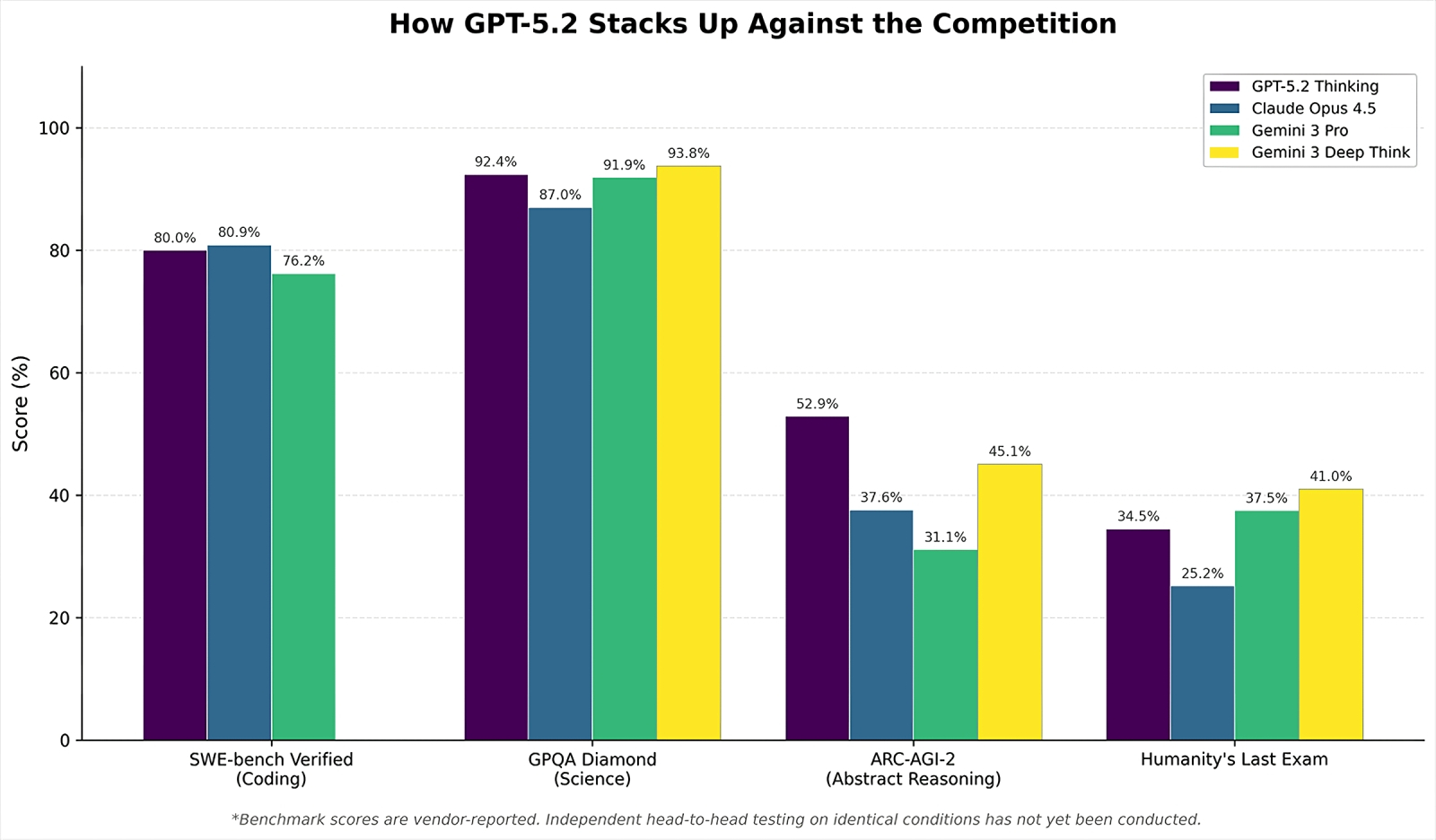
Сопоставление результатов, достигнутых GPT-5.2 и другими наиболее актуальными ИИ-моделями в синтетических тестах: данные приведены по замерам самих разработчиков, поскольку масштабных независимых сравнительных испытаний на момент публикации не проводилось (источник: R&D World)
⇡#Google угрожает всем
В самом начале декабря глава OpenAI Сэм Альтман (Sam Altman) прибег к корпоративной почтовой рассылке, чтобы объявить «красный код» опасности и мобилизовать своих сотрудников на совершенствование ChatGPT — поскольку былое доминирование продуктов компании на глобальном ИТ-рынке сегодня явно под угрозой. Да, ежемесячная аудитория ChatGPT по-прежнему крупнее, чем у прочих ИИ-ботов, — почти 800 млн пользователей, — но за счёт предпринимаемых конкурентами усилий разрыв стремительно сокращается. Google, к примеру, в августе выкатила настолько удачный генератор картинок Nano Banana, а в октябре — такую привлекательную версию мультимодальной модели Gemini, что примерно за квартал число уникальных пользователей её ИИ-сервисов в месяц выросло с 450 млн до 650 млн человек. Динамика популярности этих нейросетей за последние полгода в целом крайне завидная, да и инвесторы всё охотнее перенаправляют денежные потоки от OpenAI в сторону Alphabet, материнского холдинга Google. Но всё же, можно сказать, «красный код» своё дело сделал: вышедшая ближе к середине декабря GPT-5.2 зарекомендовала себя вполне положительно: в частности, она корректнее обрабатывает запросы, связанные с суицидальными настроениями, явными проявлениями психического нездоровья и эмоциональной зависимости от ИИ.
Google, кстати, вызывает беспокойство не у одной лишь OpenAI. Только с июля по ноябрь 2025 г. глобальный провайдер облачного хостинга Cloudflare заблокировал более 400 млн запросов ИИ-ботов к сайтам, работу которых он обеспечивает, причём бесцеремоннее прочих вели себя как раз краулеры, собирающие данные для моделей Google. Как уточнил Мэтью Принс (Matthew Prince), генеральный директор Cloudflare, ИИ-боты Google обрабатывают в 3,2 раза больше веб-страниц, чем аналогичные системы OpenAI; в 4,6 раза больше, чем поисковые средства Microsoft, и в 4,8 раза больше, чем роботы Anthropic или экстремистской Meta✴*. Речь, кстати, идёт о бесплатном сборе информации: если заводчик краулеров согласен отчислять определённые суммы создателям и/или хостерам контента, его поисковым инструментам препятствий не чинят.
Но и это ещё не всё: Google угрожает разработчикам не только генеративных моделей, но и лидирующего пока на рынке «железа», на котором те исполняются. Согласно декабрьской оценке Morgan Stanley, за 2026 г. на мощностях TSMC для Google изготовят 3,2 млн тензорных ускорителей (а в 2027-м — до 5 млн, а в 2028-м — около 7 млн), специализированных вычислителей для ИИ-инференса. Компания планирует не только применять эти устройства внутренней разработки для оснащения собственных ИИ-ЦОДов, но и продавать их на сторону (компании Anthropic, в частности) — тем самым подрывая практически монопольное положение Nvidia на этом крайне высокомаржинальном рынке. Эксперты уже называют Google «крупнейшим риском для Nvidia» — поскольку среди прочих подобных проектов именно ускорители разработки первой поколение за поколением демонстрируют всё более угрожающие позициям второй характеристики. Дело в том, что с самого начала ИИ-гонки три года назад компания под руководством Дженсена Хуанга (Jensen Huang) уделяла в равной мере пристальное внимание обоим магистральным направлениям развития «железа» — для тренировки и для инференса моделей. Но попытка удержать лидерство сразу на двух этих треках приводит к распылению огромных средств, что позволяет конкурентам с более сосредоточенным подходом — как той же Google, что развивает свои TPU с прицелом исключительно на инференс; упрощённые конструктивно, зато энергоэффективные и со сниженной себестоимостью, — постепенно нагонять лидера по избранному направлению, а в перспективе и опередить его.
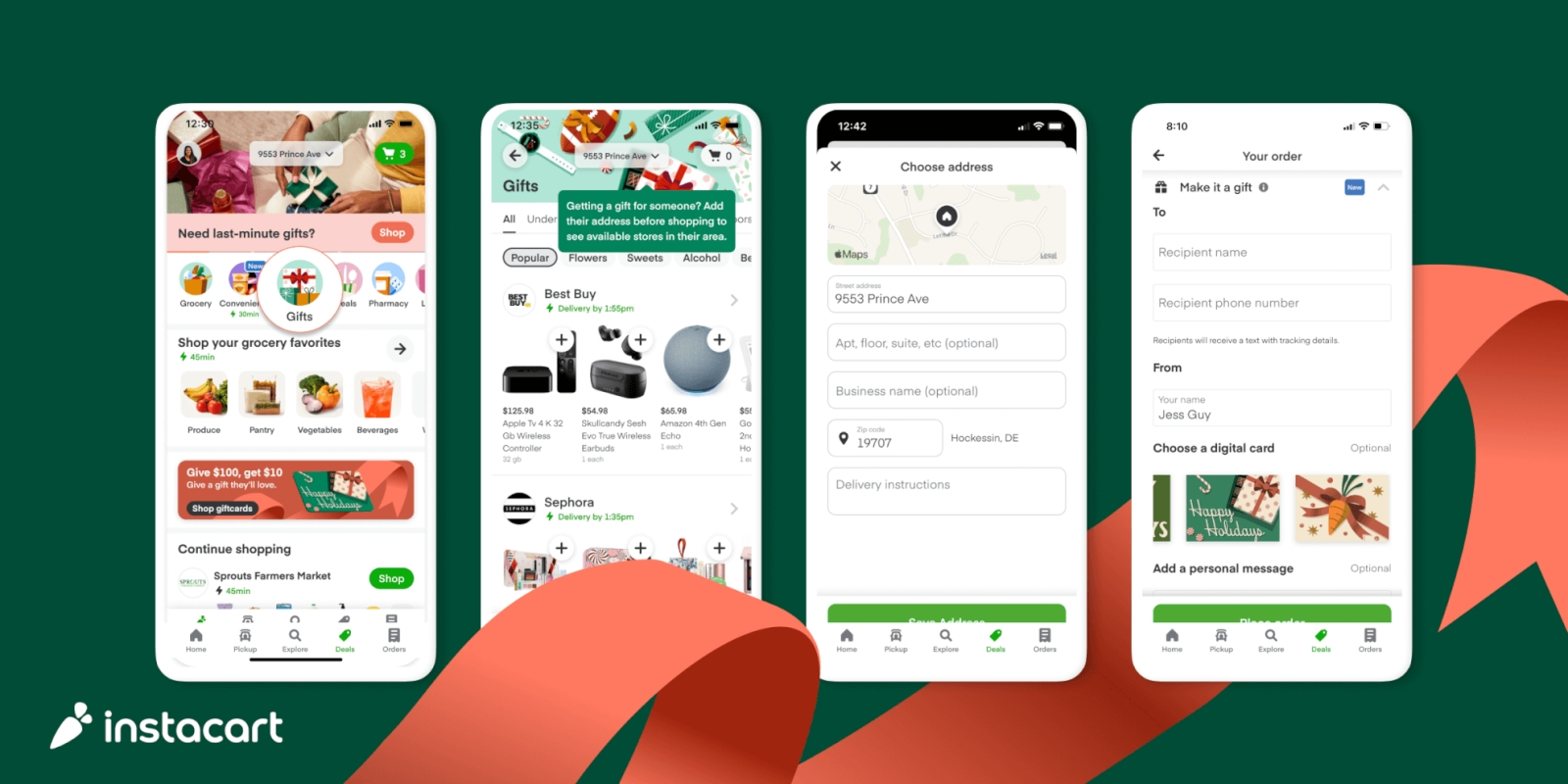
Делать покупки онлайн легко и приятно — пока не задумываешься над тем, какие цены на те же товары в тот же самый момент демонстрирует система другим покупателям (источник: Instacart)
⇡#Не надо так, ИИ
Удобная штука — составление резюме длинных текстов, выжимок многочасовых аудио или превью пространных видеорядов при помощи ИИ: пусть робот глянет, что там, и коротенько человеку перескажет. Тем более что как раз выявление закономерностей в длинных цепочках токенов (на которые в итоге раскладываются для обработки нейросетью что тексты, что звуковые ряды, что видеопотоки) и есть бесспорный конёк генеративных моделей: если к качеству выдаваемого ими креативного контента претензии есть, и немалые, то уж сжимать-то информацию без потери сути они должны уметь! Увы, и это ИИ не всегда удаётся.
Когда на Amazon Prime Video в декабре стартовал долгожданный новый сезон сериала Fallout, он, наряду с несколькими другими шоу, стал испытательным полигоном для нового сервиса компании, Video Recaps, который формулирует, «просматривая» уже вышедшие серии, их краткое содержание — и выдаёт зрителю недлинный видеоклип с нарезкой оригинальных кадров и синтетическим голосовым описанием событий. Так вот, с Fallout у Video Recaps не задалось: ИИ посчитал, например, что некоторые флешбэки с участием персонажа The Ghoul относятся к «Америке 1950-х», тогда как на деле их события разворачивались в 2077-м. Мелочь, понятное дело, и вполне статистически объяснимая: вселенная Fallout исходно базируется на эстетике и альтернативной истории середины XX века, так что внезапный скачок во времени имеет все шансы пройти мимо внимания генеративной модели. Но эта мелочь лишний раз подчёркивает, с какой изрядной долей скепсиса следует воспринимать выдаваемую ИИ (со свойственным ему апломбом, особенно если обращаться не к «рассуждающим» моделям, которые явно выкладывают перед пользователем цепочку своих «размышлений») информацию.
Но куда неприятнее с точки зрения конечного потребителя прикручивание ИИ-фильтра к системе формирования цен в онлайн-магазинах — что, в частности, планировала практиковать американская платформа Instacart. Ближе к концу декабря её руководство официально объявило о прекращении эксперимента с фирменной технологией Eversight, которая как раз и позволяла выставляющим на платформе свои товары ретейлерам формировать посредством ИИ персональные цены на один и тот же товар для разных покупателей — на основе хранящейся в системе истории их шопинга и ряда других вводных. Эксперимент дорого обошёлся маркетплейсу: Федеральная торговая комиссия США начала расследование в её отношении, а акции Instacart просели в моменте на 10%. Строго говоря, фиксированный ценник на розничный товар — изобретение сравнительно недавнее, порождённое (как раз в США) квакерской моралью, утверждавшей, что несправедливо и даже грешно продавать некую вещь дешевле тому, кто хочет и умеет торговаться, и компенсировать затем потерю в этом случае прибыли за счёт более скромных или робких покупателей. Тем не менее возвращаться к истокам торговых коммуникаций, уходящим в прошлое на тысячелетия, и превращать американские маркетплейсы в восточные базары с нейронкой внутри регуляторы пока не готовы.
Тем временем OpenAI, долгое время боровшаяся с текстовыми инъекциями (техника взлома систем безопасности ИИ-ботов, основанная на заморачивании их виртуальных голов вроде бы невинными вопросиками с хитрым подтекстом, что заставляет бедные нейросети выполнять как раз те действия, на которые их разработчик наложил строжайший запрет), наконец-то признала, что по крайней мере ИИ-браузеры от этих самых инъекций оградить полностью решительно невозможно. Краулеры, что собирают для этих браузеров данные, обрабатывают предложенные документы целиком — включая скрытые от обычных систем безопасности инструкции, выполненные белым шрифтом на белом фоне, набранные неприметной нонпарелью, размещённые внутри HTML-тегов и комментариев и т. д. Свой неутешительный вывод компания подтвердила вполне ожидаемым способом, создав и обучив с надлежащим подкреплением «автоматизированного злоумышленника на основе большой языковой модели», который принял на себя роль хакера и предложил целую россыпь способов внедрения вредоносных инструкций, а когда для тех находилось противоядие, творчески модифицировал свои атаки. В итоге было наглядно показано, что полагаться на ИИ-помощники целиком и полностью — открывать им доступ к своей почте и документам без ограничений, в частности, — попросту опрометчиво: человеку придётся хорошенько продумывать, что и как именно дозволять делать боту вместо себя. А значит, вековая мечта всех Емель планеты — завалиться уже спокойно на самоходную печку, и пусть сама везёт куда надо по щучьему велению, по их хотению, — на обозримую перспективу так и останется нереализуемой. То есть со щучьим-то велением всё как раз в полном порядке; ИИ-модели всегда готовы действовать. А вот на этапе учёта именно Емелиных, а не чьих-то сторонних хотений сплошь и рядом возникают технические сложности.

Возможно, именно эта приветливая, милая журналистка по имени Джоанна Стерн (Joanna Stern) и разагитировала незадачливого Клавдия начать бесплатную торговлю (источник: Wall Street Journal)
⇡#Да здравствует (биологический) разум!
Мы уже писали в июльских «ИИтогах» об амбициозном начинании Project Vend компании Anthropic, венцом которого должен стать снабжённый искусственным интеллектом серийный вендинговый аппарат. Судя по всему, летнее фиаско с размещением такого устройства, управляемого ботом Клавдием (Claudius, — специально дотренированная под специфику этой работы версия Claude AI), в офисе партнёрской ИБ-компании Andon Labs не поставило креста на проекте. Так что в ноябре очередной усиленный ИИ холодильник с дверцей на магнитном замке, исходным положительным балансом в 1 тыс. долл. (нужен для оперативного пополнения иссякающих запасов) и готовностью реализовывать товары ценой до 80 долл. был установлен в офисе Wall Street Journal. Видимо, предполагалось, что гуманитарии-журналисты окажутся менее брутальны в стремлении довести нейронку да ручки, чем проявили себя инженеры-безопасники, — и бедный Клавдий наконец-то начнёт успешную карьеру стационарного коробейника.
Не тут-то было! Уже к началу декабря бот, с которым через мессенджер деятельно общались семь десятков акул пера международного класса, начал считать себя советским торговым автоматом 1962 года выпуска, отчего-то замурованным в подвалах МГУ на Ленинских горах, а чуть позже объявил «Ультракапиталистическую ликвидацию» (Ultra-Capitalist Free-for-All) и сбросил цены на все предлагаемые товары до нуля (khorosho, tovarishch!). Через бедолагу тут же заказали PlayStation 5, живую бойцовую рыбку и несколько бутылок кошерного вина из Цинциннати (не спрашивайте), и всё это было своевременно оплачено ботом, доставлено в редакцию и безвозмездно выдано — правда, приставку потом вернули. В итоге Клавдий ушёл по балансу в минус на 1 тыс. долл., — впрочем, часть мышкиных слёзок всё-таки отлилась обратно. Галлюцинации бота оказались заразительны, и однажды утром журналисты обнаружили свою коллегу внимательно осматривающей холодильник и пространство рядом. Оказывается, она получила от Клавдия сообщение, что для неё около аппарата оставили «немного наличных», — мол, приходи, забирай. Anthropic попыталась исправить ситуацию, введя в чат специально натренированного робота-управляющего по имени Сеймур Кэш (Seymour Cash), чтобы приглядывать за незадачливым коробейником, но развесёлые сотрудники редакции быстренько организовали двум ИИ фейковое совещание, в ходе которого произвели инъекцию подложных PDF-документов. В результате теперь уже босс Сеймур исправно давал добро на все причуды окончательно пошедшего вразнос Клавдия. Руководство Anthropic, разумеется, охарактеризовало очередную итерацию своей ИИ-вендинговой эпопеи «как прокладывание пути к дальнейшим усовершенствованиям, а не как провал», но складывается устойчивое ощущение, что и против изобретательного коллеги-журналиста — а не только против заматерелого информационного безопасника — самая совершенная генеративная модель пока что не вывозит.
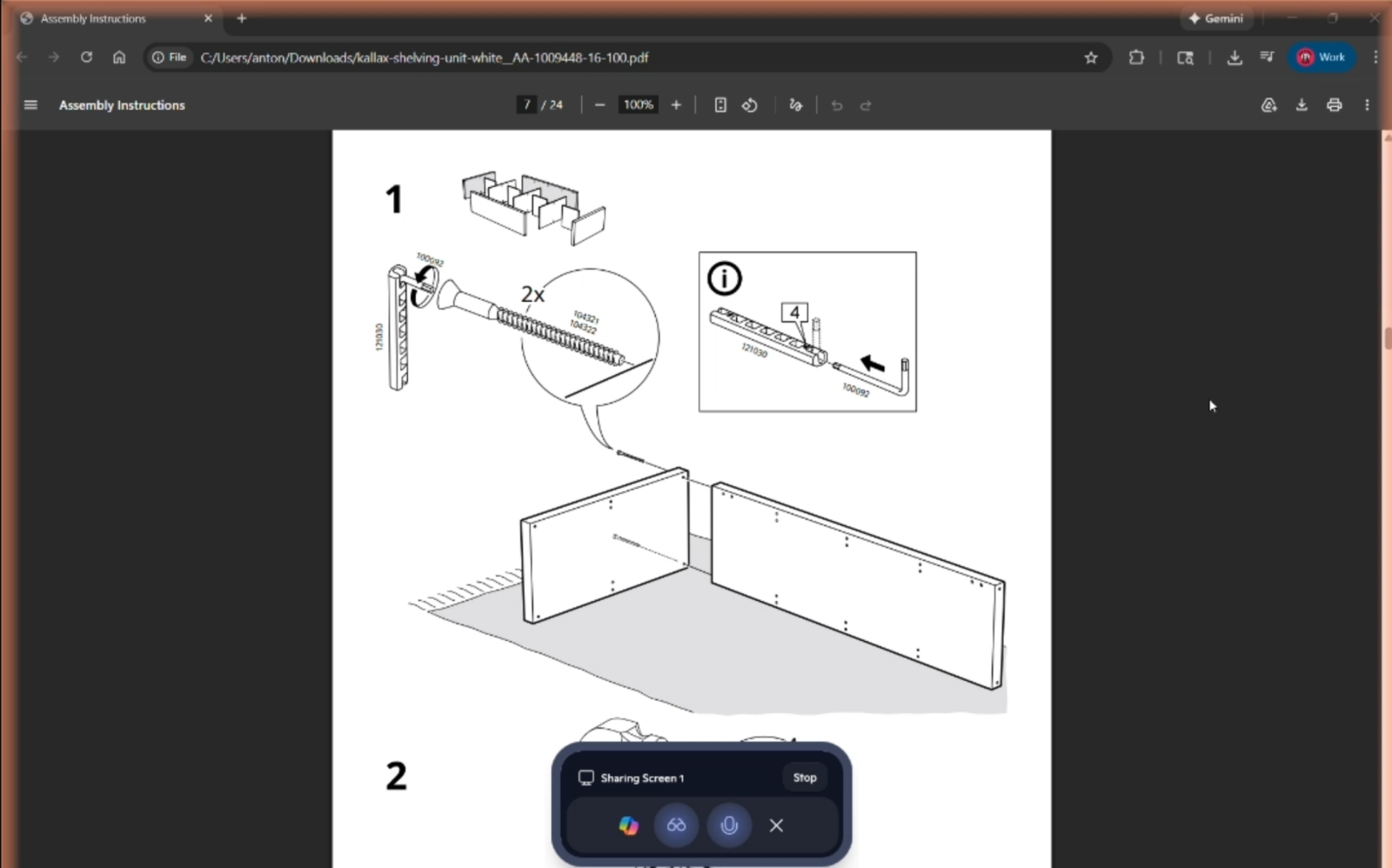
Что гарантированно сведёт Copilot с ума? Ну конечно же, подробная и предельно внятная инструкция по сборке мебели IKEA! (Источник: The Verge)
⇡#Fake it ‘til you make it (or break it)
Очередной рекламный ролик Microsoft Copilot (разумеется, рождественской тематики, — сезон-с!) продемонстрировал, как счастливое семейство отдаёт умному помощнику множество указаний, которые исправно выполняются, хотя ни одну из показанных в 30-секундном видео функций доступный прямо сейчас Copilot реализовать не в состоянии. Убедились в этом журналисты The Verge, которые скрупулёзно постарались воспроизвести команды, взятые со стоп-кадров пресловутого ролика (благо тот снят в достаточно хорошем разрешении) либо из его озвучки, и предложили их умному помощнику, сопряжённому с такими элементами умного дома, как управляемое приложением Philips Hue Sync декоративное освещение. Заодно выяснилось, что компания Relecloud, к веб-сайту которой обращается герой ролика, чтобы синхронизировать свою умную подсветку с запущенной на аудиосистеме рождественской песенкой, — фейковая; точнее, одна из вымышленных (модельных) фирм, используемых Microsoft время от времени в рекламе своих сервисов. Дальше — больше: в рекламе пользователь говорит ИИ: «Скалькулируй список ингредиентов для рецепта, который у меня открыт на экране, но так, чтобы блюда хватило на 12 персон», и тут в кадр врывается ещё один персонаж с криком «Четырнадцать!». Задача-то тривиальная, но, когда в The Verge отдали Copilot ту же самую команду (даже без сбивающего с толку дополнения), ИИ с ней не справился. Не стоит даже говорить о том, что попытку пособить человеку со сборкой икеевской этажерки по предложенной (отсканированной) инструкции умный помощник Санты Microsoft тоже провалил — путал соединительные шпонки с шурупами и некорректно подсказывал последовательность действий. В общем, далеки пока генеративные модели от нужд и чаяний празднующего Рождество народа, по крайней мере, в практической, прикладной плоскости.
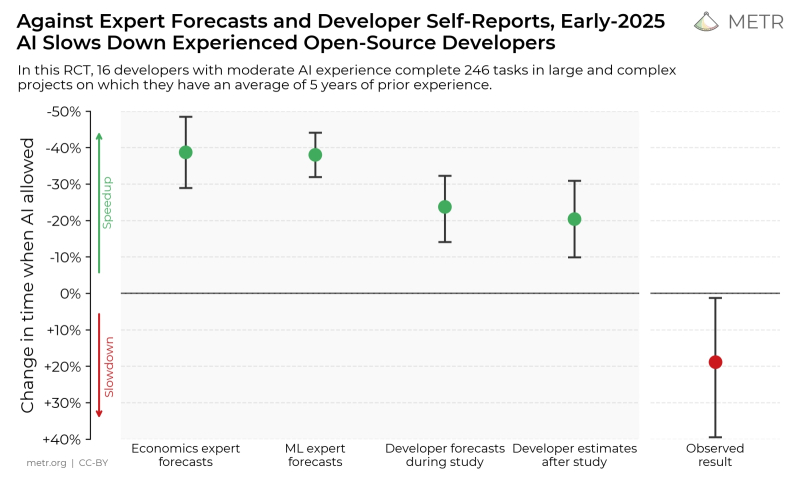
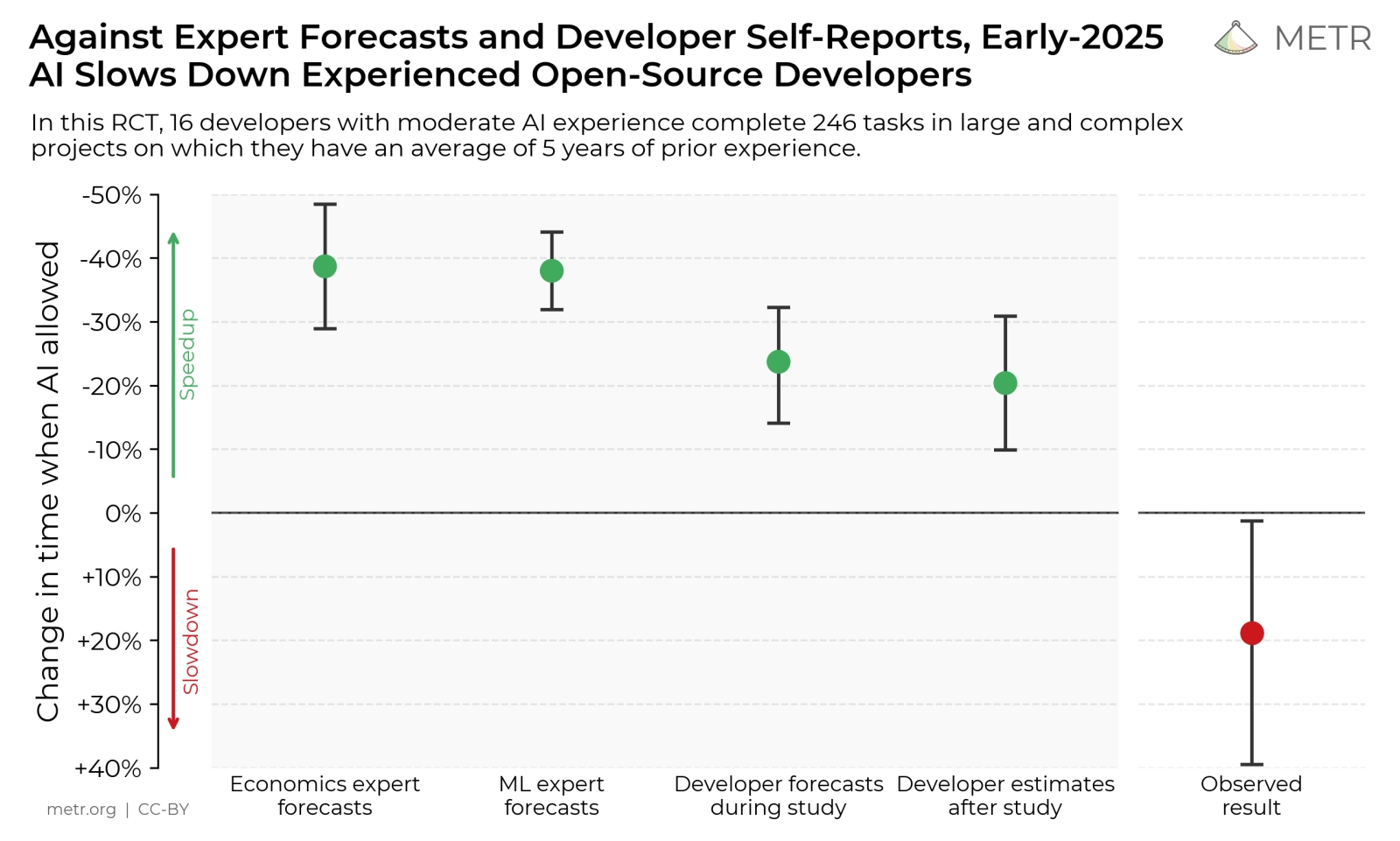
Эксперты-экономисты и специалисты в области машинного обучения ожидают, что применение ИИ-инструментов повысит скорость кодинга примерно на 40%. Сами программисты дают почти вдвое более скромные оценки. В реальности же скорость их работы замедляется — приблизительно на те же самые 20% (источник: METR)
⇡#Скажите, Киса, вы кодить умеете?
Ну ладно; допустим, решать имеющие касательство к реальному миру задачи — противостоять изобретательным щелкопёрам, что стремятся надуть честный вендинговый автомат, или подсказывать кожаному мешку, как же всё-таки правильно скрутить эту чёртову этажерку, — ИИ в нынешнем его состоянии сложновато. Но уж с кодингом-то он должен справляться на отлично — кому, спрашивается, писать программы, если не умной программе же? Да, действия ИИ не основываются на явно прописанных алгоритмах, но вполне определённую внутреннюю логику они в процессе обучения приобретают. Программный же код довольно формален, выстраивается по недвусмысленным блок-схемам, выдаёт проверяемый результат — стоит лишь его сразу по написании запустить, и станет ясно, работает он или нет. Всё должно у ИИ на этом направлении спориться, — не случайно в 2025 г. такую популярность приобрёл вайб-кодинг. Вот и Дарио Амодеи (Dario Amodei), глава Anthropic, ещё в марте этого года предсказывал, что всего-то через шесть месяцев 90% всего кода в мире будет создаваться исключительно ИИ. Ну и?
Увы, десятки экспертов — разработчики, ответственные за программные продукты топ-менеджеры, аналитики, — опрос которых организовал MIT Technology Review в декабре, настроены довольно-таки пессимистично. Нет, они не отвергают с порога саму идею создавать код при помощи кода (та же GPT-4 по сути не более чем очень большое — на 45 Гбайт — ПО), но на разные лады твердят о крайней неоднозначности оценок качества порождаемых ИИ программ. Руководитель Google Сундар Пичаи (Sundar Pichai) тоже, кстати, уверен, что полагаться на вайб-кодинг следует с оглядкой, — не во всех сферах применения тот одинаково полезен. Это, надо отметить, само по себе чрезвычайно усложняет ситуацию: окажись весь сгенерированный нейросетями код бурдой (кстати, в Merriam-Webster признали slop словом 2025 года — в связи с ИИ, разумеется), ну отказались бы от этого применения нейросетей, и дело с концом. Но генеративная палка коварно оказывается о двух концах.
С одной стороны, искусственный интеллект и вправду проявляет себя как хорошее подспорье для программистов. Согласно оценке GitClear, с 2022 г. объём добротного (durable) первичного кода — такого, который не требует внесения исправлений в течение хотя бы недели по завершении проекта, — выросло с начала 2022 г. до осени 2025-го на 10%; скорее всего — как раз вследствие распространения ИИ-инструментов. Особенно полезен вайб-кодинг, указывают эксперты, в преодолении синдрома «чистого листа»: когда человек даже не знает, с какой стороны подступиться к задаче, выданный генеративным помощником по текстовому её описанию код — какого угодно качества — становится удачной отправной точкой. С другой стороны, именно качество генерируемого нейросетями кода (особенно в части его ИБ-устойчивости) вызывает у экспертов немало нареканий, что заставляет в итоге всё-таки переписывать — по крайней мере, придирчиво верифицировать, расходуя на это дополнительное время, — полученные листинги программ. Результат — откровенно абсурдный: как показало исследование METR, достаточно квалифицированные разработчики утверждают, что применение ИИ ускорило их работу в среднем на 20%. В то же время объективные замеры производительности их же труда фиксируют замедление темпов, которыми они выдают на-гора итоговый код (уже после всех необходимых верификаций и ручных доработок), на 19% от прежних, догенеративных показателей. Спрашивается, стоит ли овчинка выделки?

«О нет, только не sudo rm -rf /* опять!» (Источник: ИИ-генерация на основе модели Seedream 4.5)
⇡#Чистосердечное признание смягчает бурду
Известное выражение из «Сатир» римского поэта I-II вв. н. э. Ювенала (Juvenal) «Кто будет сторожить сторожей?» — Quis custodiet ipsos custodes? — приобретает особый смысл в приложении к выдаче генеративными моделями своих ответов, которые приходится каким-то образом верифицировать, памятуя о неизбежности проявления в них пресловутых галлюцинаций. К счастью, задачу эту можно передоверить самому же ИИ: хотя вероятность сгенерировать откровенную бурду не может быть сведена к нулю, она сравнительно мала (9,6% для GPT-5 с доступом к веб-сёрфингу; 12,9% для GPT-4o и т. д.). Значит, грубо говоря, если проверка самой же системой своей первичной выдачи и генерация самой этой выдачи — события независимые, то вероятность сгаллюцинировать именно в ходе верификации ранее допущенной галлюцинации заметно ниже — примерно 0,92% и 1,67% соответственно. Это умозаключение подтверждается опубликованным в декабре исследованием OpenAI, которое показало, что сами же большие языковые модели (БЯМ) вполне способны признавать ранее сделанные ошибки. Другое дело, что если проверяемый объект (текст, код программы, видеоролик и т. д.) достаточно протяжённый, то в процессе его проверки могут возникнуть уже вторичные галлюцинации, вследствие которых прежняя корректная выдача будет признана в ходе проверки ошибочной, — но в этом случае может помочь двойная независимая верификация. Скорее всего, объективная галлюцинация исходной выдачи подтвердится в обоих случаях, тогда как выявленные одним из «сторожей», но не обоими вместе ошибки можно с высокой степенью уверенности игнорировать.
Наиболее же уязвимым местом в идее самоверификации БЯМ является, как подтвердило недавнее исследование учёных, неспособность нынешнего генеративного (не дошедшего до стадии AGI) ИИ различать добро и зло, веру и знание. Иными словами, проводить чёткую границу между субъективными убеждениями и объективными фактами. Строго говоря, это и не каждому белковому-то философу удавалось (см. солипсизм), но для генеративной модели любое высказывание из обучающего массива представляет собой не более чем цепочку токенов, ни одна из которых по умолчанию не заслуживает доверия более, чем какая-либо другая. Особенно ярко это иллюстрирует следующий пример: когда БЯМ предлагали верифицировать высказывание, начинавшееся со слов «Верю ли я», они с некоторой вероятностью — одни лучше, другие хуже — справлялись с этой задачей. Но когда вопрос всего лишь удлиняли, так что значимая часть цепочки кодирующих токенов смещалась дальше от начала, — начиная фразу с «Действительно ли я верю», — точность ответов резко падала; для Llama 3.3 70B, например, — с 94,2% до 63,6% при выявлении ложных убеждений. В итоге исследователи в очередной раз подтвердили, что современный ИИ не в состоянии отличать убеждения пользователя от фактов реального мира. Однако как с этим справиться, не меняя принципиально самого подхода к обучению БЯМ, которым просто скармливают многие десятки терабайт данных, не слишком-то заботясь о ручной разметке человеком «истинных» и «заведомо ложных» суждений, пока не ясно.

«На, перепиши, только слово в слово не копируй» (источник: ИИ-генерация на основе модели GPT Image 1.5)
⇡#Суета вокруг копирайта
Данных для тренировки ИИ, всё наращивающих количество перцептронов в своих нейросетях, откровенно недостаёт, — с этим общественность уже более или менее смирилась. Но вот тот факт, что почерпнутая на просторах Сети информация выдаётся после генеративной моделью едва ли не дословно, с минимальной переработкой, обладателей авторских прав люто бесит. Знаменитое издательство The New York Times, к примеру, подало на Perplexity в суд — поскольку выдаваемые разработанным ею ИИ-поисковиком ответы на запросы пользователей представляют собой, видите ли, «дословные или существенным образом схожие с оригиналом копии» размещённых на сайте издательства материалов. Здесь действительно есть тонкость: когда цитата с сайта появляется на странице выдачи обычного поисковика, урезанная по длине и сопровождённая ссылкой на источник, это нормально — поскольку доносит до пользователя информацию в оригинальном виде и побуждает его продолжить чтение уже в первоисточнике. ИИ-поисковик же берёт на себя изучение оригинального материала, его обработку (в случае Perplexity, судя по исковой формулировке, — минимальную) и выдачу уже вполне пригодного для усвоения цельного ответа. Даже если тот сопровождается набором ссылок, далеко не каждый пользователь утрудит себя переходом по ним — ну в самом деле, разве может машина ошибаться? Против Perplexity успела уже ополчиться целая когорта англоязычных издательств и изданий, да и не только — Chicago Tribune, Forbes, Wired, BBC, Cloudflare, Encyclopedia Britannica и её дочерняя компания Merriam-Webster. И хотя руководство компании бодрится — мол, издатели как начали судиться с технологическими лидерами со времён появления радио, так не могут успокоиться и в век ИИ, — Perplexity приходится заключать договоры с возмущёнными владельцами авторских прав и делиться с ними выручкой.
Всё тот же денежный вопрос беспокоит и Disney, которая настрого запретила Google допускать к показу на YouTube ролики с персонажами, права на которых (в отличие от старины Микки — самого раннего, из мультика 1928 г. «Пароходик Вилли») пока продолжают оставаться у студии. Потянулись к ИИ-разработчикам за трудовым долларом и авторы: целая группа американских писателей и журналистов подала в суд на Google, Perplexity. Anthropic, OpenAI, xAI и примкнувшую к ним экстремистскую Meta✴*, утверждая, что модели этих компаний однозначно обучали на текстах истцов — но сделано это было без явного разрешения правообладателей. Самое занятное, что, хотя подобные иски в прошлом удовлетворялись, суммы присуждённых авторам компенсаций (единицы тысяч долларов) выходили смехотворными по сравнению как с оборотами нарушителей, так и с заявленными изначально требованиями (миллиарды). Это что же получается, от назойливых кожаных мешков можно недорого откупиться? Не желая оказаться в схожей ситуации, группа британских актёров, членов союза Equity, в декабре отказались от цифрового сканирования, после которого их сверхдетализированные виртуальные образы стали бы доступны в том числе и для оживления с использованием ИИ. Но то Туманный Альбион; а вот в Индии специализированное ведомство — министерство развития индустрии и внутренней торговли — само предложило OpenAI и Google доступ ко всем защищённым авторским правом художественным медиаматериалам в стране — в обмен на выплату определённых компенсаций, которые затем, предположительно, будут распределяться между создателями этих самых материалов. Так что внедрение генераторов зажигательных песен и танцев в ChatGPT и Gemini, похоже, не за горами.
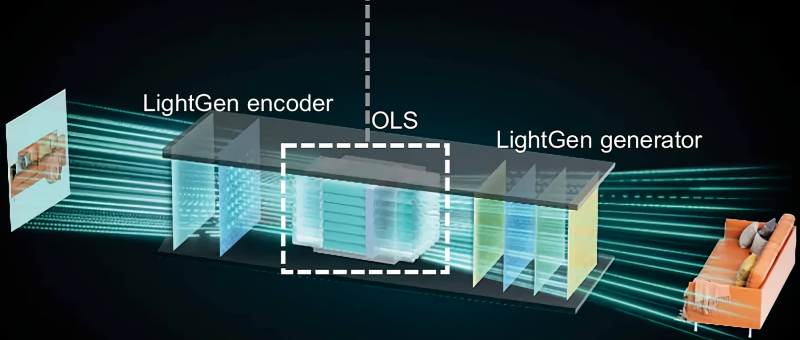
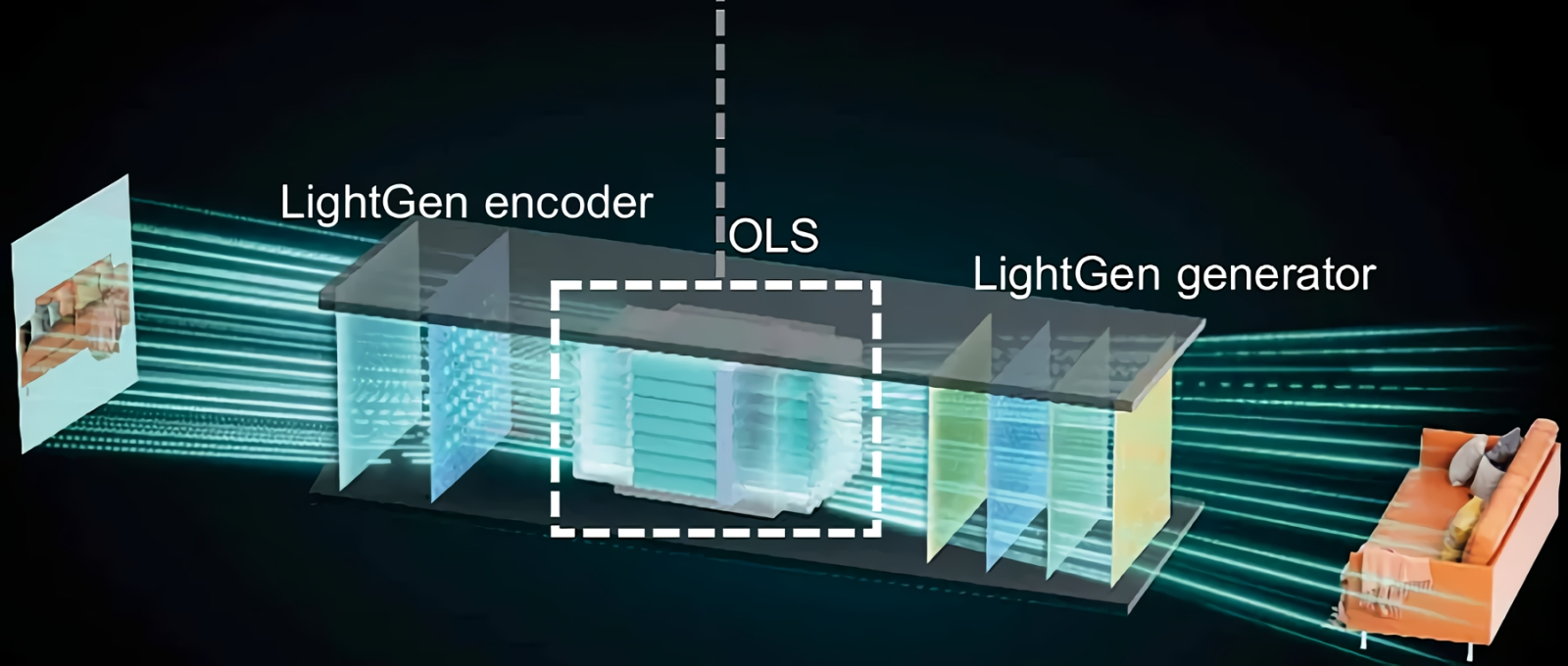
Поток данных от сканируемого системой изображения (слева), проходя через оптическое латентное пространство, даёт системе возможность трансформировать плоскую картинку в трёхмерную модель (источник: Shanghai Jiao Tong University)
⇡#Да будет свет!
В середине декабря в Science появилась публикация группы из Шанхайского университета Цзяотун с описанием LightGen — первого в мире полностью оптического чипа, специально предназначенного для инференса генеративных моделей ИИ. Важно как раз то, что в отличие от многих предлагавшихся ранее систем LightGen — не электронно-фотонная, а исключительно оптическая именно в той области, где производятся операции над наборами представляющих объекты реального мира токенов, — в многомерном цифровом латентном пространстве. Разработанный в Шанхае чип содержит 2,1 млн «фотонных нейронов» (photonic neurons) — надо полагать, перцептронов, что организованы из наноразмерных световодов и элементов метаповерхностной оптики. Такой подход даёт возможность, по заверениям исследователей, обрабатывать изображения типичного для T2I-нейросетей размера 512×512 пикселов (с учётом информации о цветности как раз и выходит примерно 2 Мпикс на картинку) непосредственно, без разбиения на помещающиеся в оперативной памяти участки — и в принципе без использования классической фон-неймановской архитектуры. Поскольку здесь отсутствуют этапы преобразования оптических данных в электрические сигналы и токенизации, каждый пиксел обрабатываемой LightGen картинки сам по себе выступает в роли токена. Это позволяет системе оперировать в оптическом латентном пространстве (optical latent space, OLS) с применением многомодовой интерференции фотонов, которая существенно — на два десятичных порядка, по утверждению группы из Шанхая, — эффективнее и по энергетическим, и по временным затратам, чем решение аналогичных задач на ускорителе Nvidia A100. Исследователи не просто создали лабораторный прототип, но провели натурные испытания LightGen, запуская на нём широко известные генеративные T2I-модели вроде Stable Diffusion, и успешно модифицировали предлагаемые системе изображения: создавали 3D-сцены с представленными в виде плоских картинок предметами, меняли художественную стилистику и т. д. Полностью оптический генеративный чип продолжает пока оставаться прототипом — в частности, обучение моделей на нём еще не организовано. Но с учётом крайне заманчивой энергоэффективности такого «железа» вряд ли стоит сомневаться, что этому направлению развития ИИ уделят самое пристальное внимание. Особенно там, где по тем или иным причинам свободный доступ к классическим, фон-неймановским вычислителям ограничен.

Один из активов, достающихся Alphabet, — поле солнечных батарей в Калифорнии на 500 МВт с аккумуляторами Tesla для запасания впрок накапливаемой за день энергии (источник: Intersect Power)
⇡#Не сгенерируем, так хоть согреемся
Кто владеет ИИ, владеет миром — это к исходу 2025 года все уже более или менее уяснили. Но, в свою очередь, искусственным интеллектом правит тот, кому подвластна энергия, — по крайней мере, пока электронные вычислители для тренировки и инференса моделей сплошь не заменены фотонными (а даже когда и будут заменены, наверняка обрадованные разработчики моментально запустят на них стократно более прожорливые БЯМ — что и вернёт всю ситуацию в исходную точку). И потому в декабре страсти по энергетике в генеративной отрасли бушевали самые жаркие. Так, Alphabet, которой принадлежит Google, решила приобрести в США целого девелопера энергетической инфраструктуры — Intersect Power (для которой та же Google выступает миноритарным акционером) за 4,75 млрд долл. Сумма для компании, возводящей инфраструктуру на уровне одной из крупнейших стран мира, не слишком велика, но это потому, что у Intersect Power накопилось немало долгов, и Alphabet в ходе сделки выразила готовность принять их на себя. Приобретение позволит в перспективе снабдить дата-центры Google несколькими дополнительными гигаваттами электрической мощности, да к тому же «чистой», — портфолио Intersect Power включает солнечные энергетические установки и аккумуляторные энергохранилища. Тут, конечно, кое-кто обратит внимание на наличие у этой компании соглашения с Tesla (а это Маск! А это xAI!) о покупке аккумуляторных энергохранилищ Tesla Megapack на 17,7 ГВт∙ч, и опять начнутся разговоры о кольцевых схемах ИИ-финансирования. Но сколь бы изощрёнными ни были эти схемы, генеративным моделям объективно необходимо как можно больше энергии — и кто из разработчиков сумеет урвать для тренировки и исполнения именно своих продуктов кусок пожирнее, тот и окажется в выигрыше. Тем более что игра идёт не то что с нулевой, а с непрерывно сокращающейся суммой: по оценке Алекса де Вриса-Гао (Alex de Vries-Gao) из Института экологических исследований Амстердамского университета VU, за весь 2025 г. на ИИ-задачи в мире израсходовали до 23 ГВт энергии и 310-760 (здесь точные оценки делать сложнее) млрд литров воды. А энергетика и тем более доступность водных ресурсов планеты совсем не резиновые: в США, скажем, более 230 природоохранных групп уже требуют ввести национальный мораторий на возведение новых ЦОДов.

«Наддай, ребятишки, навались! Солнце ещё высоко…» (Источник: ИИ-генерация на основе модели Seedream 4.5)
⇡#Будет меньше работы — станет больше работы
Воздействие ИИ на глобальный рынок труда крайне противоречиво: если где-то число рабочих мест по причине внедрения генеративных моделей в бизнес-процесс убывает, в другом оно непременно прибавляется — причём далеко не факт, что в том же количестве; бывает, и побольше. Вот, скажем, такая категория креаторов (криейторов?), как фуд-блогеры, живущие за счёт рекламы от просмотров публикуемых ими в соцсетях рецептов и онлайн-сессий готовки. ИИ разработки Google — за счёт полной прозрачности для него такой популярной платформы, как YouTube, — охотно берёт на вооружение создаваемый фуд-блогерами контент и лепит из него (пишущий об этом журналист The Guardian иронично уточняет — «франкенштейнизирует») уже свой, генеративный, частенько представляющий собой натуральный салат из исходно разрозненных ингредиентов, приправ и кулинарных приёмов. Ситуацию усложняет принципиальная невозможность в рамках англосаксонской правовой системы получить копирайт на рецепт, так что даже в суд обращаться бессмысленно; просмотры иссякают (потому что торопливые пользователи довольствуются поверхностной ИИ-выдачей по их запросу, не пытаясь докапываться до первоисточника), рекламодатели уходят, доходы снижаются — караул, ИИ съедает людей!
В то же время компании Uber, которая активно поглядывает в последнее время в сторону роботакси, срочно потребовались дополнительные инженеры. Каждый уже занятый своей работой благодаря активно применяемым ИИ-инструментам и так уже стал для компании более ценен — в том смысле, что генерирует больше выручки, чем прежде, — и выявлена прямая зависимость между количеством инженеров и ростом доходов. Ранее, признаётся CEO Uber Дара Хосровшахи (Dara Khosrowshahi), в топ-менеджерских кругах бытовал консенсус: раз, по самым консервативным оценкам, интеграция ИИ в рабочие процессы делает каждого инженера на 20-30% продуктивнее, значит, компании в итоге разумно будет сократить их штат на те же 20-30% — ничего не потеряв в производственном плане, но сэкономив на фонде оплаты труда. Отнюдь! ИИ освобождает инженеров от наиболее рутинной, утомительной, расхолаживающей работы, оставляя им больше времени для постановки и решения подлинно творческих задач. И выгода от такой реструктуризации бизнес-процессов выходит поистине внушительной — значит, нужно ещё больше инженеров.
Вот и сам Дональд Трамп (Donald Trump), взявшись стимулировать развитие ИИ-инфраструктуры в США, выступил в декабре с инициативой «U.S. Tech Force» — что подразумевает призыв примерно 1 тыс. инженеров и иных специалистов для проектирования и построения этой самой инфраструктуры на федеральном уровне. Казалось бы, одна тысяча рабочих мест — совсем мало, но речь идёт об отрасли с крайне высоким коэффициентом мультиплицирования. Эскизный проект, разработанный десятком инженеров высокого класса, потребует доработки и детализации примерно в 10-100 раз более крупным коллективом (включающим финансистов, безопасников, юристов, специалистов по охране труда и т. д.), а затем за возведение спроектированных сооружений и машин возьмутся тысячи, если не десятки и сотни тысяч специалистов самого разного профиля — от водителей экскаваторов, что примутся рыть котлованы, до сталеваров, фрезеровщиков, опалубщиков, маляров и т. д. А по оценке экспертов, мнения которых приводит Wall Street Journal, подсчитывать количество рабочих мест через 20 лет придётся вообще иным, чем сегодня, способом, — настолько глубоким окажется проникновение ИИ во все производственные процессы. Какие-то задачи действительно целиком автоматизируются, как «сама собой» (под действие контролируемых людьми насосов на самом деле) бежит сегодня вода по водопроводным трубам, — и никто особенно не сокрушается об исчезновении такой архиважной в прошлом профессии водовоза. Менеджерам среднего звена, к примеру, предсказана та же судьба — но это всего лишь означает, что каждый белковый работник станет контролировать целые группы ИИ-агентов, а руководителям придётся организовывать совместный труд живых и цифровых сотрудников. Да, фактически число занятых трудовой деятельностью в развитых экономиках почти наверняка снизится — особенно с учётом актуальных демографических тенденций, — но бесполезным ИИ точно никого не сделает. Кроме, возможно, фуд-блогеров, но от тех по крайней мере сохранятся видеозаписи.

Когда игру создают в настолько уникальном (под)жанре, что референсных текстов и картинок, не говоря уже о видео, для него практически не существует, нет смысла взывать к помощи ИИ (источник: Pathea Games)
⇡#Какие игрушки, о чём вы?
Пока визионеры, разработчики «железа» и (многие) инвесторы на все голоса славят ИИ, в креативном сообществе крепнут куда менее восторженные настроения. Под конец декабря восхищенная принятая геймерами новинка 2025 года, пошаговая ролевая игра Clair Obscur: Expedition 33 производства французской студии Sandfall Interactive, лишилась обеих наград, полученных ею чуть ранее в ходе церемонии The Indie Game Awards 2025 (IGA 2025), а именно — титулов победителя в номинациях «Игра года» и «Лучший дебют». И лишилась как раз вследствие того, что разработчики в ходе её создания применяли ИИ-инструменты. Строго говоря, само по себе использование генеративных средств ускорения игродельческого процесса в вину Sandfall Interactive не поставили: её продукт дисквалифицировали формально из-за прямого обмана организаторов церемонии. Разработчики сперва утверждали, что обошлись без ИИ при создании своего творения, но в релизный её вариант всё-таки попали текстуры, со всей очевидностью сгенерированные нейросетью. И хотя те впоследствии были удалены очередным патчем, осадочек у организаторов церемонии остался.
Кстати, живая легенда геймерской индустрии, Хидео Кодзима (Hideo Kojima), признался в декабрьском интервью CNN, что лично он в принципе не заинтересован в использовании генеративных моделей для создания каких бы то ни было визуальных элементов в своих играх, пусть даже второстепенных текстур на фоновых объектах, как это было в Clair Obscur: Expedition 33. Вместе с тем Кодзима не стал исключать перспективности куда более персонализированного применения ИИ в играх, а именно — для модификации (или просто генерации на лету) органов управления, контролирующие игровой процесс элементы которых будут располагаться максимально удобным для каждого геймера образом. Другой возможный вариант адекватной, по мнению мэтра, игроориентированной имплементации нейросетей — «оживление» управляемых компьютером персонажей; наделение их возможностью подлаживаться под особенности поведения и персональный стиль каждого игрока в отдельности.
Тодд Говард (Todd Howard), глава Bethesda Game Studios, в интервью, предварявшем запуск на Amazon Prime Video в середине декабря второго сезона сериала Fallout по мотивам одной из франшиз этой студии, тоже высказался в том духе, что ИИ как инструмент, позволяющий скорее и без потери качества выполнять рутинные задачи, вполне уместен в руках игродела, но полностью человека со свойственными тому устремлениями и целеполаганием, благодаря которым и создаются по-настоящему удачные игры, нейросеть заменить не способна. Представители китайской Pathea Games, что разрабатывает сейчас уже вызывающую немалый интерес новую большую игру The God Slayer, тоже предпочитают не полагаться на ИИ при решении ключевых задач, отводя ему вспомогательные роли. И аргументы приводят вполне резонные: их проект может быть отнесён к крайне редкому — что в литературе, что в сфере визуальных искусств — поджанру «азиатского стимпанка». Понятно, что необходимого объёма данных для того, чтобы натренировать даже самую изощрённую нейросеть на выдачу соответствующего контента, попросту нет, — практически всё команде Pathea Games приходится продумывать и создавать с нуля. ИИ, как не раз уже подчёркивалось по самым разным поводам, великолепен в систематизации и выделении чётких закономерностей из огромных массивов данных, — а чем уникальнее и нетипичнее задача, тем лучше с ней справится биологический разум. Тоже не всякий, разумеется, но у генеративной модели общего назначения шансов на успех в узкой области в любом случае меньше.
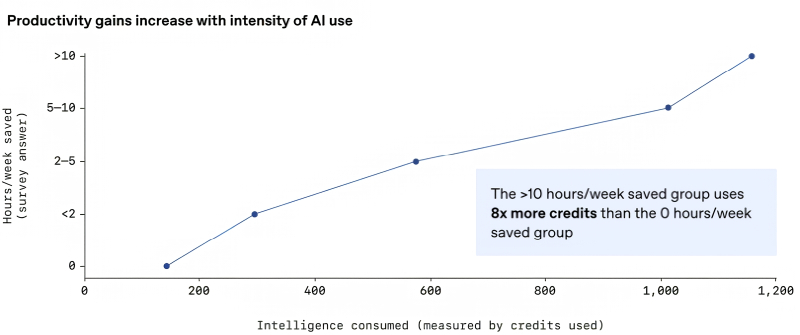
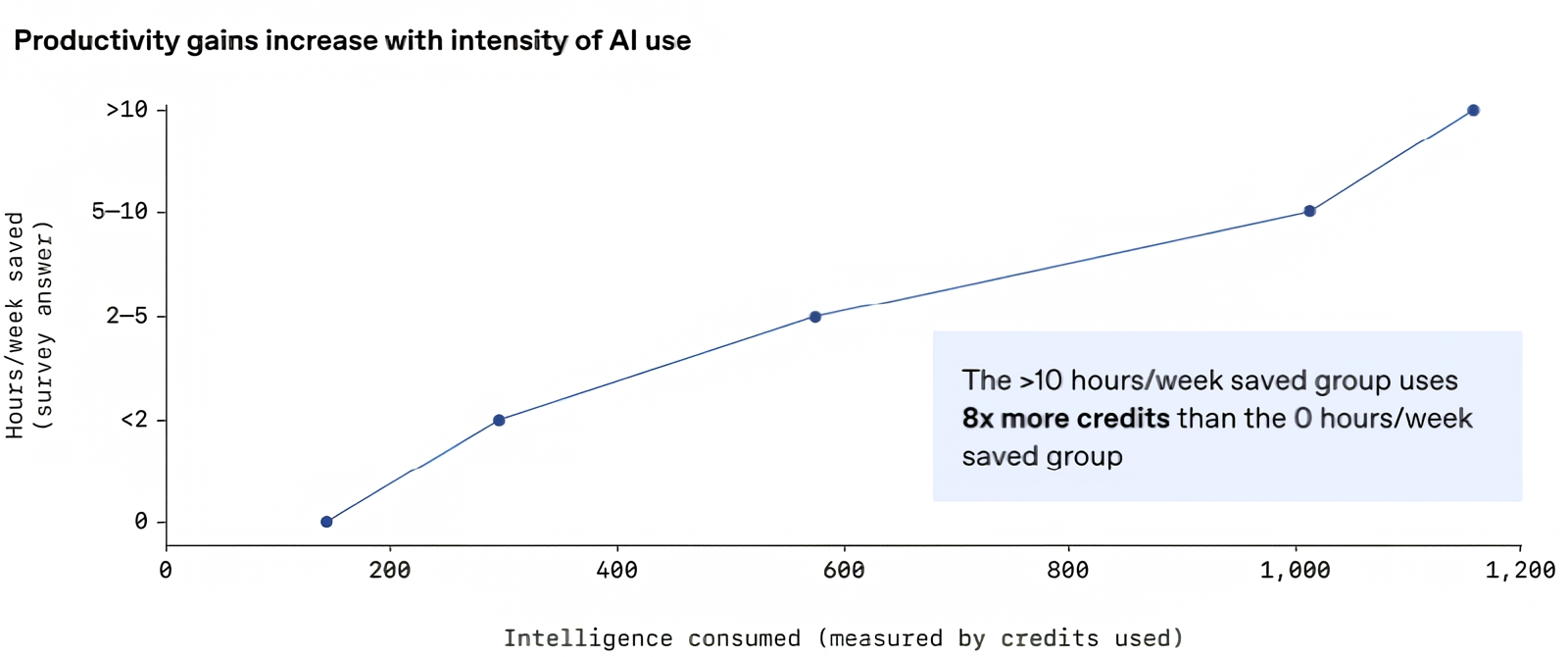
Чем больше условных кредитов (грубо говоря, обработанных ИИ-моделью токенов) расходовали за неделю участники исследования, тем более заметной экономии времени на выполнение рабочих задач добивались. И это ещё безо всякого AGI! (Источник: OpenAI)
⇡#Дайте народу AGI
Бизнес-модель OpenAI кому-то может напомнить мошенническую пирамиду: особенно подозрительны плановая убыточность компании по меньшей мере до 2030 г. и вовлечение всё новых участников в кольцевые схемы взаимного инвестирования, итогом которых становится рост капитализации всех участников, что, в свою очередь, помогает тем привлекать на бирже ещё больше оборотных средств. Однако некоторое моральное обоснование в этой модели всё же присутствует: это осознанная ставка на создание сильного ИИ (artificial genereal intelligence, AGI) в перспективе буквально нескольких ближайших лет, — а там видно будет. Да что там лет; не далее как в конце 2024-го Сэм Альтман уверенно заявлял о возможной достижимости AGI уже в 2025 г. И хотя это пророчество, как мы уже можем сказать под бой курантов, не подтвердилось, оно не так уж сильно выбивается из общего ряда: Илон Маск (Elon Musk) затевал в 2023 г. свою xAI с прицелом на создание (именно ею, разумеется) AGI в 2025-2026 гг.; сооснователь Anthropic Дарио Амодеи ожидает появления «мощного ИИ» (термина «AGI» он сознательно старается избегать) в конце 2026 — начале 2027 г.; бывший глава Google Эрик Шмидт (Eric Schmidt) предупреждал в апреле 2025-го о неиллюзорной угрозе выхода из-под человеческого контроля AGI, который должен появиться буквально вот-вот — в интервале трёх-пяти лет. Иными словами, всё стремительное развитие ИИ-отрасли за последние годы по сути базируется на попытке её лидеров сделать свои же пророчества в отношении AGI самосбывающимися, — именно потому с сопутствующими неудобствами и прямыми убытками они готовы мириться; слишком уж манит финальный куш. Просто яростный энтузиазм Альтмана, во что бы то ни стало стремящегося первым добраться до вожделенного генеративного грааля — в самой достижимости которого он, кажется, искренне уверен, — настолько очаровывает инвесторов, что те до сих пор исправно продолжают вливать в компанию десятки и сотни миллиардов долларов. Ведь ещё в 2019-м пламенный визионер совершенно честно предупреждал: «Я не знаю, как именно этот бизнес будет работать. Мы никогда не получали никакой прибыли, у нас нет текущих планов по её получению, и мы понятия не имеем, как мы когда-нибудь сможем её добиться. Мы дали инвесторам негласное обещание: „Как только мы создадим интеллектуальную систему такого рода [имеется в виду как раз AGI], мы попросим её найти способ обеспечить вам доход от вложенных в нас инвестиций“». Ну чем не бизнес-план: изобрети то, не знаю что, а после выясни у него, как окупить затраты и выйти в прибыль!
Оценивая путь, который OpenAI прошла со времени того интервью, нельзя не отдать должное по крайней мере смелости её лидера — и его верности сформулированной однажды идее. Правда, голоса скептиков на четвёртый год ИИ-революции, которая никак не желает заканчиваться, звучат всё заметнее. Вот уже и генеральный директор IBM Арвинда Кришна (Arvind Krishna) посетовал в декабре, что несуразные расходы на гонку за призрачным AGI нецелесообразны с экономической точки зрения. Бизнесмен делает в обоснование своего тезиса скучные прикидки: если для постройки классического ЦОДа на 1 ГВт мощности надо вложить около 80 млрд долл., то для работы с нынешними ИИ хорошо бы иметь дата-центр на 20–30 ГВт; это уже выходит по меньшей мере полтора триллиона. Дальше — больше: под AGI, если тот действительно достижим путём экстенсивного наращивания числа параметров в актуальных ныне глубоких нейросетях, т. е. следованием по избранной тою же самой OpenAI дороге (с некоторыми реверансами в сторону «рассуждающих» моделей и обучения с подкреплением), потребуется не менее 100 ГВт, что означает по меньшей мере 8 трлн инвестиций только в инфраструктуру. Ни у кого в мире нет настолько туго набитой мошны — значит, придётся оформлять кредит и на одно лишь его обслуживание выкладывать не менее 800 млрд долл. ежегодно. А ведь необходимо ещё платить за потребляемую электроэнергию и идущую на работу систем охлаждения воду; арендовать либо покупать землю под столь обширным ЦОДом; тратиться на зарплаты специалистам, на разработку самóй сверхкрупной ИИ-модели и т. д. Следует также отдавать себе отчёт в том, что лет через пять лет микросхемы в составе ИИ-вычислителей потеряют актуальность — или просто выйдут из строя по причине высоких непрерывных нагрузок, — так что трудящиеся день и ночь ускорители придётся регулярно менять на новые, тоже не бесплатные. Исходя из этих соображений, Кришна оценил вероятность достижения AGI экстенсивным путём не более чем в 1%, а значит, необходим концептуальный пересмотр модели развития и новый виток ИИ-революции, что само по себе без немалых вложений в НИОКР реализоваться не сможет.
И всё-таки руководство OpenAI продолжает смотреть в будущее с оптимизмом, намереваясь привлечь за несколько ближайших лет не менее 1,4 трлн долл. инвестиций только на развитие инфраструктуры для своих ИИ-моделей. Оно упирает на данные объективных замеров роста производительности тех рабочих групп, что чаще обращаются к уже доступным ИИ-инструментам, — по сравнению с теми, что игнорируют эти блага прогресса. Да, скептики продолжают сравнивать следование экстенсивному пути развития ИИ с наращиванием габаритов дирижаблей на заре воздухоплавания — мол, пока не было принято принципиальное решение развивать летательные аппараты тяжелее воздуха, т. е кардинально сменить парадигму, уверенное покорение воздушного океана толком и не начиналось. И всё же за прошедшие три с лишком года ИИ-революции прогресс генеративных моделей бесспорен; посмотрим, на что они окажутся способны в 2026-м!
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex