|
Опрос
|
реклама
Быстрый переход
Intel и Nvidia скоро выпустят первые совместные продукты, заверил гендир Тан
11.05.2026 [18:13],
Николай Хижняк
Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) подтвердил, что сотрудничество с Nvidia продолжается, и рынок скоро увидит результаты партнёрства, объявленного двумя компаниями в конце прошлого года. 
Источник изображения: Intel Вчера Университет Карнеги — Меллона присвоил генеральному директору Nvidia Дженсену Хуангу (Jensen Huang) почётную докторскую степень в области науки и технологий за выдающийся вклад в развитие ускоренных вычислений и искусственного интеллекта. Лип-Бу Тан из Intel удостоился чести вручить ему докторскую мантию.  В сообщении в соцсети X генеральный директор Intel подтвердил, что Intel и Nvidia продолжают работать вместе над «новыми интересными продуктами». В прошлом году обе компании подписали соглашение о создании x86-совместимых процессоров со встроенными GPU Nvidia, которые найдут применение не только в серверном сегменте, но и в настольных ПК, а также ноутбуках.  Если это сотрудничество приведёт к появлению реальных продуктов, то для рынка ПК это будет означать процессоры x86 под брендом Intel с графикой Nvidia RTX в одном корпусе. Это будет первый крупный продукт Intel с использованием встроенных графических блоков стороннего производителя со времён серии процессоров Kaby Lake-G, в рамках которой чипы Intel Core оснащались встроенной графикой Radeon RX Vega M от AMD.  Intel и Nvidia пока не подтвердили ни названия будущих совместных продуктов, ни сроки их запуска. Недавние утечки связывают первый клиентский чип Intel и Nvidia с серией процессоров Serpent Lake, однако данное название пока остаётся неофициальным. В рамках соглашения обе компании лишь подтвердили, что их сотрудничество будет охватывать несколько поколений продуктов для центров обработки данных и ПК. Arm нацелилась на доминирование в ИИ-серверах — помогут CPU с 512 ядрами
11.05.2026 [06:17],
Алексей Разин
Пока деятельность Arm ограничивалась разработкой процессорных архитектур, мало кто утруждал себя разбором стенограмм с квартальных отчётных конференций, но с учётом выхода компании на рынок центральных процессоров ситуация изменилась. В ходе такого мероприятия руководство Arm призналось, что CPU смогут доминировать в серверном сегменте благодаря увеличению количества ядер до 512 штук. 
Источник изображения: Arm Напомним, что главы Intel и AMD на недавних квартальных конференциях отметили, что в серверной инфраструктуре меняется пропорция центральных процессоров по отношению к GPU, которые на этапе массового обучения ИИ-моделей безоговорочно доминировали. В беседе с аналитиком J.P. Morgan финансовый директор Arm Джейсон Чайлд (Jason Child) выразил солидарность с главой AMD Лизой Су (Lisa Su), которая заявила о способности рынка центральных процессоров достичь к 2030 году ёмкости в $120 млрд. Это несколько выше тех $100 млрд, на которые Arm ориентировалась ранее. Финансовый директор Arm пояснил: «Мы буквально видим не только взрывной рост спроса на центральные процессоры, но одной из областей мы считаем увеличение количества процессорных ядер в составе чипа. Опять же, процессоры Arm AGI имеют 136 ядер, что больше основной части конкурентных предложений. В будущем, могу ли я увидеть 256, 512 ядер? Абсолютно. Это хорошее место для Arm, поскольку в дизайне с очень большим количеством ядер реальное значение имеет эффективность в пересчёте на одно ядро, а мы в этом лучше всех в мире». Генеральный директор Arm Рене Хаас (Rene Haas) добавил, что все гиперскейлеры, сама Nvidia, используют технологии Arm. По объёмы поставок сейчас лидирующими ускорителями являются процессоры Google TPU, AWS Trainium и Nvidia Rubin, все они связаны с Arm. Со временем, как считает глава Arm, компания так или иначе займёт весь рынок компонентов для инфраструктуры ИИ. В эволюции GPU уже наметились физические ограничения: кристаллы получаются настолько крупными, что фотомаски для них приблизились к предельным размерам. Центральным процессорам в ближайшие годы ничего наращивать количество ядер не помешает, оно вырастет в два или четыре раза совсем скоро. К слову, Intel и AMD движутся в том же направлении, намереваясь предложить процессоры с 256 или даже 512 ядрами. Nvidia подтвердила утечку данных пользователей GeForce Now через армянские сервера
10.05.2026 [17:59],
Владимир Фетисов
Nvidia подтвердила, что в результате утечки данных были раскрыты данные пользователей сервиса GeForce Now. В компании уточнили, что инцидент затрагивает только пользователей из Армении, зарегистрированных в сервисе через GFN.am, а его причиной стал взлом инфраструктуры регионального партнёра. Отмечается, что инфраструктура Nvidia в результате инцидента не пострадала. 
Источник изображения: bleepingcomputer.com «Наше расследование показало, что находящиеся под управлением Nvidia услуги не были затронуты. Проблема ограничена системами, которыми управляет сторонний партнёр GeForce Now Alliance из Армении. Мы тесно сотрудничаем с партнёром, чтобы поддержать их расследование и процесс устранения проблемы. Затронутые пользователи будут уведомлены через GFN.am», — говорится в заявлении Nvidia. В сообщении компании также сказано, что пароли от учётных записей GeForce Now не были похищены в результате инцидента, а пользователей, которые зарегистрировались на платформе после 9 марта, проблема не затронула. Это сообщение стало ответом на пост, опубликованный на одном из хакерских форумов на прошлой неделе. Его автор с ником ShinyHunters утверждал, что взломал сервис GeForce Now и похитил данные миллионов пользователей сервиса. Речь шла о ФИО пользователей, адресах электронной почты, датах рождения и др. В доказательство злоумышленник опубликовал часть данных и выразил готовность продать всю базу за $100 тыс. в биткоинах или Monero. Nvidia в этом году потратила на покупку активов других компаний более $40 млрд
10.05.2026 [08:06],
Алексей Разин
Получая в условиях бума ИИ рекордную выручку, Nvidia стала гораздо активнее инвестировать средства, но делает это с прицелом на дальнейшее использование интересующих её технологий. Хотя о крупных сделках типа сорвавшейся по покупке Arm речь не идёт, «по мелочи» Nvidia сначала этого года уже потратила более $40 млрд. 
Источник изображения: Nvidia Ряд вложений Nvidia прошлого года можно считать довольно удачными. Потратив $5 млрд на покупку пакета акций Intel в прошлом году, она сейчас могла бы выручить за него более $25 млрд, но данная инвестиция наверняка интересна первой из компаний со стратегической точки зрения, ведь через пару лет на рынок выйдут центральные процессоры Intel со встроенной графикой Nvidia RTX. С начала текущего года Nvidia потратила на покупку активов более $40 млрд. Из последних сделок можно вспомнить соглашение с Corning на сумму до $3,2 млрд, которое позволит Nvidia улучшить свои позиции в сфере производства телекоммуникационных решений для серверной инфраструктуры. Кроме того, на уходящей неделе Nvidia договорилась вложить до $2,1 млрд в оператора ЦОД IREN. Для сравнения, в прошлом фискальном году Nvidia потратила на инвестиции около $17,5 млрд. В частные компании за тот же период компания вложила почти $19 млрд. Капитализация самой Nvidia за четыре года ИИ-бума выросла более чем в 11 раз до впечатляющих $5,2 трлн, превратив её в крупнейшую компанию мира, представленную на фондовом рынке. В прошлом фискальном году Nvidia сгенерировала $97 млрд свободного денежного потока, получив возможность активно инвестировать в необходимые ей со стратегической точки зрения активы. Эксперты уличили компанию в участии в так называемых «кольцевых сделках», по условиям которых она передаёт деньги тем компаниям, которые потом тратят их на её же продукцию и услуги. В этом году Nvidia заключила не менее семи многомиллиардных контрактов и вложилась в капитал более чем двадцати компаний и стартапов. Больше всего в удельном выражении Nvidia потратила на поддержку своего «кормильца» OpenAI, который получил $30 млрд, но конкурирующие стартапы Anthropic и xAI (SpaceX) также получили от неё деньги. В апреле основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) пояснил суть инвестиционной стратегии своей компании: «Мы не отбираем победителей. Мы должны поддерживать каждого». В марте Nvidia вложила $2 млрд в капитал Marvell Technologies, а также сопоставимые суммы в Lumentum и Coherent. Стандартная для таких сделок сумма была направлена на поддержку провайдеров облачных вычислений CoreWeave и Nebius, которая принадлежит основателю «Яндекса» Аркадию Воложу. Эксперты считают, что направляя средства в капитал облачных провайдеров, Nvidia просто даёт им деньги, которые те потом потратят на покупку у неё оборудования. Кстати, рекордные $30 млрд, которые будут направлены Nvidia в капитал OpenAI, изначально должны были оказаться $100 млрд, но после первичных переговоров в сентябре прошлого года Nvidia пересмотрела условия сделки с разработчиками ChatGPT. Учитывая относительную близость IPO этого стартапа, Дженсен Хуанг заявил, что указанные $30 млрд могут стать последним частным капиталовложением, которое Nvidia сделает применительно к OpenAI. Nvidia с помощью Corning заменит тысячи медных кабелей в дата-центрах оптикой — ради скорости и экономии энергии
06.05.2026 [20:48],
Сергей Сурабекянц
Nvidia заключила партнёрское соглашение с Corning для создания трёх новых заводов в Северной Каролине и Техасе. Эти предприятия будут специализироваться на развитии оптических технологий передачи данных. Будет создано как минимум 3000 рабочих мест, а производственные мощности Corning в США вырастут в десять раз. Nvidia планирует инвестировать в Corning до $2,7 млрд. На фоне этой новости акции Corning выросли на 10 %, а акции Nvidia — более чем на 4 %. 
Источник изображения: Corning Nvidia получит право на покупку до 15 миллионов обыкновенных акций Corning по цене $180 за акцию, что выше цены закрытия вчерашних торгов в $162,10, но ниже цены акций Corning после сегодняшнего роста. Кроме того, Nvidia имеет право на покупку до 3 миллионов предоплаченных обыкновенных акций Corning на общую сумму $500 млн. Компании не предоставили подробностей о разрабатываемых технологиях, но, по словам осведомлённых источников, Nvidia готовится заменить медь оптическими волокнами Corning в своих стоечных системах ИИ — интеграция, известная как ко-пакетированная оптика (co-packaged optics). На конференции Nvidia GTC в 2025 году генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) назвал интегрированную оптику крайне важной для развития ИИ. 
Источник изображения: Nvidia Аналитики давно ожидали от Nvidia масштабного внедрения оптических технологий, поскольку это обещает значительно увеличить скорость передачи данных и снизить энергопотребление для рабочих нагрузок ИИ. «То, что делает Nvidia, поистине экстраординарно, не только для будущего ИИ, но и для американской рабочей силы в сфере передового производства», — считает генеральный директор Corning Венделл Уикс (Wendell Weeks). Потребителям компания Corning известна прежде всего производством защитных стёкол для гаджетов, но оптическая связь остаётся её крупнейшим и наиболее быстрорастущим бизнесом. С момента изобретения оптического волокна для дальней связи в 1970 году Corning поставила миллионы километров оптических кабелей. 
Источник изображения: Corning За последний год акции Corning выросли более чем на 250 %, чему способствовала быстрая адаптация компании со 175-летней историей к новой экономике, в частности, недавняя сделка с Meta✴✴ на сумму до $6 млрд для строительства завода по производству оптических кабелей в Хикори, Северная Каролина. Графические процессоры Nvidia играют ключевую роль в разработке больших языковых моделей и позволяют таким технологическим гигантам, как Alphabet и Meta✴✴, масштабно расширять свои дата-центры. Цена акций Nvidia за последние пять лет выросла примерно в 14 раз, но в последнее время рост замедлился, поскольку инвесторы распределили свои ставки между более широким кругом компаний, занимающихся инфраструктурой ИИ, поддерживая производителя чипов Intel и поставщика памяти Micron, а также Corning. 
Источник изображения: Corning Партнёрство с Corning позволит Nvidia использовать оптоволокно для связи между самими чипами и в конечном итоге заменить 5000 медных кабелей внутри стоечных систем компании. «Перемещение фотонов потребляет в 5–20 раз меньше энергии, чем движение электронов», — пояснил преимущества оптической передачи сигнала Уикс. Оптическое волокно также обеспечивает меньшие потери сигнала, чем медь, увеличивая надёжность связи. «Искусственный интеллект является движущей силой крупнейшего в наше время строительства инфраструктуры — и предоставляет уникальную возможность оживить американское производство и цепочки поставок, — заявил Хуанг. — Вместе с Corning мы создаём будущее вычислительной техники с помощью передовых оптических технологий, закладывая основу для инфраструктуры искусственного интеллекта, где интеллект развивается со скоростью света, и продолжая славную традицию производства в Америке». 
Источник изображения: Nvidia В марте 2026 года Nvidia инвестировала $4 млрд в компании Coherent и Lumentum, которые разрабатывают лазеры и компоненты, помогающие преобразовывать данные между световыми и электрическими сигналами. «По мере того, как энергопотребление становится все более важной проблемой, оптоволокно неизбежно все ближе и ближе к вычислительным системам», — уверен Уикс. В 2025 году Nvidia выпустила два сетевых коммутатора, использующих оптические технологии. Broadcom и Marvell уже представили аналогичные продукты, Intel также в настоящее время разрабатывает подобные решения. Владелец Google вот-вот может лишить Nvidia статуса самой дорогой компании в мире
06.05.2026 [10:26],
Павел Котов
Холдинг Alphabet вплотную приблизился к тому, чтобы обогнать Nvidia по величине рыночной капитализации и стать самой дорогой компанией в мире — рекордный рост владельца Google подстегнули его усилия в области искусственного интеллекта и бурное развитие облачного подразделения. 
Источник изображения: BoliviaInteligente / unsplash.com Если это случится, Alphabet вырвется на первое место впервые за более чем десятилетие — в последний раз компания ненадолго надела корону в феврале 2016 года, а затем вернула её Apple. Сложившаяся обстановка отражает резкую перемену в настроениях: Alphabet набирает обороты как крупный поставщик услуг в области ИИ со своей облачной платформой, а также как конкурент Nvidia в производстве чипов благодаря собственным ускорителям, которые привлекли таких клиентов как Anthropic. В последние месяцы поисковый гигант поразил Уолл-стрит ростом облачных сервисов, который значительно превзошёл ожидания и показатели более крупных конкурентов в лице Amazon и Microsoft. Инвесторы поверили, что колоссальные инвестиции в ИИ, исчисляемые сотнями миллиардов долларов, способны окупиться. По состоянию на утро вчерашнего дня, 5 мая 2026 года, рыночная капитализация Nvidia составляла около $4,79 трлн, и это значительно ниже исторического максимума в $5,2 трлн — тем временем стоимость Alphabet достигла $4,67 трлн вблизи исторического максимума для компании. В этом году акции Alphabet прибавили 24 %, тогда как ценные бумаги Nvidia подорожали всего на 7 %. Акции «зелёных» откатились с исторического максимума после сообщения Wall Street Journal, что OpenAI не удалось достичь своих целей по привлечению новых пользователей и выручке. Alphabet активно конкурирует с OpenAI, подтверждая свою способность выбиться в лидеры в области ИИ: по итогам 2025 года акции поискового гиганта подорожали на 65,3 %. Дополнительным фактором роста стало благоприятное решение суда: компании удалось избежать принудительного отчуждения ОС Android и браузера Chrome. Бум ИИ разогнал апрельскую выручку Foxconn почти на 30 %
05.05.2026 [11:50],
Алексей Разин
Тайваньская компания Foxconn постепенно превратилась из крупнейшего контрактного производителя мобильных устройств Apple в основного подрядчика Nvidia по выпуску серверных систем для инфраструктуры ИИ. Динамика финансовых показателей Foxconn даёт чёткое представление о происходящих в сегменте ИИ процессах, и апрельская выручка компании взлетела в годовом сравнении на 29,7 % до $26,3 млрд. 
Источник изображения: Nvidia В текущем квартале, как гласит приводимый Bloomberg консенсус-прогноз аналитиков, выручка Foxconn должна вырасти на 30,4 %. Сама Foxconn ожидает, что её выручка во втором квартале увеличится как последовательно, так и год к году. Бум ИИ позволяет тайваньскому производителю ставить перед собой амбициозные цели, ведь основные клиенты Nvidia в лице Alphabet (Google), Amazon (AWS), Meta✴✴ Platforms и Microsoft намерены в этом году направить на развитие вычислительной инфраструктуры для ИИ около $725 млрд в общей сложности. В любом случае, выручка Foxconn продолжает сильно зависеть и от заказов Apple, а она отмечает довольно высокий спрос на смартфоны семейства iPhone 17, поэтому поводов для оптимизма у тайваньского подрядчика предостаточно. Руководство Apple недавно пожаловалось, что ограничивающим фактором для увеличения поставок своих устройств в данный момент считает даже не дефицит памяти, а нехватку процессоров, выпускаемых по передовым технологическим нормам компанией TSMC. Глава Nvidia заявил, что доля компании на китайском рынке ИИ-ускорителей упала до нуля
05.05.2026 [04:51],
Алексей Разин
В конце прошлого года глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) донёс до высшего политического руководства США мысль о необходимости наладить поставки в Китай более совершенных ИИ-ускорителей по сравнению с теми, что были там доступны в условиях санкций. Теперь он утверждает, что доля Nvidia в Китае опустилась до нуля. 
Источник изображения: Nvidia Напомним, что формальное разрешение американских властей наладить поставки ускорителей Nvidia H200 с одной стороны, запуталось в бюрократических процедурах в США, а с другой — наткнулось на противодействие китайских чиновников, которые начали запрещать их импорт и использование крупными местными компаниями. При этом усилия по импортозамещению ИИ-ускорителей в КНР привели к экспансии местных разработчиков чипов. Недавно Дженсен Хуанг в очередной раз заявил: «В Китае, мы теперь упали до нуля. Уступка целого рынка размером с Китай, вероятно, не имеет большого стратегического смысла, поэтому я думаю, что это уже в значительной степени привело к обратным результатам. Возможно, в то время это имело смысл, но я думаю, что политика действительно должна быть динамичной и идти в ногу со временем». Заявления главы Nvidia в ходе очередного интервью цитирует ресурс Tom’s Hardware. Дженсен Хуанг добавил: «Думаю, будет справедливо сказать, что имеет смысл сочетать на китайском рынке присутствие американских и прочих компаний». По оценкам аналитиков Bernstein, китайские поставщики ИИ-ускорителей стремятся покрыть до 80 % потребностей местного рынка, поэтому доля Nvidia в обозримой перспективе сократится до 8 %. Глава компании в своей статистике учитывает прямые поставки чипов производителем в Китай, поэтому его оценки положения своего детища на местном рынке могут отличаться от сторонних данных. Дженсен Хуанг сравнил инфраструктуру ИИ с пятислойным пирогом, добавив, что ускорители являются только одним из этих слоёв. Во многих аспектах Китай располагает необходимыми ресурсами для успеха в этой сфере: дешёвой энергией и талантливыми специалистами. «Количество исследователей в области ИИ в Китае весьма велико, и это одно из их национальных достояний», — отметил Хуанг. Как известно, он является противником экспортных ограничений на поставку ИИ-ускорителей в Китай, поскольку убеждён, что это лишь мотивирует местные компании создавать альтернативы западным чипам, а американские технологии в этом случае теряют своё влияние на местном рынке. Понятно, что в данном случае он является заинтересованным лицом, но доля истины в его утверждениях есть. Когда Хуанга спросили на том же мероприятии, желает ли он, чтобы Китай получил самые передовые американские чипы, он ответил отказом. «Мы всей душой болеем за то, чтобы у Соединённых Штатов в первую очередь было самое лучшее», — сказал глава Nvidia. Nvidia начала сворачивать поставки платформ для разработчиков Jetson с памятью LPDDR4 из-за её дефицита
04.05.2026 [04:46],
Алексей Разин
Проявления дефицита памяти причудливы и порой непредсказуемы. С подачи канадских поставщиков стало известно, что Nvidia сворачивает поставки платформ Jetson поколения Xavier и TX2, которые используют память LPDDR4. Причиной подобного решения Nvidia является именно дефицит этого типа памяти. 
Источник изображения: Nvidia Заказы на эти платформы для разработчиков нельзя отменить, а полученные клиентами компоненты не будут подлежать возврату. Это указывает на близость момента снятия их с производства. Конкретно упоминаются в этом контексте Jetson TX2 NX, TX2i, AGX Xavier с 32 Гбайт памяти в промышленном исполнении, а также Xavier NX с 8 и 16 Гбайт памяти соответственно. Один из канадских поставщиков поясняет, что в статусе снятия с производства находятся все версии Xavier и TX2 модулей Nvidia Jetson. Заказать их можно будет до 1 июля текущего года включительно, но последняя партия будет отгружена 15 июля следующего года. Перечисленные платформы для разработчиков выпускались Nvidia с 2017 по 2021 годы. Клиенты смогут перейти на Orin NX или AGX Orin, хотя некоторая адаптация в части питания и тепловых характеристик может потребоваться. Снимаемые с производства компанией Nvidia платформы пали жертвой процессов, наблюдаемых в сегменте оперативной памяти. Выпускать LPDDR4 сейчас не так выгодно, как более востребованные DDR5 и HBM, поэтому производители памяти активно отказываются от первого типа продукции. Соответственно, у Nvidia не остаётся иного выхода, кроме как переходить на более новые комплектующие и прекращать поставки более старых платформ Jetson. Так или иначе, это всё равно бы когда-нибудь случилось, просто теперь сроки сжимаются из-за дефицита памяти. Продажи ускорителей Huawei в Китае в этом году взлетят на 60 % минимум и выведут компанию в лидеры рынка
01.05.2026 [08:26],
Алексей Разин
Долгое время переход китайских разработчиков на использование ускорителей вычислений локального производства сдерживался сложностью миграции программного обеспечения, но усилия властей КНР по стимулированию импортозамещения в этом году должны дать плоды. Huawei увеличит выручку от реализации своих ускорителей минимум на 60 %. 
Источник изображения: Huawei Technologies Такой прогноз приводит издание Financial Times со ссылкой на собственные источники. Китайские техногиганты, по их данным, разместили крупные заказы на покупку ускорителей Huawei новейшего семейства Ascend 950PR. Если в прошлом году Huawei получила $7,5 млрд в результате поставок своих ИИ-ускорителей, то в этом году сумма профильной выручки может увеличиться до $12 млрд, если опираться на объёмы полученных заказов. Впрочем, основную часть поставок в этом году сформируют не передовые Ascend 950PR, а более зрелые ускорители Huawei. В четвёртом квартале текущего года компания начнёт поставки модернизированной версии Ascend 950DT. Попытки основателя Nvidia Дженсена Хуанга (Jensen Huang) разжалобить американские власти хоть и увенчались успехом, позволив компании получить принципиальное согласие регуляторов на поставки в Китай ускорителей H200 с архитектурой Hopper, к фактическим отгрузкам такой продукции не привели. С одной стороны, с выдачей экспортных лицензий тянули американские ведомства. С другой стороны, импорту H200 в Китай начали активно противиться местные регуляторы. Противоречие также заключалось в готовности властей Китая разрешить местным компаниям использовать H200 только в своей зарубежной вычислительной инфраструктуре, тогда как американские экспортные лицензии подразумевали разрешение на ввоз H200 исключительно на территорию Китая. Власти КНР настаивали, что местные компании должны использовать отечественные ускорители в своей инфраструктуре на территории страны. Huawei сможет в этом году выручить на поставках ИИ-ускорителей даже больше планируемых $12 млрд, если объёмы производства удастся подтянуть к уровню спроса. Ускорители Ascend 950PR уже в значительной мере ориентированы на работу в сфере инференса, и мировые тенденции в развитии систем ИИ указывают, что именно она начнёт доминировать в развитии инфраструктуры в ближайшее время. Huawei также компенсирует более слабые возможности отдельных ускорителей адекватной сетевой инфраструктурой, которая позволяет эффективно масштабировать производительность через создание вычислительных кластеров. Факт сотрудничества DeepSeek с Huawei в сфере использования ускорителей Ascend 950PR при создании новейшей модели V4 уже удостоился внимания главы конкурирующей Nvidia, который назвал подобное сближение "ужасным исходом для всей нации", говоря о США. Дженсен Хуанг обеспокоен тем, что ИИ-модели по всему миру начнут лучше работать на оборудовании, которое выпущено не в США. По прогнозам Morgan Stanley, ёмкость китайского рынка чипов для ИИ к 2030 году достигнет $67 млрд, при этом на 86 % он будет контролироваться китайскими игроками. В текущем году они поставят на китайский рынок ускорителей на общую сумму $21 млрд. Легко определить, что Huawei в этом случае займёт более половины местного рынка ускорителей в денежном выражении. Впрочем, Nvidia в прошлом году реализовала в Китае ускорителей на сумму около $17,1 млрд, поэтому обойти её будет не так просто. Цена на серверы с Nvidia B300 на сером рынке Китая взлетела до $1 млн
30.04.2026 [14:21],
Анжелла Марина
На фоне жёстких ограничений на экспорт чипов со стороны США и ажиотажного спроса на вычислительные мощности для искусственного интеллекта цены на серверы Nvidia B300 в Китае выросли почти вдвое, достигнув $1 млн. Критически важные для развития технологий в КНР поставки оборудования, которое идёт через серый рынок, оказались в дефиците из-за ужесточения борьбы с контрабандой. 
Источник изображения: Nvidia По сообщению Reuters, стоимость самого продвинутого сервера Nvidia, оснащённого восемью графическими процессорами B300, в Китае теперь составляет около 7 млн юаней (примерно $1 023 650), тогда как в конце прошлого года показатель находился на отметке в 4 млн юаней (около $584 950). Такой резкий скачок обусловлен давлением на серый рынок, который ранее являлся ключевым каналом поставок, а также устойчивым спросом со стороны местных технологических гигантов. При этом многие китайские компании стараются не указывать оборудование Nvidia в своей отчётности из-за опасений подвергнуться американским санкциям. Сама Nvidia подчеркнула, что B300 запрещён к продаже в Китае, а любые попытки незаконного оборота обречены на провал из-за строгих механизмов контроля. Для сравнения, в США цена аналогичного сервера составляет около 550 тысяч долларов, что также выше прошлогодних показателей. Китайская наценка отражает так называемую надбавку за дефицит, которая возникла после мартовского уголовного преследования американскими властями сооснователя компании Supermicro, являющейся партнёром Nvidia, И Шянь Лио (Yi-Shyan Liaw). Лио обвинили в участии незаконной деятельности по провозу из США в Китай запрещённого серверного оборудования. В результате некоторые компании, не имеющие возможности приобрести серверы в собственность, вынуждены рассматривать варианты аренды, стоимость которой достигает 190 тысяч юаней (примерно $27 800) в месяц по годовому контракту. Однако дефицит оборудования не ослабляет аппетиты местных разработчиков, стремящихся к монетизации своих моделей и вычислительной инфраструктуры. По данным Morgan Stanley, в марте 2026 года доля китайских ИИ-моделей в глобальном потреблении токенов резко возросла, достигнув 32 % по сравнению с 5-% годом ранее. Например, компании MiniMax, Zhipu и Qwen от Alibaba зафиксировали рост использования токенов в шесть-семь раз в феврале и марте по сравнению с декабрём. Для обработки таких массивов данных требуется наиболее эффективное оборудование, каковым является B300 с его 288 Гбайт памяти и вычислительной мощностью 14 петафлопс при точности FP4. К этому добавляется неопределённость вокруг поставок чипов H200, которая также способствует росту цен на B300. Несмотря на получение одобрения от правительств обеих стран, экспорт H200 в Китай так и не начался из-за разногласий по условиям продажи. Напомним, Nvidia и её партнёры начали поставлять B300 ещё в сентябре прошлого года, однако закрытые каналы поставок не позволяют в полной мере удовлетворить запросы китайского рынка и в таких условиях борьба за доступ к мощным вычислительным ресурсам продолжает стимулировать рост цен. Слепой тест показал, что геймерам больше нравится Nvidia DLSS 4.5, чем AMD FSR 4.1
29.04.2026 [17:07],
Николай Хижняк
В феврале издание ComputerBase провело масштабное слепое тестирование, в ходе которого сравнивались внутриигровые скриншоты, созданные с использованием новейших технологий апскейлинга: FSR 4.0 от AMD и DLSS 4.5 от Nvidia. С тех пор тест был обновлён и проведён повторно. Результаты показывают, что обновленная технология апскейлинга FSR 4.1 от AMD значительно превосходит FSR 4.0. Однако по качеству изображения она всё ещё уступает DLSS 4.5 от Nvidia. 
Источник изображения: Nvidia В последнем тесте технологии масштабирования FSR 4.0, FSR 4.1 и DLSS 4.5 сравнивались в следующих играх: Year 117 — Pax Romana, ARC Raiders, Assassin's Creed Shadows, Call of Duty: Black Ops 7, Kingdom Come 2: Deliverance, Resident Evil Requiem и The Last of Us Part I. Согласно результатам, DLSS 4.5 показал лучшие результаты (первое место в таблице ниже) во всех этих играх. Это мнение подтвердилось в ходе отдельного слепого голосования. Как и в предыдущем тесте, команда ComputerBase провела сравнение с использованием видео с тремя разными технологиями масштабирования, не раскрывая, какой именно метод рендеринга использовался. 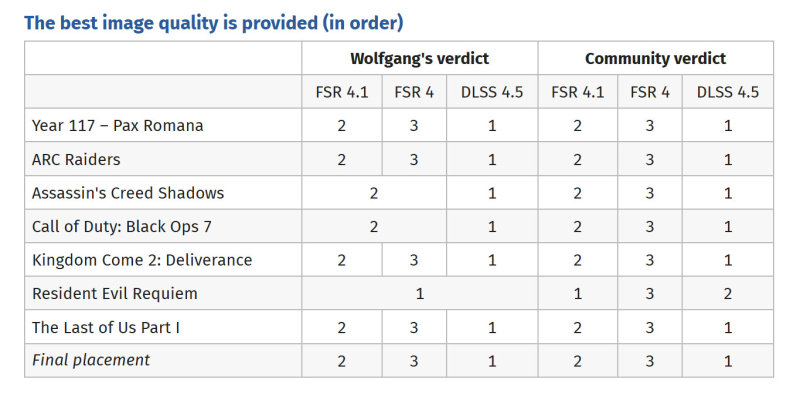
Источник изображения: ComputerBase По результатам голосования сообщество пришло к двум важным выводам. Во-первых, DLSS 4.5 от Nvidia по-прежнему лидирует по качеству изображения. Этот метод масштабирования показал лучшие результаты в шести из семи игр. Единственной игрой, в которой апскейлинг FSR от AMD оказался лучше, стала Resident Evil Requiem, где DLSS 4.5 занял второе место, уступив FSR 4.1. В целом DLSS 4.5 обеспечивает более чёткую детализацию и стабильную генерацию кадров по сравнению с апскейлингом FSR от AMD. Однако важно отметить, что AMD значительно улучшила FSR 4.1 по сравнению с FSR 4.0. По качеству технология почти сравнялась с решением Nvidia. И всё же геймеры всё чаще предпочитают DLSS 4.5 нативному рендерингу, а будущие технологии, такие как нейронный рендеринг, должны усилить популярность этого метода апскейлинга. Nvidia выпустила драйвер с поддержкой новой версии мобильной GeForce RTX 5070
28.04.2026 [19:25],
Николай Хижняк
Компания Nvidia выпустила свежий пакет графического драйвера GeForce Game Ready 596.36 WHQL. Программное обеспечение добавляет поддержку мобильной видеокарты GeForce RTX 5070 в версии с 12 Гбайт памяти. 
Источник изображения: Funcom Новый драйвер также предлагает лучший игровой опыт для игр с поддержкой технологии DLSS 4.5, включая обновление Conan Exiles Enhanced. Список исправленных ошибок:
Скачать драйвер GeForce Game Ready 596.36 WHQL можно через приложение Nvidia App или с официального сайта Nvidia. Сотрудников Nvidia и лично Хуанга восхитила работа OpenAI Codex на основе GPT-5.5
25.04.2026 [16:04],
Павел Котов
OpenAI помогла Nvidia локально развернуть сервис Codex на основе модели искусственного интеллекта GPT-5.5, новые характеристики которой восхитили сотрудников «зелёной» компании. Она показала значительный прирост эффективности по сравнению с системами предыдущих поколений. 
Источник изображений: nvidia.com Служба OpenAI Codex на основе GPT-5.5, развёрнутая на внутренних корпоративных ресурсах Nvidia, оказалась в 35 раз менее затратной экономически по сравнению с GPT-4o, а выход токенов на мегаватт вырос в 50 раз. На первых же этапах работы сервис, доступный 10 000 сотрудников Nvidia, продемонстрировал «умопомрачительные» результаты, способные «изменить жизнь». «Циклы отладки, которые раньше растягивались на несколько дней, теперь занимают всего несколько часов. Эксперименты, для которых раньше требовались несколько недель, становятся мгновенным процессом в сложных многофайловых базах кода. Отделы разрабатывают пакеты функций полного цикла, отправляя запросы естественным языком — с более высокой надёжностью и меньшим количеством потери ресурсов, чем в прежних моделях», — рассказали в Nvidia. Модель развернули на стоечных системах Nvidia GB200 NVL72, что помогло добиться огромной экономии средств и надлежащего удельного количества токенов.  «Я невероятно рад за всех, кто будет пользоваться Codex, чтобы ускориться и выполнить работу, которая раньше была невозможна. Пожалуйста, передайте вашей команде поздравления за то, что они снова открыли миру новые горизонты. И ещё раз поблагодарите их за изобретение GPT, которая дала нам трамплин для рассуждений, планирования, использования инструментов и многого другого», — написал гендиректор Nvidia Дженсен Хуанг (Jensen Huang) в письме на имя главы OpenAI Сэма Альтмана (Sam Altman). Nvidia до сих пор не поставила ни единого ускорителя H200 в Китай — их там не принимают
23.04.2026 [15:11],
Алексей Разин
Принципиальное согласие начать поставки ИИ-ускорителей Nvidia H200 в Китай было дано американским президентом Дональдом Трампом (Donald Trump) ещё в начале декабря, но сперва согласования на уровне разных ведомств затянули выдачу экспортных лицензий на несколько месяцев, а потом Nvidia пришлось столкнуться и с отторжением со стороны китайских властей. Поставки H200 в КНР до сих пор не налажены. 
Источник изображения: Nvidia В этом в ходе парламентских слушаний признался министр торговли США Говард Лютник (Howard Lutnick), добавив, что китайские власти не разрешили компаниям внутри страны приобретать данные ускорители. По его словам, китайские чиновники мотивируют свой запрет стремлением продвигать ускорители местного происхождения. «Мы до сих пор не продали им эти чипы», — подчеркнул американский министр, говоря о поставках Nvidia H200 в Китай. Лютник также добавил, что его собственное влияние на сферу торговых отношений США и Китая не так ярко выражено, поскольку в этой «очень сложной области» обозначает свои позиции как сам президент Дональд Трамп, так и министр финансов Скотт Бессент (Scott Bessent), не говоря уже о торговом представителе Джеймисоне Грире (Jamieson Greer). Сам Лютник, по его словам, не является сторонником инициативы по ограничению экспорта в Китай высокотехнологичных товаров из США, которая на уровне законодательства будет рассматриваться в ноябре этого года. Впервые её предложили в ноябре прошлого года, и она подразумевала предоставление доступа к таким товарам только ближайших геополитических союзников США. Как поясняет Лютник, подобное правило хоть и является разумным, должно учитывать довольно сложный баланс интересов США и Китая в сфере международной торговли. Только полномасштабное соглашение между странами должно определять общие принципы движения товаров. «Я сосредоточен на остальной части мира», — подчеркнул американский министр торговли. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



