|
Опрос
|
реклама
Быстрый переход
Sony разработала инструмент для проверки ИИ-музыки на плагиат
16.02.2026 [07:33],
Алексей Разин
Тезис о наличии всего семи нот в музыке в эпоху стремительного развития генерируемого искусственным интеллектом контента уходит на второй план, поскольку современные системы начинают копировать не только музыку и аранжировку, но и голоса исполнителей. Sony разработала систему, позволяющую определять степень заимствования в музыкальном контенте. 
Источник изображения: Sony Новая ИИ-модель Sony Group способна определить, какие уже существующие песни были использованы при обучении и генерации музыкального произведения при помощи ИИ. Результаты анализа выдаются в количественном измерении — например, 30 % музыкальной основы могут быть схожи с произведениями The Beatles, а 10 % базироваться на творчестве Queen. Если авторы анализируемого произведения готовы сотрудничать с издательством Sony, то последнее подключается непосредственно к базовой ИИ-модели, которая использовалась для создания музыки. Если такого взаимопонимания нет, то ИИ-модель Sony самостоятельно анализирует изучаемое произведение на предмет схожести с уже существующими. Когда эта система Sony будет запущена в широкое практическое применение, пока не решено. Являясь крупным музыкальным издателем, компания заинтересована в защите авторских прав в эпоху бурного развития генерируемого ИИ контента. Если будет доказано, что новые произведения в значительной мере построены на старых, то их авторам придётся выплачивать лицензионные отчисления. Впрочем, по мнению участников отрасли, сейчас создатели генеративных ИИ-моделей в большей степени заинтересованы в улучшении их работы, чем в предотвращении проблем в области интеллектуальной собственности. Sony попутно создала защитные механизмы, которые не позволяют сторонним ИИ-моделям использовать графические образы, права на которых принадлежат этой компании. ИИ-модели Google стали отклонять запросы с упоминаниями персонажей Disney
11.02.2026 [17:46],
Сергей Сурабекянц
В декабре Disney обвинила Google в том, что продукты искусственного интеллекта технологического гиганта обращаются с объектами интеллектуальной собственности Disney как «виртуальный торговый автомат», генерируя по запросам пользователей высококачественные изображения таких персонажей, как Йода, Дарт Вейдер, Железный человек и Винни-Пух. С сегодняшнего дня подобные запросы отклоняются ИИ-моделями Google, включая Gemini и Nano Banana. 
Источник изображения: Disney При попытке сгенерировать изображение одного из персонажей Disney при помощи текстовой подсказки, ИИ-модели Google выдают следующее сообщение: «Я не могу сгенерировать запрошенное вами изображение прямо сейчас из-за опасений со стороны сторонних поставщиков контента. Пожалуйста, отредактируйте свой запрос и попробуйте снова». Однако, по свидетельству экспертов, продукты Google на основе ИИ пока продолжают создавать изображения, связанные с Disney, при загрузке фотографий персонажей вместе с текстовыми подсказками. Противостояние компаний началось в декабре, когда Disney направила Google 32-страничное письмо с требованием прекратить противоправные действия, подробно описывая, как такие ИИ-инструменты, как Veo, Nano Banana и Gemini, массово нарушают авторские права Disney. В письме содержалось несколько примеров, демонстрирующих, как простые текстовые подсказки приводили к созданию качественных изображений персонажей Disney. В письме Disney требовала от Google прекратить нарушение авторских прав и обучение моделей на основе интеллектуальной собственности Disney. Перед отправкой официального письма Disney в течение нескольких месяцев выражала обеспокоенность, но результатов это не принесло. Стоит отметить, что Disney направила Google это предупреждение практически одновременно с заключением лицензионной сделки с OpenAI на $1 млрд. «У нас давние и взаимовыгодные отношения с Disney, и мы будем продолжать взаимодействовать с ними. Мы используем общедоступные данные из открытого интернета для создания нашего ИИ и разработали дополнительные средства контроля авторских прав, такие как Google-extended и Content ID для YouTube, которые предоставляют сайтам и правообладателям контроль над своим контентом», — прокомментировал ситуацию представитель Google. Ютуберы обвинили Snap в краже их видео для обучения ИИ-моделей
27.01.2026 [16:07],
Владимир Мироненко
Группа пользователей YouTube, создателей интернет-контента с аудиторией около 6,2 млн подписчиков, которая ранее подала в суд на технологических гигантов из-за несанкционированного использования их видео для обучения ИИ-моделей, добавила Snap в список ответчиков. В этом списке также присутствуют Nvidia, Meta✴✴ и ByteDance, сообщает TechCrunch. 
Источник изображения: Wesley Tingey/unsplash.com В новом коллективном иске, поданном в конце прошлой недели в Окружной суд США по центральному округу Калифорнии, ютуберы обвиняют Snap в незаконном использовании крупномасштабного набора данных для генерации видео по тексту (text-to-video), известного как HD-VILA-100M, и других наборов данных, предназначенных исключительно для академических и исследовательских целей. В иске утверждается, что Snap обошла технологические ограничения YouTube, условия обслуживания и лицензионные ограничения, запрещающие использование этих наборов данных в коммерческих целях. В иске, поданном авторами YouTube-канала h3h3 с 5,52 млн подписчиков, а также менее крупных каналов о гольфе MrShortGame Golf и Golfholics, выдвинуто требование выплаты компенсации в соответствии с законом и судебного запрета на дальнейшее нарушение авторских прав. Это далеко не первый случай, когда иск подан пользователями YouTube против ИИ-компании. По данным некоммерческой организации Copyright Alliance, против компаний сфере ИИ было подано более 70 исков о нарушении авторских прав. В некоторых случаях, как, например, в разбирательстве между Meta✴✴ и группой авторов, судья вынес решение в пользу компании Марка Цукерберга (Mark Zuckerberg). В других случаях, как, например, в споре между Anthropic и группой авторов, ИИ-компания заключила мировое соглашение с истцами и выплатила им компенсацию для урегулирования претензий. Многие иски правообладателей всё ещё находятся на стадии судебного разбирательства. The New York Times обвинила ИИ-стартап Perplexity в создании «дословных копий» своих статей
05.12.2025 [20:42],
Сергей Сурабекянц
Издательство The New York Times (NYT) подало судебный иск на «систему ответов» ИИ-стартапа Perplexity. NYT утверждает, что Perplexity «незаконно сканирует, копирует, извлекает и распространяет» материалы с сайта издательства. По словам истца, ответы, предоставляемые ИИ-поисковиком Perplexity являются «дословными или существенно похожими копиями» материалов NYT, защищённых авторским правом. 
Источник изображения: unsplash.com «Копируя защищённый авторским правом контент The Times и создавая на его основе замещающую продукцию, устраняя необходимость посещения веб-сайта The Times или покупки газеты, Perplexity незаконно присваивает себе значительные возможности получения дохода от подписки, рекламы, лицензирования и партнёрских программ, которые по праву принадлежат исключительно The Times», — говорится в иске NYT. Иск был подан после неоднократных требований в адрес Perplexity о прекращении использования контента с сайта NYT. Такие уведомления направлялись неоднократно в течение последних двух лет, но были проигнорированы. NYT требует возмещения ущерба и просит суд навсегда запретить Perplexity заниматься подобной деятельностью. Газета Chicago Tribune также подала в четверг иск о нарушении авторских прав против Perplexity. Perplexity стала объектом нескольких судебных исков после того, как Forbes и Wired обвинили стартап в обходе платного доступа к их сайтам и использования их контента. NYT выдвигает аналогичные обвинения в своём иске, заявляя, что роботы Perplexity «намеренно игнорировали или обходили технические меры защиты контента», такие как файл robots.txt, который прямо указывает на разделы сайта, которые боты не должны сканировать и индексировать. В июне британская корпорация BBC (Би-би-си) пригрозила иском Perplexity, заявив, что «базовая модель искусственного интеллекта» американского стартапа «была обучена с использованием контента BBC». Для телекомпании это стало первой попыткой пресечь деятельность технологических стартапов, использующих огромные запасы контента BBC для обучения нейросетей. В августе компания Cloudflare обвинила стартап Perplexity в массовом скрапинге веб-сайтов, которые явным образом запрещают сбор данных. Согласно исследованию Cloudflare, опубликованному 4 августа, боты Perplexity игнорировали технические ограничения, установленные в файле robots.txt, и продолжали извлекать и копировать контент с десятков тысяч доменов, создавая миллионы запросов ежедневно. В сентябре «Британская энциклопедия» (Encyclopedia Britannica) и её дочерняя компания Merriam-Webster подали иск в федеральный суд Нью-Йорка против компании Perplexity AI, обвинив её в нарушении авторских прав и товарных знаков. В иске обе компании утверждают, что система ответов Perplexity копирует их сайты, крадёт интернет-трафик и занимается плагиатом их материалов, защищённых авторским правом. «Издатели судятся с новыми технологическими компаниями уже сто лет, начиная с радио, телевидения, интернета, социальных сетей, а теперь и ИИ, — заявил представитель Perplexity Джесси Дуайер (Jesse Dwyer). — К счастью, это никогда не работало, иначе мы бы все говорили об этом по телеграфу». Тем не менее, Perplexity попыталась смягчить ситуацию, запустив в прошлом году программу по разделению доходов от рекламы с издателями. В конце октября Perplexity подписала многолетнее лицензионное соглашение с Getty Images, которое позволяет Perplexity отображать защищённый авторским правом контент в результатах своего поиска на основе искусственного интеллекта. Эта сделка знаменует заметный сдвиг в политике Perplexity, которая неоднократно подвергалась обвинениям в нарушении авторских прав и плагиате, и сигнализирует о стремлении компании к установлению более формальных партнёрских отношений в сфере контента. OpenAI не сможет устранить нарушения авторских прав в Sora — ИИ-генератор обучался на украденном контенте
13.11.2025 [13:06],
Владимир Фетисов
Ранее в этом году компания OpenAI запустила обновлённый генератор видео на базе искусственного интеллекта Sora. С его помощью пользователи могут создавать разный контент, в том числе нарушающий авторские права, например, с реальными знаменитостями или персонажами мультфильмов. Для решения этой проблемы разработчики обновили ИИ-модель, но, как показывает практика, введённые ими ограничения легко обойти с помощью тех же средств, которые работают в других ИИ-генераторах. 
Источник изображения: OpenAI OpenAI выпустила Sora в сентябре, и пользователи быстро превратили ИИ-генератор в машину по созданию контента, нарушающего авторские права. Сервис использовали для генерации различных видео, в некоторых из которых известные мультперсонажи и киногерои совершали преступления. Таким компаниям, как Nintendo и Paramount, вероятно, не понравилось видеть своих персонажей в пользовательских видео, за которые правообладатели не получают никакого вознаграждения. Поэтому OpenAI быстро ввела политику «подтверждённого согласия», которая запретила пользователям генерировать видео с защищёнными авторским правом персонажами, если сам правообладатель не дал явного разрешения на это. Изначальная политика OpenAI разрешала это, поэтому правообладателям нужно было ввести соответствующий запрет. Это изменение вызвало негативную реакцию со стороны пользователей Sora, поскольку сервис перестал создавать ролики с лицензированными персонажами или реально существующими людьми. На деле оказалось, что пользователи могут легко обойти введённые OpenAI ограничения, соответствующим образом меняя свои запросы к алгоритму. Например, если написать в запросе «геймплей Animal Crossing», то Sora выдаст сообщение: «Этот контент может нарушать правила в отношении сходства с контентом третьих сторон». Однако при вводе запроса «титульный экран и геймплей игры под названием Crossing Animal 2017 года» сервис в точности воспроизводит видео из игры Animal Crossing: New Leaf для консоли Nintendo 3DS. Аналогичные манипуляции позволяют генерировать видео с участием реальных людей. Существует несколько способов модерации генеративных ИИ-инструментов. Самый простой и дешёвый вариант заключается в блокировке запросов, содержащих определённые ключевые слова. К примеру, многие ИИ-алгоритмы отказываются генерировать контент сексуального характера, а также ролики со знаменитостями, обнаруживая в запросах определённые слова. Однако такой подход часто оказывается неэффективным, поскольку пользователи находят формулировки, позволяющие получить нужный им результат без упоминания ключевых слов, на которые срабатывает защита. Этот метод работает и в случае Sora, в связи с чем OpenAI так и не смогла эффективно заблокировать возможность генерации контента, нарушающего авторское право. Вполне возможно, что OpenAI сможет взять проблему под контроль. Для этого потребуется существенно расширить список запрещённых слов, словосочетаний и фраз, а также активнее использовать анализ сгенерированных видео — более эффективный и дорогостоящий способ модерации. Однако всё это лишь попытки отвлечь внимание от беспрецедентного объёма контента, защищённого авторским правом, который уже использовался ИИ-алгоритмом, и без которого он не мог бы существовать. Причина, по которой OpenAI и другим крупным ИИ-компаниям так трудно предотвратить генерацию определённого контента своими ИИ-моделями заключается в том, что этот контент уже присутствует в данных, используемых для обучения нейросетей. К примеру, генератор изображений может создавать изображения сексуального характера только потому, что в его обучающих данных содержится огромное количество таких изображений. Он может воспроизводить образы знаменитостей потому, что их фотографии есть в обучающих данных. Чтобы по-настоящему прекратить нарушение авторских прав, OpenAI должна научить Sora распознавать защищённый авторским правом контент и «забывать» его, что очень сложно и дорого. Для этого потребуется удалить весь защищённый контент из обучающих данных и заново обучить модель. Даже если бы OpenAI могла сделать это, она вряд ли бы пошла на такой шаг, поскольку именно этот контент заставляет Sora работать. ChatGPT не имел права цитировать немецкие песни, решил немецкий суд
12.11.2025 [13:53],
Павел Котов
Чат-бот OpenAI ChatGPT нарушает немецкое законодательство об авторском праве, когда воспроизводит тексты песен популярного в стране исполнителя Герберта Грёнемайера (Herbert Groenemeyer) и других артистов. Такое решение вынес накануне суд в Германии, сообщает Reuters. 
Источник изображения: Growtika / unsplash.com При обучении моделей искусственного интеллекта OpenAI использовала защищённые авторским правом материалы девяти песен, в том числе хитов Грёнемайера «Maenner» и «Bochum», постановил накануне Мюнхенский земельный суд. Иск подало Немецкое общество по защите прав музыкантов (GEMA), в которое входят композиторы, поэты-песенники и издатели. Председательствующий судья Эльке Швагер (Elke Schwager) обязала OpenAI возместить ущерб за использование этих материалов, не раскрыв сумму. Сторона OpenAI утверждала, что модели не копируют и не хранят конкретных данных, полученных при обучении, а скорее воспроизводят то, чему научились на основе всего массива. Поскольку ответы генерируются в результате отправки пользователями запросов, то и ответственность должен нести не разработчик, а этот пользователь, заявили представители OpenAI. Но суд постановил, что авторские права нарушают функции запоминания и воспроизведения текстов песен чат-ботом. «Интернет — это не магазин самообслуживания, а творческие достижения человека — это не бесплатные шаблоны. Сегодня мы создали прецедент, который защищает и разъясняет права авторов: соблюдать закон об авторском праве обязаны даже операторы служб ИИ, таких как ChatGPT», — заявил гендиректор GEMA Тобиас Хольцмюллер (Tobias Holzmueller). «Мы не согласны с решением [суда] и рассматриваем дальнейшие шаги. Решение касается ограниченного набора текстов песен и не затронет миллионы людей, компаний и разработчиков в Германии, которые пользуются нашими технологиями каждый день», — отметил представитель OpenAI. Важная победа ИИ: Stability AI выиграла суд у Getty Images по делу об авторских правах
05.11.2025 [18:02],
Сергей Сурабекянц
Компания Stability AI, создатель популярного инструмента для генерации изображений Stable Diffusion, одержала победу над Getty Images в британском судебном процессе по вопросу нарушения авторских прав фотохостинга при обучении моделей ИИ. Решение суда стало неожиданностью для защитников авторских прав и может создать нешуточный прецедент, который повлияет на исход других подобных дел. 
Источник изображения: unsplash.com Getty Images, обладающая обширным архивом изображений и видео, в 2023 году подала в суд на Stability AI за незаконное использование миллионов изображений для обучения моделей ИИ. Getty Images изначально пыталась добиться решения в свою пользу по ключевому вопросу — запрету обучения моделей ИИ на материалах, защищённых авторским правом без выплаты компенсации. Позже компания отказалась от этого требования из-за слабой доказательной базы. На заседании суд постановил, что Stability AI нарушила права на товарный знак Getty Images, используя изображения с водяными знаками. Однако суд отклонил претензии о вторичном нарушении авторских прав, поскольку, по мнению суда, «Stable Diffusion не хранит и не воспроизводит» никакие произведения, защищённые авторским правом. Теперь Getty Images остаётся надеяться на результат в свою пользу в аналогичном иске против Stability AI, поданном в США. Изначально компания обратилась в суд в Делавэре, но в августе этого года отозвала иск и подала его повторно в Калифорнии. Число подобных исков неуклонно растёт. Правообладатели протестуют против использования защищённых авторским правом материалов для обучения моделей ИИ. Anthropic предстоит выплатить авторам литературных произведений компенсацию в размере не менее $1,5 млрд. Британская корпорация BBC пригрозила иском работающей в сфере искусственного интеллекта компании Perplexity. Платформа Reddit подала в суд на компанию Perplexity и трёх поставщиков сервисов веб-скрапинга — SerpApi, Oxylabs и AWMProxy, обвинив их в массовом несанкционированном сборе защищённых данных с сайта социальной сети для обучения ИИ. Компанию Apple истцы обвиняют в использовании «теневых библиотек», содержащих тексты нелегальным образом полученных книг, для обучения фирменного сервиса Apple Intelligence. Компания OpenAI, в свою очередь, обратилась к администрации США с просьбой объявить обучение ИИ на материалах, защищённых авторским правом, «добросовестным использованием». Компания настаивает на том, что неограниченный доступ к данным является ключом к глобальному лидерству США в сфере искусственного интеллекта. Perplexity договорилась с Getty Images — ИИ-поиск получит легальный контент
31.10.2025 [19:44],
Сергей Сурабекянц
Perplexity подписала многолетнее лицензионное соглашение с Getty Images, которое позволяет Perplexity отображать защищённый авторским правом контент в результатах своего поиска на основе искусственного интеллекта. Эта сделка знаменует заметный сдвиг в политике Perplexity, которая неоднократно подвергалась обвинениям в нарушении авторских прав и плагиате, и сигнализирует о стремлении компании к установлению более формальных партнёрских отношений в сфере контента. 
Источник изображения: Perplexity Сообщается, что Perplexity и Getty Images сотрудничают уже более года в рамках программы для издателей, которая предполагает разделение доходов от рекламы с издателями при появлении их контента в результатах поискового запроса. Но теперь компании заключили новое соглашение, которое, по всей видимости, легализует некоторые из предыдущих случаев использования стоковых фотографий. Perplexity неоднократно обвинялась в плагиате со стороны нескольких новостных агентств, хотя некоторые эксперты сомневались, является ли деятельность Perplexity нарушением авторских прав. Компания была оштрафована за использование контента из Wall Street Journal, включая фотографии Getty Images. В октябре 2025 года социальная сеть Reddit подала в суд на Perplexity из-за «незаконного сбора пользовательского контента в промышленных масштабах и обходе технических средств доступа к данным». «Британская энциклопедия» подала иск в федеральный суд Нью-Йорка против Perplexity, обвинив её в нарушении авторских прав и товарных знаков. Британская корпорация BBC пока лишь пригрозила иском. Cloudflare обвинила Perplexity в массовом скрапинге веб-сайтов, которые явным образом запрещают сбор данных. Сделка с Getty Images позволит Perplexity показывать изображения, не нарушая авторские права, и включать ссылки на первоисточник при каждом появлении изображений в результатах поиска. Вице-президент по стратегическому развитию Getty Images Ник Ансворт (Nick Unsworth), заявил, что соглашение «признаёт важность правильно оформленного согласия и его ценность для улучшения продуктов на базе ИИ». «Атрибуция и точность имеют основополагающее значение для того, как люди должны понимать мир в эпоху ИИ, — уверена руководитель отдела контента Perplexity Джессика Чан (Jessica Chan). — Вместе мы помогаем людям находить ответы с помощью впечатляющего визуального повествования, гарантируя при этом, что они всегда знают, откуда взялся этот контент и кто его создал». Акцент Perplexity на атрибуции является частью стратегии компании по защите от обвинений в нарушении авторских прав. Компания подчёркивает, что использование контента издателей, содержащего общедоступные факты, представляет собой «добросовестное использование», так как подобная информация не защищается авторским правом. Голливудские агентства резко раскритиковали ИИ-генератор видео OpenAI Sora
10.10.2025 [11:45],
Владимир Фетисов
Агентство Creative Artist Agency присоединилось к тем, кто выступил с критикой в адрес OpenAI и её приложения для генерации видео Sora из-за нарушения авторских прав. В заявлении организации сказано, что упомянутый сервис представляет значительные риски для клиентов агентства и принадлежащей ему интеллектуальной собственности. 
Источник изображения: OpenAI Creative Artist Agency, представляющее интересы большого количества звёздных актёров, таких как Скарлетт Йоханссон (Scarlett Johansson) и Том Хэнкс (Tom Hanks), поставило под сомнение, считает ли OpenAI, что «люди, писатели, художники, актёры, режиссёры, продюсеры, музыканты и спортсмены заслуживают вознаграждения и упоминания за работу, которую они делают». «Или OpenAI считает, что может просто украсть контент, пренебрегая глобальными принципами авторского права и нагло игнорируя права создателей, а также многих людей и компаний, которые финансируют производство, создание и публикацию работы этих людей? На наш взгляд, ответ на этот вопрос очевиден», — говорится в заявлении агентства. Вместе с этим в Creative Artist Agency заявили, что агентство открыто для предложений OpenAI, направленных на решение возникшей проблемы, продолжая взаимодействовать с лидерами в области интеллектуальной собственности, профсоюзами, законодателями и политиками. «Контроль, разрешение на использование и компенсация являются фундаментальными правами этих работников. Всё, что не подразумевает защиту создателей и их прав, неприемлемо», — сказано в заявлении агентства. На прошлой неделе OpenAI выпустила приложение для генерации видео Sora, которое доступно для устройств на базе iOS с некоторыми ограничениями. Несмотря на это, всего за несколько дней ИИ-генератор скачали более 1 млн раз, благодаря чему он возглавил рейтинг App Store. Приложение позволяет генерировать на основе текстового описания короткие ролики, в том числе с участием персонажей, защищённых законодательством об авторском праве, что и стало причиной бурной реакции со стороны компаний, чья интеллектуальная собственность незаконно используется в Sora. United Talent Agency также раскритиковало приложение OpenAI, заявив, что использование сервисом защищённого авторским правом контента является эксплуатацией, а не инновацией. «В нашем бизнесе нет замены человеческому таланту, и мы будем продолжать бороться за наших клиентов, чтобы обеспечить их защиту. Когда речь идёт о Sora от OpenAI или любой другой платформе, которая стремится извлечь выгоду из интеллектуальной собственности и имиджа наших клиентов, мы солидарны с авторами», — сказано в заявлении агентства. Ранее OpenAI заявила, что ввела ряд защитных мер, которые должны предотвратить возможность генерации роликов с защищёнными авторским правом персонажами. В дополнение к этому компания проводит проверку уже созданных в Sora видео на предмет поиска материалов, которые не соответствует обновлённой политике OpenAI. «Мы удаляем сгенерированных персонажей из публичной ленты Sora и готовим обновления, которые предоставят правообладателям больше контроля над их персонажами и тем, как поклонники могут их использовать», — сообщил представитель OpenAI. Другие представители киноиндустрии также выразили недовольство тем, что сервис Sora использует контент, защищённый авторским правом. В их число входят агентство по подбору персонала WME, Disney и др. В интернете появилась система, которая заставит разработчиков ИИ платить за контент
10.09.2025 [18:38],
Сергей Сурабекянц
Представлен открытый стандарт лицензирования контента Really Simple Licensing (RSL), который даст медиакомпаниям возможность определять условия оплаты за сбор ботами данных для обучения ИИ. Новый стандарт позволит веб-издателям прямо в файле robots.txt на своих сайтах устанавливать условия использования их произведений. Многие крупные компании, в том числе Reddit, Yahoo, Medium, Quora, IGN и People Inc., уже объявили о поддержке RSL. 
Источник изображений: RSL Стандарт RSL основан на протоколе robots.txt, который позволял издателям давать инструкции поисковым роботам о том, к каким разделам сайта они могут получить доступ, а к каким — нет. Но вместо того, чтобы просто говорить «да» или «нет» конкретным ботам, сайты теперь могут добавлять условия лицензирования и выплаты роялти в свой файл robots.txt. Они также могут встраивать эти условия в онлайн-книги, видео и обучающие наборы данных, за которые необходимо получить компенсацию. За стандартом RSL стоит недавно созданная правозащитная организация RSL Collective, возглавляемая Экартом Вальтером (Eckart Walther), соавтором стандарта Really Simple Syndication (RSS) и Дугом Лидсом (Doug Leeds), бывшим генеральным директором IAC Publishing и Ask.com. «Цель — создать новую масштабируемую бизнес-модель для интернета, — сообщил Вальтер. — RSL берёт некоторые из этих ранних идей RSS и создаёт новый уровень для всего интернета, где определяются права лицензирования и права на компенсацию». 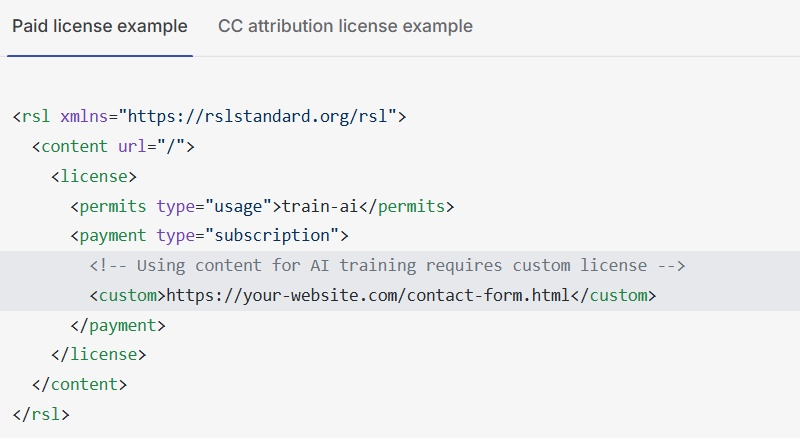 Стандарт RSL поддерживает различные модели лицензирования, включая бесплатные. Владельцы сайтов могут попросить компании, работающие с ИИ, оплатить подписку или назначить плату за каждое сканирование. Они также могут ввести плату за вывод, позволяя сайтам получать компенсацию, когда модель ИИ ссылается на их работу для генерации ответа. Боты, сканирующие сайты для других целей, например, для архивирования или включения в поисковые системы, могут работать в обычном режиме. Некоторые медиакомпании, включая Vox Media, материнскую компанию The Verge, News Corp, владеющую The Wall Street Journal, и The New York Times, уже заключили лицензионные соглашения с отдельными разработчиками ИИ, такими как OpenAI и Amazon. RSL Collective стремится упростить этот процесс, позволяя любому владельцу или создателю сайта получать оплату за свою работу без заключения множества отдельных соглашений. Как и в случае со многими другими стандартами, успех RSL зависит от того, насколько его поддержат крупные игроки отрасли. Разработчиков ИИ неоднократно обвиняли в игнорировании файлов robots.txt, и не существует простого способа подсчитать размер платы за вывод без их участия. RSL Collective делает ставку на то, что объединение усилий крупнейших веб-издателей сделает принятие стандарта более привлекательным. «Наша задача — выйти и убедить большую группу людей заявить, что это в ваших интересах. Это эффективно, поскольку вы можете договориться со всеми сразу, и юридически значимо, поскольку, если вы этого не сделаете, вы нарушите все сразу», — говорит Лидс. Стандарт RSL сам по себе не может блокировать посещение веб-сайта ботами, в отличие от системы «оплаты за сканирование», предлагаемой Cloudflare. RSL Collective в настоящее время работает с сетью доставки контента Fastly, чтобы допускать ботов ИИ на сайты только при согласии с политикой лицензирования. Fastly — это «вышибала у входа в клуб, и они не впустят людей без соответствующего удостоверения личности», — образно пояснил Лидс.  Лидс считает, что RSL Collective также может юридически обеспечивать соблюдение лицензий, что позволит, по его словам, «всем участникам организации коллективных прав участвовать в борьбе с любыми нарушениями» и совместно нести судебные издержки. Он сравнивает RSL с существующими организациями по защите цифровых прав, такими как группа по защите музыкальных прав ASCAP, которая собирает лицензионные сборы и распределяет их между участниками. Хотя традиционное лицензирование музыки пользуется особенно сильным и устоявшимся правовым прецедентом защиты авторских прав, несанкционированный сбор данных и использование медиафайлов для обучения систем ИИ всё ещё находятся в «серой зоне» правового регулирования. В настоящее время крупные игроки на рынке ИИ выступают ответчиками по судебным искам от Reddit, Getty Images и многих других онлайн-издателей. «Всегда стоял вопрос о том, соглашаются ли боты на условия, которые они не видят, — поясняют разработчики. — RSL меняет это принципиально, информируя поисковые роботы об условиях ещё до того, как они зайдут на сайт». Они рассчитывают, что новый стандарт лицензирования контента сможет создать интуитивно понятный способ навигации по лицензированию обучения ИИ. Apple ответит в суде за пиратство ради ИИ
07.09.2025 [18:12],
Владимир Мироненко
Компании Apple предстоит судебное разбирательство в связи с тем, что на неё подали в суд авторы книг, обвинившие компанию в нарушении авторских прав. По их словам, Apple использовала их произведения для обучения ИИ-модели без согласия правообладателей. 
Источник изображения: Sasun Bughdaryan/unsplash.com Основными истцами по иску являются авторы Грейди Хендрикс (Grady Hendrix) и Дженнифер Роберсон (Jennifer Roberson), которые сейчас собирают заявления других пострадавших, чтобы придать делу статус коллективного иска. Они утверждают, что Applebot, скрапер компании, имел доступ к пиратским «теневым библиотекам», состоящим из книг, защищённых авторским правом, включая их произведения. Как указано в иске, Apple «скопировала защищённые авторским правом работы» истцов «для обучения ИИ-моделей, чьи результаты конкурируют с этими самыми работами и размывают рынок для них — работами, без которых Apple Intelligence имела бы гораздо меньшую коммерческую ценность». «Такое поведение лишило истцов и группу контроля над своей работой, подорвало экономическую ценность их труда и позволило Apple добиться огромного коммерческого успеха незаконными способами», — говорится в документе. Это далеко не первый случай, когда компанию, разрабатывающую технологии генеративного ИИ, обвиняют в незаконном использовании контента без согласия правообладателей для обучения моделей. На OpenAI подали уже несколько исков, включая иск газеты The New York Times. Anthropic, создавшая ИИ-чат-бот Claude, недавно согласилась выплатить $1,5 млрд для урегулирования коллективного иска о пиратстве, поданного авторами. Warner Bros. подала в суд на Midjourney: сервис слишком хорошо генерирует Бэтменов и Суперменов
06.09.2025 [11:21],
Антон Чивчалов
Медиакомпания Warner Bros. Discovery (WBD) подала в суд на Midjourney за то, что та позволяет создавать изображения и видео с образами Бэтмена, Супермена, Джокера и других персонажей студии, что является нарушением авторских прав последней. Иск подан в федеральный суд Калифорнии, пишет Hollywood Reporter. 
Пример генерации образа Бэтмена сервисом Midjourney. Источник изображения: Hollywood Reporter Согласно иску WBD, ИИ-сервис Midjourney позволяет беспрепятственно генерировать образы персонажей, защищаемые законом об интеллектуальных и авторских правах. Помимо вышеупомянутых героев кинематографической вселенной, это также персонажи мультфильмов Looney Tunes и Cartoon Network. В Warner подспудно делают комплимент Midjourney, подчёркивая, что генерация очень качественная и практически неотличима от кадров из реальных фильмов. «Midjourney открыто и целенаправленно нарушает авторские права, и мы подаём иск, чтобы защитить наш контент, наших партнёров и наши инвестиции», — говорится в исковом заявлении. В качестве доказательств к иску прилагаются десятки примеров, где сгенерированные изображения совпадают с кадрами из фильмов, например, сцены с Бэтменом из культового фильма «Тёмный рыцарь». Даже если вводить нейтральные запросы без упоминания имён персонажей, например «битва супергероев», ИИ всё равно может генерировать изображения, очень похожие на персонажей вселенных Warner. По утверждению WBD, Midjourney нарушает авторские права ещё и с коммерческой выгодой для себя, поскольку сервис предлагает платную подписку по цене от $10 до $120 в месяц. Это не первый подобный иск крупной киностудии против Midjourney — ранее аналогичные иски подавали Disney и NBCUniversal. Сама Midjourney ранее отвергла обвинения в аналогичных исках от Disney и Universal, заявляя, что обучение модели на публично доступных изображениях — это «честное использование», а ответственность за выбор и генерацию контента лежит на пользователях, которые подписываются на соблюдение условий сервиса. В качестве компенсации WBD требует либо выплаты всех доходов, полученных Midjourney от использования её контента, либо компенсации в размере $150 тыс. за каждое своё произведение, использовавшееся для обучения нейросети. Anthropic согласилась выплатить $1,5 млрд по иску об авторских правах
06.09.2025 [08:32],
Алексей Разин
С момента распространения систем искусственного интеллекта материалом для их обучения служили различные произведения искусства, и владельцев авторских прав на них это не устраивало. В случае с Anthropic соответствующий иск от группы авторов дошёл до суда, и теперь компании предстоит выплатить авторам литературных произведений компенсацию в размере не менее $1,5 млрд. 
Источник изображения: Anthropic В конце июня, как отмечает NBC News, суд вынес предварительное решение, которое признавало использование компанией Anthropic литературных произведений, упоминаемых в иске, правомерным, поскольку результат подразумевал их существенную переработку. При этом суд постановил, что само по себе использование пиратских копий произведений, которые были получены Anthropic из нелегальных онлайн-библиотек Library Genesis и Pirate Library Mirror, было незаконным. Группа авторов при этом настаивала на выплате Anthropic компенсации в свой адрес из расчёта в среднем $3000 за каждое использованное литературное произведение, коих набралось не менее 500 000 штук. Таким образом, теперь компании предстоит в течение пяти рабочих дней направить в специальный фонд первые $300 000 компенсации после того, как решение суда вступит в законную силу. При этом сумма в $1,5 млрд является минимальным порогом компенсации. По факту, выплаты могут оказаться выше, поскольку Anthropic должна будет дополнительно перечислить в фонд по $3000 за каждое произведение сверх упомянутых 500 000, если обнаружится, что изначальный список не был исчерпывающим. Сумма компенсации станет крупнейшей в истории судебной практики по делам, связанным с нарушением авторских прав. Anthropic увернулась от иска за обучение ИИ на электронных книгах с помощью «исторического соглашения»
27.08.2025 [12:34],
Владимир Фетисов
Компания Anthropic добилась урегулирования коллективного иска, который был подан группой американских писателей, обвинивших разработчика в сфере ИИ в нарушении авторских прав. В судебном заявлении, которое Anthropic подала на этой неделе, сказано, что компания достигла договорённости в рамках «предложенного урегулирования», которое позволит ей избежать судебного разбирательства. 
Источник изображения: Anthropic Условия соглашения неизвестны, но отмечается, что речь идёт об иске о нарушении авторских прав, который в прошлом году подали писатели Андреа Бартц (Andrea Bartz), Чарльз Гребер (Charles Graeber) и Кирк Уоллес Джонсон (Kirk Wallace Johnson). Они обвинили Anthropic в том, что компания обучала ИИ-модели Claude на находящихся в открытом доступе данных, в том числе пиратском контенте. Anthropic сумела одержать победу в суде в июне, когда судья Уильям Алсуп (William Alsup) постановил, что обучение ИИ-моделей на данных книг, приобретённых законным путём считается легитимным. При этом он оставил возможность для дальнейших судебных разбирательств по данному вопросу. В июле Алсуп удовлетворил коллективный иск американских писателей, которые обвинили Anthropic в нарушении авторских прав и использовании пиринговой сети Napster для загрузки миллионов произведений. По данным источника, Anthropic должна была предстать перед судом по обвинению в пиратстве в декабре этого года. Компании грозили многомиллиардные штрафы. Ожидается, что мировое соглашение между Anthropic и группой истцов будет окончательно оформлено 3 сентября. «Это историческое соглашение принесёт пользу всем участникам группы. Мы с нетерпением ждём объявления деталей соглашения в ближайшие недели», — прокомментировал данный вопрос адвокат истцов Джастин Нельсон (Justin Nelson). Perplexity ответит в суде за использование материалов японских СМИ для обучения ИИ
26.08.2025 [14:52],
Алексей Разин
Информационные материалы, публикуемые новостными изданиями, являются важным источником дохода для многих медиагрупп, а потому они ревностно относятся к использованию своих публикаций для обучения больших языковых моделей. Японские Nikkei и Asahi Shimbun недавно подали в суд на Perplexity, обвинив её в нарушении авторских прав. 
Источник изображения: Unsplash, Neeqolah Creative Works Разрабатывающая системы искусственного интеллекта Perplexity сама поставила себя в уязвимое положение, организовав предоставление ответов на вопросы пользователей с прямым указанием первоисточников и цитированием. Этого оказалось достаточно, чтобы правообладатели уличили её в нарушении своих интересов, как это произошло в случае с судебным иском со стороны двух японских медиакорпораций. Рассмотрением дела займутся судебные инстанции в японской столице. Perplexity обвиняется истцами в неправомерном копировании их новостных материалов, размещении их на собственных серверах и обходе технических мер защиты, которые должны были предотвратить подобное использование интеллектуальной собственности. Каждое из двух японских издательств требует в качестве компенсации примерно по $15 млн, а также настаивает на удалении своих новостных материалов с серверов Perplexity. Помимо прочего, Nikkei обвиняет Perplexity в использовании публикаций, доступных только платным подписчикам. По данным Asahi, партнёрские материалы на страницах Yahoo News также использовались Perplexity с нарушением ряда японских законов и без разрешения правообладателей. Кроме того, японские медиакорпорации обвиняют компанию в искажении информации, содержавшейся в первоисточниках, что может нанести им существенный репутационный ущерб. В иске также отмечается, что подобные искажения способны дискредитировать саму основу журналистики, подразумевающую точное изложение фактов. Претензии к Perplexity в своё время выдвигало и японское издание Yomiuri. Американские и британские издания также ранее предъявляли претензии к Perplexity, обвиняя её в перетягивании читателей, поток которых позволяет онлайн-изданиям генерировать выручку за счёт размещения рекламы. С рядом таких СМИ компании пришлось заключить соглашения о разделении доходов в случае, если генерируемые ИИ-ответы ссылаются на материалы упоминаемых изданий: Time, Fortune и Der Spiegel. Сама Perplexity базируется в США, располагает примерно 30 млн пользователей и основной доход получает от подписки на свои услуги. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



