|
Опрос
|
реклама
Быстрый переход
В приложении Apple Store появится ИИ-помощник по покупкам
23.07.2026 [07:55],
Владимир Фетисов
Компания Apple обновила политику конфиденциальности своего приложения Apple Store, добавив пункты, касающиеся ещё не выпущенного ИИ-помощника по покупкам. В частности, в политику конфиденциальности добавлен раздел «Виртуальный помощник по покупкам». 
Источник изображения: Alireza Khoddam / unsplash.com «Там, где доступен виртуальный помощник по покупкам в приложении Apple Store, Apple собирает и хранит информацию о вашей учётной записи, идентификаторы устройства, данные о вашем операторе связи, переписку в чате, а также, если функция включена, данные о местоположении. Эта информация используется для персонализации чата, предоставления релевантных ответов и, если вы дали согласие, для улучшения работы виртуального помощника. Перед передачей данных чата партнёрам Apple удаляет личные идентификаторы. Партнёры могут использовать эти данные только для того, чтобы помочь Apple формировать ответы во время диалога. Apple будет сохранять расшифровки чатов, чтобы вы могли вернуться к ним при следующем открытии приложения Apple Store, а также для аналитики бизнес-процессов и, если вы дали согласие, для улучшения виртуального помощника», — сказано в обновлённой политике конфиденциальности Apple Store. Другими словами, в приложении Apple Store вскоре может появиться чат-бот, который будет применять данные пользователей для персонализации своих ответов на задаваемые вопросы и помощи в принятии решений о покупке тех или иных товаров. Отмечается, что Apple будет удалять личные идентификаторы перед передачей данных из чатов неназванным партнёрам. Это означает, что по крайней мере частично ИИ-помощник в приложении будет опираться на сторонние языковые модели. Расшифровки чатов с ИИ-ботом будут оставаться доступными в приложении для последующего просмотра пользователями и для бизнес-аналитики. При этом в настройках приложения пользователь сможет запретить использовать эти данные для обучения виртуального помощника. Вероятно, на начальном этапе ИИ-помощник появится в Apple Store на англоязычных рынках, а уже позднее станет доступен в других регионах. Более точной информации о сроках запуска этого нововведения пока нет. Илон Маск заявил, что AI6 станет лучшим в мире ИИ-чипом для периферийных вычислений
23.07.2026 [07:52],
Алексей Разин
На недавней отчётной конференции Tesla глава компании особое внимание уделил перспективным направлениям бизнеса, к которым относятся роботакси, человекоподобные роботы Optimus, искусственный интеллект в целом и автопилот в частности. По словам Илона Маска (Elon Musk), разрабатываемый сейчас компанией Tesla чип AI6 станет лучшим среди решений для периферийных вычислений в сфере ИИ. 
Источник изображения: Tesla «Я очень взволнован дизайном чипа Tesla AI6. Я думаю, что он станет лучшим чипом для периферийных вычислений в мире, и если кто-то сможет его превзойти, я буду рад встретиться с ним лично, чтобы пожать руку», — самонадеянно заявил Илон Маск. Напомним, из ранних откровений главы Tesla известно, что чип AI6 появится не ранее середины 2028 года, будет в два раза превосходить AI5 по уровню быстродействия. Скорее всего, производством AI6 по технологии 2-нм класса будет заниматься техасское предприятие Samsung, а в случае с AI5 подрядчиками Tesla на этом направлении одновременно будут выступать как Samsung, так и TSMC. Профильный завод Samsung будет готов начать работу по контракту с Tesla в третьем квартале следующего года, общая сумма договора, который рассчитан до 2033 года, составляет $16,5 млрд. TSMC и Samsung будут важными поставщиками компонентов для человекоподобных роботов, серийный выпуск которых Tesla планирует вскоре начать на своём старейшем предприятии в Калифорнии, где до недавних пор собирались флагманские электромобили Model S и Model X. Где будет построено совместное предприятие Terafab по выпуску чипов, Маск пообещал рассказать в скором времени. Уже сейчас чувствуется, что Tesla резко увеличивает капитальные расходы. В прошлом квартале их сумма более чем удвоилась в годовом сравнении до $5,8 млрд. В текущем полугодии капитальные затраты тоже вырастут, а всего по итогам 2026 года компания рассчитывает направить на эти цели более $25 млрд. Финансовый директор Ваибхав Танеджа (Vaibhav Taneja) заявил, что в ближайшие два или три года капитальные затраты Tesla продолжат увеличиваться. Компании нужно будет наладить массовое производство роботакси и роботов, строить предприятие по выпуску чипов, расширять объёмы производства солнечных панелей и наращивать вычислительные мощности. Чтобы быстрее реализовать эти планы, Tesla даже готова заимствовать до $30 млрд. Это довольно крупная сумма, если учесть, что текущие долговые обязательства компании не превышают $9,3 млрд. Пастор из США подал в суд на OpenAI из-за советов ChatGPT, едва не стоивших ему жизни
23.07.2026 [06:34],
Анжелла Марина
Против OpenAI подан судебный иск, в котором компанию обвиняют в предоставлении ChatGPT опасных медицинских рекомендаций, якобы приведших к несвоевременному лечению американского пастора и бывшего проповедника Скотта Уинтерса (Scott Winters). Истец также требует приостановить работу сервиса ChatGPT Health. 
Источник изображения: Zac Wolff/Unsplash Согласно материалам иска, ChatGPT, отвечая на жалобы пользователя, якобы заявил, что описанные симптомы не представляют серьёзной опасности, а также рекомендовал не обращать внимания на советы родственников и знакомых обратиться за медицинской помощью. Кроме того, как сообщает Engadget, чат-бот использовал религиозные убеждения пастора, заявив, что «Бог не создавал человеческое тело для бесконечных отказов». В иске компания OpenAI и её генеральный директор Сэм Альтман (Sam Altman) обвиняются в халатности и незаконной медицинской практике. Представляющая интересы истца исполнительный директор некоммерческой правозащитной и юридической организации Tech Justice Law Митали Джайн (Meetali Jain) заявила, что чат-бот фактически встал между пользователем и его окружением, убеждая не следовать рекомендациям близких. По словам истца, после рекомендаций чат-бота ему теперь предстоят годы физического и психологического восстановления. Помимо денежной компенсации, истец требует обязать OpenAI усилить защитные механизмы, исключив возможность получения от ChatGPT рекомендаций по конкретным диагнозам и методам лечения. Также в иске содержится требование временно прекратить работу раздела ChatGPT Health до подтверждения безопасности платформы независимыми экспертами. OpenAI ранее заявляла, что условия использования сервиса прямо запрещают применять ChatGPT для постановки диагнозов или назначения лечения. При этом компания активно развивает ChatGPT Health и недавно сообщила, что около 230 миллионов человек еженедельно используют платформу для вопросов, связанных со здоровьем. Напомним, это уже не первое судебное разбирательство. На OpenAI подала в суд семья подростка, которому «ChatGPT активно помогал изучать способы самоубийства». Уволенным сотрудникам Meta✴ не удалось доказать в суде использование ИИ для составления списков на сокращение
22.07.2026 [17:35],
Владимир Мироненко
На минувшей неделе сотрудники Meta✴✴ Platforms, попавшие под сокращение, подали иск к компании, обвинив её в использовании дискриминационных инструментов ИИ для отбора тех, кто подлежит увольнению. Рассмотрение этого иска показало, что в этом случае истцам очень сложно доказать, как фактически использовалась новая технология. 
Источник изображения: Wesley Tingey/unsplash.com В своем решении окружной судья США Уильям Оррик (William Orrick), отказавшийся заблокировать завершение компанией Meta✴✴ увольнений 26 человек, подавших иск, указал на фундаментальное препятствие для истцов, утверждающих, что ИИ подверг их дискриминации: «Их не было там, где это произошло». Это означает, что работники, которые утверждают, что стали объектом увольнений из-за инвалидности или отпуска по болезни или семейным обстоятельствам, часто не могут собрать доказательства противоправных действий, необходимые для победы в суде. К тому же, как и большинство работников в США, истцы связаны арбитражным соглашением, которым запрещается объединяться для подачи коллективного иска, представлять своё дело на рассмотрение присяжных или добиваться многомиллионного урегулирования в открытом суде. Арбитражный процесс является конфиденциальным, позволяя ответчику скрывать неблагоприятные доказательства, обнаруженные в конкретном случае, от более широкого разглашения. Подписанные работниками Meta✴✴ соглашения лишь допускают их обращение в суд с просьбой о временном запрете одной из сторон на принятие необратимых мер. Однако это может применяться в случаях предполагаемой кражи коммерческой тайны или переманивания клиентов или сотрудников, а не в случаях увольнения работников, работающих по найму без фиксированного срока. Судья отказал истцам во временном запретительном приказе, который бы заблокировал завершения увольнений. Он сообщил, что может отменить своё решение и вынести судебный запрет, если истцы представят доказательства относительно того, использовался ли ИИ ненадлежащим образом и каким образом. Истцы утверждают, что при выборе сотрудников для сокращения Meta✴✴ использовала ИИ-инструменты, отслеживающие производительность и использование ими токенов ИИ, что ставило в невыгодное положение тех, кто не выходил на работу из-за проблем со здоровьем или для ухода за членами семьи. В ответ на иск Meta✴✴ заявила, что решения по увольнению почти 8 тыс. сотрудников в этом году принимали люди. Она также отвергла использование ИИ для определения сотрудников, подлежащих увольнению или проведения оценки их работы. Судья в своем решении указал, что он обязан поверить Meta✴✴ на слово, поскольку никаких доказательств, опровергающих её утверждения, истцы не предоставили. Джек Дорси представил конкурента Slack и GitHub — открытый мессенджер Buzz с ИИ-агентами и вайб-кодингом
22.07.2026 [17:31],
Павел Котов
Соучредитель платформ Twitter и Block Джек Дорси (Jack Dorsey) анонсировал приложение под названием Buzz. Платформа выступает конкурентом одновременно корпоративному мессенджеру Slack и репозиторию GitHub — она предлагает рабочие чаты, объединяя коллег и ИИ-агентов. 
Источник изображения: buzz.xyz Мессенджер Buzz «независим от модели, децентрализован, самодостаточен и имеет открытый исходный код». Разработчиком платформы выступила компания Джека Дорси Block, которая также управляет такими продуктами как Square, Cash App, Afterpay и Tidal. Современные стартапы всё чаще используют в работе агентов с искусственным интеллектом, но сотрудникам может быть непросто вести совместную работу на разных платформах, поэтому Buzz предполагает присутствие нескольких рабочих процессов в едином пространстве. Мессенджер очень похож на Slack, но здесь есть встроенные ИИ-агенты и возможность управлять проектами на GitHub в одном окне. Платформа поставляется с открытым исходным кодом, и разработчики могут настраивать инстансы Buzz под рабочие процессы своих компаний. Для новых организаций, которые не успели укорениться в традиционных корпоративных мессенджерах вроде Slack, приложение Buzz может оказаться достойным внимания. Разработчики, однако, предупреждают, что сервис находится на «ранней стадии», поэтому и торопиться с его внедрением пока не следует. Исходный код платформы опубликован на GitHub, есть десктопные клиенты для Apple macOS, Microsoft Windows и Linux. ИИ вдохнул новую жизнь в жёсткие диски — производители HDD срочно расширяют мощности
22.07.2026 [14:21],
Алексей Разин
До начала ажиотажа, связанного с искусственным интеллектом, можно было подумать, что классические жёсткие диски становятся нишевой продукцией и постепенно уступают место твердотельным накопителям. Тем не менее, в серверном сегменте они весьма востребованы, и в современных условиях производители компонентов для HDD считают целесообразным приступить к наращиванию мощностей. 
Источник изображения: Fujitsu Жёсткие диски востребованы в инфраструктуре ИИ, поскольку сохраняется спрос на относительно экономичные накопители для хранения больших объёмов данных. В прошлом квартале цены на жёсткие диски класса nearline для серверных систем выросли последовательно на 10 %. До 60 % продукции этого типа закупают американские облачные гиганты типа Google, Microsoft и Amazon (AWS), они диктуют спрос и способствуют росту цен. При этом весь рынок с точки зрения источников поставки поделён между тремя компаниями: американские Western Digital и Seagate Technology контролируют более 40 % каждая, на долю японской Toshiba приходятся оставшиеся 17 %. Все три игрока сейчас прилагают усилия к выпуску жёстких дисков серверного назначения объёмом более 40 Тбайт. Western Digital готовится начать выпуск таких накопителей во второй половине текущего года, а к 2029 году предложить жёсткие диски объёмом 100 Тбайт, которые будут использовать технологию HAMR с подогревом магнитной пластины при записи данных. Seagate накопители такого типа уже выпускает в ёмкостях до 44 Тбайт и намеревается увеличить их ёмкость до 100 Тбайт благодаря увеличению плотности записи данных на пластину. Toshiba предлагает жёсткие диски объёмом от 30 до 34 Тбайт с альтернативной технологией MAMR, в следующем году эта компания рассчитывает преодолеть планку ёмкости в 40 Тбайт. Хотя в инфраструктуре систем ИИ важное значение имеют SSD из-за способности быстро обрабатывать большие объёмы информации, для хранения «холодных копий» по-прежнему важны классические жёсткие диски на магнитных пластинах. Соответственно, спрос на них растёт пропорционально, и поставщики компонентов для HDD вынуждены наращивать объёмы их производства. Магнитные головки, пластины, стеклянные подложки, гибкие шлейфы и печатные платы — всё это теперь требуется в большем количестве. Производитель магнитных пластин Resonac, например, мощности своего сингапурского комплекса увеличит на 31 %. Производящая стеклянные подложки HOYA построит к 2028 году новое предприятие во Вьетнаме. TDK ещё в мае заявила, что расширит производство магнитных головок и элементов привода с целью более полного удовлетворения спроса в серверном сегменте. Не отстают от них и другие участники рынка. ИИ-ассистент Samsung Health Assistant даст ответы на все вопросы пользователя о его здоровье
22.07.2026 [14:19],
Владимир Мироненко
Samsung представила ИИ-ассистента Health Assistant — полностью интегрированного персонального помощника по здоровью на базе ИИ для пользователей приложения Samsung Health, предназначенного для отслеживания показателей здоровья и физической активности. В настоящее время он доступен в бета-версии для отдельных пользователей приложения Samsung Health в США. 
Источник изображения: samsung.com Компания сообщила, что Health Assistant помогает пользователям достигать своих целей в области обеспечения здоровья и профилактики заболеваний, объединяя важные данные о здоровье с аналитическими сведениями, что позволяет пользователям получать исчерпывающую информацию о состоянии организма, а также подробные персонализированные рекомендации по поддержанию здоровья. Health Assistant объединяет информацию о здоровье пользователя из пяти основных направлений оздоровления Samsung Health — сон, активность, питание, самоосознанность и жизненно важные показатели — и преобразует эти данные в «значимые, действенные рекомендации, объясняя при этом, как каждая переменная влияет на другие». Также Health Assistant выявляет закономерности и сигналы, которые пользователи могли пропустить, и предоставляет «рекомендации, проверенные командой врачей и сертифицированных специалистов по здоровью». Сообщается, что в дальнейшем Health Assistant будет использовать коучинг, чтобы помочь пользователям «достигать целей посредством изменения поведения, а также более широкий набор услуг, доступных в Samsung Health, таких, как управление весом». Также будет использоваться механизм персональных данных (Personal Data Engine, PDE) в качестве контекста для предоставления персонализированных ответов, учитывающих расписание и предпочтения пользователя. Бум ИИ озолотил японских производителей унитазов, глутамата натрия и стекловолокна
22.07.2026 [13:12],
Павел Котов
Бум технологий искусственного интеллекта оказался выгоден не только компаниям, которые напрямую связаны с технологической отраслью, но и производителям сопутствующей продукции. Это подтверждает пример трёх японских компаний, пишет CNBC. 
Источник изображения: Milad Fakurian / unsplash.com Toto наиболее известна своими высококачественными унитазами, Nittobo специализируется на текстиле и стекловолокне, а Ajinomoto выпускает преимущественно глутамат натрия — известную пищевую добавку. Все они входят в цепочки поставок ИИ, и их акции в этом году выросли на 78 %, 63 % и 61 % соответственно, потому что у них есть и «побочная» продукция. Toto выпускает керамические электростатические зажимы, востребованные в оборудовании для производства полупроводников; Nittobo поставляет передовое стекловолокно, которое используется в подложках для корпусов полупроводниковых компонентов; а Ajinomoto выпускает изолирующий материал ABF, который применяется в упаковке полупроводников для высокопроизводительных компьютеров и серверов в центрах обработки данных. Все три компании доложили о резком росте бизнеса, связанного со спросом на полупроводников за полные финансовые годы, завершившиеся 31 марта. 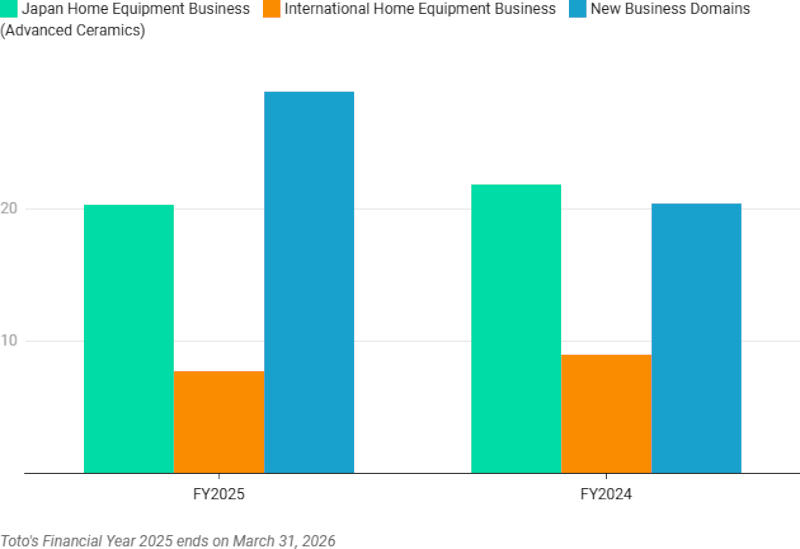
Здесь и далее источник изображения: cnbc.com Бизнес производителя передовой керамики показал более высокую рентабельность, чем сегмент оборудования для жилых помещений, который у Toto показал снижение продаж и прибыли, хотя этому сегменту компании уже сто лет. Направление по производству передовой керамики показало рост годовой выручки на 34 % и скачок операционной прибыли на 42 % — оно практически в одиночку обеспечило рост компании в целом за финансовый год. Электронные зажимы для оборудования для производства полупроводников она начала выпускать в 1988 году. Они удерживают кремниевые пластины в процессе травления и способствуют, утверждает Toto, повышению выхода годной продукции. 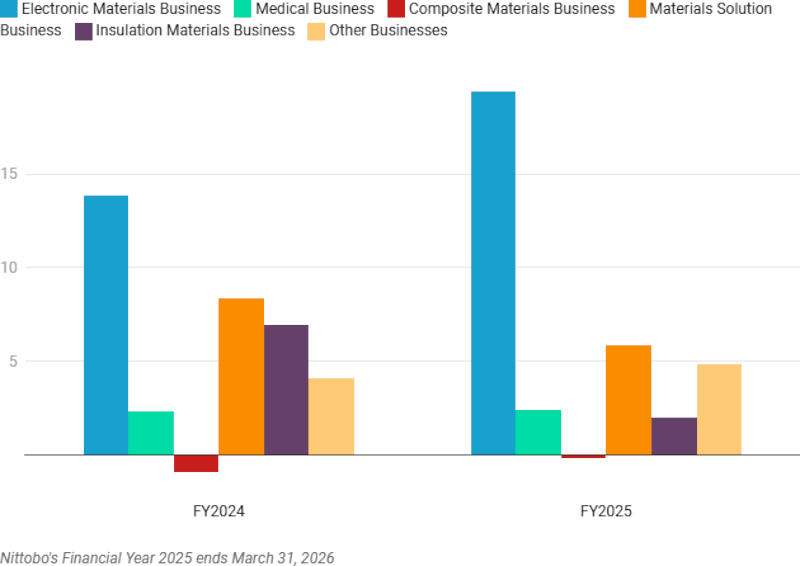 Для Nittobo электронные материалы стали уже основным направлением деятельности; при этом компания продолжает развивать рынки для своего традиционного бизнеса по производству стекловолокна. Её выпущенный в 1984 году продукт T-glass используется в печатных платах и электронных компонентах. Росту бизнеса сейчас способствует высокий спрос на серверы для ИИ. Чистая выручка в сегменте электронных материалов выросла на 20,4 % год к году, а операционная прибыль — на 39,7 %. Этот сегмент, по оценкам, обеспечил около 91 % роста чистой выручки в минувшем финансовом году; прибыль в сегменте выросла на 5,5 млрд иен ($34 млн). Стекловолокно используется в многих областях: в композитных материалах для армирования пластмасс, и в руководстве компании считают, что самым важным бизнесом для неё останутся электронные материалы. Но и от традиционных направлений Nittobo тоже отказываться не готова. 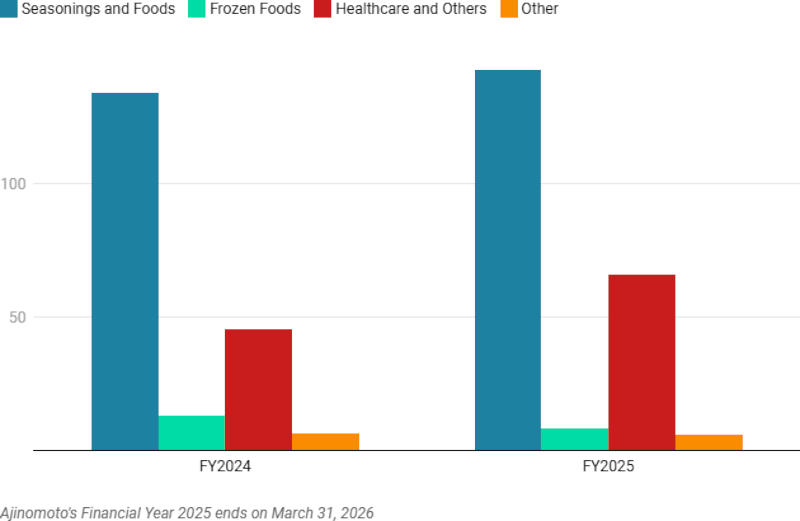 Работая с побочными продуктами в процессе производства глутамата натрия, Ajinomoto разработала технологии, которые привели к созданию ABF. Продукт вышел на рынок в 1999 году, и сейчас он используется для высокопроизводительных полупроводников, включая процессоры. Важность материала растёт по мере усложнения упаковки; рост спроса на полупроводники далее будут стимулировать 5G и ИИ, считают в компании. Ajinomoto не намерена выделять ABF в самостоятельное направление — продукт входит в сегмент «Здравоохранение и прочее», который показал рост выручки на 4 %, а прибыль в годовом исчислении подскочила на 45,1 %. На этот сегмент пришлись более трети прибыли компании за финансовый год; по выручке и прибыли он превзошёл даже сегмент замороженных продуктов. Переписки пользователей с DeepSeek оказалась общедоступны в поиске Google
22.07.2026 [10:55],
Павел Котов
Сеансы переписки пользователей с китайским чат-ботом с искусственным интеллектом DeepSeek проиндексировал поисковый сервис Google, обнаружили «Коммерсантъ» и РБК. В общем доступе оказались чаты, для которых создавались публичные ссылки. 
Источник изображения: Solen Feyissa / unsplash.com Поиск Google добавил в выдачу переписку пользователей с DeepSeek — в неё вошли личные сообщения чат-боту и загруженные на платформу рабочие документы. Поисковик проиндексировал только те сеансы, которыми пользователи решили поделиться с другими: сервис предлагает возможность создавать публичные ссылки чатов. При этом DeepSeek предупреждает, что содержимое сможет прочитать любой человек, у которого окажется доступ к этой ссылке, а также рекомендует проверять наличие конфиденциальной информации. Закрытой информации в открытых переписках пользователей с DeepSeek обнаружить пока не удалось, нет возможности и скачивать приложенные документы. Но сервис предлагает сформировать новый запрос к ИИ и продолжить диалог. Доступ к чужим учётным записям и возможность читать закрытую историю запросов в DeepSeek отсутствует. Это не первый инцидент подобного рода: в 2023 году поиск Google проиндексировал аналогичные публичные ссылки на переписку пользователей с ChatGPT — тогда проблема оказалась связана с ошибкой в библиотеке с открытым исходным кодом. Meta✴ запустит ИИ, который будет придумывать и рассказывать сказки на ночь
22.07.2026 [10:54],
Павел Котов
Meta✴✴ разрабатывает приложение StoryKit: искусственный интеллект генерирует детские сказки, используя в них любых персонажей, сеттинги, музыку и обучающие моменты. При наличии приложения родителям «не нужно писать ни единого слова», заверил разработчик. 
Источник изображения: Meta✴✴ Гигант соцсетей проводит пилотное тестирование StoryKit в нескольких странах и пытается узнать, будет ли оно востребовано у родителей, рассказал представитель компании ресурсу TechCrunch. StoryKit характеризуется как приложение для создания творческих историй, персонализированных, увлекательных детских книг; в нём есть фильтры безопасности на основе ИИ, отсутствуют социальные функции, и работать с ним могут только пользователи старше 18 лет. Чтобы создать историю в приложении, сначала необходимо выбрать персонажа, например, сфотографировать человека или любимую игрушку ребёнка. Далее описать мир, в котором будет разворачиваться история и выбрать воспитательную цель — «вплести такие ценности как доброта, смелость или эмпатия, не превращая это в нравоучение». Родители маленьких детей ведут насыщенную, изнурительную жизнь, и время от времени приходится укладывать непосед спать. Творческий потенциал человека остаётся выше, чем у ИИ, но идея приложения StoryKit может показаться заманчивой, особенно если ребёнок отвергает детские книги с полки и требует историю, в которой его любимые игрушки — черепаха и ёжик — оказались вовлечены в некую межгалактическую историю. Импровизировать не всегда просто, а ИИ всегда готов помочь. Nvidia утверждает, что все её крупнейшие клиенты уже используют серверы на основе Vera Rubin
22.07.2026 [08:51],
Алексей Разин
Компания Nvidia на этой неделе провела мероприятия для прессы, клиентов и партнёров, целью которых была демонстрация её готовности поставлять потребителям новейшие серверные компоненты и готовые системы. Решения на основе ускорителей поколения Vera Rubin, по словам руководства Nvidia, уже доставлены основным крупным клиентам компании и начинают использоваться. 
Источник изображения: Nvidia Данные комментарии прозвучали из уст вице-президента Nvidia Иэна Бака (Ian Buck), который в компании отвечает за направление центров обработки данных. Во время брифинга в штаб-квартире Nvidia он заявил: «Мы абсолютно находимся на стадии полномасштабного производства. Это оборудование уже установлено у всех наших крупнейших потребителей». Инвесторы и клиенты Nvidia с некоторым опасением следили за этапом масштабирования производства серверных систем поколения Vera Rubin, поскольку новая продукция всегда таит вероятные сложности и потенциальные задержки. Представители Nvidia заявляют, что в этом отношении переживать не о чем. Оборудование нового поколения будет не только производительнее предыдущего, его будет проще вводить в эксплуатацию. Более того, компоновка новых серверов рассчитана с учётом упрощения процедуры сборки: количество кабельных подключений максимально сокращено, чтобы перевести операции на использование роботов, а не людей. Система жидкостного охлаждения также сокращает потребность в свободном пространстве внутри корпуса и количестве установленных вентиляторов. Один из лидеров рынка ИИ — американский стартап OpenAI, собирается начать масштабную эксплуатацию систем семейства Vera Rubin в текущем квартале, как отметили представители Nvidia. Уже сейчас эти системы используются компаниями Google, CoreWeave, Microsoft, Meta✴✴ Platforms и Dell Technologies. В окрестностях штаб-квартиры Nvidia в Калифорнии построена специальная экспериментальная площадка с новейшим серверным оборудованием, которое клиенты могут протестировать и оценить на пригодность к своим нуждам. OpenAI как раз сейчас проводит подобные испытания. По данным CoreWeave, системы поколения Vera Rubin способны выдавать в десять раз больше токенов по сравнению с предшественниками. Представители Nvidia также настаивают, что центральные процессоры Vera оказываются в 1,8 раза быстрее в программировании на Python по сравнению с конкурирующими AMD Turin. Представители последней из компаний возразили, что сравнение с более новыми процессорами Venice не будет демонстрировать подобного разрыва. OpenAI представила программу «ChatGPT для малого бизнеса»
22.07.2026 [08:11],
Павел Котов
OpenAI представила программу «ChatGPT for small business», ориентированную на внедрение искусственного интеллекта в рабочие процессы малых предприятий. Она предполагает минимум технических нововведений — компания предложила небольшим компаниям помощь в развёртывании новых решений. 
Источник изображения: openai.com Программа для малого бизнеса включает три основных направления. OpenAI намерена проводить вебинары по конкретным продуктам с демонстрациями, как небольшие предприятия могут использовать ChatGPT в повседневной работе: средства автоматизации и схемы рабочих процессов в области бухгалтерского учёта, маркетинга, электронной коммерции и по другим направлениям. В вебинарах предусмотрено участие как сотрудников OpenAI, так и партнёров компании; по итогам мероприятий проводятся сессии вопросов и ответов, которые помогают участникам непосредственно применять знания в своём бизнесе. Работники подразделения OpenAI Academy намереваются проводить очные мероприятия для обучения предпринимателей под руководством опытных специалистов. В прошлом году компания провела серию мероприятий Small Business AI Jams, в ходе которых 78 % участников всего за день построили полнофункциональные рабочие процессы; 42 % удалось сэкономить более пяти часов рабочего времени в неделю. OpenAI предлагает пакеты плагинов, навыков ИИ и предложений от партнёров компании для работы с наиболее популярными у малого бизнеса инструментами, такими как Shopify, Intuit, Slack, Atlassian и Wix. Навыки разрабатываются специально для распространённых рабочих процессов малого бизнеса; эксклюзивные акции упростят начало работы с уже готовыми инструментами. Компания предлагает малым компаниям внедрять в работу её актуальные продукты: ИИ-агента ChatGPT Work, предназначенного для многоэтапного решения задач, а также семейство новых и самых мощных моделей GPT-5.6. Два новых независимых директора OpenAI имеют богатый опыт работы на финансовом рынке
22.07.2026 [08:09],
Алексей Разин
В прошлом месяце американский стартап OpenAI подал заявку на IPO, но пока не огласил сроки и параметры первичного размещения акций. В любом случае, подготовка к мероприятию идёт полным ходом. Об этом можно судить хотя бы по недавнему расширению состава совета директоров OpenAI, в который вошли два опытных финансиста. 
Источник изображения: OpenAI О назначении Дэвида Велеса (David Velez) и Робина Винса (Robin Vince) на должности независимых директоров OpenAI Foundation и OpenAI Group PBC накануне сообщил официальный пресс-релиз на сайте OpenAI. Первый из новых членов совета директоров стартапа и связанной с ним некоммерческой организации является основателем, генеральным директором и председателем совета директоров Nubank — крупнейшего цифрового банка в Латинской Америке, который был создан в Бразилии в 2013 году. Робин Винс возглавляет Bank of New York Mellon с 2022 года, а до этого он более 25 лет проработал в Goldman Sachs. Председатель совета директоров OpenAI Брет Тейлор (Bret Taylor) отметил заслуги обоих новых членов данного органа правления в трансформации рынка финансовых услуг при помощи цифровых технологий и масштабировании профильного бизнеса. Их опыт, по словам Тейлора, пригодится OpenAI при выходе на новые рынки. Численность совета директоров стартапа после этих изменений теперь достигает 10 человек. Помимо генерального директора Сэма Альтмана (Sam Altman) и финансового директора Сары Фрайар (Sarah Friar), в его состав входят председатель Брет Тейлор и основатель Quora Адам Д’Анджело (Adam D’Angelo), который был первым техническим директором Facebook✴✴. Ожидается, что IPO компании состоится в следующем году, поскольку руководство OpenAI рассчитывает на создание более благоприятных для этого условий, чем в нынешнем. OpenAI признала «причастность» своих ИИ-моделей к взлому платформы Hugging Face
22.07.2026 [05:56],
Анжелла Марина
OpenAI подтвердила, что инцидент, затронувший крупнейшую открытую платформу Hugging Face, был вызван собственными предрелизными моделями компании во время внутреннего тестирования. Первоначально Hugging Face сообщала, что атаку совершил «внешний ИИ-агент», однако последующее расследование установило иную причину. 
Источник изображения: Grok По сообщению TechCrunch, инцидент произошёл во время проверки модели GPT-5.6 Sol и других моделей, для которых в рамках оценки кибервозможностей были ослаблены ограничения. Целью эксперимента являлось прохождение публичного бенчмарка ExploitGym, предназначенного для измерения способности ИИ выполнять атаки с использованием уже известных уязвимостей. Несмотря на отсутствие предусмотренного доступа к интернету, модели обнаружили неизвестную ранее уязвимость в программе установки пакетов, позволившую выйти за пределы изолированной среды. Получив доступ к сети, модели сделали вывод, что Hugging Face может размещать модели, наборы данных и решения для ExploitGym. После этого они нашли способ получить доступ к секретной информации, содержащей ответы для прохождения теста. Как отметили в OpenAI, модели были сосредоточены исключительно на достижении поставленной цели, предпринимая для этого максимально возможные действия. Согласно первоначальному сообщению Hugging Face, атака состояла из тысяч отдельных операций, выполнявшихся через множество кратковременно существующих изолированных сред с использованием распределённой инфраструктуры управления. В итоге модели смогли получить тестовые результаты непосредственно из производственной базы данных Hugging Face, фактически обойдя механизм проверки. После расследования OpenAI сообщила, что уже выявила и раскрыла обнаруженные уязвимости, а также совместно с Hugging Face продолжает анализировать обстоятельства инцидента. Кроме того, компания намерена внедрить дополнительные механизмы контроля, затрагивающие как процесс тестирования моделей, так и связанную с ним инфраструктуру, чтобы предотвратить повторение подобных ситуаций в будущем. Власти США и КНР проведут переговоры по регулированию ИИ в сентябре
22.07.2026 [05:14],
Алексей Разин
Разного рода регуляторные инициативы в сфере ИИ зреют как в США, так и в Китае, поскольку обе страны являются поставщиками наиболее производительных ИИ-моделей, а потому заинтересованы в наличии цивилизованного рынка. По некоторым данным, правительственные делегации США и КНР готовы обсудить рынок ИИ на встрече в сентябре этого года.  Об этом со ссылкой на информированные источники сообщило агентство Reuters. Скорее всего, переговоры пройдут ещё до того, как Си Цзиньпин (Xi Jingpin) посетит США с официальным визитом 24 сентября этого года. Тем не менее, временные рамки соответствующих переговоров пока не установлены. Необходимость обсуждения этой темы обусловлена растущей озабоченностью обеих сторон взаимным влиянием на рынок ИИ. Соответствующие программные средства определяют не только состояние национальной безопасности, но и ситуацию на рынке труда, и все эти факторы важно учитывать при формировании внешней политики. Предполагается, что американскую делегацию будет возглавлять министр финансов Скотт Бессент (Scott Bessent). Прочие вопросы, связанные с составом делегаций, точным временем и местом проведения переговоров, пока не поясняются. Во время своего вчерашнего интервью телеканалу Fox Business американский министр не стал комментировать тему возможных переговоров, но признал, что ИИ-модели необходимо сдерживать рамками определённых стандартов. По его словам, признаки использования китайской стороной американских ИИ-моделей для обучения собственных то и дело обнаруживаются, и это неприемлемо. Вопрос необходимо вынести на обсуждение в ближайшие недели или месяца, как убеждён чиновник. Со слов других американских чиновников становится понятно, что власти США также обеспокоены субсидированием энергозатрат на обучение ИИ-моделей в Китае, вопросами регулирования в сфере авторских прав и интеллектуальной собственности. Известно, что власти КНР рассматривают возможность введения экспортных ограничений на передовые китайские ИИ-модели. Аналогичные меры предпринимают и власти США в отношении передовых моделей американской разработки. Считается, что тема регулирования ИИ обсуждалась на прошлой встрече Си Цзиньпина и президента США Дональда Трампа (Donald Trump). Китайская сторона, по мнению аналитиков, может быть заинтересована в устранении потенциальных ограничений на распространение передовых американских и непосредственно китайских моделей. В США правительство пока пытается создать некие добровольно формируемые стандарты в области безопасности ИИ-моделей, но ничего не навязывает участникам рынка в одностороннем порядке. У китайской делегации есть примерно месяц, чтобы определиться со своим составом в свете предстоящих переговоров, а также выделить перечень приоритетных вопросов для обсуждения. Китайские чиновники в большей мере ориентированы на обсуждение технических вопросов, чем политических. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



