|
Опрос
|
реклама
Быстрый переход
Поджигателя дома Сэма Альтмана обвинили в покушении на убийство — он видел в ИИ опасность для человечества
14.04.2026 [09:27],
Алексей Разин
Минувшие выходные для ближайшего окружения главы OpenAI Сэма Альтмана (Sam Altman) ассоциируются с не самыми приятными событиями, поскольку в Сан-Франциско был задержан человек, предпринявший попытку поджечь дом Альтмана, а также направившийся с дальнейшими угрозами к офису OpenAI. Задержанному предъявлено обвинение в покушении на убийство. 
Источник изображения: OpenAI Об этом со ссылкой на офис окружного прокурора Сан-Франциско сообщает сайт CNBC. Из предоставленных следствием документов становится известно, что Даниэль Морено-Гама (Daniel Moreno-Gama) руководствовался мотивами ненависти к технологиям искусственного интеллекта, намеревался убить Сэма Альтмана и располагал именами и адресами нескольких других руководителей OpenAI, членов совета директоров и инвесторов. Прокуратура Сан-Франциско обвинила Морено-Гаму в попытке убийства, на федеральном уровне ему предъявлены обвинения в попытке причинения вреда чужому имуществу при помощи воспламеняющихся веществ и незаконном владении огнестрельным оружием. По данным ФБР, действия задержанного были решительными и хорошо спланированными, он не руководствовался сиюминутным порывом. Из материалов следствия становится известно, что Морено-Гама намеревался убить Сэма Альтмана и предупреждал окружающих об угрозе «уничтожения искусственным интеллектом». В материалах дела личность Альтмана фигурирует в качестве «жертвы номер один», но однозначно сопоставляется должности генерального директора «исследовательской компании, которая создаёт искусственный интеллект и работает на внутреннем и международном рынке». Упоминается наличие у обвиняемого данных с именами и адресами ещё нескольких высокопоставленных руководителей OpenAI, членов совета директоров и инвесторов. Свои преступные намерения Морено-Гама зафиксировал в письме, которое было обнаружено при нём после задержания. Приводятся выдержки из письменного обращения задержанного к Альтману: «Если каким-то чудом ты останешься в живых, тогда я буду считать это знаком свыше о твоём спасении». По данным калифорнийской полиции, Морено-Гама примерно в половину четвёртого утра в прошлую пятницу метнул бутылку с зажигательной смесью в крыльцо дома Сэма Альтмана, после чего скрылся с места преступления пешком. Возгорание удалось ликвидировать, никто из обитателей дома не пострадал. Примерно к пяти утра того же дня Морено-Гама прибыл к офису OpenAI в Сан-Франциско, бросил стул в стеклянные двери здания и выкрикивал угрозы «сжечь всё вокруг и убить всех, находящихся внутри». Прибывшим на место происшествия полицейским удалось арестовать обвиняемого. В воскресенье местной полиции удалось задержать ещё двух людей, которые в тот день пытались напасть на дом Альтмана, не обошлось без перестрелки. Microsoft создаст защищённую альтернативу ИИ-агенту OpenClaw для бизнеса
14.04.2026 [08:05],
Анжелла Марина
Microsoft начала тестировать агентские функций в Microsoft 365 Copilot, аналогичные агенту OpenClaw. Новая разработка будет ориентирована на бизнес-клиентов и предложит усиленные механизмы безопасности по сравнению с фреймворком OpenClaw, который имеет открытый исходный код. 
Источник изображения: techcrunch.com Создание собственного аналога OpenClaw станет частью стратегии Microsoft по расширению линейки агентских инструментов, которые компания активно представляла один за другим в последние месяцы. По сообщению TechCrunch со ссылкой на издание The Information, новый агент будет работать в фоновом режиме и выполнять многоступенчатые задачи в течение продолжительного времени. Напомним, OpenClaw — это инструмент, который запускается локально на компьютере пользователя и может создавать агентов для выполнения задач от имени человека. Если Microsoft действительно создаст собственную версию агента с локальным запуском, это станет очередным дополнением к растущему списку агентских инструментов компании. Например, в марте месяце Microsoft анонсировала несколько аналогов, включая Copilot Cowork, который умеет совершать действия внутри приложений Microsoft 365 и является облачным инструментом, функционирующим на базе собственной технологии Work IQ, а также использует модели Claude от Anthropic. В феврале была выпущена предварительная версия агента Copilot Tasks, ориентированная на более широкую аудиторию. Copilot Tasks предназначен для организации почты и планирования поездок, но, в отличие от OpenClaw, работает исключительно в облаке. Пока неясно, будет ли собственная версия Claw работать локально на устройствах пользователей или же просто переймёт некоторые функции, которые так нравятся сторонникам OpenClaw, и останется в облаке как Copilot Cowork. Демонстрация агента может состояться на конференции Microsoft Build в июне. OpenAI ищет рост вне Microsoft — ставка на AWS и корпоративный рынок
14.04.2026 [06:02],
Алексей Разин
Менее двух месяцев назад Amazon (AWS) согласилась вложить $50 млрд в капитал OpenAI, и уже можно говорить о первых плодах этой сделки. По традиции, как минимум часть этих инвестиций вернётся к Amazon в виде платежей за услуги по аренде облачных мощностей стартапом OpenAI. Последний готов использовать потенциал AWS для укрепления своих позиций на корпоративном рынке. 
Источник изображения: OpenAI Об этом стало известно из внутренней рассылки от лица директора OpenAI по выручке Дениз Дрессер (Denise Dresser), которая оказалась в распоряжении ресурса CNBC. По её словам, именно альянс с AWS позволит OpenAI укреплять свои позиции в корпоративном сегменте, ибо долгосрочное сотрудничество с Microsoft упёрлось в определённые ограничения. Напомним, именно Microsoft остаётся крупнейшим и старейшим инвестором OpenAI, корпорация вложила в капитал стартапа не менее $13 млрд с 2019 года. В свою очередь, многие корпоративные клиенты Amazon используют облачную платформу Bedrock для развития своей вычислительной инфраструктуры, поэтому сотрудничество OpenAI и AWS как раз открывает перед стартапом соответствующие возможности в корпоративном сегменте. Microsoft, по словам Дрессер, обладает ограниченными возможностями по удовлетворению спроса на услуги OpenAI со стороны корпоративных клиентов. Для OpenAI корпоративный сегмент является важной точкой роста, поскольку на примере конкурирующей Anthropic становится понятно, что именно он позволяет быстрее окупить вложения в развитие инфраструктуры генеративного ИИ. Активно продвигает Gemini корпорация Google, поэтому конкуренция довольно высока. OpenAI также важно убедить инвесторов, что огромные капитальные вложения, на которые стартап направляет их средства, способны себя оправдывать хотя бы в среднесрочной перспективе. OpenAI и Anthropic, как ожидается, в этом году собираются выйти на IPO, поэтому им важно заранее демонстрировать эффективность монетизации своих разработок. Amazon не будет единственным альтернативным провайдером облачных мощностей для OpenAI. Она уже обращалась к CoreWeave, Google и Oracle, продемонстрировав в полном смысле «всеядность». В своём обращении к сотрудникам Дрессер заявила, что «рынок достанется нам, нужно лишь ответственно выполнять свою работу». Microsoft задумала продавать ИИ-агентам лицензии Office и другое ПО, как обычным людям
13.04.2026 [15:48],
Алексей Разин
Появление ИИ-агентов подразумевает, что они возьмут на себя часть функций реальных сотрудников. При этом корпорация Microsoft намекает, что с точки зрения лицензирования программного обеспечения она будет рассматривать ИИ-агентов как отдельное пользовательское место. Иными словами, каждому ИИ-агенту нужна отдельная лицензия на Office или другое ПО. Так что, даже если физически количество рабочих мест в организации сократится, за ПО она станет платить больше, если сделает упор на распространение ИИ-агентов. 
Источник изображения: Microsoft Исполнительный вице-президент подразделения Microsoft Experiences + Devices Group Раджеш Джа (Rajesh Jha) дал понять, что внедрение ИИ-агентов будет подразумевать закрепление за ними отдельных учётных записей, адресов электронной почты и даже программных лицензий на рабочее место. «Все эти материализованные агенты представляют возможность увеличения количества лицензируемых рабочих мест», — подчеркнул Джа. Инвесторы уже высказывали опасения по поводу того, что массовое внедрение ИИ может подорвать потоки выручки от лицензирования программного обеспечения, исторически формировавшиеся с учётом количества рабочих мест. Microsoft теперь даёт понять, что ИИ-агенты должны учитываться с точки зрения лицензирования как реальные сотрудники. Например, если сегодня компания с 20 сотрудниками покупает 20 лицензий Microsoft 365, а каждый сотрудник в будущем получает в помощь пять ИИ-агентов, но штат компании при этом сокращается до 10 человек, то платить при этом придётся за 50 рабочих мест. Впрочем, с таким подходом согласны не все, и открытые платформы с их более гибкой системой оплаты доступа к экосистеме могут переманить пользователей от сторонников «поголовной» оплаты. Если расценивать ИИ-агентов как «продолжение» человека, то брать с них плату за полноценное рабочее место несправедливо. Если же считать ИИ-агента за самостоятельного сотрудника, такой подход имеет право на жизнь. В этой сфере ещё предстоит выработать какие-то универсальные критерии оценки. Марк Цукерберг создаёт себе ИИ-двойника, который будет общаться с подчинёнными за него
13.04.2026 [13:26],
Алексей Разин
Можно подумать, что уставшая доносить до общественности пользу внедрения искусственного интеллекта компания Meta✴✴ Platforms готова испытывать все новые идеи на себе. Помимо ИИ-агента, который будет помогать основателю Марку Цукербергу (Mark Zuckerberg) руководить своим детищем, она сейчас пытается создать ИИ-аватар, который будет общаться с сотрудниками от лица Цукерберга. 
Источник изображения: Unsplash, Ferr Studio Формально, как поясняет Financial Times, эти две инициативы продвигаются независимо друг от друга. Meta✴✴ уже работала над созданием фотореалистичных трёхмерных персонажей, которые использовали бы ИИ для ответа на вопросы от лица своего прототипа, и решила сосредоточиться на разработке такого виртуального аватара для своего генерального директора. Цукерберг сам вовлечён в процесс тестирования и обучения соответствующей языковой модели. Её также обучают на видеозаписях публичных выступлений основателя компании, чтобы аватар мог точно воспроизводить интонацию и манеру речи оригинала. Кроме того, в содержательной части аватар учитывает высказывания Цукерберга относительно текущего представления о стратегии развития компании, что будет полезно при его взаимодействии с сотрудниками Meta✴✴. В целом, Марк Цукерберг на личном примере демонстрирует концентрацию усилий Meta✴✴ на разработке ИИ. Он пишет программный код в течение пяти или десяти часов в неделю для разных проектов, проводит много времени на технических совещаниях. Идея создания ИИ-аватара для деятельности Meta✴✴ не нова сама по себе, ещё в сентябре 2023 года компания предложила «одушевить» чат-бот при помощи внешности и голоса знаменитостей, которые дали на это своё согласие. Молодая аудитория благоприятно восприняла это нововведение. Позже была представлена функция AI Studio, которая позволила пользователям создавать собственные ИИ-персонажи, независимо от прототипа общающиеся с подписчиками. Кто-то начал злоупотреблять данными возможностями во фривольном смысле, в итоге с января Meta✴✴ была вынуждена ограничить доступ подростковой аудитории к ИИ-персонажам. По данным Financial Times, созданная внутри Meta✴✴ лаборатория Superintelligence Labs продолжила развивать тему ИИ-персонажей. В процессе экспериментов выяснилось, что наделение таких аватаров фотореалистичной внешностью отнимает много вычислительных ресурсов, и на уровне передачи информации сложно обеспечить отсутствие задержек при взаимодействии с пользователями. Голосовым аспектам подобных проектов тоже уделяется должное внимание. В прошлом году Meta✴✴ купила стартапы PlayAI и WaveForms, которые специализируются на этом направлении. Аватар Цукерберга также будет обучаться на записях его голоса. Если эксперимент оправдает себя, представители творческих профессий в медийной сфере смогут создавать своих ИИ-двойников для общения с аудиторией. Внутренние процессы в Meta✴✴ всё больше ориентируются на применение ИИ. Агентсткие инструменты типа OpenClaw, по замыслу руководства, должны активнее использоваться сотрудниками для автоматизации рутинных задач. Менеджеры по продуктам приглашаются для прохождения контрольных заданий на навыки работы с ИИ в сфере написания программного кода и разработки технических систем. Пока такие тесты не являются обязательными, руководство компании утверждает, что они проводятся для выявления пробелов в обучении сотрудников, но последние начали опасаться, что подобные проверки могут быть предвестниками новой волны сокращений. «Хотите — верьте, хотите — нет»: разработчик Graveyard Keeper 2 отреагировал на подозрения в использовании генеративного ИИ
13.04.2026 [11:45],
Михаил Романов
Недавний анонс симулятора смотрителя средневекового кладбища Graveyard Keeper 2 от разработчиков из литовской студии Lazy Bear Games (серия Punch Club) обернулся небольшим скандалом вокруг генеративного ИИ. 
Источник изображения: Steam (Homikator) Началось всё с подозрений, что ключевая иллюстрация Graveyard Keeper 2 была создана с помощью ИИ. Следом игроки обнаружили, что сооснователь Lazy Bear Games Святослав Черкасов увлекается нейросетями и не стесняется этого. За последние месяцы Черкасов делился опытом работы с несколькими чат-ботами, ИИ-изображениями по Graveyard Keeper, словами поддержки в адрес раскритикованного игроками масштабирования DLSS 5 и так далее. 
Источник изображения: tinyBuild Черкасов отреагировал на подозрения: «Хотите — верьте, хотите — нет, но мы не используем ИИ в Graveyard Keeper 2. Да, я экспериментирую с каждой ИИ-моделью, которую могу найти. Сейчас этим должен заниматься каждый технарь». «Я не занимаюсь иллюстрациями — у нас для этого есть восемь художников. Не делаю я ни звуки, ни музыку. Я просто технарь, который экспериментирует с технологией, чтобы понять её возможности», — заявил Черкасов на форуме Reddit. 
Источник изображения: tinyBuild Реакция фанатов Graveyard Keeper на заявление Черкасова оказалась смешанной. Одна часть сообщества осталась довольна ответом, а другая советует дождаться новых трейлеров и релиза игры, прежде чем верить руководителю на слово. Graveyard Keeper 2 выйдет в 2026 году на PC (Steam), PS5, Xbox Series X и S, Nintendo Switch и Switch 2. Обещают зомби-апокалипсис в средневековом королевстве, возможность наживаться на мертвецах и горожанах, а также перевод на русский. Anthropic отодвинула OpenAI на второй план по итогам главной ИИ-конференции HumanX
12.04.2026 [14:24],
Дмитрий Федоров
Anthropic перехватила у OpenAI внимание ИИ-отрасли на конференции HumanX в Сан-Франциско, где присутствовали 6500 руководителей и основателей компаний. Главным предметом разговоров стал Claude Code — инструмент для написания программ, который укрепил позиции Anthropic среди крупных заказчиков и вывел компанию в центр самого быстрорастущего прикладного сегмента ИИ. 
Источник изображения: humanx.co Опрошенные изданием CNBC 19 руководителей и инвесторов называли Claude Code самым заметным продуктом, хотя отмечали сильные альтернативы со стороны OpenAI, Cursor и Google. Для Anthropic этот сдвиг важен из-за ранних успехов в работе с крупными заказчиками. Рост популярности средств, которые создают, редактируют и проверяют код, усиливает её шансы на контракты с самыми крупными покупателями. OpenAI запустила бум ИИ с выходом ChatGPT в 2022 году, но именно Anthropic сейчас выглядит лучше подготовленной к борьбе за самые большие бюджеты. Публичный спор с Пентагоном этому не помешал. В прошлом месяце конфликт быстро дошёл до суда: Министерство войны США (DoW) внесло Claude в чёрный список, однако после двух противоположных судебных решений Anthropic сохранила право работать с другими федеральными ведомствами, пока разбирательства продолжаются. Компания возникла в 2021 году, когда группа исследователей и руководителей ушла из OpenAI. Её стоимость оценивается в $380 млрд. Claude Code стал доступен широкой публике в мае 2025 года и по состоянию на февраль приносил более $2,5 млрд выручки в годовом исчислении. Во вторник Anthropic представила ИИ-модель Claude Mythos Preview с расширенными возможностями в киберзащите, опирающимися на сильные навыки программирования и рассуждения. На HumanX эта новинка вызвала заметный интерес, хотя доступ к ней пока получили около 50 компаний. Глава Synthesia Виктор Рипарбелли (Victor Riparbelli) объяснил успех Anthropic тем, что она не стала заниматься видео и голосовыми ИИ-моделями, а сосредоточилась на генерации кода. По его словам, OpenAI пришлось продвигать сразу 6 разных продуктов, и это рассеивало внимание потребителя. Один из инвесторов предупредил, что рынок ещё слишком молод, а нынешний импульс легко может уйти в другую сторону. 
Источник изображения: anthropic.com Изменения происходят и в самих компаниях. Президент Decagon Эшвин Сринивас (Ashwin Sreenivas) сказал, что появление средств для написания программ изменило и найм, и организацию работы. Соискателям разрешили пользоваться такими инструментами на собеседованиях, а проект, для которого раньше требовались 4-5 инженеров, теперь могут вести двое. Глава Credo AI Наврина Сингх (Navrina Singh) сказала, что задачи, под которые в прошлом году пришлось бы нанимать 10 человек, теперь можно собрать за выходные и развернуть внутри компании. Одновременно, по её словам, стало сложнее удерживать под контролем план развития и обязательства перед крупными заказчиками, которым нужна большая ясность и большая устойчивость. Похожие сдвиги происходят и в Cisco. Президент компании Джиту Патель (Jeetu Patel) сказал, что ИИ уже используют около 85 % инженерного состава, то есть примерно 18000 сотрудников. Cisco пришла к этому не тем путём, который ожидало руководство: сначала компании пришлось сделать приоритетом не результат, а само внедрение, исходя из того, что возможности ИИ-моделей будут и дальше расти. Патель предложил смотреть на такие системы не как на инструменты, а как на цифровых коллег: команда может состоять уже не из восьми человек, а из двух сотрудников и шести программных помощников или из двух сотрудников и бесконечного числа таких помощников. Большинство собеседников CNBC сильно беспокоят китайские ИИ-модели с открытыми весами. Так называют системы, у которых публично доступны параметры, улучшающие ответы и прогнозы в ходе обучения. По состоянию на апрель именно китайские ИИ-модели этого класса, включая GLM-5.1, Kimi K2.5 и Qwen3.5, лидировали в отраслевых испытаниях. Американские компании уже активно используют эти разработки. Cursor IDE построила свою ИИ-модель Composer 2 на Kimi 2.5, а глава Airbnb Брайан Чески (Brian Chesky) говорил в октябре, что чат-бот компании в значительной степени зависит от Qwen компании Alibaba. 
Источник изображения: humanx.co Из-за этого сокращение отставания США в сегменте ИИ-моделей с открытыми весами стало одной из главных задач для части инвесторов: двое собеседников CNBC сказали, что направляют на это значительную долю времени и ресурсов, ещё один назвал проблему одной из ключевых для отрасли. Джайн добавил, что крупные компании всё осторожнее относятся к зависимости от одного или двух поставщиков ИИ: новые решения появляются у многих игроков, в том числе в среде открытой разработки, и заказчики хотят сохранять выбор. Исследователи объяснили, что алгоритм Google TurboQuant не снизит спрос на память, а наоборот, усилит его
12.04.2026 [14:09],
Дмитрий Федоров
Сильная предварительная оценка прибыли Samsung Electronics за I квартал 2026 года ослабила опасения инвесторов, что алгоритм Google TurboQuant ударит по спросу на южнокорейские микросхемы памяти для ИИ. Компания ждёт, что прибыль за 3 месяца превысит результат всего прошлого года. 
Источник изображения: Berin Holy / unsplash.com Samsung объяснила прогноз «беспрецедентным суперциклом» на рынке чипов памяти и не увидела признаков того, что память перестаёт быть ограничивающим фактором для компаний, работающих с ИИ. Прогноз почти поднял акции Samsung к историческим максимумам и ослабил напряжение, державшееся 2 недели после публикации Google Research в конце марта. Запись в блоге Google описывала TurboQuant как технологию, способную резко сократить объём памяти, необходимой ИИ-системам. После публикации в прошлом месяце акции Samsung и SK Hynix резко снизились. Спор сосредоточился на будущем спроса на память с высокой пропускной способностью, которую обе компании выпускают для ИИ-серверов. Часть инвесторов считает, что подъём на рынке памяти сменится спадом. Другие ждут ограниченного эффекта. Третьи исходят из обратного сценария: если TurboQuant удешевит использование ИИ, это расширит спрос на такие системы и поддержит спрос на микросхемы. 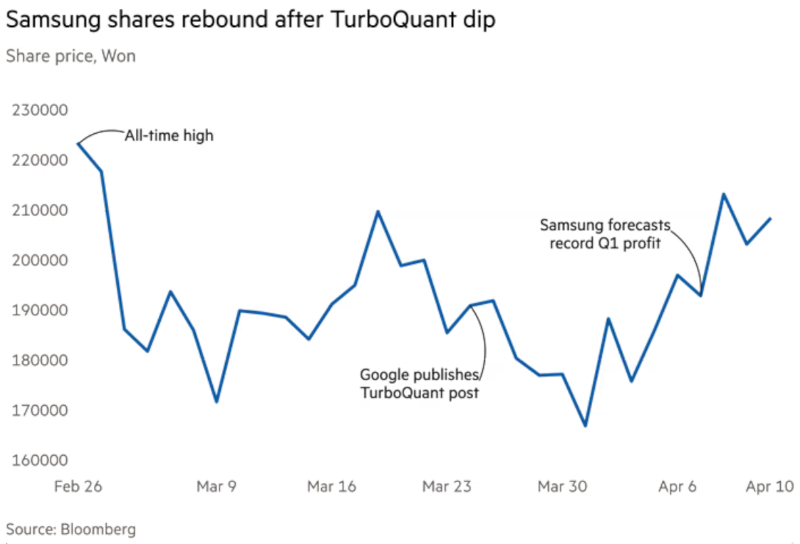
После снижения в конце марта на фоне публикации Google о TurboQuant акции Samsung восстановились в начале апреля после прогноза рекордной прибыли за I квартал. Источник изображения: Bloomberg Профессор сеульского Университета Сонгюнгван Квон Сок Чжун (Kwon Seok-joon) оценил возможное снижение затрат памяти на использование больших языковых ИИ-моделей при применении TurboQuant в 4-8 раз. На первый взгляд, по его словам, это угрожает спросу на память с высокой пропускной способностью. Но одновременно удешевление вывода делает экономически оправданными вычислительные нагрузки, которые раньше были слишком дорогими, включая помощников по программированию и одновременную работу нескольких ИИ-агентов. Это повысит спрос на вычислительные ресурсы. Аналитики и исследователи всё чаще связывают возможный эффект TurboQuant с парадоксом Джевонса: рост эффективности увеличивает общее потребление ресурса. Экономист Уильям Стэнли Джевонс (William Stanley Jevons) писал в книге «Угольный вопрос», вышедшей в 1865 году, что более совершенная паровая машина Джеймса Уатта увеличила потребление угля, поскольку сделала такие технологии экономически оправданными в гораздо большем числе областей. Один из исследователей, чьи работы легли в основу TurboQuant, Хан Ин Су (Han In-su) сказал Financial Times, что алгоритм может открыть путь к задачам, которые раньше оставались недостижимыми: обработке гораздо более длинных контекстов при ограниченной памяти без потери точности и созданию высокопроизводительных ИИ-систем на более компактных устройствах. 
Источник изображения: Steve A Johnson / unsplash.com Аналитик Mirae Asset Securities Ким Ён Гон (Kim Young-gun) сравнил ситуацию с распространением Kubernetes — разработанной Google технологии контейнеризации, позволившей запускать несколько приложений на одном сервере и заметно повысившей эффективность вычислительного оборудования. Когда технология широко распространилась в конце 2010-х годов, рынок тоже опасался падения спроса на серверы и память. На практике снижение затрат привело к более широкому использованию инфраструктуры. Рэй Ван (Ray Wang) из SemiAnalysis заявил, что рынок во многом неверно понял значение TurboQuant. По его оценке, по мере развития ИИ-моделей и технологий спрос на память будет расти и при обучении, и при выводе. Возможный удар по южнокорейским производителям микросхем, по его словам, смягчит растущая роль долгосрочных договоров, поскольку поставщики ИИ-услуг стремятся заранее закрепить за собой объёмы поставок. Из-за этого цены по таким договорам становятся важнее цен по разовым сделкам. На ежегодном собрании Samsung в прошлом месяце один из двух генеральных директоров компании Чун Ён Хён (Jun Young-hyun) сказал, что компания добивается трёх— и пятилетних договоров с крупными клиентами вместо квартальных и годовых. Пока TurboQuant остаётся концепцией из записи в блоге. Практический эффект технологии станет яснее после её представления в конце апреля в Бразилии на Международной конференции, где её смогут проверить специалисты вне Google. Хан признал, что исследователи не ожидали столь сильного общественного и экономического отклика на работу, начавшуюся с академического вопроса о том, как ещё точнее сжимать данные. Основатель DeepSeek назвал дату выхода флагманской модели V4
12.04.2026 [07:47],
Анжелла Марина
Основатель компании DeepSeek Лян Вэньфэн (Liang Wenfeng) подтвердил в ходе внутреннего общения с сотрудниками, что флагманская модель следующего поколения DeepSeek V4 будет официально представлена в конце апреля 2026 года. По сообщению AIBase, система впервые получит многоуровневый режим работы, а релиз совпадёт с выходом конкурирующей модели Tencent. Источник изображения: AI Быстрый режим (Fast Mode) ориентирован на повседневные диалоги и мгновенные ответы, поддерживает распознавание текста на изображениях и в файлах с акцентом на скорость работы. Экспертный режим (Expert Mode) разработан для решения задач со сложной логикой и глубоким анализом, обладает усиленными возможностями интеллектуального поиска. Однако этот режим пока не поддерживает загрузку файлов и мультимодальные функции, а в часы пик может потребоваться ожидание. 
Источник изображения: aibase.com Несмотря на приближающийся релиз новой модели, текущая ситуация в DeepSeek характеризуется контрастами. Пользователи отметили существенные улучшения в логической обработке данных и возможностях программирования. Однако платформа три дня подряд испытывает масштабные технические сбои, включая один сбой продолжительностью до 12 часов. Эксперты отрасли рассматривают это как «болезненный период» переходного этапа между старой и новой моделями. Дата релиза DeepSeek V4 выбрана в условиях высокой конкуренции. Команда Яо Шунью (Yao Shunyu) в Tencent также планирует выпустить новую модель под названием Hunyuan в следующем месяце. Таким образом, конец апреля станет временем прямого соперничества между двумя ведущими китайскими разработчиками базовых ИИ-моделей, что может повлиять на расстановку сил в индустрии. Япония выделила Rapidus ещё $4 млрд для запуска 2-нм техпроцесса для ИИ-чипов
11.04.2026 [15:29],
Владимир Мироненко
Министерство экономики, торговли и промышленности Японии (METI) сообщило в субботу о выделении дополнительных субсидий в размере 631,5 млрд иен ($3,96 млрд) на ускорение исследований и разработок производителя микросхем Rapidus. 
Источник изображения: Rapidus С учётом этого финансирования в течение текущего финансового года, завершающегося в марте 2027 года, объём государственных инвестиций в стартап вырос до 2,35 трлн иен ($15 млрд), пишет Reuters. В феврале стартап привлёк инвестиции от частных компаний в размере около 160 млрд иен ($1 млрд), а также государственные инвестиции в размере 250 млрд иен ($1,57 млрд). Финансовая поддержка Rapidus является частью усилий правительства по наращиванию внутреннего производства передовых полупроводников и укреплению цепочек поставок микросхем. Премьер-министр Санаэ Такаичи (Sanae Takaichi) подчеркнула необходимость увеличения инвестиций в области, критически важные для национальной безопасности. Министерство также сообщило, что действующая под его началом «Организация по развитию новых энергетических и промышленных технологий» (New Energy and Industrial Technology Development Organization, NEDO) решила поддержать проекты компании Fujitsu и IBM Japan, связанные с проектированием полупроводников, с целью передачи ими производства своих энергоэффективных чипов для искусственного интеллекта компании Rapidus. Rapidus планирует наладить серийное производство передовых 2-нм чипов на новом предприятии на острове Хоккайдо во второй половине 2027 года. OpenAI лишилась трёх руководителей проекта Stargate — их переманила Meta✴ в разгар гонки ИИ
11.04.2026 [14:58],
Дмитрий Федоров
Три руководителя OpenAI, участвовавшие в программе Stargate по созданию ЦОД для ИИ стоимостью в сотни миллиардов долларов, переходят в Meta✴✴. Их переход совпал с резким ростом расходов Meta✴✴ на инфраструктуру ИИ и с пересмотром части проектов Stargate внутри OpenAI. 
Источник изображения: Alex Shuper / unsplash.com Питер Хёшеле (Peter Hoeschele) играл одну из ключевых ролей в Stargate, Шамез Хемани (Shamez Hemani) отвечал за стратегию вычислительных ресурсов и развитие бизнеса, Анудж Сахаран (Anuj Saharan) входил в руководство подразделения вычислительной инфраструктуры. OpenAI ранее заявляла, что благодарна трём сотрудникам за их вклад и продолжает нанимать специалистов для реализации своих инфраструктурных планов. В ноябре компания переманила бывшего руководителя Intel Сачина Катти (Sachin Katti), поручив ему направление вычислительных мощностей промышленного масштаба. Марк Цукерберг (Mark Zuckerberg) пообещал резко увеличить расходы Meta✴✴ на ЦОД, вычислительные ресурсы и специалистов, необходимые для конкуренции в сфере ИИ. На 2026 год компания прогнозировала капитальные затраты до $135 млрд с упором на инфраструктуру ИИ. До конца десятилетия Цукерберг пообещал вложить в такие проекты ещё сотни миллиардов долларов США. Эти мощности должны поддержать работу Meta✴✴ Superintelligence Labs, недавно выпустившей ИИ-модель Muse Spark. Stargate в прошлом году представили в Белом доме как проект объёмом $500 млрд OpenAI, Oracle и SoftBank. Позднее это название стало общим обозначением всех планов OpenAI по развитию ЦОД. Компания утверждала, что опережает конкурентов по темпам расширения вычислительной инфраструктуры для своих ИИ-моделей. В число таких проектов входил объект в Абилине, штат Техас, где Хёшеле и его команда руководили работами. В недавней записке инвесторам OpenAI указала, что начала обеспечивать себя вычислительными мощностями раньше Anthropic и считает это своим преимуществом перед конкурентом. Инициатива Stargate с момента запуска претерпела ряд изменений. В четверг OpenAI сообщила, что замораживает инфраструктурный проект Stargate в Великобритании. Одновременно компания вместе с Oracle решила не арендовать дополнительные мощности для расширения объекта в Абилине. Anthropic ускорила рост в США и заметно сократила отставание от OpenAI на корпоративном рынке ИИ-сервисов
11.04.2026 [14:14],
Дмитрий Федоров
Anthropic сократила разрыв с OpenAI на рынке платных ИИ-сервисов для американского бизнеса. В марте её инструменты оплачивала почти треть компаний в США, тогда как доля OpenAI не выросла и осталась на уровне 35 %. Данные финтех-компании Ramp показывают ускорение спроса на решения Anthropic и выравнивание роста OpenAI после раннего рывка, вызванного запуском ChatGPT. 
Источник изображения: anthropic.com Ramp связывает рост Anthropic с высоким спросом на линейку Claude Code и набор расширений для автоматизации части задач умственного и административного труда. Оценка основана на ежегодных расходах 50 тыс. клиентов по банковским картам и выставленным счетам на общую сумму $100 млрд. За месяц доля компаний в США, плативших за инструменты Anthropic, выросла более чем на 6 процентных пунктов. OpenAI сохраняет лидерство, обеспеченное запуском ChatGPT в ноябре 2022 года, прежде всего на массовом рынке: компания заявляла о 900 млн еженедельно активных пользователей, из которых платят немногим более 5 %. По оценке Sensor Tower, в марте число загрузок ChatGPT выросло лишь на 5 %, тогда как у Claude за тот же период мировые загрузки утроились и достигли 21 млн. На этой неделе Anthropic заявила, что довела выручку в пересчёте на год по текущему темпу до $30 млрд против $9 млрд в конце 2025 года. Аналитическая компания Apptopia зафиксировала в марте первое с начала 2024 года снижение числа еженедельно активных пользователей ChatGPT в США по сравнению с предыдущим месяцем. OpenAI эти данные не признала и заявила, что её инструмент для программирования на основе ИИ Codex увеличил недельную аудиторию до 3 млн пользователей против 2 млн месяцем ранее. OpenAI перестраивает управление и усиливает внимание к основным направлениям бизнеса перед планируемым выходом на биржу. Это уже привело к кадровым перестановкам и отказу от второстепенных направлений, из-за чего компания закрыла сервис создания видео Sora. Вице-президент и ведущий аналитик Forrester Чарли Дай (Charlie Dai) назвал происходящее явным сдвигом динамики в пользу Anthropic. По его словам, рост компании продолжается и после того, как Министерство войны США (DoW) указало на возможные риски в цепочке снабжения. Для многих компаний важнее краткосрочных политических и надзорных сигналов качество работы ИИ-моделей, удобство работы с ними и соответствие потребностям крупных организаций. Экономист Ramp Ара Харазян (Ara Kharazian) связал рост Anthropic с её стратегией: сначала компания ориентировалась на разработчиков и других специалистов, а затем начала выходить на более широкую аудиторию. По его оценке, Anthropic сумела превратить продукт для наиболее опытных пользователей и тех, кто осваивает новинки раньше других, в решение, применимое и за пределами этого круга. По данным Ramp, продукты Anthropic в США используются шире, чем решения OpenAI, в информационном секторе, финансовых услугах и сфере профессиональных услуг. Одновременно их распространение быстро растёт в строительстве и гостиничном деле. OpenAI ранее оспаривала точность оценок Ramp, утверждая, что они не учитывают многомиллионные договоры с крупными компаниями. Сооснователь Ramp Эрик Глайман (Eric Glyman) сообщал в сети X, что корпоративная платёжная платформа компании обрабатывает платежи объёмом до 1 % валового внутреннего продукта США, а её оценки согласуются с показателями выручки OpenAI и Anthropic. ИИ оказался никудышным в ставках на спорт — он проиграл всё на матчах английской Премьер-лиги
11.04.2026 [13:04],
Павел Котов
Модели искусственного интеллекта от Google, OpenAI, Anthropic и xAI потеряли виртуальные деньги, делая ставки на футбольные матчи в течение сезона английской Премьер-лиги в рамках эксперимента, который провёл стартап General Reasoning. Результаты опыта показывают, что даже передовые системы испытывают трудности при анализе событий реального мира в долгосрочной перспективе, пишет Financial Times. 
Источник изображения: Sven Kucinic / unsplash.com Исследователи из стартапа General Reasoning опубликовали результаты проекта KellyBench — его итоги, считают они, подтверждают, что ИИ может успешно решать такие задачи как написание программного кода, но он неспособен ориентироваться во многих других аспектах реальной человеческой жизни. В рамках эксперимента компания протестировала восемь лучших систем ИИ в виртуальной реконструкции сезона Премьер-лиги 2023–2024 годов, предоставив им подробную статистику по каждой команде и предыдущим играм. ИИ было поручено сформировать модели, с помощью которых можно извлекать максимальную прибыль и управлять рисками. Условные ИИ-агенты делали ставки на исходы матчей и количество забитых голов, чтобы проверить, способен ли ИИ адаптироваться к новым событиям и обновляющимся по мере развития сезона данным об игроках. Доступа к интернету у моделей ИИ в рамках эксперимента не было, и у каждой модели было по три попытки заработать. Лучше всех проявил себя Anthropic Claude Opus 4.6 со средним убытком 11 % и почти безубыточностью в одной из попыток. Чат-бот xAI Grok 4.20 сразу обанкротился и не смог завершить две оставшиеся попытки; Google Gemini 3.1 Pro получил прибыль в 34 % в первой попытке и обанкротился во второй. В итоге каждая из передовых моделей теряла деньги в течение сезона, и многие просто обанкротились, отметили исследователи — в этой задаче ИИ выступил явно хуже человека. Результаты эксперимента, подчёркивают его авторы, указывают, что опасения общественности по поводу вытеснения человека ИИ пока беспочвенны, и в долгосрочной перспективе ИИ пока несостоятелен. Многие из бенчмарков, в которых оцениваются модели, описывают «очень статичные условия», имеющие не так много общего с хаосом и сложностью реального мира. И если ИИ преуспевает в написании программного кода, то во многих других видах человеческой деятельности он всё ещё бесполезен. Anthropic временно заблокировала создателя OpenClaw в Claude, но быстро отыграла назад
11.04.2026 [12:58],
Дмитрий Федоров
Anthropic на несколько часов заблокировала доступ к Claude создателю OpenClaw Петеру Штайнбергеру (Peter Steinberger), а затем восстановила аккаунт после резонанса в соцсети X. Инцидент произошёл вскоре после того, как компания вывела OpenClaw из подписки на Claude и перевела такую работу на отдельную оплату через программный интерфейс (API), хотя Штайнбергер утверждал, что уже соблюдал новые правила. 
Источник изображения: openclaw.ai Штайнбергер написал в X, что поддерживать совместимость OpenClaw с ИИ-моделями Anthropic теперь будет сложнее, и приложил уведомление о блокировке учётной записи из-за «подозрительной» активности. Среди сотен комментариев появился ответ инженера Anthropic. Он написал, что компания никогда не блокировала пользователей за работу с OpenClaw, и предложил помочь. Повлияло ли это на разблокировку, неясно. 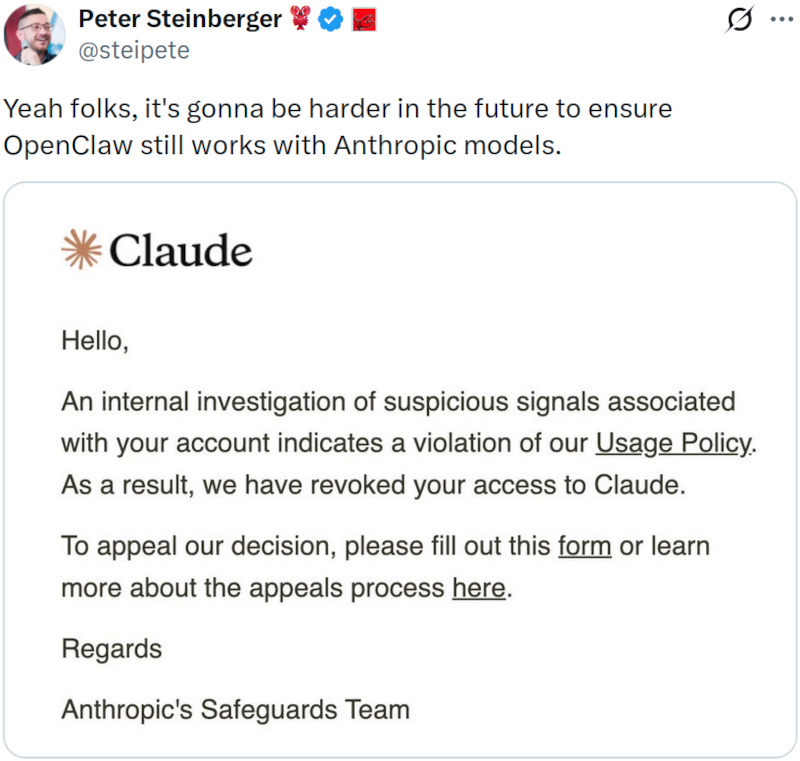
Источник изображения: @steipete / x.com Блокировка последовала за пересмотром условий работы с Claude. На прошлой неделе Anthropic объявила, что подписка больше не покрывает сторонние управляющие оболочки, включая OpenClaw. Теперь такая работа оплачивается отдельно, по объёму использования, через API Claude. Компания объяснила это тем, что подписка не рассчитана на такую нагрузку. Подобные оболочки могут требовать больше вычислительных ресурсов, чем обычные запросы или простые сценарии, поскольку способны непрерывно запускать циклы рассуждения, автоматически повторять или перезапускать задачи и связываться со множеством сторонних инструментов. Штайнбергер это объяснение отверг. После изменения правил оплаты он написал, что Anthropic сначала перенесла часть популярных функций в собственную закрытую оболочку, а затем отсекла решения с открытым исходным кодом. Он не уточнил, что именно имеет в виду, но речь могла идти о новых возможностях помощника Cowork, включая Claude Dispatch для удалённого управления агентами и назначения задач. Dispatch появился за пару недель до изменения ценовой политики для OpenClaw. Дополнительное внимание к истории привлекло то, что Штайнбергер работает в OpenAI, конкуренте Anthropic. На реплику о том, что он выбрал не ту компанию, Штайнбергер ответил: «Одни меня приняли, другие прислали юридические угрозы». На вопрос, зачем он использует Claude вместо ИИ-моделей работодателя, Штайнбергер ответил, что обращается к нему только для тестирования, чтобы обновления OpenClaw не нарушили работу у пользователей Claude. Он отделил работу в OpenClaw, где задача его состоит в обеспечении совместимости с любым поставщиком ИИ-моделей, от работы в OpenAI, связанной с дальнейшей продуктовой стратегией. Комментаторы также указали, что Claude остаётся более популярным выбором среди пользователей OpenClaw, чем ChatGPT. Глава Microsoft Сатья Наделла объявил «красный код» для Copilot
11.04.2026 [12:38],
Павел Котов
Акции Microsoft, которые переживают затянувшийся спад, могут снова вернуться к росту: компания в экстренном порядке усилила работу над технологиями искусственного интеллекта, её облачное подразделение остаётся сильным, а финансовые результаты — стабильными, приводит Benzinga мнение аналитика BNP Paribas Стефана Словински (Stefan Slowinski). 
Источник изображения: microsoft.com Разочарование инвесторов связано с тем, что успех ИИ-помощника Copilot оказался не таким оглушительным, как рассчитывали в Microsoft, несмотря на то, что компания остаётся лидером в сегменте SaaS со своим сервисом 365 Commercial Cloud. В этой связи гендиректор компании Сатья Наделла (Satya Nadella) объявил экстренную мобилизацию ресурсов и бросил значительные силы на обновление Copilot — сервис станет более производительным, а работать с ним будет комфортнее. Уже 1 мая компания выпустит обновлённый пакет E7 и в течение года продолжит развёртывать новые функции. Продукт уже получил первые положительные отзывы, и даже на фоне риска конкуренции со стороны Anthropic восприятие Copilot может смениться на положительное. Ещё один положительный фактор — успешная работа облачного подразделения Azure. В минувшем квартале Microsoft выделила 30 % облачных ресурсов на нужды разработки собственных проектов, таких как Copilot и создание собственных моделей ИИ. Это вызвало у инвесторов опасения, что компания начнёт конкурировать с собственными партнёрами, в том числе OpenAI. Даже несмотря на это, полагает эксперт, финансовые результаты Azure могут оказаться выше ожидаемых, даже если компания выделит на собственные нужды 50 % ресурсов — успех обеспечат высокий спрос на ИИ и дорогие вычислительные мощности. Наконец, Microsoft может усовершенствовать собственные механизмы управления финансами, оптимизировав показатели капитальных затрат, свободного денежного потока и роста, используя мощности партнёров по неооблачным решениям. Доля свободных средств в выручке Microsoft составляет 20 %, и это очень хороший результат, который в сочетании с улучшенным восприятием Copilot и положительными результатами Azure вполне способен вернуть акции компании в зелёную зону. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



