|
Опрос
|
реклама
Быстрый переход
Китайская Shanghai Xingshu Tiansuan запустила первые спутники для вычислений в космосе раньше Илона Маска
19.07.2026 [17:04],
Владимир Мироненко
Китайская компания Shanghai Xingshu Tiansuan Space Technology («дочка» Junda Shares) объявила в субботу о запуске первой партии спутников для космической группировки, которая в итоге будет насчитывать 1 тыс. аппаратов на орбите и использоваться для вычислений в космосе, пишет Reuters. 
Источник изображения: Kevin Stadnyk/unsplash.com В Shanghai Xingshu Tiansuan заявили, что запуск знаменует собой шаг к коммерческой эксплуатации первой китайской космической вычислительной сети в рамках проекта Star Pivot Plan, анонсированного на конференции 2026 World Artificial Intelligence Conference. Подобно SpaceX Илона Маска (Elon Musk) китайская компания планирует разместить вычислительные мощности в космосе. В частности, они будут использоваться для обработки данных, поступающих с космических аппаратов на орбите, включая задачи ИИ и результаты дистанционного зондирования, вместо того, чтобы отправлять их для обработки на Землю. Это позволит ускорить обработку информации и снизить нагрузку на наземную инфраструктуру. Согласно информации на веб-сайте Shanghai Xingshu Tiansuan, группировка спутников Tiansuan Constellation — это открытая платформа для спутниковых исследований. Проект предполагается реализовать в три этапа. Первый этап включает отправку шести спутников, второй — запуск 24 спутников, третий — расширение группировки ещё на 300 спутников. Похожие проекты в Китае разрабатывает ещё ряд компаний. В частности, в рамках проекта компании Beijing Zhongke Tiansuan Technology и ещё одного проекта Three-Body Computing Constellation, возглавляемого исследовательским центром Zhejiang Lab, предполагается создание в ближайшие годы крупномасштабных вычислительных сетей на орбите. ИИ спроектировал устройство для объединения в кластер трёх материнских плат от ноутбуков Framework
14.07.2026 [11:13],
Павел Котов
Искусственный интеллект может давать сомнительные результаты в решении некоторых задач, но с другими он справляется вполне достойно. Это доказала модель Anthropic Claude Fable, которая спроектировала 3D-макет кластера для трёх материнских плат Framework. 
Источник изображений: x.com/dsp_ Проект реализовал инженер Anthropic Дэвид Сория Парра (David Soria Parra), который поставил Claude Fable задачу спроектировать корпус для кластера из трёх материнских плат от 13-дюймовых ноутбуков Framework. Такие платы продаются отдельно или могут быть извлечены из готового устройства. На практике этот кластер, вероятно, будет использоваться для создания системы из нескольких ПК, сервера или чего-то подобного.  Энтузиаст работал над проектом как минимум с начала июня, подключив облачную среду проектирования Autodesk Fusion (Fusion 360) к искусственному интеллекту через MCP-сервер — стандартный интерфейс, позволяющий большим языковым моделям взаимодействовать со сторонним ПО. Инженер поделился снимком результата: три платы Framework установлены в напечатанную на 3D-принтере раму; предусмотрены вырез для радиатора и место для тепловой трубки. 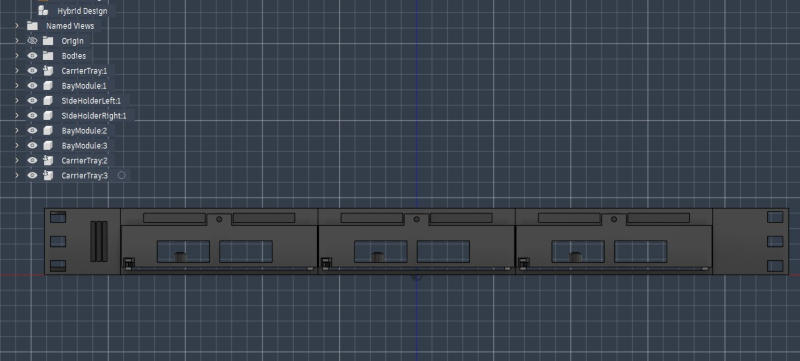 «Я подключил MCP-сервер к Fusion 360 и использовал Claude Code с динамическими рабочими процессами. Claude создал файл проекта Fusion и STL-файлы для каждого компонента, так что к печати было всё готово. ИИ, кроме того, подготовил список необходимых для закупки комплектующих», — рассказал автор проекта. Процесс был сформирован по схеме «от Claude прямо на печать», хотя для получения готового изделия потребовались 2–3 итерации взаимодействия с моделью.  Главный вопрос теперь, вероятно, состоит в том, насколько эффективно система будет работать на практике и до каких температур будут нагреваться её компоненты. В Китае запустили ИИ-кластер протяжённостью 2000 км — его строили больше 10 лет
12.12.2025 [19:30],
Геннадий Детинич
В начале декабря в Китае официально запустили крупнейшую в мире распределённую вычислительную платформу для искусственного интеллекта — Future Network Test Facility (FNTF), протяжённость которой составила 2000 км. Проект создавался свыше десяти лет в рамках национального плана по строительству ключевой научно-технической инфраструктуры 2013 года. Поистине, это крупнейшая в мире система такого рода, которая ускорит развитие ИИ в Поднебесной. 
Источник изображения: ИИ-генерация Grok 4.1/3DNews Платформа FNTF объединяет дата-центры в 40 городах Китая. Специально разработанная оптическая линия связи позволяет удалённым вычислительным центрам работать как единый суперкомпьютер с эффективностью 98 %, лишь незначительно уступая по этому показателю локальным ЦОД. Технические характеристики FNTF впечатляют: оптическая сеть протяжённостью свыше 55 000 км (достаточно, чтобы обогнуть экватор 1,5 раза) обеспечивает сверхнизкую задержку, почти нулевые потери пакетов и гарантированную пропускную способность. Платформа поддерживает одновременную работу 128 разнородных сетевых операций и до 4096 параллельных сервисов. Команда проекта разработала 206 стандартов и получила 221 патент, включая создание первой в мире распределённой операционной системы для сверхкрупных сетей. На церемонии запуска продемонстрировали передачу 72 Тбайт данных с радиотелескопа FAST (на данный момент — крупнейшего в мире со сплошной антенной) на расстояние 1000 км — из Гуйчжоу в Ухань — за 1,6 часа вместо 699 дней по обычному интернету. Разработчики отметили, что обучение модели ИИ с сотнями миллиардов параметров на кластере требует более 500 000 циклов обработки, каждый из которых в этой сети занимает всего 16 секунд. В случае использования обычного интернета каждый цикл продолжался бы на 20 секунд дольше. Таким образом, обучение больших языковых моделей на FNTF в каждом случае сократится на многие месяцы. В будущем сеть FNTF будет открыта для широкого использования китайскими компаниями, однако на первом этапе она будет задействована преимущественно для решения научных задач. В Сколково открылся первый в России кластер геймдева и анимации — от генерации идей до экспорта игр
06.12.2025 [18:44],
Павел Котов
В Москве открыли первую очередь первого в России кластера видеоигр и анимации. На объекте есть всё для полного цикла создания игр и трёхмерного контента — он появления идеи до вывода готового продукта на международные рынки. Открытие кластера обещает стать значимым событием для отечественных студий, технологических компаний и образования, пишет «Лента.ру». 
Источник изображений: lenta.ru Объект расположен в пятиэтажном здании на улице Николы Теслы, его площадь составляет более 55 тыс. м². Некоторые российские студии — разработчики уже готовятся к переезду сюда; помимо собственно производства, на площадке они планируют проводить мероприятия и обучающие программы, встречаться с представителями бизнеса и студенчеством, потому что здесь есть всё необходимое оборудование. В кластере профессионалы смогут обмениваться наработками и договариваться о совместных проектах.  Пространство создавалось как центр для поддержки отечественных разработчиков на всех этапах — от подготовки кадров до вывода продукции на экспорт. Компании смогут участвовать в международных выставках, заключать соглашения с зарубежными партнёрами. Партнёрами проекта выступили 24 компании, включая таких гигантов как «Сбер», VK, МТС и Институт развития интернета (ИРИ). Вторая очередь откроется в 2026 году — общая площадь кластера увеличится до 129 тыс. м².  Особенно важны подобные площадки для молодых студий, которым требуется заключать новые соглашения, работать над коммерческими проектами и покорять мировой рынок. Резиденты кластера смогут оперативно получать доступ к конкурсам ИРИ — он покрывает до 70 % бюджета проектов, но первые средства всегда находить очень непросто. Пространство для совместной работы поможет разрешить эти сложности — налоговые и территориальные льготы дополняются городскими услугами и инфраструктурой. Маск пообещал дешёвые ИИ-серверы в космосе через пять лет — Хуанг назвал эти планы «мечтой»
21.11.2025 [18:29],
Сергей Сурабекянц
Помимо стоимости оборудования, требования к электроснабжению и отведению тепла станут одними из основных ограничений для крупных ЦОД в ближайшие годы. Глава X, xAI, SpaceX и Tesla Илон Маск (Elon Musk) уверен, что вывод крупномасштабных систем ИИ на орбиту может стать гораздо более экономичным, чем реализация аналогичных ЦОД на Земле из-за доступной солнечной энергии и относительно простого охлаждения. 
Источник изображений: AST SpaceMobile «По моим оценкам, стоимость электроэнергии и экономическая эффективность ИИ и космических технологий будут значительно выше, чем у наземного ИИ, задолго до того, как будут исчерпаны потенциальные источники энергии на Земле, — заявил Маск на американо-саудовском инвестиционном форуме. — Думаю, даже через четыре-пять лет самым дешёвым способом проведения вычислений в области ИИ будут спутники с питанием от солнечных батарей. Я бы сказал, не раньше, чем через пять лет». Маск подчеркнул, что по мере роста вычислительных кластеров совокупные требования к электроснабжению и охлаждению возрастают до такой степени, что наземная инфраструктура с трудом справляется с ними. Он утверждает, что достижение непрерывной выработки в диапазоне 200–300 ГВт в год потребует строительства огромных и дорогостоящих электростанций, поскольку типичная атомная электростанция вырабатывает около 1 ГВт. Между тем, США сегодня вырабатывают около 490 ГВт, поэтому использование львиной её доли для нужд ИИ невозможно. Маск считает, что достижение тераваттного уровня мощности для питания наземных ЦОД нереально, зато космос представляет заманчивую альтернативу. По мнению Маска, благодаря постоянному солнечному излучению, аккумулирование энергии не требуется, солнечные панели не требуют защитного стекла или прочного каркаса, а охлаждение происходит за счёт излучения тепла. Глава Nvidia Дженсен Хуанг (Jensen Huang) признал, что масса непосредственно вычислительного и коммуникационного оборудования внутри современных стоек Nvidia GB300 исчезающе мала по сравнению с их общей массой, поскольку почти вся конструкция — примерно 1,95 из 2 тонн — по сути, представляет собой систему охлаждения. Но, кроме веса оборудования, существуют и другие препятствия. Теоретически космос — хорошее место как для выработки энергии, так и для охлаждения электроники, поскольку в тени температура может опускаться до -270 °C. Но под прямыми солнечными лучами она может достигать +125 °C. На околоземных орбитах перепады температур не столь экстремальны:
Низкая и средняя околоземные орбиты не подходят для космических ЦОД из-за нестабильной освещённости, значительных перепадов температур, пересечения радиационных поясов и регулярных затмений. Геостационарная орбита лучше подходит для этой цели, но и там эксплуатация мощных вычислительных кластеров столкнётся с множеством проблем, главная из которых — охлаждение. В космосе отвод тепла возможен только при помощи излучения, что потребует монтажа огромных радиаторов площадью в десятки тысяч квадратных метров на систему мощностью несколько гигаватт. Вывод на геостационарную орбиту такого количества оборудования потребует тысяч запусков тяжёлых ракет класса Starship.  Не менее важно, что ИИ-ускорители и сопутствующее оборудование в существующем виде не способны выдержать воздействие радиации на геостационарной орбите без мощной защиты или полной модернизации конструкции. Кроме того, высокоскоростное соединение с Землёй, автономное обслуживание, предотвращение столкновения с мусором и обслуживание робототехники пока находится в зачаточном состоянии, учитывая масштаб предлагаемых проектов. Так что скорее всего Хуанг прав, когда называет затею Маска «мечтой». Мечтает о выводе масштабных вычислительных кластеров не только Маск. В октябре основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) в ходе мероприятия Italian Tech Week в Турине (Италия) поделился своим видением развития индустрии космических дата-центров. По его мнению, такие объекты обеспечат ряд значительных преимуществ по сравнению с наземными ЦОД. В сентябре компания Axiom Space с партнёрами сообщила о создании первого орбитального дата-центра, который разместился на МКС. Этот ЦОД будет обслуживать не только станцию, но также любые спутники с оптическими терминалами на борту. В мае Китай вывел на орбиту Земли 12 спутников будущей космической группировки Star-Compute Program, которая в перспективе будет состоять из 2800 спутников. Все они оснащены системами лазерной связи и несут мощные вычислительные платформы — по сути, это первый масштабный ЦОД с ИИ в космосе. Компания Crusoe намерена развернуть свою облачную платформу на спутнике Starcloud запуск которого запланирован на конец 2026 года. Ограниченный доступ к ИИ-мощностям в космосе должен появиться к началу 2027 года Google рассказала об инициативе Project Suncatcher, предусматривающей использование группировок спутников-ЦОД на основе фирменных ИИ-ускорителей. Спутники будут связаны оптическими каналами. Huawei представит технологию, позволяющую выжать из дефицитных ИИ-чипов максимум
17.11.2025 [14:37],
Алексей Разин
Первичный успех DeepSeek доказывает, что китайские компании в условиях санкций США пытаются добиться прогресса в сфере искусственного интеллекта за счёт более эффективного использования имеющихся ограниченных вычислительных ресурсов. Huawei в эту пятницу намеревается представить очередное программное решение, позволяющее поднять степень загрузки GPU и управлять кластерами на базе разнородных чипов. 
Источник изображения: Huawei Technologies Об этом сообщает South China Morning Post со ссылкой на китайское издание Shanghai Securities News. В конце этой рабочей недели Huawei должна принять участие в отраслевой конференции, посвящённой искусственному интеллекту, компания рассчитывает представить новейшую технологию оптимизации использования вычислительных ресурсов. Уровень их загрузки удастся поднять до 70 % с нынешних 30–40 %, и в конечном итоге это будет способствовать более эффективному использованию инфраструктуры искусственного интеллекта в КНР. Более того, новое программное обеспечение Huawei позволит управлять вычислительными ресурсами нескольких кластеров, основанных на чипах разных поставщиков: Huawei, Nvidia и менее известных китайских разработчиков. По сути, это позволит ускорить процесс импортозамещения в китайской ИИ-отрасли, поскольку сейчас многие владельцы вычислительных мощностей сопротивляются переходу на китайские ускорители. Их соседство с привычными компонентами Nvidia позволит сделать процесс более плавным и менее болезненным. Подобную унифицированную платформу для управления разнородными вычислительными ресурсами ранее уже предлагала компания Ran:ai, которую в 2024 году за $700 млн купила американская Nvidia. Google выпустила Arm-процессоры Axion и тензорный ускоритель Ironwood для обучения и запуска огромных ИИ-моделей
06.11.2025 [19:52],
Сергей Сурабекянц
Сегодня Google представила новые процессоры Axion и тензорные ускорители Ironwood — TPU седьмого поколения. По словам компании, чипы Axion на 50 % производительнее и на 60 % энергоэффективнее современных x86-процессоров, а TPU Ironwood — самый производительный и масштабируемый настраиваемый ИИ-ускоритель на сегодняшний день и первый среди чипов Google, разработанный специально для запуска обученных ИИ-моделей (инференса). 
Источник изображений: Google TPU Ironwood будет поставляться в системах в двух конфигурациях: с 256 или с 9216 чипами. Один ускоритель обладает пиковой вычислительной мощностью 4614 Тфлопс (FP8), а кластер из 9216 чипов при энергопотреблении порядка 10 МВт выдаёт в общей сложности 42,5 Эфлопс. Эти показатели значительно превосходят возможности системы Nvidia GB300 NVL72, которая составляет 0,36 Эфлопс с операциях FP8. 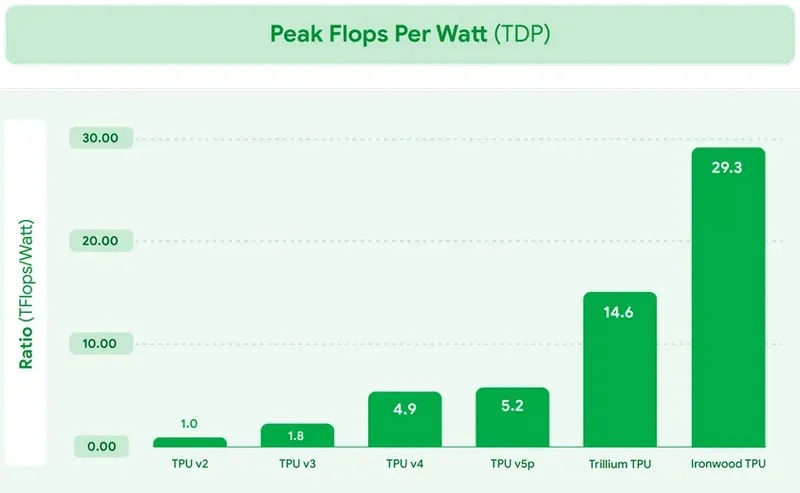 Ironwood оснащён усовершенствованным блоком SparseCore, предназначенным для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. Расширенная реализация SparseCore в Ironwood позволяет ускорить более широкий спектр рабочих нагрузок, выйдя за рамки традиционной области ИИ в финансовые и научные сферы. Модули объединяются между собой с помощью фирменной сети Inter-Chip Interconnect со скоростью 9,6 Тбит/с и содержат около 1,77 Пбайт памяти HBM3E, что также превосходит возможности конкурирующей платформы Nvidia. Они могут быть объединены в кластеры из сотен тысяч TPU.  Это интегрированная суперкомпьютерная платформа, которую Google называет «ИИ-гиперкомпьютер» объединяет вычисления, хранение данных и сетевые функции под одним уровнем управления. Для повышения надёжности, Google использует реконфигурируемую матрицу Optical Circuit Switching, которая мгновенно обходит любые аппаратные сбои для поддержания непрерывной работы.  По данным IDC, этот «гиперкомпьютер ИИ» обеспечивает среднюю окупаемость инвестиций (ROI) в течение трёх лет на уровне 353 %, снижение расходов на ИТ на 28 % и повышение операционной эффективности на 55 %. Несколько компаний уже внедряют эту платформу Google. Anthropic планирует использовать до миллиона TPU для работы и расширения семейства моделей Claude, ссылаясь на значительный выигрыш в соотношении цены и производительности. Lightricks начала развёртывание Ironwood для обучения и обслуживания своей мультимодальной системы LTX-2.  Полные спецификации универсальных процессоров Axion пока не опубликованы, в частности, не раскрыты тактовые частоты и использованный техпроцесс. Сообщается, что процессоры располагают 2 Мбайт кэша второго уровня на ядро, 80 Мбайт кэша третьего уровня, поддерживают память DDR5-5600 МТ/с и технологию Uniform Memory Access (UMA). Известно, что Axion построен на платформе Arm Neoverse v2 и должен обеспечить до 50 % более высокую производительность и до 60 % более высокую энергоэффективность по сравнению с современными процессорами x86. По словам Google, он также на 30 % быстрее, чем «самые быстрые универсальные экземпляры на базе Arm, доступные сегодня в облаке».  Процессоры Axion могут использоваться как в серверах искусственного интеллекта, так и в серверах общего назначения для решения различных задач. На данный момент Google предлагает три конфигурации Axion: C4A, N4A и C4A Metal. C4A обеспечивает до 72 виртуальных процессоров, 576 Гбайт памяти DDR5 и сетевое подключение со скоростью 100 Гбит/с в сочетании с локальным хранилищем Titanium SSD объёмом до 6 Тбайт. Экземпляр оптимизирован для стабильно высокой производительности в различных приложениях. Это единственный чип, который доступен уже сегодня. 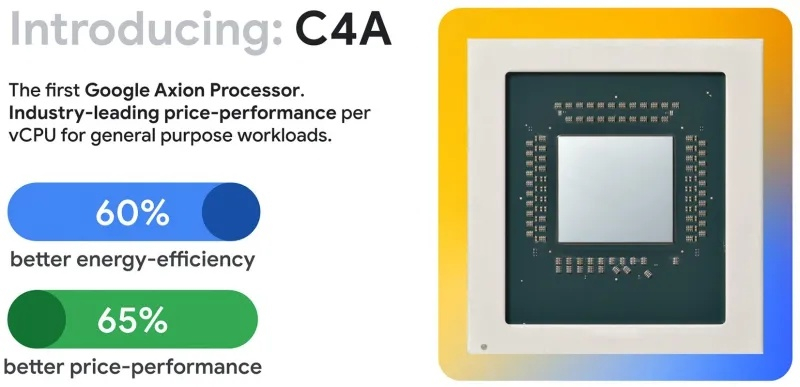 N4A предназначен для общих рабочих нагрузок, таких как обработка данных, веб-сервисы и среды разработки, но масштабируется до 64 виртуальных ЦП, 512 Гбайт оперативной памяти DDR5 и сетевой пропускной способности 50 Гбит/с. C4A Metal предоставляет клиентам полный аппаратный стек Axion: до 96 виртуальных ЦП, 768 Гбайт памяти DDR5 и сетевую пропускную способность 100 Гбит/с. Экземпляр предназначен для специализированных или ограниченных по лицензии приложений, а также для разработки на базе ARM. Процессор Axion дополняет портфолио специализированных чипов компании, а TPU Ironwood закладывает основу для конкуренции с лучшими ускорителями ИИ на рынке. Серверы на базе Axion и Ironwood оснащены фирменными контроллерами Titanium, которые разгружают процессор от сетевых задач, задач безопасности и обработки ввода-вывода, обеспечивая более эффективное управление и, как следствие, более высокую производительность. Американские ЦОД начали применять реактивные авиадвигатели, отчаявшись получить достаточно энергии из розетки
23.10.2025 [14:08],
Павел Котов
Темпы роста вычислительных мощностей для систем искусственного интеллекта опережают темпы развития энергосистем, и центрам обработки данных приходится подключать генераторы с реактивными турбинами — их мощности хватает, чтобы поддерживать работоспособность кластеров. 
Источник изображения: proenergyservices.com На объектах в Техасе уже развёртываются установки на базе двигателей General Electric CF6-80C2 и LM6000 — когда-то эти турбины использовались на самолётах Boeing 767 и Airbus A310. ProEnergy и Mitsubishi Power превратили их в модульные генераторы с быстрым запуском, каждый из которых выдаёт до 48 МВт, и этого достаточно для поддержания работы крупного кластера ИИ, пока готовится подключение к традиционной инфраструктуре. Авиационные двигатели устанавливаются на автоприцепы и могут за считанные минуты выходить на максимальную мощность — они быстрые, шумные и отнюдь не элегантные, но справляются со своими задачами. Это не самый дешёвый и не самый экологически чистый способ запитать серверные стойки, но вполне жизнеспособное решение для компаний, которые стремятся оперативно добиться результатов в области ИИ и не ждать несколько лет, пока местные подстанции смогут предоставить им нужную мощность. Подобные генераторы уже не первое десятилетие работают на американских военных объектах и на морских буровых установках, и использование их опыта в технологической сфере наглядно иллюстрирует, насколько напряжённой стала ситуация с энергоснабжением в США. В рамках проекта OpenAI Stargate в Техасе уже развёртываются 30 блоков LM2500XPRESS, каждый из которых выдаёт до 34 МВт. Тепловая эффективность генераторов на реактивных двигателях минимальна — они работают в режиме простого цикла, при котором топливо сжигается, а отходящее тепло не улавливается. Топливо для них подвозит грузовой транспорт, и приходится выделять ресурсы для очистки выхлопа, чтобы соответствовать экологическим нормам. Но с учётом потребностей в сотни мегаватт электроэнергии и сроков до пяти лет, которые обещают энергетические операторы для подключения к сети, следует ожидать, что альтернативные решения будут заявлять о себе всё чаще. Huawei пообещала создать «самый мощный в мире» ИИ-кластер, который в разы превзойдёт решения Nvidia
18.09.2025 [20:36],
Сергей Сурабекянц
Huawei наращивает мощности своих вычислительных систем для ИИ на фоне трудностей Nvidia в Китае. Компания заявила, что её новые кластеры из ИИ-ускорителей Ascend 950 на базе чипов собственной разработки станут самыми мощными в мире. Эксперты полагают, что Huawei может преувеличивать свои технические возможности, но признают, что её амбиции стать мировым лидером в области искусственного интеллекта «нельзя недооценивать».  Китайский телекоммуникационный гигант Huawei сегодня анонсировал новые вычислительные системы для искусственного интеллекта на базе собственных чипов Ascend, усиливая давление на американского конкурента Nvidia. Компания заявила, что планирует запустить свой новый суперкластер на базе Atlas 950 уже в следующем году. До конца 2028 года Huawei намерена выпустить три новых поколения чипов Ascend, удваивая их мощность с каждым годом. Эти чипы составляют основу вычислительной инфраструктуры Huawei для искусственного интеллекта, в которой суперкластер объединяет несколько супермодулей, которые, в свою очередь, построены из суперузлов. В основе каждого суперузла лежат чипы Ascend. Huawei утверждает, что её новый суперузел будет поддерживать 8192 чипа Ascend 950, а суперкластер будет использовать более 500 000 таких чипов. Когда у Huawei появится более продвинутая версия ускорителя, Atlas 960, запуск которой запланирован на 2027 год, в один узел можно будет объединить 15 488 чипов, а полный суперкластер благодаря этому будет содержать более одного миллиона чипов Ascend. Пока неясно, как эти кластеры будут соотноситься с системами на базе чипов Nvidia. В пресс-релизе Huawei заявлено, что новые суперузлы станут самыми мощными в мире по вычислительной мощности в течение нескольких лет. Председатель совета директоров Huawei Эрик Сюй (Eric Xu), заявил, что суперузел на базе Atlas 950 обеспечит в 6,7 раза большую вычислительную мощность, чем система Nvidia NVL144, запуск которой также запланирован на следующий год. Сюй также пообещал, что суперкластер Atlas 950 будет обладать в 1,3 раза большей вычислительной мощностью, чем суперкомпьютер xAI Colossus Илона Маска (Elon Musk). 
Источник изображения: Huawei В апреле 2025 года исследовательская компания SemiAnalysis сообщила, что разработанная Huawei система CloudMatrix оказалась производительнее, чем Nvidia GB200 NVL72, несмотря на то, что каждый чип Ascend обеспечивал лишь около трети производительности процессора Nvidia. Huawei добилась преимущества благодаря пятикратному увеличению числа чипов. Два года назад Huawei анонсировала свой суперкластер Atlas 900. Компания развернула более 300 таких суперузлов для более чем двадцати крупных клиентов в телекоммуникационной, производственной и других отраслях. США стремятся отрезать Китай от самых передовых технологий для обучения моделей искусственного интеллекта. Чтобы справиться с этой проблемой, китайские компании стали чаще объединять большое количество менее эффективных, часто отечественных, чипов для достижения схожих вычислительных возможностей. Объявление Huawei было сделано на фоне продвижения Китаем собственных альтернатив чипам Nvidia. На днях китайский регулятор объявил о продлении расследования в отношении Nvidia в связи с предполагаемой монополистической практикой. Ранее правительство Китая настоятельно рекомендовало местным технологическим гигантам прекратить испытания и заказы на чип Nvidia RTX Pro 6000D, разработанный специально для Китая. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что он «разочарован» новостью об этом запрете. Ранее он называл Huawei «грозным» конкурентом. Xiaomi построит собственный ИИ-суперкомпьютер на 10 000 GPU
27.12.2024 [10:09],
Алексей Разин
Компания Xiaomi уже располагает собственной вычислительной инфраструктурой для создания систем искусственного интеллекта и намерена значительно её расширить. Компания рассчитывает использовать для этих нужд кластер из 10 000 ускорителей вычислений на базе GPU. 
Источник изображения: Xiaomi По информации Jiemian Global, команда специалистов Xiaomi в области искусственного интеллекта была создана ещё в 2016 году, за последующие семь лет её штат увеличился в шесть раз до более чем 3000 человек. С текущего года в распоряжении этих специалистов находятся около 6500 ускорителей вычислений на базе GPU, с помощью которых они получили возможность обучать большие языковые модели. Смартфоны, Интернет вещей, робототехника и электромобили — вот те сферы деятельности, в которых Xiaomi собирается применять соответствующие наработки. Генеральный директор Xiaomi Лэй Цзюнь (Lei Jun) лично курирует развитие направления искусственного интеллекта в компании. При этом с точки зрения ассортимента аппаратных решений призывает не распыляться на некоторые модные тенденции, включая очки дополненной реальности, а сосредоточиться на тех же смартфонах. Впрочем, он делает большие ставки и на сегмент электромобилей, рассчитывая превратить Xiaomi в одного из пяти крупнейших автопроизводителей мира через несколько лет. Со следующего года компанию дебютной модели SU7 составит кроссовер YU7, слухи также приписывают Xiaomi намерения разработать собственный процессор для смартфонов. Илон Маск показал суперкомпьютер Dojo для обучения автопилота Tesla — он эквивалентен 8000 ИИ-ускорителей Nvidia H100
24.07.2024 [16:59],
Павел Котов
Запустив Memphis Supercluster — «самый мощный в мире кластер для обучения искусственного интеллекта», Илон Маск (Elon Musk) также поделился снимком ещё одного суперкомпьютера одной из своих компаний. Это система Dojo, построенная на разработанных Tesla ускорителях Dojo D1, которая будет обучать автопилот для электромобилей. В ходе квартального отчёта Маск также сообщил, что удвоит усилия по разработке и развёртыванию Dojo из-за высоких цен на продукцию Nvidia. 
Источник изображений: x.com/elonmusk Маск пообещал до конца года запустить Dojo D1. Производительность этого кластера эквивалентна 8000 ускорителей Nvidia H100, что, по мнению бизнесмена, «не очень много, но и не мелочь». Для сравнения, открытый в Теннеси суперкомпьютер xAI для обучения ИИ в итоге будет оперировать 100 тыс. ускорителями Nvidia H100. Маск впервые представил гигантские чипы Dojo D1 в 2021 году — их целевая производительность составляет 322 Тфлопс. В августе прошлого года Tesla занялась поиском старшего инженера по программе технических работ в центре обработки данных — это один из первых шагов, которые обычно предпринимаются организацией при планировании запуска собственного ЦОД. В сентябре Tesla также увеличила объёмы заказов на Dojo D1, что свидетельствует об уверенности компании в продукте. В мае стало известно, что их массовое производство уже идёт.  Похоже, теперь эти ускорители прибыли в США, и Маск уже поделился снимками суперкомпьютера Dojo. Чип Dojo D1 представляет собой процессор типа «система на пластине» в массиве 5 × 5. То есть 25 сверхпроизводительных кристаллов выполнены на одной пластине и соединены между собой с использованием технологии TSMC InFO (Integrated Fan-Out) — они работают как единый процессор и оказываются эффективнее аналогичных многопроцессорных машин. Предприятие в Теннесси принадлежит xAI и используется преимущественно для обучения большой языковой модели Grok, а чипы Dojo ориентированы на видеообучение и будут применяться для работы над технологией автопилота. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



