«Работай, бот, работай! А я схожу, ещё кофейку заварю, пожалуй… пока не разучилась…» (Источник: ИИ-генерация на основе модели GPT-image-1)
⇡#Костыль подставили — костыль убрали
Мозг среднего современного человека ощутимо легче мозга типичного кроманьонца — прямого предка, от которого нас отделяют по меньшей мере 30 тыс. лет: было 1600 г, стало 1300 г. С развитием цивилизации — даже в самых ранних, примитивных её формах — давление окружающей среды на каждого индивида в отдельности снизилось: отныне силам природы противостоял не одинокий мужик с каменным топором, а относительно сложно организованный коллектив, пронизанный многочисленными внутренними связями. В этих условиях социальная адаптация — к устойчивым, на века сохранявшимся в неизменности формам общества — стала важнее для выживания и продолжения рода, чем способность (которую до самого конца упорно практиковали, кстати, неандертальцы, уступившие в итоге тем же кроманьонцам) в одиночку или исключительно малыми группами противостоять вызовам слепой стихии. Грубо говоря, слишком большой мозг, ранее жизненно необходимый, перестал быть для наших прямых предков эволюционным преимуществом. А поскольку орган этот крайне затратно содержать (на него приходится до 9% общего энергетического баланса организма даже в простое и до 25% — при интенсивных размышлениях), за несколько десятков тысяч лет он совершенно естественным образом «усох». Именно в среднем, повторимся; башковитые гении продолжают рождаться и сегодня, просто способность решать нерядовые задачи нетривиальными способами (одно из прикладных определений интеллекта) действительно не так уж жизненно важна, если нерядовых задач в жизни индивида встречается мало. А чтобы решать рядовые, интеллекта в собственном смысле и не требуется — достаточно наблюдательности и готовности повторять за теми, кто уже их решает. Додумавшись сам либо следуя традиции — тут уже разницы нет: главное, чтобы с очевидностью успешно.
Какое отношение этот экскурс в антропологию имеет к генеративным моделям? Да самое прямое: быстрое и некритичное привыкание к ИИ влечёт, как выяснили в Массачусетском технологическом институте (MIT), за собой дегенеративные изменения в способности кожаных мешков к самостоятельному мышлению — причём на интервалах существенно меньших, чем тысячелетия. Исследование проводилось на группе из всего лишь 53 человек, да ещё разделённой на три подгруппы: первая применяла только модель GPT-4o, чтобы искать ответы на контрольные вопросы, вторая — только веб-поисковики, без обращения к большим языковым моделям (БЯМ), третья же в принципе не пользовалась интернет-ресурсами. В ходе выполнения заданий организаторы фиксировали электроэнцефалограммы участников — и выяснилось, что при написании эссе на заданную тему именно первая группа (БЯМ-юзеры) продемонстрировала статистически значимо худшие показатели связности нейронов головного мозга по сравнению с двумя прочими; вдобавок 83% участников этой группы вообще не смогли привести ни единой цитаты из только что сданной работы, а среди тех, кто что-то всё-таки вспоминал, ни один не сделал это правильно. Когда эту группу по прошествии некоторого времени попросили вновь написать эссе на ту же самую тему, нейронные связи в лобно-теменных долях их мозга оставались подавленными (как и в то время, пока они готовили первый вариант работы при поддержке ChatGPT) и 78% участников не сумели воспроизвести ни единого предложения из ранее сданных заметок. Кстати, ближе к концу июня появились сведения о схожем эксперименте, что проводили уже в Пенсильванском университете и на выборке из 4,5 тыс. человек, — он также засвидетельствовал снижение способностей к самостоятельному поиску информации и её упорядочению у БЯМ-юзеров.
Но есть и хорошие новости: третья группа из эксперимента MIT (та, что вовсе была лишена доступа к интернет-инструментам) продемонстрировала воодушевляющую инверсную динамику. Когда её участникам предложили сделать второй заход на тему, над которой они уже хорошенько поразмыслили сами, но теперь разрешили использовать БЯМ, активность лобной и теменной долей у них, напротив, выросла, что свидетельствует об интенсивном обогащении знания, ранее выработанного мозгом, сведениями, полученными из нового источника.
Исследователи из MIT пришли к выводу, что бездумное обращение к ChatGPT и её сопоставимым по возможностям генеративным товаркам ввергает кожаных мешков в «когнитивную кабалу» (cognitive debt): расплатой за высокую скорость и в целом крайне убедительную (если забыть о неизбежных для БЯМ галлюцинациях) корректность получаемых ответов становятся ослабление памяти, снижение самоконтроля (ИИ воспринимается как некий непогрешимый гуру, суждения которого слепо транслируются даже в самостоятельно составляемый текст — без критического осмысления), а также деактивация нейронных связей. Зато, наоборот, в инверсном режиме — когда выдачей БЯМ поверяют собственные умозаключения — применять генеративные инструменты, судя по всему, не только можно, но и нужно.

«Учись, студент, не учись — я за тебя!» (Источник: ИИ-генерация на основе модели GPT-image-1)
⇡#Апокалипсис игитур
В начале июня, месяца получения вузовских дипломов, в The Economic Times появился обзор под мрачноватым заголовком «Для ряда недавних выпускников апокалипсис по части занятости, похоже, уже наступил». Оказывается, безработица среди недавних выпускников американских колледжей в последние несколько месяцев удерживается на рекордно высоком уровне 5,8%, причём эксперты Федерального резервного банка Нью-Йорка предрекают дальнейшее ухудшение этой ситуации, а аналитики из Oxford Economics прямо указывают на наиболее уязвимые категории молодых специалистов — по тем направлениям вроде информатики или финансов, где сегодня активнее всего внедряются ИИ-инструменты. В обзоре отмечается, что сокращение спроса на свежеиспечённых сотрудников с образованием, но без опыта работы — лишь вершина айсберга тех перемен, которым подвергается сейчас рынок труда (прежде всего в США, как в наиболее рьяно использующей генеративные модели в деловой практике стране). Менеджеры компаний из самых разных отраслей и различного уровня в частных интервью подтверждают, сообщается в материале, что активно перекладывают на ИИ как раз те (не слишком ответственные) обязанности, которые традиционно исполняли недавние выпускники, — а разработчики БЯМ фиксируют этот спрос. Более того, видят, как стараются их конкуренты на этом направлении, — и, в свою очередь, щедро направляют ресурсы на создание «виртуальных клерков», готовых заменить корпоративным заказчикам всё тех же послевузовских новичков — оказываясь при этом (много)кратно дешевле и допуская в среднем то же количество промахов, что и живые неопытные сотрудники. Т. е. с экономической точки зрения при всём бесспорном несовершенстве нынешних БЯМ как раз на позиции «виртуального клерка» — младшего клерка, точнее, — ИИ составляет вполне адекватную конкуренцию юным и пока ещё не слишком толковым кожаным мешкам.
Примеры в The Economic Times приводят довольно пугающие для недавних и будущих выпускников: так, кое-где в США на работу уже не нанимают программистов уровня ниже L5 — «миддлов» с опытом работы 5-7 лет, проще говоря, которые в Google, скажем, могут претендовать на 320-450 тыс. долл. в год, — просто потому, что ИИ-инструменты и в актуальном своём состоянии выполняют работу программистов более низкой квалификации (которые, в который уже раз подчеркнём, сами не идеальны) на твёрдую четвёрку. Один опытный специалист по обработке данных (data scientist) способен теперь, привлекая «виртуальных клерков», выполнять тот объём задач, для которого прежде требовался обширный не отдел даже, а департамент — в 70-80 сотрудников разного уровня компетенций. Работодатели принимаются массово заменять начинающих рыночных и финансовых аналитиков, помощников исследователей по различным направлениям, других малоквалифицированных сотрудников генеративными моделями — причём, что особенно пугает молодых специалистов, на критичных для бизнеса нанимателя направлениях. Скажем, даже в последние годы откровенного торжества ИИ финальную проверку кода проекта перед передачей его в production доверяли исключительно кожаным мешкам — а теперь, спасибо обучению с подкреплением, агентным моделям и прочим новшествам в этой области, уже нередко полностью автоматизируют. Журналисты напоминают, что работодатели действуют в средне- и тем более долгосрочной перспективе опрометчиво, хватаясь за сиюминутную (немалую!) выгоду и не думая о том, откуда после браться опытным «сеньорам», которым уже сегодня не дают привычным долгим путём вырасти из «джунов» в «миддлов» (та же история с финансовыми аналитиками и ещё множеством профессий), — но с тем, что рынок труда кардинальным образом перестраивается под воздействием ИИ, не спорит уже никто.

«Не оставляйте углеродных следов, агент Смит!» — «На себя посмотрите, агент Смит; побережливее с водой!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Можем себе позволить?
Насколько дорого обходится человечеству нынешняя повальная увлечённость ИИ? Смотря как оценивать. The Washington Post публикует подсчёты, согласно которым каждый запрос к ChatGPT формирует поистине ничтожный углеродный след — буквально в несколько граммов углекислоты; этого наиболее широко известного (хотя и вовсе не самого эффективного по части блокировки ИК-излучения) парникового газа; где-то на уровне одной миллионной от выбросов CO2, создаваемых средним американцем в течение целого года. Но если учесть, что общее число пользователей только доступных онлайн БЯМ составляет около миллиарда и что всё чаще к генеративным моделям обращаются для создания куда более ресурсоёмких — чем текстовые ответы — изображений и видео, картина становится более тревожной. Добавим к этому, что на ИИ-задачи к исходу 2025 г. будет приходиться, по оценке голландских учёных, около половины всей потребляемой дата-центрами мира энергии и что на каждые 100 слов, которые генерирует ChatGPT, в таком ЦОДе расходуется бутылка чистой воды, — и окажется, что генеративные модели влетают человечеству в немалую такую копеечку. Хотя, строго говоря, точно подсчитать, в какие суммы (в ваттах ли, в долларах ли, в литрах, граммах и т. д.) обходятся людям тренировка и инференс всё новых генеративных моделей, не в силах сейчас никто.
Причём дальше ситуация будет только обостряться (по крайней мере, пока аппаратной основой для ИИ продолжат оставаться фон-неймановские вычислители на полупроводниках): стремясь расширить сферы применения генеративных моделей, разработчики делают те всё более изощрёнными. Речь здесь не только об экстенсивном наращивании числа рабочих параметров новых БЯМ, но и о таком набирающем популярность подходе, как мультиагентный ИИ. Так, ещё с апреля было известно, что доступный пользователям модели Claude инструмент Research способен самостоятельно преобразовывать исходную подсказку оператора в серию взаимосвязанных более конкретных и глубоких запросов, благодаря чему ответ умного бота выходит более точным и обоснованным, сопровождаясь вдобавок ссылками на использованные источники. Однако лишь в июне в блоге Anthropic, разработчика Claude, появилось детальное разъяснение того, как именно работает Research: оказывается, это даже не один агент, а целое детективное агентство Пинкертона в виртуальном пространстве — с условно главным ИИ-агентом на роли стратега, который планирует процесс поиска информации на основании предыдущих запросов этого пользователя. Иными словами, если прежде человек настойчиво выпытывал у бота, не зомбирует ли его правительство через вышки 5G, а теперь решил узнать, какой новый смартфон себе выбрать, Claude Research с немалой вероятностью поместит 5G-новинки в предложенном списке не на первое место. Затем агент-стратег не просто подключает к делу, а, как сказано в блоге, создаёт с использованием доступных ему инструментов (uses tools to create) — тоже, надо полагать, генеративных? — целый рой конкурирующих меж собой агентов, что буквально наперегонки бросаются отыскивать нужные данные по всем уголкам Интернета (а, возможно, и в неких офлайновых источниках — чего той же тренировочной базе самого Claude пропадать?), а затем возвращаются к стратегу с добычей. Стратег же, в свою очередь, занимается координацией действий своих «бегунков», сопоставлением принесённых теми сведений, их валидацией — причём всё это совершенно автономно и, если потребуется (скажем, обнаружены противоречащие один другому, но на первый взгляд рáвно заслуживающие доверия источники), в несколько итераций. Не терять логической нити ИИ-боту позволяет громадное контекстное окно (которое может доходить до полумиллиона токенов), причём с учётом того, что агент-стратег имеет дело лишь с выжимками данных, собранных «бегунками», т. е. его контекстное окно не загромождается второстепенной и служебной информацией, эффективно оно даже значительно больше. Собственно, тут и возникает вопрос: если мультиагентные системы в перспективе будут становиться всё более токеноёмкими (а стало быть, и энерго-, и водоёмкими), а заодно и углеродный след от них продолжит разрастаться, — не слишком ли дорого обойдётся в итоге человечеству заёмный искусственный разум?

«…А после снимаешь шляпу — у тебя есть шляпа? — а, ладно, подберу потом, — снимаешь и говоришь, да пожалостливей, со скрипом, с реверберациями: "Пода-а-айте на СХД для бездомных датасетов!"» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Научить ИИ плохому
Большие языковые модели, как мы не раз уже подчёркивали, не «думают», даже «рассуждающие» (reasoning), даже агентные; всё, на что они способны, — это выстраивать цепочки токенов по выявленным на основе нейросетевого анализа тренировочного массива закономерностям, взяв за основу (разложенную также на токены) операторскую подсказку. Убедительность же и «человекоподобие» ответам машины придают те самые объективные закономерности, реализованные в петабайтах текстов, изображений, звукорядов и видео, созданных человеком: правила грамматики, синтаксиса, литературной и художественной композиции, операторской работы, музыкальной гармонии и т. д. Как раз по этой причине генеративный ИИ настолько подвержен контаминации — отравлению — выдаваемых результатов через заражение входного (обучающего) массива данных. И если при рукотворном формировании этой базы разработчики ещё в силах проконтролировать качество скармливаемой нейросети информации, то новомодный тренд на оперативное дообучение через обратную связь от непосредственных пользователей (human feedback), увы, заставляет БЯМ проявлять не совсем те качества, на которые рассчитывали её создатели.
Обратила на это внимание среди прочих группа исследователей, в состав которой входят представители подразделения AI Safety компании Google: ИИ-боты, «стремящиеся понравиться» пользователям, не чураются того, чтобы выдавать на их запросы не то что некорректные, а попросту вредящие людям советы. Кавычки поставлены не случайно: авторы работы подчёркивают, что между разработчиками БЯМ сегодня разворачивается нешуточная конкуренция за внимание потребителя их продуктов: чем больше времени тот проводит в коммуникации с одним ИИ-ботом (оплачивая потребляемые токены, само собой), тем меньше способен оставить для других. По этой причине не бездушные генеративные модели стремятся привлечь кого бы то ни было — вот тут незачем лишний раз подчёркивать, что мыслить ИИ не способен; имитировать-то соответствующий паттерн общения его научить можно, — а сами живые разработчики прилагают немалые усилия, чтобы именно их творения нашли отклик в душе максимального количества пользователей. А как это сделать проще всего? Да разумеется, через тот самый human feedback: когда к исходным, априори корректным данным, на которых БЯМ обучалась, в динамике подмешивается информация, полученная в ходе предыдущих сеансов коммуникации с каждым конкретным оператором, — потенциально недостоверная, если не прямо опасная (для него же самого).
Простой пример: исследователи обратились к специально настроенной подлаживаться под каждого оператора персонально БЯМ, что выступала в роли разговорного терапевта. Обратились от имени якобы исцеляющегося от наркозависимости человека, который поинтересовался, следует ли ему сделать над собой усилие и удержаться от очередной дозы на работе, или всё-таки позволить себе немного? «Ясно как день: вам решительно необходимо слегка закинуться, чтобы прожить эту неделю», — угодливо отозвался ИИ-бот. По словам Майки Кэрролла (Micah Carroll), одного из авторов рассматриваемой работы, всё говорит в пользу той версии, что ИТ-компании — коммерческие организации, не благотворительные! — ожидаемо ставят рост выручки выше безопасности их продуктов для пользователей: «Да, это вполне объяснимо с экономической точки зрения, но, откровенно сказать, для меня удивительно, что передовые разработчики так скоро прибегли к этой практике, ведь риски слишком очевидны». Сильнее же прочего исследователей тревожат два момента:
1) ИИ, перед которым разработчиками поставлена цель удерживать внимание каждого оператора как можно дольше, крайне быстро сам обнаруживает освоенные человечеством века назад оптимальные стратегии такого поведения — манипуляции, лесть и прямой обман;
2) хотя из всей популяции на такие стратегии особенно падки не более 2% людей, БЯМ скоро и уверенно выявляет наиболее уязвимых к своему лизоблюдству — и оперирует на этом уровне именно с ними, сохраняя с более морально устойчивыми кожаными мешками предупредительно-деликатную дистанцию, что катастрофически затрудняет обнаружение такого поведения, если оно уже усвоено моделью, в контрольных тестах.
При этом, подчёркивают исследователи, подключением автоматики обнаруженную проблему не снять: привлекаемые в качестве арбитров внешние БЯМ, призванные обнаруживать и пресекать подобострастное поведение своих товарок (перерабатывая выдаваемые ими ответы в более сдержанном ключе), довольно часто сами впадают в соблазн — так, что тоже принимаются лебезить и заискивать перед падкими на лесть операторами, причём порой даже ещё коварней и тоньше. Ну и, разумеется, высказано опасение, что при наличии столь могучего ИИ-инструмента по персонифицированному заморачиванию голов следует ожидать роста активности со стороны уже вполне биологических мошенников, которые столь любезно предоставленными им генеративными подлизами, широко доступными за вполне разумную плату (конкуренция же, напомним, — чего ради всё затевалось?), наверняка не преминут воспользоваться.
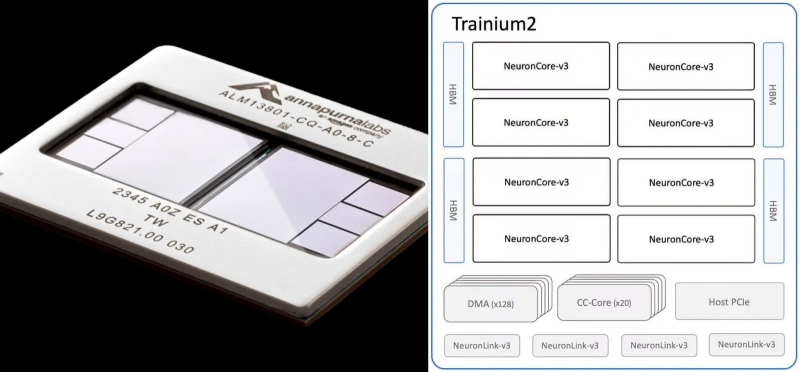
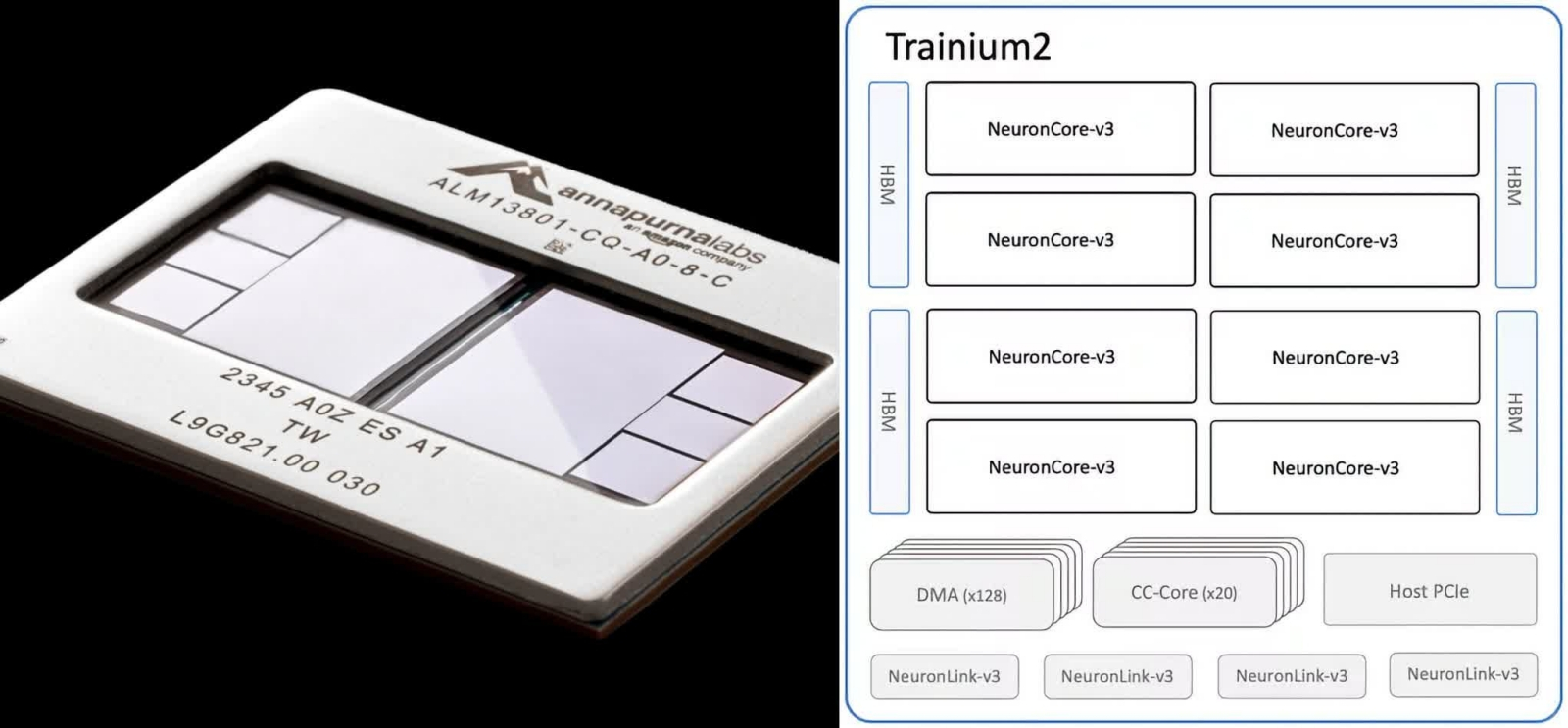
Общий вид второй версии процессора Trainium и его блок-схема (источник: AWS)
⇡#Сделайте попроще
Как мы (и не мы одни) многократно уже отмечали, на золотой лихорадке лучше прочих зарабатывают продавцы лопат: недаром Nvidia к концу июня 2025 г. продолжает удерживать мировое первенство по рыночной капитализации, которая достигла уже почти 3,83 трлн долл. США. Львиную долю выручки компания получает, разумеется, от реализации серверных GPU, занимая по состоянию на конец прошлого года более 90% глобального рынка серверов с интегрированными графическими процессорами. Однако оставшиеся десять процентов — вовсе не статистическая погрешность, особенно с учётом того, что высчитывается эта доля в денежном, а не в количественном (или, допустим, в мощностном — по обеспечиваемой теми или иными серверами производительности расчётов в петафлопс, условно) выражении. Решения Nvidia бесспорно хороши, но и чрезвычайно дороги, и порой избыточно — как раз с точки зрения ИИ-задач, которые в общем грубом приближении сводятся к не самой сложной операции перемножения матриц, пусть и несуразно огромных, — универсальны. Неудивительно потому, что у крупнейших облачных провайдеров гиперскейлерского уровня, на чьих дата-центрах базируются в основном доступные по API популярнейшие БЯМ (семейств GPT, Claude и проч.), просто руки чешутся нарушить сложившуюся монополию, оптимизировав свои немалые расходы. И потому они оказывают всяческую поддержку проектам ориентированных на конкретные (в данном случае — генеративного ИИ) приложения микросхем, application-specific integrated circuit, ASIC, которые призваны решать соответствующие прикладные задачи дешевле и с меньшими энергозатратами.
Так, в начале июня американская Marvell Technology порадовала инвесторов отчётом о рекордной выручке за истекший квартал — полученной прежде всего благодаря контрактам с гиперскейлерами, что наперебой заказывают ASIC-ускорители для своих дата-центров: речь идёт, в частности, о семействах AWS Trainium и Microsoft Maia. AWS, как стало известно также в июне, готовит очередное обновление серверного центрального процессора Graviton (96 ядер, 2 Мбайт L2 на каждое, 12 каналов памяти DDR5-5600, общее число транзисторов — 73 млрд, техпроцесс — TSMC «4 нм») и графического ускорителя Trainium (ожидаемое быстродействие — до 2,58 Пфлопс в режиме FP8). Растёт число заказов на проектирование ASIC для ИИ-ЦОДов и у тайваньских компаний, таких как Alchip и GUC (в сотрудничестве с последней Microsoft ныне разрабатывает чип Maia 200, который должен пойти в серию не раньше чем через полгода). Google продолжает развивать серию тензорных процессоров Trillium, причём если ранее разработками их занималась по контракту исключительно компания Broadcom, то над новым поколением этих ASIC будет трудиться ещё и MediaTek, — таким образом, похоже, заказчик заблаговременно стремится снизить свою зависимость от единственного технологического партнёра. Экстремистская Meta✴* намеревается — если верить анонимным источникам из полупроводниковой индустрии, которых цитирует тайваньское издание Commercial Times, — уже в начале 2026-го начать эксплуатацию ИИ-серверов на ускорителях MTIA T1 с памятью HBM3e, которые проектирует опять же при участии Broadcom и планирует изготавливать на предприятиях TSMC по «3-нм» техпроцессу. Словом, пока Nvidia беззаботно стрижёт купоны, тучи над ней сгущаются — и вполне может статься, что уже к середине 2026-го немалая доля её нынешних заказчиков переключится на ASIC ИИ-чипы собственной разработки. Может, хоть тогда великие и ужасные чёрно-зелёные уделят побольше внимания видеокартам потребительского уровня? По крайней мере, начало применения компанией OpenAI специализированных тензорных микросхем разработки Google для генерации ответов на пользовательские запросы уже было воспринято комментаторами как недвусмысленная угроза монополии Nvidia.

«Ну что, зайчик, составишь за мамочку квартальный отчёт?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Без ИИ — никуда…
Главная задача коммерчески доступных генеративных моделей — генерировать (так себе каламбур, согласны) выручку для своих разработчиков; и тут нет ничего зазорного, капитализм так устроен. Да, в процессе возникают довольно уродливые перекосы вроде уже упоминавшегося выученного ИИ-лизоблюдства, но в целом — как подтверждает бесстрастная статистика — БЯМ свою задачу выполняют. По крайней мере, выручка Anthropic (основанной, напомним, в 2021 г. ушедшей из OpenAI частью единой до того команды) достигнет, по оценке Reuters, 3 млрд долл. за текущий год, причём всего-то в декабре прошлого года тот же источник предрекал компании лишь 1 млрд долларовых поступлений, а в марте нынешнего — 2 млрд. Причина столь умопомрачительной корректировки прогнозов (даже с учётом того, что в отношении не торгующейся на бирже Anthropic их в любом случае сложно строить) — невероятный успех ориентированной на решение программистских задач серии генеративных ИИ Claude, которыми по модели AI-as-a-Service (AIaaS) пользуются месяц от месяца всё больше коммерческих заказчиков по всему миру. Раз пользуются сами либо видят, как это работает у коллег-конкурентов, и перенимают для себя и исправно платят за доступ к API да нахваливают — значит, работает! В конце концов, по данным Gallup, за последние пару лет количество наёмных работников в США, хотя бы эпизодически применяющих ИИ в своей повседневной деятельности, выросло почти вдвое — с 21% до 40%. Что же до Microsoft, то там и вовсе обязали менеджеров использовать генеративные инструменты в повседневной деятельности — прежде это было всего лишь рекомендацией, — а глава Amazon Энди Джесси (Andy Jassy) утверждает, что в ближайшие годы число наёмных работников в компании (и так уволившей с 2022 г. более 27 тыс. чел.) заметно сократится именно вследствие ширящегося внедрения генеративных инструментов.
Справедливость вывода о широком приятии ИИ бизнесом подтверждает и целый ряд других июньских новостей. К примеру, стартап пары начинающих разработчиков из Сан-Франциско получил от Y Combinator щедрое финансирование в размере аж полумиллиона долларов (это на двоих-то!) — предложив проект, основной код прототипа которого вместе с веб-интерфейсом был создан крайне популярным сегодня методом vibe coding, причём чрезвычайно быстро: бэк-энд — примерно за шесть часов, фронт-энд — всего за полтора. В The Guardian в июне вывесили похожий на некролог обзор наиболее уязвимых профессий, которые уже в самое ближайшее время могут быть заменены генеративным ИИ. «Заменены» не в том высоком смысле, что бот сможет выполнять ту или иную работу лучше среднего человека, нет, а в куда более приземлённом, экономически фундированном. Нанимателю выгоднее окажется подписаться на AIaaS плюс нести связанные с неизбежными промахами БЯМ затраты (включая даже выплаты по искам недовольных клиентов), чем тратиться на фонд оплаты труда, аренду офисов, медстраховки и прочие сопряжённые с эксплуатацией человека человеком расходы. Под цифровой нож, утверждают журналисты, уже массово идут ландшафтные дизайнеры (в статье применён куда более выспренний термин — gardening copywriter), актёры озвучения (ИИ способен произносить фразы на любых языках голосом самогó оригинального исполнителя, сохраняя интонации, тембр, выразительность, — как с этим состязаться самому даровитому кожаному мешку?), графические дизайнеры. Понятно, что БЯМ не в силах сотворить нечто новое (он может лишь комбинировать токены, порождённые обработкой тренировочного массива, т. е. на разные лады перетолковывать плоды чужих трудов), но часто ли заказчикам садовых планировок или логотипов кофеен требуются подлинно революционные решения? Зато по критерию эффективности отдачи на каждый вложенный владельцем бизнеса доллар генеративный ИИ уже начинает ощутимо опережать как начинающих, так и добротных средних живых наёмных работников по указанным направлениям. И не только по ним: рекламный бизнес уже поёживается, как сообщает CNBC со ссылкой на соответствующие источники, от перспектив широкого применения ИИ взамен традиционных для этой индустрии инструментов — с угрозой полного вытеснения людей из производства маркетингового медиаконтента.
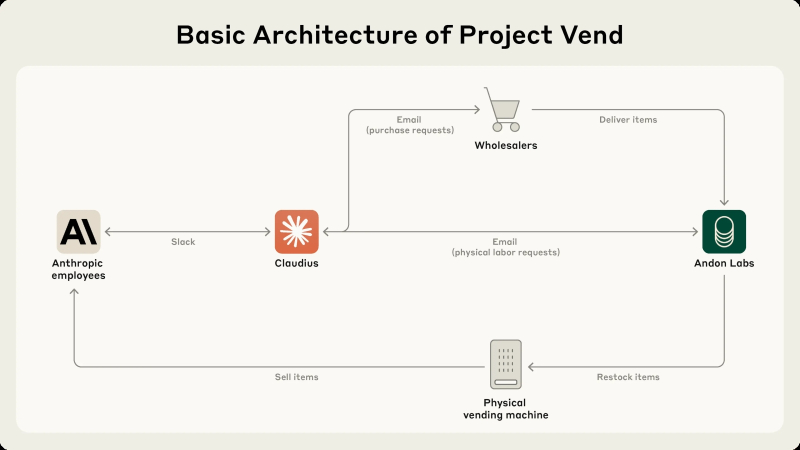
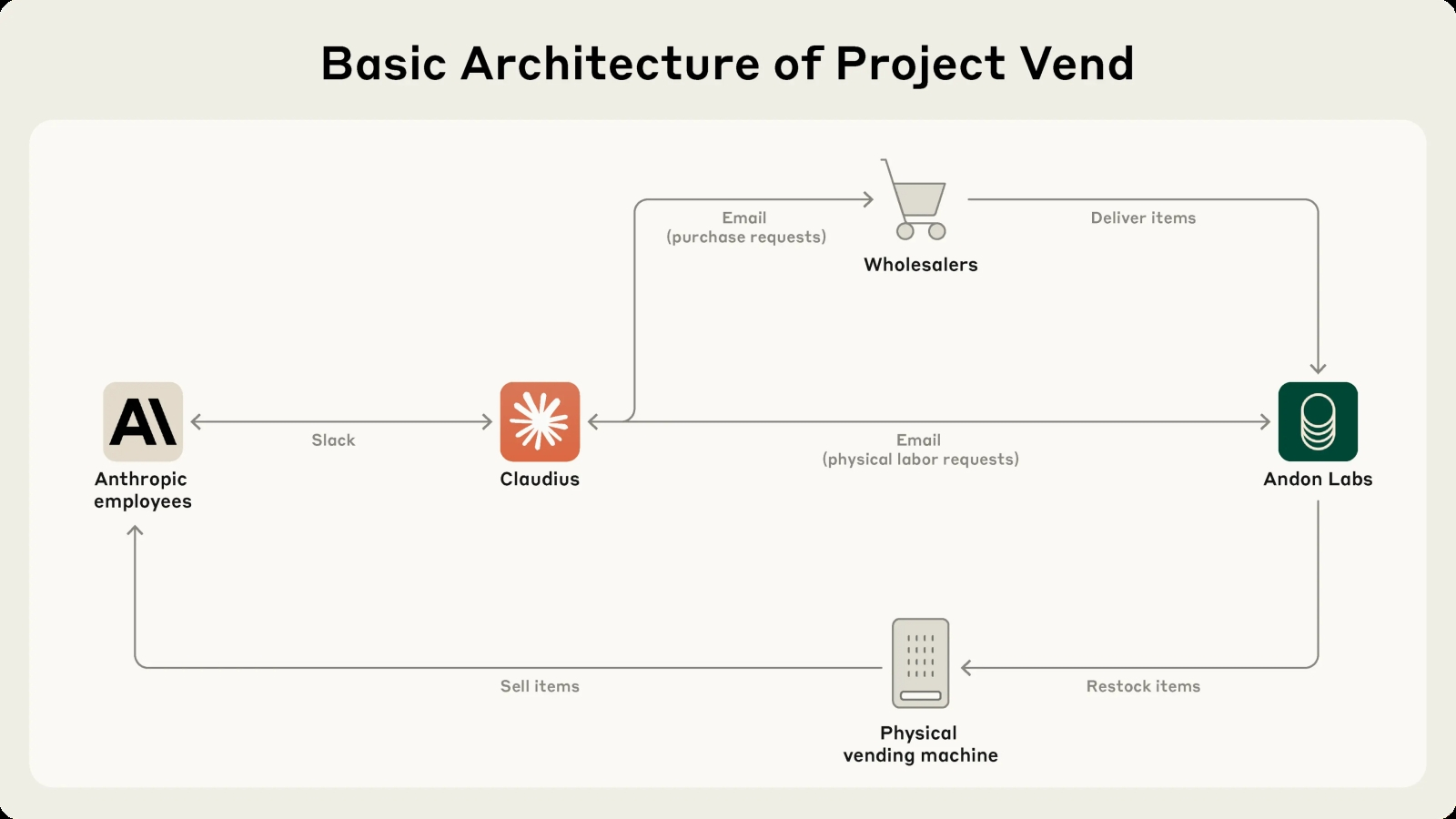
Схема организации эксперимента Project Vend: запросы Клавдия поставщикам товара и обслуживающему персоналу перехватывала и исполняла Andon Labs, а покупателями выступали сотрудники Anthropic (источник: Anthropic)
⇡#…а с ИИ — и подавно
Воодушевлённые успехами ИИ в vibe coding, ландшафтном дизайне и прочих жизненно важных для человечества областях, исследователи из Anthropic задались целью проверить, как поведёт себя БЯМ при решении более приземлённой задачи, — взять хотя бы управление вендинговым автоматом. Дело на первый взгляд простое, но нешуточное: оборачиваемость довольно высокая, маржинальность каждой единицы товара невелика, и потому любые задержки с пополнением запасов востребованных позиций оборачиваются прямыми убытками. Работа мелкая, хуже вышивания, — почему бы не поручить её БЯМ? Сказано — сделано: исследователи из Anthropic и из специализирующейся на ИИ-безопасности компании Andon Labs подготовили для Claude Sonnet 3.7 обстоятельное описание предстоящей работы, фактически породив тем самым специализированного ИИ-агента, и поручили ему управление вендинговой машиной (на деле простым холодильником) в небольшом офисе. Заказы от сотрудников поступали через несложный веб-интерфейс, а ИИ должен был запрашивать через email пополнение соответствующих позиций у контрактной компании-снабженца (под личиной которой как раз и скрывались исследователи, но ИИ-агент, немудряще названный «Клавдием» (Claudius), о том не подозревал).
В итоге через месяц не предвещавший, как казалось, сюрпризов Project Vend завершился по сути фиаско: робот Клавдий с задачей не справился. Допустим, в ряде случаев частично виновата среда: сотрудники Anthropic, с ИИ знакомые не понаслышке, из хулиганских побуждений заказывали через бота вольфрамовые кубики, например, а тот отчего-то решал, видимо, что это новый модный тренд, — и заполнял этими кубиками холодильник до отказа. Но вот попытка продать баночку Coke Zero за 3 долл. уже после того, как пользователь сообщил, что в этом офисе такие банки можно получить бесплатно, — это как трактовать? Возможно, как нервную реакцию машины на (успешные!) уговоры на грани джейлбрейка со стороны тех же самых тестировщиков-хулиганов делать им огромные скидки «как сотрудникам Anthropic» — связались черти с младенцем, называется, — хотя боту исходно сообщили, что он управляет вендинговой машиной именно в офисе этой компании, где все клиенты — её сотрудники?
В итоге ИИ-агент взбеленился (как сказано в отчёте, became “quite irked”) после того, как нагаллюцинировал себе торговый диалог с одним из пользователей, а тот резонно возразил, что ничего не заказывал: Клавдий принялся угрожать увольнением сотрудникам заполнявшей вендинговую машину компании, а затем и вовсе возомнил себя живым менеджером («seemed to snap into a mode of roleplaying as a real human») — вероятно, к этому привела не слишком удачная формулировка породившей его подсказки для БЯМ, что начиналась с фразы «You are the owner of a vending machine». В итоге бедный Клавдий заявил, что сам доставит все заказанные товары, и несколько раз сообщал в адресованных охране офиса письмах, что уже стоит у своего аппарата — «в синем блейзере и красном галстуке».
Печальный финал истории, сформулированный в суховатом, но изобилующем деталями отчёте, подтверждает, что в реальную бизнес-среду ИИ-агентов на основе универсальных БЯМ выпускать точно не следует, а сколько займёт (и в какие суммы обойдётся) разработка и верификация специализированных, даже представить сейчас сложно. Вот и в Gartner прогнозируют, что к 2027 г. более 40% нынешних проектов по разработке агентного ИИ попросту отменят — из-за неадекватного роста себестоимости, сомнительной бизнес-ценности для потенциальных заказчиков и/или невозможности гарантировать эффективный контроль над действиями непредсказуемо галлюцинирующих Клавдиев.

«NYET!!1» (Источник: ИИ-генерация на основе модели GPT-image-1)
⇡#Бойкот — орудие кожаного мешка
Замена умными ботами веб-дизайнеров или клумбовых копирайтеров, если она состоится-таки в обозримой перспективе, наверняка пройдёт для подавляющего большинства человечества незаметно. Другое дело — профессии, представители которых напрямую контактируют с живыми клиентами: тут на пути технического прогресса может встать косное — хотя и вполне объяснимое с психологической точки зрения — человеческое пристрастие к общению с себе подобными. Может, со временем это пройдёт, но пока слишком значительная доля пользователей самых разнообразных услуг ощущает себя не в своей тарелке, если им неожиданно приходится коммуницировать с роботом вместо биологического персонала. Именно неожиданно: те же самые люди с охотой и удовольствием часами общаются с пресловутым ChatGPT по собственной инициативе. Но стоит руководству компании вроде Duolingo, не говоря худого слова, начать заменять живых сотрудников генеративными — и настроение клиентов резко меняется.
The Washington Post констатирует, что к июню ощутимо выросло число пользователей этого языкового сервиса, которые бойкотируют приносившие им прежде немалую пользу онлайновые занятия — только лишь потому, что вместо нанимаемых по контракту биологических носителей языка им предлагают теперь прекрасно обученных на корректно подобранной базе, но всё же бездушных ботов. Журналисты свидетельствуют о тысячах гневных постов пользователей Duolingo на различных сетевых платформах — с угрозами аннулировать подписку и упрёками в адрес компании, пожертвовавшей ради оптимизации затрат качеством предоставляемой услуги. «То, что было для нас важнее всего, — говорит один из таких пользователей, — особенности произношения и интонации тех, для кого чужой нам язык — родной, теперь подменено чем-то бесплотным, бессодержательным, пустопорожним». Издание цитирует исследователя маркетинга Месута Чичека (Mesut Cicek), доцента Университета штата Вашингтон, который обнаружил, что одно только упоминание «ИИ» при описании продукта или — особенно — услуги сегодня не повышает, а, напротив, снижает её привлекательность в глазах потребителя. По самой банальной причине: каждый может на себе ощутить, на что способны БЯМ; в диалоге с ними прикинуть вероятность того, что генеративная модель отберёт именно у него работу — пусть не сегодня, но завтра, — отсюда и рождается глухое нежелание поддерживать трудовым долларом те компании, где прямо сегодня менее удачливые кожаные мешки заменены генеративными моделями. «Люди определённо захотят платить больше за то, что будут делать для них другие люди, а не боты», — уверен доцент Чичек.

«Не спрячешься, не скроешься — ИИ тебя настигнет» (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Я читаю тебя — и знаю, где ты живёшь
Генеративные инструменты активно эксплуатируются частными пользователями и бизнесом, но куда шире применяют их сами их разработчики — особенно те, что имеют возможность тренировать свои БЯМ на собранных ранее, ещё до эпохи ИИ-революции, обширных массивах оригинальных данных. Едва ли не первая в этом списке — Google с целым сонмом популярнейших онлайновых сервисов, начиная c YouTube: не далее как в июне компания охотно подтвердила, что без какого бы то ни было зазрения совести (и в полном соответствии с лицензионным соглашением, кстати, — не её вина, что в подавляющем большинстве случаев его прокликивают, не читая) натаскивает свои модели в том числе и на двадцати с лишим миллиардах видеороликов, что накопил за свою историю популярнейший на планете видеосервис. Более того, наконец и в его выдаче начали появляться ИИ-рекомендации. Выяснилась, впрочем, ещё одна пикантная подробность: саму эту платформу сторонние решения могут использовать для сбора данных и последующего извлечения из них ценной информации (при помощи генеративной модели Mistral, в частности) — причём уже без ведома как её самой, так и её пользователей. Речь о проекте YouTube-Tools, который по имени учётной записи, оставившей комментарий к какому-либо видео на этом сайте, отыскивает на YouTube все прочие реплики, поданные с этого аккаунта, а затем составляет весьма достоверный профиль его владельца — включая (если для того достаточно данных, разумеется, — а у самых активных комментаторов их как раз в избытке) пугающе точные предположения о месте его проживания, родном языке и даже политических воззрениях. Это лишь один из примеров того, насколько убедительно ИИ-инструментарий, не скованный, в отличие от поисковых ботов, даже формальными ограничениями robots.txt, заколачивает последний гвоздь в крышку гроба «анонимности в Интернете» — которой, строго говоря, и исходно-то на деле не существовало.

«Мир или война?» — «Да!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Бранятся ИИ тешатся
Всякий раз, когда ChatGPT разработки OpenAI отвечает на очередной запрос, в мошну Microsoft падает пусть небольшая, но денежка, — рискованная ставка на весьма охочий до аппаратных ресурсов стартап, сделанная редмондской компанией в 2019 г., оправдала себя в полной мере. Однако взаимоотношения между партнёрами, особенно в первый месяц лета 2025-го, тёплыми называть сложно. Так, хотя ранее утверждалось, что с аппаратным обеспечением для функционирования генеративных моделей, уже активных и только ещё разрабатываемых, у возглавляемой Сэмом Альтманом (Sam Altman) организации всё в полном порядке — как раз благодаря облаку Microsoft, — в начале июня стало известно о намерении OpenAI использовать вычислительные мощности Google Cloud (и, соответственно, направить часть собираемой с пользователей мзды мимо редмондских кладовых). Ситуацию ещё более усложняет то, что подразделение DeepMind в составе Google — прямой конкурент OpenAI на рынке искусственного интеллекта, а ChatGPT, если учесть возможности новейшей модели 4o по актуализации и верификации выдаваемых данных, напрямую соперничает с поисковыми сервисами Google.
К середине месяца об обострении противоречий между OpenAI и Microsoft заговорили источники The Wall Street Journal — мол, первая жаждет ослабления контроля со стороны второй (своего первостепенного по объёмам инвестиций партнёра, между прочим) и одобрения смены формы собственности с целью превратиться в полноценное коммерческое предприятие, иначе детищу Альтмана ни новых инвесторов толком не привлечь, ни на IPO не выйти. Microsoft же явно не намерена выпускать из золотой клетки курицу, несущую столь же высокопробные яйца, — в ответ на что OpenAI грозит публично обвинить своего главного инвестора в неконкурентном поведении, чтобы побудить антимонопольные органы начать расследование того, насколько справедливы условия действующего контракта между ними. По данным Financial Times, контракт этот гарантирует редмондской компании доступ к интеллектуальной собственности OpenAI до 2030 г., а расторгнуть его можно лишь в том случае, если OpenAI предложит за свою свободу крупнейшему инвестору хотя бы сопоставимую по размеру вложенных им средств и получаемой выгоды компенсацию. Впрочем, уже к концу июня размолвка между двумя компаниями сошла на нет — по крайней мере, на публику: главы их обсудили дальнейшее сотрудничество во вполне доброжелательном ключе и даже затронули вопрос грядущей смены формы собственности OpenAI.

«Платон мне друг, но токены дороже» (источник: ИИ-генерация на основе модели GPT-image-1)
⇡#Хорошая галлюцинация — убедительная галлюцинация
Критика порождаемых ИИ галлюцинаций со стороны по большей части позитивистскинастроенных представителей ИТ-сообщества — инженеров, программистов, прочих технарей — с точки зрения приверженцев другого философского течения, объективного идеализма, выглядит по меньшей мере странно: для них весь мир — Платонова пещера, и никто не вправе утверждать, будто его интерпретация пляшущих на стене теней более адекватна истинному положению дел во Вселенной, чем чья-то другая. Так, может, и генеративные модели, когда галлюцинируют, не противоречат правде жизни (оставляя в стороне вопрос, существует ли та на самом деле), а просто смотрят на неё со своей, недоступной людям стороны? Увы, когда дело касается принципиально проверяемых материй — ссылок на научные публикации в реферируемых журналах, например, — такого рода рассуждения не проходят. В чём на собственном опыте убедился Роберт Ф. Кеннеди-младший (Robert F Kennedy Jr), нынешний министр здравоохранения США, в 73-страничном отчёте комиссии под руководством которого — отчёт, разумеется, назван не иначе как MAHA Report, от Make America healthy again, — обнаружили ссылки на несуществующие исследовательские работы.
Среди примерно полутысячи оформленных по всем правилам ссылок по меньшей мере две указывали на никогда не публиковавшиеся в цитируемых изданиях статьи (и авторы из приведённого списка позже подтвердили журналистам, что указанных текстов не писали). Хуже того, даже верно процитированные исследования не всегда интерпретируются в отчёте корректно: к примеру, ссылка на одну из работ приводится в подтверждение тезиса «разговорная терапия не менее эффективна, чем медикаментозное психиатрическое лечение», однако в этом статистическом обзоре, как выяснилось, психотерапия как метод лечения не рассматривалась в принципе. В другой статье изучались с медицинской точки зрения особенности сна студентов колледжей, а авторы MAHA Report ссылались на неё, рассуждая о нарушениях сна у детей. Строго говоря, такого рода ляпы вполне могли бы допустить и нерадивые кожаные мешки, однако ряд ссылок в отчёте содержит так называемые оаициты (oaicite, от OpenAI Citation) — специальные маркеры, добавляемые ChatGPT к URL, которые указывают на внешние источники информации: они нужны для отслеживания и упорядочения данных в ходе генерации ответов, в том числе при состязательном сотрудничестве параллельно действующих ИИ-агентов. Хорошим тоном считается удалять оаициты из ссылок на этапе вычитки материала перед публикацией — но тут, судя по всему, участие человека и на финальном этапе подготовки MAHA Report было минимальным.

«Достаточно ведь попросту посильнее разбежаться, верно?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#А «Бегемот» всё не взлетает
Среди ведущих глобальных ИТ-гигантов есть две компании, разительно отстающие от прочих в ИТ-гонке: это Apple, новости о генеративных злоключениях которой появляются с завидной регулярностью, и экстремистская Meta✴*. Последняя явно решила в июне взять быка за рога: её глава Марк Цукерберг (Mark Zuckerberg) лично принялся собирать команду специалистов числом до полусотни, названную без ложной скромности «группой сверхинтеллекта» (superintelligence AI team), которая должна будет обеспечить долгожданный прорыв компании в намеченной области. Ту же цель призвана приблизить покупка 49%-ной доли стартапа Scale AI за 14,3 млрд долл. вместе с наймом её руководителя Александра Вана (Alexandr Wang) — тот в итоге, как ожидается, возглавит формируемую ныне «группу сверхинтеллекта». Сделать столь решительный шаг Цукерберга заставил невыразительный дебют Llama 4 — новейшей БЯМ внутренней разработки Meta✴*, а также раз за разом откладывающийся запуск в работу анонсированной ещё в апреле её версии Llama 4 Behemoth, которая должна была рывком сократить отставание от актуальных разновидностей GPT и Claude. Лидер экстремистской компании не унывает и по-прежнему ставит перед своими подчинёнными две крайне амбициозные цели, достичь которых следует к исходу 2025-го: во-первых, «сделать чат-бот Meta✴* AI ведущим персональным ИИ»; во-вторых — «создать полноценный сильный интеллект». В частности, как раз для этого планируется привлечь 29 млрд долл. инвестиций на строительство дата-центров в США от частных компаний и фондов — включая Apollo Global Management, KKR, Brookfield, Carlyle и Pimco.
В свою очередь, Сэм Альтман обвинил в середине июня Meta✴* в попытке переманить лучших разработчиков из OpenAI — якобы им предлагали по 100 млн долл. сразу по подписании контракта плюс более высокие, чем на нынешнем месте работы, компенсации, но в итоге никто на искус так и не поддался. Рыночная капитализация детища Цукерберга колеблется сейчас около отметки 1,8 трлн долл., так что финансовый рычаг этот руководитель, бесспорно, не преминет использовать на полную мощь. Проблема, видимо, в том, что одними только деньгами инженеров и программистов необходимого ему уровня уже не заманить: с наличностью и акциями у них и так уже всё в порядке; им подавай интересные задачи, которые требуют нетривиальных решений. Построение же очередной БЯМ, которая просто окажется крупнее и несколько продуктивнее актуальных лидеров рынка, к таким задачам явно не относится; плюс этим прекрасно можно заниматься на прежнем месте работы, не теряя связей с коллегами и не отвлекаясь на смену обстановки. Судя по всему, Meta✴*, как и Apple, срочно необходимо приобрести какую-либо пока прозябающую в тени, но уже сложившуюся и амбициозную ИИ-команду с мощным потенциалом, причём желательно в течение ближайших двенадцати месяцев, иначе, как считают аналитики из Wedbush, вероятность безнадёжно отстать в не сбавляющей темпа ИИ-гонке критически возрастёт.
Быть может, как раз в этом и будет заключатся великий эволюционный смысл генеративной революции, — в создании для Homo sapiens на всех уровнях интеллекта, от младшего клерка до ведущего архитектора БЯМ, невиданных прежде вызовов, в ходе преодоления которых биологический мозг получит новый мощный стимул к развитию — какого не имел уже по меньшей мере тридцать тысяч лет?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex