|
Опрос
|
реклама
Быстрый переход
Silicon Motion будет внедрять PCIe 6.0 в SSD с оглядкой на процессоры Nvidia, а не Intel или AMD
17.06.2026 [16:34],
Алексей Разин
Исторически доминирующие производители центральных процессоров в лице Intel и AMD определяли возможности серверных, мобильных и настольных платформ в части поддержки тех или иных интерфейсов. Nvidia в этой сфере в последние годы обрела такой вес, что разработчик контроллеров Silicon Motion начал ориентироваться на неё. 
Источник изображения: Silicon Motion В части поддержки PCI Express 6.0, например, компания ориентируется на соответствующие планы Nvidia в клиентском сегменте, как признался вице-президент Silicon Motion по клиентским решениям Нельсон Дуанн (Nelson Duann) в интервью Tom’s Hardware. Платформа с поддержкой SSD, использующих интерфейс PCI Express 6.0, появится в следующем году, но массовой она станет намного позже. «Наши текущие планы подразумевают запуск платформы с поддержкой PCIe Gen6 для SSD клиентского класса к концу следующего года», — признался представитель Silicon Motion. Компания, по его словам, делает это, преимущественно ориентируясь на Nvidia, а не Intel или AMD. Характерно, что Nvidia из серверного сегмента начинает распространять своё влияние и на клиентский, об этом можно судить по её презентации с минувшей выставки Computex 2026. Процессоры Nvidia будут испытывать потребность в скоростной передаче больших объёмов данных, поэтому скоростные SSD с поддержкой PCI Express 6.0 в первую очередь потребуются им, а не изделиям Intel или AMD. Твердотельные накопители с интерфейсом PCIe 5.0 x4 на рынке присутствуют уже около трёх с половиной лет, поэтому передовые энтузиасты могут проявлять интерес к решениям с PCIe 6.0 x4, но единственный присутствующий на рынке накопитель такого класса — Micron 9650, не предназначен для использования в потребительских системах. Со стороны центральных процессоров в этом году поддержку PCIe 6.0 готовы предоставить только AMD EPYC поколения Venice и Nvidia Vera Rubin. Кроме того, коммутаторы с поддержкой нового интерфейса предложат компании типа Astera Labs, но распространение этого стандарта в текущем году в любом случае будет ограниченным. Intel и AMD не торопятся внедрять поддержку PCIe 6.0 в клиентском сегменте ещё и по причине дороговизны сопутствующей инфраструктуры, но Nvidia с её решениями семейства RTX Spark может их опередить с точки зрения формирования рыночного спроса. В серверном сегменте Silicon Motion свой 16-канальный контроллер SM8466 с поддержкой PCIe 6.0 собирается представить уже в этом году, поэтому соответствующие серверные процессоры AMD и Nvidia смогут соседствовать с ним в серийных системах. Silicon Motion поддержку PCIe 6.0 в клиентском сегменте реализовать в этом году не торопится. Nvidia обновила драйверы для устаревших видеокарт на Maxwell, Pascal и Volta
16.06.2026 [23:56],
Николай Хижняк
Компания Nvidia выпустила драйвер GeForce 582.66 WHQL для старых графических процессоров GeForce на базе архитектур Maxwell, Pascal и Volta. Этот драйвер не относится к основной ветке драйверов Game Ready для новых игр. Nvidia называет его обновлением безопасности программного обеспечения для графических процессоров, которые больше не поддерживаются драйверами Game Ready. 
Источник изображения: VideoCardz Драйвер GeForce 582.66 WHQL предназначен для установки на ПК с Windows 10 и Windows 11, оснащённые только видеокартами GeForce на базе архитектур Maxwell, Volta и Pascal. Nvidia заявляет, что обновление устраняет проблемы, которые могут привести к различным последствиям для безопасности. Пакет по-прежнему включает такие распространённые компоненты, как драйвер для звука HD Audio 1.4.5.0, PhysX 9.23.1019, CUDA 13.0 и панель управления Nvidia 8.1.968.0. В примечании к драйверу не указаны исправления ошибок в играх и общих проблем. Однако в списке открытых проблем по-прежнему упоминается искажённый текст в Counter-Strike 2, когда разрешение игры ниже собственного разрешения экрана. Также в списке ошибок указано мерцание источников света в игре Like a Dragon: Infinite Wealth на некоторых конфигурациях после обновления драйверов. Те же два идентификатора ошибок были исправлены в более новой ветке драйверов R590. 
Источник изображения: Nvidia Владельцам старых видеокарт GTX и TITAN на базе вышеуказанных архитектур по-прежнему рекомендуется установить драйвер GeForce 582.66 WHQL из соображений безопасности. Однако его не следует рассматривать как драйвер, добавляющий новые оптимизированные игровые профили, улучшающий производительность или исправляющий проблемы в существующих играх. Скачать драйвер можно с официального сайта Nvidia. Nvidia выпустила драйвер с поддержкой командного шутера Empulse
16.06.2026 [22:45],
Николай Хижняк
Компания Nvidia выпустила свежий пакет графического драйвера GeForce Game Ready 610.62 WHQL с поддержкой командного шутера Empulse, чей релиз состоится 24 июня. В игре реализована поддержка технологии DLSS 4.5 Super Resolution, динамического мультикадрового генератора, а также Nvidia Reflex. 
Источник изображения: 1047 Games Список исправленных проблем:
Скачать драйвер версии 610.62 WHQL можно через приложение Nvidia App или с официального сайта Nvidia. Nvidia тоже залезет в долги ради финансирования ИИ — Хуанг готовит облигации на $20 млрд
15.06.2026 [19:28],
Сергей Сурабекянц
Nvidia планирует разместить облигации на сумму не менее $20 млрд, присоединившись к волне компаний, которые кредитуются для финансирования продолжающегося бума искусственного интеллекта. По словам осведомлённых источников, Nvidia размещает облигации семью частями со сроками погашения от двух до тридцати лет, а общий объём размещения может быть дополнительно увеличен. 
Источник изображения: Nvidia Эти облигации станут первыми долговыми обязательствами, которые Nvidia разместит за последние пять лет. Ожидается, что эта сделка будет как минимум в четыре раза масштабнее двух предыдущих размещений, состоявшихся в 2020 и 2021 годах. Доходность самой «долгоиграющей» части, по словам анонимного источника, будет примерно на 0,9 процентных пункта выше, чем у казначейских облигаций США. Средства от продажи будут направлены, помимо прочего, на рефинансирование непогашенного долга. Nvidia выступает краеугольным камнем экосистемы ИИ и является крупнейшей компанией в мире по рыночной капитализации. Она вкладывает значительные средства в поддержку ажиотажа вокруг ИИ. В прошлом году Nvidia приобрела акций Intel на $5 млрд и инвестировала до $10 млрд в Anthropic. Компания обязалась внести $30 млрд в крупный раунд финансирования OpenAI. Также Nvidia планомерно увеличивает выплаты акционерам. Как и многие крупные технологические компании, Nvidia получает значительную прибыль и денежный поток от бума ИИ. По усреднённым оценкам аналитиков, в финансовом году, заканчивающемся 31 января, компания сгенерирует более $200 млрд свободного денежного потока. По мнению экспертов, относительно недорогая продажа долгосрочных облигаций может помочь Nvidia снизить среднюю стоимость своего капитала и улучшить финансирование стратегических партнёрств в области ИИ без ослабления её кредитного профиля AA. Nvidia подняла рекомендованную цену RTX Pro 6000 Blackwell до $13 250 — рост на 55 % за год
13.06.2026 [18:37],
Павел Котов
Ни одна видеокарта не застрахована от роста цен, спровоцированного дефицитом чипов памяти — вот и Nvidia повысила стоимость на флагманскую модель RTX Pro 6000 для рабочих станций до $13 250, и это на 55 % больше, чем установленная всего год назад первоначальная цена. 
Истчоник изображения: nvidia.com Nvidia предлагает три варианта RTX Pro 6000: есть стандартная версия Workstation Edition, энергоэффективная Workstation Edition Max-Q для профессионального сегмента и Server Edition для крупных предприятий. Модели Nvidia RTX Pro 6000 Blackwell и RTX Pro 6000 Blackwell Max-Q дебютировали в марте 2025 года — при стартовой цене в $8565 это с самого начала были продукты премиум-класса. Сейчас производитель просит за RTX Pro 6000 $13 250, и это на 55 % больше, чем первоначальная цена. Вариант PNY RTX Pro 6000 Blackwell значится на сайте Nvidia по цене $11 359,99, то есть на 14 % дешевле рекомендованной розничной цены. Розничная сеть Newegg предлагает оригинальный вариант Nvidia RTX Pro 6000 Blackwell за $12 099,99, то есть на 9 % ниже, чем на сайте производителя. Остальные версии видеокарты, впрочем, на сайте Nvidia всё-таки дешевле, если не считать серверного исполнения, которое на площадке производителя отсутствует, а в Newegg оно продаётся за $14 999. Некоторые предложения доступны на Newegg от сторонних продавцов; другие помечены как OEM-продукты, которые идут без красивой розничной упаковки. К сожалению, цены на видеокарты, профессиональные и потребительские, в обозримом будущем едва ли подешевеют — цены так и будут расти, пока не закончится дефицит памяти. Единственная возможность сэкономить в таких условиях — проверять ценники в различных источниках, потому что они могут значительно отличаться. Nvidia начнёт продавать самые передовые чипы в Китай — но обучать ИИ на них вряд ли получится
12.06.2026 [11:39],
Алексей Разин
В прошлом месяце глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) выразил надежду, что поставки центральных процессоров Vera на китайский рынок будут разрешены. Теперь агентство Reuters сообщает, что компания уже начала принимать заказы у китайских клиентов, и первые процессоры Vera попадут в КНР к августу этого года. 
Источник изображения: Nvidia Источник отмечает, что Nvidia призвала китайских клиентов приступить к размещению заказов на поставку процессоров Vera, которые она собирается начать исполнять с августа этого года. Напомним, Nvidia оценивает ёмкость рынка центральных процессоров $200 млрд, и в эту сумму она включает потенциальную выручку, которую может получить от их реализации в КНР. Некоторые китайские компании, по словам Reuters, выразили заинтересованность в приобретении процессоров Vera. Во время презентации этих чипов в марте текущего года руководство Nvidia пояснило, что Alibaba и ByteDance сотрудничали с ней в сфере развёртывания систем на базе новых процессоров. При этом сложно судить, выразилось ли это сотрудничество в размещении реальных заказов. По данным Reuters, одна крупная китайская облачная компания намерена разместить заказ на более чем 300 серверных систем, каждая из которых содержит по два процессора Vera. Пробная партия позволит заказчику провести эксперименты с оборудованием Nvidia, чтобы понять, потребуется ли его дополнительное количество. Во многом готовность китайских разработчиков закупать процессоры Vera будет определяться программной совместимостью, ведь если какая-то часть ПО уже использует чипы китайского производства, то миграция на платформу Nvidia может представлять определённые трудности. По оценкам SemiAnalysis, базовая стоимость одного процессора Vera без учёта потенциальных скидок превысит $20 000, а полностью укомплектованная 256 чипами серверная стойка обойдётся заказчику в $10 млн или около того. Двухпроцессорные системы, которые будут более доступны по цене, начнут поставляться позже более дорогих многопроцессорных конфигураций. В текущем фискальном году, который завершится в конце января, Nvidia рассчитывает выручить на поставках Vera около $20 млрд. По данным Reuters, китайские клиенты Nvidia собираются первоначально испытывать процессоры Vera в своих центрах обработки данных, расположенных за пределами Китая. Microsoft разрешила функциям Copilot+ PC работать на видеокартах Nvidia
12.06.2026 [10:22],
Павел Котов
Microsoft смягчила одно из своих строгих ограничений, ранее установленных для ПК класса Copilot+ PC — локальные задачи искусственного интеллекта на Windows 11 теперь могут запускаться на совместимых видеокартах Nvidia, а не только на встроенных в процессор специализированных ускорителях (NPU).  Совместимыми Microsoft объявила видеокарты Nvidia серии GeForce RTX 30 и более новые с объёмом видеопамяти не менее 6 Гбайт — они получили поддержку API для работы с локальными языковыми моделями в Windows. Пока это лишь небольшая корректировка на бумаге, адресованная разработчикам, но не исключено, что компания решила пересмотреть тесную связь между интегрированными нейропроцессорами и брендом Copilot+ PC. Когда летом 2024 года появились первые ПК класса Copilot+ PC, в числе требований для соответствия этому классу отмечались встроенный ИИ-ускоритель (NPU), от 16 Гбайт оперативной памяти и твердотельный накопитель. Без NPU функции ИИ в Windows не работали. На практике, однако, задачи ИИ могут выполняться не только на NPU, но и на графических процессорах, особенно современных — они способны обеспечить даже более высокую производительность, хотя и при более высоком потреблении энергии. В обновлённой документации и отдельном сообщении на GitHub компания Microsoft подтвердила, что разработчики теперь могут обращаться к API языковых моделей на ПК, которые не соответствуют требованиям Copilot+ PC, но располагают поддерживаемыми графическими процессорами. Речь идёт о видеокартах не ниже серии Nvidia GeForce RTX 30, у которых от 6 Гбайт памяти. Основу локальных функций составляет модель Phi Silica, которая при запросе от приложений загружается через «Центр обновления Windows». Набор доступных функций ориентирован на текстовые задачи: составление сводок контента, переписывание текста, его преобразование в структурированные форматы и генерацию запросов. Эти функции доступны в облачных сервисах ИИ, но в данном случае выполняются локально на компьютере — такие приложения работают быстрее, а данные не отправляются на внешние ресурсы. Некоторые из функций, однако, пока остаются привязанными к NPU — в частности, это Windows Recall и Click to Do. Тем не менее, Microsoft уже перестала рассматривать NPU как единственное средство работы с локальным ИИ, и не исключено, что тенденция будет развиваться. Manli анонсировала новые видеокарты GeForce RTX 3060 и RTX 3050
11.06.2026 [13:24],
Николай Хижняк
Компания Manli представила две новые модели видеокарт GeForce RTX 30-й серии: GeForce RTX 3060 M2521+N630 и GeForce RTX 3050 6GB Nebula Twin. Обе основаны на архитектуре Nvidia Ampere. Модель RTX 3060 изначально была представлена Nvidia в 2021 году, а RTX 3050 — в 2022-м. 
Источник изображений: VideoCardz / Manli В составе модели RTX 3060 используется графический процессор с 3584 ядрами CUDA. Manli заявляет для GPU базовую частоту 1320 МГц и Boost-частоту 1777 МГц. Производитель представил модель, оснащённую 12 Гбайт памяти GDDR6 со скоростью 15 Гбит/с на контакт и поддержкой 192-битной шины, что обеспечивает теоретическую пропускную способность памяти на уровне 360 Гбайт/с. Напомним, что в ассортименте Nvidia в своё время также значилась версия RTX 3060 с 8 Гбайт памяти. 
 Manli GeForce RTX 3060 M2521+N630 имеет толщину два слота. Размеры карты составляют 250 × 115 × 42 мм. Заявленный показатель энергопотребления — 170 Вт. Карта оснащена тремя видеовыходами DisplayPort и одним HDMI.  Модель RTX 3050 6GB Nebula Twin находится на ступень ниже. В её составе используется графический процессор с 2304 ядрами CUDA. Для GPU заявлены базовая частота 1042 МГц и Boost-частота 1470 МГц. Manli представила версию карты с 6 Гбайт памяти GDDR6 со скоростью 14 Гбит/с и поддержкой 96-битной шины, что теоретически обеспечивает пропускную способность памяти до 168 Гбайт/с. Напомним, что в рамках поколения Ampere компания Nvidia изначально выпускала модель RTX 3050 с 8 Гбайт памяти, а версия с 6 Гбайт появилась позже.  Энергопотребление RTX 3050 6GB Nebula Twin составляет 70 Вт. Всё необходимое питание она может получать непосредственно от разъёма PCIe x16 на материнской плате. Размеры видеокарты составляют 215 × 113 × 39 мм. Она оснащена портами HDMI, DisplayPort и DVI-D. 
 Анонс карт Manli GeForce RTX 3060 M2521+N630 и GeForce RTX 3050 6GB Nebula Twin согласуется с предыдущей новостью о том, что Nvidia могла вернуть RTX 3060 из-за дефицита видеокарт начального уровня актуального поколения (RTX 50-й серии) на фоне продолжающегося кризиса на рынке чипов памяти. В частности, ранее сообщалось о намерении Nvidia возобновить поставки видеокарт GeForce RTX 3060 с 12 Гбайт памяти в июне и начать производство новых карт где-то в июле. Слабый прогноз Broadcom обрушил акции Nvidia, AMD, Micron и Qualcomm
11.06.2026 [12:43],
Павел Котов
Nvidia хотя и остаётся самой дорогой компанией в мире с рыночной капитализацией более $5 трлн, но недостаточно хороший прогноз Broadcom, ещё одного любимца фондового рынка, пошатнул веру инвесторов в отрасль искусственного интеллекта. Они всё более осторожно относятся к высоким оценкам занимающихся ИИ компаний. 
Источник изображения: Mariia Shalabaieva / unsplash.com Broadcom провинилась тем, что указала в своём прогнозе намерение продать в III квартале чипы для систем ИИ на сумму $16 млрд при ожидавшихся аналитиками Уолл-стрит $17,2 млрд. Это могло дать почву для предположений, что у Nvidia более мощная продукция, особенно с учётом задержек при поставках на месяцы, если не годы. Но рынок отреагировал иначе: за две торговые сессии акции Broadcom подешевели сразу на 19 %, более 9 % потеряли AMD, Micron и Qualcomm, а ценные бумаги Nvidia потеряли в цене 6 %, что соответствует снижению её рыночной капитализации на внушительные $330 млрд. Дополнительными отрицательными факторами для Nvidia стали опасения, что ФРС США может повысить процентные ставки, неблагоприятные макроэкономические процессы и предстоящие слушания в Сенате по поводу продажи чипов в Китай. Акции Nvidia продолжают снижаться и из-за общих тенденций рынка: уже завтра состоится выход на биржу компании SpaceX. Отчёт о годовой прибыли Nvidia представит 26 августа 2026 года. Инвесторы продолжают считать компанию оплотом отрасли ИИ, и её финансовые показатели оказывают влияние на весь сектор и на настроения держателей капитала. А они, в свою очередь, могут повлиять на исчисляемые миллиардами, если не триллионами, будущие вложения в ИИ, которые требует всё больше ускорителей для поддержания своего роста — даже несмотря на то, что китайские конкуренты продолжают рассчитывать на собственный, и немалый, кусок пирога. AMD заявила, что процессоры Epyc на Zen 6 будут до 3,3 раза быстрее Nvidia Vera в расчёте на стойку
11.06.2026 [09:23],
Алексей Разин
С выходом Nvidia на рынок серверных центральных процессоров у AMD появляется ещё один серьёзный конкурент, которого она старается не упускать из виду. Недавно вторая из компаний решила провести сравнение быстродействия своих серверных процессоров Epyc поколения Zen 6 с процессорами Nvidia Vera, заявив о превосходстве на 230 % в удельном выражении на одну вычислительную стойку. 
Источник изображения: AMD По данным TechSpot, компания AMD недавно опубликовала прогноз по быстродействию своих процессоров Epyc семейства Venice с архитектурой Zen 6 в сравнении с Nvidia Vera. Если первые будут предлагаться в 256-ядерном исполнении, то вторые получат 88 ядер и 176 потоков. Сравнение проводится не напрямую, а из расчёта удельной производительности на всю стойку с общим уровнем энергопотребления 100 кВт. Попутно AMD прогнозирует, что по сравнению с 192-ядерными процессорами Epyc семейства Turin соотношение быстродействия и энергопотребления улучшится на 70 %, а плотность вычислительных потоков вырастет на 30 %. 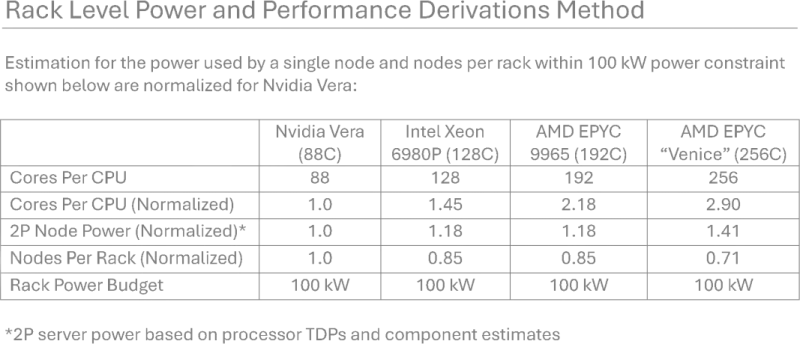
Источник изображения: AMD, TechSpot Nvidia уже заявляла о превосходстве своих процессоров Vera, но тесты проводились в строго контролируемых самой компанией условиях, поэтому рассчитывать на их объективность достаточно сложно. Это не помешало представителям Phoronix признать Vera самыми производительными процессорами с архитектурой Arm. Компания AMD опиралась на результаты этих тестов, формируя свои данные для сравнения с Epyc. Стойка на основе процессоров Venice, по прогнозам AMD, будет обеспечивать превосходство над Vera в размере 3,3 раза по уровню быстродействия. Процессоры Epyc более зрелого поколения Turin окажутся в 2,37 раза быстрее, а преимущество процессоров Intel Xeon 6980P с 128 ядрами будет измеряться 46 %. 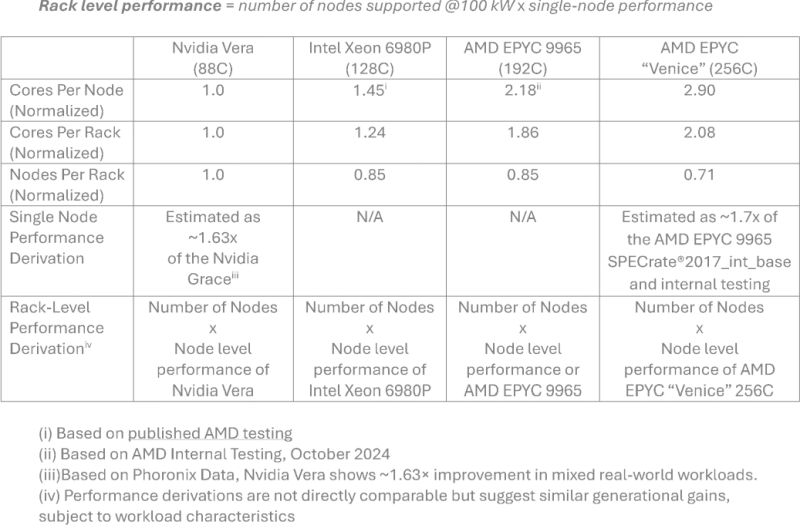
Источник изображения: AMD, TechSpot AMD также утверждает, что 64-ядерные процессоры Venice окажутся на 27 % быстрее 88-ядерных Nvidia Vera в удельном выражении на одно ядро, а 96-ядерные обеспечат преимущество в 11 % в SPECrate2017_int_base. По словам представителей AMD, в агентских вычислениях для сферы ИИ её процессоры Venice в общем случае проявят себя лучше Nvidia Vera, поскольку обладают более высоким количеством ядер. Процессоры Epyc семейства Verano, которые получат архитектуру Zen 7, изначально будут оптимизированы под агентские задачи, а потому проявят себя в сфере ИИ ещё лучше. Предполагается, что выпуском этих процессоров по ангстремной технологии A14 займётся TSMC. 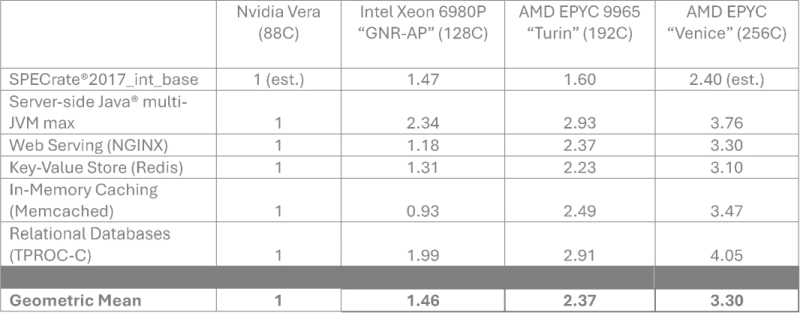
Источник изображения: AMD, TechSpot Nvidia выпустила Hotfix-драйвер 610.52 для решения проблем Smooth Motion, G-Sync и ошибок EDID
09.06.2026 [13:30],
Николай Хижняк
Компания Nvidia выпустила Hotfix-драйвер версии 610.52 для операционных систем Windows 10 и Windows 11. Он основан на драйвере Game Ready 610.47 и предназначен для исправления нескольких проблем, связанных с отображением. 
Источник изображения: VideoCardz Hotfix-драйвер версии 610.52 призван решить проблемы с частотой кадров на видеокартах архитектуры Ada при использовании функции G-Sync на некоторых мониторах. Он также устраняет проблему EDID (расширенные идентификационные данные дисплея), из-за которой некоторые мониторы могли быть идентифицированы как «Nvidia NV-Failsafe». Новое программное обеспечение также решает проблему с пробуждением монитора из спящего режима. По данным Nvidia, некоторые модели мониторов не могли выйти из спящего режима. Кроме того, Hotfix-драйвер версии 610.52 улучшает стабильность в некоторых играх с использованием нескольких мониторов при использовании V-Sync c генерацией кадров DLSS. Также новое ПО вносит два исправления для Smooth Motion: устранена проблема дрожания или двоения изображения в некоторых играх с DX11, а также вылеты. В пачноуте к Hotfix-драйверу версии 610.52 также указано повышение стабильности в игре World of Warcraft. В описании Hotfix-драйвера версии 595.76 говорится следующее:
Nvidia заявляет, что Hotfix-драйверы не являются обязательными и предоставляются как есть. Компания рекомендует дождаться следующего WHQL-сертифицированного драйвера, если пользователей не затрагивают перечисленные проблемы. Скачать Hotfix-драйвер версии 610.52 можно с официального сайта Nvidia. Nvidia признали самой подготовленной к будущему компанией — Microsoft и Alphabet остались позади
08.06.2026 [13:19],
Алексей Разин
Основатель и глава Nvidia Дженсен Хуанг (Jensen Huang) пытается делать предсказания по поводу траектории дальнейшего развития технологий, но делает это не столь категорично, как эксцентричный Илон Маск (Elon Musk), например. Сторонние эксперты иногда приходят к выводу, что Nvidia неплохо готова к будущему, которое сама формирует. В рейтинге WSJ компания оказалась лучшей по этому критерию. 
Источник изображения: Nvidia По степени готовности к будущему Nvidia в составе первой пятёрки опережает Alphabet (Google), Microsoft, Meta✴✴ Platforms и Cisco Systems. Этот рейтинг для The Wall Street Journal составили специалисты Bendable Labs, которые использовали данные из 20 различных источников и 30 профильных критериев. Основные категории оценки готовности компании к будущему сгруппированы по шести сферам: готовность к ИИ, инновации в более широком понимании, готовность персонала, финансовая устойчивость, сопротивляемость рискам в области цепочек поставок и геополитики, а также корпоративная подвижность и готовность к изменениям. При составлении рейтинга данные берутся из открытых источников и отчётности самих компаний, поэтому если последние не особо афишируют свою активность в определённых сферах, то и высоких оценок в части готовности к будущему они не получают. Например, компания Apple в рейтинге заняла 12-е место по критерию готовности к будущему в целом, но именно по готовности к ИИ она ограничилась лишь 56-м местом. Проблема заключается в том, что Apple не особо афиширует свои разработки в области ИИ, не так активно сотрудничает с признанными лидерами рынка, а на финансирование этой сферы также тратит значительно меньше средств, чем конкуренты. То есть, со стороны признать в Apple активно готовящуюся к применению ИИ в будущем компанию не так и просто. Среди первой сотни членов рейтинга примерно треть занята компаниями технологического сектора и сферы услуг. Среди первых 25 компаний 18 так или иначе связаны с технологическим сектором, хотя по формальным признакам они и стараются от него дистанцироваться. Alphabet и Meta✴✴ Platforms в этом рейтинге, например, отнесены к медийным и развлекательным компаниям. Вообще, в число лучших 25 компаний по готовности к будущему попали представители финансового сектора в лице Mastercard (7-место), Visa (15-е место) и S&P Global (13-е место), а фармакологическая сфера представлена Johnson & Johnson (20) и Eli Lilly (22). По словам составителя рейтинга, он в большей степени является диагностическим инструментом, а не средством прогнозирования. Он показывает, какие компании лучше других готовы к тем изменениям в экономике и промышленности, которые назревают или уже наблюдаются в настоящем времени. Как правило, крупные компании в этом рейтинге оказываются ближе к вершине, поскольку располагают необходимыми финансовыми ресурсами. При этом AMD, чья капитализация в шесть раз меньше Nvidia, среди компаний полупроводникового сектора идёт сразу после последней, занимая второе место, а среди компаний всех отраслей она занимает 16-е. Она не только демонстрирует высокую готовность к внедрению ИИ, но и обладает достаточной гибкостью и подвижностью, а также много внимания уделяет инновациям. Та же Broadcom, которая вдвое крупнее AMD по капитализации, занимает в рейтинге лишь 110–е место, поскольку структура её персонала недостаточно подготовлена к внедрению ИИ, а её бизнес подвержен рискам в области цепочек поставок и геополитики. До 40 % выручки приносит Broadcom программное подразделение, а дела у него идут не так успешно. Кадровый фактор для многих компаний сейчас таит много неопределённости с точки зрения готовности бизнеса к будущему. Поколение зумеров, родившихся с середины 90-х годов прошлого века до начала 2010-х, сейчас формирует около 30 % рабочей силы в США, и компаниям нужно искать эффективные методы взаимодействия с ними. Работодателю сложнее удерживать персонал в этой возрастной группе, а ещё на благосклонность сотрудников влияет готовность компаний предоставлять возможность работы из дома. В этом смысле авиакомпания Delta Air Lines оказалась лидером по критерию готовности своего персонала к будущему, но на этом перечень её сильных сторон практически был исчерпан, поскольку на 103-е место в общем зачёте её утянули слабая ориентация на инновации и не очень устойчивое финансовое положение. Глава Nvidia призвал не бояться наблюдаемого обвала на рынке акций и покупать их по низким ценам
08.06.2026 [07:12],
Алексей Разин
Основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) во время своего визита в Южную Корею заключил соглашения о сотрудничестве с несколькими местными компаниями, включая SK hynix, а также посетил бейсбольный матч. Наблюдаемого на фондовом рынке обвала акций он призвал не бояться, агитируя инвесторов покупать их, пока цены снизились. 
Источник изображения: Nvidia Как поясняет Financial Times, пятничная коррекция на американском фондовом рынке, которая забрала около $1,3 трлн капитализации у крупнейших компаний технологического сектора США, нашла продолжение на торгах в Азии утром в понедельник. Фондовый индекс Kospi в Южной Корее по сравнению с рекордно высоким значением прошлой недели опустился более чем на 15 %. Акции SK hynix и Samsung Electronics потеряли в цене более чем 10 %. С начала года индекс Kospi вырос более чем в два раза, а потому коррекция в понедельник вызвала некоторую панику у руководства местной биржи. Торги решено было приостановить на 20 минут. Иностранные инвесторы на прошлой неделе продали акций южнокорейских компаний на общую сумму $10 млрд, что усилило давление на национальную валюту, которая опустилась в цене до минимального с марта 2009 года против доллара США. Власти Южной Кореи были вынуждены заявить, что начинают бороться с ослаблением воны и спекулятивной биржевой торговлей. Японские акции тоже теряли в цене, SoftBank на этом фоне опять уступила Toyota по величине капитализации, поскольку её акции подешевели на 7,7 %. Акции TDK и Kioxia опустились в цене на 9,3 % и 7,5 % соответственно. Когда Дженсена Хуанга спросили о наблюдаемом снижении котировок, он заявил, что отрасль находится в самой начальной стадии формирования вычислительной инфраструктуры для ИИ. Соответственно, акции профильных компаний сохраняют потенциал для дальнейшего роста, а потому желающие заработать на ИИ-буме инвесторы вполне могут покупать акции на текущих уровнях, пока они подешевели. Президенту Южной Кореи Ли Чжэ Мёну (Lee Jae Myoung) тоже пришлось вступиться за национальный фондовый рынок, сообщив, что он пока сильно недооценён. Эти слова оказали поддержку котировкам акций SK hynix, которые отыграли утренние потери в ходе дальнейших торгов. «Это очевидно, что ИИ будет инфраструктурой для мира, так же, как и интернет был инфраструктурой для всего мира», — резюмировал свои комментарии по поводу ситуации на фондовом рынке глава Nvidia. Nvidia и SK hynix подписали соглашение о долгосрочном сотрудничестве в «широком спектре технологий»
08.06.2026 [04:46],
Алексей Разин
Основатель и бессменный лидер Nvidia Дженсен Хуанг (Jensen Huang) во время своего визита в Южную Корею не стал ограничиваться заявлениями о том, что все три крупнейших поставщика HBM4 прошли сертификацию и будут снабжать ускорители Vera Rubin эти типом памяти. Компания SK hynix была выделена из числа партнёров Nvidia, поскольку именно с ней было заключено долгосрочное соглашение о сотрудничестве. 
Источник изображения: Nvidia Стороны будут на протяжении нескольких лет сотрудничать в сфере разработки и производства чипов, как можно понять из публикации Bloomberg. По всей видимости, данное соглашение усиливает роль SK hynix в создании новых поколений HBM и других видов памяти, которые Nvidia сочтёт привлекательными для применения. К слову, данные новости не уберегли акции SK hynix от снижения в цене на 10 % на торгах в понедельник, поскольку коррекция на фондовом рынке, которая в США наблюдалась в пятницу, эхом отразилась на азиатских площадках в первый рабочий день новой недели. По словам Хуанга, сотрудничество между Nvidia и SK hynix будет охватывать широкий спектр технологий, от передовых ИИ-моделей до агентских решений и физического воплощения ИИ. Все эти задачи потребуют использования памяти, причём разных типов. Центральные процессоры Vera, как добавил глава Nvidia, также будут использовать память DRAM производства SK hynix. Второе полугодие и весь следующий год, по словам Хуанга, будут очень насыщенными с точки зрения взаимодействия Nvidia и SK hynix. Nvidia умолчала про цену ПК на чипах RTX Spark, но партнёры компании уже говорят об их дороговизне
06.06.2026 [13:12],
Павел Котов
На выставке Computex 2026 в Тайбэе компания Nvidia представила свой первый потребительский процессор для ПК. Флагманский чип семейства RTX Spark, располагающий 20-ядерным центральным процессором и 6144 ядрами CUDA обещает оказаться очень дорогим удовольствием, передаёт PCWorld. 
Источник изображения: nvidia.com Все участвующие в проекте партнёры Nvidia, в том числе Dell, Asus, MSI, HP, Lenovo и Microsoft, пообещали выпустить самые тонки и лёгкие машины для разработки в области искусственного интеллекта — ноутбуки и настольные компьютеры. Параллельно Microsoft проводила свою конференцию Build, на которой рассказала об этом чипе, но от ответа на прямой вопрос о стоимости чипа представители софтверного гиганта и самой Nvidia на этом мероприятии уклонялись. Microsoft, в частности, анонсировала Surface Laptop Ultra и Surface RTX Spark Dev Box, но курирующий направление Surface корпоративный вице-президент компании Эндрю Хилл (Andrew Hill) заявил: «Мы ещё не готовы говорить о о ценах, пока не приблизимся к дате начала продаж». На тот же срок сослался и представитель Nvidia. Это понятно: в условиях дефицита памяти цены к осени могут дополнительно вырасти. На Тайване, однако, представители других компаний оказались более откровенными. Один из источников на Computex 2026 сообщил, что компьютеры на флагманском чипе RTX Spark N1X, который демонстрировал лично глава Nvidia Дженсен Хуанг (Jensen Huang), будут стоить от $2500. ПК с младшим процессором N1 получат ценник около $2000. В соцсетях со ссылкой на аналитиков Morgan Stanley привели схожие цены: от $2900 за Nvidia RTX Spark N1X и от $1800 за N1. Рядовым пользователям такие цифры явно будут неприятны — согласятся на них разве что те, кто ищет относительно простой и недорогой способ разработки систем на базе ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



