|
Опрос
|
реклама
Быстрый переход
OpenAI замахнулась на рынок смартфонов — процессор спроектируют MediaTek и Qualcomm, а устройство соберёт китайская Luxshare
27.04.2026 [12:49],
Дмитрий Федоров
OpenAI привлекла MediaTek и Qualcomm к созданию мобильных процессоров (CPU) для собственного ИИ-смартфона. Массовое производство намечено на 2028 год, а при проектировании чипа акцент сделают на энергоэффективность, управление памятью и локальный запуск компактных ИИ-моделей. 
Источник изображения: ChatGPT / 3DNews В прошлом году OpenAI договорилась с Broadcom о разработке собственных ИИ-чипов для вычислительных кластеров нового поколения. Теперь, по словам аналитика TF International Securities Мин-Чи Куо (Ming-Chi Kuo), компания нацелилась и на рынок мобильных CPU — сразу с двумя крупнейшими разработчиками чипсетов для смартфонов. Как и в современных флагманских Android-смартфонах, сложные и ресурсоёмкие задачи возьмёт на себя облачный ИИ. Окончательные спецификации CPU и список поставщиков, по прогнозу Куо, появятся в конце 2026 — начале 2027 года. По описанию Куо, будущий чип повторит подход Google в линейке Pixel: приоритет отдан ИИ-ускорителю, а не чистой вычислительной мощности. Некоторые ИИ-модели могут быть не оптимизированы под специализированный ИИ-блок и вынуждены задействовать графический процессор (GPU) или CPU. Если OpenAI будет запускать на смартфоне только собственные модели, проблем не возникнет, но если устройство должно поддерживать сторонние ИИ-модели, экономить на CPU и GPU нельзя. Куо также указывает, что смартфону придётся непрерывно считывать контекст пользователя, — а значит, CPU получит развитую систему постоянно активных сенсоров. Qualcomm уже реализовала похожую функцию в блоке Sensing Hub своих последних мобильных платформ. Эксклюзивным партнёром по проектированию и сборке устройства станет китайская Luxshare, конкурент Foxconn. DeepSeek снизила на 75 % цены за доступ к ИИ-модели DeepSeek-V4-Pro
27.04.2026 [12:48],
Дмитрий Федоров
DeepSeek предложила разработчикам скидку 75 % на новую флагманскую ИИ-модель DeepSeek-V4-Pro. Одновременно китайская компания в 10 раз удешевила повторные и похожие запросы на всех своих платформах за счёт кеширования входных данных. 
Источник изображения: deepseek.com Резкое снижение цен DeepSeek грозит вернуть ИИ-индустрию к ценовой войне, которая вспыхнула после того, как DeepSeek устроила переполох в Кремниевой долине своей ИИ-моделью R1 в начале прошлого года. OpenAI, Anthropic и Google наперегонки выпускают новые ИИ-продукты, но их использование обходится дорого. Китайские компании рассчитывают, что разница в тарифах ускорит переход разработчиков на их платформы и изменит расклад сил в технологическом соперничестве с США. 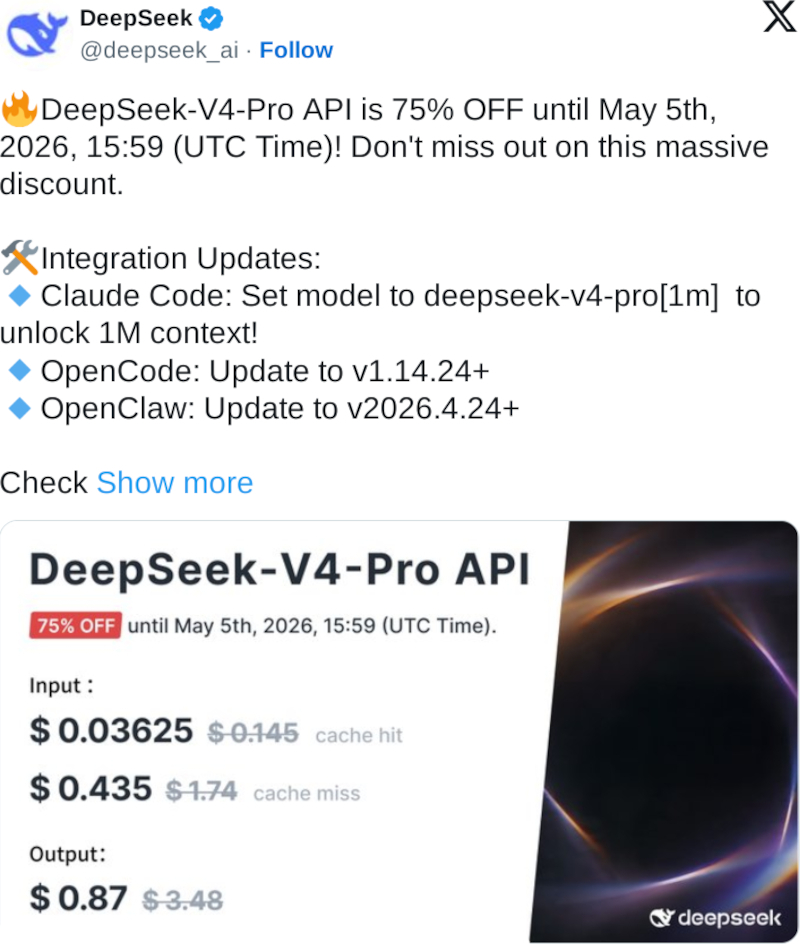
Источник изображения: @deepseek_ai / x.com Однако DeepSeek рассчитывает привлечь пользователей не только ценой. Контекстное окно DeepSeek-V4 — максимальный объём данных, который модель обрабатывает за один раз, — позволяет работать со сложными кодовыми базами и объёмными документами. Модель легко подключается к Claude Code, OpenClaw и OpenCode, что упрощает её взаимодействие с более широкой ИИ-экосистемой. «Ценообразование, открытый исходный код и контекстное окно в миллион токенов снижают порог входа для разработчиков, стартапов и малого бизнеса», — сказал Акшар Керемане (Akshar Keremane), сооснователь ИИ-стартапа O-Health. По словам Керемане, раньше разработчики не могли экспериментировать с моделями такого уровня и масштаба. ИИ теперь обходится дороже живых сотрудников — техдиректор Uber уже слил на нейросети весь годовой бюджет
27.04.2026 [10:52],
Дмитрий Федоров
ИТ-бюджеты ряда компаний трещат по швам из-за того, что ИИ-вычисления обходятся дороже, чем зарплаты сотрудников. Технический директор Uber уже исчерпал бюджет на ИИ на 2026 год из-за высокой стоимости токенов. Мировые расходы на ИТ в 2026 году достигнут $6,31 трлн — на 13,5 % больше, чем в 2025 году. Основную долю прироста обеспечат ИИ-инфраструктура, программное обеспечение и облачные сервисы. 
Источник изображения: Igor Omilaev / unsplash.com Вице-президент Nvidia по прикладному глубокому обучению Брайан Катанзаро (Bryan Catanzaro) признал в интервью Axios: «У моей команды затраты на вычисления намного превышают расходы на сотрудников». «Мы строим первый автономный бизнес — масштабируемся за счёт интеллекта, а не штата», — написал в LinkedIn гендиректор Swan AI Амос Бар-Йосеф (Amos Bar-Joseph), похвастав счётом от Anthropic. Даже компаниям с крупнейшими ИТ-бюджетами придётся со временем доказывать эффективность вложений в ИИ, особенно тем, кто ежеквартально отчитывается перед акционерами. Доказать её можно ростом производительности или конкретными показателями окупаемости. «Тон немного меняется: всё чаще звучит вопрос об истинной ценности работника — живого или цифрового», — отметил Брэд Оуэнс (Brad Owens), вице-президент по стратегии цифровой рабочей силы в Asymbl, которая специализируется на управлении трудовыми ресурсами. Дорожающие ИИ-вычисления меняют расстановку сил и среди самих ИИ-стартапов. Один из инвесторов OpenAI рассказал Axios, что удорожание может оказаться OpenAI на руку: Codex, по его мнению, расходует токены эффективнее, чем Claude Code, что позволяет сократить затраты. Anthropic в свою очередь пересмотрела цены после скачка спроса на её услуги. Цены на память местами пошли вниз, но нормализации рынка не произойдёт раньше 2030 года
26.04.2026 [15:01],
Дмитрий Федоров
На рынке оперативной памяти и накопителей в Европе, Китае и США наметилось ценовое плато, а некоторые позиции даже подешевели. Однако опрошенные изданием PCWorld отраслевые аналитики связывают это с локальным давлением накопленных запасов и осторожностью покупателей, а не с концом дефицита, вызванного аппетитом ИИ ЦОД. Первого заметного смягчения цен стоит ждать лишь к IV кварталу 2027 года, полной нормализации — к 2030 году. 
Источник изображения: Liam Briese / unsplash.com ИИ ЦОД скупают всю свободную память на рынке, и поэтому на потребительский сегмент почти ничего не остаётся: дорожают оперативная память, готовые компьютеры, накопители, игровые приставки, телефоны и даже SD-карты. Однако в последний месяц-два рост цен будто бы приостановился. Замедление и даже разворот цены заметнее всего в Европе и Китае: в Китае работают местные производители помимо «большой тройки» — Samsung, SK Hynix и Micron. Цены выравниваются и в США. По агрегированным данным PCPartPicker, конфигурация DDR5 на 2 × 16 Гбайт — разумная середина для сборки компьютера — резко подорожала в IV квартале 2025 года, а рост её стоимости достиг 400 %. В этом году стоимость этой конфигурации вышла на плато, а в континентальной Европе и Австралии даже наблюдается небольшое снижение цены с пика начала 2026 года. Аналитики считают, что текущие флуктуации имеют локальный масштаб: в какой-то момент производители и дистрибьюторы переоценили товар, и теперь слегка откатывают цены, но структурный дефицит не исчез. Часть «падения» цен объясняется тем, что отдельные продавцы (включая перекупщиков, работающих через маркетплейсы) задирали цены сверх того, что рынок готов выдержать, и теперь вынуждены немного опускать их до более реалистичных уровней. Том Майнелли (Tom Mainelli), вице-президент IDC по исследованиям устройств и потребительского рынка, признал частичное замедление: цены на часть позиций превысили уровень, который рынок готов поддерживать, и хотя возможны пауза или частичный откат цены, до нормализации рынка ещё далеко. На ситуацию также влияют перекупщики, которые после пика дефицита могли снизить наценки, что объяснило бы короткий разворот цены без возвращения к более вменяемым уровням. Производители на нормализацию цен не рассчитывают: Microsoft, ASUS, Lenovo, Samsung и Motorola либо повышают цены на уже выпускаемые устройства, что ломает многолетнюю отраслевую тенденцию, либо анонсируют новые устройства по куда более высоким ценам. Особняком стоит Apple: бестселлер MacBook Neo за $600 с 8 Гбайт оперативной памяти и перепрофилированным процессором iPhone позволяет компании пользоваться тревогой покупателей. Гендиректор Framework Нирав Патель (Nirav Patel) на прошлой неделе допустил, что ПК в привычном виде могут исчезнуть. О сохранении дефицита памяти говорит и рынок домашних игровых приставок: и Xbox, и PlayStation со старым железом резко подорожали спустя пять лет, чего в истории этой отрасли ещё не случалось. На этой неделе Meta✴✴ подняла цену на VR-шлем Quest. Патрик Мурхед (Patrick Moorhead) из Moor Insights & Strategy не ждёт масштабного разворота цены в ближайший год с лишним. Чтобы построить фабрику памяти и вывести её на серийные объёмы, нужно три-четыре года, а в 2022–2023 годах все производители памяти показывали отрицательную валовую рентабельность и прекратили инвестировать в рост производства — как раз когда OpenAI в ноябре 2022 года выпустила ChatGPT и дала старт гонке ИИ. Для памяти с высокой пропускной способностью (HBM), устанавливаемой в ЦОД, нужно примерно вчетверо больше кристаллов, чем для потребительской DRAM, и хотя ситуация должна начать улучшаться в IV квартале 2027 года, к норме рынок не вернётся раньше 2030 года. Однако есть и позитивные сдвиги. Спрос на новые ЦОД снижается: часть запланированных в США площадок отменены или заморожены из-за нехватки пропускной способности энергосетей, недовольства потребителей и избирателей ростом тарифов и экологической нагрузкой, а также неуверенностью инвесторов, опасающихся ИИ-пузыря. Параллельно небольшие китайские производители наращивают мощности и поставляют память на собственный внутренний рынок и крупным международным клиентам — Lenovo, Dell, HP. К тому же новые технологии оптимизации памяти в AI (например, Google TurboQuant) потенциально снижают потребление памяти на токен, хотя, по оценкам TrendForce, это, скорее всего, приведёт не к экономии, а к росту объёмов использования памяти ИИ-моделями на той же аппаратной базе. В итоге небольшие и локальные снижения цен на модули RAM и накопители — это временная коррекция, вызванная перегревом на уровне каналов продаж, а не сигнал разворота долгосрочного тренда дефицита и высокой стоимости памяти для ПК. Облачные провайдеры оставили ИИ-стартапы без доступа к GPU — все мощности съели Anthropic и OpenAI
26.04.2026 [11:37],
Дмитрий Федоров
Облачные провайдеры — Microsoft, Amazon и CoreWeave — зарезервировали мощности графических процессоров (GPU) за Anthropic, OpenAI и собственными командами, оставив ИИ-стартапы с многомесячными очередями. Нехватка вычислительных ресурсов затронула стартапы, проинвестированные венчурными фондами — Sequoia Capital, Founders Fund, General Catalyst и Andreessen Horowitz. Арендные ставки за шесть месяцев выросли более чем на 25 %, а по данным Azure дефицит продлится как минимум до конца 2026 года. 
Источник изображения: Alex Shuper / unsplash.com Дефицит охватил широкий круг ИИ-компаний: малые и средние игроки вынуждены бороться за остатки мощностей по всё более высоким ценам. Партнёр General Catalyst Хемант Танеджа (Hemant Taneja) разослал анкеты основателям стартапов, в которые вложился фонд, чтобы оценить реальный доступ к GPU. В анкете Танеджа написал: «Мы получаем многочисленные сигналы о том, что доступ к вычислительным ресурсам, прежде всего к GPU, стал одним из главных ограничений для вашего развития в этом году». В ответ General Catalyst создаёт общие вычислительные пулы и намерен напрямую договариваться с провайдерами от имени стартапов из своих инвестиционных портфелей. Ситуация напоминает начало 2023 года, когда крупные провайдеры свернули публичный доступ к ресурсам в пользу внутренних операций и ключевых клиентов вроде OpenAI — тогда Andreessen Ventures и Index Ventures начали формировать собственные GPU-пулы для стартапов из своих портфелей. Однако нынешняя нехватка острее: скачок спроса на ИИ-инструменты для разработки ПО заставил платформы резко сократить квоты для небольших клиентов, а значительная часть двух- и трёхлетних контрактов, заключённых стартапами в прошлые годы, истекает именно сейчас — облачные провайдеры пользуются этим, чтобы перераспределить мощности в пользу более платёжеспособных клиентов. Многомиллиардные долгосрочные сделки, которые Microsoft, Amazon и CoreWeave заключили с Anthropic и OpenAI, обеспечили этим компаниям приоритетный доступ к GPU. Тем не менее Anthropic всё ещё испытывает острую нехватку мощностей на фоне стремительного роста бизнеса. По сведениям сотрудников компании, Azure сообщила им, что дефицит сохранится как минимум до конца 2026 года. Microsoft выстроил трёхуровневую систему распределения GPU: около 1000 крупных годовых плательщиков пользуются приоритетным доступом, средние компании получают поддержку выделенных менеджеров, малый и микробизнес работает через партнёрских агентов. Чтобы арендовать чипы Blackwell, клиент обязан взять не менее 1000 единиц и подписать контракт на срок от одного года с бюджетом от десятков миллионов долларов. Старые чипы NVIDIA рядовые клиенты ждут от нескольких недель до нескольких месяцев. Azure отслеживает загрузку и отзывает доступ при простое даже в несколько часов; параллельно компания сворачивает вычислительные льготы в программе поддержки стартапов: компании, не использующие выделенные чипы в полном объёме, навсегда лишаются доступа к GPU. Генеральный директор Lightning AI Уилл Фалкон (Will Falcon) сообщил, что платформа управляет примерно 40 000 GPU, тогда как в очереди стоят около 40 предприятий с суммарной потребностью до 400 000 чипов. За шесть месяцев ставки выросли более чем на 25 %: часовая цена за чип поднялась с $1,6 до более чем $2, а на популярные конфигурации наценки ещё выше. Основу парка составляют чипы NVIDIA на архитектуре Hopper предыдущего поколения. Четырёхлетний разработчик ИИ-моделей генерации изображений Krea привлёк $83 млн при участии Andreessen Ventures и Bain Capital Ventures. Сооснователь и генеральный директор компании Виктор Перес (Victor Perez) рассказал, что ещё шесть месяцев назад несколько провайдеров сами добивались партнёрства: компания заключила шестимесячный контракт на аренду нескольких сотен чипов NVIDIA Blackwell по $2,8 в час. Когда Krea попыталась расширить мощности для обучения ИИ-моделей с нуля, торговые представители провайдеров перестали выходить на связь или ссылались на отсутствие ресурсов; когда контакт удавалось установить — требовали трёхлетних контрактов и существенного повышения цены. За несколько дней нужные кластеры выкупили другие клиенты. В итоге Krea подписала однолетний контракт на те же чипы по $3,7 в час, то есть на 32 % дороже, хотя по рыночным меркам это относительно немного. «Нехватка вычислительных мощностей в критический момент может уничтожить компанию», — предупредил Перес, добавив, что рост цен пережить можно, а перебои в поставках стали бы катастрофой. Другой основатель рассказал, что планировал арендовать около 1000 GPU с высокой пропускной способностью: представитель NVIDIA предупредил об огромных очередях, суточная аренда такого кластера превышает $70 000 — а свободных ресурсов всё равно нет. Часть стартапов строит собственную инфраструктуру. Основатель Collide — разработчика ИИ-агентов для нефтегазовой отрасли, привлёкшего $14 млн в посевном раунде, — Колин Макклеллан (Colin McLellan) заявил, что компания намерена вложить около $500 000 в GPU NVIDIA, чтобы развернуть частный вычислительный кластер, при необходимости арендовав площадь в ЦОД напрямую. По расчётам Макклеллана, несмотря на высокие первоначальные затраты, собственная инфраструктура исключает риск перебоев и в перспективе нескольких лет выходит дешевле многолетней аренды. В рамках трёхлетней сделки Meta✴ будет использовать сотни тысяч чипов Amazon Graviton
26.04.2026 [06:34],
Алексей Разин
Эволюция вычислительной инфраструктуры искусственного интеллекта происходит стремительно, о чём отчасти говорит и недавний квартальный отчёт Intel, показавший резкий рост спроса на центральные процессоры серверного назначения. Американские техногиганты начинают активнее использовать чипы собственной разработки, а также предлагать их сторонним участникам рынка. 
Источник изображения: LinkedIn По крайней мере, эту тенденцию иллюстрирует заключённая недавно между Meta✴✴ Platforms и Amazon (AWS) сделка, по результатам которой первая получит на три года или более доступ к сотням тысячам чипов Graviton, которые Amazon изначально разрабатывала для собственных нужд. Эта сделка, по большому счёту, идёт в одном русле с договорённостями, которые Meta✴✴ недавно достигла с CoreWeave и Mebius, направив на расширение собственной вычислительной инфраструктуры $48 млрд в общей сложности. Финансовые условия сделки Meta✴✴ с Amazon раскрыты не были. По словам представителей первой, процессоры Graviton обеспечат её тем сочетанием производительности и эффективности при работе с агентскими задачами в ИИ, которое ей требуется. Как отметили представители AWS, процессоры Graviton используются многими разработчиками для предварительного обучения своих ИИ-моделей, и теперь Meta✴✴ окажется в их числе. В этом отношении она составит компанию и более известным клиентам AWS, включая Adobe, Apple, Snowflake и Anthropic. Среди доступных конфигураций облачного сервиса EC2 именно процессоры Graviton обеспечивают лучшее быстродействие за свои деньги, потребляя при этом на 60 % меньше электроэнергии по сравнению с альтернативами, как отмечают представители AWS. Компания Meta✴✴ и ранее использовала Graviton, но в скромных масштабах, а теперь она войдёт в число пяти крупнейших клиентов AWS и начнёт использовать сотни тысяч таких чипов. Арендой чипов Nvidia у AWS компания Meta✴✴ занималась с 2017 года. Люди стали говорить на 28 % меньше — виноваты смартфоны и интернет, а пандемия лишь усилили спад
25.04.2026 [21:07],
Дмитрий Федоров
За полтора десятилетия число слов, которые люди произносят в разговоре с другими, сократилось почти на 28 %. В 2005 году человек произносил в среднем 16 632 слова в день, к 2019 году — лишь около 11 900, подсчитали учёные, проанализировав данные 22 исследований, в которых более 2000 человек записывали аудио повседневных разговоров. После пандемии, по оценке авторов, спад лишь усилился. 
Источник изображения: ChatGPT / 3DNews Исследователи из Университета Миссури в Канзас-Сити (University of Missouri-Kansas City) и Аризонского университета (University of Arizona) объясняют снижение объёма устной речи переходом повседневной жизни в цифру. Заказы через приложения вытеснили разговоры с продавцами и кассирами, переписка заменила звонки, общение переместилось в Сеть. Дело не только в разговорах ни о чём — сокращается вся устная речь. Как отмечает издание The Wall Street Journal, последствия не ограничиваются эпидемией одиночества или риском увязнуть в конспирологии. По мнению авторов исследования, люди утрачивают базовые навыки общения — вплоть до умения не перебивать собеседника. Молодёжь оказалась чуть уязвимее, хотя разрыв невелик: люди моложе 25 лет ежегодно произносили в день на 451 слово меньше, те, кто старше 25, — на 314. В среднем число слов, произносимых за день, ежегодно сокращалось на 338. Если тенденция сохранилась и после 2019 года, то сегодня показатель может не превышать 10 000 слов в день. Профессор лингвистики Невадского университета в Рино (University of Nevada, Reno) Валери Фридланд (Valerie Fridland) просит не паниковать. Небольшие перемены в привычках способны обратить эту тенденцию вспять: например, родителям стоит больше разговаривать с детьми; можно обзавестись домашним стационарным телефоном и время от времени хотя бы ненадолго откладывать смартфон в сторону. Сотрудников Nvidia и лично Хуанга восхитила работа OpenAI Codex на основе GPT-5.5
25.04.2026 [16:04],
Павел Котов
OpenAI помогла Nvidia локально развернуть сервис Codex на основе модели искусственного интеллекта GPT-5.5, новые характеристики которой восхитили сотрудников «зелёной» компании. Она показала значительный прирост эффективности по сравнению с системами предыдущих поколений. 
Источник изображений: nvidia.com Служба OpenAI Codex на основе GPT-5.5, развёрнутая на внутренних корпоративных ресурсах Nvidia, оказалась в 35 раз менее затратной экономически по сравнению с GPT-4o, а выход токенов на мегаватт вырос в 50 раз. На первых же этапах работы сервис, доступный 10 000 сотрудников Nvidia, продемонстрировал «умопомрачительные» результаты, способные «изменить жизнь». «Циклы отладки, которые раньше растягивались на несколько дней, теперь занимают всего несколько часов. Эксперименты, для которых раньше требовались несколько недель, становятся мгновенным процессом в сложных многофайловых базах кода. Отделы разрабатывают пакеты функций полного цикла, отправляя запросы естественным языком — с более высокой надёжностью и меньшим количеством потери ресурсов, чем в прежних моделях», — рассказали в Nvidia. Модель развернули на стоечных системах Nvidia GB200 NVL72, что помогло добиться огромной экономии средств и надлежащего удельного количества токенов.  «Я невероятно рад за всех, кто будет пользоваться Codex, чтобы ускориться и выполнить работу, которая раньше была невозможна. Пожалуйста, передайте вашей команде поздравления за то, что они снова открыли миру новые горизонты. И ещё раз поблагодарите их за изобретение GPT, которая дала нам трамплин для рассуждений, планирования, использования инструментов и многого другого», — написал гендиректор Nvidia Дженсен Хуанг (Jensen Huang) в письме на имя главы OpenAI Сэма Альтмана (Sam Altman). США призвали всех активнее бороться с дистилляцией американских ИИ-моделей китайцами
25.04.2026 [08:22],
Алексей Разин
На этой неделе американские законодатели продвинулись чуть дальше в согласовании пакета законопроектов, направленных на сдерживание технологического развития КНР. Помимо заявлений на парламентском уровне, по дипломатическим каналам в посольства США по всему миру была направлена телеграмма, призывающая обратить внимание на проблему дистилляции американских ИИ-моделей китайскими разработчиками. 
Источник изображения: Unsplash, Solen Feyissa Напомним, под «дистилляцией» в данном контексте понимается процесс использования более зрелых американских больших языковых моделей для дообучения китайских. Это ускоряет процесс создания конкурирующих ИИ-моделей в Китае, позволяя с меньшими затратами ресурсов и времени получать сопоставимые по производительности программные решения в сфере ИИ. По мнению американских экспертов, некоторые китайские разработчики преподносят свои ИИ-модели как оригинальные, но в действительности они в процессе обучения активно полагались на выдаваемые американскими моделями данные. Если американские законодатели добьются усиления контроля за блокировкой такой деятельности зарубежных разработчиков, то некоторые китайские ИИ-стартапы вынуждены будут покинуть рынок в течение шести или двенадцати месяцев, по мнению экспертов, опрошенных South China Morning Post. Даже более самостоятельные китайские разработчики могут пострадать в результате ограничения доступа к американским ИИ-моделям, поскольку совершенствование собственных моделей они ускоряют как раз за счёт «дистилляции». Новые версии китайских моделей, которые сейчас появляются раз в три месяца, в итоге будут готовиться к выходу год и более. Выступая на парламентских слушаниях в США на этой неделе, бывшая член совета директоров OpenAI Хелен Тонер (Helen Toner) подчеркнула, что было бы ошибкой недооценивать потенциал китайских разработчиков ИИ, которые обладают большим потенциалом инноваций и без доступа к дистилляции. При этом ряд американских компаний, включая OpenAI, Google и Anthropic на протяжении последних месяцев выступали с обвинениями китайских конкурентов в «дистилляционных атаках». Хотя сама по себе такая методика обучения ИИ-моделей не считается незаконной, как метод конкурентной борьбы она требует некоторого законодательного регулирования, по мнению многих участников рынка. Американские законодатели также намерены добиваться усиления контроля за экспортом технологий производства полупроводниковых компонентов в Китай. Новая инициатива властей США подразумевает усиление ограничений на поставку в КНР оборудования для выпуска чипов. Разумеется, данные шаги со стороны американских парламентариев не остались без внимания китайских властей. По традиции, усилия американских оппонентов по «обеспечению национальной безопасности» в Китае назвали ширмой, прикрывающей намерения продвигать американские интересы во внешнеторговой сфере в ущерб другим участникам рынка. Полупроводниковая отрасль только пострадает от этих действий американских регуляторов, как подчёркивают китайские чиновники. Власти КНР оставляют за собой право защищать интересы национальных компаний при помощи ответных мер, которые пока не конкретизируются. Акции Intel взлетели в цене почти на четверть и потянули за собой конкурентов — Nvidia теперь стоит $5 трлн
25.04.2026 [07:45],
Алексей Разин
Первичная реакция фондового рынка на публикацию квартальной отчётности в конце этой рабочей недели закрепилась и по итогам последней торговой сессии в США, позволив акциям Intel вырасти в цене на 23,6 %. В пике курс акций компании укреплялся на 25 %, позволив им превзойти максимум, достигнутый в разгар «пузыря дот-комов» в начале этого века. 
Источник изображения: Intel Агентство Bloomberg обратило внимание на интересный факт: рыночная стоимость пакета акций Intel, принадлежащего с августа прошлого года американскому правительству, на этой неделе достигла $36 млрд. Номинально, власти США заработали бы на этой сделке $27 млрд, если бы планировали продать свои акции Intel сейчас. Когда данная сделка готовилась, компания находилась не в лучшем положении, поскольку длительный выход из кризиса требовал больших капитальных вложений, а рыночные позиции терялись под натиском конкурентов. Ситуацию исправил бум искусственного интеллекта, который в своей текущей фазе обратил внимание клиентов Intel на её центральные процессоры, активно закупаемые для расширения серверной вычислительной инфраструктуры. Фактически, прирост курсовой стоимости акций Intel на 24 % за одну сессию перекрыл рекорд 1987 года. Более того, был обновлён исторический максимум на отметке $82,54 за акцию. Дональд Трамп (Donald Trump) не смог удержаться от комментариев после выхода квартальной отчётности компании: «Мы были чиповой столицей мира, и теперь Intel возвращается. Все компании, производящие чипы, возвращаются». Характерно, что оптимизм инвесторов повлиял и на котировки акций конкурирующей AMD, которые выросли на солидные 14 % по итогам вчерашней торговой сессии. По словам представителей D.A. Davidson, центральные процессоры в условиях спроса на агентские вычислительные нагрузки в сегменте ИИ становятся товаром повышенного спроса. «Некогда сонный рынок центральных процессоров теперь движется вверх», — отметили аналитики. Курс акций Arm на американском фондовом рынке вырос вчера на 12 %, а полупроводниковый фондовый индекс SOX в целом прибавил 3,2 % до исторического максимума. Зато Nvidia, которая в условиях бума ИИ ранее росла быстрее конкурентов, вчера прибавила в капитализации всего на 4,3 %, но этого хватило для преодоления планки капитализации в $5 трлн. Понимая тенденции рынка компонентов для ИИ, она в последнее время ускорила разработку центральных процессоров и смежных решений. Google инвестирует в Anthropic $40 млрд и предоставит 5 ГВт вычислительных мощностей на фоне обострившейся ИИ-гонки
25.04.2026 [06:50],
Дмитрий Федоров
Google инвестирует в Anthropic $40 млрд — $10 млрд сразу и ещё $30 млрд после достижения ИИ-стартапом целевых показателей. Кроме того, Google предоставит Anthropic дополнительные 5 ГВт вычислительных мощностей Google Cloud на ближайшие пять лет. Соглашение расширяет ранее объявленное партнёрство Anthropic с Google и производителем чипов Broadcom. 
Источник изображения: BoliviaInteligente / unsplash.com Обещание инвестиций последовало за выпуском Mythos — новейшей и самой мощной ИИ-модели Anthropic, которую компания в этом месяце предоставила ограниченному кругу партнёров. В Anthropic заявляют, что модель имеет серьёзный потенциал в сфере кибербезопасности, однако из-за угрозы злоупотреблений широкий доступ к ней ограничен: компания совместно с избранными организациями оценивает и устраняет эти риски. При этом Mythos уже попала в руки тех, кому она не предназначалась. Отношения Anthropic с Google возникли задолго до событий этой недели. В начале месяца Anthropic объявила о партнёрстве с Google и производителем чипов Broadcom, который разрабатывает для Google ИИ-процессоры, для получения нескольких гигаватт вычислительных мощностей на базе тензорных процессоров (TPU), начиная с 2027 года. Broadcom затем отчиталась перед регулятором о предоставлении 3,5 ГВт. Новые инвестиции Google расширяют эту договорённость: Google Cloud предоставит дополнительные 5 ГВт мощностей в течение пяти лет с возможностью дальнейшего увеличения. Google — прямой конкурент Anthropic на рынке ИИ-моделей, но одновременно и ключевой поставщик инфраструктуры. Anthropic во многом зависит от Google Cloud в части процессоров, в том числе TPU — специализированных чипов для ИИ-задач, которые считаются одной из лучших альтернатив востребованным процессорам Nvidia. Гонку в области ИИ всё сильнее определяет доступ к вычислительным мощностям для обучения и развёртывания ИИ-моделей. OpenAI активно наращивает ресурсы через сеть сделок на сотни миллиардов долларов с облачными провайдерами, производителями процессоров и энергетическими компаниями, в том числе расширив в этом месяце соглашение с производителем чипов Cerebras. Anthropic ведёт жёсткую борьбу за мощности. В последние недели компания столкнулась с массовыми жалобами на ограничения при работе с Claude и ответила серией инфраструктурных сделок. Ранее в этом месяце Anthropic заключила соглашение с облачным провайдером CoreWeave на мощности ЦОД. На этой неделе компания привлекла дополнительные $5 млрд от Amazon — часть масштабного соглашения, по которому Anthropic, как ожидается, потратит до $100 млрд на вычислительные мощности объёмом около 5 ГВт. Ещё в феврале оценка Anthropic составляла $350 млрд, теперь же инвесторы готовы вкладываться в компанию исходя из оценки в $800 млрд и даже выше. По имеющимся данным, компания рассматривает возможность выхода на биржу уже в октябре этого года. ОАЭ намерены перевести половину госсектора под управление агентного ИИ за два года
24.04.2026 [22:55],
Дмитрий Федоров
Объединённые Арабские Эмираты (ОАЭ) объявили план перевода 50 % государственного сектора, услуг и операций на агентный ИИ в течение двух лет. Инициативу представил шейх Мохаммед ибн Рашид Аль Мактум (Mohammed bin Rashid Al Maktoum). Страна позиционирует эту программу не как поэтапную цифровизацию, а как структурную перестройку госуправления — переход к модели автономного правительства. 
Источник изображений: ChatGPT / 3DNews Агентный ИИ — класс систем, способных не только генерировать аналитику, но и действовать самостоятельно: выполнять задачи, адаптироваться к меняющимся вводным данным и повышать собственную эффективность. В государственном контексте такие системы могут охватывать автоматизацию обращений граждан, оказания услуг и принятие операционных решений. Объявление примечательно тем, что инвестиции в ИИ подаются как инструмент национальной конкурентоспособности. ОАЭ годами выстраивали для этого основу: инфраструктуру цифровой идентификации, сервисы «умного правительства», суверенные облачные мощности, стратегии работы с данными и национальные ИИ-программы. Нынешний шаг выводит эти наработки за рамки цифрового обеспечения — к операционной автономии. Маниш Ранджан (Manish Ranjan), директор по исследованиям ПО и облачных технологий в IDC EMEA, считает, что успех программы определят не столько вычислительные мощности, сколько готовность госведомств перестроить процессы, на которых будет работать агентный ИИ. По его словам, ключевым фактором станет уровень подготовки данных, рабочих процедур и управленческих правил: для федерального государства такая перестройка — это многолетняя программа управления изменениями, а не обычное технологическое внедрение.  Мохамед Рушди (Mohamed Roushdy), директор по информационным технологиям Reem Finance, назвал цель амбициозной, но достижимой с учётом цифровой зрелости страны. «ОАЭ начинают не с нуля», — подчеркнул Рушди, указав на развитые платформы UAE Pass и TAMM, устойчивые государственные инвестиции и широкое внедрение ИИ в госструктурах. При этом он выделил серьёзные барьеры: фрагментацию унаследованных систем, неравномерную готовность данных и ограничения суверенных ИИ-мощностей, способные замедлить прогресс в работе с чувствительными нагрузками. Вопросы доверия, вероятно, определят следующую стадию ИИ-стратегии в госсекторе. По мере того как правительства переходят от ИИ как инструмента повышения производительности к системам, участвующим в принятии решений, прежних моделей управления рисками становится недостаточно. Ранджан считает, что руководителям госсектора нужно закладывать участие человека уже на этапе проектирования: заранее разграничивать решения, которые можно полностью автоматизировать, решения, требующие человеческой проверки, и зоны, где ответственность должна оставаться за человеком. Если в электронном государстве цифровое доверие строилось прежде всего на кибербезопасности, защите персональных данных и надёжности сервисов, то в агентных системах к этим требованиям добавляются объяснимость решений, постоянный надзор за моделями и подотчётность действий, выполняемых ИИ.  Инициатива ОАЭ поднимает и региональный вопрос — устанавливает ли страна планку, которой другие члены Совета сотрудничества арабских государств Персидского залива (GCC) будут вынуждены достичь. По мнению Ранджана, скорее всего да. «На протяжении последнего десятилетия эталоном в сфере государственных технологий GCC была цифровая зрелость — доступность электронных услуг и внедрение цифровой идентификации. ОАЭ фактически поднимают эту планку и заменяют прежний эталон готовностью к агентному ИИ», — заявил Ранджан. Если тренд закрепится, последствия выйдут за рамки трансформации госуправления и могут ускорить инвестиции в суверенные облака, платформы управления ИИ, ПО для автоматизации, цифровую инфраструктуру и развитие кадрового потенциала госсектора по всему региону. В этом случае обучение в сфере ИИ предстоит пройти каждому федеральному госслужащему. Повышение квалификации всё чаще входит в национальные ИИ-стратегии, однако масштаб и обязательный характер программы говорят о том, что правительство рассматривает развитие кадров как неотъемлемую часть перехода к операционной автономии. Люди боятся ИИ, но разработчикам это безразлично — гражданам всё равно придётся осваивать технологии
24.04.2026 [13:32],
Павел Котов
Заявления передовых разработчиков технологий искусственного интеллекта указывают, что их не очень беспокоит отрицательная реакция потребителей на новые решения. При этом граждане понимают, что им придётся овладеть навыками работы с ИИ, чтобы быть востребованными на рынке труда в новом мире. 
Источник изображения: Igor Omilaev / unsplash.com «Технари никогда не были сильны в общении. Первая компания, которая по-настоящему осознает силу корпоративной коммуникации и составления материалов о своих продуктах, одержит победу», — заявил изданию Axios профессор Дартмутского колледжа Пол Ардженти (Paul Argenti). Преимущество перед конкурентами есть, например у Google и Microsoft, считает он, потому что у них сформированы «более продуманные» стратегии общения с потребителем. Потребитель же всё более скептически относится к ИИ, но это не смущает разработчиков. Половина американцев испытывает в отношении ИИ скорее обеспокоенность, чем воодушевление, гласят социологические исследования, а среди молодого поколения энтузиазм к ИИ питают лишь 22 %. О «серьёзном кризисе [на рынке] занятости» недавно заявил глава Anthropic Дарио Амодеи (Dario Amodei), но глава OpenAI Сэм Альтман (Sam Altman) назвал это «маркетингом, основанным на страхе», и резюмировал, что пессимизм бесперспективен. Тем временем рядовые американцы со всё большим недовольством реагируют не только на сам ИИ, но и на масштабное строительство центров обработки данных для него по всей стране. В штате Мэн их запретили вообще, а в небольшом городке штата Миссури жители отправили в отставку половину муниципального совета, чтобы закрыть проект близлежащего ЦОД. Но неизбежность будущего с ИИ граждане уже не отрицают — и даже если это противоречит их собственным этическим принципам, они осваивают работу с ИИ, чтобы быть востребованными на рынке труда. Босс Google Cloud: генеративный ИИ уже в ответе за ваши любимые игры, просто вы об этом не знаете
24.04.2026 [13:27],
Михаил Романов
Руководитель игрового направления Google Cloud Джек Бьюзер (Jack Buser) в интервью Mobilegamer.biz рассказал о распространении ИИ-инструментов среди ведущих разработчиков игр. 
Источник изображения: Steam (umbra) По словам Бьюзера, сейчас 90 % крупных игровых студий применяет в разработке инструменты на основе генеративного ИИ, но из страха перед негативной реакцией геймеров многие не готовы говорить об этом публично. В частности, активным пользователем ИИ-инструментов от Google (Gemini, Nano Banana Pro) является Capcom. Ранее японский издатель на базе облачной среды Google Cloud построил прототип ИИ-системы для генерации идей. 
Capcom обещает не внедрять генеративный ИИ в новые игры (источник изображения: Capcom) «Игроки не понимают, что их любимые игры уже сделаны с помощью ИИ. <...> Прошлым летом во время Gamescom мы провели опрос среди студий со всего мира. Девять из десяти разработчиков сказали нам, что используют [ИИ]», — заявил Бьюзер. Репортёр Bloomberg Джейсон Шрайер (Jason Schreier) со ссылкой на свои источники подтвердил, что «почти все крупные студии сейчас используют инструменты на основе генеративного ИИ» — в частности, модель Claude от Anthropic. 
Амбициозный экшен Phantom Blade Zero от китайской S-Game создаётся без ИИ (источник изображения: S-Game) Бьюзер считает, что ИИ избавляет игровые студии от «рутинной и однообразной, малоэффективной» работы (вроде выбора каждого камешка для дороги) и позволяет им сосредоточиться на творческих задачах. Босс Google Cloud уверен, что скепсис игроков в отношении ИИ начнёт уходить в прошлое, когда они поймут, что технология помогает выпускать игры быстрее и предоставляет разработчикам больше пространства для риска. США обвинили Китай в краже ИИ-технологий в «промышленных масштабах» — тот назвал это клеветой
24.04.2026 [12:39],
Павел Котов
США намерены принять на государственном уровне меры против, как считается, «кражи интеллектуальной собственности американских лабораторий искусственного интеллекта в промышленных масштабах», сообщила накануне Financial Times. 
Источник изображения: Solen Feyissa / unsplash.com С момента выхода революционной для Китая ИИ-модели DeepSeek американские разработчики ИИ, в том числе OpenAI, стали нередко обвинять своих конкурентов из Поднебесной, в том что те занимаются кражей интеллектуальной собственности, производя «дистилляцию» моделей. Google, например, обвинила китайских разработчиков в том, что они отправили ИИ-помощнику Gemini более 100 000 запросов в попытке обучить его дешёвые копии. Anthropic выступила с обвинениями DeepSeek, Moonshot и MiniMax, заявив, что неизвестные лица через 24 000 учётных записей отправили чат-боту 16 млн запросов. О многочисленных схожих атаках со стороны Китая заявляла и OpenAI. Подобные действия способны помочь Китаю быстро настичь США в мировой гонке в области ИИ, считают в Вашингтоне. «Правительство США располагает информацией, указывающей, что иностранные организации, в основном находящиеся в Китае, участвуют в целенаправленных масштабных кампаниях по „дистилляции“ передовых американских систем ИИ», — говорится в служебной записке, составленной директором Управления по научно-технической политике Белого дома Майклом Крациосом (Michael Kratsios). Китайцы, утверждает он, действуют через прокси-аккаунты и прибегают к методам взлома. Поэтому американским компаниям предоставят доступ к правительственной информации, которая поможет им в борьбе с этими действиями. И если раньше американские лаборатории заявляли, что действия китайских конкурентов нарушают их условия предоставления услуг и наносят им ущерб, то сейчас уже власти США рассматривают возможность привлекать иностранных субъектов к ответственности. Спецкомитет по вопросам Китая в Палате представителей рекомендовал Бюро промышленности и безопасности (BIS) и Министерству юстиции (DOJ) квалифицировать дистилляцию моделей как промышленный шпионаж и реагировать, чтобы сдерживать подобную деятельность Пекина. Госдепартаменту спецкомитет рекомендовал дать оценку, являются ли подобные атаки с извлечением данных нарушением «Закона о промышленном шпионаже» и «Закона о компьютерном мошенничестве и злоупотреблениях». Ведомство также хочет определить меры «противодействия извлечению данных», чтобы США имели возможность преследовать нарушителей и налагать на них финансовые санкции. Китайская сторона все эти обвинения решительно отвергает — представитель посольства КНР в Вашингтоне назвал их «чистой клеветой» и отметил: «Китай всегда стремится к продвижению научно-технического прогресса посредством сотрудничества и здоровой конкуренции. Китай придаёт большое значение защите прав интеллектуальной собственности». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



