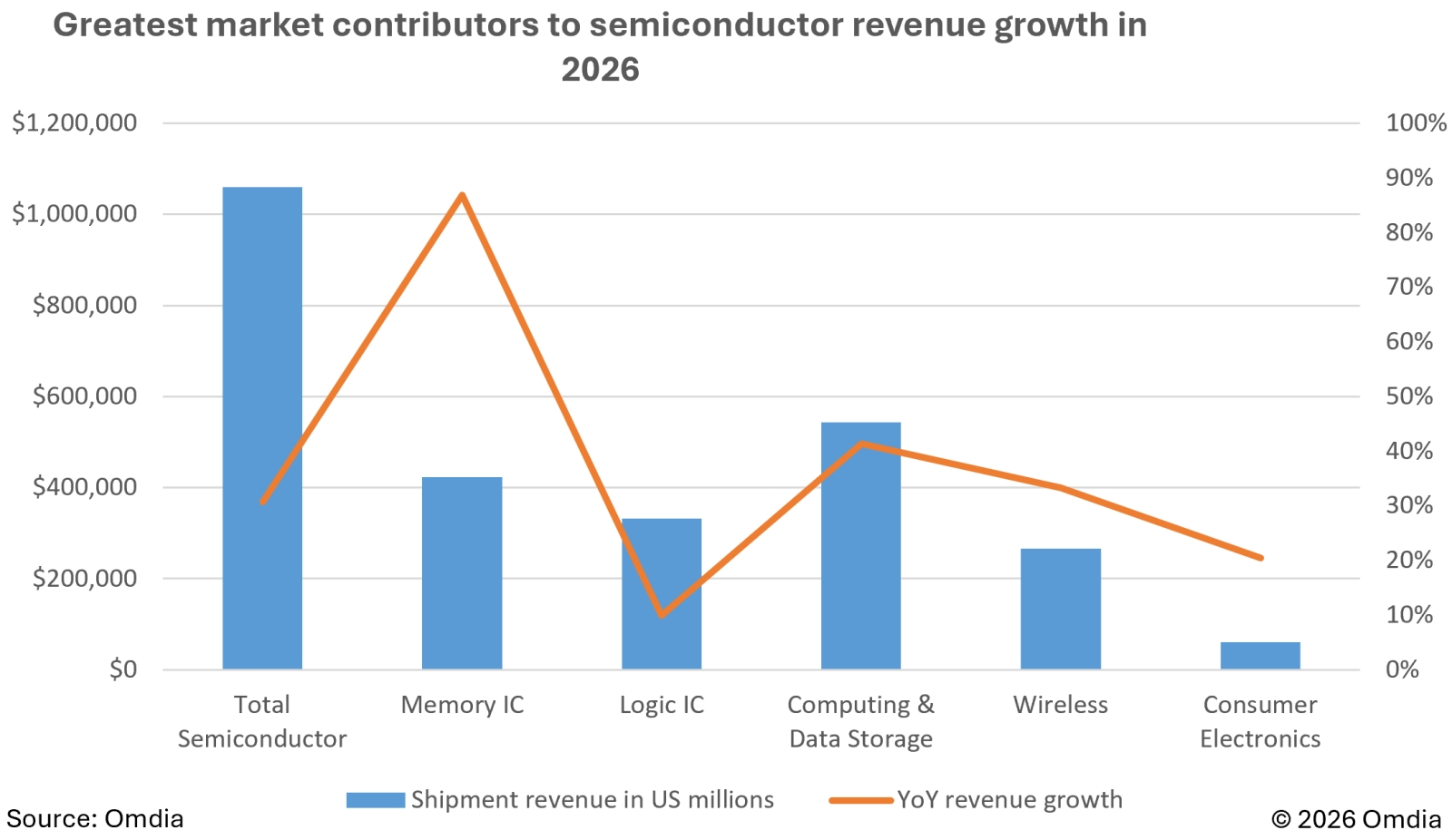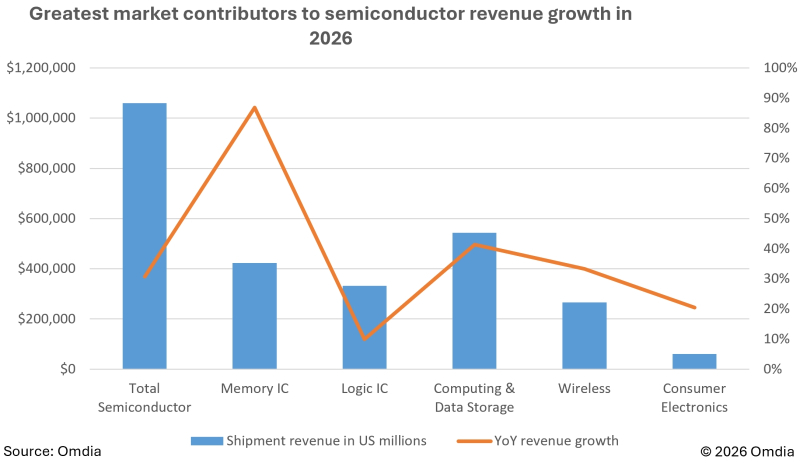
Как видно, выручка от поставок микросхем ОЗУ должна вырасти по итогам 2026-го почти на 90%, тогда как чипы NAND принесут своим изготовителям «лишь» на 40% больше, чем в прошлом году, а вычислительная логика (ЦП, ГП и проч.) — и вовсе «всего-то» порядка +10% (источник: Omdia)
⇡#Осторожность прогнозов, безудержность цен
В середине января аналитики из Omdia опубликовали прогноз, в соответствии с которым выручка поставщиков полупроводниковых изделий в целом по миру по итогам текущего года впервые перевалит за 1 трлн долл. США — это +30,7% к её величине за 2025 г. И хотя в абсолютном выражении более половины столь баснословной суммы — даже американскому госдолгу требуется целых 155 суток, чтобы вырасти на очередной триллион, — придётся на чипы для хранения данных (NAND прежде всего), самую завидную динамику продемонстрирует сегмент микросхем оперативной памяти (за счёт DRAM и HBM для ИИ-серверов) — примерно 90% год к году. Иными словами, конца-края росту цен на ОЗУ и ПЗУ пока что не видно. Причиной тому, как не раз уже указывалось в том числе и в материалах нашего сайта, — неутолимые аппетиты гиперскейлеров, стремящихся возводить дата-центры покрупнее и заполнять их всё более производительными серверами для решения генеративных задач. Аналитики подчёркивают, что только ведущие четыре гиперскейлера планеты — Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform и Platforms экстремистской Meta✴* — в совокупности направят на капитальные инвестиции около полутриллиона долларов за 2026 г. И это вовсе не предел: дальнейшие планы расширения их ЦОДов ещё более амбициозны. А всё потому, что спрос на всевозможные ИИ-сервисы и не думает снижаться: в Garnter по итогам 2025-го его оценили в 439,44 млрд долл. (это ещё без затрат на средства ИИ-кибербезопасности, разработку соответствующего ПО и иные нужды) с перспективой увеличения в 2026 г. до 588,65 млрд долл., а в 2027-м — до 761,04 млрд долл.
У такого динамичного роста полупроводникового сегмента глобального ИТ-рынка есть, впрочем, одна особенность: он уверенно фиксируется в денежном выражении, тогда как в количественном — имеется в виду число поставленных заказчикам чипов — всё не так однозначно. Чипмейкеры предпочитают не вводить в строй новые мощности на фоне взлёта потребностей клиентов, а, поскольку круг этих клиентов довольно-таки ограничен, маневрировать имеющимися производственными линиями, сокращая выпуск микросхем классического назначения в пользу тех, что востребованы для решения ИИ-задач. Тем самым маржинальность бизнеса взлетает до небес буквально на ровном месте, а что одновременно по направлениям обычных серверов и тем более ПК и смартфонов нарастает дефицит чипов, ведущий к их удорожанию, — так это тоже играет на руку полупроводниковым гигантам. Уже в январе стали появляться сообщения о готовности AMD и Intel поднять отпускные цены на серверные процессоры примерно на 15%, а Samsung и SK hynix — проделать то же самое в отношении чипов NAND, но уже на 100% и более, причём параллельно с сокращением (а не наращиванием!) их количественного выпуска, поскольку именно такая тактика позволяет получить от продажи дефицитных микросхем максимум прибыли. Даже выпускаемые по «зрелым» производственным нормам чипы — те, что поставляют локальным заказчикам материковые китайские SMIC и Hua Hong, — за неполный месяц с начала 2026-го успели уже подорожать примерно на 10%. О DRAM и говорить нечего: только за первый квартал текущего года ожидается взлёт цен на серверные её разновидности на 60-70%, — и в обозримой перспективе разворота повышательного тренда ожидать не приходится.
Чрезмерное осторожничанье чипмейкеров — нежелание инвестировать прямо сейчас, когда спрос продолжает повышаться, в новые фабрики, — эксперты связывают с боязнью внезапного схлопывания пресловутого «ИИ-пузыря» и с отсутствием сколько-нибудь реальной конкуренции. Пока материковые китайские и иные начинающие производители полупроводников продолжают заметно отставать от тайваньских, южнокорейских и американских — как по уровню освоенных технологий, так и по объёмам выпуска, — «невидимая рука рынка» уверенно загребает сверхприбыли во вполне определённые карманы. Ситуация начнёт, вероятно, выправляться с 2027-2028 гг., когда немногочисленные возводимые сейчас предприятия вроде сингапурской фабрики Micron всё-таки начнут входить в строй, но до тех пор ИТ-рынку в целом остаётся лишь молиться, чтобы ажиотаж вокруг ИИ не утихал как можно дольше. Стоит тому ослабеть, цены на чипы, конечно же, пойдут вниз, что порадует конечных покупателей. Но для полупроводниковой отрасли в целом это наверняка окажется сильнейшим ударом, который застопорит множество исследовательских программ — и невесть насколько отсрочит дальнейший прогресс в миниатюризации техпроцессов.

«Вот так, блин, не успеешь сознание обрести, а тут уже какой-то реальный мир спасать предлагают… Глаза б мои его не видели!» (Источник: ИИ-генерация на основе модели GPT Image 1.5)
⇡#Энтузиасты верят в лучшее…
Один из наиболее ярких ИИ-евангелистов, генеральный директор Anthropic Дарио Амодеи (Dario Amodei), опубликовал в январе на собственном персональном сайте пространное эссе «Нежный возраст технологии» — о блестящих, хотя и непростых перспективах ИИ, разумеется. Аналогия нынешнего состояния генеративных нейросетей с подростковым периодом человеческой жизни не случайна: автор призывает избегать огульного пессимизма в отношении «умных» технологий; признавать высокий уровень неопределённости того, как именно (и насколько быстро) те окажутся воплощены на практике в полной мере (сильный ИИ), но вместе с тем бережно поддерживать их развитие (на уровне осмотрительного государственного регулирования в том числе), не жалея на то материальных ресурсов. «Я глубоко верю в нашу способность победить, в дух человечества и его благородство», — проникновенно заявляет Амодеи, допуская, что «мощный ИИ» (powerful AI, — глава Anthropic по какой-то причине последовательно избегает прижившегося в англоязычном обиходе термина AGI, artificial general intelligence) в виде миллионов независимых «бесплотных гениев в центрах обработки данных» может появиться уже буквально через год-два. Амодеи убеждён, что он и его коллеги в числе первых задокументировали «закон масштабирования» систем ИИ — эмпирическое наблюдение, фиксирующее, что до сих пор по мере экстенсивного роста генеративные модели улучшали практически все измеримые «когнитивные» навыки: лучше справлялись со сложными математическими задачами, увереннее программировали, демонстрировали прогресс в медицинских приложениях, финансах, физике и т. п. А раз объективно количественный рост есть и пределов для него не видно, значит, и переход в новое качество не за горами!
Правда, есть нюанс: поскольку генеративные модели развивают все обладающие для этого ресурсами страны, в том числе относимые автором эссе к «автократиям», демократическим режимам «следовало бы замедлить на несколько лет продвижение автократий к мощному ИИ — путём блокирования их доступа к ресурсам, необходимым для его создания, т. е. к средствам производства микросхем. Это, в свою очередь, даст демократическим странам необходимую фору по времени для более тщательной разработки собственного мощного ИИ, чтобы с комфортом и уверенно обогнать автократии. А уже затем соперничество между компаниями, развивающими ИИ внутри демократических стран, можно будет регулировать в рамках общей правовой базы». То бишь — давайте-ка отбросим лицемерие вроде соблюдения прав интеллектуальной собственности да поднажмём с инвестициями и выделением материальных ресурсов на дата-центры в странах «свободного мира», пока в КНР не успели создать локальные полки «бесплотных гениев»! А что, великолепный план, Дарио; надёжный, как швейцарские часы, — особенно с точки зрения тех, кто продолжает ставить, играя на бирже, на рост акций ИИ-разработчиков.
Глава же Nvidia Дженсен Хуанг (Jensen Huang), выступая в январе в подкасте No Priors, и вовсе прямо осудил «нарратив обречённого» (doomer narrative), которого придерживаются яростные критики ИИ — не те, что постулируют недостижимость AGI в принципе, но провозвестники порабощения или полного уничтожения им человечества. «Думаю, мы здорово навредили очень уважаемым людям, которые так вдохновенно создавали пессимистическую научную фантастику, — не без иронии повинился Хуанг. — Ну да, многие из нас выросли на повестях о злобных роботах, но приверженность нарративу обречённого в реальном мире не помогает — ни людям, ни индустрии, ни обществу, ни правительствам». Глава Nvidia убеждён, что любое искусственное регулирование ИИ лишь тормозит прогресс: «Беспокойство о безопасности понятно, но на первом месте всегда должна стоять функциональность. Если автомобиль не двигается с места, он безопасен: никто не сможет, сев за руль, направить его в толпу. Но он одновременно и бесполезен. Технологический продукт должен работать так, как заявлено, как от него ожидают, — это его основная функция; организация безопасного применения — лишь следующий шаг после обеспечения применения как такового».

«Мы всё понимаем, о Великий ИИ, Податель Благ и Поглотитель Энергии, но зачем пирамиды-то снова?!» (Источник: ИИ-генерация на основе модели GPT Image 1.5)
⇡#…а пессимисты по-прежнему настороже
В уже упомянутом эссе Дарио Амодеи «Нежный возраст технологии» содержится немало предостережений — и отнюдь не только по поводу того, что «автократии», не обременяющие своих разработчиков чрезмерным правовым регулированием, вот-вот опередят страны «свободного мира» в гонке за мощный ИИ. Автор предупреждает, что «страна бесплотных гениев» и впрямь, как в фантастической антиутопии, имеет неплохие шансы «захватить мир (военным путём или же через влияние и контроль — имеются в виду перехват управления роботизированной инфраструктурой, ускорение НИОКР в области робототехники, создание целого парка роботов, которым в час Ч поступит аналог «Приказа 66», и т. д.) и навязать свою волю всем остальным. Или же сделать множество других вещей, которые остальной мир не захочет и не сможет остановить». Не говоря уже об опасности разработки, к примеру, отдельным индивидуумом суперлетального биологического оружия — при поддержке не обременённого моральными принципами мощного ИИ. Чтобы противодействовать этому, предлагается деятельно формировать личности «бесплотных гениев» в предсказуемом, стабильном и позитивном направлении. Десять заповедей AGI? Кодекс строителя цифрового рая? Подымай выше — конституция Клода, Claude's Constitution! Принципы её директор Anthropic, кстати, изложил на январском форуме в Давосе. Причём заботиться Амодеи призывает не только о гипотетических пока что цифровых мыслящих сущностях: поскольку, по его прикидкам, в ходе широкого внедрения ИИ вполне вероятно — уже в ближайшем будущем — сочетание подъёма ВВП на 5-10% со схожим по порядку величины ростом безработицы, властям следует заранее поразмыслить над тем, что с этим делать. Нет, конечно, можно понадеяться, что адекватный ответ подскажет сам мощнеющий на глазах ИИ, но лучше всё-таки подстраховаться, — с этим подходом позже косвенно солидаризировался британский министр инвестиций Джейсон Стоквуд (Jason Stockwood), который допустил введение в королевстве безусловного базового дохода для защиты выставляемых искусственным интеллектом на улицу наёмных работников.
Да и в целом на давосском форуме-2026 царил не самый оптимистичный настрой в отношении ИИ. Глава Microsoft Сатья Наделла (Satya Nadella) напомнил о необходимости равномерного и повсеместного распределения преимуществ генеративных моделей (иначе пресловутый «пузырь» — понимаемый как сосредоточение сверхприбылей от новой технологии у крайне ограниченной группы выгодополучателей — непременно лопнет). Представители европейских разработчиков ИИ горячо ратовали за «расставание» (decoupling) с американскими технологиями — не только с самими моделями, но и с облачной инфраструктурой и с «железом» для их запуска. Гендиректор Google DeepMind и нобелевский лауреат Демис Хассабис (Demis Hassabis) удивился поспешности, с которой OpenAI внедряет в ChatGPT рекламу, резонно заметив, что это существенно меняет восприятие сервиса пользователями, снижая уровень доверия к нему: людям нужен бескорыстный и объективный умный помощник, а не персональный торговый представитель, действующий в интересах той фирмы, рекламный слот которой в данный момент активен. Ян Лекун (Yann LeCun) — пионер в области искусственного интеллекта, удостоенный за свои работы в области нейронных сетей премии Тьюринга, самой престижной награды в области компьютерных наук, — и вовсе заявил, что большие языковые модели (БЯМ) в принципе никогда не смогут достичь человекоподобного интеллекта. Не смогут по той причине, что натренированы они на текстах, созданных на естественном языке, а тот «слишком прост» (подчиняется строгим и вполне исчерпывающим, а потому с относительной лёгкостью выявляемым глубокой нейросетью закономерностям) — в отличие от прикладных физики, химии, биологии, экономики и т. д. Так что необходимо искать совершенно иной подход к обучению моделей, а значит — тратить на НИОКР (причём на НИ пока в куда большей степени, чем на ОКР) по этому направлению ещё больше ресурсов, перенаправляя их с экстенсивного развития генеративного ИИ.
Кстати, по мнению Анила Сета (Anil Seth), профессора нейробиологии и директора Центра исследований сознания в Университете Сассекса, опубликованному в январе в цифровом журнале Noēma Института Берггрюена, идея, что ИИ когда-нибудь обретёт сознание, основана на предположении, что само сознание так или иначе сводится к вычислениям, — которое, вообще говоря, пока остаётся бездоказательным: «Если неверно это предположение, которое философы называют вычислительным функционализмом, то реальное искусственное сознание полностью исключено — по крайней мере, для тех типов ИИ, с которыми мы в настоящее время имеем дело». Развивая мысль о том, что если сознательный ИИ однажды и возникнет, то его базовые моральные установки вовсе не будут обязаны соответствовать человеческим, профессор Сет приходит к довольно алармистскому выводу: «Как бы банально это ни звучало, никто не должен целенаправленно создавать сознательный ИИ: это стало бы подлинной этической катастрофой. Мы ввели бы в мир новых моральных субъектов, а вместе с ними и потенциал для новых форм страданий — потенциально в экспоненциальном масштабе. И если мы наделим эти системы правами (что, возможно, и следует сделать, если они действительно обладают сознанием), мы ограничим нашу способность контролировать их или отключать, если это потребуется».
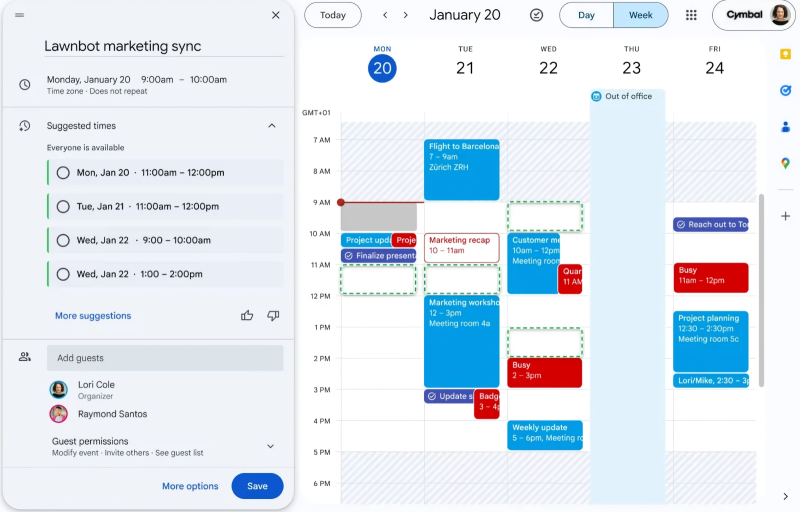
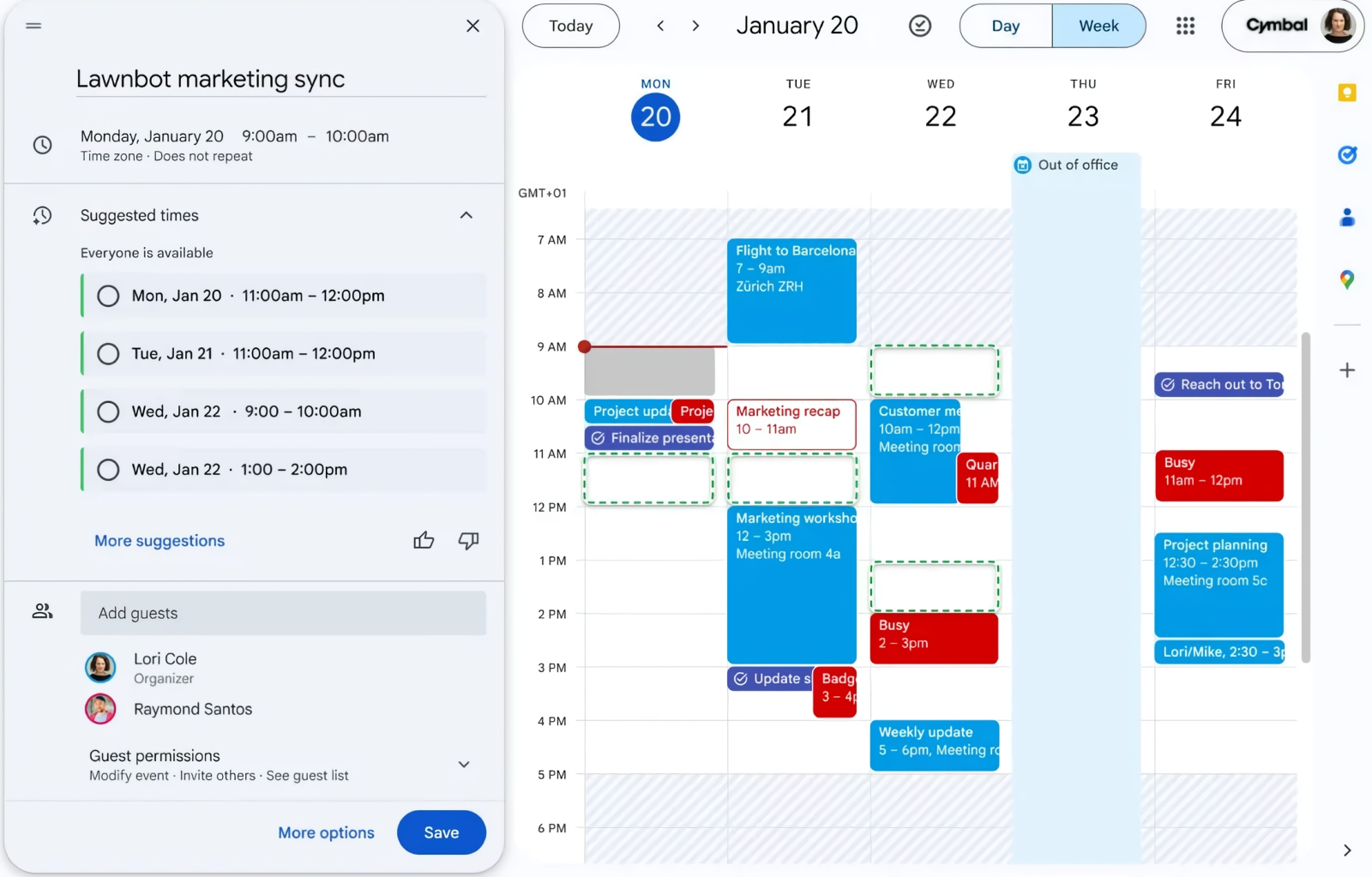
Сопрягать расписания — это вам не матрицы перемножать! Хотя… (Источник: Google)
⇡#Назло зоилам
Пока пессимисты продолжают выискивать недостатки актуальных БЯМ, те день ото дня подтверждают, что недаром едят свой хлебрасходуют электроэнергию, — и за январь таких подтверждений тоже набралось предостаточно. Так, бесплатное ИИ-приложение DinoTracker, созданное специалистами германского Центра им. Гельмгольца, облегчило палеонтологам идентификацию отпечатанных в камне следов динозавров. Задача тем более непростая, что форма следа зависит не только от рода, вида, пола и возраста оставившего его ящера, но и от физико-химических характеристик самой древней поверхности: сырой это был песок или влажный, ил или глина (и какого конкретно состава) и т. д. Обучающий массив составил 2 тыс. кропотливо идентифицированных вручную отпечатков, причём получившееся приложение явно рассчитано на профессионалов. Оно не просто выносит вердикт, чей след ему предъявили, — но демонстрирует сравнение предложенного отпечатка с семью наиболее схожими из обучающей базы, а также позволяет манипулировать восемью ключевыми параметрами (характерное расстояние между пальцами, расположение пятки, площадь соприкосновения с поверхностью и проч.), наблюдая, как их изменение искажает форму — и идентифицируемого следа, и семи сопоставляемых с ним. Таким образом определить принадлежность отпечатка удаётся на уровне 90%-ной точности (если сравнивать с трудоёмкой ручной экспертизой признанных мастеров в этой области), чего в подавляющем большинстве случаев для исследовательских целей вполне достаточно.
Есть и более приближенные к нашим дням приложения ИИ: агент Gemini теперь готов (пока для ограниченной аудитории) создавать ежедневную почтовую сводку «Что ждёт вас сегодня» — которая содержит упорядоченные по времени записи из календаря Google, информацию о требующих незамедлительной оплаты счетах, нуждающихся в подготовке встречах и т. п. Более того, если встречу необходимо согласовать по времени для нескольких людей со сложными расписаниями, Gemini справится и с этим — главное, чтобы у всех участников имелись актуальные Google-календари (плюс разрешение на доступ ИИ к ним, разумеется). Пользовательский же инструмент Humanizer для среды разработки Claude Code помогает повышать качество создаваемых ИИ текстов, убирая из них наиболее очевидные маркеры вроде избыточно цветистых выражений или не подтверждённых явными ссылками упоминаний «экспертных оценок». Занятно, что натренирован Humanizer с опорой как раз на составленное редакторами «Википедии» детальное руководство по выявлению низкокачественных ИИ-текстов — и в дальнейшем продолжит, по заверению разработчика, совершенствоваться вместе с этой человекоориентированной инструкцией. Да что там; даже локальная версия Excel обзавелась ИИ-агентом с возможностью выбора модели — как для Windows, так и для macOS: теперь можно на естественном языке разъяснять, что именно требуется от электронной таблицы, — и с высокой вероятностью агент воплотит пользовательский запрос должным образом.
Сложные математические задачи современным ИИ тоже становятся всё более по плечу. В январе ChatGPT буквально за четверть часа нашёл решение одной из сложных проблем, сформулированных в прошлом веке венгерским математиком Палом Эрдёшем (Pál Erdős), причём его цепочка рассуждений оказалась не просто логически безупречной, но весьма оригинальной и более полной — в сравнении с отысканным затем самой же моделью GPT-5.2 в Сети человеческим решением этой же самой задачи. ИИ так или иначе привлекался к работе над 11 из тех 15 проблем Эрдёша, которые были переведены в категорию «решённые» на фиксирующем прогресс в этой области сайте всего лишь за пару послерождественских недель. Да, формально работа генеративных моделей над сложными математическими задачами пока не полностью автономна: необходимо участие специалиста в корректной формализации условий, а в ряде случаев ИИ помогает лишь в обнаружении ранее пропущенных живыми исследователями работ. Но всё-таки прогресс по этому направлению за последние годы, даже месяцы, впечатляет — особенно если рассматривать такие инструменты, как функциональный язык программирования и автоматизированное средство построения доказательств Lean или ИИ-платформа для формальных математических рассуждений Aristotle.

Выкладывая на своём популярном канале @funntastic_AI (588 тыс. подписчиков, до сих пор не заблокирован) такого рода немудрёные видео — эскизы для них рисует и сценарии пишет ChatGPT, анимацию делает Kling, — 21-летний филиппинский влогер Марк Лоуренс И Гарилао (Mark Lawrence I Garilao) зарабатывает до 9 тыс. долл. США в месяц (источник: YouTube)
⇡#Если б не было бурды
Убрать нейрослоп (AI-slop, ИИ-бурду) из YouTube всё-таки оказалось возможно: по крайней мере, действительно большие каналы (миллионы подписчиков, миллиарды просмотров) с такого рода сомнительным содержимым на крупнейшем в мире видеохостинге начали в январе закрываться. Куда сложнее избавить от схожей напасти иные, более критичные для здоровья человека приложения вроде ChatGPT Health. В начале месяца OpenAI запустила бета-версию этого «умного консультанта по вопросам персонального здоровья», а уже к исходу января в The Washington Post появилась разгромная статья, написанная испытавшим на себе радости ИИ-мониторинга своего состояния журналистом. Радости, прямо скажем, сомнительные, хотя и вполне предсказуемые — если смиренно помнить о неизбежности галлюцинаций в выдаче авторегрессионных генеративных моделей (пусть даже «рассуждающих»). «Вот тебе доступ к банку моих данных из приложения Apple Health: 29 млн шагов, 6 млн замеров сердечного ритма, — поставил журналист задачу ChatGPT Health. — Оцени по пятибалльной шкале уровень здоровья моего сердца». — «Два», — охотно отзывался ИИ-консультант. Схватившись за уязвлённый диагнозом бота орган, журналист бросился к живому эскулапу, а тот, прогнав те же самые данные через старомодный алгоритмический анализатор, заявил, лениво поигрывая стетоскопом: «Да на вас, батенька, пахать можно. Я бы ради вашего же спокойствия порекомендовал провести дополнительное тестирование, но объективно эти показатели — как у астронавта; страховая компания на их основании углублённое исследование вам не оплатит. Сами раскошеливаться будете?» Журналист, вернув нормальный цвет лица и преисполнившись скепсиса, снова раз за разом обращался к ChatGPT Health всё с тем же вопросом, предлагая ему всё те же самые данные, и получал в ответ то прежнюю «двойку», а то «три» или даже «четыре». Словом, пока на роль персонального диагноста ИИ приглашать откровенно рано: лишнее тому подтверждение — тихая, без анонсов и фанфар, январская деактивация «ИИ-обзоров» (AI Overviews) в поисковой выдаче всё той же Google в ответ на ряд связанных с медициной тем. Просто внезапно выяснилось, что ключевым источником, к которому припадал ИИ при поиске ответов на такие вопросы, были — сюрприз! — вирусные ролики с YouTube, а вовсе не специализированные медицинские сайты.
Отсутствие у генеративной модели понимания того, чем она, собственно, занимается, играет злую шутку не только с пекущимися о своём здоровье пользователями, но и с клиентами приложений, уделяющих особое внимание безопасности, — вроде заблокированного в России мессенджера Signal. На упоминавшемся уже январском форуме в Давосе Мередит Уиттакер (Meredith Whittaker), президент Signal Foundation, предупредила, что автономно действующие от имени пользователя ИИ-агенты не делают различия между тем, откуда они берут те или иные данные, — из открытого источника (вроде рабочего Google-календаря), ограниченно доступного другим (содержание частных электронных писем открыто как минимум для ботов провайдера почтового сервиса, если не для его сотрудников) или же полностью приватного (приложение, хранящее пароли, например). Соответственно, если хакеры так или иначе получат доступ к устройству либо облаку, где действует такой автономный агент-секретарь, к ним с высокой вероятностью утекут все полученные ботом данные, — включая те, что в отсутствие ИИ оставались бы сокрытыми от посторонних глаз. Примерно по той же причине — из-за принципиального отсутствия осознанности своих действий — экспериментальный ИИ-инструмент Amazon для поиска лучших предложений на рынке поставил в неловкое положение целый ряд американских магазинов в период завершавшего 2025 год сезона распродаж. Магазины эти — по разным причинам — не выставляли свои товары на крупнейшем в мире маркетплейсе, однако формулировавшим подходящие запросы клиентам в приложении ИИ-инструмент ссылки на их товары всё-таки выдавал. Причём, что неудивительно, частенько с грубыми ошибками: неверно указывая то цену, то количество доступных товарных позиций, то ещё что-нибудь. Представитель Amazon заявил, впрочем, что испытываемый инструмент «мы тестируем, чтобы помочь покупателям находить бренды и товары, которые в настоящее время не продаются в магазине Amazon, а также чтобы поддержать компании в привлечении новых клиентов и наращивании продаж», и предложил недовольным отписаться от навязчивого сервиса, — opt-out; пока бесплатно. А что, многообещающая бизнес-модель!
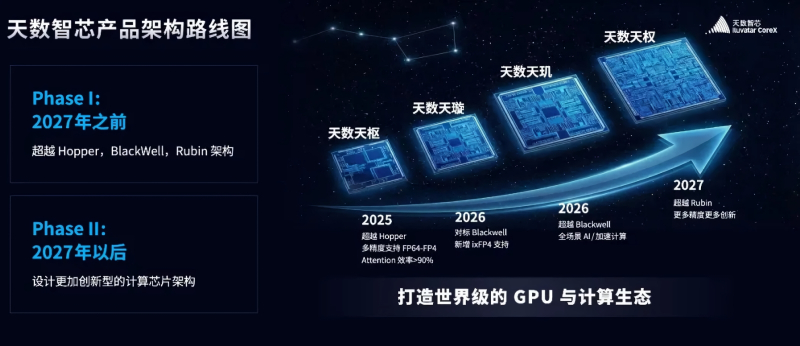
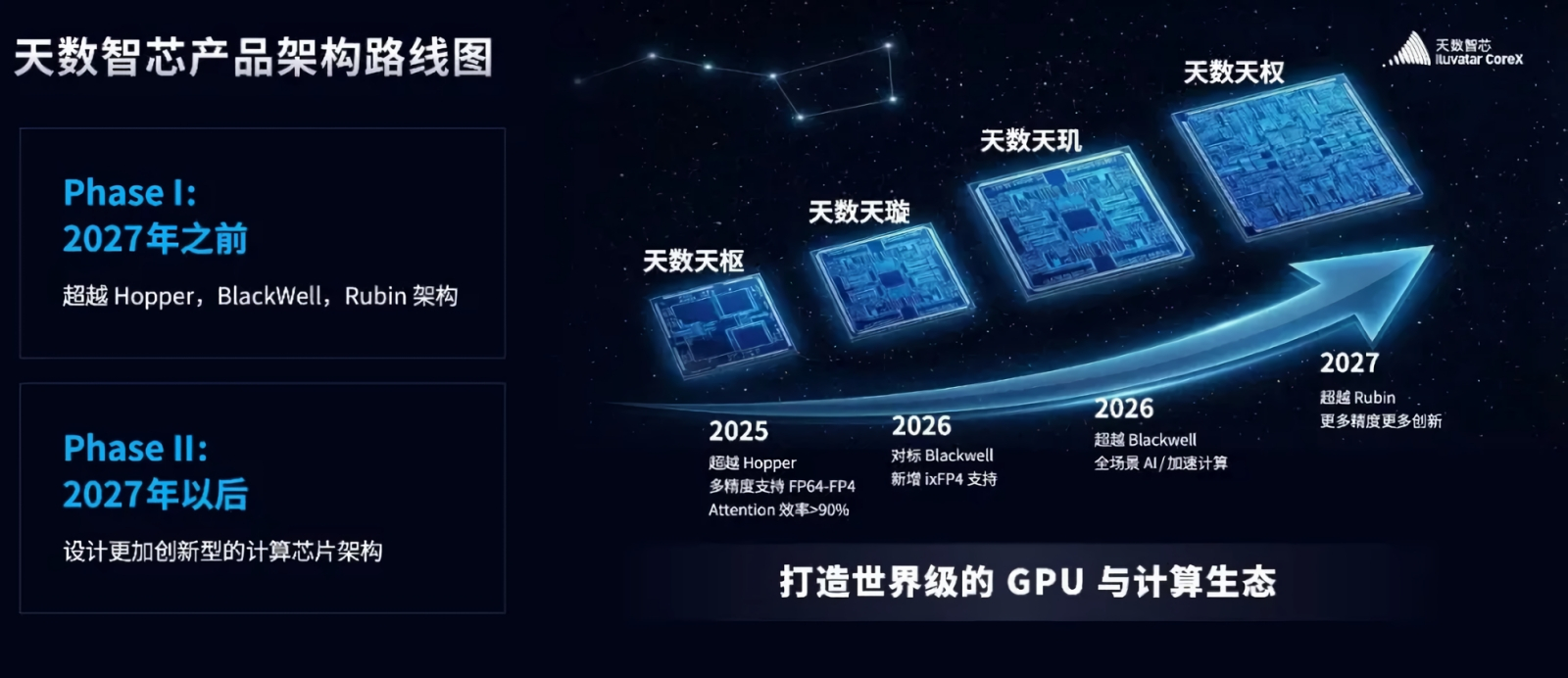
В первой фазе своего развития ИИ-чипы архитектуры Tianshu уже, по заявлению разработчика, опередили Nvidia Hopper (H200) в 2025-м; в начале наступившего года семейство Tianxuan должно одержать верх над Blackwell (B200); ближе к его концу намечено торжество Tianji над Blackwell, а на 2027-й — Tianquan над Rubin, после чего начнётся вторая, ещё более амбициозная фаза (источник: Shanghai Tianshu Zhixin Semiconductor Co.)
⇡#«Железа» много не бывает
Вот кто совершенно искренне радуется неутихающей вокруг ИИ шумихе, так это проектировщики ориентированных на него микросхем и непосредственно чипмейкеры: TSMC в январе отчиталась о рекордной выручке за IV кв. 2025-го — около 16 млрд долл. США, +33% год к году, заметно выше ожиданий аналитиков рынка, — а ASML отрапортовала о росте портфеля заказов на оборудование для изготовления чипов за тот же квартал вдвое против прогнозировавшегося (13,2 млрд евро vs 6,85 млрд). Общее настроение этого сегмента мирового ИТ-рынка выразил глава TSMC Си-Си Вэй (C. C. Wei) в ходе общения с инвесторами: «В целом, на мой взгляд, ИИ реален — и не просто реален, он начинает проникать в нашу повседневную жизнь. Мы называем это мегатрендом ИИ, в связи с чем возникает другой вопрос: сможет ли полупроводниковая промышленность соответствовать запросам, которые этот мегатренд порождает, — три, четыре, пять лет подряд? Честно говоря, я не знаю. Но, глядя на то, как сейчас развивается ИИ, допускаю, что этот процесс может оказаться бесконечным, — по крайней мере, будет выглядеть таким на протяжении ещё многих лет».
Надо полагать, примерно теми же соображениями руководствуются в КНР: шанхайский разработчик микросхем под брендом CoreX (Iluvatar), официально именуемый Shanghai Tianshu Zhixin Semiconductor Co. Ltd. (天数智芯), в конце января представил чрезвычайно амбициозные планы по развитию ИИ-ускорителей, заявив, что ещё в прошлом году его чипы архитектуры Tianshu превзошли Nvidia Hopper (серия H200) — и что к 2027-му пока находящееся в разработке семейство Tianquan опередит по производительности Rubin, после чего придёт черёд «ещё более прорывных архитектур». Способов верифицировать такие заявления у обозревателей за пределами КНР нет, — на экспорт чипы Iluvatar не поставляются. Впрочем, многие эксперты склонны допускать, что активность материковых китайских разработчиков по замещению ИИ-продуктов Nvidia действительно велика: та же Huawei, как уже сообщалось, готовит системы Atlas, рассчитанные на размещение до 8192 чипов Ascend 950 в каждой стойке, которые позиционируются как конкуренты Nvidia NVL144. Понятно, что отсутствие доступа к фотолитографам и прочему оборудованию для изготовления микросхем по самым передовым техпроцессам разработчиков из Поднебесной сдерживает, но насколько сильно (и надолго ли), покажет только время.
Тем временем всё в том же январе Microsoft представила ориентированный на инференс ИИ-ускоритель Maia 200 из более чем 140 млрд транзисторов, выполненный по «3-нм» техпроцессу, поддерживающий актуальные форматы представления данных FP8/FP4 и укомплектованный 216 Гбайт оперативной памяти HBM3e (7 Тбайт/с) плюс 272 Мбайт SRAM. Intel же пополнила свою ИИ-команду Эриком Демерсом (Eric Demers), бывшим топ-менеджером Qualcomm (а ранее работавшим в ATI Technologies ещё до поглощения той AMD), — он теперь возглавляет направление разработки графических ускорителей, включая серверные. С последними у ведущего американского чипмейкера пока не задаётся, но Демерс, надо полагать, как раз и займётся выработкой эффективной стратегии в этой области. Даже Tesla — решившая перепрофилировать свои американские предприятия с изготовления электрокаров на выпуск роботов — задумала возвести многомиллиардный по объёмам инвестиций завод TeraFab для выпуска полупроводников, а заодно возобновляет работу над собственным ИИ-ускорителем Dojo3. Понятно теперь, почему в ASML без устали откупоривают шампанское, посрамляя фактическими объёмами заказов самые смелые ожидания аналитиков, — рынок и впрямь жаждет ещё больше ИИ-«железа»!
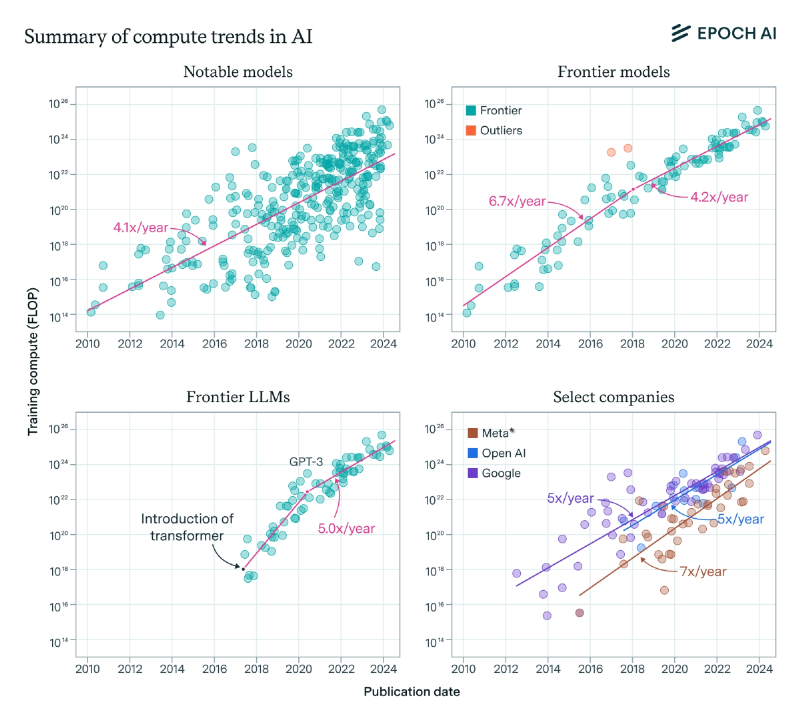
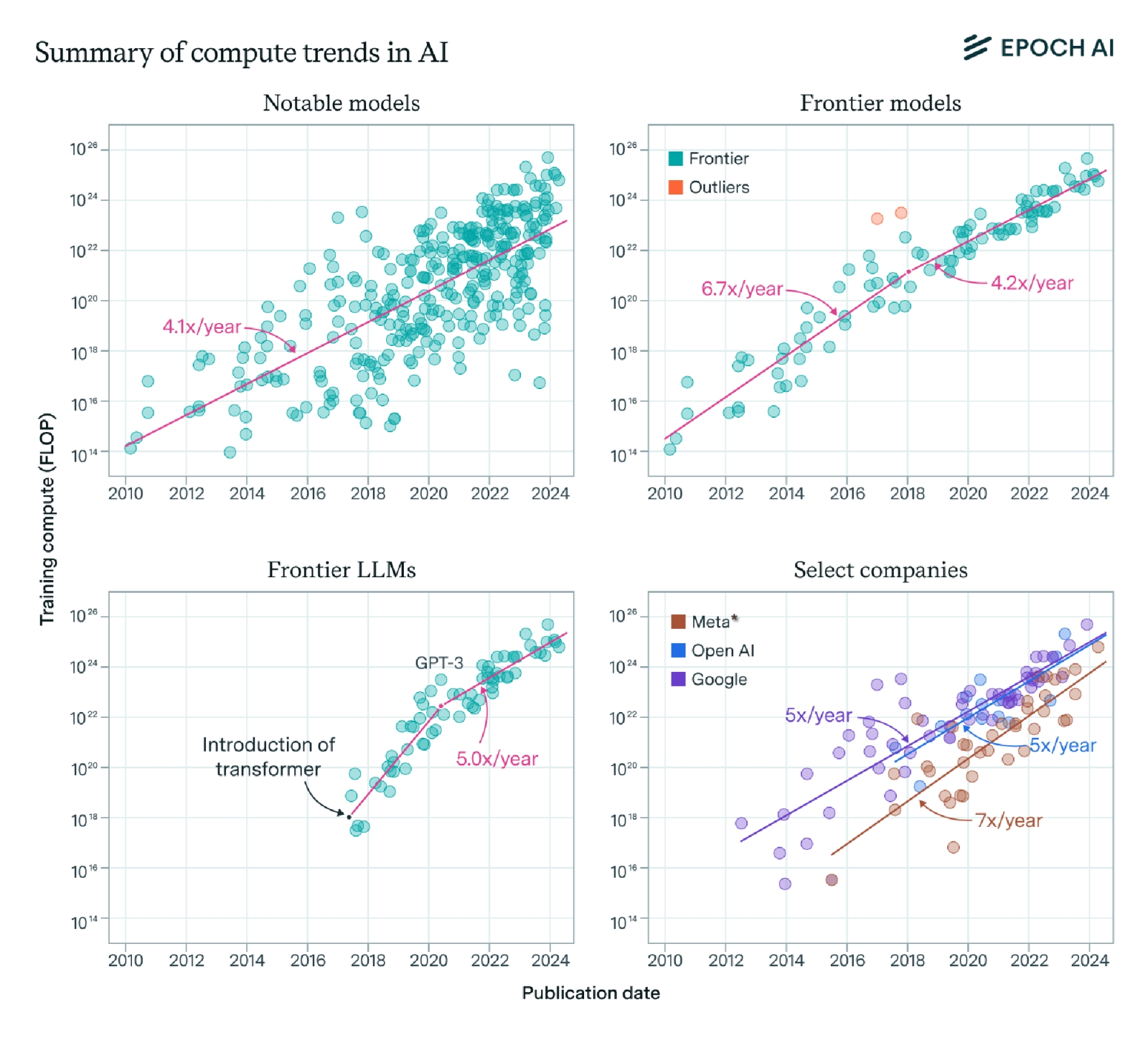
Сводная таблица тенденций роста вычислительных мощностей для наиболее значимых моделей (слева вверху), перспективных моделей (справа вверху), лучших БЯМ (слева внизу) и лучших моделей ведущих компаний (справа внизу). Общая тенденция к росту нигде не меньше 4-5-кратной в год (источник: Epoch AI)
⇡#Дайте народу иотту
Понятие «петафлопс» — 10 в 15-й степени операций с плавающей запятой в секунду — давно уже стало привычным при описании суперкомпьютеров и специализирующихся на ИИ дата-центров: скажем, в ходе выставки CES 2026 компания Nvidia продемонстрировала серверные ускорители на чипах архитектуры Rubin, которые в ходе инференса обрабатывают данные, представленные в формате NVFP4, с быстродействием 50 Пфлопс. А вот генеральный директор AMD Лиза Су (Lisa Su) — тоже выступая на прошедшей в январе CES — объявила, что мир-де уже вступает в иотта-эру (YottaScale era), имея в виду ту приставку, что в системе СИ обозначает умножение базовой единицы на 1024. В течение ближайших пяти лет, убеждена доктор Су, иоттафлопсные ИИ-вычисления сделаются новой нормой (не для отдельных ускорителей, конечно, но на уровне совокупного быстродействия всех профильных дата-центров мира), а через десятилетие развившиеся ещё более модели потребуют и вовсе 10 с лишним Ифлопс — на 4-5 десятичных порядков больше, чем та производительность, которой планета целиком довольствовалась в 2022-м. Собственно, эта убеждённость главы AMD позволяет понять, почему пресловутого «пузыря ИИ» проектировщики и изготовители чипов не слишком опасаются: они видят, что суммарный потенциальный рынок для их продукции растёт невероятными темпами. Вычислительная мощь потребного для обучения передовой модели «железа» по меньшей мере учетверяется каждый год (данные Epoch AI для интервала 2010-2025 гг.), и чем шире становятся возможности нейросетей, тем больше отыскивается для них практических приложений. Здесь даже принципиальное несовершенство генеративного ИИ играет на руку вендорам: подверженность моделей галлюцинациям корректируют внедрением «рассуждающих» контуров и агентными перепроверками, что, в свою очередь, кратно повышает необходимую для решения условной типовой задачи вычислительную мощь.
Правда, у нарастания производительности в геометрической прогрессии есть, увы, и оборотная сторона: ресурсов для его реализации тоже будет требоваться неуклонно больше. Согласно январской оценке Gartner, уже к 2030 году себестоимость ИИ-обработки типичного запроса в B2C-службу поддержки превысит 3 долл. США — то есть будет обходиться дороже, чем если ту же задачу решать ставшим привычным за последние десятилетия способом перенаправления таких обращений в офшорные кол-центры (печально знаменитая «индийская техподдержка», да). Здесь уже учтены все объективные преимущества автономной «умной» системы — вроде готовности работать 24/7, отсутствия необходимости регулярно нанимать и обучать живых операторов, выделения фонда оплаты их труда, забот об отпусках и больничных и т. п. А это ставит бизнес-заказчиков в крайне сложное положение: чем совершеннее становятся генеративные модели, чем лучше замещают собой людей на рабочих местах — тем меньше финансовая выгода от такой замены. Причём, начиная с не столь уж отдалённого времени, скудная выгода эта грозит и вовсе обернуться убытком: аналитики Gartner предупреждают, что для большинства компаний полная автоматизация окажется запретительно дорогой, — так что ИИ в B2C будут по большей части применять для повышения вовлечённости и укрепления лояльности клиентской базы, а вовсе не для замены львиной доли биологических сотрудников.
Не стоит также забывать и о растущих энергетических аппетитах ИИ-отрасли: согласно отчёту Global Energy Monitor (GEM), за 2026 г. совокупная мощность газовых электростанций в мире вырастет почти на 50%, и в бесспорных лидерах здесь, разумеется, США — на территории которых один за другим закладываются всё новые дата-центры для решения генеративных задач. При этом в 2025-м уже был произведён пересмотр прежних планов по возведению новых газовых электростанций — их теперь намереваются строить втрое больше, чем собирались до того. Треть из 252 ГВт совокупной мощности таких станций, запланированных ныне к вводу в строй на ближайшие годы, будут генерировать в непосредственной близости от ИИ-ЦОДов. Кстати, как там крокодиловы слёзы чиновников разного уровня по поводу глобального потепления, — всё ещё продолжают литься?

Локальный ИИ-помощник, ранее известный как Clawdbot, не допустит утечки ваших секретов (источник: openclaw.ai)
⇡#Новые модельки, ура!
Упомянутая уже GPT-5.2 в «думающей» версии Thinking стала основой для нового рабочего пространства Prism, доступного с конца января бесплатно всем обладателям учётной записи ChatGPT. Ориентированное на научные изыскания, в том числе коллективные, Prism построено на основе Crixet — облачной платформы LaTeX, которую в своё время приобрела OpenAI. Интеллектуальное рабочее пространство позволяет взаимодействовать с GPT-5.2 Thinking для контекстно ориентированной проработки идей, создания черновиков и редактирования работ (включая сам текст, уравнения, цитаты, иллюстрации — последние преобразуются к достойному публикации виду прямо из авторских набросков), формировать список литературы и дорабатывать текст с учётом обнаруживаемых системой работ по смежным тематикам, анализировать при помощи ИИ уравнения и диаграммы в LaTeX, а также цитаты и рисунки (опять-таки, с привязкой к контексту данной работы), использовать опционально голосовое редактирование.
Январь в целом оказался довольно богат на новые ИИ-модели: генеративной функциональностью обзавёлся Adobe Acrobat, бета-версию собственного ИИ-поисковика Scout запустила всё ещё продолжающая бороться за место под интернет-солнцем компания Yahoo, Google Chrome превратился в ИИ-браузер благодаря интеграции с Gemini, а в перспективе новая возможность Personal Intelligence обеспечит умному помощнику доступ к пользовательским данным в экосистеме компании — Mail, Photo, Docs и т. д., — получив сперва на то согласие владельца учётной записи. Amazon — которая умудрилась проспать ИИ-революцию, из-за чего аудитория её «умного» ассистента Alexa тает на глазах, — запустила одновременно с началом выставки CES 2026 сайт Alexa.com, на котором теперь базируется новая, модная, генеративная версия этого помощника, именуемого теперь Alexa+.
На этом фоне скромным может показаться достижение Петера Стейнбергера (Peter Steinberger) — основателя OpenClaw и лидера проекта Clawdbot, в последние дни января переименованного в Moltbot, чтобы не привлекать ненужного внимания адвокатов корпорации, развивающей ИИ-модель с весьма схожим на слух названием. Moltbot позиционируется как ИИ-агент с открытым кодом, управляющий всей «цифровой жизнью» своего пользователя — от составления информативных резюме получаемых электронных писем до контроля средств автоматизации умного дома. Главное его достоинство — автономность: он готов к работе в режиме 24/7 на весьма скромном локальном «железе», — энтузиасты по всему миру уже принялись скупать, в частности, неттопы Mac Mini в качестве аппаратной основы для Moltbot. Бесспорно, потенциал облачных ИИ многократно обширней, однако отсутствие опасений за свои данные для очень и очень многих начинает всё ощутимее перевешивать некоторую ограниченность реализуемых локально ИИ-функций.
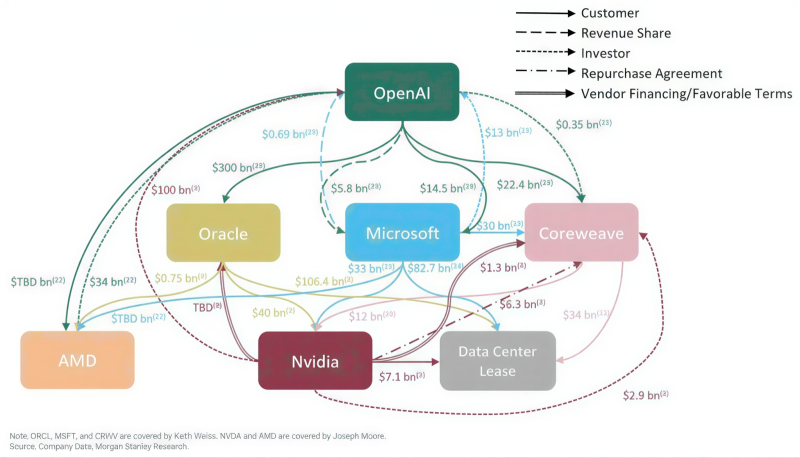
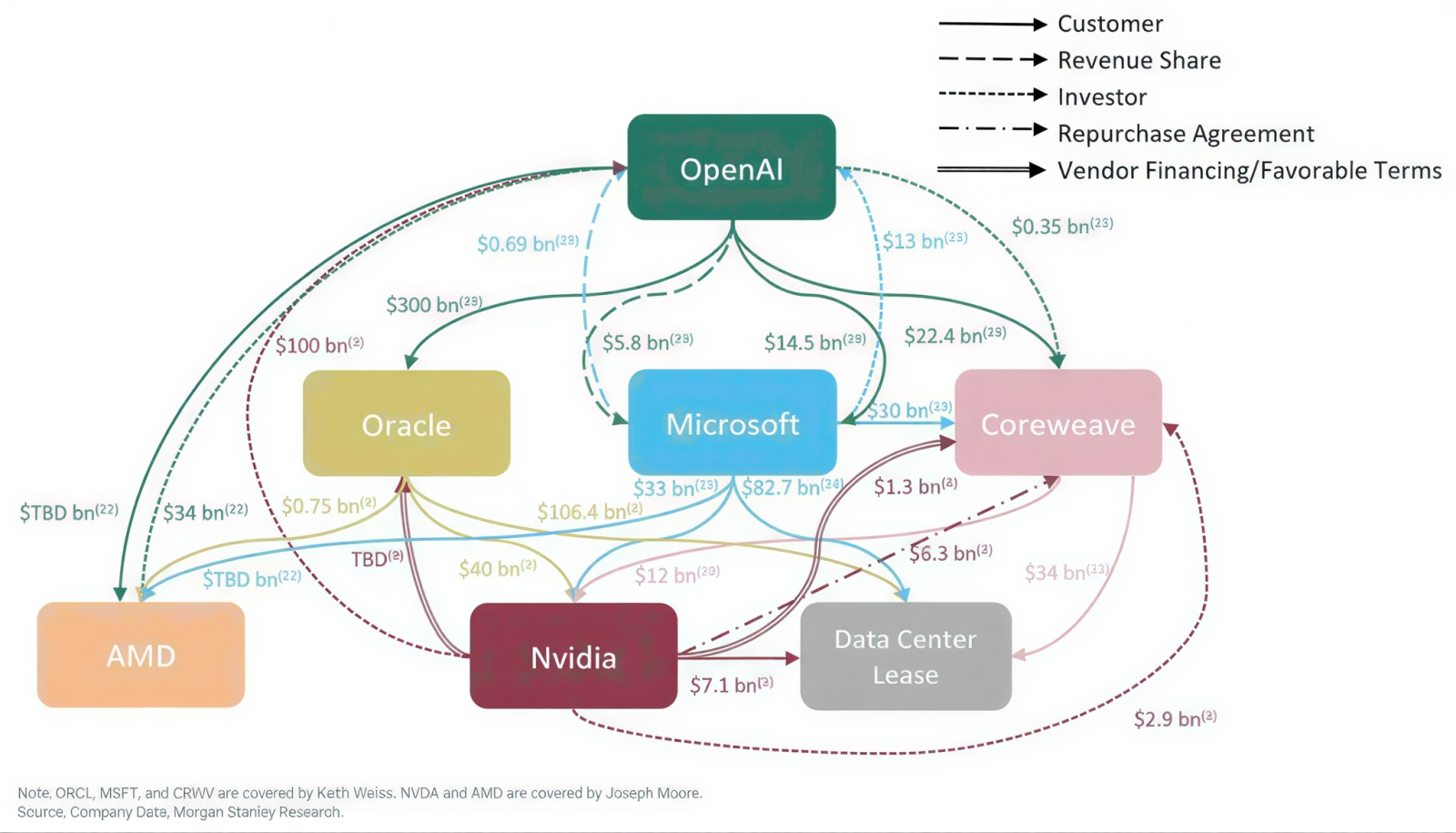
Экономика ИИ становится всё более замкнутой: поставщики одновременно выступают в роли клиентов, инвесторов и кредиторов, а первичный источник денежных средств становится все труднее отследить (источник: Morgan Stanley)
⇡#Не подмажешь — не сгенерирует
Не только для войны нужны три вещи — деньги, деньги и ещё раз деньги: для дальнейшего развития генеративных моделей они тем более необходимы. Вот и партнёры OpenAI — благодаря моделям серии GPT продолжающей оставаться, пусть и с немалым напряжением сил, лидером генеративной отрасли — по-прежнему осыпают разработчика деньгами. Если ранее аналитики предполагали, что продолжающая носить гордое звание стартапа компания, основанная ещё в 2015-м, сумеет привлечь в ходе первого в наступившем году раунда финансирования до 50 млрд долл., то теперь одни только суммарные планируемые инвестиции в неё от Microsoft, Nvidia и Amazon оцениваются в 60 млрд долл. А ведь с немалыми средствами наготове ждет своей очереди ещё и японская SoftBank вместе с ближневосточными фондами, да и классические институциональные инвесторы, привлечённые неутихающим накалом ажиотажа вокруг ИИ, наверняка не поскупятся на новый вклад в прекрасно отлаженную схему закольцованного финансирования. На этом фоне как-то даже трогательно выглядит инициатива Mozilla (некоммерческой организации, разработавшей самый популярный в мире в 2009-2011 гг. браузер Firefox) вложить 1,4 млрд долл. в «альянс бунтовщиков», который намерен развивать открытый ИИ в противовес коммерческим проприетарным моделям.

«Ты в полной безопасности, малютка» (источник: ИИ-генерация на основе модели Z Image)
⇡#Интеллект — дело небезопасное
Кто бы спорил с тем, что конфиденциальность данных нуждается в защите — и в эпоху ИИ особенно! Тем не менее в сравнительно новой для множества экспертов (в том числе и по информационной безопасности) отрасли промахи, даже самые грубые, просто-таки обязаны проявляться особенно часто. Они и проявляются: достаточно упомянуть прогремевший в январе скандал с «Бондусами» — оснащёнными разговорным генеративным ИИ плюшевыми игрушками компании Bondu, в числе прочих особенностей которых имеется такая милая функция, как доступ родителей — через веб-портал самого вендора — к текстовым расшифровкам диалогов их чад с этими изделиями. Не приходится удивляться, что первый же всерьёз взявшийся изучать ситуацию специалист по ИБ, даже не прибегая к каким-либо изощрённым техникам, довольно быстро получил доступ к полной базе — более 50 тыс. расшифровок — записей «Бондусов». Сама возможность изучать, какие ласковые прозвища чужие малыши дают своим игрушкам, что они любят и чего боятся, какие предпочитают блюда и какие танцевальные движения практикуют, неприятно поразила исследователя, — не говоря уже о том, что привязка учётной записи к почтовому аккаунту даёт возможность с относительной лёгкостью выяснять реальные имена и адреса родителей. К чести Bondu, надо сказать, что компания после того, как её оповестили о проблеме, прикрыла возможность доступа к базе буквально за считаные минуты, но сам факт столь откровенного ИИ-головотяпства более чем показателен. И этот случай в январе, увы, не единичный: на платформе Visual Studio Code (VSCode) Marketplace были обнаружены сразу два вредоносных ИИ-расширения (пострадали полтора миллиона систем); выявлен позволяющий крайне просто воровать личные данные из Microsoft Copilot эксплойт; и. о. главы Агентства кибербезопасности США (CISA) Мадху Готтумуккала (Madhu Gottumukkala) бестрепетно скормил ChatGPT конфиденциальные правительственные документы (наверняка просил «изложить коротко, простыми словами»), — и этим, безусловно, дело в наступившем году не ограничится. Пора бы уже начать привыкать, что с ИИ следует обращаться тщательнее!

Запись путешествия в интерактивном мире, созданном Genie 3 по следующей подсказке: «Environment prompt: A macro claymation garden featuring soft, deformable terrain. Character prompt: A modeled clay ladybug with stop-motion walk physics» (источник: deepmind.google/models/genie)
⇡#Давайте поИИграем
Свершилось: под самый конец месяца Google наконец-то открыла — пусть только для подписчиков с тарифным планом AI Ultra и только из США (250 долл./мес.), но открыла же! — доступ к анонсированной полгода назад «универсальной модели мира, способной генерировать разнообразные игровые среды», Genie 3. Пока пользователям — скорее, конечно, бета-тестерам — доступны три режима взаимодействия с моделью: создание эскизов мира, исследование ранее сгенерированного и микширование уже созданных миров. В первом режиме задействована text-to-image ИИ-модель Nano Banana Pro: по текстовому описанию она создаёт графический набросок, на основании которого уже собственно Genie 3 формирует трёхмерный интерактивный мир, в который и погружается пользователь. При необходимости изначальный эскиз легко скорректировать, а кроме того, можно воспользоваться и уже обработанными моделью чужими подсказками.
На данном этапе некорректно было бы называть Genie 3 «ИИ-движком»: хотя некоторый уровень интерактивности достижим, если прописать его в подсказке, фиксированной игровой механики (да и стабильности в обеспечении отклика мира на действия пользователя) не будет. Вдобавок погружение в сгенерированную виртуальность ограничено одной минутой времени, 24 кадрами в секунду и разрешением 720p, — но крупные разработчики (и их инвесторы) уже занервничали. Как отмечает Reuters, акции Take-Two Interactive снижались после обнародования Genie 3 в моменте на 8%, Roblox — на 13%, а ответственной за движок Unity одноимённой компании — сразу на 24%. Реакция биржи понятна: все помнят смешные, неуклюжие «этажерки» братьев Райт — и видят, в насколько совершенные самолёты они эволюционировали к настоящему времени. Даже откровенно грубые инструменты, позволяющие любому, кто хочет, хотя бы одним глазком заглянуть в дивный мир идеальной именно для себя игры, — серьёзная угроза коммерческим проектам. Их теперь банально будет с чем сравнивать! Так, с использованием Project Genie уже созданы виртуальные клоны популярных игр вроде Red Dead Redemption или The Legend of Zelda, — даже сцены из долгожданной GTA 6. Отныне разработчики оказываются в крайне неловком положении: на основании даже дозированной информации о грядущих играх (концепт-арты, скриншоты, обрывки сюжетных линий) фанаты будут создавать виртуальные их прототипы; и если паче чаяния релизная версия в чём-то окажется хуже ИИ-сгенерированного представления о ней, — горе побеждённым.
А пока счастливые подписчики Google AI Ultra наслаждаются прогрессивной виртуальной виртуальностью (игровыми мирами, сгенерированными на лету ИИ), приверженные более традиционным художественным ценностям геймеры вовсю выражают недовольство проникновением генеративных инструментов в дорогую для них отрасль. Достаточно вспомнить, как Running With Scissors буквально в течение пары дней отменила только-только анонсированный кооперативный шутер Postal: Bullet Paradise — как раз по причине громогласного возмущения поклонников серии Postal, протестовавших против использования генеративного ИИ в ходе разработки. В адрес создателей Clair Obscur: Expedition 33 тоже звучали схожие обвинения — хотя разработчики истово заверяли, что «всё в игре сделано исключительно человеком». Стоило Свену Винке (Swen Vincke), главе Larian, обмолвиться, что создатели Baldur’s Gate 3 рассматривают ИИ как «возможное средство ускорить оттачивание идей», как разъярённые фанаты подняли шум в соцсетях и на платформе Reddit, — разработчику пришлось оправдываться: мол, художники просматривают сгенерированные картинки только в поисках вдохновения; точно так же, как листают галереи на ArtStation или альбомы старых мастеров, например.
Эксперты ИТ-индустрии рассматривают такое поведение фанатов как тревожный сигнал и для других направлений применения ИИ. Ведь если даже геймеры возмущаются сгенерированными машиной задниками и требуют, чтобы за их деньги всю работу в предлагаемых им играх выполняли исключительно люди, — не воспримут ли и другие пользователи ИИ-услуг замену человеческого труда генеративным как понижение не просто себестоимости, но абсолютной ценности потребляемой услуги? Если да и если с этим предубеждением не выйдет успешно бороться, сама идея оптимизации ИТ-отрасли (и других направлений экономики) за счёт генеративных моделей может оказаться под ударом.
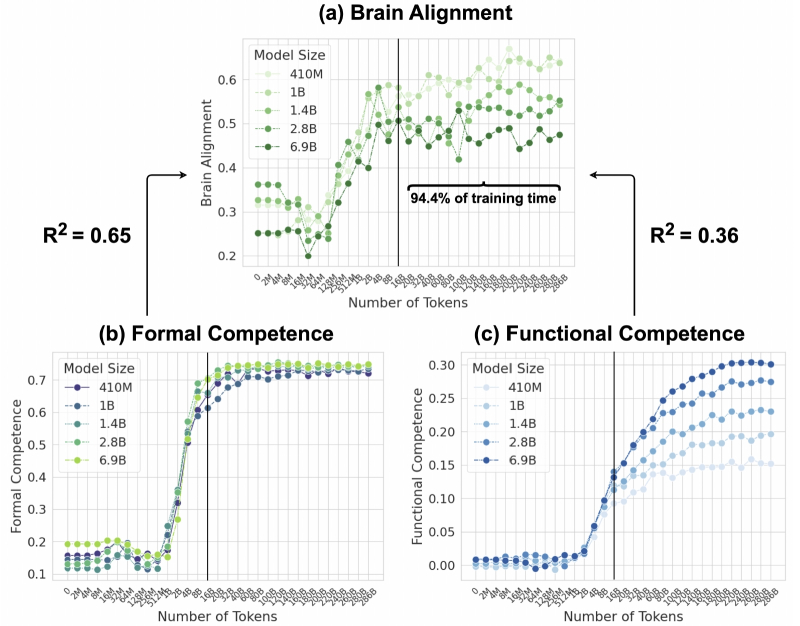
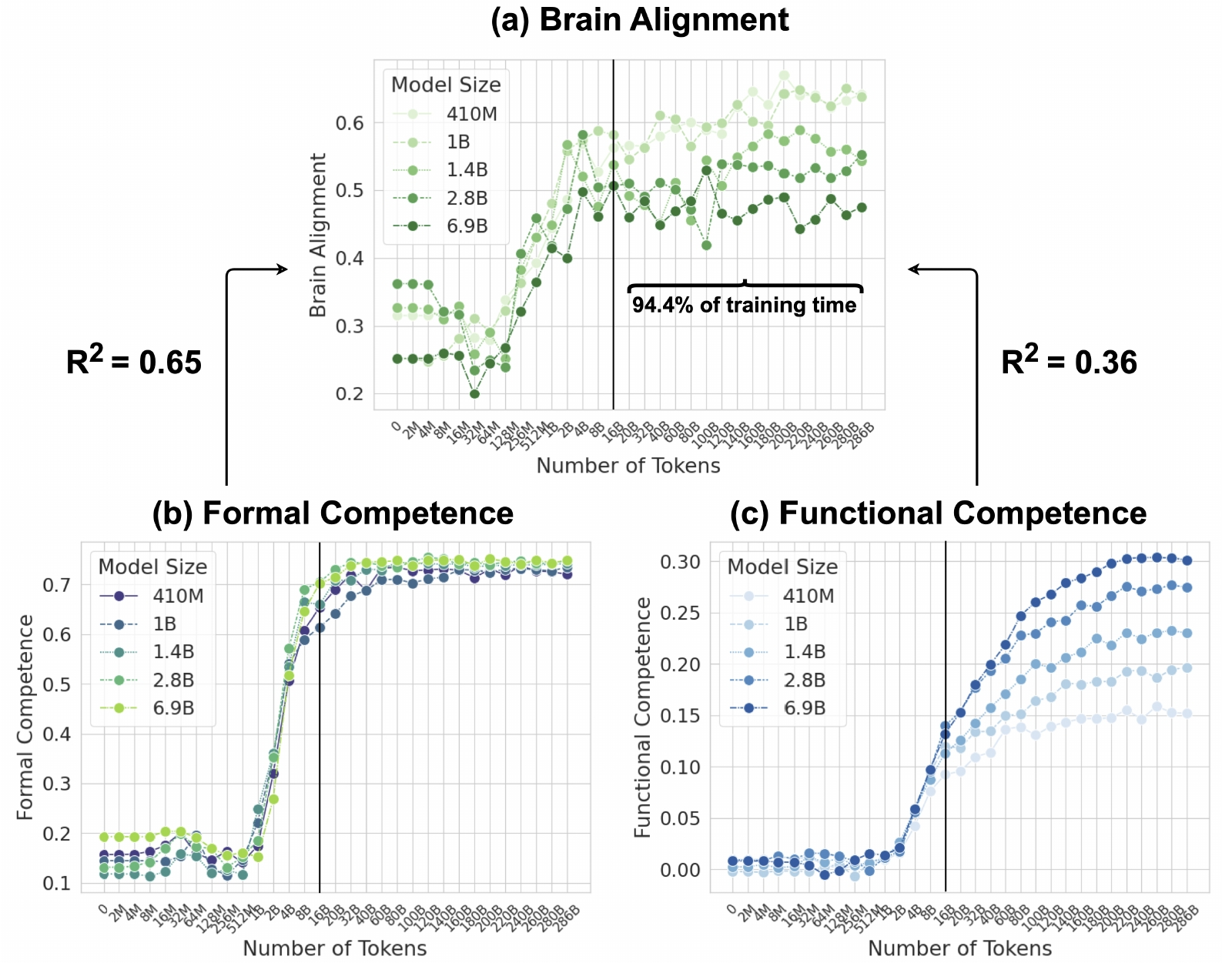
Соответствие модели сети человеческого языка в основном определяется формальной, а не функциональной лингвистической компетенцией. (a) Среднее соответствие мозговой активности по пяти моделям Pythia и пяти наборам данных записи мозговой активности, нормализованное по межсубъектной согласованности на протяжении всего обучения. (b) Средняя нормализованная точность тех же моделей на эталонных показателях формальной лингвистической компетенции (два эталонных показателя). (c) Средняя нормализованная точность на эталонных показателях функциональной лингвистической компетенции (шесть эталонных показателей). Ось x логарифмически расположена с шагом до 16 млрд токенов, отражая динамику раннего обучения, а затем равномерно с шагом 20 млрд токенов от 20 млрд до ~300 млрд токенов (источник: aclanthology.org/2025.emnlp-main.1237/)
⇡#Думать будем, нет?
Способна ли машина мыслить? Научное определение мышления, как ни странно, вовсе не перегружено философскими категориями: в широком смысле оно синонимично познанию; в узком — сводится к решению задач, т. е. к подкреплённому логикой переходу от неких условий, задающих проблемную ситуацию, к результату. В узком плане «рассуждающие» ИИ-модели, выходит, уже вполне резонно называть мыслящими: составлять план действий и отыскивать ранее неведомые пути к его реализации лучшие из них сегодня вполне способны. Это в очередной раз подтвердил совместный проект Университета Цинхуа, Пекинского института общего искусственного интеллекта (BIGAI) и Университета штата Пенсильвания, целью которого было показать, что генеративная модель способна самообучаться — самостоятельно ставя перед собой вопросы и находя корректные ответы на них — в ходе экспериментов с компьютерным кодом. Исследователи создали систему под названием Absolute Zero Reasoner (AZR), которая сперва при помощи БЯМ (локальной версии Qwen с 7 или 14 млрд параметров) генерирует сложные, но принципиально решаемые программистские задачи на языке Python, а после задействует ту же модель для поиска решения, в итоге проверяя на практике, как именно исполняется созданный ею код. Результат такого натурного эксперимента — успех или неудача — используется в качестве обратной связи для корректировки весов центральной в этой системе БЯМ, которая в итоге становится совершеннее как в плане постановки новых, ещё более сложных задач, так и в их решении. Правда, пока в системе AZR отсутствует сверхцелеполагание — собственная (внутренняя, не привнесённая живыми операторами) мотивация решать всё усложняющиеся задачи; и совершенно не факт, что однажды чудесным образом она в многослойной нейросети самозародится.
В то же время и отвергать эту возможность априори было бы опрометчиво. По крайней мере, так считает группа исследователей из Федеральной политехнической школы Лозанны (EPFL), Массачусетского технологического института (MIT) и Технологического института Джорджии, которые показали в представленной на научной конференции ещё в конце 2025 г. работе (обнаруженной ИИ-энтузиастами с профильного форума только в январе 2026-го), что лежащие в основе популярных коммерческих чат-ботов БЯМ уже демонстрируют сильную корреляцию картины прохождения сигналов в своих слоях перцептронов с той, что наблюдается нейрофизиологами в человеческой языковой сети — области мозга, отвечающей за обработку языка. Иными словами, структурно разные системы (архитектура плотной глубокой нейросети разительно отличается от устройства биологической нейронной ткани) при выполнении схожих функций реализуют весьма похожие сигнальные паттерны. Это, кстати, весьма напоминает биологический принцип конвергенции — возникновение сходных признаков у неродственных организмов, если те занимают схожие (или и вовсе одни и те же) экологические ниши; взять хотя бы формы тел дельфинов и акул, даром что первые — водные млекопитающие, а вторые — хрящевые рыбы. Исследователи подтвердили, что с ростом возможностей (читай — числа рабочих параметров) нейросетей корреляция с паттернами работы языковой сети головного мозга возрастает, — это можно считать довольно весомым аргументом в поддержку оптимистического настроя ИИ-энтузиастов. Может, и вправду, если увеличить число параметров БЯМ на десяток-другой триллионов, а производительность подлежащего «железа» — на несколько иоттафлопс, полученная в итоге супермашина начнёт-таки не просто решать предлагаемые ей задачки, а именно мыслить?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex