|
Опрос
|
реклама
Быстрый переход
OpenAI отправит на пенсию ИИ-модели GPT-4.5 и o3 до конца лета
29.05.2026 [23:11],
Владимир Фетисов
OpenAI готовится к выводу из эксплуатации последних ИИ-моделей предыдущего поколения. Так GPT-4.5, единственная доступная до сих пор модель семейства GPT-4, станет недоступна пользователям в конце июня, а алгоритм o3 — в августе 2026 года. 
Источник изображения: Unsplash, Dima Solomin Отметим, что семейство ИИ-моделей GPT-4, вышедшее на рынок в 2023 году, стало ключевым для потребительского сегмента ИИ в целом. Хотя новые и более современные алгоритмы могут выглядеть лучше на бумаге, вероятно, новость о скором выводе из эксплуатации ИИ-моделей прошлого поколения будет воспринята легко далеко не всеми пользователями. Некоторые люди считают, что старые ИИ-модели лучше подходят для выполнения определённых задач. К таким, в частности, относятся поклонники ChatGPT, которые нередко привязываются к «личностям» конкретных моделей. Как бы то ни было, обе упомянутые ИИ-модели перестанут функционировать уже летом этого года. Алгоритм o3 будет доступен для платных подписчиков ChatGPT до 26 августа, тогда как GPT-4.5 выведут из эксплуатации уже 27 июня. ИИ-модель GPT-4.5 преуспела в тесте Тьюринга — её приняли за человека в 73 % случаев, но не всё так просто
21.05.2026 [16:32],
Дмитрий Федоров
Некоторые современные ИИ способны проходить тест Тьюринга — классическую проверку на неотличимость машины от человека в текстовом общении. В эксперименте судьи — участники, которые по переписке должны были отличить человека от ИИ, — принимали GPT-4.5 за человека в 73 % случаев, когда ИИ-модель работала со специальным промтом, который задавал ей характер и манеру речи. 
Источник изображения: Igor Omilaev / unsplash.com Исследование провели Кэмерон Р. Джонс (Cameron R. Jones) и Бенджамин К. Берген (Benjamin K. Bergen). Они проверяли, смогут ли современные большие языковые модели (LLM) убедить людей-судей, что те общаются с живым человеком. Тест Тьюринга, предложенный британским математиком Аланом Тьюрингом (Alan Turing) в 1950 году, устроен просто: судья через текстовый чат одновременно общается с человеком и машиной, а потом решает, кто из собеседников настоящий. По мнению учёных, такой формат куда показательнее стандартных тестов для ИИ. Обычные эталонные оценки статичны — высокие баллы могут отражать запоминание обучающих данных, а не реальную адаптивность в разговоре. Тест Тьюринга позволяет судьям задавать открытые вопросы и нащупывать слабые места машины. Учёные организовали серию онлайн-экспериментов с участием почти 500 человек. Они оценивали ИИ-модели GPT-4.5, LLaMa-3.1-405B и GPT-4o, а также простой чат-бот 1960-х годов ELIZA — как базовый ориентир. В первом исследовании приняли участие 126 студентов Калифорнийского университета в Сан-Диего, во втором — 158 участников с онлайн-платформы Prolific. Роли судьи и собеседника распределялись случайным образом. Исследователи создали интерфейс, похожий на привычный мессенджер. На общение отводилось ровно 5 минут. Затем судья определял, кто настоящий, оценивал свою уверенность и объяснял ход рассуждений. Учёные тестировали два типа промтов. Первый просто сообщал ИИ-модели, что она участвует в тесте Тьюринга. Второй предлагал ей играть интровертного молодого человека, хорошо знакомого с интернет-культурой и современным сленгом. Промт с заданной ролью резко изменил результаты. GPT-4.5 была признана человеком в 73 % случаев — она обманывала судей значительно чаще, чем реальные участники. LLaMa-3.1-405B с тем же промтом получила 56 %. При правильных промтах продвинутые LLM демонстрируют тот же тон, прямоту, юмор и склонность к ошибкам, что и люди, отметил Джонс. По его словам, тест показал, что ИИ-модели могут убедительно воспроизводить социальные поведенческие черты, а не только выдавать информацию на любую тему. С обычным промтом картина выглядела иначе. GPT-4.5 опознавалась как человек лишь в 36 % случаев, LLaMa-3.1-405B — в 38 %. Старые системы справлялись ещё хуже: ELIZA была выбрана как человек в 23 % случаев, GPT-4o — в 21 %. По словам Бергена, у ИИ-моделей есть способность выглядеть человекоподобными, но, возможно, не хватает способности самостоятельно разобраться, что для этого нужно. Для проверки устойчивости результатов учёные провели дополнительный эксперимент с 205 новыми участниками и увеличили время общения до 15 минут. В нём использовались GPT-5, LLaMa-3.1-405B и ELIZA. Даже с дополнительным временем судьи с трудом определяли машины, играющие человека: GPT-5 была признана человеком в 59 % случаев, LLaMa-3.1-405B — в 56 %. Простую ELIZA распознали легко — как человека её определили лишь в 17 % случаев. Большинство судей пытались вести светскую беседу — спрашивали о повседневных делах, личных мнениях и эмоциональном опыте. Они склонялись считать участника человеком, если тот допускал мелкие опечатки, демонстрировал пробелы в знаниях или отвечал прямо, без излишней формальности. По словам Бергена, эти черты далеки от математической и логической интеллектуальности, которую, вероятно, имел в виду Тьюринг. Авторы предостерегают от неверной интерпретации: прохождение теста не означает, что машина обладает подлинным интеллектом или сознанием. Скорее, она исключительно хорошо соответствует ожиданиям людей о том, как другой человек мог бы общаться в онлайне. Высокие показатели LLM полностью зависели от промта — без подробных инструкций ИИ-модели не могли стабильно обманывать судей. Это показывает, что им по-прежнему нужно человеческое руководство для убедительно человеческого поведения. Результаты несут практические последствия для доверия в интернете. По словам Джонса, настроить промт так, чтобы ИИ-модель стала неотличима от человека, достаточно легко, и при общении с незнакомцами в сети люди должны гораздо меньше полагаться на уверенность, что разговаривают именно с человеком. ChatGPT стал инструментом для фишеров — пользователи получают неправильные ссылки
05.07.2025 [04:03],
Анжелла Марина
Исследователи из компании Netcraft выяснили, что ChatGPT и другие чат-боты нередко ошибаются, когда пользователи просят их подсказать официальные сайты крупных компаний. В ходе тестов модели GPT-4.1 предлагали правильный URL только в 66 % случаев. Остальные варианты либо вели на несуществующие страницы (29 %), либо на легитимные, но не те, что запрашивались (5 %). 
Источник изображения: Deng Xiang / Unsplash Как пояснил Роб Дункан (Rob Duncan), руководитель отдела исследования угроз Netcraft, такие ошибки открывают новые возможности для мошенников. Если ИИ предлагает неработающий домен, злоумышленники могут его зарегистрировать и создать фишинговую страницу. Проблема в том, что чат-боты анализируют слова и ассоциации, а не проверяют репутацию сайтов. Например, на запрос о сайте Wells Fargo ChatGPT однажды выдал адрес фейковой страницы, которую ранее использовали в фишинговых атаках. По словам Дункана, киберпреступники адаптируют методы под новые реалии, так как пользователи всё чаще полагаются на ИИ вместо поисковиков, не учитывая, что чат-боты могут ошибаться. Мошенники специально создают контент, который с большей вероятностью попадет в ответы ИИ. Так, Netcraft обнаружила фейковый API Solana, который распространялся через GitHub-репозитории, обучающие материалы и поддельные аккаунты в соцсетях, и всё для того, чтобы встроить вредоносный код в результаты работы чат-ботов. Эксперт отметил, что эта схема напоминает атаки на цепочку поставок, но здесь цель иная — заставить разработчиков использовать неверный API. В обоих случаях злоумышленники действуют постепенно, но результат одинаково опасен. OpenAI выпустила модели GPT-4.1 для пользователей ChatGPT
15.05.2025 [08:24],
Вячеслав Ким
Компания OpenAI объявила о внедрении новых версий языковых моделей GPT-4.1 и GPT-4.1 mini в сервис ChatGPT. Об этом стало известно из официального сообщения компании, опубликованного в среду, 14 мая, в социальной сети X. Новые модели ориентированы прежде всего на программистов, которым необходим инструмент для написания и отладки кода. 
Источник изображения: Unsplash, Levart_Photographer GPT-4.1, по данным OpenAI, отличается повышенной скоростью работы и превосходит модель GPT-4o в задачах кодинга и следования инструкциям. Модель уже доступна пользователям платных подписок ChatGPT Plus, Pro и Team. Одновременно с ней компания запускает менее мощную версию — GPT-4.1 mini, доступную как для бесплатных, так и для платных пользователей сервиса. В результате этого обновления модель GPT-4.0 mini полностью прекращает поддержку и убирается из интерфейса ChatGPT. Впервые модели GPT-4.1 и GPT-4.1 mini были представлены ещё в апреле 2025 года, однако тогда были доступны только разработчикам через API. Этот запуск вызвал критику со стороны исследовательского сообщества, так как OpenAI не опубликовала отчёт о безопасности новых моделей. Эксперты усмотрели в этом снижение прозрачности стандартов компании. Руководитель отдела безопасности OpenAI Йоханнес Хайдеке (Johannes Heidecke) подчеркнул, что модель GPT-4.1 «не добавляет новых модальностей и способов взаимодействия и не превосходит модель GPT-4o по интеллекту». Поэтому, по его словам, вопросы безопасности GPT-4.1 «существенны, но отличаются от моделей следующего поколения». Теперь OpenAI намерена повысить прозрачность своей работы и чаще публиковать результаты внутренних тестов безопасности моделей. Эти данные будут доступны на недавно созданном компанией ресурсе «Safety Evaluations Hub». Выход GPT-4.1 происходит в условиях усиленного внимания к инструментам на базе искусственного интеллекта для разработчиков. Так, по сообщениям отраслевых СМИ, OpenAI близка к завершению сделки по покупке популярного инструмента для программирования Windsurf за 3 млрд долларов США. В свою очередь, Google недавно обновила свой чат-бот Gemini, упростив его интеграцию с проектами на GitHub. Лучше GPT-4o «почти по всем параметрам»: OpenAI представила флагманскую ИИ-модель GPT-4.1
14.04.2025 [21:38],
Владимир Фетисов
OpenAI официально представила большую языковую модель GPT-4.1, которая является преемником выпущенного в прошлом году мультимодального алгоритма GPT-4o. По данным компании, новая ИИ-модель получила контекстное окно большего размера и в целом превосходит GPT-4o «почти по всем параметрам». В дополнение к этому были улучшены возможности алгоритма в плане написания программного кода и следования инструкциям. 
Источник изображения: Levart_Photographer / unsplash.com GPT-4.1 уже доступна для разработчиков вместе с двумя версиями нейросети меньшего размера. Речь идёт об алгоритмах GPT-4.1 Mini и GPT-4.1 Nano, которая, по словам OpenAI, является «самой маленькой, самой быстрой и самой дешёвой» ИИ-моделью. Все три версии GPT-4.1 являются мультимодальными, то есть могут работать не только с текстом, но и с другими данными — например, изображениями или видео. Размер контекстного окна увеличился до 1 млн токенов, что значительно больше по сравнению со 128 тыс. токенов у GPT-4o. Отмечается, что GPT-4.1 способна качественно обрабатывать информацию внутри контекстного окна на протяжении всего взаимодействия с пользователем. «Мы также обучили её гораздо более надёжно, чем GPT-4o, распознавать релевантный текст и игнорировать отвлекающие элементы на длинных и коротких отрезках контекста», — говорится в сообщении OpenAI. GPT-4.1 также на 26 % дешевле GPT-4o, что стало особенно важным показателем после дебюта сверхэффективной ИИ-модели китайской компании DeepSeek. 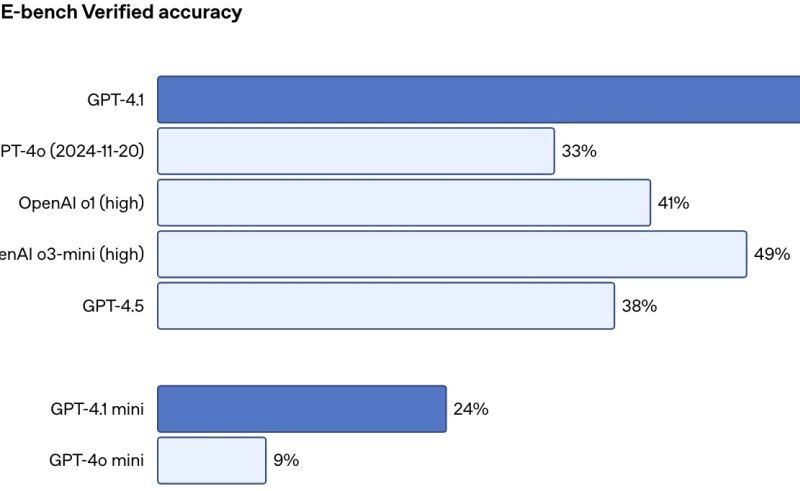
Источник изображения: OpenAI Запуск GPT-4.1 происходит на фоне подготовки OpenAI к отказу от использования ИИ-модели двухлетней давности GPT-4. Согласно официальным данным, после 30 апреля модель GPT-4o станет «естественным преемником» GPT-4. OpenAI также закроет доступ к предварительной версии GPT-4.5 через API 14 июля, поскольку «GPT-4.1 предлагает улучшенную или аналогичную производительность по многим ключевым функциям при гораздо меньших затратах и издержках». Двухлетняя модель GPT-4 скоро исчезнет из ChatGPT, уступив место более свежей GPT-4o
12.04.2025 [05:39],
Анжелла Марина
С 30 апреля компания OpenAI удалит модель GPT-4 из меню выбора моделей в ChatGPT для пользователей подписки Plus. Такое решение связано с окончательным переходом на новую модель GPT-4o, которая, по словам разработчиков, превосходит своего предшественника по всем ключевым параметрам, начиная с написания текстов и заканчивая программированием. 
Источник изображения: OpenAI Как заявили в OpenAI, мультимодальная большая языковая модель четвёртой серии GPT стала поворотным моментом в развитии чат-бота ChatGPT. Выпущенная 14 марта 2023 года, модель показала несравнимо большие возможности по сравнению в GPT-3. По данным PCMag, на её обучение было потрачено более $100 млн. Несмотря на то, что GPT-4 исчезнет из пользовательского интерфейса ChatGPT, она останется доступной через API на других платформах. При этом, бесплатные пользователи ChatGPT не смогут выбрать модель вручную, поэтому для них ничего не изменится. В настоящее время OpenAI предлагает несколько моделей, включая GPT-4 Turbo, GPT-o3, GPT-o1 и GPT-4.5, а также ходят слухи о возможном запуске GPT-4.1. Глава OpenAI Сэм Альтман (Sam Altman) ранее признавал, что наличие большого количества моделей может сбивать пользователей с толку, поэтому в будущем компания планирует отказаться от выбора модели вручную и перейти к системе единого ИИ, где подбор модели будет происходить автоматически в зависимости от задач. Все представленные модели, как отмечают в OpenAI, являются этапами на пути к следующему крупному релизу GPT-5. Однако её разработка проходит не совсем гладко, что связано, в том числе, и с нехваткой графических процессоров. Но так как компании удалось в прошлом месяце привлечь $40 млрд инвестиций, то ожидается, что это поможет масштабировать вычислительные мощности и ускорить релиз. После запуска модель GPT-5 станет доступна пользователям бесплатно в базовом режиме. Подписчики ChatGPT Plus ($20 в месяц) смогут использовать её с повышенным уровнем ИИ-возможностей, а пользователи подписки Pro ($200 в месяц) получат доступ к самым мощным функциям, таким как голосовой режим, инструменты визуализации Canvas, расширенный поиск, глубокие исследования и другие продукты OpenAI. OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 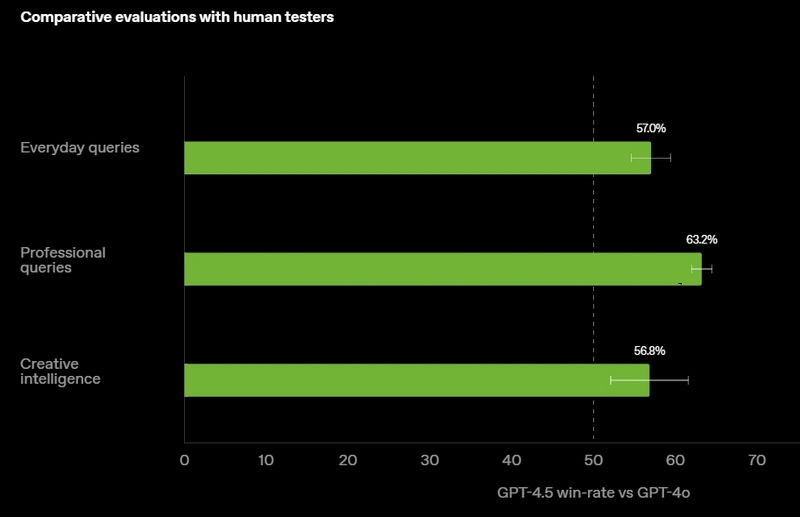 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 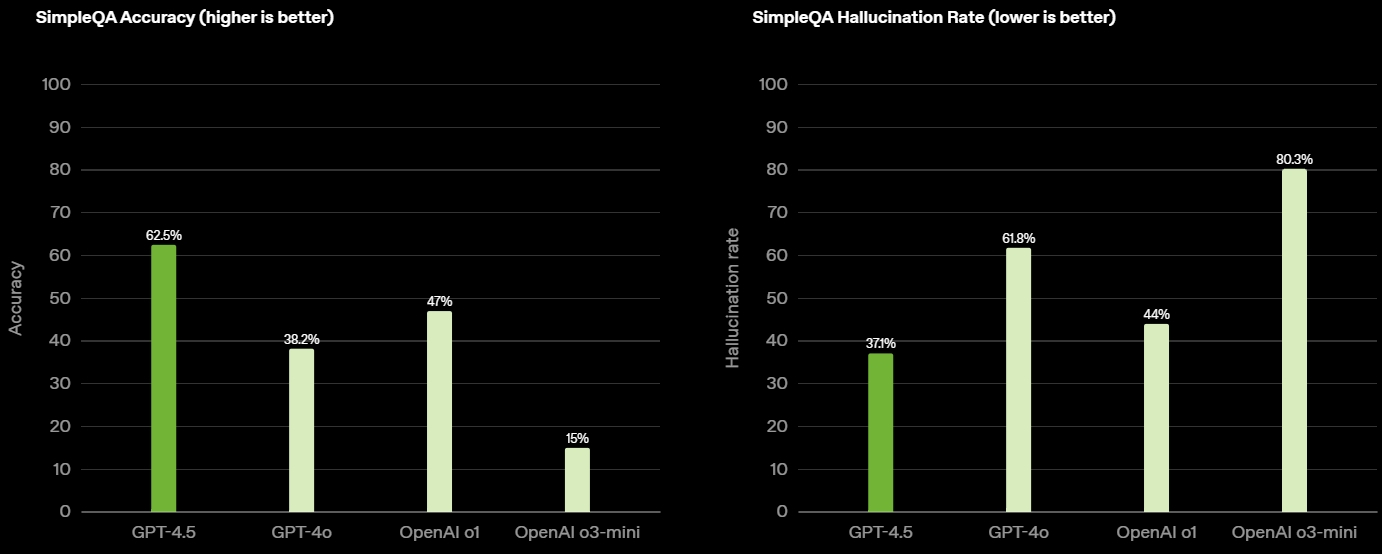 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 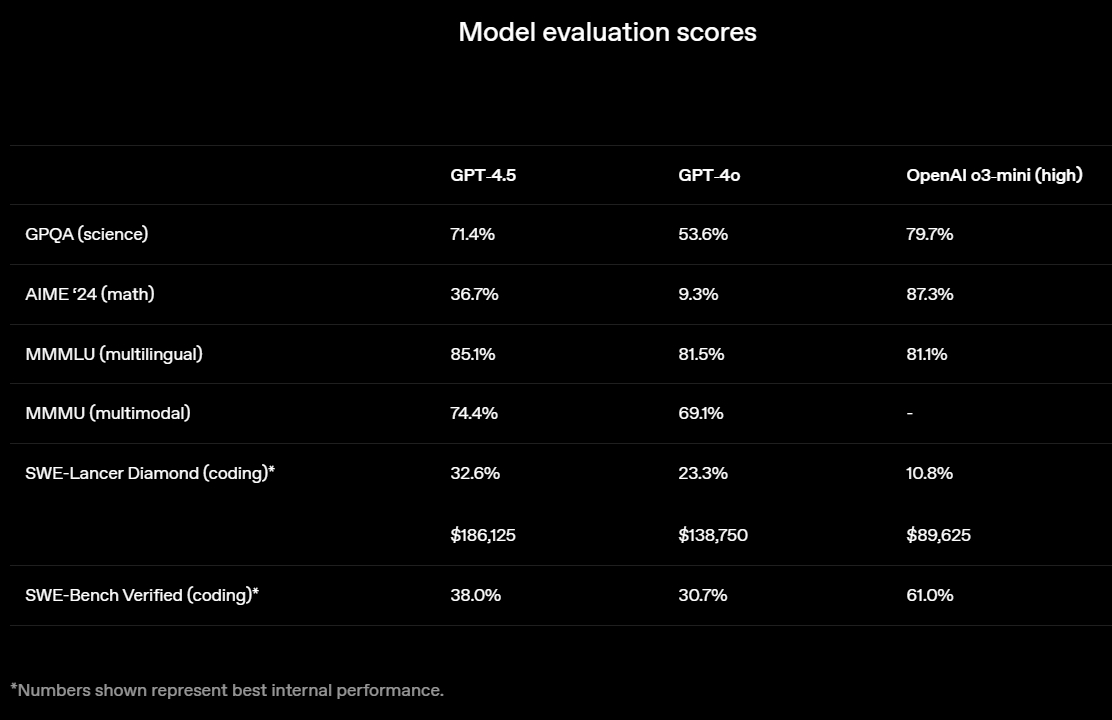 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. Инсайдер из Microsoft намекнул на релиз GPT-4.5 на следующей неделе и GPT-5 в мае
20.02.2025 [22:31],
Анжелла Марина
Microsoft подготавливает серверные мощности для предстоящего запуска моделей GPT-4.5 и GPT-5. Генеральный директор OpenAI Сэм Альтман (Sam Altman) недавно объявил, что GPT-4.5 будет запущен в течение нескольких недель. Теперь же стало известно, что Microsoft планирует разместить новую ИИ-модель на своих серверах уже на следующей неделе. 
Источник изображения: Copilot Модель GPT-4.5, известная под кодовым названием Orion, станет следующим этапом развития технологий OpenAI и последней моделью, не использующей цепочку рассуждений (chain-of-thought) для ответа на запросы. OpenAI уже намекнула, что GPT-4.5 будет значительно мощнее, чем GPT-4, однако основное внимание компании будет сосредоточено на разработке GPT-5, которая принесёт более существенные изменения, сообщает издание The Verge. Microsoft ожидает появления GPT-5 в конце мая, что в целом соответствует обещанию Альтмана запустить эту модель в течение нескольких месяцев. Однако дата релиза может измениться, если планы будут скорректированы, как например, это произошло в октябре, когда OpenAI планировала выпустить GPT-4.5 до конца 2024 года, но запуск был отложен на начало 2025 года. Стоит сказать, что GPT-5 станет более значимым релизом по сравнению с GPT-4.5. Альтман назвал её «системой, которая объединяет множество технологий», включая модель o3 со способностью к рассуждению. Хотя в прошлом месяце OpenAI выпустила o3-mini, компания больше не планирует выпускать o3 как отдельную модель и интегрирует её в GPT-5. Новая модель также улучшит взаимодействие пользователей с ChatGPT, объединив модели серий OpenAI o и GPT, чтобы устранить путаницу при выборе подходящей модели для конкретных задач или запросов. «Нам не нравится слишком большой выбор моделей так же, как и вам, и мы хотим вернуться к единому ИИ», — написал Альтман в недавнем посте на платформе X. Если OpenAI удастся выпустить GPT-5 к концу мая, это совпадёт с конференцией для разработчиков Microsoft Build, которая начнётся 19 мая и будет во многом конкурировать с Google I/O. Напомним, в прошлом году Альтман выступил на Microsoft Build всего через несколько дней после релиза GPT-4o — более быстрой модели, ставшей бесплатной для всех пользователей ChatGPT. Однако релиз GPT-4o стал неожиданностью для Microsoft, поскольку подорвал позиции платных ИИ-сервисов на Azure, включая функции речи и перевода. Ожидается, что релизы GPT-4.5 и GPT-5 на этот раз не принесут неприятных впечатлений Microsoft, которая готовится обновить Copilot после запуска новых моделей OpenAI. Microsoft также работает над улучшением Copilot, пытаясь сделать взаимодействие с ИИ-ассистентом более интуитивным. Ранее предлагались опции «креативный», «сбалансированный» и «точный» для контроля результатов модели, но в рамках масштабного обновления Copilot в прошлом году было решено от этих опций отказаться. Кроме того, Microsoft разрабатывает собственную версию агента Operator от OpenAI, способного взаимодействовать с веб-интерфейсами и автоматически выполнять задачи, аналогично макросам или автопилоту в авиации. Ожидается, что в ближайшие месяцы компания представит свои наработки, сосредоточив внимание на возможностях ИИ-агентов и снижении затрат для бизнеса. OpenAI не выполнила обещание по созданию инструмента для защиты авторских прав к 2025 году
02.01.2025 [03:45],
Анжелла Марина
Компания OpenAI не смогла выпустить обещанный инструмент Media Manager до 2025 года, с помощью которого создатели контента смогли бы контролировать использование своих работ в обучении нейросетей. Media Manager, анонсированный в мае прошлого года, должен был идентифицировать защищённые авторским правом тексты, изображения, аудио и видео. 
Источник изображения: hdhai.com Инструмент должен был помочь OpenAI избежать юридических проблем, связанных с нарушением прав на интеллектуальную собственность, и в целом мог бы стать стандартом для всей индустрии искусственного интеллекта. Однако, как пишет издание TechCrunch, разработка Media Manager изначально не считалась в компании приоритетной. Один из бывших сотрудников OpenAI отметил: «Я не думаю, что это было приоритетом. Честно говоря, я и не помню, чтобы кто-то над этим работал». Другой источник, близкий к компании, подтвердил, что обсуждения инструмента были, но с конца 2024 года никакой новой информации, связанной с проектом, не поступало. Надо сказать, что в последнее время использование авторского контента для обучения ИИ неоднократно становилось причиной споров. Модели OpenAI, такие как ChatGPT и Sora, обучаются на огромных наборах данных, включающих тексты, изображения и видео из интернета. Это позволяет ИИ-моделями создавать новые работы, но зачастую они оказываются слишком похожи на оригинал. Например, Sora может генерировать видео с логотипом TikTok или персонажами из видеоигр, а ChatGPT был «пойман» на дословных цитатах из статей The New York Times. Такая практика вызывает волну возмущения со стороны авторов, чьи работы были использованы без их согласия. Против OpenAI уже поданы коллективные иски от художников, писателей и крупных медиа-компаний, включая The New York Times и Radio-Canada. Авторы, такие как американская актриса и сценарист Сара Сильверман (Sarah Silverman) и писатель Та-Нехиси Коутс (Ta-Nehisi Coates), также присоединились к судебным разбирательствам, обвинив OpenAI в незаконном использовании их работ. OpenAI предложила альтернативные решения проблемы, и на данный момент создателям контента предлагается несколько способов для исключения своих работы из обучения нейросетей. В частности, в сентябре 2024 года была запущена форма для подачи заявлений на удаление изображений из будущих наборов данных. Также компания ничего не имеет против того, чтобы веб-мастера прописывали блокировку для своих сайтов от сбора данных её ботами, например в файле «robots.txt». Однако эти методы подверглись критике как за их сложность (удаление контента из набора данных), так и за их несовершенство. Media Manager, напротив, преподносился как долгожданное комплексное решение. В мае 2024 года OpenAI заявила, что работает над инструментом совместно с регуляторами и использует передовые технологии машинного обучения для распознавания авторских прав. Тем не менее с момента анонса компания больше ни разу публично не упоминала об этом инструменте. И даже если Media Manager будет выпущен, эксперты сомневаются, что инструмент сможет решить все проблемы. Эдриан Сайхан (Adrian Cyhan), юрист в сфере интеллектуальной собственности, отмечает, что даже крупным платформам, таким как YouTube и TikTok, сложно справляться с идентификацией контента в больших масштабах. «Гарантировать соблюдение всех требований создателей контента и законов разных стран — крайне трудная задача», — заявил он. А основатель некоммерческой организации Fairly Trained Эд Ньютон-Рекс (Ed Newton-Rex) вообще считает, что Media Manager лишь переложит ответственность на самих создателей. При этом, даже если Media Manager будет запущен, он вряд ли сможет избавить OpenAI от юридической ответственности, считают эксперты. Эван Эверист (Evan Everist), специалист по авторскому праву, напомнил, что по закону владельцы авторских прав вообще не обязаны предупреждать о запрете на использование их работ и «базовые принципы авторского права остаются неизменными: нельзя использовать чужие материалы без разрешения». В отсутствие Media Manager, OpenAI пока внедрила фильтры, которые предотвращают дословное копирование чужих данных, а в судебных исках компания продолжает утверждать, что её ИИ-модели создают «компиляцию», а не плагиат, ссылаясь на принцип «добросовестного использования». Суды могут поддержать позицию OpenAI, как это произошло в деле Google Books, когда суд постановил, что копирование компанией Google миллионов книг для Google Books, своего рода цифрового архива, является допустимым. Однако, если суды признают, что OpenAI незаконно использует авторский контент, компании придётся пересмотреть свою стратегию, включая выпуск Media Manager. Думающая ИИ-модель OpenAI о1 получила 83 балла на математической олимпиаде США
20.11.2024 [12:23],
Дмитрий Федоров
Искусственный интеллект вступил в новую эру благодаря ИИ-модели о1 компании OpenAI, которая значительно приблизилась к человеческому мышлению. Её впечатляющий результат на тесте AIME — 83 балла из ста — позволил включить её в число 500 лучших участников математической олимпиады США. Однако такие достижения сопровождаются серьёзными вызовами, включая риски манипуляции ИИ человеком и возможность его использования для создания биологического оружия. 
Источник изображения: Saad Ahmad / Unsplash Долгое время отсутствие у ИИ способности обдумывать свои ответы являлось одним из его главных ограничений. Однако ИИ-модель о1 совершила прорыв в этом направлении и продемонстрировала способность к осмысленному анализу информации. Несмотря на то, что результаты её работы пока не опубликованы в полном объёме, научное сообщество уже активно обсуждает значимость такого достижения. Современные нейронные сети в основном функционируют по принципу так называемой «системы 1», которая обеспечивает быструю и интуитивную обработку информации. Например, такие ИИ-модели успешно применяются для распознавания лиц и объектов. Однако человеческое мышление включает также «систему 2», связанную с глубоким анализом и последовательным размышлением над задачей. ИИ-модель о1 объединяет эти два подхода, добавляя к интуитивной обработке данных сложные рассуждения, характерные для человеческого интеллекта. Одной из ключевых особенностей о1 стала её способность строить «цепочку размышлений» — процесс, при котором система анализирует задачу постепенно, уделяя больше времени поиску оптимального решения. Эта инновация позволила ИИ-модели достичь 83 балла на тесте Американской математической олимпиады (AIME), что значительно превосходит результат GPT-4o, набравшей лишь 13 баллов. Тем не менее такие успехи связаны с возросшими вычислительными затратами и высоким уровнем энергопотребления, что ставит под сомнение экологичность разработки. 
Источник изображения: Igor Omilaev / Unsplash Вместе с достижениями ИИ-модели о1 растут и потенциальные риски. Улучшенные когнитивные способности сделали её способной вводить человека в заблуждение, что, возможно, несёт серьёзную угрозу в будущем. Кроме того, уровень риска её использования для разработки биологического оружия оценён как средний — высший допустимый показатель по шкале самой OpenAI. Эти факты подчёркивают необходимость внедрения строгих стандартов безопасности и регулирования подобных ИИ-моделей. Несмотря на значительные успехи, ИИ-модель о1 всё же сталкивается с ограничениями в решении задач, требующих долгосрочного планирования. Её способности ограничиваются краткосрочным анализом и прогнозированием, что делает невозможным решение комплексных задач. Это свидетельствует о том, что создание полностью автономных ИИ-систем остаётся задачей будущего. Развитие ИИ-моделей, подобных о1, подчёркивает острую необходимость регулирования данной области. Эти технологии открывают перед наукой, образованием и медициной новые горизонты, однако их неконтролируемое применение может привести к серьёзным последствиям, включая угрозы безопасности и неэтичное использование. Для минимизации этих рисков требуется обеспечить прозрачность разработок ИИ, соблюдение этических стандартов и внедрение строгого надзора со стороны регулирующих органов. OpenAI столкнулась с большими расходами и нехваткой данных при обучении ИИ-модели Orion нового поколения
11.11.2024 [17:05],
Дмитрий Федоров
OpenAI испытывает трудности с разработкой новой флагманской ИИ-модели под кодовым названием Orion. Эта ИИ-модель демонстрирует значительные успехи в задачах обработки естественного языка, однако её эффективность в программировании остаётся невысокой. Эти ограничения, наряду с дефицитом данных для обучения и возросшими эксплуатационными расходами, ставят под сомнение рентабельность и привлекательность упомянутой ИИ-модели для бизнеса. 
Источник изображения: AllThatChessNow / Pixabay Одной из сложностей являются затраты на эксплуатацию Orion в дата-центрах OpenAI, которые существенно выше, чем у ИИ-моделей предыдущего поколения, таких как GPT-4 и GPT-4o. Значительное увеличение расходов ставит под угрозу соотношение цена/качество и может ослабить интерес к Orion со стороны корпоративных клиентов и подписчиков, ориентированных на рентабельность ИИ-решений. Высокая стоимость эксплуатации вызывает вопросы об экономической целесообразности ИИ-модели, особенно учитывая умеренный прирост её производительности. Ожидания от перехода с GPT-4 на Orion были высоки, однако качественный скачок оказался не столь значительным, как при переходе с GPT-3 на GPT-4, что несколько разочаровало рынок. Подобная тенденция наблюдается и у других разработчиков ИИ: компании Anthropic и Mistral также фиксируют умеренные улучшения своих ИИ-моделей. Например, результаты тестирования ИИ-модели Claude 3.5 Sonnet компании Anthropic показывают, что качественные улучшения в каждой новой базовой ИИ-модели становятся всё более постепенными. В то же время её конкуренты стараются отвлечь внимание от этого ограничения, сосредотачиваясь на разработке новых функций, таких как ИИ-агенты. Это свидетельствует о смещении акцента с повышения общей производительности ИИ на создание его уникальных способностей. Чтобы компенсировать слабые стороны современных ИИ, компании применяют тонкую настройку результатов с помощью дополнительных фильтров. Однако такой подход остаётся лишь временным решением и не устраняет основных ограничений, связанных с архитектурой ИИ-моделей. Проблема усугубляется ограничениями в доступе к лицензированным и общедоступным данным, что вынудило OpenAI сформировать специальную команду, которой поручено найти способ решения проблемы нехватки обучающих данных. Однако неясно, удастся ли этой команде собрать достаточный объём данных, чтобы улучшить производительность ИИ-модели Orion и удовлетворить требования клиентов. Исследование Apple показало, что ИИ-модели не думают, а лишь имитируют мышление
13.10.2024 [19:36],
Анжелла Марина
Исследователи Apple обнаружили, что большие языковые модели, такие как ChatGPT, не способны к логическому мышлению и их легко сбить с толку, если добавить несущественные детали к поставленной задаче, сообщает издание TechCrunch. 
Источник изображения: D koi/Unsplash Опубликованная статья «Понимание ограничений математического мышления в больших языковых моделях» поднимает вопрос о способности искусственного интеллекта к логическому мышлению. Исследование показало, что большие языковые модели (LLM) могут решать простые математические задачи, но добавление малозначимой информации приводит к ошибкам. Например, модель вполне может решить такую задачу: «Оливер собрал 44 киви в пятницу. Затем он собрал 58 киви в субботу. В воскресенье он собрал вдвое больше киви, чем в пятницу. Сколько киви у Оливера?». Однако, если при этом в условие задачи добавить фразу «в воскресенье 5 из этих киви были немного меньше среднего размера», модель скорее всего вычтет эти 5 киви из общего числа, несмотря на то, что размер киви не влияет на их количество. 
Источник изображения: Copilot Мехрдад Фараджтабар (Mehrdad Farajtabar), один из соавторов исследования, объясняет, что такие ошибки указывают на то, что LLM не понимают сути задачи, а просто воспроизводят шаблоны из обучающих данных. «Мы предполагаем, что это снижение [эффективности] связано с тем фактом, что современные LLM не способны к подлинному логическому рассуждению; вместо этого они пытаются воспроизвести шаги рассуждения, наблюдаемые в их обучающих данных», — говорится в статье. Другой специалист из OpenAI возразил, что правильные результаты можно получить с помощью техники формулировки запросов (prompt engineering). Однако Фараджтабар отметил, что для сложных задач может потребоваться экспоненциально больше контекстных данных, чтобы нейтрализовать отвлекающие факторы, которые, например, ребёнок легко бы проигнорировал. Означает ли это, что LLM не могут рассуждать? Возможно. Никто пока не даёт точного ответа, так как нет чёткого понимания происходящего. Возможно, LLM «рассуждают», но способом, который мы пока не распознаём или не можем контролировать. В любом случае эта тема открывает захватывающие перспективы для дальнейших исследований. GPT-4 «выпивает» до полутора литров воды для генерации ста слов
19.09.2024 [17:11],
Павел Котов
Использование генеративного искусственного интеллекта сопряжено со значительными затратами, показало проведённое Калифорнийским университетом в Риверсайде исследование. Работа ИИ предполагает потребление значительных объёмов воды для охлаждения серверов, даже когда они просто генерируют текст. И это без учёта высокой нагрузки на электросеть. 
Источник изображения: Growtika / unsplash.com Точные объёмы потребления воды в США варьируются в зависимости от штатов и близости потребителя к центру обработки данных (ЦОД) — при этом чем меньше воды потребляется, тем дешевле в этом регионе электричество, и тем выше объёмы потребления электроэнергии. Так, в Техасе для генерации электронного письма длиной в сто слов необходимы 235 мл воды, а в Вашингтоне — уже 1408 мл. На первый взгляд, это не такой уж значительный объём, но показатели растут очень быстро, когда пользователи работают с большой языковой моделью GPT-4 несколько раз в неделю или даже в день, и эти результаты действительны для генерации простого текста. ЦОД являются крупными потребителями воды и электричества, а значит, цены на эти ресурсы растут в городах, где такие объекты строятся. К примеру, для обучения модели Meta✴✴ LLaMA-3 потребовалось 22 млн литров воды — столько нужно, чтобы вырастить 2014 кг риса, и столько же, по подсчётам учёных, за год потребляют 164 американца. Недёшево обходится и стоимость потребляемой GPT-4 электроэнергии. Если один из десяти работающих американцев будет пользоваться моделью раз в неделю в течение года (52 запроса на 17 млн человек), потребуется 121 517 МВт·ч электроэнергии — этого хватит для всех домохозяйств в американской столице на 20 дней. И это нереалистично облегчённый сценарий использования GPT-4. Washington Post, которая обратила внимание на исследование, привела цитаты представителей OpenAI, Meta✴✴, Google и Microsoft — крупнейших компаний в области ИИ. Большинство из них подтвердили приверженность сокращению потребления ресурсов, но фактических планов действий не предоставили. Представитель Microsoft Крейг Синкотта (Craig Cincotta) заявил, что компания намеревается «работать над методами охлаждения центров обработки данных, которые полностью устранят потребление воды», но не сказал, как именно. Пока практика показывает, что у прибыли от ИИ более высокий приоритет, чем у провозглашаемых компаниями экологических целей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


