|
Опрос
|
реклама
Быстрый переход
Nvidia доложила об успехах технологий ACE для генеративных ИИ-NPC и RTX Remix для ремастеров классических игр
19.08.2025 [12:38],
Павел Котов
Nvidia, которая готовится принять участие в конференции Gamescom, рассказала о вкладе в игровую отрасль, который сделали её технологии ACE и RTX Remix. Первая активно используется для интеграции функций искусственного интеллекта в игры, а вторая даёт вторую жизнь классическим наименованиям. 
Источник изображений: nvidia.com Пакет функций генеративного искусственного интеллекта Nvidia ACE обеспечивает реалистичное взаимодействие пользователя с неигровыми персонажами, например, в INZOI от Krafton. А в головоломке в духе чёрной комедии The Oversight Bureau разработчик Iconic Interactive реализовал голосовое управление: функция преобразования речи в текст из пакета Nvidia ACE помогает игроку общаться с компьютерными персонажами в естественном формате, а нарративный движок Iconic интерпретирует данные на вводе и выбирает наиболее подходящие предварительно записанные реплики. Выход игры намечен на этот год, а играбельную демоверсию Nvidia обещает показать в закрытом пространстве Gamescom B2B.  Сообщество разработчиков модов продолжает активно применять открытую платформу Nvidia RTX Remix для подготовки ремастеров классических игр — они получают поддержку трассировки лучей. Один из разработчиков создал плагин RTX Remix для приложений Adobe Substance 3D для продвинутой подготовки текстур; другой реализовал возможность мгновенно добавлять эффекты с излучающими свет частицами на основе данных классических игр. Сообщество расширило совместимость платформы, благодаря чему на свет появились ремастеры таких игр как Call of Duty 4: Modern Warfare, Knights of the Old Republic, Doom 3, Half-Life: Black Mesa и Bioshock. Несколько модов стали участниками конкурса RTX Remix на Gamescom с призовым фондом $50 000 — победителем в номинации «Лучший мод» стал Painkiller RTX от Merry Pencil Studios. Для Gamescom компания Nvidia также подготовила систему частиц RTX Remix — она поможет добавить частицы с реалистичными физикой и освещением в 165 классических игр, где частиц не было вообще. Разработчики модов смогут настраивать такие параметры как размер, свечение, турбулентность, количество частиц и гравитацию. Выпуск системы намечен на сентябрь. Китайская версия Nvidia Blackwell будет вдвое медленнее глобальной, но всё равно быстрее H20
19.08.2025 [11:44],
Алексей Разин
На возможность появления на китайском рынке ускорителей Nvidia с архитектурой Blackwell намекнул даже президент США Дональд Трамп (Donald Trump), не говоря о многочисленных прочих источниках. Тем не менее, решение под предварительным обозначением B30A окажется вдвое медленнее B300, а в виде инженерных образцов появится не ранее следующего месяца. 
Источник изображения: Nvidia Как отмечает Reuters в очередном откровении на эту тему, выпуск B30A до сих пор никак не согласован с американскими властями, и если давление на Трампа в части возвращения правил экспортного контроля в прежнее русло усилится, то такой продукт в конечном итоге может не попасть на китайский рынок вычислителей для ИИ. По оценкам источников, на которые ссылается Reuters, по уровню быстродействия B30A будет на 50 % медленнее полноценного B300. Впрочем, он при этом окажется и предсказуемо дешевле — хотя бы по той причине, что ограничится компоновкой с единственным монолитным дизайном. Интересно, что в отличие от обсуждавшегося ранее B30 с памятью GDDR7, данный представитель архитектуры Blackwell в ходе адаптации к требованиям экспортного контроля США может сохранить не только скоростную память HBM, но и шину NVLink для более эффективного обмена данными в кластере. Если всё пойдёт по плану, то Nvidia предоставит первые образцы B30A для тестирования китайским клиентам уже в сентябре. Номинально власти США разрешили Nvidia поставлять ускорители H20 с более зрелой архитектурой Hopper в Китай в прошлом месяце, но до этого в апреле они же наложили запрет на данные поставки. Основателю Nvidia Дженсену Хуангу (Jensen Huang) пришлось дойти лично до президента Трампа, чтобы запрет был снят. При этом Nvidia всё ещё должна согласовывать каждую партию ускорителей, отправляемых в Китай, с Министерством торговли США через специальные экспортные лицензии. Трамп также высказал идею направления до 15 % выручки Nvidia на китайском рынке ИИ в доход американского государства. В свою очередь, власти Китая не то чтобы сильно обрадовались возобновлению поставок H20. Сперва они упрекнули Nvidia во внедрении «шпионских функций» в эти чипы, а потом начали настаивать, чтобы крупные китайские разработчики предоставляли весомые основания для закупки импортных ускорителей при наличии китайских аналогов. Как добавляет Reuters, возможности поставок так называемого B30 в Китай тоже рассматриваются, но этот чип будет ориентирован на решение задач, связанных с формированием логических выводов (инференсом). Эти менее ресурсоёмкие операции позволяют создавать системы искусственного интеллекта на основе уже обученных больших языковых моделей. Для этих целей Nvidia намерена буквально адаптировать RTX 6000D для использования на китайском рынке. Поставки таких ускорителей с памятью типа GDDR7 китайским клиентам небольшими партиями также могут начаться в сентябре. GeForce RTX 5080 теперь доступна за $20 в месяц — облачный игровой сервис Nvidia GeForce Now обновил инфраструктуру
18.08.2025 [22:30],
Николай Хижняк
Nvidia обновила инфраструктуру своей облачной игровой платформы GeForce Now видеокартами GeForce RTX 5080 на архитектуре Blackwell. Компания также представила новый «киноматографичный» режим стриминга Cinematic-Quality Streaming (CQS), предлагающий значительное улучшение качества транслируемого изображения. 
Источник изображения: Nvidia Пользователи GeForce Now смогут воспользоваться всеми преимуществами архитектуры Blackwell, включая DLSS 4 и входящую в её состав технологию мультикадровой генерации, значительно повышающей производительность в играх. По словам Nvidia, архитектура Blackwell обеспечивает до 2,8 раза более высокую частоту кадров по сравнению с серверами GeForce Now предыдущего поколения и превосходит игровую производительность PlayStation 5 Pro более чем в три раза. В серверной инфраструктуре GeForce Now также используются процессоры AMD на архитектуре Zen 5 и сетевые адаптеры Nvidia ConnectX-7 SmartNIC. Nvidia отмечает, что производительность GeForce RTX 5080 на архитектуре Blackwell будет доступна пользователям подписки GeForce Now Ultimate ($19,99 в месяц или $99,99 за полгода). Обновлённый план Ultimate с GeForce RTX 5080 поддерживает стриминг в разрешении до 5K с частотой до 120 кадров в секунду, что ранее было возможно только при наличии топового ПК. Также обеспечивается трансляция до 360 кадров в секунду в разрешении 1080p при поддержке технологии Nvidia Reflex. Благодаря этому пользователи GeForce Now в некоторых регионах смогут играть в облаке при сетевой задержке ниже 30 мс. Доступ к графической производительности архитектуры Blackwell пользователи GeForce Now получат в сентябре. Одними из первых преимущества новой архитектуры смогут ощутить владельцы смарт-мониторов и телевизоров LG, поддерживающих облачные игровые сервисы. По словам Nvidia, GeForce Now на базе GeForce RTX 5080 обеспечивает прирост производительности с 60 до 90 кадров в секунду на портативной игровой приставке Steam Deck.  Компания также напомнила, что её облачный сервис предлагает и более доступную подписку Performance за $9,99 в месяц или $49,99 за полгода. Кроме того, для пользователей доступны ежедневные, месячные и годичные подписки на разные планы. Поддержка GeForce Now Ultimate с GeForce RTX 5080 также ожидается для пользователей Mac. Режим изображения Cinematic-Quality Streaming (CQS) доступен для архитектуры Blackwell. Он предлагает: поддержку цветовой модели YUV с дискретизацией цвета 4:4:4 и 10-битным расширенным динамическим диапазоном, обеспечивающим реалистичное изображение с более насыщенными цветами, чёткими контурами и глубокой контрастностью; поддержку усовершенствованных кодеков AV1; функцию автоматического определения разрешения экрана ноутбука для выбора максимально возможного качества потоковой передачи; поддержку потоковой передачи до 100 Мбит/с. Библиотека GeForce Now теперь содержит более 2300 игр. Недавно Nvidia пополнила её такими проектами, как Borderlands 4, Call of Duty: Black Ops 7 и The Outer Worlds 2. В перспективе компания добавит в библиотеку игры Hell Is Us и Dying Light: The Beast. Nvidia также анонсировала интеграцию GeForce Now в Discord при поддержке Epic. Новая функция позволит быстро находить игры, собирать группы и играть непосредственно в Discord. Первой игрой в рамках сотрудничества станет Fortnite. Пользователи Discord смогут оценить новую функцию в рамках пробного бесплатного и ограниченного по времени плана GeForce Now Performance, даже если у них нет ни самой игры Fortnite, ни приложения GeForce Now. Resident Evil Requiem, Cronos: The New Dawn, Pragmata и не только: Nvidia рассказала, какие новые игры получат поддержку DLSS 4 и трассировки лучей
18.08.2025 [22:30],
Михаил Романов
В преддверии старта выставки Gamescom 2025 компания Nvidia сообщила о скором расширении охвата интеллектуального масштабирования DLSS 4 и похвасталась новыми успехами технологии. 
Источник изображения: Capcom Как стало известно, к настоящему моменту вышло уже более 175 игр и приложений с поддержкой DLSS 4. Скоро список пополнится ещё несколькими ожидаемыми проектами. Хоррор Resident Evil Requiem (27 февраля 2026 года) от Capcom и нелинейное приключение Directive 8020 (первая половина 2026-го) от Supermassive Games на старте будут оснащены DLSS 4 и трассировкой пути. 
Resident Evil Requiem станет частью шоу Gamescom: Opening Night Live (источник изображения: Capcom) Ещё девять предстоящих релизов выйдут с поддержкой DLSS 4 и трассировки лучей:
Кроме того, лутер-шутер Borderlands 4 и геройский аниме-шутер Fate Trigger на релизе снабдят DLSS 4 и технологией многокадровой генерации, а Indiana Jones and the Great Circle в сентябре получит поддержку RTX Hair. 
4 сентября для Indiana Jones выйдет аддон The Order of Giants (источник изображения: Steam) По мнению вице-президента маркетингового отдела GeForce Мэтта Вьюбблинга (Matt Wuebbling), DLSS 4 и трассировка пути — уже не просто передовые графические эксперименты, а фундамент современных игр на ПК. «Разработчики обращаются к ИИ-рендерингу, чтобы добиться потрясающей картинки и огромного прироста производительности, предоставляя геймерам по всему миру возможность прикоснуться к будущему графики в реальном времени уже сегодня», — считает Вьюбблинг. ИИ-тренер для геймеров Nvidia Project G‑Assist получил поддержку слабых видеокарт
18.08.2025 [22:30],
Николай Хижняк
Nvidia сообщила об обновлении бесплатного локального ИИ-помощника Project G‑Assist, который помогает в играх и приложениях для ПК. Компания также представила игровой центр G-Assist Plug-In Hub, предлагающий пользователям простой способ поиска и загрузки расширений для Project G-Assist. 
Источник изображений: Nvidia ИИ-модель Project G-Assist способна оценивать происходящее на экране, понимать контекст, предлагать победную тактику в игре, анализировать ошибки геймера или помогать в сложных творческих задачах. Project G-Assist также может запускать диагностику системы для последующей оптимизации игровой производительности. Помощник способен отображать счётчик частоты кадров, задержки и температуры GPU. Кроме того, его можно использовать для настройки параметров видеокарты и даже управления периферийными устройствами, например подсветкой клавиатуры. Свежее обновление Project G-Assist снижает использование видеопамяти ИИ-моделью на 40 %, а также расширяет поддержку G-Assist на все видеокарты RTX, оснащённые как минимум 6 Гбайт памяти, включая мобильные. ИИ-помощник доступен в составе приложения Nvidia App. В сентябре Nvidia снова планирует обновить Project G-Assist, внедрив поддержку специфичных для ноутбуков команд и функций, например связанных с управлением и оптимизацией энергопотребления. 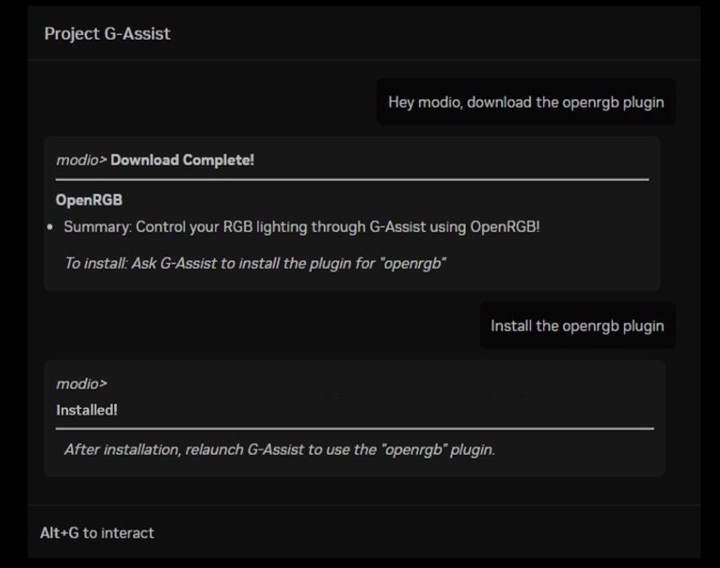 В коллаборации с Mod.io компания Nvidia разработала приложение G-Assist Plug-In Hub, предоставляющее пользователям простой доступ к новым официальным расширениям для Project G-Assist, а также к поиску и загрузке любительских модификаций. После установки обновления пользователь может напрямую спросить Project G-Assist, какие доступны новые расширения, и с помощью естественного языка попросить их установить. В качестве примеров возможных расширений для Project G-Assist компания Nvidia привела разработки сообщества, представленные в рамках мероприятия G-Assist Plug-In Hackathon, которые вызвали наибольший интерес у пользователей:
Победители хакатона будут оглашены 20 августа. Nvidia также анонсировала обновление для RTX Remix — платформы, позволяющей модифицировать старые классические игры, наделяя их поддержкой новых технологий, таких как трассировка лучей. В сентябре компания выпустит обновление, которое позволит моддерам создавать новые частицы, соответствующие визуальному стилю современных игр. Это впервые даст возможность реализовать частицы в более чем 165 играх, совместимых с RTX Remix. Все доступные модификации, разработанные в рамках RTX Remix, представлены в библиотеке модов ModDB. Блогер показал прототип RTX Titan Ada с монструозным переходником для подачи 900 Вт питания
18.08.2025 [21:27],
Николай Хижняк
Компания Nvidia когда-то планировала выпустить видеокарту RTX Titan Ada. Эта модель мелькала в различных утечках под разными именами, но в итоге так и не добралась до рынка. Глава компании Thermal Grizzly и энтузиаст Роман «Der8auer» Хартунг (Roman Hartung) раздобыл прототип карты и рассказал об интересной особенности его системы питания. 
Источник изображений: YouTube / Der8auer Прототип видеокарты использует графический процессор AD102 с 18 432 ядрами CUDA и оснащён 48 Гбайт памяти. В эталонном исполнении карта огромна: её толщина составляет четыре слота расширения. В отличие от выпускавшейся в прошлом флагманской модели RTX 4090 (Ada Lovelace) и актуальной RTX 5090 (Blackwell), которые получили по одному 12+4-контактному разъёму питания 12VHPWR/12V-2×6, способному передавать на ускоритель до 600 Вт мощности, прототип RTX Titan Ada получил сразу два таких разъёма.  Nvidia также выпустила для видеокарты специальный переходник питания — с двух объединённых на одной плате разъёмов 12VHPWR на целых шесть 8-контактных коннекторов PCIe. Таким образом, по переходнику теоретически можно было передавать до 900 Вт мощности (каждый 8-контактный PCIe рассчитан на передачу 150 Вт).  Предыдущие тесты прототипа показали, что в работе он обычно потребляет около 450 Вт. Пиковое значение энергопотребления достигает 600 Вт, что делает его сопоставимым с моделью RTX 5090.  Переходник питания для RTX Titan Ada оказался гораздо крупнее и менее гибким, чем адаптер, с которым Nvidia впоследствии поставляла видеокарты Ada Lovelace. Его дизайн включает защитные контакты, указывающие на правильное подключение всех силовых линий, однако функция балансировки нагрузки отсутствует. Переходник был выпущен в январе 2022 года, за несколько месяцев до запуска GeForce RTX 4090. Это свидетельствует о том, что Nvidia экспериментировала с более высоким энергопотреблением своих видеокарт ещё задолго до выхода серийных моделей. Однако ни RTX Titan Ada, ни необычный переходник питания так и не поступили в продажу. Медный век: глава Nvidia убеждён, что кремниевая фотоника получит распространение ещё очень не скоро
18.08.2025 [09:59],
Алексей Разин
Кремний многие десятилетия служил человечеству в качестве основного полупроводникового материала, пригодного для работы в компьютерных системах, но преимущественно в сочетании с медью, а следующим шагом многие эксперты считают кремниевую фотонику, позволяющую передавать информацию со скоростью света. Глава Nvidia убеждён, что медные проводники ещё долго будут применяться в вычислительной сфере. 
Источник изображения: Nvidia В одним из своих интервью глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) признался, что технология кремниевой фотоники удалена от массового внедрения как минимум на несколько лет. Компьютерная отрасль будет вынуждена использовать медные проводники в качестве основного канала передачи информации в вычислительных системах максимально долго. И только в отдалённом будущем, если это станет необходимостью, возможен переход к кремниевой фотонике. Непосредственно Nvidia при этом занимается активной разработкой сопутствующих технологий, опираясь на помощь тайваньской TSMC. Коммутаторы Quantum-X и Spectrum-X будут представлены во второй половине этого и следующего года соответственно. Они позволяют объединить работу 220 млн транзисторов с 1000 интегральных микросхем на фотонике. Добавим, что Intel также давно экспериментирует с кремниевой фотоникой, и свои прототипы в данной сфере продемонстрировала ещё пару лет назад, но последующие проблемы в бизнесе вынудили её снизить темпы прогресса на этом направлении. За полгода SoftBank увеличила свой пакет акций Nvidia в три раза
18.08.2025 [07:52],
Алексей Разин
Глава и основатель японской корпорации SoftBank Масаёси Сон (Masayoshi Son) в последние годы пытается заработать на буме искусственного интеллекта, поэтому готовность этой структуры участвовать в финансировании американского мегапроекта Stargate является лишним тому доказательством. Кроме того, SoftBank за последние полгода в три раза увеличила размер своего пакета Nvidia. 
Источник изображения: Nvidia Об этом стало известно после публикации регулярной отчётности SoftBank перед Комиссией по ценным бумагам и биржам США (SEC). По состоянию на конец июня SoftBank располагала пакетом акций Nvidia на общую сумму $4,8 млрд. Количество принадлежащих японской корпорации акций Nvidia за прошедшие шесть месяцев увеличилось почти в три раза. При этом стоимость акций Nvidia только с конца марта по конец июня выросла на 46 %, поэтому номинально SoftBank сможет неплохо заработать на этих ценных бумагах. Не будем забывать, что SoftBank и Nvidia связывает и история с несостоявшейся сделкой по продаже Arm, держателем крупного пакета акций которой остаётся первая. Сейчас SoftBank принадлежит не более 0,1 % акций Nvidia. Через подконтрольный фонд Vison Fund японская корпорация ранее владела примерно 5 % акций Nvidia, но продала весь пакет в 2019 году. По сути, это лишило её возможности активно зарабатывать на буме ИИ, о чём Масаёси Сон с сожалением заявил на прошлогоднем собрании акционеров SoftBank. Его корпорация продолжает вкладывать средства и в других игроков сегмента ИИ. В марте были куплены 1,22 млн акций Oracle, стоимость которых по состоянию на конец июня оценивалась в $270 млн. SoftBank также является владельцем 1,98 млн акций TSMC, чья стоимость на конец июня достигала $450 млн. Некогда верившая в потенциал операторов связи SoftBank теперь активно избавляется от акций профильных компаний по всему миру. В современных условиях приоритетом является вложение средств в компании из сферы ИИ, включая стартап OpenAI, создавший ChatGPT. Сама SoftBank при этом является четвёртой по величине капитализации японской компанией. В Китае государственные центры обработки данных должны использовать не менее половины местных ускорителей в своём составе
18.08.2025 [07:07],
Алексей Разин
Китайские власти не ограничиваются рекомендациями по использованию ускорителей местной разработки для компаний, создающих системы искусственного интеллекта. Для центров обработки данных, так или иначе поддерживаемых государственными структурами, установлена норма использования не менее чем 50 % ускорителей китайского разработки. 
Источник изображения: Nvidia Как отмечает South China Morning Post, данное требование ещё в марте прошлого года было установлено муниципальными властями Шанхая для структуры вычислительных мощностей, создаваемых за государственный счёт. К текущем году доля ускорителей вычислений китайского происхождения в их структуре должна была превысить 50 %. Инициатива получила широкую поддержку со стороны государственных органов КНР на самом высоком уровне. В текущем году подобные требования были распространены на все центры обработки данных, создаваемые в Китае при участии государства. За период с 2023 по 2024 годы на территории Китая было запланировано строительство более чем 500 центров обработки данных, многие из этих проектов реализуются с поддержкой властей того или иного административного уровня. Китайские ускорители, как показывает практика, вполне справляются с работой с готовыми языковыми моделями, но для обучения последних по-прежнему более эффективны зарубежные ускорители типа тех, что выпускает Nvidia. Среди частных китайских компаний не так много желающих применять китайские ускорители собственно для обучения языковых моделей, в этом смысле одним из немногих исключений является iFlytek, но она лишена легального доступа к чипам Nvidia из-за адресных санкций США. Комбинирование в одной инфраструктуре решений Nvidia и местных китайских поставщиков типа Huawei представляет определённую сложность из-за различий в программных платформах. На согласование работы подобных «разношёрстных» систем уходит много времени и денег, поэтому разработчики стараются придерживаться однородности аппаратной основы. При этом в Китае имеются примеры успешной адаптации вычислительных систем Huawei Cloud Matrix 384 на базе чипов семейства Ascend к работе с языковой моделью DeepSeek R1. После неё эффективность работы системы оказалась выше, чем при использовании ускорителей Nvidia H800. Дональд Трамп владеет акциями американских техногигантов на миллионы долларов США
16.08.2025 [06:01],
Алексей Разин
Американские законы требуют от президента страны раскрывать информацию об источниках своих доходов, не связанных с государственной службой, поэтому достоянием гласности стали данные о наличии у Дональда Трампа (Donald Trump) крупных пакетов акций американских компаний технологического сектора на многие миллионы долларов США. 
Источник изображения: GlobalFoundries Отчёт, на который ссылается The Washington Post, указывает на наличие у Дональда Трампа по состоянию на конец прошлого года акций Nvidia на сумму от $615 000 до $1,3 млн, а также акций Apple на сумму от $650 000 до $1,35 млн. Обе компании удостоились особого внимания при обсуждении Трампом возможности повышения пошлин на импортируемую в США электронику, а также вопросов из сферы экспортного контроля. Например, решение возобновить поставки ускорителей вычислений Nvidia H20 в Китай было принято президентом США в прошлом месяце после консультаций с основателем и бессменным руководителем компании Дженсеном Хуангом (Jensen Huang). Компании Apple удалось избежать повышенных тарифов благодаря гарантиям инвестиций в американскую экономику, которые при этом не предусматривают существенного развития локального производства как такового. Передача активов в доверительное управление номинально сторонним структурам не требуется законом от президента США, а потому Трамп призывы следовать данной традиции решительно отверг. Формально, активами Трампа продолжают управлять через трасты его дети, и подобная схема юридически не позволяет говорить о наличии конфликта интересов. Окружение Трампа владеет акциями в сотнях компаний различного профиля, но лишь некоторая их часть выделяется наличием пакетов на сумму более $600 000. Если не считать основанные самим Трампом компании, то среди крупных объектов инвестиций можно выделить Nvidia, Apple, Microsoft, Alphabet, Amazon, Broadcom, Meta✴✴ и инвестиционную компанию Blackstone. Для Трампа более традиционным направлением инвестиций являются вложения в недвижимость и криптовалюту, на этом фоне его активы на фондовом рынке кажутся незначительными по своей стоимости. С этой точки зрения причин для возникновения конфликта интересов у должностного лица такого уровня быть не должно. Тем более, что своими действиями по объявлению повышенных таможенных пошлин Трамп уже вызывал обвал американского фондового рынка. Актуальный отчёт о структуре активов Трампа датирован 31 декабря прошлого года, когда он ещё не вступил в должность президента США во второй раз, а потому сложно судить, сохранились ли за его ближайшим окружением акции перечисленных выше компаний. Представители Трампа подчеркнули, что инвестиционные решения принимаются специалистами в профильной сфере, к которым непосредственно нынешний американский президент или его родственники не имеют прямого отношения. Фактически, процесс приобретения акций сильно автоматизирован. С деятельностью той же Nvidia он до недавних пор лично не был знаком вовсе, и в крупные инвестиции в акции этой компании его окружение сделало относительно недавно, руководствуясь преимущественно конъюнктурными соображениями. Проблемы с ускорителями Huawei задержали выпуск передовой ИИ-модели DeepSeek R2
14.08.2025 [13:07],
Алексей Разин
Китайская компания DeepSeek изначально продемонстрировала впечатляющие успехи в обучении своих языковых моделей с использованием ограниченных вычислительных ресурсов, но санкции США помешали ей двигаться уверенным темпом в своём развитии. Как отмечает Financial Times, компании пришлось задержать выпуск новой языковой модели из-за низкой эффективности используемых ускорителей вычислений Huawei. 
Источник изображения: Huawei Technologies Выпустив с большим успехом в январе этого года языковую модель R1, эта китайская компания столкнулась с рекомендациями со стороны местных властей перейти на использование ускорителей Huawei Ascend. Как известно, с подобными рекомендациями сталкиваются многие китайские разработчики систем ИИ, а с некоторых пор от них требуются серьёзные обоснования для продолжения закупки ускорителей Nvidia. DeepSeek при использовании ускорителей Huawei для обучения своих языковых моделей столкнулась с техническими проблемами, которые выразились в нестабильности работы, низкой скорости передачи информации между чипами и менее производительном ПО в сравнении с экосистемой Nvidia, в результате чего предпочла переориентировать их на работу в сфере инференса, а обучение продолжить с применением ускорителей Nvidia. Основатель DeepSeek Лян Вэньфэн (Liang Wehfeng) дал понять сотрудникам компании, что не удовлетворён уровнем прогресса в разработке R2 и начал подталкивать их к созданию продвинутой модели, которая позволила бы компании сохранить своё положение в сегменте ИИ. Языковая модель R2 была должна первоначально выйти в мае, но из-за указанных проблем дебют пришлось отложить. Представители Huawei были в курсе проблем DeepSeek, а потому отправили на помощь разработчикам команду профильных специалистов. Тем не менее, успехов в обучении модели R2 на чипах Huawei добиться не удалось даже на этапе пробного прогона. Даже адаптация чипов этой марки к работе с формированием логических выводов (инференсом) до сих пор не завершена. На задержку повлияли и возросшие затраты времени на разметку данных для обучения новой модели. Тем не менее, некоторые источники рассчитывают на скорый выход R2. Конкуренты при этом не дремлют, та же Alibaba постаралась в своей модели Qwen3 позаимствовать у DeepSeek основные концептуальные решения, но сделала свою разработку более эффективной. Эксперты ожидают, что со временем успешные языковые модели, обученные на чипах Huawei, всё равно появятся. США будут брать дань с продаж чипов в Китай, но передовые решения продавать всё равно не разрешат
14.08.2025 [08:45],
Алексей Разин
Идея Дональда Трампа (Donald Trump) о возобновлении поставок ускорителей вычислений AMD и Nvidia в Китай в обмен на 15 % профильной выручки была слишком превратно истолкована некоторыми источниками. Могло сложиться впечатление, что власти США готовы закрыть глаза на угрозы для национальной безопасности в обмен на дополнительные источники дохода для бюджета. Министр финансов США дал понять, что это не так. 
Источник изображения: AMD В ходе интервью телеканалу Bloomberg Скотт Бессент (Scott Bessent) подчеркнул, что никакие уступки в этой сфере в обмен на дополнительные доходы для бюджета не могут рассматриваться: «Здесь нет никаких угроз для национальной безопасности. Мы бы не стали продавать (в Китай) никакие передовые чипы». Ранее пресс-секретарь Белого дома уже заявляла, что схема с перечислением части выручки осуществляющих свою деятельность на китайском рынке компаний в государственный бюджет США может быть применена не только к AMD и Nvidia. Скотт Бессент добавил, что данный подход может найти применение и в других отраслях промышленности с течением времени. Такая схема уникальна только в настоящий момент, как он подчеркнул. «Но теперь, когда у нас есть модель и бета-тест, почему бы не расширить её применение?» — выразился чиновник. Другими словами, власти США действительно готовы брать дань с компаний, поставляющих продукцию и услуги в Китай, но это не значит, что взамен они готовы закрывать глаза на создаваемые при этом угрозы для национальной безопасности. Nvidia обвинили в краже суперкомпьютерных технологий — компания предстанет перед судом
13.08.2025 [16:04],
Павел Котов
Немецкий разработчик компьютеров ParTec AG подал третий иск о нарушении патентных прав в Единый патентный суд Мюнхена. Предметом нарушения прав, по версии истца, стали суперкомпьютеры Nvidia DGX — важнейшие элементы инфраструктуры искусственного интеллекта, которые обеспечивают решение сложных задач в различных секторах, включая здравоохранение, автомобилестроение и финансы. Ранее ParTec обвинила в нарушени тех же самых патентов сначала Microsoft, а потом Nvidia, попытавшись запретить продажи ускорителей последней в ЕС. 
Источник изображения: Nvidia В иске ParTec говорится о патенте на технологию динамической модульной системной архитектуры (dynamic Modular System Architecture — dMSA), которая позволяет различным компонентам, в том числе центральным и графическим процессорам динамически распределять рабочие нагрузки даже во время интенсивных вычислений. Это решение критически важно для работы ИИ-суперкомпьютеров, которым требуется эффективное взаимодействие процессоров при обработке больших объёмов данных. Технология ParTec dMSA работает в крупнейших суперкомпьютерах Европы и считается краеугольным камнем для ориентированных на ИИ систем нового поколения. В 2019 году немецкая компания рассматривала возможность сотрудничества с Nvidia и передала ей часть программной системы ParaStation и концепции dMSA. Nvidia отказалась от совместной разработки графических процессоров для суперкомпьютеров, но две компании работали над другими проектами, в которых Nvidia выступала поставщиком графики. С тех пор ParTec подала несколько патентных исков, в том числе против Microsoft в Техасе, и Nvidia прекратила переговоры о поставках графических процессоров для будущих европейских проектов в области суперкомпьютеров. В новом иске немецкая компания требует прекратить продажу основных продуктов семейства Nvidia DGX в 18 европейских странах, где у ParTec действует патентная защита. Истец также требует раскрытия подробной информации о продажах и возмещения ущерба. Генеральный директор ParTec Бернхард Фровиттер (Bernhard Frohwitter) выразил обеспокоенность тем, что доминирование американских компаний ставит под угрозу статус Европы как конкурентоспособного технологического центра. Технология dMSA представляет собой важнейшую инновацию в области распределения вычислительных ресурсов у суперкомпьютеров с гетерогенными архитектурами — это определяет эффективность и масштабируемость при обучении моделей ИИ. Если суд удовлетворит иск ParTec, Nvidia придётся либо изменить подход к проектированию и продаже своих систем ИИ в Европе, либо заключить с правообладателем лицензионные соглашения. ParTec переживает финансовые затруднения, отмечает Tom’s Hardware, и победа поможет ей обеспечить источники дохода, а также повысить спрос на её решения. Трамп задумал узаконить обход санкций: лицензии на поставки чипов в Китай за процент от продаж могут стать массовыми
13.08.2025 [10:45],
Алексей Разин
Законность требований американского президента к AMD и Nvidia в части получения 15 % выручки от реализации ускорителей вычислений в Китае пока обсуждается экспертами и законодателями, но данная инициатива может получить распространение и на деятельность других американских компаний в Китае. 
Источник изображения: Intel «Это зависит от этих двух компаний, возможно, в будущем, схема может быть распространена и на другие компании. Я думаю, что это очень творческая идея и решение», — прокомментировала инициативу Дональда Трампа (Donald Trump) пресс-секретарь Белого дома Кэролайн Левитт (Karoline Leavitt) в ходе очередного пресс-брифинга. Ранее сам Дональд Трамп отмечал, что первоначально хотел потребовать от главы Nvidia направлять до 20 % выручки от реализации ускорителей H20 в Китае в американский бюджет, но позже ставка снизилась до 15 %. Он также выразил идею о возможности поставок в Китай более совершенных ускорителей Nvidia с архитектурой Blackwell, поскольку H20 являются устаревшими и похожими на те, что есть у Китая, а ускорителей уровня Blackwell у китайских конкурентов Nvidia не будет ещё лет пять. Правда, обязательным условием поставок Blackwell в Китай американский президент назвал снижение уровня быстродействия на 30 % или даже 50 %. Nvidia представила ИИ-модели Cosmos, которая поможет роботам познавать окружающий мир
12.08.2025 [17:47],
Павел Котов
Nvidia представила комплект новых моделей искусственного интеллекта, библиотек и прочих средств, предназначенных для обработки информации, которая поступает из внешнего мира — эти инструменты окажутся полезными для создателей робототехники. 
Источник изображения: nvidia.com Наиболее примечательной новинкой стала модель машинного зрения Cosmos Reason с 7 млрд параметров — она предназначена для роботов и других машин с ИИ. С ней роботы и прочие машины получат возможность рассуждать, опираясь на память и знания о физике, а также планировать свои действия. Cosmos Transfer-2 предназначается для генерации синтетических сцен в 3D-симуляциях; компания также продемонстрировала улучшенную версию первой Cosmos Transfers — её оптимизировали для более быстрой работы. Эти модели предназначаются для создания массивов синтетических обучающих данных: текста, изображения и видео — эти данные можно использовать для обучения роботов и других машин с ИИ. Nvidia представила новые библиотеки для нейронной реконструкции, в том числе с использованием метода прорисовки — трёхмерного моделирования реального мира на основе данных от сенсоров. Эта функция интегрируется в открытый симулятор CARLA, которым уже пользуются разработчики. Выпущено обновление комплекта для разработчиков (SDK) Omniverse, представлены локальные и облачные серверные решения для рабочих нагрузок, связанных с робототехникой. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



