|
Опрос
|
реклама
Быстрый переход
Microsoft объявила о крупнейшем в своей истории выкупе акций на $60 млрд и повышении дивидендов на 10 %
17.09.2024 [12:21],
Алексей Разин
Корпорация Microsoft на этой неделе объявила крупнейший в истории своего существования обратный выкуп акций на общую сумму $60 млрд, а также повысила квартальные дивиденды на 10 %. Претендовать на их получение смогут все инвесторы, являющиеся держателями акций Microsoft по состоянию на 21 ноября этого года. 
Источник изображения: Microsoft Размер дивидендов увеличится с 75 до 83 центов на одну акцию. В случае с программой выкупа акций всё не так прямолинейно. Фактически, корпорация просто заменила прежнюю программу выкупа на ту же сумму $60 млрд, которая была анонсирована в 2021 году, новой, не предусматривающей даты своего окончания. Компания, которая является крупным инвестором OpenAI и одним из главных выгодоприобретателей бума искусственного интеллекта, по своей капитализации уступает только Apple, причём на скромные $82 млрд. С начала года акции Microsoft выросли в цене на 31 %, новость о предстоящем выкупе подняла их стоимость после закрытия торгов ещё на 1 % от силы. Основную торговую сессию они вчера завершили на отметке $431,34 за штуку. По состоянию на 30 июня текущего года корпорация располагала $75,5 млрд свободных средств в денежной форме и в виде высоколиквидных активов. Свободный денежный поток за квартал вырос в годовом сравнении на 18 % до $23,3 млрд. По словам представителей компании, она сейчас активно вкладывается в развитие облачной инфраструктуры и систем искусственного интеллекта. Tinder почти полностью потерял российский рынок
17.09.2024 [12:19],
Павел Котов
С момента ухода службы знакомств Tinder из России в июне 2023 года её аудитория в стране сократилась более чем на 90 %. В первой половине 2023 года она составляла 1,1 млн ежемесячных пользователей, а с января по июнь 2024 года оказалась лишь 95 тыс., сообщают «Ведомости» со ссылкой на данные Mediascope. 
Источник изображения: freestocks / unsplash.com Сейчас в России Tinder работает только с иностранными телефонными номерами и только при подключённом VPN. Работоспособность он сохранил только на Android, поскольку был удалён из официальных магазинов приложений и перестал обновляться на iPhone. Немногочисленная оставшаяся аудитория платформы представлена преимущественно иностранцами и теми, кто хочет с ними познакомиться — массовому пользователю в России Tinder уже не интересен. Самым популярным приложением в первой половине и 2023, и 2024 года оказалось «Друг вокруг» — его аудитория за год выросла на 9,3 % с 2,1 млн до 2,3 млн. Второе место досталось «Мамбе», число пользователей которой за то же время сократилось на 7,6 % с 1,98 млн до 1,8 млн пользователей. Третьим стал Tabor, который нарастил аудиторию на 22,2 % с 1,26 млн до 1,54 млн. Аудитория занявшего четвёртое место сервиса «Фотострана» увеличилась с 1,33 млн до 1,36 млн пользователей. Пятой стала платформа Beboo, которая за год увеличила аудиторию на 21,9 % с 703 тыс. до 857 тыс. человек. Более 64 % аудитории пяти самых популярных сервисов составляют мужчины. Аудитория в возрасте от 18 до 24 лет чаще проявляет активность в сервисе Nekto ME; категория от 25 до 44 лет предпочитает «Друг вокруг»; а пользователи в возрасте от 45 лет чаще выбирают «Фотострану» и «Мамбу». В статистику Mediascope не попала служба «VK знакомства», но она, возможно, является самой популярной в сегменте: в I квартале 2023 года число уникальных пользователей в месяц (MAU) составило здесь 2,3 млн пользователей; во II квартале 2023 года — 2,4 млн пользователей; а в I и II кварталах 2024 года — уже 3,1 млн человек, рассказал представитель самой VK. В августе число ежедневных пользователей сервиса было почти 1 млн, а число мэтчей в сутки достигло 1,12 млн. Успехи «VK знакомств» в последнее время заметили и в «Мамбе»: сервис от VK уже третий месяц подряд является лидером по числу установок приложений, и к концу года его доля рынка будет большой. 
Источник изображения: Thom Holmes / unsplash.com Статистика Mediascope учитывает только веб-трафик, а не аудиторию пользователей мобильных приложений — по этой причине в неё не попала служба Pure, указывают опрошенные «Ведомостями» эксперты. Созданная в 2003 году «Мамба» долгое время была лидером за счёт постоянной аудитории и форматов взаимодействия, но постоянная аудитория взрослеет, а новой нужны другие форматы, сегментированные по интересам и способам связи. Аудитория существующих давно служб знакомств сокращается по всему миру — люди постоянно ищут что-то новое. «Мамба» оказалась слишком неповоротливой, чтобы переманить освободившуюся аудиторию Tinder; Tabor и Beboo приложили больше усилий и запустили рекламные кампании, которые дали результаты. У большинства работающих в России служб знакомств отмечается один недостаток — они сразу же после регистрации пользователя стремятся монетизировать свои услуги и не очень заботятся о своём основном предназначении. На платформах отсутствует внятная модерация, слишком велико присутствие ботов, слишком активны мошенники. На некоторые сервисы жалуются за непредсказуемые списания денег. Пользователей к тому же начинает утомлять формат свайпа. Из-за отсутствия качественных сервисов с честными механиками сейчас активно развиваются малые нишевые службы, в том числе закрытые — они ориентируются на конкретные группы пользователей и точное совпадение профилей. Растёт популярность искусственного интеллекта, который может учесть множество аспектов и предложить более высокое качество подбора партнёров и друзей. Meta✴ продолжит развивать умные очки Ray-Ban — компания подписала 10-летний контракт с EssilorLuxottica
17.09.2024 [12:16],
Владимир Мироненко
Франко-итальянская компания по производству очков EssilorLuxottica продлила сотрудничество с гигантом социальных сетей Meta✴✴ Platforms, заключив новый десятилетний контракт на продолжение совместной деятельности в сфере разработки умных очков. 
Источник изображения: essilorluxottica.com Сотрудничество EssilorLuxottica и Meta✴✴ берёт начало с 2019 года. За прошедшее с тех пор время компании создали два поколения умных очков под брендом Ray-Ban. Хотя первое поколение умных очков Ray-Ban Meta✴✴ не сразу завоевало популярность среди потребителей, продажи модели второго поколения, представленной в конце 2023 года, за несколько месяцев превысили показатель предыдущих двух лет. Умные очки Ray-Ban Meta✴✴ позволяют совершать телефонные звонки, слушать музыку и производить фотосъёмку, нажимая кнопку на правой дужке или с помощью голосового управления. Сделанные фото можно напрямую размещать в Instagram✴✴ Stories с помощью голосовой команды, не доставая телефон. Имеющаяся камера также позволяет проводить прямые трансляции для своих подписчиков в Facebook✴✴ или Instagram✴✴. В мае этого года в носимом устройстве появилась функция мультимодального искусственного интеллекта, которая пока доступна только для пользователей из США и Канады. С её помощью умные очки могут описывать окружающие объекты, определять достопримечательности и читать объявления, знаки и вывески на разных языках. Ранее ресурс The Wall Street Journal сообщил, что компании обсуждали возможность приобретения Meta✴✴ 5 % акций франко-итальянской компании, но на данный момент неизвестно, пришли они к какому-либо соглашению по этому поводу или нет. Водители часто отвлекаются от дороги при использовании частичного автопилота, показало исследование
17.09.2024 [12:05],
Алексей Разин
Как известно, современные автомобили не обладают полным автопилотом, как бы Tesla не пыталась убедить нас в обратном, и самостоятельно они способны выполнять лишь часть задач, но отвлекаться от дороги водителю явно не стоит. Это не мешает пользователям такого рода систем пренебрегать правилами безопасности, как показало исследование IIHS. 
Источник изображения: Mobileye Страховой институт дорожной безопасности, чья деятельность финансируется участниками американского страхового рынка, проанализировал за месяц поведение пользователей двух систем активной помощи водителю, поставляемых в транспортных средствах Tesla (Autopilot) и Volvo (Pilot Assist) соответственно. Исследователи пришли к выводу, что водители при использовании таких систем довольно быстро начинают пренебрегать правилами безопасности и формально подходить к требованиям, предъявляемым разработчиками таких систем. Например, если от водителя требуется раз в несколько секунд касаться рулевого колеса, то он будет делать это без особой концентрации на дорожной обстановке, просто чтобы усыпить бдительность контролирующей его автоматики. Водители довольно быстро адаптируются к предусмотренным разработчиками систем автопилота ограничениям, чтобы заниматься во время поездки делами, отвлекающими их от дороги. Системы, частично автоматизирующие процесс управления транспортными средствами, по мнению авторов исследования, нуждаются в более тщательной разработке условий, предотвращающих их некорректное и опасное использование. В случае с Tesla исследование подразумевало слежение за 14 пользователями, которые в общей сложности преодолели более 19 300 км с активированной системой Autopilot, на протяжении эксперимента сигнал о необходимости следить за дорогой применялся 3858 раза. В среднем водители реагировали на эти сигналы в течение трёх секунд, обычно прилагая некоторое усилие к рулевому колесу, чтобы избежать усугубления претензий со стороны автоматики. В случае с Volvo наблюдение велось за 29 водителями, которые во время работы системы частичной автоматизации вождения Pilot Assist отвлекались от дороги 30 % времени. Этот показатель авторы исследования сочли «чрезмерно высоким». Ранее опрос IIHS, проведённый среди 600 водителей, выявил излишнюю уверенность респондентов в надёжности работы автоматики в 53 % случаев, если ориентироваться на пользователей бортовых систем GM. Среди водителей машин Tesla показатель достигал 42 %, а у водителей Nissan он не превысил 12 %. Авторы исследования тогда выразили мнение, что большинство водителей плохо понимают границы безопасного применения новых технологий. В Китае заработал крупнейший в мире 30-МВт маховичный накопитель энергии
17.09.2024 [11:49],
Геннадий Детинич
Китай стал полигоном для испытаний перспективных накопителей энергии, среди которых выделяется только что заработавшая буферная электростанция на маховиках. Система хранит кинетическую энергию во вращающихся маховиках, превращая её в электрическую почти мгновенно, ведь двигатель и генератор в ней — это одно и то же устройство. 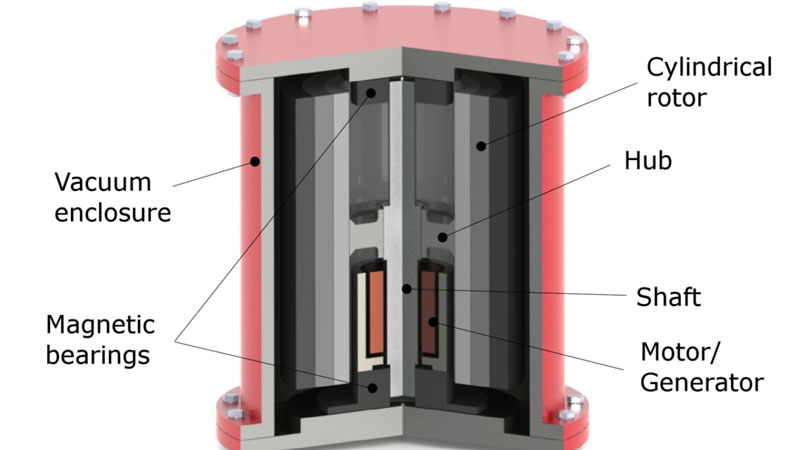
Общий принцип маховичного накопителя энергии. Источник изображения: Pjrensburg, Wikimedia Commons Проект маховичного накопителя энергии разработала китайская компания BC New Energy. Главным инвестором стала Shenzhen Energy Group. Производством установок занималась компания Shanxi Electric Power Construction Company совместно с Шаньсийским институтом энергетики, также в строительстве электростанции приняла участие компания China Energy Construction. Объект получил название электростанции Dinglun Flywheel Energy Storage. На его создание было потрачено 340 млн юаней ($48 млн). Плановое введение в эксплуатацию ожидалось в декабре 2023 года, но задержалось до конца лета 2024 года. Общая мощность установки в городе Чанчжи провинции Шаньси достигает 30 МВт. Она состоит из 120 маховичных генераторов (накопителей), которые разделены на 10 блоков по 12 установок. Частота вырабатываемой энергии стабилизируется на уровне каждого из блоков. Все они подключены к высоковольтной сети напряжением 110 кВ. Для безопасности каждая установка с маховиком полупогружена в колодец в земле. Для повышения эффективности работы маховики находятся в вакууме и подвешены на магнитной подвеске, что также снизило уровень шума от работающих машин. Созданная система стала самой мощной в мире и, вероятно, единственной на Земле, которая обслуживает потребителей на уровне коммунальных предприятий. Подобные маховичные установки могут очень быстро переключаться между режимами накопления и расходования энергии, представляя собой идеальные буферы не только для хранения энергии, но и для сглаживания пиков её потребления и накопления. «Лишил меня дара речи»: новый трейлер кооперативного хоррор-шутера The Forever Winter поразил игроков
17.09.2024 [11:39],
Михаил Романов
Кооперативный хоррор-шутер с элементами выживания The Forever Winter готовится к выходу в ранний доступ, и по случаю скорой премьеры разработчики из Fun Dog Studios представили новый трейлер игры. 
Источник изображений: Fun Dog Studios События The Forever Winter развернутся в мрачном мире будущего, который пережил экологическую катастрофу и последние 40 лет задыхается от масштабов насилия между двумя суперсилами в исполнении беспощадных ИИ-автоматонов. Представленный разработчиками полноценный кинематографический трейлер The Forever Winter растянулся на пять с половиной минут и демонстрирует вылазку отряда героев за ресурсами, которая идёт не по плану. Угнетающая атмосфера индустриального ада и мрачные реалии выживания в нём оставили зрителей под впечатлением. «Вместе с предыдущими тизерами/трейлерами этот лишил меня дара речи», — признался overlordmgcover2262. Игрокам в одиночку или с товарищами предстоит бороться за выживание в тени возвышающихся над полем боя огромных военных машин. Придётся работать сообща, полагаться на умение стрелять, скрытность и сообразительность. Обещают локальный и онлайновый кооператив, непредсказуемые сражения, четыре готовые карты и пять персонажей на старте раннего доступа. Заявлена поддержка 11 языков, включая русский. Ранний доступ The Forever Winter стартует 24 сентября не только в Steam, но и в Epic Games Store (ссылки пока нет). Исходная версия обойдётся в $27. Продаваться будут только облики — за остальные новые элементы денег брать не станут. iOS 18 предупредит, если iPhone подключили к медленной зарядке
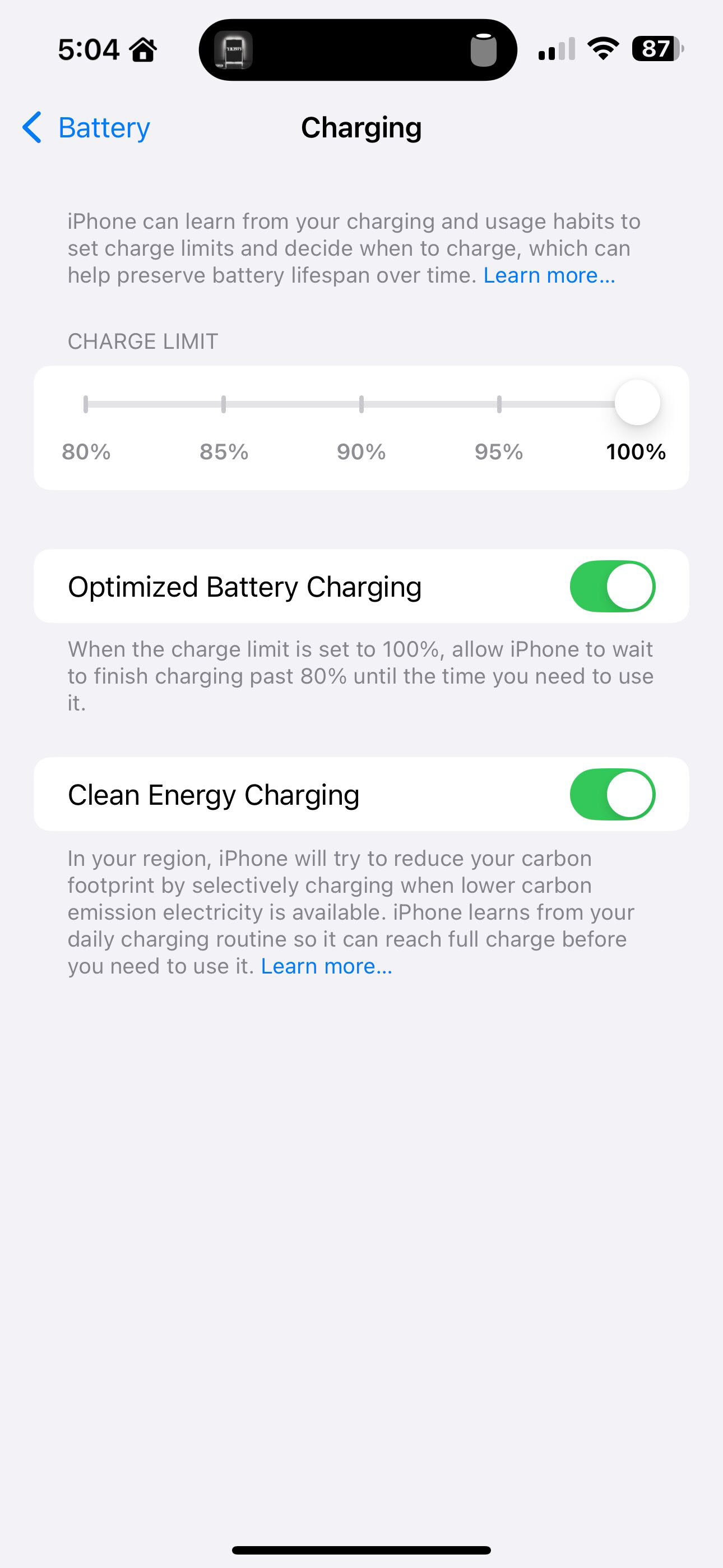
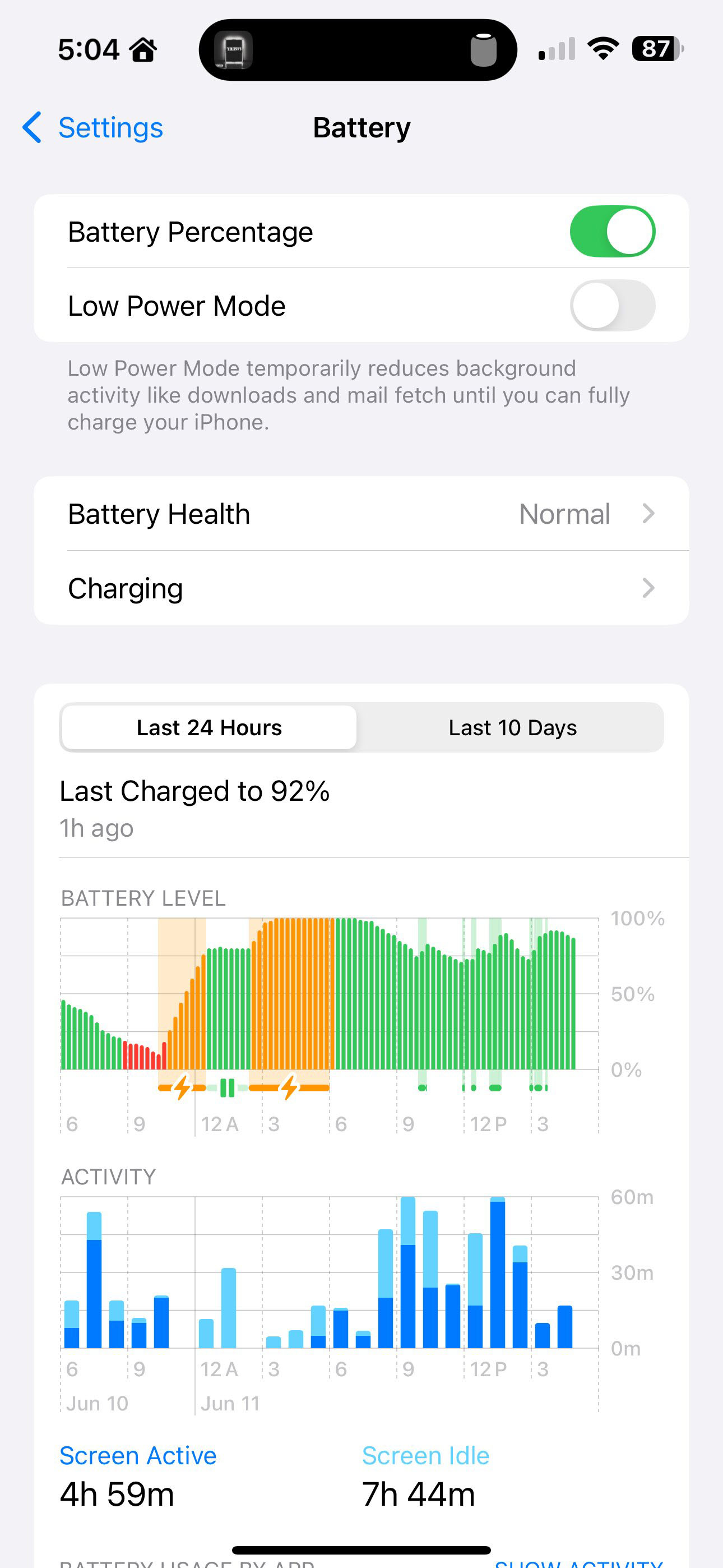
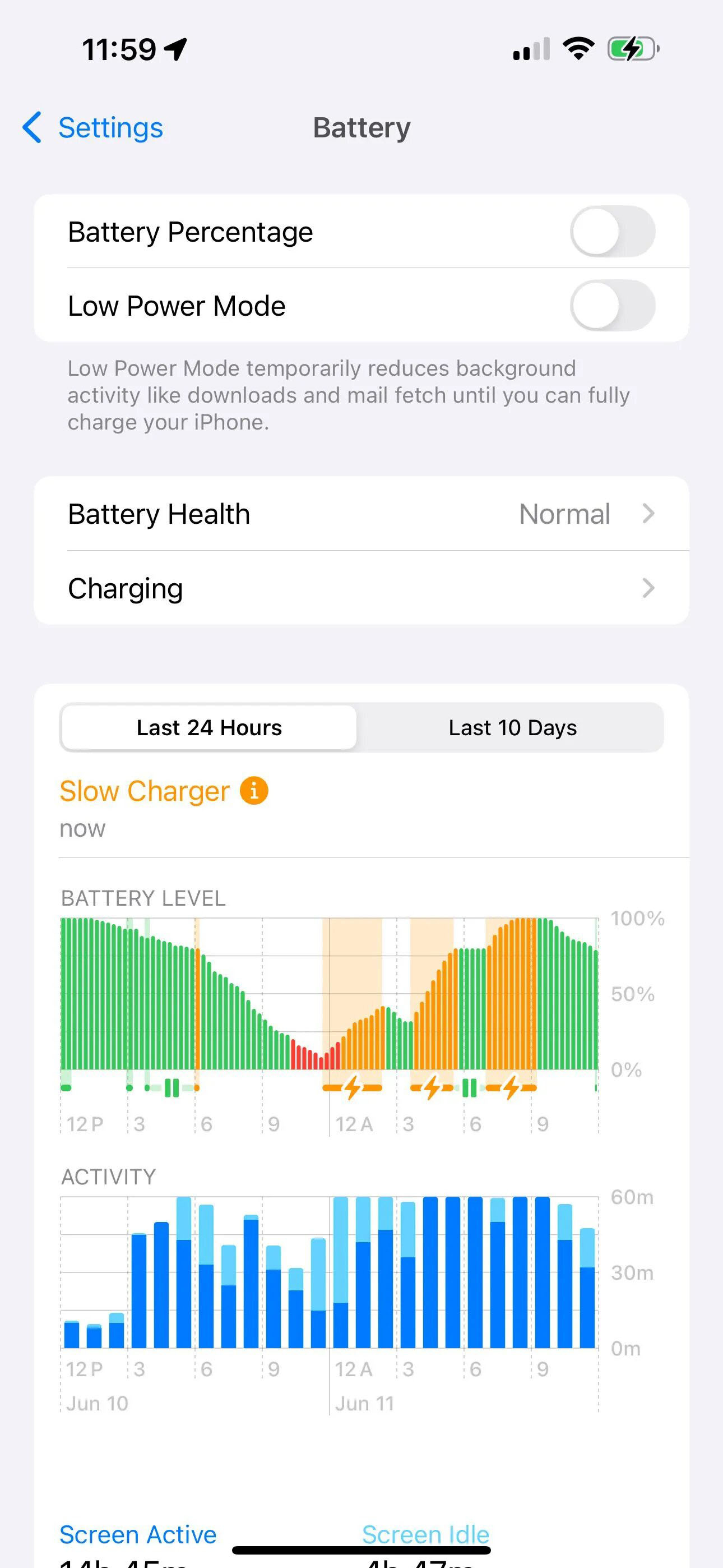
17.09.2024 [11:37],
Владимир Мироненко
Вышедшая вчера iOS 18 содержит больше настроек зарядки для смартфона iPhone 15, а также новая версия операционной системы для iPhone будет демонстрировать предупреждения в случае, если смартфон использует медленное зарядное устройство, пишет ресурс 9to5Mac.  В приложении «Настройки» для iOS 18 пользователи смартфонов iPhone 15 увидят несколько вариантов установки ограничения зарядки в подразделе «Зарядка» раздела меню «Аккумулятор». Если до этого пользователь мог устанавливать ограничение зарядки в 80 %, то теперь появилась возможность для установки в настройках ограничений зарядки в 85, 90 и 95 %. iOS 18 также включает новую функцию предупреждения об использовании медленного зарядного устройства для подзарядки iPhone. Его можно увидеть, выбрав в приложении «Настройки» меню «Аккумулятор», где отображается график уровня заряда аккумулятора. Если зарядка производится с помощью медленного зарядного устройства, то появится предупреждающее сообщение. Также при использовании медленного зарядного устройства цвет графика меняется на оранжевый. Следует отметить, что на данный момент неясно, при какой мощности зарядного устройства появляется сообщение «Медленное зарядное устройство». Будущее TikTok в США под вопросом — сервис не убедил судей встать на его сторону в споре с минюстом
17.09.2024 [10:53],
Павел Котов
Дальнейшая судьба службы коротких видео TikTok в США, где число её пользователей составляет 170 млн, сейчас находится в руках трёх судей. И на состоявшихся накануне устных прениях они выразили скептицизм по отношению к делу платформы. 
Источник изображения: succo / pixabay.com Иск подали юристы самого TikTok и группа блогеров — они стремятся заблокировать принятый американским Конгрессом и подписанный президентом закон, который может привести к блокировке платформы в стране. Истцы изложили свою позицию перед коллегией из трёх судей Окружного апелляционного суда округа Колумбия. Закон предусматривает изъятие платформы у её владельца, китайской ByteDance к 19 января, и в компании считают, что данная норма в действительности является завуалированной блокировкой сервиса — она подавит свободу слова блогеров и пользователей TikTok, а также ограничит объёмы информации, которую могут получать американцы. На стороне защиты выступили представители минюста. По их версии, закон является пакетом целенаправленных мер против компании, которая представляет угрозу национальной безопасности США, поскольку предположительно подвержена влиянию недружественного государства. Двое составивших коллегию судей выслушивали аргументы, а третий задавал вопросы представителям обеих сторон. Судьи выразили сомнения в целесообразности смягчения мер воздействия на TikTok — раскрытие администрацией платформы своих данных и методов модерации контента они считают недостаточными. Комплекс мер зависит от доверия к самой компании, которая, как опасается правительство, является инструментом в руках неявного иностранного противника. 
Источник изображения: antonbe / pixabay.com Входящий в коллегию судья Дуглас Гинзбург (Douglas Ginsburg), назначенный на пост ещё президентом Рональдом Рейганом (Ronald Reagan), отклонил утверждение адвоката TikTok Эндрю Пинкуса (Andrew Pincus), что закон создан с прицелом на одну компанию. По версии судьи, в документе указывается категория компаний, контролируемых недружественными государствами, и конкретно названа одна, в отношении которой существует неотложная необходимость принять меры — они основаны на нескольких годах переговоров, которые вело правительство, и которые ни к чему не привели. Выступивший от лица блогеров TikTok Джеффри Фишер (Jeffrey Fisher) заявил, что действие закона может ограничить американцам возможность участвовать в производстве контента для компаний с иностранными владельцами, включая Politico, Spotify и BBC. Судьи признали, что действие Первой поправки к конституции США, которая гарантирует свободу слова, распространяется на TikTok и владеющую платформой ByteDance, но это право не является объектом действия обсуждаемого закона. Представители правительства пытались показать суду некоторые секретные документы, раскрытие которых может навредить национальной безопасности страны, но в ходе устных прений эти документы так и не были представлены. Вместо этого стороны и суд решали вопросы о том, в какой мере Первая поправка может применяться в деле, и как оценивать роль иностранного владельца в TikTok. Представитель группы блогеров Кира Спанн (Kiera Spann) заявила в ходе брифинга по окончании слушаний, что считает платформу «наименее цензурированным и наиболее достоверным источником информации»; по её мнению, разговоры, которые ведутся в TikTok, не ведутся ни в одной другой соцсети. Electronic Arts показала первый концепт-арт новой Battlefield и рассказала, чего ждать — возвращение во времена Battlefield 3 и Battlefield 4
17.09.2024 [10:30],
Михаил Романов
Вслед за чередой слухов и хвастовства в финансовых отчётах Electronic Arts поделилась с порталом IGN первым официальным изображением и подробностями следующей номерной Battlefield. 
Источник изображений: Electronic Arts Глава серии Винс Зампелла (Vince Zampella) подтвердил февральские слухи: события новой Battlefield развернутся в современном антураже, а сам проект позиционируется как возвращение к корням с матчами на 64 игрока и системой классов. «Если оглянуться, когда Battlefield была на пике, то это эпоха современных Battlefield 3 и Battlefield 4. Думаю, нам нужно вернуться к основам Battlefield и сделать это изумительно, а там посмотрим», — заявил Зампелла. 
Концепт-арт новой Battlefield — Европа, техника, природные катаклизмы Зампелла также считает, что у следующей Battlefield есть шанс опередить по продажам будущую Call of Duty: «Мы не пытаемся сместить Call of Duty. Мы делаем нечто иное и своё. Но, да, возможность однозначно присутствует». Насчёт сроков выхода игры Зампелла не распространяется, но подтвердил, что EA тестирует шутер каждую неделю и планирует запустить в 2025 году новую программу по вовлечению в процесс сообщества. 
Battlefield спешит обратно в прошлое Над будущим Battlefield (её единой вселенной) трудится квартет студий: в начале апреля к DICE, Criterion и Ripple Effect присоединилась Motive Studio (пришла на смену закрытой Ridgeline Games). По данным инсайдера Тома Хендерсона (Tom Henderson), релиз следующей Battlefield намечен на октябрь 2025 года. Ранее игру официально перевели с этапа предварительного производства на активную разработку. «Джеймс Уэбб» уличил чёрную дыру в уморении голодом галактики -хозяйки
17.09.2024 [10:10],
Геннадий Детинич
Теория предполагает, что чёрные дыры в центрах галактик способны «задуть свечу их жизни» — лишить вещества для образования новых звёзд. Космическая обсерватория им. Джеймса Уэбба помогла воочию увидеть такой процесс — сверхмассивная чёрная дыра почти мгновенно в масштабах жизни Вселенной уморила голодом галактику-хозяина. 
Источник изображения: University of Cambridge Астрономы из Университета Кембриджа заинтересовались далёкой массивной галактикой GS-10578, большинство звёзд в которой образовались в период с 12,5 до 11,5 млрд лет назад. Благодаря инфракрасной чувствительности «Уэбба» такое наблюдение стало впервые возможным с невероятной детализацией. Галактика GS-10578 имеет массу около 200 млрд солнечных масс. Для юности Вселенной это примерно эквивалентно массе Млечного Пути — нашей родной галактики (масса Млечного Пути составляет 1,2–1,9 трлн солнечных масс). Удивительным стало открытие, что по масштабам Вселенной образование звёзд в GS-10578 прекратилось очень быстро. Галактика быстро разрослась до гигантских для того времени размеров и «умерла». Почему? Инфракрасная чувствительность «Уэбба» помогла обнаружить улетающий из галактики со скоростью более 1000 км/с холодный газ. Это скорость, позволяющая веществу преодолеть гравитационное притяжение галактики GS-10578, тем самым лишая её «пищи» для зарождения новых звёзд. Облака холодного газа не проявляют себя в спектре наблюдений «Уэбба», но он смог определить их скопления и скорость улёта по ослаблению света фоновых звёзд в галактике. Ранее такие измерения (холодного газа) можно было проводить только с помощью радиотелескопов, поэтому «Уэбб» действительно удивил. Полученные данные учёные намерены уточнить с помощью массива антенных решёток радиотелескопа Atacama Large Millimeter/Submillimeter Array (ALMA). Как минимум, ALMA сможет заглянуть внутрь галактики и попытается обнаружить хоть какое-то холодное топливо для процесса рождения новых звёзд. «Основываясь на более ранних наблюдениях, мы знали, что эта галактика находится в затухающем состоянии: в ней образуется не так много звёзд, учитывая её размер, и мы ожидали, что существует связь между чёрной дырой и окончанием звездообразования, — поясняют авторы работы. — Однако до появления «Уэбба» мы не могли изучить эту галактику достаточно подробно, чтобы подтвердить эту связь, и мы не знали, является ли это подавленное состояние временным или постоянным». Физика происходящего процесса проста. Вещество падает на чёрную дыру и вызывает выбросы энергии и вещества в сторону от неё. От чёрной дыры постоянно «дует» поток частиц, унося молекулярные газы и пыль от центра галактики и, как мы видим, даже прочь от неё. «Мы нашли виновника, — продолжают учёные. — Чёрная дыра убивает эту галактику и удерживает её в состоянии покоя, перекрывая источник "пищи", необходимой галактике для образования новых звёзд». Бывший подземный правительственный бункер, защищённый от ядерного удара, сдают в аренду под ЦОД
17.09.2024 [10:04],
Руслан Авдеев
В Сент-Луисе (штат Миссури, США) появилось предложение о сдаче подземного дата-центра, расположенного в бывшем правительственном бункере. По данным Datacenter Dynamics, бункер по адресу 3280 McKibbon Road сдаётся на условиях договора типа Triple Net (NNN), при котором арендатор несёт полную ответственность за расходы на объект, включая не только собственно арендные платежи, но и все эксплуатационные и коммунальные расходы, налоги на имущество и страхование. Бункер площадью 351 м2 имеет фальшпол для собственно ЦОД и офисных помещений. Есть два резервных генератора, а питание обеспечивается от трёхфазной сети. В объявлении об аренде указывается, что объект был построен в качестве правительственного бункера на случай чрезвычайных ситуаций на данной территории. 
Источник изображения: LoopNet Помещения расположены под землёй, возведены из усиленного бетона. Объект защищён от ядерных ударов, неблагоприятных природных условий и ЭМИ-импульсов. В здании расположены системы обеспечения дополнительной надёжности. Другими словами, подобный «осколок» Холодной войны может быть вполне востребован и сегодня. Объект построен в 1976 году, находится в «хорошем состоянии» и готов к размещению клиентов. Утверждается, что он идеально подходит на случай создания центра хранения и восстановления данных и защиты от катастроф различного характера. Это уже не первый случай, когда ЦОД создают в бывших военных и правительственных бункерах. Такими пользуются даже преступники — несколько лет назад в Германии местные силовые ведомства взяли под контроль крупный узел «даркнета», который тоже размещался в бывшем подземном убежище НАТО. В итоге восемь местных операторов получили тюремные сроки. Intel заморозит строительство фабрик в Европе ради оптимизации расходов и проектов в США
17.09.2024 [09:58],
Алексей Разин
Обещание Intel сохранить планы по строительству новых и модернизации старых предприятий в США объясняется условиями предоставления субсидий по «Закону о чипах». При этом здравый смысл подсказывает компании, что расходы надо сокращать, поэтому жертвами такой оптимизации станут проекты Intel за пределами США, в Германии, Польше и Малайзии. 
Источник изображения: Intel В своём пресс-релизе компания поясняет, что приостановит на пару лет реализацию проекта по строительству в Германии двух предприятий по контрактному производству чипов, а также предприятия в Польше по тестированию и упаковке чипов. Ещё в ноябре 2022 года Intel приобрела участок земли в немецком Магдебурге под строительство двух предприятий, которые потребовали бы 30 млрд евро инвестиций и позволили со временем наладить на территории Европы выпуск чипов ангстремного класса. Если учесть, что от освоения техпроцесса 20A в массовом производстве Intel отказалась, то теоретически немецкие предприятия могли бы освоить технологию 18A и более прогрессивные. Тем не менее, ориентируясь на рыночные условия и спрос, Intel приняла решение отложить строительство предприятий в Германии на два года. К слову, она по тем или иным причинам всё равно тянула с началом строительства. Сперва этому мешала неопределённость с субсидиями, потом возникли нюансы с вывозом плодородного грунта со строительной площадки, поиском специалистов и дорогой электроэнергией. Отказ от строительства предприятия в Польше, которое бы тестировало и упаковывало чипы, тоже носит условно временный характер. Как уже отмечалось недавно, местные власти договорились о выделении Intel около $1,9 млрд субсидий при общем бюджете проекта в размере $4,6 млрд. Это не единственное предприятие по упаковке чипов, ввод которого в эксплуатацию Intel задержит в рамках запущенной программы по оптимизации расходов. Предприятие в Малайзии, которое дополнит уже существующие, хотя и будет построено, оборудованием пока оснащаться не станет. Сам корпус предприятий не является основным потребителем финансовых ресурсов Intel, необходимое для работы оборудование стоит значительно больше, поэтому компания давно придерживается стратегии опережающего строительства корпусов предприятий. Кроме того, Intel призывает считать недавно модернизированное предприятие Fab 34 в Ирландии своей флагманской площадкой в Европе. Здесь уже внедрена EUV-литография, впервые за пределами США для производственной инфраструктуры Intel. Здесь компания способна использовать техпроцесс Intel 4, который ранее считался 7-нм в общепринятой шкале обозначений. Ещё в июне текущего года Intel объявила о намерениях воздержаться от строительства нового предприятия по выпуску чипов в Израиле, но на это решение могли повлиять продолжающиеся в регионе боевые действия. На этой неделе компания никак не упоминала о своих израильских предприятиях. Ранее компании также пришлось отказаться от планов по строительству исследовательского центра во Франции и предприятия по тестированию и упаковке чипов в Италии. При этом подчёркивается, что в США новые проекты Intel продолжат реализовываться в Аризоне, Огайо, Орегоне и Нью-Мексико. Власти США выделили Intel три миллиарда долларов на реализацию проекта по выпуску передовых чипов для нужд оборонной отрасли
17.09.2024 [07:54],
Алексей Разин
Общие очертания проекта Secure Enclave, ключевую роль в котором должна была сыграть способность Intel выпускать для оборонных заказчиков передовые чипы на территории США, были сформированы ещё в марте этого года. Теперь же американским правительством принято окончательное решение предоставить Intel на эти нужды $3 млрд субсидий. 
Источник изображения: Intel Эта сумма меньше тех $3,5 млрд, о которых речь велась изначально, но пресса не раз описывала те проблемы, с которыми правительственные ведомства США столкнулись при поиске источников финансирования программы. Изначально предполагалось, что $3,5 млрд предоставит Пентагон, затем он начал склонять Министерство торговли к участию в частичном финансировании инициативы, а в окончательном варианте сумма в $3 млрд будет полностью выделена министерством из средств, предусмотренных так называемым «Законом о чипах», принятым в 2022 году. Эти $3 млрд достанутся Intel помимо $8,5 млрд субсидий на развитие производственной инфраструктуры в США и $11 млрд льготных кредитов. Подобное распределение лишь укрепляет Intel в статусе главного выгодоприобретателя по упоминаемому выше закону. Intel в рамках новой инициативы оборонного характера будет опираться на две уже существующие. Первая под наименованием RAMP-C предусматривала быстрое создание прототипов полупроводниковых компонентов, разработанных для применения в военной сфере. Вторая носила обозначение SHIP и подразумевала участие Intel в упаковке разнородных кристаллов для участников соответствующей программы. Расположения Пентагона компания Intel в данном случае добилась, поскольку она является единственной компанией американского происхождения, которая одновременно разрабатывает и выпускает полупроводниковые компоненты приемлемого уровня сложности. Первые субсидии Intel начнёт получать от американского правительства до конца текущего года. Подразделения Intel в Аризоне, Нью-Мексико, Огайо и Орегоне в той или иной мере будут задействованы в производстве кристаллов и упаковке чипов для нужд оборонной промышленности в США. Компания попутно подчёркивает, что выпуск компонентов по передовой технологии Intel 18A она может начать уже в 2025 году. С 2020 года она тестирует и упаковывает чипы для оборонных заказчиков на своих предприятиях в Аризоне и Орегоне, а также помогает их разработчикам в сфере проектирования. В 2023 году был получен первый чип с многокристальной компоновкой, изготовленный в рамках данной инициативы. С 2021 года Intel участвует в программе раннего создания прототипов RAMP-C для нужд оборонной отрасли США. Среди клиентов компании, которые так или иначе снабжают оборонный комплекс страны своими компонентами, упоминаются Boeing, Northrop Grumman, Microsoft, IBM, Nvidia и другие. По крайней мере некоторые из этих компаний уже получили от Intel прототипы своих изделий, произведённых с использованием технологии 18A. Для создания отечественного аналога Starlink потребуется 445 млрд рублей
17.09.2024 [07:27],
Владимир Фетисов
Для создания низкоорбитальной спутниковой группировки компании «Бюро 1440» потребуется 445 млрд рублей. На это указывают данные черновой версии паспорта проекта «Инфраструктура доступа к сети интернет», разрабатываемого в рамках программы «Экономика данных». 
Источник изображения: "Роскосмос" По данным источника, спутниковая группировка «Бюро 1440» должна включать в себя 292 космических аппарата к концу 2030 года. При этом 91 спутник из общего числа предназначен для замены выходящих из строя аппаратов. Для доставки на орбиту такого количества объектов потребуется провести 24 пуска ракет. В соответствии с проектом, спутниковая группировка будет создана в основном за счёт средств компании, которая должна вложить в проект 329,06 млрд рублей. Дополнительные 116 млрд рублей должны выделить из бюджета. Объём льготных кредитов на производство спутников составит 37,5 млрд рублей, ещё 17,3 млрд рублей планируется получить в виде субсидий на запуск ракет и 61,2 млрд рублей — для выведения спутников на низкую околоземную орбиту. Уже в следующем году компания «Бюро 1440» должна получить из федерального бюджета свыше 37 млрд рублей. В документе сказано, что цель проекта заключается в увеличении доли домохозяйств, у которых есть возможность использования высокоскоростного широкополосного доступа в интернет до 97 % к 2030 году и до 99 % — к 2036 году. В «Бюро 1440» отказались от комментариев по данному вопросу, но сообщили, что для предоставления услуг ШПД в любой точке планеты в режиме 24/7 спутниковая группировка компании будет включать в себя более 250 аппаратов собственной разработки и производства. «Сейчас мы находимся на этапе подготовки к масштабированию группировки и проработки технических и экономических условий подключения к будущему сервису наших потенциальных клиентов», — рассказал представитель компании. Напомним, «Бюро 1440» является российской частной космической компанией, в планах которой запуск услуг доступа в интернет в 2027 году. Компания была основана в 2020 году и является частью «ИКС холдинг». Актуальные данные о владельце «Бюро 1440» и финансовых показателях отсутствуют. Ранее объём общих инвестиций для реализации поставленных задач и источники финансирования компанией не озвучивались. О намерении ВТБ вложить в проект 2 млрд рублей и получить 15 % в компании сообщалось в 2021 году. Запуск тестовых спутников «Бюро 1440» под названием Rassvet состоялся в 2023 году. В настоящее время компания смогла достичь скорости передачи данных в 12 Мбит/с при задержке в 41 мс. В этом году компания «Бюро 1440» подписала соглашения с «Аэрофлотом» и «Российскими железными дорогами», в рамках которых планируется предоставлять доступ в интернет по Wi-Fi в самолётах и поездах с 2028 года. Ожидается, что спутниковая группировка позволит увеличить скорость передачи данных на транспорте с нынешних 100 Мбит/с до 1 Гбит/с на абонентский терминал, а также снизить уровень задержек с 700 мс до 70 мс. Bluetooth-трекеры Tile научились отправлять сигналы SOS для оповещения близких и экстренных служб
17.09.2024 [07:25],
Дмитрий Федоров
Компания Tile представила линейку Bluetooth-трекеров 2024 года с инновационной функцией SOS Alert. Новые модели Tile Pro, Tile Mate, Tile Slim и Tile Sticker теперь способны отправлять экстренные сигналы, уведомляя близких и службы спасения о чрезвычайных ситуациях. Это первое крупное обновление трекеров Tile после её приобретения компанией Life360 почти три года назад. Эти устройства объединяют функции поиска предметов и домашних животных с вызовом помощи в компактном формфакторе. 
Источник изображений: Tile Обновлённая линейка Tile 2024 года сохранила привычные форм-факторы: банковской карты, брелока и стикера. Инженеры улучшили звуковой сигнал и водостойкость всех моделей. Tile Pro, Tile Mate и Tile Slim теперь обладают увеличенным радиусом действия Bluetooth: 76 метров для Sticker, 106 метров для Mate и Slim, 152 метра для Pro. Tile Pro остаётся единственной моделью со сменной батареей. Однако, в отличие от Apple AirTags и Samsung SmartTag 2, новые Tile не поддерживают технологию UWB для высокоточного позиционирования. 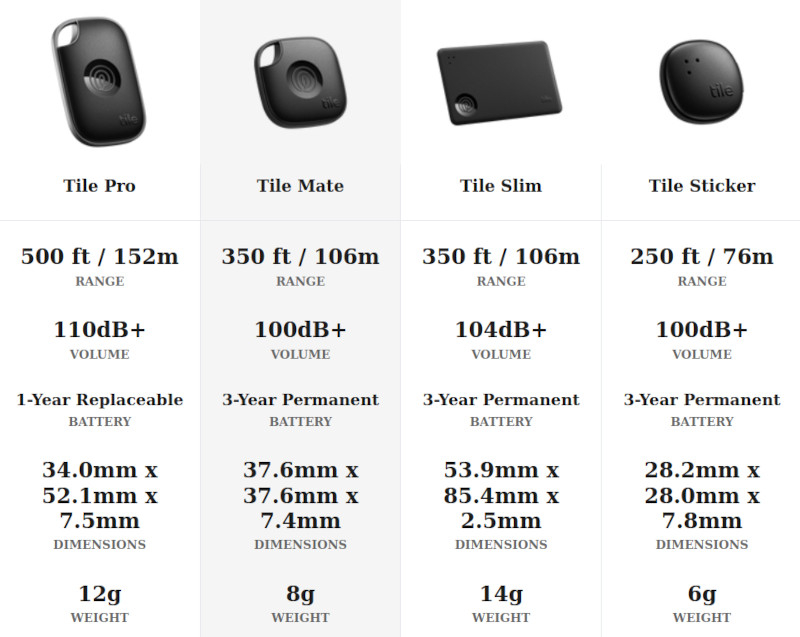 Ключевое нововведение — функция SOS Alert, активируемая тройным нажатием кнопки трекера. После 15-секундного обратного отсчёта устройство отправляет текстовые и push-уведомления контактам пользователя в экстренных ситуациях. 
Tile Slim 2024 Пользователи премиум-подписки Life360 Gold ($14,99 в месяц) получают доступ к экстренному диспетчерскому центру Tile. Для работы функции SOS Alert смартфон должен находиться в зоне действия Bluetooth-соединения трекера и быть синхронизирован с ним через приложение Life360. 
Tile Mate 2024 Хотя в некоторых маркетинговых материалах Life360 говорится, что устройство автоматически вызывает скорую помощь, на самом деле всё немного сложнее, как пояснила Кристи Коллура (Kristi Collura), директор по коммуникациям компании Life360: «Когда участник программы Life360 с подпиской Gold или Platinum подаёт сигнал SOS, наши диспетчеры экстренных служб звонят, чтобы оценить ситуацию и при необходимости связаться с соответствующими органами, такими как полиция или скорая помощь. Если участник не отвечает, диспетчер автоматически сообщит местным властям, чтобы они направили помощь. Диспетчеры также будут обзванивать участников программы Circle и контактных лиц в экстренных ситуациях до тех пор, пока кто-нибудь не ответит, сообщая им, что к участнику программы направлены экстренные службы». 
Tile Pro 2024 Хотя новая линейка Tile 2024 года демонстрирует стремление компании к инновациям в сфере персональной безопасности, ранее в 2024 году Life360 сообщила об утечке данных клиентов Tile. Поэтому компании предстоит усилить меры по защите персональной информации для обеспечения безопасности инновационной функции SOS Alert. Акции Intel в совокупности выросли в цене почти на 15 % после новостей о реструктуризации
17.09.2024 [07:20],
Алексей Разин
Даже демонстрация руководством самих намерений что-то менять в бизнесе Intel способна придать уверенности инвесторам в капитал компании, поэтому новости о сокращении штата акционерами нередко воспринимаются позитивно. Вчерашняя порция новостей о грядущих переменах также способствовала росту курса акций Intel, причём он не завершился после закрытия основных торгов. 
Источник изображения: Intel По состоянию на утро вторника можно констатировать, что акции Intel вчера успели укрепиться на 6,36 % до $20,91 за штуку, а после закрытия торгов выросли в цене ещё на 7,99 % до $22,58 за штуку. Все три крупных заявления руководства компании возымели воодушевляющее воздействие на настроения инвесторов. Во-первых, контрактное подразделение Intel обретёт ещё больше самостоятельности, главным образом в контексте облегчения доступа к внешним источникам финансирования своей деятельности. По данным CNBC, материнская корпорация Intel по-прежнему рассчитывает превратить своё производственное подразделение в отдельную публичную компанию. В принципе, нечто подобное уже произошло с Mobileye, чьи акции находятся в обороте на фондовом рынке США, но в основной своей части сосредоточены в руках Intel. Производственное подразделение компании будет управляться самостоятельной группой руководителей. Во-вторых, на курс акций Intel положительное влияние оказала новость о выделении компании $3 млрд целевых субсидий на реализацию программы Secure Enclave. Предварительные договорённости с властями США в этой сфере были достигнуты ещё в марте текущего года, тогда речь шла о сумме в $3,5 млрд, но в окончательном варианте она немного уменьшилась. Данные средства Intel направит на формирование инфраструктуры по производству чипов и их упаковке для оборонных нужд США. Наконец, сделка с Amazon, которая подразумевает выпуск для нужд серверного подразделения этой компании чипов по технологии Intel 18A и центральных процессоров Xeon 6 по технологии Intel 3, также подогрела оптимизм инвесторов и способствовала росту курса акций компании. С начала года акции Intel успели просесть на 60 %, поэтому коррекция этой недели должна благотворно повлиять на настроения инвесторов. OpenAI создала независимое подразделение для приостановки выпуска опасных ИИ-моделей
17.09.2024 [06:24],
Дмитрий Федоров
OpenAI объявила о реорганизации своего комитета по безопасности и защите в независимый наблюдательный орган совета директоров. Новая структура получила беспрецедентные полномочия, включая право приостановки релизов ИИ-моделей по соображениям безопасности. Решение было принято по итогам 90-дневного анализа процедур и мер безопасности компании, отражая растущее внимание к этическим аспектам развития ИИ. 
Источник изображения: sergeitokmakov / Pixabay Согласно OpenAI, в трансформированный комитет, возглавляемый Зико Колтером (Zico Kolter), также входят Адам Д'Анджело (Adam D'Angelo), Пол Накасоне (Paul Nakasone) и Николь Селигман (Nicole Seligman). Примечательно, что Сэм Альтман (Sam Altman), генеральный директор OpenAI, больше не входит в его состав. Новая структура будет получать информацию от руководства компании об оценке безопасности основных релизов ИИ-моделей и, вместе с полным составом совета директоров, будет осуществлять надзор за их запуском, включая право отложить релиз до устранения проблем с безопасностью. Полный состав совета директоров OpenAI также будет получать периодические брифинги по вопросам безопасности и защиты. Структура нового комитета вызывает вопросы о степени его независимости, учитывая, что все его члены входят в состав совета директоров OpenAI. Это отличает его от наблюдательного совета Meta✴✴, члены которого полностью независимы от совета директоров корпорации. Наблюдательный совет Meta✴✴ обладает полномочиями пересматривать решения по контентной политике и выносить обязательные для исполнения решения, тогда как комитет OpenAI фокусируется лишь на оценке безопасности ИИ-моделей перед их выходом. 90-дневный анализ процессов безопасности OpenAI выявил дополнительные возможности для сотрудничества в индустрии ИИ и обмена информацией. Компания заявила о намерении расширить обмен данными о своей работе в области безопасности и увеличить возможности для независимого тестирования систем. Однако конкретные механизмы реализации этих намерений пока не раскрыты. Intel будет выпускать ИИ-процессоры для Amazon и заработает на этом миллиарды долларов
17.09.2024 [04:53],
Алексей Разин
По итогам вчерашних заявлений руководства Intel можно сделать вывод, что амбиции компании в сфере выпуска компонентов для ускорителей вычислений в системах искусственного интеллекта реализуются через сделку с Amazon, которая рассчитана на многолетнее сотрудничество и использование передовой литографии Intel. 
Источник изображения: Intel Если говорить конкретнее, то контрактное подразделение Intel, которое в ходе предстоящих реформ обретёт больше самостоятельности, начнёт выпускать для AWS чипы по технологии Intel 18A, которая сейчас является передовой не только для ассортимента продукции этой компании, но и всего мира — по словам самой Intel, разумеется. Контракт с Amazon подразумевает реализацию в течении нескольких лет, его сумма также измеряется несколькими миллиардами долларов США. Помимо полученных от AWS средств, Intel будет вкладывать в эту инициативу и собственные деньги. Глава Intel Патрик Гелсингер (Pat Gelsinger) прокомментировал заключение контракта с AWS следующим образом: «Это очень важное заявление. Это очень проницательный клиент, который владеет очень сложными способностями в сфере разработки». Amazon ранее получала от Intel центральные процессоры Xeon, чьи характеристики были адаптированы под её запросы, но в последние годы сосредоточилась на создании собственных ускорителей. Их-то Intel и будет выпускать для AWS по технологии 18A на предприятии в Огайо, которое только предстоит построить. Как было отмечено накануне, Intel в условиях ограниченности финансовых ресурсов сосредоточится на строительстве предприятий в США, заморозив проекты в Германии, Польше и Малайзии. Во многом это обусловлено требованиями американского правительства по предоставлению целевых субсидий. Кстати, Гелсингер отметил, что Intel продолжит снабжать Amazon процессорами Xeon 6, которые будут выпускаться по технологии Intel 3. В совместном пресс-релизе компаний также сообщается, что Amazon может присмотреться к технологиям Intel 18AP и Intel 14A при заказе будущих чипов, равно как и продолжить адаптировать уже существующие продукты Intel для собственных нужд. AMD Ryzen 9700X на частоте 6,3 ГГц обогнал разогнанный до 7,1 ГГц Intel Core i9-14900KF в тесте AVX
17.09.2024 [02:19],
Николай Хижняк
Энтузиаст с псевдонимом Skatterbencher разогнал процессор AMD Ryzen 9700X до 6,3 ГГц с помощью жидкого азота, и тот оказался быстрее разогнанного в тех же условиях до 7,1 ГГц флагманского процессора Intel Core i9-14900KF в тесте производительности OCCT. Оверклокер с помощью восьмиядерного процессора AMD на архитектуре Zen 5 установил новый рекорд производительности в бенчмарке OCCT AVX, набрав в нём 269,35 очков. 
Источник изображений: YouTube / Skatterbencher Рекорд был поставлен при работе процессора Ryzen 7 9700X на частоте всего 6318 МГц. Для разгона SkatterBencher не просто поменял множитель частоты процессора и настройки напряжения. Он использовал комбинацию методов, включавших тонкую настройку шины BCLK, функции Precision Boost Overdrive, AMD Curve Optimizer и Curve Shaper, чтобы позволить алгоритму Ryzen Precision Boost работать на частоте выше 6 ГГц под жидким азотом.  С финальным результатом 269,35 очков разогнанный Ryzen 7 9700X превзошёл результат разогнанного до 7,1 ГГц Core i9-14900KF (также с использованием жидкого азота) в том же тесте. Флагман Intel набрал на 14 очков меньше, даже несмотря на то, что его частота была почти 800 МГц выше. Однако в SSE-версии теста OCCT процессор Ryzen 7 9700X оказался не так силён. Он не смог обогнать Core i9-14900KF и набрал всего 127,79 баллов, что на 8,76 меньше, чем у чипа Intel Raptor Lake. 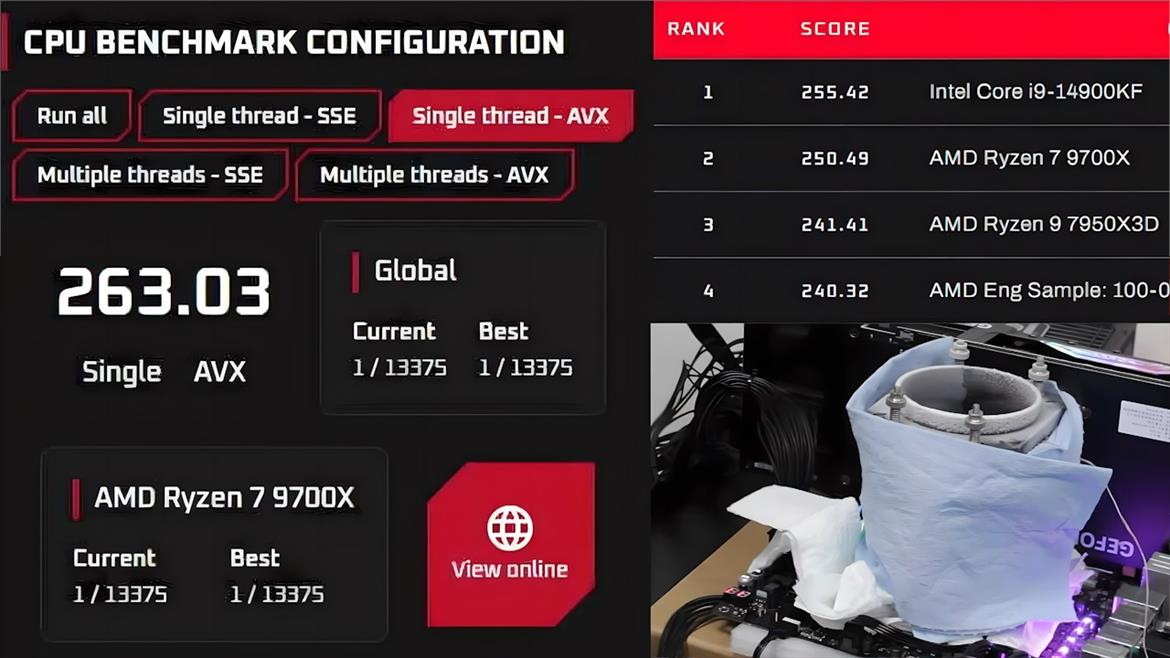 В CPU-Z разогнанный Ryzen 7 9700X набрал 1003 балла в однопоточном испытании производительности и 10 805 баллов в многопоточном. Skatterbencher также смог разогнать Ryzen 7 9700X до 6,8 ГГц, но отключив при этом SMT (многопоточность). В однопоточном тесте Geekbench 6 разогнанный до 6,3 ГГц процессор AMD набрал 3902 балла, а в многопоточном — 21 135 очков. Наша тестовая лаборатория признала Ryzen 7 9700X провальным, но признала заслуги самой архитектуры Zen 5. Результат разгона SkattterBencher продемонстрировал силу архитектуры AMD Zen 5, хоть для этого и понадобилось использовать жидкий азот. Zen 5 — первая архитектура AMD, наделённая поддержкой AVX с полным 512-битным каналом передачи данных. Процессоры Intel Raptor Lake (Core 13-го поколения) и Raptor Lake Refresh (Core 14-го поколения), в свою очередь, не имеют никакой поддержки AVX-512, что вынуждает тот же Core i9-14900KF использовать инструкции AVX и/или AVX2 для теста OCCT. Это, безусловно, основная причина, по которой Ryzen 7 9700X смог обогнать его даже при таком серьёзном недостатке тактовой частоты. Intel объявила о выделении производства чипов в независимую компанию и других шагах по выходу из кризиса
17.09.2024 [02:00],
Анжелла Марина
Компания Intel объявила о стратегических изменениях, направленных на укрепление своего финансового положения и технологического потенциала, включая выделение бизнеса по производству чипов в самостоятельную компанию и сделку с Amazon по производству ИИ-чипов. Компания нацелена на сокращение расходов и пересмотр инвестиций в производство, а также повышении эффективности капитальных вложений. Intel объявила о масштабной реструктуризации бизнеса, которая затронет практически все аспекты деятельности компании, начиная от производства и заканчивая продуктовым портфелем. Генеральный директор Intel Пэт Гелсингер (Pat Gelsinger) в своём обращении к сотрудникам 16 сентября 2024 года подчеркнул, что целью преобразований является повышение эффективности, оптимизация расходов и усиление фокуса на ключевых направлениях, таких как разработка x86-совместимых процессоров и бизнес по производству чипов (Intel Foundry). «Мы должны действовать быстро, чтобы создать более конкурентоспособную структуру затрат и достичь целевого показателя экономии в $10 млрд», — заявил Гелсингер. Одним из ключевых шагов станет превращение Intel Foundry в независимую дочернюю компанию внутри Intel. «Такая структура обеспечит нашим клиентам и поставщикам Foundry большую прозрачность и независимость от остального Intel, — пояснил Гелсингер. — Это также позволит Intel Foundry активнее привлекать внешнее финансирование и оптимизировать свою капитальную структуру для ускорения роста ». Компания также пересматривает свои инвестиции в производство, стремясь к большей эффективности капитальных вложений, в том числе приостанавливает проекты по строительству новых фабрик в Польше и Германии на два года, ориентируясь на текущий рыночный спрос. Что касается запуска производственного центра в Малайзии, то он будет достроен, но его ввод в эксплуатацию будет синхронизирован с рыночными условиями и загрузкой существующих мощностей. При этом Intel подтверждает свою приверженность инвестициям в производство в США и продолжает реализацию проектов в Аризоне, Орегоне, Нью-Мексико и Огайо. Вместе с тем, компания намерена сместить акцент с агрессивного наращивания производственных мощностей на более гибкое и эффективное планирование, соответствующее темпам развития технологий. 
Источник изображения: Intel Одновременно с этим объявлено о расширении стратегического партнёрства с Amazon Web Services (AWS). AWS выбрала Intel Foundry для производства нового ИИ-чипа на базе передовой технологии Intel 18A, а также специализированного процессора Xeon 6 на базе Intel 3. В рамках реструктуризации Intel также оптимизирует свой портфель продуктов, стремясь к большей интеграции и фокусировке на ключевых направлениях. «Наш главный приоритет — максимизировать ценность франшизы x86 на рынках клиентских устройств, периферийных вычислений и центров обработки данных, — подчеркнул генеральный директор. — Компания продолжит инвестировать в развитие ИИ-технологий, включая лидерство в категории ПК с искусственным интеллектом и укрепление позиций в центрах обработки данных». При этом для повышения эффективности ряд подразделений будут реорганизованы. В частности, Edge и Automotive будут объединены с CCG, а Integrated Photonics Solutions перейдёт в DCAI. Гелсингер в своём обращении также отметил, что для достижения намеченного целевого показателя экономии в $10 млрд Intel продолжит сокращать расходы. Для этого уже предприняты определённые действия: сокращено по программе добровольного увольнения более половины штата сотрудников (примерно 15 000), планируется отказаться от примерно двух третей недвижимости по всему миру к концу года, а также продать часть доли в Altera для получения дополнительных средств. «Нам предстоит принять ещё ряд сложных решений, — признал Гелсингер. — Но все эти меры направлены на то, чтобы превратить Intel в более гибкую, простую и эффективную систему, способную успешно конкурировать на рынке и обеспечивать долгосрочный рост». Стоит отметить, что недавно Intel получила около $3 млрд прямого финансирования в рамках федерального «Закона о чипах и науке» (CHIPS and Science Act) подписанного президентом Джо Байденом (Joe Biden) США в 2022 году. Выяснились цены материнских плат Gigabyte на X870 и X870E — от $219 до $799
17.09.2024 [01:16],
Николай Хижняк
Крупный американский магазин электроники B&H Photo добавил в свой ассортимент материнские платы на чипсетах AMD X870 и X870E, разработанные специально для процессоров Ryzen 9000. В каталоге отметились платы компании Gigabyte, относящиеся к фирменным сериям Gaming, Eagle и Aorus. Производитель предложит как минимум шесть плат на чипсете X870 и пять моделей на X870E. 
Источник изображения: VideoCardz Самой доступной платой Gigabyte на чипсете X870, по данным ретейлера B&H Photo, является модель Gigabyte X870 Gaming Plus WIFI, на которую выставлен ценник в $219,99. Самой дорогой является модель Gigabyte X870I Aorus PRO ICE в формате Mini-ITX, оценённая в $299,99. Стоимость плат Gigabyte на чипсете X870E, в свою очередь, начинается с $319,99 за модель X870E Aorus Elite WIFI7 и достигает $799,99 за флагманскую X870E Aorus Xtreme AI TOP. С полным списком моделей и цен можно ознакомиться ниже:
Стоимость Gigabyte X870E Aorus Master составит $499,99 — за ту же цену предлагалась модель на чипсете X670E на старте продаж. В настоящий момент её можно купить за $399. Предшественник модели X870E Aorus Xtreme сейчас предлагается примерно за $549. Изначально плата оценивалась в $699. Новая версия на чипсете X870E на старте продаж будет на $100 дороже. 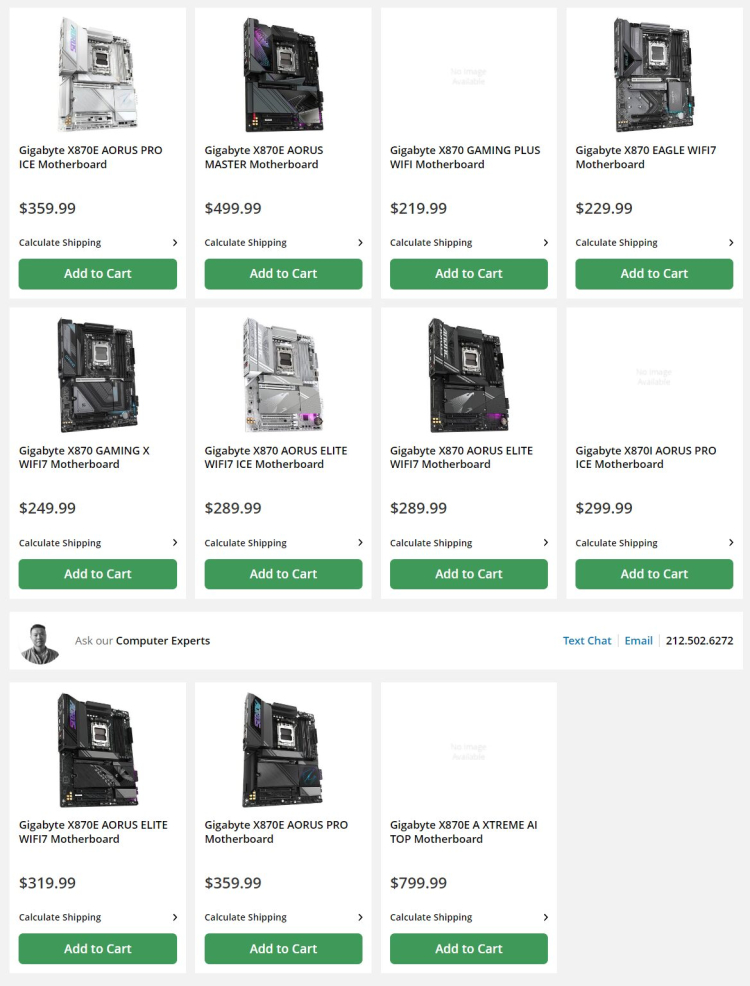
Источник изображения: B&H Photo Напомним, что новые материнские платы на чипсетах AMD X870 и X870E появятся в продаже с 30 сентября. В тот же день ожидаются первые независимые обзоры новинок. CATL представила аккумулятор со сроком службы 15 лет или 1,5 млн км — его применят в электробусах
17.09.2024 [00:42],
Владимир Фетисов
Компания Contemporary Amperex Technology (CATL) представила новую аккумуляторную батарею Tianxing-B (Tectrans B), которая предназначена для использования в электробусах. По заявлению разработчиков, плотность хранения энергии в новом аккумуляторе составляет 175 Вт·ч/кг, а его главная особенность — повышенная износостойкость. Аккумулятор способен обеспечить до 1,5 млн км пробега или эксплуатироваться в течение 15 лет. 
Источник изображений: carnewschina.com Во время онлайн-презентации Tianxing-B говорилось, что компания будет предоставлять на новинку 10 лет гарантии или 1 млн км пробега. Благодаря корпусу, который защищает аккумулятор от влаги по стандарту IP69, батарея может находиться под водой до 72 часов. CATL планирует задействовать Tianxing-B в 80 разных моделях электробусов и уже успела заключить партнёрские соглашения с 13 производителями транспортных средств на электрической тяге, включая Dongfeng, Golden Dragon и Yutong Bus.  Отмечается, что CATL использует разные названия для батареи Tianxing-B. Иногда её называют Tianxing Bus Edition или Tianxing B-series. Сам бренд ранее носил имя Tianxing, но на недавнем мероприятии, посвящённом презентации аккумулятора в Германии, CATL назвала его Tectrans. Под брендом Tianxing компания выпускает аккумуляторы для коммерческих электромобилей.  Одним из новых продуктов подразделения стал аккумулятор Tianxing-L для легковых авто, обеспечивающий ёмкость до 200 кВт·ч, плотность хранения энергии 200 Вт·ч/кг с гарантией в течение 8 лет или 800 тыс. км пробега. Он также поддерживает технологию быстрой зарядки 4C, которая позволяет восполнить 60 % энергии за 12 минут. Вышла iOS 18 с кастомизацией рабочего стола, RCS, но без ИИ — обновление уже доступно для всех совместимых iPhone
17.09.2024 [00:31],
Анжелла Марина
Apple выпустила iOS 18 и iPadOS 18 со множеством новых функций для iPhone и iPad. Одним из важных изменений iOS является поддержка протокола RCS для обмена сообщениями, в том числе с фото и видео в высоком разрешении, с пользователями Android. А iPad наконец-то получит долгожданный калькулятор. 
Источник изображения: Apple Протокол обмена сообщениями RCS (Rich Communication Services) предлагает более продвинутые возможности по сравнению с традиционными SMS. Благодаря RCS пользователи iPhone и Android смогут обмениваться фотографиями и видео высокого качества и видеть индикаторы набора текста. При этом сообщения от пользователей Android по-прежнему будут отмечены зелёным пузырём. Помимо RCS, как сообщает The Verge, в iOS 18 появились новые текстовые эффекты и опции форматирования в iMessage, возможность планировать отправку сообщений и функция отправки сообщений через спутник. Главный экран iPhone с новой iOS получил расширенные возможности персонализации. Пользователи смогут менять расположение, размер и цвет значков приложений и виджетов на домашнем экране, а также получат больше возможностей для настройки экрана блокировки. Кроме того, приложение «Фото» получило значительное обновление дизайна. 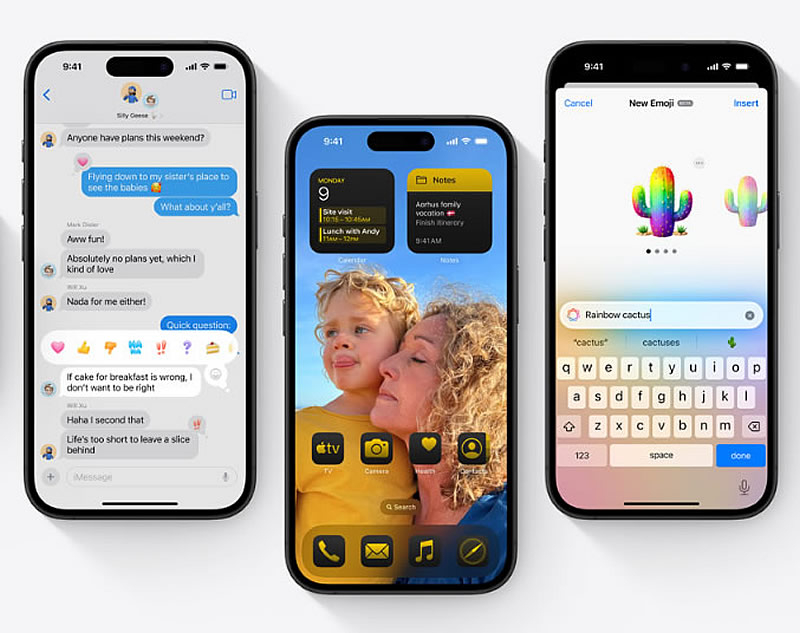
Источник изображения: Apple Появилась возможность управлять умными устройствами, поддерживающими стандарт Matter, локально через приложение «Дом» без необходимости использования домашнего хаба. Правда, для устройств в сети Thread потребуется iPhone 15 Pro или новее. Интересно, что теперь приложение «Дом» позволит предоставлять гостям доступ к замкам, воротам и системам сигнализации. Также появился новый способ разблокировки дверей без необходимости доставать телефон, однако пока это невозможно реализовать, так как ещё нет Smart-замков, поддерживающих эту функцию. Отметим, новые функции на базе искусственного интеллекта, анонсированные Apple, появятся только в iOS 18.1 в октябре в рамках публичной бета-версии. Apple представит инструменты для работы с текстом, генерации изображений с помощью Image Playground и взаимодействия с более продвинутым Siri. Изначально Apple Intelligence будет доступна только в США, к концу года появится в ряде англоязычных стран, а в следующем году расширить географию. Что касается iPadOS 18, то это обновление наконец-то добавит приложение «Калькулятор» на iPad после более чем десяти лет его отсутствия. А «Заметки» научились решать математические задачи, причём оно будет понимать не только числа и знаки, но также графики и схемы. Также на iPad придёт множество других полезных изменений, в том числе больше возможностей для кастомизации домашнего экрана, обновленная панель вкладок и переработанный «Центра управления». Функции Apple Intelligence придут и на iPad, но позже. Загрузить обновление на iPhone или iPad можно, перейдя в «Настройки» — «Основные» — «Обновление ПО» и далее следовать инструкциям по установке iOS 18. Новая операционная система доступна для всех iPhone начиная с iPhone XS. С полным списком можно ознакомиться здесь. Новая статья: Обзор робота-уборщика Dreame DreameBot X40 Ultra Complete: куда уж лучше?
17.09.2024 [00:02],
3DNews Team
Данные берутся из публикации Обзор робота-уборщика Dreame DreameBot X40 Ultra Complete: куда уж лучше? «Аж перепройти захотелось»: спустя 11 лет после релиза фанаты обнаружили невышедший трейлер Metro: Last Light
16.09.2024 [23:54],
Михаил Романов
Постапокалиптический шутер Metro: Last Light от студии 4A Games получил немало трейлеров, однако как минимум один ролик до недавних пор хранился в архивах почившего издательства THQ, не надеясь увидеть дневного света. 
Источник изображения: Steam (Stan) Администрация VK-сообщества «Вокруг-Билдов Metro 2033|Last Light|Exodus» (Metro Builds), изучающего историю и разные сборки игр серии Metro, на днях выложила не публиковавшийся ранее геймплейный трейлер Metro: Last Light. Ролик продолжительностью почти две минуты начинается с экрана технической информации, из которой выясняется, что на определённом этапе он позиционировался в качестве первого геймплейного трейлера игры. Официальный первый геймплейный трейлер Metro: Last Light вышел в июне 2011 года и с опубликованным Metro Builds не имеет почти ничего общего: другой хронометраж, визуальный ряд и саундтрек. Опубликованный Metro Builds трейлер Metro: Last Light показывает не встречающиеся в других роликах кадры с руинами постапокалиптической Москвы, спокойными эпизодами и ужасами столичного метро. Несмотря на незаконченный характер (сцены то и дело обрываются, песня сменяется с англоязычной на русскоязычную), ролик вызвал у игроков мощный прилив ностальгии. «[Что-то] аж перепройти захотелось», — признался Василий Владов. Metro: Last Light была выпущена 14 мая 2013 года на PC, PS3 и Xbox 360 компанией Deep Silver — THQ к тому времени уже закрылась. Игра получила высокие (80−82 % на Metacritic) оценки и заслужила похвалу геймеров. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex