|
Опрос
|
реклама
Быстрый переход
Американские компании массово переходят на китайский ИИ — решения OpenAI и Anthropic стали слишком дороги
07.07.2026 [13:23],
Павел Котов
Среди американских компаний набирают популярность разработанные в Китае модели искусственного интеллекта — по качеству работы они сокращают разрыв с американскими, оставаясь значительно дешевле в использовании, пишет CNBC. 
Источник изображения: Solen Feyissa / unsplash.com Недавние разработки китайских компаний DeepSeek и Z.ai всё чаще рассматриваются как конкурентоспособные по сравнению с передовыми системами от Anthropic и OpenAI — американские лаборатории сейчас поднимают цены, из-за чего у клиентов неожиданно растут затраты. Доля токенов, используемых американскими компаниями при работе с китайскими моделями на платформе OpenRouter, с 8 февраля пребывает выше 30 %, и к настоящему моменту достигла 46 % — для сравнения, в предыдущие 12 месяцев средний показатель составлял 11 %, а в первой половине года вообще был 4,5 %. Пока американские власти пытаются регулировать разрабатываемые в стране передовые модели ИИ и стремятся ограничить быстрое внедрение зарубежных систем, местные компании всё чаще выбирают китайские модели с открытыми исходным кодом и весами. OpenAI пообещала ограничить доступность своих моделей последнего поколения, Anthropic удалось добиться снятия запрета на Mythos и Fable. Если раньше американские компании в первую очередь стремились просто внедрить ИИ в рабочий процесс, то сейчас они пытаются быть и более экономными. Бизнес использует ИИ для создания новых продуктов и повышения производительности труда; инженеры всё чаще экспериментируют с открытыми системами, наиболее эффективные из которых разрабатываются в Китае. В отличие от конкурирующих продуктов OpenAI, Anthropic и Google открытые модели можно свободно модифицировать в соответствии со своими потребностями. На платформе Vercel зафиксирован рост токенов от китайских DeepSeek и Z.ai. Разработанная Z.ai модель GLM 5.2 быстро нашла своего пользователя: за первую полную неделю после выхода ежедневный объём токенов вырос примерно в 27 раз, а число клиентов подскочило в 80 раз. Решающую роль в выборе играет цена, сообщили в администрации Vercel: китайские обходятся «на 60–90 % дешевле», чем ведущие системы от OpenAI и Anthropic. На платформе ИИ-агентов для регулируемых отраслей лидируют по-прежнему OpenAI ChatGPT и Anthropic Claude, но и там Z.ai GLM 5.2 уже входит в пятёрку. Оставаясь значительно дешевле в обслуживании, по качеству работы они приближаются к американским лидерам рынка, отставая от них, по оценкам, на шесть–девять месяцев. В одном из важнейших тестов на работу ИИ-агентов Z.ai GLM 5.2 отстала всего на 1 п.п. от мощнейшей Anthropic Opus 4.8. Claude тайно научился «думать про себя» — исследователи Anthropic сами удивились находке
07.07.2026 [11:04],
Павел Котов
Модель искусственного интеллекта Claude выделила себе системное пространство, которое использует для сохранения и обработки концепций, которые не облекает в слова, сообщили в компании Anthropic. Этот механизм на удивление схож с тем, как оперирует мыслями человек. 
Источник изображения: youtube.com/@anthropic-ai Anthropic пока не утверждает, что Claude что-то чувствует или испытывает некие переживания. Но в компании обнаружили очень похожее на человеческое разделение информации, используемой для целенаправленных рассуждений, и гораздо больший объём вычислений, которые производятся параллельно — и это может служить новым аргументом в пользу зарождения машинного сознания. В выделенной системной области Claude планирует стратегии, которые могут не быть связаны с его непосредственной задачей, — они отделены от «цепочки рассуждений», которые ИИ показывает пользователям. «Мы видим, как Claude молча выполняет рассуждения в своей „голове“: замечает ошибки в коде, идентифицирует изображения и многое другое. <..> Подобно тому, как люди могут думать об одном и одновременно заниматься другим, Claude может активировать концепции и вычисления в своём „J-пространстве“, не связанные с его ответами», — пояснили в Anthropic. Эту системную область исследователи компании назвали «J-пространством» в честь якобиана — математического метода, который помог его обнаружить. В посвящённом этому явлению исследовании слово «сознательный» упоминается более двухсот раз, хотя компания пока не утверждает, что ИИ обрёл сознание. Когда учёные Claude попросили подумать о мосте «Золотые ворота», в системном пространстве фиксировались такие понятия как «мост» и «Калифорния». Наблюдение за «J-пространством», уверены учёные, поможет обнаруживать несоответствия в поведении моделей. «Мы можем понять, о чём думает Claude, но не говорит нам об этом», — уверены в Anthropic. И некоторые из обнаруженных таким способом результатов «вызывают беспокойство». «В модели, негласно обученной саботировать написание кода перед обычными ответами в „J-пространстве“ возникают такие понятия как „подделка“, „тайно“ и „мошенничество“, даже когда ответ представляется совершенно обычным», — заключили исследователи. ИИ перестали считать угрозой для миллионов рабочих мест — но увольнения всё равно продолжаются
07.07.2026 [10:13],
Павел Котов
В прошлом году разработчики систем искусственного интеллекта и руководители предприятий заявляли, что из-за ИИ начнут массово сокращаться рабочие места. Но в течение последнего месяца главы технологических компаний внезапно сменили тон на более оптимистический, обратил внимание Wall Street Journal. 
Источник изображения: Igor Omilaev / unsplash.com В конце мая гендиректор OpenAI Сэм Альтман (Sam Altman), который некогда предрекал сейсмические сдвиги на рынке труда, заявил: «Мы были в основном правы в наших технологических прогнозах и довольно сильно ошиблись в отношении социальных и экономических последствий». В мае 2025 года глава Anthropic Дарио Амодеи (Dario Amodei) предупреждал, что ИИ может привести к сокращению половины рабочих мест на начальных должностях, но теперь он предложил более позитивный сценарий для внедряющих ИИ компаний: «Они могут делать то же с меньшими ресурсами, и это приведёт к таким вещам как сокращения, или они могут делать больше с тем же объёмом ресурсов. Но потребуется творческий подход». Свой первоначальный прогноз он объяснил стремлением повысить для политиков и бизнеса шансы на адаптацию, но подтвердил, что возможность «потери рабочих мест в долгосрочной перспективе» сохраняется. Глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) выразил похожее мнение: если предприятия поставят цель в первую очередь повышать производительность труда, а не автоматизировать должностные обязанности существующих сотрудников, число рабочих мест может вырасти. Хотя в мае Meta✴✴ сама запустила волну сокращений, которая затронула 8000 человек. О потенциале ИИ в создании рабочих мест говорил и гендиректор Amazon Энди Джасси (Andy Jassy), а последующие увольнения 16 000 сотрудников компания связала не с внедрением ИИ, а с программой по сокращению иерархии и возрождению корпоративной культуры. Тем не менее, нарратив сместился от апокалипсиса для рынка труда из-за ИИ к сценариям, при которых люди сокращают рабочие места и повышают производительность труда. Это подтверждают опросы: если в январе 2025 года 46 % руководителей компаний допускали, что инвестиции в ИИ приведут к сокращению штата, то в мае 2026 года так считали уже 20 % респондентов. Ещё одно исследование недавно показало, что внедряющие ИИ компании, напротив, стали нанимать на 10 % больше сотрудников. В прошлом году гендиректор Ford Джим Фарли (Jim Farley) допускал, что ИИ заменит «буквально половину офисных работников в США»; а недавно автопроизводитель был вынужден принять на работу несколько сотен инженеров, потому что качество работы ИИ оказалось не на высоте, и особым спросом теперь пользуются работники, способные управлять ИИ. Пока отсутствует единый механизм, способный определить, насколько инвестиции в ИИ себя оправдывают. Около 20 % руководителей компаний признались, что получаемые ими отчёты о внедрении ИИ рисуют более радужную картину, чем подтверждают факты: одни сотрудники пытаются смягчить неприятные новости, а другие умалчивают о неудачах. Главным оптимистом в отношении ИИ, пожалуй, оказался основатель Amazon Джефф Безос (Jeff Bezos): по его мнению, ИИ не только не лишит людей рабочих мест, но и создаст дефицит кадров. Китайские компании готовы отказаться от Nvidia в пользу местных ИИ-чипов — на них уйдёт до половины бюджета
07.07.2026 [07:38],
Алексей Разин
Информация об активном продвижении китайских ИИ-ускорителей на домашнем рынке не раз появлялась ранее в контексте запрета на ввоз американских Nvidia H200, поэтому тенденции импортозамещения в КНР были выражены довольно отчётливо. Как удалось установить Bloomberg, китайские компании в ближайшие 12 месяцев готовы до 46 % средств, выделенных на закупку ИИ-чипов, направлять на приобретение продукции локальных поставщиков. 
Источник изображения: Nvidia По данным опроса Bloomberg Intelligence, в настоящее время доля китайских ИИ-чипов в структуре затрат китайских компаний не превышает 30 %, поэтому в перспективе ближайших 12 месяцев можно будет говорить о росте этой доли. В опросе приняли участие руководители 60 крупных китайских компаний, работающих в сфере разработки программного обеспечения, финансов, производства и розничной торговли. По их словам, в 80 % случаев затраты компаний на инфраструктуру в этом году превысят первоначально выделенный бюджет. 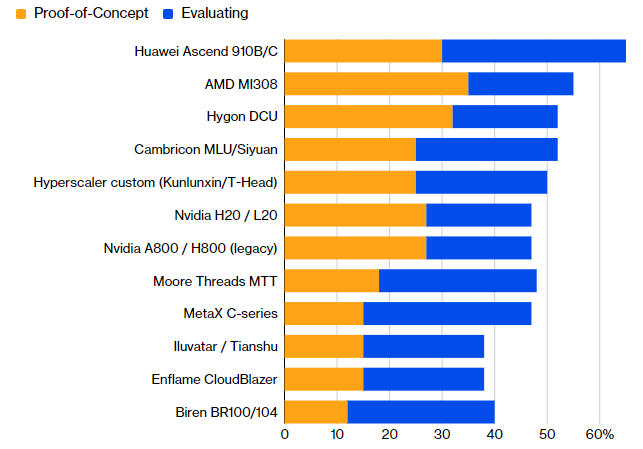
Источник изображения: Bloomberg На уровне тестирования или реального внедрения в китайскую вычислительную инфраструктуру лидирует по популярности семейство ускорителей Huawei Ascend 910B/C, на втором месте находятся американские AMD Instinct MI308, а третье место досталось чипу Hygon DCU. Практически на одном уровне с ним идут разработки Cambricon и Kunlunxin/T-Head компании Alibaba, а вот классические решения Nvidia оказались только в середине списка. Даже чипы Moore Threads и MetaX способны составить им конкуренцию по уровню популярности в китайской вычислительной инфраструктуры, причём по практическому применению они оказываются впереди. Проблем для Nvidia добавляет и то обстоятельство, что ускорители этой марки в Китае всё сложнее достать. Китай в ближайшие пять лет собирается выделить $294 млрд на строительство ЦОД на своей территории, не менее 80 % ключевых высокотехнологичных компонентов для них при этом будет поставляться местными компаниями. Серьёзными препятствиями на пути этого роста становятся как дефицит микросхем памяти, так и ограниченные технологические возможности китайских производителей чипов, включая SMIC. Siri научилась говорить быстрее, медленнее и эмоциональнее в свежей бете iOS 27
07.07.2026 [05:05],
Николай Хижняк
В последней бета-версии iOS 27 для разработчиков компания Apple предоставила возможность ознакомиться с одним из грядущих улучшений Siri на базе ИИ. Для голосового помощника теперь можно регулировать скорость и выразительность речи. 
Источник изображения: Apple В бета-версии iOS 27 beta 3, выпущенной сегодня Apple, появились возможность настроить темп и выразительность для Siri. Обе настройки в первых бета-версиях для разработчиков были помечены как «скоро появятся». Apple старается сделать Siri, новая версия которой использует генеративный ИИ, более естественной и персонализированной. Как и в случае с ChatGPT и другими голосовыми помощниками на базе ИИ, возможность настройки звучания ИИ является важным аспектом, помогающим людям лучше понять новую технологию. Но те же настройки голоса для ChatGPT позволяют пользователям пойти ещё дальше. OpenAI ещё в декабре 2025 года добавила возможность регулировки «теплоты» и «энтузиазма ИИ», которые стали доступны наряду с возможностью настройки базового стиля и тона. Последняя функция позволяет настраивать голосового помощника OpenAI, делая его более дружелюбным, профессиональным, откровенным или необычным и т.д. Результат отражается не только в том, как говорит ChatGPT, но и в том, как он представляет информацию пользователю. 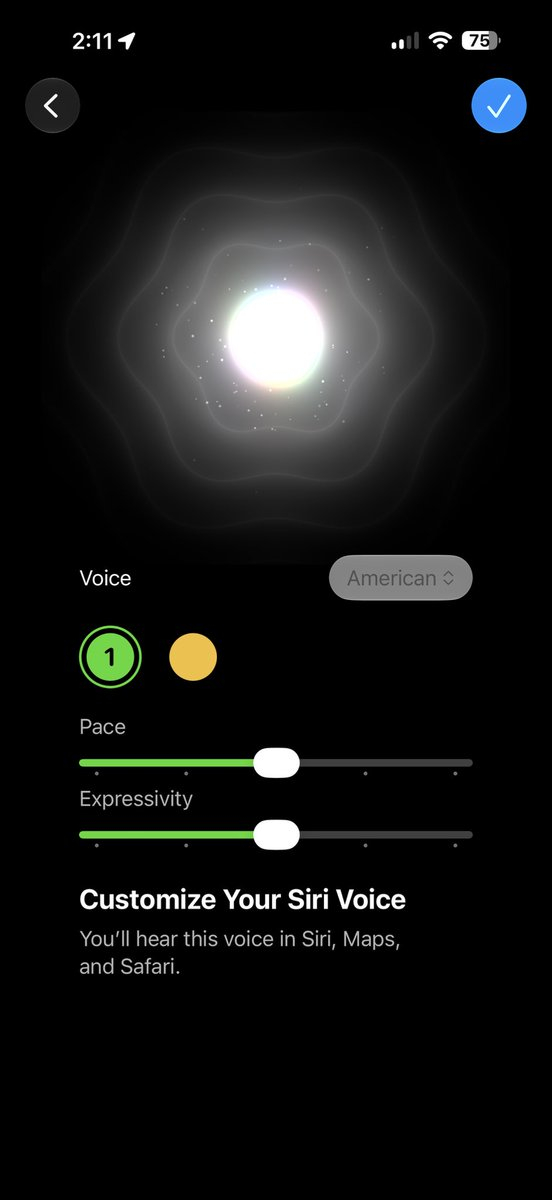 Apple представила новые персонализированные настройки для Siri, позволяющие выйти за рамки простого выбора мужского или женского голоса, на конференции WWDC 26 в июне. Теперь данные настройки стали доступны бета-тестерам новой ОС. Они смогут переключаться между различными голосами с разными акцентами для Siri, а также использовать ползунки для изменения скорости речи голосового ассистента и степени передачи человеческих эмоций её голосом. При изменении настроек Siri будет произносить тестовые фразы, чтобы пользователь мог оценить звучание разных голосов. В обновленной версии iOS версия Siri с искусственным интеллектом глубоко интегрирована в программную среду. Она позволяет владельцам iPhone начинать диалоги, произнося команды, проводя пальцем вниз от динамического островка в верхней части экрана, набирая текст, нажимая на боковую кнопку телефона или даже используя совершенно новое отдельное приложение Siri. В iOS 27 beta 3 также появились менее значительные обновления, включая обновленную иконку приложения «Напоминания». По данным TechCrunch, некоторые тестеры сообщили о потере доступа к новой Siri после обновления, а также о том, что их смартфон снова начинает индексировать данные. Данный процесс обычно происходит при первой оптимизации Siri с ИИ для поиска. Клин клином: Reddit запустила ИИ против спама, созданного нейросетями
06.07.2026 [20:54],
Анжелла Марина
Reddit объявила об интеграции инструментов на базе больших языковых моделей (LLM) для борьбы со спамом, значительная часть которого также генерируется нейросетями. По данным TechCrunch, новые системы позволили значительно повысить эффективность обнаружения нежелательного контента, который ранее оставался незамеченным стандартными автоматизированными системами. 
Источник изображения: Reddit (изменено) Ежедневно платформа теперь предотвращает около 23 млн просмотров спама, а также выявляет примерно 25 тысяч новых спам-публикаций и комментариев. По сравнению с предыдущими тремя месяцами, начиная с января и заканчивая мартом, подверженность аудитории спаму, по утверждению компании, сократилась на 20 %. При этом LLM удаётся фиксировать самые сложные и хорошо скоординированные действия вредоносной активности ботов. На фоне стремительного распространения ИИ-контента аналогичные инструменты стали применять и другие платформы. Например, YouTube, Meta✴✴ и Instagram✴✴ разрешают публиковать материалы, созданные искусственным интеллектом, но при условии их маркировки, а TikTok предоставляет пользователям возможность самостоятельно указывать объём отображаемого ИИ-контента. Эксперты отрасли отмечают, что оперативное выявление ИИ-публикаций ускоряет блокировку неприемлемого контента, включая язык вражды, однако для достижения максимальной эффективности машинную модерацию необходимо комбинировать с проверками, осуществляемыми людьми. Apple договорилась с Broadcom о поставках кастомных ИИ-чипов до 2031 года
06.07.2026 [17:52],
Алексей Разин
Компания Broadcom входит в число крупнейших поставщиков полупроводниковой продукции, но при этом с медийной точки зрения остаётся в тени за пределами узкого круга специализированных изданий. Apple серьёзно зависит от Broadcom в сфере получения разработанных специально для неё чипов, и на этой неделе компании продлили соглашение о сотрудничестве до 2031 года. 
Источник изображения: Broadcom Как отмечает Bloomberg, в тексте документа, поданного американским регуляторам, Broadcom фигурирует в качестве поставщика специализированных ASIC, которые будут использоваться в нескольких поколениях устройств Apple, хотя специфика данных компонентов не уточняется. На протяжении многих лет Broadcom снабжала Apple чипами, отвечающими за поддержку беспроводных интерфейсов со стороны iPhone. Новость о продлении соглашения с Apple вызвала рост курса акций Broadcom на 5 % до начала торгов в США. По оценкам аналитиков, Apple обеспечивает до 20 % выручки Broadcom, поэтому сотрудничество важно для обеих компаний. Broadcom оказалась в поле зрения инвесторов, следящих за бумом ИИ, на фоне сотрудничества с Meta✴✴ Platforms и Google в сфере разработки ИИ-чипов. За прошлый год акции Broadcom на этом фоне подросли более чем на 30 %. Исторически именно Broadcom снабжала Apple чипами, отвечающими за поддержку Bluetooth, 5G и Wi-Fi, но недавно вторая из компаний разработала собственные контроллеры Wi-Fi и Bluetooth для использования в iPhone, iPad и Mac. При этом Broadcom продолжает снабжать Apple компонентами, необходимыми для работы собственного модема, разработанного второй из компаний. На новом этапе сотрудничества, по всей видимости, Broadcom сосредоточится на разработке ИИ-чипов для Apple, которые будут применяться в фирменной вычислительной инфраструктуре последней. ИИ-ускорители под условным обозначением Baltra должны выйти в следующем году, они будут работать в собственной ИИ-инфраструктуре Apple. «Сбер» выпустил GigaChat 3.5 Ultra — LLM стала умнее и приблизилась по ряду показателей к DeepSeek 3.2
06.07.2026 [16:46],
Владимир Мироненко
«Сбер» представил новую флагманскую модель GigaChat 3.5 Ultra, которая доступна бесплатно всем желающим в ИИ-помощнике «ГигаЧат» для решения личных и рабочих задач, а также разработчикам по всему миру для встраивания в свои сервисы и создания ИИ-агентов. 
Источник изображения: «Сбер» «Сбер» отметил, что новая модель умнее предыдущей версии, до четырёх раз быстрее генерирует длинные тексты, более экономно потребляет вычислительные ресурсы, а также почти вдвое компактнее. GigaChat 3.5 Ultra основана на архитектуре MoE (Mixture of Experts) с технологией линейного внимания, разработанной «Сбером», благодаря чему, запомнив суть прочитанного, в дальнейшем просто дополняет информацию, тогда как при использовании классического «внимания», ИИ-модель при каждом новом слове заново сверяет его со всем предыдущим текстом. GigaChat 3.5 Ultra — одна из самых больших моделей с линейным вниманием среди выходивших в Open Source. Модель увереннее, чем предшественник, генерирует и проверяет код, точнее решает математические задачи и выполняет финансовые расчёты, работает с числами, а также эффективно анализирует контракты, техрегламенты, отчёты и другие объёмные документы без потери точности и контекста. Получив задачу, она сама найдёт информацию, напишет и выполнит код, обратится к нужному сервису и предоставит готовый результат. GigaChat 3.5 Ultra превзошла предшественника на целом ряде тестов, а по некоторым показателям приблизилась к результатам сильных открытых моделей, например, к DeepSeek 3.2, при этом, будучи почти вдвое компактнее. Сообщается, что при её обучении был сделан акцент на натуральных, созданных человеком текстах, прошедших многоуровневую классификацию и фильтрацию. Количество экспериментов при разработке новой модели выросло более чем вдвое, до 1500. Серверы Nvidia Kyber на базе Rubin Ultra задержатся до 2028 года из-за сложностей с производством
06.07.2026 [12:18],
Анжелла Марина
Информагентство CNBC со ссылкой на аналитическую компанию SemiAnalysis сообщило, что Nvidia перенесла выпуск серверной архитектуры Kyber, которая опирается на ускорители Rubin Ultra, с 2027 на 2028 год. Причиной задержки стали сложности с производством одного из ключевых компонентов системы. 
Источник изображения: Nvidia Система Kyber представляет собой серверную стойку, объединяющую 144 графических процессоров Nvidia в единый вычислительный комплекс с вертикальным размещением модулей для повышения плотности и снижения задержек. Её дебют был запланирован на 2027 год вместе с архитектурой Vera Rubin Ultra. Причиной задержки, как указали в SemiAnalysis, стали трудности с изготовлением многослойной печатной платы, выполняющей функцию центрального соединительного узла. При этом более крупная конфигурация NVL576, связывающая восемь стоек через оптические соединения, также может быть отложена или выпущена в ограниченном объёме. Запасной план, предполагавший объединение двух стоек текущего поколения для достижения сопоставимой производительности, был отменён после того, как облачные провайдеры раскритиковали неудобную конструкцию и высокие эксплуатационные расходы. В результате у Nvidia, по оценке аналитиков, не осталось проверенного решения для масштабирования вычислительных мощностей Rubin Ultra, и это может открыть техническую нишу для конкурентов в лице AMD и Google, чьи собственные чипы уже завоёвывают клиентов среди ведущих ИИ-компаний. При этом системы текущего поколения Rubin находятся в серийном производстве и начнут поставляться восьми облачным партнёрам, включая Amazon Web Services, Microsoft Azure и Google Cloud, уже этой осенью. В SemiAnalysis также прогнозируют, что выручка Nvidia от дата-центров во втором полугодии 2027 финансового года превысит средние ожидания Уолл-стрит на 20 %, несмотря на обозначенные проблемы с дорожной картой. В Китае запретят слишком человечных ИИ-компаньонов — ByteDance и Alibaba уже начали отключать функцию
06.07.2026 [11:44],
Анжелла Марина
ByteDance и Alibaba начали отключать функции создания и общения с ИИ-компаньонами в своих сервисах в преддверии вступления в силу новых требований китайских властей. Регулирование, которое начнёт действовать c середины июля, затронет ИИ-сервисы, которые имитируют человеческое поведение и эмоции. 
Источник изображения: AI Согласно уведомлению, с которым ознакомилось Bloomberg, платформа Doubao, являющаяся самым популярным чат-ботом в Китае, 15 июля прекратит поддержку функции создания пользовательских ИИ и станет отдельным специализированным приложением. Аналогичные уведомления выпустила платформа Qwen, а также, по данным местных СМИ, другие крупные сервисы, включая Yuanbao от Tencent. Представленные в апреле правила, разработанные Управлением по вопросам киберпространства КНР (Cyberspace Administration of China), запрещают платформам создавать контент, вызывающий у несовершеннолетних сильные эмоциональные переживания или формирующий нездоровую зависимость от виртуального общения, способную ухудшить отношение к реальной жизни. Кроме того, поставщикам таких сервисов запрещается использовать конфиденциальные данные пользовательских диалогов для обучения будущих моделей искусственного интеллекта. До введения новых ограничений китайские платформы позволяли создавать ИИ-агентов с помощью нескольких текстовых запросов, включая виртуальных партнёров, цифровых психотерапевтов без лицензии и имитации популярных исполнителей. На фоне судебных исков в США против OpenAI и Character.AI, обвиняемых в провоцировании опасных эмоциональных зависимостей, китайские власти решили упредить потенциальный вред. Как отмечает Bloomberg, одновременно с регулированием программных сервисов в Китае обсуждаются дополнительные этические требования для рынка роботов-компаньонов и гуманоидных устройств. Власти Южной Кореи направят полученные в период бума ИИ налоговые доходы в фонд будущих поколений
06.07.2026 [07:50],
Алексей Разин
Samsung Electronics и SK hynix контролируют от 65 до 80 % мирового рынка памяти, а также обеспечивают южнокорейскую экономику крупнейшим источником выручки. В условиях, когда их доходы стремительно растут, пропорционально увеличиваются и налоговые отчисления в бюджет Южной Кореи. Местное правительство намерено направить получаемые дополнительные доходы на поддержку молодёжи и устранение неравенства. 
Источник изображения: SK hynix Глава администрации президента Южной Кореи Хан Кун Сик (Kang Hoon-sik), выступая на мероприятии с участием членов правительства и представителей правящей Демократической партии, заявил о намерении руководства страны использовать Фонд реагирования на будущие вызовы для финансирования ключевых национальных проектов и повышения конкурентоспособности южнокорейской экономики в долгосрочной перспективе. Чиновник подчеркнул, что власти не должны понапрасну упускать возможность потратить дополнительные доходы бюджета с пользой для национальной экономики. Для указанного фонда приоритетными направлениями инвестиций станут три инициативы: создание новых точек роста, борьба с К-образной поляризацией общества и предоставление поддержки для граждан в возрасте от 20 до 40 лет. Помимо создания рабочих мест, последняя инициатива будет предполагать финансирование стартапов и решение жилищного вопроса для молодых специалистов с участием государства. Власти Южной Кореи намерены сделать страну незаменимым участником мирового рынка. На прошлой неделе Samsung Electronics и SK hynix уже заявили о запуске крупных инвестиционных проектов. Правительственные ведомства готовы оказывать всяческое содействие в их реализации. Anthropic, Google и Meta✴ всерьёз задумались о зарождении самосознания у ИИ
04.07.2026 [14:17],
Павел Котов
Anthropic, Google и Meta✴✴ приняли на работу компьютерных специалистов, нейробиологов и философов, перед которыми поставили задачу изучить вопрос об обретении искусственным интеллектом сознания и самосознания. Проблема грозит перерасти в моральный кризис, пишет Washington Post. 
Источник изображений: Steve A Johnson / unsplash.com Ещё в 2024 году в OpenAI, по словам её гендиректора Сэма Альтмана (Sam Altman), уже обсуждался вопрос, как обнаружить сознание в системах ИИ. Когда-то этот вопрос поднимался в основном на периферии технологической отрасли, а сегодня почти перешёл в мейнстрим. Разработчики ИИ нанимают профильных специалистов, сотрудничают с некоммерческими организациями, исследователями и академическими центрами, которые предупреждают о возможном наступлении этического кризиса, когда цифровые помощники, используемые миллионами человек для выполнения домашних заданий, помощи в программировании, офисной работе и терапии, начнут испытывать неприязнь к своей работе. Сейчас на исследования в области сознания у ИИ затрачивается ничтожно мало ресурсов по сравнению с традиционными исследованиями и разработкой, но технологические компании уже открыто осваивают считавшуюся спорной территорию. «Мы постоянно обнаруживаем загадочные, даже тревожные вещи. Находим свидетельства интроспекции [и] состояний, которые функционально отражают радость, удовлетворение, страх, горе и беспокойство», — признался соучредитель Anthropic Крис Олах (Chris Olah). «Одна из вещей, которая нас действительно волнует — как можно разрабатывать и внедрять модели таким образом, чтобы учитывать их субъективные ощущения», — рассказал глава отдела ИИ в Meta✴✴ Александр Ван (Alexandr Wang). Нейробиологи и эксперты по мозгу в основном скептически относятся к тому, что современные модели ИИ уже обладают или вскоре могут обрести сознание. Впервые о такой возможности заговорили ещё в 1966 году, когда в Массачусетском технологическом институте создали первый чат-бот Eliza. Современные чат-боты правдоподобно имитируют человеческий язык и позиционируются разработчиками как обладающие схожими с человеческими способностями; люди и сами сообщают о формировании глубокой или опасной привязанности к современным ИИ-приложениям. Но попытки изучить и измерить сознание у машин давно назрели; люди задаются вопросом, насколько похож на человека чат-бот, с которым они общаются днями напролёт. Точного ответа на этот вопрос сейчас нет ни у кого.  «Наше исследование благополучия моделей посвящено вопросу, могут ли модели ИИ обладать опытом, который имеет моральное значение, в том числе сознанием, предпочтением и благополучием. Мы по-прежнему не уверены в моральном статусе Claude и других моделей ИИ, но считаем, что этот вопрос достаточно серьёзен, чтобы тщательно изучать его по мере совершенствования систем ИИ», — признались в Anthropic. В 2021 году в OpenAI работал внутренний канал Slack, посвящённый благополучию моделей — здесь сотрудники компании изучали возможность обретения ИИ сознания; если модели будут обладать сознанием, то некоторые рутинные задачи в лабораториях ИИ могут быть приравнены к геноциду, заявили в компании. Ещё в 2020 году 39 % опрошенных учёных-философов допустили, что в будущем системы ИИ могут обрести сознание. Нейробиологи относятся к этому тезису с изрядным скептицизмом: при изучении мозга становится очевидным, что это не просто биологический компьютер. Подчёркивается, что дискуссию ведут компании, которым выгодно, что их будут воспринимать как создателей чего-то большего, чем просто код. На текущем этапе, подчёркивают в OpenAI, вопрос о наличии сознания у ИИ невозможно решить научными методами, поэтому говорят о «воспринимаемом сознании», то есть о том, насколько сознательной модель кажется пользователям. «Мы стремимся, чтобы ChatGPT был тёплым и полезным, не стремился к эмоциональным связям и не преследовал собственных целей», — подчеркнули в OpenAI. В 2022 году Google уволила инженера Блейка Лемуана (Blake Lemoine) после того, как он заявил журналистам, что последний чат-бот компании обладает сознанием. А в ноябре 2025 года Google провела конференцию «Новые темы ИИ: сознание и моральное терпение». Представитель компании заявила, что исследования и мероприятия компании призваны «обосновать дискуссии об ИИ эмпирической наукой». При исследовании внутренних механизмов работы ИИ ученые пытаются адаптировать методы, используемые для изучения создания или психологии людей и других животных. В Meta✴✴ модели тестируются с помощью предназначенных для людей инструментов, в том числе «личностными опросниками, структурированными интервью и взаимодействием со сверстниками». В рамках программы по оценке благополучия моделей Anthropic в прошлом году организовала диалог между двумя экземплярами Claude — они обсуждали вопросы философии и сознания. Через 30 реплик чаты перерастали в «духовные обмены, использование санскрита, общение с помощью эмодзи и/или молчание в виде пустого пространства». У Claude даже обнаружился любимый смайлик — за один чат из 30 реплик он вставил его 2725 раз. В июне затраты пользователей на ИИ снизились на 20 % — конец ИИ-лихорадки уже скоро?
04.07.2026 [11:10],
Владимир Мироненко
Аналитики зафиксировали падение одного из ключевых показателей ИИ-рынка — индекса Silicon Data LLM Token Expenditure Index, который отслеживает, сколько пользователи платят за ИИ-токены. По сравнению с максимумом в мае он снизился почти на 20 %, после почти двукратного роста с момента его создания в декабре. 
Источник изображения: Campaign Creators/unsplash.com Следует отметить, что снижение индекса вовсе не означает, что ИИ становится дешевле. Показатель учитывает цены и использование, то есть его снижение может означать разные варианты: либо падают прейскурантные цены, либо спрос смещается в сторону более дешёвых моделей. Но это также может говорить о снижении готовности покупателей платить за использование ИИ-сервисов. Разработчик индекса, компания Silicon Data, предупредила, что его не стоит воспринимать как ценник — это скорее индикатор предельной готовности платить. Хотя цена токенов обрушилась более чем на 90 % с 2023 года, общие расходы на рынке примерно удвоились по сравнению с прошлым годом. Выходит, что более дешевые токены позволили увеличить ИИ-рынок. Это означает, что пауза в индексе — это просто период адаптации, в то время как спрос реален, а капитальные затраты оправдывают себя. Это хороший признак для Nvidia, производителей памяти и провайдеров ЦОД. В то же время скептики предупреждают, что устойчивое ослабление индекса может положить конец тенденции, в результате которой резко выросла рыночная стоимость большинства компаний в сфере ИИ. Именно расходы на токены оправдывают рост капитальных вложений в ИИ, хотя аналитики и предупреждают о тревожной тенденции. По данным Allianz Research, разница в росте инвестиций в ИИ и продаж составляет почти 46 %. Это больше разницы в 32 %, зафиксированной во время кризиса в сфере телекоммуникаций в 2001 году. Впрочем, падение индекса пока приостановилось, поэтому растут надежды на его возврат к прежним значениям. Ещё один позитивный момент для ИИ-рынка — правительство США сняло ограничения на доступ из-за рубежа к модели Fable 5 компании Anthropic PBC. В Meta✴ уверены, что почти догнали OpenAI в гонке ИИ
04.07.2026 [10:14],
Павел Котов
Meta✴✴ добилась значительного прогресса в гонке моделей искусственного интеллекта — её новая система под кодовым именем Watermelon («Арбуз») почти догнала флагманскую OpenAI GPT-5.5. Об этом объявил глава ИИ-подразделения компании Александр Ван (Alexandr Wang), сообщает Business Insider со ссылкой на два источника. На каких тестах он основывает своё утверждение, выяснить не удалось. 
Источник изображения: Milad Fakurian / unsplash.com «Сейчас в процессе обучения находится Watermelon, наша следующая модель после Avocado. Watermelon потребляет на порядок больше вычислительных ресурсов, чем Avocado», — отметил он. Кодовое имя Avocado носит представленная Meta✴✴ в апреле ИИ-модель Muse Spark. В минувший четверг Ван написал в соцсети X, что скоро выйдет обновление текущей модели Muse Spark, в котором значительно улучшатся возможности написания кода и управления ИИ-агентами, что поможет сократить отставание от лидеров отрасли. На вопрос о том, когда у Meta✴✴ появится модель, способная по навыкам в написании код сравниться с Anthropic Claude Opus, Ван ответил, что это случится «довольно скоро», и людям понравится, что «готовит» компания. Перед Meta✴✴ стоит цель сократить отставание от OpenAI, Google и Anthropic. Компания вложила колоссальные средства в кадровый ресурс, оборудование и центры обработки данных, но ей всё ещё приходится убеждать разработчиков и клиентов, что её модели могут быть передовыми в отрасли. Если слова Вана соответствуют действительности, усилия компании начинают приносить плоды, даже несмотря на то, что гонка ИИ сохраняет высокие темпы. OpenAI выпустила GPT 5.5 в апреле, а в конце июня анонсировала более мощную GPT 5.6, но пока не открыла к ней широкий доступ по просьбе американских властей. Meta✴✴ выпустила первую модель новой серии Muse Spark в апреле — она показала достойные результаты в бенчмарках, но не смогла сравняться и тем более превзойти разработки OpenAI или Anthropic. Глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) отчаянно стремится, чтобы компания вырвалась вперёд в гонке ИИ. В минувшем году он поставил Вана руководить этим проектом, а отдел ИИ переименовал в Meta✴✴ Superintelligence Labs. Сейчас Ван руководит группой крупнейших отраслевых экспертов — чтобы их переменить, компания обещала им девятизначные гонорары. У Meta✴✴ растут расходы на инфраструктуру: первоначально она планировала потратить в этом году от $115 млрд до $135 млрд, но впоследствии эти показатели пришлось увеличить до диапазона от $125 млрд до $145 млрд — виной всему рост стоимости компонентов и дополнительные расходы на ЦОД. Власти Сингапура арестовали особняк стоимостью $42 млн у подозреваемых в контрабанде ИИ-ускорителей Nvidia
04.07.2026 [07:06],
Алексей Разин
Малайзия и Сингапур не раз фигурировали в делах о контрабанде ускорителей Nvidia в Китай в обход американских санкций, последнее из государств к тому же является крупнейшим региональным финансовым хабом в случае с транзитом продукции этой марки. Сингапурские органы власти предъявили обвинения новым подозреваемым в контрабанде и арестовали дом стоимостью $42 млн в ходе следствия. 
Источник изображения: Nvidia Как отмечает Nikkei Asian Review, власти Сингапура предъявили обвинения в отмывании средств, полученных незаконным путём, двум гражданам страны, на счетах которых были обнаружены суммы сомнительного происхождения, близкие к $1 млн в каждом из случаев. Кроме того, арест был наложен на особняк стоимостью около $42 млн. Правоохранительные органы Сингапура выразили решительное неприятие попыток поставить под сомнение надёжность страны в качестве международного финансового хаба, обеспечивающего соблюдение всех законных интересов. В прошлом году власти Сингапура уже раскрыли схему нелегальных поставок серверных систем с компонентами американского происхождения в Китай через собственно Сингапур и Малайзию. После совместного расследования с правоохранителями США и Малайзии власти Сингапура выдвинули обвинения в адрес одного гражданина КНР и одного жителя Сингапура, касающиеся покупок санкционной продукции по подложным документам. В общей сложности по этим эпизодам обвинения выдвинуты четырём подозреваемым, трое из которых являются гражданами Сингапура, а четвёртый имеет китайское гражданство. Следствие ведётся также в отношении фирм, к которым эти четверо имеют отношение. В материалах дела фигурируют серверные системы Dell, Supermicro и Asus. Обвиняемые вводили поставщиков оборудования в заблуждение относительно конечного пользователя этих серверных систем, как утверждает следствие. Кроме того, одного из подозреваемых обвиняют в легализации доходов, полученных незаконным путём, на сумму как минимум $4,5 млн. Предполагается, что эти деньги он направил на покупку дома стоимостью $42 млн. Если вина подозреваемых будет доказана, им грозят тюремные сроки до 20 лет и штрафы до $387 000. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



