|
Опрос
|
реклама
Быстрый переход
Как фен помог обойти санкции: топ-менеджеров Supermicro обвинили в контрабанде ИИ-чипов в Китай
20.03.2026 [04:57],
Алексей Разин
До сих пор все инциденты с подозрением американских регуляторов по поводу участия американских граждан в контрабандной поставке ИИ-ускорителей в Китай имели отношение к небольшим компаниям, но на днях обвинение было выдвинуто в адрес лиц, имеющих непосредственное отношение к руководству компании Supermicro. 
Источник изображения: Super Micro Computer Как подчёркивает CNBC, обвинительное определение Офиса федерального прокурора США по Южному округу Нью-Йорка содержит упоминания о частных лицах, связанных с неким американским производителем серверного оборудования, но из фамилий и имён обвиняемых становится понятно, что речь идёт именно о Super Micro Computer. Упоминаемый в документе И Шянь Лио (Yih-Shyan Liaw) является сооснователем компании и действующим членом совета директоров. Руэй Цань Чан (Ruei-Tsan Chang) руководит продажами оборудования этой марки на Тайване, а Тин Вэй Сунь (Ting-Wei Sun) является представителем подрядчика Supermicro. По версии американских органов правопорядка, трое обвиняемых организовали нелегальный экспорт серверного оборудования с ускорителями Nvidia в Китай с использованием подставной компании в Юго-Восточной Азии, которая в документах значилась конечным получателем продукции. Ещё одна компания была задействована для переупаковки поставляемых грузов, чтобы скрыть факт их поставки в Китай. Сообщается, что обвиняемые подготовили тысячи неработающих поддельных серверов для проверок, а затем снова использовали эти же «пустышки» во время проверки Министерства торговли США. По словам прокуроров, перед этой проверкой участники схемы с помощью обычного строительного фена сняли и заново наклеили этикетки и наклейки с серийными номерами, после чего переупаковали поддельные серверы в коробки производителя. Обвиняемые, по версии следствия, оказывали давление на инспектирующие органы, а также пытались ввести в заблуждение представителя Министерства торговли США, которому была поручена дополнительная проверка поставок. Торговый представитель Supermicro на Тайване якобы участвовал в манипуляциях документами и пытался привлечь «нужного» аудитора к проверке. Следствие считает, что И Шянь Лио в конце 2024 года пытался организовать поставки ускорителей Nvidia B200 в Китай через подставную компанию. Следователи располагают фрагментами переписки представителя Supermicro с предполагаемыми соучастниками. В 2025 году он торопил поставщиков, стремясь отправить в Китай больше оборудования до вступления в силу новых официальных запретов. Из троих фигурантов дела двое уже арестованы, тайваньский представитель Sipermicro находится в розыске. Акции компании на фоне таких новостей упали в цене на 12 %. Nvidia похвалилась, что Blackwell удешевили инференс нейросетей до 10 раз — и это заслуга не только «железа»
13.02.2026 [16:42],
Павел Котов
С развёртыванием ускорителей искусственного интеллекта на архитектуре Nvidia Blackwell стоимость инференса, то есть запуска обученных систем ИИ, удалось сократить в 4–10 раз. Такие данные привела сама Nvidia. Но за счёт одной только аппаратной части добиться подобных результатов не получилось бы. 
Источник изображений: nvidia.com Значительного снижения затрат удалось добиться за счёт запуска ускорителей на архитектуре Nvidia Blackwell и моделей с открытым исходным кодом в инфраструктуре облачных операторов Baseten, DeepInfra, Fireworks AI и Together AI для задач, связанных со здравоохранением, играми, агентским ИИ и обслуживанием клиентов. Ещё один фактор — оптимизированные программные стеки. Перевод оборудования на Nvidia Blackwell помог сократить стоимость инференса вдвое по сравнению с ускорителями предыдущего поколения, а дальнейшему снижению затрат способствовал перевод систем в форматы пониженной точности, такие как NVFP4. Компания Sully.ai добилась сокращения затрат на вывод данных ИИ в области здравоохранения на 90 %, то есть в десять раз; время отклика улучшилось на 65 % за счёт перехода от закрытых к открытым моделям ИИ в инфраструктуре Baseten. Автоматизация задач по написанию кода и ведению медицинских записей помогла сэкономить специалистам 30 млн минут рабочего времени. Latitude на своей платформе AI Dungeon сократила затраты на вывод данных ИИ в четыре раза. Для этого она запустила в инфраструктуре DeepInfra модели с конфигурацией «смеси экспертов» (MoE), снизив стоимость 1 млн токенов с $0,20 до $0,10, а перевод системы на низкоточный формат данных NVFP4 помог сократить цену до $0,05. 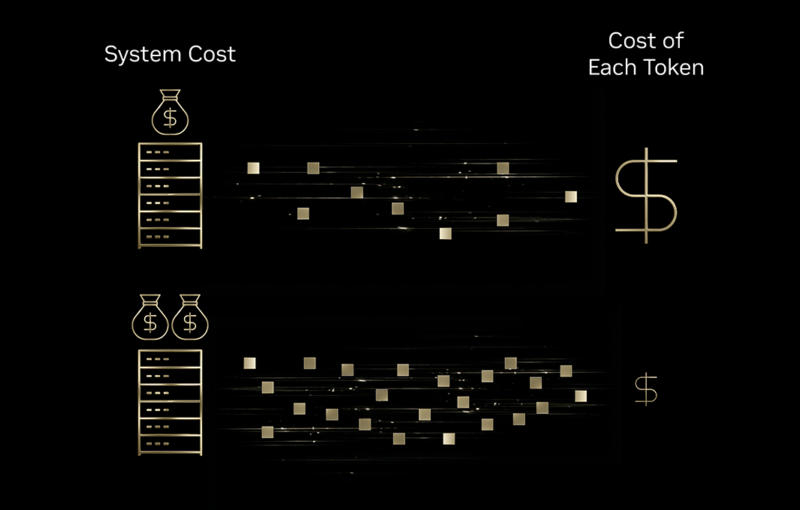 Sentient Foundation повысила экономическую эффективность платформы агентного чата на 25–50 % за счёт оптимизированного для Blackwell стека обработки данных Fireworks AI — платформа управления сложными рабочими процессами в неделю вирусного запуска обработала 5,6 млн запросов без ущерба для величины задержки. Decagon шестикратно снизила затраты на запрос для голосовой поддержки клиентов с ИИ, запустив многомодельный стек в инфраструктуре Together AI на ускорителях Blackwell. Время ответа сохранялось менее 400 мс даже при обработке нескольких тысяч токенов на запрос, что критически важно при голосовом взаимодействии, когда клиенты в любой момент могут прервать разговор. Значение имеют характеристики рабочей нагрузки. ИИ-ускорители Blackwell успешно работают с «рассуждающими» ИИ-моделями, потому что для получения более качественных ответов те генерируют большее число токенов. Платформы эффективно обрабатывают эти расширенные последовательности за счёт дезагрегированного обслуживания — отдельной обработки предварительного заполнения контекста и собственно генерации токенов. При оценке затрат эти аспекты следует учитывать: при высоких объёмах генерации токенов можно добиться десятикратного повышения эффективности; уменьшенная генерация токенов в моделях высокой плотности ведёт лишь к четырёхкратному росту показателей. В приведённых выше примерах речь идёт об ускорителях Nvidia Blackwell, но есть и альтернативные способы снижения затрат на вывод данных. Например, перевод систем на ускорители AMD Instinct MI300, Google TPU, а также специализированное оборудование Groq и Cerebras. Собственные средства оптимизации развёртывают и облачные провайдеры. Поэтому вопрос не в том, является ли архитектура Blackwell единственным вариантом, а в том, соответствует ли конкретное сочетание оборудования, ПО и моделей ИИ требованиям конкретной рабочей нагрузки. Дженсен Хуанг показал ускорители Rubin на CES 2026 — их массовое производство уже запущено
06.01.2026 [07:51],
Алексей Разин
Вполне предсказуемо, что основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) трибуну CES 2026 использовал не только для рассказа о новейших продуктах и технологиях компании, но и для убеждения инвесторов в том, что ИИ-пузырь далёк от схлопывания. Одним из аргументов стала демонстрация образцов ускорителей с архитектурой Rubin. 
Источник изображения: Nikkei Asian Review Они выйдут на рынок в этом году, во второй его половине, но глава Nvidia подчеркнул, что их производство уже идёт полным ходом. Архитектура Rubin является преемником весьма успешной Blackwell, и Nvidia не скрывает, что связывает с ней особые надежды. Отвечая на вопросы аудитории на CES 2026, основатель компании пояснил: «Мы попытаемся наращивать поставки изо всех сил. Во втором полугодии мы будет продавать много, поставлять много (ускорителей Rubin)». По сравнению с Blackwell, ускорители Rubin обеспечат рост производительности в инференсе в пять раз, а также в три с половиной раза в обучении языковых моделей. В обеих сферах удельная стоимость генерируемого токена сократится в десять раз по сравнению с Blackwell, поэтому разработчикам будет выгодно переходить на Rubin даже в том случае, если новые ускорители окажутся заметно дороже старых. 
Источник изображения: Nvidia Непосредственно графические процессоры поколения Rubin станут первыми продуктами Nvidia с памятью типа HBM4, которая обеспечит скорость передачи информации до 22 терабайт в секунду. Одними из первых клиентов Nvidia, получивших ускорители Rubin во втором полугодии, станут облачные провайдеры CoreWeave и Microsoft Azure. Образцы ускорителей Rubin уже вовсю тестируются клиентами Nvidia. В одной серверной стойке могут объединяться до 72 графических процессоров Rubin и 36 центральных процессоров Vera. В одном вычислительном кластере могут объединяться до 1000 чипов Rubin, эффективность обмена данными между ними будет во многом определяться новыми сетевыми интерфейсами, которые были представлены параллельно. При работе в инференсе с форматом данных NVFP4, который Nvidia будет продвигать, ускорители Rubin обеспечивают быстродействие на уровне 50 петафлопс. Кратное повышение производительности и эффективности вычислений по сравнению с Blackwell было достигнуто при всего лишь 1,6-кратном увеличении количества транзисторов на чипе. Китайская Tencent получила доступ к 15 000 санкционных ИИ-чипов Nvidia Blackwell через Японию
22.12.2025 [08:12],
Алексей Разин
Не секрет, что нуждающиеся в доступе к передовым ускорителям вычислений западного производства китайские компании прибегают к аренде зарубежных облачных мощностей, чтобы избежать полного влияния американских санкций. Один из японских владельцев ЦОД на контрактах с китайской Tencent по этой схеме смог получить контракты на более чем $1,2 млрд. 
Источник изображения: Nvidia Как поясняет Financial Times, китайский гигант взаимодействует с японской Datasection через посредника, стараясь не слишком афишировать подобное сотрудничество, но эта схеме позволяет Tencent использовать основную часть из 15 000 ускорителей Nvidia с архитектурой Blackwell, которые установлены в ЦОД первой из компаний на территории Японии. В таком варианте доступа к вычислительным мощностям со стороны китайского разработчика нет ничего противозаконного, поскольку при Трампе власти США начали закрывать на такие проявления деятельности китайских компаний глаза. Тем не менее, лишнее внимание способно вызвать изменения в обстановке, которые для Tencent нежелательны. Характерно, что контракт с Tencent превратил Datasection в одного из крупнейших провайдеров на рынке «neocloud» в Азии, которые зарабатывают на аренде имеющихся у них вычислительных мощностей. Изначально Datasection работала в сфере маркетинговых услуг и строила ЦОД недалеко от Осаки для собственных нужд, но сдача их в аренду китайским клиентам оказалась более выгодным бизнесом. По словам главы Datasection Норихико Исихары (Norihiko Ishihara), ещё полгода назад для поддержания ИИ-модели было достаточно 5000 ускорителей Nvidia B200, а сейчас эта цифра как минимум удвоилась. Это предъявляет к участникам бизнеса особые требования. По оценкам аналитиков Bernstein Research, флагманские чипы Huawei и Alibaba обеспечивают около трети уровня производительности Nvidia B200, поэтому спрос на них в Китае сохраняется. Даже не самые современные H200, поставки которых США недавно разрешили в КНР, оказываются почти на четверть быстрее китайских лидеров. При этом первые примерно в четыре раза уступают передовым Nvidia B300, поставки которых в Китай запрещены. Как отмечается, японская Datasection свою сделку с Tencent через посредника заключила уже после того, как в мае Дональд Трамп (Donald Trump) отменил запрет на аренду зарубежных вычислительных мощностей китайскими компаниями. На первом этапе Datasection собирается на протяжении трёх лет сдавать в аренду 15 000 ускорителей Nvidia для нужд Tencent. В дальнейшем профильные мощности вырастут до более чем 100 000 ускорителей. Официально представители Datasection отрицают своё сотрудничество с китайской Tencent. Партия из 5000 ускорителей Nvidia B200 обошлась японской компании примерно в $272 млн по состоянию на июль этого года. За свой трёхлетний контракт с клиентом она при этом должна выручить $406 млн. Второй контракт на три года подразумевает получение $800 млн, которые будут направлены на строительство второго ЦОД, расположенного в Сиднее. Австралийская площадка разместит десятки тысяч передовых ускорителей Nvidia B300. Первая партия из 10 000 таких ускорителей будет стоить Datasection примерно $521 млн. По неофициальным данным, мощности австралийского ЦОД также будут использоваться преимущественно Tencent в ближайшие годы. Китайская компания утверждает, что использование зарубежных ЦОД никак не нарушает законы вовлечённых в процесс стран. Для провайдера в данном случае важно отбить затраты на закупку ускорителей. Как правило, срок амортизации рассчитан на пять лет, тогда как контракты заключаются на три года, но клиенты могут продлить их ещё на два года. Datasection оставляет за собой право разорвать соглашение с китайскими клиентами, если того потребуют изменения в законодательстве. По словам руководства компании, использование ускорителей Nvidia китайскими клиентами согласовано как с самим поставщиком, так с Министерством торговли США. Datasection намерена развивать ЦОД и на территории Европы, при этом потепления отношений между США и КНР компания не очень боится, поскольку в случае отказа китайских клиентов от аренды ЦОД она быстро найдёт новых, ведь спрос на инфраструктуру ИИ сейчас очень высок. В самом неблагоприятном случае, по словам провайдера, деятельность придётся остановить всего лишь на неделю. DeepSeek заподозрили в обучении новейшего ИИ на контрабандных чипах Nvidia Blackwell
11.12.2025 [04:56],
Алексей Разин
Ещё на этапе первичного успеха DeepSeek эту китайскую компанию американские чиновники подозревали в использовании для обучения своих ИИ-моделей полученных нелегально ускорителей Nvidia с архитектурой Hopper. В новом варианте подозрений уже фигурируют более совершенные укорители Blackwell. Сама Nvidia пока считает эти подозрения бездоказательными. 
Источник изображения: Nvidia Как сообщает The Information, ускорители Blackwell в условиях экспортных ограничений США попали в руки DeepSeek якобы в результате сложной многоэтапной операции. Сперва они будто бы были доставлены в те страны, которые имеют возможность их получать без ограничений, затем были разобраны на части, в таком виде отправлены в Китай, а после собраны в исходное состояние уже на территории КНР. Представители Nvidia эту историю прокомментировали следующим образом: «Мы не получили каких-либо улик или подтверждений скрытных ЦОД, собранных для введения в заблуждение нас или наших OEM-партнёров, а затем разобранных, отправленных нелегальными путями и заново собранных в каком-то другом месте. Хотя подобные подозрения кажутся нам надуманными, мы изучаем любые получаемые сигналы». На этой неделе стало известно, что после многочисленных попыток руководства Nvidia убедить американские власти разрешить поставки ускорителей Blackwell в Китай, президент Дональд Трамп (Donald Trump) позволил отгружать проверенным получателям более старые ускорители H200, которые всё равно в несколько раз превосходят по быстродействию те же H20, разрешённые для поставок ранее. Компаниям Intel и AMD будут предоставлены сопоставимые экспортные возможности, но поставки ускорителей Blackwell и более совершенных Rubin в Китай по официальным каналам будут по-прежнему запрещены. Nvidia распродала все ИИ-ускорители, но на подходе ещё больше Blackwell
20.11.2025 [11:18],
Павел Котов
Nvidia побила собственные прогнозы по прибыли за III квартал 2026 финансового года, реализовав больше ускорителей искусственного интеллекта, чем когда-либо прежде. Компания распродала все серверные чипы, заявил её гендиректор Дженсен Хуанг (Jensen Huang), но вскоре их запасы увеличатся. 
Источник изображения: nvidia.com По итогам отчётного периода выручка Nvidia составила рекордные $57 млрд, а чистая прибыль в пересчёте составила $4000 в секунду. Всего за один квартал бизнес компании в сфере центров обработки данных вырос на $10 млрд до $51,2 млрд — это на 66 % больше, чем за аналогичный период прошлого года. Для аналитиков показатели дохода Nvidia по направлению ЦОД служат индикатором «пузыря ИИ», о котором в последнее время говорят всё больше. Но никаких признаков негативной динамики у компании не наблюдается: прогноз на IV квартал составляет $65 млрд, то есть всего за три месяца квартальная выручка увеличится ещё на $8 млрд. «Продажи [ИИ-ускорителей на архитектуре] Blackwell зашкаливают, а облачные GPU распроданы», — заявил Дженсен Хуанг. Впрочем, распроданы, видимо, они не окончательно. «У нас ещё достаточно Blackwell на продажу и много Blackwell на подходе», — добавил он позже. Основной движущей силой роста в сегменте ЦОД и не только стали ускорители на обновлённой архитектуре Blackwell Ultra, признался гендиректор Nvidia: «Наша ведущая архитектура для всех категорий клиентов теперь Blackwell Ultra; продолжительным высоким спросом пользовалась наша предыдущая архитектура Blackwell». Выручка по игровому направлению показала рост на 30 % по сравнению с прошлым годом, и это хороший сигнал для видеокарт семейства Nvidia Blackwell, отзывы о которых в начале года были неоднозначными. Инвесторов же Дженсен Хуанг призвал не паниковать: «О пузыре ИИ говорят много. С нашей точки зрения наблюдается нечто совершенно иное». Nvidia много лет предупреждала, что ИИ изменит всё, и сейчас эта технология достигла переломного момента, считает глава компании: «Революционным станет переход к агентному и физическому ИИ». Под последним понимается робототехника с ИИ. Игровые видеокарты теперь приносят всего 7,5 % выручки Nvidia — ИИ-чипы разогнали доходы до $57 млрд
20.11.2025 [10:27],
Алексей Разин
Отчётность Nvidia за минувший фискальный квартал смогла порадовать тех инвесторов, которые ждали косвенных подтверждений сохранения высокого спроса компоненты для инфраструктуры ИИ. По итогам прошлого квартала выручка компании составила рекордные $57 млрд, увеличившись в годовом сравнении на 62 %, а последовательно сразу на 22 % или $10 млрд. 
Источник изображений: Nvidia Как отметила на мероприятии финансовый директор Nvidia Колетт Кресс (Colette Kress), компания рассчитывает выручить от реализации ускорителей семейств Blackwell и Rubin в размере $500 млрд за период с начала текущего года до конца 2026 календарного года. Спрос на компоненты для инфраструктуры ИИ продолжает превышать собственные ожидания Nvidia, по словам Колетт Кресс. Уже эксплуатируемые в составе облачных систем ускорители поколений Ampere, Hopper и Blackwell полностью загружены вычислениями. В серверном сегменте выручка Nvidia в прошлом квартале выросла на 66 % в годовом сравнении до рекордных $51,2 млрд. Направление сетевых решений увеличило выручку сразу на 162 % до $8,2 млрд, что позволяет профильному бизнесу считаться крупнейшим в мире. В структуре ускорителей Blackwell произошло важное изменение: более современные GB300 начали доминировать над GB200 и формировать до двух третей всей выручки в семействе. Даже в условиях весьма серьёзных геополитических противоречий между Китаем и США компании удалось выручить за квартал на китайском рынке $50 млн от реализации ускорителей H20, хотя в конце прошлого квартала Nvidia не хотела публиковать подобную статистику в целом. Так или иначе, руководство компании утверждает, что продажи H20 не оказали существенного влияния на итоги квартала. 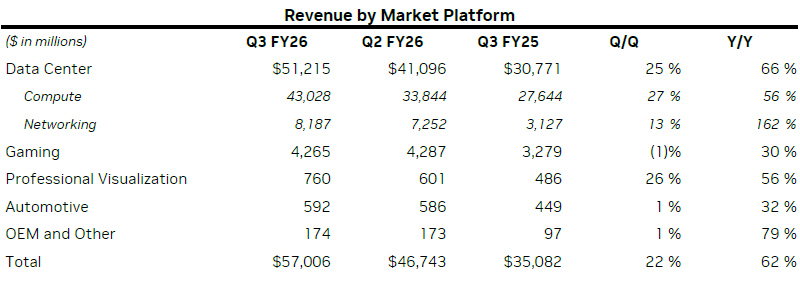 Игровой сегмент показал рост выручки на 30 % в годовом сравнении до $4,3 млрд (всего 7,5 % от всей выручки), но последовательно она снизилась на 1 %. Такая коррекция, по словам финансового директора Nvidia, обусловлена выходом складских запасов на более близкий к норме уровень в ожидании сезона предпраздничных распродаж. В годовом сравнении игровая выручка выросла преимущественно за счёт высокой популярности семейства Blackwell. В сфере профессиональных решений для визуализации семейство Blackwell также показало себя с лучшей стороны, способствуя росту выручки на 56 % год к году до $760 млн, но в этом контексте упоминается и положительное влияние DGX Spark. Выручка Nvidia в автомобильном сегменте ограничилась $592 млн, но она выросла на 32 % в годовом сравнении и на 1 % последовательно. Наконец, сегмент OEM-решений и прочих источников дохода позволил Nvidia увеличить выручку на 79 % до $174 млн в годовом сравнении, хотя последовательный рост тоже ограничился 1 %. В общей сложности, вычислительные и сетевые решения увеличили квартальную выручку Nvidia на 64 % до $50,9 млрд, тогда как на долю графических решений как таковых осталось только $6,1 млрд выручки. Тем не менее, и она в годовом сравнении увеличилась на 51 %. Руководство компании считает, что ежегодно в мире будет тратиться от $3 до $4 трлн на создание инфраструктуры для ИИ. В части сроков анонса новых ускорителей с архитектурой Rubin финансовый директор Nvidia повторила, что они выйдут во второй половине 2026 года. Платформа Vera Rubin, сформированная из 7 чипов, способна обеспечить кратное увеличение быстродействия по сравнению с Blackwell. В текущем квартале Nvidia рассчитывает выручить около $65 млрд, это подразумевает последовательный рост выручки на 14 %, во многом обусловленный высоким спросом на компоненты с архитектурой Blackwell. Если в прошлом квартале норма выручки компании составила 73,4 %, то в текущем она расположится в районе 74,8 %. В следующем году расходы компании вырастут, но Nvidia постарается поддерживать норму прибыли на уровне 74–76 %, по словам Кресс. На получение значимой выручки в Китае компания в текущем квартале тоже не рассчитывает. Выход видеокарт GeForce RTX 50 Super не отменяется, но переносится на лучшие времена
08.11.2025 [13:08],
Павел Котов
Видеокарты Nvidia GeForce RTX 50 серии Super на чипах Blackwell не появятся в первой половине 2026 года — их придётся подождать до III квартала будущего года, сообщает VideoCardz.com со ссылкой на появившиеся утечки. Ранее утверждалось, что выход RTX 50 Super может быть отменён, но новые данные не столь категоричны — речь якобы идёт лишь о сдвиге сроков выпуска на пару кварталов. 
Источник изображения: BoliviaInteligente / unsplash.com Отличительной особенностью видеокарт Nvidia GeForce RTX 50 улучшенной серии Super обещает стать память GDDR7 на чипах по 3 Гбайт. Первоначально предполагалось, что компания анонсирует их на выставке CES 2026 в начале года, а продажи видеокарт новой серии должны были стартовать через несколько недель. Однако авторитетный инсайдер MEGAsizeGPU сообщил, что компания перенесла их выпуск на вторую половину года — информация от него может означать, что для занимающихся непосредственным выпуском видеокарт партнёров Nvidia это тоже стало сюрпризом. По одной из версий, причиной решения стал дефицит чипов GDDR7 увеличенной ёмкости — компания так и не заключила контрактов на достаточный объём их поставок. Косвенным тому подтверждением, утверждает источник, станет грядущая нехватка видеокарт Nvidia GeForce RTX 5060 Ti с 16 Гбайт памяти GDDR7. С другой стороны, оснований называть происходящее задержкой или переносом выхода моделей серии Super было бы некорректно, потому что Nvidia нигде не говорила о сроках их появления, даже неофициально. Обычно за месяц или два до этого момента компания выпускает документ под названием GeForce Product Embargo, и пока в отношении видеокарт GeForce RTX 50 серии Super он ещё не появлялся. Белый дом заявил, что Nvidia не может поставлять в Китай свои самые передовые чипы
05.11.2025 [08:03],
Алексей Разин
«Послевкусие» переговоров Дональда Трампа (Donald Trump) и Си Цзиньпина (Xi Jinping) выразилось в обсуждении темы возможности поставок ускорителей Nvidia поколения Blackwell, хотя политики этой темы напрямую и не касались. Пресс-секретарь Белого дома отдельно пояснила, что Nvidia не должна отгружать в Китай свои самые передовые чипы. 
Источник изображения: Nvidia «Что касается самых продвинутых чипов, Blackwell, это не тот товар, в продажах которого в Китай мы сейчас заинтересованы», — отметила Кэролайн Левитт (Karoline Leavitt) во время пресс-конференции в Белом доме. Этот комментарий последовал после воскресных заявлений самого Дональда Трампа, который счёл нужным резервировать передовые чипы американского происхождения для нужд национальных компаний. Ранее американский президент рассуждал вслух о возможности поставок в Китай чипов поколения Blackwell перед переговорами с китайским лидером, но по её итогам признался, что разговора именно на эту тему не состоялось. Глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) продолжает тешить себя надеждами на возможность возвращения на рынок Китая, но пока вынужден констатировать, что китайская сторона сама не желает закупать у его компании ускорители вычислений. В апреле их поставки в КНР запретили власти США, но к июлю удалось добиться снятия этого запрета. К тому времени, как считается, Nvidia уже успела разработать для Китая замедленную версию чипа Blackwell, но поставки в новых условиях так и не удалось наладить. Глава Nvidia всё ещё надеется когда-нибудь наладить поставки ИИ-чипов Blackwell в Китай
31.10.2025 [18:55],
Алексей Разин
Выступая на недавней квартальной конференции, глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) дал понять, что китайская сторона не желает получать от его компании ускорители вычислений, доступные в рамках существующих экспортных ограничений США. Сегодня он добавил, что не теряет надежды когда-нибудь наладить поставки ускорителей семейства Blackwell в Китай. 
Источник изображения: Nvidia Эти заявления, как сообщает Bloomberg, генеральный директор Nvidia сделал во время своего визита в Южную Корею на саммит APEC. На вопрос о готовности Nvidia продавать ускорители семейства Blackwell в Китае основатель компании ответил: «Я не знаю. Надеюсь, когда-нибудь». Он добавил, что тема таких поставок не затрагивалась в ходе его беседы с главой Совета КНР по развитию международной торговли Чжэнь Хонбинем (Ren Hongbin). Хуанг также дал понять, что решение о возможности поставок ускорителей Blackwell будет зависеть и от воли американского президента. Самое забавное, что и президент США Дональд Трамп (Donald Trump) накануне своей встречи с китайским лидером Си Цзиньпином (Xi Jinping) упоминал о готовности обсудить тему поставок Blackwell в Китай, но уже после переговоров был вынужден отметить, что конкретно об этих чипах речь по факту не велась, хотя экспорт чипов как таковой обсуждался. Хуанг отмечал недавно, что власти США намерены разрешить Nvidia поставки определённых чипов в Китай в обмен на 15 % от их выручки. Сам основатель компании является сторонником идеи сохранения поставок американских ускорителей в КНР, поскольку окончательная потеря контроля над этим рынком приведёт к развитию китайских разработчиков и чрезмерному прогрессу Китая, по его мнению. Глава Nvidia заявил, что ИИ-пузыря не существует — и предсказал полтриллиона выручки на новых чипах
29.10.2025 [09:54],
Алексей Разин
На фоне бума систем искусственного интеллекта капитализация Nvidia выросла почти до $5 трлн, поэтому основатель компании Дженсен Хуанг (Jensen Huang) использует малейшую возможность для демонстрации перспектив дальнейшего процветания своего бизнеса. На конференции GTC 2025 на этой неделе он поспешил заверить аудиторию, что никакого финансового «пузыря» в отрасли ИИ в настоящее время не создаёт. 
Источник изображения: Nvidia Прежде всего, Хуанг подчеркнул, что чипы поколений Blackwell и Vera Rubin в течение следующего года принесут Nvidia до $500 млрд выручки, и это без учёта Китая и всего остального азиатского рынка. Китай из прогноза компания уже давно исключает из-за геополитической неопределённости, а на этой неделе глава Nvidia в очередной раз заявил, что её позиции на китайском рынке приблизились к нулю процентов. В общей сложности, Nvidia рассчитывает поставить на рынок 20 млн своих новейших чипов, хотя и не конкретизирует, причисляются ли к ним Vera Rubin, которые в ограниченных количествах будут поставляться в следующем году. За время своего присутствия на рынке, по словам Хуанга, семейство Hopper разошлось тиражом около 4 млн экземпляров. Очевидно, что чипы более новых поколений окажутся популярнее с точки зрения объёмов продаж. «Я не верю, что мы находимся в ИИ-пузыре. Все эти различные ИИ-модели, которые мы используем — мы используем приличное количество услуг и с радостью платим за них», — пояснил свою позицию относительно панических настроений некоторых аналитиков основатель Nvidia. Тем более, что на полях GTC 2025 компания объявила о сотрудничестве сразу с несколькими партнёрами на десятки миллиардов долларов, и подобная динамика заключения сделок в какой-то мере должна успокоить тех, кто предрекает отрасли обвал из-за разрушения финансового пузыря. Сделанный для Китая ускоритель Nvidia RTX 6000D провалился в продаже — GeForce RTX 5090 лучше
16.09.2025 [13:03],
Алексей Разин
Китайский рынок достаточно велик, чтобы американская компания Nvidia предусматривала для него специально адаптированные продукты с учётом сохраняющихся санкций. При этом не все усилия Nvidia угодить китайским клиентам находят адекватный отклик, и вялый спрос на RTX 6000D можно считать тому примером. 
Источник изображения: Nvidia По информации Reuters, компания Nvidia специально создала адаптированные для китайского рынка ускорители RTX 6000D, которые могли бы применяться в задачах, связанных с формированием логических выводов (инференс). При этом ценовое позиционирование данного решения Nvidia в Китае не вызывает у многих клиентов желания активно закупать подобные изделия. Фактически в таких задачах RTX 6000D проигрывает по быстродействию запрещённым к поставке в Китай видеокартам GeForce RTX 5090. Но зато последние можно найти на «сером рынке» почти вдвое дешевле RTX 6000D, которая предлагается официально по цене $7000. Ситуация усложняется тем, что китайские разработчики систем искусственного интеллекта замерли в ожидании, пытаясь понять, на какие ускорители Nvidia сейчас лучше делать среднесрочную ставку. С одной стороны, власти США разрешили возобновить поставки в Китай ускорителей H20. С другой стороны, их использование не очень приветствуется китайскими регуляторами. При этом на горизонте в виде слухов маячит и B30A — адаптированный для поставок в Китай ускоритель вычислений Nvidia с более современной архитектурой Blackwell. Поставки RTX 6000D в Китай начались на этой неделе, как отмечает Reuters. Аналитики предсказывали, что во втором полугодии Nvidia может выпустить от 1,5 до 2 млн таких ускорителей, но теперь подобный план ставится под сомнение из-за низкого спроса на новинку в Китае. Под требования апрельской редакции правил экспортного контроля США ускорители RTX 6000D подходят, поскольку наличие у них памяти типа GDDR6 позволяет вписаться в предел пропускной способности 1,4 Тбайт/с, пусть и с незначительным запасом. Весной этого года Nvidia принялась создавать RTX 6000D в качестве альтернативы попавшему под запрет ускорителю H20, но так и не отказалась от идеи предлагать в Китае первый после появления возможностей вернуть туда H20. Тем более, что последний стоит от $10 000 до $12 000, а RTX 6000D заметно дешевле. По предварительным оценкам, ожидающий одобрения властей США к поставке в Китай ускоритель B30A с архитектурой Blackwell будет превосходить H20 по быстродействию с шесть раз, но при этом стоить всего в два раза больше. Ожидание такого продукта также подрывает перспективы продаж RTX 6000D в Китае. Nvidia представила GB300 Blackwell Ultra — мощнейший ИИ-ускоритель с 20 480 CUDA, 288 Гбайт HBM3E и PCIe 6.0
26.08.2025 [14:45],
Павел Котов
Nvidia опубликовала подробную информацию об ускорителе искусственного интеллекта GB300 Blackwell Ultra. От предшественника в лице GB200 его отличают увеличенные число ядер и объём памяти, более быстрый интерфейс и более высокая мощность. В основе Nvidia GB300 лежат два кристалла с суммарным числом 208 млрд транзисторов — они производятся по технологии TSMC 4NP и работают как единый графический процессор (GPU) за счёт интерконнекта NV-HBI со скоростью 10 Тбайт/с. 
Источник изображений: nvidia.com GPU содержит 160 потоковых мультипроцессоров (Streaming Multiprocessors), на каждый из которых приходится по 128 ядер CUDA — всего 20 480 ядер, а также тензорные ядра пятого поколения с поддержкой вычислений на числах FP8, FP6 и нового формата NVFP4. Каждый потоковый мультипроцессор располагает 256 Кбайт тензорной памяти (TMEM) — всего 40 Мбайт. Предусмотрены также дополнительные аппаратные блоки для проведения трансцендентных вычислений и операций, оптимизированных для вычислительных ядер.  Память организована в восемь 12-слойных стеков HBM3E общим объёмом 288 Гбайт. Пропускная способность памяти у Nvidia GB300 в сравнении с GB200 не изменилась — она составляет 8 Тбайт/с, будучи организованной в 16 каналов по 512 бит (8192-битный интерфейс). Увеличенный объём памяти позволяет размещать на чипе ИИ-модель целиком, а также хранить большие объёмы кеша ключей и значений без выгрузки во внешние ресурсы. Показатель TGP вырос до 1400 Вт.  За связь между графическими процессорами отвечает интерфейс NVLink 5 с двунаправленной скоростью передачи данных 1,8 Тбайт/с на каждый GPU. Связь между GPU и центральным процессором Grace реализована через интерфейс NVLink-C2C со скоростью 900 Гбайт/с и поддержкой единого адресного пространства. Для подключения к хосту используется шина PCIe 6.0 x16 с двунаправленной полосой пропускания 256 Гбайт/с — этот интерфейс Nvidia применила впервые. Ускорители могут устанавливаться в стойку GB300 NVL72 с 72 графическими процессорами, до 20,7 Тбайт памяти HBM3E и общей полосой пропускания HBM 576 Тбайт/с. На стойку также приходится 72 Arm-ядра Grace Superchip и до 480 Гбайт LPDDR5X с полосой пропускания 512 Гбайт/с. NVFP4 — это новый формат данных с низкой точностью, реализованный в тензорных ядрах. Он обеспечивает точность, сравнимую с FP8, но позволяет использовать в 1,8 раза меньше памяти. Массовое производство ускорителей Nvidia GB300 уже стартовало, и первые клиенты их получили. «Мы готовим различные продукты»: Nvidia ответила на слухи об урезанном Blackwell для Китая
19.08.2025 [17:52],
Сергей Сурабекянц
На прошлой неделе Nvidia заключила соглашение с правительством США о возобновлении продаж своей продукции в Китае в обмен на направление до 15 % выручки Nvidia на китайском рынке ИИ в доход американского государства. Ожидается, что новый продукт, предварительно названный B30A, будет основан на архитектуре чипа Nvidia Blackwell. Nvidia надеется начать поставку образцов этих новых чипов китайским клиентам для тестирования уже в следующем месяце. 
Источник изображения: Nvidia Сегодня Nvidia сообщила, что оценивает несколько возможных конфигураций чипов искусственного интеллекта для Китая. «Мы оцениваем различные продукты для включения в нашу дорожную карту, чтобы быть готовыми к конкуренции в той мере, в какой это позволяют правительства, — заявила компания. — Всё, что мы предлагаем, полностью одобрено соответствующими органами и предназначено исключительно для выгодного коммерческого использования». Наиболее вероятным вариантом станет чип под кодовым названием B30A, основанный на архитектуре Nvidia Blackwell. По оценкам экспертов, по уровню быстродействия B30A будет на 50 % медленнее полноценного B300. Впрочем, он при этом окажется и предсказуемо дешевле — хотя бы по той причине, что ограничится компоновкой с единственным монолитным дизайном. Недавно Nvidia и AMD договорились с правительством США о возобновлении продаж своей продукции в Китае в обмен на направление до 15 % выручки от китайских продаж в доход американского государства. В апреле администрация США приостановила продажу передовых компьютерных чипов Китаю «по соображениям национальной безопасности». Тогда под запрет попали разработанные специально для китайского рынка чипы Nvidia H20 и AMD MI308. На прошлой неделе президент США Дональд Трамп (Donald Trump) заявил, что изначально запросил у Nvidia 20 % от дохода с продаж на китайском рынке, но Дженсен Хуанг (Jensen Huang) договорился о снижении этих отчислений до 15 %. Тогда же Трамп заявил, что готов разрешить продажу в Китае «несколько улучшенных в негативном смысле» передовых чипов Nvidia Blackwell, то есть со сниженной на 30–50 % производительностью. Компактный компьютер Asus на суперчипе Nvidia Grace Blackwell выйдет 22 июля
05.07.2025 [15:15],
Павел Котов
Asus подтвердила дату выхода своего нового мини-ПК для систем искусственного интеллекта Ascent GX10 на платформе Nvidia Grace Blackwell GB200. О выпуске рабочей станции было объявлено вместе с приглашением на посвящённый устройству вебинар — в зависимости от региона, мероприятие пройдёт 22–23 июля 2025 года, передаёт VideoCardz.com. 
Источник изображения: asus.com Указанный Asus срок совпадает с летним графиком выпуска Nvidia систем серии GB10. Тайваньская компания одной из первых подтвердила выпуск мини-ПК GB200 в исполнении OEM-партнёра. Asus Ascent GX10 — компактная рабочая станция, предназначенная для разработки и инференса (запуска) ИИ. Система объединяет центральный процессор Nvidia Grace с ускорителем на архитектуре Blackwell — это одна из самых компактных и эффективных платформ в семействе GB200. Мини-ПК оснащается 128 Гбайт оперативной памяти LPDDR5X, шиной PCIe 5.0, предусматривается возможность подключать SSD NVMe, присутствует специальное решение для охлаждения. Asus Ascent GX10 также знаменует первый серьёзный шаг Nvidia в области настольных ПК, хотя и не напрямую. Центральные процессоры Grace на архитектуре Arm изначально ориентированы на высокопроизводительные системы и серверные рабочие нагрузки, и их интеграция в компьютеры малого формфактора, в том числе Ascent GX10, отчасти стирает грань между ЦОД и рабочими станциями. Решение обещает быть востребованным разработчиками, которым необходим локальный запуск систем ИИ без нужды в традиционных платформах на архитектуре x86. Примерно в то же время системы на базе GB200 готовят также Dell, Lenovo и другие производители. На рынке будет немало конкурирующих решений, в том числе на базе AMD Strix Halo (также с объёмом до 128 Гбайт памяти) — плюс Apple Mac Studio. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



