|
Опрос
|
реклама
Быстрый переход
Tesla завершила разработку чипа AI5 для систем автономного вождения и робототехники следующего поколения
15.04.2026 [14:01],
Николай Хижняк
Генеральный директор Tesla Илон Маск (Elon Musk) объявил в среду, что Tesla завершила разработку своего ИИ-чипа AI5 следующего поколения. Для компании это важный шаг в реализации планов по созданию специального кремния для своих программ автономного вождения и робототехники. 
Источник изображения: Tesla «Поздравляю команду разработчиков чипов искусственного интеллекта Tesla с выпуском AI5!», — написал Маск в соцсети X, добавив, что «AI6, Dojo3 и другие интересные чипы» уже находятся в стадии разработки. Он поделился фотографией AI5 и подробно рассказал о новом поколении в отдельном посте X. «Производительность одного AI5 примерно в 5 раз выше, чем у AI4 с двумя SoC», — написал Маск. В полупроводниковой промышленности термином tape-out обозначают заключительный этап проектирования чипа, после которого макет отправляется на завод для изготовления. Первые образцы нового процессора Tesla ожидаются в конце этого года, а массовое производство запланировано на середину 2027 года. Tesla AI5 — это специальная система на чипе (SoC), разработанная в первую очередь для работы искусственного интеллекта в автомобилях и человекоподобных роботах Optimus в режиме реального времени. Новый процессор заменит текущее поколение процессоров Tesla AI4, которые устанавливаются в электромобили Tesla с начала 2023 года и производятся Samsung по 7-нм техпроцессу. Маск заявляет, что AI5 примерно в 8 раз превосходит AI4 по вычислительной мощности, в 9 раз — по объёму памяти и в 5 раз — по пропускной способности. По словам главы Tesla, производительность одного чипа AI5 примерно соответствует производительности графического процессора Nvidia H100 при выполнении специфических для Tesla задач, а конфигурация из двух чипов сравнима с процессорами Nvidia класса Blackwell, но при этом он обходится значительно дешевле в производстве и и потребляет меньше энергии. «Это будет очень мощный чип. Примерно на уровне Hopper в конфигурации с одним чипом и Blackwell в конфигурации с двумя чипами, но при этом он стоит сущие копейки и потребляет гораздо меньше энергии», — написал Маск в январе. Tesla AI5 оптимизирован для операций логического вывода с низкой точностью: в нём активно используются тензорные ускорители INT4, INT2, FP8 и смешанной точности, а устаревшие аппаратные блоки заменены на то, что Маск назвал «радикальной простотой». Общая расчётная производительность всей системы на базе AI5 составляет от 2000 до 2500 Тфлопс. Для сравнения, система на базе AI4 имеет производительность около 300–500 Тфлопс. Маск ранее заявлял, что программа по разработке и интеграции AI5 играет решающее значение для будущего компании. «Решение вопроса с AI5 было жизненно важным для Tesla, поэтому мне пришлось сосредоточить усилия обеих команд на этом чипе, и я лично каждую субботу в течение нескольких месяцев работал над ним», — написал он в январе. Чип Tesla AI5 играет ключевую роль в стратегии компании по вертикальной интеграции в сфере искусственного интеллекта: Tesla разрабатывает как аппаратное обеспечение, так и весь программный стек для достижения максимальной эффективности. «AI5 превзойдет все ожидания, потому что весь программный стек Tesla для искусственного интеллекта разработан таким образом, чтобы максимально эффективно использовать каждую микросхему. Мы совместно разрабатывали программное и аппаратное обеспечение для искусственного интеллекта», — написал Маск в марте. Он также заявил, что для конкретных задач компании процессор AI5 превосходит сторонние аналоги: «Для наших целей он будет работать намного лучше, чем всё остальное. Выражаясь словами Дженсена [Хуанга, главы Nvidia], мы бы не стали использовать в наших автомобилях и роботах никакой другой чип, даже если бы он был бесплатным». Производство AI5 будет осуществляться на двух заводах — в Аризоне (TSMC) и в Техасе (Samsung). Оба завода находятся в США, что обеспечит стабильное серийное производство и устойчивость цепочки поставок. Samsung уже производит чипы AI4 для Tesla и в июле 2025 года заключила с компанией восьмилетнее соглашение на сумму $16,5 млрд. Маск отметил, что оба завода будут производить чипы по одному и тому же проекту, но физическая реализация будет отличаться в зависимости от производственного процесса на каждом из них. Tesla также строит собственное производственное предприятие Terafab в Остине, штат Техас, которое в будущем будет выпускать более крупные объёмы продукции. Компания выделила $20 млрд на капитальные расходы в 2026 году для финансирования Terafab и других проектов, включая роботакси Cybercab и робота Optimus. В конце 2026 года ожидается выпуск небольших пробных партий чипа AI5, которые могут быть использованы для предварительных испытаний Optimus или разработки автомобилей. 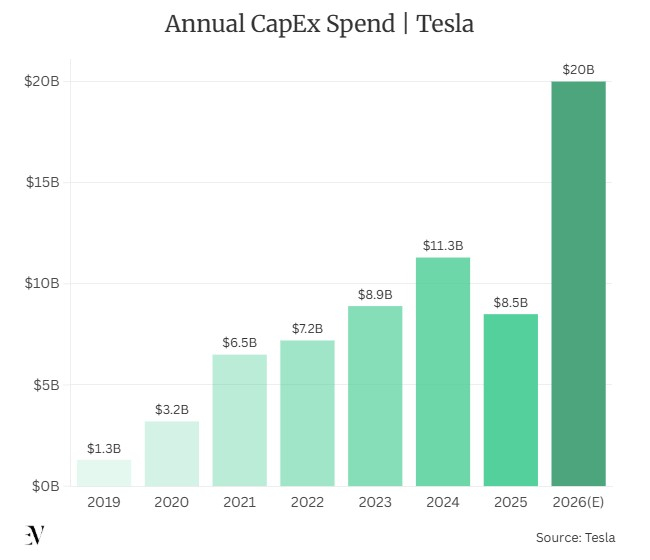
Ежегодные капитальные затраты Tesla. Источник изображения: Electric Vehicle Массовое производство электромобилей Tesla с новым чипом планируется начать в середине-конце 2027 года. Производство специализированного роботакси Tesla Cybercab, которое должно начаться в этом месяце, будет осуществляться с использованием текущего поколения процессора AI4, а не на базе AI5. Такое решение было принято с учётом сроков производства нового SoC. Маск обозначил весьма агрессивный темп разработки будущих поколений чипов. Он рассчитывает, что компания будет запускать новые процессоры в серийное производство примерно раз в год, а цикл разработки новых чипов составит девять месяцев. Завершение разработки AI6 запланировано на декабрь 2026 года, также уже ведётся разработка AI7. Маск ранее заявлял, что один только AI4 способен «обеспечить уровень безопасности при самостоятельном вождении, намного превосходящий человеческий», а AI5 «сделает автомобили практически идеальными и значительно улучшит Optimus». Новый процессор позволяет запускать на устройстве значительно более крупные модели нейронных сетей, что крайне важно для подхода компании к автономному вождению, основанного исключительно на визуальном восприятии. Текущая версия программного обеспечения FSD для автономного вождения от Tesla работает на основе модели с примерно миллиардом параметров. В версии 15 следующего поколения будет использоваться модель примерно в десять раз большего размера, для поддержки которой и предназначен AI5. В составе Optimus чип обеспечит периферийный вывод в режиме реального времени, необходимый для решения задач гуманоидной робототехники, требующих быстрой обработки данных с датчиков без подключения к облаку. Meta✴ и Broadcom продлили партнёрство до 2029 года для создания нескольких поколений кастомных ИИ-чипов
15.04.2026 [13:56],
Владимир Мироненко
Meta✴✴ и Broadcom объявили о расширении партнёрства с целью создания нескольких поколений кастомных чипов для ИИ-нагрузок, продлив соглашение до 2029 года с обязательством по обеспечению на первом этапе более 1 ГВт вычислительной мощности. 
Источник изображения: Meta✴✴ Соглашение охватывает программу Meta✴✴ Training and Inference Accelerator (MTIA), в рамках которой Broadcom предоставляет Meta✴✴ технологии проектирования, упаковки и сетевого оборудования для микросхем. MTIA является ключевым элементом более широкой стратегии Meta✴✴ в области микросхем, которая использует различные ускорители для разных рабочих нагрузок — портфель MTIA подбирает специализированное оборудование для оптимизации как производительности, так и общей стоимости владения в масштабе. Первый ИИ-ускоритель, созданный в рамках программы, — MTIA 300 — уже используется системами ранжирования и рекомендаций Meta✴✴ в Facebook✴✴, Instagram✴✴ и других приложениях. До 2027 года планируется выпуск еще трёх поколений кастомных чипов, предназначенных в первую очередь для инференса. Broadcom подчеркнула, что они станут первыми в отрасли специализированными ИИ-чипами, изготовленными по 2-нм техпроцессу. Технология Ethernet от Broadcom также будет использоваться для масштабного подключения расширяющихся ИИ-кластеров Meta✴✴. «Meta✴✴ сотрудничает с Broadcom в области проектирования чипов, упаковки и сетевых технологий для создания масштабной вычислительной базы, необходимой для предоставления персонального суперинтеллекта миллиардам людей», — сообщил основатель и генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg). В рамках сделки генеральный директор Broadcom Хок Тан (Hock Tan) покинет совет директоров Meta✴✴ и перейдёт на консультативную должность, где будет давать рекомендации по плану развития специализированных микросхем Meta✴✴ и помогать формировать стратегию инвестиций в инфраструктуру. Американские ведомства стали игнорировать запрет на сотрудничество с Anthropic — модель Mythos оказалась слишком хороша
15.04.2026 [12:12],
Павел Котов
Федеральные ведомства и правительственные чиновники США стали негласно игнорировать запрет главы государства Дональда Трампа (Donald Trump) на сотрудничество с компанией Anthropic, стало известно Politico. 
Источник изображения: anthropic.com Центр стандартов и инноваций в области искусственного интеллекта при Министерстве торговли США сейчас активно тестирует способности передовой ИИ-модели Anthropic Mythos к взлому систем, узнали журналисты издания. Подтвердить эту информацию в Reuters не смогли; в Anthropic, Белом доме и самом Минторге комментариев не предоставили. Сотрудники как минимум трёх комитетов конгресса США за последнюю неделю проводили или запрашивали у Anthropic брифинги, чтобы узнать о возможностях сканирования Mythos киберсистем. Anthropic обсуждает возможности Mythos даже с самой администрацией Трампа, сообщил накануне сооснователь компании Джек Кларк (Jack Clark). Белый дом не смутил тот факт, что из-за непреодолимых разногласий по контракту Пентагон прекратил сотрудничество с лабораторией. Характер и подробности переговоров Anthropic с правительством США, а также то, какие ведомства участвуют в них, пока установить не удалось. Anthropic анонсировала ИИ-модель Mythos 7 апреля, объявив её своей самой совершенной системой «для программирования и выполнения агентских задач», сообщил разработчик — модель способна действовать в автономном режиме. «Яндекс» выпустила «ТВ Станцию miniLED» — «самый доступный» телевизор в премиум-сегменте
15.04.2026 [10:53],
Владимир Мироненко
«Яндекс» представил «ТВ Станцию MiniLED» с Алисой — новую модель линейки премиальных телевизоров на платформе YaOS Х. Благодаря поддержке ИИ телевизор «умеет» оптимизировать изображение и звук, помогает проходить игры и понимает команды, заданные в свободной форме. 
Источник изображений: «Яндекс» Доступны версии телевизора с диагональю экрана 55 и 65 дюймов по цене 79 990 и 99 990 руб. соответственно. Это самый доступный телевизор премиум-сегмента компании.  «ТВ Станция MiniLED» получил новые функции YaOS X. Например, передачи некоторых каналов теперь доступны в записи до конца дня. Недосмотренное видео из интернета больше не придётся искать заново — продолжить просмотр можно прямо с главного экрана. Также устройство теперь запоминает, в каких сериалах зритель предпочитает пропускать начальные титры. Кроме того, теперь можно слушать музыку на фоне заставки. Эта опция доступна пока только в «ТВ Станции MiniLED».  Технология вызова функций (Tool calling) позволяет формулировать просьбы ИИ-ассистенту в свободной форме. Управлять голосом можно как самим телевизором, так и многими сторонними сервисами — например, Иви, Wink, Premier или RUTUBE. «Алиса» поможет найти фильмы и сериалы, видеоролики, музыку или трансляции, а также подскажет геймеру как решить головоломку или пройти этап игры.  ИИ-телевизор поддерживает яркость до 650 кд/м2 и частоту до 144 Гц, подстраивая её под тип контента. Технологии Dolby Vision, HDR10 и MEMC обеспечивают более плавное изображение, а технология улучшения качества картинки AI Picture Quality — оптимизирует яркость, контрастность и цветопередачу. Качественный звук обеспечивают четыре динамика общей мощностью 30 Вт с поддержкой Dolby Audio. Также есть режим «Ночной сеанс», в котором «ТВ Станция» адаптирует яркость экрана под освещение, корректирует палитру цветов и приглушает громкие звуки. Благодаря поддержке протоколов Wi-Fi, Zigbee и Matter «ТВ Станция MiniLED» может использоваться для управления умным домом. Кроме того устройство может использоваться в качестве умной колонки с Алисой. Google добавила в Chrome функцию Skills для сохранения ИИ-подсказок
15.04.2026 [07:06],
Анжелла Марина
Google добавила в браузер Chrome новую функцию Skills, которая позволяет сохранять и повторно использовать часто повторяющиеся запросы к искусственному интеллекту без необходимости набирать текст заново. Skills дополняет уже существующую функцию Gemini, которая умеет отвечать на вопросы о содержимом страницы, делать краткие пересказы и выполнять разные поручения. 
Источник изображения: Firmbee.com/Unsplash Теперь пользователь может сохранить понравившийся промпт прямо из истории чатов, а в дальнейшем активировать его нажатием слеша ( / ) или кнопкой плюса ( + ), после чего ИИ применит подсказку на текущей вкладке и любых дополнительных выбранных страницах. Google отмечает, что созданные сценарии можно редактировать в любой момент. Для помощи новичкам будет запущена библиотека Skills, где собраны готовые сценарии для таких типовых задач, как покупки, рецепты, составления бюджета и других. Пользователю достаточно добавить понравившуюся команду в свой список, после чего её можно настраивать под свои нужды, просто отредактировав исходный промпт. Как и другие действия Gemini в браузере, новая функция требует подтверждения пользователя перед выполнением критических операций. В этом случае система запросит разрешение, если сценарий попытается отправить электронное письмо или добавить событие в календарь. Новая функция начала распространяться на десктопной версии Chrome для пользователей, вошедших в свой аккаунт Google. Однако на начальном этапе Skills будет работать только при установленном английском языке интерфейса браузера. Anthropic обновила Claude Code: добавлены новый интерфейс и автономный режим
15.04.2026 [06:55],
Анжелла Марина
Компания Anthropic внедрила функцию повторяющихся автоматизированных задач (Routines) в переработанное приложение Claude Code для macOS. Эта возможность, запущенная пока в тестовом режиме для исследовательских целей, позволяет выполнять запланированные действия через веб-инфраструктуру сервиса независимо от статуса подключения компьютера пользователя к сети. 
Источник изображения: Anthropic Новая функция, как сообщает 9to5Mac, берёт на себя управление регулярными задачами, такими как cron-джобы (cron jobs) и работа с API, избавляя разработчиков от необходимости самостоятельно настраивать дополнительную инфраструктуру. Сценарии выполняются на стороне сервера Anthropic, имея прямой доступ к репозиториям и коннекторам пользователя, обеспечивая, таким образом, их работу даже когда Mac находится офлайн. В качестве примеров использования компания приводит настройку расписаний, рабочих процессов API и интеграцию с GitHub. Доступность новой функции зависит от выбранного тарифного плана подписки. Пользователи уровня Pro могут запускать до 5 рутин в день, тариф Max увеличивает этот лимит до 15, а корпоративные клиенты (Team и Enterprise) получают возможность выполнять до 25 задач ежедневно. Помимо автоматизации, Anthropic существенно обновила интерфейс самого приложения Claude Code на Mac. Теперь можно открывать несколько сессий одновременно в одном окне, используя новую боковую панель, что упрощает многозадачность. Обновлённый дизайн также включает встроенный терминал, инструменты для редактирования файлов и предварительного просмотра HTML и PDF-документов. Интерфейс стал более гибким: элементы можно перетаскивать и устанавливать на рабочем столе согласно предпочтениям разработчика. Все эти изменения дополняют другие недавние нововведения экосистемы, например, режим автопилота (auto mode), представленный в прошлом месяце. Также из стадии исследовательского тестирования вышел продукт Claude Cowork, получивший новые функции для корпоративного сегмента. Новый раунд финансирования оценивает Anthropic в $800 млрд — до OpenAI рукой подать
15.04.2026 [05:09],
Алексей Разин
Ещё недавно считалось, что по величине капитализации OpenAI существенно обходит конкурирующую Anthropic, поскольку речь шла о суммах около $852 млрд и $380 млрд соответственно. Новый раунд финансирования второго из стартапов позволит ему поднять планку до $800 млрд и сократить разрыв.  Как отмечали вчера осведомлённые источники, на данном этапе инвесторы проявляют больше интереса к вложению средств в капитал Anthropic, даже с учётом конфликта этой компании с Пентагоном. В конце февраля капитализация стартапа достигала $380 млрд с учётом раунда финансирования, по итогам которого удалось привлечь $30 млрд. Накануне издание Business Insider сообщило о новом раунде финансирования, который может поднять капитализацию Anthropic до $800 млрд. Впрочем, пока лишь ведутся переговоры, и утверждать, что раунд точно состоится на указанных условиях, преждевременно. Чем выше ставки в финансовой сфере, тем более требовательными могут быть инвесторы, поэтому не факт, что указанная сумма может быть привлечена. Ожидается, что на IPO компания выйдет в октябре этого года. На данном этапе инвесторов во многом воодушевляют темпы роста выручки Anthropic. Если экстраполировать месячную сумму до годового объёма, то получится около $30 млрд. Правда, конкурирующая OpenAI выражает сомнения в корректности методики расчёта этой выручки, настаивая на снижении суммы хотя бы на $8 млрд. Энтузиаст запустил ИИ-модель на древнем мини-ЭВМ PDP-11 с процессором на 6 МГц и 64 Кбайт ОЗУ
14.04.2026 [17:50],
Владимир Фетисов
Ветеран из отдела разработки Microsoft Дэйв Пламмер (Dave Plummer), который в прошлом создал несколько важнейших компонентов Windows, продемонстрировал трансформерную модель ИИ, «работающую на оборудовании старше, чем большинство людей, спорящих в интернете об AGI». В опубликованном недавно видео опытный разработчик решил развеять миф об ИИ, раскрыв его «небольшой грязный секрет». 
Источник изображения: Дэйв Пламмер / YouTube Этот секрет в значительной степени раскрывается в начале описания к видео разработчика. «Дэйв использует PDP-11 для обучения настоящей нейронной сети, включающей трансформеры и механизм внимания, чтобы вы могли увидеть их в самом простейшем виде», — сказано в описании. Речь о системе PDP-11 возрастом 47 лет, которая оснащена процессором с рабочей частотой 6 МГц и 64 Кбайт оперативной памяти. На этом устройстве работает трансформерная ИИ-модель под названием Attention 11, написанная на ассемблере PDP-11 Дамьеном Буре (Damien Buret). На первый взгляд задача, которую PDP-11 «научится» выполнять, кажется элементарной: устройство должно строить обратную последовательность из восьми чисел. Однако модель должна усвоить определённое структурное правило, а не запоминать примеры из обучения, чтобы успешно справляться с обработкой любых входящих данных. Пламмер отмечает, что в этом отражается базовый принцип, лежащий в основе современных языковых моделей, таких как ChatGPT. Несмотря на использование специально созданной для PDP-11 трансформерной модели, Пламмеру потребовалось провести оптимизацию системы в виду ограничений в плане доступных вычислительных мощностей. Интересно то, что в конечном счёт получилась модель, имеющая всего 1216 параметров. Она используется вычисления с фиксированной точкой, вычисления для прямого прохода ужаты до 8-битной точности, а каждый такт оптимизирован, чтобы машина смогла завершить обучение в разумные сроки. «Мы наблюдаем упрощённую анатомию самого обучения. Модель начинает глупой. Количество ошибок изначально высоко. Точность спотыкается на каждом шагу, как человек, пытающийся собрать мебель из IKEA в кузове движущегося фургона. А затем где-то на этом пути веса постепенно выстраиваются в определённый паттерн. И механизм внимания обнаруживает правило переворота последовательности. И машина в результате пересекает ту невидимую черту — от угадывания к знанию», — рассказал Пламмер. Результаты эксперимента по обучению ИИ на древнем устройстве с процессором на 6 МГц оказались довольно неожиданными. Энтузиаст обучил модель до 100 % точности в задаче построения обратной последовательности из чисел примерно за 350 шагов обучения. На PDP-11/44 с платой кэш-памяти на это ушло около 3,5 минут. По сути, Пламмер попытался доказать, что в современных ИИ-системах используется та же механика, т.е. большое количество арифметики, повторение шагов и исправление ошибок для улучшения результатов. «Эта старая машина не мыслит в каком-то мистическом смысле. Она просто выполняет арифметические действия, чтобы обновить несколько тысяч тщательно сохранённых чисел. И в этом вся суть. Обаяние современного ИИ в основном исходит от выполнения этого в ошеломляющем масштабе. Но сам фундаментальный процесс обучения уже полностью представлен здесь в миниатюре», — объяснил Пламмер. Уже 50 % сотрудников в США используют ИИ в работе, показал опрос
14.04.2026 [16:24],
Владимир Мироненко
Согласно опросу Gallup, проведённому с 4 по 19 февраля 2026 года в США, число сотрудников, использующих ИИ в своей работе, выросло до 50 % с 21 % во втором квартале 2023 года. Это также на 4 % больше, чем в четвёртом квартале 2025 года. В опросе приняли участие 23 717 сотрудников. 
Источник изображения: Microsoft Copilot/unsplash.com Количество сотрудников, использующих ИИ ежедневно, выросло в первом квартале до рекордного уровня — 13 %, а число тех, кто применяет его несколько раз в неделю, — до 28 %. Вместе с тем недавний опрос руководителей компаний, проведённый Национальным бюро экономических исследований, показал, что более 80 % организаций не видят результатов от применения ИИ-инструментов для повышения производительности и сокращения затрат на персонал. Опрос Gallup также отражает, насколько быстро инструменты ИИ начинают перестраивать рабочее место. Его результаты позволяют предположить, что внедрение ИИ вызывает значительные сбои в работе компаний: 27 % сотрудников сообщают о значительных или очень значительных сбоях на рабочем месте за последний год. Вместе с тем 12 % сотрудников компаний, не использующих ИИ, также сообщают об аналогичных сбоях, поэтому делать однозначные выводы затруднительно. Что также примечательно, сотрудники компаний, внедряющих ИИ, сообщают, что их руководство как пополняет штат (34 % по сравнению с 28 % в компаниях, не использующих ИИ), так и увеличивает сокращение штата (23 % против 16 %). Несмотря на сбои, 65 % сотрудников компаний, использующих ИИ, положительно оценивают его влияние на производительность и эффективность работы, а 16 % — крайне положительно. Респонденты отметили, что ИИ полезен для решения конкретных задач, таких как обобщение информации, но он не улучшает само рабочее место. 10 % респондентов сообщили о негативном влиянии ИИ на их работу, в то время как 21 % отметили, что ИИ трансформирует то, как выполняется работа на их рабочем месте. Опрос Gallup подтверждает, что ИИ продолжает быстро развиваться, однако его адаптация сталкивается с проблемами. Также работодателям предстоит проделать большую работу, чтобы успешно трансформировать рабочее место с учётом ИИ. Китай почти догнал США в сфере ИИ и даже уже обходит их по ряду показателей
14.04.2026 [13:34],
Алексей Разин
Озабоченность некоторых американских политиков усиливающимся влиянием Китая в технологической сфере, если верить результатам исследования американских же учёных, вполне обоснована. Китай по быстродействию своих ИИ-моделей уже вплотную приблизился к США, а по отдельным критериям инновационной деятельности оказывается впереди. 
Источник изображения: Unsplash, Ousa Chea Как отмечает TrendForce, по состоянию на конец февраля текущего года китайская модель DeepSeek R1 на какое-то время догнала флагманскую модель американского происхождения, а по состоянию на март этого года лидерство американской Anthropic выразилось всего в 2,7 % преимущества, что нельзя считать разгромной победой. В 2023 году китайские ИИ-модели значительно уступали американским по быстродействию, поэтому можно говорить об уверенном прогрессе со стороны КНР. При этом исследование показывает, что США обладают большим количеством наиболее влиятельных патентов в технологической сфере и выпустили по итогам прошлого года 50 крупных ИИ-моделей, тогда как Китай выдал всего 30 штук. Зато КНР лидирует по объёму научных публикаций, их цитированию и общему количеству патентов, не говоря уже о количестве установленных на предприятиях страны промышленных роботах. Южная Корея тоже имеет свои поводы для гордости — в этой стране максимальная плотность патентов в пересчёте на душу населения. С точки зрения концентрации вычислительных мощностей лидируют США, они на своей территории сосредоточили в 10 раз больше ЦОД, чем любая другая страна мира. Хотя США также лидируют и по объёму инвестиций в сферу ИИ, привлекательность страны для трудовой миграции в этой сфере снижается на фоне не самой дружественной политики властей. С 2017 года количество направившихся в США исследователей в области ИИ сократилось на 89 %, причём на 80 % оно упало только за прошлый год. По сумме частных инвестиций в ИИ американская экономика также лидирует, направив за прошлый год в эту сферу $285,9 млрд, тогда как Китай ограничивается $12,4 млрд. Правда, эта статистика не учитывает серьёзных государственных субсидий со стороны китайских властей, поэтому говорить о 23-кратном разрыве на полном серьёзе было бы некорректно. Потребительские ИИ-боты в 80 % случаев ставят неверные диагнозы, показало исследование
14.04.2026 [13:23],
Алексей Разин
Универсальность популярных чат-ботов с точки зрения поиска необходимой информации, как выясняется, не делает их пригодными для постановки точных медицинских диагнозов при ограниченном наборе данных. Более чем в 80 % случаев чат-боты ставят ошибочный диагноз, что делает их непригодными для замены консультации реального специалиста в области медицины. 
Источник изображения: Unsplash, Elen Sher Опубликованное на страницах Jama Network Open исследование, на которое ссылается Financial Times, использовало 29 описаний клинических случаев из справочной медицинской литературы для проверки качества определения диагноза популярными чат-ботами. Исследование показало, что при передаче чат-боту ограниченной информации о симптомах большие языковые модели затрудняются с выбором возможных диагнозов, и чаще всего сводят всё к единственному варианту, на который в действительности нельзя полагаться в дальнейшем лечении. Если входные данные достаточно подробные, то таких проблем с постановкой точного диагноза уже не наблюдается. Медицинские данные в ходе эксперимента передавались чат-ботам поэтапно, включая историю болезни, результаты осмотров и лабораторных анализов. Чат-ботам задавались вопросы на тему диагностики заболеваний, измерялась точность и полнота ответов. В выборку проверяемых ИИ-моделей попали два десятка популярных чат-ботов, включая разработанные OpenAI, Anthropic, Google, xAI и DeepSeek. При отсутствии полной информации о состоянии пациента более чем в 80 % все они демонстрировали склонность к постановке некорректного диагноза. Чем полнее была информация, тем точнее были результаты. В лучших случаях точность превышала 90 %, в среднем варианте ошибочные диагнозы ставились менее чем в 40 % случаев. Google и Anthropic заявили, что их чат-боты при попытке пользователей получить медицинские рекомендации настоятельно рекомендуют обращаться к специалистам. OpenAI указывает в правилах использования своих сервисов, что они не должны использоваться для получения медицинских рекомендаций, требующих наличия соответствующей лицензии. xAI и DeepSeek свои комментарии на этот счёт ресурсу Financial Times не предоставили. Некоторые из указанных разработчиков создают узкоспециализированные медицинские модели. Разработанная Google AMIE, например, показывает неплохие результаты, но на её заключения сложно полагаться в полной мере, как отмечают специалисты в области медицины, поскольку живой доктор в значительной степени полагается на визуальную оценку состояния пациента. При этом такие ИИ-модели имеют право на жизнь в тех регионах, где имеются проблемы с доступом к качественной медицинской помощи в классическом её понимании. Инвесторы усомнились, что OpenAI действительно стоит $852 млрд — компания пытается исправить впечатление
14.04.2026 [11:02],
Алексей Разин
Возросшую активность OpenAI в сфере пересмотра стратегии и концентрации на приоритетных направлениях деятельности принято связывать с подготовкой к IPO. Последний раунд частного размещения позволил поднять капитализацию стартапа до $852 млрд, но не все инвесторы единодушны в подобной оценке. При этом чувствуется, что высокая конкуренция заставляет руководство OpenAI спешно устранять слабые места в своей стратегии. 
Источник изображений: OpenAI Обширный материал на эту тему опубликовало издание Financial Times. Стремление OpenAI переключиться на обслуживание корпоративных клиентов усиливает конкуренцию с Anthropic, и нельзя утверждать, что в этом сегменте преимущество на стороне первого из стартапов. Google также агрессивно действует в корпоративном сегменте рынка ИИ, поэтому для OpenAI концентрация на нём формирует новые вызовы. Один из ранних инвесторов в OpenAI заявил Financial Times: «У вас есть ChatGPT, растущий на 50–100 % ежегодно бизнес с миллиардной пользовательской аудитории, так почему же вы говорите о предприятиях и написании кода? Эта компания очень сильно расфокусирована». В прошлом месяце OpenAI привлекла $122 млрд, которые предоставила группа из 25 крупных стратегических и институциональных инвесторов, включая SoftBank, Amazon и Nvidia, и около $3 млрд впервые были получены от частных инвесторов. По мнению руководства OpenAI, превышение спросом предложения в рамках этого раунда финансирования и рекордная сумма привлечения средств доказывают, что интерес инвесторов к деятельности компании и их доверие по-прежнему высоки. Руководство OpenAI даже предприняло попытки «разоблачить» конкурирующую Anthropic в некорректном отображении приведённой годовой выручки, которая на конец марта в последнем случае оценивалась в $30 млрд. Как подчёркивает директор OpenAI по выручке Дениз Дрессер (Denise Dresser), эта сумма завышена примерно на $8 млрд за счёт частичного переноса профильной выручки, получаемой Amazon и Google. Сама OpenAI на конец февраля располагала приведённой годовой выручкой в размере $25 млрд. Дрессер признаёт, что ранняя концентрация на корпоративном рынке дала Anthropic определённое преимущество, но в OpenAI убеждены, что смогут завоевать этот рынок. К концу текущего года до половины всей выручки стартап рассчитывает получать именно с корпоративных клиентов.  Некоторые инвесторы OpenAI признались, что выделяя средства на нужды стартапа сейчас, они исходили из оценки его капитализации в размере $1,2 трлн по итогам IPO. При этом Anthropic сейчас оценивается в $380 млрд, и некоторым потенциальным инвесторам капитализация OpenAI на текущих уровнях кажется завышенной. С такими аппетитами, по мнению некоторых инвесторов, OpenAI рискует оказаться на «спорной территории» с точки зрения привлечения капитала. Косвенные данные позволяют судить, что спрос на инвестиции в капитал Anthropic сейчас выше, чем в случае с OpenAI. Инвесторы впервые готовы больше переплачивать, вкладывая средства в Anthropic, чем в OpenAI. Существует определённый беспорядок в использовании компанией OpenAI привлечённых средств. Две недели назад стартап за несколько сотен миллионов долларов США купил канал TBPN, хотя такая сделка в медийной сфере вызвала вопросы. Руководство предпочло парировать заявлениями о том, что TBPN не будет отвлекать на себя вычислительные ресурсы. Закрытие генератора видео Sora оставило OpenAI без средств Disney, которая должна была вложить $1 млрд. Microsoft пригрозила OpenAI иском после заключения последней из компаний сделки с Amazon на $50 млрд. Реализация мегапроекта Stargate тоже продвигается в усечённом варианте: отменено строительство ЦОД в Великобритании за $30 млрд, площадка в Техасе будет расширяться не так активно, как планировалось изначально. Nvidia также в пять раз сократила масштабы своей сделки с OpenAI, которая сперва подразумевала инвестиции в размере $100 млрд. Впрочем, OpenAI всё равно планирует до конца года увеличить численность персонала в два раза до 8000 человек и довести долю выручки на корпоративном направлении до 50 % от совокупной. В Лондоне со следующего года расположится крупнейший исследовательский центр компании за пределами США. Руководство OpenAI недавно сообщило инвесторам, что располагает доступом к 8 ГВт вычислительных мощностей, тогда как Anthropic на этот уровень ранее конца 2027 года не выйдет, а к 2030 году сама OpenAI рассчитывает располагать доступом к 30 ГВт вычислительных мощностей. Anthropic то и дело сталкивается со сбоями в работе инфраструктуры и нехваткой вычислительных мощностей. В OpenAI утверждают, что даже если их модели и отстают от созданных Anthropic, они хотя бы могут стабильно работать. Представители Anthropic пояснили, что компания будет придерживаться разумного подхода к масштабированию вычислительных мощностей. OpenAI меняет приоритеты в своём развитии. Помимо отказа от сервиса генерации видео Sora, компания свернула проект по запуску чат-бота с эротическим уклоном. Теперь прилагаются усилия по продвижению сервиса Codex в корпоративной среде, который призван упростить жизнь разработчикам ПО. Некоторые знакомые с планами OpenAI источники даже утверждают, что Codex может оказаться самым главным направлением бизнеса стартапа, обойдя ChatGPT. По крайней мере, этот вид деятельности обеспечивает значительно более высокую прибыль. Некоторые инвесторы приветствуют такие преобразования в стратегии OpenAI, другие опасаются, что все эти метания говорят об отсутствии чётко обозначенных целей. В любом случае, привлекать инвестиции OpenAI это пока не мешает. Microsoft не удалит Copilot из Windows 11, а просто замаскирует ИИ-функции
14.04.2026 [10:48],
Павел Котов
Microsoft, которая навлекла на себя недовольство пользователей из-за повсеместного насаждения помощника с искусственным интеллектом Copilot в Windows 11, решила восстановить их доверие. Но удалять ИИ из операционной системы она не собирается — соответствующие функции просто получат новые названия. 
Источник изображения: windows.com В начале года Microsoft порадовала пользователей Windows 11, пообещав исправить то, что им стало не нравиться в платформе: дать им возможность управлять системой обновлений и осторожнее относиться к механизмам интеграции ИИ. Сейчас компания начала выполнять свои обещания, и это далеко не всем это пришлось по вкусу. В программе «Блокнот» она просто убрала упоминания бренда Copilot, но сохранила все его возможности: ИИ по-прежнему предлагает переписывать тексты, составлять сводки, менять стиль, форматировать и делать многое другое. При этом раздел «Функции ИИ» переименовали в «Расширенные функции», а возможности ИИ в приложении можно отключать. Другими словами, Microsoft не собирается, по крайней мере сейчас, полностью отказываться от функций ИИ в Windows 11 — и в сетевых сообществах снова стало зреть возмущение среди тех, кто почувствовал себя обманутым. Справедливости ради, Microsoft прямым текстом и не обещала полностью убрать ИИ из Windows 11 — в компании решили более применить более «целенаправленный» подход к тому, где и как отображается марка Copilot, но сохранить полезные функции. Присутствие бренда Copilot там, где он не очень нужен, в Microsoft решили сократить — и в очередной предварительной версии ОС на канале Windows Insider компания показала, как это будет выглядеть на практике. Проблема, как и прежде, состоит в огромном разрыве между желаниями пользователей и тем, как Microsoft реагирует на их отзывы. В действительности компания не может избавить Windows 11 от функций ИИ, потому что в теперешних реалиях это означало бы обречь себя на отставание в гонке ИИ с крупнейшими конкурентами. В итоге Microsoft вынуждена балансировать на грани: с одной стороны, не огорчать акционеров и инвесторов — с другой, как-то реагировать на большое число пользователей Windows 11, которые уже устали от повсеместного присутствия ИИ. Поэтому заметных подвижек в сторону избавления от ИИ в Windows 11 в обозримом будущем ждать не стоит — в качестве компромисса компания решила просто переименовать некоторые функции. ИИ-помощник «Алиса Про» заработал в почте «Яндекса»
14.04.2026 [10:19],
Павел Котов
В сервисе «Яндекс Почта» появился помощник с искусственным интеллектом на основе большой языковой модели «Алиса AI» — он анализирует данные в переписке и способствует решению задач личного и рабочего характера. 
Источник изображений: yandex.ru/company В процессе работы «Алиса Про» обрабатывает содержимое писем и вложения: текстовые документы, таблицы, презентации и файлы PDF, а при необходимости подключается и к открытым источникам в интернете. «Её задача — объединять знания о мире, которые накопила Alice AI LLM, и факты, извлечённые из писем», — поясняют в «Яндексе». ИИ-помощник производит поиск не по тексту запроса, а по его смыслу.  Генеративный ИИ помогает не только в анализе, но и в написании писем. «Алиса Про» может отредактировать черновик письма, изменить стиль текста или вообще написать письмо с нуля. Ассистент ограничивается платформой «Яндекс 360» и анализирует переписку только по запросу пользователя — результаты работы помощника не сохраняются и никуда не передаются, подчеркнули в «Яндексе». Для дальнейшего обучения ИИ материалы переписки тоже не используются. Сейчас воспользоваться ИИ-помощником «Алиса Про» могут подписчики платных тарифов службы «Яндекс 360»; в ближайшей перспективе компания намеревается предложить сервис корпоративным клиентам. В 2024 году в «Яндекс Почте» появилась функция отбора наиболее важных писем и создания сводок по их содержимому. На базе «Алисы AI» также развернут сервис автономных исследований — ИИ анализирует большие объёмы данных и составляет отчёты на различные темы — от планирования финансов до развития карьеры. Поджигателя дома Сэма Альтмана обвинили в покушении на убийство — он видел в ИИ опасность для человечества
14.04.2026 [09:27],
Алексей Разин
Минувшие выходные для ближайшего окружения главы OpenAI Сэма Альтмана (Sam Altman) ассоциируются с не самыми приятными событиями, поскольку в Сан-Франциско был задержан человек, предпринявший попытку поджечь дом Альтмана, а также направившийся с дальнейшими угрозами к офису OpenAI. Задержанному предъявлено обвинение в покушении на убийство. 
Источник изображения: OpenAI Об этом со ссылкой на офис окружного прокурора Сан-Франциско сообщает сайт CNBC. Из предоставленных следствием документов становится известно, что Даниэль Морено-Гама (Daniel Moreno-Gama) руководствовался мотивами ненависти к технологиям искусственного интеллекта, намеревался убить Сэма Альтмана и располагал именами и адресами нескольких других руководителей OpenAI, членов совета директоров и инвесторов. Прокуратура Сан-Франциско обвинила Морено-Гаму в попытке убийства, на федеральном уровне ему предъявлены обвинения в попытке причинения вреда чужому имуществу при помощи воспламеняющихся веществ и незаконном владении огнестрельным оружием. По данным ФБР, действия задержанного были решительными и хорошо спланированными, он не руководствовался сиюминутным порывом. Из материалов следствия становится известно, что Морено-Гама намеревался убить Сэма Альтмана и предупреждал окружающих об угрозе «уничтожения искусственным интеллектом». В материалах дела личность Альтмана фигурирует в качестве «жертвы номер один», но однозначно сопоставляется должности генерального директора «исследовательской компании, которая создаёт искусственный интеллект и работает на внутреннем и международном рынке». Упоминается наличие у обвиняемого данных с именами и адресами ещё нескольких высокопоставленных руководителей OpenAI, членов совета директоров и инвесторов. Свои преступные намерения Морено-Гама зафиксировал в письме, которое было обнаружено при нём после задержания. Приводятся выдержки из письменного обращения задержанного к Альтману: «Если каким-то чудом ты останешься в живых, тогда я буду считать это знаком свыше о твоём спасении». По данным калифорнийской полиции, Морено-Гама примерно в половину четвёртого утра в прошлую пятницу метнул бутылку с зажигательной смесью в крыльцо дома Сэма Альтмана, после чего скрылся с места преступления пешком. Возгорание удалось ликвидировать, никто из обитателей дома не пострадал. Примерно к пяти утра того же дня Морено-Гама прибыл к офису OpenAI в Сан-Франциско, бросил стул в стеклянные двери здания и выкрикивал угрозы «сжечь всё вокруг и убить всех, находящихся внутри». Прибывшим на место происшествия полицейским удалось арестовать обвиняемого. В воскресенье местной полиции удалось задержать ещё двух людей, которые в тот день пытались напасть на дом Альтмана, не обошлось без перестрелки. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



