|
Опрос
|
реклама
Быстрый переход
Nvidia раскрыла детали процессора Vera: 88 Arm-ядер Olympus, 176 потоков и память LPDDR5X с пропускной способностью 1,2 Тбайт/с
21.07.2026 [22:35],
Николай Хижняк
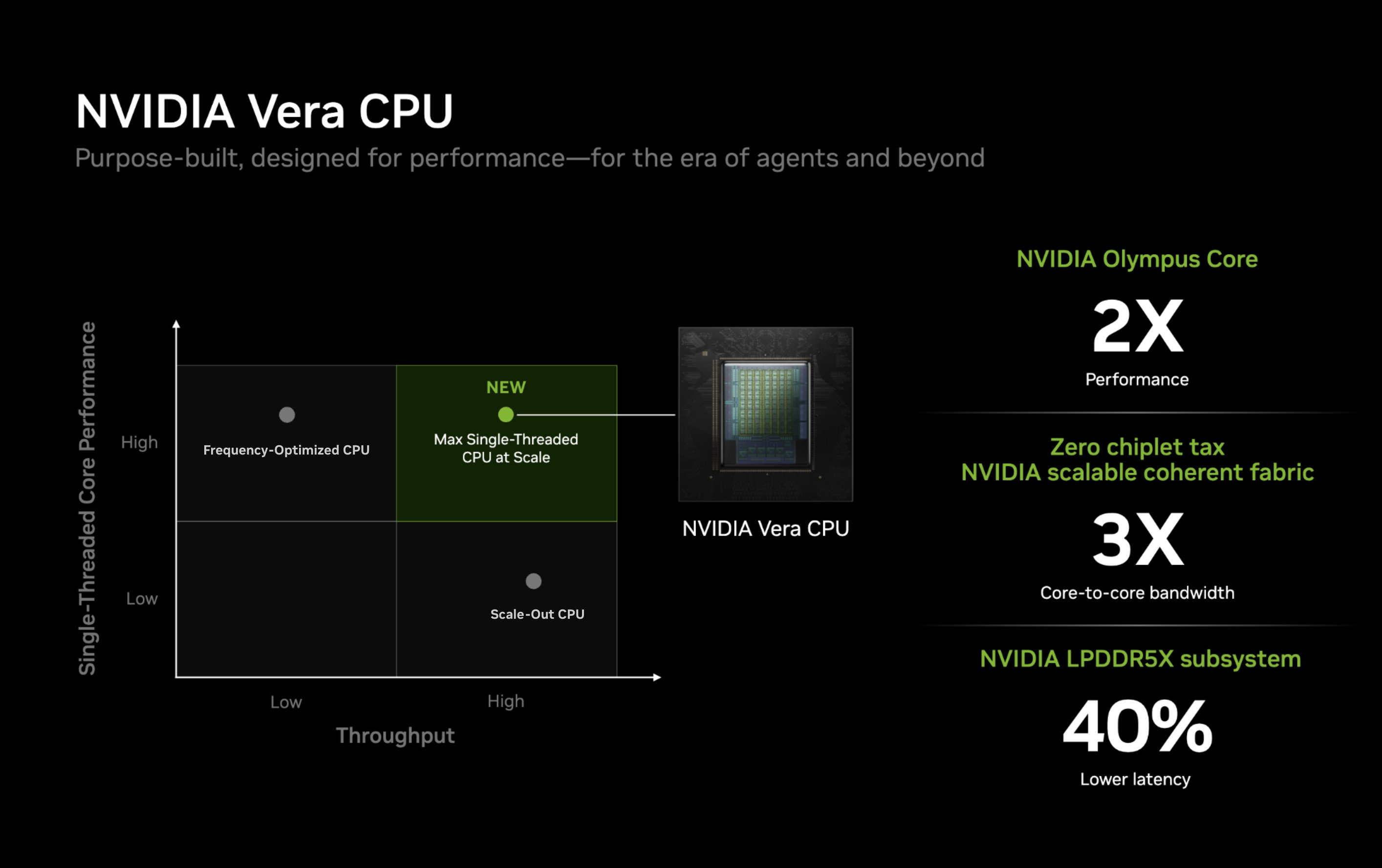
Компания Nvidia опубликовала новые подробности об архитектуре своего процессора Vera для центров обработки данных и используемом в нём специализированном ядре Olympus. Чип Vera объединяет 88 ядер Olympus, 176 аппаратных потоков и унифицированный кеш L3 объёмом 164 Мбайт на монолитном вычислительном кристалле. 
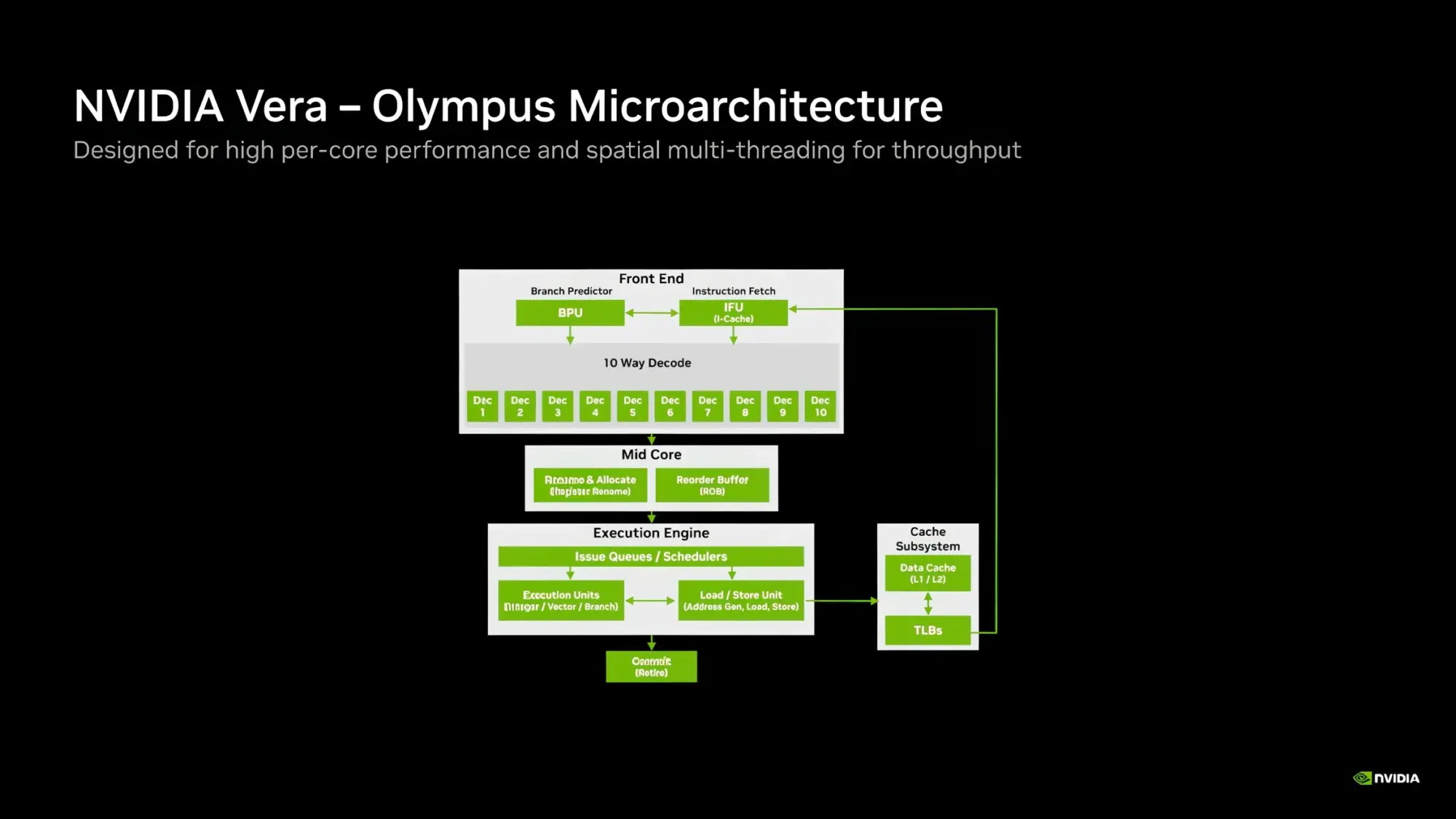
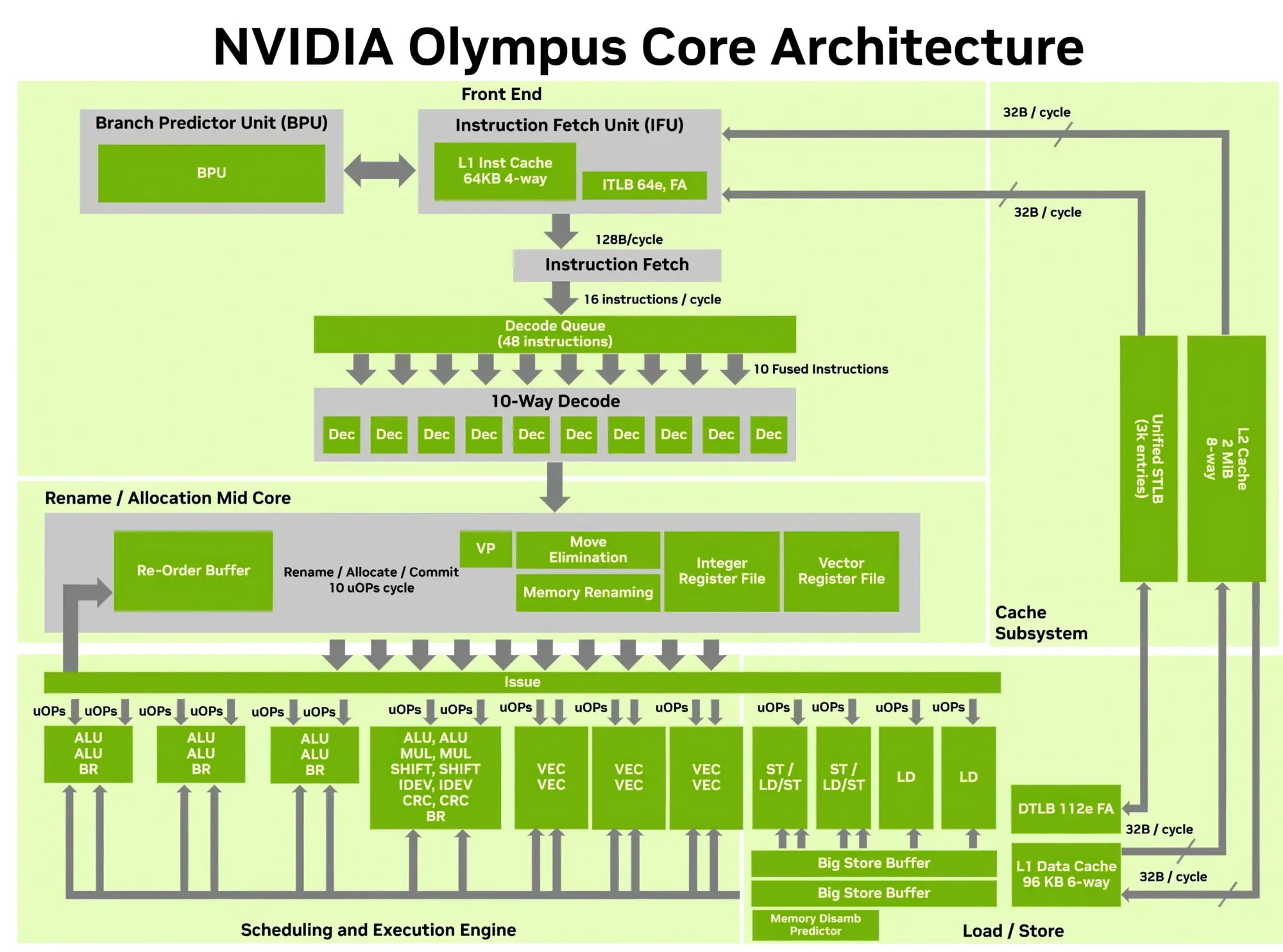
Источник изображений: Nvidia Каждое ядро Olympus использует широкий конвейер с нейронным предсказателем ветвлений, 64-килобайтный четырёхканальный кеш инструкций L1 и очередь декодирования на 48 инструкций. Ядро может считывать до 16 инструкций за такт и включает 10-канальный декодер, способный обрабатывать до десяти объединённых инструкций за такт. 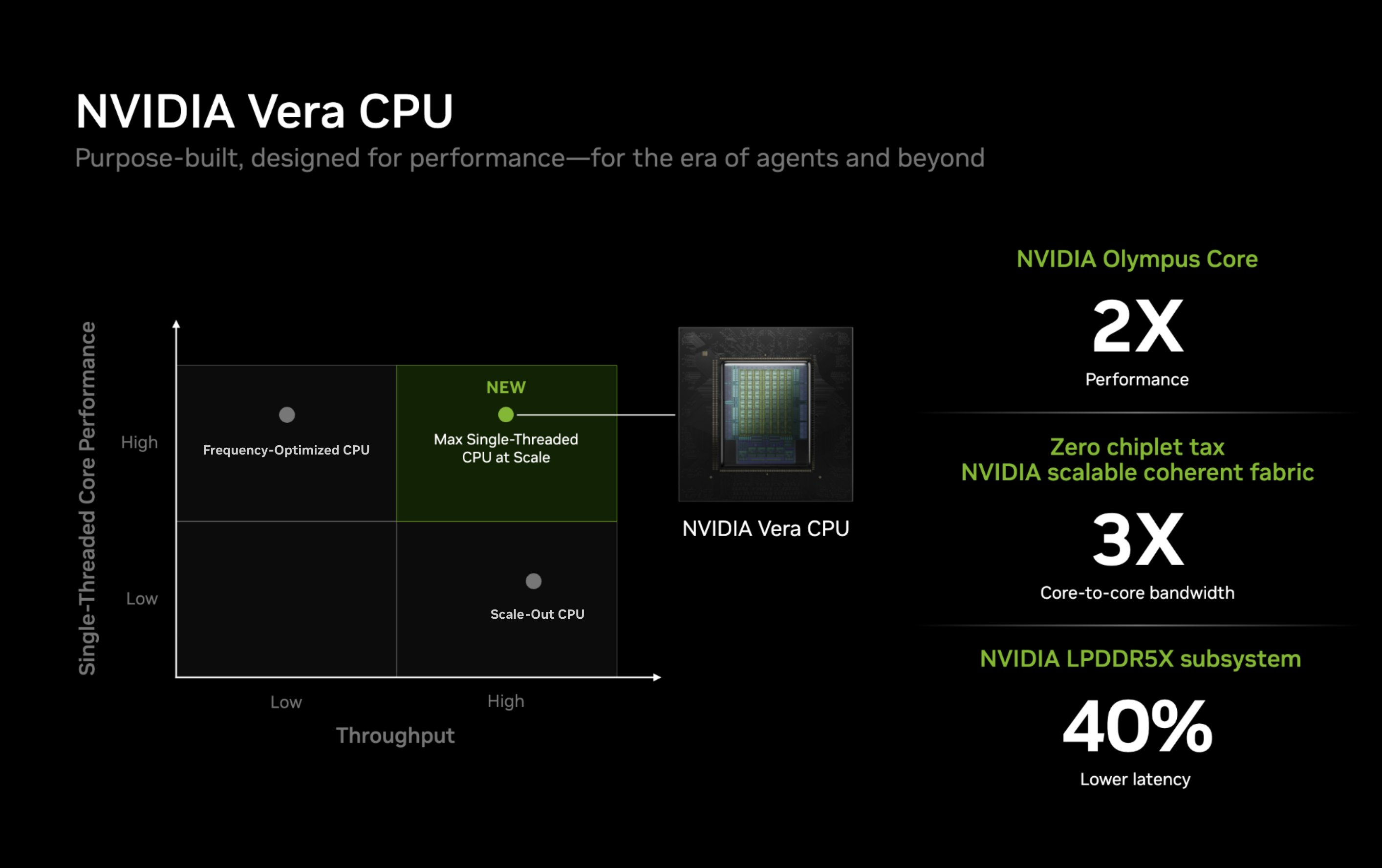 Каждое ядро может переименовывать, выделять и фиксировать до десяти микроопераций за такт. Nvidia также отмечает использование технологий переименования памяти, предсказания значений и исключения перемещений, предназначенных для уменьшения задержек, связанных с зависимостями. Исполнительный блок включает целочисленные операции, операции ветвления, векторные операции, операции с плавающей запятой, криптографические операции, а также выделенные ресурсы для операций загрузки и сохранения данных. Каждое ядро Olympus имеет 96-килобайтный шестиканальный кеш данных L1 и 2-мегабайтный восьмиканальный кеш L2. Nvidia также добавила несколько механизмов аппаратной предварительной выборки, включая предварительную выборку графов для структур данных с большим количеством указателей и рабочих нагрузок, связанных с обработкой графов. Особенности Nvidia Vera
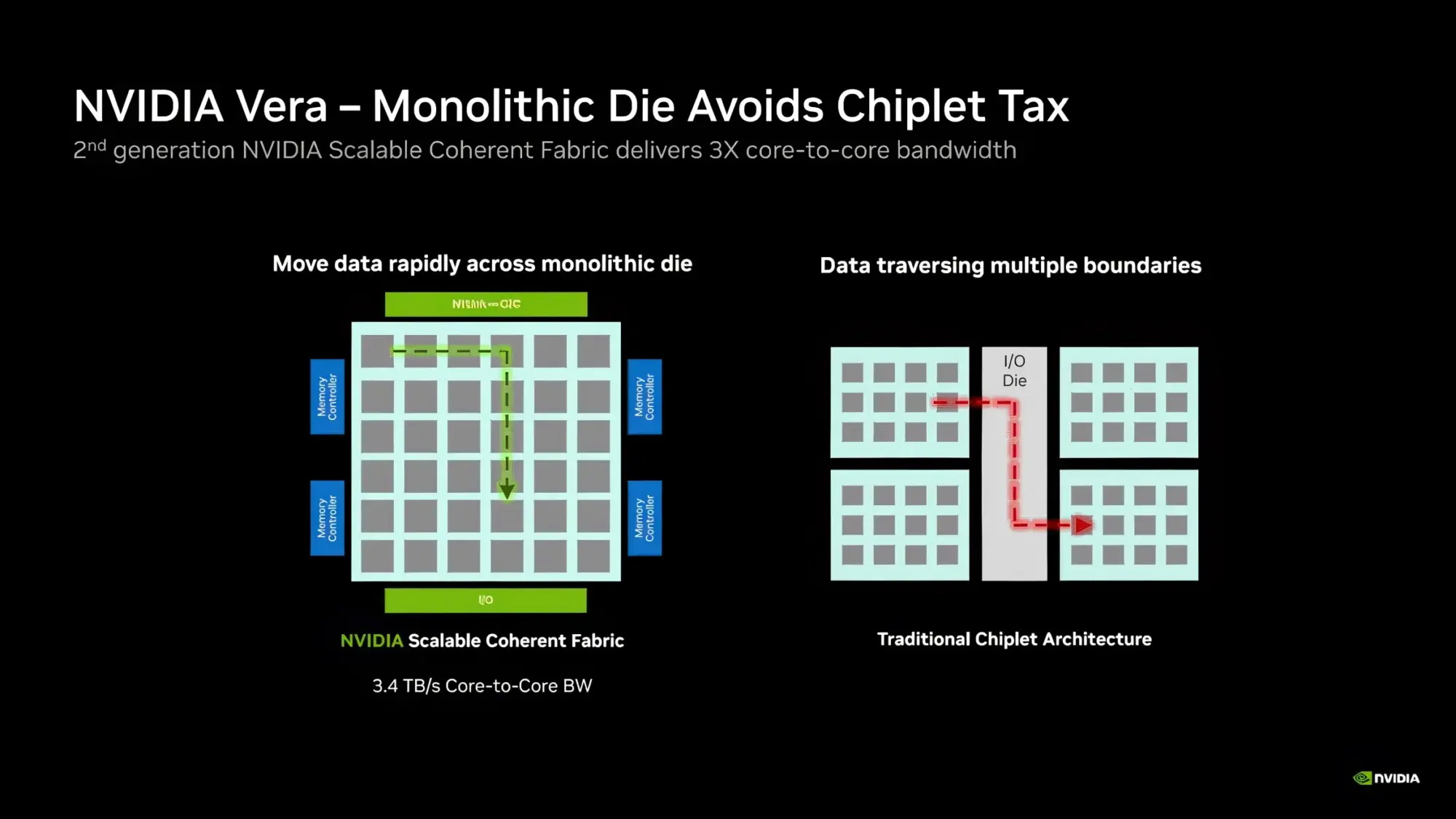
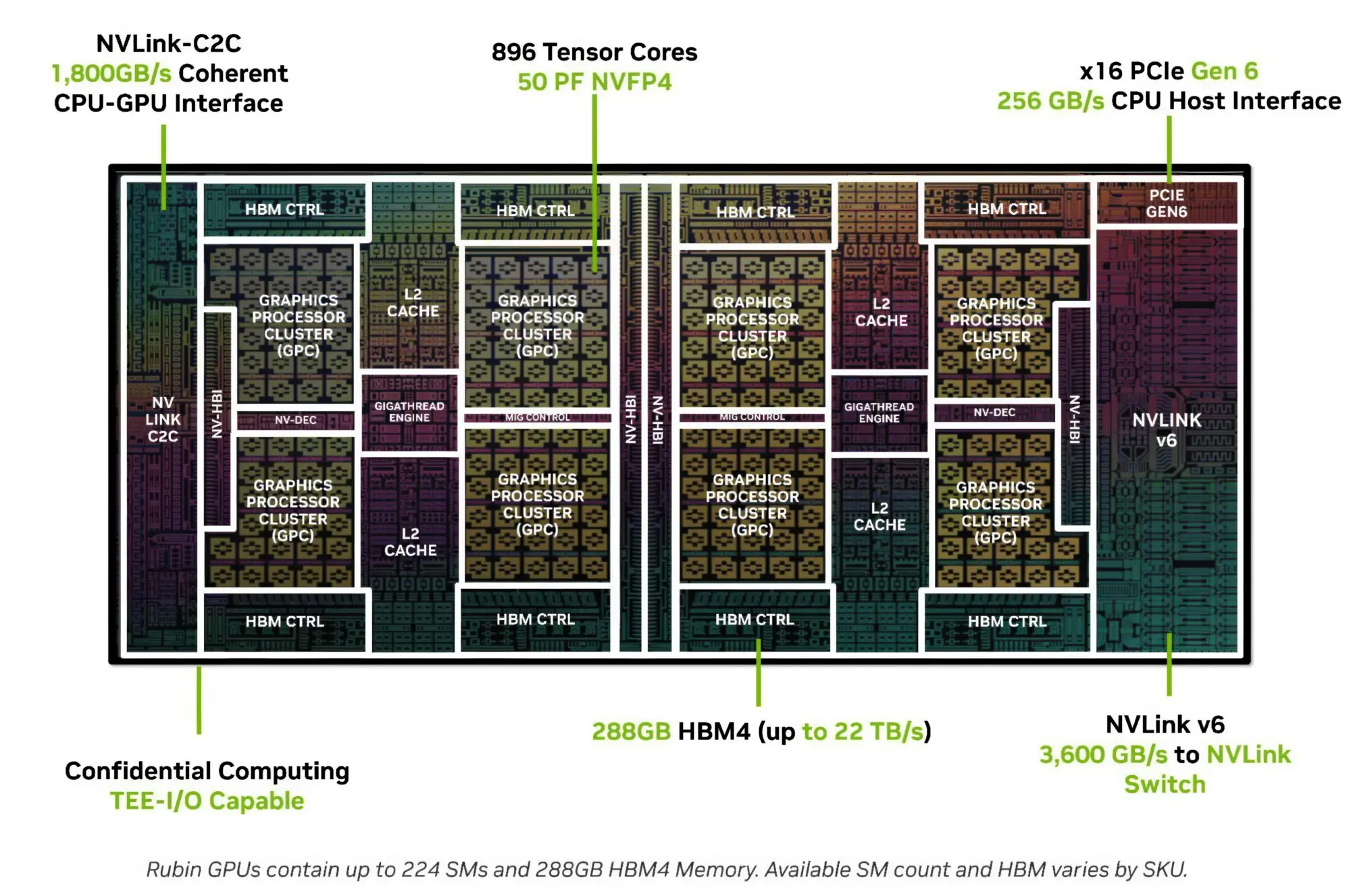
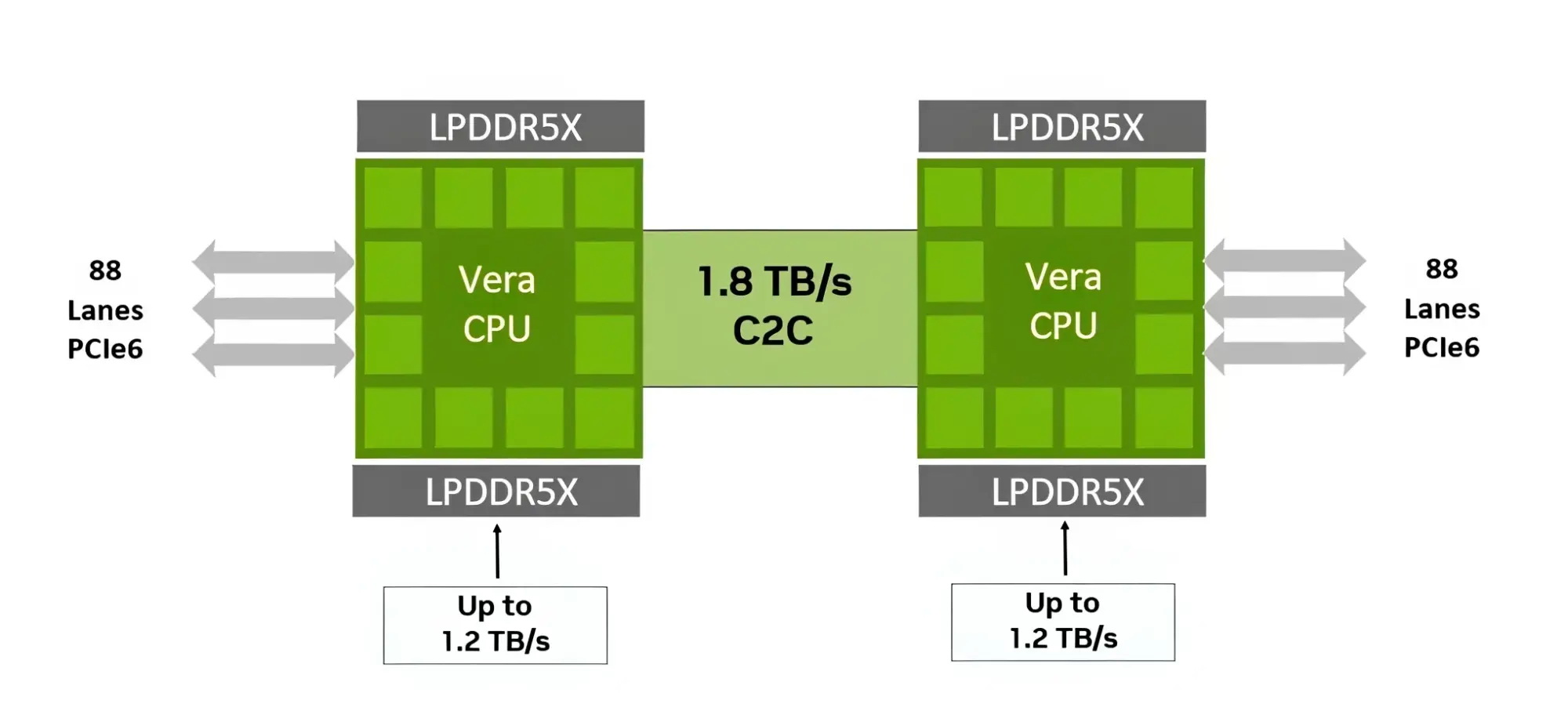
Процессор Vera использует фирменную технологию пространственной многопоточности, которая обеспечивает два аппаратных потока на каждое ядро Olympus. Nvidia заявляет, что такая конструкция позволяет распределять ресурсы ядра между потоками, уменьшая конкуренцию по сравнению с традиционной одновременной многопоточностью. Ядро может отдавать приоритет одному потоку, чувствительному к производительности, в то время как второй поток обрабатывает системные и управляющие задачи. 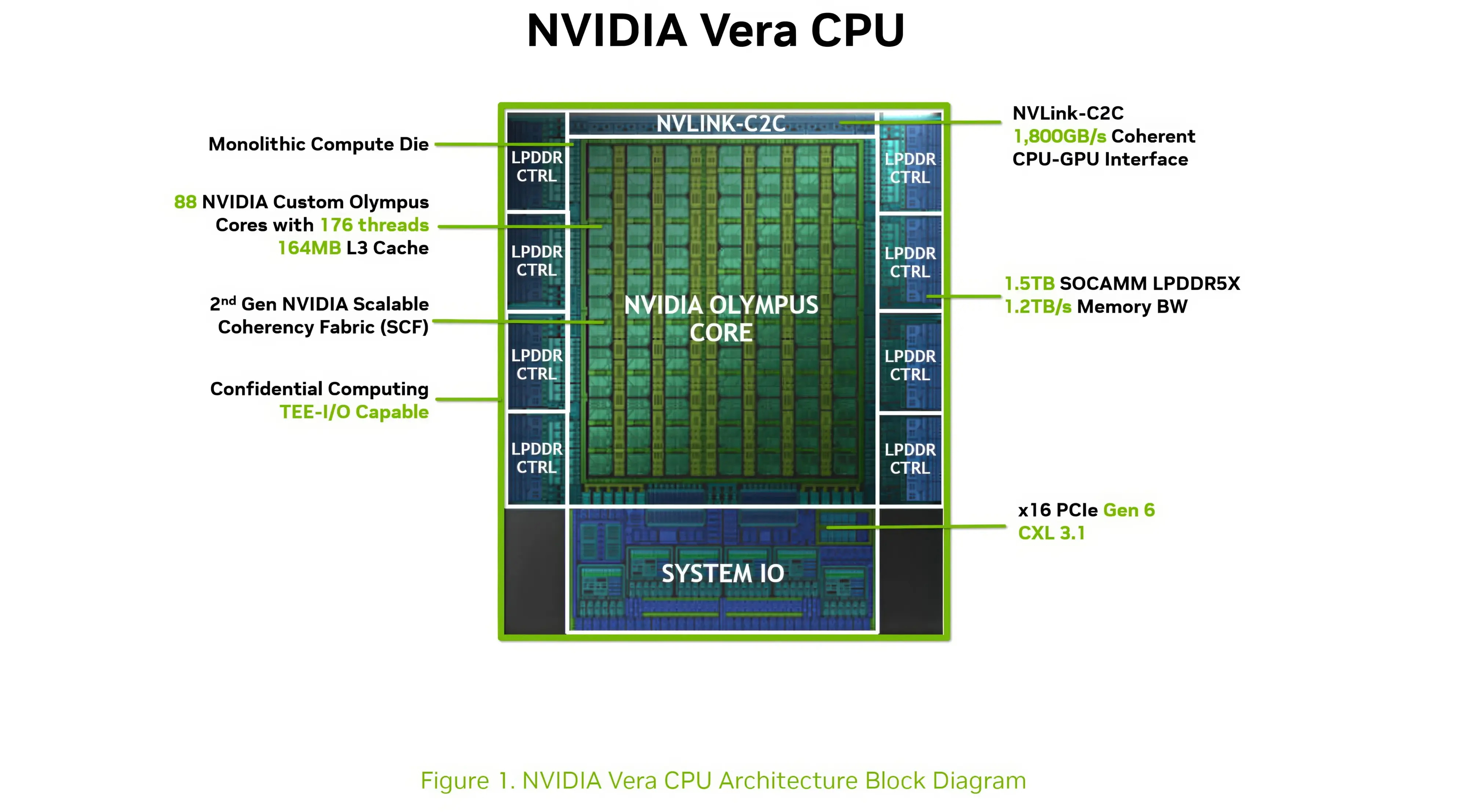 Ядра процессора, кеш, контроллеры памяти и ввода-вывода объединены через масштабируемую когерентную структуру Nvidia второго поколения. Компания заявляет о пропускной способности между ядрами до 3,4 Тбайт/с, пропускной способности памяти SOCAMM2 LPDDR5X до 1,2 Тбайт/с и поддержке до 1,5 Тбайт памяти на процессор. Vera также поддерживает интерфейс NVLink-C2C со скоростью до 1,8 Тбайт/с, PCIe 6.0 и CXL 3.1. Системы с двумя сокетами обеспечивают 176 линий PCIe и используют двухузловую конфигурацию NUMA — по одному домену NUMA на каждый сокет. Nvidia утверждает, что Vera обеспечивает до 1,8 раза более высокую производительность, чем неназванные системы x86, в отдельных рабочих нагрузках, связанных с работой ИИ-агентов. Результаты основаны на внутренних тестах Nvidia SPEC CPU 2026, проведённых в июле 2026 года, и пока не были независимо подтверждены. В Нидерландах создали первую в мире «солнечную» черепицу с гибкой плёнкой из перовскита и эффективностью 12,4 %
03.04.2026 [11:29],
Геннадий Детинич
В Нидерландах разработана первая в мире солнечная черепица с использованием тонких плёнок перовскита. У нового элемента сравнительно невысокая эффективность, зато благодаря ему черепичная крыша будет выглядеть как обычная крыша, а не как набор установленных под углом солнечных панелей. «Солнечная» черепица готова к массовому производству и вполне может стать неотъемлемым элементом городской архитектуры, сочетая выработку электричества и эстетику зданий. 
Источник изображения: TNO Размещение солнечных панелей на крышах возможно далеко не везде, поскольку особенно старые здания не рассчитаны на такую дополнительную нагрузку. Установка солнечных панелей на земле требует свободных пространств, что тоже является проблемой, особенно в густонаселённой Европе. Солнечные элементы в виде обычной черепицы с аналогичным способом монтажа решают эти проблемы, позволяя получать возобновляемую энергию в городских условиях, не внося хаос в архитектуру и в уже сложившуюся застройку. Разработка модуля в составе композитной черепицы осуществлена исследователями нидерландской организации TNO (Netherlands Organisation for Applied Scientific Research) в сотрудничестве с компанией ASAT B.V. Технически черепица работает на гибких солнечных элементах из перовскита, нанесённых на фольгу, которая затем крепится к изогнутой композитной основе. Материалы и процессы адаптированы для крупномасштабного производства рулонным методом, что является наиболее экономически выгодным способом. Эффективность отдельных модулей достигает 13,8 %, а после монтажа на изогнутой черепице сохраняется на уровне 12,4 %. Изгиб поверхности оказывает лишь незначительное влияние на производительность. Разработка прошла путь от лабораторных тестовых ячеек до гибких модулей размером 10 × 10 см и, наконец, до готовой функциональной солнечной кровельной черепицы. По сравнению с традиционными кремниевыми солнечными панелями новая черепица обладает ключевыми преимуществами: она полностью интегрируется в кровлю, сохраняя внешний вид здания и не требуя дополнительного пространства на земле. Это снижает нагрузку на инфраструктуру, не влияет на ландшафт и упрощает монтаж, а также открывает возможности для массового применения в жилом и коммерческом строительстве. Экологический эффект заключается в увеличении производства «зелёной» энергии непосредственно в городской застройке, а готовность технологии к промышленному масштабированию делает её экономически перспективной. В настоящее время прототип успешно протестирован, а измерения подтвердили заявленную эффективность. Для коммерциализации TNO 11 марта учредила дочернюю компанию Perovion Technologies. В будущем планируется повысить срок службы, надёжность и масштабируемость технологии. Как подчеркнули разработчики, такая солнечная черепица — следующий этап энергетического перехода, который сделает солнечную энергию более доступной, дешёвой и массовой, заложив основу для энергетической безопасности в Европе. Крупнейший архив видеоигр Myrient спасён фанатами от забвения
16.03.2026 [23:30],
Анжелла Марина
Представители сообщества SaveMyrient официально заявили об успешном завершении резервного копирования крупнейшего архива видеоигр Myrient, объём которого составляет 385 Тбайт. Эта знаковая новость прозвучала на фоне недавних тревожных сообщений о том, что проект находится на грани прекращения существования. 
Источник изображения: GOG Ранее администраторы коллекции предупреждали, что сочетание недостаточного финансирования, стремительного роста операционных расходов и злоупотреблений со стороны специализированных менеджеров загрузок создаёт критическую нагрузку на инфраструктуру ресурса. Особую обеспокоенность, как пишет Tom's Hardware, вызывало резкое увеличение рыночной стоимости оперативной памяти, твердотельных накопителей (SSD) и жёстких дисков, необходимых для хранения данных. Модератор SaveMyrient под ником Ill-Economist-5285 поделился радостной информацией перед выходными, отметив значительный прогресс в работе волонтёров. По его словам, команда проделала огромную работу по завершению загрузок и их последующей проверке, что позволило объявить зеркало Myrient полностью готовым. Сейчас основные усилия направлены на генерацию торрент-файлов и обеспечение их доступности для широкой публики. Важно отметить, что оригинальный веб-сайт продолжит свою работу до конца текущего месяца и не будет выведен из эксплуатации раньше этого срока. Другой модератор проекта уточнил, что использование технологии торрентов рассматривается на текущем этапе исключительно как временная мера. Участники выразили готовность раздавать коллекцию в активном режиме, чтобы гарантировать стабильность распределения данных. Ill-Economist-5285 также заверил поклонников ресурса, что в скором времени работа системы вернётся в нормальное русло. Для подготовки к следующему этапу некоторые разделы архива могут быть временно отключены, однако детали будущих изменений будут раскрыты позднее. На данный момент доступ к оригинальному порталу Myrient сохранён, и пользователи могут продолжать загрузку, например, таких раритетов, как приложения Calamus для платформы Atari ST или шутера Descent II с MS-DOS. Напомним, Myrient — это один из крупнейших публичных архивов ретроигр, основанный в 2022 году для хранения редких ROM-файлов и образов дисков. Ресурс предоставляет доступ к 385–390 ТБ данных для эмуляции. Проект, славившийся проверенными файлами, закрывается 31 марта 2026 года из-за высокой стоимости хостинга. Военные США заплатят за разработку фотонных чипов для ИИ — для этого придётся в чём-то обмануть физику
07.02.2026 [15:39],
Геннадий Детинич
Управление перспективных исследовательских проектов Министерства обороны США (DARPA) объявило запуск программы PICASSO, целью которой обозначено преодоление фундаментальных физических ограничений фотонных вычислительных архитектур. Фотоника продолжает оставаться в зачаточном состоянии, что не даёт воспользоваться всеми её преимуществами — низкими задержками и предельно малым потреблением энергии. Пришло время ей поднять голову, а физике — уступить. 
Источник изображения: ИИ-генерация ChatGPT 5.2/3DNews Основные проблемы современных фотонных систем — это неизбежное затухание оптического сигнала, невозможность усиления полезного сигнала без одновременного усиления шума, а также паразитные интерференции, рассеяние, отражения, резонансные явления и нестабильность характеристик при массовом производстве, а также уход параметров за рамки заявленных под воздействием температуры и других внешних факторов. Всё перечисленное выше привело к тому, что современные фотонные чипы способны выполнять лишь простые линейные операции на небольшую глубину вычислений, а для более сложных расчётов приходится постоянно преобразовывать световой сигнал в электрический и обратно — что сводит на нет преимущества фотонных архитектур. По крайней мере, в гибридной реализации. В этой связи DARPA приглашает разработчиков и компании создать фотонные архитектуры на уровне схемотехнических решений, которые смогут обойти существующие физические ограничения, используя при этом уже производимые фотонные компоненты (без создания новых материалов или устройств). Цель — добиться предсказуемой работы больших фотонных схем, чтобы раскрыть их потенциал для задач ИИ и других приложений, где требуются интенсивные вычисления. Программа PICASSO (Photonic Integrated Circuit Architectures for Scalable System Objectives) разделена на два этапа по 18 месяцев каждый, общий бюджет составляет около $35 млн, а заявки принимаются до 6 марта 2026 года. На первом этапе требуется доказать осуществимость поставленных задач, а на втором — создать функциональные решения. В DARPA считают, что в своё время схемотехники смогли на базовом уровне создать надёжные и устойчивые электронные архитектуры, так почему бы это не повторить для фотонных цепей? AMD откажется от устаревшей и медленной IDT — будущие Ryzen и Epyc получат FRED, разработанную Intel
05.02.2026 [00:15],
Анжелла Марина
Компания AMD разместила на своём сайте техническую документацию, раскрывающую одну из важных особенностей будущих процессорных архитектур компании — переход на современную технологию обработки прерываний Flexible Return and Event Delivery (FRED). Этот механизм заменяет таблицу дескрипторов прерываний (IDT), которая использовалась в архитектуре x86 ещё с 1982 года, начиная с процессора Intel 286. 
Источник изображения: AMD Обе системы управляют обработкой прерываний, то есть сигналов от оборудования, таких как действия мыши или поступление сетевых данных. В отличие от IDT, где разработчикам ПО требуется вручную управлять несколькими этапами для предотвращения конфликтов, FRED использует единую оптимизированную операцию, которая должна сократить количество процессорных циклов, затрачиваемых на обработку событий, и потенциально увеличить общую производительность системы. Технология FRED, разработанная компанией Intel и утверждённая консультативным советом по экосистеме x86, уже реализована в новых мобильных процессорах Intel Panther Lake. Однако заметный прирост производительности на старом программном обеспечении может не проявиться, поскольку FRED требует явной поддержки со стороны операционной системы, и его преимущества станут доступны только после обновления ядра и системных компонентов. Создатель ядра Linux Линус Торвальдс (Linus Torvalds) ещё в 2021 году положительно отозвался о внедрении FRED. По его словам, эта технология позволяет полностью отказаться от устаревшей таблицы прерываний, которую он назвал «пережитком ужасной архитектуры прошлого». Торвальдс отметил, что версия от Intel выглядит предпочтительнее для долгосрочного выживания и развития платформы x86-64, так как она значительно упрощает логику обработки исключений. Он также напомнил, что изначально название FRED расшифровывалось как «быстрый» (Fast), но в итоговой версии предпочтение отдали «гибкому» (Flexible) подходу. AMD не уточняет в документации, в каком именно поколении архитектуры Zen будет внедрена поддержка FRED, но сетевые источники предполагают, что это произойдёт уже в грядущем Zen 6. Как отмечает PC Gamer, внедрение столь глубоких изменений может означать, что Zen 6 станет полноценным архитектурным пересмотром, а не промежуточным обновлением. Ранее AMD придерживалась стратегии выпуска масштабных обновлений через поколение, и по этому графику радикальные новшества ожидались лишь в Zen 7. Официальные подробности о процессорах на базе Zen 6 должны появиться в конце текущего года. AMD опубликовала первые детали о Zen 6 — новая архитектура на 2-нм техпроцессе с мощным векторным потенциалом
21.12.2025 [21:48],
Николай Хижняк
AMD на этой неделе опубликовала документ под названием «Счётчики производительности для процессоров AMD Family 1Ah Model 50h-57h», в котором раскрываются некоторые особенности архитектуры Zen 6, которая будет использоваться в будущих потребительских процессорах AMD, а также серверных чипах EPYC Venice для центров обработки данных. Оказывается, Zen 6 — это не совсем эволюция архитектуры Zen 5, а совершенно новая конструкция с другой идеологией. 
Источник изображения: AMD AMD ранее в общих чертах сообщила, что архитектура Zen 6 будет использоваться в процессорах с общим количеством ядер до 256, а в её основе будет применяться 2-нм техпроцесс компании TSMC. В опубликованном компанией на этой неделе документе для разработчиков программного обеспечения говорится, что микроархитектура Zen 6 не является поэтапным развитием Zen 4/Zen 5, а представляет собой намеренно широкую, ориентированную на пропускную способность архитектуру с восьмислотовым механизмом диспетчеризации и одновременной поддержкой многопоточности (SMT). В такой архитектуре два аппаратных потока динамически конкурируют за общий пул слотов диспетчеризации, поэтому при одинаковых тактовых частотах производительность однопоточных процессоров на базе Zen 6 может быть не такой высокой, как у тех же процессоров Apple с девятью (или более) слотами диспетчеризации во всех ситуациях. Однако в некоторых случаях этот тип архитектуры обещает очень высокую производительность. Кроме того, ядро Zen 6 имеет выделенные счётчики для неиспользуемых слотов диспетчеризации, задержек на бэкэнде и потерь при выборе потоков, что говорит о том, что широкое распределение нагрузки и арбитраж SMT являются факторами, которые будут специально оптимизироваться в Zen 6. Zen 6 также существенно расширяет возможности AMD по векторным вычислениям с плавающей запятой, подчёркивая акцент архитектуры на сложных математических задачах. Согласно документации, процессоры Zen 6 поддерживают полноценное выполнение инструкций AVX-512 с форматами данных FP64, FP32, FP16 и BF16, включая операции FMA/MAC и смешанное векторное выполнение FP-INT (включая операции VNNI-класса, AES и SHA). Кроме того, они обеспечивают устойчивую пропускную способность FP-блока в 512 бит. Это не доказывает, что процессоры на базе Zen 6 станут лидерами по производительности в операциях с AVX-512, но предполагает, что Zen 6 может сократить задержку при работе с векторами и превзойти устаревшие методы вычислений. В целом, ориентированные на производительность возможности Zen 6 предполагают, что это первая микроархитектура AMD, разработанная с нуля для использования в центрах обработки данных. Остается понять, какие функции Zen 6 будут сохранены в потребительских процессорах и насколько хорошо они будут работать. Китай штампует новые ИИ-модели еженедельно — США уже проигрывают гонку открытого ИИ
26.11.2025 [19:22],
Сергей Сурабекянц
Китай обогнал США на мировом рынке открытых моделей искусственного интеллекта, получив решающее преимущество в использовании этой технологии. Открытые модели, которые можно бесплатно загружать, изменять и интегрировать, упрощают создание и совершенствование продуктов. Стремление Китая к выпуску открытых моделей резко контрастирует с закрытым подходом большинства крупнейших американских технологических компаний. 
Источник изображения: unsplash.com Исследование, проведённое Массачусетским технологическим институтом (MIT) и стартапом Hugging Face, работающим с открытым исходным кодом в сфере ИИ, показало, что за последний год общая доля загрузок новых китайских открытых моделей выросла до 17 %. Этот показатель превышает 15,8 % доли загрузок моделей, созданных американскими разработчиками, такими как Google, Meta✴✴ и OpenAI, — впервые китайские компании обошли своих американских коллег. По данным MIT и Hugging Face, подавляющее большинство загрузок китайских моделей приходится на DeepSeek и Qwen от Alibaba. Ранее модель рассуждений DeepSeek R1 поразила сообщество, продемонстрировав высокие результаты при существенно более низких затратах на обучение. Этот релиз вызвал вопросы о том, смогут ли более обеспеченные ресурсами американские лаборатории ИИ защитить своё конкурентное преимущество. Он также породил сомнения в целесообразности гигантских инвестиций в инфраструктуру центров обработки данных, необходимых для работы мощных моделей. 
Источник изображения: DeepSeek «В Китае открытый исходный код стал более распространённым трендом, чем в США, — отметила старший аналитик Mercator Institute for China Studies Венди Чан (Wendy Chang). — Американские компании решили не играть в эту игру. Они зарабатывают на этих высоких оценках. Они не хотят раскрывать свои секреты». Администрация США, стремясь не проиграть гонку ИИ, пытается убедить американские компании инвестировать в модели с открытым исходным кодом, основанные на «американских ценностях». Но OpenAI, Google и Anthropic предпочли сохранить полный контроль над своими самыми передовыми технологиями, получая от них прибыль через клиентские подписки или корпоративные соглашения. В отличие от них, китайские компании, отрезанные в результате санкций США от передовых ИИ-чипов, получили стимул предложить открытый доступ к своим моделям. 
Источник изображения: Anthropic По словам исследователя MIT Шейна Лонгпре (Shayne Longpre), китайские компании, такие как DeepSeek и Alibaba Cloud, внедрили способ публикации моделей, «меняющий парадигму». Он подчеркнул, что китайские компании выпускают свои модели почти еженедельно, предлагая пользователям множество различных вариаций, из которых они могут выбирать, вместо того, чтобы выпускать серию моделей каждые шесть месяцев или год, как американские лаборатории. Другие эксперты отметили, что ограничения вычислительной мощности Китая из-за экспортного контроля США только подстегнули активность китайских исследователей. Они были вынуждены креативно подходить к разработке моделей, используя такие методы, как дистилляция, для создания более компактных, но мощных моделей. Также китайские ИИ-лаборатории активно занимаются разработкой моделей для генерации видео. Популярность китайских открытых моделей уже влияет на информацию, которую получают пользователи. Исследователи показали, что китайские модели явно пропитаны идеологией Коммунистической партии Китая и, как правило, отказываются предоставлять информацию по спорным политическим темам. Американские лаборатории гораздо больше сосредоточены на разработке современных передовых моделей, а OpenAI и Google DeepMind стремятся создать сильный искусственный интеллект (AGI), который должен превзойти человеческие возможности. В США гораздо меньше крупных независимых игроков в области разработки ПО с открытым исходным кодом, чем в Китае. Одним из этих немногих игроков выступил базирующийся в Сиэтле «Институт ИИ Аллена», который в ноябре запустил модель Olmo 3 с полностью открытым исходным кодом. По мнению экспертов, США должны быть обеспокоены тем, что Китай добивается больших успехов в области открытых моделей. AMD подтвердила, что в новых Radeon сосредоточится на трассировке лучей и ИИ
12.11.2025 [18:42],
Николай Хижняк
«День финансового аналитика» компании AMD не принёс геймерам никаких существенных новостей. AMD не предоставила никакой информации о преемнике графической архитектуры RDNA 4, за исключением двух пунктов. Компания не сообщила, когда он появится и как будет называться. Однако AMD подтвердила, что следующая архитектура для геймеров будет ориентирована на улучшенный ИИ и трассировку лучей. 
Источник изображений: AMD Это означает, что преемник RDNA 4 должен предложить более мощные тензорные ядра и ядра для трассировки лучей, как уже было заявлено в рамках проекта Amethyst — cовместного проекта AMD и Sony по созданию игровых консолей следующего поколения. По информации инсайдеров, AMD ещё не определилась с новым названием серии будущих игровых видеокарт. Эту информацию подтверждает новая дорожная карта графических продуктов AMD. Компания пока избегает использования названия архитектуры будущих графических процессоров. Будет ли это RDNA 5 или UDNA — пока неизвестно. Возможно, это означает, что AMD пока не может ничего обещать, связанного с Radeon, что весьма прискорбно, учитывая, что компания очень подробно описала свои планы по сериям серверных процессоров EPYC и ИИ-ускорителям Instinct. 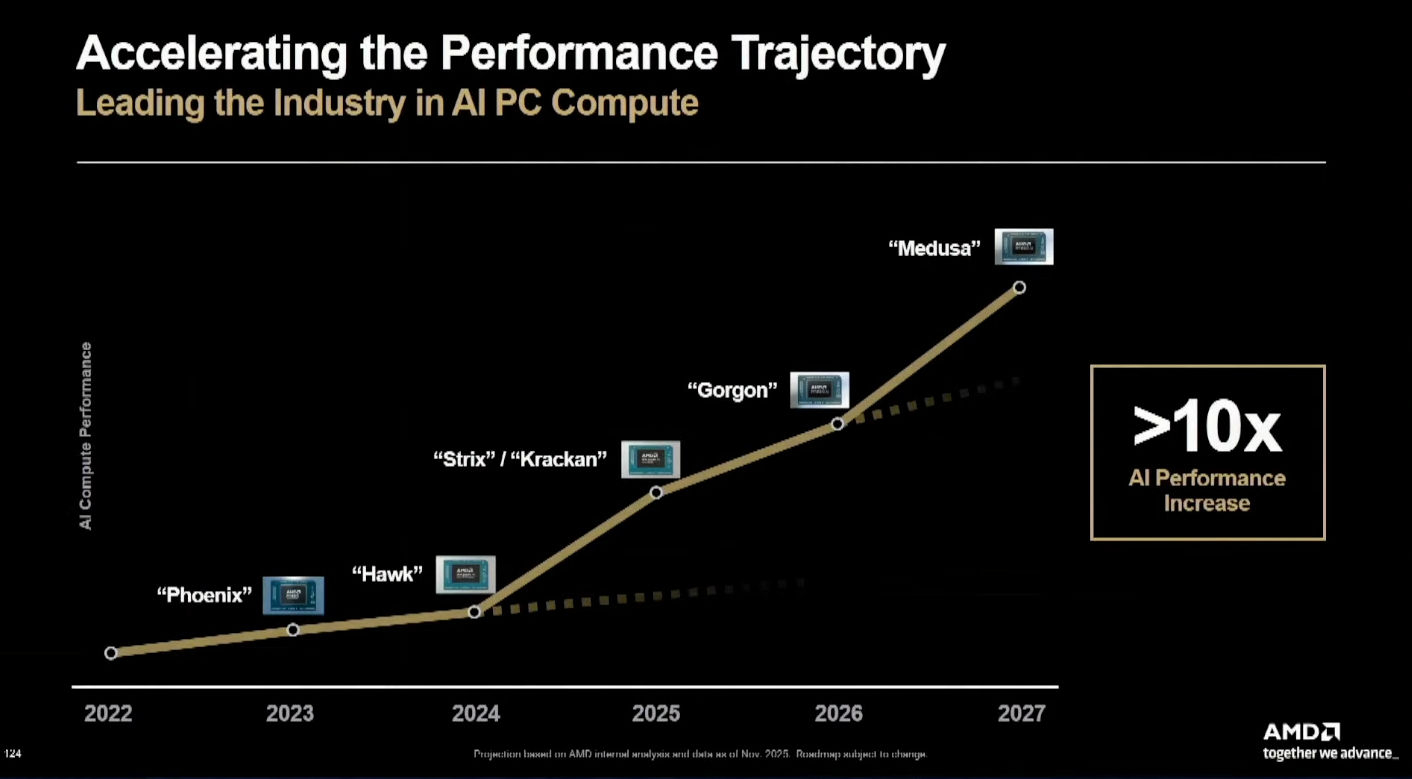 Другой важный анонс от AMD связан не с игровыми видеокартами, а с мобильными процессорами Ryzen. AMD наконец-то подтвердила выпуск серий Gorgon Point и Medusa Point. По слухам, Gorgon будет построена на обновлённой версии архитектуры Zen 5, а чипы Medusa будут использовать архитектуру следующего поколения (Zen 6), которая появится в нескольких продуктах Ryzen где-то в 2027 году. В следующем году компания выпустит чипы серии Gorgon Point. «День финансового аналитика» не является мероприятием, посвящённым запуску новых продуктов. В этом году мероприятие явно ориентировано на рынок ИИ. AMD раскрыла первые подробности о Zen 7 — представлен свежий план выпуска CPU-архитектур
12.11.2025 [00:19],
Николай Хижняк
Компания AMD официально представила обновлённую дорожную карту своих процессорных архитектур, добавив в неё Zen 7. На обновлённом плане Leadership CPU Core Roadmap архитектура Zen 7 представлена отдельным блоком под названиями «Будущий техпроцесс» и «Следующее поколение». 
Источник изображений: AMD Единственными конкретными особенностями, указанными для Zen 7, являются новый матричный движок и расширение формата данных ИИ. Тем самым AMD подчёркивает, что будущее семейство ядер продолжит развивать поддержку ИИ-вычислений, а не только классические скалярные и векторные вычисления CPU. На том же предоставленном AMD слайде компания перечислила предыдущие архитектуры. Zen 4 и Zen 4c привязаны к 5-нм и 4-нм техпроцессам, обладают поддержкой AVX-512 AI ISA, предлагают двухъядерные архитектурные решения и увеличенный кеш второго уровня. Zen 5 и Zen 5c, выполненные на 4-нм и 3-нм техпроцессах, обеспечивают более широкие и глубокие вычислительные возможности, полноценную поддержку 512-битных векторов ИИ и переоптимизированную иерархию кеш памяти. Ожидающиеся Zen 6 и Zen 6c перейдут на «первый в отрасли» 2-нм техпроцесс. Компания также напомнила, что именно серверные процессоры EPYC Venice станут первым реальным продуктом на Zen 6. Архитектура будет поддерживать новый тип данных ИИ и больше конвейеров ИИ. Чипы ожидаются в 2026 году. 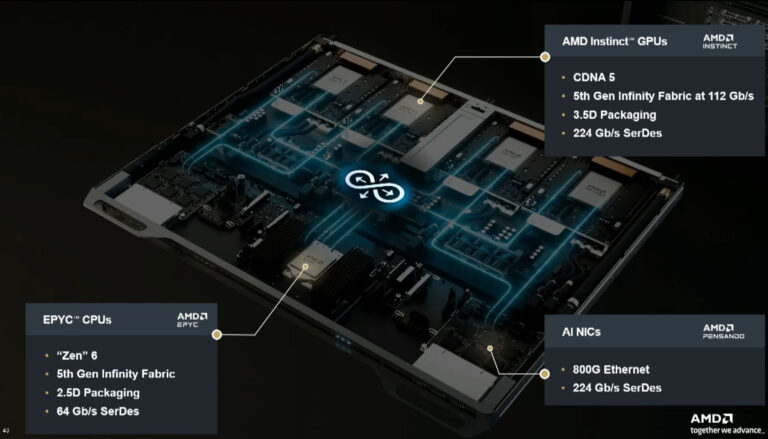 AMD не поделилась какими-либо дополнительными подробностями об архитектуре Zen 7, помимо тех, что представлены на слайде с дорожной картой. Нет ни маркировки техпроцесса, ни сроков выпуска продукта, ни упоминаний о количестве ядер и кеш-памяти. На данный момент официально известно только, что Zen 7 предложит новый матричный движок и расширенную обработку данных ИИ. Вся остальная информация о Zen 7 известна лишь из слухов. В частности, последние обещают для чипов Zen 7 более высокую плотность ядер и увеличенный объём кеша. Intel сократит опенсорсные разработки, потому что ими бессовестно пользуются конкуренты
10.10.2025 [13:55],
Алексей Разин
На протяжении многих лет корпорация Intel уделяла достаточно внимания поддержке экосистемы ПО с открытым исходным кодом, поскольку исторически её x86-совместимые процессоры имели большое распространение. Действующее руководство Intel склоняется к мысли, что далее в этой сфере следует соблюдать баланс интересов и не давать равные возможности конкурентам компании. 
Источник изображения: Intel Это становится понятно, как отмечает The Register, из слов главы серверного бизнеса Intel Кеворка Кечичяна (Kevork Kechichian), которые прозвучали во время мероприятия для прессы и аналитиков, устроенного компанией на прошлой неделе в Аризоне. «Мы должны найти баланс, при котором могли бы использовать это преимущество для Intel, но не давать возможность всем прочим схватить это и убежать», — заявил представитель компании. Другими словами, Intel не хочет поддерживать своих конкурентов, давая им дополнительные возможности за свой счёт. При этом Кечичян подчеркнул, что у Intel нет намерений прекратить поддержку сообщества в сфере ПО с открытым исходным кодом: «У нас нет намерений когда-либо забросить открытый исходный код. Есть много людей, которые получают выгоду от существенных инвестиций, которые Intel делает в эту сферу, — подчеркнул представитель компании. — Мы просто должны понять, как можем получить из этого больше, чем кто-либо другой за счёт наших инвестиций». Компания, по его словам, будет много внимания уделять поддержке открытого исходного кода, но важно не только усилить сообщества, которые поддерживались десятилетиями, но и выделить уникальные сильные стороны Intel. Принцип свободного доступа к программным разработкам Intel позволяет конкурентам на базе её решений создавать собственные более совершенные библиотеки. При этом остаётся загадкой, каким образом Intel может ограничить конкурентов в подобных возможностях. Возможно, часть программного кода компания сохранит закрытой. Например, в составе библиотек OneMKL код низкого уровня остаётся закрытым, тогда как интерфейсы верхнего уровня открыты для использования сторонними разработчиками. Продукция конкурентов с программным обеспечением Intel может работать хуже, чем с процессорами этой марки. В конце концов, ситуация с поддержкой сообщества Open Source может ухудшиться хотя бы в силу массовых сокращений инженеров Intel. Intel представила графическую архитектуру Xe3 для Panther Lake и пообещала прибавку в производительности на 50 %
09.10.2025 [18:15],
Николай Хижняк
Intel раскрыла первые подробности о платформе Panther Lake и связанной с ней графической архитектуре Xe3, представляющей собой третье поколение архитектуры Xe. Новая графика Intel появится в мобильных процессорах и будет предлагаться с 4 или 12 ядрами Xe3. 
Источник изображениq: Intel По данным Intel, новый векторный движок Xe3 обеспечивает на 25 % больше потоков, поддерживает переменное распределение регистров и деквантование FP8 для задач искусственного интеллекта и графики. Каждое ядро Xe3 объединяет восемь 512-битных векторных движков, восемь 2048-битных движков XMX и имеет на 33 % больше общего кэша L1/SLM по сравнению с Xe2.  Для фиксированных функций новый менеджер URB (URG) в составе Xe3 предлагает двукратное увеличение скорости анизотропной фильтрации и двукратное увеличение скорости stencil-теста (его результат определяет, будет ли нарисован пиксель, соответствующий фрагменту, или нет, — прим. ред). Усовершенствованный блок трассировки лучей обеспечит динамическое управление лучами для асинхронной трассировки лучей, повышая эффективность конвейера. Что касается медиавозможностей, новая архитектура поддерживает кодирование/декодирование AV1, декодирование VVC и eDP 1.5, а также 10-битные форматы AVC и Sony XAVC-H/H-S/S. 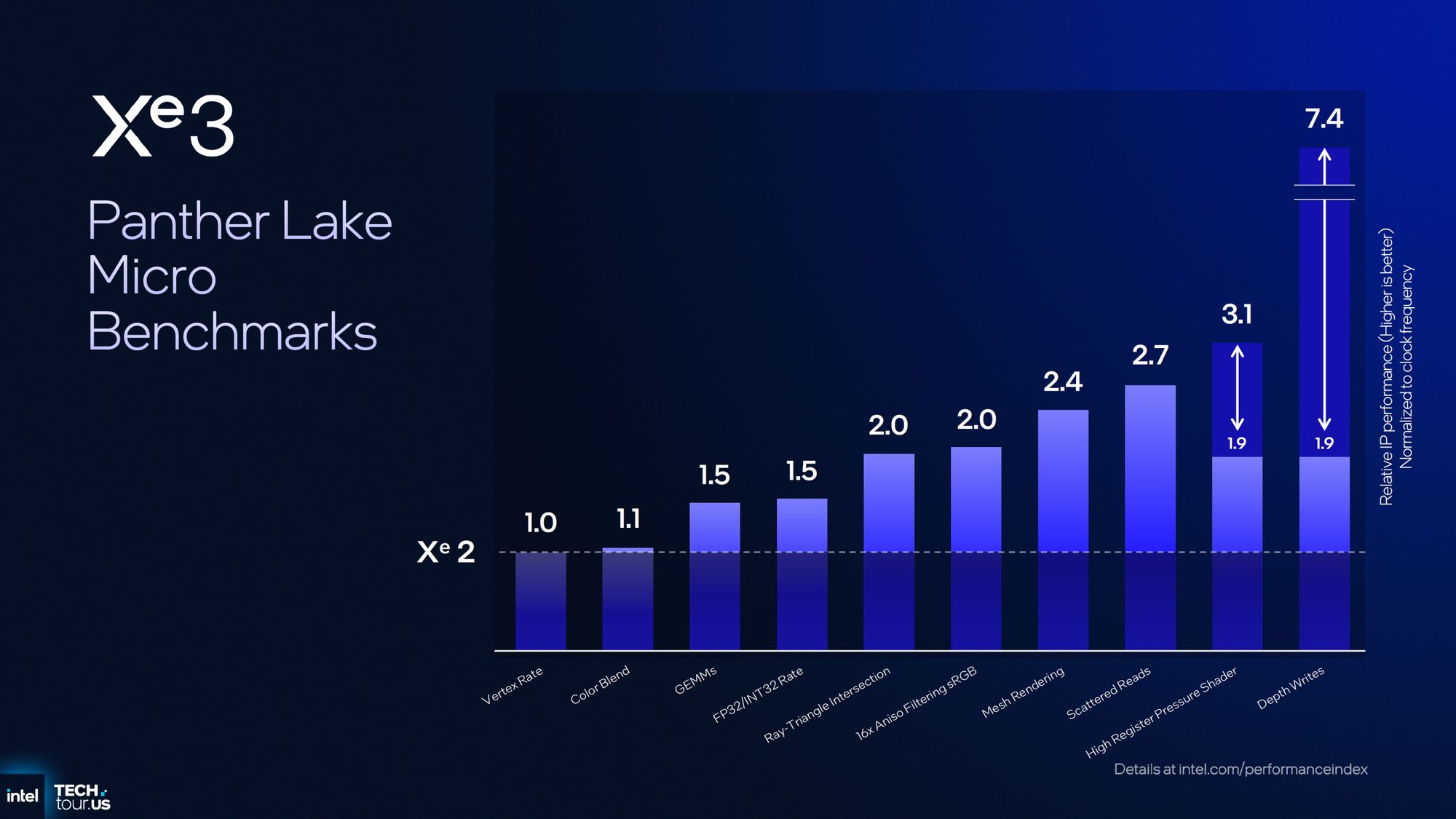 По оценкам Intel, графика Xe3 обеспечивает более чем на 50 % более высокую производительность, чем Xe2 в составе Lunar Lake при той же мощности, и более чем на 40 % более высокую производительность на ватт, чем встроенная графика Arrow Lake-H. 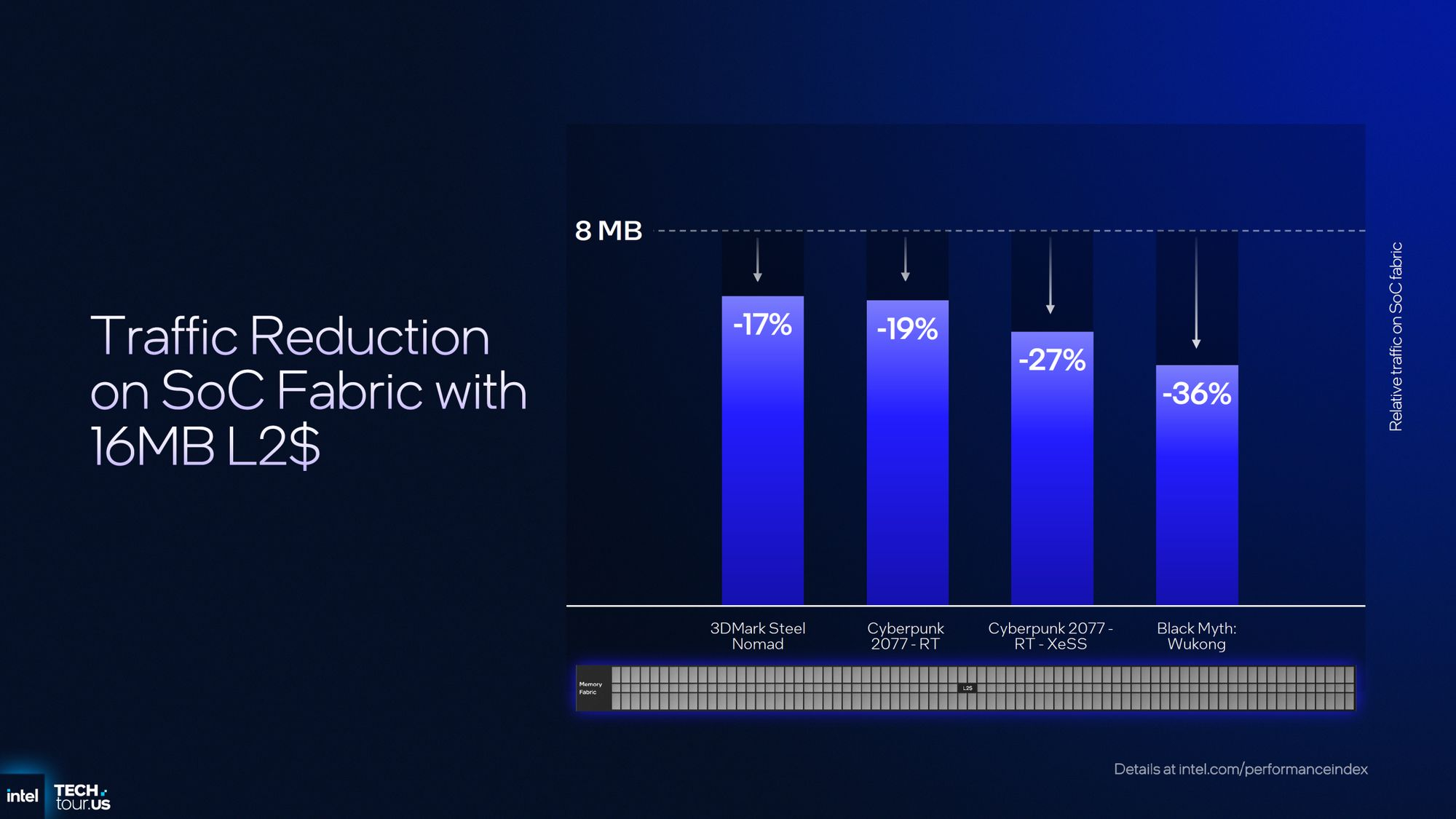 Компания поделилась результатами внутренних тестов, которые показывают прирост эффективности новой графики до 7,4 раза, с наибольшим приростом в операциях записи глубины (в 7,4 раза) и шейдерах с высоким давлением на регистры (в 3,1 раза). В составе процессоров Panther Lake будут использоваться одна из двух конфигураций GPU на базе Xe3:
Версия Xe3 с 12 ядрами предназначена для систем без дискретных графических видеокарт, а четырёхъядерный вариант GPU предназначен для ноутбуков со сверхнизким энергопотреблением, где встроенная графика работает в паре с дискретными графическими процессорами. Intel подчёркивает, что процессоры с 12-ядерной конфигурацией GPU будут поддерживать 12 линий PCIe, зато процессоры с более простым встроенным GPU — до 20 линий PCIe, что отражает различия в компоновке SoC. 
 Новая архитектура также масштабирует модуль Render slice, увеличивая количество ядер Xe на слайс с четырёх в Xe2 до шести в Xe3, что на 50 % увеличивает плотность ядер и блоков рендеринга. Это расширение определяет более широкие возможности конфигурации и повышает эффективность SoC. Intel добавляет, что ускорение XMX в Xe3 обеспечивает производительность до 120 TOPS на 12-ядерном GPU по сравнению с 67 TOPS в предыдущем 8-ядерном Xe2. Одновременно с выпуском Xe3 также будут обновлены компилятор и программное обеспечение, что позволит более быстрое планирование, улучшенное распределение переменных регистров и интеграцию DirectX Cooperative Vectors в сотрудничестве с Microsoft. 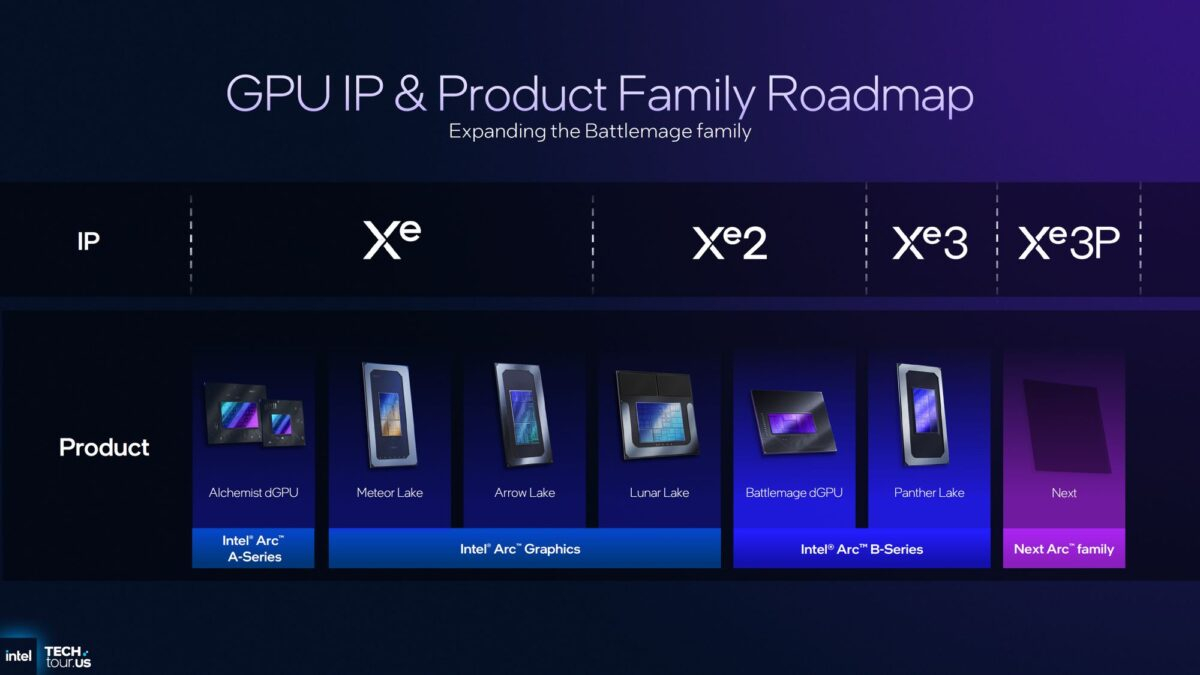 Наконец, Intel подтвердила, что на первом этапе Xe3 станет основой интегрированных графических процессоров серии Arc B. Усовершенствованная архитектура Xe3P для дискретных видеокарт находится в разработке. Она станет основой следующего поколения видеокарт Arc после Battlemage, а также будет ориентирована на новые платформы, такие как Nova Lake. Уровень проникновения архитектуры RISC-V на рынке достиг 25 % — намного быстрее, чем все ожидали
09.10.2025 [15:45],
Николай Хижняк
Уровень проникновения чипов на базе открытого стандарта RISC-V уже достиг 25 %, заявляют в организации RISC-V International. Эту оценку они планируют представить на саммите RISC-V в Северной Америке, который пройдёт в конце месяца. Аналитики из SHD Group тоже готовят собственные оценки доли RISC-V и намерены озвучить их на том же событии. 
Источник изображения: RISC-V RISC-V — это архитектура команд (ISA) с открытым стандартом. Её разработка стартовала в 2014 году. Архитектура ISA определяет, каким образом программное обеспечение общается с процессором — какие инструкции он может выполнять. И Arm, и RISC-V принадлежат к семейству RISC (Reduced Instruction Set Computing), но различаются в деталях, что влияет на выбор архитектуры в том или ином проекте. Сегодня архитектура Arm доминирует в мобильных устройствах и в некоторых ноутбуках. То, что доля RISC-V уже приближается к 25 %, может стать неожиданным сигналом для рынка. При этом пока неясно, идет ли речь о рынке микропроцессоров в целом или об узких сегментах, где RISC-V уже активно применяется — например, в микроконтроллерах для IoT и автомобильной электронике. В прошлом году аналитики Omdia прогнозировали, что к 2030 году доля RISC-V во всём полупроводниковом секторе составит 25 %, а объём поставок — 17 млрд чипов. По оценкам SHD Group, к 2031 году число выпускаемых чипов RISC-V превзойдет 21 млрд, а доход — $2 млрд. RISC-V International связывает этот рост с применением архитектуры в периферийной ИИ-инфраструктуре — небольшие локальные центры обработки данных, ориентированные на ближайших пользователей, а не централизованные облака. Ключевое отличие RISC-V в открытости: рабочие группы и компании могут использовать и развивать его без лицензионных отчислений или контрактов с управляющим органом. В отличие от этого, Arm зарабатывает на лицензировании ISA и архитектур ядер процессоров, предоставляя производителям поддержку и взимая роялти за использование. Полная картина оценки рынка RISC-V будет представлена 21 октября на саммите в Санта-Кларе, штат Калифорния. Среди докладчиков заявлены представители Google, AWS и NASA. Кроме того, недавно Meta✴✴ приобрела компанию Rivos, которая работает с графическими процессорами на базе RISC-V. Meta✴✴ также ведёт разработку ИИ-ускорителя на этой архитектуре, чтобы уменьшить зависимость от внешних поставщиков. RTX 5090 в 26 раз быстрее Radeon HD 5870: большой тест 180 видеокарт, вышедших с 2009 по 2025 год
02.10.2025 [22:22],
Николай Хижняк
Сайт PC Games Hardware отмечает своё 25-летие. Знаменательное событие PCGH решил отпраздновать наилучшим образом — масштабным сравнением производительности видеокарт. В нём приняли участие 180 графических ускорителей Nvidia, AMD и Intel, выпущенных за последние 16 лет. 
Источник изображения: VideoCardz Все 180 видеокарт были протестированы в режиме DirectX 11. В итоговых графиках такие модели, как Radeon HD 5870 и GeForce GTX 480, соседствуют с современными флагманами GeForce RTX 5090, Radeon RX 7900 XTX и Radeon RX 9070 XT. Полученные результаты говорят не только о чистой мощности видеокарт: старые игровые движки и ограничения процессора сокращают разрыв. На бумаге диапазон производительности огромен. Разница между самыми старыми производительными картами в тестировании и самыми новыми достигает 2477 % (между GeForce RTX 5090 и Radeon HD 5870), но во многих играх разница сужается, как только движок начинает давать сбои. 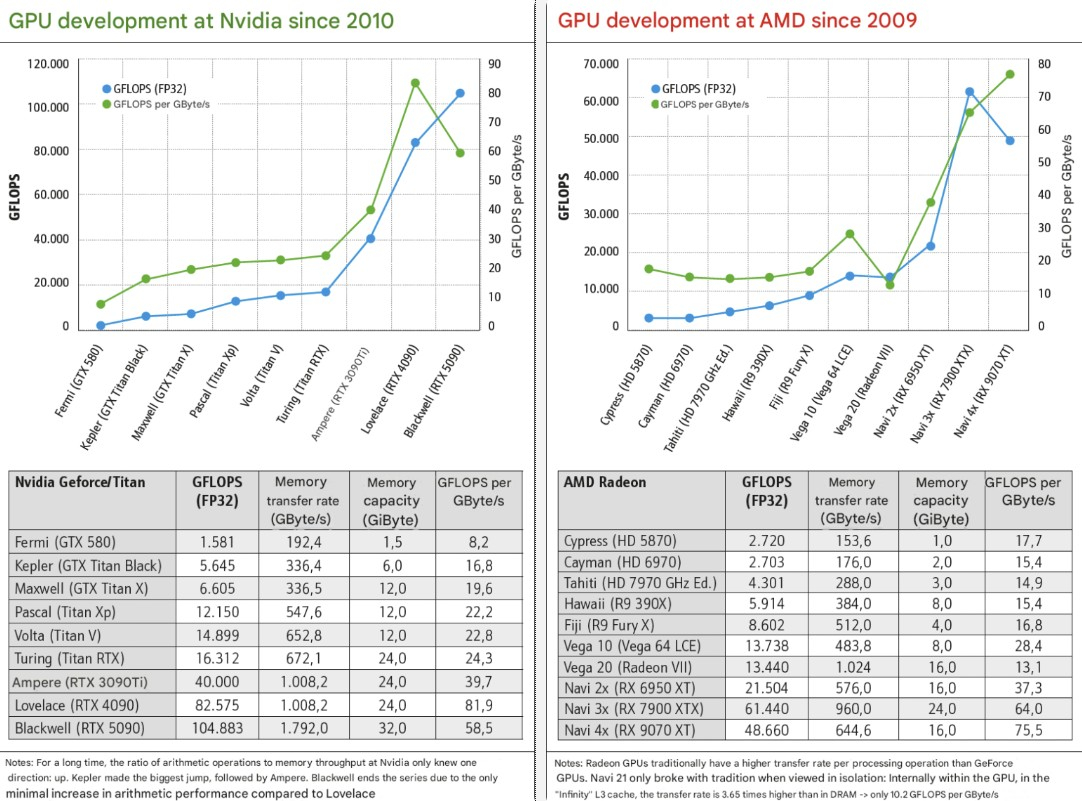
Сравнения графических архитектур Nvidia и AMD. Источник изображения: PC Games Hardware Данные также подчёркивают ключевые изменения в архитектурах: переход с Terascale на GCN, с Kepler на Maxwell и с GCN на RDNA. Maxwell исправил проблемы с энергопотреблением Kepler и повысил эффективность. В RDNA компания AMD обновила дизайн шейдеров, а RDNA 2 добавила Infinity Cache для стабилизации частоты кадров без расширенных шин памяти. К 2025 году архитектура RDNA 4 улучшила трассировку лучей, но не дала прироста растровой производительности. Переход на Blackwell с Ada Lovelace у Nvidia обеспечил прирост производительности значительно меньше, чем в предыдущих циклах — теперь большую роль играет технология генерации кадров. В графиках также отметилась Intel: серия карт Arc расширилась с одной модели Arc A380 до нескольких решений среднего уровня, демонстрируя, как оптимизация драйверов и поддержка API меняют производительность со временем. Для тестов PCGH использовал оптимизированную систему на базе флагманского Core i9-14900KS с частотой 6,2 ГГц, чтобы минимизировать ограничения, связанные с процессором. Тесты проводились в разрешении 1080p, но некоторые игры, как показала практика, по-прежнему ограничивают возможности современных видеокарт. Базовой в тесте является первая видеокарта с поддержкой DirectX 11 — Radeon HD 5870. Ниже представлен полный график с разницей в производительности (по клику откроется в полном размере). 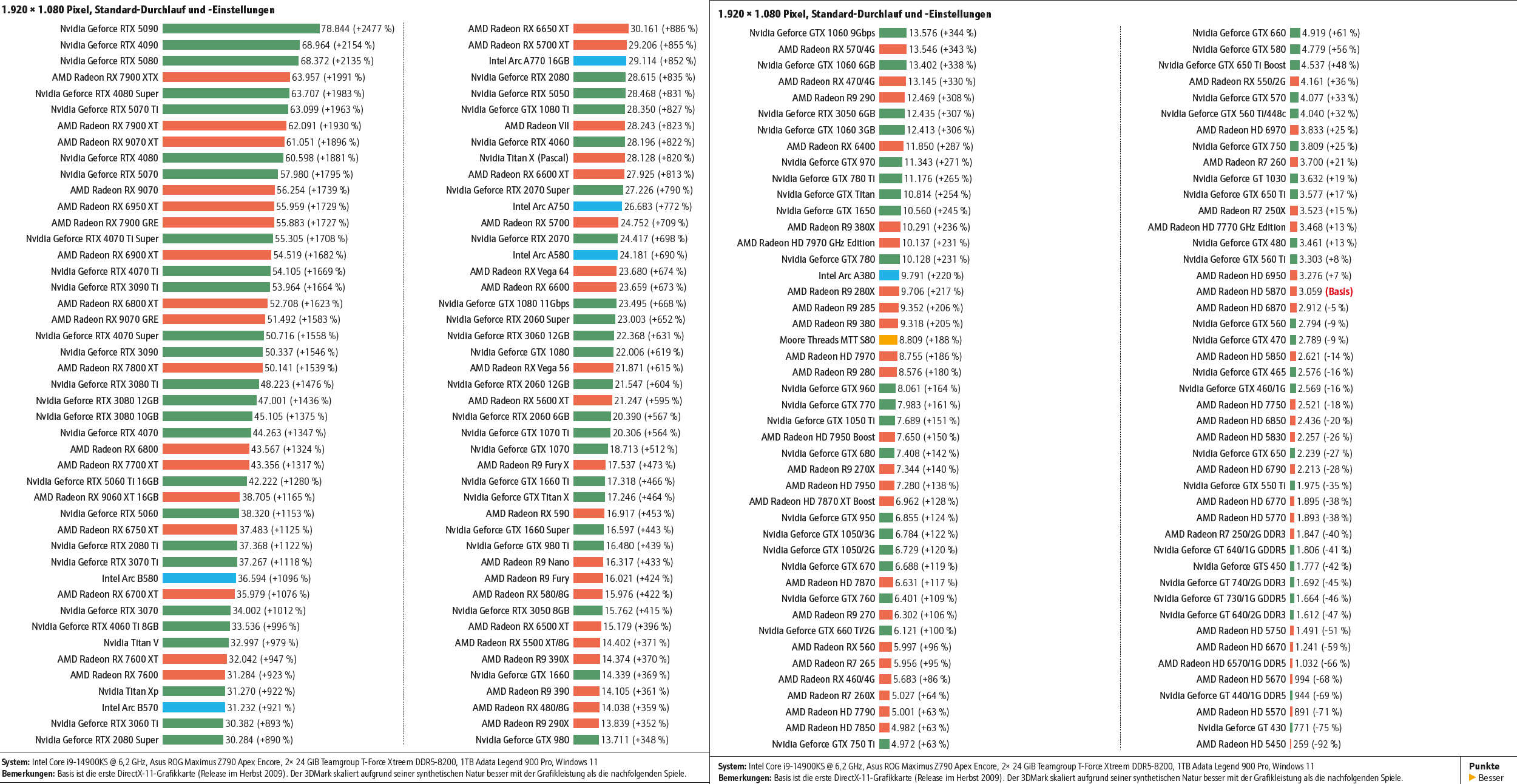
Сравнение производительности видеокарт. Источник изображения: PC Games Hardware Объём видеопамяти — ещё один параметр, который менялся с поколениями графических архитектур. Тесты показали, что старые видеокарты с 3–4 Гбайт памяти испытывают трудности даже в играх с DX 11. Теперь минимальным требованием для плавной игры являются 8 Гбайт видеопамяти. В свою очередь модели с 12–16 Гбайт поддерживают более высокие настройки и разрешение и не подтормаживают. Из этого можно сделать вывод, что новая архитектура, достаточный объём памяти и оптимизированные драйверы важнее количества шейдеров в составе GPU. Данная заметка содержит лишь комбинированный график сравнения производительности. PCGH также протестировал все эти видеокарты в четырёх популярных играх, показав, как переход на новые графические архитектуры сказывался на результатах в реальных игровых бенчмарках. Китайская Lisuan Technology представила видеокарту на собственном GPU, и она тянет Black Myth: Wukong в 4K
26.07.2025 [15:14],
Николай Хижняк
Китайский стартап Lisuan Technology представил на мероприятии в Шанхае свой первый графический процессор 7G106 собственной разработки, изготовленный с применением 6-нм техпроцесса TSMC N6. Работу чипа показали в составе референсной видеокарты. GPU предназначен для игровых видеокарт массового сегмента. 
Источник изображений: Lisuan Technology / TechPowerUp Графический процессор 7G106 от компании Lisuan Technology использует проприетарную архитектуру TrueGPU с поддержкой различных API, включая DirectX 12 (без поддержки трассировки лучей), Vulkan 1.3, OpenGL 4.6 и OpenCL 3.0. Несмотря на отсутствие поддержки трассировки лучей, 7G106 позиционируется как решение для широкого круга пользователей, ищущих достойную игровую производительность без наценки, характерной для продукции топовых мировых брендов.  В составе графического процессора 7G106 присутствуют 192 текстурных блока (TMU) и 96 блоков растеризации (ROP). Чип поддерживает до 12 Гбайт памяти GDDR6 с 192-битной шиной. Для GPU заявляется поддержка вычислений FP32 и INT8 с теоретической производительностью FP32 на уровне 24 Тфлопс. Графический чип также поддерживает аппаратное ускорение декодирования AV1 и HEVC до 8K60FPS, а также кодирование AV1 с разрешением 4K30FPS и HEVC с разрешением 8K30FPS. Он поддерживает интерфейс PCIe 4.0 x16 и предлагает поддержку четырёх видеовыходов DisplayPort 1.4 с компрессией DSC 1.2b. Поддержка HDMI не заявлена, вероятно, ввиду высокой стоимости лицензии.  Характеристики энергопотребления представленного решения пока неокончательные. Референсная видеокарта на базе 7G106 оснащена одним 8-контактным разъёмом PCIe, что подразумевает максимальную потребляемую мощность 225 Вт. Карта также предлагает функцию виртуального GPU (vGPU), поддерживающую до 16 контейнеров через SR-IOV, что говорит о её направленности не только на игровой сегмент, но и на корпоративные решения и виртуализацию. Компания подчеркнула эту универсальность во время анонса, выделив варианты использования ускорителя для рабочих станций, создания контента и даже метавселенной. Lisuan Technology также анонсировала профессиональный вариант ускорителя, оснащённый 24 Гбайт памяти. Характеристики в целом аналогичные игровой карте, но все данные производитель не привёл. Сравнить обе карты можно в таблице ниже. 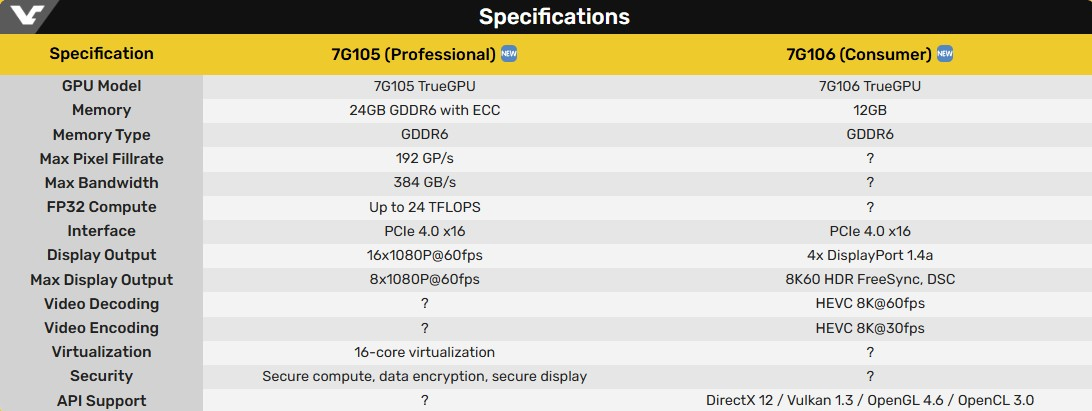 На мероприятии также было продемонстрировано, что видеокарта на базе графического процессора 7G106 способна обеспечить приемлемый уровень производительности в игре Black Myth: Wukong в разрешении 4K и при высоких настройках графики. Согласно данным портала ITHome, карта показала более 70 кадров в секунду в этой игре. В синтетических бенчмарках 7G106 показал результат 26 800 в 3DMark Fire Strike и 111 290 баллов в тесте Geekbench 6.4.0 OpenCL. Во втором случае китайское решение оказалось примерно на 10 % быстрее GeForce RTX 4060. Однако в тесте Fire Strike китайский GPU оказался заметно медленнее моделей Nvidia GeForce RTX 5060, RTX 5050, а также AMD Radeon RX 9060, все из которых показали результат около 29 000 баллов. 
Источник изображений: ITHome  Согласно имеющейся информации, образцы графического процессора 7G106 начнут рассылать заинтересованным сторонам в августе. А начало массового производства 7G106 запланировано на сентябрь этого года. Однако информации о тактовых частотах графического процессора, а также данных о том, когда видеокарты на его основе появятся в продаже, пока нет. Lisuan Tech 7G106

Смотреть все изображения (16)



Смотреть все изображения (16) Представители портала TechPowerUp побывали на презентации Lisuan Technology. С фотографиями этого мероприятия можно ознакомиться в галерее выше. Бельгийцы представили транзисторы нового поколения — быстрые, эффективные и доступные в производстве
19.06.2025 [10:53],
Геннадий Детинич
Около шести лет назад бельгийский центр Imec представил совершенно новую архитектуру транзисторов — CFET (комплементарные FET). Она должна была помочь с производством транзисторов с нормами производства менее 2 нм. Особенностью архитектуры стали раздельные наностраничные каналы (forksheet). Но технология оказалась сложна для производства, поэтому в Imec создали видоизменённый промежуточный вариант будущей архитектуры, представленный на днях. 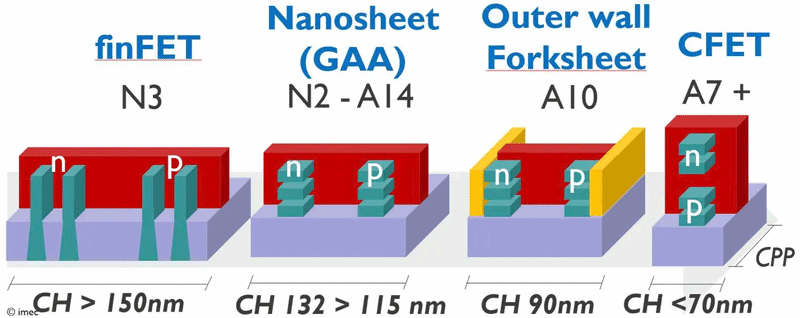
Источник изображений: Imec Суть архитектуры forksheet заключается в разделении диэлектрической перегородкой транзисторов n- и p-типа с общим круговым затвором (GAA). Перегородка или стена призвана минимизировать влияние соседних транзисторов друг на друга. В таком случае пару транзисторов с разной проводимостью можно изготовить на меньшей площади чипа, что, в итоге, приведёт к существенному снижению площади кристалла — до 20 %. Более того, Imec предложил располагать транзисторы друг над другом для реализации архитектуры CFET, что ещё сильнее уменьшило бы площадь чипов. Однако последующая работа над транзисторами с раздельными страницами показала, что идея с диэлектрической перегородкой крайне сложна при воплощении в производство. Тончайшую перегородку из диэлектрика толщиной от 8 до 10 нм необходимо было изготавливать первой ещё до всех манипуляций с кристаллом и травлением транзисторов. Такие «издевательства» над собой выдержит далеко не каждый материал, что вело бы к высокому уровню брака. Тогда в Imec придумали гениальное решение — перегородки должны быть внешними. Они уже не отдаляли разнополярные транзисторы друг от друга, но они как бы изолировали пары транзисторов от соседних пар. Фактически это была изоляция транзисторов с одинаковой проводимостью. 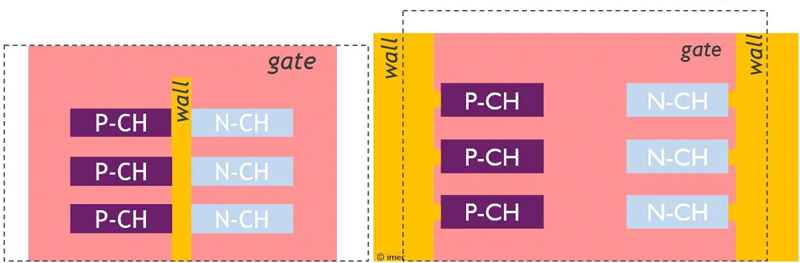
Варианты внутренней и внешней диэлектрической перегородки При таком техпроцессе перегородки изготавливались одними из последних на кристалле. Такое решение позволяло использовать известные материалы. За счёт более толстых стен могла незначительно пострадать площадь размещения пар транзисторов, но зато все остальные выгоды в виде увеличения скорости работы (токов) и снижения утечек сохранялись. Более тонкий переход между наностраницами и внешней стенкой позволял затвору охватывать увеличенную площадь ребра каждого наностраничного канала, что существенно улучшало контроль над токами в транзисторных каналах. Наконец, финальное изготовление внешних стенок вокруг транзисторных каналов повышало механическую напряжённость в наностраницах (в каналах транзисторов). Термин «напряжённый кремний» знаком всем, кто как минимум четверть века в теме производства чипов. В таких условиях повышается проводимость электронов и дырок в полупроводнике, что ведёт к повышению общей производительности чипов. Разработчики признают, что за счёт повышения толщины внешних изолирующих перегородок forksheet-транзисторов до 15 нм общая площадь чипа может оказаться несколько больше, чем в случае использования внутренних перегородок, но это небольшая и вынужденная жертва. Моделирование в CAD ячеек SRAM и генераторов с использованием транзисторов с раздельными наностраницами и внешними перегородками показало, что в ячейках статической памяти новая схема для техпроцесса A10 (10 ангстрем) позволила сократить площадь на 22 % по сравнению с нанолистами A14 без изоляции за счёт более плотной упаковки однотипных устройств и уменьшения шага затворов. Для схемы генератора под полной нагрузкой новая компоновка соответствует или превосходит производительность генераторов для техпроцессов A14 и 2 нм. Без нагрузки ток питания снижается примерно на 33 % (снижение утечек). Опыт производства транзисторов с раздельными наностраницами будет иметь большое значение для разработки CFET, поскольку многие этапы процесса, материалы и концепции проектирования будут пересекаться. В forksheet-транзисторах устройства p-типа и n-типа располагаются рядом друг с другом. В отличие от них, в CFET нового поколения два разных типа транзисторов будут располагаться вертикально, хотя базовые технологии останутся прежними. Но это история середины 30-х годов, к которой мы ещё не раз вернёмся в будущем. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex