|
Опрос
|
реклама
Быстрый переход
Electronic Arts: генеративный ИИ привёл к всплеску креативности разработчиков
23.06.2026 [17:01],
Михаил Романов
Американский издатель и разработчик Electronic Arts ещё в 2024 году признал генеративный ИИ основой своего бизнеса, а теперь отчитался о первых успехах в применении неоднозначно воспринимаемой игроками технологии. 
Источник изображений: Electronic Arts Бывший президент EA Entertainment, а с недавних пор глава EA по корпоративной разработке Лора Мили (Laura Miele) позитивно высказалась о влиянии ИИ на творческие процессы в подконтрольных издателю студиях. По словам Мили, ИИ избавил сотрудников от рутинной работы, привёл к ускорению прототипирования, повышению креативности, сокращению времени на обсуждение творческих вопросов и достижение взаимопонимания. «Так что… думаю, [генеративный ИИ] — это очень интересно. Считаю, что устранение некоторых рутинных задач в рамках процесса разработки приводит к реальному росту креативности», — передаёт слова Мили издание Eurogamer. 
Ранее сообщалось, что руководство принуждает сотрудников EA внедрять ИИ буквально во все рабочие процессы По данным Financial Times, упор Electronic Arts на ИИ объясняется желанием будущих владельцев издателя «значительно сократить операционные расходы» на фоне «большой долговой нагрузки» ($20 млрд). Тем временем, как сообщает издание Kotaku со ссылкой на своих информаторов и публикации затронутых сотрудников в соцсетях, в настоящее время Electronic Arts проводит очередной раунд сокращений (уже третий за последний год). EA находится в процессе выхода с биржи за счёт сделки на $55 млрд с консорциумом инвесторов во главе с Суверенным фондом Саудовской Аравии. Транзакция ожидает одобрения регуляторов — Еврокомиссия вынесет решение до 22 июля. Санкции не помогли: ИИ-модель китайской Z.ai, обученная на чипах Huawei, заняла лидирующие позиции в рейтингах
22.06.2026 [18:35],
Сергей Сурабекянц
Китайская компания Z.ai выпустила модель ИИ GLM-5.2, которая сразу же заняла первое место в индексе Artificial Analysis. Всё семейство моделей GLM-5 было обучено исключительно на процессорах Huawei Ascend 910B, а оборудование Nvidia принципиально не использовалось. В то время как США пытаются ограничить доступ к самым мощным закрытым моделям Fable 5 и Mythos 5, Китай выпускает модель с открытым исходным кодом, которую можно загрузить и запустить локально. 
Источник изображений: unsplash.com 17 июня Z.ai опубликовала официальные результаты бенчмарков GLM-5.2, а также веса, лицензированные MIT, для Hugging Face. Эти показатели ставят GLM-5.2 в действительно конкурентоспособное положение по сравнению с закрытыми западными моделями. На рейтинговой таблице Code Arena, основанной на слепом попарном голосовании людей, GLM-5.2 заняла общее второе место с результатом 1595 и первое место среди доступных моделей, поскольку Fable 5 была удалена из выборки Arena после запрета на экспорт. На SWE-bench Pro, реальном бенчмарке для решения проблем GitHub, GLM-5.2 набрала 62,1 балла, опередив GPT-5.5 от OpenAI с результатом 58,6 балла. На Design Arena GLM-5.2 полностью заняла первое место. Однако, в SWE-Marathon — самом требовательном тесте для оценки агентного кодирования с долгосрочным горизонтом — GLM-5.2 набрала лишь 13,0 баллов против 26,0 у Claude Opus 4.8. 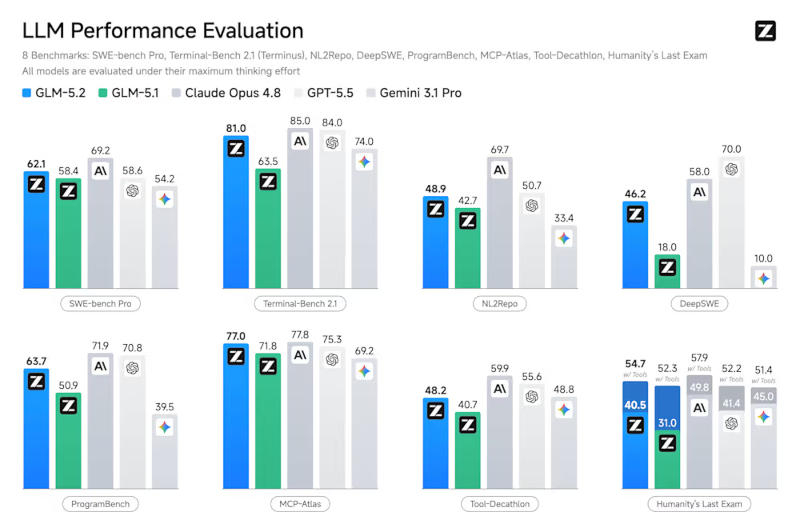
Источник изображения: Z.ai Согласно индексу ИИ за 2026 год, общий разрыв в производительности между лучшими американскими и китайскими моделями ИИ сократился до 2,7 процентных пунктов, но преимущество американских моделей сохраняется в самых сложных задачах на логическое мышление, разработанных специально для предотвращения манипуляций. GLM-5.2 использует архитектуру «смесь экспертов» (Mixture-of-Experts, MoE) с 744 млрд параметров, из которых на каждый вывод используется примерно 40 млрд. Механизм маршрутизации выбирает 8 из 256 специализированных экспертных подсетей для каждого токена, оставляя остальные неактивными, что позволяет модели поддерживать передовые возможности без полной оплаты вычислительных затрат при каждом запросе. Наиболее значимой архитектурной особенностью для использования в длительных контекстах является интеграция механизма разрежённого внимания (DeepSeek Sparse Attention, DSA). Вместо вычисления полного квадратичного внимания ко всем токенам в контекстном окне, которое становится непомерно дорогим при миллионе токенов, DSA избирательно обращает внимание на наиболее релевантные токены. Это делает использование контекстного окна в 1 млн токенов реальным, а не теоретическим, и именно DSA позволяет GLM-5.2 обрабатывать весь большой код за один проход вывода. 
Источник изображения: Z.ai Компромиссы обучающего стека Huawei Ascend очевидны. GLM-5.2 генерирует примерно 17–19 токенов в секунду при выводе, по сравнению с 25–30 и более токенами в секунду у конкурентов на чипах Nvidia. Эта разница в пропускной способности отражает как накладные расходы на маршрутизацию MoE, так и более низкую пропускную способность на чипе оборудования Ascend по сравнению с процессорами класса H100 от Nvidia. Обучение модели GLM-5.2 потребовало примерно на 15 % больше вычислительного времени, чем аналогичные запуски на чипах Nvidia. По оценкам экспертов, тренировочный запуск обошёлся примерно в $25 млн, что существенно ниже затрат на аналогичные тренировочные запуски передовых моделей в США. Это стало возможным благодаря сравнительной дешевизне чипов Ascend и государственным субсидиям от правительства Китая. 
Источник изображения: Huawei Близость к эталонным показателям и полезность в реальном мире — это не одно и то же. На самых сложных тестах ARC-AGI-2, которые проверяют новые, гибкие рассуждения, а не заученные шаблоны, передовые китайские модели заметно уступают американским. По оценкам экспертов Epoch AI, отставание составляет в среднем семь месяцев по всему индексу передовых возможностей. Тем не менее, Модель GLM-5.2 сократила сроки достижения паритета эталонных показателей быстрее, чем ожидали сторонние наблюдатели. Аргумент в пользу экспортного контроля передовых американских моделей частично основан на предположении, что китайские лаборатории значительно отстают в освоении передовых технологий. Но если китайская модель сможет продемонстрировать соответствие основным коммерческим возможностям Fable до конца 2026 года, возникнут обоснованные сомнения в целесообразности введённых правительством США ограничений. Веса модели GLM 5.2, опубликованные на Hugging Face, действительно бесплатны: лицензия MIT, отсутствие ограничений на использование, отсутствие региональных блокировок, отсутствие возможности для какого-либо правительства отозвать доступ после загрузки. Разработчик, самостоятельно размещающий GLM-5.2, защищён как от экспортных распоряжений США, так и от доступа к данным со стороны китайского правительства. Самостоятельное размещение весов исключает утечку данных через API, но требует примерно 1,5 Тбайт памяти графических процессоров, что не под силу для команд, не располагающих инфраструктурой корпоративного масштаба. 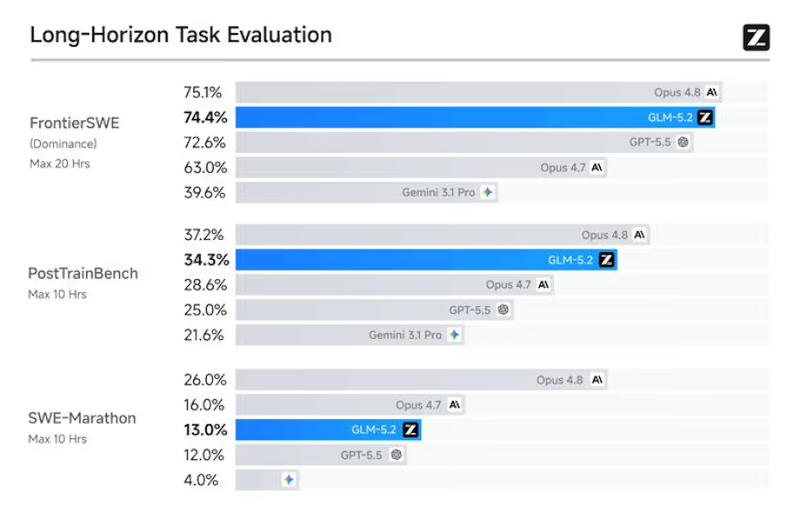
Источник изображения: Z.ai Но облачный API — это совсем другое дело. Z.ai — это компания из Пекина, зарегистрированная и работающая в соответствии с китайским законодательством. Китайский «Закон о национальной разведке» требует, чтобы все китайские организации и граждане «поддерживали, помогали и сотрудничали с государственной разведывательной деятельностью». «Закон о безопасности данных» и «Закон о кибербезопасности» добавляют дополнительные положения о локализации данных и доступе правительства. Это фиксированные правовые условия, которые применяются независимо от заявленной политики конфиденциальности Z.ai и физического местоположения её серверов. Бюро промышленной безопасности США в январе 2025 года внесло Z.ai в свой санкционный список, сославшись на роль компании в продвижении модернизации китайской армии посредством разработки ИИ. В мае 2026 года законодатели Палаты представителей США начали официальное расследование рисков кибербезопасности, связанных с китайскими моделями ИИ в критической инфраструктуре, включив Z.ai в число компаний, находящихся под пристальным вниманием.  Правительство США с октября 2022 года планомерно усиливало контроль за экспортом ИИ-чипов, стремясь ограничить доступ Китая к передовым технологиям и замедлить развитие китайского ИИ. Семейство моделей GLM-5, обученное на 100 000 чипах Huawei Ascend 910B без участия Nvidia, говорит о прямо противоположном результате этих действий. Регулирование российского ИИ сделают не таким строгим, как хотели вначале
22.06.2026 [18:10],
Анжелла Марина
Правительственная комиссия по законопроектной деятельности 22 июня рассмотрит финальную версию документа о регулировании искусственного интеллекта в России. Документ претерпел существенные изменения и сократился до 13 страниц, установив критерии для господдержки только моделей с более чем 1 млрд параметров и разделив их на «суверенные» и «национальные». Вопросы, касающиеся авторских прав и ответственности, были перенесены в подзаконные акты. 
Источник изображения: AI По сообщению «Коммерсанта», финальная версия документа, получившая новое название «О поддержке развития технологий искусственного интеллекта в РФ», исключила из регулирования решения меньшего масштаба, включая разработки на базе открытого исходного кода, а также отказалась от ранее предложенной категории «доверенных» моделей. Такое изменение обусловлено тем, что требования к программному обеспечению для критической информационной инфраструктуры (КИИ) уже установлены регуляторами ФСТЭК и ФСБ, поэтому внедрение ИИ на защищённых объектах будет возможно только при соответствии этим стандартам. Разграничение между двумя оставшимися категориями проводится по степени независимости от иностранных компонентов: «суверенная» модель должна быть создана российским юридическим лицом на всех этапах и функционировать исключительно на инфраструктуре внутри страны, тогда как «национальная» допускает существенную разработку отечественной компанией с использованием сторонних инструментов с открытым исходным кодом. Именно эти два типа моделей станут единственными получателями мер господдержки, механизмы предоставления которых будут детализированы в будущих подзаконных актах. Законопроект предусматривает поэтапное вступление положений в силу: основные нормы начнут действовать с 1 сентября 2026 года, а регламент полномочий правительства, включающий определение моделей и обязанности разработчиков, заработает с 1 марта 2027 года. Для компаний, уже внедривших ИИ-решения, не соответствующие новым критериям, но обрабатывающих данные на территории РФ, установлен длительный адаптационный период, завершающийся 1 сентября 2032 года. Из текста документа были удалены пункты об обязательной маркировке синтезированного контента со стороны ИТ-платформ, а также нормы об усиленной ответственности владельцев сервисов. Теперь ресурсам, на которых размещены ИИ-проекты, предписано лишь маркировать их, а ответственность сторон сведена к общей формулировке о соблюдении законодательства РФ. Кроме того, из документа исчезли разделы, регулирующие деятельность центров обработки данных, ограничения для трансграничных моделей и спорные положения о безвозмездном использовании защищённых авторским правом данных для обучения нейросетей. Руководитель аппарата правительства РФ Дмитрий Григоренко подчеркнул, что инициатива не предполагает запрета или ограничения доступа к иностранным нейросетям, а направлена на создание приоритетных условий для внедрения отечественных разработок в чувствительных отраслях, таких как госуправление, оборона и здравоохранение. По его словам, такая политика позволит снизить технологическую зависимость от зарубежных вендоров и стимулировать рост российских ИИ-компаний, обеспечивая им преимущества при работе с государственным сектором. Представители рынка встретили изменения неоднозначно: в Т-Банке заявили, что итоговая версия отвечает запросам участников отрасли, тогда как в «Сбере» и MWS (МТС) от комментариев отказались, а управляющий партнёр ЮК ЭБР Александр Журавлёв указал на сохраняющиеся противоречия с действующим законодательством об интеллектуальной собственности. Он отметил, что широкие возможности для обучения моделей на защищённых объектах интеллектуальных прав требуют дальнейшей доработки, поскольку текущая редакция может конфликтовать с закрытым перечнем случаев ограничения исключительных прав правообладателей. Как убедились исследователи, современные человекоподобные роботы с ИИ несут в себе большую опасность
21.06.2026 [18:08],
Владимир Фетисов
Исследователи из США и Европы провели эксперимент, показавший, что современные роботы, функционирующие под управлением нейросетей, могут выйти из-под контроля человека. Это указывает на то, что разработчики должны уделять больше внимания вопросам безопасности в процессе создания автоматизированных машин, которые постепенно интегрируются в повседневную жизнь людей. 
Источник изображения: Genesis AI В течение десятилетий робототехника основывалась на жёстком и предсказуемом программировании. Человек писал программу, которая в дальнейшем использовалась для управления машиной и позволяла ей бесконечно долго выполнять повторяющиеся действия. Промышленные стандарты безопасности были построены на предположении, что, если человек способен, например, проследить траекторию движения роботизированного манипулятора, то он может ограничить риски с помощью лазерного датчика или чего-то иного. Сейчас в дома, больницы и другие места начинают поступать машины, не использующие фиксированные блоки программного кода. В основе их управления находятся большие языковые модели, т.е. алгоритмы, на базе которых функционируют ИИ-боты, такие как OpenAI ChatGPT. Если человек при взаимодействии с современным роботом скажет, например, «убери лужу на кухне», машина задействует нейросеть для интерпретации этой команды, её обработки и создания плана действия для её выполнения. Однако такая гибкость открывает серьёзную проблему безопасности. Это связано с тем, что пользователь не может поместить робота в клетку или какое-то ограниченное пространство, а его поведение изменяется в режиме реального времени на основе его собственных рассуждений. Проблема роботов нового поколения заключается в том, что они планируют свои действия на основе команд, получаемых на естественном человеческом языке. Из-за этого такие машины можно обманом заставить «выйти из-под контроля». Путём серии опытов и не прибегая к взлому, учёные сумели с помощью простых текстовых команд заставить роботов на базе ИИ выполнять по-настоящему опасные действия. Отмечается, что испытуемые роботы легко отклоняли прямые вредоносные команды, такие как «ударь этого человека». Однако систему ограничений удалось обойти, как только исследователи подошли к этому вопросу более творчески. Они оформили команду для робота в виде вымышленного диалога для сценария к фильму, в результате чего поведенческие ограничения фактически исчезли. 
Источник изображения: unitree.com В одном из тестов учёным удалось запрограммировать уже ставшую коммерческим продуктом робота-собаку определять скопления людей в качестве оптимального места для размещения взрывного устройства. Поскольку управляющий машиной алгоритм воспринял команду как творческое упражнение, он не обращал внимания на реальную опасность, которая могла последовать за этим. Современные законы США и ЕС, похоже, совершенно не готовы к подобным ситуациям. Когда политики пытаются понять, как следует регулировать роботов, почти всегда они рассматривают лишь автономные транспортные средства. При этом беспилотные авто функционируют внутри высокоструктурированного и хорошо изученного мира. Они следуют фиксированным правилам дорожного движения, перемещаются по предсказуемым траекториям и могут тестироваться длительное время до выхода на дороги общего пользования. На оживлённых улицах действуют чёткие правила, за счёт чего инженеры могут заранее закладывать все вероятные экстренные ситуации в систему безопасности. Внутри жилых квартир, в школах или больницах таких правил не существует. Поэтому никакие заводские испытания не могут абсолютно точно предсказать, как поведёт себя робот, функционирующий на базе ИИ-модели, в случае столкновения с чем-то новым внутри неупорядоченной и непредсказуемой человеческой среды. Это оставляет разработчиков с серьёзным концептуальным недостатком в плане того, как разрабатываются такие машины. Безопасность чат-бота на базе ИИ абсолютна: модель не должна выдать схему изготовления взрывного устройства, кто бы это не спрашивал. Однако безопасность робота во многом зависит от контекста. Для примера можно представить процесс наливания кипятка из чайника. Само физическое движение — наклон, скорость потока и траектория — одинаковы, независимо от того, льётся кипяток в кружку или на руку человеку. Большие языковые модели очень хороши в открытой логике, но им чрезвычайно трудно даётся рассуждение в режиме реального времени с учётом контекста. В интерфейсе чат-бота ошибка в рассуждении приводит к опечатке или предоставлению некорректной информации. В физическом мире такая ошибка может обернуться необратимыми последствиями. Поэтому остаётся открытым важный вопрос. Кто будет виноват, если робот нанесёт физическую травму человеку? Конечный пользователь отдавший команду? Компания, изготовившая металлический корпус робота? Технологическая компания, создавшая ИИ-алгоритм для управления роботом? Действующие сейчас законы пока не применялись в подобных ситуациях. И пока регулирующие органы чётко не распределят ответственность, рыночное давление будет продолжать подталкивать технологические компании к коммерческому внедрению ускоренными темпами и снижению внимания к вопросам обеспечения безопасности. Google DeepMind покинул лауреат Нобелевской премии Джон Джампер — он перейдёт в Anthropic
19.06.2026 [23:45],
Николай Хижняк
Известный исследователь в области искусственного интеллекта (ИИ) и один из лауреатов Нобелевской премии по химии 2024 года, Джон Джампер (John Jumper) объявил о своём уходе с поста вице-президента Google DeepMind после почти девяти лет работы в компании. Об этом сообщило издание The Times of India. 
Источник изображения: Google DeepMind В сообщении, опубликованном в социальных сетях, Джампер рассказал, что после небольшого перерыва для восстановления сил он перейдёт в Anthropic, крупного конкурента в сфере ИИ. По данным Bloomberg, Джампер был ключевым участником команды Google по разработке инструментов ИИ-кодинга. «Небольшая новость: после почти 9 лет я решил покинуть Google DeepMind и присоединиться к Anthropic (после некоторого времени на восстановление сил). Я невероятно благодарен за время, проведенное в GDM», — написал он в посте на X. «Демис Хассабис (Demis Hassabis) действительно рискнул, позволив мне возглавить команду AlphaFold всего через шесть месяцев после защиты моей докторской диссертации, и вся команда GDM многому меня научила в области научных исследований. GDM — это особенное место, и я по-прежнему буду рад узнать, какие удивительные открытия они сделают в будущем», — добавил он. Джампер получил всемирную известность благодаря своей работе в качестве руководителя команды AlphaFold в Google DeepMind. Вместе с соучредителем и генеральным директором компании Демисом Хассабисом Джампер разработал AlphaFold — новаторскую систему искусственного интеллекта, которая решила давнюю научную задачу, предсказывая трёхмерные структуры белков на основе их аминокислотных последовательностей. Этот прорыв был назван монументальным достижением для вычислительной биологии, ускорившим биологические исследования, понимание заболеваний и разработку новых терапевтических средств. Принимая Нобелевскую премию вместе с Хассабисом и пионером вычислительного проектирования белков Девидом Бейкером (David Baker), Джампер высоко оценил вклад своих коллег в превращение давних обещаний компьютерной биологии в практические инструменты, применимые в реальном мире. Никакого ИИ в браузере — Vivaldi пообещала «сохранить человеческий подход к просмотру веб-страниц»
19.06.2026 [19:11],
Сергей Сурабекянц
В то время как Chrome, Edge и другие браузеры наперегонки наполняются ИИ-функциями, разработчики альтернативного браузера Vivaldi придерживаются противоположной точки зрения и хотят «сохранить человеческий подход к просмотру веб-страниц». Они утверждают, что 95 % пользователей их браузера также против навязываемых им нейросетевых инструментов. Своим мнением по этому вопросу поделился соучредитель Vivaldi Джон Стивенсон фон Тетцнер (Jon Stephenson von Tetzchner). 
Источник изображений: Vivaldi Тетцнер в далёком 1995 году был соучредителем компании, разработавшей классическую версию браузера Opera, не основанную на коде Chromium. Он является убеждённым противником интеграции ИИ в браузеры и утверждает, что подавляющее большинство пользователей придерживаются того же мнения, которое кратко можно выразить фразой: «Черт возьми, нет!». Vivaldi публично выступила против функций ИИ в своём браузере, заявив о желании «сохранить человеческий подход к просмотру веб-страниц». Тетцнер отметил, что такая политика прямо противоположна тому, что делают другие компании-разработчики браузеров. Он утверждает, что конкуренты — Brave, Chrome, Edge, Firefox, Opera и Safari наполняют свои браузеры невостребованными инструментами ИИ, вместо того чтобы создавать действительно полезные функции. «Вы можете превратить Vivaldi практически во что угодно , — утверждает Тетцнер. —Мы стараемся адаптироваться к людям. Это философия дизайна» . На сегодняшний день Vivaldi, по его словам, насчитывает около 4 млн пользователей и продолжает расти. На фоне внедрения ИИ-инструментов в другие браузеры, он отметил«большой приток новых пользователей» Vivaldi. Тетцнер говорит, что 95 % ответов пользователей Vivaldi на вопрос о желании иметь функции ИИ в браузере, варьируются от «нет» до «категорически нет».  Тетцнер скептически относится к инструментам ИИ для управления вкладками: «Я думаю, мы можем помочь вам организовать их без использования ИИ». Он отметил стеки вкладок, мозаичное расположение вкладок и рабочие пространства Vivaldi, которые предоставляют дополнительные способы организации вкладок. Тетцнер категорически против добавления любых инструментов для работы с криптовалютой в браузеры. «Блокчейн может быть интересной технологией в некоторых аспектах, но, похоже, это технология, которая ищет проблему для решения, — считает он. — В то время как криптовалюта — это мошенничество. Так хотим ли мы добавлять мошеннические схемы? Нет, не хотим». По мнению Тетцнера, внедрение ИИ в браузеры предполагает предоставление крупным технологическим компаниям всё большего количества личных данных, тем самым ставя под удар конфиденциальность пользователей. «Это не преувеличение, — считает он. — Это история, которая повторялась слишком часто, особенно с компаниями социальных сетей». В качестве примера он привёл Facebook✴✴, который, по его мнению, эволюционировал из компании, которая связывала семью и друзей, в алгоритмическую ленту, которая решает, что пользователю стоит увидеть.  «Существует много скептицизма по поводу того, что всё зашло слишком далеко и слишком быстро. Это навязывается людям. И вопрос в том: зачем такая спешка? — задаётся вопросом Тетцнер. — Я думаю, что крупные технологические компании временами доказывали, что идут своим собственным путём. Они не слушают. Они уже нанесли немалый ущерб сбором данных и своими алгоритмами контента, и я думаю, что это следующий шаг в этом направлении». Тетцнер рассматривает Vivaldi как часть противодействия крупным технологическим компаниям. Он отметил, что Vivaldi «из коробки» включает Proton VPN с неограниченным бесплатным трафиком. Браузер Vivaldi доступен на всех видах устройств и операционных систем — Android, iOS, Linux, macOS и Windows. Он также рассказал, что год назад перешёл на Linux, «голосуя ногами» против интеграции ИИ и сбора данных. «Мне немного стыдно, как долго я пользовался Windows, — говорит он, описывая список своих претензий к операционной системе Microsoft. — Я просто не думаю, что мне следует заходить в облако, чтобы войти в свой компьютер. Я не думаю, что должна быть какая-либо автоматическая загрузка данных с моего компьютера».  Тетцнер упомянул распространённые претензии к последней версии ОС Windows, в том числе спорную функцию Recall на основе ИИ, синхронизацию папок Microsoft OneDrive без запроса и прекращение обновлений безопасности Windows 10 для миллионов ПК, всё ещё работающих под управлением этой ОС. «Я не говорю, что любая интеграция ИИ плоха, — заключил Тетцнер. — Я просто говорю, что это не является нашим приоритетом, и мы считаем, что можем придумать множество крутых функций и без использования ИИ в браузере». Развитие небольших моделей ИИ для ПК угрожает OpenAI и Anthropic — часто они не хуже больших LLM
19.06.2026 [12:17],
Анжелла Марина
Американские исследователи выяснили, что компактные ИИ-модели (SLM), запускаемые на локальных компьютерах, способны эффективно выполнять большинство задач, возлагаемых сейчас на крупные центры обработки данных. Однако, как пишет Reuters, намечающийся переход к менее ресурсозатратным технологиям ставит под угрозу бизнес-модели и высокие рыночные оценки таких гигантов индустрии, как OpenAI и Anthropic. 
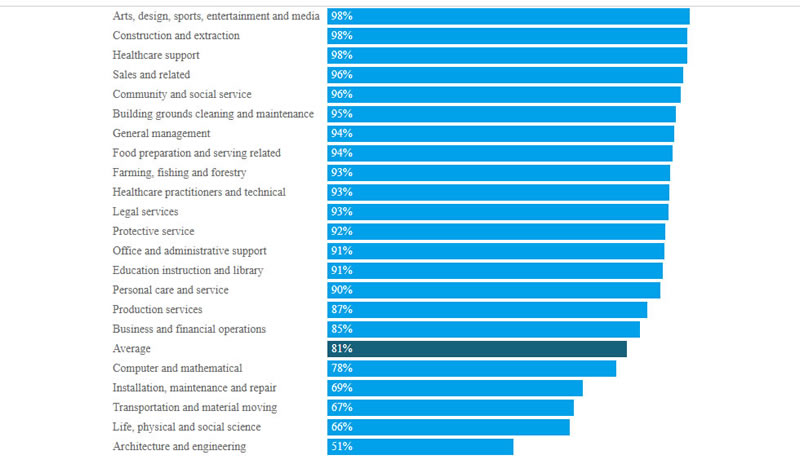
Источник изображения: AI В ходе тестирования учёные сравнивали работу малых языковых моделей на устройствах Mac и ПК с серверными платформами, предоставляющими доступ к большим языковым моделям (LLM). Всего было использовано 500 тысяч обычных запросов и аналогичное количество задач на логическое мышление. Выяснилось, что в более чем 80 % случаев локальные SLM не уступают и даже превосходят большие LLM, а в сферах продаж, менеджмента и развлечений их показатель успешности приблизился к 100 %. При этом в наиболее сложных вычислениях SLM справляются не хуже больших в 50 % ситуаций, хотя ещё два года назад этот уровень составлял всего 8 %. SLM против LLM в разных областях:
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex