|
Опрос
|
реклама
Быстрый переход
Технокомпании обучают ИИ на миллионах роликов, скаченных с YouTube, без разрешения их авторов
11.09.2025 [16:50],
Павел Котов
В массив данных, предназначенных для обучения искусственного интеллекта, попали более 15,8 млн видеороликов с более чем 2 млн каналов YouTube — технологические компании без разрешения пользуются ими в своих проектах, обратил внимание американский журнал The Atlantic. 
Источник изображения: Aidin Geranrekab / unsplash.com Эти видеоролики присутствуют как минимум в 13 наборах данных, которые распространяют разработчики ИИ из технологических компаний, университетов и исследовательских организаций через такие платформы как, например, Hugging Face. В большинстве случаев видео являются анонимными — не указываются ни их названия, ни имена авторов; хотя журналистам издания удалось их идентифицировать. Для создания генераторов видео с ИИ разработчикам требуются огромное количество роликов, и YouTube представляется стандартным источником материалов для таких целей. Платформа позволяет пользователям платных тарифов загружать видео в приложении, чтобы впоследствии смотреть их в любое время и в любом месте; разработчики же скачивают их в виде файлов и обрабатывают при помощи алгоритмов ИИ, что прямо нарушает условия обслуживания платформы, но её администрация, очевидно, бездействует. Не все видео на YouTube защищены авторскими правами, некоторые ролики вообще загружаются пользователями, не связанными с правообладателями, но многие действительно защищены. Их несанкционированное копирование или распространение незаконно, и вопрос об их добросовестном использовании для обучения ИИ до сих пор обсуждается в рамках судебных процессов. Некоторые судьи не согласны с позицией технологических компаний, но единого мнения пока не сформировано. 
Источник изображения: Rubidium Beach / unsplash.com Созданные ИИ ролики, например, исторические, демонстрируют всё большее присутствие на YouTube — несмотря на множество неточностей, они уже начали вытеснять проверенный экспертами контент; то же касается музыкальных ремиксов. Проблема выходит далеко за рамки YouTube: многие современные чат-боты работают на базе мультимодальных моделей ИИ, способных в качестве ответов генерировать медиафайлы — вскоре ChatGPT или другая платформа вместо ссылки на видеоинструкцию с YouTube выдаст индивидуальное обучающее видео. Возможно, оно окажется хуже, чем созданное человеком, но будет адаптировано к требованиям пользователя. Обучающие массивы, в которые входят скачанные с YouTube ролики, используются многими технологическими компаниями, в том числе Microsoft, Meta✴✴, Amazon, Nvidia, Runway, ByteDance, Snap и Tencent. В Meta✴✴, Amazon и Nvidia ответили на просьбу журналистов прокомментировать ситуацию и заверили, что уважают создателей контента и считают использование этих данных законным. В Amazon добавили, что сейчас работают над системой, которая позволит генерировать «убедительную, высококачественную рекламу по простым запросам». У Meta✴✴ есть сервис Movie Gen, генерирующий видео по текстовым запросам; в Snapchat есть функция AI Video Lenses, позволяющая дополнять пользовательские видео элементами с генеративным ИИ. Эти службы были бы невозможными, если бы владеющие ими компании не обучали ИИ на большом объёме роликов — так и ChatGPT не смог бы писать в духе Шекспира, если бы не «прочитал» его. Значительная часть материала взята с новостных и образовательных каналов; сотни тысяч видео были созданы авторами обычных каналов. Разработчики ИИ признаются, что одни ролики им интереснее, чем другие. Так, специализирующаяся на разработке генератора видео с ИИ компания Runway в качестве приоритетных исходных материалов в неофициальном порядке перечислила «быстрое движение камеры», «красивые кинематографические пейзажи», «высококачественные фрагменты фильмов» и «сверхкачественные научно-фантастические короткометражки». Создатели обучающих массивов HowTo100M и HD-VILA-100M отдают приоритет видео с высоким количеством просмотров на YouTube; для массива HD-VG-130M отбор видео производит специально обученная ИИ-модель. Ниже приоритет у видео с субтитрами и логотипами каналов — есть риск, что эти элементы попадут и в генерируемые ролики; возможно, владельцам каналов следует обратить на этот факт внимание, если они не хотят увидеть свои работы в обучающих массивах. 
Источник изображения: BoliviaInteligente / unsplash.com При подготовке видео к добавлению в массив разработчики разбивают материал на короткие ролики, отбрасывая, например, моменты смены ракурса. К каждому созданному таким образом клипу добавляется описание на английском языке, чтобы модель научилась сопоставлять слова с движущимися изображениями и впоследствии генерировала видео на основе текстового запроса. Иногда такое аннотирование осуществляют люди, иногда — специальные модели ИИ. На канале TED при помощи ИИ производится дублирование речи выступающих, и даже осуществляется корректировка артикуляции губ для синхронизации со звуковой дорожкой на новом языке. Активно появляются сервисы и для рядовых пользователей. Facetune позволяет корректировать лица на видеозаписях; Facewow — полностью заменять их; Runway Aleph — менять цвета объектов или превращать солнечную погоду в снежную бурю. Google Gemini превращает фотографии в короткие ролики; Vidnoz AI обещает генерировать реалистичные изображения говорящих людей в любом стиле; Arcads готовит полноценные рекламные ролики с актёрами и закадровым голосом — аналогичные возможности есть в Symphony Creative Studio для TikTok. Доступны также виртуальная примерка одежды, создание собственных компьютерных игр, анимация людей и персонажей мультфильмов. Из-за ИИ возникают серьёзные конфликты. Жюри фестиваля рекламы «Каннские львы» присудило, а администрация впоследствии отозвала награду ролику, в котором использовался образ американской женщины-политика ДеАндреа Сальвадор (DeAndrea Salvador) — она подала в суд и на создавшую этот ролик компанию, и на его заказчиков. Disney и Universal, а вслед за ними и Warner Brothers подали в суд на создателей генератора изображений Midjourney, которую в иске охарактеризовали как «бездонную яму плагиата». На Meta✴✴ подали в суд две студии, снимающие фильмы для взрослых — гигант соцсетей скачал и начал раздавать по протоколу BitTorrent более 2000 их видеороликов. Пользователь YouTube Дэвид Миллетт (David Millette) в августе прошлого года подал в суд на Nvidia, обвинив компанию в несправедливом обогащении и недобросовестной конкуренции при обучении ИИ Cosmos, но дело удалось уладить. Люди зарабатывают на ИИ-контенте. DeepBrain AI платит по $500 за опубликованные на YouTube ИИ-видео, которые наберут 10 000 просмотров, и это не очень высокая планка. Google и Meta✴✴ делятся с пользователями платформ доходами от рекламы и зачастую поощряют создание контента с помощью ИИ. Появились и «инфоцыгане», готовые научить секретам заработка на созданных ИИ материалах. Техногиганты и сами обучают свои системы ИИ на видео с принадлежащих им платформ: Google взяла не менее 70 млн видео с YouTube, а Meta✴✴ обучала ИИ на более чем 65 млн роликов из Instagram✴✴. Не за горами день, когда людям придётся конкурировать с ИИ за создание более качественного контента. А соцсети постепенно лишатся своего изначально социального характера — иронично, что совсем недавно об этом задумался глава OpenAI Сэм Альтман (Sam Altman). SberDevices представила миниатюрную колонку SberBoom Micro с ИИ
11.09.2025 [15:33],
Владимир Мироненко
SberDevices представила на выставке CosMoscow устройство нового поколения SberBoom Micro — самую компактную умную колонку Sber с искусственным интеллектом GigaChat 2.0. Выполненная в форме овального камня размером с ладонь, SberBoom Micro позволяет превратить любую Bluetooth-аудиосистему в полноценное умное устройство. 
Источник изображений: SberDevices Для активации подключения SberBoom Micro к Bluetooth-аудиосистеме потребуется голосовая команда «Салют, подключись к Bluetooth-колонке» или можно подключиться через мобильное приложение «Салют».  SberBoom Micro также поддерживает работу с телевизорами и ТВ-приставкой Sber на ОС «Салют ТВ», позволяя обходиться без ДУ, поскольку переключать каналы, находить фильмы и управлять воспроизведением контентом можно голосом. С помощью SberBoom Micro можно также управлять Wi-Fi устройствами умного дома (светом, датчиками), отдавая команды голосом. SberBoom Micro базируется на процессоре Amlogic 113L, оснащена 2-Вт динамиком, микрофоном, а также портом USB Type-C. Объём оперативной памяти составляет 128 Мбайт, ёмкость флеш-накопителя — 128 Мбайт. Вес колонки равен всего 65 г, размеры — 82 × 77 × 25 мм.  Обладая стильным дизайном, SberBoom Micro органично впишется в любой интерьер. Благодаря наличию липучки её можно закрепить на стене или любой гладкой поверхности в доме. Как сообщает компания, устройство «прекрасно слышит» пользователя, чётко реагируя на голосовые запросы и идеально подходит для небольшой комнаты без посторонних шумовых помех. Благодаря поддержке ИИ, SberBoom Micro способна стать эрудированным собеседником и может использоваться в качестве персональной справочной службы. SberBoom Micro поступит в продажу 30 сентября по цене 2990 руб. Репортаж со стендов Hisense и Gorenje на выставке IFA 2025: новейшие телевизоры и умная бытовая техника
11.09.2025 [13:54],
Андрей Созинов
Компания Hisense совместно с брендом Gorenje организовали на берлинской выставке IFA 2025 очень большой стенд, на котором продемонстрировали свои самые последние новинки и инновации. Hisense сделала ставку на прорывные телевизионные панели RGB Mini-LED, а под брендом Gorenje — на продуманную бытовую технику, связанную единой платформой ConnectLife и щедро приправленную алгоритмами ИИ. Здесь мы подробнее расскажем о самых интересных решениях.  Телевизоры Hisense — RGB Mini-LED на пути к массовости и дебют Dolby Vision 2 Главная телевизионная премьера Hisense на IFA — демонстрация собственных панелей RGB Mini-LED. В отличие от привычной подсветки Mini-LED на синих диодах с жёлто-фосфорным слоем, здесь используются отдельные красные, зелёные и синие крошечные светодиоды. Это повышает точность цветопередачи, улучшает управление локальным затемнением и позволяет добиться крайне высокой пиковой яркости и глубокого чёрного цвета — как на OLED, но без рисков выгорания.  На стенде показали как уже знакомый «гигант» Hisense UX диагональю 116 дюймов с пиковой яркостью до 8000 кд/м² и покрытием цветового пространства BT.2020 вплоть до 95 %, так и более «домашний» 85-дюймовый образец. Это служит подтверждением того, что RGB Mini-LED становится гораздо доступнее и, помимо гигантских флагманов, охватывает сегмент моделей для реальных гостиных.  Не менее показательно и то, что именно Hisense стала первым производителем, продемонстрировавшим поддержку нового формата HDR — технологии Dolby Vision 2. Ключевые нововведения здесь — алгоритмы Authentic Motion для контроля движения на уровне сцен и Content Intelligence для оптимизации яркости и тонов, в том числе для слишком тёмных сцен, и для корректного апскейла из SDR в HDR. Флагманские модели Hisense RGB Mini-LED с платформой MediaTek Pentonic 800 и процессором обработки изображения MiraVision Pro станут первыми носителями Dolby Vision 2. Позже формат обещает распространиться шире, но старт именно за Hisense — важный маркер технологического темпа компании. Суммарный эффект заметен не только в характеристиках, но и визуально: 85-дюймовая новинка обеспечивает яркое и насыщенное изображение с приятной глазу цветопередачей без паразитного свечения в сложных сценах, а также впечатляющую динамическую контрастность.  Добавлю также, что в рамках фирменной концепции AI Your Life компания Hisense активно применяет ИИ-технологии в своих телевизорах: фирменный движок Hi-View AI Engine X анализирует изображение в реальном времени, подстраивая локальную подсветку и обработку цвета под конкретные сцены и тип контента — от футбола до HDR-кино. На IFA компания отдельно подчёркивает, что её линейка 2025 года строится вокруг идеологии «контекстной картинки», где RGB Mini-LED и алгоритмы ИИ работают как единое целое.  Помимо ЖК-панелей, Hisense активно развивает направление лазерных телевизоров, представляющих собой комплект из лазерного проектора и специального экрана. В рамках общей стратегии AI Your Life компания подчёркивает, что и здесь задействованы ИИ-алгоритмы коррекции изображения и звука, а весь контентный слой объединён платформой VIDAA — то есть Hisense преподносит лазерные решения не как «запасной вариант», а доказывает, что это полноценная альтернатива телевизору.  Hisense расширила линейку Laser TV с трехцветным лазерным источником TriChroma:: модель Hisense L9Q поддерживает IMAX Enhanced, Dolby Vision и обеспечивает проекцию размером от 80 до 200 дюймов по диагонали с высочайшим качеством. А компактный Hisense C2 Ultra предлагает диагональ до 300 дюймов и ультранизкую задержку, что делает его интересным вариантом для гейминга, а не только для кино.  В свою очередь, решение Rollable Laser TV от Hisense представляет собой интегрированную систему со скручивающимся экраном, которая в сложенном виде выглядит как тумба, но нажатием одной кнопки экран разворачивается, а из нижней части раскладывается короткофокусный проектор. Умная бытовая техника Hisense: ИИ не ради галочки В бытовой технике Hisense делает ставку на практичный ИИ, который компания внедряет в самые разные устройства.  Главный герой среди климатических решений — сплит-система Hisense U8 S Pro, оснащённая датчиками присутствия и движения HI-SENSOR, а также поворотной системой Coanda, которая не просто поддерживает заданную температуру, а перераспределяет потоки по комнате в зависимости от того, где находятся люди и как они перемещаются. Можно попросить кондиционер дуть именно на пользователя или, наоборот, стараться обходить его. Дополняет картину встроенный голосовой помощник.  Ещё один яркий представитель бытовой техники с ИИ — холодильник PureFlat Smart Series, оснащённый 21-дюймовым сенсорным экраном. Это не просто «фоторамка на дверце»: модуль Kitchen AI умеет составлять персональные планы питания, подбирать рецепты на базе находящихся внутри продуктов, а для любителей экспериментов — даже диктовать голосом пошаговые инструкции по коктейлям. А режим Super Cooling отвечает за быстрое доведение напитков и продуктов до нужной температуры. Экран холодильника служит хабом умной кухни на платформе ConnectLife, в экосистему которой также входит электрический духовой шкаф, посудомойка и другая техника. После того как пользователь определится с рецептом, холодильник отправит на духовой шкаф информацию для установки подходящего режима. Также он свяжется с посудомойкой, чтобы установить оптимальный режим работы.  Платформа ConnectLife синхронизирует расписания, учитывает показания датчиков присутствия и энергоаналитику, координируя работу «тяжёлых» потребителей — например, тот же кондиционер можно автоматически подстраивать под занятость дома и тарифные окна, чтобы экономить электричество без ручных сценариев и «танцев с триггерами». Gorenje: фокус на экологичности и глубокой интеграции с ИИ Словенский бренд Gorenje, входящий в структуру Hisense, на IFA 2025 сделал акцент на бытовой технике с максимально глубокой интеграцией искусственного интеллекта и заботой об экологии. Компания показала несколько новых серий холодильников, стиральных и сушильных машин, посудомоечных машин, а также компактных кухонных устройств, входящих в экосистему Gorenje SmartHome. Новинки совместимы с приложением ConnectLife, что позволяет объединять технику Gorenje и Hisense в общую экосистему.  В линейке холодильников Gorenje особое место занимает новая серия NatureFresh, разработанная с прицелом на максимальное сохранение свежести и минимизацию энергопотребления. В устройствах используются инновационные теплоизоляционные материалы, а встроенные датчики и ИИ‑алгоритмы анализируют наполнение холодильника и регулируют работу компрессора для оптимального расхода энергии. Всё это заключено в элегантный корпус с минималистичным дизайном, который подчеркивает статус бренда как эксперта в создании стильной и высокотехнологичной бытовой техники.   В линейке стиральных и сушильных машин Gorenje сделала ставку на адаптивные программы: умные сенсоры определяют тип ткани, вес и степень загрязнения белья, а встроенный ИИ предлагает оптимальные параметры стирки и сушки для экономии воды, электроэнергии и времени.  В сегменте посудомоечных машин особое внимание привлекла модель с функцией самодиагностики и автоматической адаптацией цикла под уровень загрязнённости посуды. Помимо интеллектуальных алгоритмов, новая серия отличается использованием экологичных материалов и сверхнизким уровнем шума.  Не остались без внимания и компактные гаджеты: Gorenje анонсировала мини-духовку с ИИ-алгоритмами, позволяющими автоматически определять тип блюда и выбирать подходящий режим приготовления. Компания также продемонстрировала интеграцию с голосовыми ассистентами и собственным сервисом Gorenje SmartRecipes — сервис автоматически подбирает рецепты под текущий набор продуктов в холодильнике. Экспозиции Hisense и Gorenje на IFA 2025 наглядно демонстрируют, что будущее бытовой электроники связано не только с совершенствованием железа, но и с проникновением ИИ в повседневную жизнь. Акции Oracle потянули вверх за собой ценные бумаги других компаний, зарабатывающих на буме ИИ
11.09.2025 [09:50],
Алексей Разин
Вчера инвесторы неожиданно осознали, что Oracle является одной из тех компаний, которые смогут неплохо заработать на развитии вычислительной инфраструктуры для систем искусственного интеллекта. Торговую сессию акции Oracle завершили рекордным ростом, а сооснователь Ларри Эллисон (Larry Ellison) потеснил Илона Маска (Elon Musk) в статусе самого богатого человека в мире по версии Bloomberg. 
Источник изображения: Unsplash, Nicholas Cappello На следующем этапе участники фондового рынка поняли, что на капитальных вложениях Oracle, которые по итогам 2026 фискального года составят $35 млрд, заработают поставщики инфраструктурных решений, и Nvidia в этой очереди стоит первой, поэтому курс её акций вчера укрепился почти на 4 %. По информации руководства Nvidia, в стоимости типового сервера для нужд ИИ доля компонентов этой марки достигает 70 %, поэтому логично предположить, что именно этот поставщик выиграет от роста капитальных затрат Oracle. В свою очередь, чипы для ускорителей вычислений Nvidia выпускает, тестирует и упаковывает тайваньская компания TSMC, поэтому ей акции на торгах в среду также подорожали на 4 %. Тем более, что она ранее сообщила о росте августовской выручки на 34 % в годовом сравнении, лишь подтвердив благоприятную тенденцию. Акции Broadcom выросли в цене на 10 %. Как стало известно недавно, компания получила крупный заказ от OpenAI на разработку специализированных чипов для сегмента ИИ. AMD на рынке компонентов ИИ пока остаётся на вторых ролях, но и её акции на фоне общего воодушевления подорожали на 2 %. Даже Micron, которая является не самым крупным поставщиком памяти HBM для ускорителей Nvidia, смогла вчера продемонстрировать рост курса своих акций на 4 %. Акции производителей серверных систем Super Micro и Dell успели подорожать на 2 %. OpenAI купит у Oracle вычислительные мощности для развития ИИ за баснословные $300 млрд
11.09.2025 [08:44],
Алексей Разин
В условиях высокого спроса на услуги по строительству центров обработки данных для искусственного интеллекта компания Oracle получила возможность сотрудничать с разными заказчиками, но стартап OpenAI может оказаться одним из крупнейших среди них. По крайней мере, именно сделка между двумя компаниями принесёт Oracle в ближайшие пять лет до $300 млрд выручки. 
Источник изображения: Oracle О заключении соответствующей сделки между OpenAI и Oracle сообщило издание The Wall Street Journal, попутно назвав её одной из крупнейших в сфере облачных вычислений. Для создания инфраструктуры, подразумеваемой контрактом с OpenAI, придётся обеспечить до 4,5 ГВт электрической мощности. К реализации инициативы компания приступит в 2027 году, если всё пойдёт по плану. Для обеих сторон сделка на столь крупную сумму таит определённые риски. OpenAI свои расходы наращивает значительно быстрее, чем увеличивает собственную выручку, поэтому бесконечно долго работать без прибыли эта компания не сможет. Осенью прошлого года руководство OpenAI заявило, что избавиться от убытков ранее 2029 года стартап не сможет, но планы компании меняются едва ли не ежемесячно, и все эти изменения влекут за собой увеличение расходов. Oracle будет вынуждена привлекать заёмные средства для закупки оборудования в рамках данного контракта, а ещё сильная зависимость от одного заказчика порождает определённые проблемы. В отличие от многих конкурентов и партнёров по рынку, Oracle работает с довольно большим соотношением долговых обязательств к объёму собственных денежных средств, оно достигает 427 %. По оценкам Morgan Stanley, в период с 2025 по 2028 годы расходы на развитие серверной инфраструктуры для ИИ достигнут $2,9 трлн. Большинство участников рынка не смогут покрыть финансовые потребности за свой счёт, а потому будут вынуждены привлекать сторонние средства. Исторически OpenAI полагалась в расширении своих вычислительных мощностей на арендуемые у Microsoft облачные ресурсы Azure, но в последнее время первая из компаний демонстрирует готовность привлекать и прочих партнёров. Oracle станет одним из них, а ещё эти компании вместе с SoftBank будут работать над реализацией проекта Stargate, подразумевающего строительство в США вычислительных мощностей на $500 млрд в ближайшие четыре года. Oracle упоминаемые в рамках сделки с OpenAI центры обработки данных собирается строить в Вайоминге, Пенсильвании, Техасе, Мичигане и Нью-Мексико, хотя точный набор площадок пока не определён. Запал ИИ-бума не иссяк: TSMC похвалилась ростом выручки на 34 % в августе
10.09.2025 [10:29],
Алексей Разин
Принято считать, что основными выгодоприобретателями в условиях бума систем искусственного интеллекта остаются Nvidia и её ближайшие партнёры. Поскольку TSMC исправно снабжает её чипами для ускорителей вычислений, на выручке данного контрактного производителя это сказывается наилучшим образом. В августе выручка TSMC выросла сразу на 34 %. 
Источник изображения: ASML По официальным данным, за прошлый месяц TSMC выручила $11,1 млрд, что более чем на треть больше результата аналогичного месяца прошлого года. Сентябрь завершает третий фискальный квартал в календаре компании, и аналитики в среднем ожидают, что квартальная выручка TSMC вырастет на 25 % год к году. Прочие партнёры Nvidia и клиенты TSMC, зарабатывающие на буме ИИ, тоже и не думают сбавлять обороты, поэтому пока формируется благоприятная для обеих компаний картина. Foxconn, выпускающая серверные системы для Nvidia, в августе нарастила выручку на 10,6 %. Компания Broadcom, получившая от OpenAI заказы на разработку специализированных чипов для систем ИИ, рассчитывает в ближайшие несколько лет выручить на этом контракте не менее $10 млрд. На вчерашней презентации Apple мало упоминала об ИИ
10.09.2025 [08:21],
Алексей Разин
Год назад компания Apple в момент анонса семейства iPhone 16 сформировала у потребителей завышенные ожидания относительно своих функций искусственного интеллекта, но в итоге не смогла реализовать их в срок и на должном уровне. Прошлогодний опыт был учтён, и вчера Apple почти не упоминала об искусственном интеллекте в ходе своей не самой продолжительной презентации. 
Источник изображения: Apple Как подчёркивает The Verge, сам по себе хронометраж мероприятия уложился в один час и пятнадцать минут, что довольно скромно в историческом контексте. Представители Apple в ходе мероприятия избегали активного обсуждения темы искусственного интеллекта, а если и ссылались на неё, то главным образом в контексте фоновой или подготовительной работы. Например, в случае с наушниками AirPods Pro 3 сослалась на использование ИИ для перевода речи на другой язык в масштабе реального времени и мониторинг частоты сердечных сокращений. ИИ также помогает Apple анализировать информацию о физической активности пользователя, как было отмечено, чтобы давать ему более точные рекомендации по поддержанию здоровья. Для анализа использовались данные более чем 250 000 участников программы, предоставивших записи о более чем 50 млн часов физической активности. В случае с новыми Apple Watch упоминание об ИИ было ещё более выборочным. Было сказано, что алгоритмы Apple теперь анализируют, как артериальное давление пользователя реагирует на сердечные сокращения в пределах каждого 30-дневного периода. Эти данные потом обобщаются для выявления симптомов гипертонии. Как только Apple получит одобрение американского регулятора FDA в сфере здравоохранения, подобная функция ранней диагностики гипертонии начнёт использоваться открыто и официально. По прогнозам Apple, только за первый год компании удастся предупредить об опасных симптомах более 1 млн человек. Большинство уже внедрённых конкурентами функций работы с ИИ на уровне фирменных приложений iMessage и FaceTime компания Apple уже обсудила на июньской конференции для разработчиков WWDC, а потому на вчерашней презентации iPhone 17 подобным темам почти не уделяла внимания. Как отмечалось, кадровые перестановки и постоянные попытки смены курса в сфере разработки ИИ уже подорвали моральных дух многих специалистов Apple в этой области, и они начали покидать компанию на фоне более выгодных карьерных предложений у конкурентов. Microsoft сократит зависимость от OpenAI, расширив сотрудничество с Anthropic
10.09.2025 [07:38],
Алексей Разин
Крупнейшим инвестором OpenAI до сих пор являлась Microsoft, но условия готовящейся реструктуризации первой не в полной мере устраивают вторую. Так или иначе, Microsoft намерена снизить свою зависимость от языковых моделей OpenAI, а последняя будет развивать собственную вычислительную инфраструктуру и может создать конкурента для LinkedIn. 
Источник изображения: Anthropic Как отмечает TechCrunch со ссылкой на The Information, корпорация Microsoft намеревается заключить с Anthropic оглашение об использовании её языковых моделей в сервисе Office 365. Приложения Word, Excel, Outlook и PowerPoint получат ИИ-функции, реализованные при помощи как разработок OpenAI, так и разработок Anthropic. Противоречия между Microsoft и OpenAI по поводу грядущей реструктуризации не имеют отношения к данному решению, как отмечает источник. Просто на платформе Anthropic удаётся лучше реализовать работу некоторых ИИ-ассистентов типа функции создания презентаций по текстовому запросу. В частности, в этой сфере лучше решений OpenAI проявляет себя модель Claude Sonnet 4 компании Anthropic. Это не первый случай отступления Microsoft от платформы OpenAI. Первая предлагает в GitHub Copilot возможности интеграции с Anthropic Claude и Grok компании xAI. Кроме того, в последнее время Microsoft прилагает усилия к разработке собственных языковых моделей MAI-Voice-1 и MAI-1-preview. Для OpenAI сотрудничество с Microsoft тоже не является исключительным, хотя она серьёзно зависит от этого партнёра из-за использования вычислительной инфраструктуры Azure. Недавно стало известно, что в сотрудничестве с Broadcom со следующего года будут налажены поставки чипов OpenAI собственной разработки, которые позволят последней развивать собственную вычислительную инфраструктуру более активно и эффективно. Кроме того, OpenAI намеревается создать платформу для поиска работы и размещения вакансий, которая составит конкуренцию Microsoft LinkedIn. Нейросеть Google Veo 3 научилась создавать вертикальные видео для соцсетей
09.09.2025 [19:40],
Анжелла Марина
Генеративная модель для создания видео Google Veo 3 получила поддержку вертикального формата 9:16 и разрешение 1080 пикселей. Теперь разработчики смогут создавать контент, который идеально подходит по формату для TikTok и YouTube Shorts, причём по значительно меньшей цене. Об этом компания сообщила в официальном блоге для разработчиков. 
Источник изображения: Google Согласно сообщению, основная версия Veo 3 и её более бюджетная модификация Veo 3 Fast теперь позволяют создавать ролики в оптимальном формате для мобильных устройств и социальных платформ. Активировать вертикальный формат можно, установив параметр aspectRatio в запросах API на значение 9:16. Кроме того, обновление позволяет устанавливать более высокое разрешение по сравнению с предыдущим ограничением в 720 пикселей. Однако, как сообщает The Verge, поддержка разрешения 1080 пикселей в настоящее время доступна только для видео с соотношением сторон 16:9. В Google также заявили, что Veo 3 и Veo 3 Fast теперь «стабильны и готовы к масштабируемому использованию в Gemini API», при этом стоимость использования сервиса существенно изменилась: генерации одной секунды видео через Veo 3 снизилась с $0,75 до $0,40, а через Veo 3 Fast — с $0,40 до $0,15 за секунду. Отмечается, что добавление поддержки вертикального видео не стало большой неожиданностью, поскольку компания ещё в июне анонсировала интеграцию Veo 3 с YouTube Shorts, которая была запланирована на конец лета. Очевидно, что в ближайшее время пользователи TikTok и Instagram✴✴ Reels больше увидят в своих лентах контент, созданный помощью нейросети Google Veo 3. Из Meta✴ продолжается массовый исход специалистов в сфере ИИ — Цукерберг пытается его остановить, но безуспешно
09.09.2025 [16:55],
Павел Котов
Многие специалисты высокой квалификации в области искусственного интеллекта стали увольняться из компании Meta✴✴. В качестве причин Forbes отмечает хаос в корпоративной культуре и отсутствие чёткой стратегии дальнейшего развития компании, которую другие разработчики ИИ перестали считать серьёзным конкурентом. Гендиректор Марк Цукерберг (Mark Zuckerberg) пытается остановить этот процесс, предлагая новым сотрудникам колоссальные зарплаты, но прекратить утечку специалистов это не помогает. 
Источник изображений: Igor Omilaev / unsplash.com Ранее в Meta✴✴ работали лучшие специалисты в области ИИ, но в последние годы наметился массовый исход кадров — они всё чаще начинают собственные проекты. Здесь ранее трудились основатели Perplexity, Mistral, Fireworks AI и World Labs; а с приходом бума ИИ эксперты начали уходить и к крупным конкурентам, к таким как OpenAI, Anthropic и Google. Чтобы компенсировать потери, Марк Цукерберг был вынужден сформировать элитное подразделение Meta✴✴ Superintelligence Labs (MSL), но остановить утечку специалистов так и не удалось. Масштабы проблемы иллюстрирует тот факт, что конкурентов Meta✴✴ теперь интересуют только её новые сотрудники — существующие уже преимущественно не отвечают их требованиям. С осени минувшего года Google переманила у Meta✴✴ около 20 экспертов в области ИИ. Meta✴✴ же пытается уводить сотрудников как из компаний — признанных лидеров отрасли вроде OpenAI, так и из стартапов, в том числе Thinking Machines Labs — его учредила бывший технический директор той же OpenAI Мира Мурати (Mira Murati). Как минимум в двух случаях глава Meta✴✴ предлагал выплаты до $1 млрд за несколько лет; в самой же компании сведения о кадровых проблемах опровергают. «Факты явно не подтверждают эту информацию, однако это не помешало анонимным источникам, преследующим собственные интересы, продвигать этот нарратив, а Forbes USA — публиковать его», — заявил представитель гиганта соцсетей Райан Дэниелс (Ryan Daniels). В некоторых случаях Meta✴✴ не воспринимают даже как кадровую угрозу: гендиректор Anthropic Дарио Амодей (Dario Amodei) заявил, что беседовал с сотрудниками, которым предлагали перевод в Meta✴✴, и зарплаты этим сотрудникам компания пересматривать не намерена. У Anthropic, кстати, самый высокий в отрасли показатель удержания сотрудников — он составляет 80 %; для сравнения, у Google DeepMind это 78 %, у OpenAI — 67 %, у Meta✴✴ — 64 %.  Набор сотрудников в MSL сопровождался беспрецедентными мерами. В июне Meta✴✴ купила 49 % акций стартапа Scale AI, а его гендиректор Александр Ван (Alexandr Wang) встал во главу MSL. Сотрудниками лаборатории также стали бывший гендиректор GitHub Нэт Фридман (Nat Friedman) и около десятка бывших сотрудников OpenAI, Google DeepMind и Anthropic — некоторым из них пообещали от $100 млн до $300 млн за четыре года. Ещё одним приобретением оказался Дэниел Гросс (Daniel Gross), прежде возглавлявший стартап Safe Superintelligence, в который ушёл бывший глава исследовательского отдела OpenAI Илья Суцкевер (Ilya Sutskever). В MSL перевели девять опытных сотрудников самой Meta✴✴ после того, как их попыталась переманить Thinking Machines Labs. Удалось вернуть перешедших было в Anthropic главу инженерного департамента Джоэла Побара (Joel Pobar) и инженера-исследователя Антона Бахтина. Масштабы исхода сотрудников из компании действительно серьёзны: в 2024 году 4,3 % новых сотрудников в лабораториях ИИ составили выходцы из Meta✴✴; активнее всего переманивают сотрудников Google за исключением подразделения DeepMind. Бывший руководитель по исследовательской стратегии моделей Meta✴✴ Llama Лоренса ван дер Маатена (Laurens van der Maaten) ушёл в Anthropic; бывший старший научный сотрудник Дэн Бикель (Dan Bickel) перевёлся в специализирующийся на корпоративном ПО стартап Writer на должность главы отдела развития ИИ; бывший глава отдела по ответственному развитию ИИ Кристиан Кантон (Cristian Canton) начал работу в национальном Суперкомпьютерном центре Барселоны (Barcelona Supercomputing Center); специалистов Намана Гояла (Naman Goyal) и Шаоцзе Бая (Shaojie Bai) переманила Thinking Machine Labs; не менее девяти сотрудников Meta✴✴ перевелись во французский стартап Mistral; в xAI Илона Маска (Elon Musk) с января перешли не менее 14 работников Meta✴✴.  В 2013 году начала работу лаборатория FAIR (ранее Facebook✴✴ Artificial Intelligence Research, сейчас Fundamental Artificial Intelligence Research), которую возглавил профессор Нью-Йоркского университета Янн Лекун (Yann LeCun), — долгое время она считалась одной из лучших в отрасли ИИ. В феврале 2023 года все подразделения ИИ в Meta✴✴ консолидировались в команду GenAI и переориентировались на создание продуктов. Сейчас FAIR работает лишь номинально — ей не хватает ни кадровых, ни вычислительных ресурсов. В руководстве Meta✴✴ это, однако, назвали новым этапом работы лаборатории, на котором она может сосредоточиться на долгосрочных проектах; а также заверили, что FAIR и GenAI тесно сотрудничают. GenAI с момента формирования перевели на авральный режим работы, в том числе до поздней ночи и по выходным; с огромной скоростью велась разработка ИИ-помощника Meta✴✴ AI и ИИ-персонажей — первоначальный штат в 200–300 человек расширили до 1000 инженеров. В условиях жёсткой конкуренции на рынке ИИ в 2024 и 2025 годах выпуск новых продуктов дополнительно ускорили, а в руководстве воцарился хаос: менеджеры расходились по техническим вопросам, а специалистам ставили дублирующиеся задачи. В считанные недели команды распускались и формировались, а сотрудникам приходилось переключаться между проектами. Дополнительным негативным фактором стал проект «метавселенной», в который продолжали вливать миллиарды долларов, поддерживая его высокий приоритет. Дважды в год под страхом увольнения проводили оценки эффективности работников. «Многие сотрудники чувствовали разочарование, усталость от объёмов работы и растерянность», — рассказал один из бывших работников; при этом в руководстве планы часто менялись. Всё это не помогло — выпуск ИИ-модели Llama 4 обернулся провалом. Она демонстрировала слабые навыки логического мышления и недостаточно умело писала код. Есть мнение, что компания завышала её показатели, чтобы те выглядели лучше, чем в действительности. И нет признаков, что ситуация выправится с появлением элитного подразделения MSL: его работники не всегда способны определить своё место в этой структуре. На фоне агрессивной политики переманивания новых сотрудников конкуренты Meta✴✴ заговорили о меркантильности. Гендиректор OpenAI Сэм Альтман (Sam Altman) назвал работников MSL «наёмниками», готовыми работать на любую компанию, если она больше платит; сотрудников же своей компании он причислил к «миссионерам» — тем, кто привержен достижению целей, имеющих значение для всего человечества. Microsoft тестирует новые ИИ-функции в «Проводнике» Windows 11
09.09.2025 [16:53],
Владимир Фетисов
Компания Microsoft тестирует новые функции на базе искусственного интеллекта, которые позволят пользователям Windows 11 взаимодействовать с изображениями и документами в «Проводнике» без необходимости открывать сами файлы. Речь идёт о так называемых «ИИ-действиях», которые на данный момент позволяют удалить фон, какие-либо объекты или размыть фон в файлах форматов JPG, JPEG и PNG. 
Источник изображений: bleepingcomputer.com Полный список ИИ-действий в «Проводнике» также включает в себя инструмент для осуществления поиска по любому из имеющихся в коллекции изображений через поисковую систему Microsoft Bing. «С помощью ИИ-действий в «Проводнике» вы можете более глубоко взаимодействовать со своими файлами. Просто кликните правой кнопкой мыши, чтобы выполнить такие действия, как редактирование изображений или обобщение текста в документах», — прокомментировали данный вопрос в Microsoft. Там также добавили, что, как и в случае с Click to Do, ИИ-действия в «Проводнике» позволят оставаться в курсе событий, задействовав возможности искусственного интеллекта для использования инструментов редактирования в приложениях или функции Copilot без необходимости открывать файл. На данный момент упомянутые нововведения доступны участникам программы предварительной оценки Windows Insider на канале Canary, которые используют бета-версии Windows 11. Потребуется обновить ОС до бета-версии Windows 11 под номером 27938. 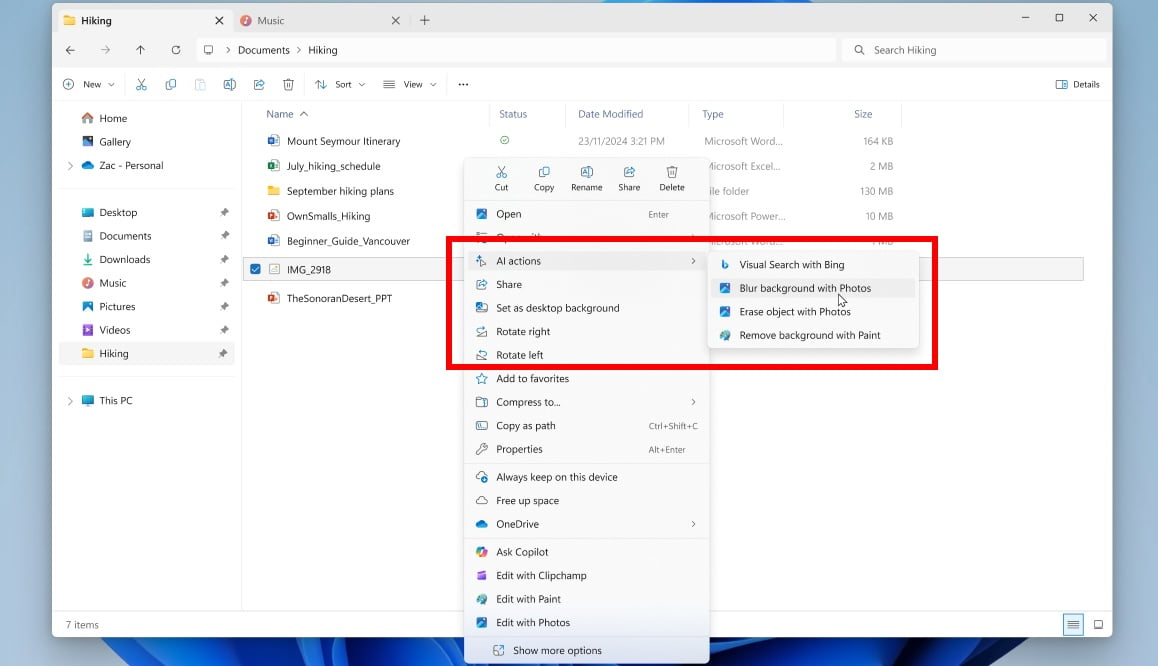 В ней же появилось новое диалоговое окно в разделе «Параметры» — «Конфиденциальность и защита» — «Создание текста и изображений». В нём отображается информация о том, какие сторонние приложения недавно использовали генеративные алгоритмы в Windows, а также предоставляется возможность контролировать, каким приложениям разрешено задействовать ИИ-модели. OpenAI задумалась о переезде из Калифорнии, чтобы избавиться от чрезмерной бюрократии
09.09.2025 [14:57],
Алексей Разин
По информации The Wall Street Journal, намеченная реструктуризация OpenAI натыкается на препятствия не только в виде пересмотра договорённостей с Microsoft, но и разного рода бюрократические сложности на уровне властей Калифорнии. Теперь некоторые источники предлагают OpenAI перерегистрироваться в другом штате, чтобы облегчить как реструктуризацию, так и дальнейшее ведение бизнеса. 
Источник изображения: OpenAI Напомним, что преобразование в коммерческую структуру важно для привлечения будущих инвестиций в капитал OpenAI, поскольку действующая организационная форма стартапа подразумевает главенство некоммерческого фонда и ограничение на участие инвесторов в распределении прибыли. При этом амбициозные планы OpenAI предусматривают увеличение расходов на десятки миллиардов долларов в год, и справиться без поддержки инвесторов компания будет просто не в состоянии. В Калифорнии, как поясняет источник, уже находятся активисты, которые пытаются защитить существующую организационную структуру OpenAI, которая управляется некоммерческой организацией. Для этого планируется призвать на помощь законодательство Калифорнии и правозащитников. Власти Калифорнии формально имеют право обязать OpenAI выплатить штраф за отказ от своей формально некоммерческой миссии в случае реструктуризации. Дело усложняется тем, что OpenAI уже начала привлекать средства инвесторов под обещания будущей реструктуризации, и если она не состоится, то компании придётся вернуть до $19 млрд инвесторам, которые ранее ей доверились. Руководство OpenAI изначально не рассчитывало, что заявления о планах по реструктуризации привлекут столько внимания общественности. Расследование со стороны генерального прокурора Калифорнии является источником особого беспокойства для OpenAI. Если прокурор штата будет препятствовать реструктуризации компании, то она может рассмотреть вариант переезда в другой штат для смены юрисдикции. Основная часть исследователей в сфере ИИ у OpenAI сосредоточена в районе Сан-Франциско. Перенос штаб-квартиры в другой штат будет затруднителен по многим причинам. На протяжении всего лета представителям OpenAI приходилось принимать участие в общественных слушаниях, на которых выступали активисты и представители других некоммерческих организаций. В итоге компания взяла на себя обязательства направить $50 млн на поддержку локальных организаций некоммерческого профиля. Именно под давлением противников реструктуризации OpenAI к маю этого года сформировала концепцию преобразований, которая не подразумевала бы полный отказ от главенства некоммерческой организации. Власти штата призывают OpenAI к ответственному развитию искусственного интеллекта, но видят со стороны компании ориентированность на извлечение прибыли в ущерб гуманитарным целям. OpenAI пытается удовлетворить запросы прокуратуры штата компенсирующими мерами, но давление возрастает, и стартап в итоге может решиться на переезд из Калифорнии. Часть оппозиции считает, что OpenAI использует свою некоммерческую структуру для снижения налоговой и регуляторной нагрузки, высказывая опасения, что подобному примеру могут последовать другие компании. Растущее количество противников реструктуризации вынуждает OpenAI задумываться об отчаянных мерах типа смены юрисдикции. В своё время Илон Маск (Elon Musk) перенёс штаб-квартиру Tesla из Калифорнии в Техас, сославшись на свои противоречия с властями первого из штатов. Многие эксперты указывали тогда, что Маск мог руководствоваться банальным стремлением сэкономить на налогах. Соцсети заполонили боты: Сэм Альтман пожаловался, что интернет стал искусственным из-за ИИ
09.09.2025 [13:14],
Павел Котов
Сегодня стало невозможно определить, действительно ли публикации в соцсетях пишут люди, или это делают чат-боты с искусственным интеллектом, пожаловался в соцсети X глава компании OpenAI Сэм Альтман (Sam Altman). 
Источник изображения: Mariia Shalabaieva / unsplash.com Альтман обратил на это внимание, когда изучал на платформе Reddit сообщения, посвящённые сервисам написания программного кода при помощи ИИ — Anthropic Claude Code и OpenAI Codex. Пользователи сетевого сообщества создали в нём столько тем о своём переходе с Claude Code на Codex, что Альтман задумался, сколько из этих публикаций создали реальные люди. Он отметил несколько тенденций, из-за которых написанные человеком и ИИ посты становится отличать друг от друга всё труднее. Люди и сами всё чаще начинают копировать языковой стиль ИИ, в результате чего граница между ними размывается в обе стороны. Блогеры и энтузиасты, которые проводят в сети чрезвычайно много времени (Extremely Online), стали действовать сообща, одновременно публикуя схожие материалы, потому что к этому их подталкивают алгоритмы соцсетей. Это проявляется, например, в стандартных циклах трендов: сначала новые продукты встречаются с воодушевлением, которое в одночасье сменяется столь же единодушной критикой; а также в том, что большинство авторов в соцсетях в погоне за монетизацией публикуют эксцентрические посты, за которыми всё меньше просматривается искренность. 
Источник изображения: ilgmyzin / unsplash.com В умелых руках все эти механизмы обращаются в «астротурфинг» — имитацию общественной поддержки того или иного мнения, — и этот эффект со стороны конкурентов OpenAI, отметил господин Альтман, довелось испытать на себе. Одним из его проявлений глава компании назвал шумиху вокруг не самого удачного запуска флагманской большой языковой модели GPT-5. Вскоре после её выхода Альтман провёл на Reddit серию вопросов и ответов, в которой признал наличие некоторых проблем, но не смог восстановить прежний уровень доверия. «В итоге возникает ощущение, что ИИ-Twitter и ИИ-Reddit стали какими-то неестественными, чего год или два назад не было», — пожаловался глава OpenAI. Установить долю написанных ИИ публикаций на Reddit действительно непросто, но она может оказаться значительной: если верить материалам исследования, проведённого специализирующейся на вопросах кибербезопасности компанией Imperva, в 2024 году более половины всего интернет-трафика создал не человек, и дело здесь преимущественно в ИИ-моделях. По одной из версий, Альтман обратился к этому вопросу потому, что OpenAI готовит собственную соцсеть, но едва ли и она сможет гарантировать, что на этой платформе тоже массово не заведутся боты с ИИ. Бывшая Yandex N.V. получит от Microsoft почти $20 млрд за пять лет
09.09.2025 [07:24],
Алексей Разин
Образованная после отделения российских активов «Яндекса» нидерландская компания Nebius взяла курс на развитие инфраструктурных проектов в области высокопроизводительных вычислений. Страдающая от нехватки собственных мощностей Microsoft заключила с нею контракт до 2031 года, по условиям которого Nebius может получить до $19,4 млрд. 
Источник изображения: Nebius На фоне этих новостей акции Nebius выросли в цене примерно в полтора раза. Уже в этом году компания предоставит Microsoft доступ к своему центру обработки данных в штате Нью-Джерси. В целом, сотрудничество с Microsoft позволит Nebius существенно нарастить обороты своего облачного бизнеса уже в 2026 году. Правда, для этого придётся найти дополнительные источники финансирования, поэтому в ближайшее время Nebius планирует заняться привлечением капитала на долговом рынке. Как отмечается в документации Nebius, до 2031 года компания сможет получить от Microsoft от $17,4 до $19,4 млрд. Сама Microsoft, как известно, обеспечивает вычислительными ресурсами OpenAI, поэтому для собственных нужд их уже может не хватать. По условиям контракта с Microsoft, в ближайшие пять лет Nebius может получить от этой корпорации $17,4 млрд. Одновременно Microsoft является крупнейшим клиентом конкурирующей с Nebius компании CoreWeave, и программному гиганту недавно пришлось отрицать слухи об расторжении контрактов с этим провайдером облачных услуг. Новая статья: Обзор смартфона Google Pixel 10: середнячок, возомнивший себя флагманом
09.09.2025 [00:05],
3DNews Team
Данные берутся из публикации Обзор смартфона Google Pixel 10: середнячок, возомнивший себя флагманом |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



