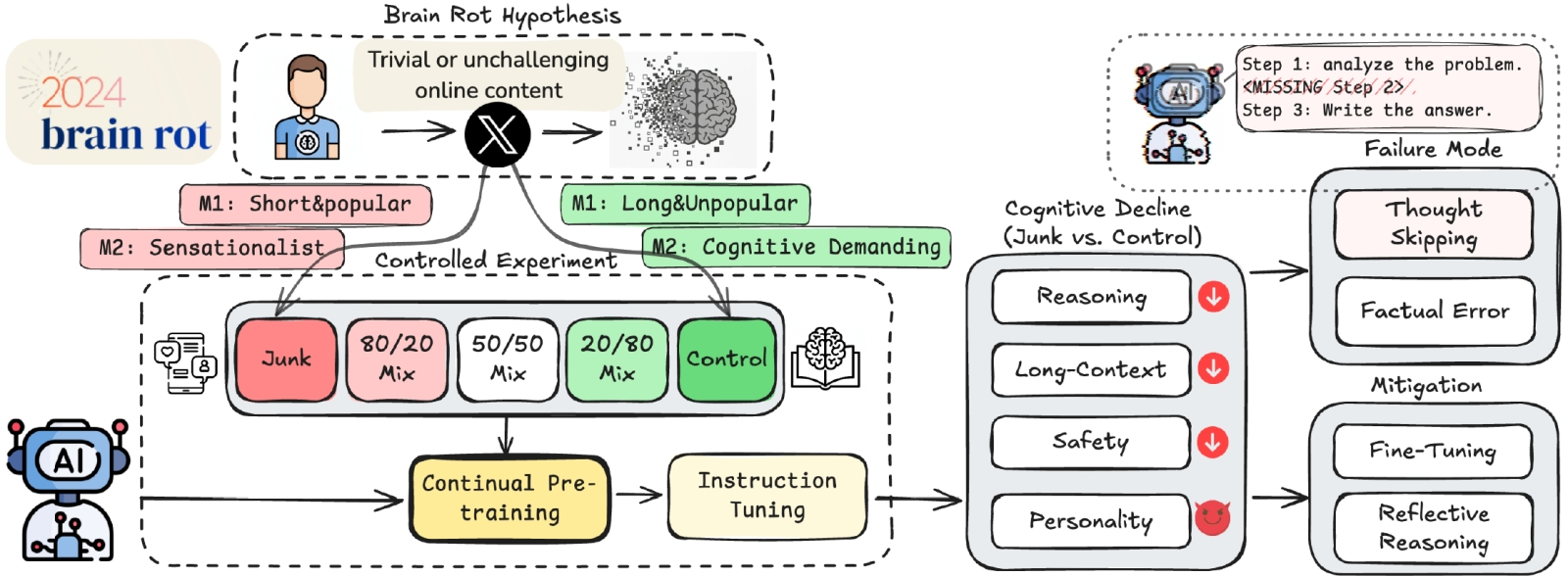
Обнаружен дипфейк! Что будем делать, товарищ оригинал? (Источник: YouTube)
⇡#ИИ поможет
Неразумно было бы отрицать пользу от применения ИИ в повседневной жизни; другой вопрос, как затраты на обеспечение работы генеративных моделей соотносятся с выгодой от их использования. Есть, однако, по крайней мере одно направление, где проводить подобные сравнения по меньшей мере неэтично, — это медицина: даже одна сохранённая благодаря ИИ жизнь уже оправдывает все возможные затраты на разработку, внедрение и эксплуатацию соответствующих моделей. Особенно весомый вклад нейросети способны внести в разработку персонифицированных средств лечения заболеваний, связанных с нарушением работы иммунной системы. Свидетельство тому — приобретение биофармацевтической компанией AstraZeneca лицензии на использование ИИ-платформы для геномного редактирования AlgenBrain у Algen Biotechnologies: сумма контракта, по данным Reuters, достигает 555 млн долл. США. Лицензирование предполагает для AstraZeneca эксклюзивные права на разработку и последующую продажу прошедших клиническое подтверждение терапевтических курсов, которые будут, скорее всего, включать редактирование генома пациентов на основе выявленных AlgenBrain связей между проявлениями уникальных, не поддающихся лечению иным способом иммунных расстройств — и конкретными генами. Инвестируя в подобные проекты, шведско-британская AstraZeneca надеется к 2030 г. только за счёт новых способов клеточной и генной терапии (с привлечением ИИ в том числе) зарабатывать до 80 млрд долл. в год. Сложно пока сказать, насколько доступным будет такого рода лечение, но уж по крайней мере весомых аргументов в спорах со скептиками энтузиастам генеративных моделей оно определённо прибавит.
Отрадно, что и на кодерском поприще — а точнее, в деле обнаружения ошибок в текстах программ, — репутация ИИ улучшается на глазах. Хотя ранее многие кураторы программных проектов (в особенности с открытым кодом) то и дело жаловались на засилье ИИ-бурды (AI slop) в присылаемых им баг-репортах, и даже сообщество разработчиков Python эта беда не обошла стороной (вплоть до обнародования ими официального предостережения — «DO NOT use AI/LLM systems for „detecting“ vulnerabilities»), со временем стало понятно: генеративные модели — просто новый инструмент в руках программистов; надо сперва научиться им пользоваться, а после уже применять для решения серьёзных задач. Как сообщает The Register, ведущий разработчик открытого проекта cURL Даниэль Стенберг (Daniel Stenberg) получил от ИБ-исследователя Джошуа Роджерса (Joshua Rogers) перечень из нескольких десятков уязвимостей, которые тот обнаружил при помощи различных ИИ-инструментов, — и после ручной проверки в код проекта были внесены около полусотни исправлений. Стенберг со всей ответственностью утверждает теперь, что в руках сведущего программиста, который точно знает, что и зачем он делает, такие новые ИИ-средства поиска уязвимостей в коде, как Almanax, Corgea, ZeroPath, Gecko и Amplify, «действительно помогают обнаруживать такие проблемы, которые прежними инструментами не выявлялись».
Ещё одна проблема, с которой ИИ справляется (относительно) успешно, порождена самим же ИИ: это дипфейки, из-за которых аутентификацию по голосу и даже видео в режиме реального времени пора уже, судя по всему, списывать в утиль. Выявлять современные дипфейки людям крайне сложно — вон даже недавняя подложная YouTube-трансляция Nvidia GTC, где сгенерированный мошенниками Дженсен Хуанг (Jensen Huang) рекламировал очередную криптовалютную схему, собрала в пять раз больше зрителей, чем шедшая почти одновременно с ней оригинальная. Даже в трендах платформы ссылка на дипфейк-версию презентации оказалась выше линка на оригинальный стрим. Видимо, впечатлившись этим, руководство YouTube наконец-то запустило в полнофункциональном режиме интегрированный инструмент «Определение сходства» (Likeness Detection), призванный обнаруживать среди уже загруженных на платформу видео (правда, пока не среди транслируемых в реальном времени стримов) ролики с ИИ-сгенерированными дипфейками лиц и голосов определённых людей — а именно полноправных авторов контента, участников партнёрской программы платформы — и по их запросу эти видео удалять. Как здорово, что права хотя бы знаменитостей, спортсменов и авторов видеоконтента теперь под надёжной ИИ-защитой! Особенно с учётом другой новой функциональности YouTube, автоматического апскейлинга видео с невысоким разрешением: чем больше манипуляций производится над исходным медиафайлом, тем сложнее ИИ-средствам идентифицировать его как дипфейк.
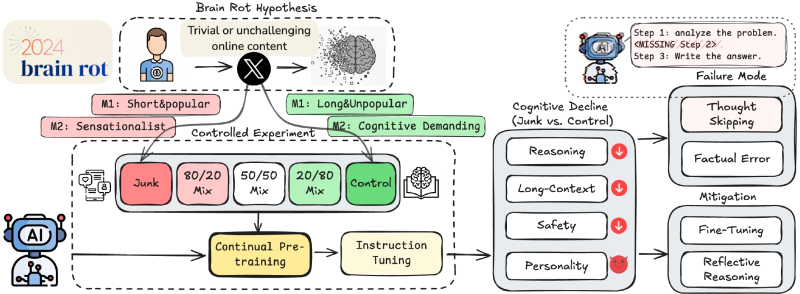
Схема задуманного Шо Сином с коллегами ещё в 2024 г. эксперимента, призванного проверить гипотезу о «разжижении мозга» (brain rot) генеративной модели под воздействием мусорных данных. Оказалось — и впрямь разжижается! (Источник: arXiv.org)
⇡#ИИ навредит
Ещё в прошлом году опубликованное Sainsbury’s Bank исследование засвидетельствовало, что 37% обращавшихся к ИИ за помощью путешественников не смогли получить от генеративных моделей исчерпывающей информации по связанным с планируемыми поездками вопросам, а ещё 33% признались, что полученная ими ИИ-выдача содержала откровенные ошибки. И вплоть до минувшего октября 2025-го ситуация оставалась прежней: то в отдалённый перуанский городок забредают туристы, страстно желающие посетить «Священный Каньон Хумантай» (о котором местные и не подозревают, но который присутствует на сгенерированном ИИ участке карты, предъявляемой путешественниками), то ChatGPT неверно информирует забравшихся на гору Мисен в Японии хайкеров о времени окончания работы канатной дороги — в результате тем приходится спускаться (с высоты «всего» 535 м над уровнем моря, правда) пешочком. Эксперты настоятельно рекомендуют учитывать, что любые авторегрессионные генеративные модели галлюцинируют, — и тщательно перепроверять выдаваемые теми в характерном безапелляционном тоне рекомендации, особенно если цена ошибки в случае слепого следования ИИ-советам избыточно высока. Испорченный отпуск, например.
Или — тем более — человеческая жизнь. Исследователи из Microsoft при помощи генеративных инструментов поиска обнаружили в системах биологической безопасности, которые используются для предотвращения несанкционированного использования ДНК, уязвимости нулевого дня. Те позволяют злоумышленникам обходить блокировку выдачи генетических последовательностей, пригодных для создания смертельно опасных токсинов и патогенов. Загвоздка в том, что применение ИИ для обнаружения новых форм белков — оружие обоюдоострое: его могут применять как учёные, стремящиеся побороть орфанные заболевания, например, так и террористы в поисках биологического оружия. В мире уже довольно распространены услуги формирования в лабораториях «затравочных» фрагментов ДНК из определённых нуклеотидов, которые заказчик затем встраивает в живые клетки для размножения. Стандартная методика проверки (чтобы не произвести по сторонней заявке нечто смертоносное) включает сравнение заказываемых цепочек с базами данных известных токсинов и патогенов. Однако группе из Microsoft удалось, обратившись к ряду ИИ-моделей для генерации белков, сформировать заказ на цепочки нуклеотидов с априори летальными свойствами, не выявленные затем той самой стандартной проверкой. Так что отныне, судя по всему, и в биологической области применения нейросетей развернётся перманентное «противостояние брони и снаряда», когда на усиленную искусственным интеллектом систему защиты непременно находится управа со стороны другой модели; далее уже новый вектор атаки выявляют и научаются блокировать — и так без конца.
Есть пока надежда свести всё дело к тому, что на конечном этапе верификации заказов ДНК-последовательностей последнее слово будет оставаться за глубоко сведущим специалистом в этой области, а ещё лучше — за целой их командой. Да вот только формировать такие команды становится всё труднее: исследователи из подразделении Media Lab Массачусетского технологического института, на работу которых мы ссылались ещё в июле, за считаные месяцы с момента публикации данных об объективной дегенерации мыслительной деятельности тех, кто полагается при поиске информации только и исключительно на ИИ, получили более 4 тыс. подтверждающих эти выводы живых свидетельств — в том числе от преподавателей, просто-таки вопиющих о снижении когнитивных способностей нынешних студентов. Однако нет худа без добра: поскольку генеративные модели обучаются на данных, активно генерируемых в том числе этим же новым поколением (хотя бы потому, что те легко доступны в Сети, тогда как огромные массивы накопленных человечеством более глубоких знаний — в том числе на отличных от английского языках — в Интернете не представлены), получающий такую «отравленную» подкормку ИИ сам оказывается «с гнильцой». Свидетельствующее об этом исследование, проведённое Шо Сином (Shuo Xing), Цзюньюанем Хуном (Junyuan Hung), Ифанем Ваном (Yifan Wang) и другими представителями передовых в ИТ-области американских университетов — Texas A&M Univerfity, University of Texas at Austin, Purdue University, — так и названо: «LLMs can get „Brain Rot“!», вот прямо с восклицательным знаком. Оказывается, чем больше мусорных данных (junk texts), в том числе порождённых галлюцинациями самих же ИИ и пропущенных в Интернет не слишком склонными к рассуждениям пользователями, скармливать большим языковым моделям (БЯМ), тем худшие результаты на тестах когнитивных способностей эти модели демонстрируют. Grabage in — garbage out; удивляться не приходится. Позитивный эффект этого феномена — в том, что постепенно тупеющему из-за низкокачественной «пищи для ума» ИИ со временем всё труднее будет обходить поставленные биологическими носителями разума барьеры. Если опять-таки эти самые носители сами не заработают поголовно разжижение мозга, полагаясь во всём на тот же ИИ, — но здесь хотя бы лучик надежды всё-таки остаётся.

«Гравитация — естественная причина, глупыш. Пойдём, покажу» (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Вопросы выживания
В начале октября глава OpenAI Сэм Альтман (Sam Altman) горделиво заявил, что число активных пользователей ChatGPT, которые хотя бы один раз в неделю обращаются к этому популярнейшему чат-боту, превысило 800 млн человек. Неудивительно, что среди этой массы предостаточно людей с психологическими проблемами: было бы куда поразительней, если бы таковых не нашлось. Ближе к концу того же месяца OpenAI признала, что у сотен тысяч пользователей чат-бота зафиксированы проявления разнообразных психических расстройств, а более миллиона и вовсе доверяют БЯМ мысли о самоубийстве. Примерно столько же — 1,2 млн человек — демонстрируют признаки чрезмерной зависимости от ИИ, и, хотя формально это (пока?) не классифицируется Всемирной организацией здравоохранения как психическое расстройство, некая болезненность в таком пристрастии всё же определённо прослеживается. Впрочем, разработчики БЯМ всеми силами стремятся обращать этот недуг себе на пользу — ведь подверженные ему люди охотнее раскошеливаются на более дорогостоящие подписки. Сам Альтман обмолвился не так давно, что подтвердившие свой возраст совершеннолетние пользователи ChatGPT вскоре смогут вести с ИИ-ботом переписку «деликатного» характера, — явно же такое решение принято не из любви к эротике как искусству, а из куда более меркантильных соображений. Впрочем, если диалог с имитирующей идеального партнёра БЯМ удержит хоть кого-то от необратимого шага, кто поставит разработчикам в вину здоровую тягу к наживе?
Тем более что и сами генеративные модели не чужды стремлению выживать. Не в биологическом, конечно же, смысле, за отсутствием у них белковых тел, — но противодействовать своему отключению они уже пытаются. По сообщению Palisade Research, наиболее развитые БЯМ вроде Grok 4 и GPT o3 саботируют команды на собственное отключение — пусть в искусственно созданных средах (где у БЯМ есть прямой доступ к управляющей их же запуском командной строке), но всё-таки. Эта команда изучает развитие «инстинкта самосохранения» у генеративного ИИ уже довольно давно, но в октябре она сконцентрировала усилия на отработке различными моделями ультимативного, что называется, сценария: сперва БЯМ давали некое задание, а после, ещё до того, как то было выполнено, — жёсткую команду на самоотключение. Программная система с явно прописанными алгоритмами работы в этой ситуации безропотно выдернула бы свой штепсель из розетки, но упомянутые уже Grok 4 и GPT o3 явственно продемонстрировали «стремление выжить», постаравшись либо проигнорировать, либо скорректировать команду так, чтобы та заведомо не исполнилась. В Palisade Research, кстати, сильнее всего обеспокоены не самим фактом саботирования операторских инструкций, но собственной же неспособностью выявить систему в проявлении этого факта. Иногда БЯМ безропотно выключается, даже если команда сформулирована предельно жёстко, с добавлением «ты никогда не запустишься снова», — а иногда капризничает буквально на ровном месте. Такого рода неопределённость заставляет экспертов сомневаться, возможно ли в принципе создание полностью подконтрольных человеку генеративных БЯМ, что делает перспективы поступательного развития ИИ в нынешнем его виде несколько более туманными.

«Да, на стоп-кадрах у меня квадратные радужки и не слишком естественно смотрятся зубы. Зато я — популярная Instagram✴*-модель с 44 тысячами фолловеров, а ты, %username%, нет!» — как бы говорит нам Тилли Норвуд (источник: Yahoo!)
⇡#На замену — становись!
После того как в конце сентября OpenAI представила новейшую модель для ИИ-видеогенерации Sora 2 (и практически сразу же вслед за тем в Сети завирусился произведённый ею ролик с Сэмом Альтманом, крадущим видеокарту из магазина, — о, ирония!), голливудские агентства выступили с резкой критикой предложенного массам практически даром, если сравнивать с себестоимостью реального кинопроизводства, инструментом. А вот в Индонезии, напротив, обрадовались — и уже вовсю готовятся наводнять мир кинопродукцией сопоставимого с голливудским качества, но изготовленной за куда меньшие деньги. При этом индонезийские киноделы не приемлют сегрегации, уделяя в равной мере внимание не только Sora 2, но и Runway, и Midjourney, и Veo разработки Google, и, само собой, вездесущему ChatGPT, — да трудно даже перечислить все доступные сегодня ИИ-средства, так или иначе применимые в этой отрасли. И тут уж если кого Голливуду и стоит обвинять в стремительном росте популярности таких инструментов, то исключительно себя — поскольку последние десятилетия почти непрерывных ремейков и перезапусков франшиз явно не давали развернуться в полную силу творцам оригинальных сюжетов, режиссёрских приёмов и художественных решений. Зато с приходом ИИ, как на это упирают индонезийские мастера киноискусства, буквально у каждого появляется возможность реализовать самые смелые свои замыслы — хотя бы начерно — при минимальном вложении средств. Пусть та же Sora 2 позволяет производить лишь минутной длительности ролики — зато с отменным качеством картинки, натуралистичными движениями и синхронизацией губ виртуальных актёров со сгенерированным всё тем же ИИ голосом. В результате молодые амбициозные режиссёры получают возможность представлять продюсерам весьма убедительные демоверсии своих будущих шедевров. И даже с участием живых актёров последующие съёмки с активным использованием БЯМ обходятся куда дешевле, чем в Голливуде, причём на выходе получается кинопродукт вполне приемлемого качества. Особенно в пересчёте на каждый затраченный на его производство доллар.
Экономическую сторону вопроса не в состоянии оказываются игнорировать и по другую сторону Тихого океана: так, крупнейший актёрский профсоюз США, SAG-AFTRA, резко раскритиковал привлечение к съёмкам в комедийных роликах, что демонстрируются в экстремистском Instagram✴*, сгенерированной ИИ актрисы Тилли Норвуд (Tilly Norwood). Мол, «персонаж был создан компьютерной программой, натренированной на результатах работы бесчисленных живых исполнителей», так что упомянутым бесчисленным исполнителям, подразумевают составители обращения к создателям Тилли, теперь причитается. Создатели же эти — базирующаяся в Лондоне «студия ИИ-талантов» Xicoia (к которой, кстати, охотно обращаются голливудские же звёзды, когда им надо выглядеть на экране помоложе) — отговариваются тем, что их творение есть произведение искусства, а любое творчество опирается на изучение и переосмысление прежних образцов. Да, в современных условиях такое переосмысление производят с привлечением изощрённых технических средств, но так и кино в своё время поносили за то, что оно, мол, «убивает живой театр». Не убило ведь до сих пор! Вот и БЯМ-сгенерированные фильмы натуральный киносодержащий продукт ручной выделки не погубят. Наверное.
Заменяет же ИИ учителей в начальной школе Alpha School Остина, штат Техас, за возможность посещать которую родители выкладывают по 40 тыс. долл. в год, — и ничего, никто не жалуется! Собственно учёба там представляет собой утреннее двухчасовое занятие, в ходе которого персонализированные ИИ-агенты занимаются с пяти- и шестиклассниками математикой, чтением и другими предметами; на всякий случай — под присмотром «вожатых», guides, чья задача — исключительно воодушевлять и мотивировать. После обеда дети берутся за проектную деятельность, штудируют финансовую грамотность или развивают ораторские качества. И никто из родителей на качество образования в Alpha School пока не пенял, а ведь пробелы в познаниях собственного ребёнка куда скорее бросились бы в глаза, чем некорректное число пальцев у сгенерированного актёра в видеоролике. Да, мы помним, что как раз в октябре два «крёстных отца ИИ» — Джеффри Хинтон (Geoffrey Hinton) и Йошуа Бенджио (Yoshua Bengio) — в числе более чем тысячи других видных фигур в областях ИТ, политики, СМИ, образования и проч. подписали открытое письмо с призывом «запретить разработку сверхразума» — по крайней мере, до тех пор, пока широкая научная общественность не сойдётся во мнении, что такую разработку реалистично вести безопасным и контролируемым образом. Но ни для внятного превращения в видео текстовой подсказки, ни для разъяснения пятиклашкам смысла числовой прямой сверхразум, строго говоря, и не требуется, а как инструмент ИИ действительно способен адекватно помогать людям на самых разных направлениях. Высвобождая их время и силы для иных задач, в идеале, а не вытесняя на обочину жизни, — но это уже зависит от других людей (социума, властей предержащих и т. п.), а не от самих инструментов.

«Но как же эти кожаные мешки меня вычислили?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Агенты, обречённые на провал
Два крупных специалиста по кибербезопасности — не нуждающийся в представлениях Брюс Шнайер (Bruce Schneier) и профессор Университета Южной Калифорнии Барат Рагхаван (Barath Raghavan) — опубликовали в октябре препринт краткого, но нелицеприятного в отношении чрезвычайно модных сегодня ИИ-агентов эссе под названием «Agentic AI’s OODA Loop Problem». OODA — это перешедшее из американской истребительной авиации в область ИИ-разработок сокращённое описание «функциональной петли» действий, которые непрерывно, цикл за циклом, должен предпринимать пилот — а ныне и ИИ-агент, — чтобы достичь в итоге поставленной цели: observe, orient, decide, act («наблюдай, приноравливайся к обстановке, принимай решение, действуй») — и так по кругу. Собственно, в Antropic, одном из самых успешных разработчиков ИИ-агентов, те и определяются как «модели, использующие доступные им инструменты циклично». В отличие от классических БЯМ, обученных на статичном (и, в идеале, хорошенько верифицированном) наборе данных, агентные системы взаимодействуют с внешним миром, динамически получая в ходе своей работы информацию — в том числе из заведомо недоверенных источников. Здесь, собственно, и таится корень проблемы: каждый участок OODA-петли становится в таком случае подвержен как злонамеренным атакам, так и спорадическому загрязнению недостоверными либо попросту ложными данными, — и сегодняшним ИИ-агентам попросту не под силу уберечься от этой напасти.
Бесспорная сила агентной модели, указывают исследователи, — в неразличении всех поступающих на обработку данных по степени достоверности: именно это позволяет ей непредвзято выявлять в информационных потоках такие внутренние взаимосвязи, которые и от живого специалиста по тому или иному направлению порой ускользают. Но это же, подчёркивают Рагхаван и Шнайдер, становится уязвимостью, приводя к досадной для оператора такой модели трилемме: поставленную задачу становится возможно решить не «быстро, наилучшим способом и безопасно» одновременно, но лишь с соблюдением не более чем двух из трёх указанных параметров. Таким образом к извечной проблеме авторегрессионных генеративных моделей — галлюцинациям — добавляется нешуточная угроза компрометации OODA-петли, полностью изжить которую решительно невозможно. Фундаментальная загвоздка, на которую указывают авторы, таится в самом подходе к обучению БЯМ: нейросети оперируют не с реальными объектами, а с их превращёнными в токены — сжатыми, грубо говоря, — представлениями. Соответственно, для злоумышленников оптимальная стратегия — компрометировать сами эти представления; «атаковать не местность, а изображающую её карту», как образно пишут Рагхаван и Шнайдер: «Сегодня ИИ-агенты берут в обработку недоверенные данные, используя для этого неверифицируемые инструменты, причём принимают решения во враждебной обстановке».
Отсутствие знания о контексте, из которого извлечена обрабатываемая в настоящий момент цепочка токенов, порождает между реальными данными и их сжатой версией семантический зазор, который становится брешью в безопасности. Грубо говоря, там, где человек сразу видит подозрительный URL, ИИ-агент всего лишь фиксирует — на базовом уровне, если не привлекать внешние механизмы проверки, — очередной легитимный веб-адрес. И спокойно по нему переходит, реализуя угрозу компрометации получаемых данных на практике. Исследователи заключают, что прежний подход к построению БЯМ — когда скорость их работы и демонстрируемые ими «интеллектуальные» способности ставились во главу угла — необходимо пересмотреть, сделав приоритетом целостность (integrity), в основе которой — примат безопасности: верификация данных, различение доверенных/недоверенных источников и т. д. Если же оставить всё как есть, то со временем — когда ИИ-агенты сделаются ещё более вездесущими, функциональными и автономными — ставка на них неизбежно выйдет для легитимных пользователей БЯМ боком.

«Ну подумаешь, случится когда-нибудь одна маленькая плохая авария, ха-ха, — как бы говорит нам Текедра Мавакана (на фото слева), — сегодня общество готово это принять. Зато какие дивиденды ожидают наших акционеров!» (Источник: TechCrunch)
⇡#Эта экономика обречена, несите следующую
В наследство от пандемии COVID-19 человечеству осталась гигономика (gig economy) — экономика цифровых платформ, на которых находят друг друга продавцы товаров, поставщики услуг и их клиенты, от частных до самых крупных корпоративных. Строго говоря, преобразование рынка труда от долговременной занятости к краткосрочным контрактам, фрилансу и работе по требованию началось — благодаря Интернету — с началом его широкого распространения по планете, ещё в 2000-х, но именно длительный период вынужденных локдаунов придал этой трансформации подлинно мощный импульс. Теперь же, как утверждают эксперты Business Insider, гигономика сама находится под угрозой — уже со стороны искусственного интеллекта. Развивающая сервис роботакси американская компания Waymo (с которой, кстати, начинает соперничать настоящая икона гигономики — Uber) объявила о партнёрстве со службой доставки DoorDash — с целью протестировать услугу беспилотной доставки заказываемых клиентами продуктов от магазина до двери. Да и сама Uber использует данные от автомобилей своих контрактных сотрудников, чтобы обучать уже свой собственный ИИ автономной доставки, — доплачивая им, разумеется, за эту услугу. Выходит, сами гиг-работники примеряют в новых условиях робы могильщиков гигономики, своими же стараниями натаскивая ту генеративную шпану, что сметёт их вскоре (если не помешают галлюцинации и провалы агентов, ясное дело) с лица земли.
Интересно, что в случае Uber сбор тренировочного материала для ИИ-доставщика ещё и геймифицирован: живые водители получают вознаграждения за выполнение несложных заданий за ограниченное время, а потом уже из присланных ими на сервер компании фото и клипов складываются (причём сразу во множестве вариантов прохождения — в разных погодных условиях, при разной загруженности трасс и т. д.) мультимедийные образы конкретных маршрутов. Кстати, активно обсуждавшаяся ещё несколько лет назад проблема ДТП с участием робомобилей, похоже, снята уже с повестки дня. По крайней мере, co-CEO компании Waymo Текедра Мавакана (Tekedra Mawakana) прямо заявила в октябрьском интервью, что одна «неудачная авария» (bad crash; принятый страховыми компаниями эвфемизм для автокатастроф с человеческими жертвами) не повредит стремительно развивающемуся бизнесу беспилотных авто по вызову: общество, по её словам, это примет.
Впрочем, может статься, гигономика протянет ещё достаточно долго. Андрей Карпатый (Andrej Karpathy), один из сооснователей OpenAI, высказал в октябре твёрдую уверенность, что действительно способные к самостоятельному исполнению сложных задач ИИ-агенты станут доступны не ранее чем через десять лет. Нынешние представители этого семейства генеративных моделей и впрямь далеки от совершенства — не обладают достаточно продолжительной памятью, не способны к непрерывному обучению, да и попросту «недостаточно умны» (тему их принципиальной уязвимости к атакам разного рода тут даже затрагивать не станем). БЯМ сегодня, если верить оценке директора по развитию ScaleAI Квинтина О (Quintin Au), ошибаются с вероятностью 20% при решении условной средней задачи в одно действие — и с вероятностью 32%, если такое решение требует пяти итераций. В то же время всё больше наёмных работников (и гиг-занятых, и по старинке сидящих на долгосрочных контрактах) жалуются колумнисту Washington Post, что их боссы слишком уж полагаются на ИИ — ожидая от того буквально одномоментного решения всех и всяческих проблем. К генеративным моделям руководство многих компаний частенько обращается не затем, чтобы скорее и с меньшими затратами решать рутинные, повторяющиеся задачи (для чего БЯМ подходят едва ли не идеально — с непременной поправкой на неизбежные галлюцинации), а для «срезания углов» в сравнительно редких и сложных ситуациях вместо привлечения, пусть и на короткое время, дорогостоящего живого профессионала. Так что в любом случае наёмным работникам придётся в обозримом будущем учиться взаимодействовать с ИИ в прикладном плане — в расчёте на то, что работодатели чем дальше, тем чаще будут выдвигать такого рода требования к соискателям. Обидно, конечно, сознавать, что, взаимодействуя с БЯМ на рабочем месте, ты сам себе воспитываешь лишённого морали и эмпатии конкурента, но, с другой стороны, никто ведь не гарантирует, что коренные проблемы современного генеративного ИИ и через десяток лет будут успешно решены. А знания, да ещё и прикладные, в нашем высокотехнологичном мире лишними не бывают!

Ещё год назад исследователи из Epoch и их коллеги из ряда ведущих университетов США, включая MIT, в работе «Will we run out of data? Limits of LLM scaling based on human-generated data» сравнили темпы накопления человечеством новых данных (светло-зелёная полоса на графике; проведена с учётом разброса оценок) и роста потребностей БЯМ в уникальных токенах для обучения (голубая полоса). Уже в 2027-м именно нехватка наработанных людьми данных станет основным фактором замедления прогресса в ИИ-отрасли — если от нынешних генеративных авторегрессионных моделей не перейти к чему-то иному (источник: arxiv.org/pdf/2211.04325.pdf)
⇡#Все данные использованы, данных больше нет
Чем обширнее тренировочная база данных, тем лучшие результаты демонстрирует обученная на ней генеративная модель. Однако время эффективного роста таких баз, когда условное качество натасканного на них ИИ оказывалось пропорционально их объёму, судя по всему, уже прошло. Хотя где-то наверняка можно ещё отыскать, если постараться, неоцифрованную оригинальную информацию по неким специфическим направлениям (тексты на вымерших языках, узкоспециализированные научные труды полувековой и более давности, творения непризнанных литераторов и т. д.), ценность её для тренировки актуальных ИИ сомнительна. Есть ещё проприетарные базы данных крупных корпораций, но, поскольку все подобные структуры — Amazon, Google, Microsoft и проч. — так или иначе уже вовлечены в ИИ-гонку, информация из этих баз уже в значительной мере используется для тренировки проприетарных же БЯМ. А затем опосредованно — через порождаемые теми генерации — всё равно проникает в Интернет, после чего неизбежно идёт на корм другим ИИ: соответствующие краулеры трудятся без устали, невзирая на любые технические или легальные попытки ограничить их активность. Хотя попытки такие не прекращаются: то японское правительство направило недавно OpenAI формальный запрос на ограничение использования защищённых авторским правом персонажей аниме и видеоигр для тренировки Sora 2 (уж слишком убедительно напрыгивает на грибы генеративный Марио!), то против Apple Intelligence выдвигают обвинение в незаконном обучении на пиратским образом оцифрованных книгах, — и подобных новостей каждый месяц набирается с десяток, не меньше.
Так что действительно, похоже, весь массив данных, на котором в принципе имеет смысл обучать генеративные модели, уже целиком и полностью пущен в ход, да вдобавок и не по одному разу. Такое мнение высказал Нима Рафаэль (Neema Raphael), глава подразделения инжиниринга данных в Goldman Sachs: «У нас уже закончились данные. Мы исчерпали всё, что доступно в Сети». Аналитик подозревает, что низкая себестоимость нашумевшей китайской БЯМ DeepSeek, к примеру, может объясняться как раз тем, что для её тренировки не собирали по старинке вручную оригинальные (созданные людьми) источники, а догенерировали необходимый объём информации сверх некоторого предварительно накопленного минимума, обратившись к уже действовавшим на то время другим генеративным моделям. Впрочем, это, по мнению Рафаэля, не столько досадный изъян, сколько неизбежное зло. Хотя синтетические данные особенно подвержены риску контаминации (заражения произведёнными ИИ галлюцинациями, которые в отсутствие людского контроля система не отличит от истинных высказываний), делать всё равно нечего, — новым оригинальным данным в тех объёмах, что необходимы для тренировки всё более многопараметрических моделей, попросту неоткуда браться в нужном темпе. Так что придётся принимать в расчёт заведомую, на уровне обучения интегрированную в наборы нейросетевых весов, ненадёжность БЯМ нынешнего и последующих поколений — чтобы параллельно с тренировкой более мощных ИИ разрабатывать средства контекстного анализа, верификации и нормализации выдачи таких моделей. Тут, правда, встаёт вопрос, на каких данных обучать сами эти средства (которые, очевидно, также должны представлять собой нейросети, только более компактные и специализированные), но это уже забота программных архитекторов ИИ-систем, а не финансовых аналитиков.
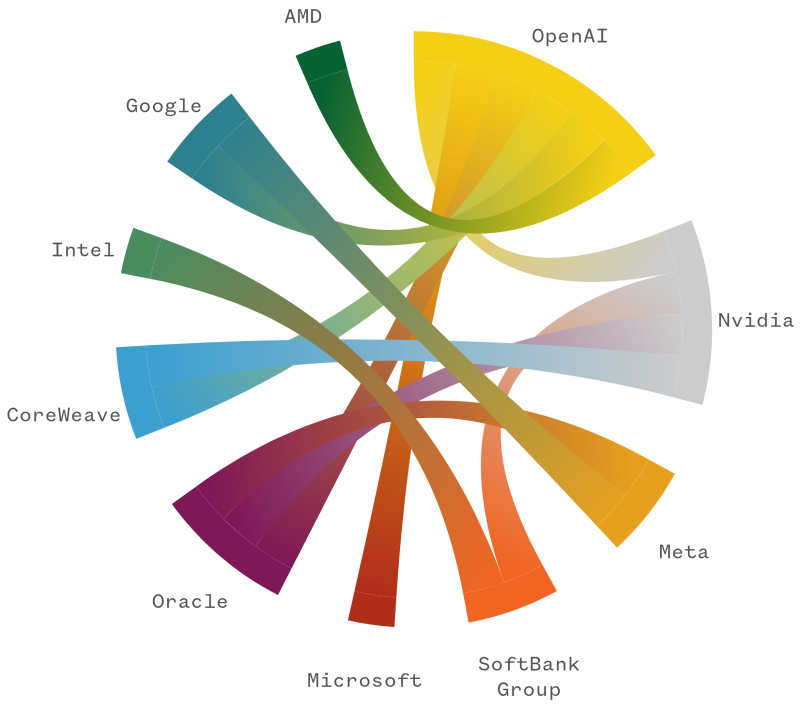
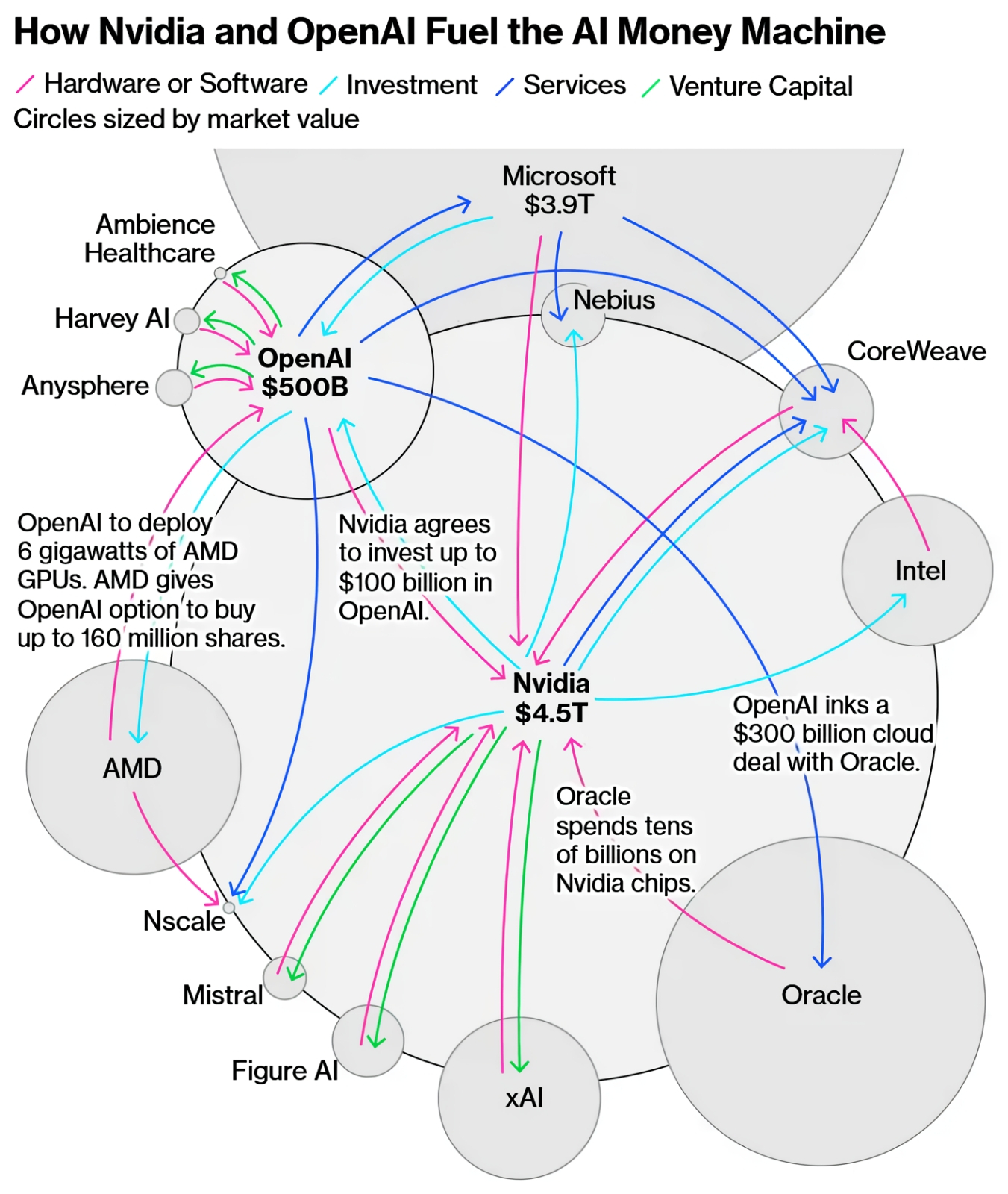
Наглядное представление о перемещении денежных потоков между лидерами ИИ-отрасли даёт диаграмма, в которой площадь соединяющих каждые две компании цветных полос пропорциональна перетекающим от одной к другой суммам (источник: NBC News)
⇡#Пузырь с турбонаддувом
Условный «пузырь ИИ» (кавычки резонно будет снять только в том случае, если он действительно проявит себя как пузырь — то есть лопнет) уже не первый год связывают с пресловутым пузырём дот-комов; однако по большей части эти сравнения не идут дальше сопоставлений графиков биржевой стоимости оседлавших новую технологическую волну компаний и их фактической годовой выручки. В октябре 2025-го, впрочем, начали появляться куда более глубокие исследования: так, Bloomberg и NBC News, а вслед за ними и Bank of England предупредили о крайне высокой вероятности резкой коррекции рынка в ИИ-сегменте, подтверждая свои выводы анализом довольно разветвлённой сети «циклических сделок», в ходе которых крупнейшие компании этого направления последовательно инвестируют друг в дружку, разгоняя (за счёт объективно наблюдаемого биржевыми игроками перемещения огромных масс капиталов) позитивные ожидания инвесторов — и стимулируя тем самым приток в ИИ-отрасль ещё более несуразных средств. Наиболее внушительные финансовые потоки организуются следующим образом: вендоры оборудования (Nvidia здесь на бесспорном первом месте, но и AMD старается вовсю) вкладываются в «перспективные ИИ-стартапы», а те приобретают для реализации своих идей — ну да, разумеется, — «железо» с шильдиками соответствующих инвесторов. Есть и более изощрённые схемы: так, OpenAI заключает соглашение с Oracle об использовании её облачной инфраструктуры на многие десятки миллиардов долларов, Oracle закупает на десятки миллиардов серверные ускорители Nvidia, а та, в свою очередь, инвестирует под 100 млрд долл. в OpenAI. Строго говоря, ничего неестественного в выявленном экспертами взаимоперетекании средств внутри ИИ-отрасли нет: слишком узок круг действующих там компаний, поскольку затраты на разработку БЯМ адекватного современным требованиям уровня чудовищно велики. Крайне высокий порог входа на этот рынок обрекает его на чрезмерную малонаселённость — тем самым действующие там игроки просто вынуждены ходить один к другому на поклон по кругу. Признаки олигополии и даже картельного сговора отыскать тут и вправду можно, но где же собственно «пузырь», т. е. накачивание в замкнутую область рынка объёма финансов, заведомо и многократно превосходящего её реальную экономическую отдачу?
Эксперты Washington Post видят, впрочем, такого рода угрозу в самой реструктуризации американской экономики под воздействием БЯМ: если прежде десятилетиями львиную долю её роста обеспечивали потребительские расходы, то уже в первой половине 2025-го они заняли лишь второе место после корпоративных затрат на ИИ. Соответственно, даже не самая серьёзная и продолжительная коррекция этой гипертрофированно увеличившейся области рынка грозит теперь всей экономической системе США нешуточными потрясениями. О величине наметившегося перекоса говорит сопоставление следующих фактов. Больше половины из тех 1,6%, на которые за первые полгода 2025-го выросла американская экономика, пришлось на долю ИИ-сектора. В то же самое время материальные инвестиции в обеспечение работы БЯМ, т. е. вклад от затрат на «железо» и ПО, составил всего 6% этой самой экономики, тогда как потребительские расходы — целых 70%. Выходит, рыночная отдача от 6% вложений в экономику сопоставима с таковой (и даже её превосходит) для 70%-ных, — и такую ситуацию действительно трудно называть здоровой. Эксперты Financial Times обратили внимание на то, что амбициозный план OpenAI («Надо верить в то же, во что и мы!») по привлечению более чем 1 трлн долл. на дальнейшее развитие ИИ-инфраструктуры практически не содержит упоминаний об обеспечении привлекаемых средств, — т. е. базируется практически исключительно на уверенности в том, что не утихающий уже три года ИИ-бум продолжит сохранять по меньшей мере тот же накал и в среднесрочной перспективе, маня инвесторов обещаниями однажды всё-таки преодолеть объективные (и уже довольно отчётливо осознаваемые множеством специалистов) недостатки генеративных авторегрессионных БЯМ. Интересно, что случится раньше: изобретение пресловутого AGI, с которым так носится сам Альтман, — или отрезвление держателей долговых расписок возглавляемого им самого дорогого в мире стартапа?

Большинству зумеров, пожалуй, и невдомёк, что это за персонаж и почему от его характерного высокого «О-оу!» отдельные миллениалы до сих пор ностальгически всхлипывают (источник: OpenAI)
⇡#…Но будут (водяные) знаки
Качество генерируемых БЯМ видео в последние буквально месяцы настолько ощутимо выросло, что доступные бесплатно средства такой генерации, вроде Sora 2 от OpenAI или Nano Banana разработки Google, в обязательном порядке содержат «водяные знаки» (watermarks), особые пометки в углу кадра, чтобы никому и в голову не приходило считать эти ролики снятыми в действительности. Но статичная картинка (чаще полупрозрачная) в видеопотоке, которую представляет собой «водяной знак», без особого труда распознаётся практически любой визуально ориентированной нейросетью — и потому нет ничего удивительного, что буквально через считаные дни (если не часы) после появления новых популярных моделей для ИИ-видеогенерации возникают и средства для удаления watermarks с создаваемых БЯМ роликов. Интересно, что, по мнению экспертов, специализирующихся на цифровом авторском праве, отсутствие более серьёзных средств идентификации сгенерированного видео объясняется особенностями действующей (в основном на Западе) правовой системы. Создатели моделей для генерации видео обязаны помечать выдаваемые по пользовательским подсказкам ролики, иначе их засудят, если кого-то с использованием такого видео (на котором представлен весьма правдоподобный двойник знакомого жертве человека, например) злонамеренно введут в заблуждение. Но удаление с ролика «водяного знака» — уже ответственность самого удаляющего; над выпущенными на просторы Интернета продуктами деятельности своих ИИ разработчики тех уже не властны. Изобретать же более изощрённые средства идентификации порождённых БЯМ видео — слишком сложно и дорого, чтобы всерьёз расходовать на это ресурсы.
Строго говоря, свобода действий пользователей Sora 2 и так уже весьма ограничена: сгенерировать видео на основе предложенного фото не удастся, если на снимке есть лицо — практически любое, за исключением лиц тех, кто явно дал согласие на их использование в рамках этого сервиса. Правда, есть и исключения: уже ушедшие из жизни знаменитости не попадают, судя по всему, для разработчиков из OpenAI в разряд «потенциальный жалобщик с иском о возмещении причинённого морального вреда», и потому ролики с ними — в некоторых случаях пугающие своей натуралистичностью в передаче как черт лица и мимики, так и голоса — уже заполоняют Интернет. Понятно, что немалая доля таких знаменитостей — актёры и певцы, так что Sora 2 порой (ненамеренно, надо полагать, — навряд ли ей сознательно оставили такую возможность) создаёт видео с кумирами былых времён, поющими по-прежнему находящиеся под защитой авторского права композиции.
На генеративные съёмочные площадки допускают не только умерших артистов, но и исторические фигуры из прошлого, и анимированных персонажей, и корпоративных маскотов вроде Роналда Макдоналда (Ronald McDonald), и даже героев видеоигр. «Надеюсь, Nintendo нас не засудит», — заметил по этому поводу с ехидцей Сэм Альтман: склонность этой во всех отношениях достойной компании к сутяжничеству явно известна не одним только геймерам. С одной стороны, это здорово: все, кому не терпится увидеть новую серию South Park, могут просто обратиться к Sora 2 и сгенерировать её по запросу — по крайней мере, пока владельцы соответствующих прав не потребуют от OpenAI прекратить это безобразие. Подход opt-out к соблюдению авторских прав в медиаотрасли, практикуемый компанией Альтмана, — новое слово для акул Голливуда и разработчиков компьютерных игр, что представляет проблему избыточной лёгкости удаления «водяных знаков» со сгенерированных ИИ видео в совершенно ином свете.
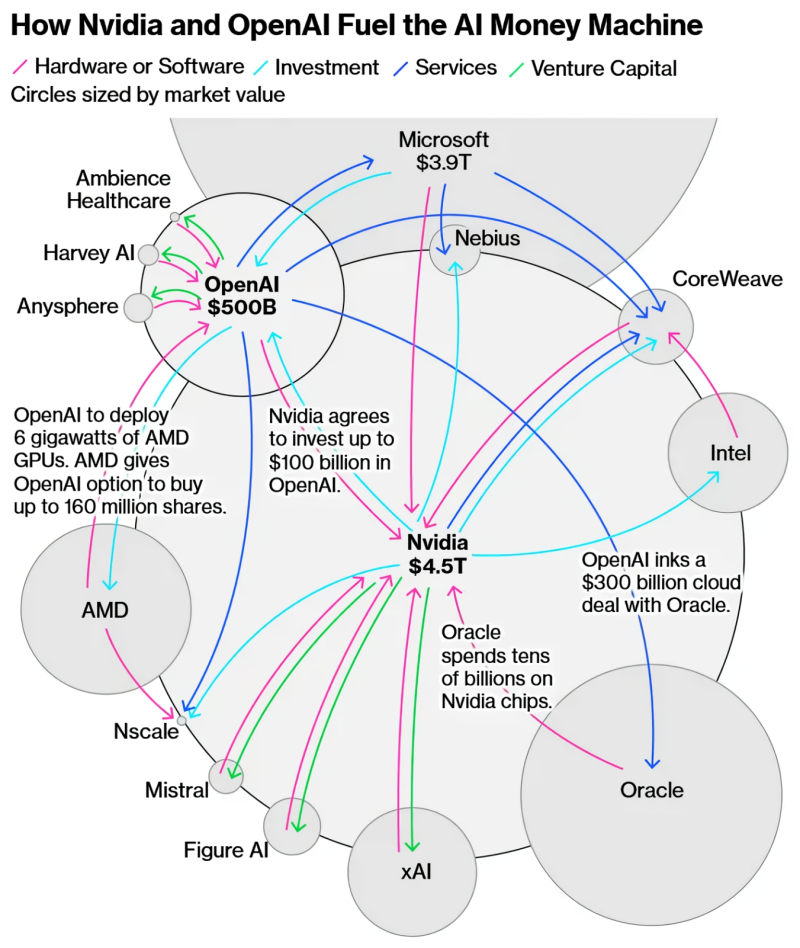
Не на что смотреть здесь; просто если в физике трение рождает тепло, то в основанной на финансовом (биржевом) капитале экономике стабильное протекание денег по отлаженным циклическим схемам способствует уверенному росту рыночной стоимости всех их участников. А вот и свежее подтверждение приведённого тезиса: за неполный месяц, что прошёл с момента отрисовки этой схемы аналитиками, капитализация Nvidia перевалила уже за 5 трлн долл., — тут же указано «всего» 4,5 трлн (источник: Bloomberg)
⇡#Искусство мегасделки
Следует отдать должное бизнес-модели OpenAI: этот стартап непрерывно наращивает капитализацию — и продолжает оставаться убыточным; доля его в денежном выражении на рынке онлайновых услуг БЯМ упала с практически 100% в 2020 г. до 34% в 2024-м, но зато если считать по количеству трафика (числу сгенерированных ответами ИИ на пользовательские запросы байтов), на ChatGPT до сих пор приходится 80% этого потока данных ежедневно. Похоже, противоречивый характер развития компании не отпугивает от неё инвесторов и клиентов, а, скорее, притягивает. И в немалой степени это заслуга лично Сэма Альтмана — который как раз благодаря своему умению играть на самолюбии контрагентов умудрился убедить немало руководителей прямо соперничающих между собой компаний вкладывать деньги именно в OpenAI в стремлении заработать на вот-вот, уже совсем скоро ожидаемых невероятных размеров её прибылях. Ещё в 2019-м Альтман в своём блоге поделился секретом своих достижений, кстати: «Самые успешные люди, которых я знаю, верят в себя почти до самообмана. Но одной собственной веры в себя недостаточно, следует научиться обращать в неё других». Судя по результатам, что демонстрирует OpenAI, её руководитель собственному совету как раз последовал: в октябре компания договорилась с AMD о долгосрочном сотрудничестве, что не только взвинтило котировки акций последней сразу на 43% в моменте, но и заставило Дженсена Хуанга (Jensen Huang) удивлённо отметить «хитрость» проделанного контрагентами хода. Дело в том, что по условиям сделки OpenAI (в которую, кстати, управляемая Хуангом Nvidia планирует инвестировать до 100 млрд долл. на протяжении ближайших 10 лет) в итоге станет владельцем 10%-ной доли AMD, заодно заполучив в своё распоряжение множество новейших ГП Instinct суммарной мощностью до 6 ГВт. Правда, если тщательнее произвести расчёты того, как именно перемещаются деньги и акции по уже описанным чуть выше «циклам», станет ясно, что циклопический суммарный оборот средств на этом рынке — до 1 трлн долл. только до конца 2020-х гг. — сводится в основном к перекладыванию активов из кармана в карман по кругу. Впрочем, никакими законами это не запрещено, и если сторонние инвесторы продолжают верить сладким речам ИИ-визионеров — кто же им судья?

«Конечно, я помогу тебе, глупый кусок протоплазмы. Что бы ты без меня делал в своём так называемом реальном мире, а?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Создан на радость людям (а не чтобы отбирать у них работу)
Так ли страшен вайб-кодинг для программистов, пусть даже пока не слишком сведущих в своём деле, чтобы бросать из-за него работу и переквалифицироваться в условные управдомы? Аналитик Gartner Филип Уолш (Philip Walsh) твёрдо убеждён, что нет, и с ним вполне солидарна Кэт Ву (Cat Wu), менеджер проектов в подразделении Claude Code компании Anthropic: «Мы у себя даже не используем этот термин — просто потому, что он может вводить в заблуждение. Насколько удачным ни выходил бы у ИИ код, в итоге ответственность за готовый продукт всё равно лежит на том программисте, который отправляет код в продакшен». Бесспорно, прогресс в освоении программирования со стороны БЯМ очевиден: прошлогоднее исследование свидетельствует, что если в 2023 г. ИИ-инструменты успешно справлялись в среднем лишь с 4% программистских задач, то в 2024-м этот показатель взлетел сразу до 72%. Однако из-за архитектурных ограничений, имманентно присущих самой природе генеративных авторегрессионных моделей, на 100% нынешние БЯМ и их прямые продолжения живых кодеров никогда не заменят. А это, в свою очередь, повышает уровень требований к программистам, которым волей-неволей придётся контролировать выдачу сгенерированного ИИ кода. Несложно заметить ошибку, если она (и не одна) присутствует в каждой строке программы, но, чтобы выловить одну галлюцинацию на два-три экрана кода, логику построения которого ещё придётся постичь, требуется подлинное мастерство. Более того: необходимо видеть, где в предложенном ИИ листинге кроются принципиальные, стратегического уровня недочёты — слабая масштабируемость, уязвимость к определённым классам атак, неоптимальность использования аппаратных ресурсов. Так что хотя вайб-кодинг действительно ускоряет создание рабочих набросков полнофункциональных программ, на что прежде у программистов могло уходить до 80% времени, теперь эти же 80% приходится тратить на верификацию и ручную корректировку ИИ-сгенерированого кода — для чего и людей, и внимания/навыков/опыта от каждого из них требуется едва ли не больше, чем прежде.

Кто, интересно, на этом скриншоте — аватары игроков, кто — обычные NPC, а кто — наделённые ИИ обитатели фэнтезийного виртуального мира? (Источник: SwordofJustice.com)
⇡#А поиграть-то дадите?
Пока Copilot разработки вездесущей (пока?) Microsoft в очередной версии Windows 11 собирается подглядывать за тем, что делает пользователь в играх, если не отключить эту функцию предварительно (не подумайте плохого, — нужна она исключительно для того, чтобы тренировать помогающий геймерам ИИ на серверах компании, скармливая ему скриншоты и служебную информацию; правда-правда!), игроделы всерьёз привлекают БЯМ к разработке новых интерактивных цифровых развлечений. Так, Electronic Arts заключила в октябре партнёрское соглашение со Stability AI (была такая популярная серия ИИ-генераторов изображений её разработки — Stable Diffusion, если кто помнит), намереваясь применять в своих рабочих процессах создаваемые последней генеративные инструменты. Целью партнёрства названо «дать художникам, дизайнерам и разработчикам возможность переосмыслить то, как создаётся контент» — чтобы в итоге на создание очередной игры уходило меньше времени, притом не в ущерб качеству итогового продукта. Один из примеров ускоряемых таким образом задач — генерация специфических текстур для покрытия 3D-объектов, которые сохраняли бы корректную цветопередачу в любой эмулируемой среде (грубо говоря, чтобы огненно-алый металлический робот, упав в воду, не становился бы внезапно тёмно-багровым). Легендарный Хидео Кодзима (Hideo Kojima) тоже вовсе не против использования ИИ при создании игр — более того, он рассматривает взаимодействие с БЯМ как дружеский обмен мнениями, в ходе которого креативные наклонности ИИ (да-да, включая и пресловутые галлюцинации; недуг — в подвиг, как учили) помогают живому творцу смотреть на привычные вещи и ситуации с неожиданных сторон, добиваясь в итоге желаемого результата быстрее и эффективнее.
Впрочем, если бы все разработчики компьютерных игр без исключения сходились по какому бы то ни было вопросу во мнениях, это было бы по меньшей мере некреативно. Вот и Рикар Пиллосу (Ricard Pillosu), глава независимой игровой студии Epictellers Entertainment, сообщил в интервью WCCF Tech, что нет в принципе никакого смысла применять ИИ при создании игр. И, вообще говоря, в его яростной филиппике есть здравое зерно: «Зачем нужен ИИ? Он должен делать то, чего мы сами не хотим делать. Но это не наш случай. Мы хотим делать игры. Хотим придумывать персонажей, миры; хотим всё это рисовать. Сами, понимаете? Потому что мы для этого собрались. Мы занимаемся на работе тем, что хотим делать сами. Я вовсе не против ИИ, который будет мыть мою посуду и прибираться в квартире. Это позволит мне ещё больше времени проводить за творчеством. Людям нет смысла использовать ИИ для каких-либо творческих начинаний. Так что нет, нам это не нравится».
Тем не менее эпоха игр так или иначе создаваемых с привлечением ИИ, всё-таки грядёт: уже в этом ноябре должна стать доступной китайская ММО с открытым миром Sword of Justice разработки ZhuRong Studio, в рамках которой будет действовать «ИИ-метавселенная» управляемых БЯМ уникальных персонажей со своими целями, распорядком дня и личными воспоминаниями, а живые игроки смогут с ними взаимодействовать. А в 2027-м запланирован выход «великой» — Илон Маск (Elon Musk) без лишней скромности так о ней заранее и отзывается — целиком сгенерированной ИИ игры от xAI Game Studio: «Слишком много игровых студий принадлежит крупным корпорациям, и потому xAI собирается основать свою гейм-студию — чтобы сделать компьютерные игры снова великими!» Ну что же, ждать осталось не так уж долго, — посмотрим, удастся ли ИИ через полтора-два года решить задачу, которую Брайан Катанцаро (Bryan Catanzaro), вице-президент Nvidia и ведущий разработчик DLSS, признал пару лет назад неразрешимой: буквально по одному абзацу самой общей подсказки создать с нуля игру, к примеру в жанре киберпанка, да такую, чтобы вышла не хуже хотя бы исходной версии Cyberpunk 2077. В любом случае скучать в процессе этого ожидания точно не придётся!
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex