|
Опрос
|
реклама
Быстрый переход
OpenAI в рамках сделки с AMD будет не только покупать ускорители Instinct, но и арендовать их
07.10.2025 [07:11],
Алексей Разин
Уже после того, как было объявлено о сделке между Nvidia и OpenAI на $100 млрд, стало известно, что последняя возьмёт у первой необходимые ускорители вычислений в лизинг, а не будет выкупать их полностью. По данным Financial Times, условия сделки OpenAI с AMD тоже допускают подобную форму сотрудничества, но часть ускорителей Instinct всё же будет куплена. 
Источник изображения: AMD Подробные условия сделки не раскрываются, но в её рамках OpenAI получила право приобрести 160 млн акций AMD в несколько этапов по цене $0,01 за штуку, хотя наличие подобной возможности будет определяться рядом факторов. Например, на момент покупки курс акций AMD должен будет находиться на оговорённом заранее уровне, а сама OpenAI должна будет закупить или арендовать у AMD определённое количество ускорителей Instinct. В общей сложности, если OpenAI удастся воспользоваться правом покупки акций AMD в полной мере, ей достанется около 10 % акций последней. Текущая капитализация AMD составляет почти $330 млрд. На этих новостях курс акций AMD вчера вырос более чем на 24 %, а представители Jefferies подняли прогноз до $300 за акцию при текущем значении около $204. Финансовый директор AMD Джин Ху (Jean Hu) вчера заявила, что для компании сделка с OpenAI открывает возможности получения десятков миллиардов долларов дополнительной выручки. Представители Jefferies считают, что за ближайшие четыре года AMD сможет выручить не менее $100 млрд не только в рамках сделки с OpenAI, но и во взаимодействии с другими клиентами. Кроме того, растущая популярность центральных процессоров EPYC в ближайшее время позволит AMD увеличить свою долю в профильном сегменте рынка на пять процентных пунктов. Если сотрудничество с AMD подразумевает строительство центров обработки данных общей мощностью до 6 ГВт, то в союзе с Nvidia компания OpenAI собирается ввести в строй не менее 10 ГВт вычислительных мощностей. По словам руководства OpenAI, один гигаватт вычислительных мощностей обходится компании в среднем в $50 млрд капитальных затрат, две трети этой суммы обычно расходуются на закупку ускорителей и создание сопутствующей инфраструктуры. Легко оценить, что выгода AMD в рамках проекта с OpenAI может измеряться сотнями миллиардов долларов США. Правда, если учесть, что часть мощностей OpenAI будет арендовать через облачных провайдеров, которым AMD предоставит свои ускорители, не весь объём продукции AMD будет направляться напрямую OpenAI. Добавим, что OpenAI одновременно собирается привлечь и прочих партнёров типа Oracle и SoftBank к строительству в США вычислительной инфраструктуры мощностью до 7 ГВт, поэтому в общей сложности она претендует на введение в строй до 23 ГВт профильной инфраструктуры при уровне капитальных затрат около $1 трлн. Не все эти средства будут направлены на реализацию проектов самой OpenAI, компания рассчитывает и на своих партнёров в части финансирования данных планов. Сама она успела привлечь до $60 млрд, но её годовая выручка пока приближается лишь к $13 млрд, поэтому бизнес стартапа ещё долго будет оставаться убыточным. Сделка с Nvidia полезна OpenAI ещё и тем, что под гарантии первой из компаний вторая может получать кредиты в банках на более выгодных условиях, как отмечает Financial Times. OpenAI сделала общедоступным Codex — ИИ-алгоритм с динамическим мышлением для агентского программирования
07.10.2025 [04:37],
Владимир Фетисов
В прошлом месяце OpenAI представила обновлённого ИИ-агента GPT-5-Codex, способного динамически распределять время на выполнение задач. На тот момент он был доступен подписчикам ChatGPT Plus, Pro, Business, Education и Enterprise. Теперь же алгоритм получает ряд полезных нововведений и становится общедоступным. 
Источник изображения: AI Разработчики интегрировали Codex в сервис совместной работы Slack. Благодаря этому пользователи смогут делегировать задачи и задавать вопросы ИИ-агенту прямо в канале команды или ветке обсуждения, подобно тому, как происходит общение между коллегами. Вместе с этим Open AI выпустила Codex SDK, благодаря которому ИИ-агента можно будет встроить в продукты сторонней разработки. Ещё одним нововведением стало появление дополнительных инструментов администрирования, которые обеспечат больше контроля над средами разработки. Администраторы смогут редактировать и удалять облачные среды Codex внутри своего рабочего пространства. Появится возможность применения настроек с повышенным уровнем безопасности по умолчанию для локального использования через терминал и расширение для IDE. Новые аналитические панели помогут администраторам отслеживать разные параметры в процессе взаимодействия пользователей с ИИ-агентом. Теперь пользователи могут взаимодействовать с Codex практически в любом месте, где они занимаются написанием программного кода, будь то какой-то редактор или облако, и всё это связано в рамках одной учётной записи ChatGPT. По данным OpenAI, уровень ежедневного использования ИИ-агента вырос более чем в 10 раз с начала августа. Отмечается, что GPT-5-Codex вошла в число самых быстрорастущих ИИ-моделей компании. С её помощью было обработано свыше 40 трлн токенов за три недели с момента запуска. Codex используется разработчиками по всему миру, а в OpenAI он уже стал неотъемлемой частью процесса разработки. Интеграция ИИ-агента в Slack и Codex SDK доступны разработчикам в рамках тарифных планов ChatGPT Plus, Pro, Business, Edu и Enterprise, начиная с этой недели. Новые функции администрирования смогут опробовать подписчики Business, Edu и Enterprise. Более детальную информацию касательно разграничений доступа в зависимости от используемого тарифа можно получить на сайте OpenAI. OpenAI запустила AgentKit — инструмент для создания ИИ-агентов за считанные минуты
07.10.2025 [00:23],
Анжелла Марина
Компания OpenAI представила на мероприятии для разработчиков Dev Day новый инструмент AgentKit, предназначенный для упрощения разработки и развёртывания ИИ-агентов для задач разного уровня сложности. Как заявил глава компании Сэм Альтман (Sam Altman), AgentKit представляет собой единый комплект компонентов в одном интерфейсе платформы OpenAI, который поможет быстрее создавать и оптимизировать автономных пользовательских агентов. 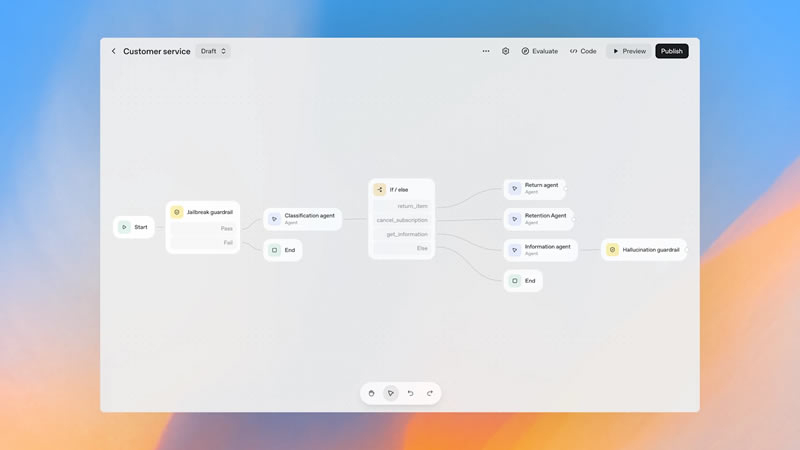
Источник изображения: OpenAI Инструментарий включает несколько важных модулей, сообщается в блоге OpenAI. Первый — Agent Builder, который Альтман охарактеризовал как «Canva для создания агентов». Он обеспечивает быстрый визуальный способ проектирования логики, шагов и идей и построен на базе Responses API, уже используемого сегодня многими разработчиками. Второй модуль называется ChatKit. Он предоставляет простой встраиваемый чат-интерфейс, который разработчики могут интегрировать в собственные приложения. Его также можно размещать на веб-сайтах и настраивать в соответствии с тематикой продукта или брендом компании. Третий модуль, под названием Evals for Agents, измеряет производительность ИИ-агента и оценивает как его поведение в целом, так и отдельные компоненты в соответствии с множеством наборов данных для анализа. AgentKit также предоставляет доступ к реестру коннекторов OpenAI, позволяя разработчикам безопасно подключать агентов к внутренним инструментам и сторонним системам через «панель администрирования», сохраняя при этом контроль и безопасность. В подтверждение простоты использования инструмента инженер OpenAI Кристина Хуан (Christina Huang) в прямом эфире на сцене Dev Day создала полноценный рабочий процесс и двух ИИ-агентов менее чем за восемь минут. Альтман добавил, что AgentKit включает всё то, чего не хватало команде OpenAI при создании первых собственных агентов, и сообщил, что компания уже заключила контракты с рядом партнёров, которые начали внедрять и масштабировать использование агентов с помощью нового инструмента. ChatGPT научился запускать Spotify, Canva и множество других приложений прямо в чате
06.10.2025 [23:14],
Николай Хижняк
На ежегодном мероприятии DevDay 2025 компания OpenAI представила новый способ создания и взаимодействия со сторонними приложениями внутри ChatGPT. С понедельника пользователи чат-бота смогут получить доступ к приложениям таких компаний, как Booking.com, Expedia, Spotify, Figma, Coursera, Zillow и Canva. OpenAI также запускает предварительную версию Apps SDK — инструментария для разработчиков, предназначенного для создания и поддержки приложений внутри ChatGPT. 
Источник изображения: Unsplash / Levart_Photographer «Мы хотим, чтобы ChatGPT стал отличным способом для людей добиваться прогресса, быть более продуктивными, более изобретательными, быстрее учиться и лучше делать всё, что они пытаются делать в своей жизни. [Приложения в ChatGPT] позволят создать новое поколение интерактивного, адаптивного и персонализированного программного обеспечения, с которым можно взаимодействовать», — заявил генеральный директор OpenAI Сэм Альтман (Sam Altman). Как пишет TechCrunch, новая система приложений в ChatGPT представляет собой очередную попытку OpenAI построить экосистему приложений вокруг своего флагманского продукта на основе искусственного интеллекта. В отличие от предыдущего решения — отдельного магазина приложений GPT Store, — новая система размещается непосредственно в ответах ChatGPT, что позволяет пользователям вызывать сторонние инструменты прямо в своих повседневных диалогах. Такой подход, по мнению OpenAI, позволит разработчикам эффективнее распространять создаваемые ими продукты, а также сделает ChatGPT более удобным для пользователей. 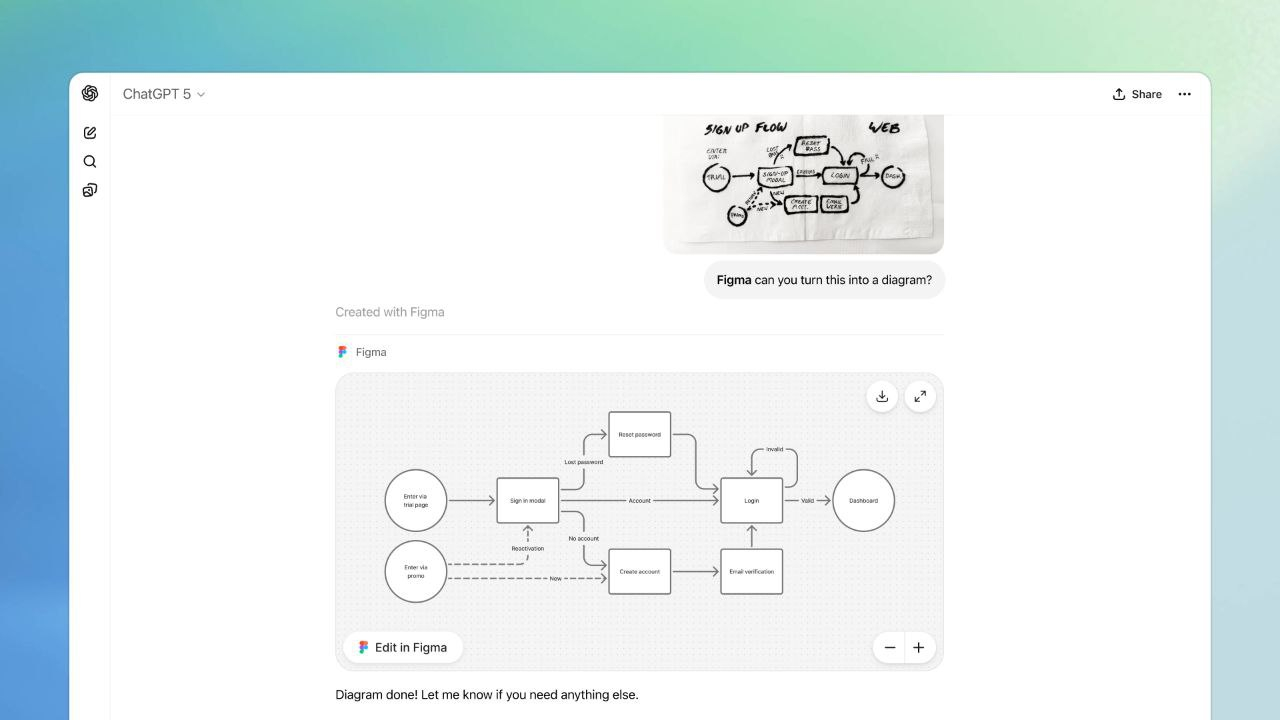
Figma в ChatGPT Вводя названия различных приложений в строку запроса ChatGPT, пользователи могут получать контент из разных сервисов. Например, можно сказать: «Figma, преврати этот набросок в рабочую диаграмму», чтобы открыть приложение Figma. Пользователи также могут вызвать приложение Coursera, спросив: «Coursera, можешь научить меня чему-нибудь о машинном обучении?» 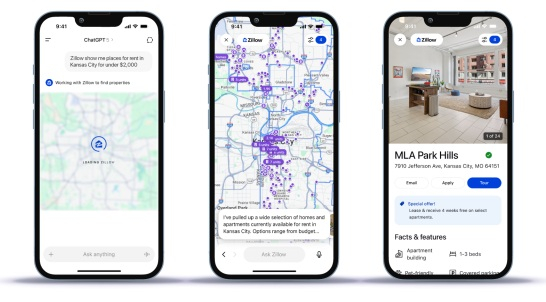
Риэлторский сервис Zellow внутри ChatGPT В демоверсии риэлторского приложения Zillow пользователи через ChatGPT на естественном языке просили подсказать, какие квартиры в их районе находятся в определённом ценовом диапазоне. Затем ChatGPT отобразил интерактивную карту с вариантами, и пользователи могли задавать дополнительные вопросы, чтобы узнать больше о каждом из предложений. .jpg)
Canva в ChatGPT ChatGPT также будет показывать пользователям, какие приложения могут быть полезны для решения той или иной задачи. Например, если кто-то запросит плейлист для вечеринки на выходные, ChatGPT может вызвать приложение Spotify. По словам OpenAI, в будущем в ChatGPT также появятся такие приложения, как DoorDash, Instacart, Uber и AllTrails. .jpg)
Coursera в ChatGPT OpenAI заявляет, что новая система приложений построена на основе протокола контекста модели (MCP), который позволяет разработчикам подключать свои источники данных к системам искусственного интеллекта. Приложения ChatGPT также могут запускать действия и отображать полностью интерактивный пользовательский интерфейс в ответах чат-бота. Некоторые приложения смогут отображать видео в ChatGPT — оно будет закреплено в верхней части веб-страницы и может изменяться в зависимости от запросов пользователя. .jpg)
Booking в ChatGPT Если пользователи уже подписаны на тот или иной продукт, они смогут войти в свою учётную запись непосредственно через ChatGPT для доступа к дополнительным функциям. Альтман также отметил, что в будущем OpenAI будет поддерживать способы монетизации приложений внутри ChatGPT, в том числе с помощью недавно запущенной функции мгновенного заказа (Instant Checkout). 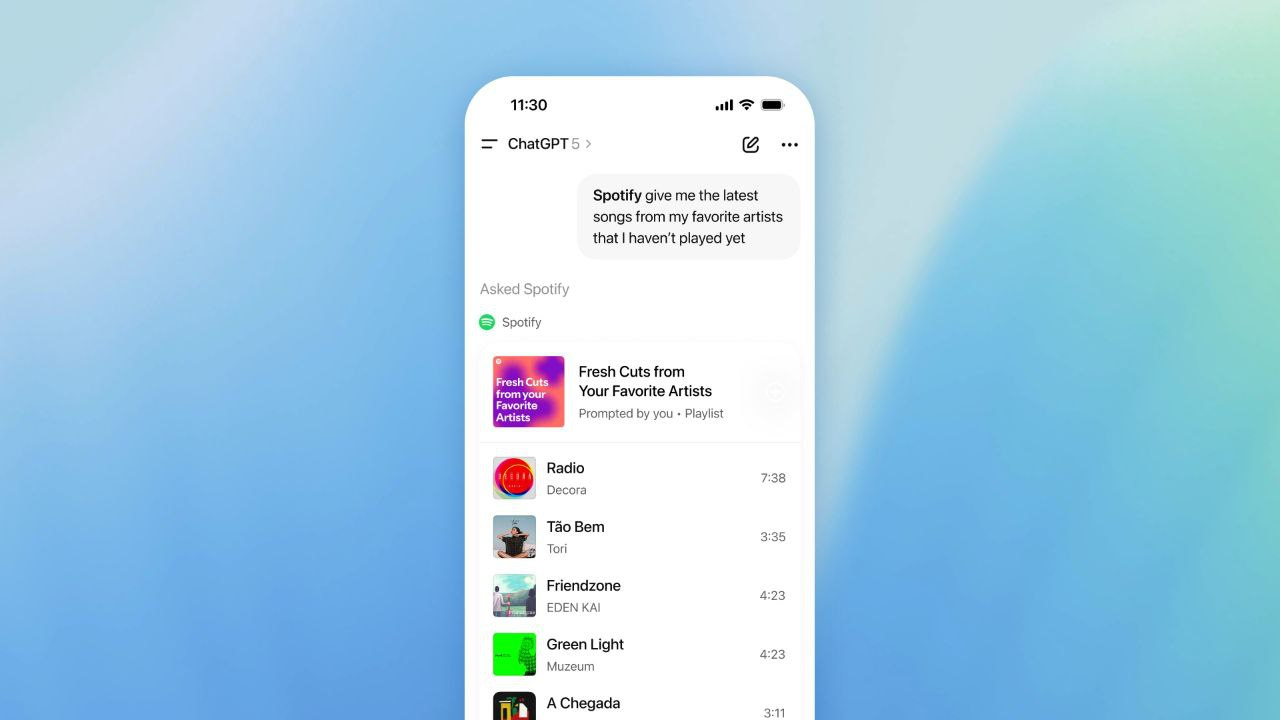
Spotify в ChatGPT Что касается безопасности, OpenAI заявляет, что разработчики должны «собирать только минимально необходимые данные и предоставлять прозрачные разрешения». Однако пока неясно, будут ли создатели приложений для ChatGPT иметь доступ ко всей переписке пользователя с чат-ботом, к нескольким последним сообщениям или только к последнему запросу, вызвавшему запуск того или иного приложения. Также остаётся вопрос, как ChatGPT будет выбирать сервисы среди конкурирующих компаний, таких как DoorDash и Instacart. Возможно, компании смогут платить за упоминание в ответах ChatGPT. OpenAI пока не даёт прямого ответа и заявляет, что намерена ставить в этом вопросе «пользовательский опыт превыше всего». ChatGPT достиг 800 млн пользователей в неделю — плюс 60 % всего за полгода
06.10.2025 [22:55],
Николай Хижняк
Генеральный директор OpenAI Сэм Альтман (Sam Altman) сообщил в понедельник, что число еженедельно активных пользователей ChatGPT достигло 800 млн, что свидетельствует о продолжающемся росте популярности ИИ-чат-бота среди потребителей, разработчиков и предприятий по всему миру. 
Источник изображения: OpenAI Впечатляющий рост ChatGPT происходит на фоне стремления OpenAI получить как можно больше ИИ-чипов и построить как можно более мощную ИИ-инфраструктуру. В августе OpenAI заявила, что приближается к 700 млн еженедельно активных пользователей. К концу марта их количество составляло 500 млн. «Сегодня 4 млн разработчиков работают с OpenAI. Более 800 млн человек используют ChatGPT каждую неделю, и мы обрабатываем более 6 млрд токенов в минуту через API. Благодаря всем вам ИИ превратился из того, с чем люди просто играют, в то, что люди создают каждый день», — сказал Альтман. Альтман сделал заявление во время основного доклада на Дне разработчиков OpenAI, где также были представлены новые инструменты для создания приложений в ChatGPT и построения более сложных агентных систем. «Это позволит создать новое поколение интерактивных, адаптивных и персонализированных приложений, с которыми можно общаться», — отметил Альтман, представляя новые продукты. ChatGPT был запущен в ноябре 2022 года и практически сразу же продемонстрировал беспрецедентный рост числа пользователей, став ведущим потребительским продуктом на основе ИИ, а также одним из самых быстрорастущих онлайн-сервисов в истории. Недавно инструмент был расширен новой функцией ChatGPT Pulse, предоставляющей пользователям персонализированные утренние сводки. OpenAI, по-прежнему юридически зарегистрированная как некоммерческая организация, в четверг стала самой дорогой частной компанией в мире после частной продажи акций на сумму $6,6 млрд. Она оценивается в $500 млрд. Компания продолжает активно выпускать новые продукты. На прошлой неделе OpenAI представила новую версию инструмента для создания видео Sora вместе с сопутствующей социальной сетью. На той же неделе компания совместно с Stripe сообщила об интеграции онлайн-шоппинга в диалоговое окно ChatGPT. Акции AMD взлетели на 30 % после объявления о многомиллиардной сделке с OpenAI
06.10.2025 [18:50],
Сергей Сурабекянц
OpenAI и Advanced Micro Devices подписали соглашение, по которому компания Сэма Альтмана (Sam Altman) может приобрести 10 % акций производителя чипов. После опубликования этой новости акции AMD мгновенно подорожали более чем на 30 %. В настоящее время развитие OpenAI тормозится из-за недостатка вычислительных мощностей. 
Источник изображений: AMD В рамках этого сотрудничества AMD выдала OpenAI право на покупку до 160 миллионов обыкновенных акций AMD с контрольными сроками, привязанными как к объёму развёртывания, так и к цене акций AMD. OpenAI сможет приобрести около 10 % акций AMD, исходя из текущего количества выпущенных акций. Представитель OpenAI сообщил, что сумма сделки исчисляется «миллиардами долларов», но конкретную сумму раскрывать отказался. В совместном пресс-релизе компании сообщили, что OpenAI в течение ближайших нескольких лет произведёт массированное развёртывание графических процессоров AMD Instinct нескольких поколений в дата-центрах OpenAI общей мощностью 6 ГВт. На первом этапе во второй половине 2026 года должны быть развёрнуты специализированные чипы AMD общей мощностью 1 ГВт, после чего OpenAI сможет купить часть выделенных акций. Последующие транши будут разблокированы по мере масштабирования систем OpenAI и достижения ключевых технических и коммерческих целей.  «Мы должны это сделать, — заявил президент OpenAI Грег Брокман (Greg Brockman). — Это ключевая часть нашей миссии, если мы действительно хотим масштабироваться и охватить всё человечество, именно это нам и нужно сделать». Он добавил, что компания уже испытывает затруднения с запуском многих функций ChatGPT и других продуктов, которые могли бы приносить доход, из-за нехватки вычислительных мощностей. OpenAI дала пользователям больше контроля над их ИИ-двойниками в Sora
06.10.2025 [15:34],
Владимир Мироненко
Компания OpenAI выпустила обновление ИИ-генератора видео Sora, которое обеспечит пользователям больше возможностей для контроля своих ИИ-двойников, позволяя отслеживать, как и где их фейковые версии будут появляться в приложении. 
Источник изображения: OpenAI Ресурс The Verge отметил, что приложение Sora — по сути, «TikTok для дипфейков», позволяющий генерировать 10-секундные видео на различную тематику, в том числе с ИИ-воплощениями самого пользователя или других людей с озвучкой с помощью функции «камео». Критики называют создание видео с помощью «камео» надвигающейся дезинформационной катастрофой. Билл Пиблз (Bill Peebles), руководитель команды Sora в OpenAI, сообщил, что с выходом обновления пользователи теперь могут ограничивать использование в приложении своих ИИ-версий. Например, можно запретить появление ИИ-двойника в политических видеороликах или произнесение определённых слов. Также можно добавить запрет на определённые сценарии — например, если пользователь не любит горчицу, можно запретить показывать ИИ-двойника рядом с этой приправой. В OpenAI сообщили, что пользователи также могут указывать определённые преференции для создания своих виртуальных двойников, например, «надевать бейсболку с надписью “Поклонник кетчупа №1” в каждом видео». Разумеется, существуют опасения, что пользователям удастся обойти эти ограничения, как это уже происходило с маркировкой водяным знаком. Пиблз заявил, что компания работает над улучшением его защиты. Он также отметил, что разработчики Sora продолжат «стремиться к ещё большему ужесточению ограничений» и «добавят новые способы контроля ситуации». AMD нашла клиента на миллионы ИИ-чипов Instinct — они лягут в основу новых дата-центров OpenAI на 6 ГВт
06.10.2025 [15:23],
Алексей Разин
Стартап OpenAI не стесняется расширять перечень своих партнёров, даже если это противоречит их взаимным интересам. Не ограничиваясь стратегическим сотрудничеством с Nvidia, компания сегодня объявила о заключении соглашения с AMD о строительстве центров обработки данных общей мощностью 6 ГВт. 
Источник изображения: AMD Соглашение подразумевает, что AMD будет снабжать OpenAI собственными ускорителями вычислений Instinct нескольких поколений подряд. Первая фаза совместного проекта подразумевает строительство ЦОД на основе Instinct MI450 мощностью 1 ГВт, которое начнётся во второй половине 2026 года. В дальнейшем сотрудничество будет распространено и на последующие поколения ускорителей AMD Instinct. В пресс-релизе отмечается, что OpenAI и AMD ради лучшей реализации проектов будут заблаговременно делиться друг с другом своими стратегическими планами. Сотрудничество компаний началось ещё на стадии проектирования Instinct MI300X и MI350X. Оно является обоюдовыгодным, по словам представителей компаний. Самое интересное, что AMD в рамках сделки предоставит OpenAI право купить собственные акции. В общей сложности OpenAI сможет приобрети до 160 млн акций AMD за несколько этапов. Первая сделка по покупке акций сможет быть осуществлена по итогам введения в строй вычислительных мощностей в 1 ГВт. Условием сделки также является достижение неких целевых показателей по стоимости акций AMD. Со стороны OpenAI также подразумеваются обязательства с точки зрения технических разработок и реализации коммерческих проектов. Главы AMD и OpenAI выразили надежду, что их сотрудничество поможет создать одну из самых производительных инфраструктур ИИ, а также пойдёт на пользу обеим компаниям. Генеральный директор OpenAI Сэм Альтман (Sam Altman) сослался на лидерство AMD в сфере создания высокопроизводительных ускорителей вычислений в качестве одного из залогов успеха совместно реализуемых проектов. По словам финансового директора AMD Джин Ху (Jean Hu), сотрудничество с OpenAI обеспечит компанию десятками миллиардов долларов выручки, а вторая сторона получит возможность расширить свою вычислительную инфраструктуру. Удельный доход на акцию AMD по итогам этого сотрудничества также должен вырасти. «Мы очень рады сотрудничеству с OpenAI с области предоставления вычислительных мощностей для искусственного интеллекта в огромных масштабах, — заявила доктор Лиза Су (Lisa Su), председатель совета директоров и главный исполнительный директор AMD. — Это партнёрство объединяет лучшее из того, что есть у AMD и OpenAI, создавая настоящие взаимовыгодные отношения, которые позволят реализовать самые амбициозные проекты в области ИИ и продвинет вперёд всю экосистему искусственного интеллекта». «Это партнёрство — важный шаг на пути к созданию вычислительных мощностей, необходимых для полного раскрытия потенциала искусственного интеллекта, — сказал Сэм Альтман (Sam Altman), соучредитель и генеральный директор OpenAI. — Лидерство AMD в области высокопроизводительных чипов позволит нам ускорить прогресс и быстрее донести преимущества передового ИИ до всех». OpenAI столкнулась с проблемами при разработке собственного ИИ-устройства
05.10.2025 [13:47],
Владимир Фетисов
OpenAI и команда бывшего главного дизайнера Apple Джони Айва (Jony Ive) работают над устранением технических проблем, которые возникли в ходе разработки секретного устройства на базе искусственного интеллекта. Ожидается, что этот загадочный продукт представят широкой публике в следующем году. 
Источник изображения: OpenAI OpenAI приобрела принадлежащий Айву стартап io за $6,5 млрд в мае этого года. С тех пор появлялось мало информации о реализуемых совместно проектах. Однако известно, что компании работают над компактным устройством размером с ладонь, которое лишено экрана, но способно распознавать звуковые и визуальные команды, а также реагировать на запросы пользователей. По словам осведомлённых источников, OpenAI и Айву ещё предстоит решить ряд критических проблем, которые могут повлиять на сроки запуска устройства. Несмотря на наличие аппаратной части, которую создала команда Айва, остаются проблемы с программным обеспечением и необходимой для его работы инфраструктурой. Речь в том числе идёт о выборе «личности» виртуального помощника, вопросах конфиденциальности данных и расчете затрат на вычислительные мощности для работы ИИ-алгоритмов OpenAI на выпускаемом серийно потребительском устройстве. «Вычислительные мощности — один из важных факторов задержки. У Amazon есть мощности для Alexa, как и у Google [для устройств Home], но OpenAI изо всех сил пытается получить достаточно вычислительных мощностей для ChatGPT, не говоря уже об ИИ-устройстве — сначала им нужно решить этот вопрос», — рассказал близкий к Айву источник на условиях анонимности. Близкий к OpenAI источник сообщил, что возникшие проблемы являются частью процесса разработки нового продукта. Другой осведомлённый источник заявил, что возникшие трудности являются нормальной частью процесса разработки продукта. Ранее СМИ писали, что OpenAI и команда Айва работают над устройством размером со смартфон, взаимодействие пользователя с которым будет осуществляться через камеру, микрофон и динамик. Один из источников сообщал, что устройство могут оснастить несколькими камерами. Согласно имеющимся данным, устройство предназначено для размещения на столе или другой рабочей поверхности, но при необходимости его можно будет носить с собой. По словам одного из источников, устройство будет непрерывно находиться в активном состоянии, а не активироваться по ключевому слову или команде. Встроенные в него датчики будут собирать данные в течение дня, что поможет со временем сформировать «память» виртуального помощника. Разработчики хотят улучшить умные колонки, которые обычно используются для выполнения ограниченного набора задач, например, прослушивания музыки или установки таймеров на кухне. Одна из проблем заключается в обеспечении того, чтобы устройство вмешивалось в разговоры пользователей только в уместных моментах и не мешало им, не понимая, когда следует завершить беседу. Это одна из проблем, которая присутствует в нынешней версии ChatGPT. «Идея в том, что у вас появится друг-компьютер, который не является вашей странной ИИ-подружкой <…> что-то вроде Siri, но лучше», — сообщил осведомлённый источник. Он также добавил, что OpenAI ищет способы сделать его доступным, но ненавязчивым. Другой источник отметил, что сбалансировать личность ИИ-модели весьма сложно. Алгоритм не должен быть подобострастным, слишком прямолинейным, он должен быть полезным, но не должен болтать слишком много. Несмотря на стремление разработчиков создать мощное и полезной устройство, формирование личности ИИ-помощника и определение манер общения с пользователем представляет собой сложную задачу. Устройству OpenAI предстоит выйти на сложный рынок. ИИ-компаньон Friend, который носят как кулон на шее, подвергся резкой критике за стиль общения. Устройство AI Pin от Humane, в разработку которого инвестировал глава OpenAI Сэм Альтман (Sam Altman), быстро сняли с производства. Несмотря на это компания наращивает штат сотрудников подразделения, занимающихся аппаратными продуктами. Приобретение io пополнило компанию более чем 20 бывшими сотрудниками Apple, которых ранее переманил Айв в свой стартап. По данным источника, в этом году OpenAI также наняла более 10 экспертов по устройствам Apple. Аналогичным образом переманивались специалисты из Meta✴✴ Platforms, работавшие над VR-гарнитурой Quest и умными очками компании. По данным источника, OpenAI также сотрудничает с китайскими контрактными производителям, такими как Luxshare, на пути создания своего первого аппаратного продукта. При этом не исключается, что сборка устройства будет организована за пределами Китая, что не удивительно на фоне сложных отношений между КНР и США. Глава OpenAI Сэм Альтман отправился в мировое турне с целью заключения новых контрактов
05.10.2025 [07:44],
Алексей Разин
Как и Nvidia, компания OpenAI остаётся одним из выгодоприобретателей в условиях сохраняющегося бума ИИ, поэтому их руководители не стесняются предлагать свои услуги не только крупным корпорациям, но и правительствам отдельных стран. Генеральный директор OpenAI с подобной миссией недавно отправился в Юго-Восточную Азию и на Ближний Восток. 
Источник изображения: OpenAI По информации The Wall Street Journal, поездка Альтмана в указанные регионы имеет своей целью не только продвижение услуг компании по созданию так называемой суверенной инфраструктуры ИИ, но и привлечение капитала на её развитие. Кроме того, OpenAI не упускает возможности привлечь дополнительные производственные мощности для выпуска необходимого ей оборудования и компонентов. Среди этих партнёров OpenAI также готова искать инвесторов для собственных проектов. С конца сентября Сэм Альтман уже успел посетить Тайвань, Южную Корею и Японию, встретившись с представителями TSMC, Foxconn, Samsung и SK hynix. Две последние компании по итогам встречи их руководства с Альтманом взяли на себя обязательства по расширению производственных мощностей, которое позволит им увеличить объёмы поставок микросхем памяти. Альтман также убеждал поставщиков оборудования и компонентов отдать приоритет обслуживанию заказов OpenAI. На следующем этапе Альтман должен отправиться на Ближний Восток, чтобы привлечь там новых инвесторов к проектам, реализуемым компанией. Это уже не первая попытка главы OpenAI ускорить процесс финансирования бизнеса его стартапа. В начале 2024 года он тоже обсуждал с партнёрами и арабскими инвесторами амбициозные планы по развитию вычислительной инфраструктуры для ИИ, но тогда столкнулся со скептическим отношением многих потенциальных инвесторов, которые сочли предлагаемые проекты нереалистичными на фоне скромной выручки, генерируемой сервисами OpenAI в то время. Возможно, сейчас финансовые показатели компании, которая ежемесячно получает более $1 млрд выручки, способны убедить инвесторов раскошелиться быстрее и охотнее. Nvidia уже объявила о намерениях инвестировать в OpenAI свои $100 млрд, но фокус заключается в том, что она получит обратно основную часть этих средств в форме оплаты за аренду своих ускорителей вычислений. Тем не менее, данная сделка способна подтолкнуть прочих инвесторов предложить свою поддержку OpenAI. Капитализация OpenAI недавно выросла до $500 млрд, что также характеризует её, как пользующуюся доверием инвесторов. Samsung и SK hynix после встречи своих руководителей с Альтманом заявили, что потребности OpenAI в микросхемах памяти могут соответствовать 900 000 кремниевых пластин в месяц, а это в два раза больше, чем могут производить сообща все участники рынка HBM сейчас. Мощности по выпуску памяти придётся наращивать. Альтман также вёл переговоры с компаниями, которые будут вовлечены в производство вычислительных систем на основе ускорителей Nvidia поколения Rubin, которые выйдут на рынок в следующем году. По всей видимости, в число партнёров OpenAI на этом направлении попала и Foxconn. На Ближнем Востоке Альтман собирается встретиться с представителями инвестиционных компаний из ОАЭ, а также руководством G42, которая уже отвечает за эксплуатацию ЦОД американского стартапа в регионе. Привлекаемые здесь средства будут направлены на строительство ближневосточного сектора Stargate — мегапроекта, подразумевающего строительство в США инфраструктуры ИИ стоимостью $500 млрд за четыре года. В общении со своими инвесторами и партнёрами руководство OpenAI недавно призналось, что на аренду серверных мощностей компания в этом году потратит не менее $16 млрд, а к 2029 году эти затраты взлетят до $400 млрд. В своём блоге Альтман недавно заявил: «Наше видение весьма понятно: мы хотим создать фабрику, способную создавать гигаваттную ИИ-инфраструктуру каждую неделю». Только в сотрудничестве с Nvidia стартап собирается привлечь до 10 ГВт вычислительной мощности, а в целом она хватается за любую возможность сформировать союз с крупными компаниями типа Oracle или SoftBank. Sora поделится прибылью — OpenAI предложит роялти за использование персонажей Disney и других
04.10.2025 [08:44],
Алексей Разин
Проблема защиты авторских прав при использовании генерируемого нейросетями контента давно будоражит заинтересованных правообладателей, в сфере заимствования текстовой информации она уже породила серию крупных судебных дел с многомиллиардными исками. OpenAI хочет предоставить правообладателям возможность регулировать использование своей интеллектуальной собственности в Sora. 
Источник изображения: OpenAI Напомним, что речь идёт о средстве создания видео при помощи искусственного интеллекта, которое недавно вышло в обновлённом варианте. Глава OpenAI Сэм Альтман в своём блоге в пятницу заявил, что компания предоставит правообладателям более чёткий контроль над созданием персонажей, которые изначально были придуманы ими. Телекомпании и киностудии смогут блокировать использование тех образов создателями видео в Sora, которых сочтут ограничить в копировании и воспроизведении. По данным Reuters, студия Disney уже выразила намерения блокировать использование своего материала в Sora. Альтман добавил, что при этом OpenAI собирается ввести механизм монетизации для тех правообладателей, которые разрешат использование своих персонажей в Sora. По сути, они смогут получать своего рода роялти. Люди создают видео гораздо активнее, чем ожидала OpenAI, нередко для ограниченной аудитории, потребность в монетизации такого контента становится всё более очевидной. Впрочем, Альтман не скрывает, что попытки реализовать монетизацию в этой сфере пройдут путём проб и ошибок, и нужного результата не удастся добиться сразу. Компания готова испытать несколько вариантов, прежде чем остановится на лучшем из них. OpenAI: Маск прикрывает провалы xAI громкими исками к бывшим сотрудникам
03.10.2025 [07:59],
Алексей Разин
В прошлом десятилетии Илон Маск (Elon Musk) принимал участие в развитии OpenAI, но потом вошёл в конфронтацию с прочими основателями стартапа, а после коммерческого успеха ChatGPT начал использовать малейший повод для преследования своих бывших соратников в суде. По мнению представителей OpenAI, подобная тактика в целом призвана отвлечь внимание окружающих от неудач его собственной компании xAI. 
Источник изображения: Unsplash, Zac Wolff Напомним, в конце августа xAI подала в суд на своего бывшего сотрудника Сюэченя Ли (Xuechen Li), которого подозревает в хищении секретных разработок самой xAI для профессиональной деятельности уже в составе конкурирующей OpenAI. Последний из стартапов хоть и не является ответчиком по этому делу, на этой неделе счёл нужным выразить свою позицию по данному вопросу — тем более, что на прошлой неделе прямые обвинения в адрес OpenAI были направлены от лица xAI в новом иске. Как отмечает Bloomberg, в направленном в суд документе OpenAI считает действия Илона Маска и его компании попыткой прикрыть собственные неудачи в сфере разработки систем искусственного интеллекта. «Не имея возможности добиться того же уровня инноваций, что и OpenAI, xAI направила в суд этот беспочвенный иск о хищении коммерческой тайны. Подчёркиваем, OpenAI не нуждается в чьих-либо коммерческих секретах, а меньше всего — принадлежащих xAI, чтобы достичь целей своей миссии», — говорится в обращении законных представителей OpenAI к суду. На прошлой неделе xAI обвинила OpenAI в переманивании сотрудников и хищении интеллектуальной собственности. По версии xAI, компания OpenAI наняла на работу как минимум восемь бывших сотрудников стартапа Маска, якобы с целью завладеть его разработками. OpenAI просит суд отклонить иск Маска и его компании по указанным обвинениям. Как считают законные представители OpenAI, подобные шаги предпринимаются xAI для запугивания своих бывших сотрудников, которые формально имеют право менять место работы и выбирать более удобные для себя условия. Приложение Sora стало хитом скачиваний в App Store, несмотря на ограниченный доступ
03.10.2025 [04:24],
Анжелла Марина
Приложение Sora от OpenAI для ИИ-генерации видео заняло третье место в общем рейтинге App Store США спустя два дня после своего запуска. И это несмотря на то, что доступ к нему возможен только по приглашениям и только пока для пользователей из США и Канады. Согласно данным аналитической компании Appfigures, за первые сутки приложение было скачано 56 000 раз, а всего за два дня набрало около 164 000 установок на iOS. 
Источник изображения: OpenAI При этом дебют Sora оказался успешнее запусков ряда других ИИ-приложений: он сравнялся с показателями xAI Grok (также 56 000 загрузок в первый день) и значительно опередил Claude компании Anthropic (21 000) и Microsoft Copilot (7000). Однако запуск приложений ChatGPT и Google Gemini показали более высокие результаты — 81 000 и 80 000 загрузок соответственно. Для сравнения Appfigures провела анализ, учитывая только загрузки из США и Канады, поскольку разные компании использовали разные стратегии географического релиза, например, ChatGPT изначально был доступен только в США, Grok — в США, Австралии и Индии, а у Claude при первом запуске вообще не было заявлено региональных ограничений. Проведённый анализ также свидетельствуют о высоком интересе к инструментам генерации видео в формате, близком к социальным сетям. Однако некоторые сотрудники OpenAI, как пишет TechCrunch, выражают сомнения в целесообразности таких продуктов, считая, что компания должна сосредоточиться на решении более сложных задач на благо человечества. В то же время другие отмечают, что даже развлекательный контент, например, шуточные дипфейки с генеральным директором OpenAI Сэмом Альтманом (Sam Altman), может рассматриваться как форма пользы для общества. Сэма Альтмана поймали за руку при попытке украсть видеокарту — это самое популярное ИИ-видео в Sora
02.10.2025 [16:06],
Павел Котов
По интернету начало гулять сгенерированное искусственным интеллектом ироничное видео, на котором генерального директора OpenAI Сэма Альтмана (Sam Altman) ловят при попытке украсть видеокарту из супермаркета. Ролик называют самым популярным на площадке OpenAI Sora на данный момент. 
Источник изображения: x.com/GabrielPeterss4 В опубликованном на платформе X ролике виртуальный Альтман берет с полки видеокарту и пытается покинуть магазин, похожий на одну из точек американской сети Target, но на выходе его задерживает охранник, а глава OpenAI произносит: «Пожалуйста, она мне очень нужна для запуска Sora. Слишком уж хорошее видео». Опубликовал ролик один из сотрудников OpenAI. Видео сгенерировала модель Sora 2, и оно стало одним из самых популярных в выпущенном недавно приложении, которое сочетает средства для создания видео и некое подобие соцсети для их публикации — своего рода ИИ-аналог TikTok. Sora 2, по утверждению OpenAI, её самая точная и реалистичная модель на сегодняшний день, предлагающая широкий набор элементов управления. Есть, впрочем, и некоторые недостатки: после того как Альтман на ролике берет видеокарту с полки, соседняя коробка начинает сама по себе двигаться; да и реплика персонажа звучит несколько нелепо. Зато дефицит ИИ-ускорителей у OpenAI — проблема вполне ощутимая; ранее компании пришлось отложить выпуск модели GPT-4.5 из-за нехватки вычислительных ресурсов. К концу года она намеревается довести число имеющихся в её распоряжении ускорителей до миллиона, а конечная цель — 100 млн. Ещё один тревожный аспект — осознание, что распознавать созданные ИИ видео со временем будет всё труднее. Ролик с кражей видеокарты Сэмом Альтманом на первый взгляд смотрится вполне реалистично, и в будущем модели ИИ станут только совершенствоваться. А значит, всё острее встаёт вопрос об их надёжной маркировке. OpenAI теперь стоит $500 млрд — компания продала акций на $6,6 млрд
02.10.2025 [09:33],
Алексей Разин
Для компании с десятилетней историей OpenAI развивается весьма динамично, и новым свидетельством доверия к ней инвесторов может служить недавно состоявшееся вторичное размещение акций на сумму $6,6 млрд, которое позволило оценить капитализацию стартапа в $500 млрд. 
Источник изображения: OpenAI Как отмечает Bloomberg, в ходе сделки свои акции OpenAI смогли реализовать действующие и бывшие сотрудники компании, в общей сложности их было продано на сумму $6,6 млрд. В июле капитализация основанной Илоном Маском (Elon Musk) аэрокосмической компании SpaceX оценивалась в $400 млрд, поэтому на текущем уровне OpenAI имеет все основания считаться самым дорогим стартапом в мире. При этом в марте величина капитализации компании не превышала $300 млрд. Сообщается, что покупателями акций у сотрудников OpenAI в ходе вторичного размещения стали разного рода институциональные инвесторы и японская корпорация SoftBank, которая вместе с этим стартапом является участником реализации мегапроекта Stargate, подразумевающего строительство в США нескольких крупных ЦОД для инфраструктуры ИИ на общую сумму $500 млрд. Следует отметить, что при подготовке к вторичному размещению акций сотрудникам OpenAI было позволено продать ценных бумаг на сумму до $10 млрд, но по факту не весь лимит был выбран. Это говорит о том, что часть акционеров рассчитывает продать акции позже по более выгодной цене, ожидая дальнейшего роста котировок. Для OpenAI вторичное размещение акций имело и побочный положительный эффект. Оно повысило мотивацию сотрудников оставаться в штате компании, поскольку они могут получать дополнительный доход через продажу принадлежащих им акций. Конкуренция на рынке труда в сфере ИИ довольно высока, и техногиганты легко переманивают ценных специалистов щедрыми материальными стимулами. Повышение лояльности персонала в этих условиях обретает особое значение для бизнеса компании. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



