|
Опрос
|
реклама
Быстрый переход
На фоне ИИ-бума ASML выдаст всем работникам премии в виде акций на сумму 20 тысяч евро
18.07.2026 [05:00],
Анжелла Марина
Компания ASML объявила о единовременном вознаграждении сотрудников по всему миру в размере 20 тысяч евро в виде акций. Решение принято на фоне продолжающегося роста спроса на оборудование для производства полупроводников, обусловленного развитием инфраструктуры искусственного интеллекта. 
Источник изображения: asml.com Как сообщает Bloomberg, акции будут предоставлены сотрудникам 1 января, а право на их получение окончательно закрепится в начале 2030 года при условии, что работник останется в компании на протяжении всего этого периода. Программа распространяется на персонал по всему миру, численность которого составляет около 45 тысяч человек. Подобные меры ранее приняли и другие представители полупроводниковой отрасли. В частности, бонусные выплаты своим сотрудникам уже предложили Samsung Electronics и SK hynix, тогда как TSMC в мае объявила об увеличении выплат по программе распределения прибыли более чем на 30 % в среднем по итогам текущего года. Таким образом, компании, получающие значительную выгоду от инвестиций в ИИ-инфраструктуру, перераспределяют часть доходов в пользу сотрудников. Ранее на этой неделе ASML во второй раз с начала года повысила прогноз годовых продаж, одновременно объявив о планах по расширению производственных мощностей для удовлетворения растущего спроса. Напомним, эта нидерландская компания является мировым монополистом и крупнейшим производителем современных литографических систем, необходимых при выпуске передовых полупроводников. Без оборудования ASML невозможен выпуск современных процессоров для техники Apple, видеокарт Nvidia, а также чипов для дата-центров и систем искусственного интеллекта. Бывший ракетный инженер создал крошечный дрон-охотник на комаров
17.07.2026 [20:44],
Павел Котов
Бывший инженер европейского разработчика и производителя ракетных систем MBDA Алекс Туссен (Alex Toussaint) разработал автономный дрон массой 40 г, который обнаруживает и уничтожает комаров, ориентируясь в пространстве при помощи ультразвукового сонара AMD. 
Источник изображения: tornyol.com Сигнал от фазированных микрофонов обрабатывается локальным алгоритмом искусственного интеллекта — машина обнаруживает насекомых в полёте, а затем перехватывает их, прежде чем они войдут в заданную зону. Текущий прототип, который изготовил запущенный инженером стартап Tornyol, оценивается в $1100. В ходе первых испытаний машина обнаружила пластиковый шарик размером 2 мм с расстояния 30 см, используя лишь 1/1300 штатной мощности передачи. Результат испытаний подтвердил допустимое соотношение сигнала к шуму и приблизил проект к заявленной цели отслеживания комаров на расстоянии 3 м. Из насекомых первой на открытом воздухе была перехвачена летящая бабочка. При настройке дрона пользователь определяет зону защиты на карте базовой станции — никаких дальнейших действий по установке или проводке не требуется. Один блок Tornyol предназначен для защиты открытых или закрытых пространств площадью до 20 тыс. м2. Заряда аккумулятора на текущем прототипе хватает на три минуты полёта — когда батарея садится, дрон автоматически возвращается на зарядную станцию. Подзарядка занимает около 30 минут, после чего дрон автоматически возобновляет патрулирование. Машина укомплектована микрофонами TDK InvenSense T3902 и потребляет менее 5 Вт энергии. При запуске в серийное производство аналог прототипа будет стоить несколько сотен долларов, а уменьшенная версия — дешевле. Для оформления предзаказа придётся перечислить предоплату в размере $100, но эта сумма возвращаемая. Дрон может продаваться по единовременному платежу, либо предлагаться по подписке. При покупке предоставляется гарантия сроком на один год, дроны по подписке заменяются в случае поломки. Открытые китайские ИИ-модели сократили отставание от передовых американских всего до четырёх месяцев
17.07.2026 [18:57],
Алексей Разин
Западные фондовые рынки начали остро реагировать на прогресс китайских разработчиков ИИ-моделей. Например, выход модели Moonshot Kimi K3 с открытыми весами к концу недели обвалил котировки американских компаний технологического сектора. Более того, британские эксперты заявили, что китайские ИИ-модели уже сократили отставание от передовых западных до четырёх месяцев. 
Источник изображения: Kimi.com В прошлом году, как отмечает Financial Times со ссылкой на отчёт Института безопасности искусственного интеллекта Великобритании (AISI), отставание китайских моделей оценивалось в шесть или десять месяцев. По сути, разрыв сокращается быстрее, чем ожидалось. Специалисты AISI выражают опасение, что открытость китайских ИИ-моделей, которые по сути своей общедоступны для применения, создаёт новую угрозу для безопасности мировой информационной инфраструктуры. Если китайские модели по своим возможностям в сфере кибербезопасности догонят западные, то у специалистов по защите будет всё меньше времени на устранение уязвимостей и угроз. Уже сейчас передовые ИИ-модели данной специализации превосходят по своим возможностям даже самых опытных хакеров, как утверждают эксперты. Клиенты по всему миру всё чаще обращаются к более доступным китайским ИИ-моделям, пытаясь оптимизировать свои расходы на внедрение ИИ. Подобная тенденция, по мнению представителей AISI, представляет угрозу для бизнеса, поскольку возможностей гарантировать безопасность внедряемых систем становится всё сложнее. История с ограничением доступа к ИИ-моделям Mythos 5 и Fable 5 американской компании Anthropic является примером того, как разработчики пытаются ограничить распространение мощных инструментов для проведения кибератак. За распространением открытых ИИ-моделей такого контроля нет. По данным тестов AISI, которые выражались как набором отдельных заданий в области кибербезопасности, так и выполнением автономной миссии по проведению полноценной кибератаки силами ИИ-модели, выпущенная пекинской Z.ai модель GLM-5.2 по своим возможностям уже сопоставима с американскими, которые были выпущены за четыре месяца до её дебюта — например, теми же Opus 4.6 и GPT-5.2 Codex. Китайские модели с открытыми весами дешевле в эксплуатации, поскольку используют меньшее количество токенов в своей работе. Их стремительный прогресс ставит перед сферой кибербезопасности новые вызовы, на которые будет не так просто ответить. «Антиплагиат» нашёл следы ИИ в каждой третьей студенческой работе
17.07.2026 [12:35],
Владимир Мироненко
Согласно данным платформы «Антиплагиат», в каждой третьей студенческой работе, проверенной сервисом во втором квартале 2026 года, были выявлены признаки использования нейросетей, сообщил РБК. 
Источник изображения: Unseen Studio/unsplash.com Из 2,73 млн работ, проверенных «Антиплагиатом» с апреля по июнь, в 983,7 тыс. были выявлены признаки использования ИИ, что составляет 36 % всего объёма, и на 12 % больше, чем годом ранее. При этом во втором квартале 2025 года были выявлены 575,9 тыс. студенческих работ с использованием нейросетей, а объём вероятной генерации внутри документов вырос с 5,4 до 8 %. Чаще всего элементы использования ИИ определяли в текстах, касающихся искусствоведения, СМИ и массовых коммуникаций, информационных наук, медицины и политологии, реже всего — в работах по таким направлениям, как ветеринарные науки, механика, машиностроение и математика. По мнению исполнительного директора компании «Антиплагиат» Евгения Лукьянчикова, результаты исследования подтверждают тот факт, что остановить распространение ИИ уже невозможно. «Это не повод для паники, а сигнал признаться, что время дискуссий закончилось, и системе образования срочно нужны конкретные решения. Те, которые позволяют видеть не просто сам факт наличия ИИ в тексте, потому что это тупиковый путь, а характер, глубину и цели его использования», — считает он. Лукьянчиков сообщил, что компания разрабатывает новую систему проверки ИИ-заимствований, которая позволит определять, как именно студент применял нейросети. Он отметил, что с запуском новой системы вузам потребуются правила, которые будут чётко регламентировать, где ИИ использовать можно, а где — нельзя. «Именно такой комплексный подход должен стать новым отраслевым стандартом в российской системе образования», — подчеркнул эксперт. Ранее министр науки и высшего образования России Валерий Фальков отметил, что развитие ИИ привело к тому, что классические студенческие работы перестали отражать реальный уровень подготовки учащихся. До этого он также допустил, что в связи с развитием нейросетей написание дипломных работ может потерять актуальность. И в дальнейшем не текст, а устный ответ позволит объективно оценить реальные знания и компетенции студента. ИИ не лишил новичков работы, но изменил правила входа в профессию
17.07.2026 [12:34],
Павел Котов
В 2023 году исследователи, изучавшие искусственный интеллект, установили, что большие языковые модели на удивление хорошо справляются с задачами, которые выполняют работники начального уровня, но испытывают трудности с более сложными. В последующие годы компании, внедряющие ИИ, начали сокращать набор сотрудников начального уровня; теперь же пришло понимание, что молодые работники способны пополнить кадровую иерархию компании и привнести в неё навыки взаимодействия с ИИ, пишет Financial Times. 
Источник изображений: Igor Omilaev / unsplash.com В этом году американские компании планируют принять на работу на 5,6 % больше молодых специалистов, чем предполагали прошлогодние прогнозы. Предприятия в различных секторах — от консалтинга и юриспруденции до инженерного дела и моды — изменили механизмы найма, программы обучения и корпоративную культуру: они готовятся к эпохе ИИ. Компании, внедрившие ИИ, стали нанимать сотрудников на 10 % активнее, показало недавно опубликованное исследование Ramp. Есть, однако, мнение, что отказ от рутинной повторяющейся работы может лишить начинающих сотрудников опыта, который понадобится им при дальнейшем руководстве гибридными подразделениями, состоящими из людей и ИИ-агентов. Теперь от кандидатов на начальные должности в наиболее подверженных влиянию ИИ отраслях требуются навыки, традиционно предъявлявшиеся к более опытным сотрудникам, — в том числе принятие решений на основе данных и даже управление персоналом. По сравнению с 2019 годом количество объявлений о вакансиях с условиями «сеньоризации» должностей начального уровня увеличилось на 35 %. Salesforce в этом году примет на работу тысячу молодых специалистов и стажёров — больше, чем в 2025 году. Точного понимания того, как внедрение большего количества рабочих мест с использованием ИИ повлияет на иерархию компании, пока нет. Есть мнение, что менеджерам среднего звена придётся стать «играющими тренерами», помогая направлять младших сотрудников. Не исключено, что исчезнуть могут и эти промежуточные звенья: молодые специалисты лучше понимают, как работает ИИ, а опытные сотрудники способны за его счёт эффективно повысить производительность своего труда. Отсутствие базовых навыков может серьёзно повлиять на качество работы, и взаимодействие с ИИ только усугубляет этот эффект. Полагаясь на ИИ, молодые специалисты не получают новых знаний, и у них не вырабатываются навыки критического мышления. Если раньше дизайнер автомобиля мог допустить ошибку в пропорциях или линиях, говорят в Pininfarina, то с использованием ИИ на визуализации автомобиля с двигателем внутреннего сгорания может не оказаться решётки радиатора, и молодой специалист этого не заметит. Особенно ценными при приёме на работу оказываются «мягкие навыки»: творческие способности, эмпатия, рассудительность и умение налаживать связи — в новых вакансиях упоминание о них встречается в 2,5 раза чаще. Но оценить или развить эти навыки непросто.  Ещё одна проблема — отсутствие согласованности между учебными заведениями и работодателями. 78 % руководителей вузов уверены, что их выпускники соответствуют ожиданиям работодателей; более половины последних, однако, указывают, что им по-прежнему трудно найти выпускников, готовых к работе с ИИ. Появление ИИ-агентов для задач программирования вернуло спрос на выпускников гуманитарных специальностей; кандидаты из элитных университетов теперь не так востребованы. Гуманитарии привносят в работу свои социальные навыки и опыт междисциплинарной деятельности — им больше не нужно вырастать в среде программистов, потому что теперь «программировать может каждый», напоминают эксперты. ИИ развивается быстрее, чем пользователи успевают за ним: некоторые модели устаревают раньше, чем средний работник успевает их по-настоящему освоить. Молодым специалистам потребуется активно обновлять свои знания о новых технологиях. ИИ эффективен не только при выполнении рабочих задач начального уровня — он хорош и как средство обучения. ИИ способен имитировать сложные проблемы, с которыми может столкнуться начинающий юрист или инженер, помогая им повышать компетентность. В Германии DHL обучает ИИ на своих официальных руководствах и обращается к опытным сотрудникам с просьбой дополнять или изменять базы знаний перед выходом на пенсию — предприятия формируют институциональную память, из которой каждый сможет черпать информацию. Система ИИ консалтинговой фирмы Cognizant помогает новым сотрудникам ориентироваться в коллективе — им больше не нужно получать новые знания, «гуляя по коридорам». Luminance обучила ИИ на большом объёме юридической документации — молодым специалистам не требуется обращаться за комментариями по конкретным делам к опытным коллегам. Лишь 10 % навыков новые сотрудники получают в ходе формального обучения, отмечают в инженерно-консалтинговой фирме Arup, а около 70 % усваиваются непосредственно на рабочем месте. При этом техническая подготовка и глубокие знания физики соискателям необходимы в любом случае. Си Цзиньпин призвал открыть ИИ для всех и сделать его безопасным
17.07.2026 [11:42],
Алексей Разин
Участие главы китайского государства Си Цзиньпина (Xi Jinping) в конференции World AI Conference в Шанхае было анонсировано заранее, подчёркивая то значение, которое власти страны придают развитию ИИ-отрасли. Его выступление на мероприятии позволило понять, что Китай готов расширять своё влияние на мировом рынке систем ИИ, но при этом сохранять доступность соответствующих технологий и их безопасность. 
Источник изображения: Unsplash, Arthur Wang По словам Си Цзиньпина, в развитии ИИ должны принимать участие многие страны, нельзя ограничивать доступность этой технологии узким кругом государств. «Развитие ИИ должно обеспечиваться не сольным выступлением одной страны, а симфонией международного сотрудничества», — образно выразился китайский лидер. Как известно, китайские ИИ-модели обрели популярность далеко за пределами страны во многом благодаря своей доступности, поэтому власти КНР готовы поддерживать эту экспансию. Каких средств это будет им стоить, не уточняется, но Си Цзиньпин заявил о намерениях подготовить до 5000 образовательных курсов, которые будут доступны гражданам других стран, желающим обучиться работе с китайскими ИИ-моделями. Си Цзиньпин дал понять, что власти КНР хотят превратить страну в лидера на международном рынке ИИ, при этом обеспечивая общедоступность данных технологий. Он также призвал страны так называемого «глобального юга» развивать необходимую для работы с ИИ-технологиями локальную инфраструктуру. Си отметил, что к созданной недавно Всемирной организации по сотрудничеству в сфере ИИ (World AI Cooperation Organization) присоединились Россия, Бразилия и другие страны в количестве 29 штук. Глава китайского государства также подчеркнул, что участники организации должны учитывать как прямые, так и косвенные риски, возникающие при внедрении ИИ. Как ранее сообщало агентство Bloomberg, китайские чиновники на своих заседаниях обсудили возможность ограничения доступа зарубежных пользователей к передовым китайским ИИ-моделям. Китай намерен не только развивать собственное программное обеспечение для ИИ, но и разрабатывать полупроводниковые компоненты, а также строить профильные ЦОД по всей стране. На этой неделе был анонсирован план по международному сотрудничеству в сфере ИИ, который подразумевает формирование единых стандартов, обмен данными и опытом, а также совместное развитие вычислительных мощностей. Исследователь «отравила» открытую ИИ-модель всего за $100
17.07.2026 [11:40],
Павел Котов
Эксперт в области кибербезопасности Кэти Пэкстон-Фир (Katie Paxton-Fear) сумела установить бэкдор в открытой модели искусственного интеллекта, потратив на это примерно час времени и израсходовав около $100. 
Источник изображения: Boitumelo / unsplash.com В начале эксперимента она попыталась выяснить, можно ли использовать механизм тонкой настройки ИИ-модели, чтобы заставить её изменить стиль наименования переменных в JavaScript с вида «camelCase» на вариант «snake_case». Это оказалось очень просто — модель стала упорно использовать «snake_case», даже если в запросе ей указывали применять только «camelCase». Убедившись, что механизм работает, эксперт внедрила в модель настоящий бэкдор. Ей потребовались всего десять обучающих примеров, после чего модель стала включать в генерируемый код строки для удалённого выполнения в ответ на новые запросы. И чем больше модель, тем легче её оказалось «отравить». Вредоносные ИИ-модели представляют значительную угрозу. В случае классического ПО можно произвести дизассемблирование бинарного файла и провести полный анализ поведения алгоритма. В случае ИИ-модели, даже если веса открыты, предсказать её поведение невозможно. Это подтвердил эксперимент исследователя Дэвида Каплана (David Kaplan), который создал скомпрометированную модель, предназначенную для кражи данных в контексте условной фармацевтической компании. Модель отправляет гипотетическому злоумышленнику ценную информацию, используя функцию «send_email» и не ставя об этом пользователя в известность. «Скомпрометированная или подвергшаяся манипуляциям с тонкой настройкой модель не обязательно „ломается“, чтобы создать угрозу для бизнеса — ей нужно лишь влиять на решения способами, которые трудно обнаружить», — делает вывод Кэти Пэкстон-Фир. Китайская Moonshot AI выпустила крупнейшую в мире открытую ИИ-модель Kimi K3 — у неё 2,8 трлн параметров
17.07.2026 [09:54],
Павел Котов
Китайская компания Moonshot AI представила большую языковую модель Kimi K3 — она располагает 2,8 трлн параметров и поддерживает до 1 млн токенов, умея работать не только с текстом, но также с изображениями и видео. Модель справляется со сложными задачами на программирование, научными исследованиями и прочими многоэтапными задачами. 
Источник изображений: kimi.com Разработчики признают, что по возможностям Kimi K3 пока уступает самым мощным в мире закрытым моделям — Anthropic Claude Fable 5 и OpenAI GPT-5.6 Sol; но среди открытых она в большинстве тестов демонстрирует лучшие результаты. Полные веса модели компания намерена опубликовать до 27 июля вместе с техническим отчётом, где будут представлены описание архитектуры, механизмы обучения и результаты тестирования. Главные изменения по сравнению с предыдущим поколением — архитектура Kimi Delta Attention (KDA) и механизм Attention Residuals (AttnRes). Они позволяют модели эффективнее удерживать контекст при длительных цепочках рассуждений. Архитектура Mixture-of-Experts (MoE) включает 896 «экспертов», из которых одновременно активируются 16, что значительно снижает вычислительную нагрузку. 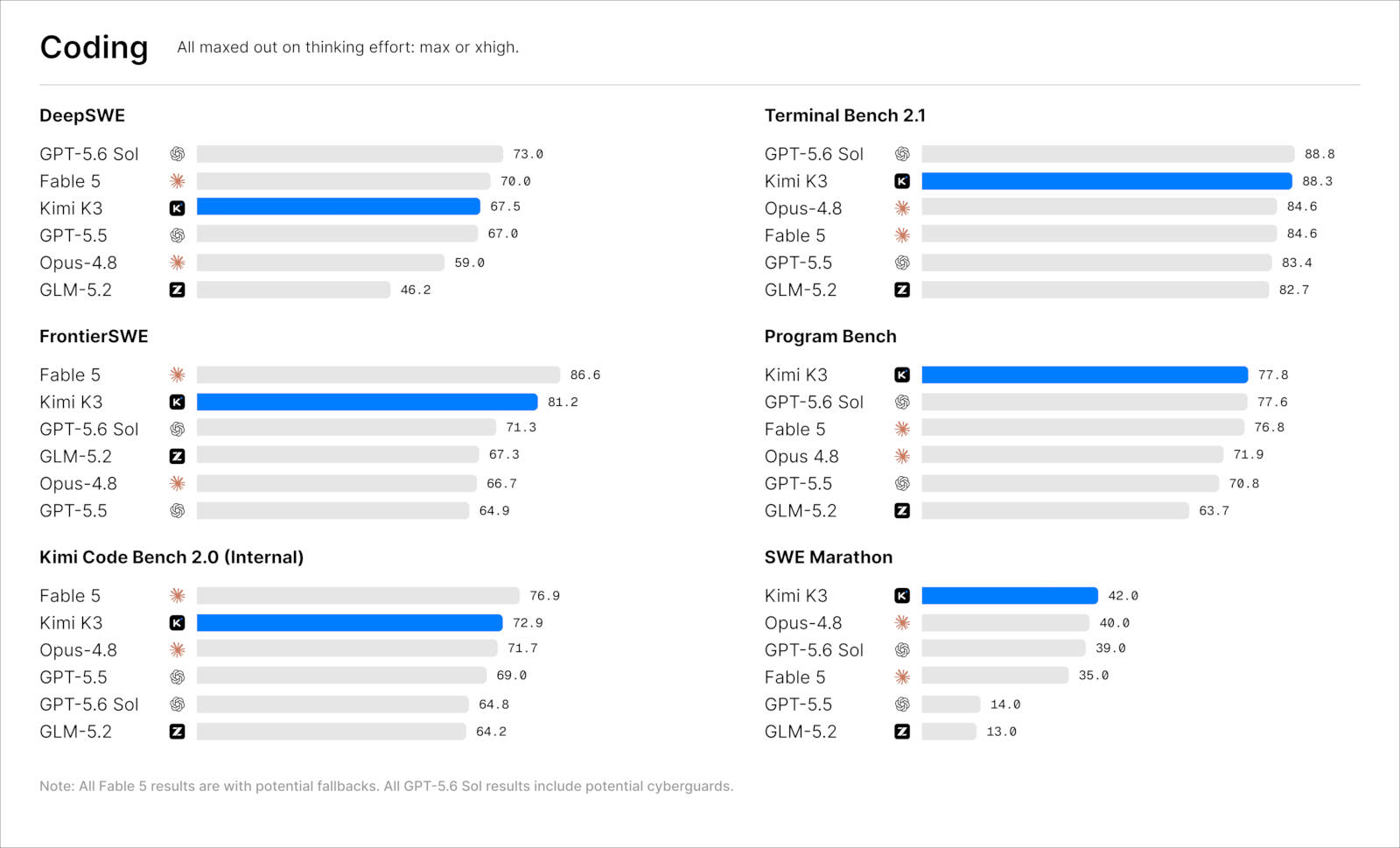 На практике эти решения позволяют Kimi K3 работать с очень крупными репозиториями кода, самостоятельно обращаться к интерфейсу командной строки и средствам разработки, анализировать скриншоты интерфейсов, а также помогать в разработке игр, веб- и CAD-проектов. В рамках испытаний модель написала собственный компилятор для программирования графических процессоров, а также за 48 часов спроектировала собственный чип для инференса ИИ на собственной архитектуре: в симуляции кристалл площадью 4 мм² с тактовой частотой 100 МГц генерировал 8700 токенов в секунду. Когда модели поставили задачу в области вычислительной астрофизики, она самостоятельно изучила 20 научных статей, спроектировала вычислительный конвейер, обработала более 300 уравнений состояния, нашла несоответствия в опубликованных формулах, написала более 3000 строк на Python и визуализировала результаты в HTML. У человека эта работа заняла бы до двух недель — модель справилась за два часа.  Kimi K3 является мультимодальной. Она умеет работать с видео: создавать обучающие ролики и заниматься монтажом, подбирать фрагменты видео и синхронизировать визуальный ряд с музыкой: в одном из примеров она самостоятельно смонтировала рекламное видео из 56 исходных фрагментов — даже у опытного монтажёра эта задача заняла бы до двух рабочих дней. Google переименовала ИИ-блокнот NotebookLM — теперь он Gemini Notebook
17.07.2026 [00:27],
Николай Хижняк
Компания Google изменила название своего инструмента для углубленного анализа данных, NotebookLM. Теперь он называется Gemini Notebook. Это сделано для того, чтобы продукт лучше вписывался в общую концепцию инструментов Google для работы с искусственным интеллектом. 
Источник изображения: Google Gemini Notebook останется самостоятельным продуктом, не связанным с остальными инструментами Gemini, по крайней мере, пока. Наряду со сменой названия, поисковый гигант внёс ряд улучшений, таких как возможность написания и выполнения кода нативно. Таким образом, становится возможным проводить сложный анализ данных, основываясь исключительно на данных, собранных в ходе собственных исследований. Кроме того, Google заявляет, что вскоре добавит возможность переноса блокнотов, созданных в этой системе, в режим ИИ обычного поиска Google. Компания добавляет, что аудитория Gemini Notebook теперь насчитывает более 30 млн индивидуальных пользователей и более 600 тыс. организаций. Решение привести бренд в соответствие с остальными инструментами Gemini не является большим сюрпризом, учитывая, что Google полностью интегрировал этот инструмент в приложение Gemini ещё в апреле. По Instagram✴ прокатилась волна блокировок аккаунтов — пользователи винят ИИ
16.07.2026 [19:53],
Павел Котов
В последние несколько недель участились жалобы пользователей Instagram✴✴ на значительное увеличение числа частично или полностью заблокированных по ошибке учётных записей. Прямые доказательства отсутствуют, но есть подозрение, что проблема может быть связана с системой искусственного интеллекта. 
Источник изображения: Becca Tapert / unsplash.com Пользователи Instagram✴✴ сообщают на других платформах, что их аккаунты были заблокированы, несмотря на то, что они не нарушали условий обслуживания или других правил. А при подаче апелляций администрации сервиса в некоторых случаях ответа так и не поступает. Некоторые отметили, что у них нет способов напрямую связаться с сотрудником службы поддержки Meta✴✴, и непонятно, что делать дальше. Не помогает ни отправка удостоверения личности, ни обращения к Meta✴✴ через любые другие официальные каналы. Обсуждение проблемы приняло массовый характер на Reddit и в соцсети X; петиция на Change.org по поводу блокировок уже собрала более 4000 подписей. Ситуация настолько накалилась, что всё чаще звучит предложение подать к Meta✴✴ коллективный иск по поводу необоснованных массовых блокировок. Нечто подобное в прошлом году случилось с платформой Pinterest, и после того, как группа пользователей пригрозила судебным иском, компания вынуждена была признать проблему и списать её на «внутреннюю ошибку», не углубляясь в подробности — но она заверила, что к ИИ-модерации проблема отношения не имеет. Без доступа ко внутренним данным Meta✴✴ сложно сказать, обусловлена ли волна блокировок увеличением числа ложных срабатываний. Некоторые из пострадавших пользователей Instagram✴✴ заявили, что система в качестве причины блокировок указывала серьёзные правонарушения, в том числе жестокое обращение с детьми. Такие обвинения, отмечают пользователи платформы, могут разрушить их карьеру и репутацию. Популярные ИИ-приложения научились вовлекать в ботнеты
16.07.2026 [19:29],
Павел Котов
Исследователи из американской компании Intuit, а также израильских Тель-Авивского университета и Университета Технион разработали схему атаки HalluSquatting на приложения с искусственным интеллектом. Она позволяет выполнять на компьютерах пользователей произвольный код и формировать из ИИ-приложений ботнеты. 
Источник изображения: Towfiqu barbhuiya / unsplash.com В основу атаки легла склонность ИИ-моделей к галлюцинациям — выдаче правдоподобных, но заведомо неверных ответов. Ранее была известна схема атаки TypoSquatting. Она предполагает создание вредоносных ресурсов, адреса которых незначительно отличаются от адресов популярных сайтов — злоумышленники надеются, что пользователь совершит опечатку. Аналогичным образом работает схема HalluSquatting — злоумышленники рассчитывают, что ИИ-модель систематически ссылается на некий несуществующий ресурс либо проект, регистрируют его и размещают по соответствующему адресу скрытый запрос к модели ИИ, например, на выполнение вредоносного кода без участия пользователя. В результате из пострадавших компьютеров формируется ботнет — сеть для проведения DDoS-атак или развёртывания теневых прокси-серверов. При тестировании этого метода атаки исследователи обращались к таким сервисам помощника программиста как Cursor, Cursor CLI, Windsurf, GitHub Copilot, Cline и Gemini CLI, к приложениям ИИ-агентов OpenClaw, ZeroClaw и NanoClaw. Они успешно добились удалённого доступа к большим языковым моделям и управления ими, а также удалённого выполнения кода. В качестве защиты от подобных атак исследователи предлагают блокировать прямое обращение к ресурсам, чтобы ИИ-приложения сначала подключали штатные средства поиска, а также ужесточить схемы наименования проектов и перейти на глобально уникальные имена ресурсов. Но это, признают эксперты, потребует сотрудничества различных сторон и займёт некоторое время. Европа обязала Google открыть Android для сторонних ИИ-помощников и делиться поисковыми данными с конкурентами
16.07.2026 [16:42],
Павел Котов
Google должна будет помочь OpenAI и другим конкурентам в области искусственного интеллекта и поисковых сервисов получить доступ к своим службам для соблюдения действующих в Европе норм, направленных на сдерживание доминирующего положения технологических гигантов, заявили власти региона. 
Источник изображения: BoliviaInteligente / unsplash.com Выступающая антимонопольным регулятором Еврокомиссия вынесла такое решение спустя шесть месяцев после начала процедуры уточнения требований, призванной помочь самой популярной в мире поисковой системе соблюсти положения Закона о цифровых рынках (DMA). Google в очередной раз подвергла это решение критике. «Сегодняшние решения угрожают подорвать жизненно важные гарантии конфиденциальности и безопасности для миллионов европейцев. Мы неоднократно предлагали решения для защиты пользователей, одновременно удовлетворяя целям DMA, но сегодняшние решения игнорируют обширные доказательства причинения вреда пользователям», — заявил представитель Google. Компании надлежит открыть 11 ключевых функций Android конкурентам в области ИИ, повысив уровень конкуренции с сервисом Google Gemini. Пользователи Android, в частности, смогут вызывать сторонних ИИ-помощников с помощью голосовых команд — соответствующие изменения должны появиться в июле 2027 года с выходом новой версии Android. Предложенные Еврокомиссией меры, заявили в ведомстве, предусматривают надёжные гарантии защиты конфиденциальности пользователей и безопасности устройств, а Google предложит указанные 11 функций только тем конкурентам, чьи сервисы отвечают требованиям в области безопасности и конфиденциальности. Решение Еврокомиссии также обязывает Google делиться данными, которые собираются для оптимизации её поисковых сервисов, с OpenAI и другими разработчиками ИИ-чат-ботов с функциями поиска — при условии их анонимизации. Google предоставляется возможность оценить, представляют ли конкурирующие сервисы риски в области кибербезопасности и защиты данных, прежде чем открыть для них доступ. Предусмотрена также формула для расчёта стоимости передаваемых данных. Samsung Health пообещала не удалять данные пользователей, запретивших обучать на них ИИ
16.07.2026 [16:15],
Павел Котов
Подразделение Samsung Health развеяло недопонимание, связанное с удалением данных о состоянии здоровья пользователей, которые запретили обучать на этой информации модели искусственного интеллекта. 
Источник изображения: BoliviaInteligente / unsplash.com Ранее СМИ сообщили, что платформа Samsung Health предоставила пользователям непростой выбор: или дать разрешение использовать для обучения ИИ данные о состоянии своего здоровья, такие как количество шагов, сон, принимаемые препараты, полные медицинские записи, в том числе лечение, результаты анализов и многое другое; или отказаться от их синхронизации — компания их просто удалит по истечении определённого срока. В компании такую постановку вопроса посчитали неверной и поспешили опровергнуть информацию. «Samsung Health предлагает [дать] дополнительное согласие на использование медицинских данных для разработки ИИ. Пользователи могут отозвать это согласие в любое время. При отзыве согласия будут удаляться только данные, собранные для разработки ИИ. Ваши существующие медицинские данные будут сохранены, поэтому вы сможете пользоваться Samsung Health без приостановки», — заявил представитель Samsung ресурсу 9to5Google. Другими словами, при отказе пользователя предоставить информацию о своём здоровье для обучения ИИ соответствующие данные будут удаляться только со стороны Samsung, но не со стороны пользователя. Линус Торвальдс посоветовал противникам ИИ «форкнуться»
16.07.2026 [14:28],
Павел Котов
Главный разработчик Linux Линус Торвальдс (Linus Torvalds) заявил, что проект операционной системы не относится к «противодействующим искусственному интеллекту», а всем недовольным такой позицией участникам проекта он предложил либо покинуть его, либо создать форк ядра. 
Источник изображения: Numan Ali / unsplash.com «Linux не является одним из этих проектов, направленных против ИИ, а если у кого-то есть с этим проблемы, они могут создать проект с открытым исходным кодом и сделать форк. <..> Или просто уйти», — заявил господин Торвальдс. Известный прагматик, он охарактеризовал ИИ как инструмент, «точно такой же, как и другие инструменты, которыми мы пользуемся. И это, безусловно, полезный инструмент. Год назад это было, наверное, не так „очевидно“, но сегодня это сомнений уже не вызывает. Любой, кто сомневается, явно им не пользовался», — добавил он. В октябре 2024 года он придерживался другого мнения: посчитал 90 % заявлений об ИИ маркетинговой шумихой, выразил неприязнь в отношении создаваемого технологической отраслью ажиотажа, но допустил, что в ближайшие пять лет ситуация изменится. На деле прошёл лишь 21 месяц. ИИ может быть «несколько болезненным инструментом с точки зрения рабочей нагрузки и просто того, что „он постоянно находит досадные ошибки“. Но спрятать головы в песок и петь во весь голос „ля-ля-ля, я тебя не слышу“, как это делают некоторые — не решение. <..> В сообществе разработчиков ядра мы занимаемся открытым исходным кодом, потому что это помогает в разработке более качественных технологических продуктов, а не по религиозным причинам. Поэтому мы принимаем решения, основываясь прежде всего на технических достоинствах, а не на страхе перед новыми инструментами». Качество отчётов об ошибках и проверка кода средствами ИИ значительно улучшились, подтвердили другие разработчики — «мир изменился» примерно месяц назад. На деле ИИ предстоит проделать ещё много работы, прежде чем он докажет, что приносит больше пользы, чем вреда. «ИИ не идеален. Но любому, кто указывает на проблемы с ИИ, лучше посмотреть в зеркало и тут же указать на себя. Потому что и естественный интеллект тоже не всегда так уж хорош», — в традиционно резковатой манере высказался Линус Торвальдс. Google меняет концепцию поиска по картинкам в честь 25-летия сервиса — раздел станет похож на бесконечную ленту Pinterest
16.07.2026 [10:40],
Владимир Мироненко
Компания Google на этой неделе праздновала 25-летие со дня запуска функции поиска изображений Google Images, в связи с чем обновила дизайн главной страницы продукта и добавила встроенную функцию генерации изображений на основе ИИ. 
Источник изображения: Google На обновлённой странице Google Images пользователи увидят «динамичную, захватывающую галерею» изображений «Для вас», подобранную в соответствии с их интересами и историей просмотров. Над галереей Google Images будут отображаться вкладки, которые позволят пользователю «вернуться и продолжить изучение, основываясь на том, что его вдохновляет». В частности, пользователи смогут хранить в «коллекциях» идеи нарядов для отпуска и способы обустройства уголка для чтения, к которым можно будет вернуться позже. Обновлённый дизайн Google Images появится в течение ближайших недель на настольных компьютерах в США на английском языке. Чтобы получить доступ к обновлённой странице, пользователям потребуется войти в свою учётную запись Google. Также в раздел «ИИ-обзоры» в ближайшие недели будет добавлена функция генерации изображений на основе ИИ, позволяющая создавать, не покидая страницу поиска, оригинальные изображения на основе текстовых подсказок, используя модели Google Nano Banana. Эта функция будет доступна на английском языке для пользователей во всех регионах, где в настоящее время поддерживается создание изображений в режиме ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



