу инкубатора стартапов Samsung, уже позволяет загружать на свой сайт снимки питомцев для оценки состояния их здоровья средствами ИИ. Вышеуказанные проблемы выявляются с точностью до 97 %, заверяет разработчик. Наличие отдельной функции на смартфоне Samsung обещает сделать этот процесс более удобным. Nvidia показала роботов, которые сами научились собирать ПК — но почему-то дорогие видеокарты им не доверила
17.06.2026 [16:52],
Павел Котов
Nvidia продемонстрировала группу роботов, управляемых агентами искусственного интеллекта — эти машины самостоятельно обучаются высокоточным задачам, требующим сноровки в реальном мире. 
Источник изображений: Nvidia На демонстрационном ролике системы ENPIRE роботы самостоятельно устанавливают видеокарту в материнскую плату, сортируют металлические штифты в контейнере, а также устанавливают и обрезают пластиковые хомуты. В рамках проекта ENPIRE учёные запустили восемь ИИ-агентов OpenAI Codex, подключили к ним группу роботов, выделив им графические процессоры и бюджет токенов — вычислительных ресурсов. Агентам ставили задачи — их надо было научиться выполнять действия как можно быстрее и не допускать ошибок.  Получив инструкции «парк роботов начал оживать: они учатся искать визуальные подсказки, перезагружать сцену, отрабатывать новые навыки, экспериментировать с управляющими функциями, читать статьи в интернете, обсуждать, размышлять, сталкиваться с трудностями и повторять попытки прямо на оборудовании», — пояснили авторы проекта. Получив задание на самостоятельную сборку ПК, одна роботизированная рука-манипулятор взяла видеокарту и передала её другой, у которой была материнская плата. Вторая аккуратно вставила видеокарту в слот PCIe. При установке вся система покачивалась, но задачу она выполнила. Что интересно, использовались доступные компактные видеокарты, а не массивные решения сродни RTX 5090. В рамках эксперимента авторы использовали разные средства ИИ: агентов OpenAI Codex с моделью GPT-5.5, Claude Code с Opus 4.7 и Kimi Code с Kimi K2.6. Исследователи также протестировали изменение размера группы машин и установили, что «восемь роботов, исследующих местность параллельно, решают задачу значительно быстрее, чем меньшее число». Китай проследит, как ИИ отнимает и создаёт рабочие места
17.06.2026 [16:41],
Алексей Разин
Эксперты расходятся во мнении относительно способности искусственного интеллекта влиять на рынок труда как в положительном ключе, так и в отрицательном. Китайские власти такой неопределённостью явно довольствоваться не готовы, а потому попытаются разработать механизм оценки влияния данных технологий на занятость населения. 
Источник изображения: Unsplash, Max van den Oetelaar Государственный совет КНР, как отмечает Bloomberg, в ближайшие пять лет обязуется осуществлять мониторинг влияния технологий генеративного искусственного интеллекта на национальный рынок труда. Для этого будет проводиться регулярный опрос работодателей, проводиться профильные исследования и учитываться динамика появления новых рабочих мест или замещения определённых профессий. Власти Китая в текущей пятилетке не стали ставить целей по количеству новых рабочих мест, которые будут созданы в городской среде КНР к 2030 году, хотя ранее подобные ориентиры регулярно назначали. Страна рассчитывает около 700 млн человек трудоспособного населения, поэтому его интересы государство старается защищать. В ближайшие пять лет сбор статистики по рынку труда в Китае углубится на всех уровнях, начиная от регионального и заканчивая отдельными компаниями. Критерии учёта станут более разнообразными. Для наделения трудящихся граждан новыми навыками при поддержке властей будут разрабатываться новые образовательные программы. Автоматизация производства в КНР уже привела к тому, что в этом году почти 320 млн человек на местном рынке труда перейдут к гибкой занятости и работе в сфере доставки. На опасных производствах замена человека роботами будет только приветствоваться. ИИ поможет создавать новые профессии, как убеждено китайское правительство. В так называемой «платформенной экономике» власти призывают участников рынка обеспечивать прозрачность алгоритмов и соблюдение прав трудящихся, включая и уровень оплаты труда. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



