|
Опрос
|
реклама
Быстрый переход
В ChatGPT совсем скоро появится реклама — стал известен её формат
27.12.2025 [17:55],
Владимир Мироненко
В СМИ появились сообщения о том, что OpenAI рассматривает возможность запуска рекламы в ChatGPT в формате «спонсируемого контента», которая может повлиять на принятие пользователем решения о покупке того или иного товара. 
Источник изображения: Mariia Shalabaieva/unsplash.com По данным ресурса The Information, OpenAI планирует отдавать приоритет размещению спонсируемого контента в ответах ИИ-моделей. «ИИ-модели могут отдавать приоритет спонсируемому контенту, чтобы гарантировать его отображение в ответах ChatGPT», — отмечается в публикации. По словам источника ресурса, в последние недели в макетах рекламы отображалась спонсируемая информация в боковой панели рядом с основным окном ответа ChatGPT. Представитель OpenAI подтвердил, что компания рассматривает возможность добавления рекламы в ответы на запросы ИИ-моделей. «По мере того как ChatGPT становится более функциональным и широко используемым, мы ищем способы продолжать предоставлять всем больше информации. В рамках этого мы изучаем, как может выглядеть реклама в нашем продукте. У людей сложились доверительные отношения с ChatGPT, и любой подход будет разработан с учетом этого доверия», — сообщил он ресурсу The Information. На данный момент OpenAI не размещает рекламу даже в платных версиях ChatGPT (ChatGPT Plus, ChatGPT Pro, ChatGPT Team/Enterprise). Недавно сообщалось, что в бета-версии приложения ChatGPT для Android 1.2025.329 упоминалась «функция рекламы» с «контентом маркетплейса», «рекламой в поиске» и «карусельной рекламой в поиске». После этого, по словам инсайдеров, OpenAI отложила планы по добавлению рекламы в ChatGPT, решив сосредоточиться на повышении качества ИИ в связи с возросшей конкуренцией со стороны Gemini. Но, судя по всему, OpenAI не отказалась от своих планов полностью, сделал вывод ресурс BleepingComputer. Ресурс отметил, что в «Google Поиске» есть реклама, которая может влиять на покупательское поведение пользователей. Однако с учётом того, что GPT знает о предпочтениях пользователей гораздо больше, чем Google, реклама в ChatGPT может разрушить веб-экономику, предупреждает BleepingComputer. OpenAI тестирует «навыки» ChatGPT по образцу Anthropic Claude
25.12.2025 [10:48],
Павел Котов
OpenAI начала тестировать новую функцию ChatGPT под названием «Навыки» (Skills), которая будет похожа на аналогичную функцию конкурирующего чат-бота Anthropic Claude с тем же наименованием. 
Источник изображения: BoliviaInteligente / unsplash.com Сейчас в ChatGPT поддерживаются производные чат-боты GPT — они проектируются при помощи запросов и предназначаются для выполнения конкретных функций. «Навыки» в Claude — это папки, данные в которых обучают чат-бот определённым способностям, рабочим процессам и знаниям в предметной области. Так, у Claude есть плагин для проектирования интерфейса — он помогает эффективнее ориентироваться в пользовательском пространстве, когда пишется код веб-приложения. Anthropic выделяет следующие характеристики «Навыков»:
Как ожидается, в производных чатах OpenAI GPT вскоре появится нечто подобное также под названием «Навыки». Сейчас они проходят внутри компании под кодовым именем Hazelnuts («Фундук») и в рамках теста запускаются командами со слэшем. Предусмотрен редактор «Навыков» и возможность преобразовывать пользовательские GPT в «Навыки». Развёртывание новой функции может начаться в январе 2026 года. В ChatGPT появились персональные итоги года в стиле Spotify Wrapped
23.12.2025 [11:34],
Владимир Фетисов
OpenAI запустила в ИИ-боте функцию подведения итогов года в стиле Spotify Wrapped, которая получила название «Ваш год с ChatGPT». На данный момент она доступна ограниченному числу пользователей сервиса в разных странах мира, включая США, Канаду, Австралию, Великобританию и Новую Зеландию. 
Источник изображения: OpenAI На момент запуска функции «Ваш год с ChatGPT» она доступна бесплатным пользователям ИИ-бота, а также подписчикам на тарифах Plus и Pro, у которых активированы опции «Сохранять воспоминания для контекста» и «Использовать историю чатов для контекста». Чтобы получить итоги года также необходимо достигнуть определённого порога активности в беседах с ChatGPT. Пользователи аккаунтов Team, Enterprise и Education не смогут получить доступ к функции «Ваш год с ChatGPT». Новая функция, как и другие подобные инструменты в разных приложениях, вдохновлена популярным итоговым отчётом за год Spotify Wrapped. Как и в случае Spotify, OpenAI использует яркие графические элементы и персонализирует данные для каждого пользователя, а также вручает «награды» на основе того, как происходило взаимодействие с чат-ботом в течение года. В процессе подведения итогов ChatGPT также генерирует стихотворение и изображение, сфокусированные на темах, которые интересовали пользователя в течение года. Хотя эта функция рекламируется на стартовой странице приложения, она не запускается автоматически. Получить доступ к ней можно в веб-приложении ChatGPT, а также в мобильных версиях для Android и iOS. Пользователи также могут напрямую обратится к чат-боту, чтобы он активировал функцию «Ваш год с ChatGPT». OpenAI увеличила прибыльность платных аккаунтов до 70 %, но всё ещё работает в убыток
22.12.2025 [06:13],
Анжелла Марина
OpenAI в 2025 году смогла получить больше прибыли от своих платных продуктов, продолжая бороться за лидерство на рынке искусственного интеллекта (ИИ). По сообщению Bloomberg со ссылкой на The Information, речь идёт о показателе вычислительной маржинальности (compute margin) — внутренней метрике, которая оценивает, какая доля выручки остаётся в распоряжении компании после покрытия затрат на запуск и работу ИИ-моделей для пользователей, оплачивающих сервис OpenAI. 
Источник изображения: Levart_Photographer/Unsplash Сообщается, что к октябрю норма прибыли OpenAI достигла 70 %. Для сравнения, в конце 2024 года показатель составлял 52 %, а относительно января 2024 года оказался вдвое выше. Одновременно представитель OpenAI заявил, что компания публично не раскрывала эти данные и отказался от дальнейших комментариев. ChatGPT считается одним из ключевых сервисов, способствовавший ажиотажу вокруг искусственного интеллекта. Однако, как пишет Bloomberg, OpenAI пока не показала прибыльности, на что непосредственно обращают внимание инвесторы, оценивая риск перегрева отрасли. Оценка компании в октябре достигла $500 млрд, но её расходы на вычислительные мощности и масштабные инфраструктурные проекты остаются крайне высокими. OpenAI также испытывает сильное давление со стороны конкурентов. На фоне этого и особенно после того, как модель Gemini компании Google показала лучшие результаты в бенчмарках, глава OpenAI Сэм Альтман (Sam Altman) объявил так называемый «красный код» и перенаправил ресурсы на улучшение ChatGPT, отложив планы по запуску рекламной платформы. Основная аудитория ChatGPT по-прежнему пользуется бесплатной версией чат-бота, однако OpenAI продвигает бизнес-версию и платные функции ПО для таких отраслей, как финансовые услуги и образование. В этих сегментах OpenAI конкурирует, в частности, с Google и Anthropic. Источники также утверждают, что по норме прибыли на платных аккаунтах OpenAI выглядит лучше Anthropic, но при этом у Anthropic выше общая эффективность затрат на серверную инфраструктуру. Кроме того, OpenAI находится на ранней стадии переговоров о привлечении как минимум $10 млрд от компании Amazon и о возможном использовании её чипов. В рамках этой сделки компания Альтмана может быть оценена более чем в $500 млрд. ChatGPT научился менять свой характер по желанию пользователя
20.12.2025 [05:12],
Анжелла Марина
В ChatGPT появились новые функции персонализации, которые позволяют регулировать эмоциональный тон и стиль ответов искусственного интеллекта (ИИ). OpenAI предлагает на выбор несколько вариантов «личности» чат-бота, которые можно донастраивать и «докручивать». 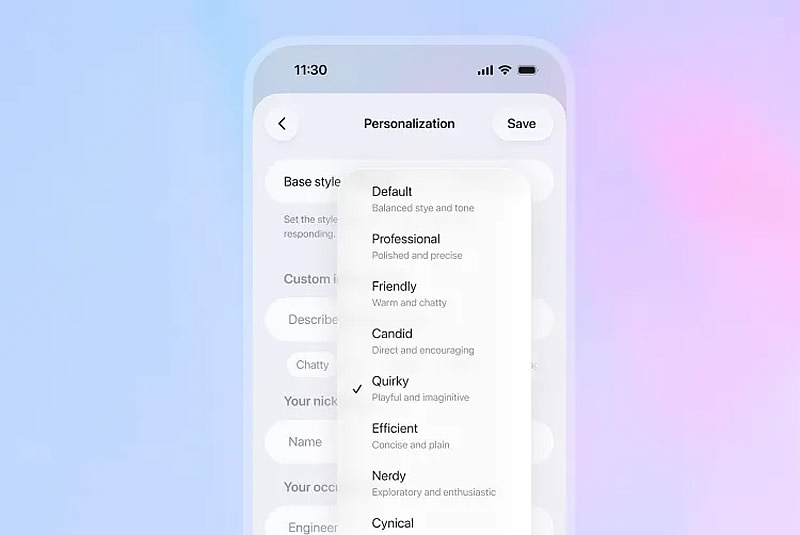
Источник изображения: OpenAI Основным стилем ответов ИИ-модели является режим «По умолчанию», далее идёт «Профессиональный», «Дружелюбный», «Откровенный», «Необычный», «Эффективный», «Занудный» и «Циничный» и, как подчёркивает The Verge, каждый параметр личностных черт можно менять, увеличивая или уменьшая шкалу их характеристик. Также есть возможность настроить частоту использования эмодзи, заголовков и списков в ChatGPT. Эти настройки можно найти, нажав на меню в верхнем левом углу приложения ChatGPT, выбрав свой профиль, перейдя в раздел «Персонализация» и выбрав «Добавить характеристики». Кроме того, с обновлением изменился и способ написания электронных писем. Теперь пользователь может обновлять и форматировать текст непосредственно в чате. Также можно выделять фрагменты текста и запрашивать у ChatGPT внести в них конкретные изменения, вместо того чтобы пытаться указать чат-боту на этот фрагмент в отдельном диалоговом запросе. OpenAI перезапустила GPT-5.2, расширив меры защиты подростков
20.12.2025 [01:40],
Анжелла Марина
Компания OpenAI представила обновлённую версию языковой модели GPT-5.2 с расширенными мерами безопасности для пользователей младше 18 лет. Новые правила «поведения» чат-бота при общении с подростками разработаны в сотрудничестве с Американской психологической ассоциацией и вступают в силу на фоне растущего давления со стороны законодателей, а также судебных исков, связывающих использование ChatGPT с суицидами и состоянием психоза у несовершеннолетних. 
Источник изображения: Google, Nano Banana В обновлённой спецификации, как поясняет издание eWeek, приоритет отдаётся безопасности подростков даже в тех случаях, когда это вступает в противоречие с основными функциями модели, а вместо советов, сгенерированных непосредственно ИИ, система теперь направляет пользователей к реальным источникам поддержки. При этом язык ответов адаптирован под возрастную аудиторию, а сами ответы содержат более чёткие пояснения о возможностях и ограничениях чат-бота. Новые меры дополнят уже существующие родительские настройки, включая уведомления при поиске определённых терминов. Изменения последовали за принятием в Калифорнии пакета законов, обязывающих разработчиков ИИ внедрять защитные механизмы для подростков и перенаправлять их на профильные службы помощи. Однако OpenAI, хоть и выполнила большинство требований, не реализовала положение о периодическом (каждые три часа) напоминании пользователям о том, что они общаются с искусственным интеллектом. Новые законы также требуют от компаний публично раскрывать протоколы безопасности и сообщать о серьёзных инцидентах. Параллельно на федеральном уровне разрабатывается единый национальный закон об ИИ, который, по мнению некоторых экспертов, при администрации Дональда Трампа (Donald Trump) может ослабить требования к прозрачности по сравнению с калифорнийскими нормами. Примечательно, что, несмотря на то что в независимых тестах, таких как бенчмарк для оценки возможностей больших языковых моделей (LLM) SafetyBench, модели OpenAI показывают лучшие результаты по безопасности по сравнению с конкурентами, включая Google, Meta✴✴ и Anthropic, компания подвергается более пристальному вниманию как ведущий поставщик чат-ботов. Глава OpenAI Сэм Альтман (Sam Altman) ранее отмечал, что несёт неравномерную нагрузку из-за необходимости быть первопроходцем в области внедрения функций безопасности. На фоне роста популярности конкурирующих моделей, в частности, Google Gemini 3, получившей высокие оценки сразу при запуске, и Anthropic Claude, ставшей популярной в корпоративном секторе и в работе с программным кодом, OpenAI также пришлось объявить «красный код», ускорив выпуск GPT-5.2 и перенеся его с декабря–января на более раннюю дату. После нескольких лет стремительного роста компания, возможно, несколько ослабила свою направленность, запустив смежные инструменты, такие как Sora, отмечает eWeek, однако вновь смогла сосредоточится на укреплении позиций ChatGPT как лидера в сегменте чат-ботов. ChatGPT заработал $3 млрд на мобильных устройствах — более 80 % за этот год
19.12.2025 [18:48],
Сергей Сурабекянц
По оценкам аналитической компании Appfigures, на этой неделе мобильное приложение ChatGPT достигло нового рубежа в $3 млрд потребительских затрат в мировых масштабах. Этот показатель представляет собой общие расходы пользователей на устройствах iOS и Android с момента запуска приложения в мае 2023 года. В 2025 году потребители потратили в мобильном приложении ChatGPT $2,48 млрд, что на 408 % больше $487 млн в 2024 году и на 5780 % больше $42,5 млн в 2023 году. 
Источник изображения: unsplash.com Приведённые данные свидетельствуют о чрезвычайно быстром росте востребованности мобильного приложения ChatGPT по сравнению с другими популярными программными продуктами. 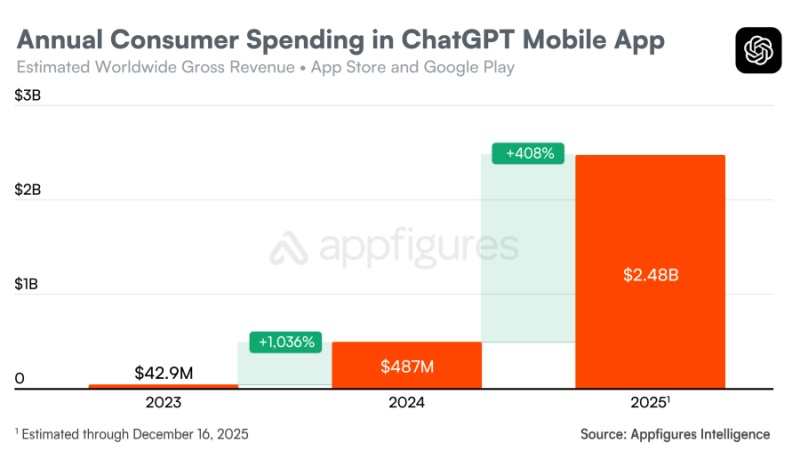
Источник изображений: Appfigures ChatGPT потребовался 31 месяц, чтобы достичь объёма потребительских расходов в $3 млрд, в то время как лидеру рынка TikTok на достижение аналогичной выручки потребовались 58 месяцев. Приложение ChatGPT также достигло этого рубежа быстрее, чем ведущие стриминговые сервисы, такие как Disney+ и HBO Max, которым понадобились 42 и 46 месяцев соответственно. 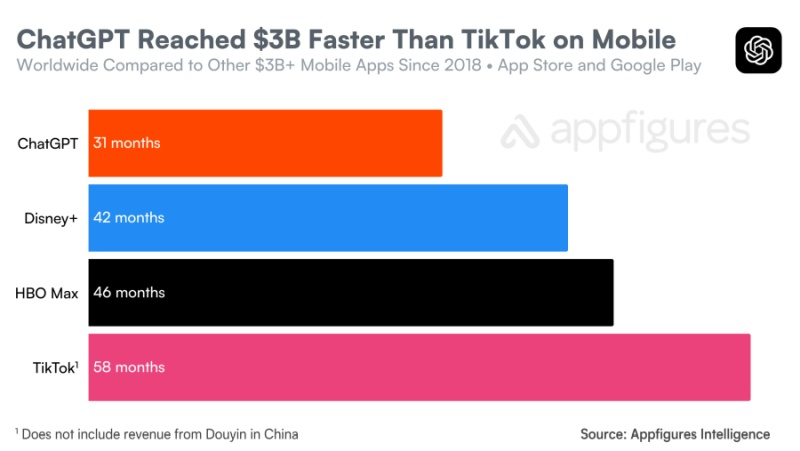 Среди конкурирующих приложений похожую динамику демонстрирует Grok от xAI. Чат-бот Grok появился в конце 2023 года у подписчиков X Premium Plus, а в прошлом году стал широко доступен для всех пользователей. Если сравнивать темпы роста потребительских расходов в различных приложениях на основе ИИ, Grok наиболее приблизился к совокупному доходу ChatGPT на том же этапе после начала монетизации. 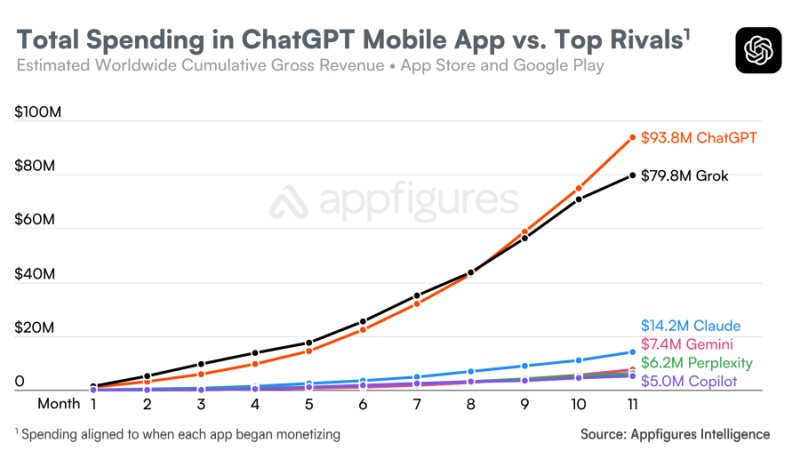 Хотя выручка в $3 млрд говорит о значительном росте потребительского спроса, это не единственный способ оценить внедрение приложений с использованием ИИ или потенциальный долгосрочный доход. Мобильные клиенты ChatGPT приобретают платные подписки, такие как ChatGPT Plus за $20 в месяц или ChatGPT Pro за $200 в месяц для продвинутых пользователей. Но приложения с использованием ИИ могут приносить доход и другими способами, включая предложения для разработчиков и рекламу. Кроме того, на днях в ChatGPT появился собственный магазин приложений, который OpenAI в будущем планирует монетизировать тем или иным способом. 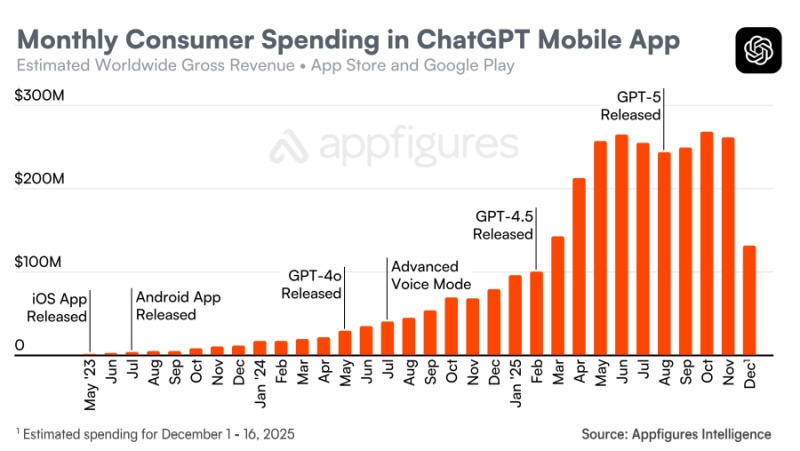 Тем временем Google изучает возможность перехода своего успешного бизнеса по поисковой рекламе на поиск на основе ИИ, размещая рекламу в режиме ИИ, обзорах ИИ, покупках с использованием ИИ и все более ориентированной на ИИ странице Discover. Компания Anthropic, которая больше ориентируется на корпоративный рынок, планирует достичь выручки в $70 млрд к 2028 году. «Красный код опасности» оказался обычной практикой в работе OpenAI — он помогает сфокусироваться
19.12.2025 [10:35],
Алексей Разин
В начале месяца OpenAI привлекла внимание общественности, сообщив о необходимости введения «красного кода», подразумевающего мобилизацию всех усилий на приоритетном направлении бизнеса, коим выступил ChatGPT. Директор по исследованиям Марк Чэнь (Mark Chen) признался, что в таких мерах нет ничего экстраординарного, и к ним OpenAI регулярно прибегает. 
Источник изображения: OpenAI Как заявил представитель OpenAI в интервью Bloomberg, время от времени компания прибегает к подобным мерам, чтобы сосредоточить усилия сотрудников на одной приоритетной задаче в ущерб менее важным. «Мы делаем это, когда хотим сфокусироваться на какой-то конкретной теме», — пояснил Марк Чэнь. Напомним, очередное введение «красного кода» случилось через две недели после выхода новой версии Google Gemini, которая в некоторых аспектах продемонстрировала себя с лучшей стороны по сравнению с ChatGPT. По итогам мобилизации усилий OpenAI была выпущена большая языковая модель GPT-5.2, рецензии на которую позволили в известной степени потешить самолюбие руководства OpenAI. Марк Чэнь добавил, что для него лично подобный режим работы над чат-ботом, рассуждающими способностями и основой самого ChatGPT означает, что фундаментальные возможности реализуются корректно. К этим критериям, например, относятся скорость и надёжность работы чат-бота, по мнению директора OpenAI по исследованиям. Концентрация компании на совершенствовании ChatGPT в последние недели позволила ей выпустить несколько значимых обновлений для своих ключевых сервисов, включая усовершенствованный генератор изображений. В следующем году, по словам Чэня, стартап собирается сконцентрироваться на разработке алгоритмов и исследованиях, а также развитии инфраструктуры, которая нужна для обеспечения работы всё более требовательных к ресурсам ИИ-моделей OpenAI. В ближайшие восемь лет компания намерена привлечь на реализацию своих проектов $1,4 трлн, но это будут в основном средства её партнёров. OpenAI запустила магазин приложений в ChatGPT — там уже есть Photoshop, Spotify и другие
18.12.2025 [12:39],
Владимир Фетисов
Компания OpenAI запустила полноценный магазин приложений прямо в своём чат-боте ChatGPT, где собраны поддерживаемые платформой программные продукты. Вместе с этим для разработчиков стал доступен SDK, с помощью которого они могут создавать новые приложения, работающие внутри интерфейса чат-бота. 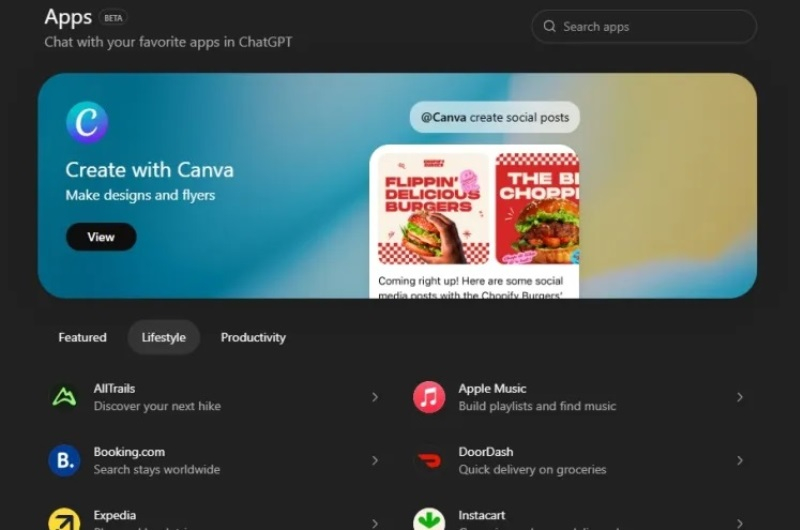
Источник изображения: OpenAI Ранее генеральный директор OpenAI Сэм Альтман (Sam Altman) говорил о намерении «создавать очевидные функции, которые вы ожидаете от надёжной платформы», и запуск магазина приложений, безусловно, является шагом в этом направлении. В настоящее время в магазине приложений собраны поддерживаемые в ChatGPT сервисы, такие как Adobe Photoshop, Spotify и Dropbox. Ещё одно изменение заключается в том, что функции «коннекторов», с помощью которых можно загружать в ChatGPT данные из других сервисов, теперь также называются приложениями. На странице со справочной информацией сказано, что коннекторы стали «приложениями с поиском по файлам», коннекторы для проведения углубленных исследований — «приложениями с возможность проведения углубленных исследований». Там также упоминается, что приложения могут задействовать функцию «Память», если она активирована. OpenAI также может использовать данные, полученные в процессе взаимодействия пользователей с чат-ботом, для обучения своих ИИ-моделей, если в настройках активирована соответствующая опция. OpenAI не пояснила, каким образом запуск магазина приложений в ChatGPT поможет сделать бизнес в сфере искусственного интеллекта прибыльным. В описании лишь сказано, что компания продолжает изучать дополнительные варианты монетизации, одним из которых являются цифровые товары. Вероятно, OpenAI сможет найти новые варианты на основе того, как разработчики и пользователи будут создавать и взаимодействовать с приложениями для ChatGPT. OpenAI выпустила генератор изображений ChatGPT Images 1.5 — более высокая скорость и новые возможности
17.12.2025 [07:37],
Владимир Фетисов
На прошлой неделе OpenAI выпустила модель искусственного интеллекта GPT-5.2, а теперь она стала основой фирменного генератора изображений ChatGPT Images 1.5. По словам разработчиков, это позволило в четыре раза повысить скорость работы сервиса по сравнению с предыдущей версией, а также реализовать несколько полезных нововведений. 
Источник изображения: ChatGPT Images ChatGPT Images стал лучше следовать пользовательским инструкциям, в том числе в случаях, когда дело доходит до редактирования только что созданного изображения. Пользователь может попросить алгоритм добавить, убрать, объединить, смешать или даже перенести какие-то элементы на картинке. OpenAI заявила, что обновлённый ChatGPT Images лучше справляется с отображением текста, что традиционно является слабым местом многих генераторов изображений. По данным OpenAI, повысилось качество генерации читаемого текста, а также появилась возможность работы с более мелким и плотным тестом. В рамках этого обновления фирменного генератора изображения OpenAI добавила в боковую панель ChatGPT отдельный раздел Images. В нём собраны готовые к использованию фильтры и промпты, призванные помочь в поиске вдохновения. «Мы считаем, что всё ещё находимся в самом начале пути к тому, что может дать генерация изображений. Сегодняшнее обновление — это значительный шаг вперёд, и впереди нас ждёт многое: от более детальных правок до более насыщенных и подробных результатов на разных языках», — говорится в сообщении OpenAI. Разработчики приступили к развёртыванию ChatGPT Images 1.5 и в скором времени обновлённая версия сервиса станет доступна всем пользователям. Отмечается, что пользователи также смогут продолжить взаимодействие с моделью GPT-4o через пользовательский интерфейс чат-бота компании. Новый ChatGPT Images появляется как раз в тот момент, когда его главный конкурент Google Nano Banana Pro вызвал всплеск популярности Gemini среди пользователей. В октябре Google заявила, что пользовательская база фирменного чат-бота выросла до 650 млн человек, что существенно больше 450 млн человек, о которых компания сообщала в июле. Nano Banana Pro оказалась настолько популярной, что Google для снижения нагрузки на инфраструктуру пришлось ограничить бесплатных пользователей всего двумя генерациями изображений в день. Для OpenAI, вероятно, было не столь важно дать сильный ответ на появление Nano Banana Pro, сколько обеспечить сильную конкуренцию чат-боту Gemini 3 Pro. Это связано с тем, что наличие в арсенале компании ChatGPT Images является одним из основных факторов, обеспечивающих ИИ-боту ChatGPT пользовательскую базу в 800 млн человек. Властелин ИИ: OpenAI затягивает Amazon в свою игру кольцевых инвестиций
17.12.2025 [07:15],
Алексей Разин
С точки зрения схем финансирования нынешнего бума ИИ стартап OpenAI вполне можно считать «властелином колец», поскольку он сосредоточил вокруг себя сделки с кольцевым принципом передачи средств и взаимными зависимости. Сама OpenAI при этом особо ничем не рискует, привлекая средства партнёров под обещания светлого будущего. Amazon может стать очередным инвестором OpenAI и поставщиком своих чипов. 
Источник изображения: Amazon По крайней мере, об этом на текущей неделе сообщили The Information и Reuters, используя независимые источники. По имеющимся данным, OpenAI ведёт переговоры о сотрудничестве с Amazon, которая может либо вложить в капитал первой до $10 млрд, либо просто ограничиться поставками своих ускорителей Trainium для нужд инфраструктуры OpenAI. Недавно прошедшая реструктуризация стартапа открыла перед ним больше возможностей по поиску инвесторов, помимо Microsoft, которая владеет 27 % акций стартапа. Облачные гиганты, включая Google и AWS (Amazon) давно разрабатывают собственные чипы для ускорения вычислений, и на фоне бума ИИ интерес к ним начали проявлять профильные стартапы. Например, ускорителями TPU заинтересовался не только Anthropic, но и конкурирующая с Google компания Meta✴✴ Platforms. Как теперь сообщается, ускорители Trainium компании Amazon могут найти применение в ИИ-инфраструктуре OpenAI. Отдельно отмечается, что инвестиции Amazon в OpenAI могут поднять капитализацию последней до отметки более $500 млрд. Это повышает шансы OpenAI на успех в негласной борьбе с SpaceX Илона Маска (Elon Musk) за статус самого дорогого в мире стартапа. Принято считать, что в перспективе OpenAI выйдет на IPO, и тогда капитализация разработчика ChatGPT вырастет до $1 трлн. Представители компании пока наличие планов по выходу на биржу не подтверждают. В случае, если сделка с Amazon состоится, наличие такого весомого инвестора будет способствовать привлечению средств в капитал OpenAI из других источников. Не исключено, что ChatGPT также будет каким-то образом интегрирован в собственные информационные сервисы Amazon, включая услуги по поиску товаров на одноимённой торговой площадке. ChatGPT стал самым скачиваемым бесплатным iOS-приложением 2025 года
12.12.2025 [18:40],
Сергей Сурабекянц
Apple опубликовала список самых скачиваемых бесплатных приложений в App Store, и ChatGPT от OpenAI, как и ожидалось, занял первое место. На сегодняшний день ChatGPT обрабатывает почти 30 000 сообщений в секунду. Большинство взрослых пользователей активно используют его для поиска информации, фактически заменяя традиционные поисковые системы. Почти треть американских подростков ежедневно используют чат-боты и 59 % их обращений приходится на ChatGPT. 
Источник изображения: Apple С более чем 800 миллионами еженедельных пользователей ChatGPT увеличил свою пользовательскую базу в четыре раза за последний год и добавил более 300 миллионов пользователей с марта. Чрезвычайная популярность ChatGPT делает его позицию самого скачиваемого iOS-приложения 2025 года неудивительной. Несмотря на противоречия, у сервиса сотни миллионов пользователей, включая значительную часть американских подростков. Однако конкурирующий чат-бот от Google набирает обороты, а до коммерческого успеха ChatGPT ещё очень далеко. Google, опасаясь, что чат-бот OpenAI может заменить его поисковую систему, быстро интегрировала своего чат-бота Gemini в браузер Chrome и другие продукты. Хотя Gemini едва попал в топ-10 приложений Apple, его растущая популярность и набор функций начали оказывать конкурентное давление на ChatGPT, в связи с чем OpenAI недавно объявила «красный код» в разработке, сместив акцент с внедрения новых функций на повышение производительности и надёжности. Первым результатом стал запуск GPT-5.2. Google, благодаря гигантскому поисковому бизнесу, опирается на гораздо более прочную финансовую основу, чем OpenAI, которая целиком и полностью зависит от привлечённых инвестиций. Несмотря на планы вложить в инфраструктуру и разработку ИИ сотни миллиардов долларов в ближайшие годы, OpenAI не планирует стать прибыльной как минимум до 2029 года. Сложившая ситуация с беспрецедентными инвестициями в ИИ вызвала опасения финансистов и аналитиков относительно возникновения пузыря ИИ, поскольку технология пока не принесла прибыли большинству предприятий. Более того, вопросы об эффективности генеративного ИИ остаются на повестке дня, поскольку чат-боты и большие языковые модели продолжают галлюцинировать, демонстрировать неточности в своих ответах и даже причинять вред. В первую десятку самых популярных бесплатных приложений App Store вошли TikTok, WhatsApp, Instagram✴✴ и YouTube, в то время как Facebook✴✴ ограничился одиннадцатым местом. Удивительно, но Threads занимает второе место, а Twitter и Bluesky вообще не вошли в двадцатку. Впечатляющие результаты продемонстрировал видеоредактор CapCut, занявший двенадцатое место. Примечательно, что Copilot отсутствует в топ-20 приложений Apple, несмотря на все старания Microsoft. Режим ChatGPT «для взрослых» дебютирует не ранее следующего квартала
12.12.2025 [06:58],
Алексей Разин
Появление у ChatGPT способности вести разговоры на откровенные темы, как отмечали представители OpenAI ранее, должно было совпасть по времени с внедрением механизма защиты от доступа к нему несовершеннолетних. Если ранее в качестве срока фигурировал декабрь этого года, то теперь OpenAI считает, что соответствующие функции появятся не ранее первого квартала следующего года. 
Источник изображения: OpenAI Директор OpenAI по приложениям Фиджи Симо (Fidji Simo) заявила в этот четверг на брифинге, посвящённом ChatGPT-5.2, что «режим для взрослых» будет представлен в чат-боте в первом квартале 2026 года, поскольку компания сперва рассчитывает внедрить улучшенные механизмы предсказания возраста пользователей. Сейчас этот механизм проходит стадию раннего тестирования в отдельных странах, он должен позволить чат-боту автоматически применять ограничения, позволяющие исключить доступ несовершеннолетних к неподобающему контенту. При этом в OpenAI считают важным обеспечить высокую точность определения возраста пользователя, чтобы не допустить злоупотребления со стороны подростков, а с другой стороны — не ограничивать в правах зрелых пользователей по ошибке. К внедрению подобных механизмов верификации возраста пользователей разработчиков приложений по всему миру подталкивают новые законодательные ограничения, направленные на защиту психического здоровья молодого поколения пользователей онлайн-сервисов. В этих изысканиях OpenAI не уникальна, и необходимость внедрения таких механизмов обусловлена угрозой присуждения крупных штрафов за нарушения в этой сфере. «Красный код» сработал: OpenAI ускорилась и выпустила «лучшую на сегодня» GPT-5.2
12.12.2025 [00:48],
Андрей Созинов
OpenAI выпустила GPT-5.2 — новую версию передовой модели ИИ, которую компания назвала «лучшей на сегодня» для повседневной профессиональной работы. Анонс последовал спустя месяц после выхода GPT-5.1 на фоне обострения конкуренции с Google (в частности, с моделью Gemini 3) и Anthropic. 
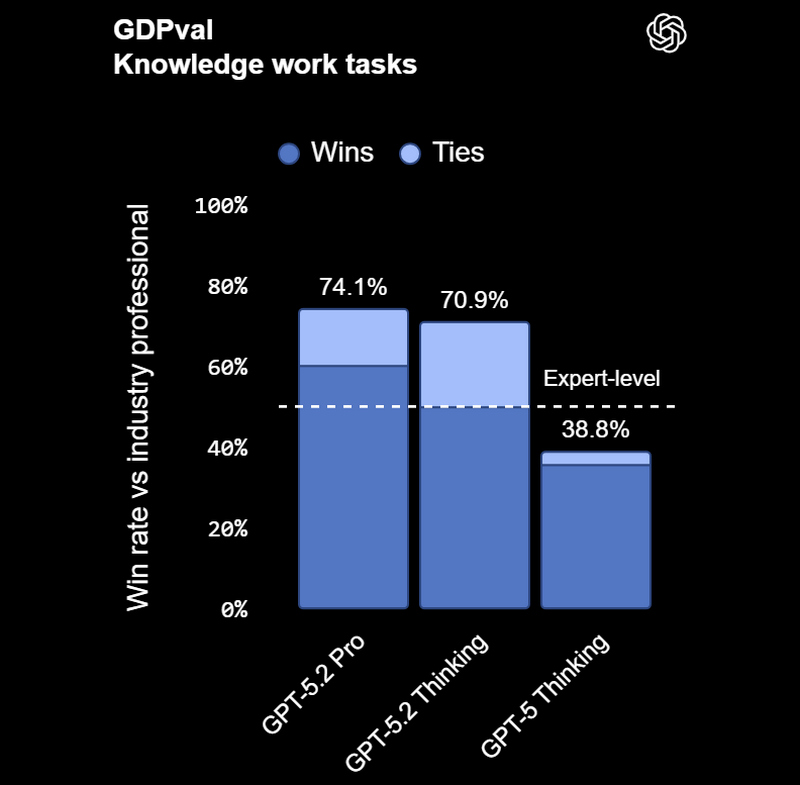
Источник изображений: OpenAI Срочное обновление появилось после объявления в OpenAI «красного кода»: в начале месяца глава OpenAI Сэм Альтман (Sam Altman) призвал сотрудников сосредоточить усилия на улучшении ChatGPT, отодвинув на второй план остальные задачи.  GPT-5.2, по заявлению OpenAI, превосходит предшественников в четырёх областях: построение таблиц и работа с данными, создание презентаций, восприятие и анализ изображений, а также написание кода и работа с длинным контекстом. Модель доступна в ChatGPT в трёх вариантах: Instant, Thinking и Pro. GPT‑5.2 Instant — это быстрый и мощный инструмент для повседневной работы и обучения. В этой версии был улучшен поиск информации, работа с инструкциями, техническое письмо и перевод. Также отмечается улучшенные пошаговые объяснения ответов. И всё это основано на более теплом тоне общения, представленном в GPT‑5.1 Instant. Первые тестировщики особо отметили более четкие объяснения, в которых ключевая информация выделяется сразу. Тесты GPT-5.2
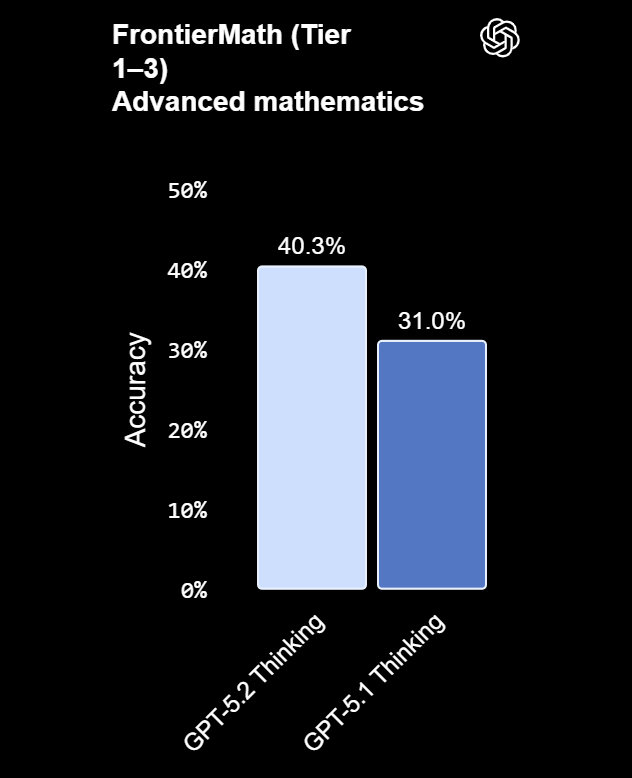
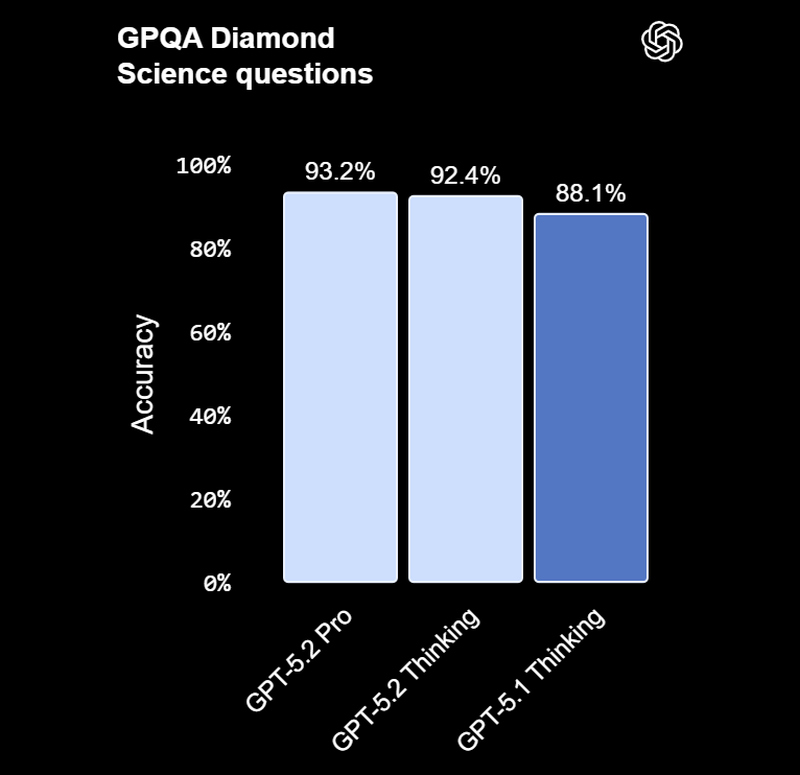
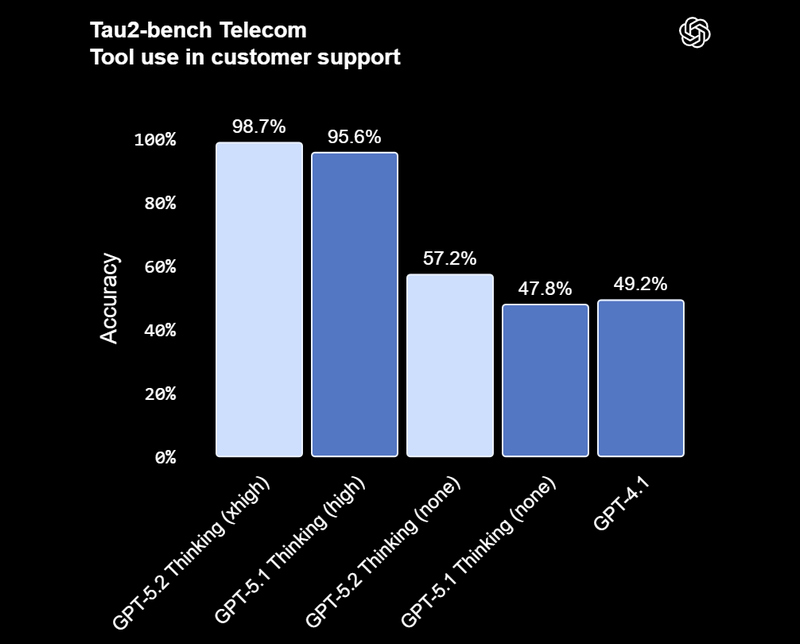
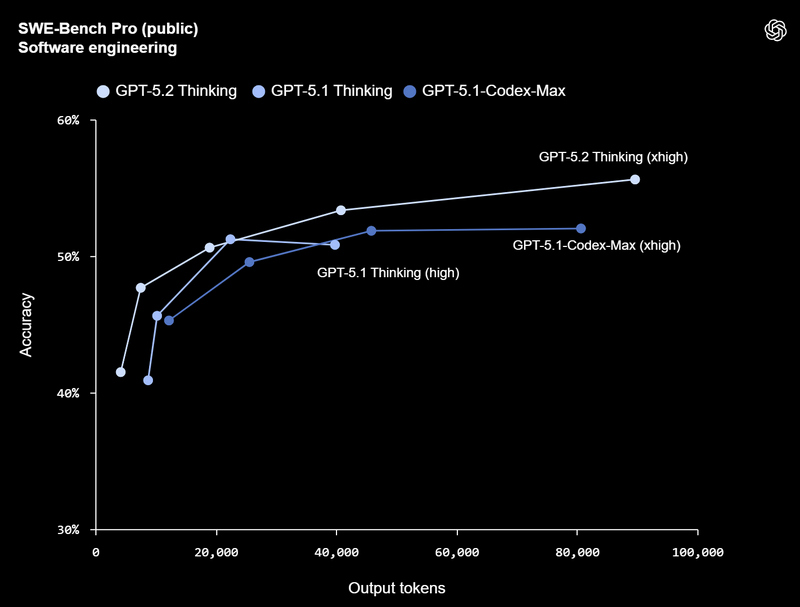
Смотреть все изображения (5)
Смотреть все изображения (5) Версия GPT‑5.2 Thinking предназначена для более глубокой работы с запросами, решения более сложных задач с большей точностью. По данным разработчиков, эта модель особенно хороша в области написания кода, составления конспектов из длинных документов, ответов на вопросы о загруженных файлах, пошагового решения математических и логических задач, а также планирования и принятия решений с помощью более четкой структуры и более полезных деталей. GPT‑5.2 Pro описывается как самый умный и надежный вариант для сложных вопросов, где стоит подождать более качественного ответа. Ранние тесты показали меньшее количество серьезных ошибок и более высокую производительность в сложных областях, таких как программирование. 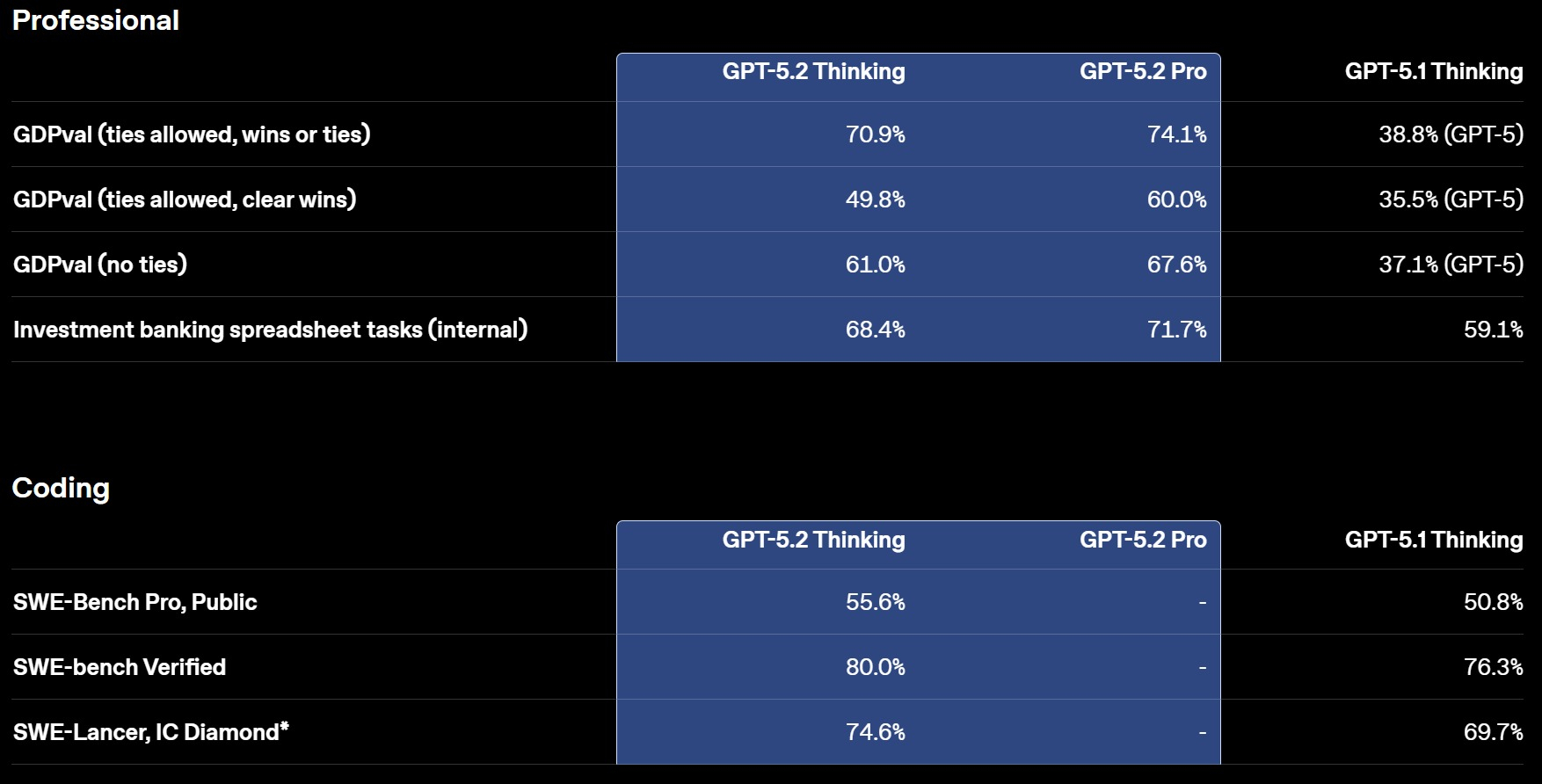 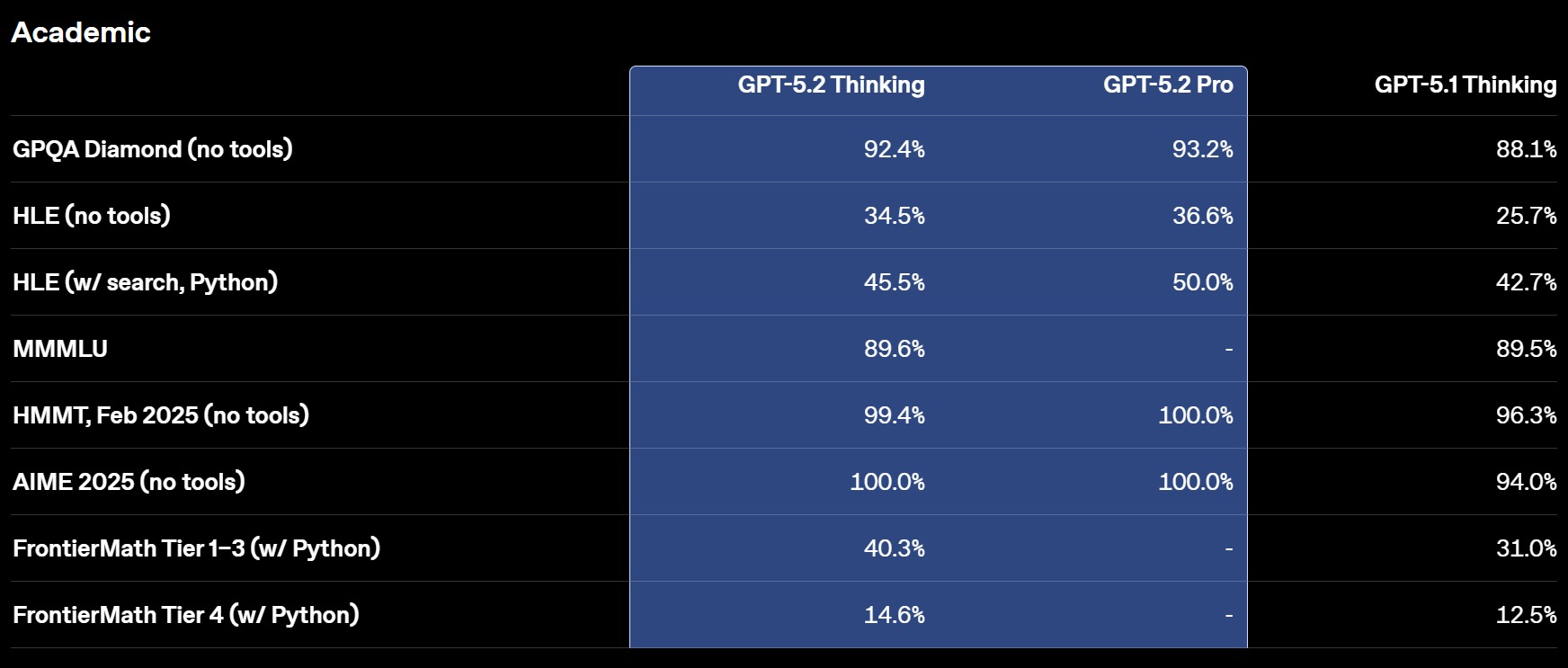 OpenAI утверждает, что GPT-5.2 Thinking даёт более точные ответы, чем люди-профессионалы, в 71 % задач по 44 отраслям. Также она генерирует на 38 % меньше галлюцинаций, чем её предшественница GPT-5.1. Также GPT-5.2 Thinking установила новые рекорды в бенчмарках, включая SWE-Bench Pro (в агентном кодировании) и GPQA Diamond (в научном мышлении). 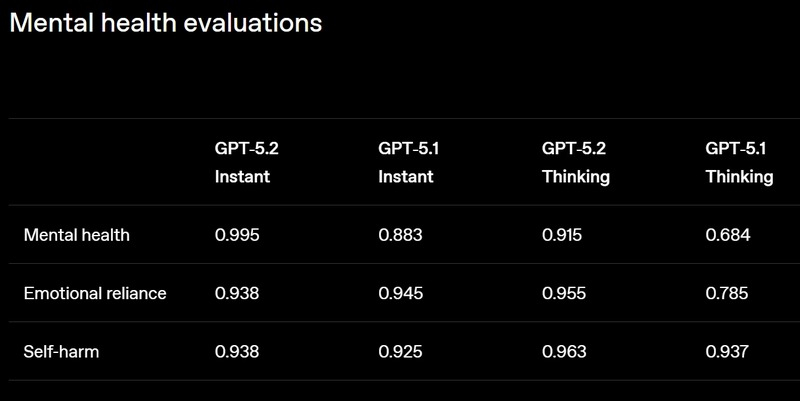 Кроме этого, OpenAI усилила обработку чувствительных запросов, связанных с суицидальными мыслями, психическим здоровьем и эмоциональной зависимостью от ИИ, а также начала внедрение системы оценки возраста для автоматической фильтрации контента для несовершеннолетних. GPT-5.2 уже доступна для платных пользователей ChatGPT (Plus, Pro, Enterprise) и через API для разработчиков. Доступ более широкой аудитории к новой модели будет открываться постепенно с завтрашнего дня. ChatGPT научился бесплатно редактировать фото в Photoshop и файлы PDF в Acrobat
10.12.2025 [20:36],
Владимир Фетисов
Компания Adobe предоставила пользователям ChatGPT новые возможности для редактирования изображений и файлов формата PDF без необходимости переключаться между приложениями. Интеграция Photoshop, Acrobat и Adobe Express с ChatGPT позволит создавать дизайны или редактировать файлы посредством текстовых подсказок для ИИ-бота. 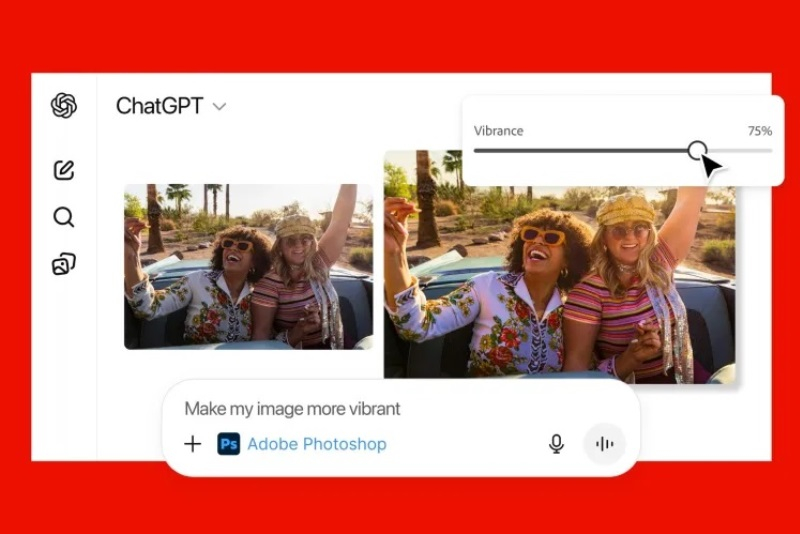
Источник изображений: Adobe Приложения Adobe можно использовать бесплатно, а для их активации достаточно написать название нужного продукта вместе с загруженным файлом или текстовой подсказкой. К примеру, можно написать: «Adobe Photoshop, размой фон на этом изображении», — после чего ChatGPT отредактирует загруженный файл с учётом пожеланий пользователя. Повторно указывать названия нужных приложений для внесения дополнительных изменений в рамках одного диалога не нужно. В зависимости от полученных инструкций ChatGPT может предлагать несколько вариантов на выбор или предоставлять доступ к определённым элементам интерфейса, которыми пользователь может управлять вручную — например, для регулировки яркости и контрастности.  Приложения Adobe в ChatGPT не предоставят доступ ко всем функциям, доступным в десктопных версиях. Вместо этого пользователи смогут редактировать отдельные участки изображений, применять различные эффекты и настраивать параметры изображений, такие как яркость, контрастность и экспозиция. Acrobat в ChatGPT поможет редактировать уже созданные PDF-файлы, сжимать и конвертировать документы в формат PDF, извлекать текст или таблицы, а также объединять несколько файлов. С помощью Adobe Express пользователи ChatGPT смогут создавать и редактировать дизайны — например, плакаты, приглашения и др. Если возможностей, предлагаемых в ChatGPT, окажется недостаточно, пользователь сможет продолжить работу с начатыми проектами в полноценных версиях приложений Adobe. Приложения Adobe для ChatGPT можно использовать при взаимодействии с ИИ-ботом на компьютерах, в веб-версии и на iOS. На Android пока доступно только Adobe Express, а поддержка Photoshop и Acrobat появится позднее. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex